

An Underwater Dense Small Object Detection Model Based on YOLOv5-CFDSDSE

Abstract
:1. Introduction
- (1)
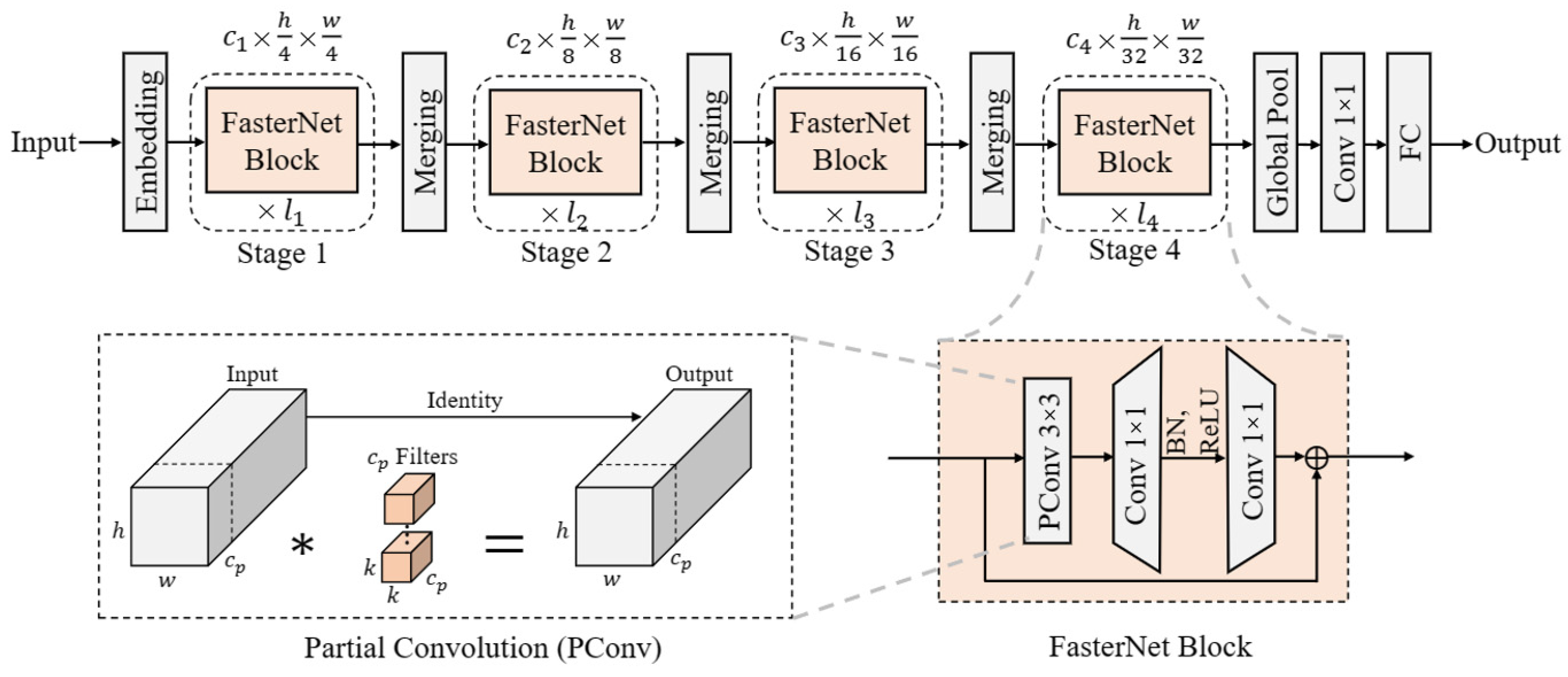
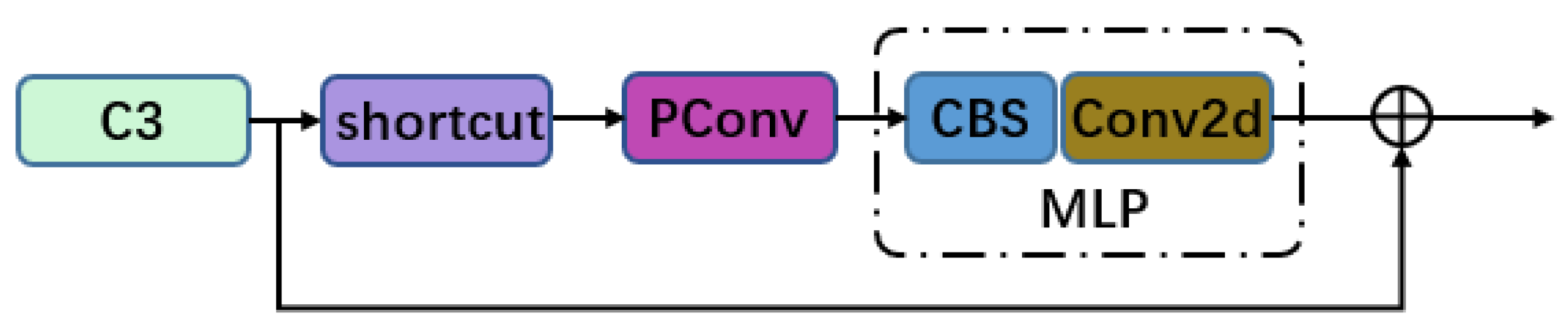
- A new structure Cfnet is proposed, which is an efficient fusion of C3 and FasterNet structures, reduces the number of parameters, increases the detection speed, and, at the same time, has a high detection accuracy;
- (2)
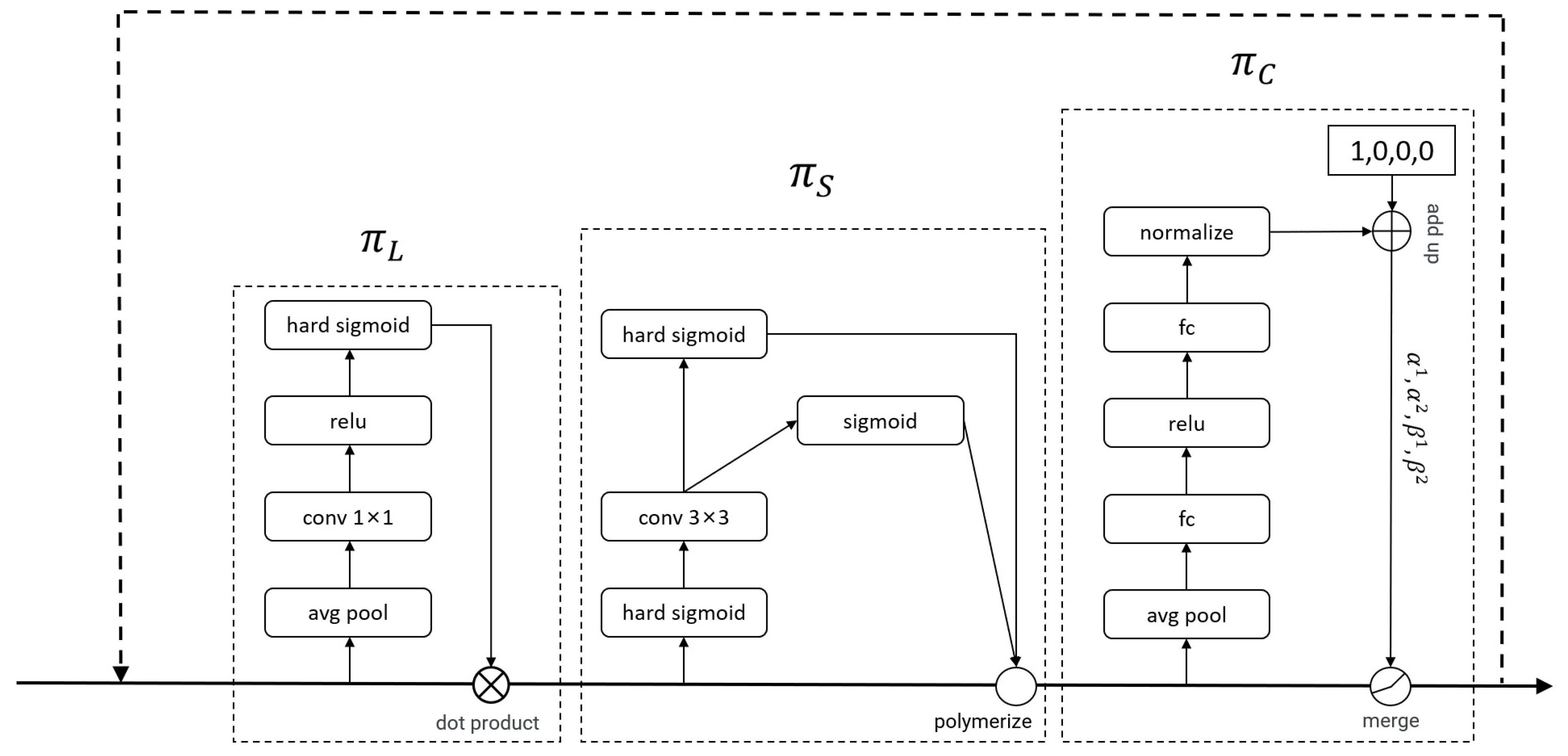
- The Dyhead replaces the original detection head, improving the model’s ability to detect multi-scale and multi-category targets, which is especially effective for underwater dense small object detection;
- (3)
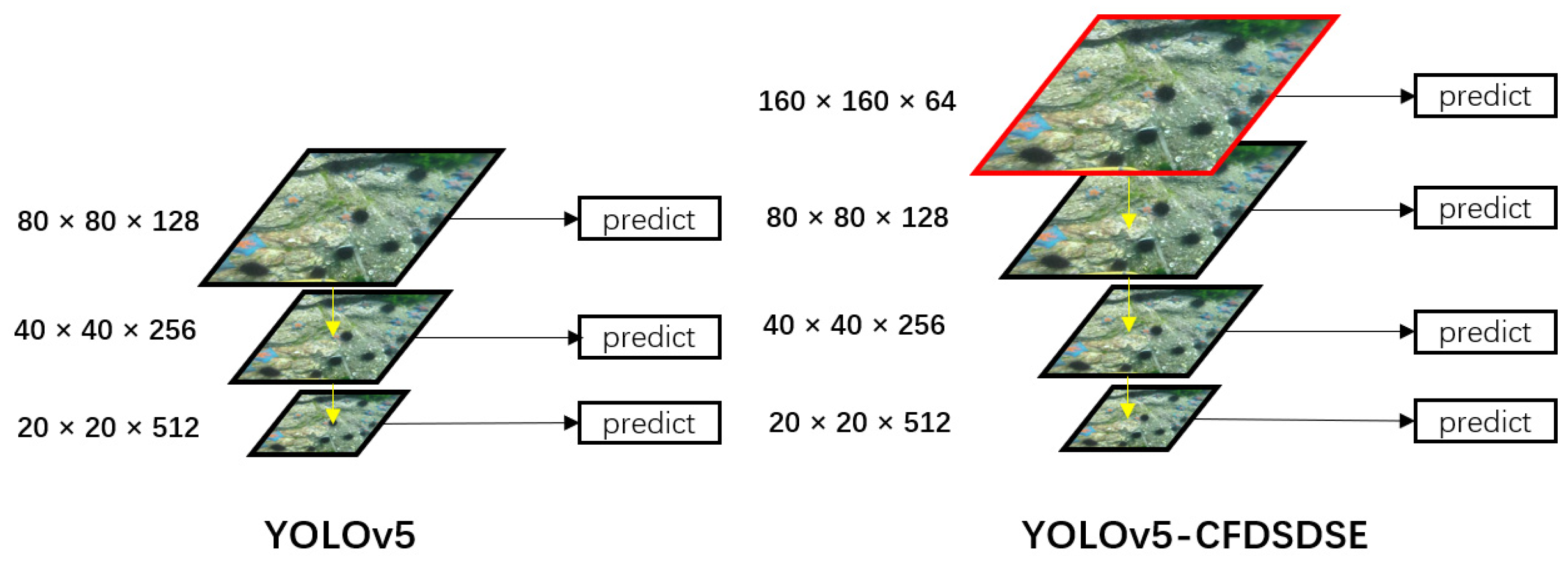
- The SD layer is added, improving the model’s performance for underwater small object detection;
- (4)
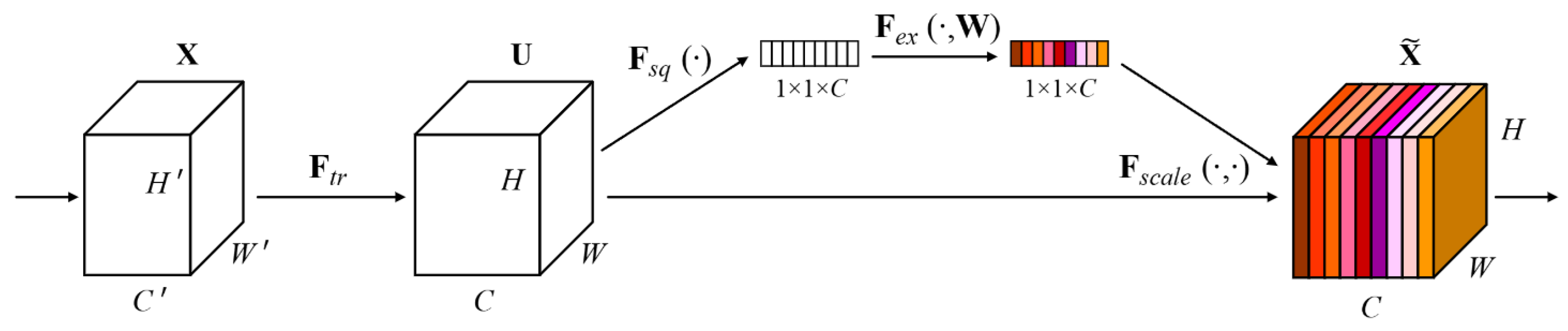
- The attention mechanism SE is introduced to make the model capture the global context information more completely.
2. Related Work
3. Methodology
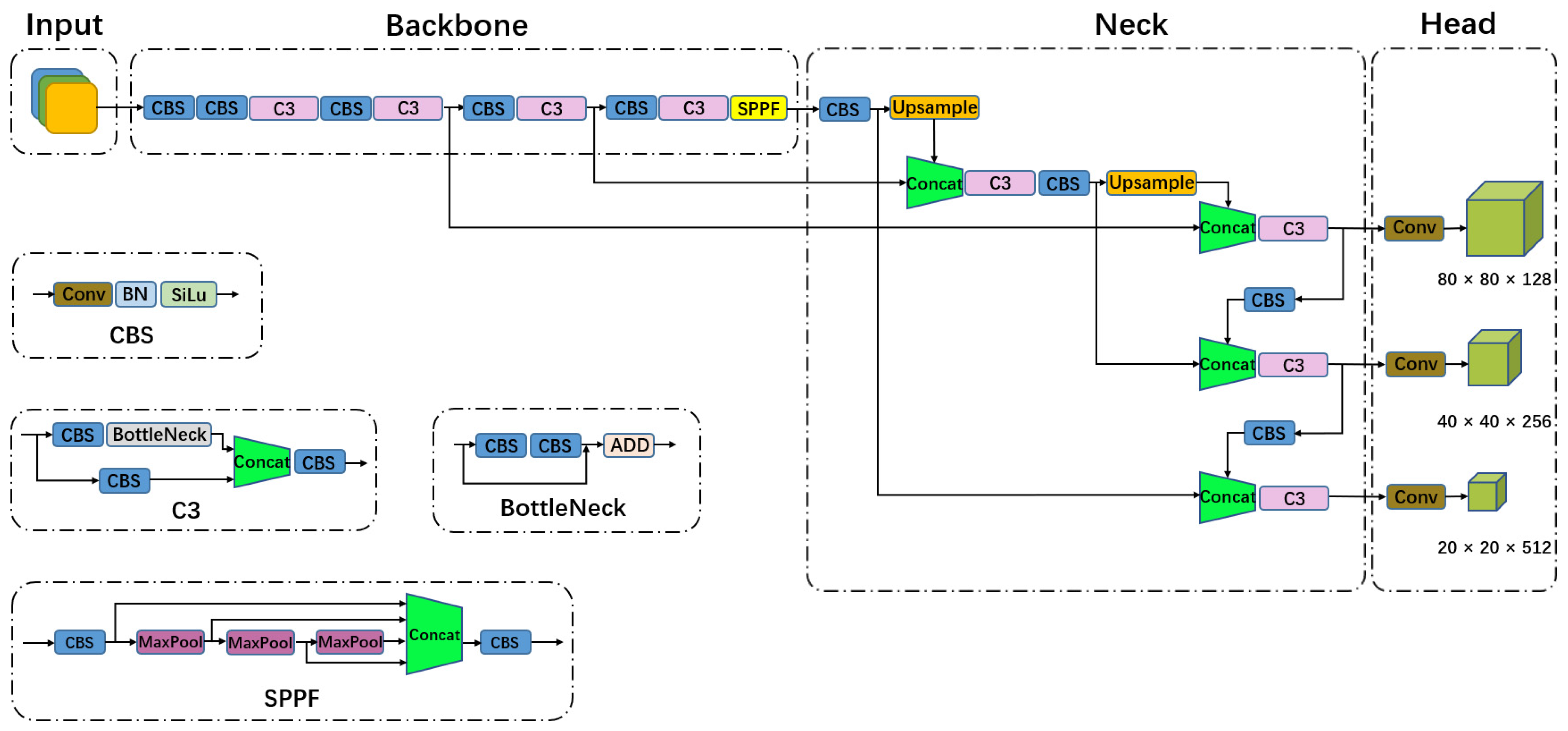
3.1. YOLOv5
3.2. CFnet
3.3. Dyhead
3.4. SD
3.5. SE Attention
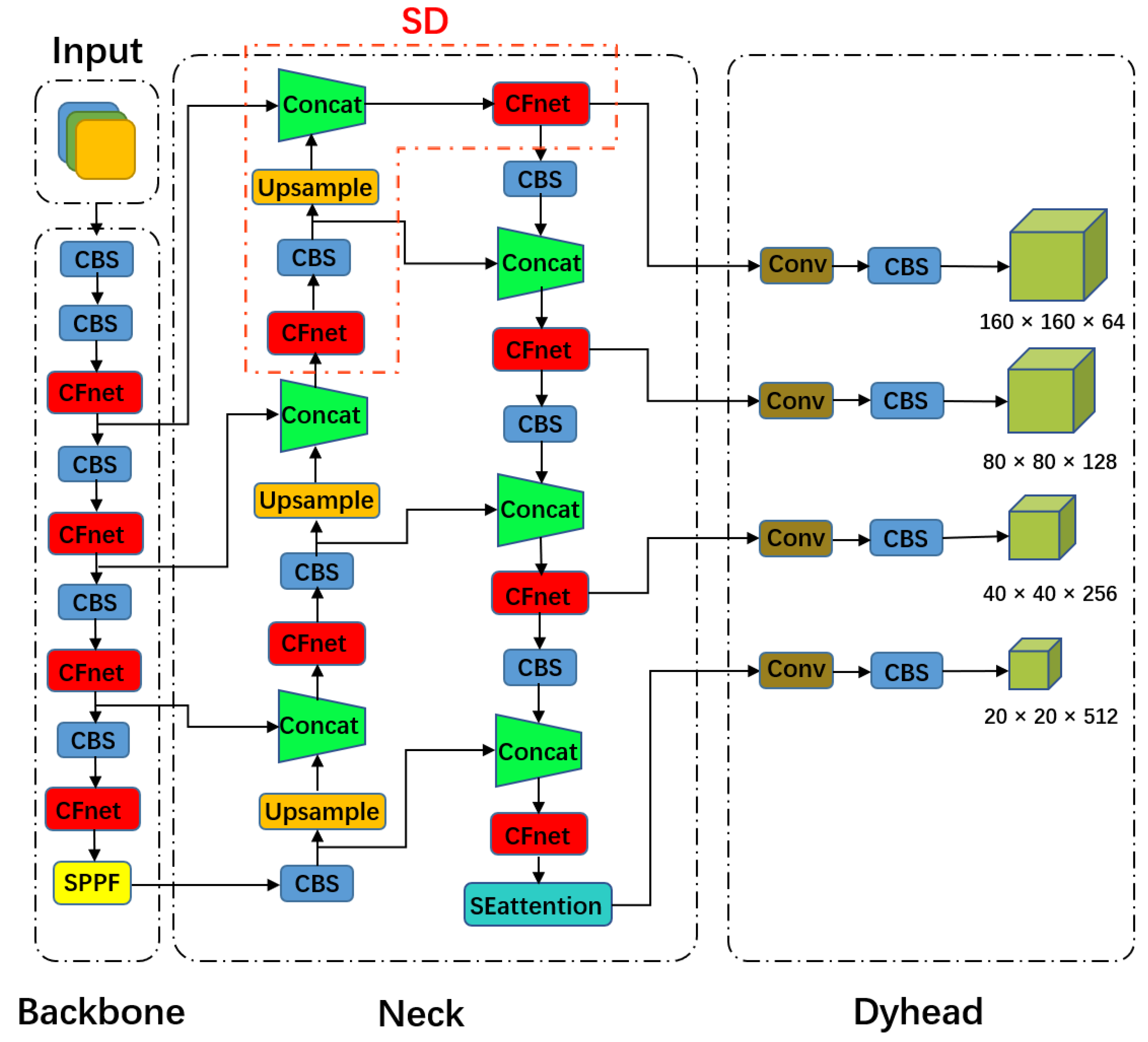
3.6. YOLOv5-CFDSDSE
4. Experiment
4.1. Experimental Environment
4.2. Experimental Data Set
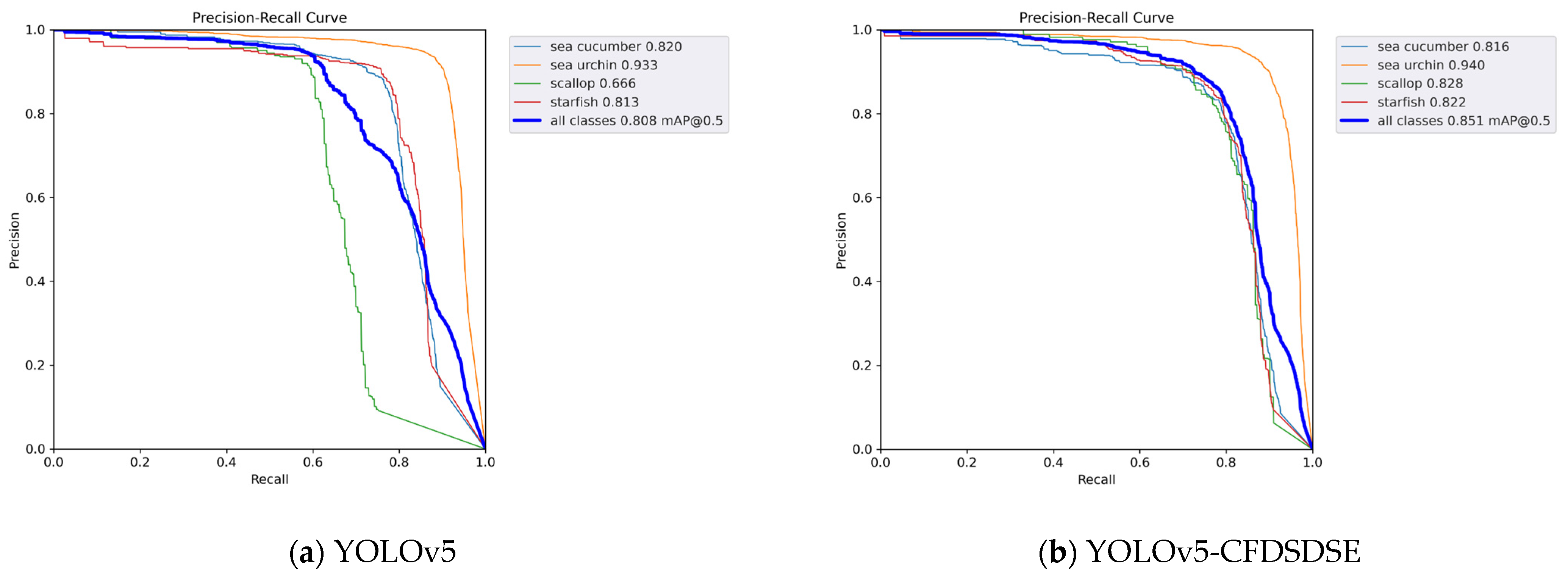
4.3. Comparison Experiment
4.4. Ablation Experiment
4.5. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, K.; Cui, W.; Chen, C. Review of Underwater Sensing Technologies and Applications. Sensors 2021, 11, 7849. [Google Scholar] [CrossRef]
- Pellegrino, F.A.; Vanzella, W.; Torre, V. Edge detection revisited. IEEE Trans. Syst. Man Cybern. Syst. 2004, 34, 1500–1518. [Google Scholar] [CrossRef]
- Ehrenfried, K. Processing calibration-grid images using the hough transformation. Meas. Sci. Technol. 2002, 13, 975–983. [Google Scholar] [CrossRef]
- Omachi, S.; Omachi, M. Fast Template Matching with Polynomials. EEE Trans. Image Process. 2007, 16, 2139–2149. [Google Scholar] [CrossRef]
- Guenther, N.; Schonlau, M. Support Vector Machines. Stata J. 2016, 16, 917–937. [Google Scholar] [CrossRef] [Green Version]
- Scornet, E. Random Forests and Kernel Methods. IEEE Trans. Inf. Theory 2016, 62, 1485–1500. [Google Scholar] [CrossRef] [Green Version]
- Shichao, Z.; Xuelong, L.; Ming, Z.; Xiaofeng, Z.; Debo, C. Learning k for kNN Classification. ACM Trans. Intell. Syst. Technol. 2017, 8, 43. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-Sign Detection and Classification in the Wild. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, June 26–1 July 2016. [Google Scholar]
- Liu, K.; Peng, L.; Tang, S. Underwater Object Detection Using TC-YOLO with Attention Mechanisms. Sensors 2023, 23, 2567. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zhang, Z.; Dai, F.; Bu, Y.; Wang, H. Monocular Vision-Based Underwater Object Detection. Sensors 2017, 17, 1784. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Ling, Y.; Zhang, L. Accurate Fish Detection under Marine Background Noise Based on the Retinex Enhancement Algorithm and CNN. J. Mar. Sci. Eng. 2022, 10, 878. [Google Scholar] [CrossRef]
- Liu, J.; Liu, S.; Xu, S.; Zhou, C. Two-Stage Underwater Object Detection Network Using Swin Transformer. IEEE Access. 2022, 10, 117235–117247. [Google Scholar] [CrossRef]
- Wei, X.; Yu, L.; Tian, S.; Feng, P. Underwater target detection with an attention mechanism and improved scale. Multimed. Tools Appl. 2021, 80, 33747–33761. [Google Scholar] [CrossRef]
- Al Muksit, A.; Hasan, F.; Bhuiyan Emon, M.F.H.; Haque, M.R.; Anwary, A.R.; Shatabda, S. YOLO-Fish: A robust fish detection model to detect fish in realistic underwater environment. Ecol. Inform. 2022, 72, 101847. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, G.; Li, H.; Liu, H.; Tan, J.; Xue, X. Underwater target detection algorithm based on improved YOLOv4 with SemiDSConv and FIoU loss function. Front. Mar. Sci. 2023, 10, 1153416. [Google Scholar] [CrossRef]
- Shi, Y. An Underwater Target Wake Detection in Multi-Source Images Based on Improved YOLOv5. IEEE Access. 2023, 11, 31990–31996. [Google Scholar] [CrossRef]
- Li, J.; Liu, C.; Lu, X.; Wu, B. CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water 2022, 14, 2412. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Z.; Jin, B.; Yu, W. A Real-Time Fish Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2023, 11, 572. [Google Scholar] [CrossRef]
- Wang, J.; Qi, S.; Wang, C.; Luo, J.; Wen, X.; Cao, R. B-YOLOX-S: A Lightweight Method for Underwater Object Detection Based on Data Augmentation and Multiscale Feature Fusion. J. Mar. Sci. Eng. 2022, 10, 1764. [Google Scholar] [CrossRef]
- Ultralytics. yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 18 May 2020).
- Chen, J.; Kao, S.-H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic ReLU. arXiv 2020, arXiv:2003.10027II. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Jiang, L.; Wang, Y.; Jia, Q.; Xu, S.; Liu, Y.; Fan, X.; Li, H.; Liu, R.; Xue, X.; Wang, R.; et al. Underwater Species Detection using Channel Sharpening Attention. In Proceedings of the 29th ACM International Conference on Multimedia, New York, NY, USA, 20–24 October 2021; pp. 4259–4267.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | mAP@0.5 | Precision | Recall | Number of Parameters |
|---|---|---|---|---|---|
| RetinaNet | EfficientNet | 60.1% | 58.0% | 62.8% | 37.5 M |
| CenterNet | ResNet18 | 74.1% | 73.2% | 75.3% | 30.21 M |
| Faster-RCNN | ResNet18 | 74.7% | 53.4% | 83.0% | 47.60 M |
| SSD | MobileNetV3 | 76.3% | 75.8% | 79.2% | 4.92 M |
| YOLOX-tiny | Darknet53 | 78.4% | 80.3% | 75.8% | 5.70 M |
| YOLOv5s | CSPDarknet53 | 80.8% | 85.5% | 75.8% | 7.03 M |
| YOLOv7-tiny | CSPDarknet53 | 82.1% | 82.6% | 76.7% | 6.02 M |
| YOLOV5-CFDSDSE | CSPDarknet53 | 85.1% | 86.7% | 80.2% | 6.52 M |
| Case | CFnet | Dyhead | SD | SE | mAP@0.5 | mAP@0.5:0.95 | Training Time | Inference Time | SODR | Number of Parameters |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | 80.8% | 47.2% | 1.42 h | 1.5 ms | 78.2% | 7.03 M |
| 2 | √ | × | × | × | 83.2% | 47.6% | 1.15 h | 1.5 ms | 77.8% | 5.80 M |
| 3 | × | √ | × | × | 82.8% | 47.4% | 1.85 h | 4.0 ms | 85.1% | 7.59 M |
| 4 | × | × | √ | × | 83.6% | 47.7% | 2.79 h | 1.9 ms | 89.6% | 7.17 M |
| 5 | × | × | × | √ | 81.0% | 47.1% | 1.54 h | 1.6 ms | 81.5% | 7.06 M |
| 6 | √ | √ | × | × | 83.9% | 48.2% | 2.70 h | 4.0 ms | 82.9% | 6.37 M |
| 7 | √ | √ | √ | × | 84.5% | 48.1% | 3.95 h | 5.8 ms | 90.5% | 6.49 M |
| 8 | √ | √ | √ | √ | 85.1% | 48.6% | 4.09 h | 5.9 ms | 91.1% | 6.52 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Li, Y.; Wang, J.; Li, Y. An Underwater Dense Small Object Detection Model Based on YOLOv5-CFDSDSE. Electronics 2023, 12, 3231. https://doi.org/10.3390/electronics12153231
Wang J, Li Y, Wang J, Li Y. An Underwater Dense Small Object Detection Model Based on YOLOv5-CFDSDSE. Electronics. 2023; 12(15):3231. https://doi.org/10.3390/electronics12153231
Chicago/Turabian StyleWang, Jingyang, Yujia Li, Junkai Wang, and Ying Li. 2023. "An Underwater Dense Small Object Detection Model Based on YOLOv5-CFDSDSE" Electronics 12, no. 15: 3231. https://doi.org/10.3390/electronics12153231