
A Specialized Database for Autonomous Vehicles Based on the KITTI Vision Benchmark


Abstract
:1. Introduction
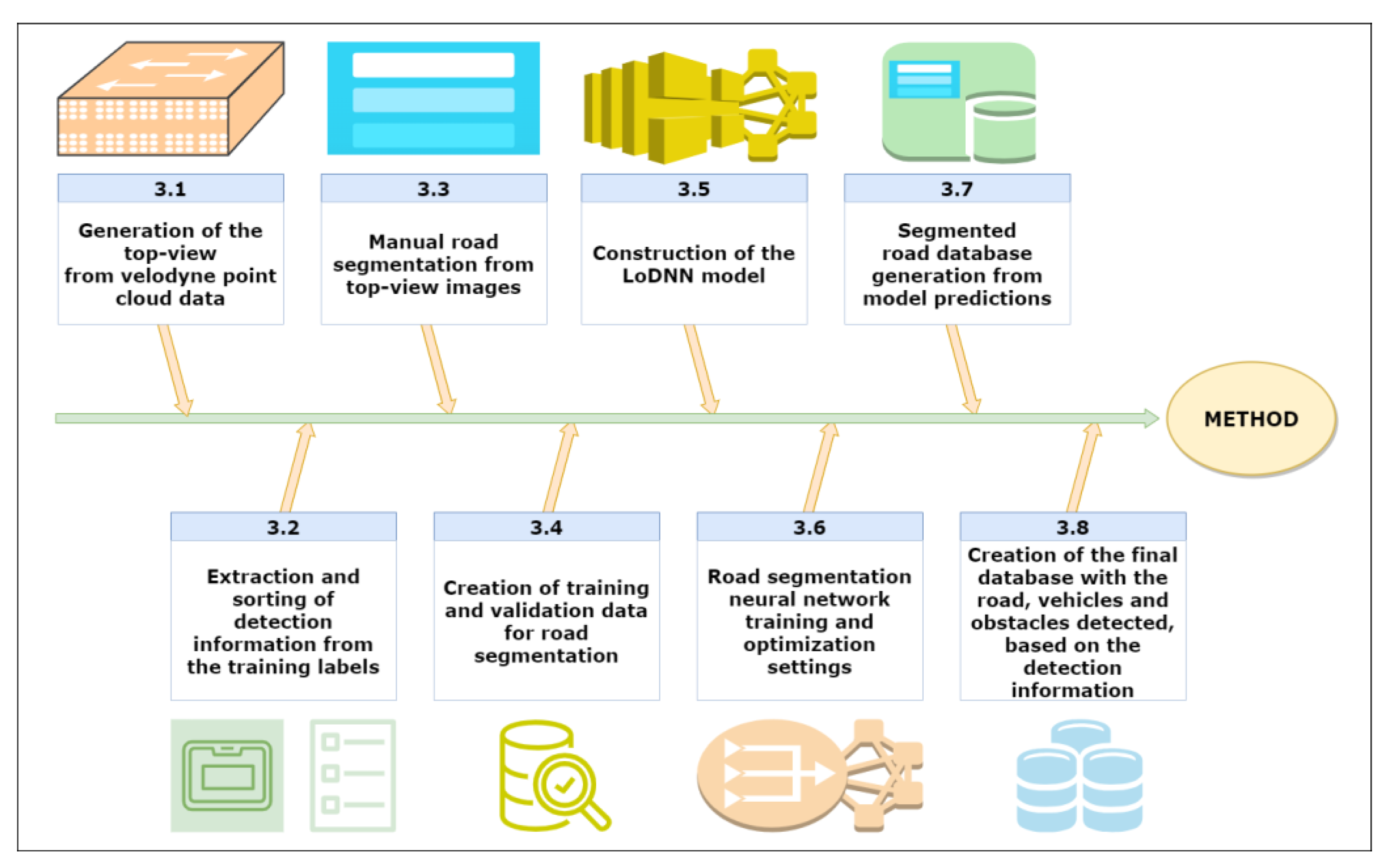
- A step-by-step explanation of the method used during database production, divided into eight sections, with an emphasis on ways of reproducing the process of database creation in order to allow for the possibility of taking different considerations into account when creating any of the three types of formats, such as considering different types of classes or different methods of creating ground-truth segmentation maps.
- The creation of a database that includes 7481 top-view segmentation map files of urban scenes, segmenting the road, background, cars, vans, and pickups. These types of files do not exist in other databases, as far as we are aware, and are necessary for environmental perception in autonomous vehicles. In addition, the method of their creation is included, highlighting that the database only has biases during path segmentation because the objects of interest are found through certain mathematical manipulations.
- The results of road segmentation metrics F1-95.77, AP-92.54, ACC-97.53, PRE-94.34, and REC-97.25 are superior to the state-of-the-art.
2. Related Work
2.1. Semantic Segmentation Top-View Works Related to Autonomous Vehicles
2.2. LiDAR Semantic Segmentation Top-View Works Related to Autonomous Vehicles
2.3. Databases for Autonomous Vehicle Research
2.4. Databases for Autonomous Vehicles with Segmented Scenes
2.5. Research in Respect of KITTI Vision Benchmark Dataset
3. Materials and Methods
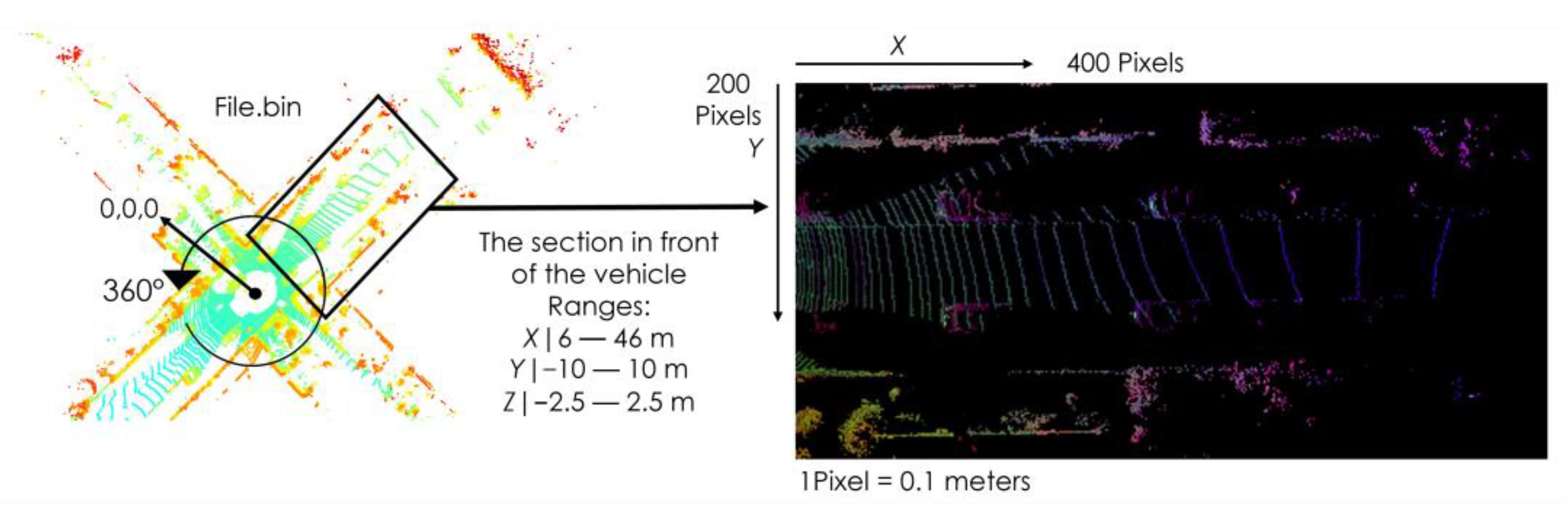
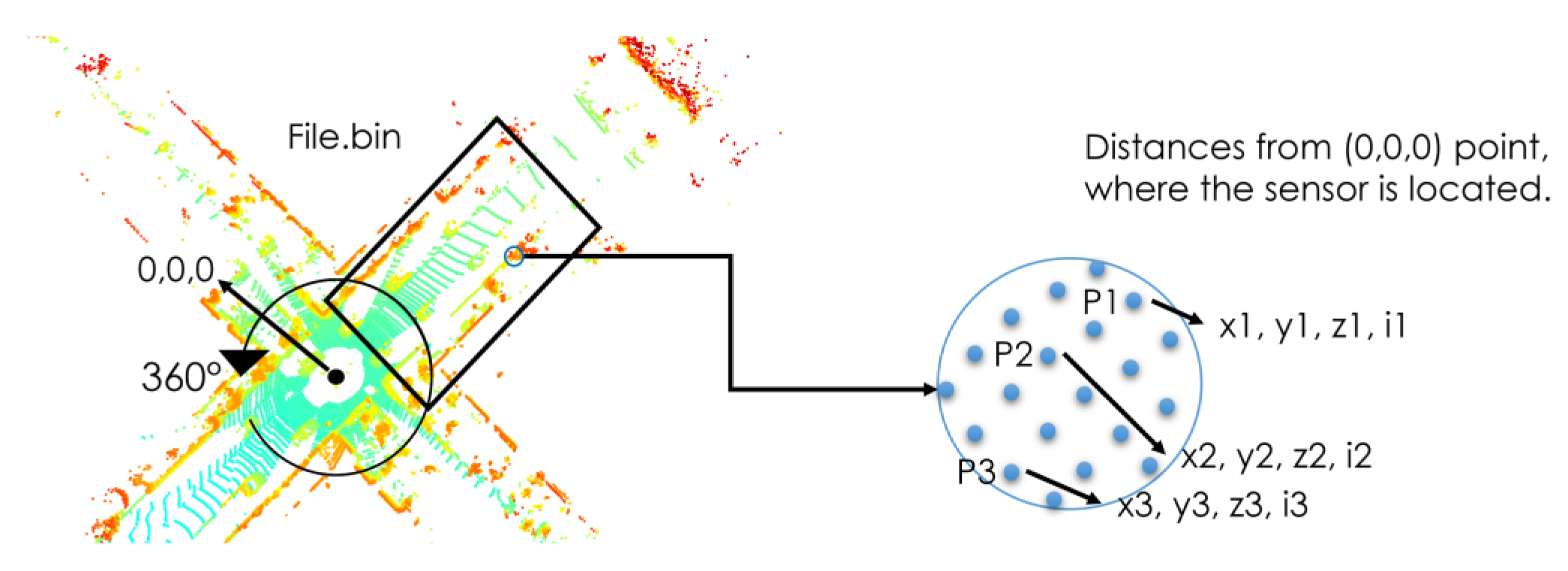
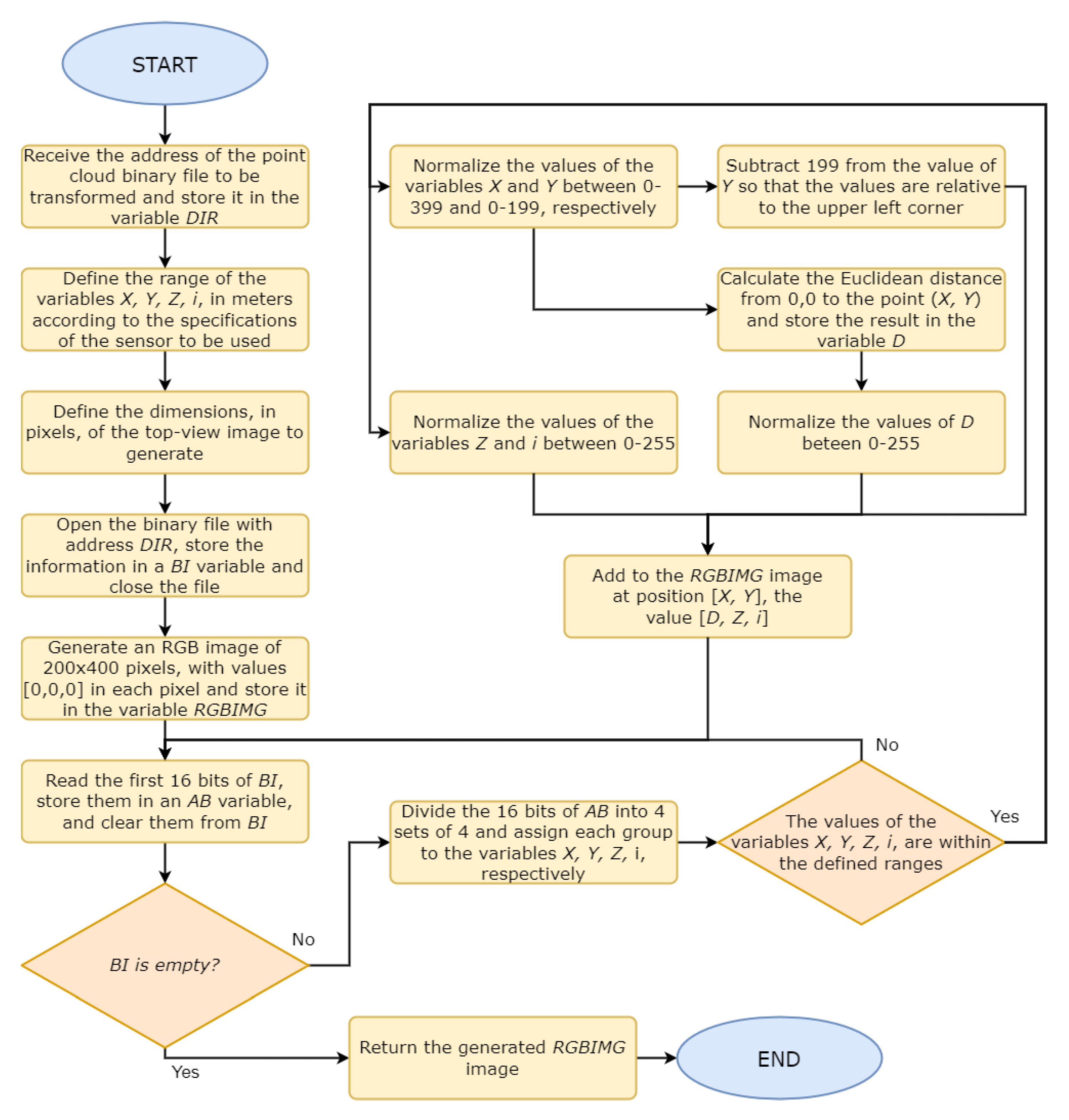
3.1. Generation of the Top-View from the Velodyne Point Cloud Data
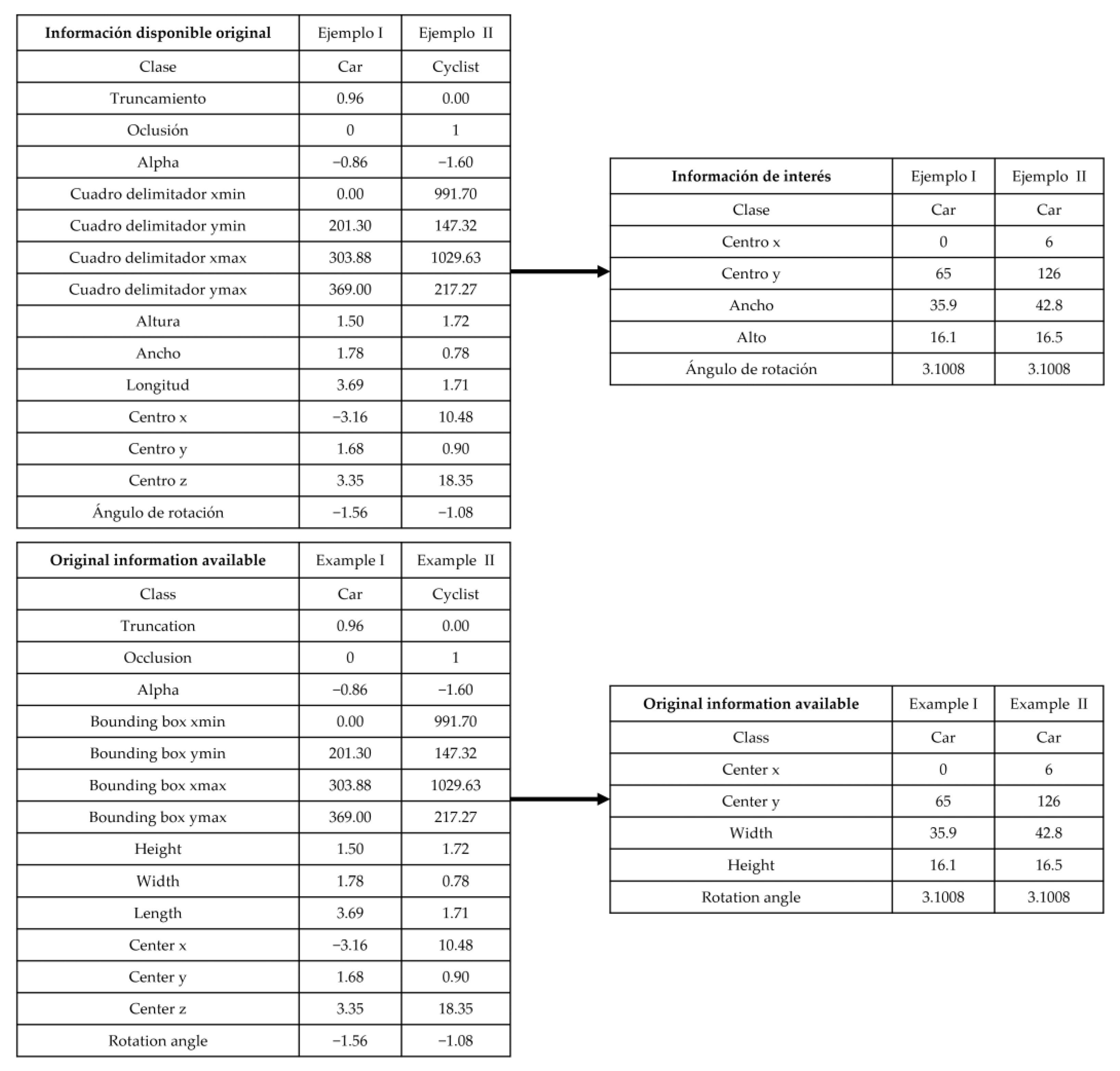
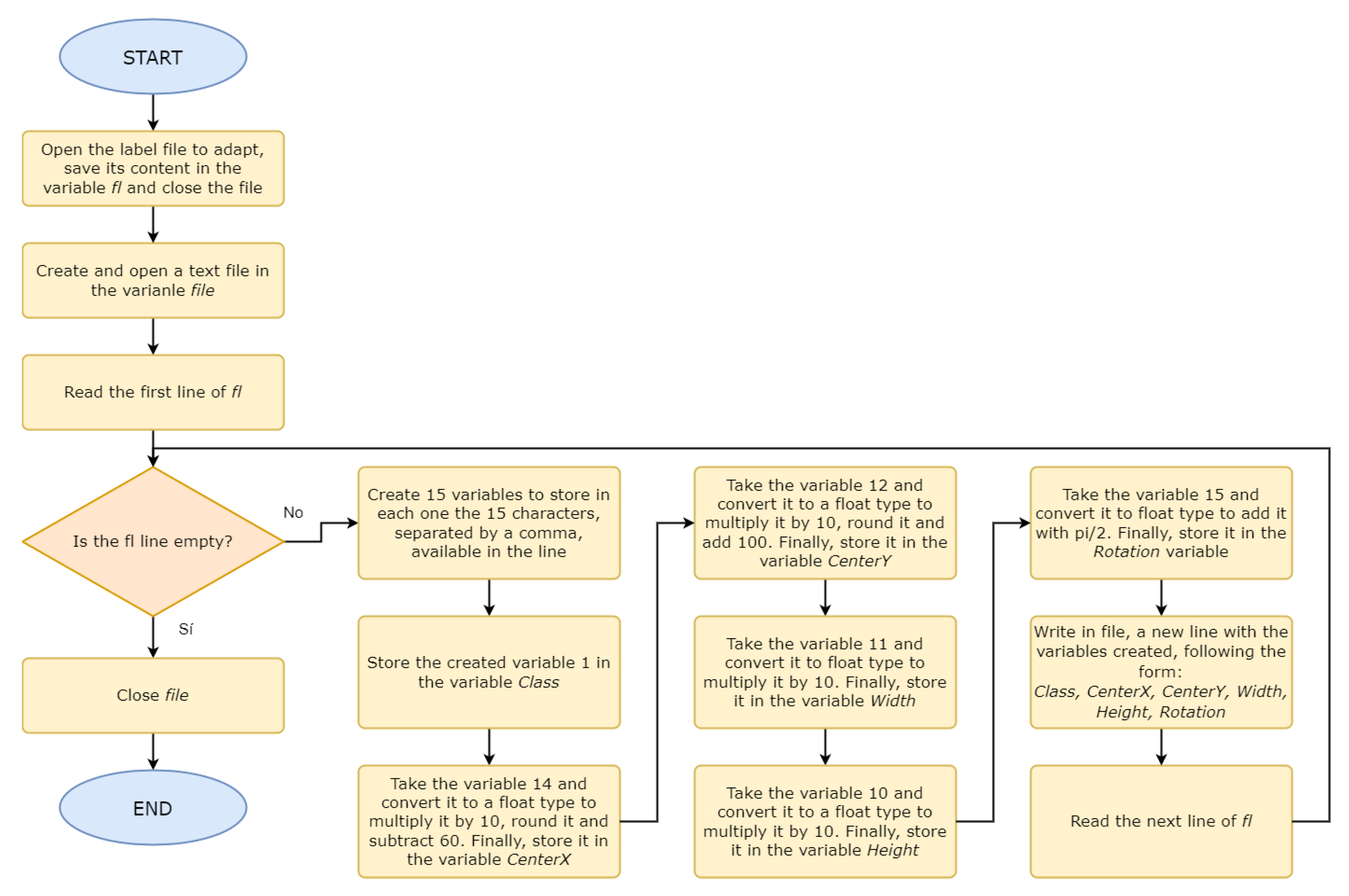
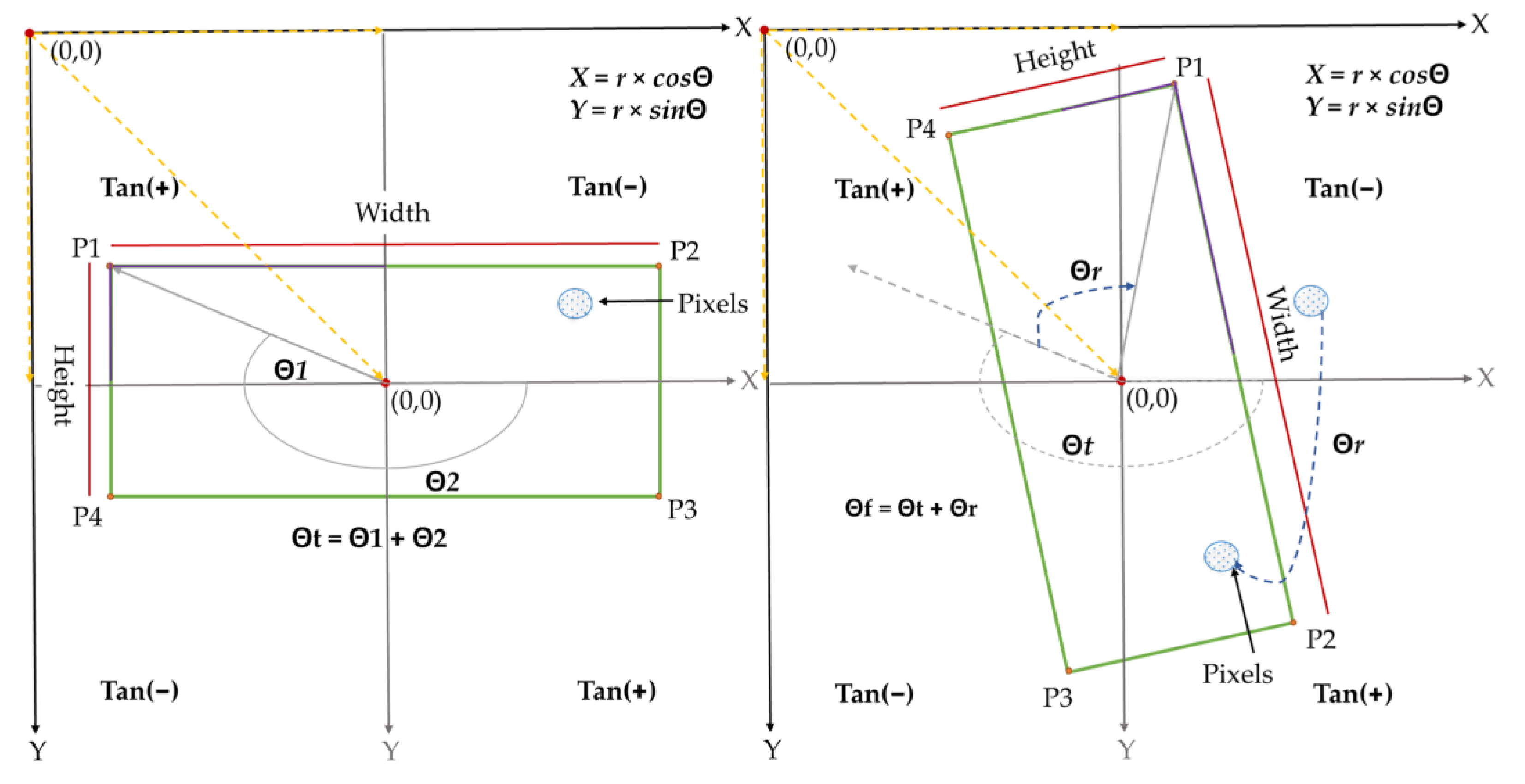
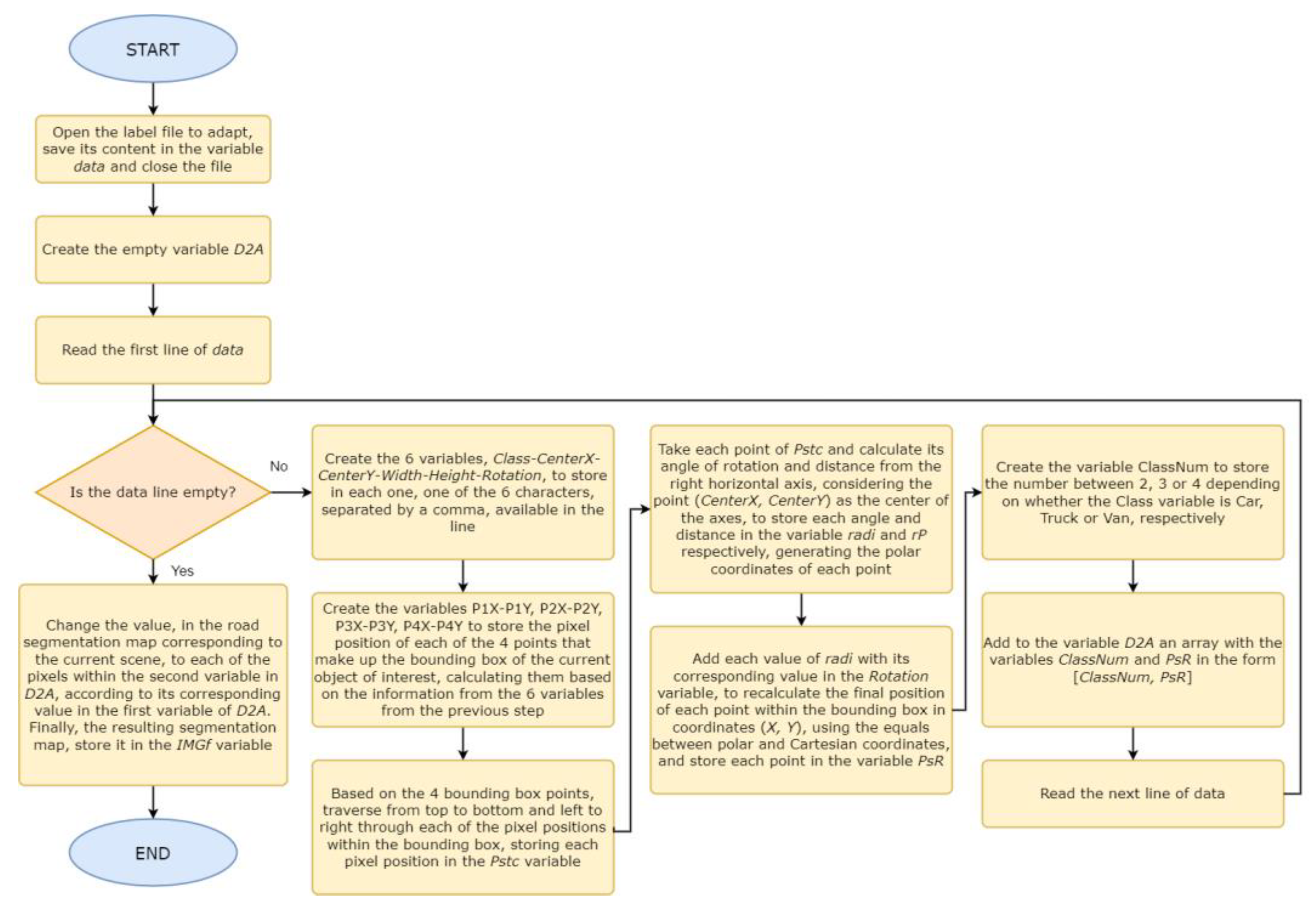
3.2. Extraction and Arrangement of the Detection Information from the Training Labels
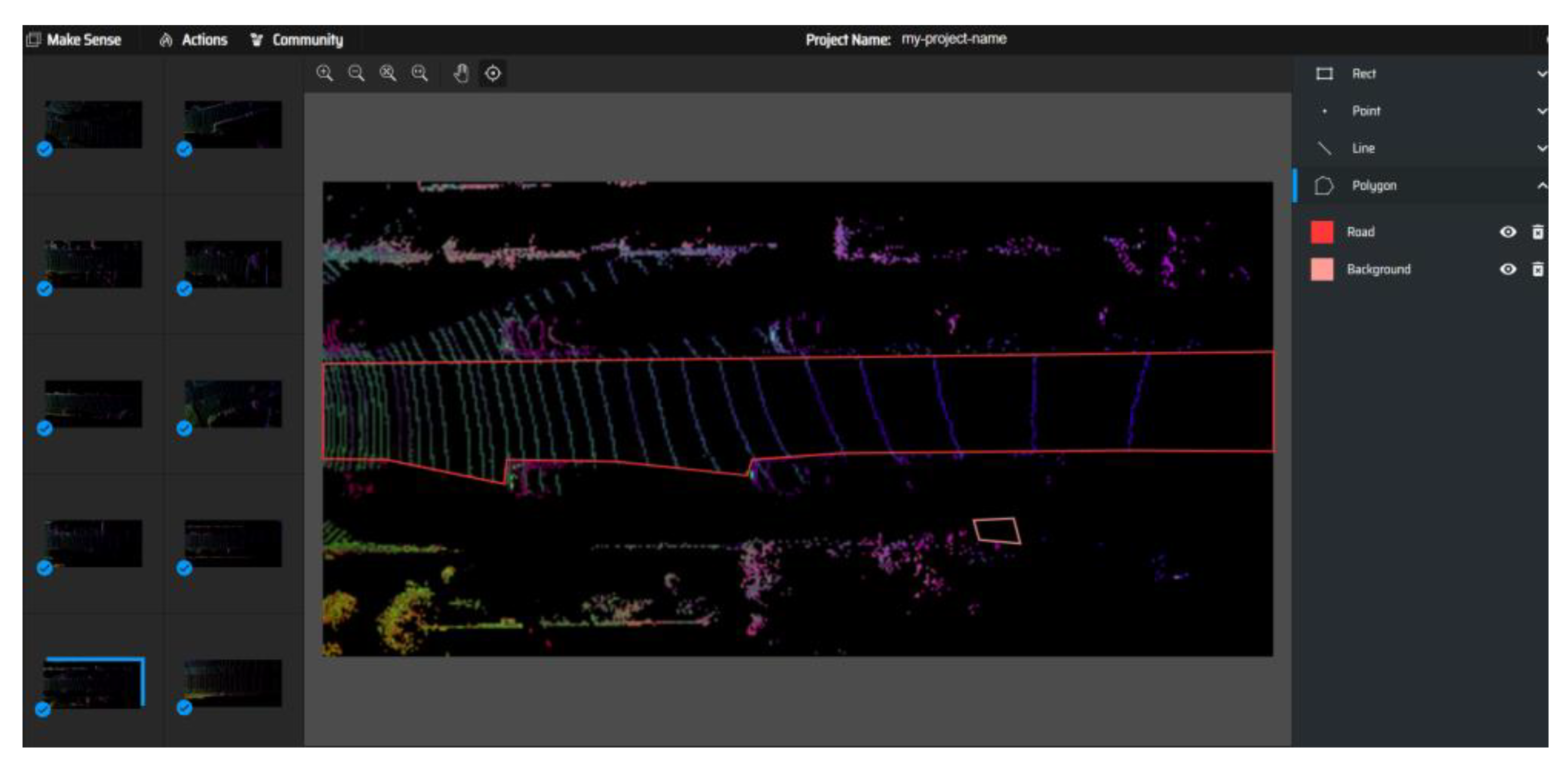
3.3. Manual Road Segmentation from Top-View Images
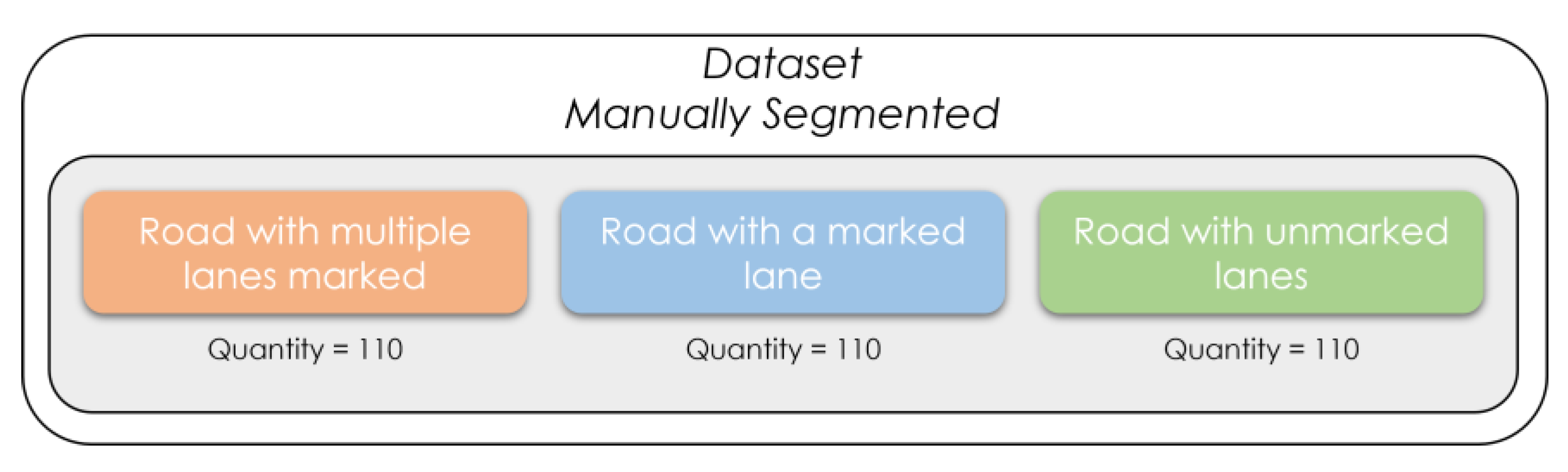
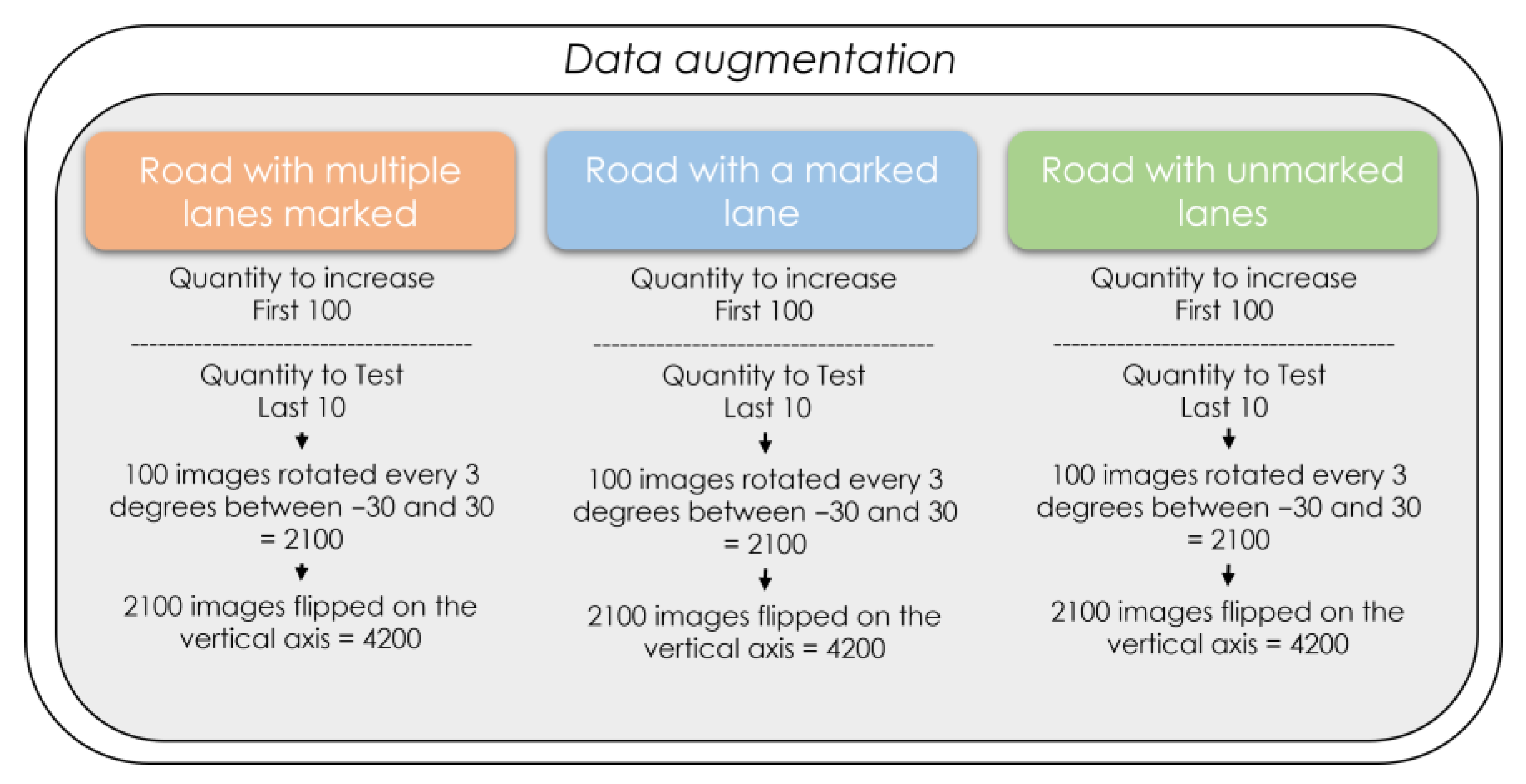
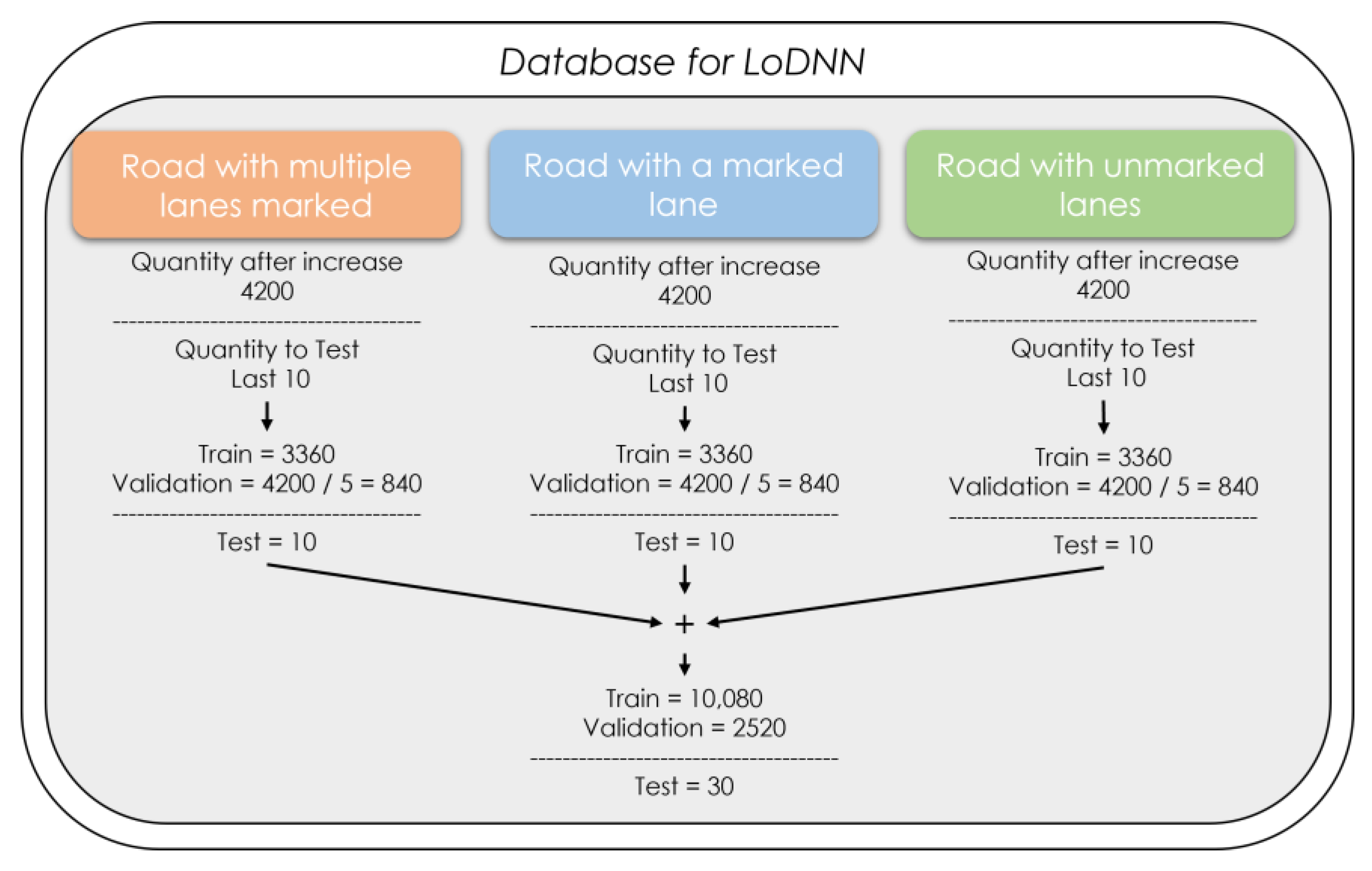
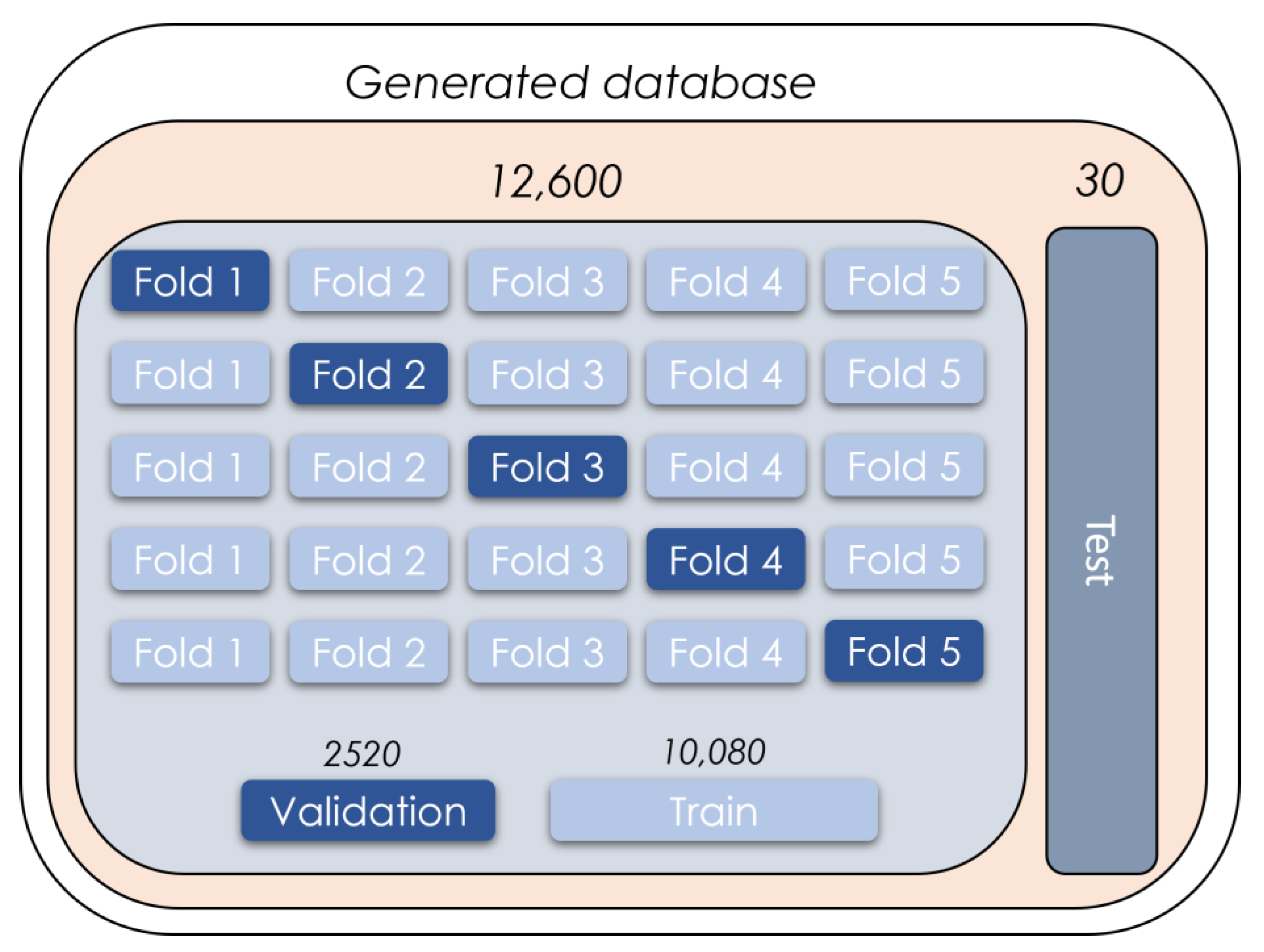
3.4. Creation of Training and Validation Data for Road Segmentation
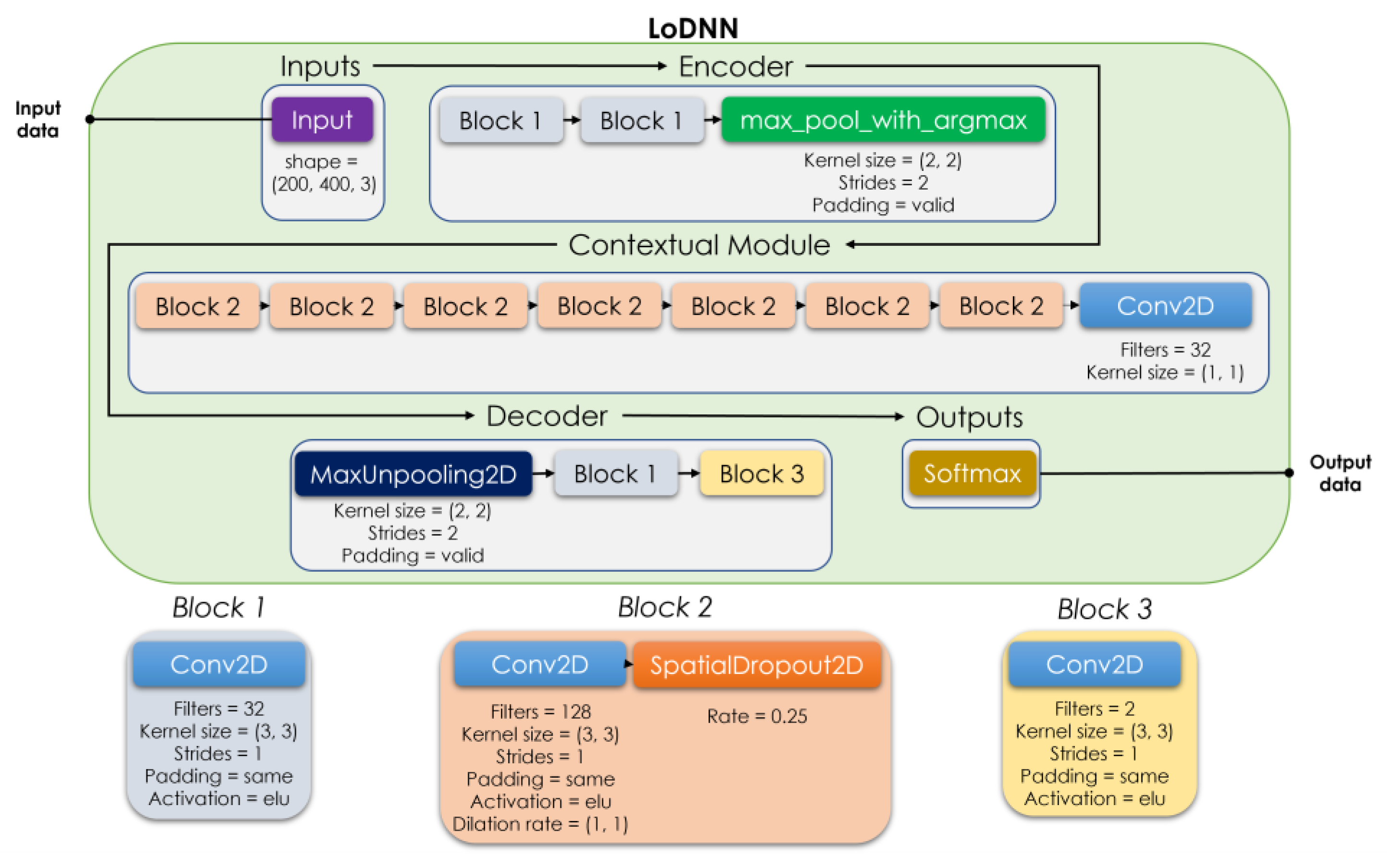
3.5. Construction of the LoDNN Model
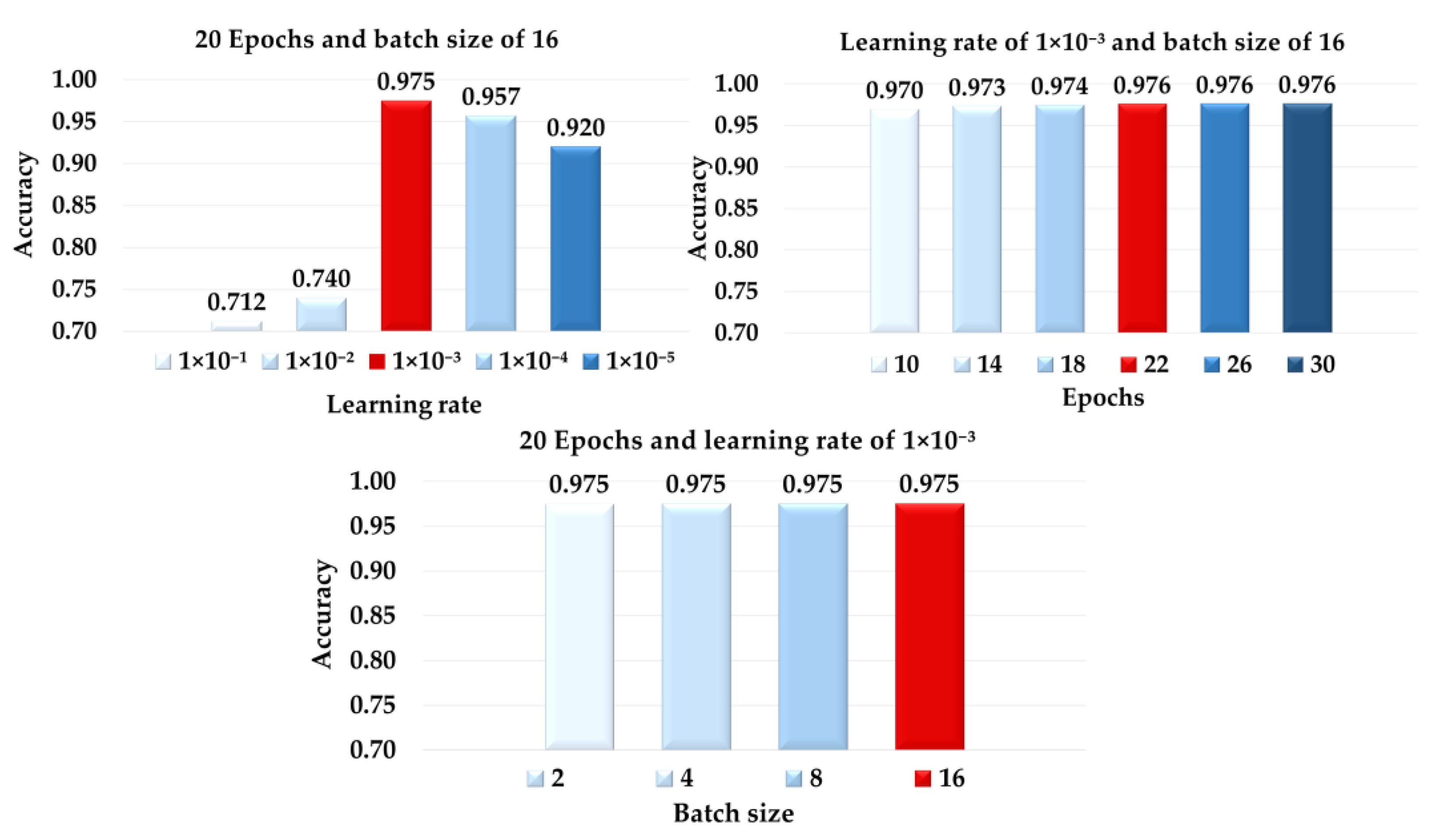
3.6. Training the Neural Network for Road Segmentation and Adjustments for Optimization
3.7. Generation of the Segmented Road Database from Model Predictions
3.8. Creation of the Final Database with the Path, Vehicles, and Obstacles Detected, Taking the Detection Information as a Reference
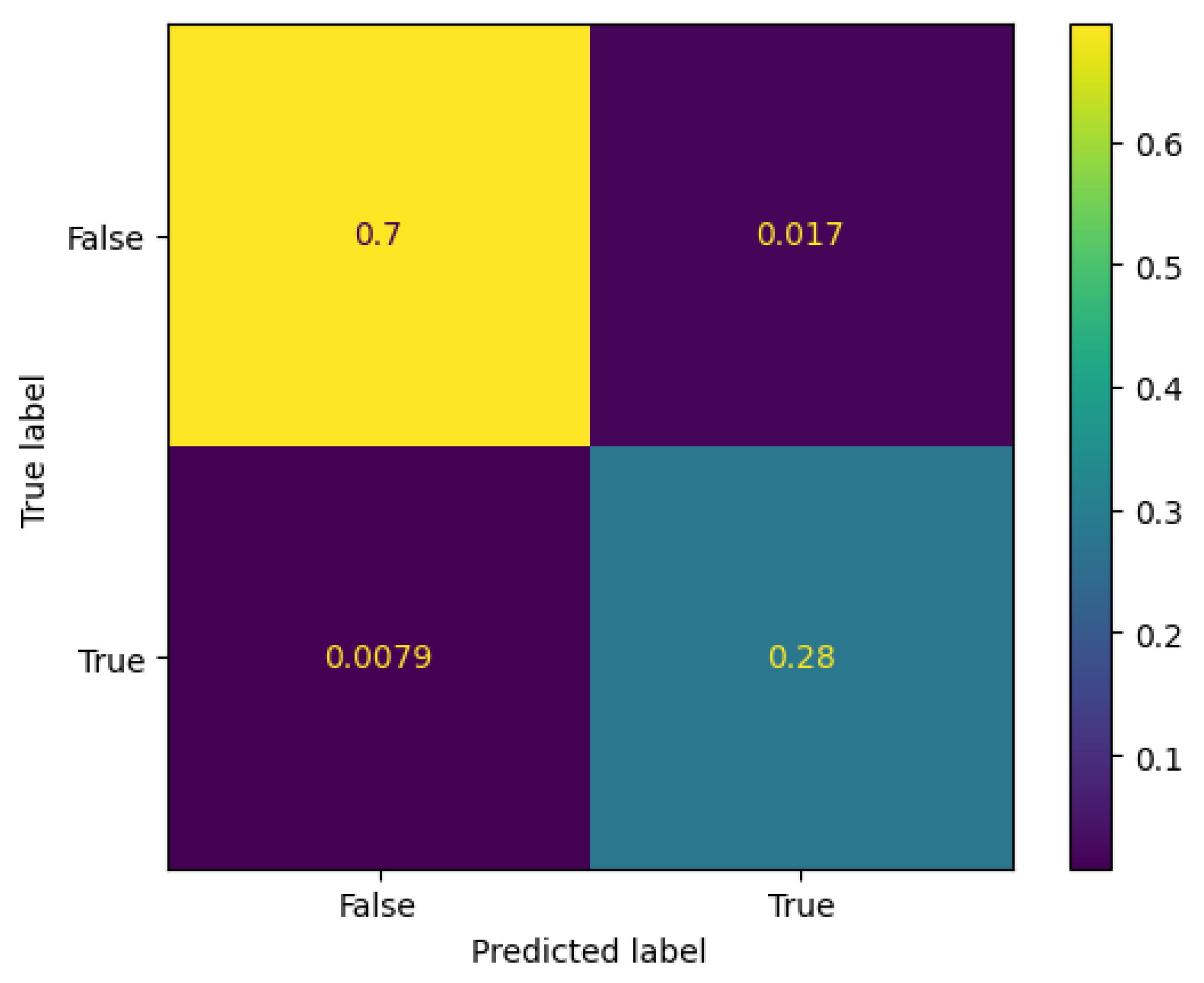
4. Results
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Society of Automotive Engineers International. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-road Motor Vehicles; SAE International: Warrendale, PA, USA, 2018; pp. 1–35. [Google Scholar]
- National Highway Traffic Safety Administration. Automated Driving Systems 2.0: A Vision for Safety; National Highway Traffic Safety Administration: Washington, DC, USA, 2017. [Google Scholar]
- Bachute, M.R.; Subhedar, J.M. Autonomous Driving Architectures: Insights of Machine Learning and Deep Learning Algorithms. Mach. Learn. Appl. 2021, 6, 100164. [Google Scholar] [CrossRef]
- Dewangan, D.K.; Sahu, S.P. RCNet: Road classification convolutional neural networks for intelligent vehicle system. Intell. Serv. Robot. 2021, 14, 199–214. [Google Scholar] [CrossRef]
- Gkolias, K.; Vlahogianni, E.I. Convolutional Neural Networks for On-Street Parking Space Detection in Urban Networks. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4318–4327. [Google Scholar] [CrossRef]
- Chen, L.; Lin, S.; Lu, X.; Cao, D.; Wu, H.; Guo, C.; Liu, C.; Wang, F.-Y. Deep Neural Network Based Vehicle and Pedestrian Detection for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Song, W.; Zou, S.; Tian, Y.; Fong, S.; Cho, K. Classifying 3D objects in LiDAR point clouds with a back-propagation neural network. Hum.-Cent. Comput. Inf. Sci. 2018, 8, 29. [Google Scholar] [CrossRef] [Green Version]
- Lu, W.; Zhou, Y.; Whan, G.; Hou, S.; Song, S. L3-Net: Towards Learning Based Lidar Localization for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6382–6391. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Chen, B.; Gong, C.; Yang, J. Importance-Aware Semantic Segmentation for Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2019, 20, 137–148. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Hu, Y.H.; Qiu, J. RailNet: A Segmentation Network for Railroad Detection. IEEE Access 2019, 7, 143772–143779. [Google Scholar] [CrossRef]
- Lyu, Y.; Bai, L.; Huang, X. Road segmentation using CNN and distributed LSTM. In Proceedings of the IEEE International Symposium on Circuits and Systems, Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Xia, X.; Meng, Z.; Han, X.; Li, H.; Tsukiji, T.; Xu, R.; Zheng, Z.; Ma, J. An automated driving systems data acquisition and analytics platform. Transp. Res. Part C 2023, 151, 104120. [Google Scholar] [CrossRef]
- Liu, W.; Xia, X.; Xiong, L.; Lu, Y.; Gao, L.; Yu, Z. Automated Vehicle Sideslip Angle Estimation Considering Signal Measurement Characteristic. IEEE Sens. J. 2021, 21, 21675–21687. [Google Scholar] [CrossRef]
- Xia, X.; Hashemi, E.; Xiong, L.; Khajepour, A. Autonomous Vehicle Kinematics and Dynamics Synthesis for Sideslip Angle Estimation Based on Consensus Kalman Filter. IEEE Trans. Control Syst. Technol. 2023, 31, 179–192. [Google Scholar] [CrossRef]
- Yang, D.; Li, L.; Redmill, K.; Ozguner, U. Top-view trajectories: A pedestrian dataset of vehicle-crowd interaction from controlled experiments and crowded campus. In Proceedings of the IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019; pp. 899–904. [Google Scholar]
- Azimi, S.M.; Fischer, P.; Korner, M.; Reinartz, P. Aerial LaneNet: Lane-Marking Semantic Segmentation in Aerial Imagery Using Wavelet-Enhanced Cost-Sensitive Symmetric Fully Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2920–2938. [Google Scholar] [CrossRef] [Green Version]
- Pek, C.; Manzinger, S.; Koschi, M.; Althoff, M. Using online verification to prevent autonomous vehicles from causing accidents. Nat. Mach. Intell. 2020, 2, 518–528. [Google Scholar] [CrossRef]
- The KITTI Vision Benchmark Suite. Available online: http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=bev (accessed on 22 February 2023).
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Ozturk, O.; Saritürk, B.; Seker, D.Z. Comparison of Fully Convolutional Networks (FCN) and U-Net for Road Segmentation from High Resolution Imageries. Int. J. Environ. Geoinform 2020, 7, 272–279. [Google Scholar] [CrossRef]
- Carneiro, R.V.; Nascimento, R.C.; Guidolini, R.; Cardoso, V.B.; Oliveira-Santos, T.; Badue, C.; De Souza, A.F. Mapping Road Lanes Using Laser Remission and Deep Neural Networks. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Prophet, R.; Li, G.; Sturm, C.; Vossiek, M. Semantic segmentation on automotive radar maps. In Proceedings of the IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019; pp. 756–763. [Google Scholar]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR–camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.S.; Jo, J.H.; Park, T.H. Segmentation of Vehicles and Roads by a Low-Channel Lidar. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4251–4256. [Google Scholar] [CrossRef]
- Boulch, A.; Le Saux, B.; Audebert, N. Unstructured point cloud semantic labeling using deep segmentation networks. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, EG 3DOR, Lyon, France, 23–24 April 2017; pp. 17–24. [Google Scholar]
- Caltagirone, L.; Scheidegger, S.; Svensson, L.; Wahde, M.F. Fast LIDAR-based road detection using fully convolutional neural networks. In Proceedings of the IEEE Intelligent Vehicles Symposium, Los Angeles, CA, USA, 11–14 June 2017; pp. 1019–1024. [Google Scholar]
- Zhang, W.; Sun, X.; Zhou, L.; Xie, X.; Zhao, W.; Liang, Z.; Zhuang, P. Dual-branch collaborative learning network for crop disease identification. Front. Plant Sci. 2023, 14, 1117478. [Google Scholar] [CrossRef]
- Zhao, W.; Li, C.; Zhang, W.; Yang, L.; Zhuang, P.; Li, L.; Fan, K.; Yang, H. Embedding Global Contrastive and Local Location in Self-Supervised Learning. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 2275–2289. [Google Scholar] [CrossRef]
- Zhang, W.; Li, Z.; Sun, H.; Zhang, Q.; Zhuang, P. SSTNet: Spatial, Spectral, and Texture Aware Attention Network Using Hyperspectral Image for Corn Variety Identification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D tracking and forecasting with rich maps. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8740–8749. [Google Scholar]
- Mandal, S.; Biswas, S.; Balas, V.E.; Shaw, R.N.; Ghosh, A. Motion Prediction for Autonomous Vehicles from Lyft Dataset using Deep Learning. In Proceedings of the 2020 IEEE 5th International Conference on Computing Communication and Automation, ICCCA 2020, Greater Noida, India, 30–31 October 2020; pp. 768–773. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2443–2451. [Google Scholar]
- Janai, J.; Güney, F.; Behl, A.; Geiger, A. Computer Vision for Autonomous Vehicles: Problems, Datasets and State of the Art; Foundations and Trends® in Computer Graphics and Vision; Now Publishers Inc.: Hanover, MD, USA, 2020; Volume 12, pp. 1–308. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11618–11628. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. arXiv 2019, arXiv:1904.01416. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1067–1073. [Google Scholar]
- Wen, L.H.; Jo, K.H. Fast and Accurate 3D Object Detection for Lidar-Camera-Based Autonomous Vehicles Using One Shared Voxel-Based Backbone. IEEE Access 2021, 9, 22080–22089. [Google Scholar] [CrossRef]
- Al-refai, G.; Al-refai, M. Road object detection using Yolov3 and Kitti dataset. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 48–53. [Google Scholar] [CrossRef]
- Fan, Y.C.; Yelamandala, C.M.; Chen, T.W.; Huang, C.J. Real-Time Object Detection for LiDAR Based on LS-R-YOLOv4 Neural Network. J. Sens. 2021, 2021, 11. [Google Scholar] [CrossRef]
- Make Sense. Available online: https://www.makesense.ai/ (accessed on 26 May 2023).
- Welcome to Python. Available online: https://www.python.org/ (accessed on 9 March 2023).
- Oliveira, G.L.; Burgard, W.; Brox, T. Efficient deep models for monocular road segmentation. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Daejeon, Republic of Korea, 9–14 October 2016; pp. 4885–4891. [Google Scholar]
- Mohan, R. Deep Deconvolutional Networks for Scene Parsing. arXiv 2014, arXiv:1411.4101. [Google Scholar]
- Laddha, A.; Kocamaz, M.K.; Navarro-Serment, L.E.; Hebert, M. Map-supervised road detection. In Proceedings of the IEEE Intelligent Vehicles Symposium, Gothenburg, Sweden, 19–22 June 2016; pp. 118–123. [Google Scholar]
- Mendes, C.; Frémont, V.; Wolf, D. Exploiting fully convolutional neural networks for fast road detection. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 3174–3179. [Google Scholar]
- Munoz, D.; Bagnell, J.A.; Hebert, M. Stacked Hierarchical Labeling. In Computer Vision—Eccv 2010, Pt Vi; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6316, pp. 57–70. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Berneshawi, A.; Ma, H.; Fidler, S.; Urtasun, R. 3D object proposals for accurate object class detection. Adv. Neural Inf. Process. Syst. 2015, 2015, 424–432. [Google Scholar]
- Patrick, Y.; Shinzato, D.F.W.; Stiller, C. Road Terrain Detection: Avoiding Common Obstacle Detection Assumptions Using Sensor Fusion. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 687–692. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | F1 | AP | ACC | PRE | REC |
|---|---|---|---|---|---|
| LoDNN-I (proposal) | 95.77 | 92.54 | 97.53 | 94.34 | 97.25 |
| Methods | F1 | AP | PRE | REC |
|---|---|---|---|---|
| LoDNN-I (proposal) | 95.77 | 92.54 | 94.34 | 97.25 |
| LoDNN [28] | 94.07 | 92.03 | 92.81 | 95.37 |
| Up-Conv-Poly [44] | 93.83 | 90.47 | 94.00 | 93.67 |
| DDN [45] | 93.43 | 89.67 | 95.09 | 91.82 |
| FTP [46] | 91.61 | 90.96 | 91.04 | 92.2 |
| FCN-LC [47] | 90.79 | 85.83 | 90.87 | 90.72 |
| HIM [48] | 90.64 | 81.42 | 91.62 | 89.68 |
| NNP [49] | 89.68 | 86.5 | 89.67 | 89.68 |
| RES3D-Velo [50] | 86.58 | 78.34 | 82.63 | 90.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ortega-Gomez, J.I.; Morales-Hernandez, L.A.; Cruz-Albarran, I.A. A Specialized Database for Autonomous Vehicles Based on the KITTI Vision Benchmark. Electronics 2023, 12, 3165. https://doi.org/10.3390/electronics12143165
Ortega-Gomez JI, Morales-Hernandez LA, Cruz-Albarran IA. A Specialized Database for Autonomous Vehicles Based on the KITTI Vision Benchmark. Electronics. 2023; 12(14):3165. https://doi.org/10.3390/electronics12143165
Chicago/Turabian StyleOrtega-Gomez, Juan I., Luis A. Morales-Hernandez, and Irving A. Cruz-Albarran. 2023. "A Specialized Database for Autonomous Vehicles Based on the KITTI Vision Benchmark" Electronics 12, no. 14: 3165. https://doi.org/10.3390/electronics12143165