


3D Pose Recognition of Small Special-Shaped Sheet Metal with Multi-Objective Overlapping

Abstract
:1. Introduction
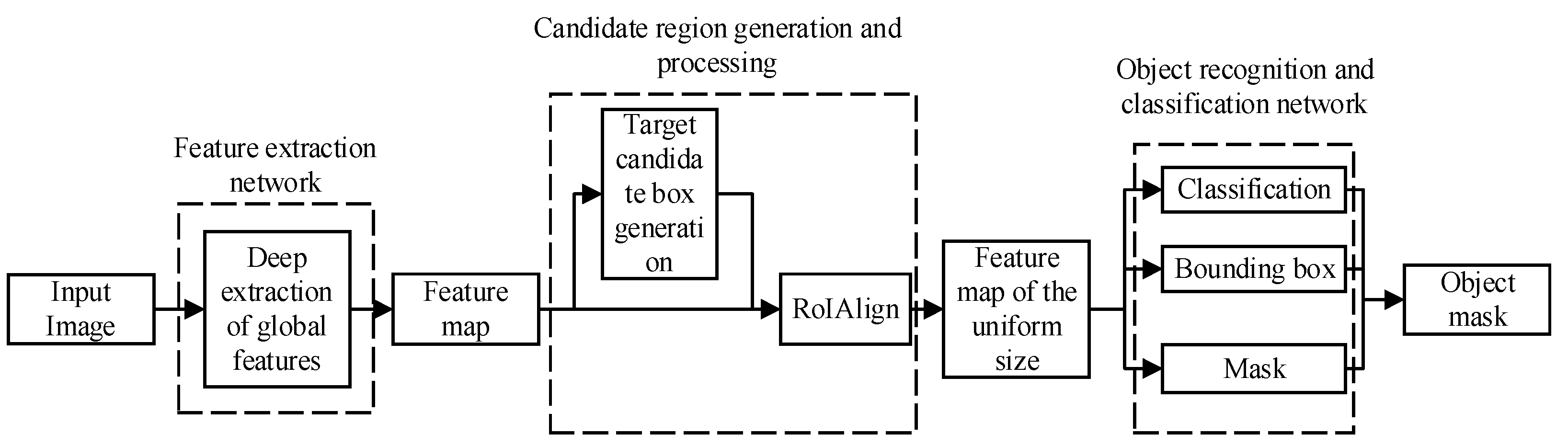
2. A Multi-Object Overlapping Case Segmentation Model Method for Metal Profiled Thin Parts
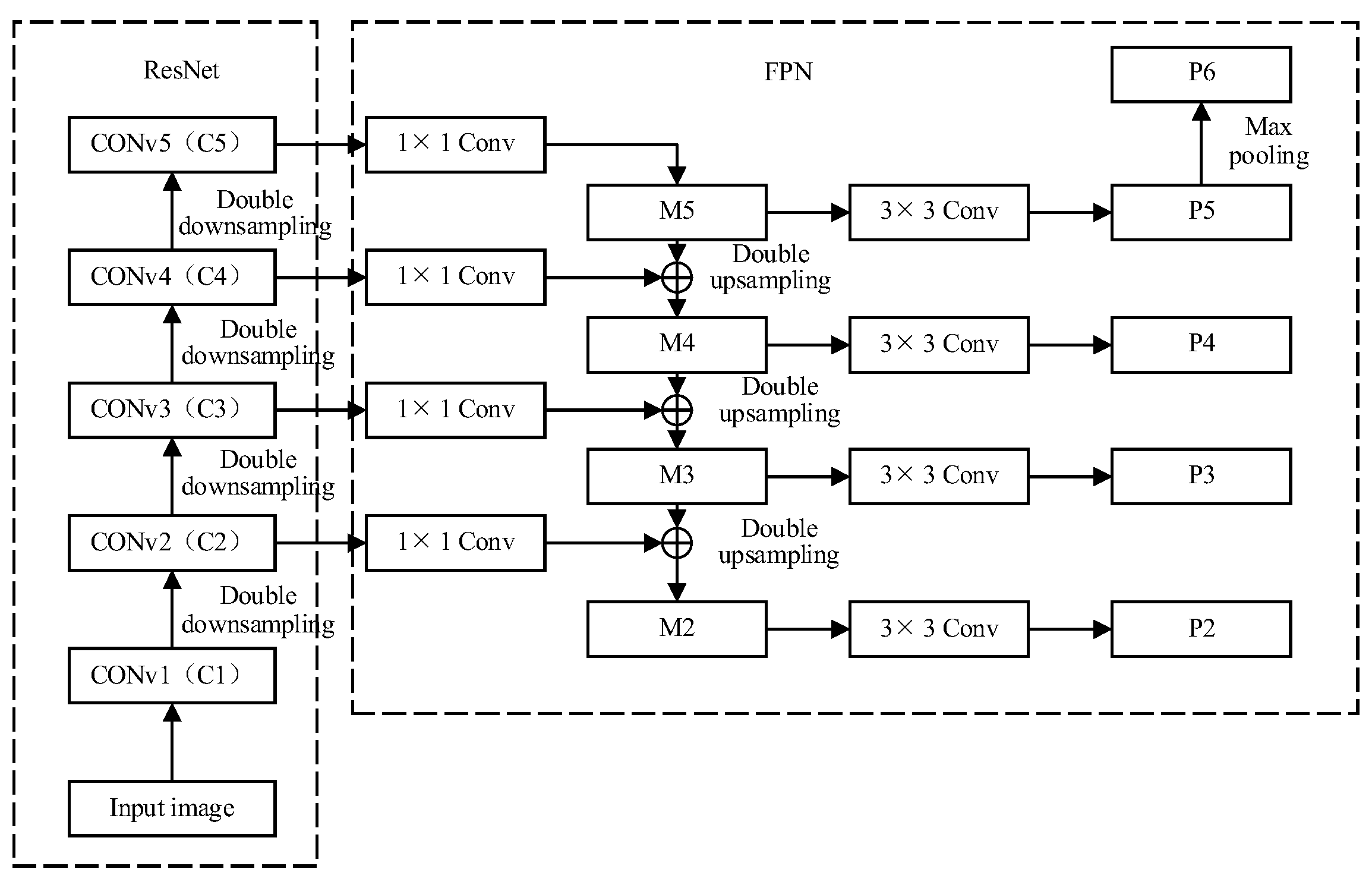
2.1. Feature Extraction Network Construction of Instance Segmentation Model for Generating Object Masks
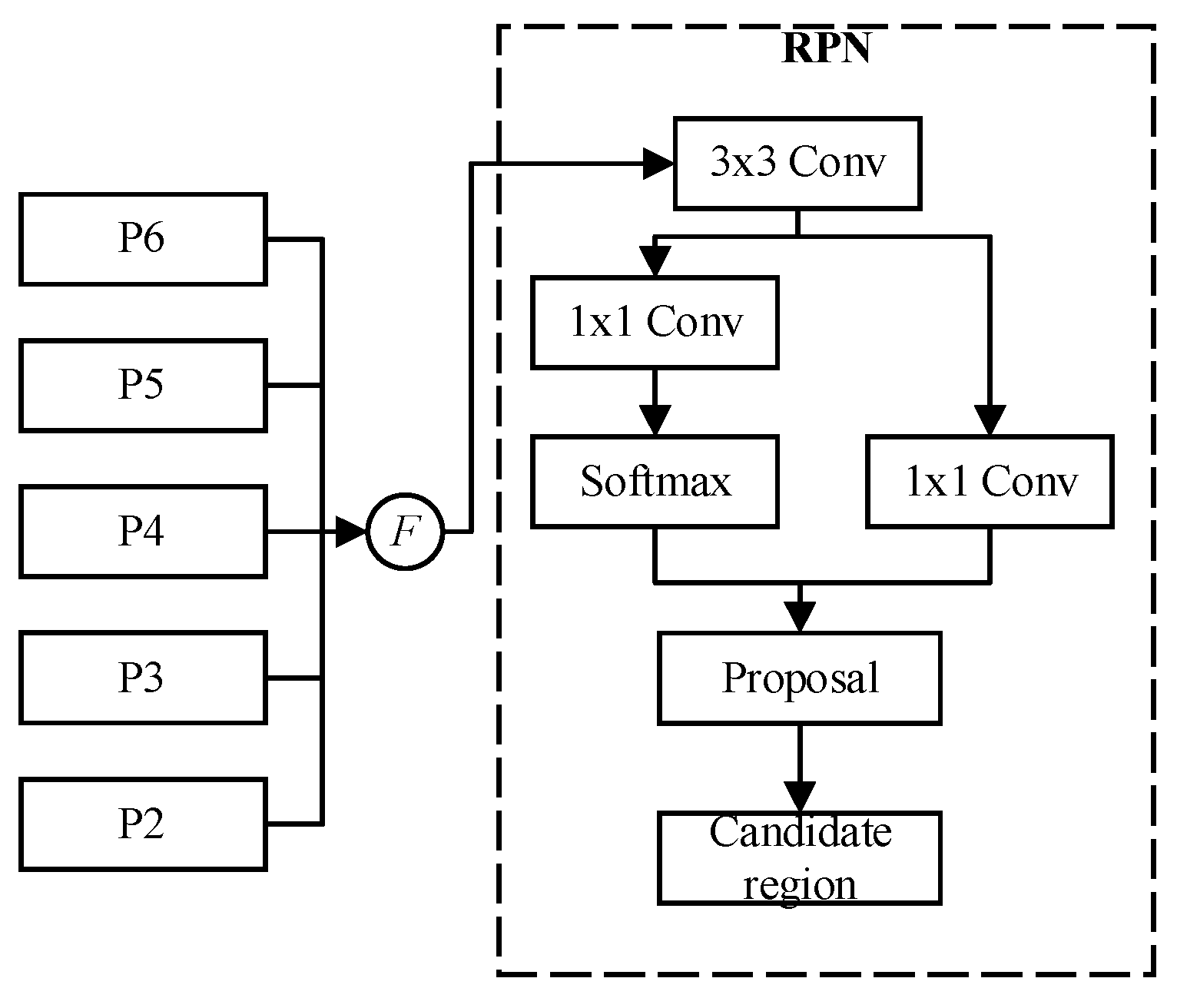
2.2. Feature Map Candidate Region Generation Network
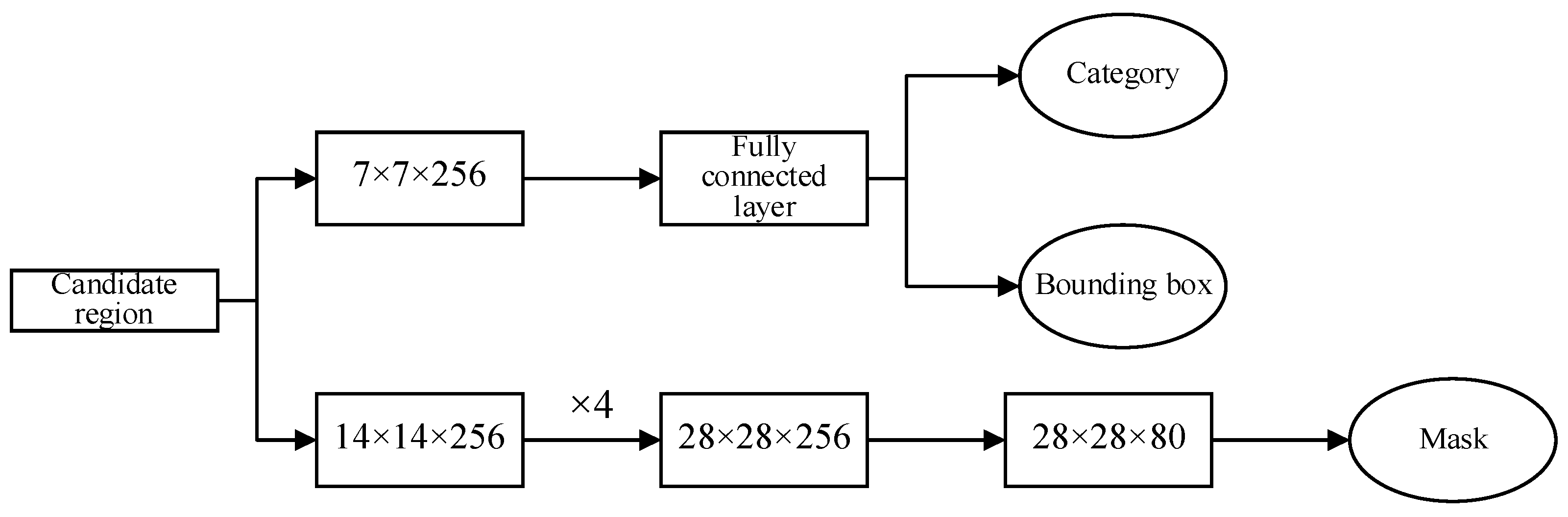
2.3. Object Recognition and Classification Network
2.4. Model Calculation Complexity
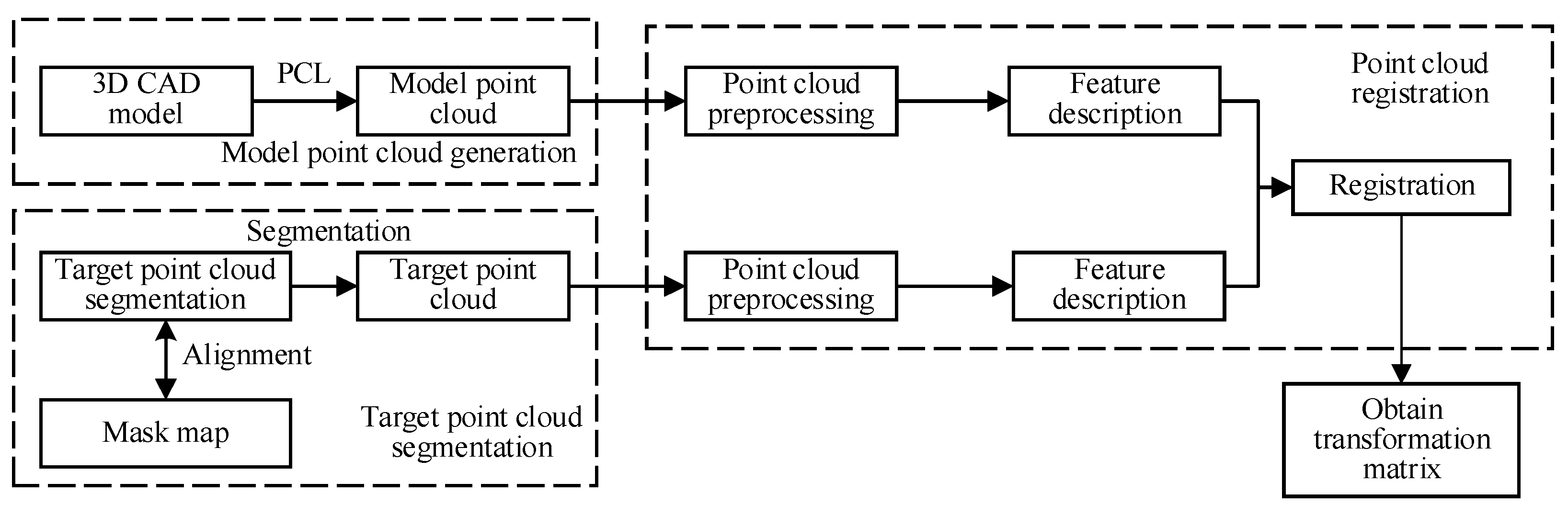
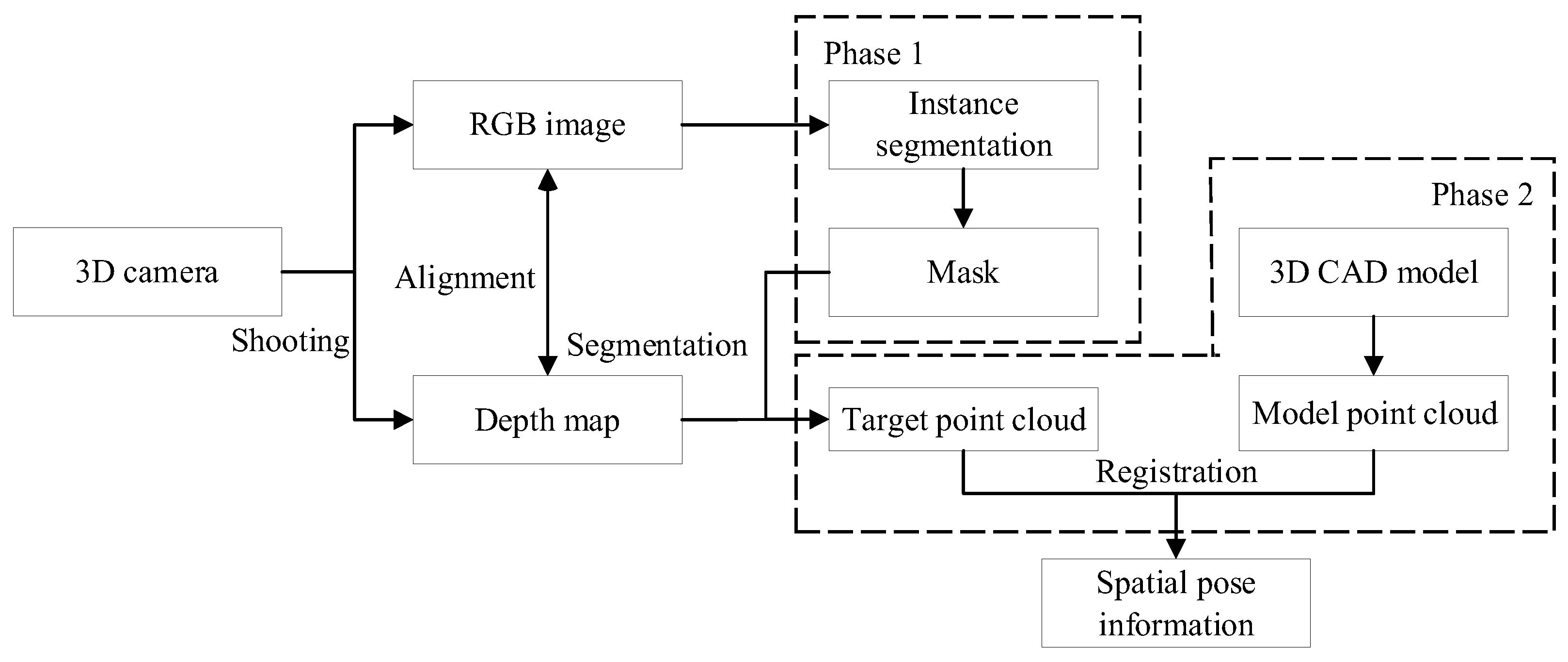
3. Pose Estimation Method of Metal Deformed Thin Parts Based on 3D Point Cloud
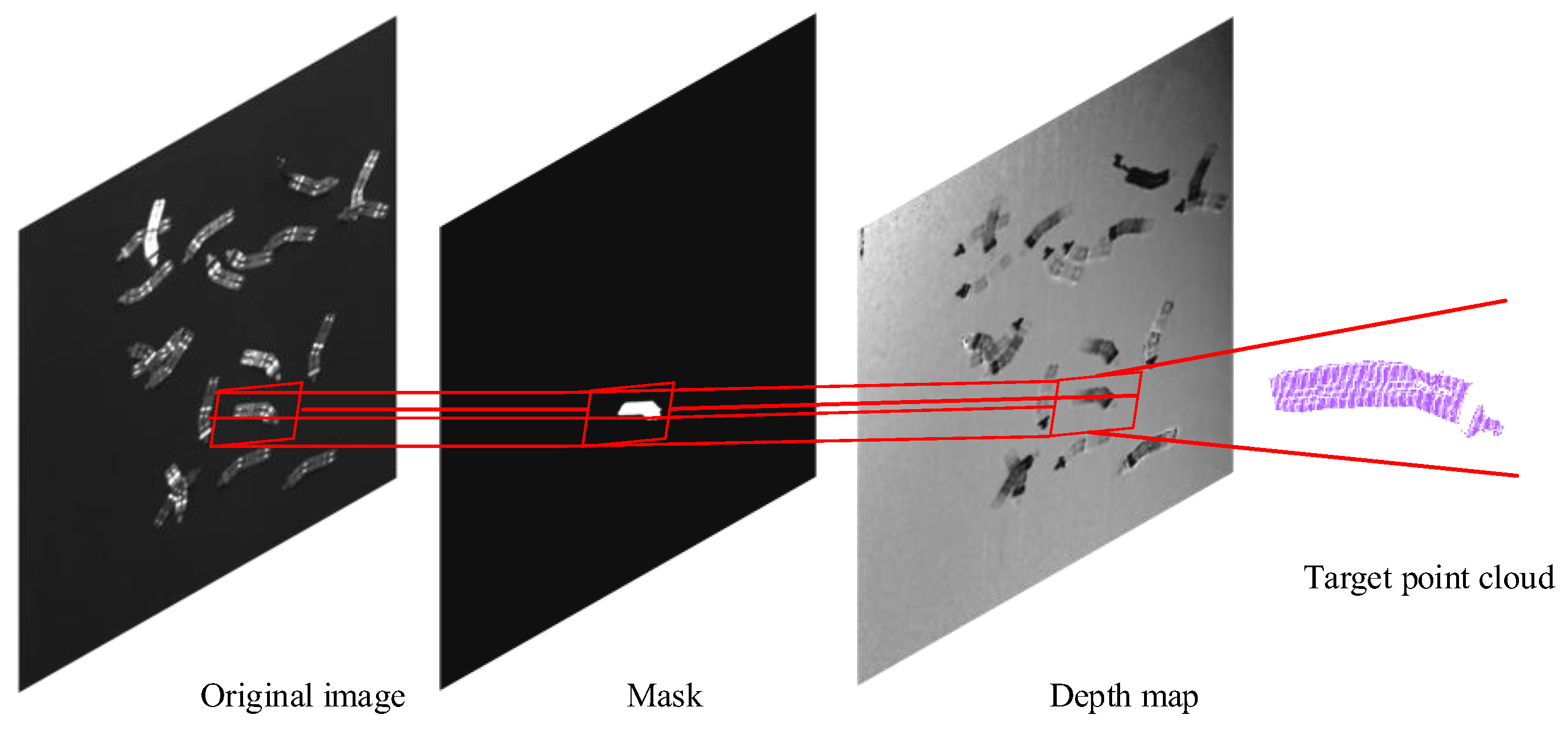
3.1. Target Point Cloud Segmentation and Model Point Cloud Generation
3.2. Registration of Target Point Cloud and Model Point Cloud
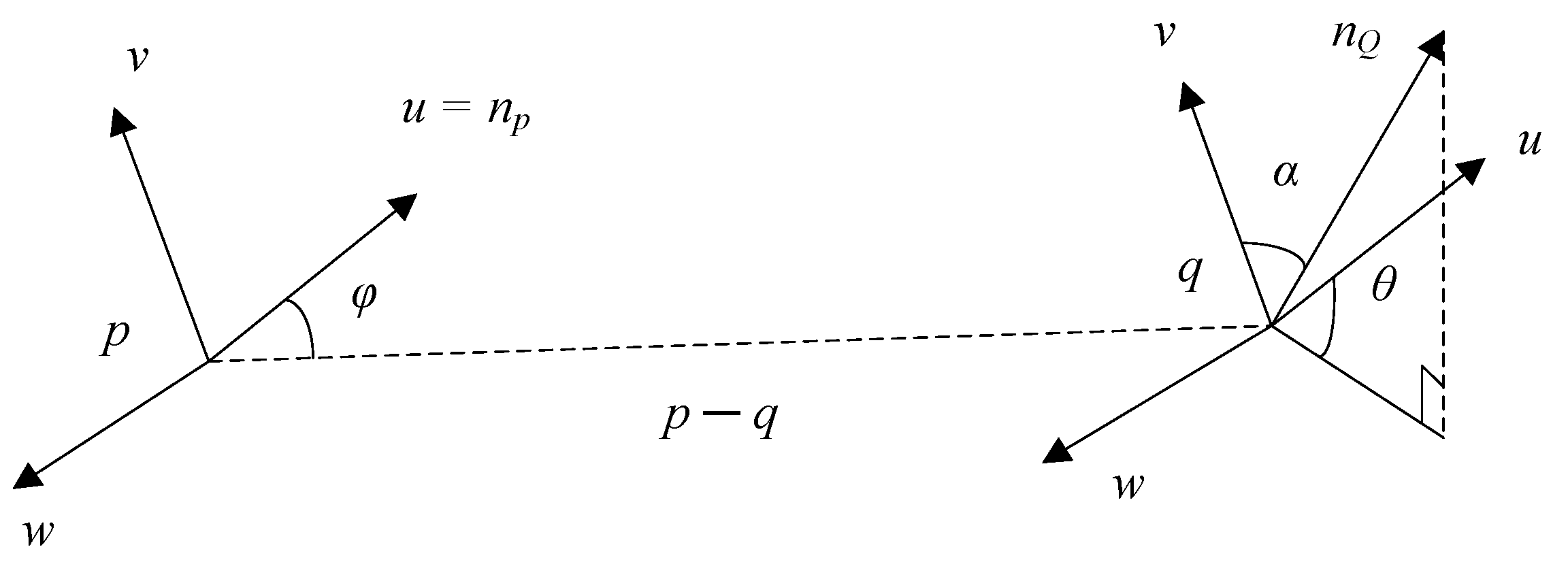
3.2.1. Establish Point Cloud Feature Descriptor
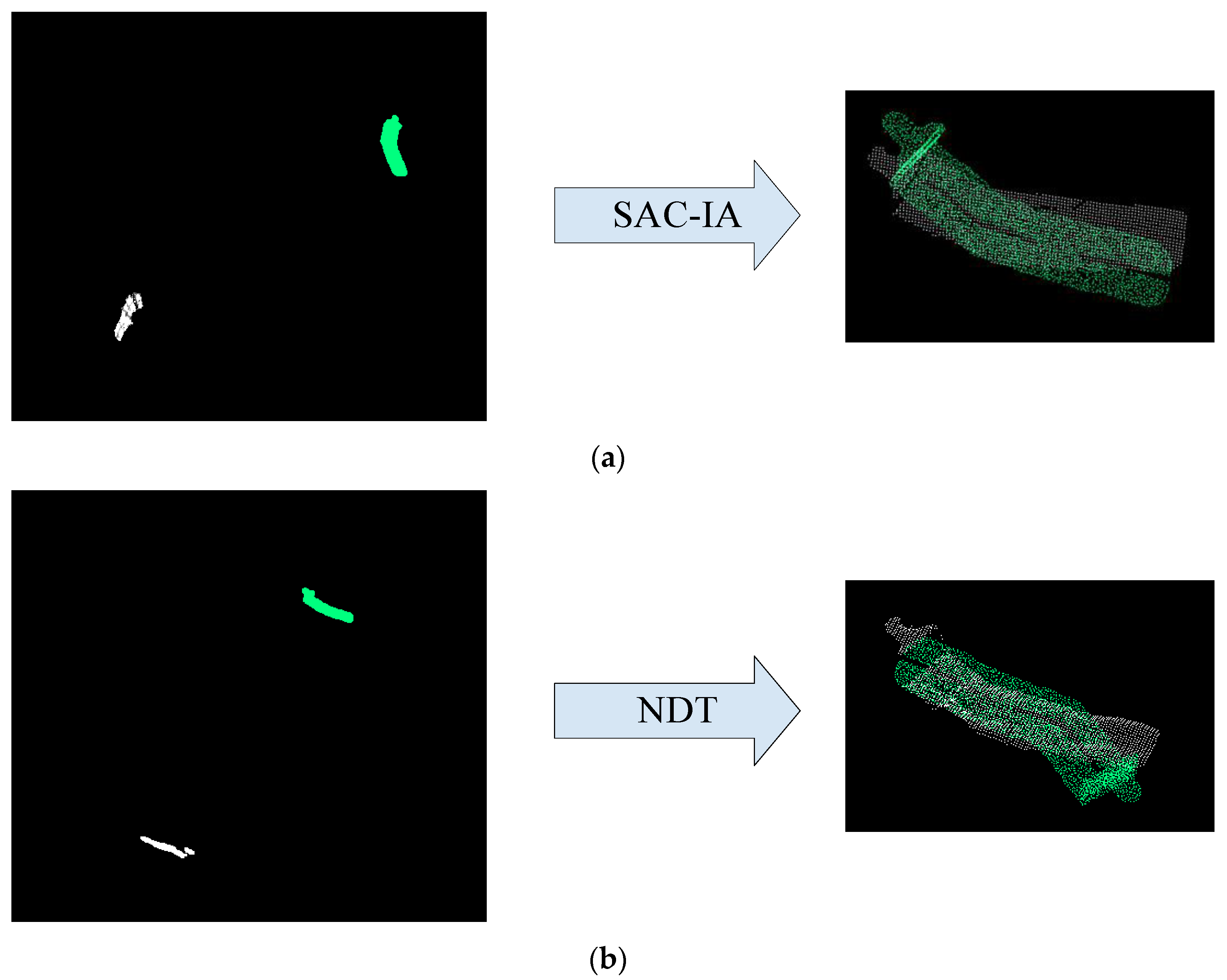
3.2.2. Point Cloud Coarse Registration Algorithm
- (1)
- Coarse registration algorithm based on SAC-IA. Based on the FPFH feature descriptor, we searched the corresponding points in the point cloud and then used the sampling consistency to iterate continuously to remove the wrong corresponding points and solve the rigid transformation matrix with minimal registration errors. The specific implementation steps are as follows.
- (2)
- Coarse registration algorithm based on NDT. The NDT algorithm converts the solution of the rigid transformation matrix into the solution of the optimal value of the probability distribution function. In other words, it uses the continuously differentiable probability density function to describe the distribution of points in the point cloud and then solves the optimal solution of the likelihood function from the template point cloud to the target point cloud to obtain the transformation matrix. The specific steps are as follows:
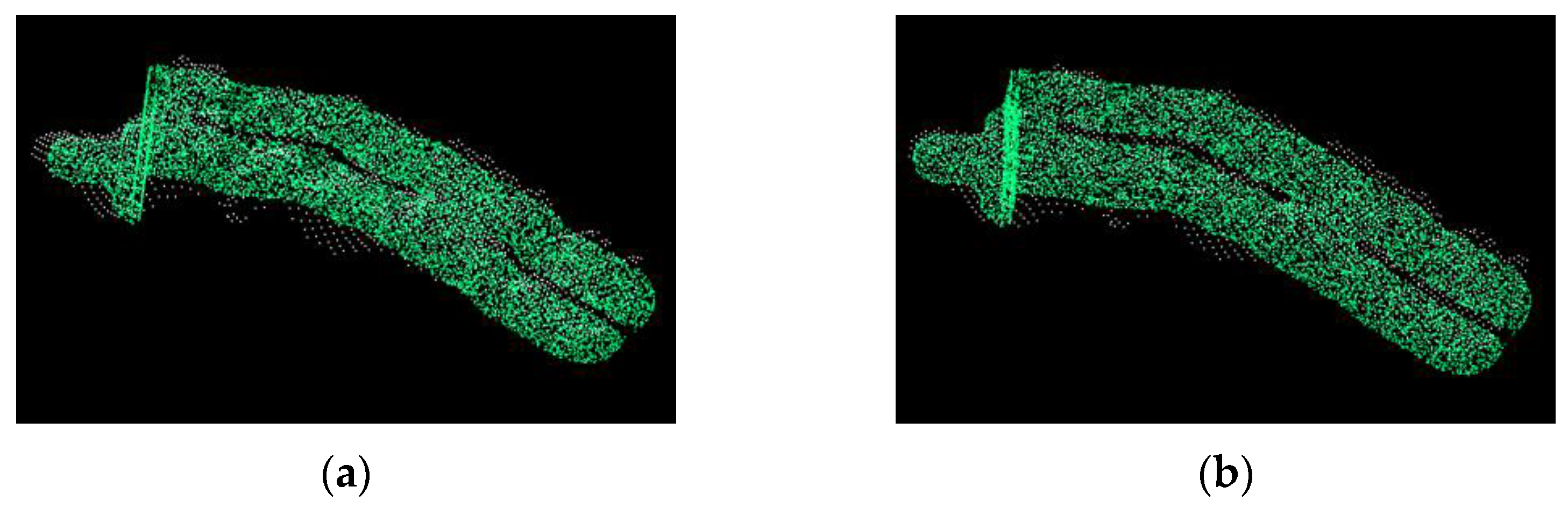
3.2.3. Point Cloud Fine Registration Algorithm
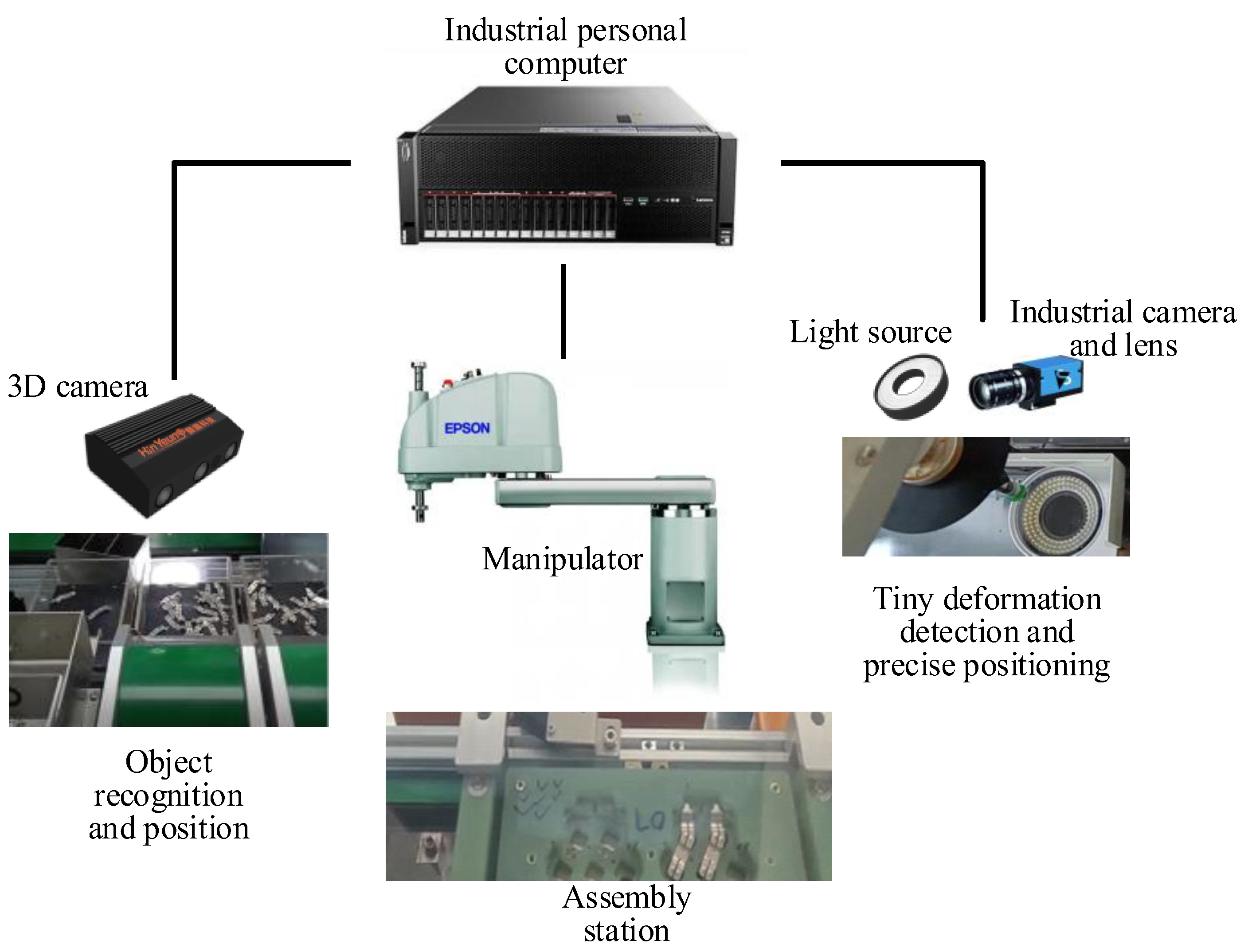
4. Experimental Verification and Testing
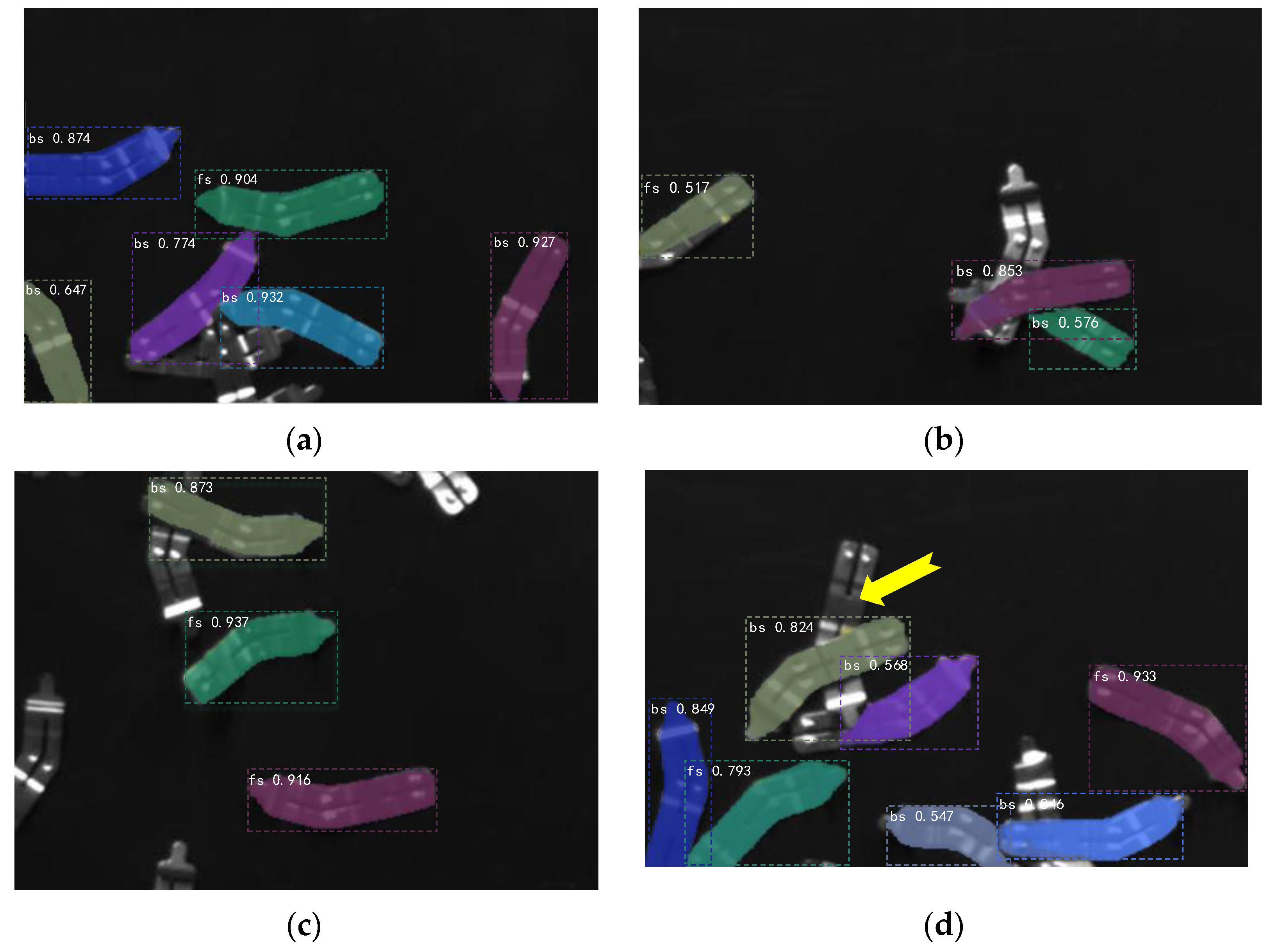
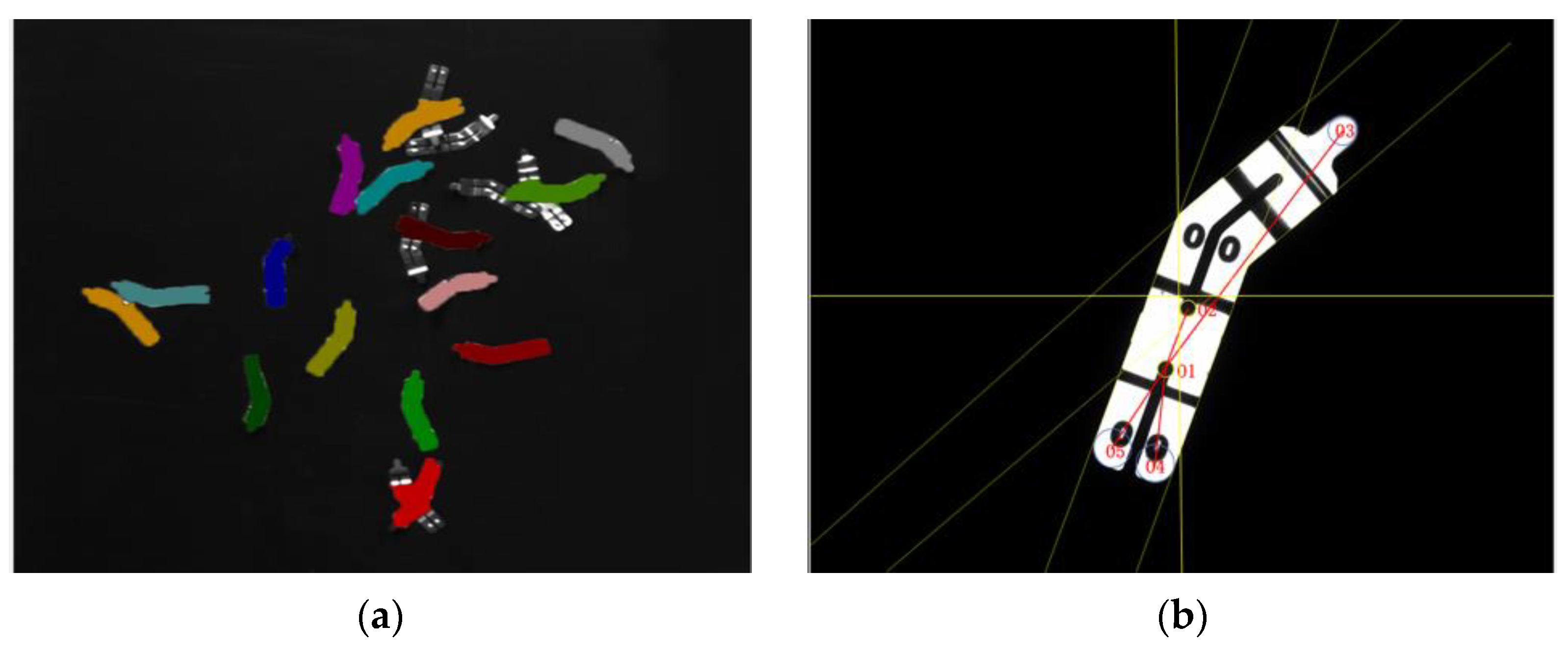
4.1. Instance Segmentation Experiment and Analysis
4.1.1. Custom Data Set Building
4.1.2. Model Training Details Settings
4.1.3. Experimental Results and Evaluation Analysis
4.2. 3D Point Cloud Registration Experiment and Analysis
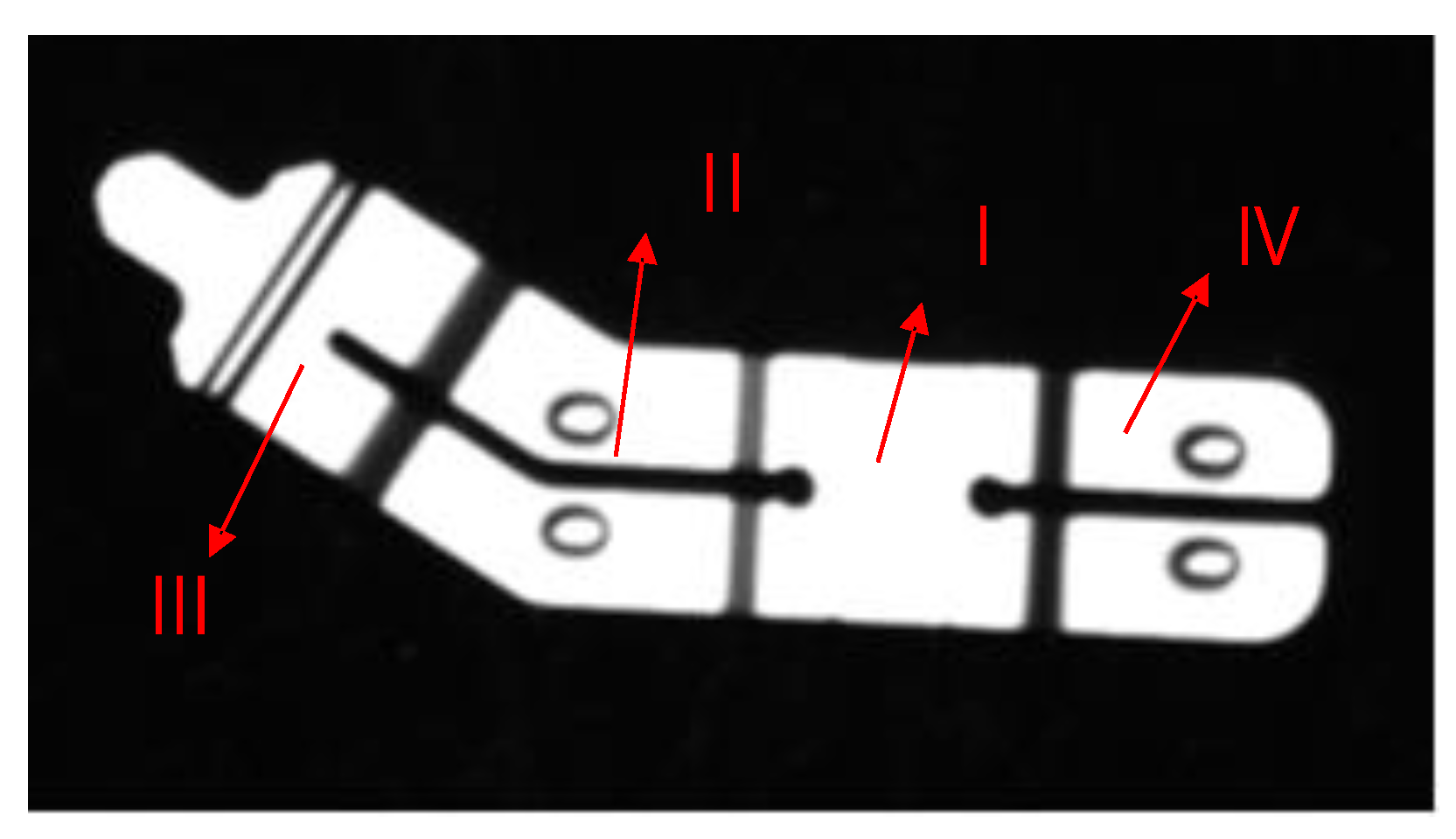
4.2.1. Generation of Target Point Cloud and Model Point Cloud of Nickel Sheets
4.2.2. Registration Experiment of Target Point Cloud and Model Point Cloud
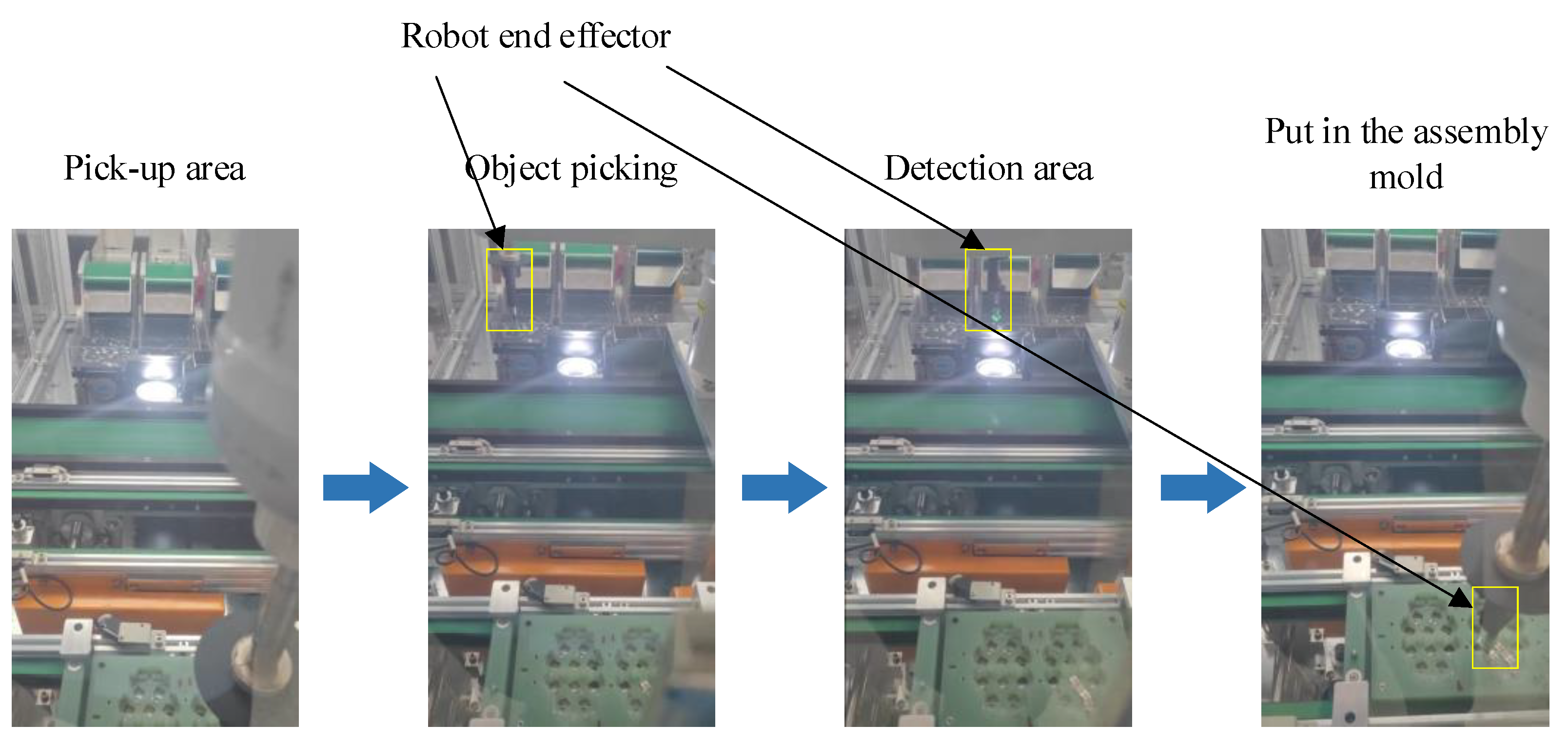
4.3. Practical Application Test
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, T.X.; Jiang, M.Z.; Feng, M.C. Vision-based target recognition and location for picking robot: A review. Chin. J. Sci. Instrum. 2021, 42, 28–51. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In IEEE Transactions on Pattern Analysis & Machine Intelligence; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367. [Google Scholar]
- Sun, Y.; Su, L.; Luo, Y.; Meng, H.; Li, W.; Zhang, Z.; Wang, P.; Zhang, W. Global Mask R-CNN for marine ship instance segmentation. Neurocomputing 2022, 480, 257–270. [Google Scholar] [CrossRef]
- Yang, H.; Zheng, L.; Barzegar, S.G.; Zhang, Y.; Xu, B. BorderPointsMask: One-stage instance segmentation with boundary points representation. Neurocomputing 2022, 467, 348–359. [Google Scholar] [CrossRef]
- Xu, Y.; Arai, S.; Liu, D.; Lin, F.; Kosuge, K. FPCC: Fast point cloud clustering-based instance segmentation for industrial bin-picking. Neurocomputing 2022, 494, 255–268. [Google Scholar] [CrossRef]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Chen, X.; Girshick, R.; He, K.; Dollar, P. Tensormask: A foundation for dense object segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2061–2069. [Google Scholar]
- Yang, Z.; Dong, R.; Xu, H.; Gu, J. Instance Segmentation Method Based on Improved Mask R-CNN for the Stacked Electronic Components. Electronics 2020, 9, 886. [Google Scholar] [CrossRef]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. Solo: Segmenting objects by locations. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 649–665. [Google Scholar]
- Hua, J.; Hao, T.; Zeng, L.; Yu, G. YOLO Mask, an Instance Segmentation Algorithm Based on Complementary Fusion Network. Mathematics 2021, 9, 1766. [Google Scholar] [CrossRef]
- Song, S.; Xiao, J. Sliding shapes for 3d object detection in depth images. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 634–651. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Yi, L.; Zhao, W.; Wang, H.; Sung, M.; Guibas, L.J. Gspn: Generative shape proposal network for 3d instance segmentation in point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3947–3956. [Google Scholar]
- Chen, H.; Li, L.; Chen, P.; Meng, R. 6D Pose Estimation Network in Complex Point Cloud Scenes. J. Electron. Inf. Technol. 2022, 44, 1591–1601. (In Chinese) [Google Scholar]
- Gao, N.; Shan, Y.; Zhao, X.; Huang, K. Learning category-and instance-aware pixel embedding for fast panoptic segmentation. In IEEE Transactions on Image Processing; IEEE: New York, NY, USA, 2021; pp. 6013–6023. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, R. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chu, J.; Zhang, Y.; Li, S.; Leng, L.; Miao, J. Syncretic-NMS: A merging non-maximum suppression algorithm for instance segmentation. IEEE Access 2020, 8, 114705–114714. [Google Scholar] [CrossRef]
- Lee, H.; Lee, J.S.; Choi, H.C. Parallelization of Non-Maximum Suppression. IEEE Access 2021, 9, 166579–166587. [Google Scholar] [CrossRef]
- Li, M.; Chen, D.; Liu, S.; Liu, F. Prior mask R-CNN based on graph cuts loss and size input for precipitation measurement. IEEE Trans. Instrum. Meas. 2021, 70, 1–15. [Google Scholar] [CrossRef]
- Liu, C.; Yu, S.; Yu, M.; Wei, B.; Li, B.; Li, G.; Huang, W. Adaptive smooth l1 loss: A better way to regress scene texts with extreme aspect ratios. In Proceedings of the 2021 IEEE Symposium on Computers and Communications (ISCC), Athens, Greece, 5–8 September 2021; pp. 1–7. [Google Scholar]
- Xu, Y.; Jung, C.; Chang, Y. Head pose estimation using deep neural networks and 3D point clouds. Pattern Recognit. 2022, 121, 108210. [Google Scholar] [CrossRef]
- Song, W.; Jiang, W.; Lou, Z. Rapid batch three-dimensional reconstruction of point clouds based on multi-label classification. Laser Optoelectron. Prog. 2021, 58, 75–85. (In Chinese) [Google Scholar]
- Guo, N.; Zhang, B.; Zhou, J.; Zhan, K.; Lai, S. Pose estimation and adaptable grasp configuration with point cloud registration and geometry understanding for fruit grasp planning. Comput. Electron. Agric. 2020, 179, 105818. [Google Scholar] [CrossRef]
- Chen, F.; Chen, W.; Qin, F. A pose estimation method for disordered sorting. Autom. Appl. 2021, 12, 147–150. [Google Scholar]
- Wang, P.; Xu, G.; Cheng, Y.; Yu, Q. A simple, robust and fast method for the perspective-n-point Problem. Pattern Recognit. Lett. 2018, 108, 31–37. [Google Scholar] [CrossRef]
- Wu, H.; Xu, Z.; Liu, C.; Akbar, A.; Yue, H.; Zeng, D.; Yang, H. LV-GCNN: A lossless voxelization integrated graph convolutional neural network for surface reconstruction from point clouds. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102504. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, C.; Liu, B.; Wu, Y. Leveraging local and global descriptors in parallel to search correspondences for visual localization. Pattern Recognit. 2022, 122, 108344. [Google Scholar] [CrossRef]
- Zhong, L.; Ying, J.; Yang, H.; Jin, L. Triple screening point cloud registration method based on image and geometric features. Optik 2021, 246, 167763. [Google Scholar] [CrossRef]
- Iqbal, M.Z.; Bobkov, D.; Steinbach, E. Fuzzy logic and histogram of normal orientation-based 3D keypoint detection for point clouds. Pattern Recognit. Lett. 2020, 136, 40–47. [Google Scholar] [CrossRef]
- Zhang, Z.; Dai, Y.; Sun, J. Deep learning based point cloud registration: An overview. Virtual Real. Intell. Hardw. 2020, 2, 222–246. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Zhang, Y.; Ai, M. Robust symmetric iterative closest point. ISPRS J. Photogramm. Remote Sens. 2022, 185, 219–231. [Google Scholar] [CrossRef]
- Sun, C. Technology and Application of Small-Defect Vision Detection and Recognition under Multi-Objective; Guangdong University of Technology: Guangzhou, China, 2022. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Numeric Value | Description |
|---|---|---|
| backbone | ResNet + FPN | backbone network |
| image_per_gpu | 1 | number of images per load |
| learning_momentum | 0.9 | learning momentum |
| learning_rate | 0.001 | learning rate |
| weight decay | 0.0001 | learning rate decay |
| steps_per_epoch | 700 | steps per time |
| epoch | 230 | number of sample traversals |
| mask_shape | [28, 28] | mask size |
| rpn_train_anchors_per_image | 256 | number of bounding boxes |
| Backbone Network | AP0.5 Value of Front Side | AP0.5 Value of Reverse Side | mAP0.5 |
|---|---|---|---|
| ResNet50 + FPN | 97.6% | 96.8% | 97.2% |
| ResNet101 + FPN | 97.8% | 97.2% | 97.5% |
| Backbone Network | 360 × 240 | 1080 × 980 |
|---|---|---|
| ResNet50 + FPN | 0.617 s | 1.563 s |
| ResNet101 + FPN | 1.236 s | 3.291 s |
| Pose | Front Side Faces Up | Back Side Faces Up | Occluded Front Side Faces Up | Occluded Back Side Faces Up |
|---|---|---|---|---|
| Time (ms) | 524.00 | 593.00 | 455.00 | 471.00 |
| Average registration time (ms) | 510.75 | |||
| Pose | Front Side Faces Up | Back Side Faces Up | Occluded Front Side Faces Up | Occluded Back Side Faces Up |
|---|---|---|---|---|
| Time (ms) | 548.00 | 618.00 | 486.00 | 494.00 |
| Average registration time (ms) | 531.50 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Y.; Chen, G.; Liu, X.; Sun, C.; Huang, Z.; Lin, S. 3D Pose Recognition of Small Special-Shaped Sheet Metal with Multi-Objective Overlapping. Electronics 2023, 12, 2613. https://doi.org/10.3390/electronics12122613
Deng Y, Chen G, Liu X, Sun C, Huang Z, Lin S. 3D Pose Recognition of Small Special-Shaped Sheet Metal with Multi-Objective Overlapping. Electronics. 2023; 12(12):2613. https://doi.org/10.3390/electronics12122613
Chicago/Turabian StyleDeng, Yaohua, Guanhao Chen, Xiali Liu, Cheng Sun, Zhihai Huang, and Shengyu Lin. 2023. "3D Pose Recognition of Small Special-Shaped Sheet Metal with Multi-Objective Overlapping" Electronics 12, no. 12: 2613. https://doi.org/10.3390/electronics12122613