
Lightweight Strawberry Instance Segmentation on Low-Power Devices for Picking Robots

Abstract
:1. Introduction
- (1)
- We present a lightweight yet effective framework for strawberry instance segmentation running on low-power devices for picking robots, which can directly segment each strawberry without relying on object detection.
- (2)
- We design a novel feature aggregation network to aggregate features with different scales extracted from different levels of the backbone network, which can increase the resolution and reduce the channels of features.
- (3)
- Experimental results demonstrate that our model achieves a good trade-off between accuracy and inference speed running on the low-power device.
2. Related Work
2.1. Instance Segmentation
2.2. Fruit Localization
2.3. Lightweight Detection and Segmentation
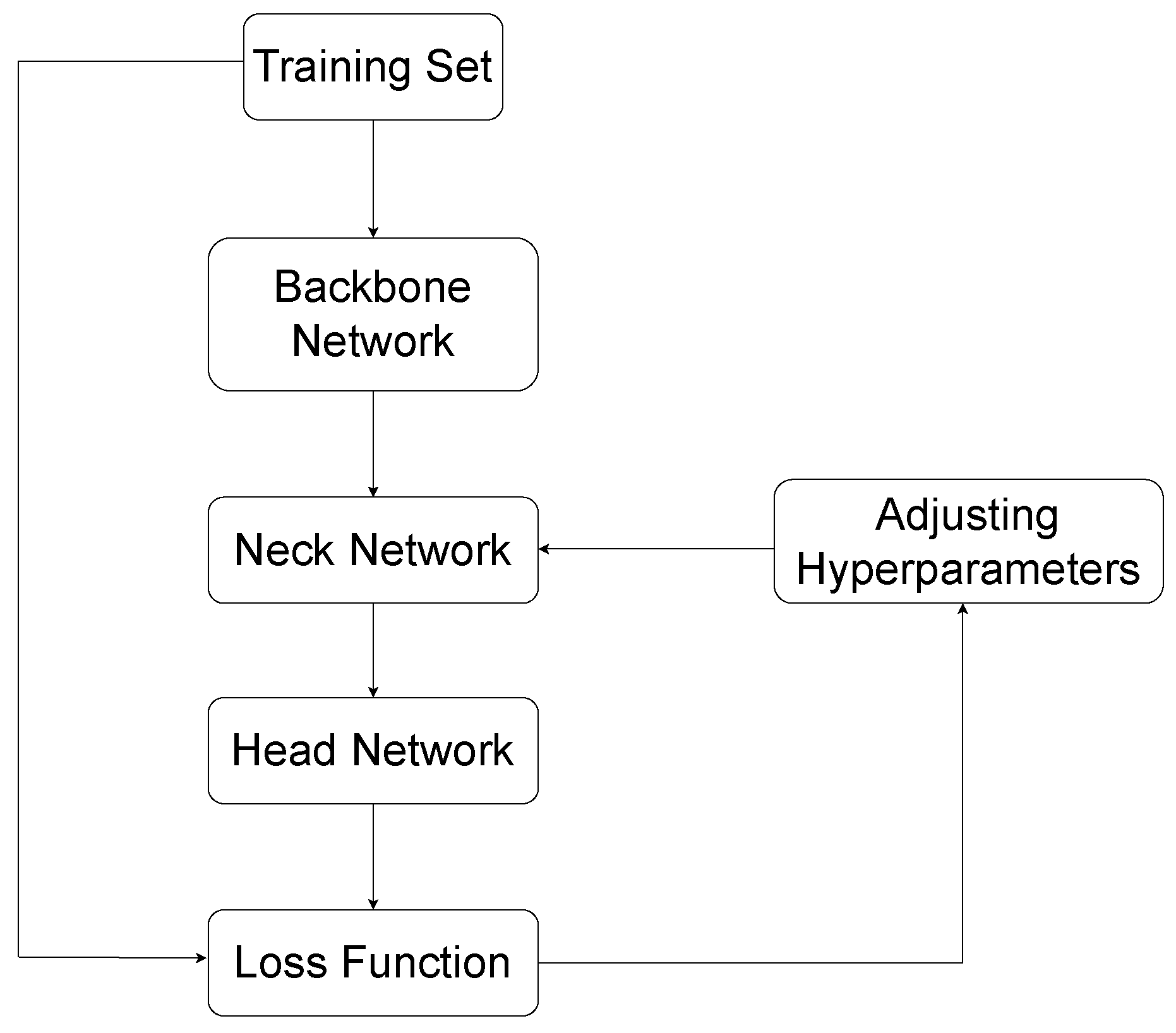
3. Methods
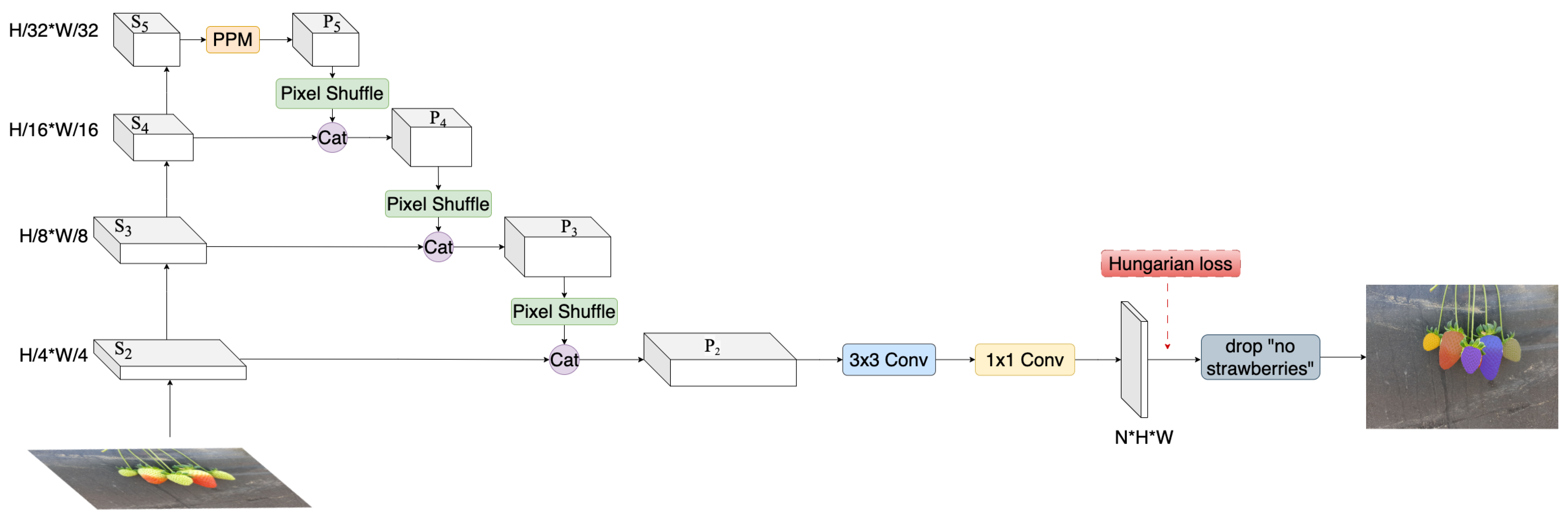
3.1. StrawSeg Architecture
3.1.1. Backbone
3.1.2. Neck
3.1.3. Head
3.2. Label Assignment and Training Loss
3.3. Inference
4. Experiments
4.1. Dataset and Metrics
4.1.1. Dataset
4.1.2. Metrics
4.1.3. Implementation Details
4.2. Comparison with State-of-the-Art Methods
4.3. Ablation Studies
4.3.1. Structure of the Neck Module
4.3.2. Stage of Output Feature Maps
4.3.3. Scale of Input Image
4.3.4. Number of Convolution Layers in the Neck
4.3.5. Number of Predicting Masks
4.3.6. Hyperparameters of Loss Functions
4.3.7. Usage of NMS
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Preter, A.D.; Anthonis, J.; Baerdemaeker, J.D. Development of a Robot for Harvesting Strawberries. IFAC-PapersOnLine 2018, 51, 14–19. [Google Scholar] [CrossRef]
- Charania, I.; Li, X. Smart farming: Agriculture’s shift from a labor intensive to technology native industry. Internet Things 2020, 9, 100142. [Google Scholar] [CrossRef]
- Hernandez-Martinez, N.R.; Blanchard, C.; Wells, D.; Salazar-Gutierrez, M.R. Current state and future perspectives of commercial strawberry production: A review. Sci. Hortic. 2023, 312, 111893. [Google Scholar] [CrossRef]
- Jia, W.; Tian, Y.; Luo, R.; Zhang, Z.; Lian, J.; Zheng, Y. Detection and segmentation of overlapped fruits based on optimized mask R-CNN application in apple harvesting robot. Comput. Electron. Agric. 2020, 172, 105380. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Santos, T.T.; Souza, L.L.d.; Santos, A.A.d.; Avila, S. Grape detection, segmentation, and tracking using deep neural networks and three-dimensional association. Comput. Electron. Agric. 2020, 170, 105247. [Google Scholar] [CrossRef] [Green Version]
- Zeng, T.; Li, S.; Song, Q.; Zhong, F.; Wei, X. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Ning, Z.; Luo, L.; Ding, X.; Dong, Z.; Yang, B.; Cai, J.; Chen, W.; Lu, Q. Recognition of sweet peppers and planning the robotic picking sequence in high-density orchards. Comput. Electron. Agric. 2022, 196, 106878. [Google Scholar] [CrossRef]
- Borrero, I.P.; Santos, D.M.; Arias, M.E.G.; Ancos, E.C. A fast and accurate deep learning method for strawberry instance segmentation. Comput. Electron. Agric. 2020, 178, 105736. [Google Scholar] [CrossRef]
- Borrero, I.P.; Santos, D.M.; Vazquez, M.J.V.; Arias, M.E.G. A new deep-learning strawberry instance segmentation methodology based on a fully convolutional neural network. Neural Comput. Appl. 2021, 33, 15059–15071. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the MICCAI, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H. Conditional convolutions for instance segmentation. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020; pp. 282–298. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9156–9165. [Google Scholar]
- Zhang, R.; Tian, Z.; Shen, C.; You, M.; Yan, Y. Mask Encoding for Single Shot Instance Segmentation. In Proceedings of the CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 10223–10232. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. SOLO: Segmenting Objects by Locations. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020; pp. 649–665. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. SOLOv2: Dynamic and Fast Instance Segmentation. In Proceedings of the NeurIPS, Virtual, 6–12 December 2020. [Google Scholar]
- Xie, E.; Sun, P.; Song, X.; Wang, W.; Liu, X.; Liang, D.; Shen, C.; Luo, P. PolarMask: Single Shot Instance Segmentation With Polar Representation. In Proceedings of the CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 12190–12199. [Google Scholar]
- Dong, B.; Zeng, F.; Wang, T.; Zhang, X.; Wei, Y. SOLQ: Segmenting Objects by Learning Queries. In Proceedings of the NeurIPS, Virtual, 6–14 December 2021. [Google Scholar]
- Hu, J.; Cao, L.; Lu, Y.; Zhang, S.; Wang, Y.; Li, K.; Huang, F.; Shao, L.; Ji, R. ISTR: End-to-End Instance Segmentation with Transformers. In Proceedings of the CVPR, Virtual, 19–25 June 2021; pp. 8737–8746. [Google Scholar]
- Cheng, T.; Wang, X.; Chen, S.; Zhang, W.; Zhang, Q.; Huang, C.; Zhang, Z.; Liu, W. Sparse Instance Activation for Real-Time Instance Segmentation. In Proceedings of the CVPR, New Orleans, LA, USA, 18–24 June 2022; pp. 4423–4432. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, M.; Jia, W.; Wang, Z.; Niu, Y.; Yang, X.; Ruan, C. An accurate detection and segmentation model of obscured green fruits. Comput. Electron. Agric. 2022, 197, 106984. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Liu, T.H.; Nie, X.N.; Wu, J.M.; Zhang, D.; Liu, W.; Cheng, Y.F.; Zheng, Y.; Qiu, J.; Qi, L. Pineapple (Ananas comosus) fruit detection and localization in natural environment based on binocular stereo vision and improved YOLOv3 model. Precis. Agric. 2023, 24, 139–160. [Google Scholar] [CrossRef]
- Kang, H.; Wang, X.; Chen, C. Accurate fruit localisation using high resolution LiDAR-camera fusion and instance segmentation. Comput. Electron. Agric. 2022, 203, 107450. [Google Scholar] [CrossRef]
- Zhang, Y.M.; Lee, C.C.; Hsieh, J.W.; Kuo Chin, F. CSL-YOLO: A new lightweight object detection system for edge computing. arXiv 2021, arXiv:2107.04829. [Google Scholar]
- Cui, M.; Lou, Y.; Ge, y.; Wang, K. LES-YOLO: A lightweight pinecone detection algorithm based on improved YOLOv4-Tiny network. Comput. Electron. Agric. 2023, 205, 107613. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar]
- Gui, Z.; Chen, J.; Li, Y.; Chen, Z.; Wu, C.; Dong, C. A lightweight tea bud detection model based on Yolov5. Comput. Electron. Agric. 2023, 205, 107636. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Li, K.; Wang, J.; Jalil, H.; Wang, H. A fast and lightweight detection algorithm for passion fruit pests based on improved YOLOv5. Comput. Electron. Agric. 2023, 204, 107534. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Cheng, B.; Schwing, A.G.; Kirillov, A. Per-Pixel Classification is Not All You Need for Semantic Segmentation. In Proceedings of the NeurIPS, Virtual, 6–14 December 2021. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the ICPR, Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the ECCV, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Gong, K.; Liang, X.; Li, Y.; Chen, Y.; Yang, M.; Lin, L. Instance-Level Human Parsing via Part Grouping Network. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 770–785. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Backbone | Method | Params | FPS (3090) | FPS (Jetson) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MobileNetV2_0.25 | Baseline | 68.2 | 82.4 | 74.0 | 26.8 | 68.1 | 94.0 | 0.18 M | 140 | 16 |
| SparseInst | 65.0 | 80.2 | 69.0 | 24.6 | 66.4 | 87.2 | 0.20 M | 121 | 13 | |
| Ours | 72.9 | 86.4 | 78.5 | 29.1 | 74.8 | 94.4 | 0.15 M | 155 | 20 | |
| MobileNetV2_0.5 | Baseline | 76.2 | 86.7 | 79.3 | 30.1 | 80.6 | 96.0 | 0.65 M | 119 | 14 |
| SparseInst | 77.9 | 89.9 | 83.0 | 33.5 | 81.2 | 97.3 | 0.75 M | 97 | 12 | |
| Ours | 79.7 | 90.6 | 84.3 | 41.0 | 82.7 | 96.4 | 0.53 M | 139 | 19 | |
| MobileNetV2_1.0 | Baseline | 68.2 | 80.3 | 71.2 | 28.9 | 71.0 | 88.7 | 2.50 M | 114 | 12 |
| SparseInst | 79.6 | 89.7 | 83.8 | 38.3 | 83.4 | 96.0 | 2.86 M | 89 | 10 | |
| Ours | 80.0 | 89.8 | 83.8 | 40.9 | 83.3 | 97.1 | 1.97 M | 131 | 17 |
| Methods | ||||||
|---|---|---|---|---|---|---|
| Yu et al. [5] | 45.4 | 76.6 | 47.1 | 07.4 | 50.0 | 78.3 |
| Perez-Borrero et al. [9] | 43.8 | 74.2 | 45.1 | 07.5 | 51.8 | 75.9 |
| Perez-Borrero et al. [10] | 52.6 | 69.4 | 57.8 | 17.0 | 65.3 | 53.3 |
| Ours | 80.0 | 89.8 | 83.8 | 40.9 | 83.3 | 97.1 |
| Module | FPS (3090) | ||||||
|---|---|---|---|---|---|---|---|
| Backbone only | 52.5 | 76.5 | 55.2 | 7.3 | 50.8 | 82.0 | 194 |
| +PPM | 58.7 | 80.1 | 62.4 | 10.5 | 58.3 | 89.1 | 145 |
| +FAN | 74.0 | 86.8 | 78.1 | 37.4 | 75.8 | 93.0 | 152 |
| +PPM+FAN | 79.7 | 90.6 | 84.3 | 41.0 | 82.7 | 96.4 | 139 |
| +PPM+FAN+ASPP | 79.5 | 89.8 | 83.4 | 37.4 | 83.7 | 97.0 | 108 |
| Stage | FPS (3090) | ||||||
|---|---|---|---|---|---|---|---|
| 58.7 | 80.1 | 62.4 | 10.5 | 58.3 | 89.1 | 145 | |
| 72.3 | 86.9 | 76.5 | 27.4 | 75.2 | 94.2 | 141 | |
| 72.2 | 85.4 | 75.9 | 28.6 | 75.0 | 93.2 | 140 | |
| 79.7 | 90.6 | 84.3 | 41.0 | 82.7 | 96.4 | 139 |
| Scale | FPS (3090) | ||||||
|---|---|---|---|---|---|---|---|
| 704 | 70.1 | 83.4 | 74.9 | 31.5 | 71.0 | 92.3 | 119 |
| 640 | 79.7 | 90.6 | 84.3 | 41.0 | 82.7 | 96.4 | 139 |
| 512 | 74.9 | 87.1 | 80.0 | 32.9 | 78.2 | 93.6 | 141 |
| Number of Conv | FPS (3090) | ||||||
|---|---|---|---|---|---|---|---|
| w/o | 71.4 | 85.9 | 75.4 | 33.4 | 71.4 | 92.0 | 144 |
| 1 | 79.7 | 90.6 | 84.3 | 41.0 | 82.7 | 96.4 | 139 |
| 2 | 75.4 | 84.7 | 78.8 | 37.4 | 77.9 | 93.9 | 134 |
| Number of Masks | ||||||
|---|---|---|---|---|---|---|
| 30 | 68.4 | 79.9 | 73.3 | 33.9 | 76.8 | 83.5 |
| 21(Ours) | 79.7 | 90.6 | 84.3 | 41.0 | 82.7 | 96.4 |
| 1 | 1 | 67.6 | 81.0 | 70.7 | 26.5 | 69.3 | 89.8 |
| 10 | 1 | 72.5 | 85.1 | 76.5 | 31.4 | 75.7 | 91.1 |
| 1 | 10 | 75.1 | 87.4 | 79.6 | 36.8 | 76.1 | 95.8 |
| 1 | 20 | 79.7 | 90.6 | 84.3 | 41.0 | 82.7 | 96.4 |
| 1 | 30 | 77.8 | 89.6 | 82.9 | 36.2 | 81.2 | 95.5 |
| Postprocessing | ||||||
|---|---|---|---|---|---|---|
| w/o NMS | 76.3 | 86.4 | 80.5 | 37.7 | 79.5 | 94.5 |
| Ours | 79.7 | 90.6 | 84.3 | 41.0 | 82.7 | 96.4 |
| Methods | ||||||
|---|---|---|---|---|---|---|
| Baseline | 44.6 | 74.7 | 46.5 | 2.7 | 26.5 | 54.9 |
| SparseInst | 44.1 | 72.9 | 46.5 | 2.9 | 27.2 | 56.2 |
| Ours | 47.7 | 76.4 | 50.9 | 4.4 | 28.8 | 58.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, L.; Chen, Y.; Jin, Q. Lightweight Strawberry Instance Segmentation on Low-Power Devices for Picking Robots. Electronics 2023, 12, 3145. https://doi.org/10.3390/electronics12143145
Cao L, Chen Y, Jin Q. Lightweight Strawberry Instance Segmentation on Low-Power Devices for Picking Robots. Electronics. 2023; 12(14):3145. https://doi.org/10.3390/electronics12143145
Chicago/Turabian StyleCao, Leilei, Yaoran Chen, and Qiangguo Jin. 2023. "Lightweight Strawberry Instance Segmentation on Low-Power Devices for Picking Robots" Electronics 12, no. 14: 3145. https://doi.org/10.3390/electronics12143145