


Imperfect-Information Game AI Agent Based on Reinforcement Learning Using Tree Search and a Deep Neural Network

Abstract
:1. Introduction
- An extended multiplayer game search tree combined with a reinforcement learning (RL) technique and deep learning is proposed. We incorporate an internalized MDP network model to internalize the simulation state and reduce the simulation cost. Then, we also introduce the additional player position and state-action information into the search tree and network policy estimation to realize the dynamic transition of the internal state.
- A normal agent with imperfect information is trained through dropout learning. With the utilization of the improved strategies achieved by the RL agent and the dropout learning technique, our approaches can effectively handle the decision-making problems of Mahjong.
- The convergence and performance of our method are demonstrated by successfully implementing a Mahjong agent with good performance and comparing it to several existing models through accuracy on test data and tournament confrontation. Finally, we conduct tests on online game platforms against human players to further validate the practicality of the proposed agent.
2. Related Work
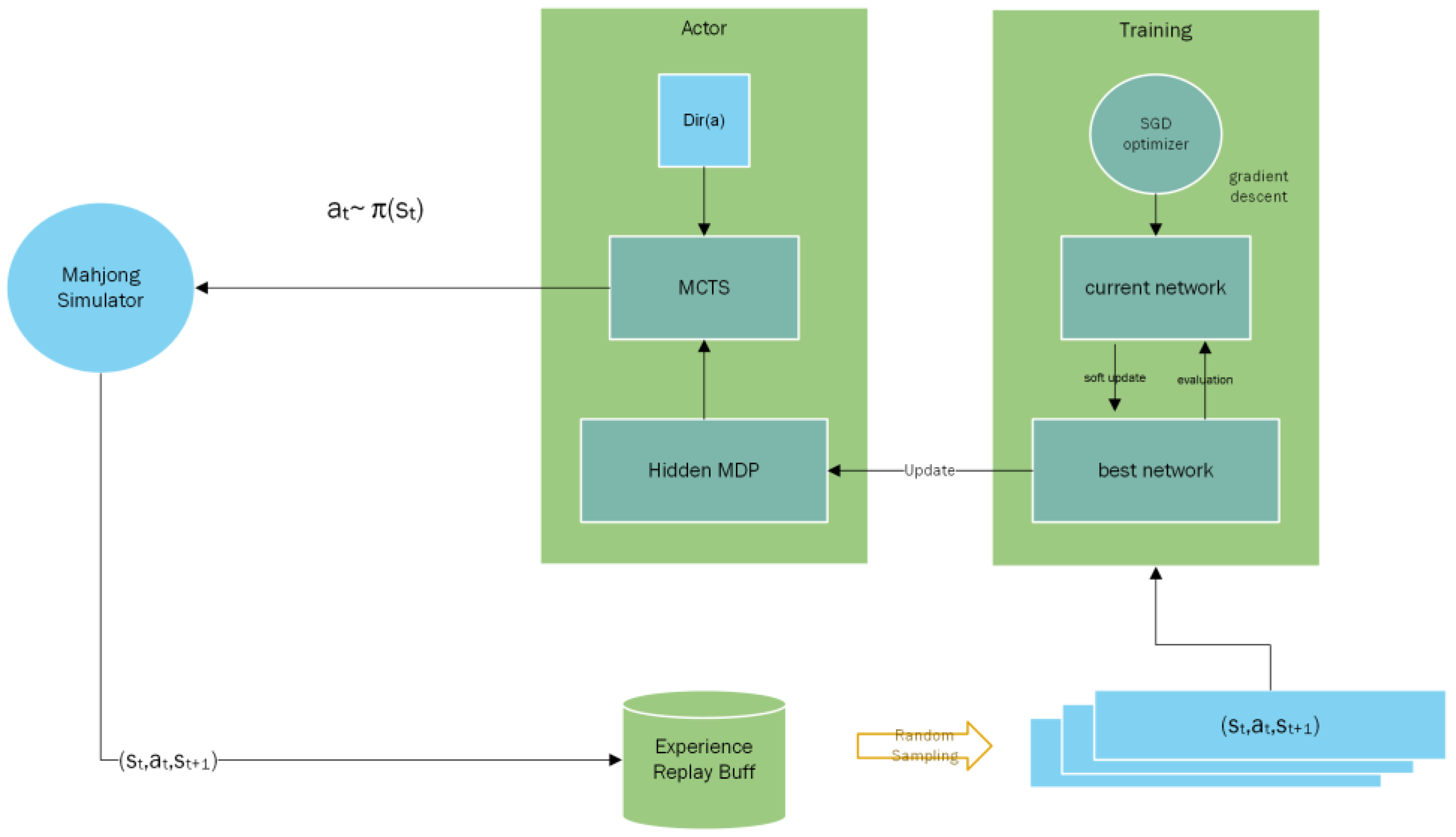
3. Reinforcement Learning Algorithm
3.1. Tree Search Learning Algorithm for Mahjong
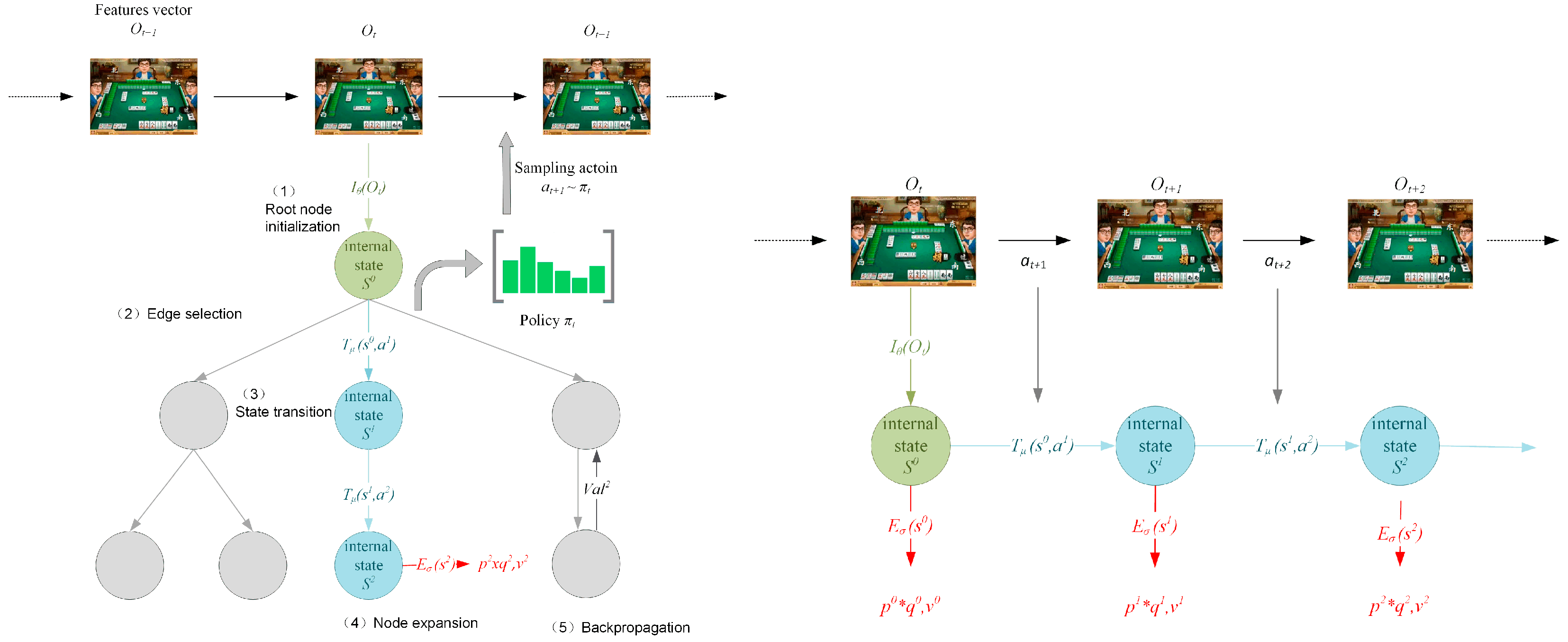
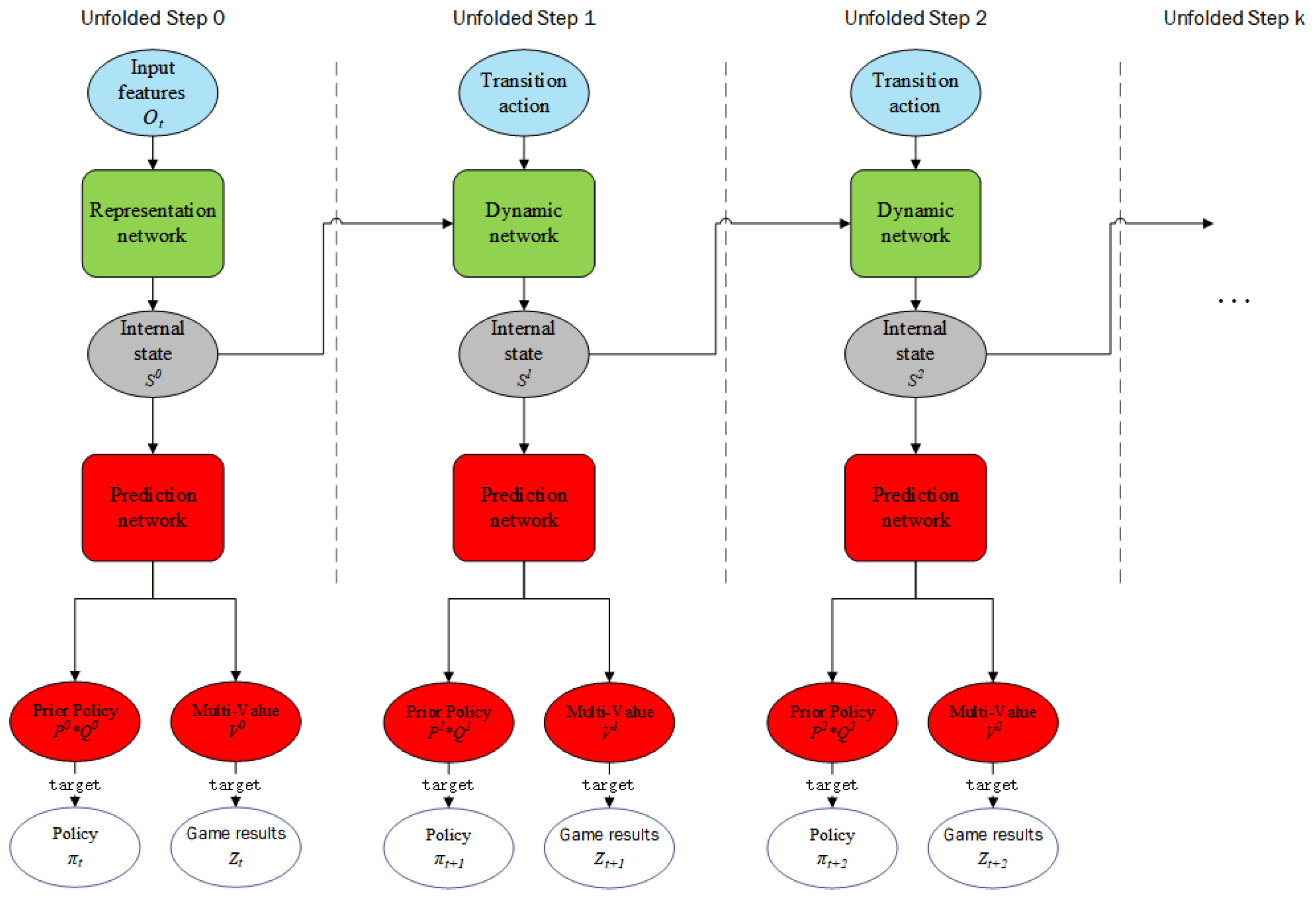
3.1.1. Internalized MDP-Based MCTS Learning Algorithm
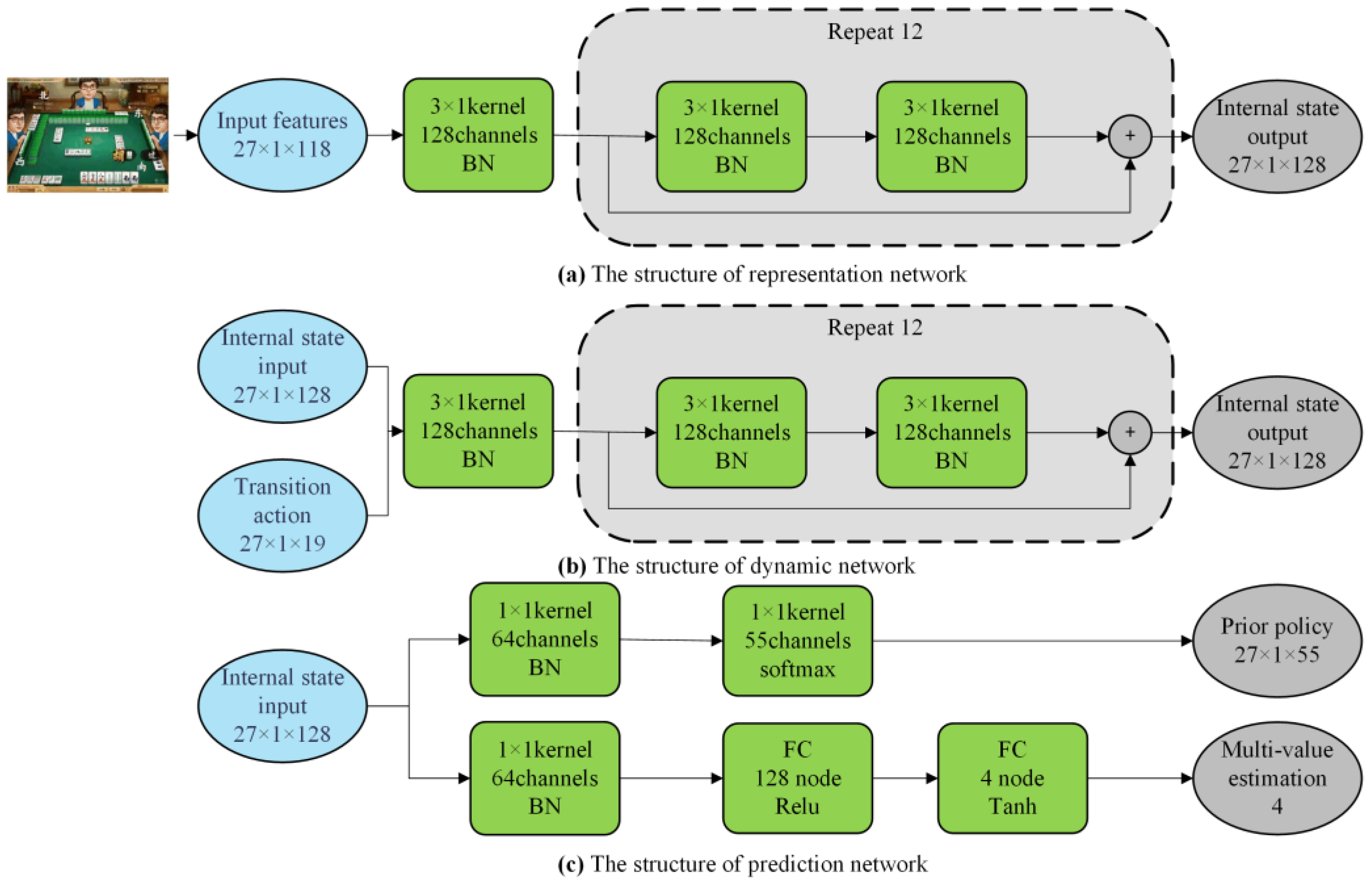
- Initialization of the root node. If the root node of the Mahjong game tree has not been initialized before, we use the representation network to calculate its internal state:
- 2.
- Selection of edges. Selecting the edge along a path with the upper confidence bound (UCB) algorithm [39] until an uninitialized (empty) leaf node is reached. In detail, the statistics of the current node corresponding to the current player are used to determine the next search edge. The UCB algorithm used is shown below:
- 3.
- State transition. After reaching an uninitialized leaf node, we utilize the dynamic network to compute the internal state of this node with its parent internal state (the latest state) and the transition action combined with additional Mahjong transition information as the network input:
- 4.
- Initialization of the leaf node. After obtaining the internal state () of the new leaf node, we need to create and initialize all edges of this node. First, we use the prediction network to calculate the prior policy in combination with rule-related transition information of Mahjong and the value estimation vector of all players:
- 5.
- Backpropagation and updating. Finally, we update the statistics of all nodes along the path. For each , where denotes the depth index of the new leaf node, we compute the change of the player position variable corresponding to the stored variable :
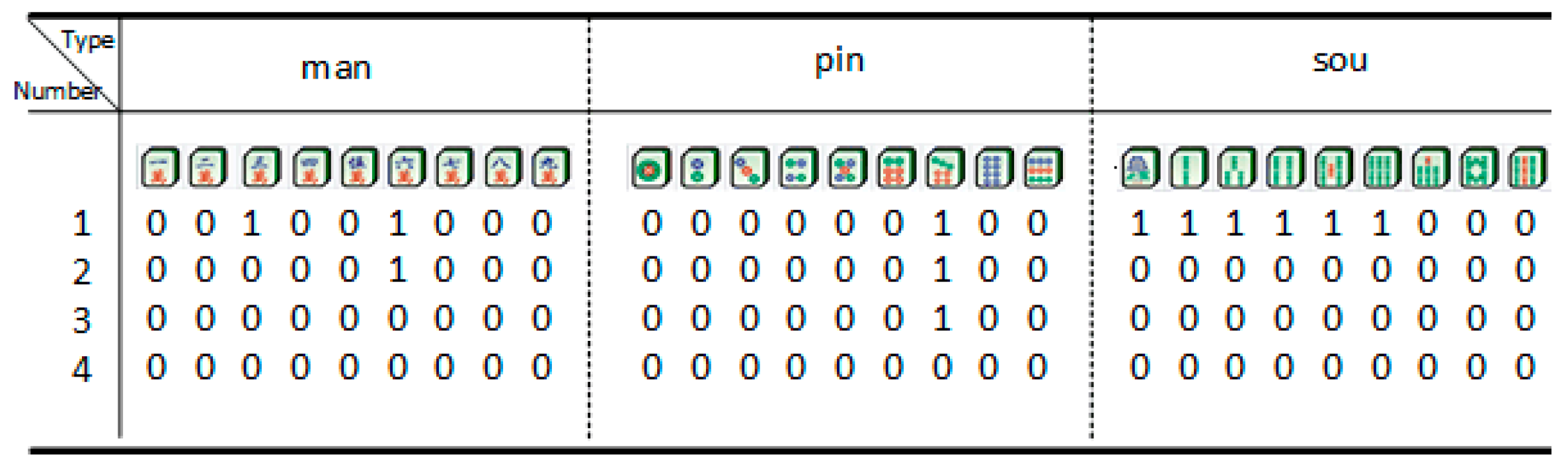
3.1.2. Game Information Representation
3.1.3. MDP Model Input
3.1.4. MDP Model Output
3.1.5. Network Implementation
3.2. Dropout Learning
3.2.1. Learning Algorithm with Bernoulli Random Matrix
3.2.2. Network Implementation of the Normal Agent
3.3. Training Process
| Algorithm 1 The internalized MDP-based MCTS tree search |
| Input: : input features vector in step t; : network parameters Output: : policy probability vector |
| 1. Initialize three functional networks , , ; set the maximum number of simulations per move ; |
| 2. for |
| 3. : set the root node as current node; : reset the index of search depth; |
| 4. //current node isn’t leaf node |
| 5. k++ |
| 6. //determine the next edge according to Formula (2) |
| 7. //go to the child node and set it as current node |
| 8. end while |
| 9. if //current node is root node |
| 10. , //utilize the representation network to compute the internal state of root node and initialize the player position variable of root node |
| 11. else |
| 12. //utilize the dynamic network to compute the internal state of the child node after state transition. |
| 13. , store , //utilize the prediction network to compute related estimations and initialize related statistics information according to Formula (5) and (6). |
| 14. Backpropagation and update related statistics of each node along the path according to Formula (7)–(9) |
| 15. end for |
| 16. Get the tree search policy π corresponding to the visit count of all edges of the root node. |
4. Experimental Results and Analysis
4.1. Experiment Settings
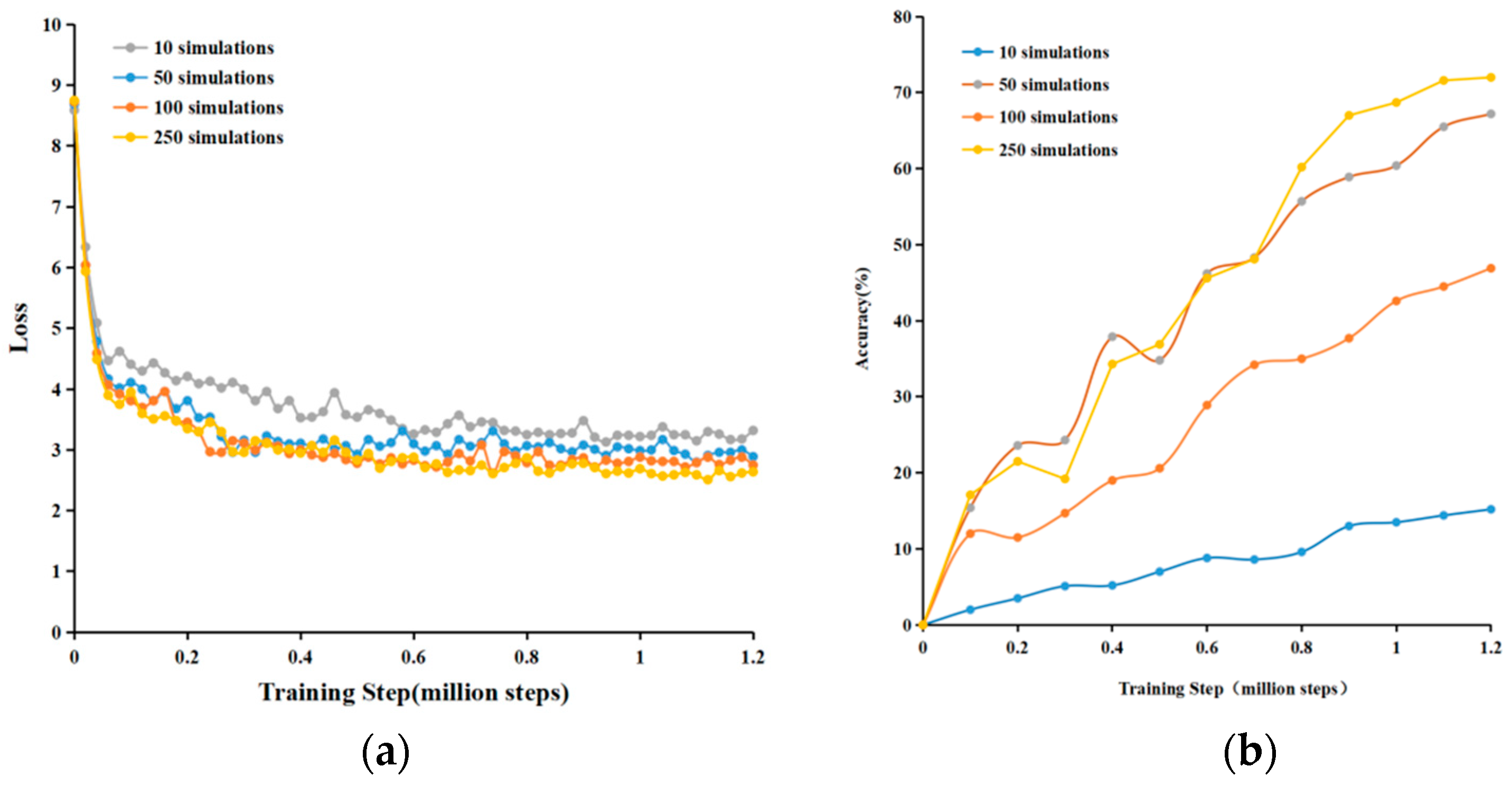
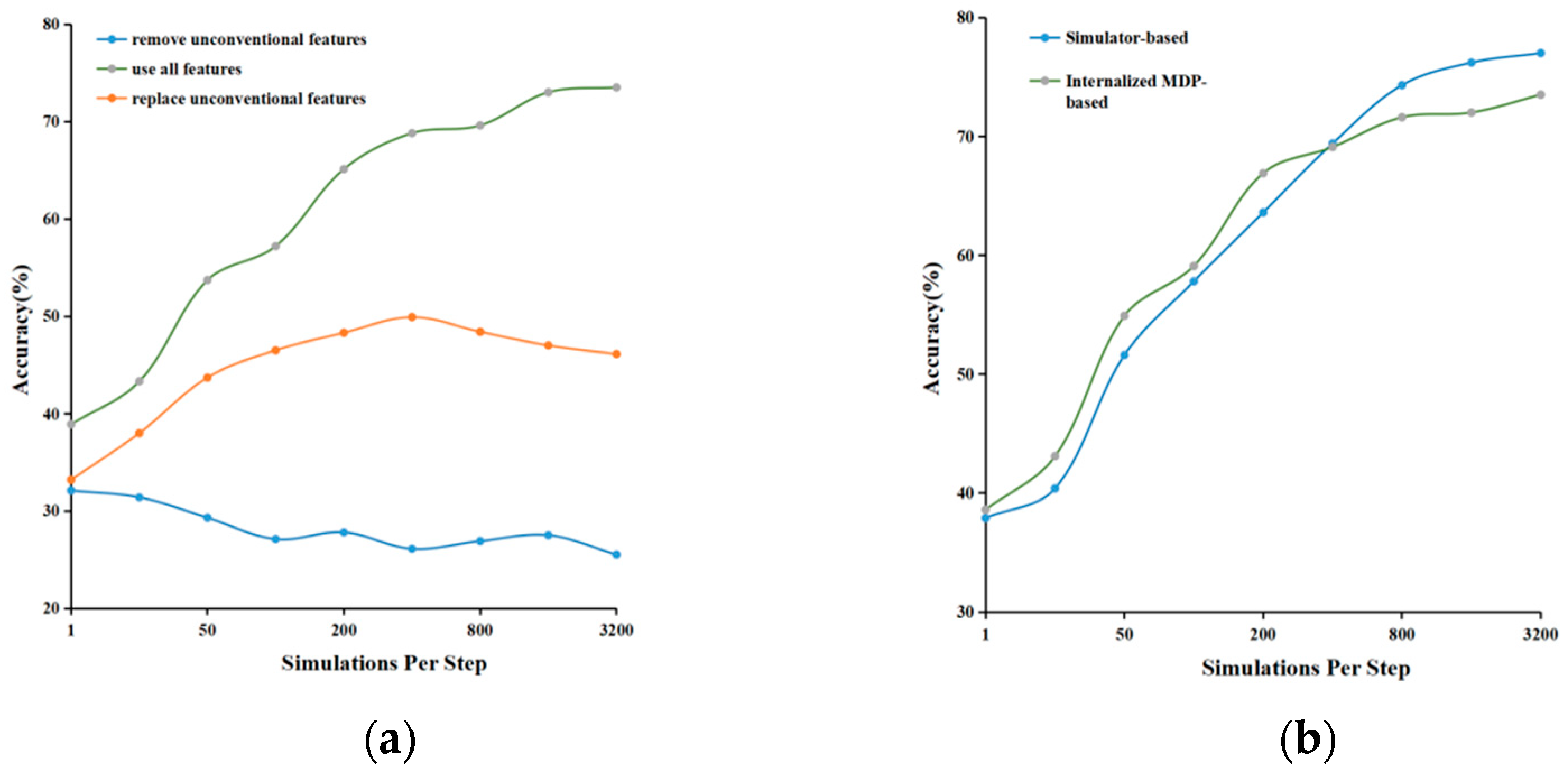
4.2. Model Performance Validation
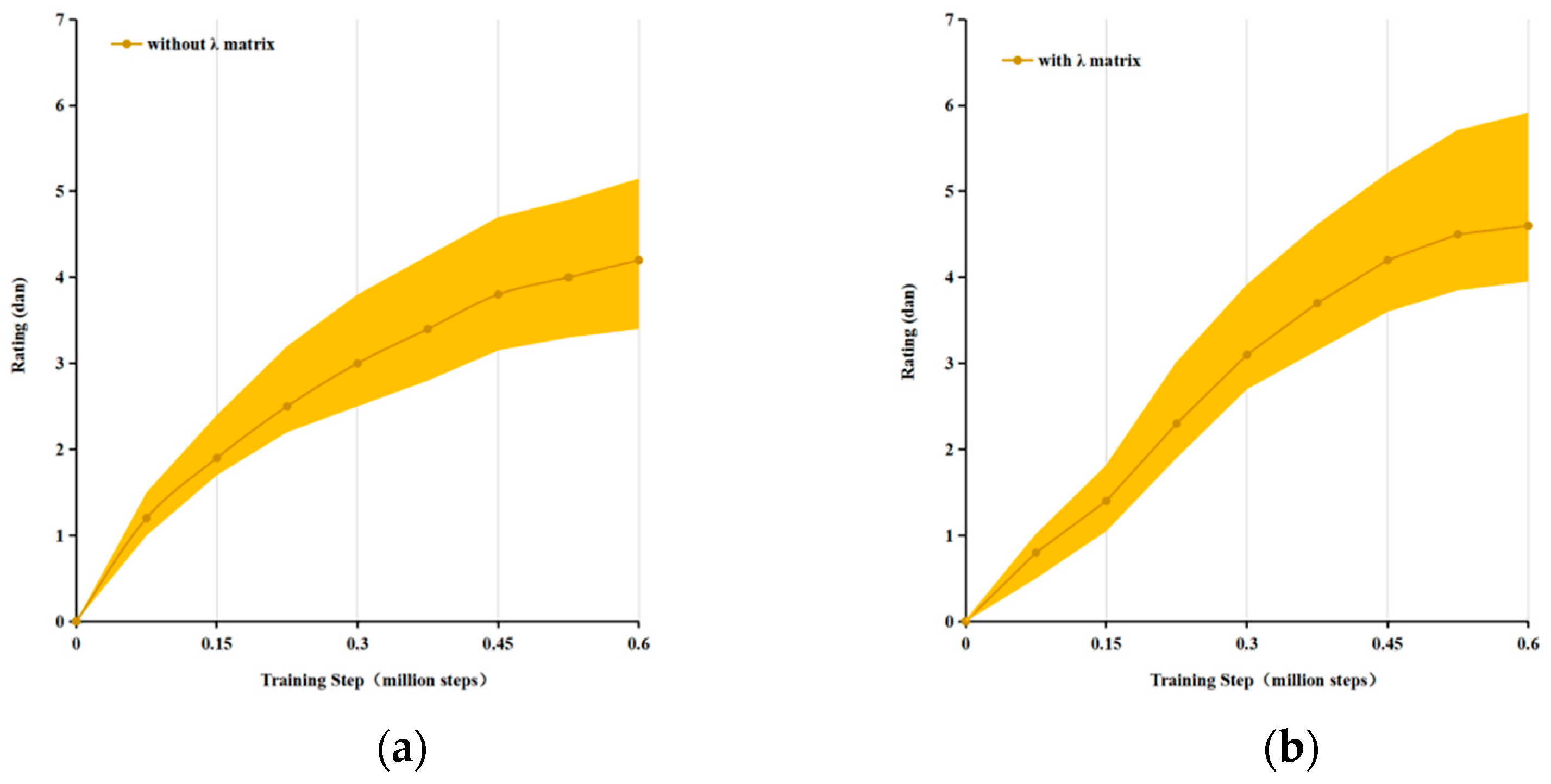
4.3. Offline Experiment
4.4. Online Experiment
5. Discussions and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Mahjong Game Rules
- 1.
- Terminology
- Definition 1—Ready Hand
- Definition 2—Chow
- Definition 3—Pong
- Definition 4—Open Kong
- Definition 5—Closed Kong
- Definition 6—Add Kong
- Definition 7—Hu (Win)
- 2.
- Game rules

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Multiplier | Number of Suits | Tiles Combination |
|---|---|---|---|
| X-normal (Ping Hu) | 6 | 3 | |
| Y-bump series Z-pure series | 8 12 | 3 1 | |
| Q-seven pairs (Qi Dui) | 12 | 3 |
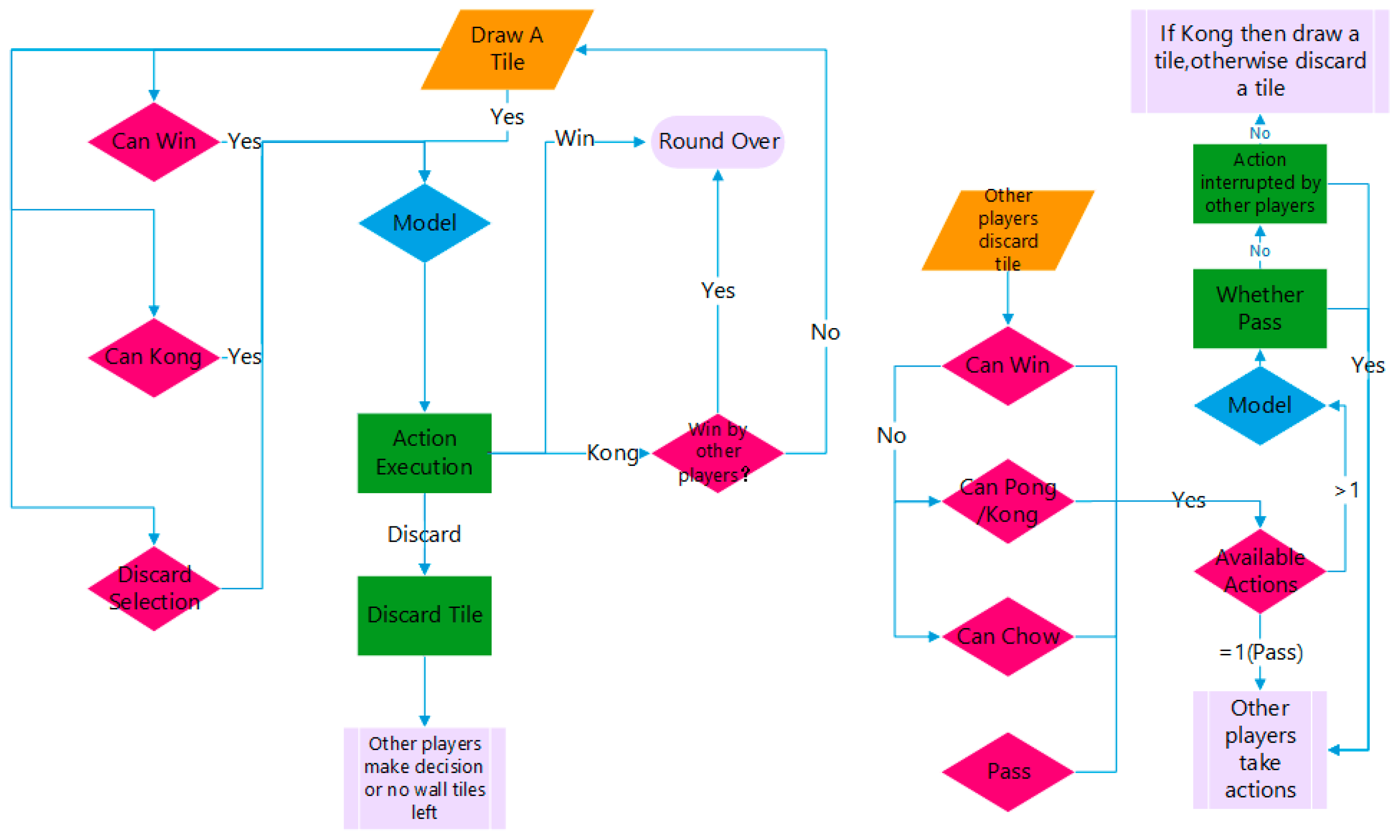
Appendix B. Strategy Flow of Agent Model

Appendix C. Implementation of Tree Search Algorithm

- Simulation: Playing data are generated through the internalized MDP-based MCTS model that interacts with the Mahjong simulator. Specifically, 250 simulations in each step during training and the first 15 actions are randomly sampled from the policy in order to extend the coverage of trajectory data. For the remaining steps, the action with the highest probability is selected. Furthermore, we also add Dirichlet noise Dir() [45] to the prior policy of the root node to encourage the exploration of new strategies, which is related to the expected number of actions or moves. So, we have:In the above equation, in our experiment in order to randomly sample about 10 moves over all legal moves. In addition, we also randomly sample actions of the other-discard step in order to further improve the Mahjong game trajectory data.
- Training: Networks were trained with stochastic gradient descent and momentum item [46], and the annealing method is also used to gradually reduce the learning speed, from an initial speed 0.01 to 0.001 and 0.0001 after the 10th and 20th iterations of the model version, respectively. The batch size is 256, momentum item parameters: alpha = 0.9, beta = 0.99. All of the training data follows the experience replay buffer design, which always stores the training data of the latest several model versions and regularly removes outdated training data.
- Update: For each model version update, the current version is matched against the last best version with a thousand games. Then, we compare the winning rate of the two models to obtain the best version among them.
Appendix D. Experiment Configurations

| Key | Type | Description |
|---|---|---|
| Pong | string | Pong meld, e.g., “222M” |
| Chi | string | Chow meld, e.g., “234S” |
| Kong | string | Kong meld, e.g., “3333S” |
| Seat | string | Current player seat, e.g., “1” |
| History | array | Action or move history sequence, e.g., “[“1,Chi,234S”,“1,Dis- card,5M”]” |
| Hand | string | Player hand tiles, e.g., “33M2468P6678S123Z” |
| Key | Type | Description |
|---|---|---|
| Code | int | http status code, e.g., 100 |
| Err_msg | string | error message, e.g., “illegal” |
| Action_content | string | tiles of action, e.g., “123M” |
| Action_type | string | type, e.g., “Pong” |
References
- El Rhalibi, A.; Wong, K.W.; Price, M. Artificial intelligence for computer games. Int. J. Comput. Games Technol. 2009, 2009, 251652. [Google Scholar] [CrossRef]
- Bourg, D.M.; Seeman, G. AI for Game Developers; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2004. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Zheng, J. Research and Application of Computer Games with Imperfect Information; South China University of Technology: Guangzhou, China, 2017. [Google Scholar]
- Brown, N.; Gross, A.L.S.; Sandholm, T. Deep counterfactual regret minimization. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- DeepMind. AlphaStar: Mastering the Real-Time Strategy Game StarCraft II. DeepMind. 2019. Available online: https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii (accessed on 1 June 2022).
- Statt, N. OpenAI’s Dota 2 AI Steamrolls World Champion E-Sports Team with Back-to-Back Victories. The Verge. 2019. Available online: https://www.theverge.com/2019/4/13/18309459/openai-five-dota-2-finals-ai-bot-competition-og-e-sports-the-international-champion (accessed on 10 June 2022).
- Shahbazi, Z.; Byun, Y.-C. Agent-Based Recommendation in E-Learning Environment Using Knowledge Discovery and Machine Learning Approaches. Mathematics 2022, 10, 1192. [Google Scholar] [CrossRef]
- Platas-López, A.; Guerra-Hernández, A.; Quiroz-Castellanos, M.; Cruz-Ramírez, N. Agent-Based Models Assisted by Supervised Learning: A Proposal for Model Specification. Electronics 2023, 12, 495. [Google Scholar] [CrossRef]
- Heidari, A.; Jamali, M.A.J.; Navimipour, N.J.; Akbarpour, S. A QoS-Aware Technique for Computation Offloading in IoT-Edge Platforms Using a Convolutional Neural Network and Markov Decision Process. IT Prof. 2023, 25, 24–39. [Google Scholar] [CrossRef]
- Amiri, Z.; Heidari, A.; Navimipour, N.J.; Unal, M. Resilient and dependability management in distributed environments: A systematic and comprehensive literature review. Clust. Comput. 2023, 26, 1565–1600. [Google Scholar] [CrossRef]
- Dao, G.; Lee, M. Relevant Experiences in Replay Buffer. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence, SSCI 2019, Xiamen, China, 6–9 December 2019. [Google Scholar] [CrossRef]
- Cortes, C.; Mohri, M.; Rostamizadeh, A. L2 regularization for learning kernels. In Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence, UAI 2009, Montreal, QC, Canada, 18–21 June 2009. [Google Scholar]
- Hoffer, E.; Banner, R.; Golan, I.; Soudry, D. Norm matters: Efficient and accurate normalization schemes in deep networks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Andrew, A.M. Reinforcement Learning: An Introduction. Kybernetes 1998, 27, 1093–1096. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 2000, 12, 1057–1063. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.I.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, Conference Track Proceedings, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Ueno, T.; Maeda, S.I.; Kawanabe, M.; Ishii, S. Generalized TD learning. J. Mach. Learn. Res. 2011, 12, 1977–2020. [Google Scholar]
- Jang, B.; Kim, M.; Harerimana, G.; Kim, J.W. Q-Learning Algorithms: A Comprehensive Classification and Applications. IEEE Access 2019, 7, 133653–133667. [Google Scholar] [CrossRef]
- Baxter, L.A.; Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; Wiley Publishing: Hoboken, NJ, USA, 1995; Volume 37. [Google Scholar] [CrossRef]
- Farquhar, G.; Rocktäschel, T.; Igl, M.; Whiteson, S. TreeqN and ATreEC: Differentiable tree-structured models for deep reinforcement learning. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Conference Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef]
- Ginsberg, M.L. GIB: Imperfect Information in a Computationally Challenging Game. J. Artif. Intell. Res. 2001, 14, 303–358. [Google Scholar] [CrossRef]
- Frank, I.; Basin, D. Search in games with incomplete information: A case study using Bridge card play. Artif. Intell. 1998, 100, 87–123. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Mizukami, N.; Tsuruoka, Y. Building a computer Mahjong player based on Monte Carlo simulation and opponent models. In Proceedings of the 2015 IEEE Conference on Computational Intelligence and Games, CIG 2015, Tainan, Taiwan, 31 August–2 September 2015. [Google Scholar] [CrossRef]
- van Rijn, J.N. Mahjong solitaire computing the number of unique and solvable arrangements. Mathematics 2011, 51, 32–37. [Google Scholar]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Li, J.; Koyamada, S.; Ye, Q.; Liu, G.; Wang, C.; Yang, R.; Zhao, L.; Qin, T.; Liu, T.-Y.; Hon, H.-W. Suphx: Mastering mahjong with deep reinforcement learning. arXiv 2020, arXiv:2003.13590. [Google Scholar]
- Gao, S.; Li, S. Bloody Mahjong playing strategy based on the integration of deep learning and XGBoost. CAAI Trans. Intell. Technol. 2022, 7, 95–106. [Google Scholar] [CrossRef]
- Liu, K.; Bellet, A.; Sha, F. Similarity learning for high-dimensional sparse data. arXiv 2015, arXiv:1411.2374. [Google Scholar]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Wolff, E. Very High Resolution Object-Based Land Use–Land Cover Urban Classification Using Extreme Gradient Boosting. IEEE Geosci. Remote. Sens. Lett. 2018, 15, 607–611. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, S. A Review of Mahjong AI Research. In Proceedings of the 2020 2nd International Conference on Robotics, Intelligent Control and Artificial Intelligence (RICAI ‘20), Shanghai, China, 17–19 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 345–349. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Tsantekidis, A.; Passalis, N.; Tefas, A. Recurrent neural networks. Deep. Learn. Robot. Percept. Cogn. 2022, 30, 101–115. [Google Scholar] [CrossRef]
- Browne, C.B.; Powley, E.; Whitehouse, D.; Lucas, S.M.; Cowling, P.I.; Rohlfshagen, P.; Tavener, S.; Perez, D.; Samothrakis, S.; Colton, S. A Survey of Monte Carlo Tree Search Methods. IEEE Trans. Comput. Intell. AI Games 2012, 4, 1–43. [Google Scholar] [CrossRef]
- Gonçalves, R.A.; Almeida, C.P.; Pozo, A. Upper confidence bound (UCB) algorithms for adaptive operator selection in MOEA/D. In Evolutionary Multi-Criterion Optimization, Proceedings of the 8th International Conference, EMO 2015, Guimaraes, Portugal, 29 March–1 April 2015; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9018, p. 9018. [Google Scholar] [CrossRef]
- Tuglu, N.; Kuş, S. q-Bernoulli matrices and their some properties. Gazi Univ. J. Sci. 2015, 28, 269–273. [Google Scholar]
- Rolnick, D.; Ahuja, A.; Schwarz, J.; Lillicrap, T.P.; Wayne, G. Experience replay for continual learning. Adv. Neural Inf. Process. Syst. 2019, 32, 78–89. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6 July–11 July 2015; Volume 1. [Google Scholar]
- Gao, S.; Okuya, F.; Kawahara, Y.; Tsuruoka, Y. Supervised learning of imperfect information data in the game of mahjong via deep convolutional neural networks. Inf. Process. Soc. Jpn. 2018, 4, 56–78. [Google Scholar]
- Wang, J.; Xu, X.H. Computer Game: The Frontier of Artificial Intelligence: National University Student Computer Game Contest. Comput. Educ. 2012, 163, 14–18. [Google Scholar]
- Yoon, J.; Jeong, B.; Kim, M.; Lee, C. An information entropy and latent Dirichlet allocation approach to noise patent filtering. Adv. Eng. Informatics 2021, 47, 101243. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16–21 June 2013. PART 3. [Google Scholar]
- Mirsoleimani, S.A.; Plaat, A.; Herik, J.V.D.; Vermaseren, J. An analysis of virtual loss in parallel MCTS. ICAART 2017. In Proceedings of the 9th International Conference on Agents and Artificial Intelligence, Lisbon, Portugal, 22–24 February 2013; Volume 2. [Google Scholar] [CrossRef]
- Dean, J.; Corrado, G.S.; Monga, R.; Chen, K.; Devin, M.; Le, Q.V.; Mao, M.Z.; Ranzato, M.A.; Senior, A.; Tucker, P.; et al. Large scale distributed deep networks. Adv. Neural Inf. Process. Syst. 2012, 2, 25–28. [Google Scholar]












| Features | Number of Channels | Description |
|---|---|---|
| Hand tiles of each player | 4 × 4 | Private tiles of each player |
| Total discard tiles of each player | 4 × 4 | Discard tiles of each player |
| Recent 4 discard tiles of each player | 4 × 4 | Recent discard of each player |
| Melds tiles of each player | 4 × 4 | Melds tiles of each player |
| Wall tiles | 10 | Top ten tiles of wall tiles |
| Current score of each player | 11 × 4 | Score is divided into 11 integer intervals for each player |
| Features | Number of Channels | Description |
|---|---|---|
| Tile type | 1 | Tile type of action |
| Action type | 10 | 10 types of actions 1 |
| The change of the player position variable | 4 | The change of next player’s position variable after taking action 2 |
| Additional player state | 4 | The next player state after taking action 3 |
| Action Type | Number of Channels | Action Type | Number of Planes |
|---|---|---|---|
| Discard | 4 × 4 | Chow_Right | 1 |
| AddKong | 4 × 4 | Chow_Middle | 1 |
| Pass | 4 × 4 | Pong | 1 |
| ClosedKong | 1 | OpenKong | 1 |
| Chow_Left | 1 | Hu (Win) | 1 |
| No | Feature |
|---|---|
| 1 | Player’s own hand tiles |
| 2 | Discard tiles of each player |
| 3 | Melds tiles of each player |
| 4 | Current score of each player |
| Method | Parameters | Value |
|---|---|---|
| Tree Search Learning | Dirichlet_noise_alpha | 0.9 |
| Simulation_count | 250 | |
| Total_training_steps | 1.2 million | |
| L2_penalty_alpha | 1.0 × 10−4 | |
| Batch_size | 256 | |
| Initial training speed | 0.01 | |
| Optimizer | SGD + momentum | |
| Simulation CPU threads per agent | 25 | |
| Simulation GPU threads per agent | 5 | |
| Data generation agent used | 10 | |
| Dropout Learning | Batch_size | 512 |
| Channels | 256 | |
| Initial_learning_rate | 0.001 | |
| L2 penalty item | 1.0 × 10−4 | |
| Momentum_alpha_beta | 0.9, 0.99 | |
| Total_training_steps | 0.66 million | |
| Dropout_decay_rate | 0.1 | |
| Dropout_decay_steps | 60 thousand |
| Model | Highest Accuracy | Mean Accuracy |
|---|---|---|
| Simulator-based MCTS Model | 70.5% | 69.6% |
| MDP-based MCTS Model | 73.0% | 72.0% |
| Previous Works | 88.2% | 68.8% |
| AI Model/Engine | Number of Games | Stable Rank |
|---|---|---|
| Proposed agent | 3328 | 5 dan |
| Baseline player Tenhou-Bot | 1095 | 3 dan |
| Bakuuchi | 30,516 | 6 dan |
| Professional human player | - | 5 dan |
| Score Multiplier | One | Two | Four | Eight | More |
|---|---|---|---|---|---|
| Total | 378 | 38 | 8 | 3 | 1 |
| Occurrence Rate | 88.3% | 8.9% | 1.9% | 0.7% | 0.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouyang, X.; Zhou, T. Imperfect-Information Game AI Agent Based on Reinforcement Learning Using Tree Search and a Deep Neural Network. Electronics 2023, 12, 2453. https://doi.org/10.3390/electronics12112453
Ouyang X, Zhou T. Imperfect-Information Game AI Agent Based on Reinforcement Learning Using Tree Search and a Deep Neural Network. Electronics. 2023; 12(11):2453. https://doi.org/10.3390/electronics12112453
Chicago/Turabian StyleOuyang, Xin, and Ting Zhou. 2023. "Imperfect-Information Game AI Agent Based on Reinforcement Learning Using Tree Search and a Deep Neural Network" Electronics 12, no. 11: 2453. https://doi.org/10.3390/electronics12112453