


Enhanced-Deep-Residual-Shrinkage-Network-Based Voiceprint Recognition in the Electric Industry
Abstract
:1. Introduction
- (1)
- The continuous deepening of the model leads to the degradation of the network performance.
- (2)
- The error gradient used to update the network weights keeps increasing or decreasing, which results in a gradient explosion and gradient disappearance.
- (3)
- A low accuracy for short-time speech recognition and a low recognition accuracy in noisy scenarios.
- (4)
- A poor robustness.
- (1)
- We divide the voiceprint recognition in a noisy environment into two main parts: the first part performs the noise reduction on the voice dataset, and the second part aims to realize identity matching by voiceprint recognition. In the noise reduction part, we model the voice signal features using a dual-path convolutional recurrent network (DPCRN) [3] in a noisy electric environment and set the model learning target as the complex ratio mask (CRM). First, we use the spectrogram of the noisy voice signals as the inputs to the encoder. Subsequently, an RNN is used in the frequency domain to capture the long-term speech’s harmonic correlations [4]. Finally, the real and imaginary parts of the CRM are output at the decoder. The learning objective is optimized by a signal approximation (SA), and the multiplication of the estimated CRM with the noisy signal spectrogram is performed to achieve the noise reduction process.
- (2)
- For the voiceprint recognition, an enhanced deep residual shrinkage network (EDRSN) is proposed in a noisy electric environment. The proposed EDRSN scheme reconstructs the network structure based on a deep residual shrinkage network (DRSN) [5] and combines the convolutional block attention mechanism (CBAM) [6] and the hybrid dilated convolution (HDC) [7]. Meanwhile, we combine the EDRSN with traditional voice processing methods to accomplish the voiceprint recognition in noisy environments. After the noise reduction by DPCRN, we enhance the voice segments in the voice signals by pre-emphasizing and eliminating the silent segments by an endpoint detection to facilitate the extraction of voiceprint features. Finally, the soft thresholding mechanism of EDRSN is utilized to further distinguish and eliminate the noisy features, and the CBAM and HDC are taken to extract the effective vocal features and improve the recognition accuracy.
- (3)
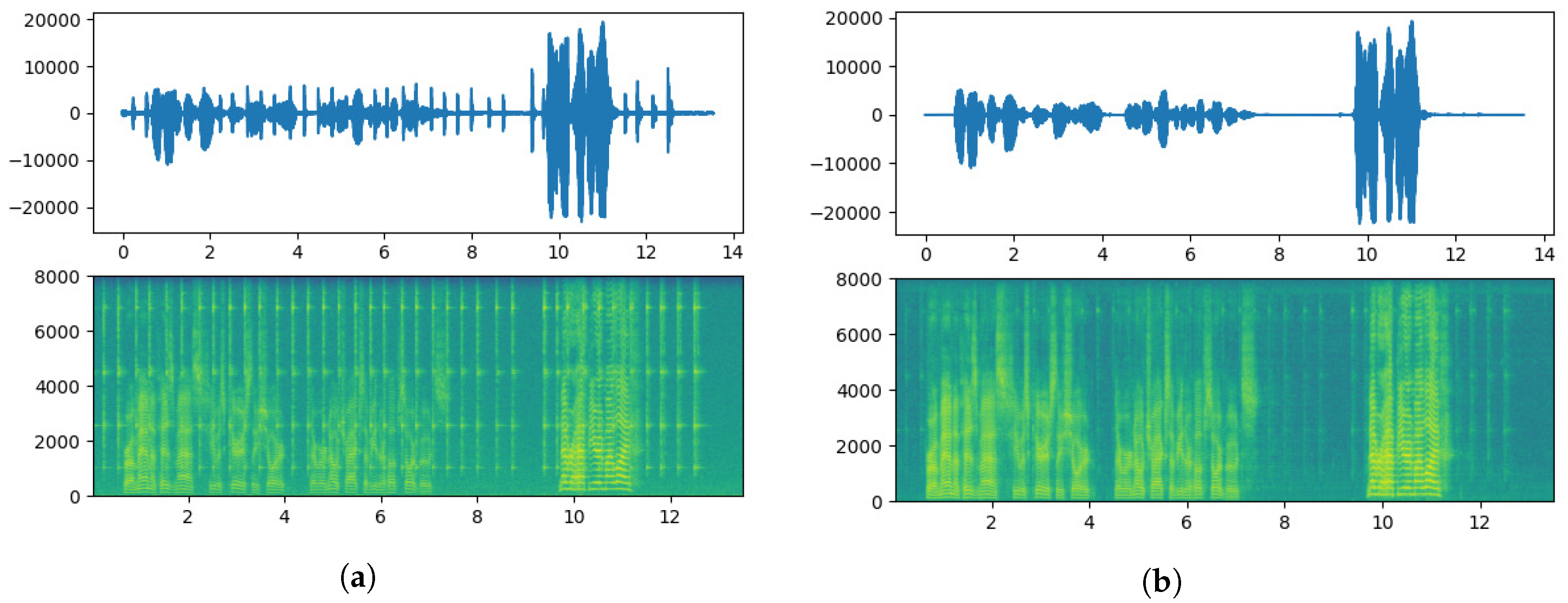
- Simulation results are provided to verify the accuracy of the proposed scheme in voice recognition. Based on the comparison of the time–frequency spectrograms before and after noise reduction, it is shown that the DPCRN is able to reduce the background noise in the voice signals. Furthermore, numerical results show that the proposed EDRSN model has a better accuracy in voiceprint recognition than the other neural network models while ensuring a lower complexity.
2. Related Work
3. Noise Reduction
3.1. Noise Reduction Theory
3.2. Noise Reduction Process
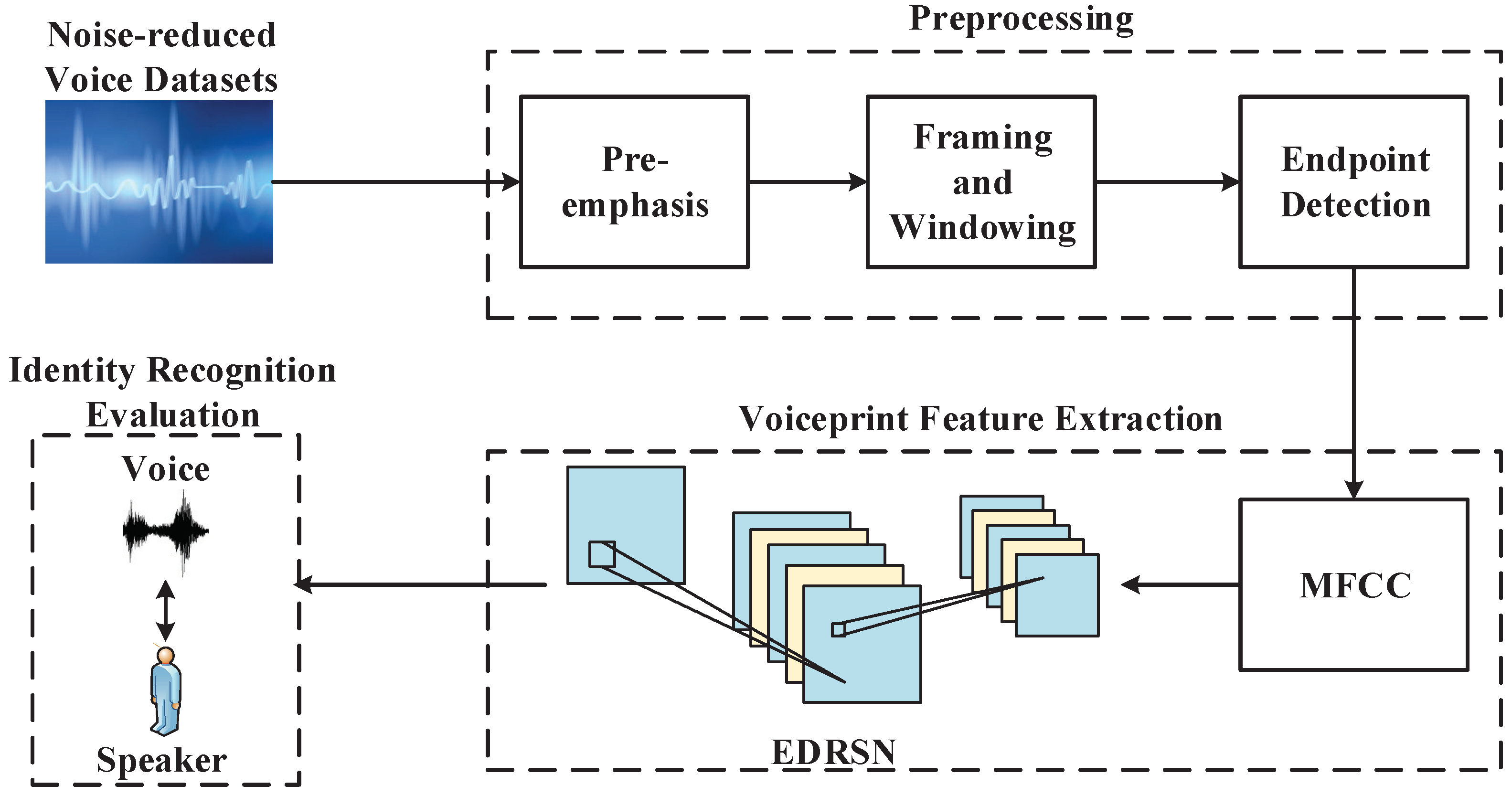
4. Voiceprint Recognition
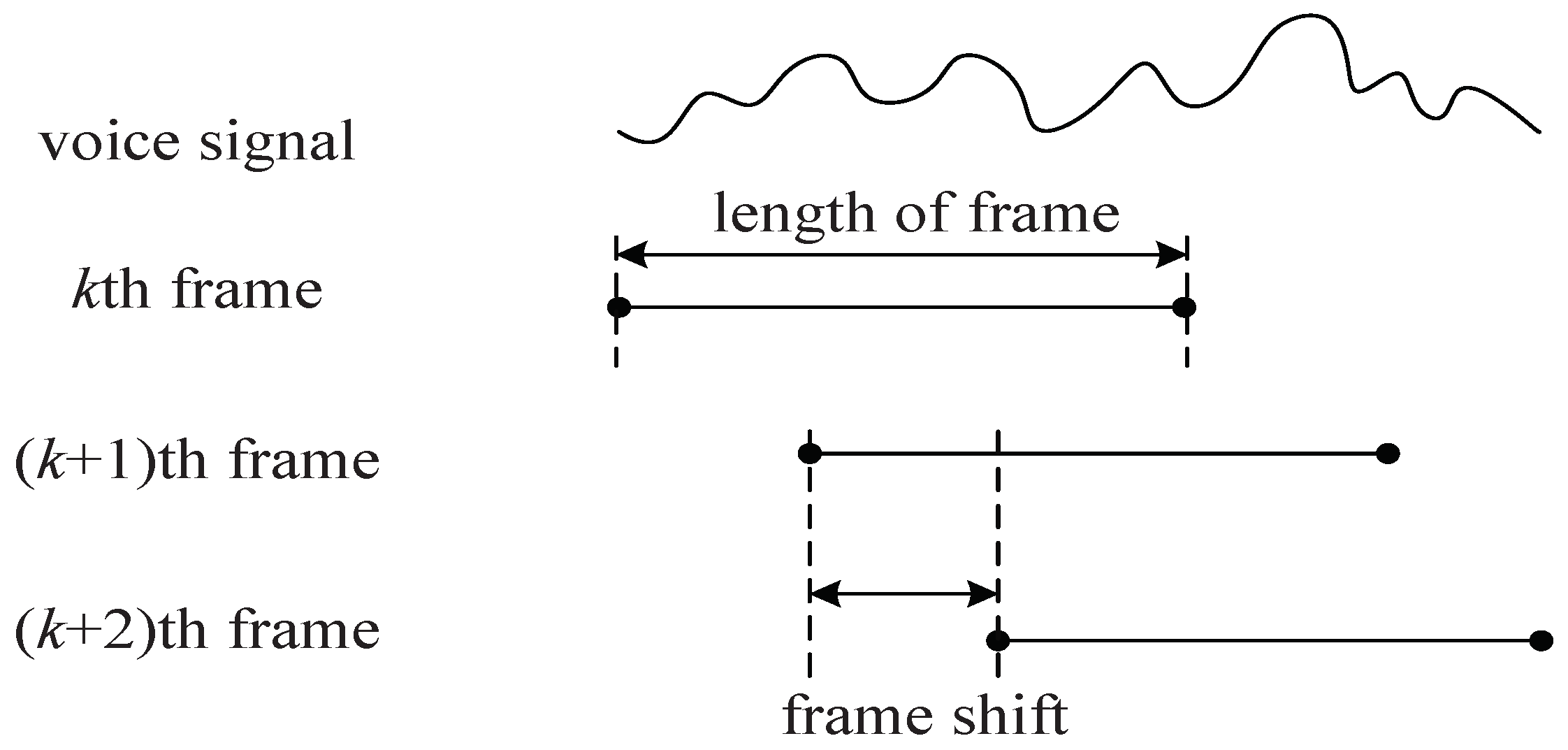
4.1. Preprocessing
4.2. Voiceprint Feature Extraction
4.3. Identity Recognition Evaluation
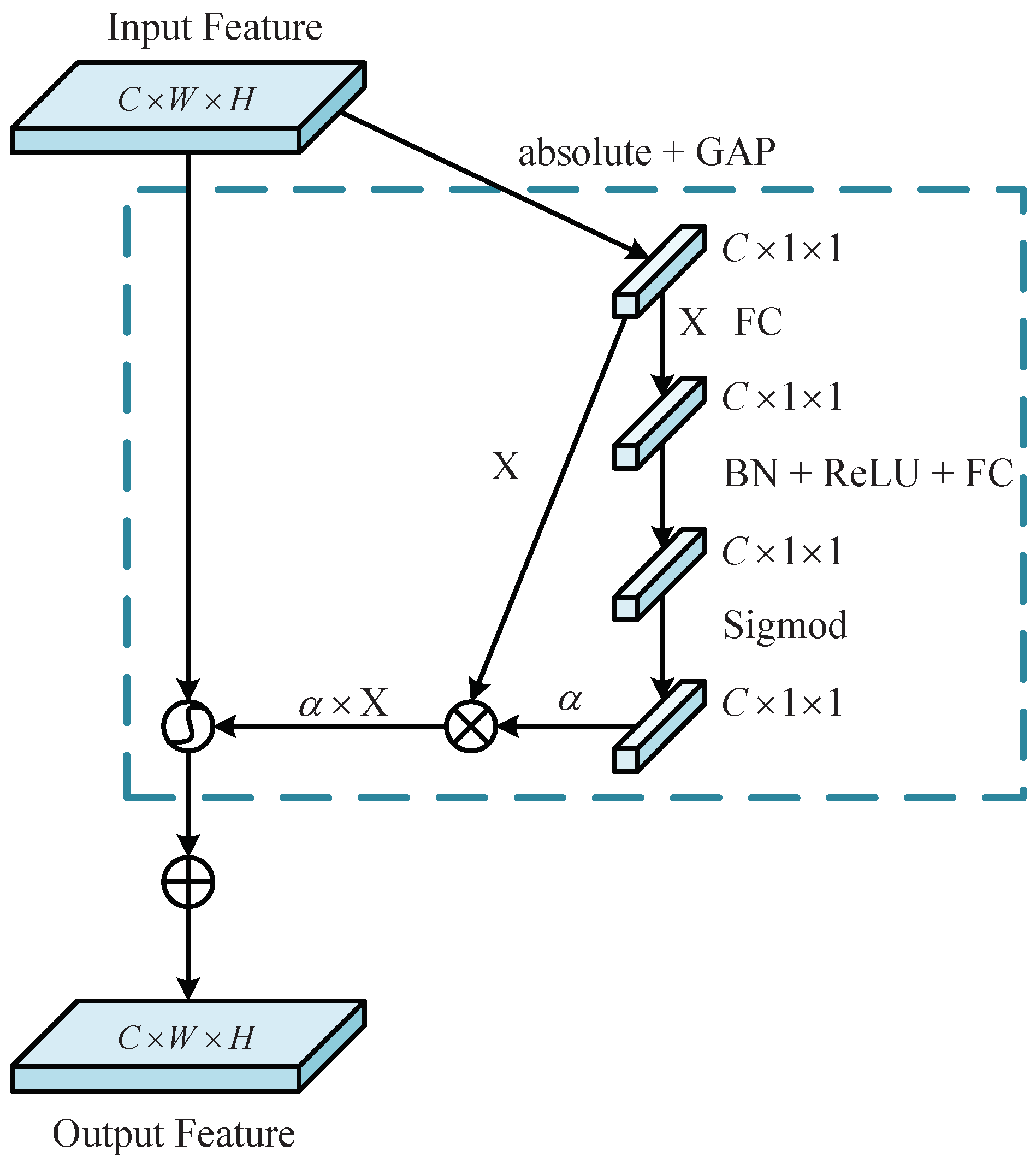
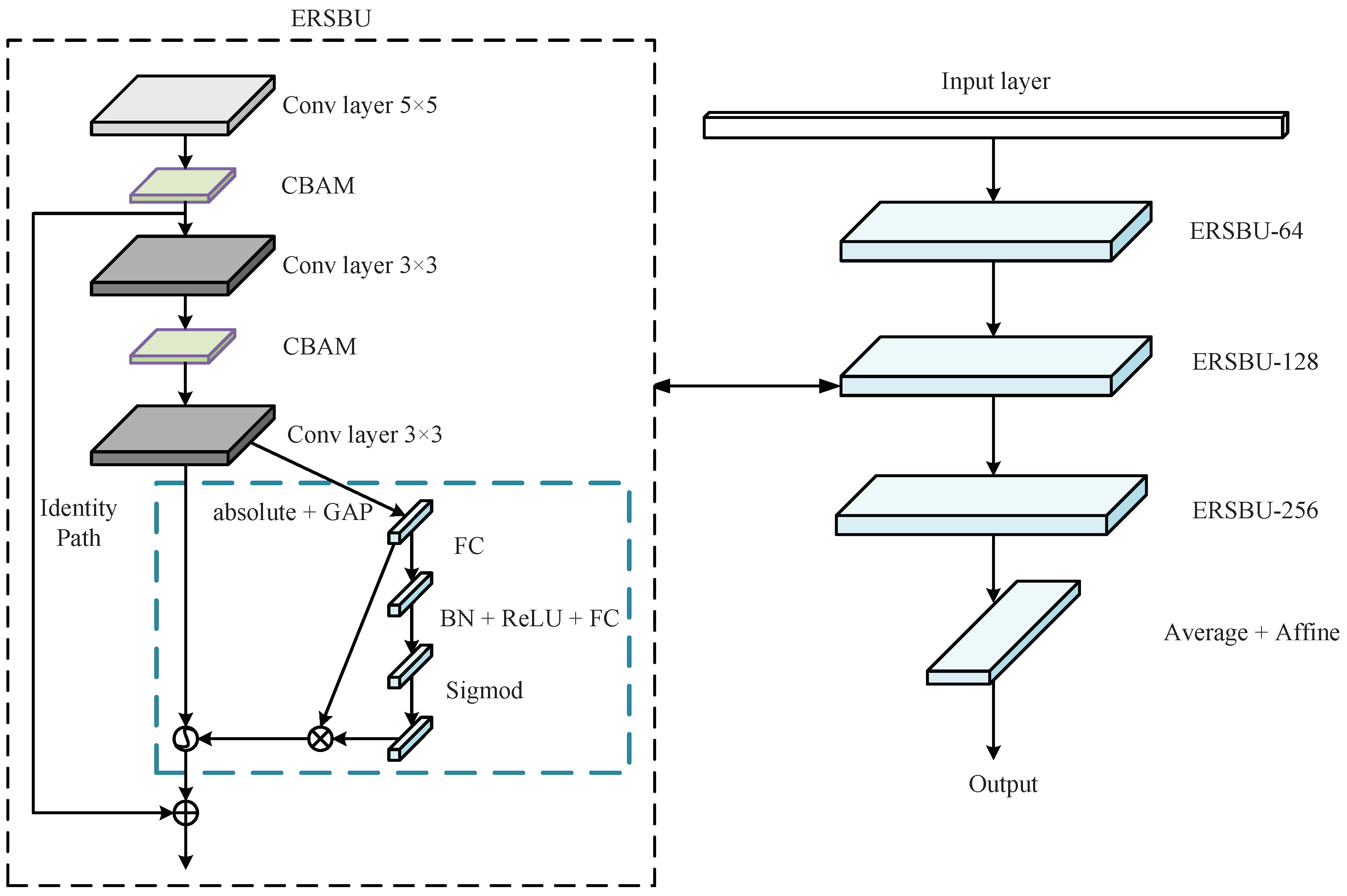
5. Enhanced Deep Residual Shrinkage Network
5.1. Deep Residual Shrinkage Network
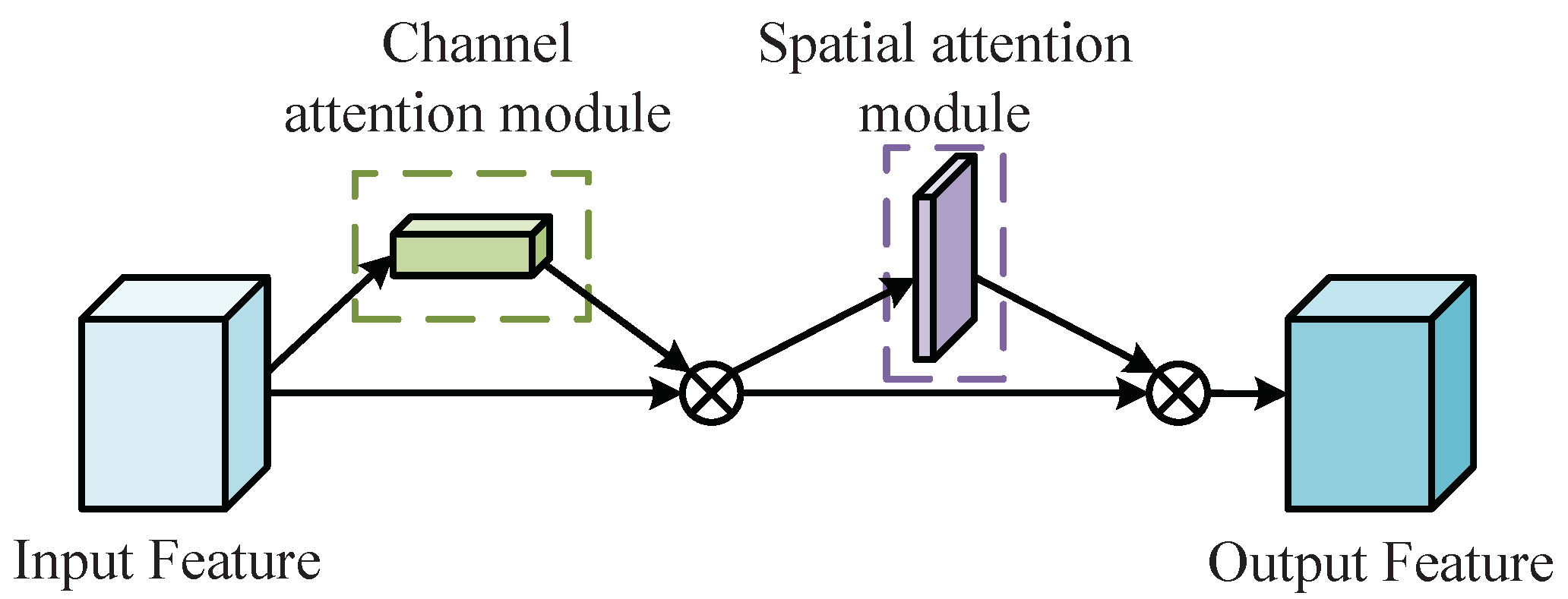
5.2. Convolutional Block Attention Mechanism Module
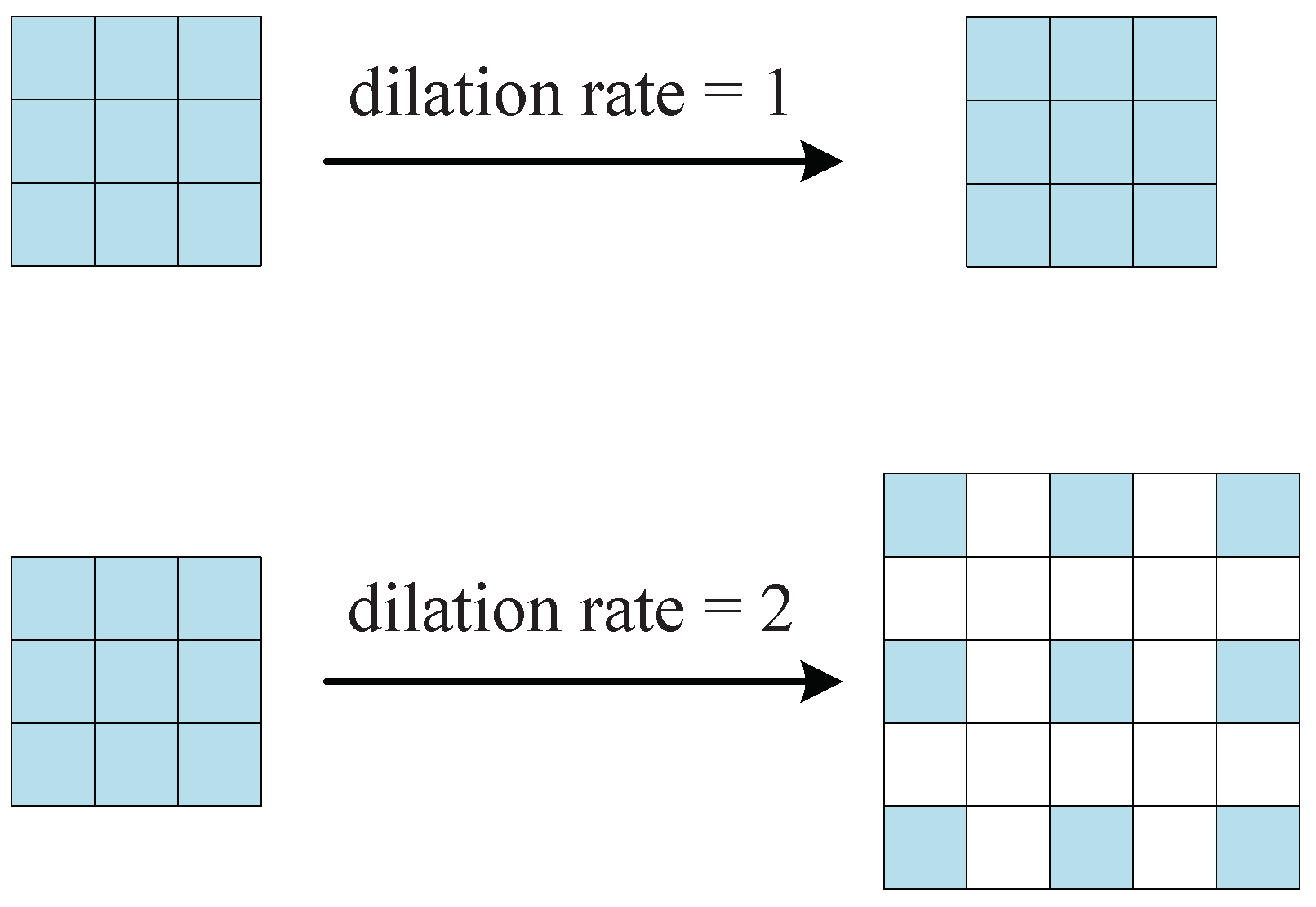
5.3. Hybrid Dilated Convolution
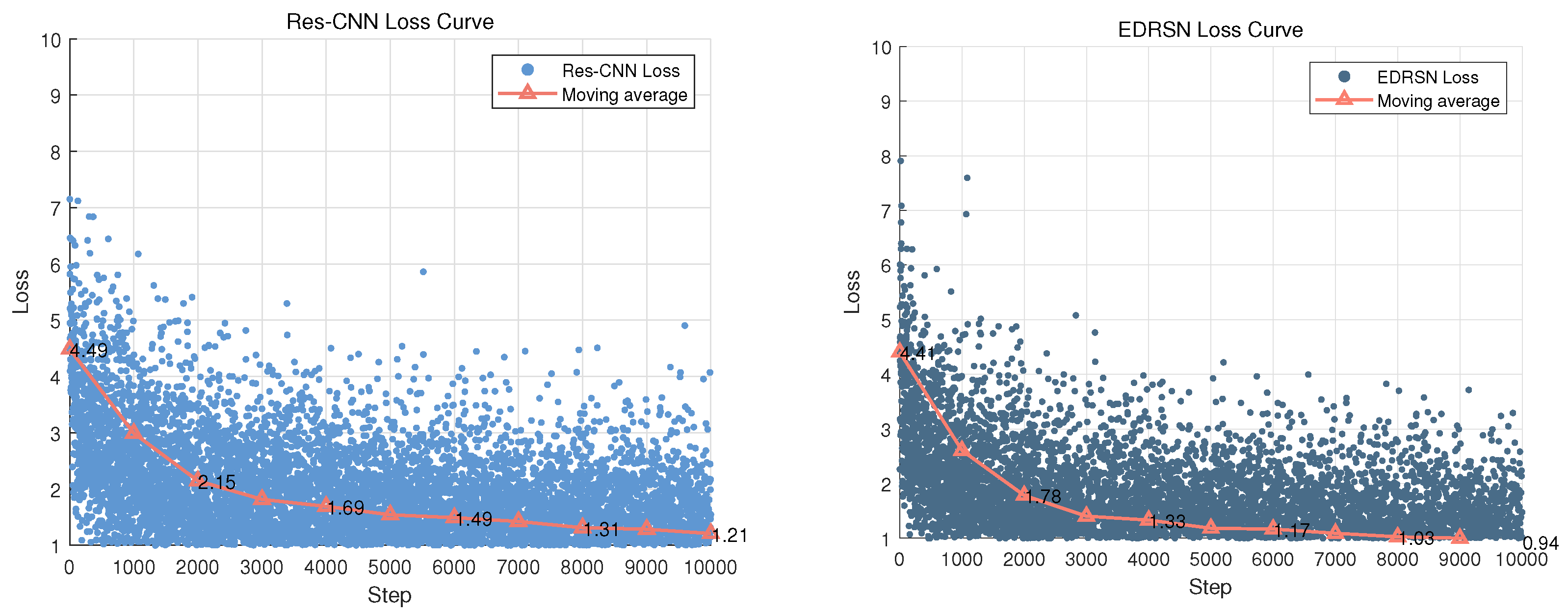
6. Simulation Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, Z.; Zhang, X.; Wang, L.; Li, Z. Study and implementation of voiceprint identity authentication for Android mobile terminal. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Jin, X.; Zhang, Y.; Wang, X. Strategy and coordinated development of strong and smart grid. In Proceedings of the IEEE PES Innovative Smart Grid Technologies, Tianjin, China, 21–24 May 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Le, X.; Chen, H.; Chen, K.; Lu, J. DPCRN: Dual-path convolution recurrent network for single channel speech enhancement. arXiv 2021, arXiv:2107.05429. [Google Scholar]
- Le, X.; Lei, T.; Chen, K.; Lu, J. Inference Skipping for More Efficient Real-Time Speech Enhancement With Parallel RNNs. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2411–2421. [Google Scholar] [CrossRef]
- Lin, N.; Chen, G.; Zhou, Q.; Liu, C. Dilated Residual Shrinkage Network for SAR Image Despeckling. In Proceedings of the 2021 IEEE 6th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 22–24 October 2021; pp. 503–507. [Google Scholar] [CrossRef]
- Yang, J.; Jiang, J. Dilated-CBAM: An Efficient Attention Network with Dilated Convolution. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 15–17 October 2021; pp. 11–15. [Google Scholar] [CrossRef]
- Liu, R.; Cai, W.; Li, G.; Ning, X.; Jiang, Y. Hybrid Dilated Convolution Guided Feature Filtering and Enhancement Strategy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5508105. [Google Scholar] [CrossRef]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef] [Green Version]
- Juang, B.; Levinson, S.; Sondhi, M. Maximum likelihood estimation for multivariate mixture observations of markov chains (Corresp). IEEE Trans. Inf. Theory 1986, 32, 307–309. [Google Scholar] [CrossRef]
- Kenny, P.; Boulianne, G.; Ouellet, P.; Dumouchel, P. Joint factor analysis versus eigenchannels in speaker recognition. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 1435–1447. [Google Scholar] [CrossRef] [Green Version]
- Jagtap, S.S.; Bhalke, D.G. Speaker verification using gaussian mixture model. In Proceedings of the 2015 International Conference on Pervasive Computing (ICPC), Pune, India, 8–10 January 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Variani, E.; Lei, X.; McDermott, E.; Moreno, I.L.; Gonzalez-Dominguez, J. Deep neural networks for small footprint text-dependent speaker verification. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4052–4056. [Google Scholar] [CrossRef] [Green Version]
- Hughes, T.; Mierle, K. Recurrent neural networks for voice activity detection. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7378–7382. [Google Scholar] [CrossRef] [Green Version]
- Snyder, D.; Ghahremani, P.; Povey, D.; Garcia-Romero, D.; Carmiel, Y.; Khudanpur, S. Deep neural network-based speaker embeddings for end-to-end speaker verification. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 165–170. [Google Scholar] [CrossRef]
- Nathwani, K.; Vincent, E.; Illina, I. DNN Uncertainty Propagation Using GMM-Derived Uncertainty Features for Noise Robust ASR. IEEE Signal Process. Lett. 2018, 25, 338–342. [Google Scholar] [CrossRef] [Green Version]
- Yuan, W.; Dong, B.; Wang, S.; Unoki, M.; Wang, W. Evolving multi-resolution pooling CNN for monaural singing voice separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 807–822. [Google Scholar] [CrossRef]
- Berdibaeva, G.K.; Bodin, O.N.; Kozlov, V.V.; Nefed’ev, D.I.; Ozhikenov, K.A.; Pizhonkov, Y.A. Pre-processing voice signals for voice recognition systems. In Proceedings of the 2017 18th International Conference of Young Specialists on Micro/Nanotechnologies and Electron Devices (EDM), Erlagol, Russia, 29 June–3 July 2017; pp. 242–245. [Google Scholar] [CrossRef]
- Üstün, B.; Avci, K. A new hybrid window based on cosh and hamming windows for nonrecursive digital filter design. In Proceedings of the 2015 23nd Signal Processing and Communications Applications Conference (SIU), Malatya, Turkey, 16–19 May 2015; pp. 2282–2285. [Google Scholar] [CrossRef]
- Serbes, A. Fast and efficient sinusoidal frequency estimation by using the DFT coefficients. IEEE Trans. Commun. 2019, 67, 2333–2342. [Google Scholar] [CrossRef]
- Wang, X.; Ying, T.; Tian, W. Spectrum representation based on STFT. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Chengdu, China, 17–19 October 2020; pp. 435–438. [Google Scholar] [CrossRef]
- Wu, B.; Wu, H. Scalable similarity-consistent deep metric learning for face recognition. IEEE Access 2019, 7, 104759–104768. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Ma, X.; Jiang, B.; Li, X.; Zhang, X.; Liu, X.; Cao, Y.; Kannan, A.; Zhu, Z. Deep speaker: An end-to-end neural speaker embedding system. arXiv 2017, arXiv:1705.02304. [Google Scholar]
- Zhang, K.; Sun, M.; Han, T.X.; Yuan, X.; Guo, L.; Liu, T. Residual networks of residual networks: Multilevel residual networks. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1303–1314. [Google Scholar] [CrossRef] [Green Version]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep Residual Shrinkage Networks for Fault Diagnosis. IEEE Trans. Ind. Inform. 2020, 16, 4681–4690. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Chen, W.; Wang, H.; Chen, Y. Deep learning seismic random Noise attenuation via improved residual convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 59, 7968–7981. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Technologies | Datasets | Results |
|---|---|---|---|
| GMM-UBM | GMM | TIMIT corpora | Accuracy: 80.83% |
| JFA | GMM | NIST | EER 1: 5.2% |
| RNN | DL | Self-collected datasets | FAR 2: outperformed GMM by 26% |
| d-vector DNN | DL | Self-collected datasets | EER: outperformed i-vector by 14% |
| End-to-end DNN | DL | US English speech | EER: outperformed i-vector by 29% |
| GMMD DNN | DL | CHiME | WER 3: outperformed baseline by 16% |
| Layer | Structure | Stride | Dim |
|---|---|---|---|
| Input | - | - | - |
| ERSBU-64 | 5 × 5, 64 | 2 × 2 | 2048 |
| [3 × 3, 64] × 2 | 1 × 1 | 2048 | |
| ERSBU-128 | 5 × 5, 128 | 2 × 2 | 2048 |
| [3 × 3, 128] × 2 | 1 × 1 | 2048 | |
| ERSBU-256 | 5 × 5, 256 | 2 × 2 | 2048 |
| [3 × 3, 256] × 2 | 1 × 1 | 2048 | |
| Average | - | - | 2048 |
| Affine | 2048 × 256 | - | 256 |
| K.l2normalize | - | - | 256 |
| Output | - | - | - |
| Parameter | Value |
|---|---|
| Input Shape | (160, 64, 1) |
| Size of batch | 20 |
| No. of epochs | 50 |
| Learning rate | 0.001 |
| Optimization function | Adam |
| Loss function | Triplet |
| Models | Parameters | Trainable Parameters | Nontrainable Parameters |
|---|---|---|---|
| CNN | 4.936 M | 4.926 M | 0.010 M |
| Res-CNN | 4.936 M | 4.926 M | 0.010 M |
| EDRSN | 3.804 M | 3.800 M | 0.004 M |
| EDRSN + CBAM | 3.849 M | 3.845 M | 0.004 M |
| Models | Loss | Accuracy | F-Measure |
|---|---|---|---|
| CNN | 0.7629 | 86.54% | 0.7124 |
| Res-CNN | 0.3507 | 92.38% | 0.7799 |
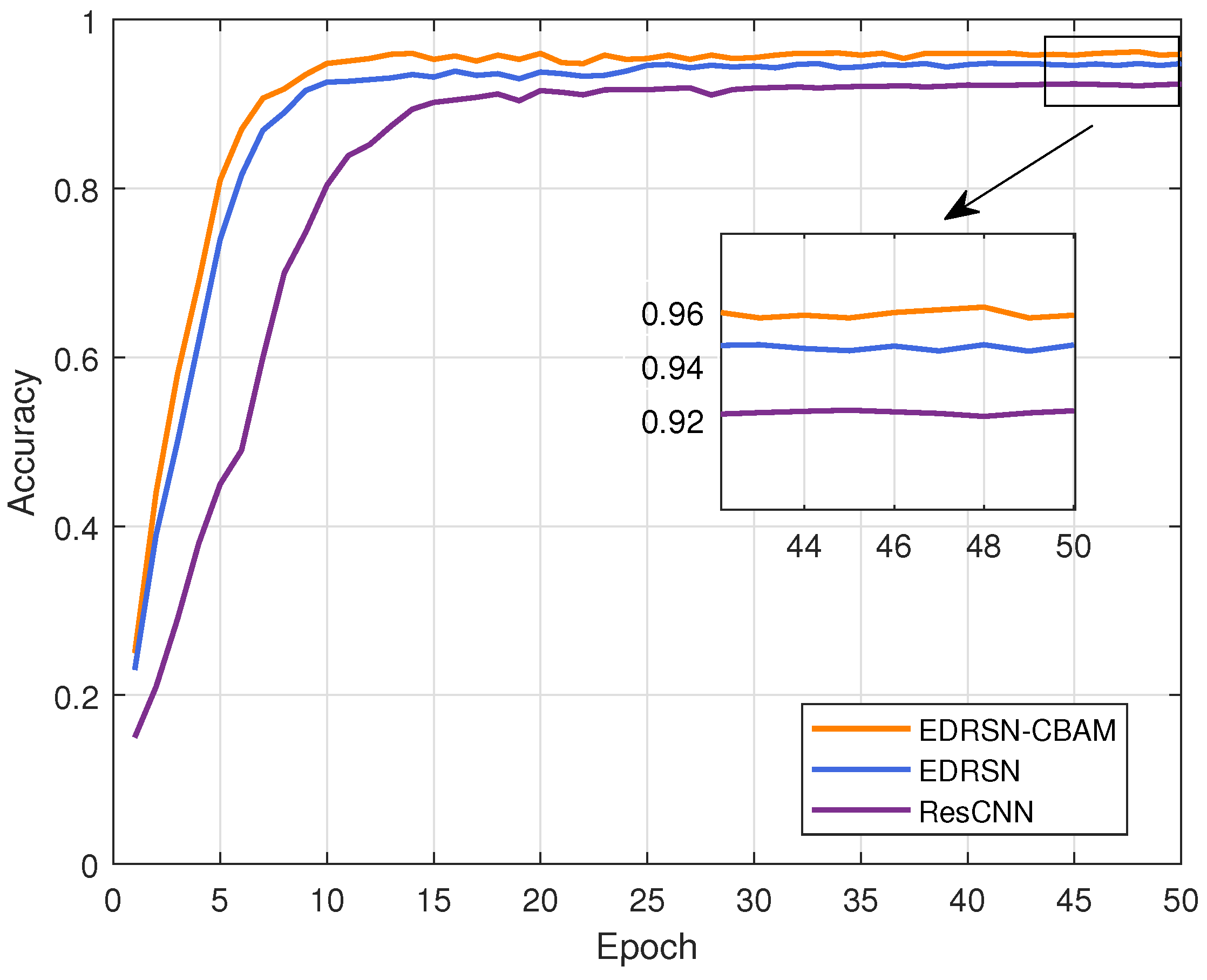
| EDRSN | 0.2146 | 94.83% | 0.8235 |
| EDRSN + CBAM | 0.1785 | 96.02% | 0.8462 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Zhai, H.; Ma, Y.; Sun, L.; Zhang, Y.; Quan, W.; Zhai, Q.; He, B.; Bai, Z. Enhanced-Deep-Residual-Shrinkage-Network-Based Voiceprint Recognition in the Electric Industry. Electronics 2023, 12, 3017. https://doi.org/10.3390/electronics12143017
Zhang Q, Zhai H, Ma Y, Sun L, Zhang Y, Quan W, Zhai Q, He B, Bai Z. Enhanced-Deep-Residual-Shrinkage-Network-Based Voiceprint Recognition in the Electric Industry. Electronics. 2023; 12(14):3017. https://doi.org/10.3390/electronics12143017
Chicago/Turabian StyleZhang, Qingrui, Hongting Zhai, Yuanyuan Ma, Lili Sun, Yantong Zhang, Weihong Quan, Qi Zhai, Bangwei He, and Zhiquan Bai. 2023. "Enhanced-Deep-Residual-Shrinkage-Network-Based Voiceprint Recognition in the Electric Industry" Electronics 12, no. 14: 3017. https://doi.org/10.3390/electronics12143017