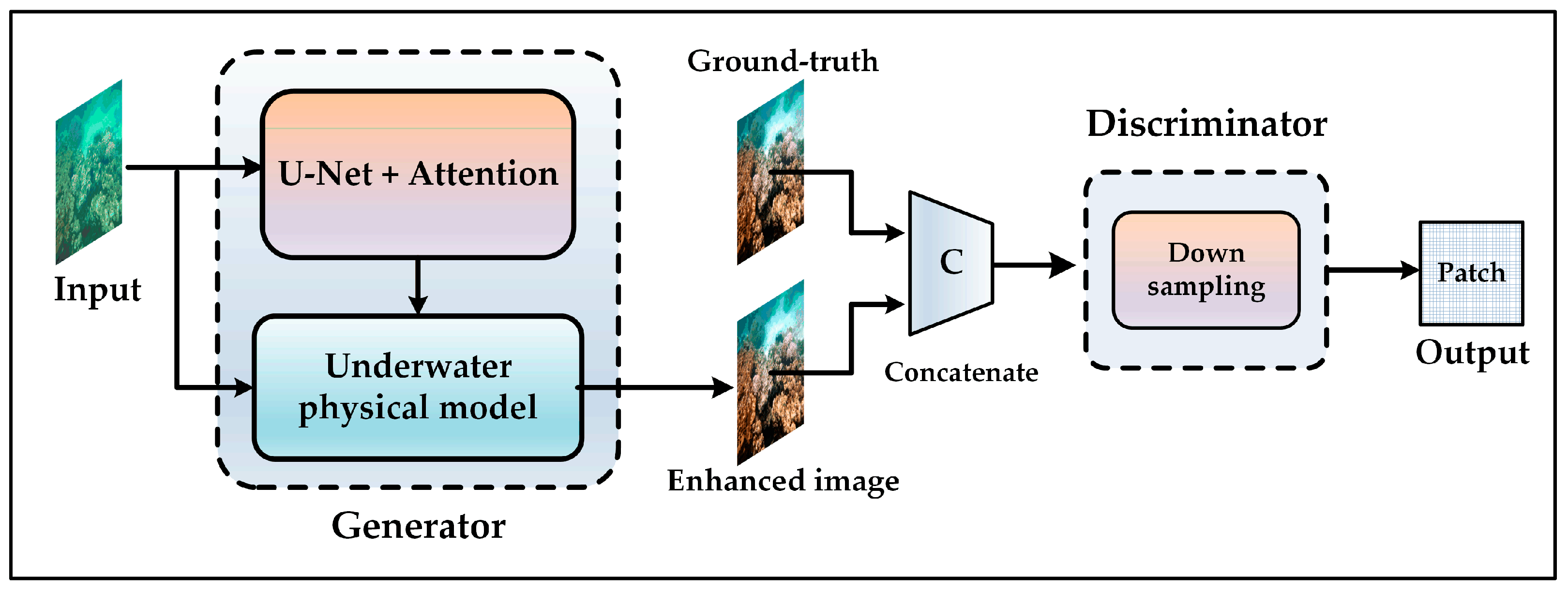
2.1. Generator Network
In
Figure 2, the structure of the generator is embedded in the down-sampling convolution layer and up-sampling transposed convolution layer of U-Net to form the CBLA module and the TBRA module, respectively, for optimizing the extracted image features. The generator was used to estimate the parameter estimation image of the physical model. Afterward, the real and clear underwater image was inverted by combining the parameter estimation image with the original underwater image.
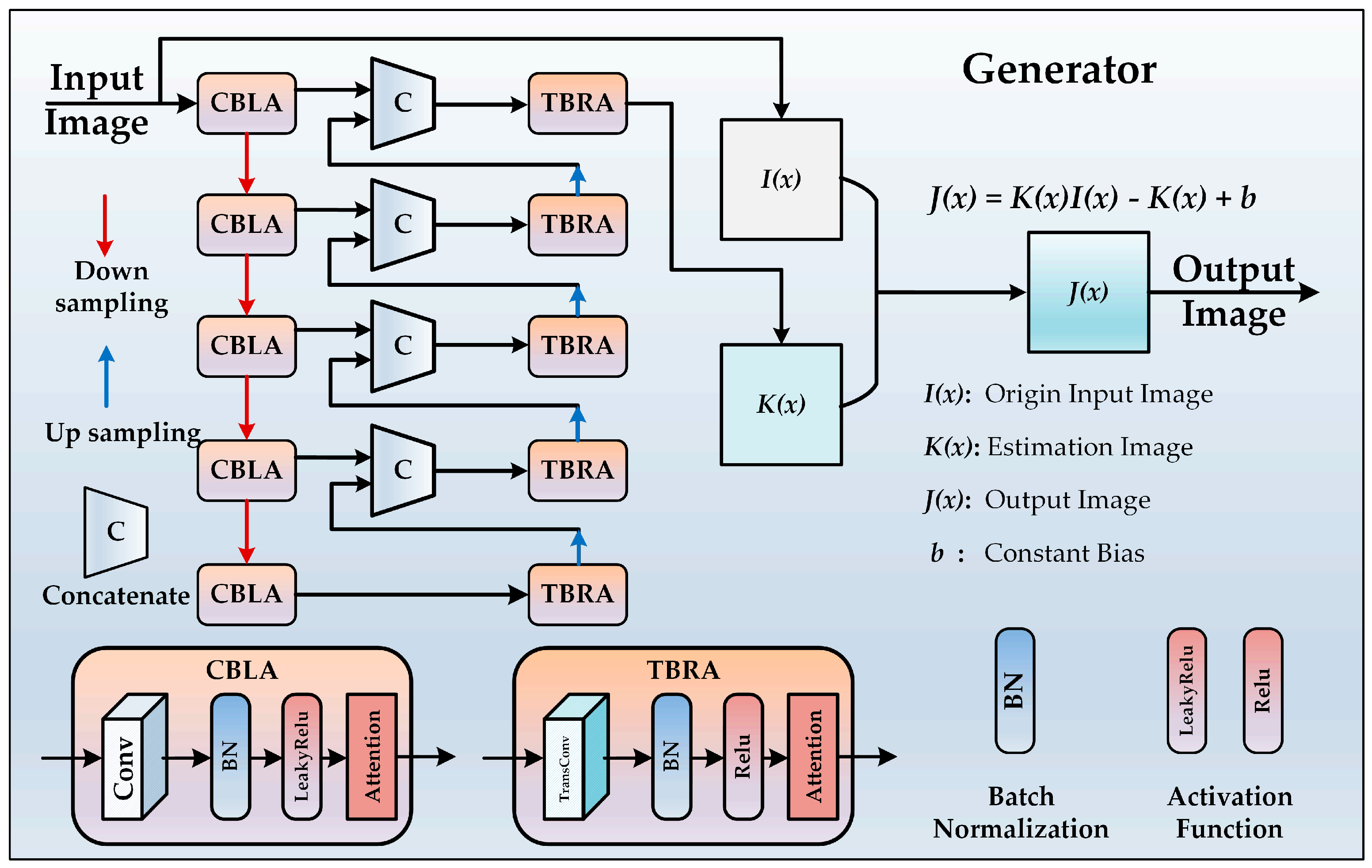
U-Net is an encoder–decoder network that down-samples the images by using convolution for obtaining low-dimensional features. Then, the network up-samples the features based on transposed convolution to reconstruct the image. In addition, the output of each encoder skip to its corresponding mirror module in decoder preserves the spatial dependence of the encoder. This idea has proved to be effective [
31,
32].
The structure of U-Net is shown in
Figure 3. The input image was reshaped to
. The low-dimensional feature map of
was obtained by using five encoding modules. Afterward, the low-dimensional features and the output of the corresponding decoding module were stacked and used as the input of the decoding module. The encoding module included a 2-D convolution layer with
kernels and two steps, a batch normalization layer (BN) [
33], a leaky ReLU activation function [
34], and a channel attention mechanism module. The decoding module included a 2-D transposed convolution layer with
kernels and two steps, a batch normalization layer, a ReLU activation function [
34], and a channel attention mechanism module.
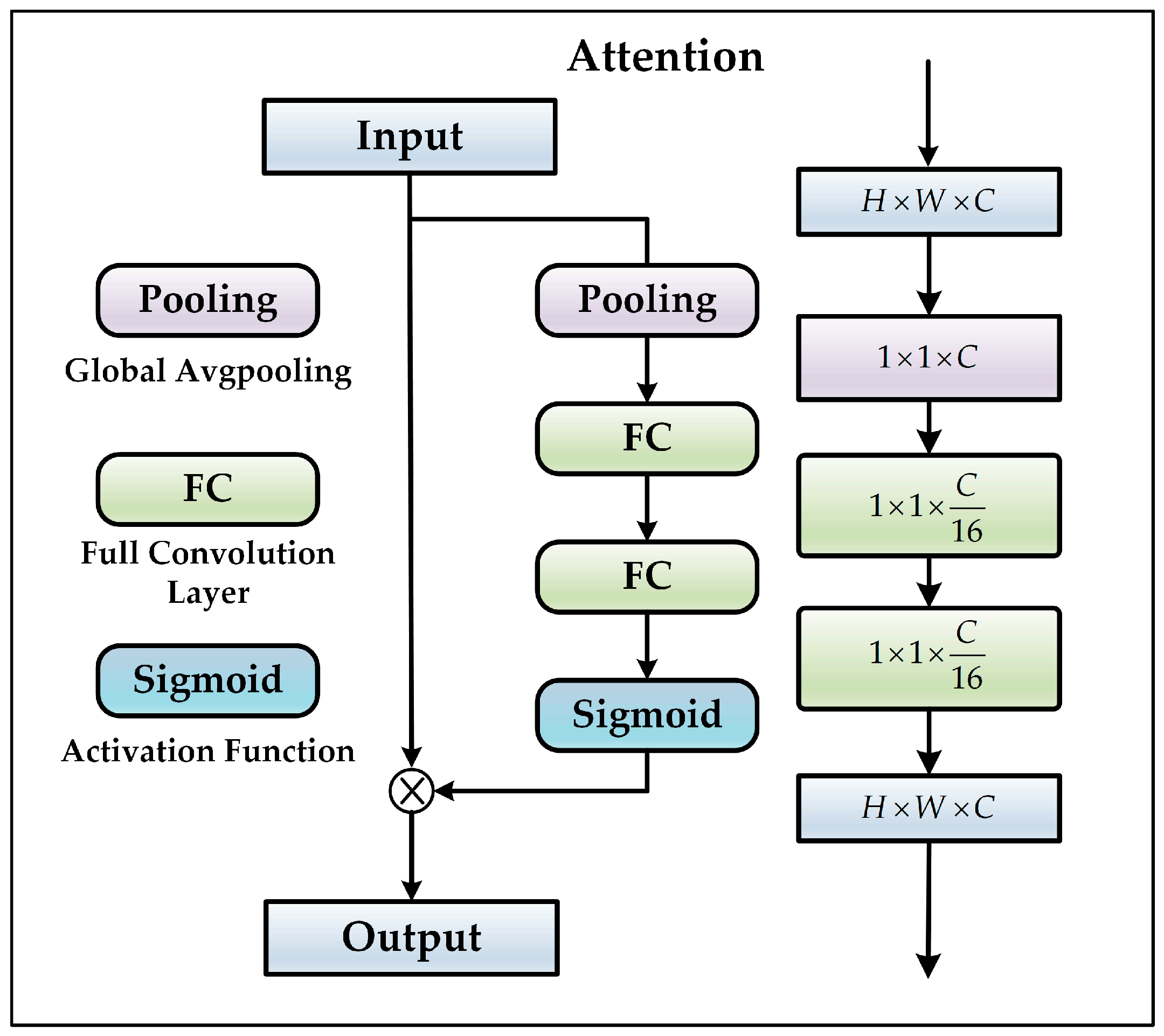
In this model, the channel attention mechanism was added to each convolutional layer and transposed convolutional layer of U-Net as an additional layer of the network to optimize the input features. The specific structure of the module is shown in
Figure 4.
The channel attention mechanism first utilized global average pooling to generate channel statistics and then utilized fully connected layers and a sigmoid function to capture channel dependencies [
35]. The specific method was to learn the generation of channel weights. The channel attention mechanism could perform feature recalibration and strengthen the feature representation of the network to optimize the parameter estimation of the subsequent physical model.
The first step was the extraction operation, in which an
feature with a height of
, a width of
, and a channel of
was transformed into
feature with a global receptive field to a certain extent. The global average pooling is expressed as
where
represents the global average pooling and
represents the value of the characteristic of the
c-th channel at
.
Second, the weight generation operation sent the global characteristics of the global average pooling output to two fully connected layers for learning, so as to display the correlation between the geo-modeling channels [
16]. Finally, the normalized weight was obtained by the sigmoid function. This is mathematically expressed as
where
and
represent the sigmoid function and the rectified linear unit (ReLU), respectively.
represents the learnable parameters of the first fully connected layer, and
represents the learnable parameters of the second layer.
The last step was the scale operation, which weighted the generated weights to the previous features channel by channel and completed the recalibration of the input features on the channels. This is mathematically expressed as follows:
where
means adjusting the height and width of
.
The output of U-Net was used as the input of an underwater physical model [
13], which is mathematically expressed as follows:
where
represent the total signal received by the camera, the direct transmission component, the forward scattering component, and the background scattering component, respectively. Since the object was relatively close to the camera, the forward scattering component could be ignored, and only the direct transmission component and the background scattering component were retained [
16]. So the underwater optical imaging model was simplified as follows:
where
is the observed image,
is the theoretically real and clear underwater image, and
represents the background light source.
is the residual energy ratio after it was captured by the camera, and it is mathematically expressed as follows:
in which
represents the attenuation coefficient of light sources with different wavelengths, and
represents the distance between the underwater scene and the camera. In order to obtain the real underwater image,
can be rewritten as follows:
and
are used as parameters for estimating
as follows:
The final underwater physical model is mathematically expressed as follows:
where
is a constant, which is one by default.
Then, we use the improved U-Net to estimate , so as to integrate the physical model into the generator. In the architecture of the proposed generator, represents the input original underwater image, represents the image generated by the generator, is used as a learnable parameter to fine-tune the final output result, and is the final generated image that is sent to the discriminator along with the real sample of the original underwater image.
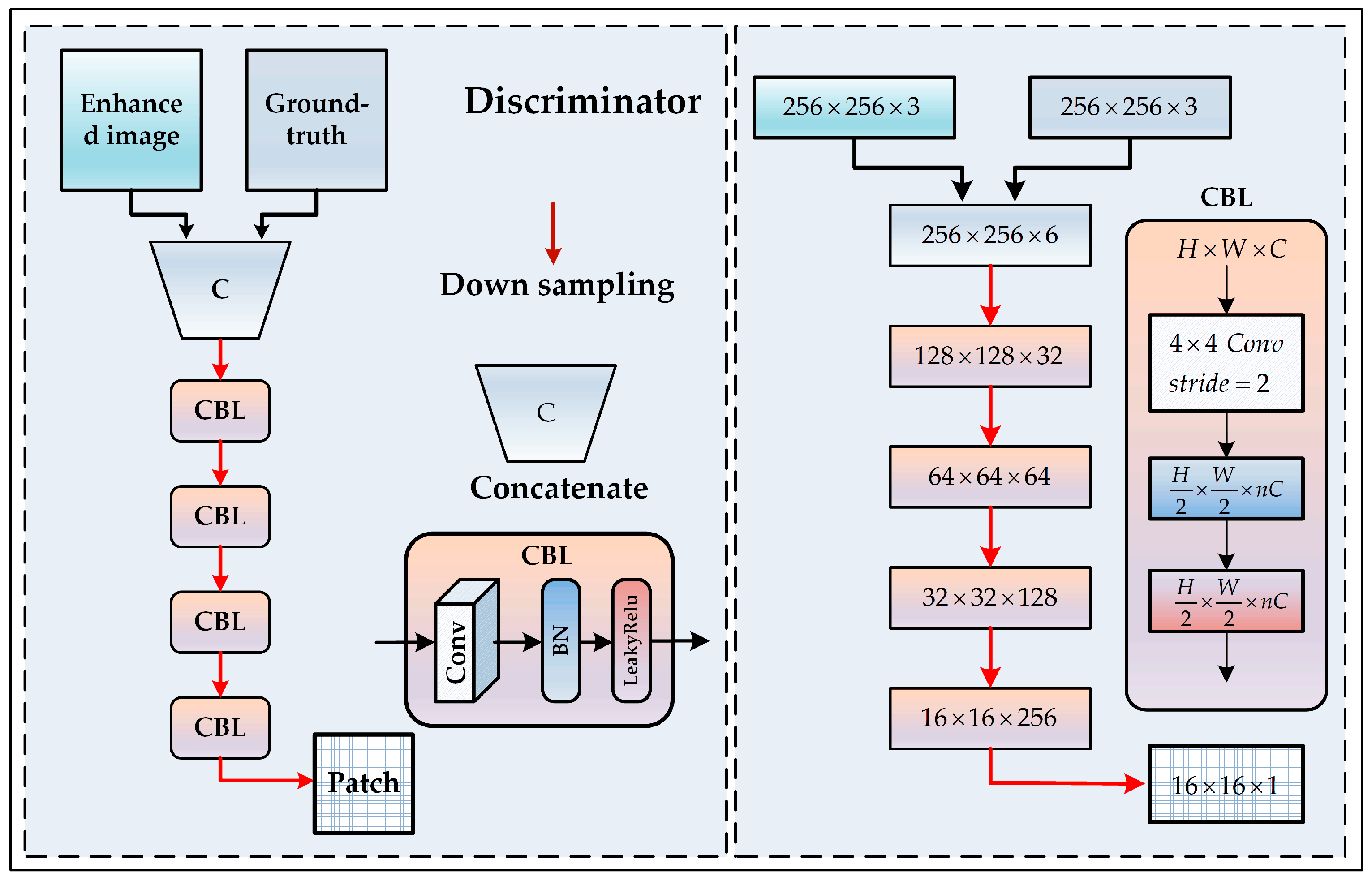
2.3. Loss Function
The loss function was mainly used to guide the network model parameters in the direction of minimum loss. In this paper, we designed a loss function that integrated the adversarial loss, the global loss, and the perceptual loss to guide the training of the generative adversarial network.
The adversarial loss was caused by the game between the generator and discriminator. The generator constantly updated the network parameters to generate an image consistent with the real reference image. On the other hand, the discriminator continuously judged whether the generated image was original or fake.
where
represents the generator,
represents the discriminator,
represents the source domain (low-quality underwater image), and
represents the target domain (clear underwater image). The generator
aims to minimize the loss
, while the discriminator aims to maximize
.
Many current methods show that adding
or
loss can result in the images generated by the generator having a better global similarity [
31,
36]. It is noteworthy that the
loss is less robust, and it is easier to introduce blur in the image. In this paper, the
loss (global loss) had a better effect and is expressed as follows:
The perceptual loss was beneficial for making the generator
attain the texture information of the image. According to its calculation method, we defined the perceptual loss
. In this method, the features in the generated image and the real image were extracted by using VGG-19. The Euclidean distance between the high-dimensional feature maps extracted by them in block5_conv2 layer was calculated. The VGG-19 is a pre-trained network. The perceptual loss is mathematically expressed as follows:
The adversarial loss, the global loss, and the perceptual loss were combined, and the following loss function was obtained:
where
and
are hyperparameters, which are used to adjust the proportion of global loss and perceptual loss in the loss function. In order to select the appropriate hyperparameters so that the fusion loss could achieve the optimal effect, we referred to the previous work [
25] and determined the value range of the two hyperparameters to be (0, 1). Then, under the same experimental conditions, we fine-tuned the parameters with a step size of 0.1 and recorded the loss on the EUVP dataset, and the final results are shown in
Figure 6. The experiments showed that
had the best effect.
2.4. Image Evaluation Metrics
For evaluating the image quality, this study adopted well-known image evaluation metrics, such as peak signal-to-noise ratio (PSNR) [
17,
32] and structural similarity (SSIM) [
37]. The commonly used evaluation metrics in underwater image processing include underwater image quality measure (UIQM) [
38] and underwater color image quality evaluation (UCIQE) [
39].
The PSNR was obtained by calculating the mean square error (MSE) between the generated image and the real value of the original input. This is mathematically expressed as follows:
where
and
represent the real values of the generated image and the original image, respectively. The
represents the mean square error between the generated image and the original image. The larger the value of PSNR, the lower was the noise in the image.
The natural image had strong correlations between each channel and each pixel value in the channel. These correlations contained important feature information regarding the object structure in the visual scene. The SSIM refers to the difference in brightness, contrast, and structure between two images. The SSIM was computed by using the expression
where
and
represent the real values of the generated image and the original image, respectively;
represents the average value of each channel of the image;
represents the variance of each channel of the image; and
represents the covariance between
and
. In addition,
and
were used to ensure the stability of the numerical values. The larger the value of SSIM, the more similar were the structures of the two images.
The UIQM is a special metric for evaluating the underwater image quality proposed by Panetta et al. [
40]. This metric did not need the real value corresponding to the original image. The UIQM obtained the final result by quantifying the color, sharpness, and contrast and weighting it. This is expressed as
where
represents the test image.
,
, and
represent the color, definition, and contrast of the quantized image, respectively, and
,
, and
represent the weight of each component. As the value of metric became larger, the color of the image was closer to the image in the normal state.
UCIQE is a new measurement method proposed by Yang et al. [
39]. The method compared the pixels per inch distribution of underwater images in CIELAB color space with subjective image quality perception. This method was a linear combination of chromaticity, saturation, and contrast, and was used to quantify the uneven color projection, blur, and low contrast of the underwater images. The metric is mathematically expressed as follows:
where
is the test image;
is the standard deviation of chromaticity;
is the brightness contrast;
μs is the average value of saturation; and
,
, and
are the weighting coefficients. The larger the value of this metric was, the thicker was the color of the image.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}