1. Introduction
With the improvement in people’s network security awareness, more and more websites and applications choose to encrypt their network traffic. Nowadays, the Secure Socket Layer/Transport Layer Security (SSL/TLS) protocol is the most frequently used encryption protocol. The intention of traffic encryption is to protect users’ information from leakage, but an attacker can also encrypt their malicious data to carry out an attack secretly. Traditional intrusion-detection technologies have difficulty dealing with encrypted traffic, which means the attack activity can bypass the detection engine.
Traditional traffic classification methods are mainly port-based, payload-based, or statistic-based [
1,
2]. The port-based and payload-based methods are unable to detect encrypted malicious traffic [
3]. As for the statistic-based method, its detection accuracy depends heavily on the design of its statistical features, so improper features will limit the detection accuracy [
4].
In recent years, deep neural network (DNN)-based model such as the convolutional neural network (CNN) and recurrent neural network (RNN) have achieved great success in the fields of image classification and natural language processing [
5,
6], and have been applied in the field of cryptanalysis. By automatically extracting features from traffic, these methods can avoid the problem of selecting artificial features, and achieve good detection performance. However, a DNN relies on large-scale and high-quality training data to achieve good performance. When training samples are insufficient, it is difficult to build an effective detection model. So, when a new type of attack appears, since the number of labeled samples is small at that time, it is difficult to train a detection model with good performance. In addition, for the multiclassification case, since the number of training samples of each class will be less, a detection model based on a deep-learning method will face the same problem. Deep forest is a multilayer model based on a decision tree ensemble that has been used in the field of image classification, and has proved suitable for small-scale and unbalanced data detection [
7,
8]. Therefore, aiming at the high-precision detection of SSL/TLS-encrypted malicious traffic, we proposed a DF-IDS method based on deep forest for small-scale and unbalanced data.
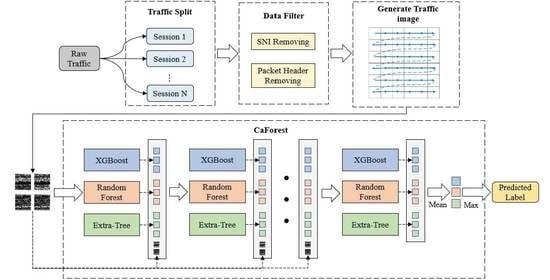
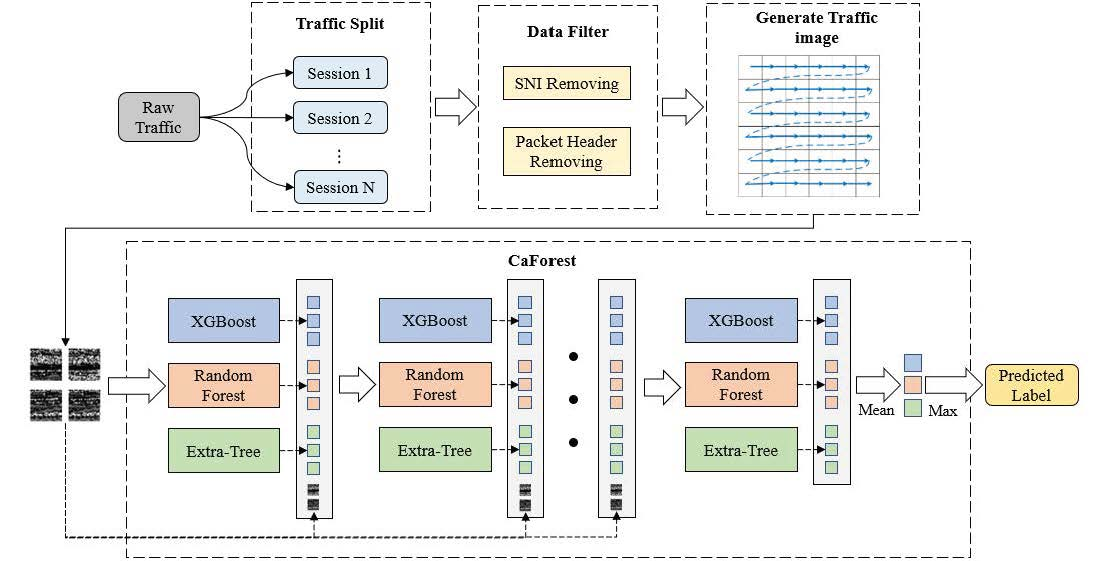
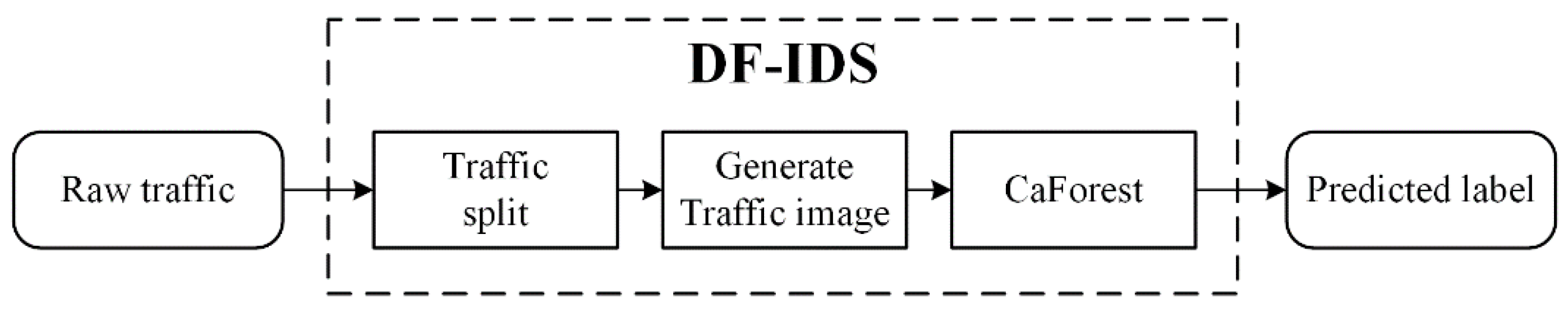
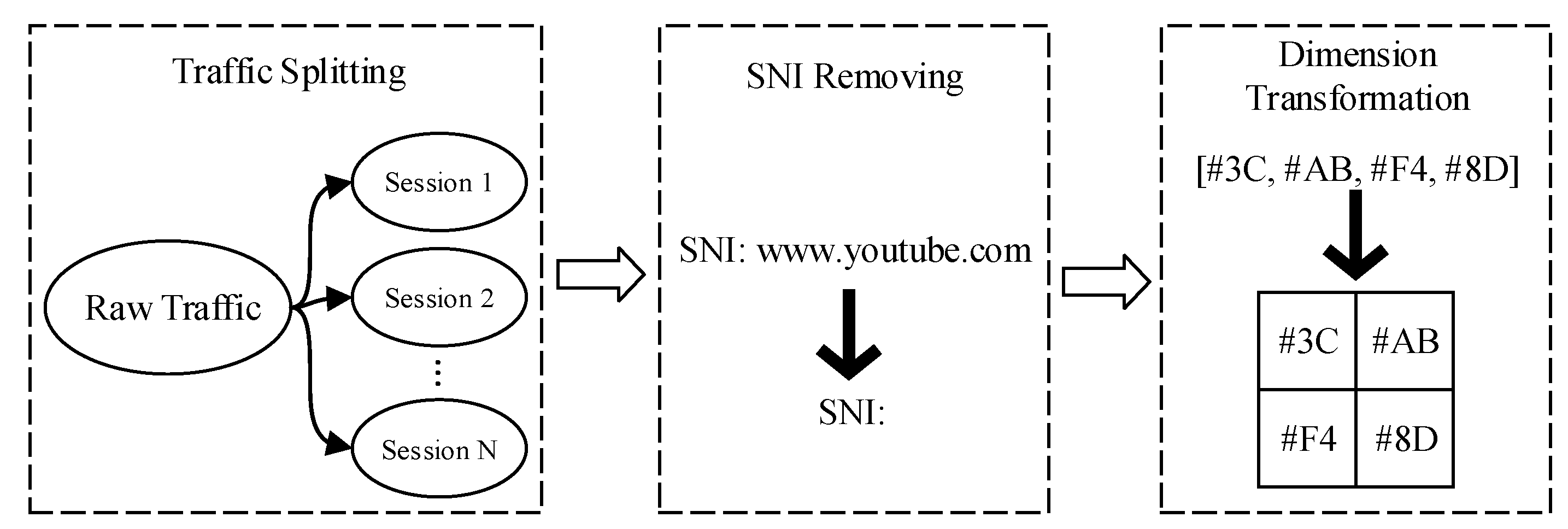
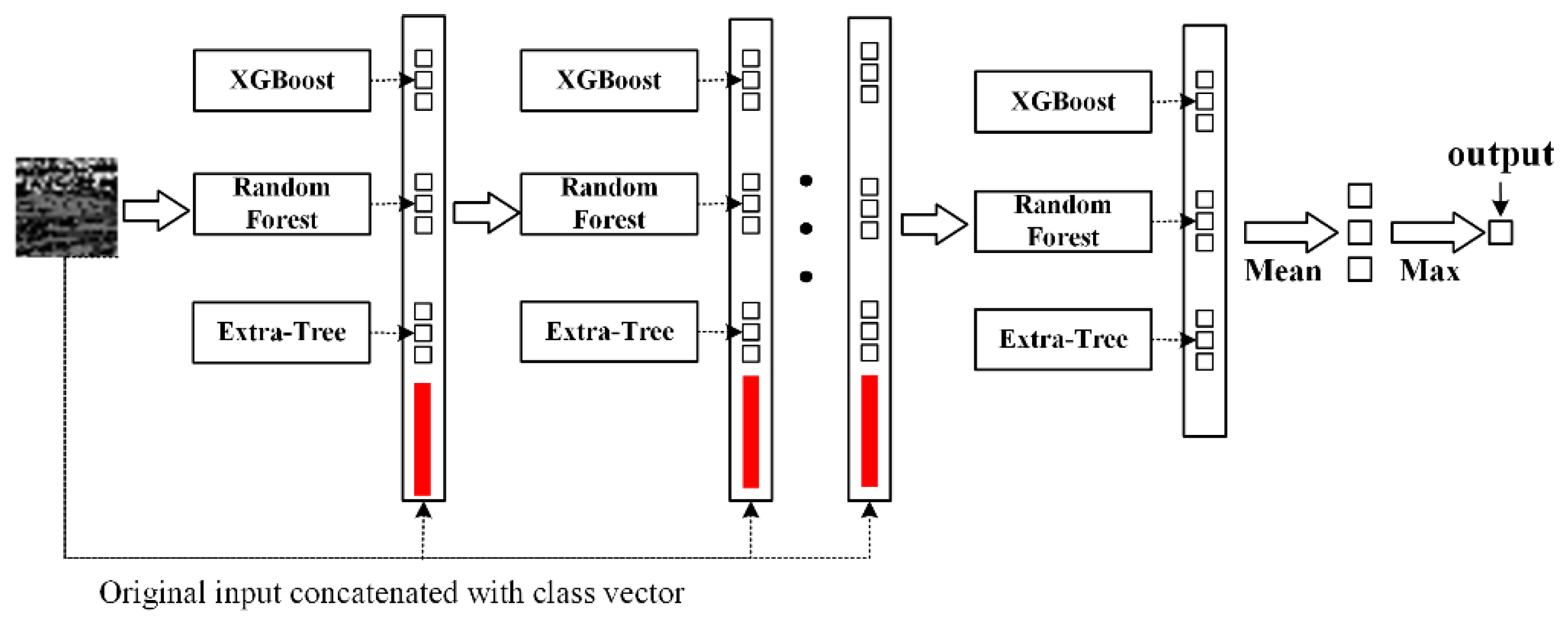
The scope of this paper is detection of network intrusion. The purpose of the proposed work was to solve the existing deep-learning models’ problem due to a lack of data. The main contribution of this paper was to propose a deep-forest-based anomaly-intrusion detection framework named DF-IDS for small-scale and unbalanced SSL/TLS encrypted malicious traffic. In this framework, firstly, according to the characteristics of SSL/TLS-encrypted malicious traffic, the original traffic was split into sessions and converted to a traffic image as the input of the detector. Then, based on deep-forest technology, and considering both the detection accuracy and efficiency, an improved gcForest framework named CaForest was designed. This framework could integrate various type of base classifiers, and the depth of model could automatically adjust according to the data. DF-IDS realized high-precision encrypted malicious traffic detection on small-scale and unbalanced data.
The remainder of this paper is organized as follows.
Section 2 introduces work related to encrypted traffic detection.
Section 3 presents our DF-IDS method, including the data-preprocessing method and the design of the detection model.
Section 4 presents the experiments and results to evaluate our method, and we compare our method with other works.
Section 5 closes with our conclusions and plans for future work.
Table 1 shows all acronyms used in this paper.
2. Related Work
With the development of deep-learning technology, many researchers have applied it to encrypted traffic classification. Most studies currently available were focused on the classification of benign network traffic, such as video flow, chat flow, file flow, and so on. Lotfollahi et al. [
9] used a stacked autoencoder (SAE) and a 1D convolutional neural network (1D-CNN) to detect encrypted benign traffic. They extracted the first 1500 bytes starting from the IP header of each packet, masked the IP address and port number, then applied SAE or 1D-CNN to train the classifiers. In this work, a single packet was used as the input sample, so the sequential correlation of the entire flow was not well utilized. Vu et al. [
10] extracted the head of a packet starting from the IP layer and the first n bytes of payload, and utilized long short-term memory (LSTM) as the classification model; this method achieved a high F1 score of 0.98. However, since different types of encrypted traffic have specific IP addresses and port numbers in the head of network packets, the classification results may have been affected by these factors [
9]. Wang et al. [
11] proposed an end-to-end encrypted traffic-classification method based on 1D-CNN. They extracted the first 784 bytes of each flow or session as the input, and achieved a precision of 85.8% and a recall of 85.9% in a 12-classification experiment. Zou et al. [
12] proposed a cascade model of CNN and LSTM. They used any three consecutive packets in a session and extracted the first 784 bytes of each packet starting from the IP layer, then reshaped these data into a 2D image as the input. Here, CNN was used to extract spatial features, and LSTM was adopted to find the temporal relevancies of the spatial features. Using the same dataset as a reference [
11], the average precision and recall were increased by 5%. Lopez-Martin et al. proposed a classification model named gaNet-C [
13] by using hyperbolic tangent (tanh) layers as the final layer of each “building block”, adding a sigmoid fully connected (FC) layer prior to any network output, and applying a log loss instead of a quadratic loss as the cost function. Experiments on an unbalanced dataset showed that the accuracy of gaNet-C could achieve 94%, the recall was 60%, and the precision was 85% in binary classification. Zeng et al. [
14] proposed a framework called deep-full-range (DFR), in which 1D-CNN, LSTM, and SAE were employed. They extracted the first 900 bytes of each data file as the input. The experiments on the ISCX VPN-non VPN traffic dataset showed that the model’s performances based on 1D-CNN and LSTM were better than that of SAE.
At present, the features used for encrypted malicious traffic detection are mainly based on statistical characteristics. Prasse et al. [
15] combined byte-related features, time-related features, and domain name features to train an LSTM-based classifier. Their experiments showed that the performance of the detector with combined features was better than that of the detectors using a single type of feature. In their method, the domain name was used; however, since the domain name is easier to be modified or forged by attackers, a detector trained with this information may be easily fooled. Anderson et al. [
16] considered that different software had different preference when using protocols such as TLS, domain name system (DNS) and Hypertext Transfer Protocol (HTTP), so they used not only statistical features, but also TLS handshake metadata, DNS contextual flow linked to the encrypted flow, and the HTTP headers of the HTTP contextual flow. The experiments showed that their work effectively reduced the false-alarm rate. This work proved that the SSL/TLS handshake metadata was useful in detecting SSL/TLS-encrypted malicious traffic. In addition, Anderson et al. [
17] extracted 22 standard features for TLS-encrypted session traffic based on Williams’ work [
18], and enhanced them to obtained 319 enhanced features. Six common machine-learning algorithms, such as support vector machine (SVM), random forest (RF), and decision tree, were used to build models. The experiments on two large-scale datasets showed that, with the enhanced features, the performance of the classifiers were improved, and models based on a decision tree or RF had better classification accuracies. Shekhawat et al. [
19] proposed to use byte-related features, time-related features and SSL/TLS-protocol-related features. They conducted classification with SVM, RF, and XGBoost, and achieved accuracies of 91.22%, 99.8%, and 99.88%, respectively, in binary classification. Their experiments showed that the decision tree ensemble model performed better than SVM. This work also proved that SSL/TLS protocol information is useful for classification. Stergiopoulos et al. [
20] selected the size of packet, the size of payload, the size ratio of payload to packet, the size ratio of current packet to previous packet, and the interarrival time as features. They used a classification and regression tree (CART) decision tree and the K-NN (k-nearest neighbors) algorithm as classifiers, and achieved an accuracy of 94.5% in a binary-classification experiment. However, in the case of small-scale data, the accuracy dropped to 88.8%.
A summary of related works and ours are shown in
Table 2. It can be seen that most studies were focused on the classification of benign application traffic in end-to-end mode, or benign and malicious binary classification in feature-based methodology. Only a few studies aimed at malicious multiclassification in end-to-end mode. At the same time, although many studies realized classification of encrypted traffic based on a deep-learning method, which proved the effectiveness of the deep-learning method in the task of encrypted traffic classification, these works were all based on a large number of samples. Since the main characteristic of a deep-learning-based classifier is its reliance on a large number of training samples, when the number of training samples is insufficient, such as 1000 samples or less, a model based on deep learning can easily fall into overfitting, making it difficult to obtain a high detection accuracy. In view of this problem, we designed a novel deep-forest-based algorithm for encrypted malicious traffic with small-scale and imbalanced data.
5. Conclusions
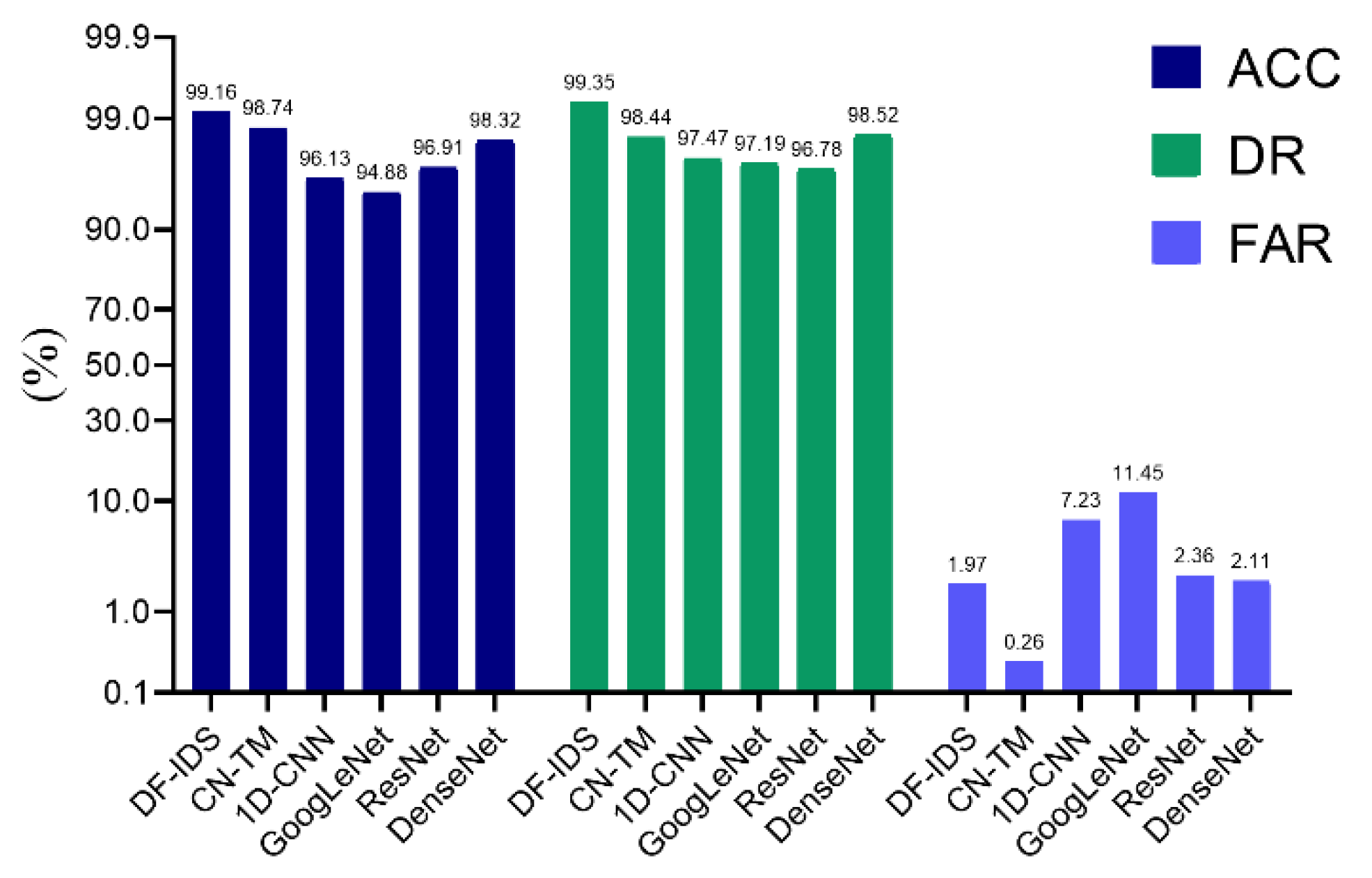
To solve the problem of the detection of SSL/TLS-encrypted malicious traffic, a DF-IDS detection method was proposed in this paper. This method avoided the problem of feature design and extraction by splitting raw traffic according to session and converting it into an image to achieve end-to-end detection. Focusing on the small-scale and unbalanced data, a CaForest model was built based on a deep forest and gcForest framework. By integrating various basis classifiers, such as random forest, Extra Trees, etc., the model could detect encrypted malicious traffic with high accuracy and a low false-alarm rate. It achieved a fine-grained multiclassification of malicious traffic, and realized the early detection of encrypted malicious traffic.
One of the main problems of CaForest is that the speed is sometimes too slow, so a new parallel framework, such as Ray, should be considered. In addition, more types of base classifiers can be applied to achieve a better performance. While this paper focused on SSL/TLS-encrypted traffic, in future work, we will perform more research on other encrypted traffic.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}