1. Introduction
X-ray technology has developed quickly since Roentgen discovered the X-ray in 1895 [
1]. It has many successful applications in a wide range of fields and continues to advance nowadays. X-ray radiology is a universal non-destructive testing approach. In the traditional fluoroscopy process, internal structures of a three-dimensional object are compressed into a two-dimensional image along the direction of X-rays, resulting in overlapping of all structures within the object, and the clarity in the region of interest is greatly reduced. Although traditional perspective imaging technology has achieved some successes in generating images of the clear plane of interest, it does not increase the contrast between different substances in the object, nor does it fundamentally remove other structures other than the focal plane, thus significantly impairing image quality. Modern tomography, known as CT, was invented by Hounsfield [
2]; it is a method of reconstructing tomography images based on projection data (sinograms) from multiple angles around the inspected object. During the imaging process, each reconstruction slice is independent from each other, so the interference of different slices in traditional perspective imaging processes is fundamentally eliminated, and the structural contrast is significantly enhanced; at the same time, gray values of the image pixels in the tomographic image can truly correspond with the material density of the measured object, and a small density change inside the object can be easily detected and located, which is crucial for industrial non-destructive testing. In fact, the low-contrast detection ability is a key difference between CT and X-ray technologies. This is also the most important reason why CT is rapidly popularized in the field of industrial testing. Despite the imaging quality of CT being outstanding, the inspection speed of traditional CT is generally slow. Several works have been conducted to elevate the imaging speed [
3,
4,
5,
6,
7].
In general, there are two main solutions to increase the imaging speed, either through hardware improvements or through advanced reconstruction algorithms. When it comes to hardware, parallel computing ability is crucial. Such computing units with parallel computing ability such as FPGA and GPU can significantly increase the imaging speed. When it comes to algorithms, the deep-learning neural network is now applied to analytical or iteration algorithms to increase the computing speed while maintaining the reconstruction quality [
8,
9,
10,
11].
The advancement of CT imaging techniques has spurred the evolution of CT image reconstruction algorithms. Traditional CT reconstruction algorithms include two main categories: analytical reconstruction algorithms and iterative reconstruction algorithms. Compared with the iterative algorithm, the analytical algorithm has the characteristics of fast reconstruction speed, simple error analysis and small occupation of computing resources; it is the mainstream algorithm applied in the current CT system. In recent years, with the development of deep-learning, it has many applications in the field of biomedical CT imaging, such as image segmentation, attenuation correction and noise reduction. Survarachakan S et al. investigated the effects of image enhancement techniques on the performance of deep learning-based vessel segmentation in hepatic CT images [
12]. Choi Bo-Hye et al. trained a deep neural network using a large dataset of paired MR and PET images and used it to estimate the attenuation map from the MR images. The proposed method achieved accurate attenuation correction, as evidenced by improved PET image quality and increased correlation between the PET images and the gold standard transmission-based attenuation correction [
13]. Dao-Ngoc L. et al. proposed a novel algorithm for generative noise reduction in dental cone beam computed tomography imaging; it uses a selective anatomy analytic iteration approach to iteratively estimate the high-quality CBCT image from a low-quality noisy image. Ref. [
14] proposed a novel deep learning approach for low-dose CT imaging which utilizes an iterative training process to learn a mapping between low-dose and fully sampled CT images, resulting in high-quality reconstructed images even at very low radiation doses [
15]. Xu et al. presented a deep convolutional neural network for CT image deconvolution which aims to reduce the effects of blur and noise in the image [
16].
Many works have been performed to apply X-ray technology to industrial inspection. X-ray tomography has been a typical technology in the non-destructive testing area. Detailed studies of classical tomography development can be found elsewhere [
17,
18,
19,
20,
21,
22]. Over the past half century, with further developments in electronics and computers, X-ray computed tomography (CT) achieved rapid development. In the early 1970s, CT was used merely in the medical field, but it started to appear in the industrial field with the evolution of industrial non-destructive technology. Gilboy et al. presented the applications of the X-ray technique in the industrial area [
23]. Reimers P. et al. discussed the development of non-destructive testing (NDT) with X-ray computed tomography [
24]. Kress J. W. et al. designed an X-ray radiographic system with the ability of three-dimensional tomographic reconstruction [
25]. Oster R. et al. demonstrated the usage of CT for optimizing the manufacturing techniques with some supportive experiments [
26]. The rapid advancement of deep learning technology has also brought a revolutionary impact on the field of industrial automation, and many application scenarios have emerged: Liu C et al. proposed an online layer-by-layer surface topography measurement method based on deep learning which can more accurately capture the changes and details of surface topography in additive manufacturing process [
27]. Elhefnawy M. et al. used sensors and other data sources to collect data from industrial processes and generate polygons that represent normal working conditions and then used deep learning algorithms to identify any deviations that were inconsistent with that polygon for fault classification [
28]. Ma Z. et al. proposed a lightweight network structure based on a convolutional neural network, and adopted a strategy based on sliding windows and image pyramids to effectively detect defects of different sizes and shapes in the manufacturing process of aluminum alloy strips [
29]. Monica L. Nogueira et al. used CSI (confocal scanning interferometry) strength images for machine learning classification of ultra-precision diamond turning surface fractures [
30]. Chuqiao Xu et al. proposed a knowledge-enhancing deep learning method for vision-based yarn profile detection. This method combines traditional image processing techniques and deep learning techniques to improve the accuracy and stability of contour detection by introducing prior knowledge [
31].
With the in-depth application of CT technology in the fields of three-dimensional imaging, medical navigation and rapid security inspection, new requirements such as low-dose imaging, quantitative imaging and rapid imaging have also put forward higher requirements for CT imaging technology, but the development of standard scanning trajectory CT systems represented by circular trajectory scanning and spiral trajectory scanning has encountered bottlenecks in terms of faster imaging speed and high imaging quality. In recent years, non-standard trajectory scanning and distributed multi-light source imaging have greatly expanded the application scenarios of CT systems and have shown great potential in solving problems such as large-channel imaging and high-speed imaging.
Today’s CT machine is a complex system with gantry rotation. Inevitably, the weight of the slip ring motor and the centrifugal force severely limits the rotation speed and thus limits the sweep speed of the whole system as well. To overcome this problem, the stationary CT system has became a good choice. Avilash Cramer et al. designed a stationary computed tomography for space and other resource-constrained environments [
32]. Tao Zhang et al. designed a stationary computed tomography with X-ray source and detector in linear symmetric geometry [
33]. Hongguang Cao et al. proposed a stationary real-time CT imaging system comprising an annular photon counting detector, an annular scanning X-ray source and a scanning sequence controller [
34]. Derrek Spronk et al. designed and evaluated a stationary head computed tomography system using a carbon nanotube X-ray source array which could significantly reduce the radiation dose while maintaining high-quality imaging [
35]. Qian, Xin et al. developed a high-resolution stationary digital breast tomosynthesis system using a distributed carbon nanotube X-ray source array. The study showed that this new system achieved improved image quality and spatial resolution compared to conventional tomosynthesis systems [
36]. However, the energy level is limited so that it can only be applied for human body tissues; when it comes with industrial productions, especially metal objects, X-rays with much higher energy are needed to penetrate the inspected objects. If we use this architecture with traditional X-ray tubes, the volume and heat dissipation requirements are difficult to satisfy.
In this paper, we proposed a novel structure of industrial CT inspection system; it has the advantage of acquiring high quality projections in multiple angles for CT reconstruction and highly integrated into the production line so that the inspection procedure can be performed on a conveyor belt. The whole production efficiency will be improved greatly by this structure. Each inspection module in our proposed system consists of a pair of X-ray source and detector. To maintain the short-time advantage and overcome the spatial limitation of stationary CT, 60 modules distribute not only radially but also along the axis in space to acquire projections up to 60 angles, which is sufficient for high quality CT reconstruction based on the traditional FBP algorithm and deep-learning neural network. The filtered back projection (FBP) algorithm is a classical method widely applied in CT image reconstruction. Since its first introduction in the 1970s by R. A. Crowther and colleagues [
37], FBP has become the mainstream technology in the field of CT image reconstruction due to its advantages in computational efficiency and image quality. The fundamental idea of the FBP algorithm is to first perform an inverse radon transform on the projection data, followed by filtering and finally implementing the back projection operation on the image plane. If the inspection modules distribute only radially, they interfere with each other, but the distribution along the axis can avoid this problem.
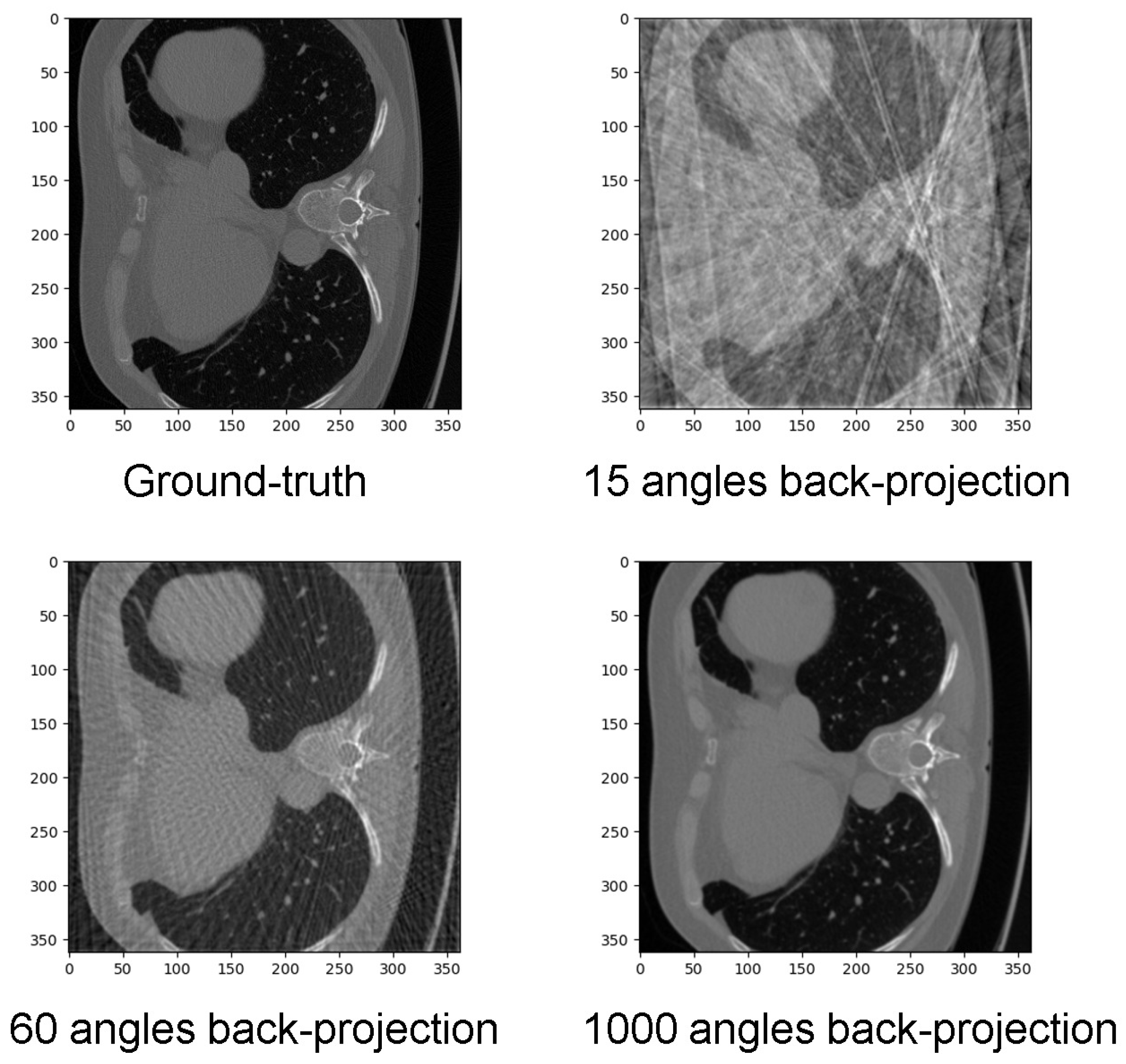
Sparse angle computed tomography reconstruction is a technique used to reconstruct CT images from a limited set of projections. The number of projections used to reconstruct the image is an important factor that determines the quality of the reconstruction. When using a limited number of projections, there is a trade-off between the quality of the reconstructed image and the computational complexity of the reconstruction algorithm. If too few projections are used, the reconstructed image may be noisy and contain artifacts. On the other hand, using too many projections may increase the computational complexity of the reconstruction algorithm and lead to longer reconstruction times. In the case of sparse-angle CT reconstruction, using 60 angles for the projections is a common practice because it strikes a balance between image quality and computational complexity. This number of projections has been found to provide a good balance between noise reduction and preserving image details while still being computationally feasible. It is also a compromise between the typical 180-degree scan of a full CT scan and the more limited number of projections used in other sparse-angle CT reconstruction techniques. Many related works also use 60-angle projection data for sparse-angle CT reconstruction, such as [
10,
38].
Traditional industrial CT mainly uses a cone beam X-ray source and an X-ray flat panel detector to collect circular trajectory projection data by rotating the measured object on a rotating stage and uses the FDK reconstruction algorithm to reconstruct the three-dimensional volume of the measured object [
39]. This form of scanning needs to use manual or six-axis robots to fix the measured object on a rotating platform before scanning the measured object and then performs scanning and imaging steps. There are two major drawbacks to this form of scanning. First, because the size of the measured object is limited by the X-ray flat panel detector, and the flat panel detector is generally unable to produce a larger size, the size of the measured object is often limited. Second, the use of manual or six-axis robots to fix the measured object and then scan the form greatly reduces the detection efficiency, which makes the CT non-destructive testing link in the actual production process often adopt the method of random sampling inspection. Unfortunately, random sampling inspection cannot guarantee a 100% pass rate for the measured product.
Our proposed structure can be easily integrated into the production line, which greatly improves the efficiency of non-destructive testing and brings a 100% pass rate for the measured products. In addition, since line array X-ray detector can have a very long size, the size of the measured object will no longer be subject to strict restrictions. Through the deployment of deep-learning neural networks, many fewer projections are needed for reconstruction through a well-trained neural network, and it greatly shortens the reconstruction time and provides a solution for real-time CT.
2. Hardware Design
2.1. System Structure
The main parts of our CT system include a fan beam X-ray source and a linear X-ray detector. The X-ray detector we use is the X-scan ME Series produced by Detection Technology, and the X-ray source is the IXS1203 microfocus X-ray source produced by VJX-ray; the voltage range of the X-ray source tube is 40–120 kV, the tube current range is 0.05–0.3 mA and the focal size is 50 μm. The total cost of our proposed system is about USD 700,000.
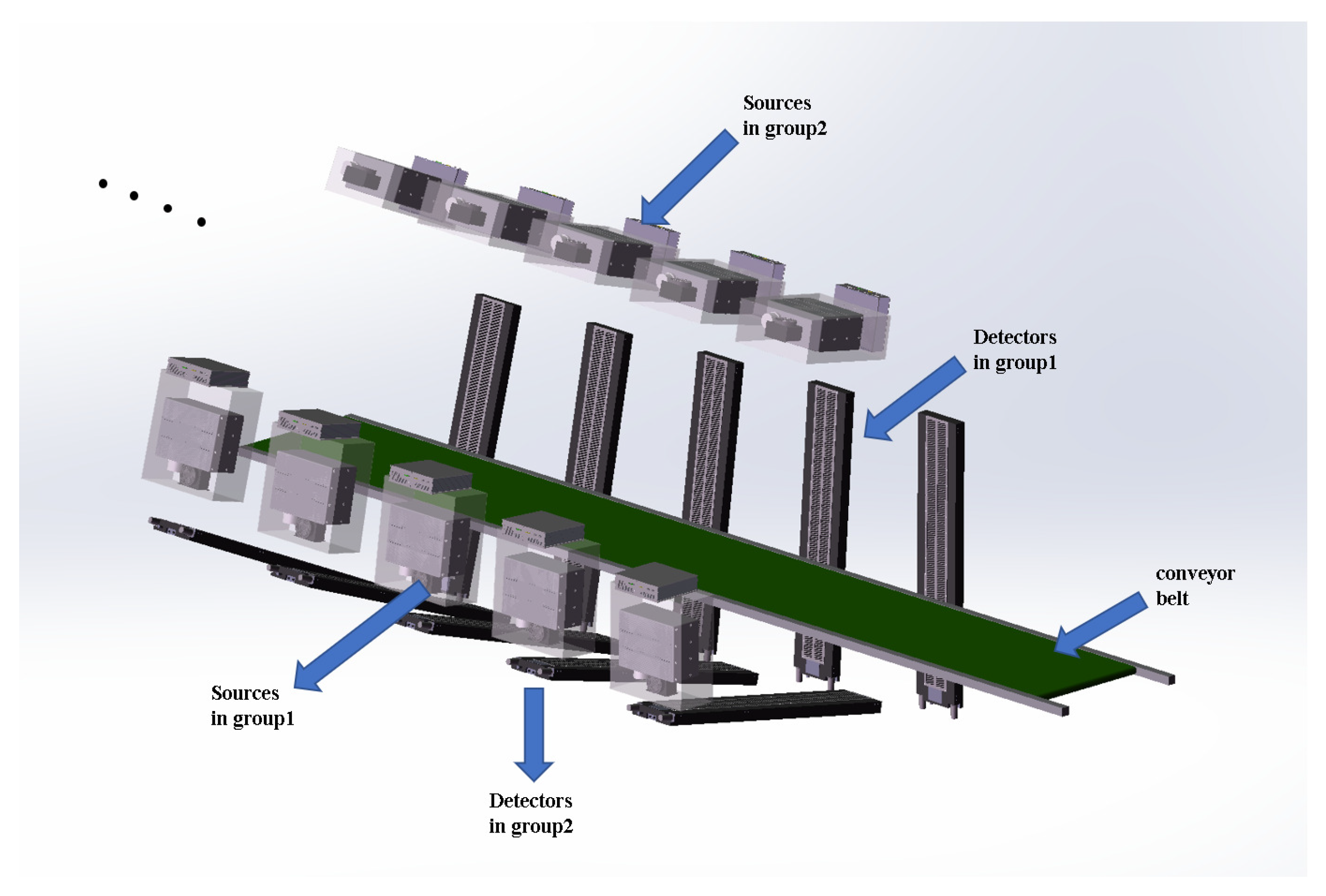
In order to reduce the space needed between the scanner, we combine these two main parts into a pair of detection module. As is shown in
Figure 1, the imaging modules in group 1 and in group 2 are distributed staggered, and the circumferential distance is 105 degrees.
The detector specifications of our system are illustrated in
Table 1; inspected slice numbers in each object can be calculated based on those parameters:
In Equation (
1),
K refers to the inspected slice numbers in each measured object on the conveyor belt,
L(m) refers to measured object length,
S(m/s) refers to line speed,
P(s) refers to counting period and
T(s) refers dead time. To make sure the inspected slices in different measured objects are aligned, e.g., the location of slice 1 in measured object 1 is consistent with the location of slice 1 in measured object 2. Only in this way will projections in different angles of each slice be guaranteed to locate in the same plane, which avoids distortion during the reconstruction process. The frame rate for our real-time imaging can be calculated as follows:
Imaging quality can be modified by controlling the number of energy bins:
where
Q refers to the quality of projections,
A refers to Active area length,
w refers to Detector element width,
b refers to energy bins and
Pr refers to Pixel dynamic range. Projection quality determines the quality of reconstructed slices.
The equipment is based on the principle of CT slice imaging, with the difference being that the X-ray source and detector through the spiral array arranged with the detected work-piece around the motion direction for the work-piece that is panning on the conveyor belt; whenever one of the interfaces passes through all the detection modules, the reconstruction process is completed.
In parallel beam X-ray CT reconstruction, when the detector rotates 360
around the object, the projection data generated by each ray is measured twice, and each projection data point in the range of 180
to 360
is a repeated acquisition of projected data in the range of 0
to 180
, which is redundant, so the detector only needs to rotate 180
to provide sufficient projection data for image reconstruction. Similarly, in the sector beam X-ray CT reconstruction, the projection data generated by each ray when the detector rotates 360
has also been measured twice, and in the actual data acquisition process, there is no need to perform a 360
full scan, and the scanning angle can be less than 360
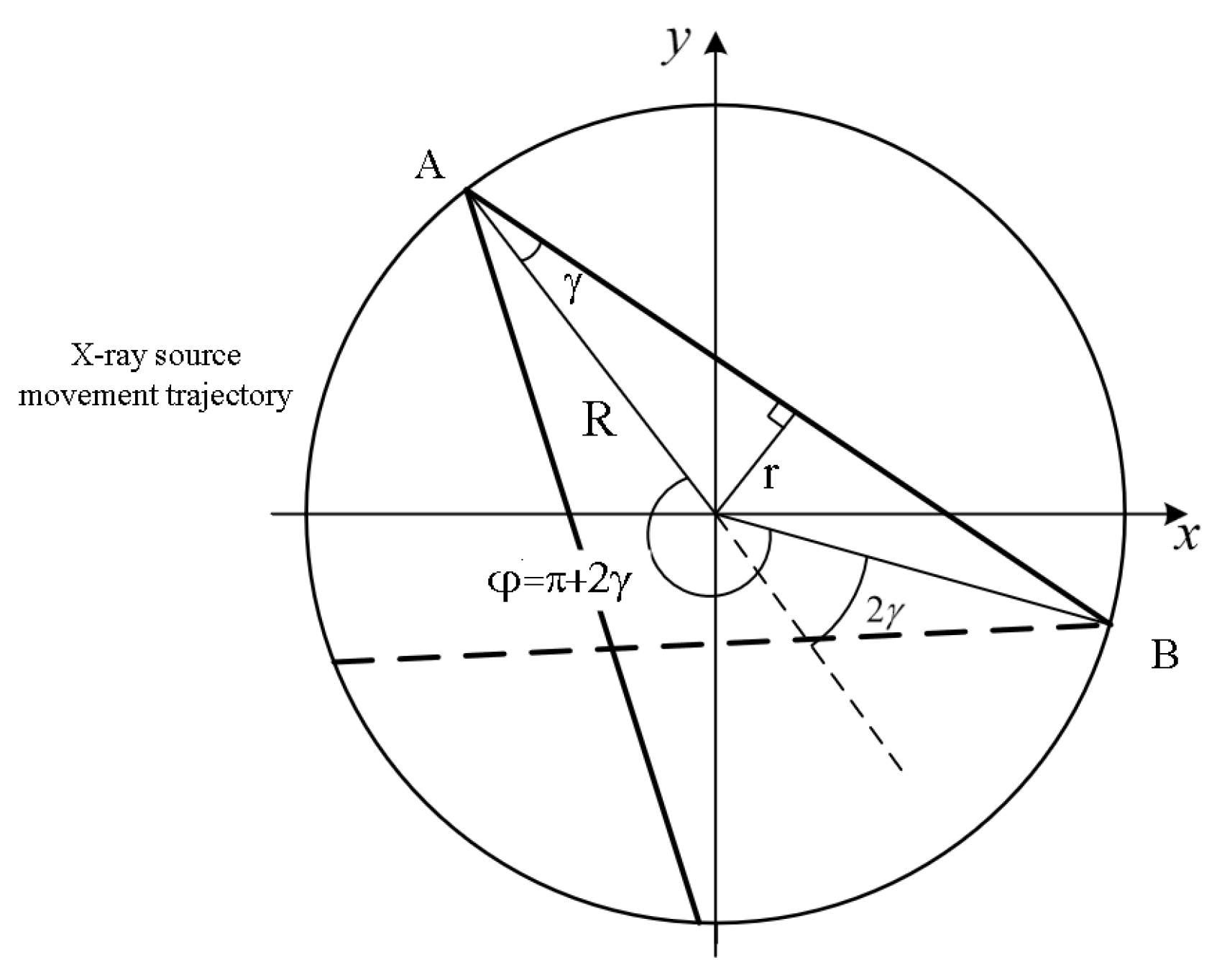
, which is called short scanning. As is shown in the
Figure 2, when the sector beam light source rotating around a circular trajectory rotates from position A to position B, the first X-ray of the position A sector beam coincides with the last ray of the position B sector beam, and each point in the field of view is covered by rays distributed in an angle range of at least 180
, from which the minimal rotation angle
can be derived:
where
r is the radius of the field of view, and
R is the distance between the source and the axis of rotation. One slice of volume is complete when all the needed projections are back projected. In our system,
r is around 280 mm, and
R is around 1661 mm. Based on Equation (
4), the minimal rotation angle is 199.41 degrees. We designated the distribution angle of all the detection module as 206.5 degrees for calculation convenience.
As is shown in
Figure 3, the X-ray source and X-ray detector in the first group are aligned in pairs, and correspondingly, the X-ray source and the X-ray detector in the second group are aligned in pairs as well. The distance between two adjacent sources or two adjacent detectors in each group along the direction of the conveyor belt is 735 mm, and the angle between them is 3.5 degrees around the circumferential direction of the conveyor.
In the reconstruction process, it is necessary to obtain a sufficient angle of projection data in order to ensure the image quality of the reconstructed slices. The device obtains cross-section projection data at 60 different angles for slice image reconstruction through the arrangement of 60 pairs of X-ray sources and detectors. The circumferential angle interval between each group of light source detectors is 3.5, and the total detection angle is 206.5. In order to reduce the minimum distance between each pair of X-ray source and detector and make the equipment more compact as a whole, a space-interleaved arrangement is adopted.
From 0
to 101.5
, X-ray sources and detectors are arranged every 3.5
, and a total of 30 pairs are arranged, forming the first group. From 105
to 206.5
, other pairs of X-ray sources and detectors are arranged every 3.5
for a total of 30 pairs as well, forming a second group, and the two groups add up to a total of 60 pairs of X-ray sources and detectors; the overall view and side view of the system is shown in
Figure 4.
With the development of modern industry, industrial CT plays a major role in non-destructive testing and reverse engineering. The results of non-destructive testing of products using industrial CT show that industrial CT technology has high detection sensitivity for various common defects such as porosity, inclusion, pinhole, shrink hole, and delamination. It can accurately determine the size of these defects and locate their position in the object as well. Compared with other conventional non-destructive testing technologies, the spatial and density resolution of industrial CT technology is less than 0.5%, the imaging size accuracy is high, and it is not limited by the type and geometry of the work-piece material. It can generate three-dimensional images of material defects, which is of great research and application value in the detection of defects such as structural dimensions, material uniformity, micro-pore rate and overall micro-cracks, inclusions, porosity and abnormally large grains in the work-piece to be inspected.
2.2. Data Processing
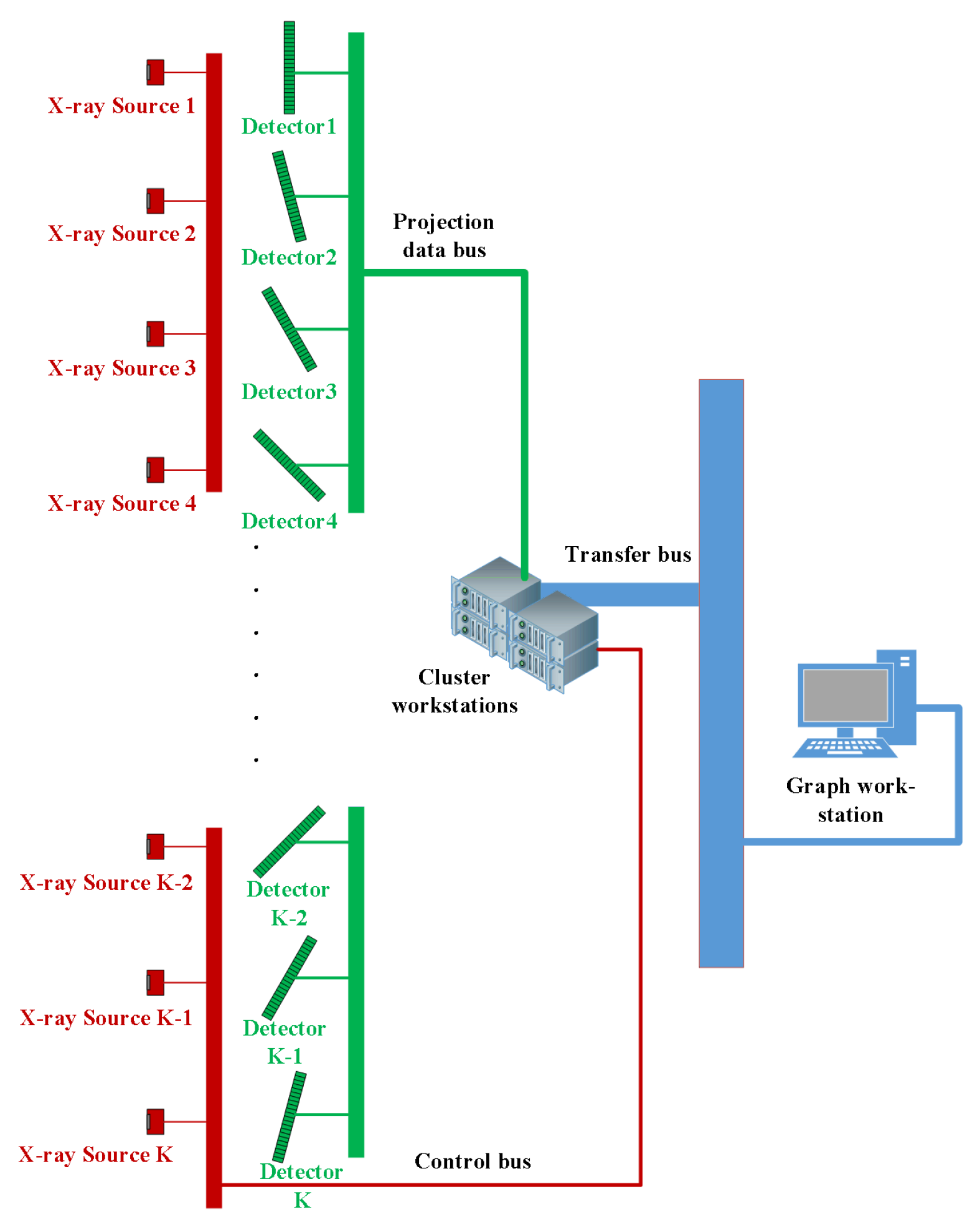
The data collected by the detectors were sent to the cluster workstation with GPU for processing. The X-ray intensity data after attenuation was divided by the X-ray intensity data without any attenuation. Projections were acquired after this process. The data transmission network is shown in
Figure 5.
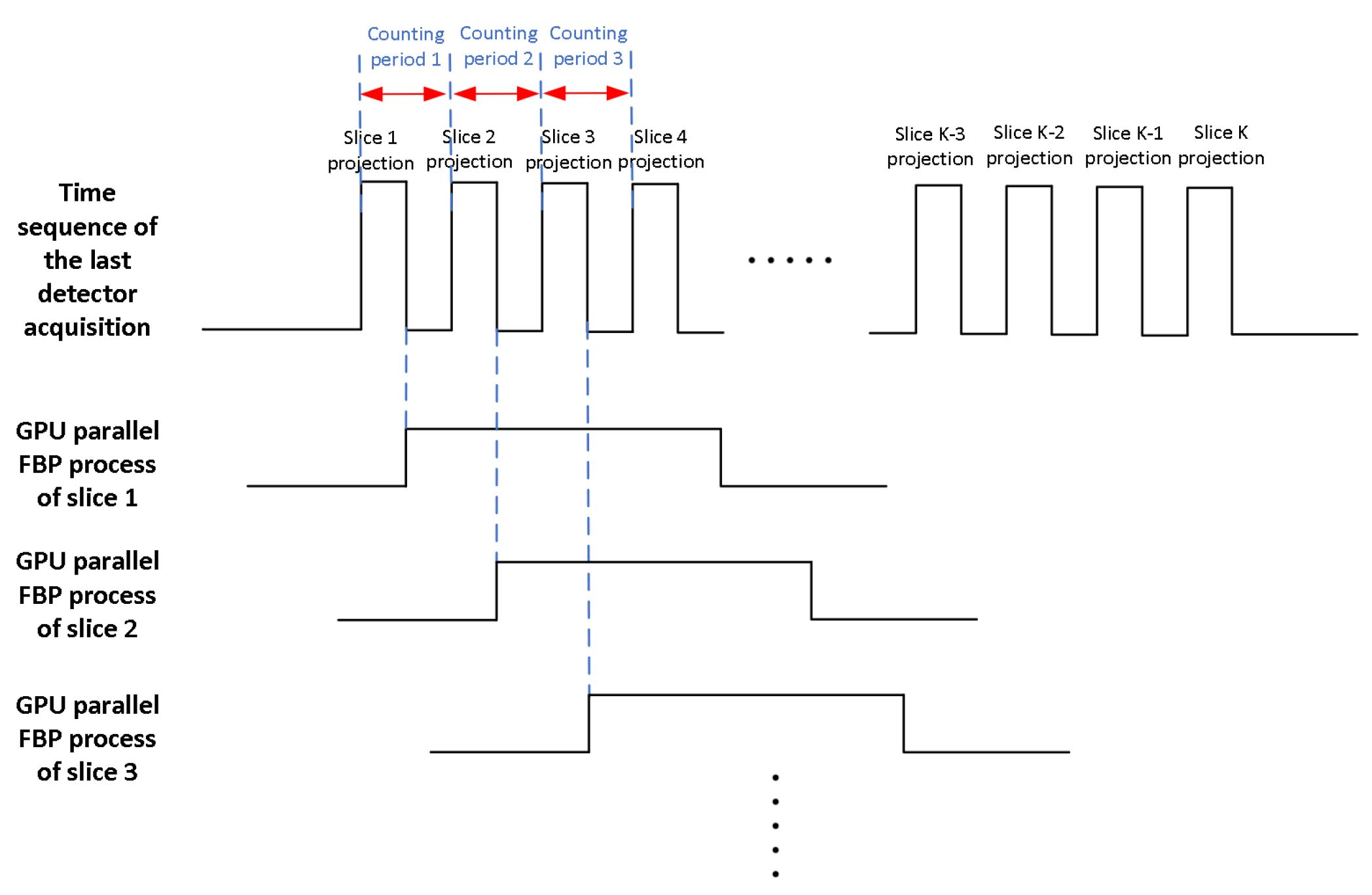
Usually, a rotary CT scanner acquires all the projection data after one rotational scan and carries out the reconstruction procedure. Before the projection data of the next slice was collected, the FBP reconstruction procedure in GPU has already finished. Therefore, the parallel computing power of GPUs is not well tapped, and the low computing efficiency is not suitable for real-time imaging. In our proposed structure, after projection data in the last angle were acquired by the detector, the reconstruction procedure in this slice of interest was executed. By the time the last projection of the next slice of interest was collected, which is much shorter than the imaging algorithm, the reconstruction procedure of this new slice of interest was executed in parallel in the GPU. Thus, the parallel computing power of GPUs is well exerted. Time sequence of data processing is shown in
Figure 6.
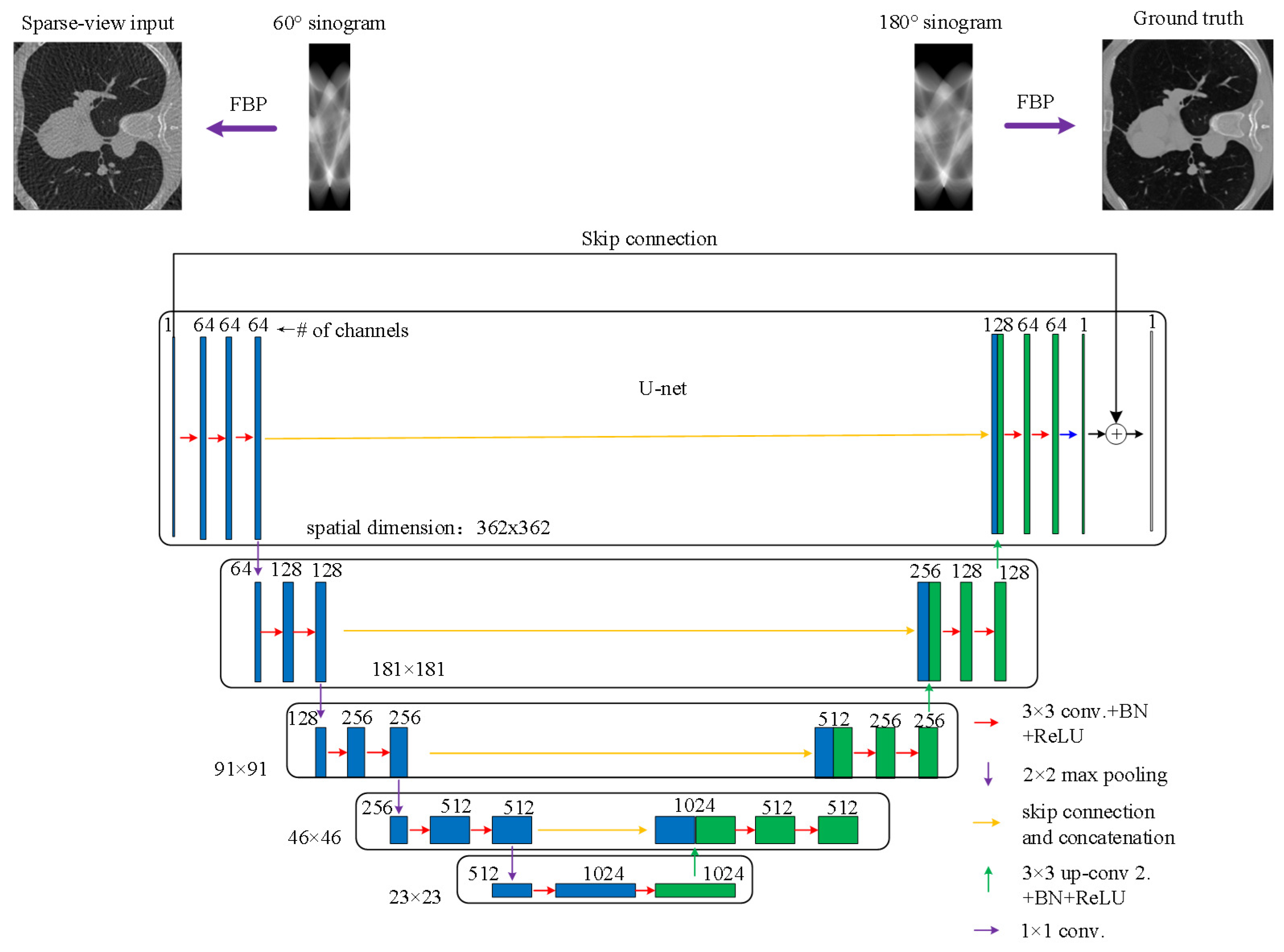
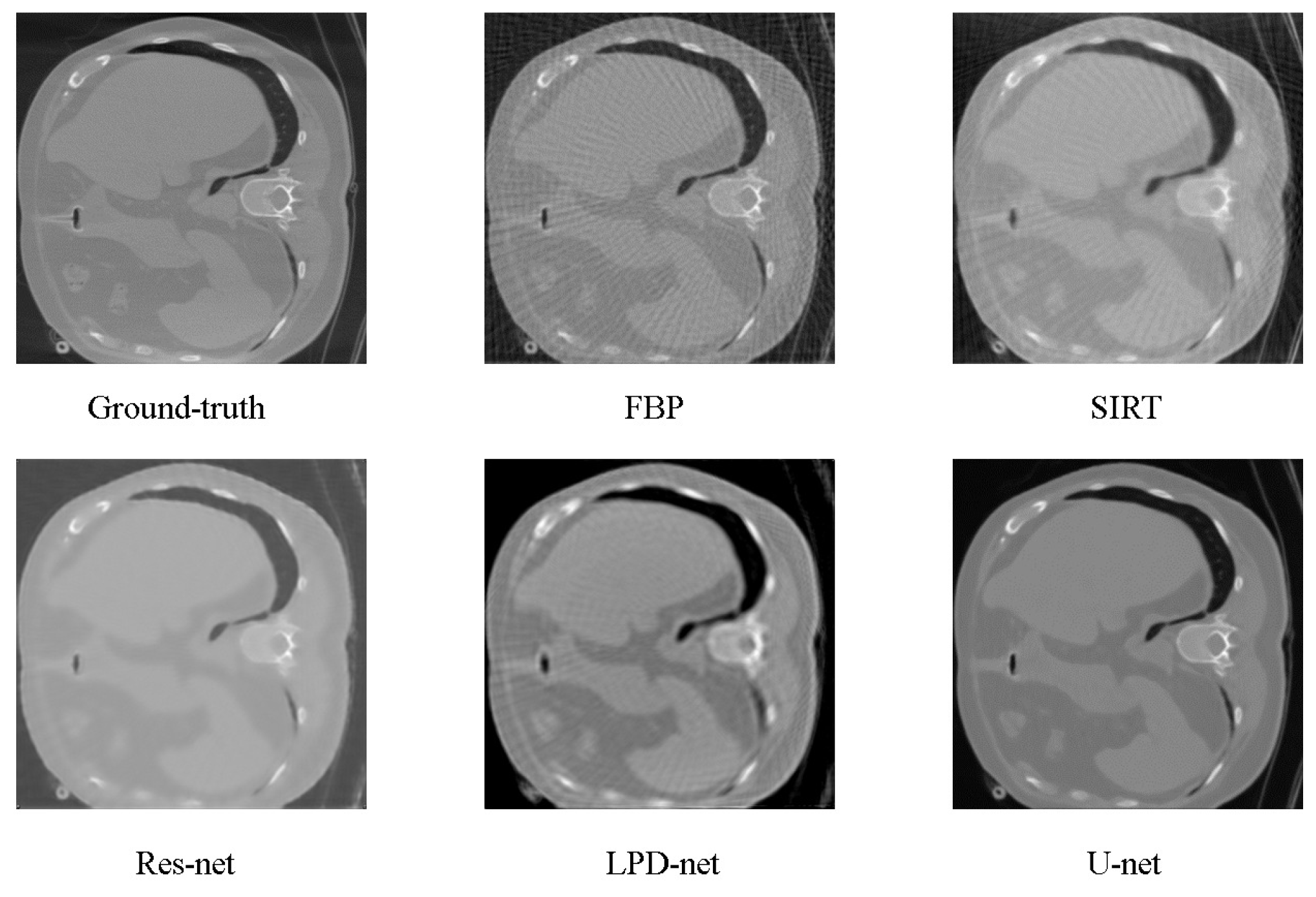
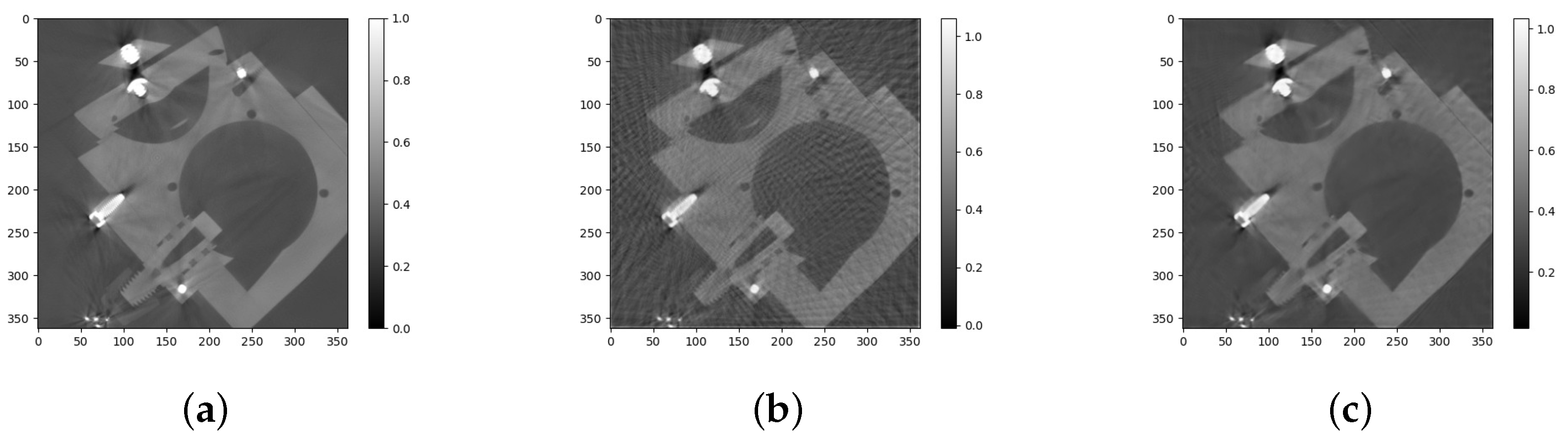
In our implementation we preferred to create a continuous reconstruction scheme where the filtered and back-projected slice enter into the system as soon as a new series of projections were read in. In this way, we have a continuous stream of projections that were received from the detectors and a continuous stream of reconstructed slices that was sent to the image processing stage. In such a way, objects can be continuously processed even if they only have a small gap between them on the conveyor. We implemented the FBP algorithm on the cluster workstation with the GPU to perform the filtered back-projection after the projections were read by detectors. The reconstruction results were then sent to the graphics workstation for post processing by deep learning.
4. Discussion and Conclusions
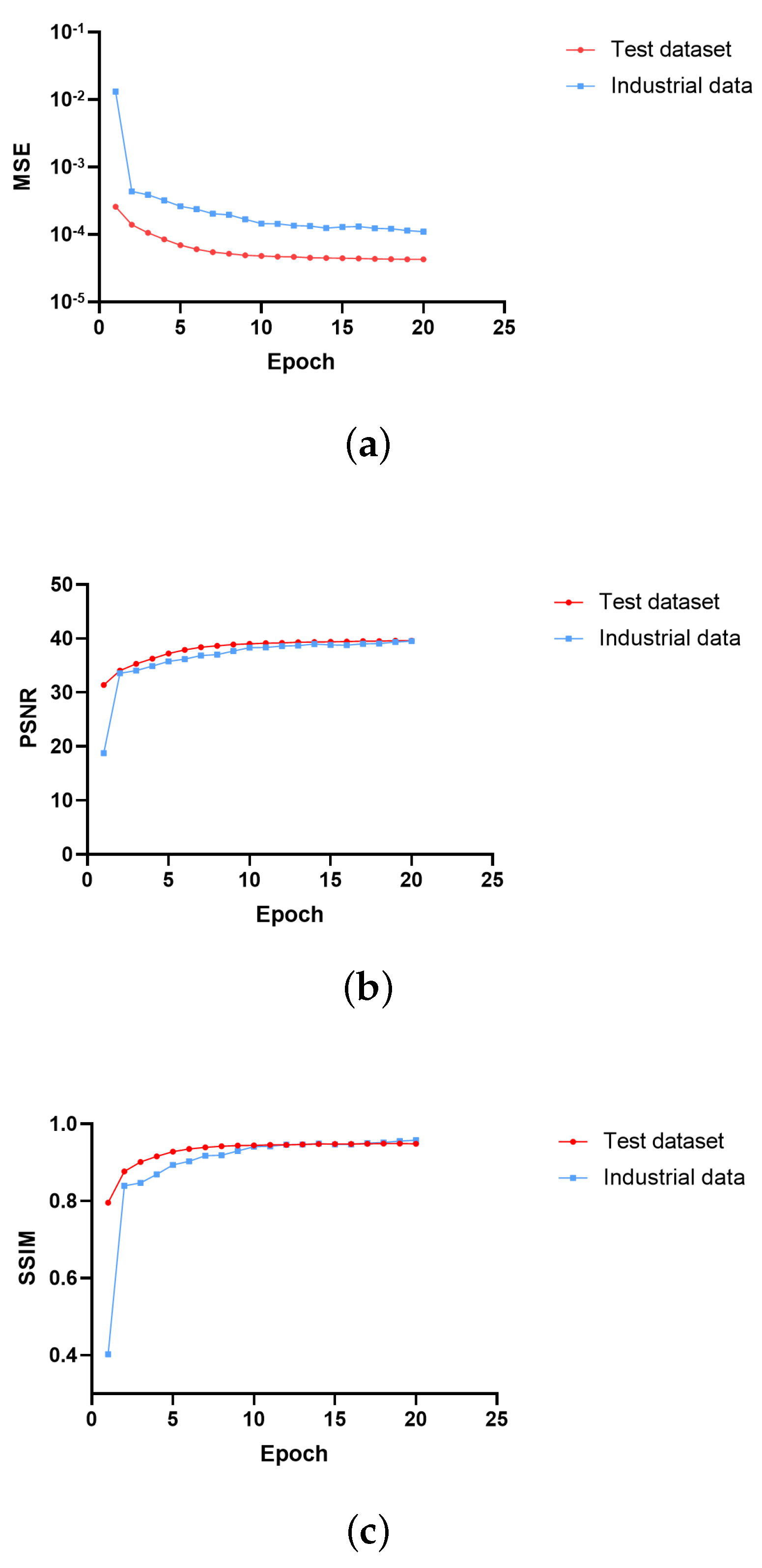
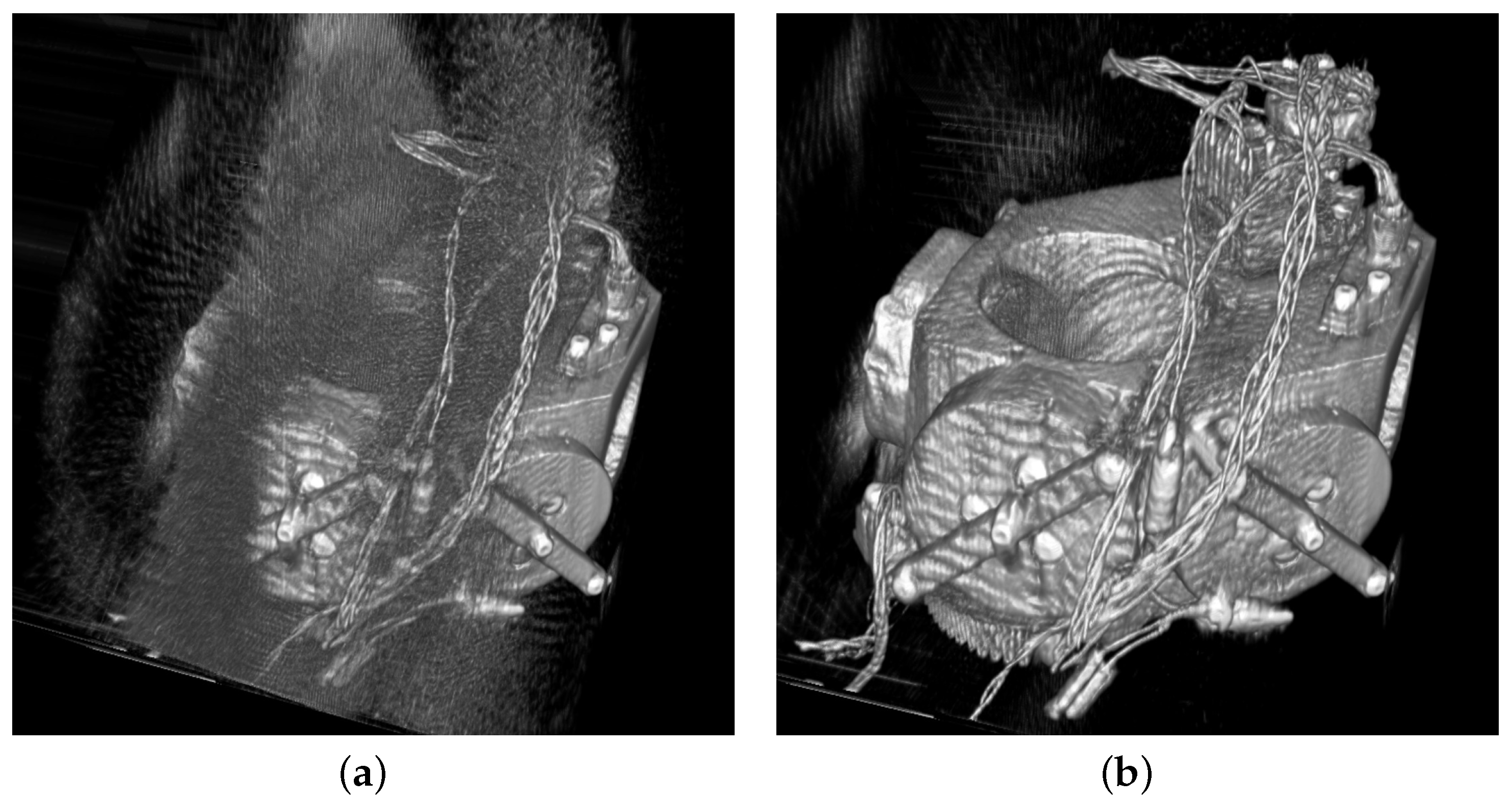
In our simulation, the slices of interest of the inspected object were successfully constructed in a short time by the CT structure we proposed. The inspection part is highly integrated into the whole production line so that the quality inspection has been simplified and the production cycle has been greatly shortened. Meanwhile, a sufficient quantity of X-ray detectors and the deep-learning reconstruction method make sure that the quality of the reconstructed slices satisfies the needs of defect detection.
The micro-focal X-ray source used in our system has a focal size of 50 m, and it can meet the need for clear imaging on detectors with pixel dimensions in the hundreds of m range. In order to control the cost of the entire system, we currently choose a detector with a pixel size of 0.8 mm, i.e., 800 m. Since the measured objects are roughly halfway between the X-ray source and X-ray detector, the magnification is about 2. Theoretically, the maximum spatial resolution is up to 400 m (half the pixel size of the detector), which is sufficient for non-destructive testing of some large internal defects. For some smaller defects, we can choose detectors with smaller pixel size to cope with higher detection needs, and the common pixel sizes of the detectors on the market are 0.1 mm, 0.2 mm, 0.4 mm, and 0.8 mm.
By adjusting the key parameters of the system, the real-time imaging frame rate and image quality are variable. Slices of comprehensive structure and dangerous sections can be scanned with higher frame rates and imaging quality, while some irrelevant slices can be scanned with lower frame rates and imaging quality. Computing power is effectively saved in this arrangement. Some other solutions can also apply in our system, such as inspecting the object in the region of interest so that the reconstruction time can be decreased [
56].
This is the first time training the network using a medical dataset and applying it to industrial CT reconstruction. The medical CT data can be viewed as the source domain, and the acquired industrial CT data can be viewed as the target domain. Transfer learning can greatly reduce the training time and deployment cycle by applying the pre-trained model from the source domain to the target domain.
In a further study, we will focus on reducing the needed projection number for reconstruction by optimizing the deep-learning reconstruction network and applying the knowledge of transfer learning [
57]. In this way, the number of X-ray sources and detectors can be further reduced, and the system structure complexity and the cost will be reduced as well.
With the guarantee of imaging quality and imaging speed, our proposed system provides an ideal solution for the sorting, grading, quality inspection, material analysis and optimization of complex manufacturing processes in recycling, food processing, mining and other process industries. It can also be applied in the field of security as well.
Our proposed system can significantly increase the speed and accuracy of inspection in production processes, and it is convenient to be integrated into production lines. Evaluation metrics and inspection images are updated in real time, and the quality of each product can be verified.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}