
MRLBot: Multi-Dimensional Representation Learning for Social Media Bot Detection
Abstract
:1. Introduction
- The generalization ability of detection methods; existing detection models may only be applicable to particular OSNs, and their performance on other OSNs may be suboptimal,
- Traditional feature engineering-based methods can be expensive and susceptible to evasion; the manual extraction of distinctive features to discern between malicious bots and legitimate users requires significant domain expertise and human resources. Moreover, when malicious bots enhance their anti-detection capabilities, the originally defined feature set may lose its effectiveness,
- Insufficient exploration of user relationships; existing detection methods that rely on user relationships demand substantial time and computational resources. Furthermore, considering the privacy regulations of OSNs, potential features should be extracted from a restricted and accessible set of user relationships to the fullest extent feasible.
- We propose a behavior representation learning model, DDTCN. The model abstracts user activities on social networks to obtain behavior sequences, which are then encoded using the contextual global feature extraction ability of Transformer for time series. A CNN encoder–decoder is subsequently cascaded to extract local information from the sequences. Additionally, the representation ability of the output vectors is enhanced through the proposed Transformer dual decoder;
- This paper presents a network representation learning model, IB2V, based on latent communities. Additionally, we propose an incremental learning strategy for large-scale network graphs to reduce the time cost of generating representations for newly added nodes, while maintaining the performance of the model. The model learns the structural features of node neighborhoods through a novel random walk algorithm, while also preserving the internal structure of communities and the correlations between them;
- We design a generalized detection framework for various social network platforms, achieved through unified input from multiple platforms. The framework integrates components for behaviora; representation and relationship representation learning to generate fused representations, thereby enhancing detection performance.
2. Related Works
2.1. Graph-Based Detection Approaches
2.2. Node-Based Detection Approaches
3. Preliminaries
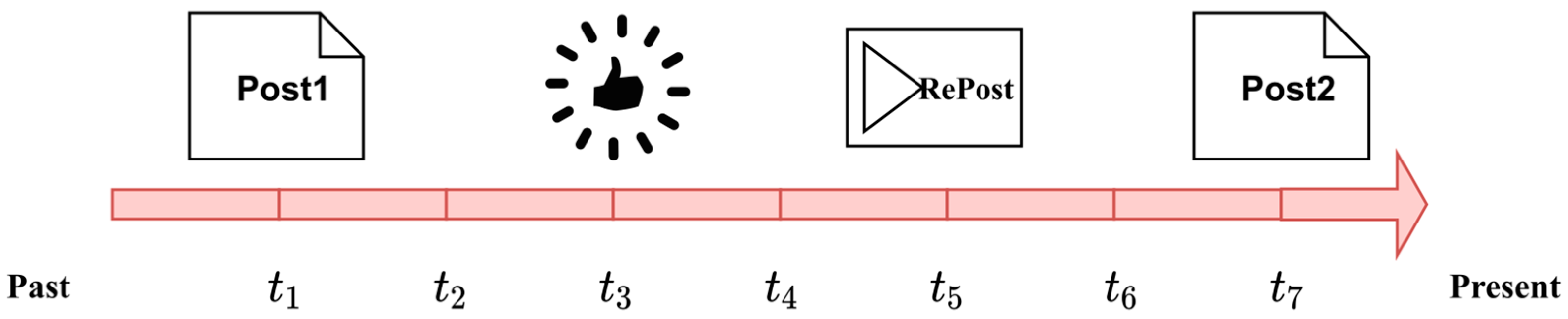
3.1. User Behaviors in Social Networks
3.2. User Relationships in Social Networks
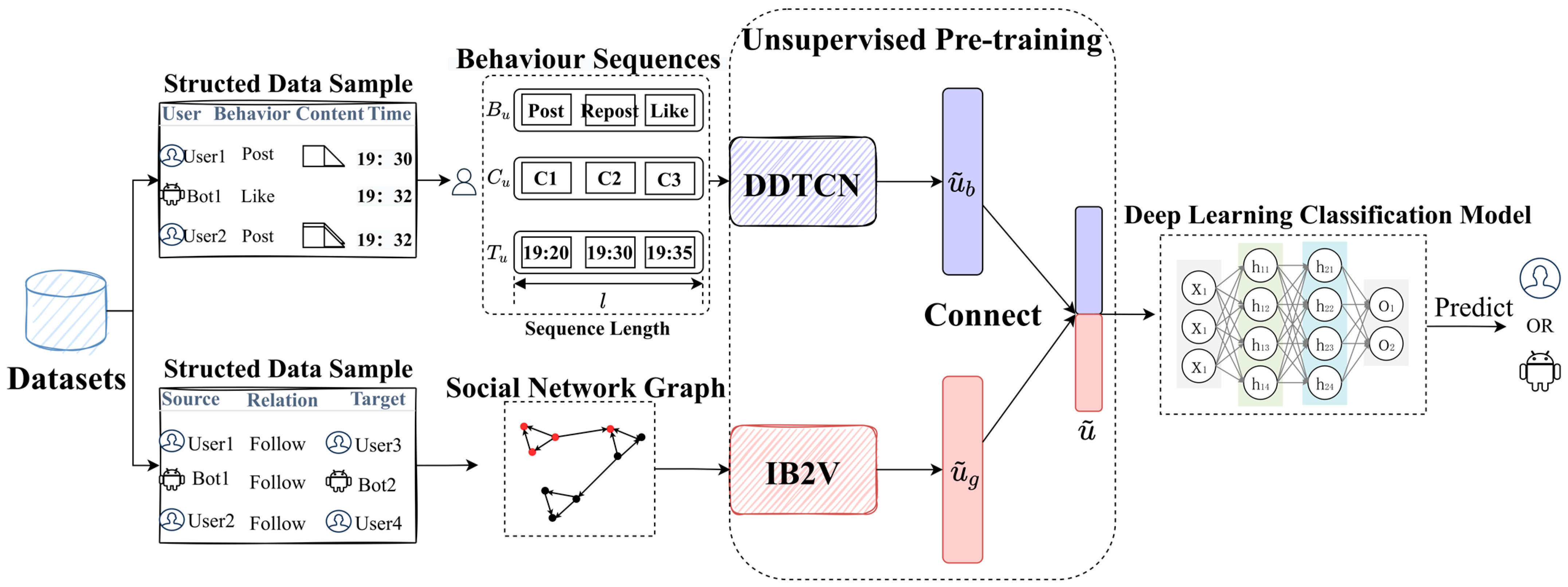
4. MRLBot: Methodology
- Data restructuration and preprocessing; due to potential differences in structured rules across diverse datasets, it is advisable to restructure the data for further preprocessing and expansion. The rules for data restructuration are formulated based on the user behaviors and relationships defined in Section 3.1 and Section 3.2. Each record in the table represents the behavior of each user or bot at a specific time point, including the behavior type and posted content, as well as interaction relationships. Preprocessing for the restructured data involves aggregating the records to generate user behavior sequences (, , ), and to build the social network relationship graph, , with a focus on each user and each relationship (source node and target node),
- The generation and fusion of multi-dimensional user representations; the behavior sequences are input into the behavior representation learning model, DDTCN, and the directed weighted graph is input into the relationship representation learning model, IB2V. Through unsupervised learning, optimizers are performed separately to generate behavior representations and relationship representations that capture each user’s characteristics. Then, these two types of representations are concatenated to complete the fusion of multi-dimensional representations,
- The training and detection of the deep learning classifier; a fully connected neural network is employed to construct the classifier, with the fused representations serving as input, to achieve an accurate detection framework. During the training process of the detection framework, hyperparameters are adjusted to ensure optimal performance. Additionally, a labeled dataset is utilized to train the classifier, facilitating the effective judgment and identification of malicious SMBs based on different user representations.
4.1. DDTCN: Behavioral Representation Learning Model
- Incorporating a CNN encoder–decoder concatenated with Transformer to capture both local and global information of user behavior simultaneously;
- Adding a parallel decoder on top of Transformer to retain diverse information and further mitigate information loss during the generation of user behavior representations.
4.1.1. Transformer Encoder
4.1.2. CNN Encoder–Decoder
4.1.3. Transformer Dual Decoder
4.1.4. Optimization Objectives
| Algorithm 1: Training algorithm of DDTCN |
|
4.2. IB2V: Relationship Representation Learning Model
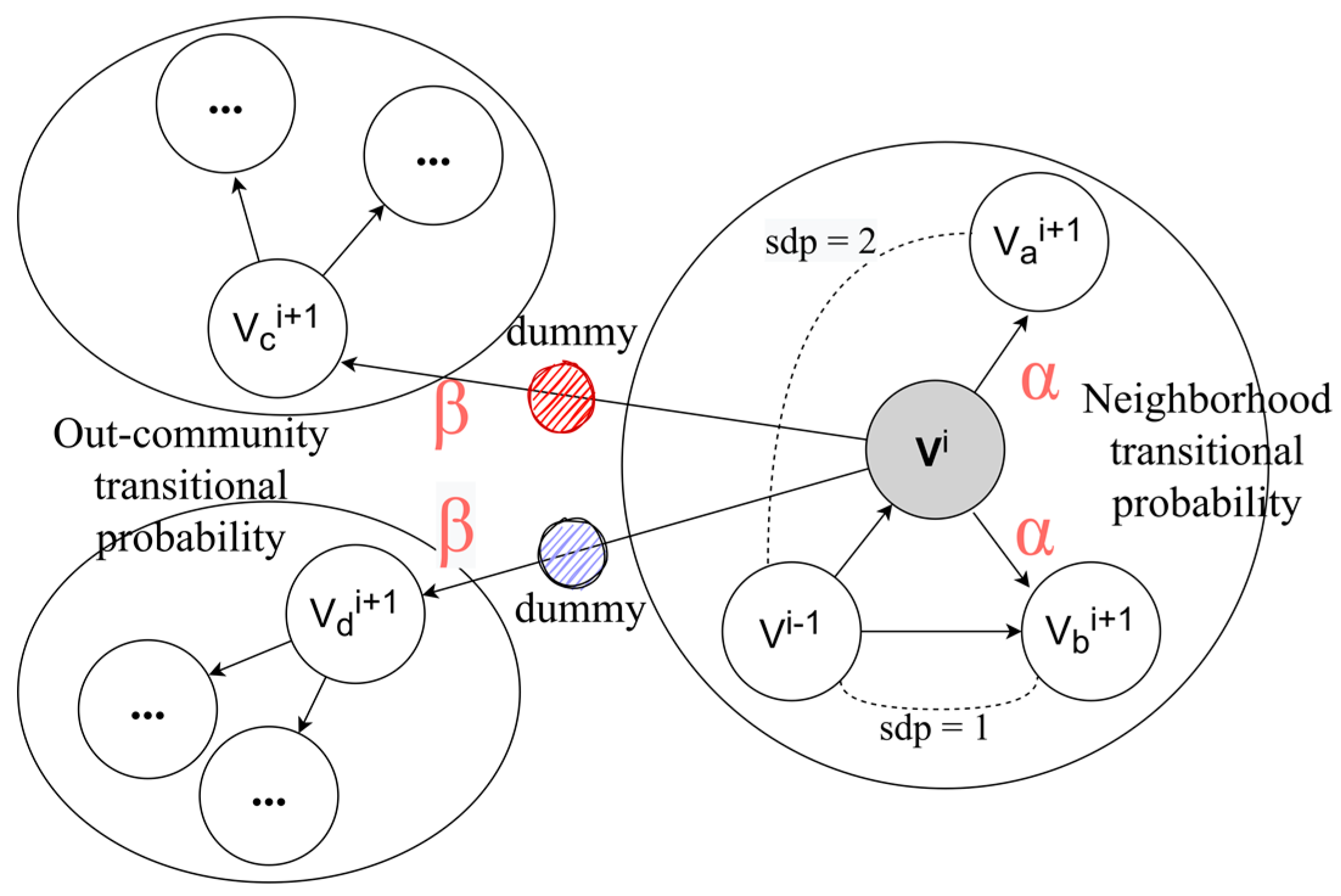
- Outer-community association. During the random walk process, in case of cross-community movement, dummy nodes related to the communities are added between the nodes and participate in the similarity calculation of context neighborhoods;
- An incremental learning strategy. This strategy aims to learn representation vectors of newly added nodes while maintaining model performance as much as possible, avoiding the retraining of the entire graph structure and reducing time costs.
4.2.1. Intra- and Outer-Community-Oriented Random Walks
4.2.2. Node Representation Learning and Optimization Objectives
4.2.3. Incremental Learning Strategy
- Specifically, the model first conducts community detection and saves the community membership for each node;
- Then, the original social graph is converted into a community graph, where nodes are represented as communities. Based on the saved community information and structure, newly added nodes are integrated into the community graph and undergo a new round of community detection to determine their community membership;
- Then, the newly added nodes are used as the starting point for the random walk process, which generates context sequences after sampling from the new social graph;
- In the final step, the representations of old nodes are fixed, and the Skip-gram model is used to learn the representations for all new nodes.
5. Experiments and Discussions
5.1. Datasets and Evaluation Metrics
- Cresci-2015 [29] (Twitter). The statistical information of the dataset is presented in Table 2, comprising 5301 users, out of which 3351 accounts are labeled as bots, accounting for 63% of all users. This dataset includes tweet records and user profiles of relevant users, and consists of five sub-datasets: TFP, E13, FSF, INT, and TWT. All sub-datasets have label information, with users annotated as either bots or normal users.
- Social-Spammer [30] (Tagged). This dataset is collected from the Tagged social networking website and contains a large labeled dataset of bots. It encompasses a total of 5,607,454 accounts with their profiles, 912,280,409 relationship records between accounts, and timestamps of interactions. This dataset forms a heterogeneous network with seven different types of relationships between users (“Message”, “Pet Game”, “Meet-Me Game”, “Add Friend”, “Give A Gift”, “Report Abuse”, and “View Profile”). Among these, 221,305 accounts are labeled as bots, which constitutes 3.9% of all accounts.
- MicroblogPCU [31] (Weibo). This dataset is collected by researchers for spam detection in Weibo, and includes basic attribute of users, as well as the content they posted and corresponding timestamps. It contains a total of 48,848 Weibo posts and 781 accounts. Among all the accounts, the number of labeled normal users is 113, and the number of malicious bots is 66.
- TwiBot-22 [32] (Twitter), a comprehensive graph-based Twitter bot detection benchmark that presents the largest dataset to date. The dataset contains 1,000,000 users (39,943 accounts are labeled as bots), 86,764,167 tweets, and 170,185,937 edges between users.
5.2. Experimental Setups
- AdaBoost [14]. This method uses a 10-dimensional feature set based on user profiles and employs AdaBoost for bot classification. The feature “favorite_counts” is present in the Cresci-2015 dataset. but it is not available in the other two datasets, and thus is not used in experiments involving these datasets.
- DeeProBot [33]. This method uses metadata from user profiles and replaces the descriptive text in the metadata with pre-trained global word embeddings. The model consists of LSTM and fully connected layers to handle mixed types of features, including numerical, binary, and text. As the datasets used in this paper lack “Sentiment” and “Timing” features; these features are not taken into consideration during input construction.
- BotRGCN [11]. The authors constructed a heterogeneous graph from the follower relationships, embedding multimodal user semantics and attribute information into the graph, and applied graph convolutional network for detecting bots. Since the dataset used in this paper do not include account avatars, this feature is not considered when constructing inputs.
- SATAR [22]. This method is an unsupervised Twitter user representation learning framework that jointly utilizes semantic, attribute, and neighborhood information, and employs a co-influence module to aggregate this information.
5.3. Experimental Results
5.4. Discussions
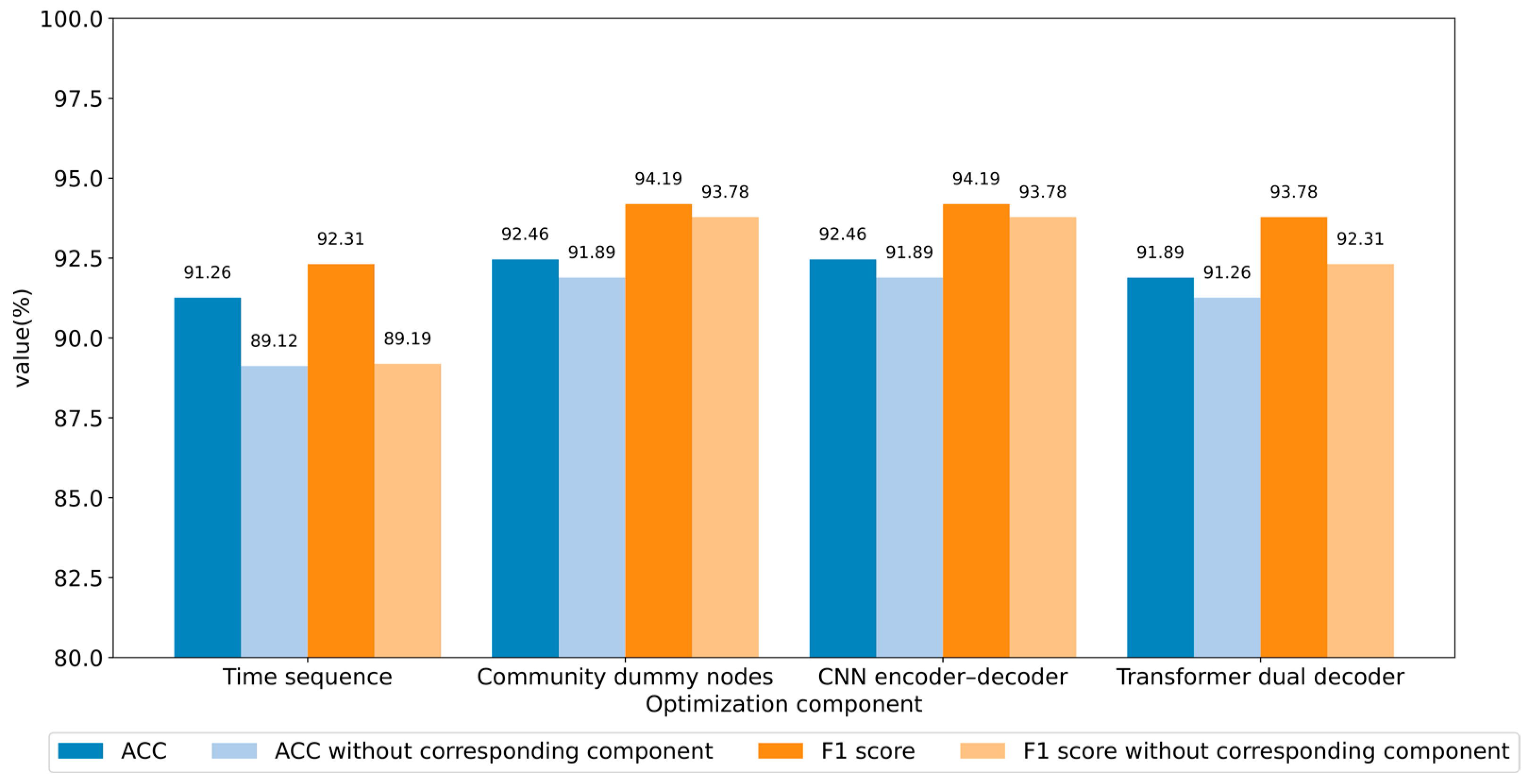
5.4.1. Ablation Study
- Timestamp sequence. The model variants consist of TCN and TCNpos. TCN (Transformer Convolutional Network) is the structure of DDTCN in MRLBot without the dual decoder, reconstructing only the published content in the decoder part. TCNpos replaces time embedding with position embedding in the input layer.
- Community dummy nodes. The control groups are IB2V and Bot2Vec.
- CNN encoder–decoder. The control groups are DDTCN and DDTN, with DDTN being a variant of our model that does not utilize CNN autoencoder.
- Transformer dual decoder. The control groups are DDTCN and TCN.
5.4.2. Efficiency of Incremental Learning Strategy
5.4.3. Validity of Relationship Strength
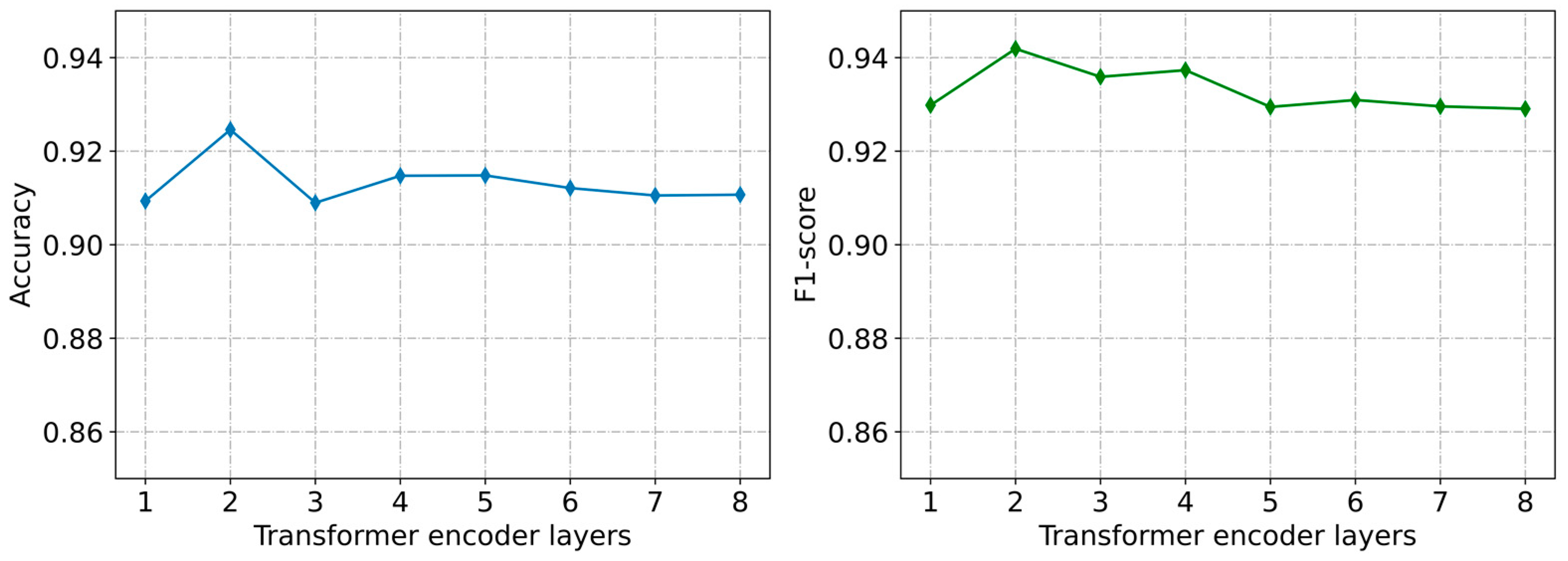
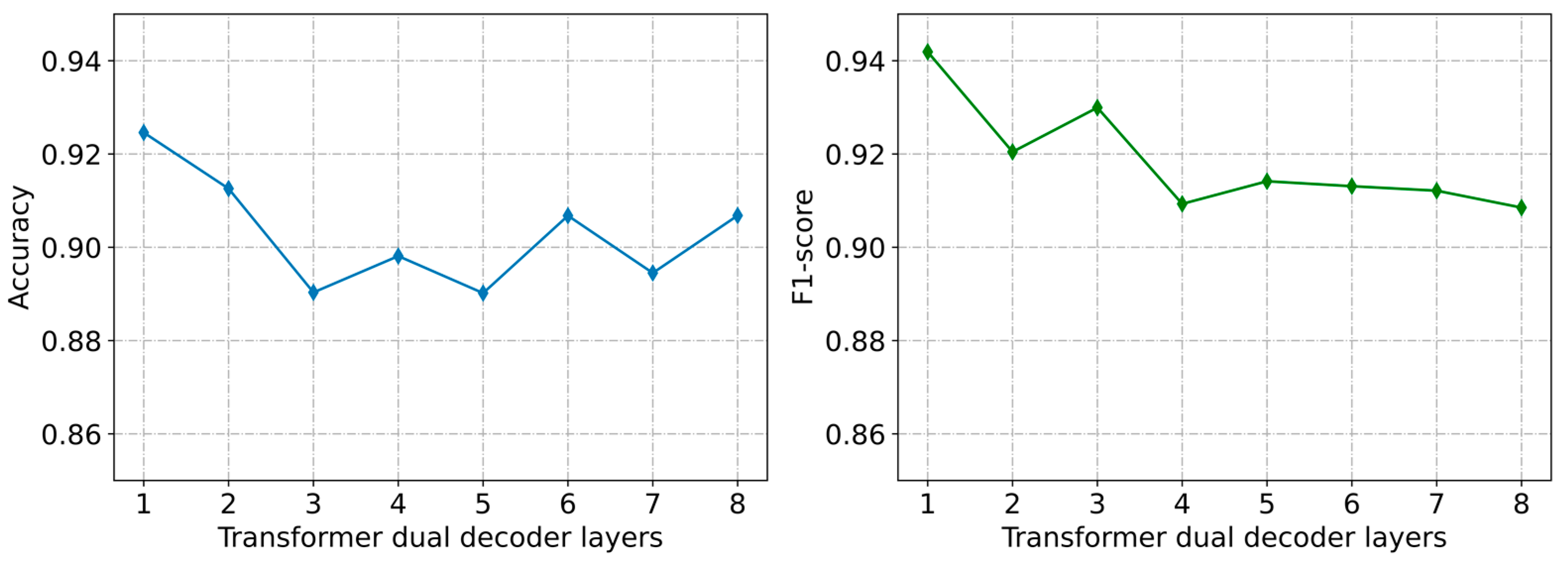
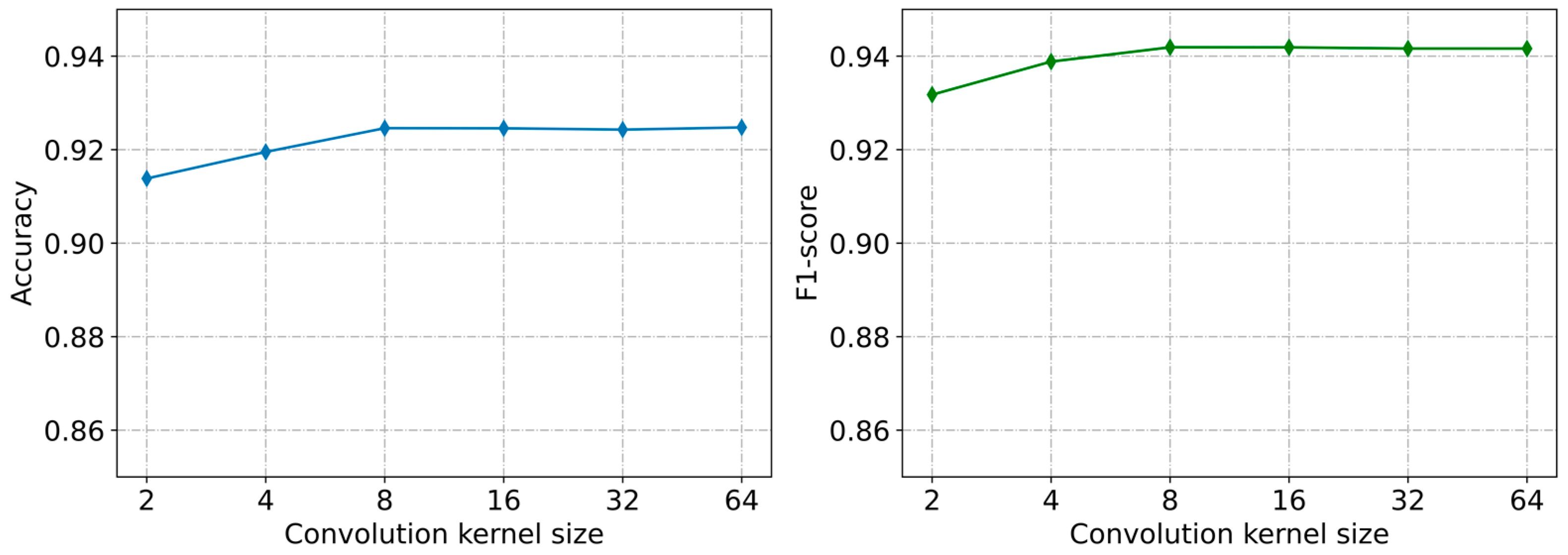
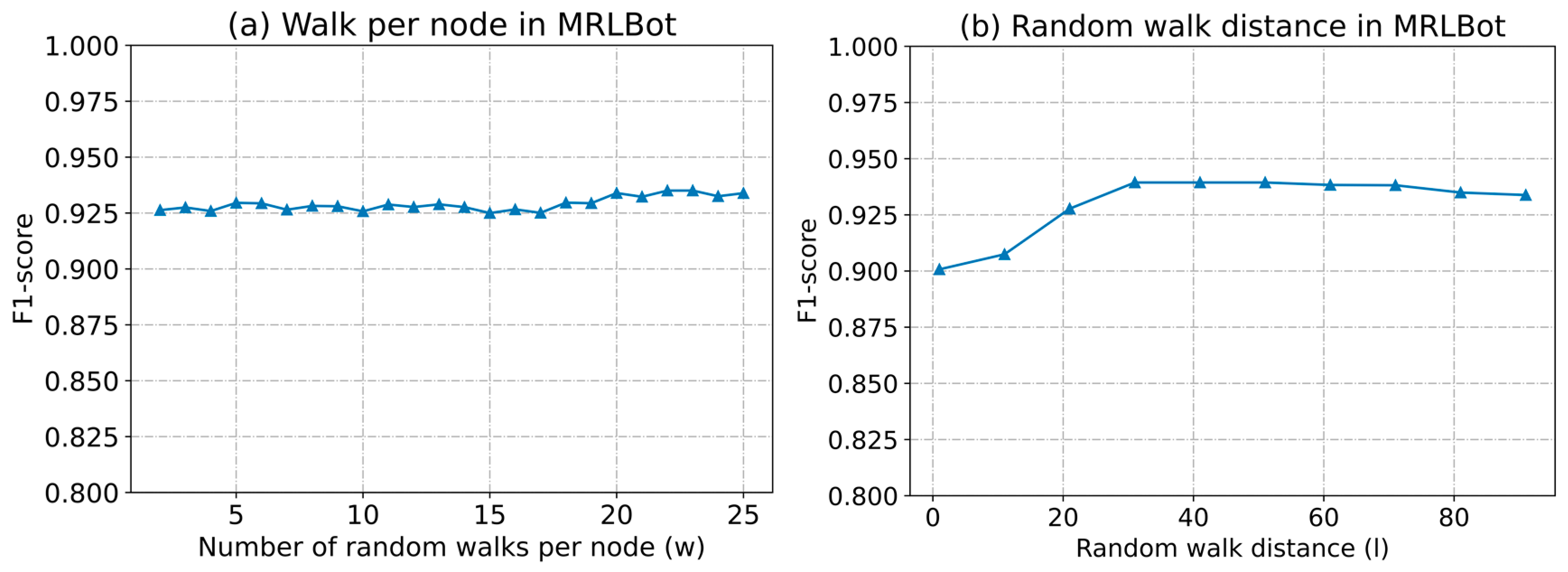
5.4.4. Parameter Sensitivity of the Model
5.4.5. Limitations
- Limitations of research hypotheses. In Section 3, we simplified user behaviors and relationships in social networks, which is a critical weakness and a simplification of the research work. In actual social networks, user behaviors and relationships are more complex and have more variables. Furthermore, the hypothesis method we employed is based solely on past research and historical experience, without taking into account future changes. There are two main limitations to this approach. Firstly, due to the reduction in variables considered, the detection performance may decrease in the real environment, even though the rationality of the research is guaranteed. Secondly, attackers may bypass the detection methods we proposed by disguising software robots as real users based on these assumptions.
- Limitations of technical methods. During the representation fusion stage, we concatenated representations of different dimensions, which has the potential to affect the final performance.
- Limitations of experimental scenarios. All experiments in this paper were conducted using publicly available datasets and did not involve actual online environments. These datasets were collected by researchers in the past, and the performance on these datasets can indicate whether or not the detection method was effective in the past time period. However, it is also important to consider the timeliness of the detection method; that is, whether or not it is effective in the latest time period. Real-time monitoring in online environments requires more complex engineering work and will be the focus of our future research.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Subrahmanian, V.S.; Azaria, A.; Durst, S.; Kagan, V.; Galstyan, A.; Lerman, K.; Zhu, L.; Ferrara, E.; Flammini, A.; Menczer, F. The DARPA Twitter Bot Challenge. Computer 2016, 49, 38–46. [Google Scholar] [CrossRef]
- Ratkiewicz, J.; Conover, M.; Meiss, M.; Gonçalves, B.; Flammini, A.; Menczer, F. Detecting and tracking political abuse in social media. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 297–304. [Google Scholar]
- Bessi, A.; Ferrara, E. Social bots distort the 2016 US Presidential election online discussion. First Monday 2016, 21, 11. [Google Scholar]
- Orabi, M.; Mouheb, D.; Al Aghbari, Z.; Kamel, I. Detection of bots in social media: A systematic review. Inf. Process. Manag. 2020, 57, 102250. [Google Scholar] [CrossRef]
- Feng, B.; Li, Q.; Pan, X.; Zhang, J.; Guo, D. Groupfound: An effective approach to detect suspicious accounts in online social networks. Int. J. Distrib. Sens. Netw. 2017, 13, 1550147717722499. [Google Scholar] [CrossRef]
- Dorri, A.; Abadi, M.; Dadfarnia, M. Socialbothunter: Botnet detection in twitter-like social networking services using semi-supervised collective classification. In Proceedings of the 2018 IEEE 16th International Conference on Dependable, Autonomic and Secure Computing, 16th International Conference on Pervasive Intelligence and Computing, 4th International Conference on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; pp. 496–503. [Google Scholar]
- Abu-El-Rub, N.; Mueen, A. Botcamp: Bot-driven interactions in social campaigns. In Proceedings of the The World Wide Web conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2529–2535. [Google Scholar]
- Yu, Z.; Lian, J.; Mahmoody, A.; Liu, G.; Xie, X. Adaptive User Modeling with Long and Short-Term Preferences for Personalized Recommendation. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 4213–4219. [Google Scholar]
- Pham, P.; Nguyen, L.T.; Vo, B.; Yun, U. Bot2Vec: A general approach of intra-community oriented representation learning for bot detection in different types of social networks. Inf. Syst. 2022, 103, 101771. [Google Scholar] [CrossRef]
- Magelinski, T.; Beskow, D.; Carley, K.M. Graph-hist: Graph classification from latent feature histograms with application to bot detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 5134–5141. [Google Scholar]
- Feng, S.; Wan, H.; Wang, N.; Luo, M. BotRGCN: Twitter bot detection with relational graph convolutional networks. In Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Virtual, The Netherlands, 8–11 November 2021; pp. 236–239. [Google Scholar]
- Feng, S.; Tan, Z.; Li, R.; Luo, M. Heterogeneity-aware twitter bot detection with relational graph transformers. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 30 July 2022; pp. 3977–3985. [Google Scholar]
- Daouadi, K.E.; Rebaï, R.Z.; Amous, I. Bot detection on online social networks using deep forest. In Artificial Intelligence Methods in Intelligent Algorithms, Proceedings of 8th Computer Science Online Conference, Volume 2, Online, 24–27 April 2019; Springer: Cham, Switzerland, 2019; pp. 307–315. [Google Scholar]
- Kudugunta, S.; Ferrara, E. Deep neural networks for bot detection. Inf. Sci. 2018, 467, 312–322. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, L.; Gong, N.Z. Sybilblind: Detecting fake users in online social networks without manual labels. In Proceedings of the Research in Attacks, Intrusions, and Defenses: 21st International Symposium, RAID 2018, Heraklion, Crete, Greece, 10–12 September 2018; pp. 228–249. [Google Scholar]
- Ping, H.; Qin, S. A social bots detection model based on deep learning algorithm. In Proceedings of the 2018 IEEE 18th International Conference on Communication Technology (ICCT), Chongqing, China, 8–11 October 2018; pp. 1435–1439. [Google Scholar]
- Wei, F.; Nguyen, U.T. Twitter bot detection using bidirectional long short-term memory neural networks and word embeddings. In Proceedings of the 2019 First IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Los Angeles, CA, USA, 12–14 December 2019; pp. 101–109. [Google Scholar]
- Stanton, G.; Irissappane, A.A. GANs for semi-supervised opinion spam detection. arXiv 2019, arXiv:1903.08289. [Google Scholar]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. DNA-inspired online behavioral modeling and its application to spambot detection. IEEE Intell. Syst. 2016, 31, 58–64. [Google Scholar] [CrossRef]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. Social fingerprinting: Detection of spambot groups through DNA-inspired behavioral modeling. IEEE Trans. Dependable Secur. Comput. 2017, 15, 561–576. [Google Scholar] [CrossRef]
- Mazza, M.; Cresci, S.; Avvenuti, M.; Quattrociocchi, W.; Tesconi, M. Rtbust: Exploiting temporal patterns for botnet detection on twitter. In Proceedings of the 10th ACM Conference on Web Science, Boston, MA, USA, 30 June–3 July 2019; pp. 183–192. [Google Scholar]
- Feng, S.; Wan, H.; Wang, N.; Li, J.; Luo, M. Satar: A self-supervised approach to twitter account representation learning and its application in bot detection. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; pp. 3808–3817. [Google Scholar]
- Bach, N.X.; Long, D.H.; Phuong, T.M. Recurrent convolutional networks for session-based recommendations. Neurocomputing 2020, 411, 247–258. [Google Scholar] [CrossRef]
- Zhang, J.; Bai, B.; Lin, Y.; Liang, J.; Bai, K.; Wang, F. General-Purpose User Embeddings based on Mobile App Usage. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Electr Network, Virtual, 23–27 August 2020; pp. 2831–2840. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 17 October 2021; pp. 367–376. [Google Scholar]
- Chen, Y. Convolutional Neural Network for Sentence Classification. Master′s Thesis, University of Waterloo, Waterloo, ON, Canada, August 2015. [Google Scholar]
- De Meo, P.; Ferrara, E.; Fiumara, G.; Provetti, A. Generalized louvain method for community detection in large networks. In Proceedings of the 2011 11th International Conference on Intelligent Systems Design and Applications, Cordoba, Spain, 22–24 November 2011; pp. 88–93. [Google Scholar]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. Fame for sale: Efficient detection of fake Twitter followers. Decis. Support Syst. 2015, 80, 56–71. [Google Scholar] [CrossRef]
- Fakhraei, S.; Foulds, J.; Shashanka, M.; Getoor, L. Collective spammer detection in evolving multi-relational social networks. In Proceedings of the 21st Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1769–1778. [Google Scholar]
- Gu, B.; Zhai, Z.; Li, X.; Huang, H. Towards Fairer Classifier via True Fairness Score Path. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 3113–3121. [Google Scholar]
- Feng, S.; Tan, Z.; Wan, H.; Wang, N.; Chen, Z.; Zhang, B.; Zheng, Q.; Zhang, W.; Lei, Z.; Yang, S. TwiBot-22: Towards graph-based Twitter bot detection. arXiv 2022, arXiv:2206.04564. [Google Scholar]
- Hayawi, K.; Mathew, S.; Venugopal, N.; Masud, M.M.; Ho, P.-H. DeeProBot: A hybrid deep neural network model for social bot detection based on user profile data. Soc. Netw. Anal. Min. 2022, 12, 43. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Relationship Strength | Allocation Rule | |
|---|---|---|
| Very Weak | 1 | |
| Weak | 2 | |
| Medium | 3 | |
| Strong | 4 | |
| Very Strong | 5 |
| Sub-Datasets | Accounts | Tweets | Friend Relationships | Follow Relationships |
|---|---|---|---|---|
| TFP | 469 | 563,693 | 241,710 | 258,494 |
| E13 | 1481 | 2,068,037 | 667,225 | 1,526,944 |
| FSF | 1169 | 22,910 | 253,026 | 11,893 |
| INT | 1337 | 58,925 | 517,485 | 23,173 |
| TWT | 845 | 114,192 | 729,839 | 28,588 |
| Total number of accounts | 5301 | |||
| Number of bots | 3351 (63%) |
| Metrics | Formula | Description |
|---|---|---|
| Accuracy (ACC) | Classification accuracy is the percentage of all categories identified correctly. | |
| Precision | The ratio of the number of correctly identified malicious SMBs to the total number of identified samples. | |
| Recall | The ratio of the number of correctly identified malicious SMBs to the number of samples that should be identified. | |
| F1 score | F1 score is a statistical metric to measure model accuracy. Both accuracy and recall are considered in the metric. |
| Hyperparameters | Settings |
|---|---|
| User behavior sequence length (l) | 64 |
| Embedding dimension (d) | 128 |
| Representation dimension | 128 |
| Transformer Encoder layers | 2 |
| Transformer dual-decoder layers | 1 |
| Convolution kernel size () | [8, d] |
| Skip-gram sliding window size () | 7 |
| Negative sampling sample size () | 5 |
| Random walk distance () | 30 |
| Number of random walks per node () | 20 |
| Return parameter () | 1 |
| In–out parameter () | 1 |
| Out-community parameter (r) | 1 |
| DNN Layers | 3 |
| Dropout rate | 0.1 |
| Learning rate | 1 × 10−4 |
| Methods | Cresci-2015 | TwiBot-22 | ||||||
|---|---|---|---|---|---|---|---|---|
| ACC | Precision | Recall | F1 | ACC | Precision | Recall | F1 | |
| AdaBoost [14] | 0.7533 | 0.9982 | 0.6095 | 0.7574 | 0.7650 | 0.8000 | 0.1499 | 0.2474 |
| DeeProBot [33] | 0.8427 | 0.9296 | 0.7931 | 0.8559 | 0.6587 | 0.4431 | 0.6198 | 0.5167 |
| BotRGCN [11] | 0.9652 | 0.9551 | 0.9917 | 0.9731 | 0.7966 | 0.7481 | 0.4680 | 0.5750 |
| SATAR [22] | 0.9342 | 0.9066 | 0.9988 | 0.9505 | 0.7822 | 0.7270 | 0.4510 | 0.5567 |
| MRLBot | 0.9725 | 0.9654 | 0.9920 | 0.9785 | 0.8025 | 0.7845 | 0.5050 | 0.6145 |
| Methods | Social-Spammer | MicroblogPCU | ||||||
|---|---|---|---|---|---|---|---|---|
| ACC | Precision | Recall | F1 | ACC | Precision | Recall | F1 | |
| AdaBoost [14] | 0.9655 | 0.5456 | 0.7529 | 0.6327 | 0.8991 | 0.8571 | 0.8322 | 0.8445 |
| DeeProBot [33] | 0.9633 | 0.5248 | 0.7412 | 0.6145 | 0.9052 | 0.8507 | 0.8655 | 0.8580 |
| BotRGCN [11] | 0.9967 | 0.9429 | 0.9755 | 0.9589 | 0.9108 | 0.8636 | 0.8767 | 0.8701 |
| SATAR [22] | 0.9960 | 0.9319 | 0.9695 | 0.9503 | 0.9121 | 0.8529 | 0.8856 | 0.8689 |
| MRLBot | 0.9962 | 0.9325 | 0.9742 | 0.9529 | 0.9254 | 0.8806 | 0.9088 | 0.8945 |
| Strategies | Dataset Size | ||||
|---|---|---|---|---|---|
| 60% | 70% | 80% | 90% | 100% | |
| Original learning | 0.9431 | 0.9744 | 0.9782 | 0.9521 | 0.9529 |
| Incremental learning | 0.9210 | 0.9352 | 0.9288 | 0.9035 | 0.8975 |
| Strategies | Dataset Size | ||||
|---|---|---|---|---|---|
| 60% | 70% | 80% | 90% | 100% | |
| Original learning | 23,752 | 28,502 | 35,253 | 38,003 | 42,454 |
| Incremental learning | 15,500 | 19,681 | 23,922 | 26,832 | 31,269 |
| Graph Type | Social-Spammer Dataset | |||
|---|---|---|---|---|
| ACC | Precision | Recall | F1 | |
| Directed unweighted graph | 0.9951 | 0.9176 | 0.9622 | 0.9394 |
| Directed weighted graph | 0.9954 | 0.9204 | 0.9671 | 0.9432 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, F.; Sun, Y.; Li, Y. MRLBot: Multi-Dimensional Representation Learning for Social Media Bot Detection. Electronics 2023, 12, 2298. https://doi.org/10.3390/electronics12102298
Zeng F, Sun Y, Li Y. MRLBot: Multi-Dimensional Representation Learning for Social Media Bot Detection. Electronics. 2023; 12(10):2298. https://doi.org/10.3390/electronics12102298
Chicago/Turabian StyleZeng, Fanrui, Yingjie Sun, and Yizhou Li. 2023. "MRLBot: Multi-Dimensional Representation Learning for Social Media Bot Detection" Electronics 12, no. 10: 2298. https://doi.org/10.3390/electronics12102298