4.1. Experimental Flow and Evaluation Metrics
To investigate the effectiveness of the proposed defense system, 4 experiments were conducted as described below.
- Experiment 1.
Extract variants from test data for validation.
- Experiment 2.
Use Suricata with the ET ruleset applied to examine the effectiveness of conventional methods against known attacks and variants.
- Experiment 3.
Use RapidMiner to examine the effectiveness of the proposed method against known attacks and variants.
- Experiment 4.
Use a turn generation program to generate rules for attacks that exploit Log4Shell and compare the generated rules with those contained in the Snort Community ruleset.
The ET ruleset used in Experiment 2 was downloaded in January 2023. Although the ruleset available for download was divided into files by category, the experiment was conducted so that all files were read.
In Experiment 3, we used a machine with an Intel Xeon W-1270 CPU and 40 GB of memory for machine learning with Rapid Miner. It should be noted that machine learning using RapidMiner requires a lot of memory, so machines with less than 40 GB of memory may be affected. In addition, the machine learning methods shown in the experimental results are based on the selective use of one of the best-performing methods available in RapidMiner.
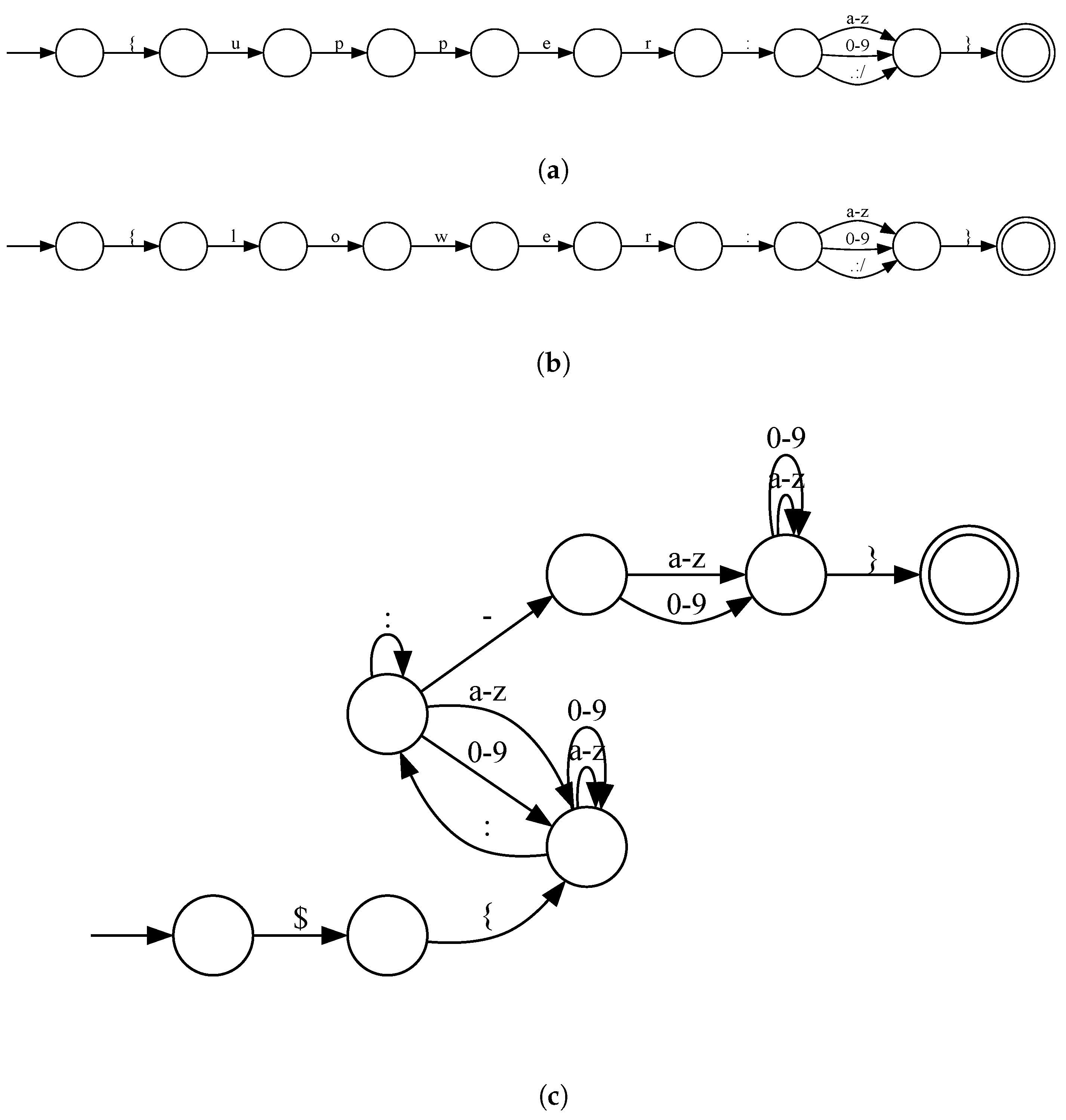
The Snort Community rule set used in Experiment 4 was downloaded in March 2023. It includes rules for other attacks as well as Log4Shell, but only rules related to Log4Shell were extracted. We extracted rules that contain “Log4j” or “Log4Shell” in the comment of the rule. The extraction resulted in 36 rules, but only one rule corresponding to all three obfuscation methods, and the non-obfuscated attack pattern shown in
Figure 1 was used in the experiment.
The True Positive Rate (TPR) and the True Negative Rate (TNR) obtained from this experiment were used to compare discrimination performance. To compare the performance of each machine learning method and conventional method, the following indices are used as evaluation measures.
A discrimination method with a higher TPR (lower false negative rate) is suitable for this research because a higher True Positive Rate indicates that more URL strings that should be discriminated as “attack” were discriminated as “attack”. On the other hand, a higher true negative rate (lower false positive rate) indicates that more URL strings that should be identified as “clean” are identified as “clean”, and a discrimination method with a higher true negative rate is less likely to incorrectly identify the URL string “clean” URL string as “attack”.
The True Positive Rate (TPR) and True Negative Rate (TNR) used as evaluation measures can be derived using the following equations.
In the above equation,
denotes a true positive (an attack was correctly judged as an attack),
a false negative (an attack was incorrectly judged as not an attack),
a true negative (a non-attack was correctly judged as not an attack), and
a false positive (a non-attack was incorrectly judged as an attack). (false positives).
Next, we describe the training and test data. The training data used were 33,088 accesses collected in the WordPress data collection environment over a three-month period from 29 October 2021, to 22 January 2022. The data used as test data consisted of 7195 accesses collected in the WOWHoneypot data collection environment during a one-month period from December 2021 to January 2022.
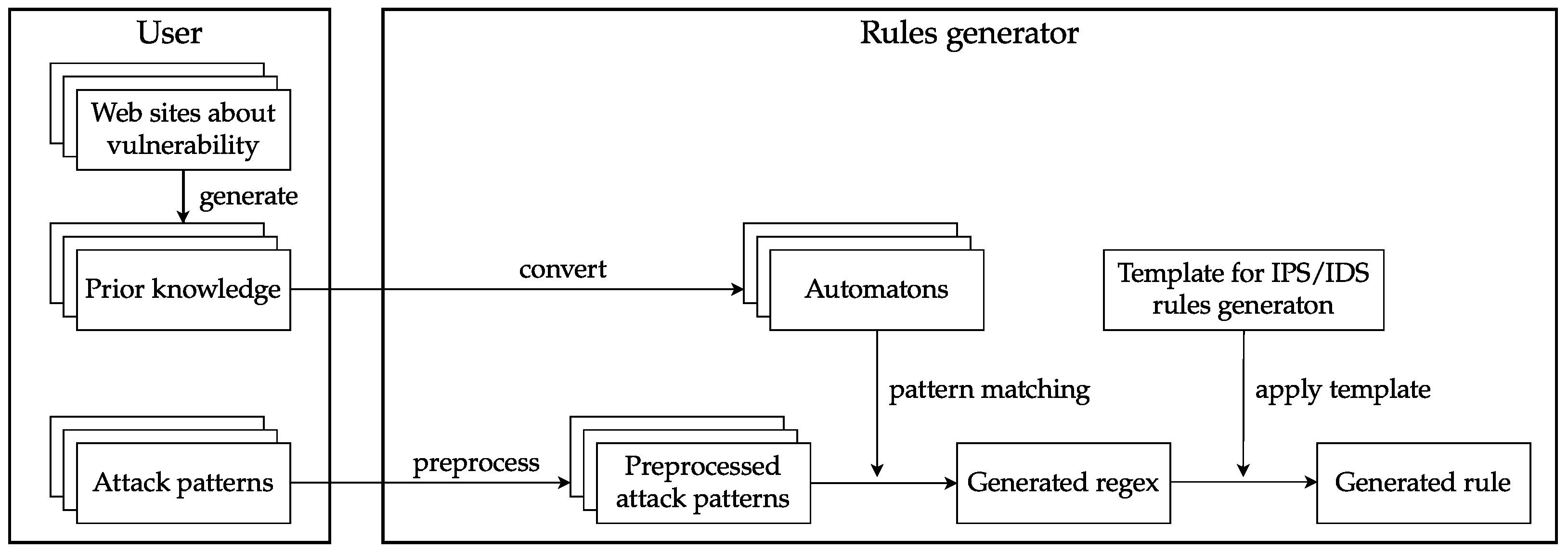
Next, the rules generator was used to generate regex patterns for Log4Shell’s obfuscated attack patterns, which were converted into rules that could be applied to Snort, the IDS. We compared these rules with the rules included in the Snort Community ruleset. The evaluation metrics used in the comparison are described below.
Detection rate
The value of how many alerts were correctly issued for accesses that should have been alerted as attacks. The detection rate
can be derived by the following equation, where
is defined as true positive (alerts were issued for attacks) and
as false negative (no alerts were issued for attacks).
Understandability
This value represents the understandability of the regex pattern. Assuming that selection, repetition, negation, etc., are defined as complex regexes, with the number of complex regexes in the conventional method defined as
and the number of complex regexes in the proposed method as
, the understandability is obtained by the following equation.
Since this metric compares the number of complex regexes, the experiment examines the number of complex regexes in each regex pattern to calculate understandability.
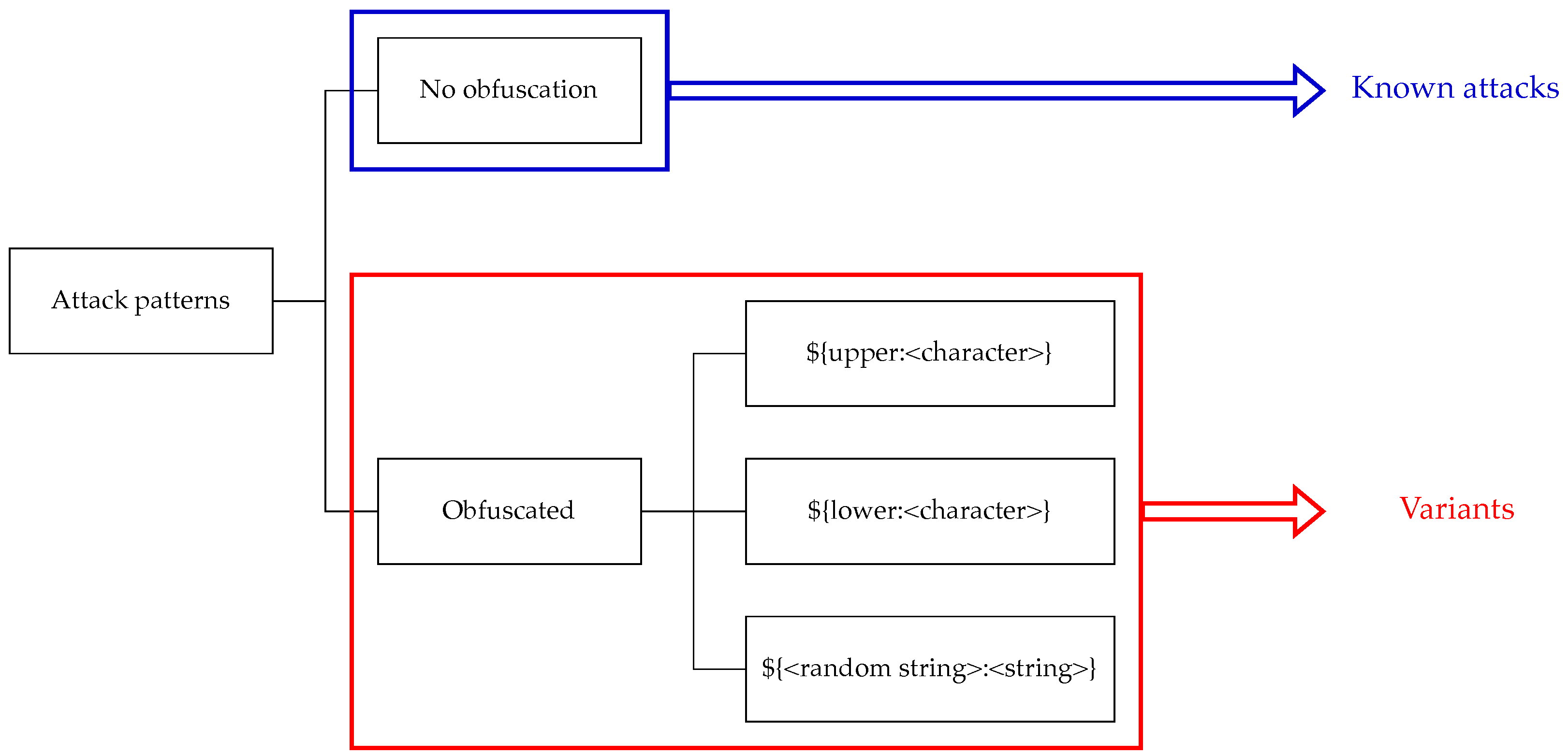
The URL strings used to test the generated rules were generated for 161 accesses related to the Log4Shell exploit, out of approximately 250,000 accesses collected in the WordPress data collection environment from 29 October 2021 to 5 June 2023, for approximately 18 months. Rule generation was performed. The Snort Community ruleset was used for comparison with the generated rules, and one of the rules in the Snort Community ruleset was selected for performance comparison, corresponding to one of the attack patterns, including obfuscated ones that exploit Log4Shell. The 161 attack patterns used for rule generation include all the obfuscation methods of the attack patterns that exploit Log4Shell shown in
Figure 1, as well as some attack patterns that are not obfuscated. Therefore, those attack patterns cover all variations of the attack patterns that exploit Log4Shell.
The prior knowledge used to generate the regex patterns and rules is shown below. Note that this prior knowledge is a modification of the prior knowledge shown in the example used to illustrate the rule generation flow so that it can handle uppercase alphabetic characters.
$\{upper:([a-zA-Z0-9]|:|:|\. |/)\} is used as one of the obfuscation methods. Therefore, this obfuscation is called upper obfuscation.
$\{lower:([a-zA-Z0-9]|:|\. |/)\} is used as one of the obfuscation methods. Therefore, this obfuscation is called lower obfuscation.
$\{([a-zA-Z0-9]|:)+:\-([a-zA-Z0-9])+\} is used as one of the obfuscation methods. Therefore, this obfuscation is called obfuscation of random strings.
If multiple obfuscation methods are used in combination, their order of appearance is not considered.
The attack patterns used to generate the regex patterns and rules are the 10 attack patterns generated by the program that generates the attack patterns for Log4Shell, which we created [
35]. These variations and the number of each are shown in
Table 2.
4.2. Experimental Results
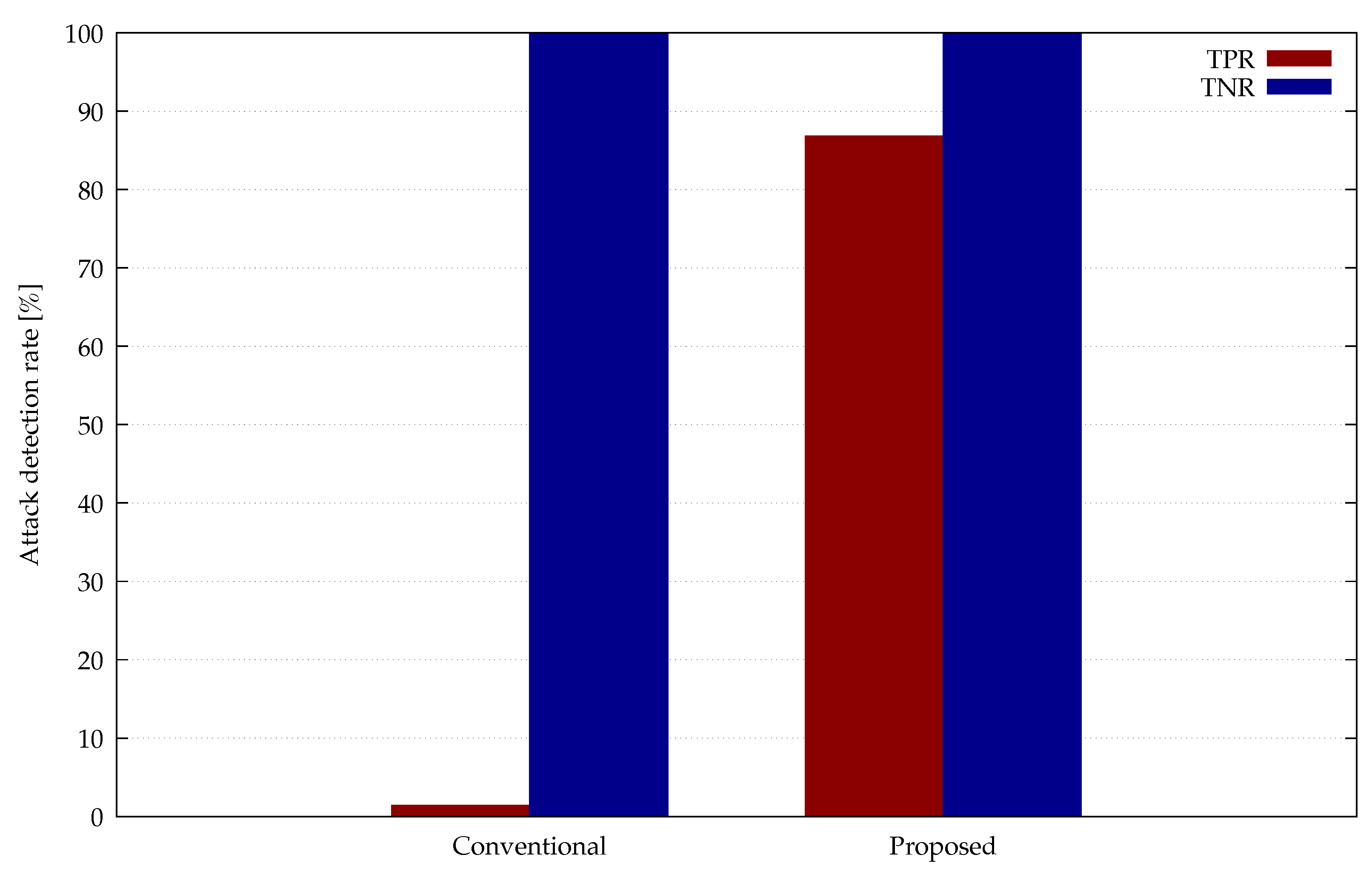
A comparison between the conventional and proposed methods for the true positive and true negative rates for known attacks is shown in
Figure 13. The y-axis is the value of each evaluation index, with higher values indicating better discrimination performance.
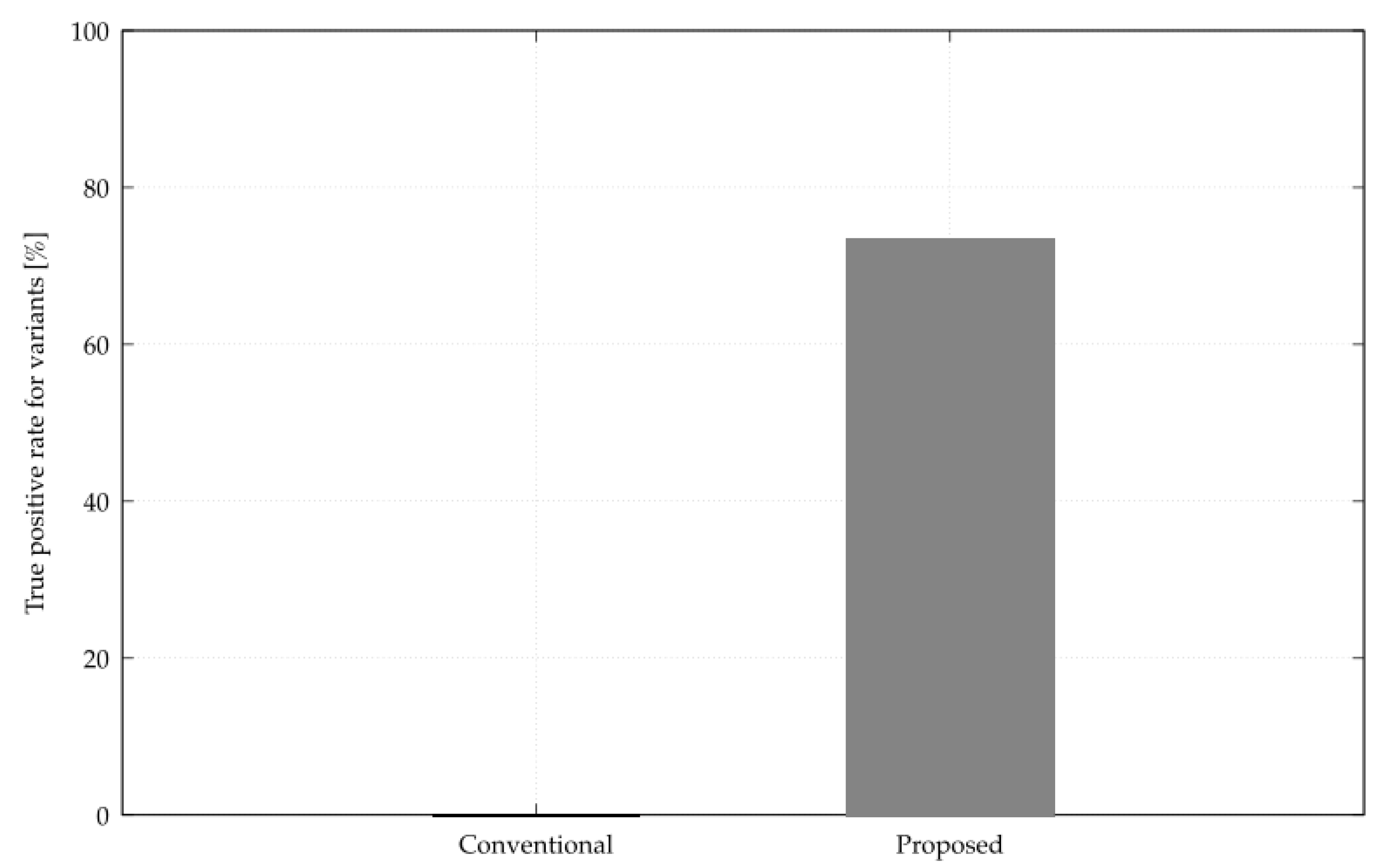
Next, a comparison between the conventional and proposed methods for the true positive rate for variant attacks is shown in
Figure 14. The y-axis is the value of the true positive rate, with higher values indicating more attacks can be detected.
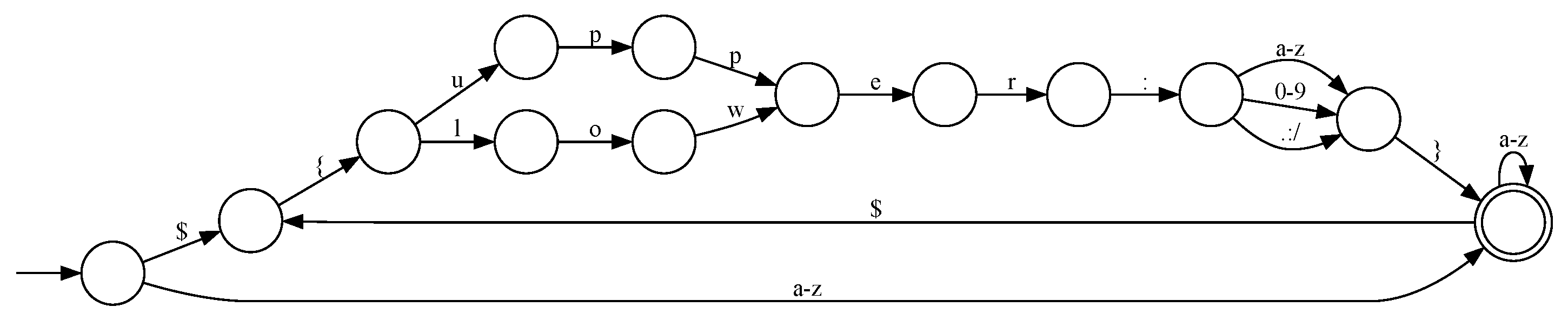
Using the 10 attack patterns described above, rule generation resulted in one regex pattern shown below.
The regex pattern shown above was then used to generate rules applicable to Snort. The generated rule is shown below.
alert tcp $EXTERNAL_NET any -> $HOME_NET $HTTP_PORTS (msg:‘‘Log4Shell’’; flow:to_server,established; pcre:‘‘/(\$\{([a-zA-Z0-9]|:)+:\-([a-zA-Z0-9]|:)+\}|[a-zA-Z]|[0-9]|\$|\{|:|\-|/|\.|\})+/U’’; metadata:policy balanced-ips drop, policy connectivity-ips drop, policy max-detect-ips drop, policy security-ips drop, ruleset community, service http; classtype:attempted-user; sid:58724; rev:6;)
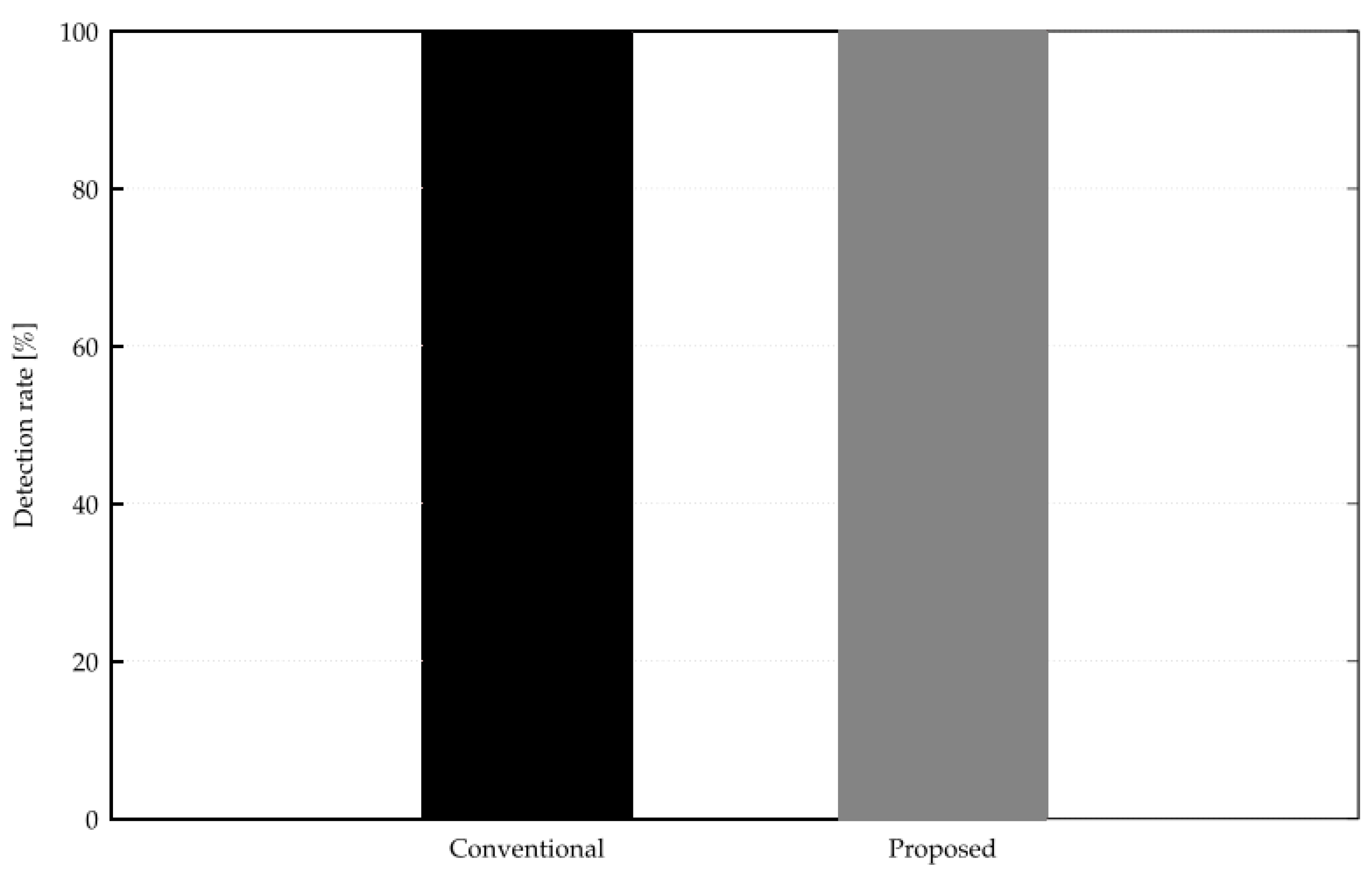
The results of applying the above rule to Snort and examining the attack detection rate using the aforementioned 161 attack patterns and comparing it with the conventional method using the Snort Community ruleset are shown in
Figure 15. The y-axis is the attack detection rate, and a higher value indicates that the attack was detected.
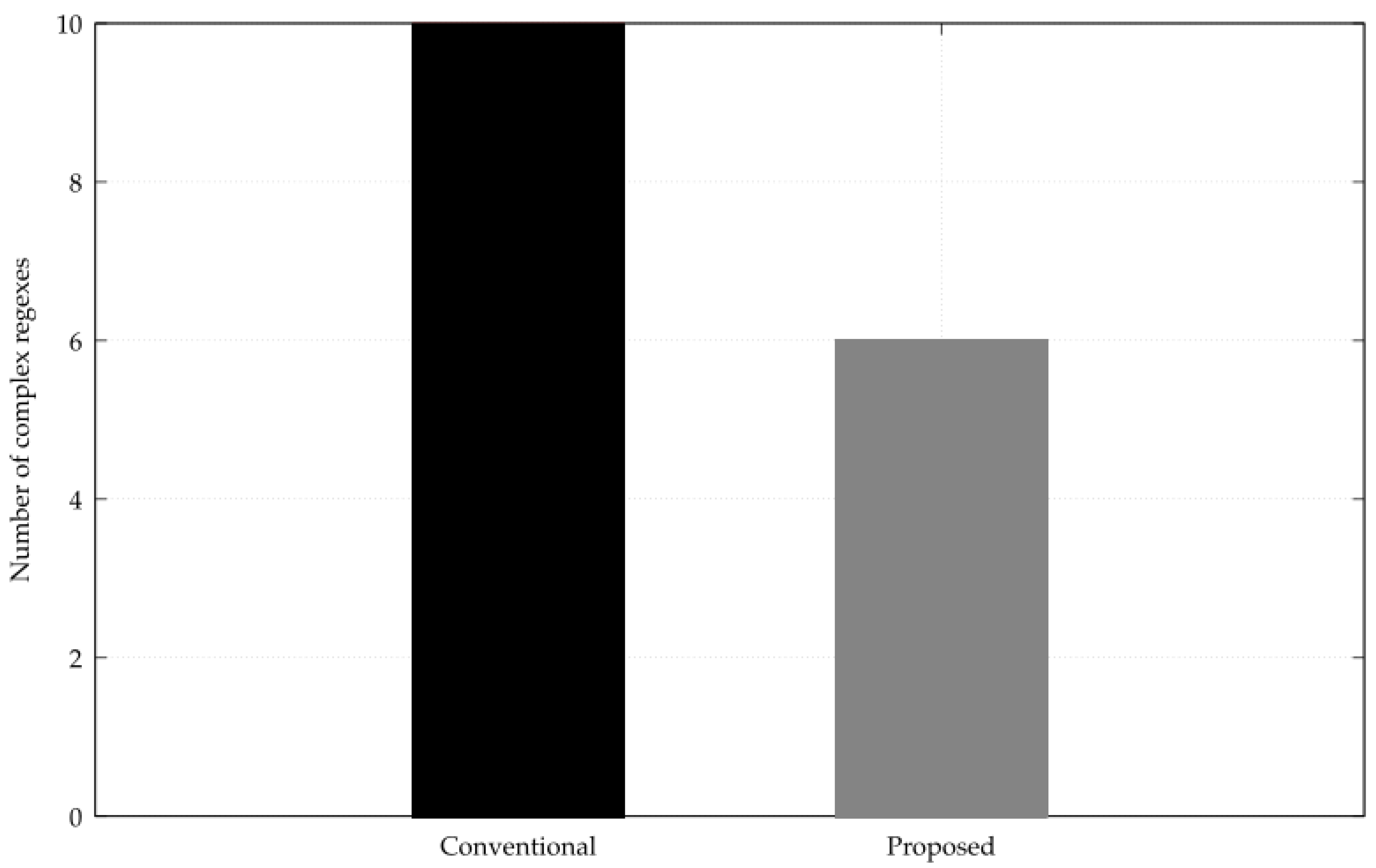
Next, the comparison of the number of complex regex patterns of the rules generated by the conventional method and the proposed method is shown in
Figure 16. The y-axis is the number of complex regexes, with lower values indicating greater understandability, as defined in the evaluation metrics.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}