1. Introduction
Digital images are a commonly used medium, especially for informal information sharing. However, image contents can be changed without difficulty by using specific software. Usually, resizing [
1], gamma correction [
2], sharpening [
3], and smoothing [
4] operations are used to produce a convincing fake image. Image forensics provides the details of past operations applied to the image. This paper’s primary objective was to detect the low-pass filter operation usually used for smoothing. Three commonly used low-pass filters—Gaussian, median, and averaging—are addressed in this paper. The images displayed in
Figure 1 show the visual effect on the image after low-pass filtering and JPEG compression. Uncompressed images are displayed in the first row, and their compressed version of 75 quality factor in the second row. The structural similarity index measure (SSIM) [
5] relates to visual quality. The first image in the first row is the reference image, and its assumed SSIM quality value (SQ) is 1.0. In the first row, the second, third, and fourth images are averaging- (SQ = 0.48), Gaussian- (SQ = 0.92), and median-filtered (SQ = 0.52) images, respectively. The Gaussian-filtered image is created using a Gaussian filter with a standard deviation of 0.5 and a filter window size of 3 × 3. The SQ is highest for the Gaussian-filtered image after the original image. The SQ is related to visual quality. In the second row, compressed images are displayed with their corresponding SQs. The SQ has dropped greatly for a compressed Gaussian-filtered image compared to other filtered images. However, the SQ value of the compressed Gaussian-filtered image is highest in the compressed filtered images.
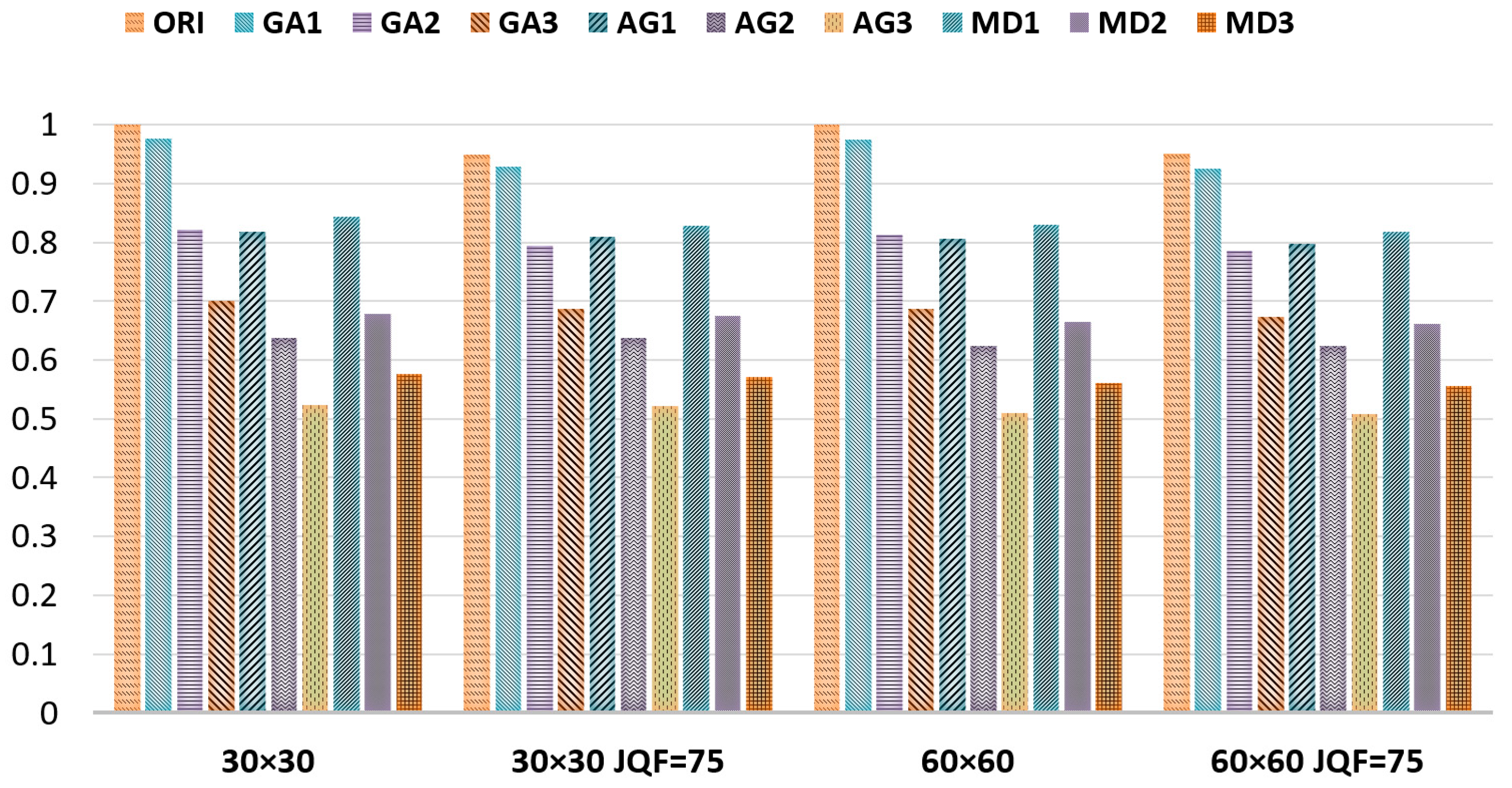
The means of SSIM quality values (SQ) are displayed in
Figure 2 to observe the general behavior of filtered images. The low-pass filters were applied to one thousand images with dimensions 30 × 30 and 60 × 60. ORI denotes the non-filtered images. GA1, GA2, and GA3 indicate the Gaussian-filtered images of filter sizes 3 × 3, 5 × 5, and 7 × 7. Likewise, AG represents averaging-filtered images, and MD denotes median-filtered images. JPEG-compressed images are also considered with quality factor (JQF) 75. It can be observed from the figure that as the filter size is enlarged, the SQ value declines. The SQ values of GA are followed by those for AG and MD.
One more image quality indicator—perception-based image quality evaluator (PIQUE) [
6]—is considered for analysis. PIQUE is a no-reference quality metric for blind image quality assessment. The covariance plot of the PIQUE score is displayed in
Figure 3 to reveal the difference in nature of non-filtered, low-pass-filtered images for all ten classes, including three low-pass filters with different parameters. In
Figure 3a, uncompressed images are considered; in
Figure 3b, compressed images with JQF = 75 are considered to evaluate the PIQUE score.
As discussed above, the low-pass-filtered images with low-potency filters, such as filter size 3 × 3, have less difference in SQ compared to non-filtered images. Researchers suggest several schemes to address the issue of low-pass filtering. Kirchner and Fridrich [
7] detected median filtering by measuring the co-occurrence between pixels. Similarly, Chen et al. [
8] and Agarwal & Jung [
4] measured the co-occurrence of pixels using some additional modifications. Chen et al. [
8] also added local features by calculating local correlation. Agarwal and Jung [
4] utilized the higher-significance bit-plane to improve the detection capability on low-pass-filtered images. Gupta and Singhal [
9] exploited the discrete cosine domain to extract four features of first-order moments. The autoregressive model detects filtering in schemes [
10,
11,
12]. Kang et al. [
10] considered the model of order ten to detect median filtering. Yang et al. [
11] applied the 2D model on several types of difference arrays for better results. Rhee [
12] considered the bit planes to boost performance using the autoregressive model. Chen et al. [
13] introduced the deep neural network to recognize median-filtered images. The network had five convolutional layers, and median-filter residual images were considered for training. The deep neural network of Liu et al. [
14] utilized the discrete Fourier transform domain images to detect low-pass filtering. The network had merely two convolutional layers and pooling layers. The Zhang et al. [
15] deep neural network contained squeeze and excitation blocks to detect three types of low-pass filtering. The computational cost of the Zhang et al. network is expensive. Yu et al. [
16] preprocessed the images with several high-pass filters before sending them to a deep neural network with four convolutional layers. The co-occurrence and autoregressive model extracted the prevailing manual scheme features. In the prevailing convolutional neural network (CNN)-based schemes, altered arrangements of layers are performed to improve the performance. However, deep neural network schemes provide better results than the prevailing manual schemes. In this paper, a hybrid scheme is proposed that has a deep neural network at its core. The proposed scheme has superior recognition competency and reasonable computational expense. The key highlights of the proposed scheme are as follows:
The proposed scheme is suitable for detecting various types and strengths of low-pass filters. The scheme is suitable for large- and small-dimension uncompressed and JPEG-compressed images.
The convolutional neural network of the proposed scheme comprises merely nine convolutional layers with a lesser number of kernels.
The global variance pooling layer is introduced to improve the detection performance of the deep neural network of the proposed scheme.
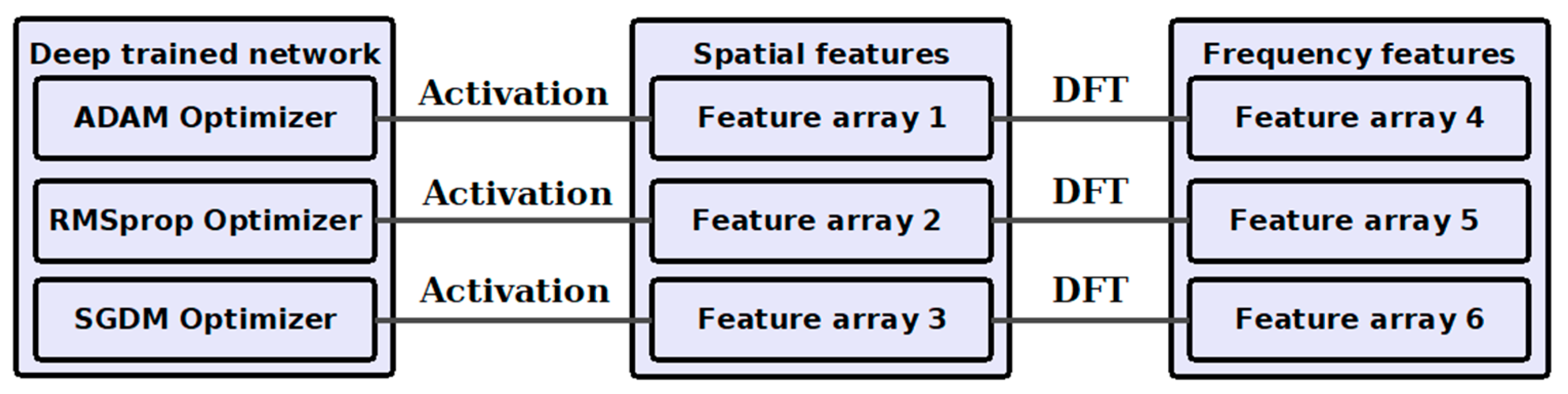
Feature arrays from trained networks are combined to boost detection accuracy. The network is trained using three different solvers.
The spatial domain and discrete Fourier transform domain features are concatenated to enhance the potential of the proposed scheme.
A leaky ReLU layer is employed instead of a conventional ReLU layer to optimize the results.
A tri-layered neural network classifier is employed to classify a different set of images that are processed by low-pass filters.
The remainder of the paper is structured as follows:
Section 2 describes the suggested technique. Multiple features are fetched in the proposed scheme using two global pooling layers and three optimizers. Spatial domain features are also mapped in the frequency domain. Both domain features are concatenated for better results. The experiment’s findings for the proposed scheme and the paper’s conclusions are discussed in
Section 3 and
Section 4, respectively.
2. Proposed Scheme
Low-pass filtering is applied for smoothing and blurring the image. In this paper, a robust scheme is suggested to detect low-pass filtering. The proposed scheme incorporates the features of spatial and frequency domains by using three different solvers in a convolutional neural network. First, the proposed deep neural network is explained. It is found from the regressive experimental analysis that for low-pass filtering detection, a light neural network provides better results than a CNN that has residual connections and a high number of parameters. The ResNet [
17] and other computationally expensive CNNs do not provide satisfactory detection performance.
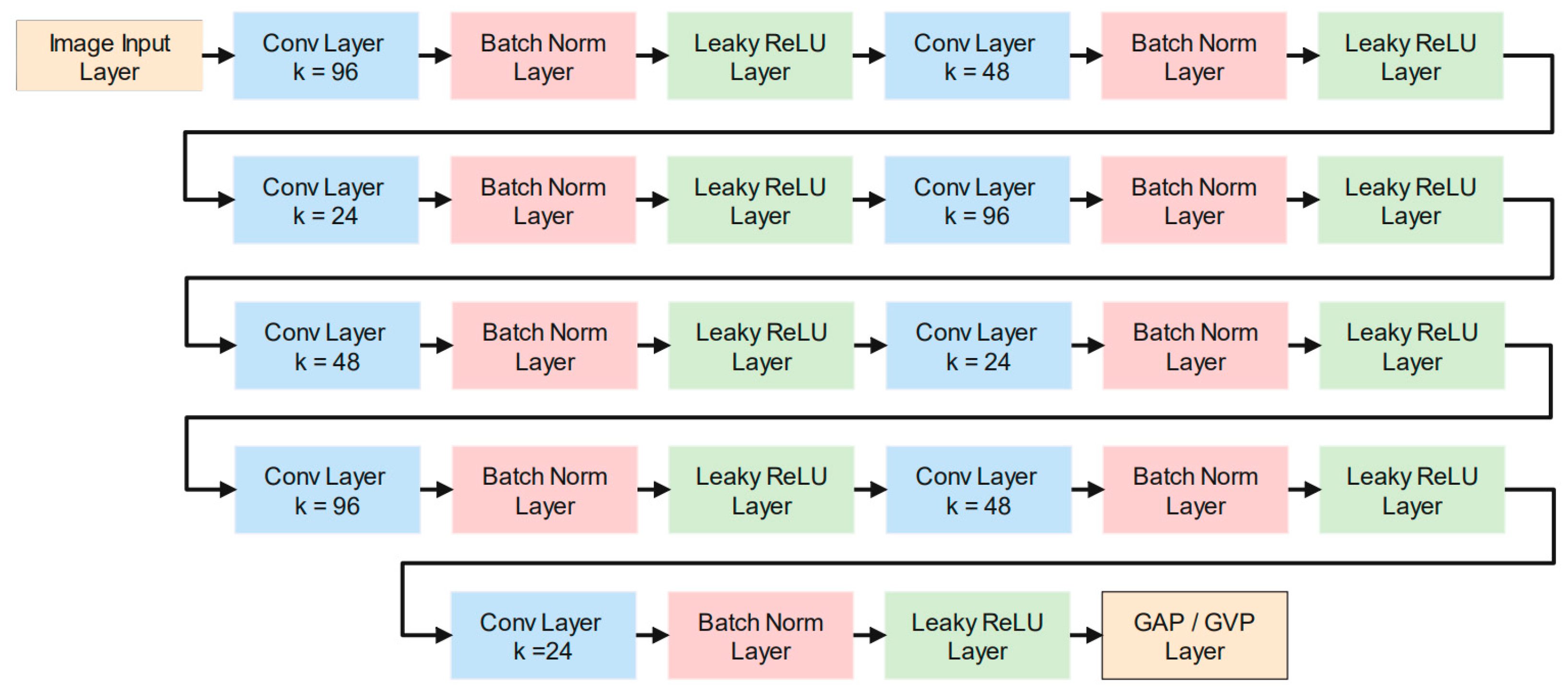
Figure 4 presents a proposed deep neural network containing nine two-dimensional (2D) convolutional (Conv) layers. A batch normalization (Batch Norm) layer and a leaky ReLU layer trail each 2D convolutional layer. A leaky ReLU layer is used instead of the conventional ReLU layer in the proposed convolutional neural network to improve detection capability. In a leaky ReLU layer, every negative element is multiplied by a constant real positive number (
c). The elements greater than or equivalent to zero stay the same. The leaky ReLU layer (
LR) can be defined as follows:
However, every negative element is assigned a zero value, and positive elements remain unchanged in the conventional ReLU layer. ReLU layer (
R) can be defined as follows:
There are 96, 48, 24, 96, 48, 24, 96, 48, and 24 kernels in the head 2D convolutional layer to the last convolutional layer. Several combinations of layers and the number of kernels were tried. However, the suggested convolutional neural network was found more suitable. No other pooling layers were used in the network to protect against the loss of information between the convolutional layers. The global pooling layers were used to amplify the performance. Global average pooling (GAP) and global variance pooling (GVP) layers were considered.
Subsequently, in the last leaky ReLU layer, global pooling layers were used to boost the detection capability. In some previous schemes [
18,
19], the global average pooling layer enhanced the stego image detection accuracy. The proposed scheme also introduces a global variance pooling layer to make the robust feature array.
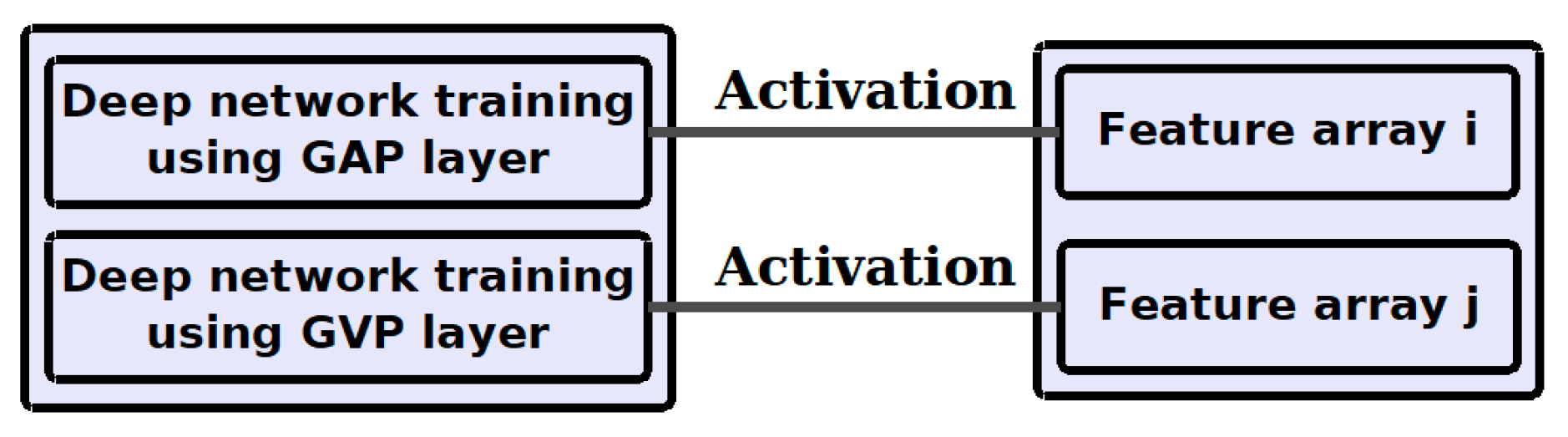
Figure 5 displays layouts of the global average and variance pooling layers. Instead of calculating the average of the feature map, variance is calculated in the global variance pooling layer.
The CNN was trained twice, once using the GAP layer and once using the GVP layer. Further, an activation function was applied, as displayed in
Figure 6, to extract the feature arrays. The feature arrays i and j were concatenated. The variance provides the additional details of low-pass-filtering traces that assist in distinguishing non-filtered and filtered images.
Three different solvers were used in network training to strengthen the feature array. These solvers are adaptive moment (Adam), root mean square propagation (RMSprop), and stochastic gradient descent with moment (Sgdm). The activation function was applied to the trained network, as displayed in
Figure 7. Feature arrays were fetched from the trained networks to acquire the benefit of three solvers. Each feature array was also converted into the DFT domain. The conversion of features in the DFT domain is beneficial in steganalysis by Wang et al. [
20]. This fact is also found relevant in the experimental analysis of our work. This process created six feature arrays. In the proposed CNN, two types of global pooling layers were used, one layer at a time. Therefore, a total of twelve feature arrays were formed. These twelve feature arrays were concatenated to generate a single feature array.
Further, a tri-layered neural network classifier was applied to feature arrays to classify non-filtered and low-pass-filtered images. A tri-layered neural network classifier provided better results than softmax, support vector machine, and linear discriminant analysis classifiers in our experimental analysis. Fifty epochs were engaged to train the network. Mini batch sizes of 300 and 150 were deliberated separately for images with dimensions 60 × 60 and 30 × 30. The proposed work was performed on a system with the following hardware details: NVIDIA GeForce RTX3070, Intel(R) Core (TM) i7-10700K CPU @ 3.80 GHz, and 32 GB RAM. The network learning duration is displayed in
Table 1 with Adam, RMSprop, and Sgdm solvers for ten class categorizations. In the case of uncompressed images, learning time is compared to compressed images due to more information content.
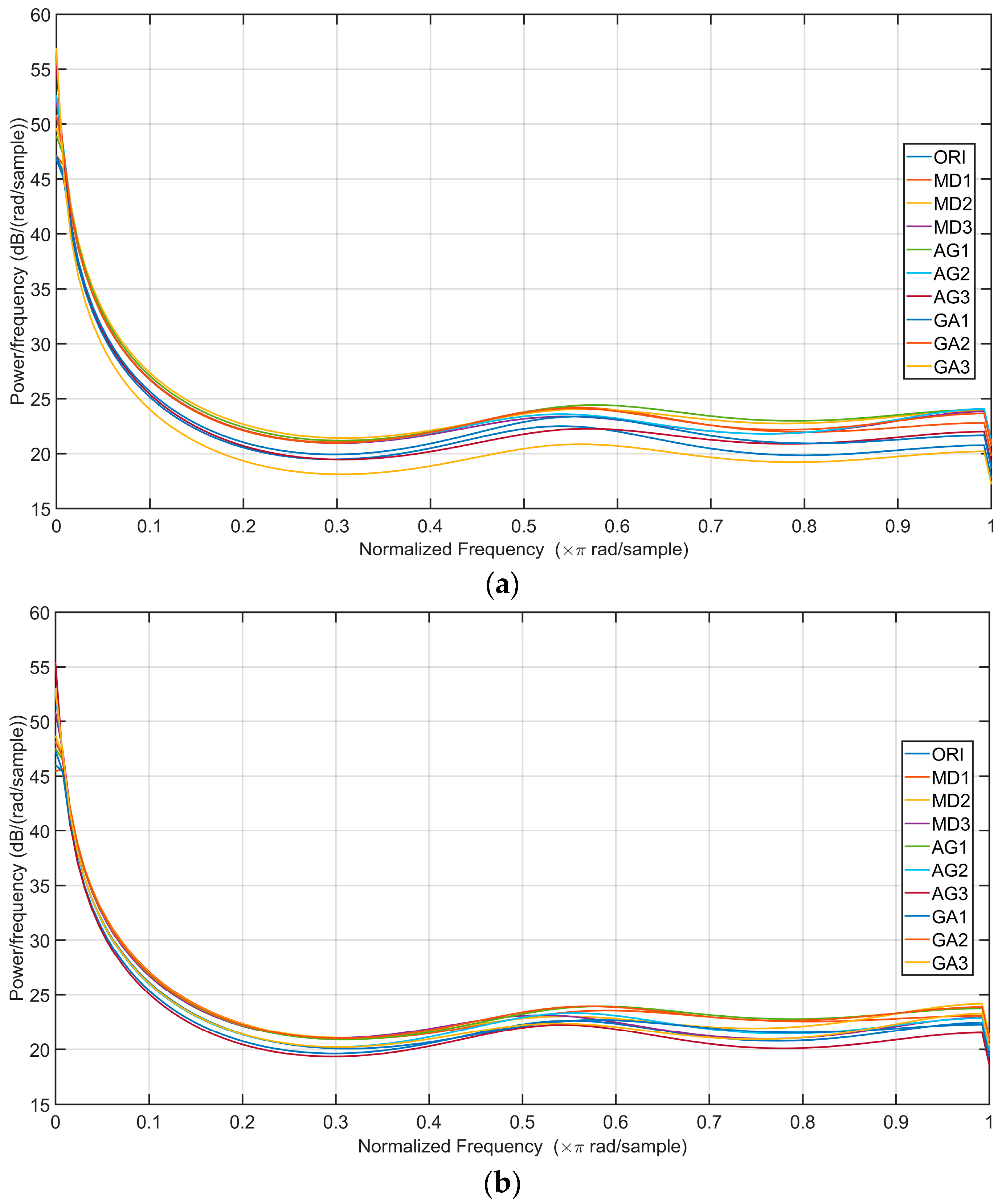
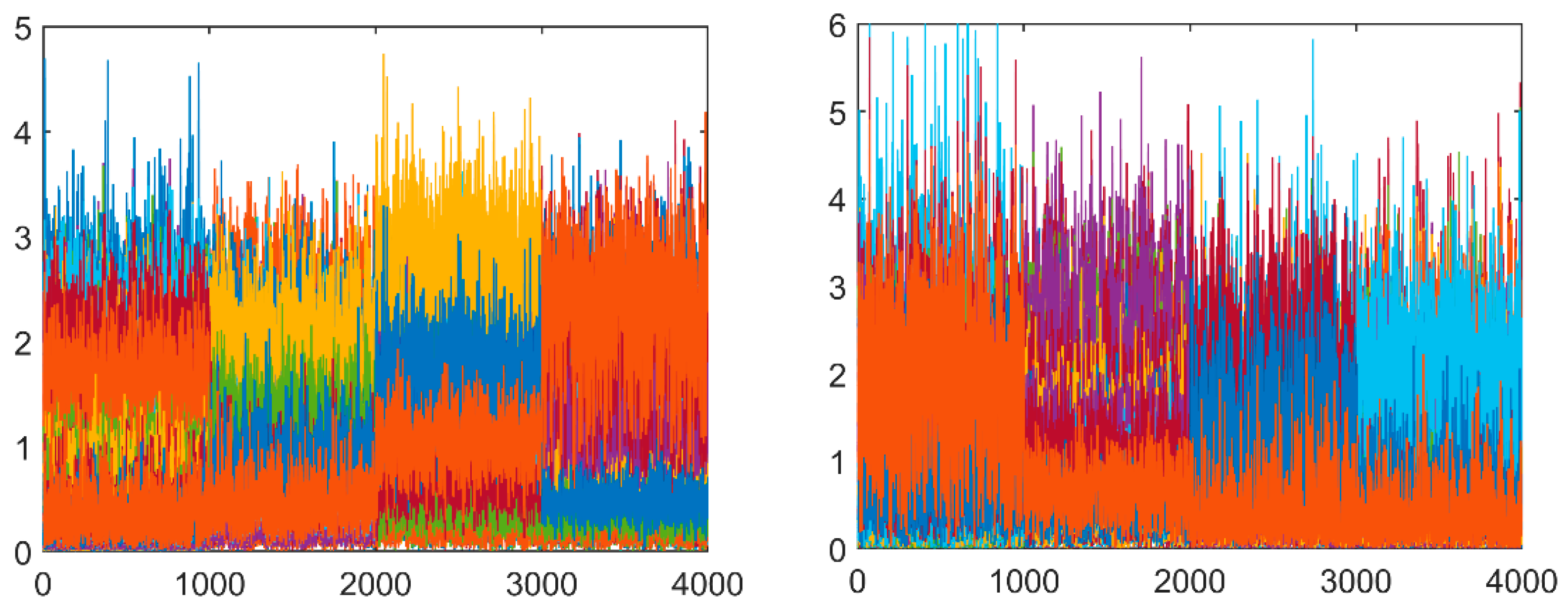
In
Figure 8, feature arrays are displayed for four classes of non-filtered images and median-filtered images that were processed with filter sizes 3 × 3, 5 × 5, and 7 × 7. The first plot shows the feature arrays of the uncompressed images with dimensions 30 × 30, and the second plot displays the feature arrays of the compressed images with JQF = 75 and size 30 × 30. It can be perceived from
Figure 8 that feature arrays of uncompressed images are more distinguishable than compressed images. This distinguishability of feature arrays is also reflected in the experimental analysis, indicating that the detection performance on uncompressed images is superior to compressed images.
3. Experimental Analysis and Discussion
This paper proposes a scheme to detect low-pass filtering in images. An image set was created from three different image datasets, i.e., UCID [
21], BOSSBase 1.01 [
22], and NRCS [
23], to assess the detection scheme. UCID dataset comprises 1338 uncompressed color images with dimensions 512 × 384. The BOSSBase 1.01 dataset has ten thousand uncompressed grayscale images with dimensions 512 × 512. Two thousand high-resolution images were taken from an NRCS photo gallery containing landscapes, soil, etc. Thirty-five thousand images of size 60 × 60 were generated by cropping images in random order. The images with dimensions 30 × 30 were generated by selecting an interior chunk of images with dimensions 60 × 60. Respective low-pass filtered images were generated by applying a particularly low-pass filter. In the case of training the network, twenty thousand images in the required category were taken. Fifteen thousand images were employed for training. Uncompressed and JPEG-compressed images of quality factor 75 were considered for rigorous experimental analysis. JPEG compression was applied after filtering.
The proposed scheme is denoted as Z1, Z2, and Z3 while using Sgdm, Adam, and RMSprop, respectively, as solvers. ZALL represents the final scheme by concatenating the feature arrays of Z1, Z2, and Z3. ORI stands for unfiltered images. Both spatial and frequency domain features were concatenated for better results. The Gaussian-filtered images of sizes 3 × 3, 5 × 5, and 7 × 7 are designated as GA1, GA2, and GA3, respectively. In the same way, AG stands for averaging-filtered images, and MD for median-filtered images. Two, four, and ten categories were classified using a tri-layered neural network classifier for in-depth analysis.
Table 2 and
Table 3 display the detection accuracy of two-class classification. The detection accuracy of the four-class classification is shown in
Table 4 and
Table 5. The detection accuracy of the ten-class classification is given in
Table 6 and
Table 7.
In
Table 2, the classification accuracy is shown between non-filtered (ORI) and filtered images, i.e., between two classes. The classification accuracy is more than 99%, except for the ORI-GA1 pair (84.72%) for 30 × 30 uncompressed images. Images with dimensions 60 × 60 follow a similar pattern; except for the ORI-GA1 pair (91.87%), the classification accuracy is greater than 99%. Therefore, the results for the 60 × 60 uncompressed images are not displayed in the table.
In
Table 3, outcomes for compressed images with JQF = 75 and dimensions of 30 × 30 or 60 × 60 are exhibited. Gaussian-filtered images GA1, GA2, and GA3 are created using the 0.5, 1.0, and 1.5 standard deviations; due to this, ORI-GA1 has the least detection accuracy. ZALL provides 93.06% classification accuracy on ORI-MD1 pairs on the 30 × 30 images. In the case of the 3 × 3 filter, the ORI-AG1 pair has the highest detection accuracy, i.e., 96.49%, compared to pairs ORI-GA1 and ORI-MD1. For low-pass filters of size 5 × 5, the detection accuracies are 96.26%, 99.39%, and 98.87% for ORI-GA2, ORI-AG2, and ORI-MD2, respectively. The detection accuracies for low-pass filters of size 7 × 7 are nearly 99%.
In
Table 4, detection accuracies are demonstrated for four-class classification in the case of the Gaussian filter using the proposed scheme on uncompressed images. ORI, GA1, GA2, and GA3 are the four classes. Detection accuracies are displayed for individuals and four classes (overall). Most of the misclassification is in the ORI and GA1 classes. However, the ZALL delivers 95.71% and 98.85% overall classification accuracy for the 30 × 30 and 60 × 60 images, respectively. The median- and averaging-filtered results are not included in
Table 4. Regarding median and averaging filtering, ZALL delivers 98.89% and 99.93% overall classification accuracy, respectively, for 30 × 30 images. The general classification accuracy of median and averaging filtering is more than 99.61% and 99.97%, respectively, for the 60 × 60 images.
In
Table 5, four-class classification was executed using the proposed scheme on compressed images of JQF = 75. Overall detection accuracy on test images is 81.62% and 89.25% in the case of Gaussian-filtered images for the 30 × 30 and 60 × 60 images, respectively. The overall detection accuracy for averaging-filtered images is 96.85% for the 30 × 30 images and 99.02% for the 60 × 60 images. Overall classification accuracy for median-filtered images is 92.09% for the 30 × 30 images and 97.81% for the 60 × 60 images.
ZALL provides the highest detection accuracy, as shown in
Table 6, on uncompressed images of dimensions 30 × 30 or 60 × 60 for ten-class classification. In ten classes, one is ORI class; three are Gaussian-filtered, three are averaging-filtered, and three are median-filtered class. Images were classified simultaneously using a tri-layered neural network classifier. The overall detection accuracies are 97.83% and 99.26% on the 30 × 30 and 60 × 60 images, respectively. On observing the misclassified images, the number of misclassified images is highest between ORI and GA1, as the GA1 variance is only 0.5.
Table 7 displays results for ten-class classification on compressed images (JQF = 75) of dimensions 30 × 30 or 60 × 60. ZALL also delivers the maximum number of correct predictions. The average detection accuracies are 79.25% and 89.05% on the 30 × 30 and 60 × 60 images, respectively. There is approximately a ten percent difference between detection accuracies for the 30 × 30 and 60 × 60 images. The environment is challenging, as the same filter with a different configuration is also included with other filters.
The proposed scheme was compared with some other prevalent schemes [
8,
10,
11,
13,
14,
15] for ten-class classification overall detection accuracy. The schemes [
8,
10,
11] rely on manual feature fetching. The scheme in [
8] is well known as GLF. The features are fetched by co-occurrence and correlation within the pixels. The schemes [
10,
11] exploit the autoregressive model. The results of deep neural network schemes are far better than manual schemes, as apparent from
Table 8. The techniques [
13,
14,
15] originated using a deep learning network. Chen et al. [
13] utilized the five convolutional layers and considered the residual images and pooling layers. Liu et al. [
14] considered the frequency domain, max-pooling layers, and only two convolutional layers. Zhang et al. [
15] used squeeze and excitation blocks. In the proposed scheme, multiple measures are applied to improve the detection accuracy. The suggested design adds the global variance pooling layer to enhance the deep neural network’s detection capabilities. The spatial and discrete Fourier transform domain features are concatenated to enrich the feature array. Feature arrays from three trained networks are combined, and a leaky ReLU layer is used instead of a traditional ReLU layer to improve the outcomes. Therefore, the results of the proposed scheme are better. The proposed scheme results are superior to Zhang et al. [
15] by at least three percent. The presented scheme results are also much higher than results from other schemes [
8,
10,
11,
13,
14].













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}