1. Introduction
High-resolution remote sensing images contain rich geographic information and have many potential applications in areas including agricultural monitoring, land use, and urban planning [
1,
2], making the intelligent analysis of remote sensing images a topic of considerable interest. The semantic segmentation of remote sensing images is a significant image processing task [
3,
4], aiming to categorize each pixel and mark it as the corresponding category [
5]. Remote sensing images are characterized by high quantities, complex backgrounds, and large scale changes. The process of manually annotating data is labor-intensive and prone to error. The rapid and accurate automatic extraction of object information from remote sensing images has become an urgent need.
There are three main semantic segmentation methods used for remote sensing images: traditional methods, machine learning, and deep learning. In the early days, traditional remote sensing image segmentation mostly relied on shallow features of the image, including the texture, edges, and geometric shapes of the target. Common segmentation methods based on image pixels include thresholding, edge detection, and region-based segmentation. Cuevas et al. [
6] presented an automatic image segmentation approach that implements multi-thresholding through differential evolution optimization. This method is capable of dynamically selecting optimal thresholds while maintaining the primary features of the original image. Chen et al. [
7] employed the Canny edge detector for edge detection on multispectral images and performed multi-scale segmentation on the detected edge features. The integration of edge information and segmentation scale effectively controlled the merging procedure of neighboring image objects. Byun et al. [
8] achieved initial segmentation through an improved seed region-growing program and obtained segmentation results using a region adjacency graph to merge regions. To cope with complex remote sensing image segmentation scenarios, the simple linear iterative clustering (SLIC) superpixel segmentation algorithm, which utilizes the K-means clustering algorithm, is widely utilized in the remote sensing field. Csillik et al. [
9] used SLIC superpixels to quickly segment and classify remote sensing data. Model-based segmentation methods based on Markov random fields are also widely used, which improve segmentation accuracy by introducing contextual information. Sziranyi et al. [
10] applied unsupervised clustering to fused image series using cross-layer similarity measures and then performed multi-layer Markov random field segmentation. To overcome the constraints of single shallow-feature-based segmentation approaches, hybrid feature combination segmentation methods have been proposed, such as combining edge detection with region-based segmentation to enhance the quality of the segmentation outcomes. Zhang et al. [
11] introduced a hybrid approach to region merging. This method utilizes the globally most similar region to establish the initial point for region growing and enhances the optimization ability for local region merging. These traditional methods rely too heavily on shallow features of the image, and pixel features are easily affected by factors such as the lighting, the presence of clouds and fog, and the sensors, resulting in insufficient reliability. The ability of machine learning to learn features and geometric relationships between images has received attention. Mitra et al. [
12] used the support vector machine (SVM) algorithm to solve the problem of insufficient labeled pixels required for supervised pixel classification in remote sensing images. Bruzzone et al. [
13] introduced an enhanced support-vector-machine-based semi-supervised approach for remote sensing image classification. By leveraging both labeled and unlabeled samples, this method effectively tackles the ill-posed problem. Pal et al. [
14] used a random forest classifier to select the best category. Mellor et al. [
15] used a random forest classification model to classify forest cover areas on multispectral remote sensing images. These methods heavily rely on handcrafted features, which result in a poor generalization capability [
16,
17].
With a high-resolution background, due to the impact of the spatiotemporal environment, objects of the same type present different spectral features, and the utilization of shallow features is inadequate for capturing the complexity of remote sensing images, thereby leading to limited segmentation accuracy. Deep learning methods have begun to attract attention as computing power has improved rapidly, since deep neural networks can automatically learn features in large datasets and extract deep semantic features of images, showing excellent performance. Classic segmentation models have begun to emerge. Long et al. [
18] pioneered the fully convolutional network (FCN) semantic segmentation model, enabling pixel-level image classification. In a FCN, the traditional fully connected layer in the final layer of the network is replaced by a convolutional layer, allowing the network to accept inputs of arbitrary sizes and produce feature maps of the same size as the input. Zhong et al. [
19] used an FCN to extract buildings and roads, which could better capture ground target features compared to traditional neural networks, but the eight-fold upsampling method lost image detail information. A series of segmentation networks using an encoder–decoder structure have been proposed, such as SegNet [
20] and U-Net [
21]. Cao et al. [
22] proposed the Res-UNet network, which addresses the problems of gradient vanishing and feature loss in deep neural networks by introducing residual connections. Although it has achieved high segmentation accuracy in high-resolution remote sensing forest images, its segmentation performance for small target tree species is poor. Based on U-Net, Li et al. proposed MACU-Net [
23], which utilizes asymmetric convolutions to replace regular convolutions and enhance the feature extraction capability, thus improving the utilization rate of features, but the segmentation of ground object boundaries is still not clear enough. To avoid reducing the size of the receptive field when obtaining feature maps at various scales, the utilization of dilated convolution [
24] to perform convolution operations on input images is widespread. PSPNet [
25] is a model based on pyramid pooling that implements the pyramid pooling module at the last layer to extract contextual information at different scales. DeeplabV1 was proposed in [
26], which utilizes dilated convolution to perform convolution operations on input images in VGG [
27] and then adds a conditional random field (CRF) module at the output end for post-processing to obtain relatively accurate contours. In DeeplabV2 [
28], dilated convolutions are extensively applied to feature maps at multiple scales to capture contextual information at different levels, thereby improving segmentation accuracy. DeeplabV3 [
29] optimized the ASPP module by adding average pooling and batch normalization operations to improve the feature representation and model generalization capabilities. Removing the CRF as a post-processing module still achieved good segmentation results. DeeplabV3+ [
30] included a decoder module to fuse shallow features in the encoder with deep features output by the encoder in order to further optimize the edges and details of the segmentation results. Compared with classical semantic segmentation methods, DeeplabV3+ can segment ground objects in complex remote sensing images, but it still faces challenges such as the inaccurate segmentation of small targets and blurred boundary information. Wang et al. [
31] introduced a class feature attention mechanism into the DeeplabV3+ network to enhance the correlation between different categories and effectively extract and process semantic information of diverse categories.
The attention mechanism holds great importance in the field of deep learning. It can assist a model in identifying useful information within the input data, suppressing irrelevant information, and enhancing performance and efficiency. SENet [
32] assigns different weights to each channel by learning the correlation between feature channels. The Efficient Channel Attention Network (ECA-Net) [
33] models the interactions between convolutional feature channels and introduces an adaptive channel attention mechanism, optimizing the negative impact of dimensionality reduction in SENet. To account for information interaction in the spatial dimension, Woo et al. [
34] introduced the Convolutional Block Attention Module (CBAM), which uses a channel attention module and a spatial attention module in series to perform adaptive feature refinement, in contrast to methods that employ costly and complex techniques such as non-local or self-attention blocks. The Coordinate Attention (CA) mechanism [
35] encodes each spatial position, which aids in capturing global contextual information and long-range dependencies. It proves particularly effective for remote sensing images, where spatial relationships and geometric information play a crucial role, enabling neural networks to better comprehend input data and improve prediction accuracy.
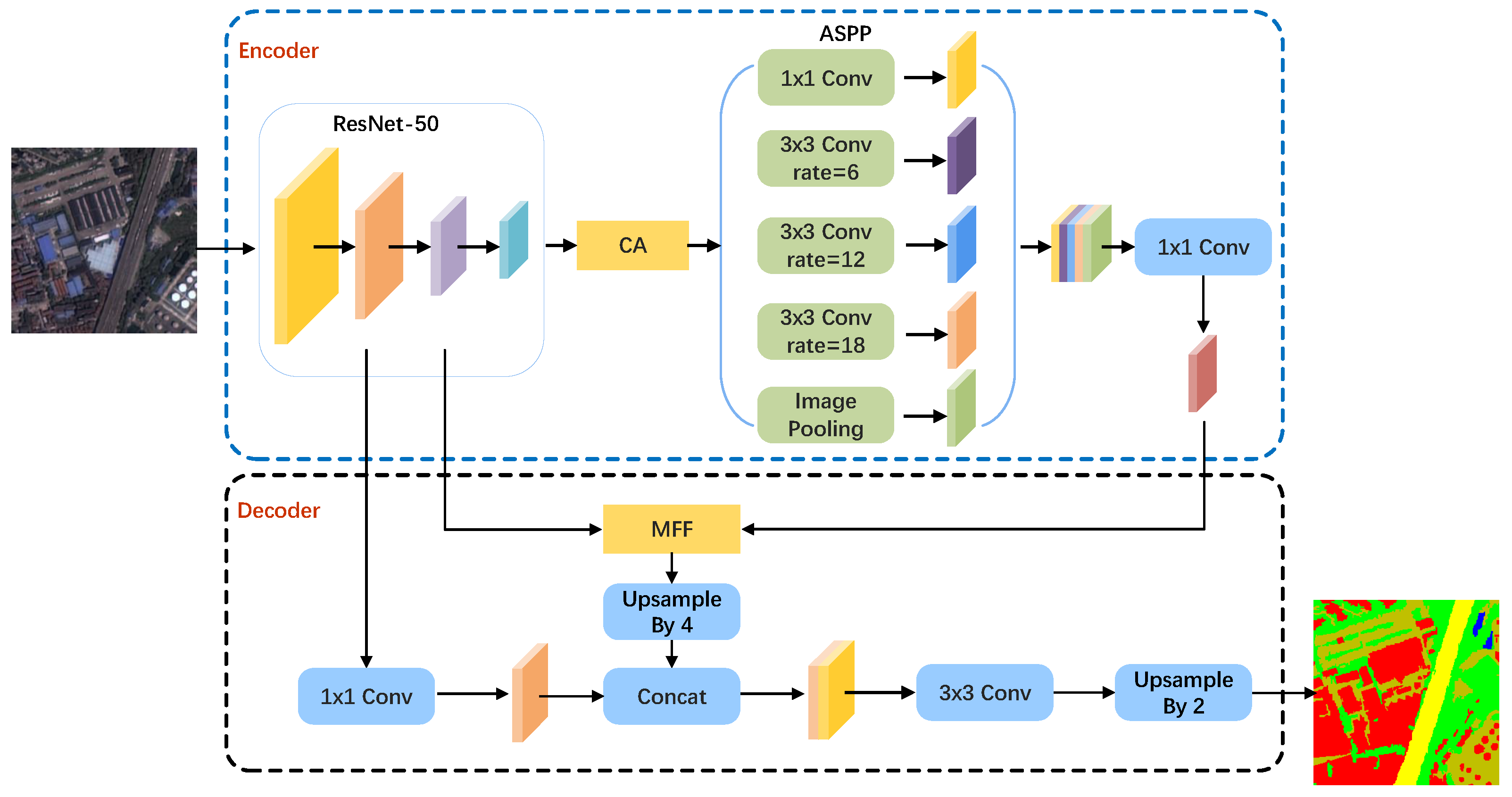
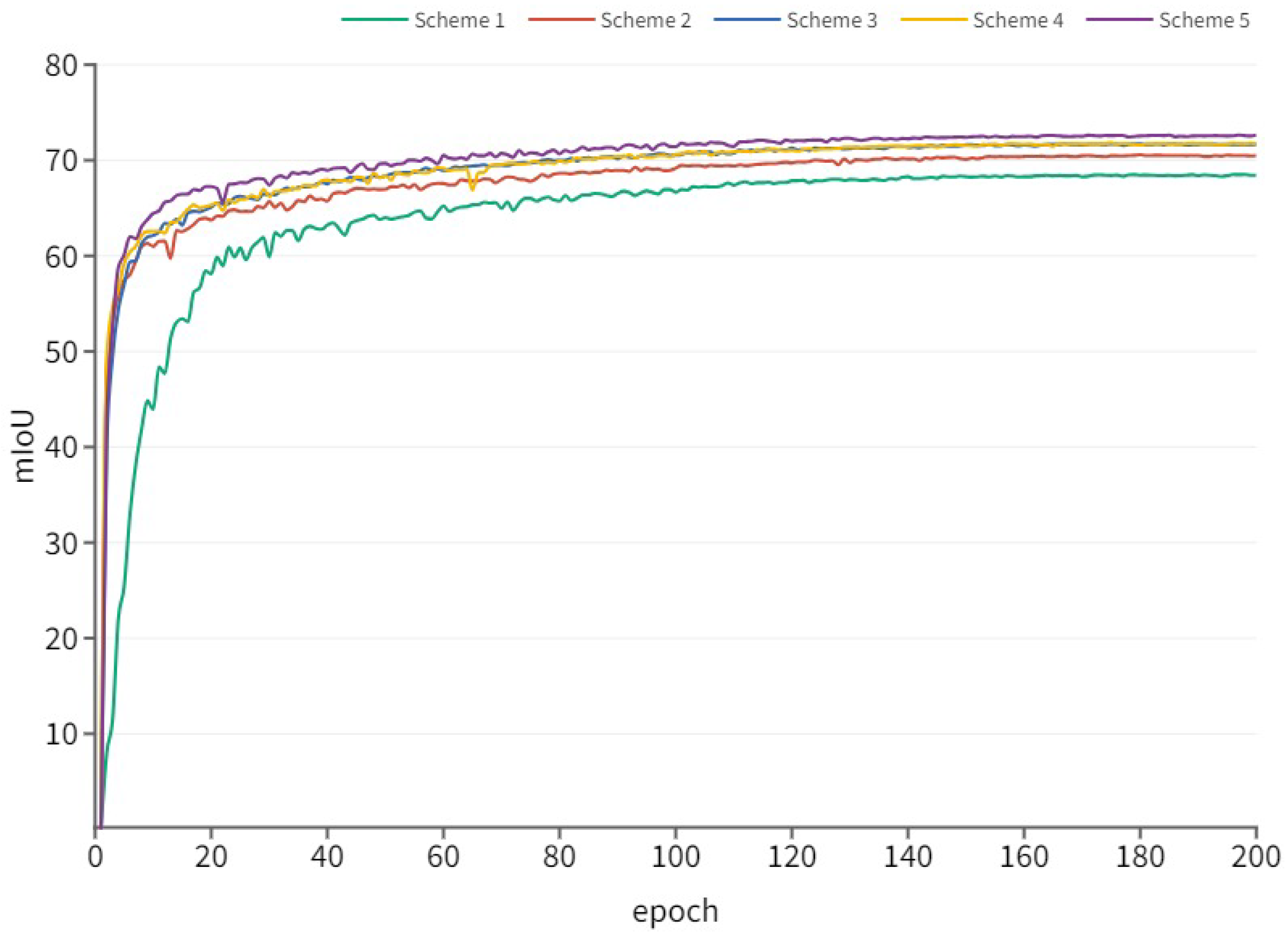
To address the intricate scenarios encountered in object classification for remote sensing images, the proposed RSLC-Deeplab model was designed by combining attention mechanisms and feature fusion methods to automatically extract different ground objects from remote sensing images. To compare the segmentation performance, various segmentation networks including RSLC-Deeplab, DeeplabV3+, U-Net, PSP-NET, and MACU-Net were evaluated on the publicly available WHDLD dataset through experiments. The experimental results showed that RSLC-Deeplab outperformed other comparison networks, effectively enhancing the segmentation ability and reducing the training cost.
2. Methodology
The traditional DeeplabV3+ model was proposed by a team at Google. On the basis of DeeplabV3, DeeplabV3+ has undergone fundamental architectural changes. DeeplabV3+ uses Xception [
36] as the backbone network, eliminates the use of fully connected Conditional Random Fields (CRF), and uses DeeplabV3 as the encoder to design a new encoder–decoder structure. In the encoder, a deep convolutional neural network is employed to extract features from the input image. Then, ASPP obtains rich contextual information by utilizing multi-scale atrous convolution and pyramid pooling from the output features of the backbone network. The semantic information features of various scales are integrated, and the fused high-level semantic features with multiple scales are adjusted in terms of channel number and upsampled using bilinear interpolation. In the decoder, the upsampled high-level semantic features are used to restore spatial resolution. During the process of feature map resolution recovery, the low-level features extracted from the backbone network are concatenated with the high-level features. The low-level features possess better perceptual abilities for capturing fine-grained details, such as small objects or edges, resulting in improved accuracy when localizing and segmenting small objects within the image. Finally, four-times bilinear interpolation upsampling is used to generate the final prediction image.
The feature extraction process in the DeeplabV3+ network utilizes the Xception backbone network. The Xception backbone network possesses a substantial amount of layers and parameters, resulting in high model complexity and a slow training speed. Based on improvements made to the original DeeplabV3+ model, RSLC-Deeplab is proposed to enhance the segmentation performance and training efficiency, as shown in
Figure 1. The main contributions of the RSLC-Deeplab model proposed in this paper are as follows:
In the encoder, ResNet-50 is used instead of the original Xception as the feature extraction module, which can capture more refined features.
After the backbone network, the CA module is introduced to embed positional information into the channel attention mechanism, enabling neural networks to better comprehend input data and improve prediction accuracy.
In the decoder, we designed an MFF module, which captures and refines low-level spatial features using asymmetric convolution and then fuses them with high-level abstract features to mitigate the influence of background noise and restore the lost detailed information in deep features.
Figure 1.
Structure diagram of RSLC-Deeplab.
Figure 1.
Structure diagram of RSLC-Deeplab.
2.1. Optimized Feature Extraction Module
In the encoder, the feature extraction network for RSLC-Deeplab is ResNet-50 [
37], and
Table 1 depicts its structure. We know that the depth of a network is crucial for effective feature extraction. Deep convolutional networks utilize an end-to-end multi-layer approach to integrate features at different levels, achieved through the stacking of convolutional layers and downsampling layers. When the network is stacked to a certain depth, gradient vanishing and gradient explosion problems will occur. Data preprocessing and the incorporation of batch normalization (BN) in the network are effective solutions to address these issues. However, as the network depth increases and convergence is achieved, another challenge emerges: the accuracy tends to reach a plateau and subsequently deteriorate rapidly. Therefore, ResNet introduces a residual structure to alleviate the degradation problem of network performance.
Compared to traditional convolutional neural networks, the residual structure can directly pass low-level features to high-level layers through shortcut connections, which enhances the smooth flow of information within the network. This helps the network to better capture details and local features and improves the reusability of features, thereby enhancing the network’s performance. The shortcut connection skips the connection of one or more layers and directly combines its output with the output of the stacked layers. This approach not only avoids introducing additional parameters or computational complexity, but also facilitates gradient propagation and enables feature reuse. The formula is as follows:
where
x and
y represent the input and output features, respectively, and the function
represents the residual mapping composed of stacked nonlinear layers. For residual networks with different network depths, there are two different residual structures. The residual structure on the left of
Figure 2 is suitable for networks with fewer layers, while the residual structure on the right is more suitable for networks with more layers. In ResNet-50, the
function of the residual structure is composed of three stacked layers: 1 × 1, 3 × 3, and 1 × 1 convolution. The channel number is first reduced by 1 × 1 convolution, then 3 × 3 convolution is performed, and finally the channel number is restored by 1 × 1 convolution.
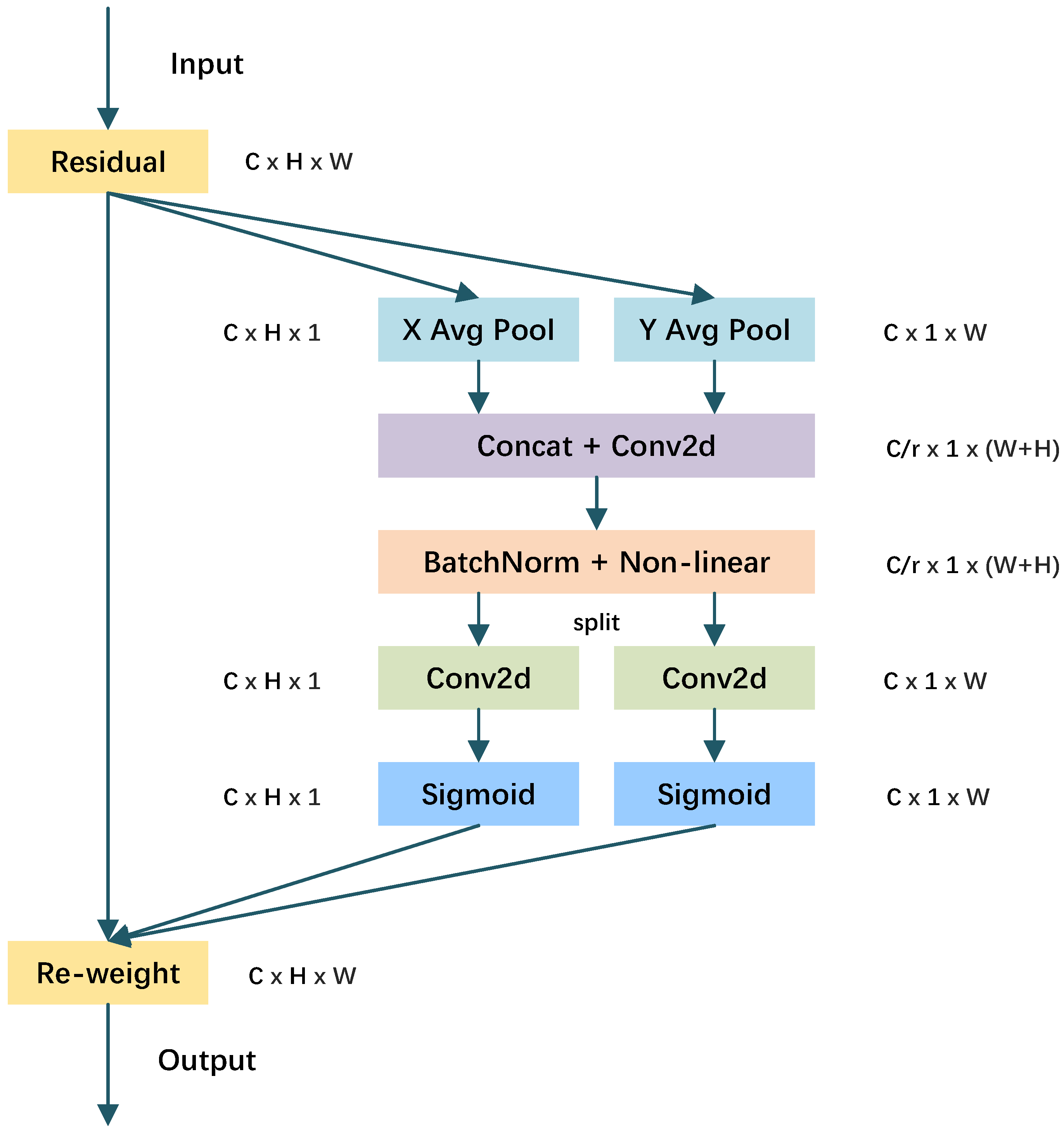
2.2. CA Module
The origin of attention mechanisms can be traced back to studies on human vision, where researchers aimed to develop models of visual selective attention that could simulate the intricate process of human visual perception. It has been empirically established that incorporating attention mechanisms into convolutional neural networks enhances the ability to capture crucial information. The core principle underlying attention mechanisms entails learning the regions of interest in each image via the process of forward propagation and negative feedback, followed by the assignment of appropriate attention weights. In order to effectively capture the relationships between channels, a Coordinate Attention (CA) module is introduced subsequent to the feature extraction network module. The CA module is mainly implemented through two steps: embedding coordinate information and generating coordinate attention. The CA module dynamically adjusts weights to model dependencies between different distances, enabling the model to better capture global information within images. The specific structure is depicted in
Figure 3.
Due to the prevalent utilization of global pooling in channel attention mechanisms for the purpose of globally encoding spatial information, there exists a potential risk of losing positional information. In the coordinate information embedding module, for the input feature X, a pooling kernel of dimensions (H,1) and (1,W) is employed to encode each channel along the horizontal and vertical coordinate directions, respectively. By using a pair of one-dimensional features to encode the features of each location into a unique vector, the network can better understand and utilize location information. Consequently, the output of the
c-th channel, characterized by a height (
h) and width (
w), can be expressed as follows:
By combining features along both the horizontal and vertical directions, a set of feature maps that are sensitive to directional information is generated. This pair of transformations helps the attention block gain the ability to apprehend distant correlations within a particular spatial orientation while upholding the integrity of precise positional data in the alternative spatial orientation. Consequently, such operations assist the network in effectively locating desired objects. After performing cascaded operations on the aggregated feature maps, they are further processed using a 1 × 1 convolutional transformation function,
F, which is expressed as follows:
where
denotes the concatenation operation along the horizontal and vertical coordinate directions,
denotes the non-linear activation function, and
f represents the intermediate feature map that encodes spatial information. Subsequently,
f is partitioned into two separate tensors, namely
and
, along the spatial dimension. Here, the variable
r specifically denotes the reduction ratio employed to regulate the block size within the SE block. Subsequently,
and
undergo separate 1 × 1 convolutions, denoted as
and
, respectively, to match the channel dimensions of the input tensor
X, as follows:
where
represents the sigmoid activation function. Then,
and
are expanded as attention weights, and the final output
Y of CA is as follows:
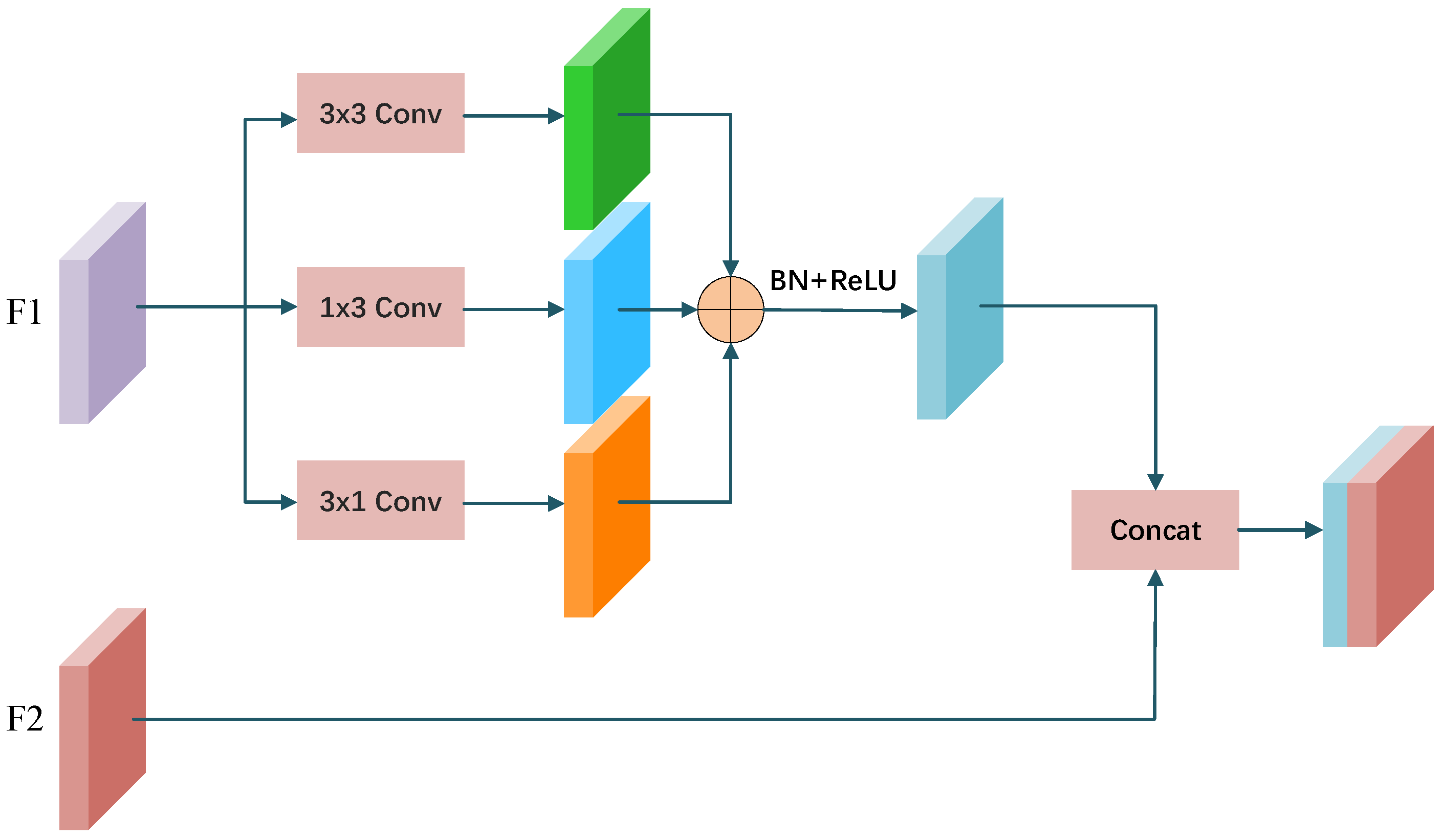
2.3. MFF Module
Due to the three downsampling operations in the feature extraction process of the backbone network, the decrease in resolution leads to the loss of spatial information for finer details. In the decoder part of the original DeeplabV3+ network model, the problem of lost segmentation object detail is improved to some extent by directly concatenating the deep features output by the encoder with the shallow features from the backbone network, but it is still not precise enough for segmenting complex objects such as object boundaries and small targets. To further improve segmentation accuracy, a multilevel feature fusion module (MFF) is introduced, as illustrated in
Figure 4.
During the process of multilevel feature fusion, the shallow features. , obtained from the third downsampling of the backbone network and the deep features, , from the encoder output are used as inputs. To fuse the local spatial information in with the global semantic information in , asymmetric convolution is utilized to extract features from the shallow features, , which are then concatenated and fused with the deep features, . By effectively combining shallow and deep features, this method enhances the overall accuracy of the segmentation model.
Compared to normal convolution, asymmetric convolution has a stronger feature representation ability. The weights of the square convolution kernel are typically larger than those of the corners, which can lead to uneven feature refinement. Asymmetric convolution uses three parallel convolutional layers: 3 × 3 convolution, 1 × 3 convolution, and 3 × 1 convolution. The 3 × 3 convolution obtains features from a larger receptive field, while the 1 × 3 and 3 × 1 convolutions can obtain receptive fields in the horizontal and vertical directions, respectively. This allows the network to effectively collect the correlation information of different spatial scales, which is particularly useful for tasks such as semantic segmentation, where capturing detailed spatial information is crucial. Finally, the outcomes of three convolution operations are added to further enrich the spatial features. The formula for asymmetric convolution is
where
is the input feature,
is the output feature,
is the expected value of the input,
is a small constant to ensure numerical stability,
and
represent the two trainable parameters of the BN layer, and
represents the ReLU activation function.


 ,
, 

{kind=link}
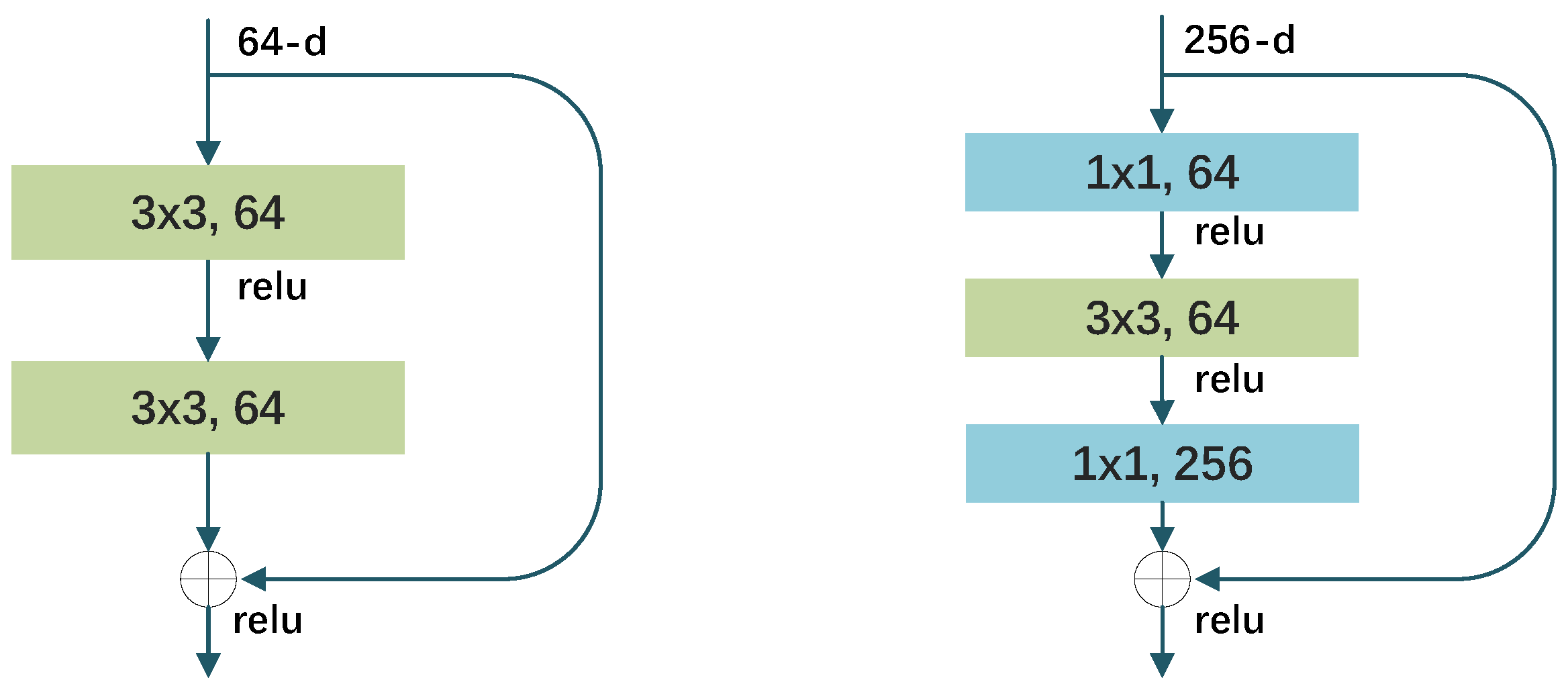{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







