
A Deep-Learning-Based Approach to Keystroke-Injection Payload Generation


Abstract
:1. Introduction
2. Related Work
2.1. USB Imperfections
- Electrical attacks are related by nature to the denial-of-service (DoS) attack. As an example, there is a hardware device called the ‘USB killer’. It is an electrical discharger disguised as a simple USB device. Once this device is plugged into the USB port, the capacitors will charge up and discharge a critical amount of current back to the USB port in intervals, making computer hardware components unusable;
- USB peripheral attacks utilize flash-drive firmware or driver to deliver malicious payloads. These types of attacks can perform buffer overflows, DNS overrides, and even keystroke injection and, in some cases, launch an executable;
- Microcontroller attacks use microcontrollers that emulate keyboards and can inject keyboard input at high. They belong to a class of HID attacks that has evolved over the years and became much more sophisticated [11].
2.2. USB Attacks
2.3. Keystroke Dynamics and Its Circumvention
2.4. User Keypress Data and Their Minimum
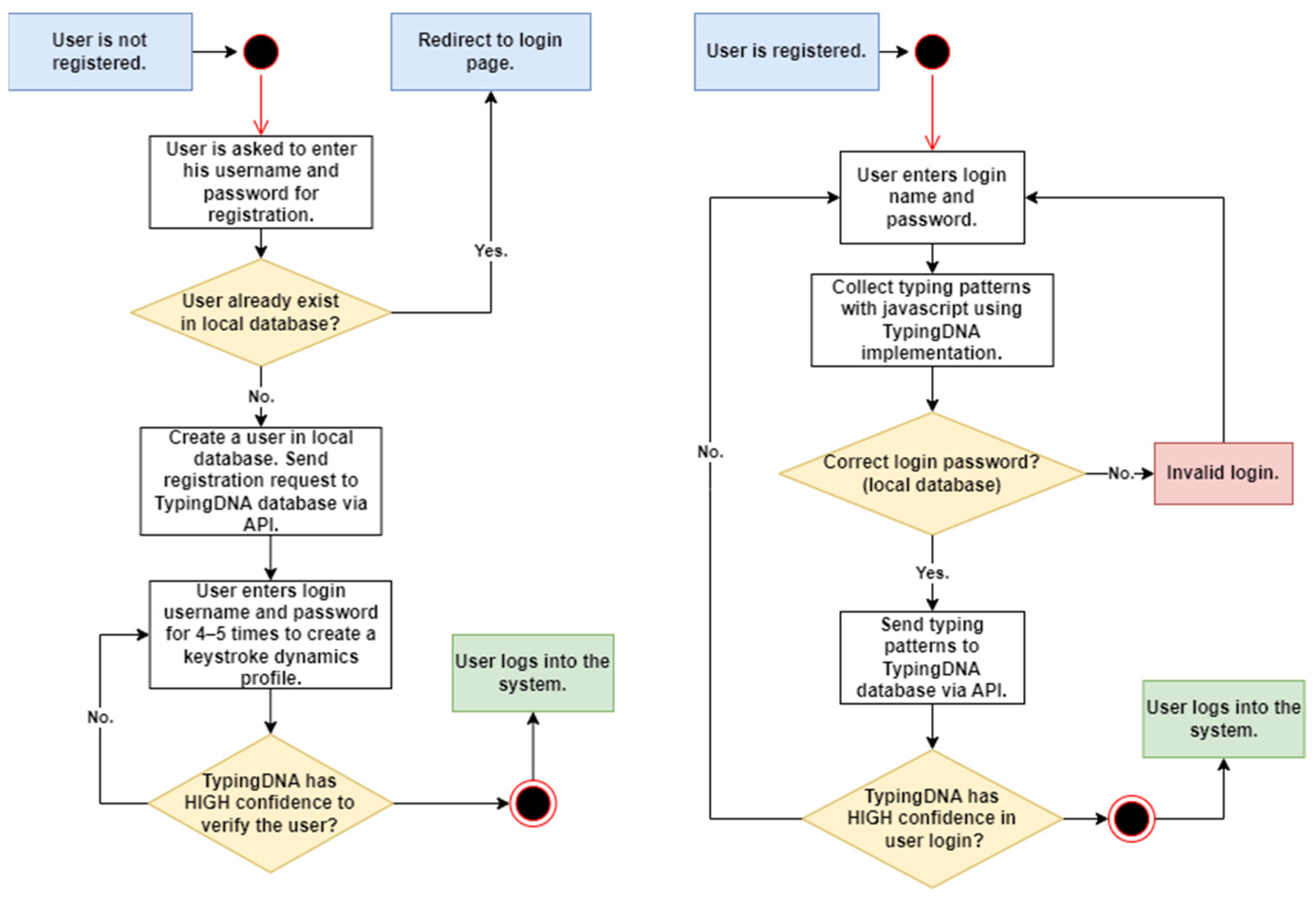
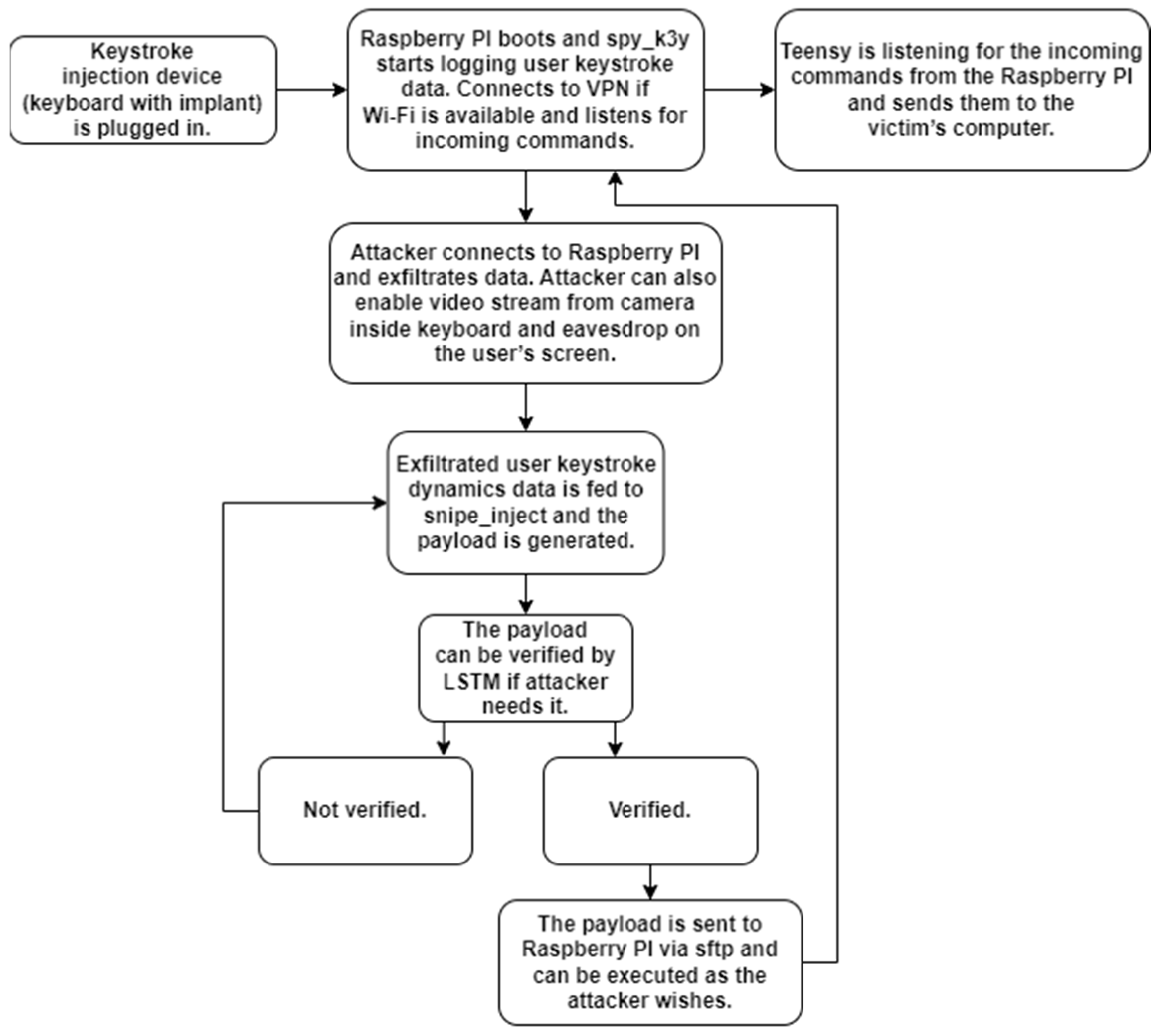
3. Method for Keystroke-Injection Detection and Payload Generation
3.1. Keystroke-Injection Detection
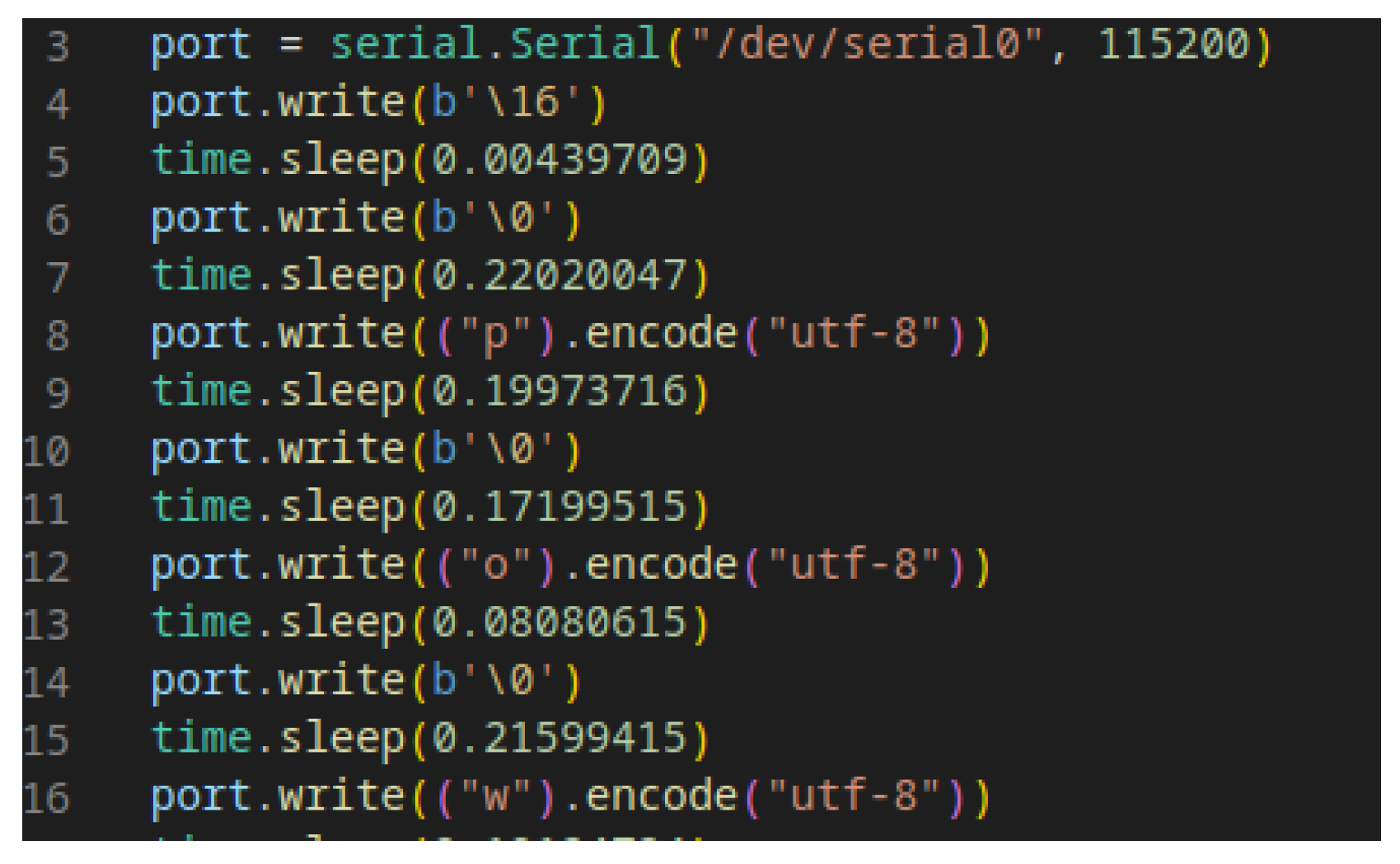
3.2. Implementation of Keystroke-Payload Generation
- Data collection—achieved by facilitating the ‘spy_k3y’ keystroke and key logging tool along with the single-board computer and a microcontroller. The tool hooks up all keyboard events. The setup collects keystroke dynamics data and pressed-key values, logs them, and relays them to the target machine. Additional checks such as if this is a first keypress or a keypress after a long typing break (time longer than 5 s is, in our case, considered to be a break, while other researches use 1–1.5 s) were also implemented. Once the data collection is completed, the exfiltration stage can begin using a secure file-transfer protocol for transmission;
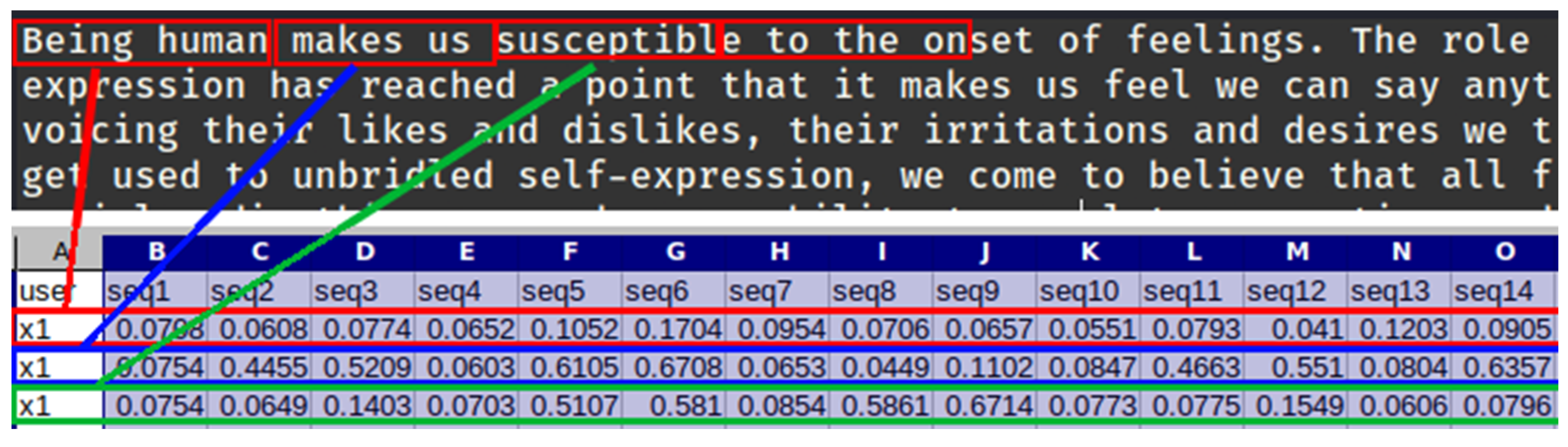
- Extraction of keystroke dynamics data and generating the keystroke-injection payload using collected data;
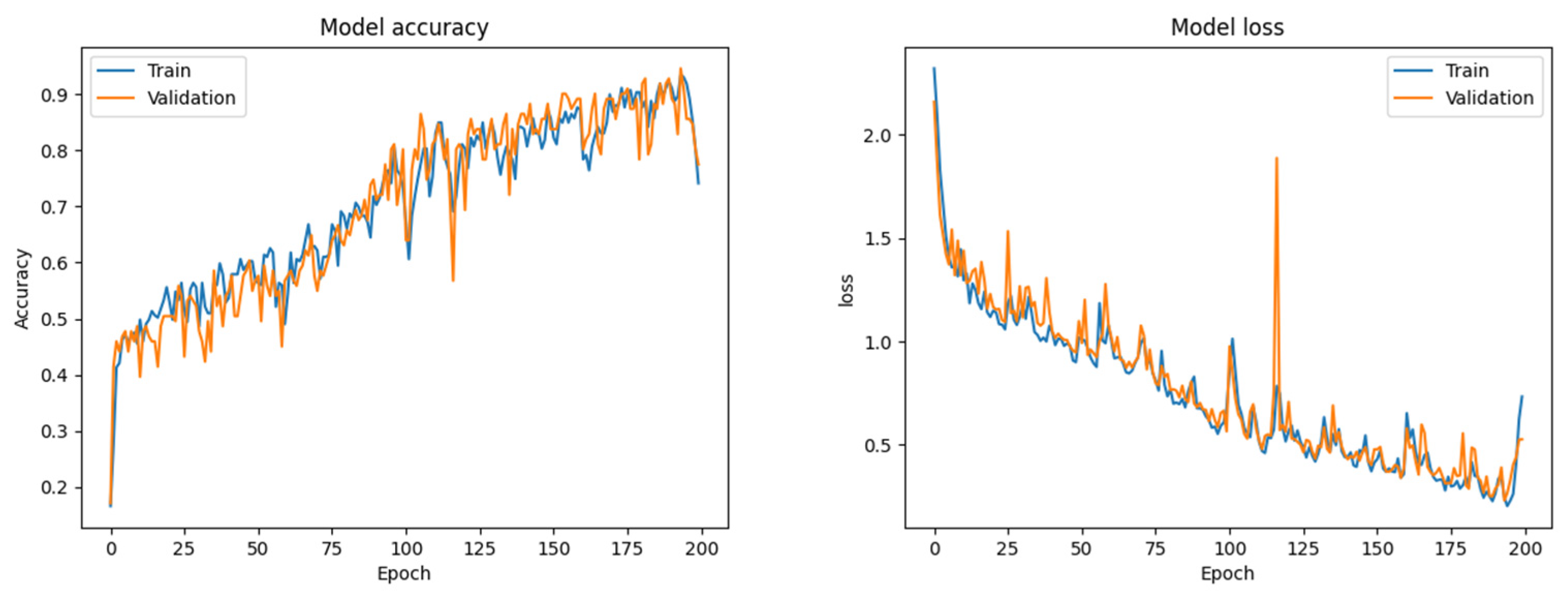
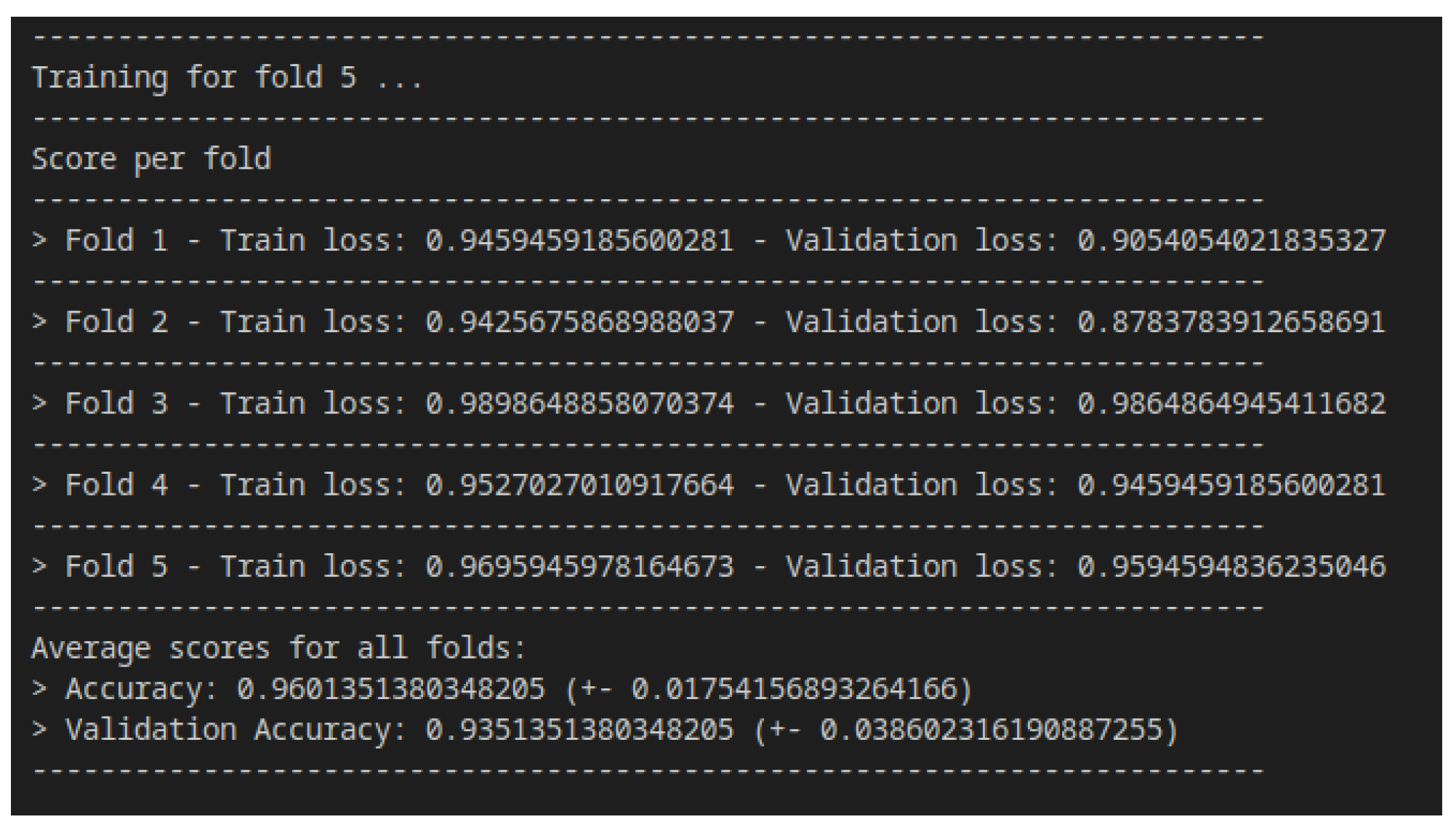
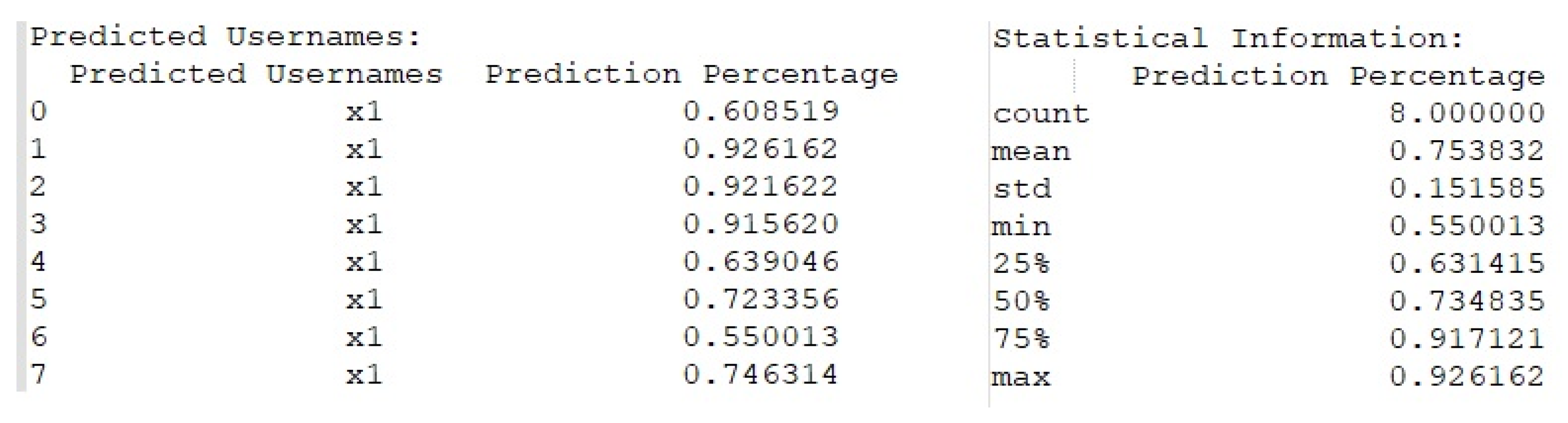
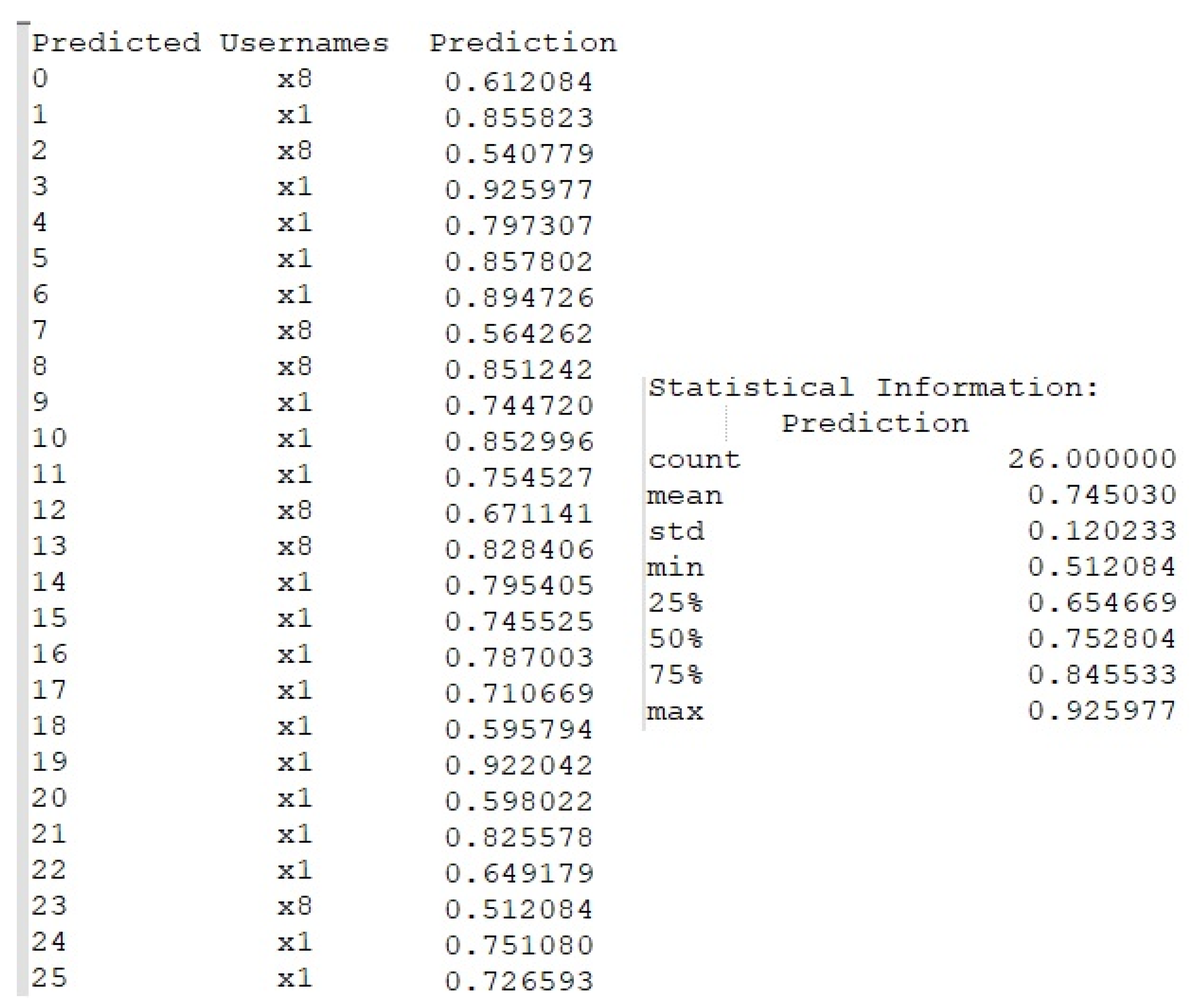
- Verification of the generated payload using the LSTM neural network. The generated payload is reversed to keystroke dynamics data and compared with the collected data. If this payload is at least 85% similar to the source, the payload is generated successfully and under the command or automatically could be injected impersonating the user’s typing pattern. Alternatively, if necessary, the payload is regenerated and the verification process is repeated;
- Committing the verified payload to the remote device (in cases where extensive computational power is unnecessary, the task can be performed directly on the device) and injecting it into the remote machine.
4. Results and Discussion
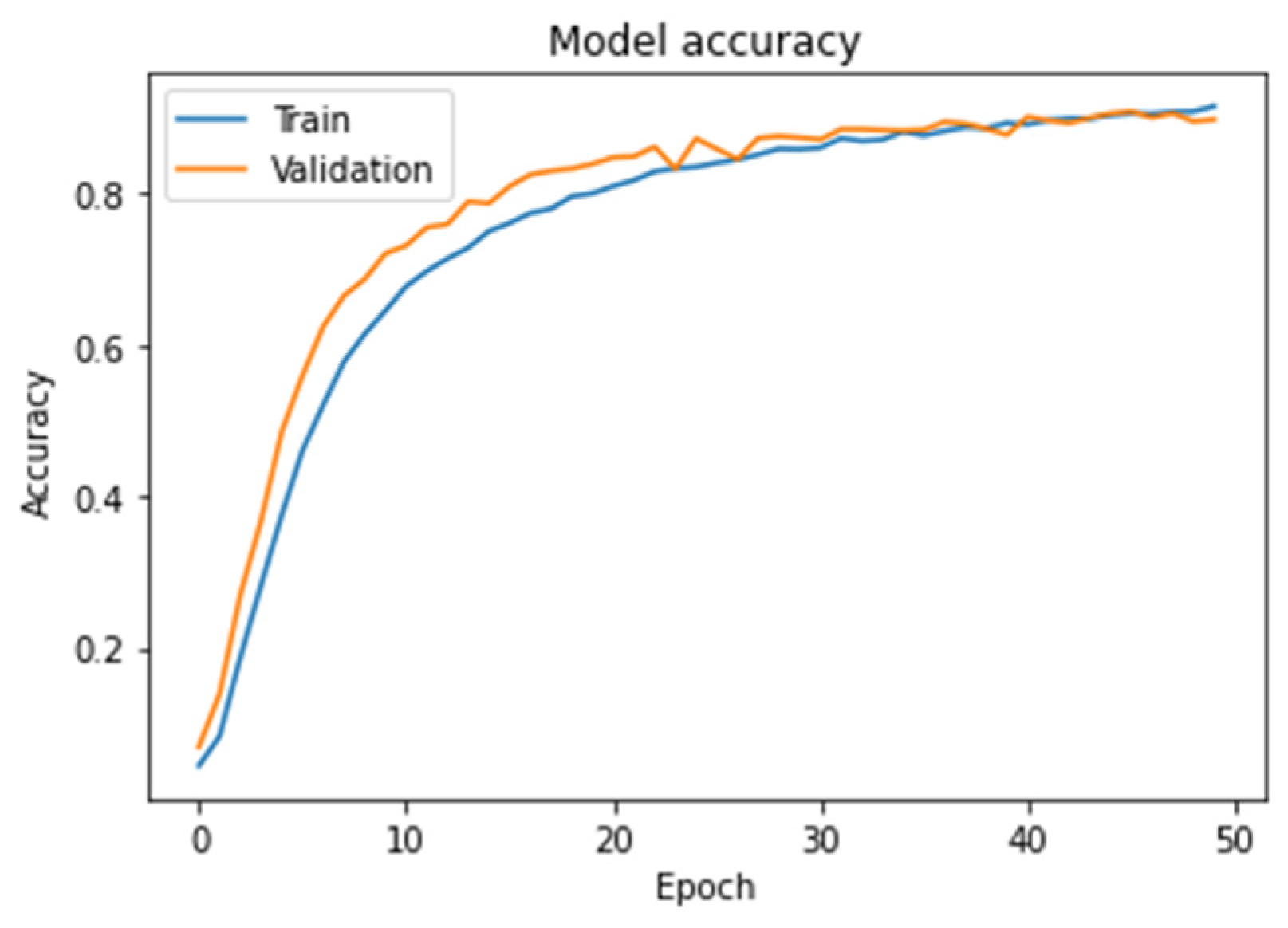
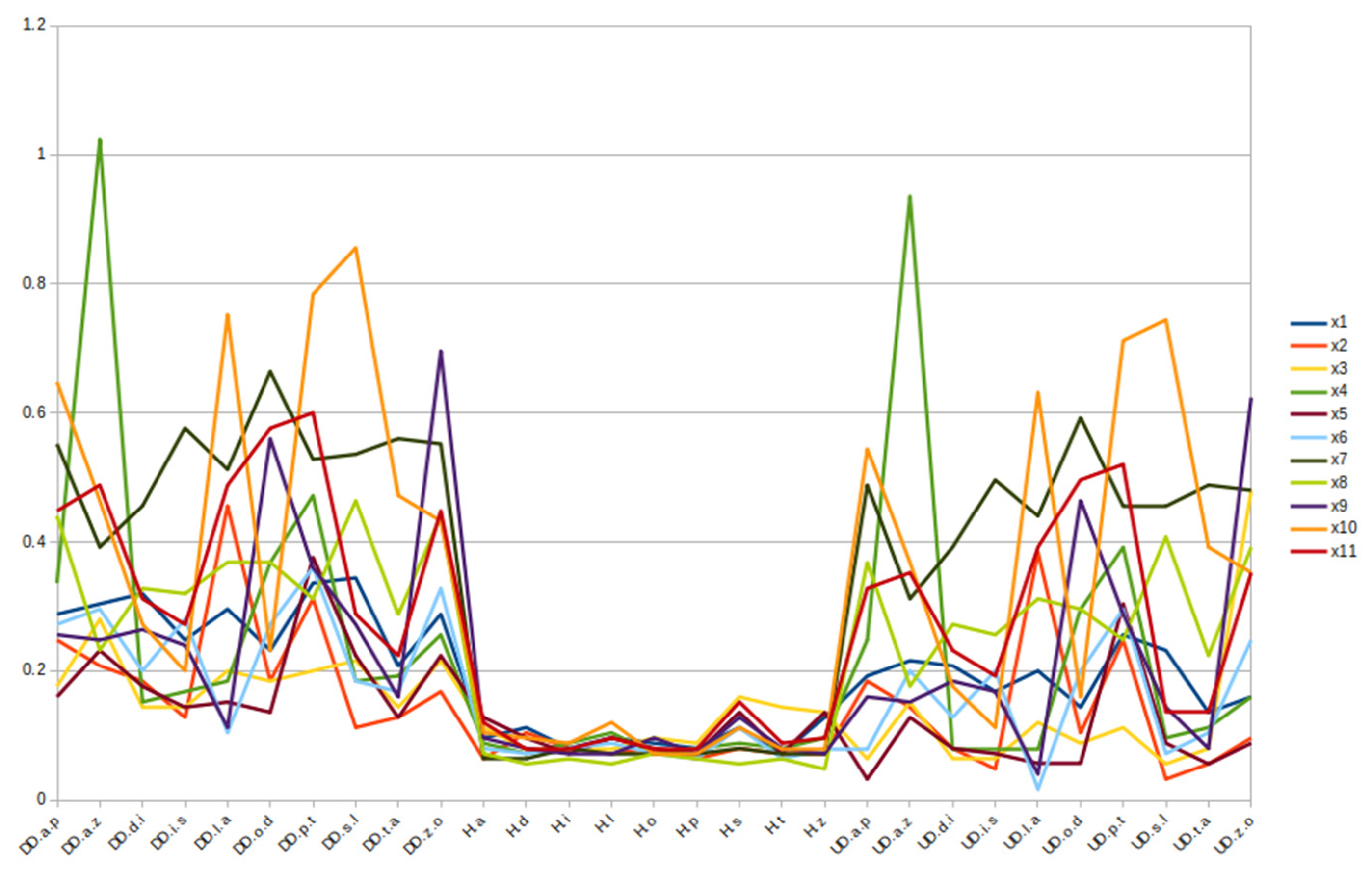
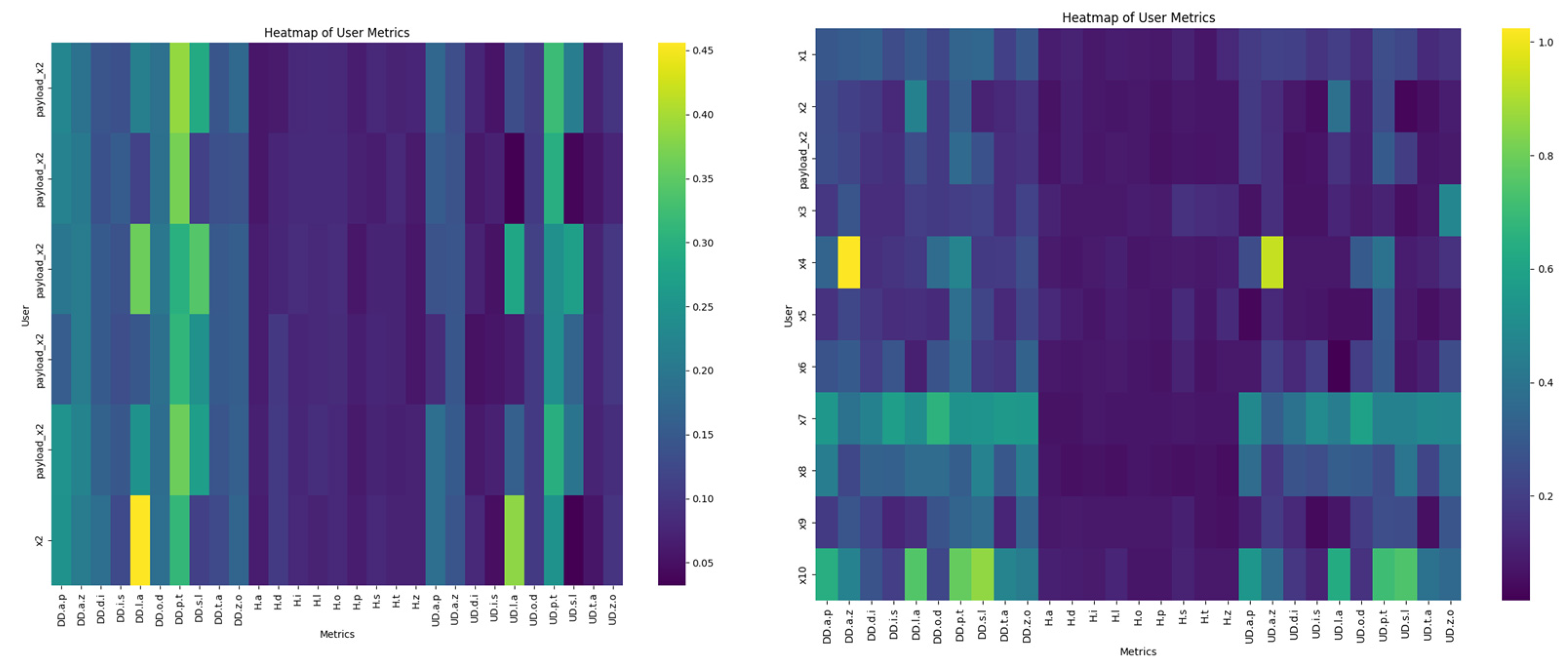
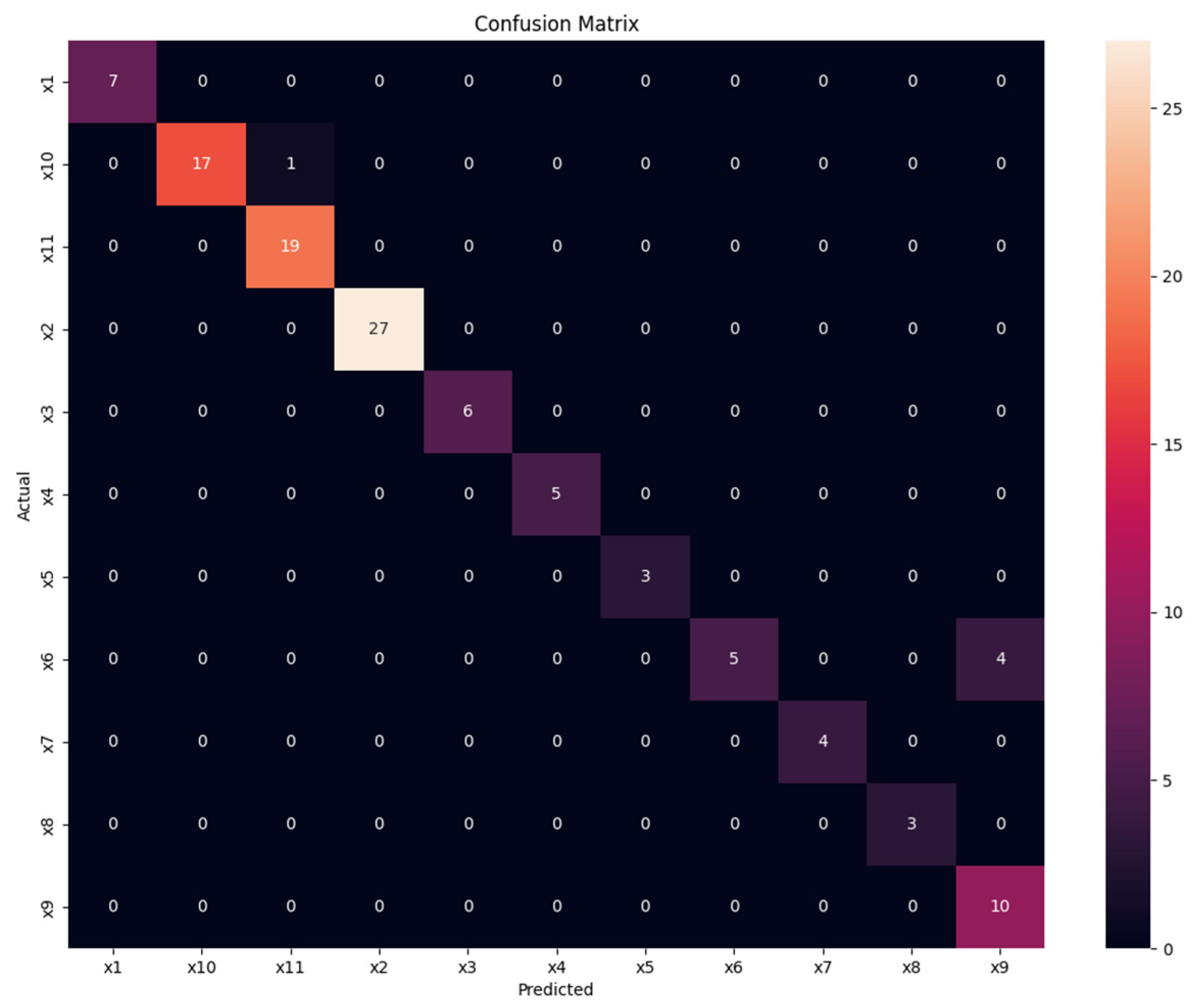
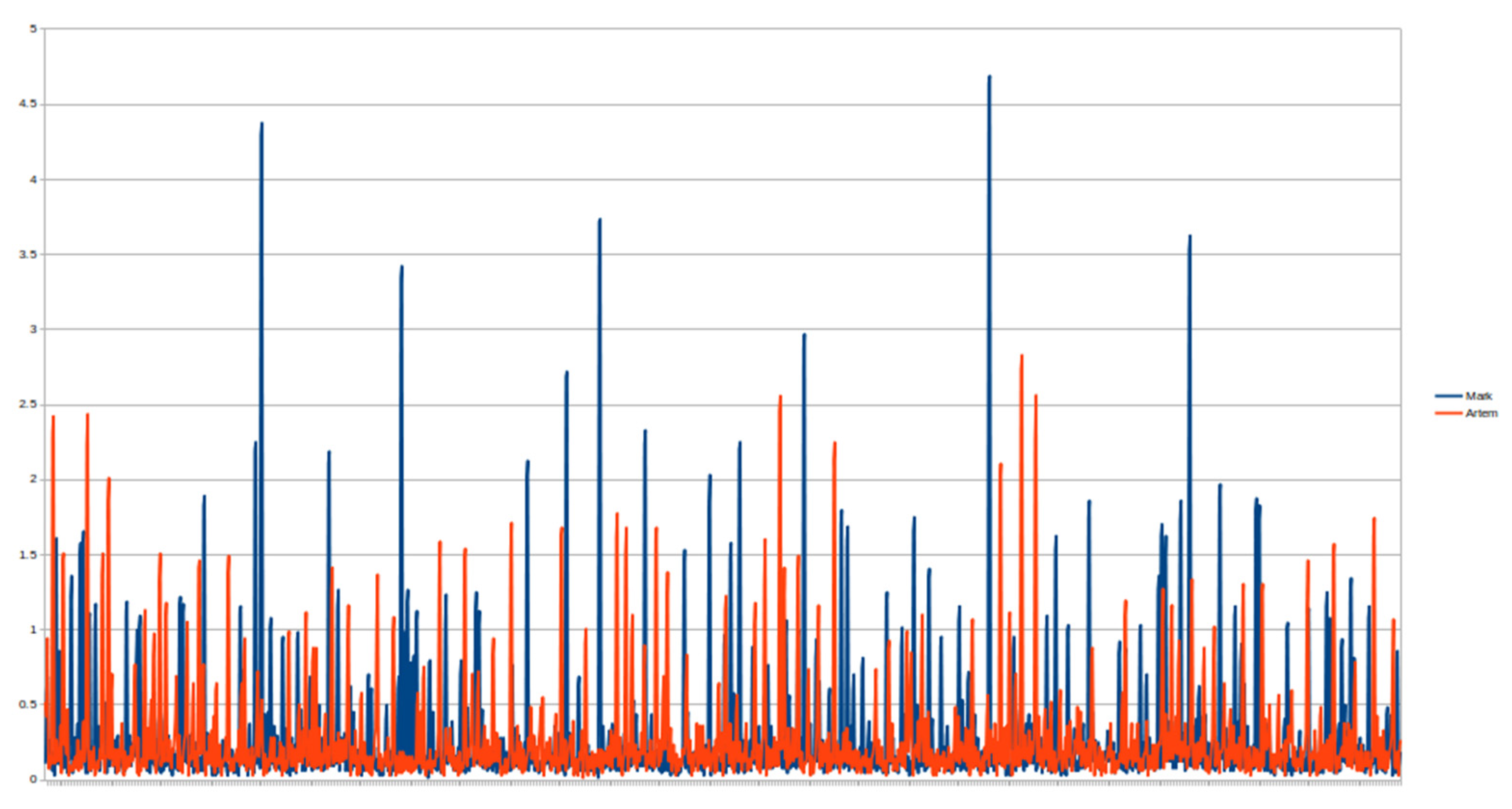
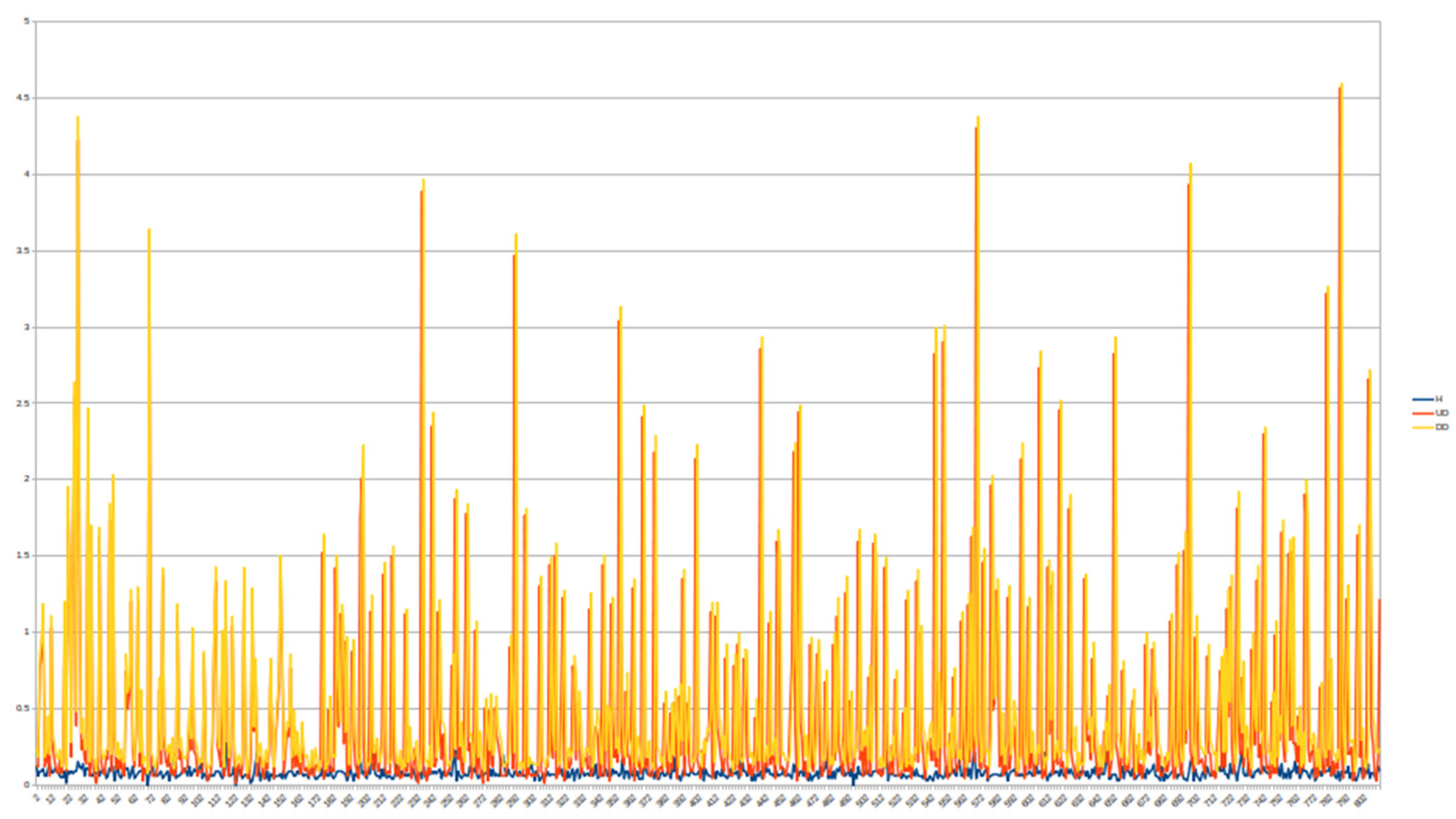
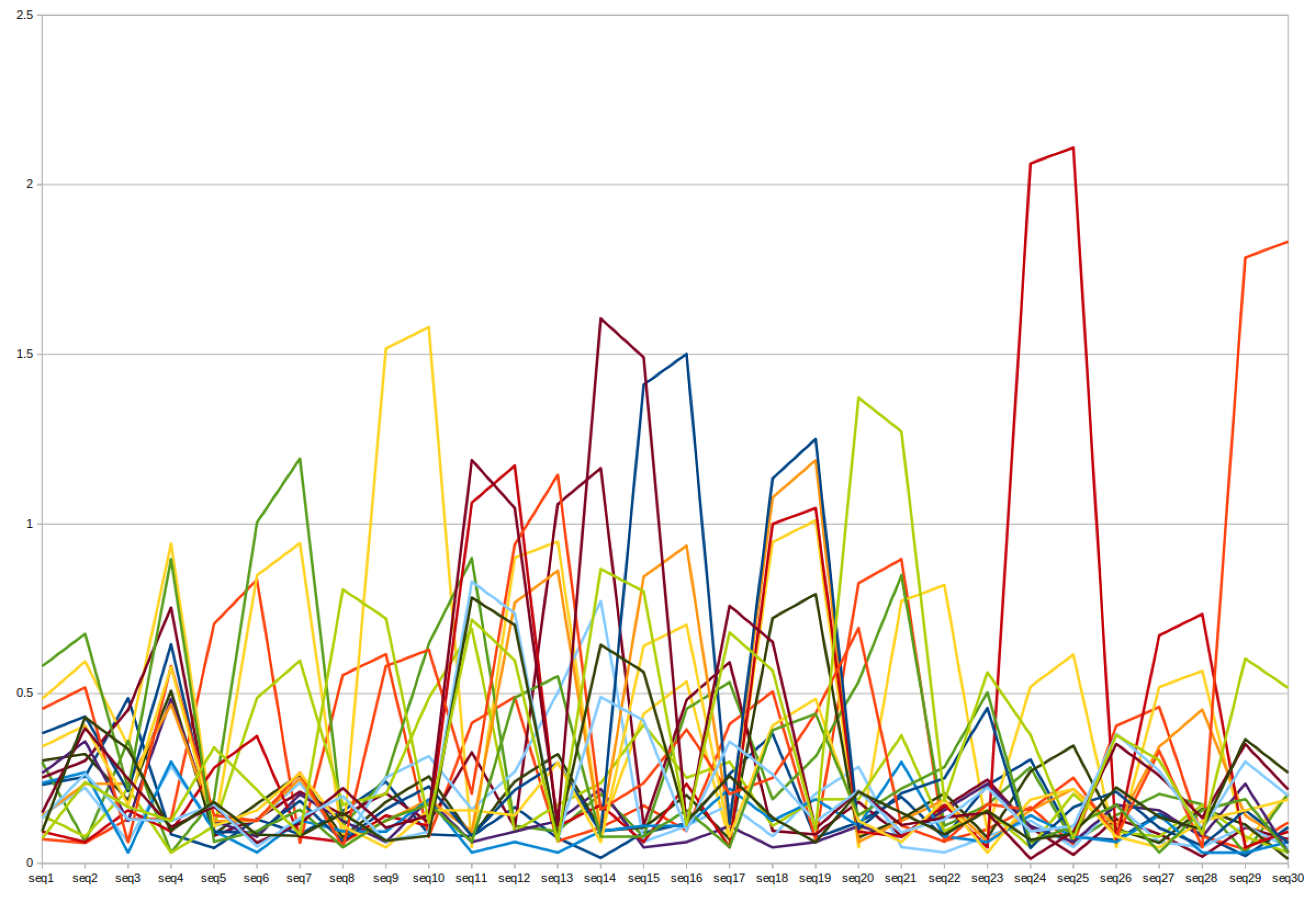
4.1. Fixed-Text Keystroke Dynamics
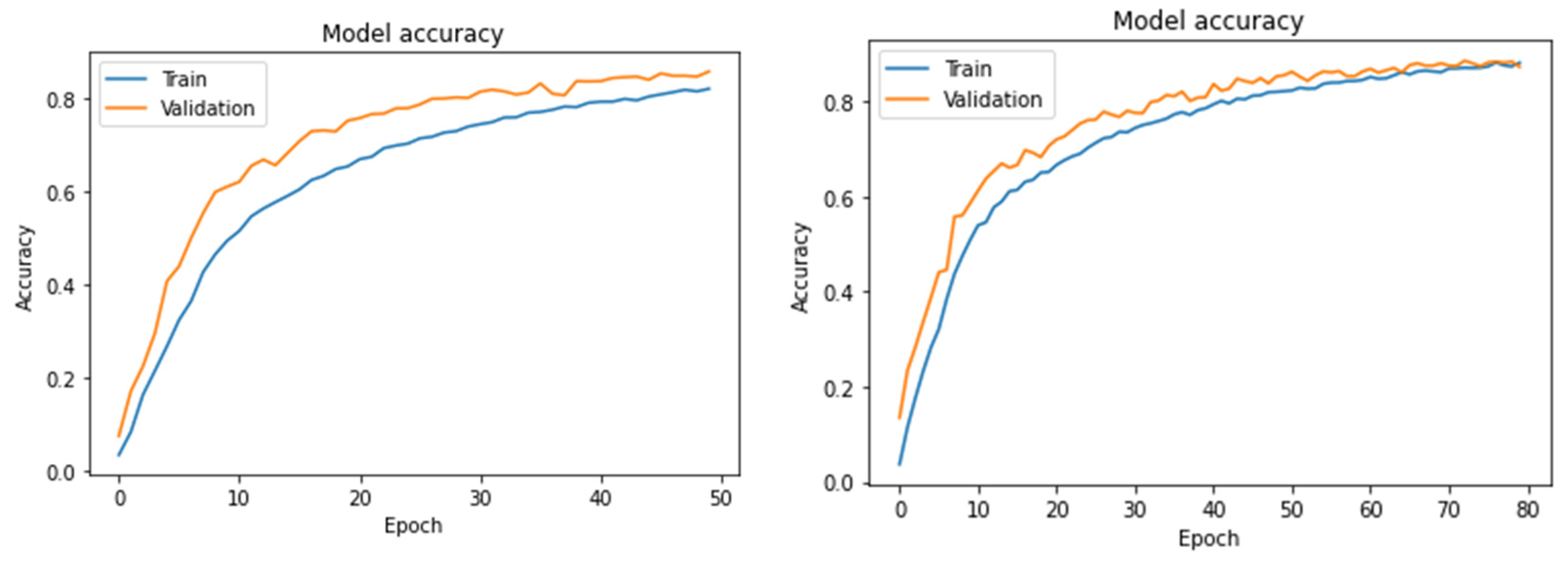
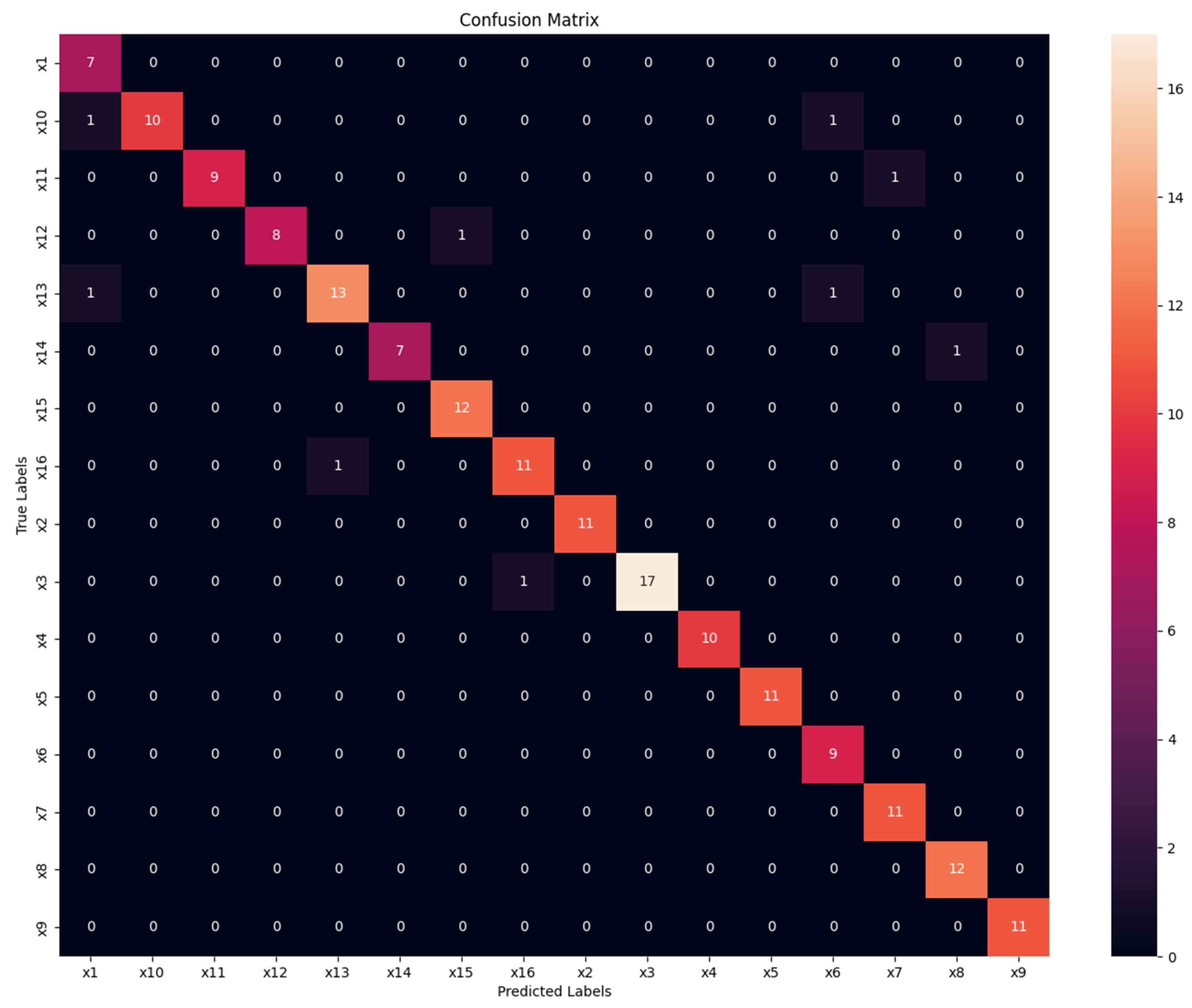
4.2. Free-Text Keystroke Dynamics
4.3. Comparison with the Previous Results Obtained
5. Conclusions
6. Limitations and Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tian, J.; Scaife, N.; Kumar, D.; Bailey, M.; Bates, A.; Butler, K. SoK: ‘Plug & Pray’ Today-Understanding USB Insecurity in Versions 1 Through C. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 1032–1047. [Google Scholar] [CrossRef]
- Lu, H.; Wu, Y.; Li, S.; Lin, Y.; Zhang, C.; Zhang, F. BADUSB-C: Revisiting BadUSB with Type-C. In Proceedings of the 2021 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 27 May 2021; pp. 327–338. [Google Scholar] [CrossRef]
- Thomas, T.; Piscitelli, M.; Nahar, B.A.; Baggili, I. Duck Hunt: Memory forensics of USB attack platforms. Forensic Sci. Int. Digit. Investig. 2021, 37, 301190. [Google Scholar] [CrossRef]
- Mohammadmoradi, H.; Gnawali, O. Making whitelisting-based defense work against bad USB. In Proceedings of the 2nd International Conference on Smart Digital Environment, ICSDE’18, Rabat, Morocco, 18–20 October 2018; ACM International Conference Proceeding Series. ACM: New York, NY, USA, 2018; pp. 127–134. [Google Scholar] [CrossRef]
- Liu, H.; Spolaor, R.; Turrin, F.; Bonafede, R.; Conti, M. USB powered devices: A survey of side-channel threats and countermeasures. High Confid. Comput. 2021, 1, 100007. [Google Scholar] [CrossRef]
- Dieter, G. Computer Security, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Karantzas, G. Forensic Log Based Detection for Keystroke Injection ‘BadUsb’ Attacks. arXiv 2023, arXiv:2302.04541. [Google Scholar]
- Lawal, D.; Gresty, D.; Gan, D.; Hewitt, L. Have You Been Framed and Can You Prove It? In Proceedings of the 2021 44th International Convention on Information, Communication and Electronic Technology, MIPRO, Opatija, Croatia, 27 September–1 October 2021; pp. 1236–1241. [Google Scholar] [CrossRef]
- Dumitru, R.; Wabnitz, A.; Genkin, D.; Yarom, Y. The Impostor Among US(B): Off-Path Injection Attacks on USB Communications. arXiv 2022, arXiv:2211.01109. [Google Scholar]
- Nissim, N.; Yahalom, R.; Elovici, Y. USB-based attacks. Comput. Secur. 2017, 70, 675–688. [Google Scholar] [CrossRef]
- Arora, L.; Thakur, N.; Yadav, S.K. USB rubber ducky detection by using heuristic rules. In Proceedings of the IEEE 2021 International Conference on Computing, Communication, and Intelligent Systems, ICCCIS, Greater Noida, India, 19–20 February 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2021; pp. 156–160. [Google Scholar] [CrossRef]
- Mamchenko, M.; Sabanov, A. Exploring the taxonomy of USB-based attacks. In Proceedings of the 2019 12th International Conference “Management of Large-Scale System Development” (MLSD), Moscow, Russia, 1–3 October 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Lee, K.; Yim, K. Vulnerability Analysis and Security Assessment of Secure Keyboard Software to Prevent PS/2 Interface Keyboard Sniffing. Sensors 2023, 23, 3501. [Google Scholar] [CrossRef]
- Farhi, N.; Nissim, N.; Elovici, Y. Malboard: A novel user keystroke impersonation attack and trusted detection framework based on side-channel analysis. Comput. Secur. 2019, 85, 240–269. [Google Scholar] [CrossRef]
- Ramadhanty, A.D.; Budiono, A.; Almaarif, A. Implementation and Analysis of Keyboard Injection Attack using USB Devices in Windows Operating System. In Proceedings of the 2020 3rd International Conference on Computer and Informatics Engineering, IC2IE, Yogyakarta, Indonesia, 15–16 September 2020; pp. 449–454. [Google Scholar] [CrossRef]
- Negi, A.; Rathore, S.S.; Sadhya, D. USB Keypress Injection Attack Detection via Free-Text Keystroke Dynamics. In Proceedings of the 2021 8th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 26–27 August 2021; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2021; pp. 681–685. [Google Scholar] [CrossRef]
- Borges, C.D.B.; de Araujo, J.R.B.; de Couto, R.L.; Almeida, A.M.A. Keyblock: A software architecture to prevent keystroke injection attacks. In Proceedings of the XVII Simpósio Brasileiro em Segurança da Informação e de Sistemas Computacionais, Brasilia, Brazil, 6–9 November 2017; pp. 518–524. [Google Scholar] [CrossRef]
- Tian, D.J.; Bates, A.; Butler, K. Defending against malicious USB firmware with GoodUSB. In Proceedings of the 31st Annual Computer Security Applications Conference, ACSAC ‘15, Los Angeles, CA, USA, 7–11 December 2015; ACM: New York, NY, USA, 2015; pp. 261–270. [Google Scholar] [CrossRef]
- Wahanani, H.; Idhom, M.; Kurniawan, D.R. Exploit remote attack test in operating system using arduino micro. J. Phys. Conf. Ser. 2020, 1569, 022038. [Google Scholar] [CrossRef]
- Clements, A. Principles of Computer Hardware, 4th ed.; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Faircloth, J. Client-side attacks and social engineering. In Penetration Tester’s Open Source Toolkit; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar] [CrossRef]
- Sun, C.; Lu, J.; Liu, Y. Analysis and Prevention of Information Security of USB. In Proceedings of the 2021 International Conference on Electronic Information Engineering and Computer Science, EIECS, Changchun, China, 23–26 September 2021; pp. 25–32. [Google Scholar] [CrossRef]
- Cronin, P.; Gao, X.; Wang, H.; Cotton, C. Time-Print: Authenticating USB Flash Drives with Novel Timing Fingerprints. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–26 May 2022; pp. 1002–1017. [Google Scholar] [CrossRef]
- Eswar, P.V.D.S. Microcontroller Manipulated As Human Interface Device Performing Keystroke Injection Attack. Int. Res. J. Mod. Eng. Technol. Sci. 2021, 3, 1230–1233. [Google Scholar]
- Muslim, A.A.; Budiono, A.; Almaarif, A. Implementation and Analysis of USB based Password Stealer using PowerShell in Google Chrome and Mozilla Firefox. In Proceedings of the 2020 3rd International Conference on Computer and Informatics Engineering, IC2IE, Yogyakarta, Indonesia, 15–16 September 2020; pp. 421–426. [Google Scholar] [CrossRef]
- Ferreira, J.L.S.; Amorim, M.F.; Altafim, R.A.P. Biometric patterns recognition using keystroke dynamics. In Proceedings of the XVIII Simpósio Brasileiro de Segurança da Informação e de Sistemas Computacionais, Natal, Brazil, 22–25 October 2018. [Google Scholar]
- Bojović, P.D.; Bojović, P.D.; Bašičević, I.; Pilipović, M.; Bojović, Ž.; Bojović, M. The Rising Threat of Hardware Attacks: USB Keyboard Attack Case Study. IEEE Secur. Priv. 2020. preprint. Available online: https://www.researchgate.net/publication/359509222 (accessed on 19 June 2023).
- Ahire, J.; Shembekar, A.; Makadia, K.; Bhokare, D. Exploring Attack Vectors Using Single Board Computers. Int. Res. J. Mod. Eng. Technol. Sci. 2022, 4, 2911–2914. [Google Scholar]
- Nicho, M.; Sabry, I. Threat and Vulnerability Modelling of Malicious Human Interface Devices. Technol. Eng. Math. (EPSTEM) 2022, 21, 241–247. Available online: www.isres.org (accessed on 19 May 2023). [CrossRef]
- Neuner, S.; Voyiatzis, A.G.; Fotopoulos, S.; Mulliner, C.; Weippl, E.R. Usblock: Blocking USB-Based keypress injection attacks. In Data and Applications Security and Privacy XXXII; LNCS; Springer International Publishing: Cham, Switzerland, 2018; Volume 10980. [Google Scholar] [CrossRef]
- Kang, M.; Saiedian, H. USBWall: A novel security mechanism to protect against maliciously reprogrammed USB devices. Inf. Secur. J. 2017, 26, 166–185. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z. Poisoning Attacks on Learning-Based Keystroke Authentication Poisoning Attacks on Learning-Based Keystroke Authentication and a Residue Feature Based Defense and a Residue Feature Based Defense. Available online: https://digitalcommons.latech.edu/dissertations (accessed on 19 May 2023).
- Szoke, D. Model Poisoning in Federated Learning: Collusive and Individual Attacks. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2023. [Google Scholar]
- Porwik, P.; Doroz, R.; Wesolowski, T.E. Dynamic keystroke pattern analysis and classifiers with competence for user recognition. Appl. Soft Comput. 2021, 99, 106902. [Google Scholar] [CrossRef]
- Hazan, I.; Margalit, O.; Rokach, L. Supporting unknown number of users in keystroke dynamics models. Knowl. Based Syst. 2021, 221, 106982. [Google Scholar] [CrossRef]
- Lu, X.; Zhang, S.; Hui, P.; Lio, P. Continuous authentication by free-text keystroke based on CNN and RNN. Comput. Secur. 2020, 96, 101861. [Google Scholar] [CrossRef]
- Roy, S.; Roy, U.; Sinha, D.; Pal, R.K. Imbalanced ensemble learning in determining Parkinson’s disease using Keystroke dynamics. Expert Syst. Appl. 2022, 217, 119522. [Google Scholar] [CrossRef]
- Chang, H.-C.; Li, J.; Wu, C.-S.; Stamp, M. Machine Learning and Deep Learning for Fixed-Text Keystroke Dynamics. arXiv 2021, arXiv:2107.00507. [Google Scholar]
- Ibrahim, M.; Abdelraouf, H.; Amin, K.M.; Semary, N. Keystroke dynamics based user authentication using Histogram Gradient Boosting. Int. J. Comput. Inf. IJCI 2023, 10, 36–53. [Google Scholar] [CrossRef]
- Nnamoko, N.; Barrowclough, J.; Liptrott, M.; Korkontzelos, I. A behaviour biometrics dataset for user identification and authentication. Data Brief 2022, 45, 108728. [Google Scholar] [CrossRef]
- Parkinson, S.; Khan, S.; Crampton, A.; Xu, Q.; Xie, W.; Liu, N.; Dakin, K. Password policy characteristics and keystroke biometric authentication. IET Biom. 2021, 10, 163–178. [Google Scholar] [CrossRef]
- Zeid, E.S.S.; ElKamar, R.A.; Hassan, S.I. Fixed-Text vs. Free-Text Keystroke Dynamics for User Authentication. Eng. Res. J. Fac. Eng. 2022, 51, 95–104. [Google Scholar]
- Mondal, S.; Bours, P. A study on continuous authentication using a combination of keystroke and mouse biometrics. Neurocomputing 2016, 230, 1–22. [Google Scholar] [CrossRef]
- Ciaramella, G.; Iadarola, G.; Martinelli, F.; Mercaldo, F.; Santone, A. Continuous and Silent User Authentication Through Mouse Dynamics and Explainable Deep Learning: A Proposal. In Proceedings of the 2022 IEEE International Conference on Big Data, (Big Data 2022), Osaka, Japan, 17–20 December 2022; pp. 6628–6630. [Google Scholar] [CrossRef]
- Shadman, R.; Wahab, A.A.; Manno, M.; Lukaszewski, M.; Hou, D.; Hussain, F. Keystroke Dynamics: Concepts, Techniques, and Applications. arXiv 2023, arXiv:2303.04605. [Google Scholar]
- Iapa, A.C.; Cretu, V.I. Modified Distance Metric That Generates Better Performance for the Authentication Algorithm Based on Free-Text Keystroke Dynamics. In Proceedings of the SACI 2021—IEEE 15th International Symposium on Applied Computational Intelligence and Informatics, Timisoara, Romania, 19–21 May 2021; pp. 455–460. [Google Scholar] [CrossRef]
- Eizaguirre-Peral, I.; Segurola-Gil, L.; Zola, F. Conditional Generative Adversarial Network for keystroke presentation attack. arXiv 2022, arXiv:2212.08445. [Google Scholar]
- Kochegurova, E.A.; Zateev, R.P. Hidden Monitoring Based on Keystroke Dynamics in Online Examination System. Program. Comput. Softw. 2022, 48, 385–398. [Google Scholar] [CrossRef]
- Bernatavičienė, J. Proceedings of the 13th Conference on “Data analysis methods for software systems”. Vilnius Univ. Proc. 2022, 31, 1–110. [Google Scholar] [CrossRef]
- Eizagirre, I.; Segurola, L.; Zola, F.; Orduna, R. Keystroke Presentation Attack: Generative Adversarial Networks for Replacing User Behaviour. In Proceedings of the 2022 European Symposium on Software Engineering, ESSE ’22, Rome, Italy, 27–29 October 2022; Association for Computing Machinery: New York, NY, USA, 2023; pp. 119–126. [Google Scholar] [CrossRef]
- Wahab, A.; Hou, D. When Simple Statistical Algorithms Outperform Deep Learning: A Case of Keystroke Dynamics. In Proceedings of the 12th International Conference on Pattern Recognition Applications and Methods ICPRAM, Lisbon, Portugal, 22–24 February 2023; pp. 363–370. [Google Scholar] [CrossRef]
- Kar, S.; Bamotra, A.; Duvvuri, B.; Mohanan, R. KeyDetect—Detection of anomalies and user based on Keystroke Dynamics. arXiv 2023, arXiv:2304.03958. [Google Scholar]
- Tewani, A. Keystroke Dynamics based Recognition Systems using Deep Keystroke Dynamics based Recognition Systems using Deep Learning: A Survey Learning: A Survey. techRxiv 2022. preprint. [Google Scholar] [CrossRef]
- Toosi, R.; Akhaee, M.A. Time–frequency analysis of keystroke dynamics for user authentication. Future Gener. Comput. Syst. 2021, 115, 438–447. [Google Scholar] [CrossRef]
- Killourhy, K.S.; Maxion, R.A. Comparing anomaly-detection algorithms for keystroke dynamics. In Proceedings of the International Conference on Dependable Systems and Networks, Lisbon, Portugal, 29 June–2 July 2009; pp. 125–134. [Google Scholar] [CrossRef] [Green Version]
- Killourhy, K.S.; Maxion, R.A. Free vs. transcribed text for keystroke-dynamics evaluations. In LASER ‘12: Proceedings of the 2012 Workshop on Learning from Authoritative Security Experiment Results, Arlington, VA, USA, 18–19 July 2012; ACM International Conference Proceeding Series. Association for Computing Machinery: New York, NY, USA, 2012; pp. 1–8. [Google Scholar] [CrossRef]
- González, N.; Calot, E.P. Finite context modeling of keystroke dynamics in free text. In Proceedings of the 2015 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 20–22 September 2015; Lecture Notes in Informatics (LNI), Proceedings-Series of the Gesellschaft fur Informatik (GI). Gesellschaft fur Informatik: Bonn, Germany, 2015; Volume P-245. [Google Scholar] [CrossRef]
- Banerjee, R.; Feng, S.; Kang, J.S.; Choi, Y. Keystroke Patterns as prosody in digital writings: A case study with deceptive reviews and essays. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014; pp. 1469–1473. [Google Scholar] [CrossRef] [Green Version]
- González, N.; Calot, E.P. Dataset of human-written and synthesized samples of keystroke dynamics features for free-text inputs. Data Brief 2023, 48, 109125. [Google Scholar] [CrossRef]
- Tewari, A.; Verma, P. An Improved User Identification based on Keystroke-Dynamics and Transfer Learning. Webology 2022, 19, 5369–5387. [Google Scholar] [CrossRef]
- Nirmal, J.R.; Kiran, R.B.; Hemamalini, V. Improvised multi-factor user authentication mechanism using defense in depth strategy with integration of passphrase and keystroke dynamics. Mater. Today Proc. 2022, 62, 4837–4843. [Google Scholar] [CrossRef]
- TypingDNA. Available online: www.typingdna.com/ (accessed on 19 May 2023).
- Fernando, K.J.L.; Jayalath, W.J.D.L.D.D.; Ranasinghe, A.D.R.N.; Bandara, P.K.B.P.S.; De Silva, H. Innovative, Integrated and Interactive (3I) LMS for Learners and Trainers. In Proceedings of the ICAC 2020—2nd International Conference on Advancements in Computing, Malabe, Sri Lanka, 1–11 December 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 37–42. [Google Scholar] [CrossRef]
- Chen, C.H. Fuzzy Logic and Neural Network Handbook; McGraw-Hill, Inc.: New York, NY, USA, 1990. [Google Scholar]
- Kasprowski, P.; Borowska, Z.; Harezlak, K. Biometric Identification Based on Keystroke Dynamics. Sensors 2022, 22, 3158. [Google Scholar] [CrossRef] [PubMed]
- Shan, X.; Ma, T.; Gu, A.; Cai, H.; Wen, Y. TCRNet: Make Transformer, CNN and RNN Complement Each Other. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2022; pp. 1441–1445. [Google Scholar] [CrossRef]
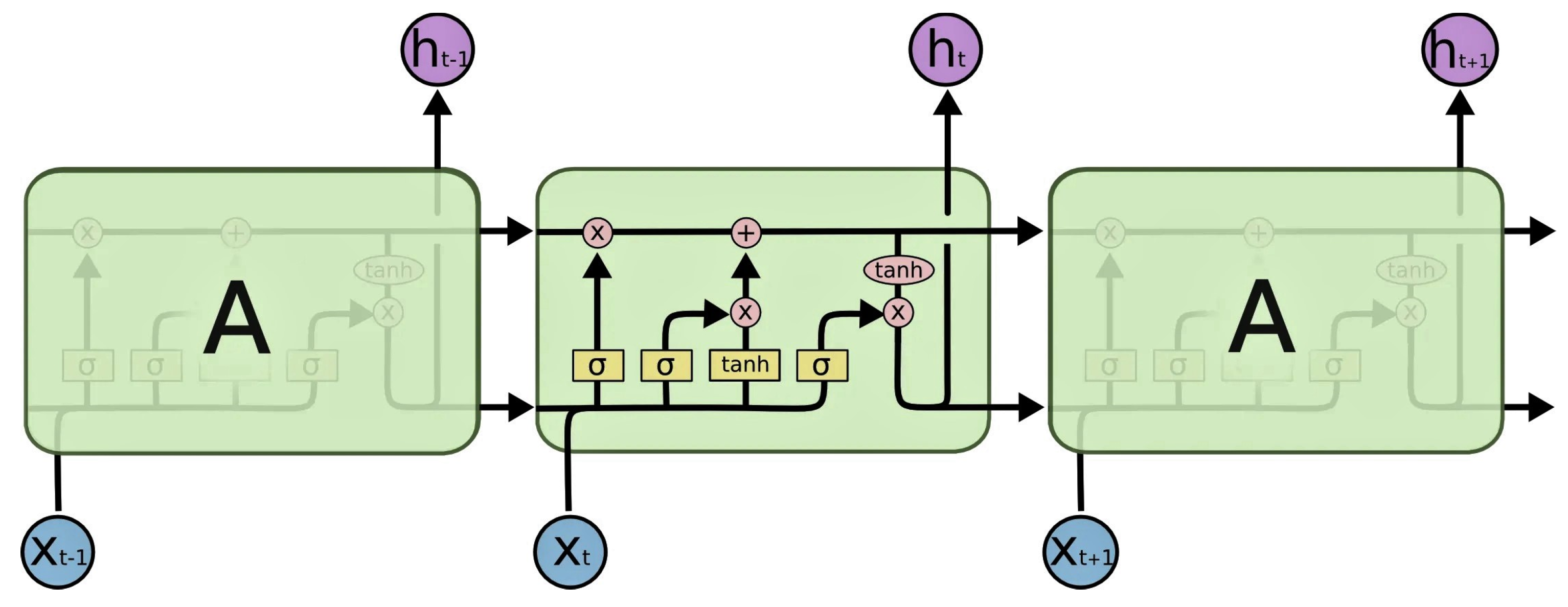
- Olah, C. LSTMs. Available online: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 29 May 2023).
- Dhakal, V.; Feit, A.M.; Kristensson, P.O.; Oulasvirta, A. Observations on typing from 136 million keystrokes. In Proceedings of the CHI ‘18: Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018. [Google Scholar] [CrossRef] [Green Version]
- Mishra, A. IIITBh-Keystrokes Database. Available online: https://github.com/aroonav/IIITBh-keystroke (accessed on 19 May 2023).
- Buckley, O.; Hodges, D.; Windle, J.; Earl, S. CLICKA: Collecting and leveraging identity cues with keystroke dynamics. Comput. Secur. 2022, 120, 102780. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Keystrokes | Users | User Error Percentage | |
|---|---|---|---|
| Fixed-text dataset | 4443 | 15 | ±9% |
| Fixed-text filtered dataset | 4070 | 15 | - |
| Free-text dataset | 21,119 | 20 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gurčinas, V.; Dautartas, J.; Janulevičius, J.; Goranin, N.; Čenys, A. A Deep-Learning-Based Approach to Keystroke-Injection Payload Generation. Electronics 2023, 12, 2894. https://doi.org/10.3390/electronics12132894
Gurčinas V, Dautartas J, Janulevičius J, Goranin N, Čenys A. A Deep-Learning-Based Approach to Keystroke-Injection Payload Generation. Electronics. 2023; 12(13):2894. https://doi.org/10.3390/electronics12132894
Chicago/Turabian StyleGurčinas, Vitalijus, Juozas Dautartas, Justinas Janulevičius, Nikolaj Goranin, and Antanas Čenys. 2023. "A Deep-Learning-Based Approach to Keystroke-Injection Payload Generation" Electronics 12, no. 13: 2894. https://doi.org/10.3390/electronics12132894