1. Introduction
The most recent definition of sepsis defines the syndrome as a “life-threatening organ dysfunction due to a dysregulated host response to infection” [
1,
2]. Sepsis is a highly complex and heterogeneous syndrome, which is influenced by two types of characteristics: those associated with the patient (e.g., immunologic status, age, comorbidities) [
3,
4], and those associated with the infection (e.g., site of infection, pathogen type, virulence) [
1,
5]. As a consequence, their relative contribution to organ damage may vary across patients due to the combinations of such characteristics: sepsis is a common pathway from infection to death. Kidneys, liver, lungs, heart, the central nervous system, and the hematologic system are among the most commonly affected [
2].
Management is a major challenge for healthcare systems, affecting high- and low-income countries alike [
6]. Sepsis continues to be a leading cause of death worldwide; in 2017, there were an estimated 48.9 million cases and 11 million sepsis-related deaths worldwide [
7]. Globally, it is associated with a 10–20% in-hospital mortality rate [
2,
8,
9,
10]. Sepsis can also be very expensive to treat, the costs for sepsis management in U.S. hospitals rank highest among admissions for all disease states, amounting to over USD 20 billion in 2011, growing to over USD 23 billion in 2013, and cost more than USD 24 billion annually [
9,
11,
12,
13].
Various investigations have demonstrated that early diagnosis and appropriate antibiotic therapy have the potential to reduce mortality among the septic population [
14,
15,
16]. Despite this, detecting sepsis at this stage of the disease is difficult. One of the main reasons is that sepsis is a heterogeneous syndrome whose course depends on different pathophysiological mechanisms, complexity in clinical context, and clinical phenotypes. For clinicians and researchers, the challenge is to objectively assess the true magnitude of organ failure for each patient [
17]. There is also a lack of accurate diagnostic tools [
18]. Different and complex scoring systems have been defined for bedside evaluation, allowing early detection of patient deterioration [
2,
19,
20]. Several scores are currently used, such as: Acute Physiology and Chronic Health Evaluation (APACHE II) [
21], Simplified Acute Physiology Score (SAPS II) [
22], Sequential Organ Failure Assessment (SOFA) [
23], and Quick SOFA (qSOFA) [
2], which have been validated to assess illness severity from the weighted combination of clinical and laboratory measures. However, these scoring systems, indeed useful for predicting general deterioration or mortality in studies conducted in intensive care units (ICU), cannot identify sepsis with high sensitivity and specificity at an individual level [
2,
24]. In addition, they present significant errors at patient data in clinical use, showing methodological weaknesses [
25].
The accelerating generation of vast amounts of healthcare data will completely change the nature of medical care. The clinical decision support systems that integrate both laboratory data and biomarkers have the potential to greatly improve patient outcomes [
26,
27,
28]. Assessing the utility of these complex datasets for supporting clinical decisions is the aim of most current research projects [
29,
30]. Recent studies have deployed ensemble models using real-world events to find important predictive parameters to track down those patients who are at the highest risk of death [
31].
In the last decade, a substantial number of papers have been published on clinical applications of machine learning for the early prediction of sepsis in ICU [
32,
33,
34,
35,
36,
37,
38,
39]. However, there are important disparities in the identification of sepsis cohorts due the use of various approaches and considerable heterogeneity in definitions [
30,
32,
40]. Many studies use ICD coding [
36,
41,
42], which is considered an unreliable tool with limitations in identifying septic patients [
43,
44,
45]. Others are based on systemic inflammatory response syndrome (SIRS) [
37,
46] or use the latest sepsis-3 criteria [
47,
48,
49]. The major concerns regarding the clinical applicability and the actual accuracy of these models are related with the definition of sepsis, the identification of organ dysfunction, and the selection of input features [
32,
50,
51,
52,
53,
54,
55]. By strategically deploying machine learning (ML) models and carefully selecting underlying data, cohorts, and features, algorithm developers can mitigate these concerns [
51,
52].
Several works used vital signs measurements and laboratory test results in order to develop models to predict sepsis during ICU stay [
56,
57]. Some trained ML algorithms using physiological parameters only, as input features. For example, in [
49] the authors used six vital signs—heart rate (HR), respiratory rate (RR), temperature (T), peripheral oxygen saturation (
SpO2), systolic blood pressure (SBP), and diastolic blood pressure (DBP)—as the inputs in an XGBoost model. Recent studies have investigated the change in variability of vital sings with a set of the following four features: arterial pressure (AP), HR, RR and T. They developed a support vector machine (SVM) algorithm achieving a 0.88 AUC-ROC for predicting four hours before the sepsis onset [
58]. Other models have added the use of laboratory test results, demographics, and comorbidities to improve the results [
42,
59]. In another study, a collection of six continuous minute-by-minute physiological data (HR, RR, T,
, SBP, DBP) and the white blood cell (WBC) count were used in a random forest (RF) model with a 0.8 sensitivity within an hour before the sepsis onset [
37]. In [
60], the authors used 34 physiological variables, of which 5 were vitals and 29 were laboratory values in a multitask Gaussian process through a deep recurrent neural network model. Others have added the use of the six vitals, Ph, WBC, and the age to be analyzed as times series in the inSight model [
41] for a 0.92 AUC-ROC.
Although there is no database with labeled sepsis cases, many studies have used the MIMIC II and MIMIC III databases. Using these databases, a wide range of prediction models have been applied for the early detection of sepsis. Some of the most prominent are artificial neural networks (ANN) [
46], deep temporal convolution networks [
61], deep learning (DL) models [
48], RFs [
37], and SVMs [
58,
62]. Although some of these recent efforts are promising, the lack of comparability of these studies does not allow a direct comparison [
33,
48]. In order to reduce this gap in a meaningful way and promote the cooperation between clinicians and researchers, the first contribution of this work is the provision of a reference database for researchers. This was developed with a detailed analysis of organs dysfunction related with sepsis patients on the MIMIC-III database.
Furthermore, this research explores the use of a proposed ML-based ensemble classification technique to develop a model for early sepsis prediction. The role of feature selection methods on the performance of the proposed ML model was investigated. To summarize, this work focuses on answering the following questions:
- 1.
What are the most relevant factors associated with the early prediction of ICU sepsis?
- 2.
Do ML techniques, especially ensemble models, outperform the current sepsis mortality scoring?
The contributions of this work are summarized as follows:
An applicable framework is proposed for identifying sepsis onset cases in ICU for adult patients. This structured approach yields a cohort selection well suited for identifying organs dysfunction and suspected infection, following the SEPSIS-3 definition.
An accurate and explainable sepsis prediction ensemble model is also proposed based on a comprehensive list of critical features from ICU patients. The model is based on a new ensemble algorithm using vital signs, laboratory test results, and demographics tabular variables as input. We discuss the development of different ML models, and the results are compared with the traditional scoring system.
The effects of various feature selection methods on the identification of the relevant features for 24, 12, and 6 h observation windows were analyzed, and the results were evaluated for 1 h prediction time.
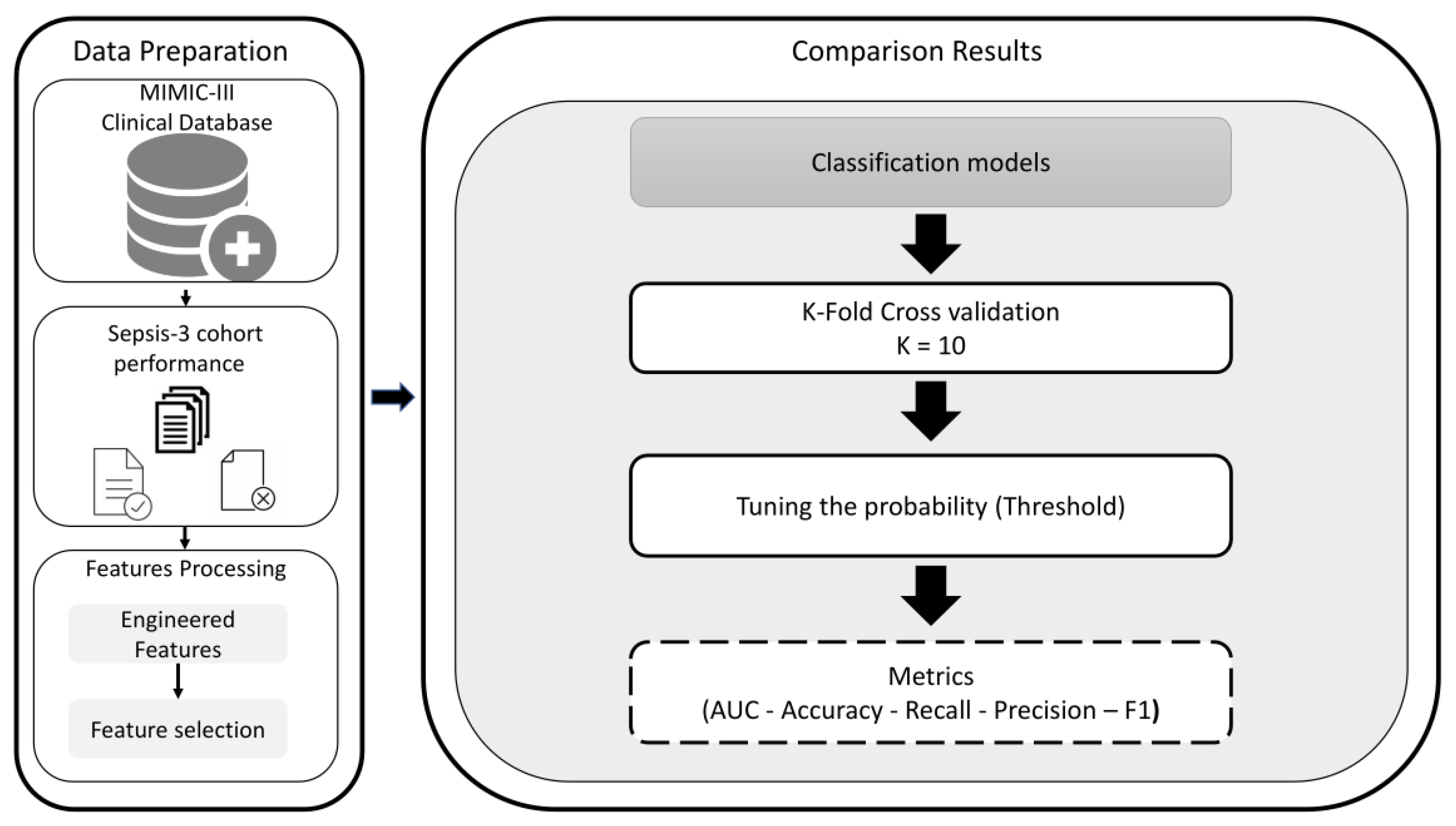
2. Materials and Methods
This section details the selected dataset, preprocessing steps, and feature selection in the experiments, following the methodology described in
Figure 1.
2.1. Data Source
We used the de-identified public database MIMIC-III v1.4, which contains patient data from the Beth Israel Deaconess Medical Center (BIDMC, Boston, MA, USA) [
63]. The database uses two information systems, Philips CareVue Clinical and IMDsoft MetaVision ICU, that have very different data structures. MIMIC III contains detailed information on more than 60,000 stays corresponding to more than 40,000 patients. The data are associated with 53,423 distinct hospital admissions for adult patients [
64].
2.2. Data Selection
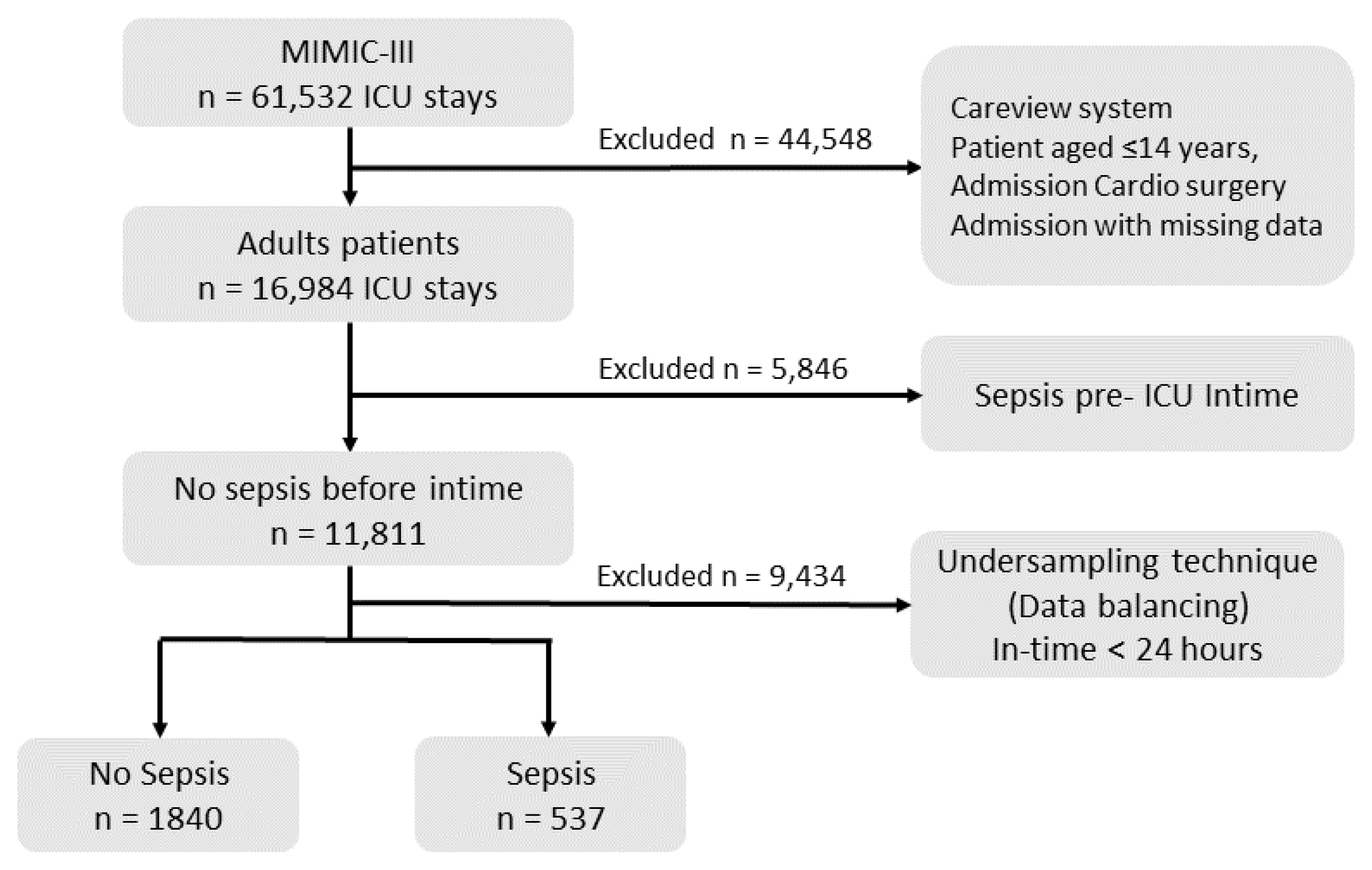
The aim of data preprocessing is improving the quality of the collected dataset. The data preprocessing includes selection patients cohort, data balancing, removing outliers, and handling missing data.
Figure 2 details the number of patients in each step and the exclusion steps performed.
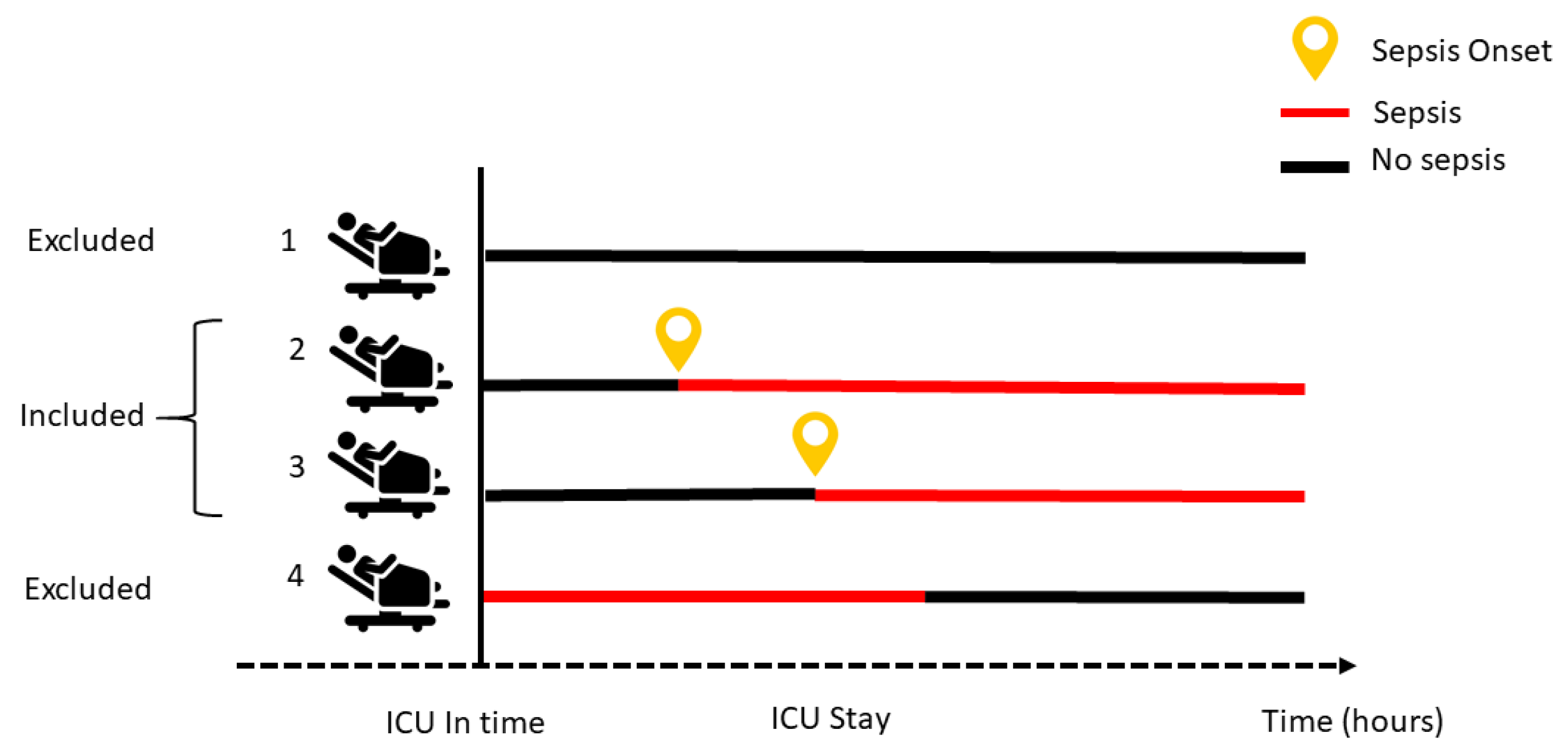
The first step of dataset preprocessing was the selection of the patient cohort. For this selection, we took into account different patient characteristics, as shown in
Figure 3 and described below.
For this study, we worked only with adult patients, considering as such all patients older than 14 years. For this, following the approach proposed by [
63], we used the age logged at the time of ICU admission.
For consistency and because the important data for identifying suspected infection does not appear in the CareVue system or on admission for cardio surgery, we decided to select only data collected via Meta Vision [
64]. MIMIC III contains missing and outliers values during the admission and ICU stay for many reasons, including medical equipment failure, systems errors, and others. In this work, those patients with features with more than 60% missing data were entirely removed. Following the medical specialist recommendation, all the outliers were removed from the dataset. Patients that had at least three records for vital signs were selected; other features with missing data were imputed using k-nearest neighbors imputation [
65].
Since the purpose of this study is the prediction of sepsis, we also excluded patients who were admitted to the ICU with sepsis, following the sepsis-3 criteria [
2]. This means that we chose to focus only on those patients who developed organs dysfunctions related to sepsis at any time during the ICU stay (
Figure 3).
2.3. Sepsis-3 Cohort Performance
For developing a prediction sepsis model, defining the sepsis cohort and the onset is important because this is the reference time to take the prior data. The structured approach used here yielded a well-suited cohort selection, firstly identifying the suspected infection and secondly the organs dysfunction following sepsis-3 [
2,
40]. To create this particular population, the sepsis-3 MIMIC III query reported by [
30,
59] was edited and used in Postgres. The code of the SQL query to obtain the cohort is available on Github (
https://github.com/Biocamacho/Sepsis-cohort, accessed on 2 April 2022).
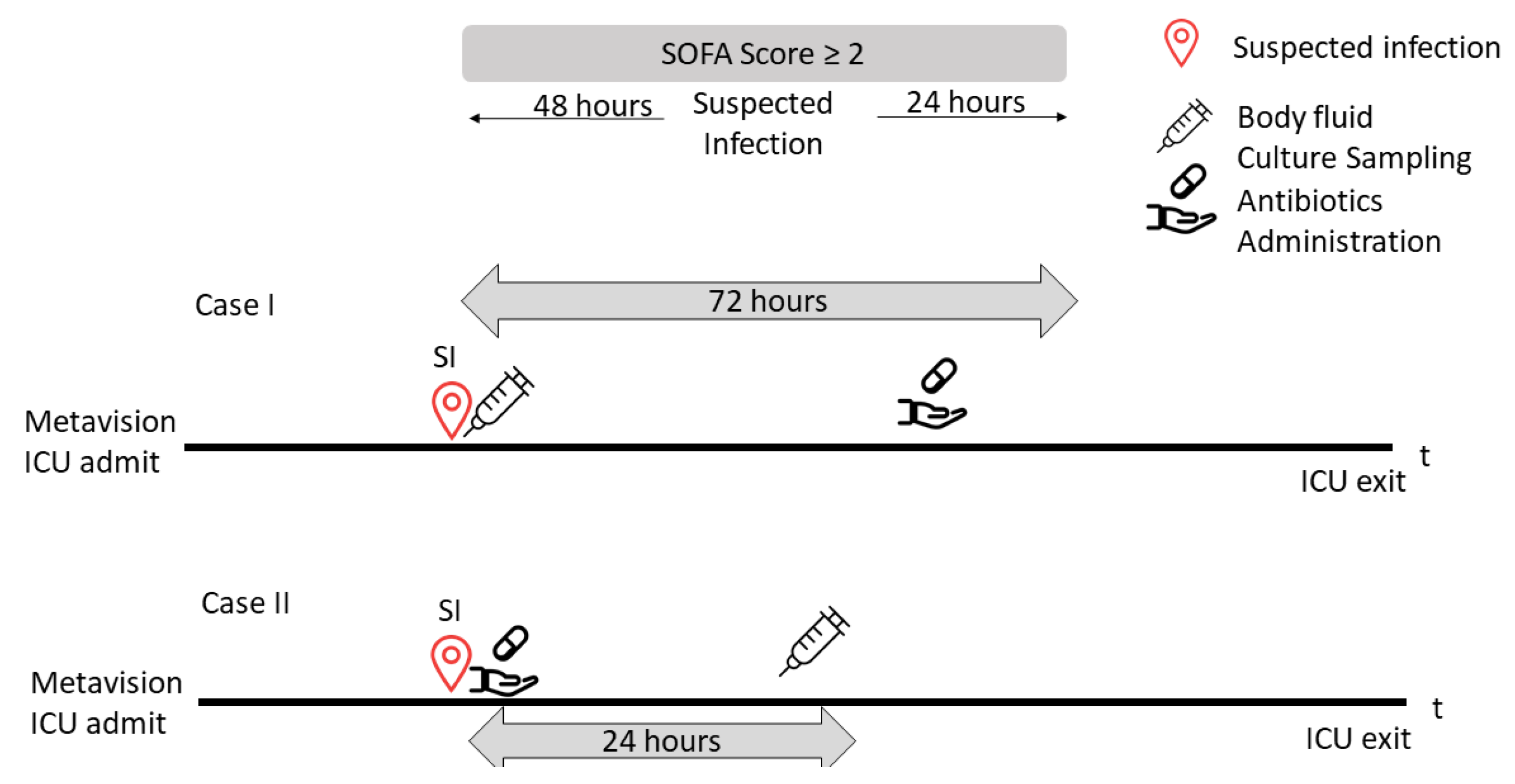
Suspected infection is defined as the administration of antibiotics and sampling of body fluid culture in a specified period.
Figure 4 shows two examples, one referring to each case. Case I illustrates an example of a patient having a body fluid culture sampling at a specified time prior to antibiotics administration. In that case, the time of suspected infection was when the culture sampling was ordered. The second case (Case II) shows a patient who was administered antibiotics at a time prior to the culture sampling. In that case, the time of suspected infection was when the antibiotics were administered to the patient.
We retrieved all the timestamps of antibiotic administration and body fluid sampling over the length of ICU stay. That is, if the culture was obtained before the antibiotic, then the medication was required to be administered within 72 h, whereas if the antibiotic medication was administered first, then the sampling was required within 24 h. In this study, for each timestamp, when the first suspected infection episode was identified, we extracted the 72 h window of data for each patient, before the episode.
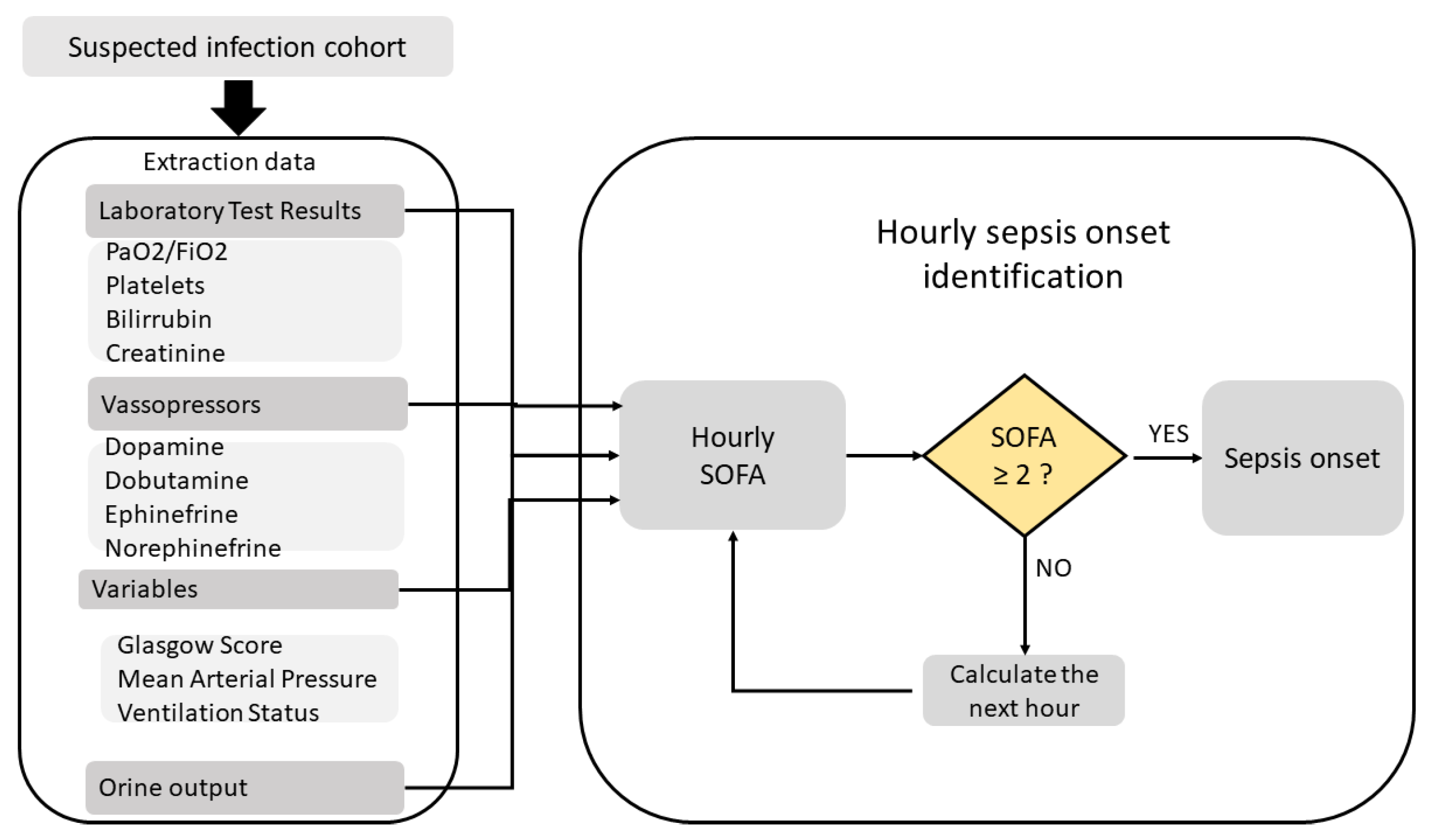
An organ dysfunction can be identified as an acute change in total SOFA ≧ 2 points consequent to the infection [
23]. Afterwards, we calculated the SOFA score at each hour for the suspected infection cohort in a 72 h window, considering a period of 48 h before and up to 24 h after the onset of infection, using several queries reported by [
59]. Using the Postgres function detailed in
Figure 5, we extracted all the variables used in SOFA score from laboratory test results, and the Glasgow score, the ventilation status, and the vasopressors from the charted events. Finally, we labeled those patients with a SOFA score in this window increased by two or more points as “sepsis onset”.
Table 1 shows the summary of characteristics of this population. The table shows how the dataset is divided in two groups: those who developed sepsis and those who did not. A total of 2377 patients met the inclusion criteria. They had a mean age of 62 years and there were no notable differences in comorbidities (diabetes, cancer, and Elixhauser index), mortality, and weight, but sepsis patients had a longer overall length of stay.
2.4. Feature Selection and Extraction
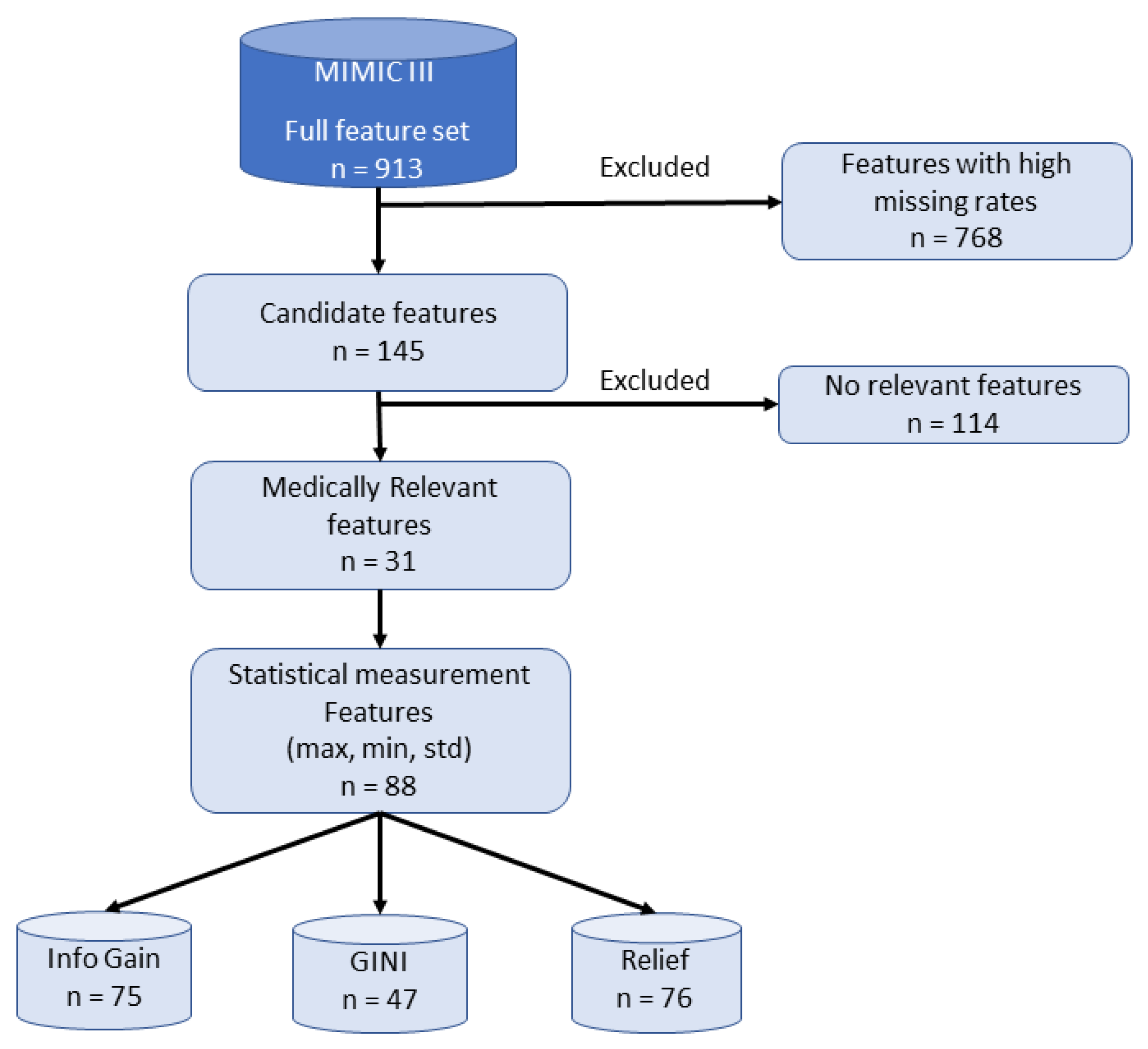
We processed the dataset to determine the candidates features to be used as input for the prediction models, excluding those features with a high missing rate, as we detail in
Figure 6. In this work, the queries provided by [
30,
59] for the selected patient cohort were extended and refined.
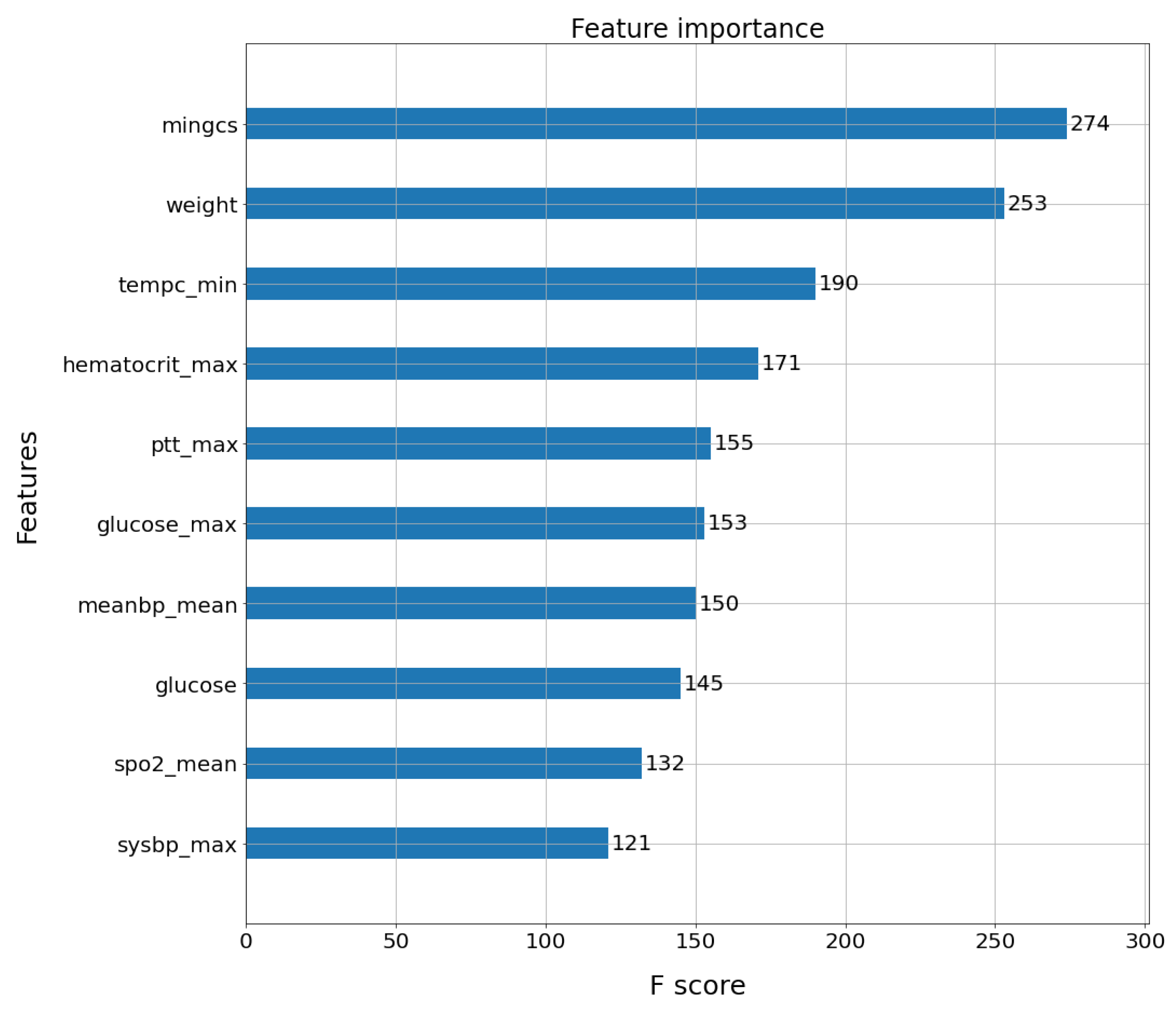
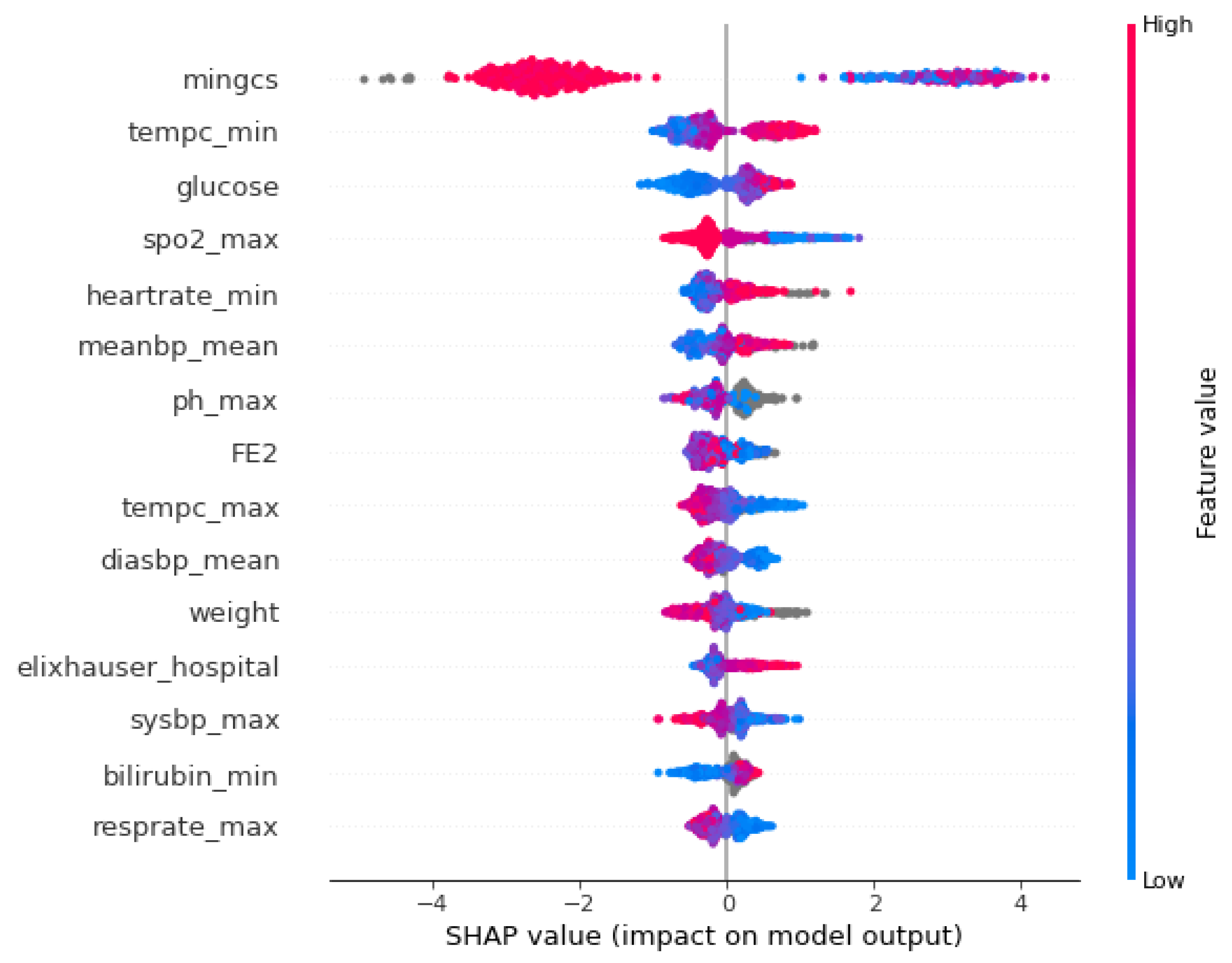
In the present research, 145 features were scanned and based on the medical knowledge of an expert physician, and the 31 medically relevant features (MRF) for sepsis prediction were gathered. The complete set of patient features included was grouped into three categories: physiological data (e.g., heart rate, temperature, etc.), laboratory test results (e.g., white blood count, glucose, hematocrit, hemoglobin, creatinine, bicarbonate, PH, and arterial blood gases) and demographics/score (age, Elixhauser Index, weight, and Glasgow coma score). According to [
57], we developed two engineered features to improved predictive performance: (a) shock index [
66] and (b) the product of age and systolic blood pressure (min, mean, and max, labeled as FE1, FE2, and FE3, respectively). All the features included are listed in
Table 2. Several articles and books have mentioned those particular variables being effective and therefore should be considered during sepsis diagnosis [
2,
18,
67].
Following [
56,
57,
58], we calculated statistical measures including the mean, maximum (max), minimum (min), and standard deviation (std) for laboratory and physiological data. We extracted 88 statistical features from the 31 MRF to represent the patients. As shown in
Figure 6, we applied a feature selection process to select the most important features prior to classification.
Feature selection has proven to be a successful preprocessing step in ML applications, building a subset of the original features with the following specific advantages: (a) avoiding overfitting, (b) improving model performance, (c) increasing speed, (d) providing cost-effective models. Feature selection methods are also classified into filters, embedded methods, and wrappers, depending on the relationship with the learning method [
68]. Wrappers and embedded techniques have a higher risk of overfitting and are very computationally intensive [
69]. In this study, it was preferred resorting to filter models because they are computationally simple and fast because they are independent of any learning methods, focusing on the general characteristics of the data [
70]. In filter models, features are first scored and ranked according to the relevance to the class label, and then are selected based on a threshold value [
71]. For each feature, each of these feature selection models has an evaluation value. Features with evaluation values greater than the threshold are chosen. Several feature selection processes exist, such as the one used by [
72]. In this study, the most common filter techniques were defined to perform setting the threshold to 0.002. The filter techniques used for feature selection are: information-gain-based methods [
73], relief [
74], and Gini.
Table A1 details the features names used in every feature set.
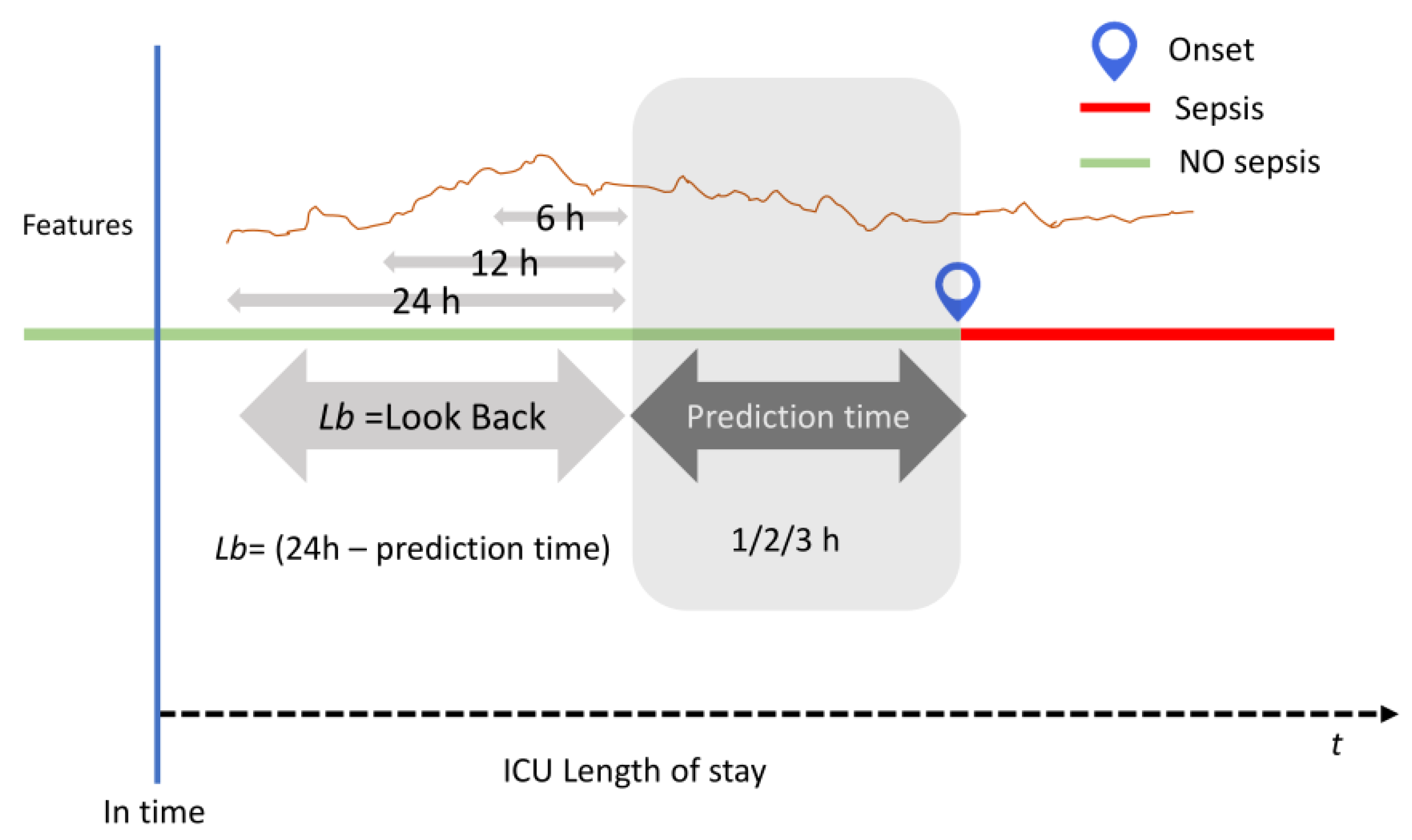
2.5. Prediction Methodology
To support the exhaustive comparison experiments, three long observational periods were considered and defined as the look back (LB) sequences of values that were used to predict. For each subset extracted earlier, three-time frames (24, 12, or 6 h) for the LB data were the inputs for the models. Finally, three horizons (1, 2, or 3 h) were defined as the prediction time to evaluate and compare the performance of all the models developed using the test set. The illustration of prediction methodology is shown in
Figure 7.
2.6. Classification Models
In the present research, an experimental comparison study of traditional and ensemble supervised models of ML has been developed to predict sepsis during ICU stay. The following section defines the conventional classification models used and a few more ensemble methods.
2.6.1. Support Vector Machine (SVM)
Proposed by [
75], this model is based on kernel classification to map N dimensional input data sets into a higher dimensional feature space. SVMs try to find the optimal generalization separating hyperplanes solving quadratic programming, represented by Equation (
1).
SVMs depend on a small subset of training dataset called support vectors. In the input space, each training datum is considered as an N dimensional vector X and its label is or .
2.6.2. K-Nearest Neighbor (KNN)
As a local classification method, KNN is based on the labels of the K-nearest patterns in data space [
76]. This method assumes that all the instances correspond to points in the n-dimensional space. After defining a specific distance, a neighbor is nearest if it has the smallest distance in the n-dimensional feature space. The most commonly used distance is the Euclidean (Equation (
2)).
The distance between two instances, and , is defined by , where denotes the value of the rth attribute of instance x.
2.6.3. Artificial Neural Network (ANN)
This model consists of three layers: an input layer, a hidden layer, and an output layer [
76]. This layer has interconnected neurons with weights and specific activation functions. The layers transform the data and pass them to the next layer. ANN can perform the task by learning from its previous inputs. Given a network with a fixed set of units and interconnections, this network adjusts the weights using the back-propagation learning process.
2.6.4. Naïve Bayes (NVC)
This classifier applies tasks where each instance
x is represented by a conjunction of attribute values and where the target function can take on any value from some finite set [
76]. This model is described through the construction of a Bayesian probabilistic model that assigns a posterior class probability to an instance: [
77]. The NVC uses these probabilities to assign an instance to a class, applying Bayes’ theorem, as shown in Equation (
3).
2.6.5. Random Forest (RF)
This classifier consists of a collection of classification or regression trees, which are simple models using binary splits on predictor variables to determine outcome predictions. The process is called feature sampling [
78]. The trees are the base learners for RF, and the prediction is defined by classifying the data with each tree and collecting a majority rule on the whole forest. Through the bagging mechanism, each tree is built using a different bootstrap sample of the dataset.
2.6.6. AdaBoost
Adaptive boosting (AdaBoost) is defined by Freund and Schapire [
79] as a boosting ensemble learning model that selects various classifier instances by preserving an adaptive weight distribution over the training examples. It is the sum of the weights of the misclassified instances divided by the total weight of all instances [
80]. Following each cycle, the weight distribution is updated based on the prediction results from the training samples. The weight of correctly classified instances is reduced, while the weight of misclassified instances is increased. Thus, AdaBoost produces a set of “easy” instances that are correctly classified with low weight and a set of “hard” ones that are misclassified with high weight. In the following iteration, a classifier is built for the reweighed data, which consequently focuses on classifying the hard instances correctly. This process continues for various cycles until, finally, AdaBoost linearly combines all the component classifiers into a single final hypothesis. Greater weights are given to component classifiers with a lower training error.
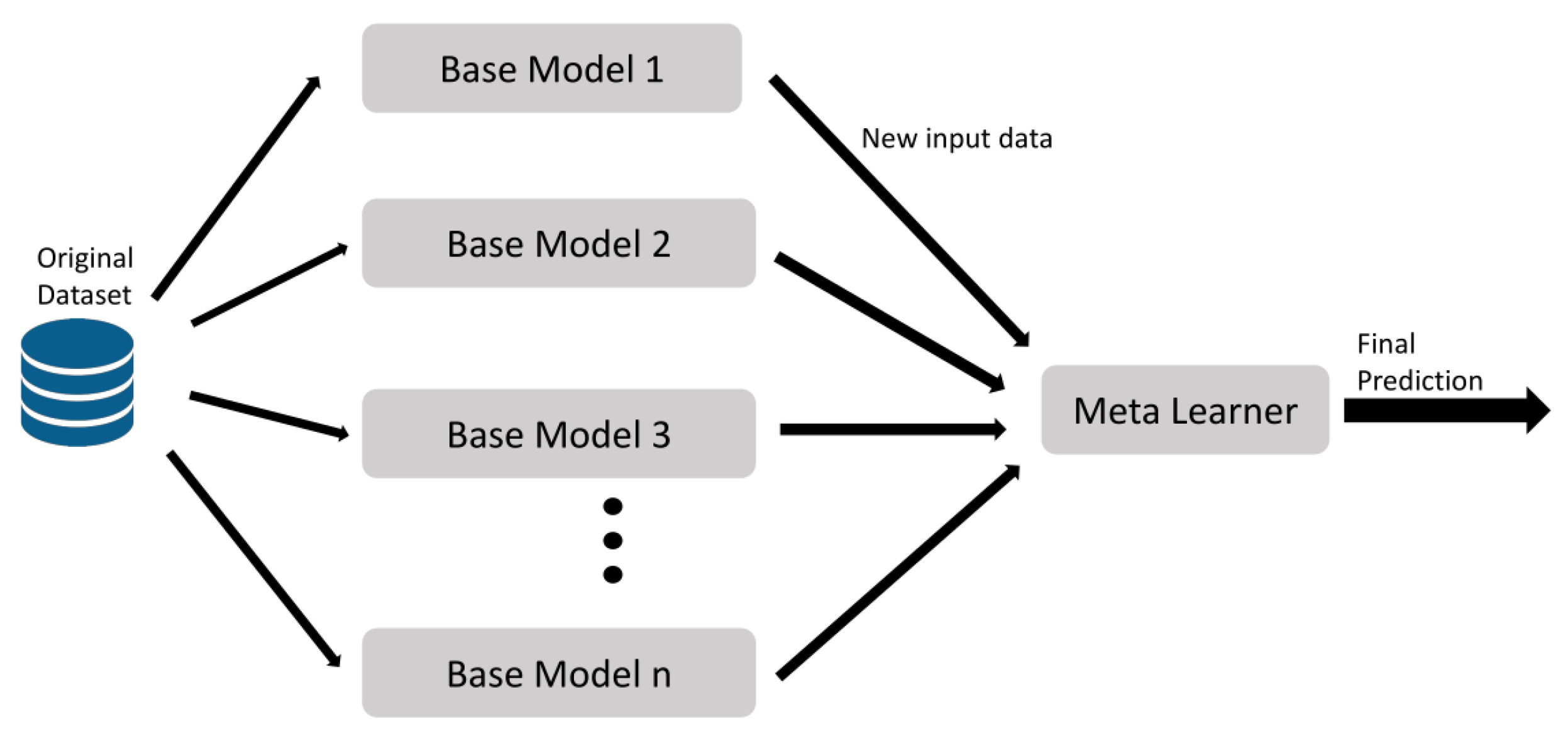
2.6.7. Stacking
Stacking is an ensemble learning technique that combines in parallel a set of different classifiers by training a meta-classifier to output a strong prediction based on the various models predictions [
81].
Figure 8 shows the stacking model, which implements the following steps: first, all the base models compute on the original dataset; second, the predictions made by these classifiers are considered as a new input data to the final model; eventually, a learning process occurs using this new input to obtain a final prediction.
2.6.8. XGBoost
Extreme gradient boosting (XGBoost) [
82] is another ensemble of classifiers, considered as an optimized gradient tree boosting model, based on algorithmic optimizations and hyperparameters to perform the learning process and control the overfitting. The most important factor behind the XGBoost model is the tree learning algorithm for handling sparse data. XGboost use an objective function to optimize the loss function, considering the results from the previous level, and adds regularization to perform the results.
2.7. Performance Metrics and Model Evaluation Procedures
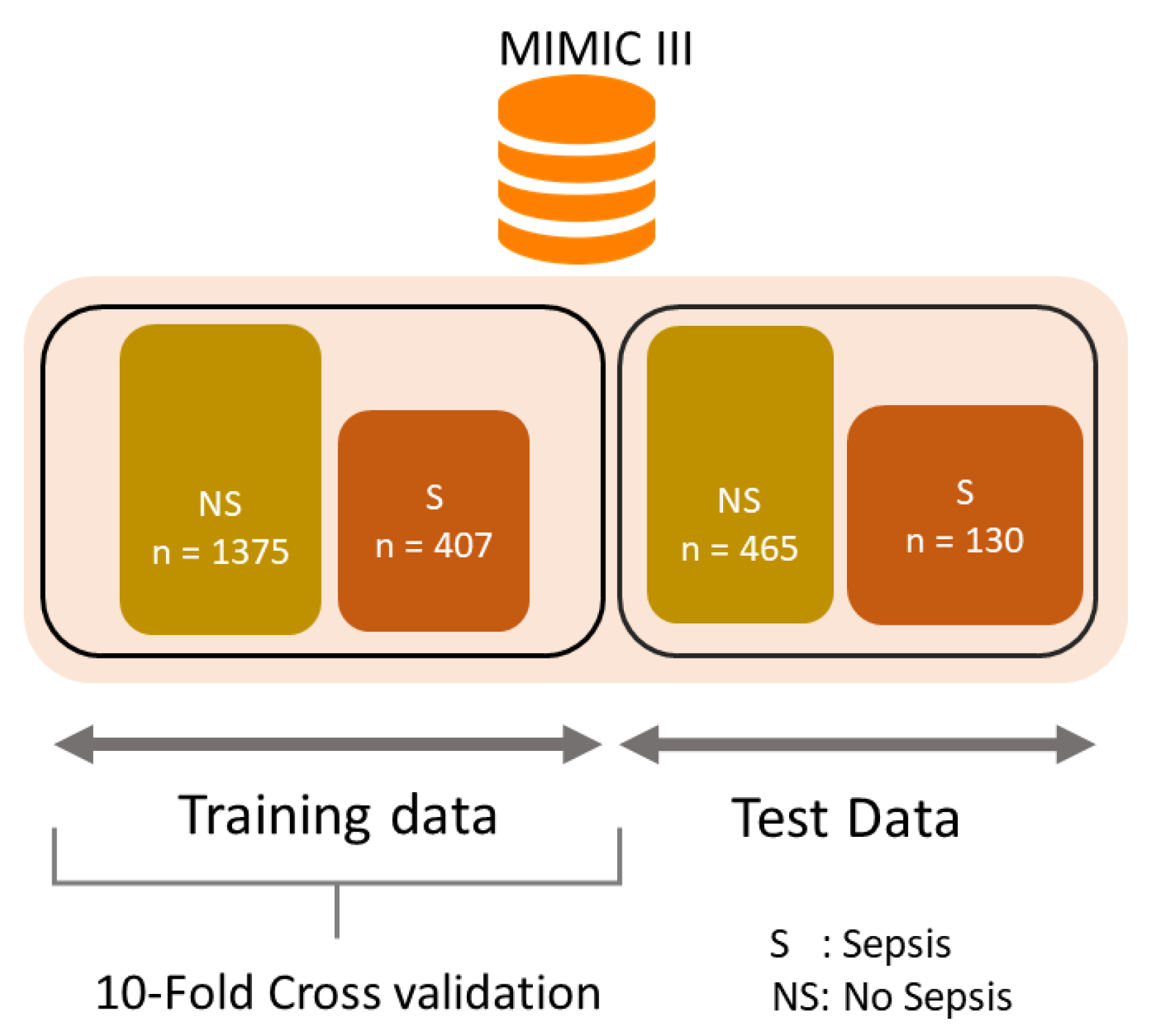
To evaluate all the predictions models train–test split procedure and k-fold cross-validation were used as model evaluation procedures. The dataset was randomly divided into training set (75%) and test set (25%).
Figure 9 shows the structure of train and test data sets. In this study, a 10-fold cross-validation method was used for selecting the best model for training [
76]. Cross-validation is defined as a method for the evaluation of the performance of a predictive model. Statistical analysis will generalize to an independent dataset. K-fold cross-validation is a method for dividing the original sample randomly into
K sub-samples. The model is then tested using a single sub-sample as validation data, while the remaining
sub-samples are used as training data. These process is repeated
K times, with one of the
K sub-samples representing as the validation data.
Class imbalance is a particular problem in medical datasets. In MIMIC-III, a majority patient had no sepsis (94.5%) and a minority of patients were sepsis diagnosed (5.5%) during ICU Stay. Two techniques are the most commonly used for data sampling: oversampling and undersampling. The latter, according to the research, has shown to be the superior option over oversampling [
83,
84]. In this research, the random undersampling technique was used to improve the data balance by removing patients from the prevalent class (no sepsis). Therefore, the undersampling process cut the sample to 2377 patients (77.4% no sepsis; 22.5% sepsis).
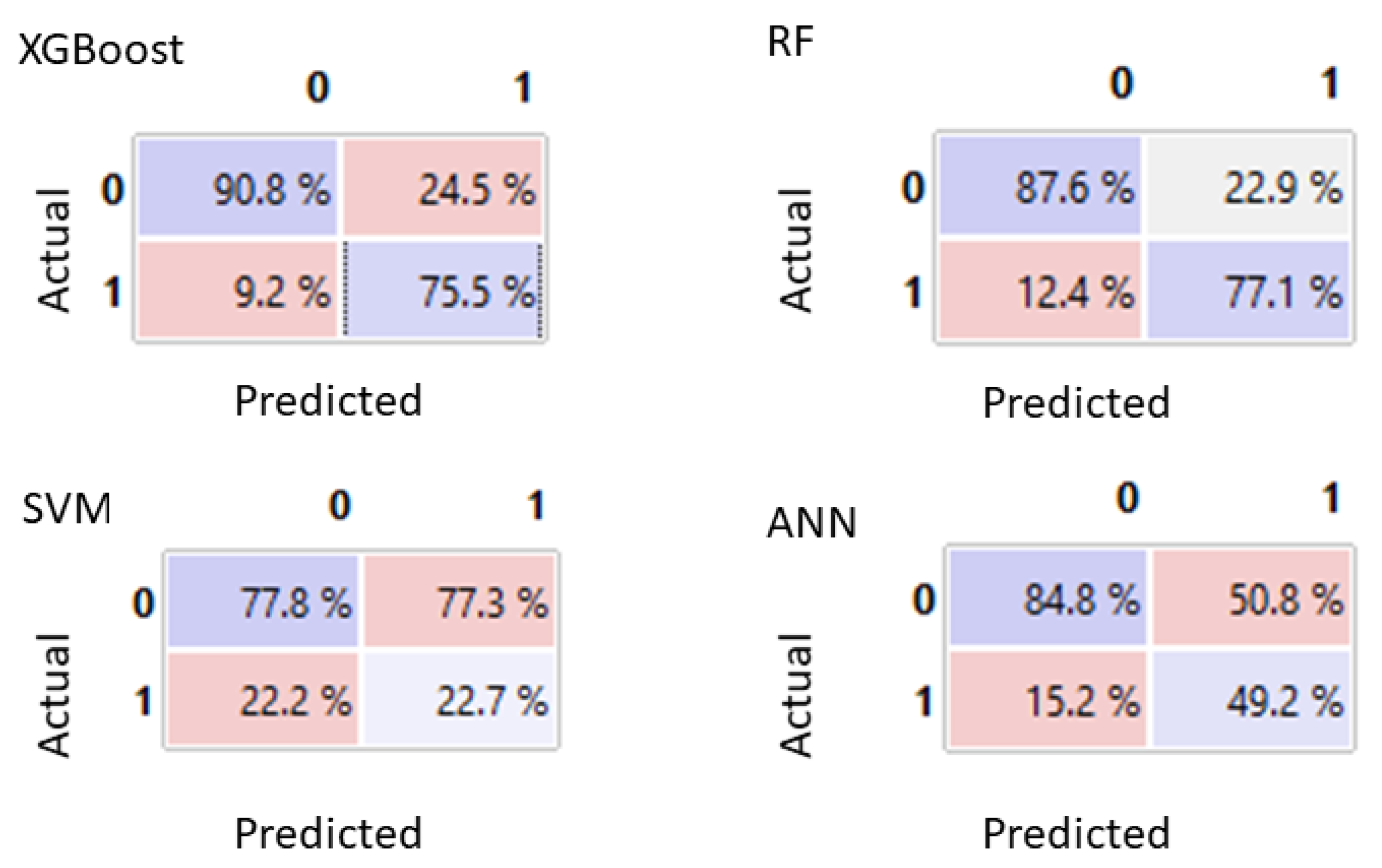
For each model included in this study, different metrics were obtained to evaluate the performance according to [
85]: area under receiver operating characteristic (AUC-ROC), accuracy, F1 score, recall, specificity, and precision as the evaluation metrics to report results. A binary classification allows to create a confusion matrix, as shown in
Table 3, based on the following four categorizations of predictions:
True positives (TP): instances correctly labeled as positive.
False positives (FP): negative instances incorrectly labeled as positive.
True negatives (TN): instances correctly labeled as negative.
False negatives (FN): positive instances incorrectly labeled as negative.
Accuracy measures indicate that the overall proportion of labels were correctly identified.
score is defined as the harmonic mean of
and
that sets their trade-off.
indicates the proportion of correctly predicted sepsis cases from the sepsis set.
Likewise, specificity represents the proportion of correctly predicted no-sepsis cases among the no-sepsis group. The AUC-ROC value considers the sensitivity against the specificity at various threshold settings. Lastly,
gives us the proportion of cases which were identified as having sepsis who actually had sepsis.
The performance of each classifier was evaluated with a number of comparisons including qSOFA and SOFA Score.
2.8. Selection of Classification Models
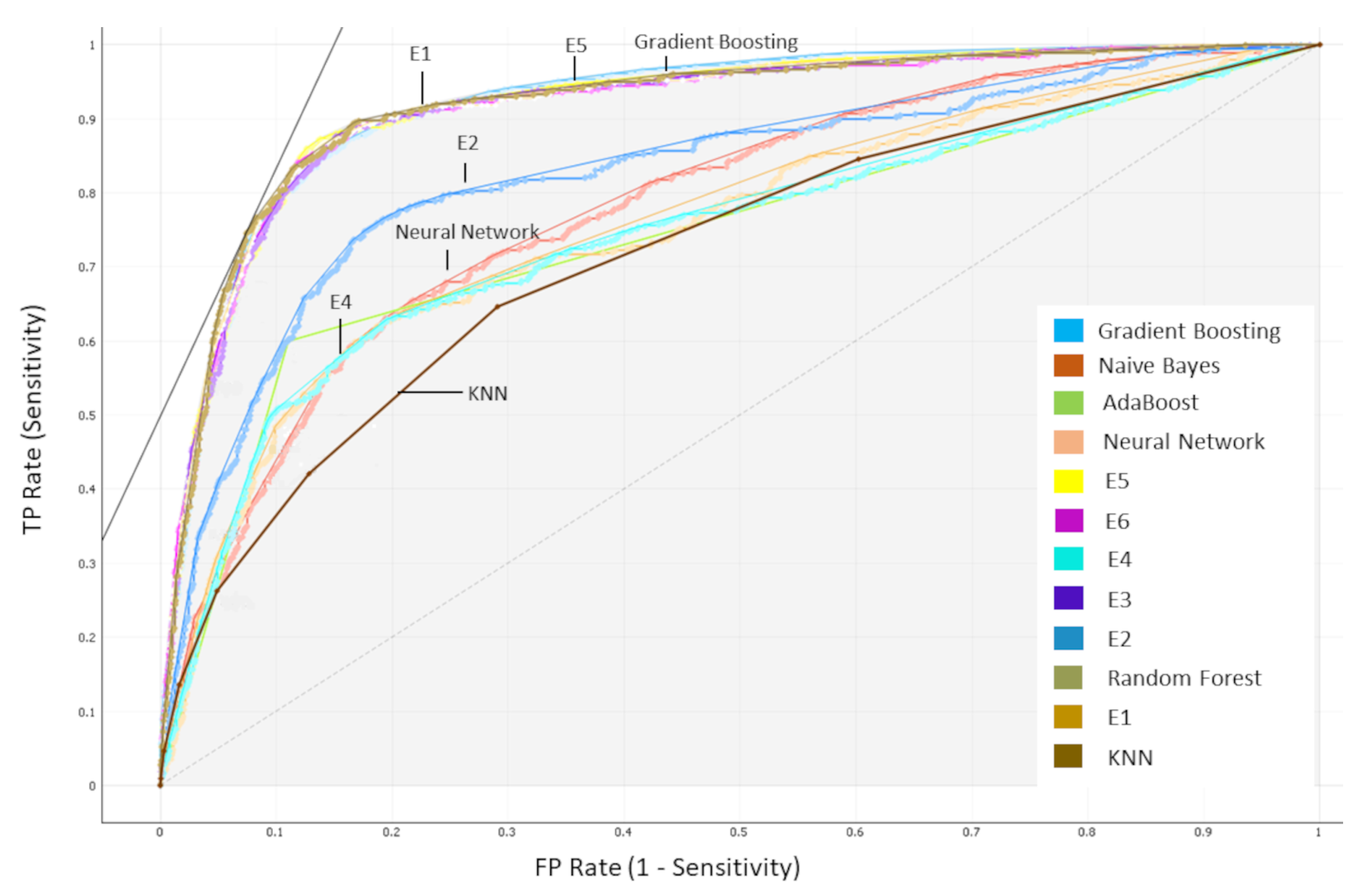
Several comparison experiments were performed using the following conventional classification models: SVM, KNN, RF, ANN, Naïve Bayes, and the combination with ensemble models: boosting (Adaboost and XGBoost) and stacking schemes.
An ensemble selection approach was used to achieve improved performance. The models were implemented in Orange version 3.31 [
86] and Phyton using Google Colab infrastructure [
87].
In the present study, three different prediction times (pt = 1/2/3 h) were considered. Therefore, nine different data collections were produced considering the different LB defined. For all the developed models, the performances were evaluated and compared against the traditional medical scores: the qSOFA and the SOFA Score.
4. Conclusions
Early diagnosis and an appropriate antibiotic therapy of sepsis is crucial but sometimes challenging. Several patient-health-score-based prediction systems have been employed for evaluating the early detection of patient deterioration. However, these scoring systems are useful for predicting general deterioration or mortality, but cannot identify sepsis in patients with high sensitivity and specificity at individual level. The increasing availability and the versatility of healthcare data suggest to implement ML techniques to develop models for predicting sepsis.
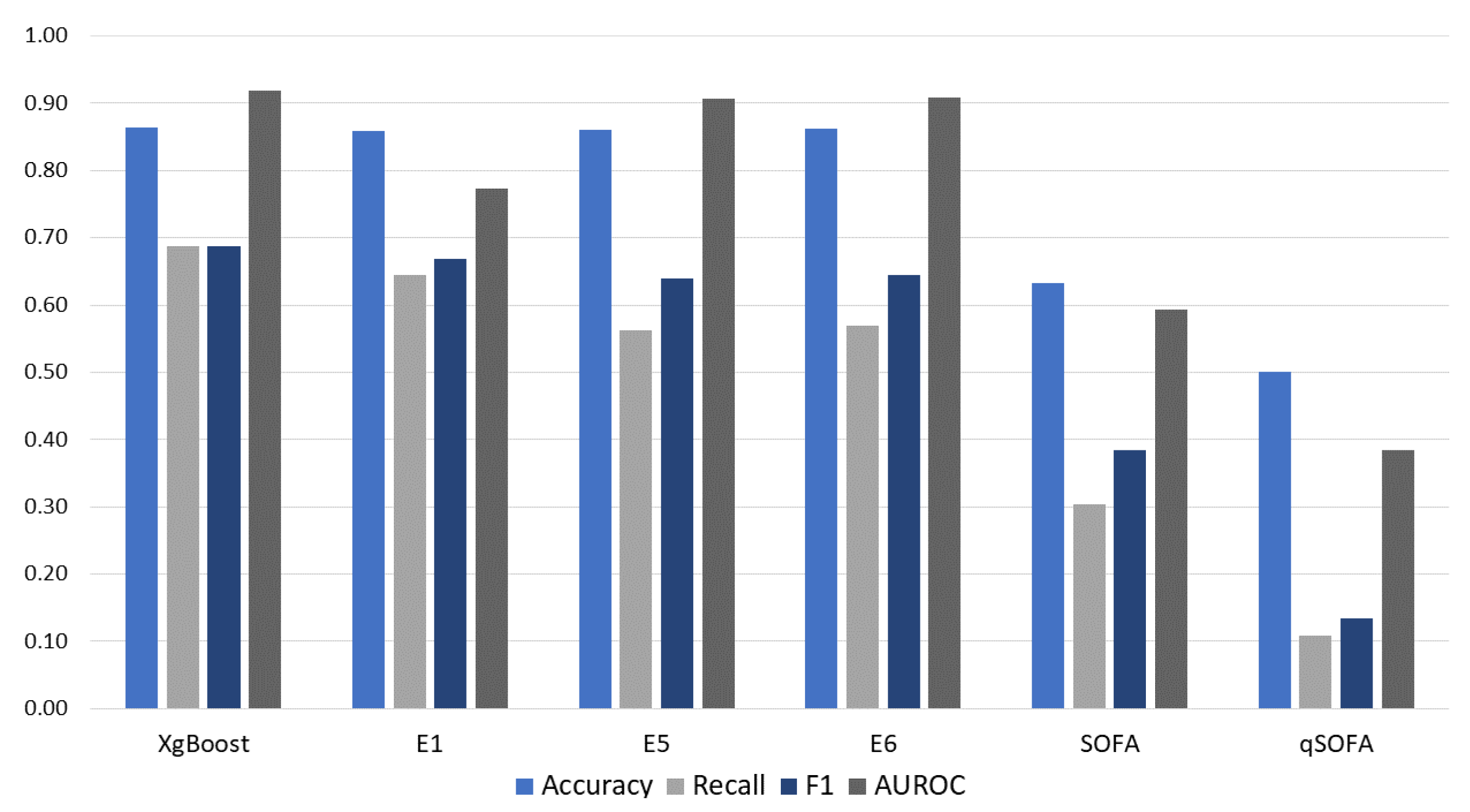
In this study, several ML-based models were applied for sepsis prediction using vital signs, laboratory test results, and demographics variability. The results demonstrate overall higher performance of ML models over the commonly used SOFA and qSOFA scoring systems at the time of sepsis onset.
The results reveal high metrics when using ensemble models and feature selection strategies for predicting sepsis. Particularly, this study demonstrated better results for information gain compared with conventional feature selection techniques. The addition of some variables from laboratory test results as input variables overall increases the model performance.
This work provides a consistent set of comparison of ML models for sepsis early prediction on the large healthcare datasets, following the sepsis-3 definition and selecting features in a meaningful way. The results are a strong motivator for implementing these ensemble models for early sepsis prediction in ICU cases.
In this study, the 12 ML models were computed with various feature windows for 1, 2, and 3 h of sepsis prediction. The ensemble models combining the variability of physiological data and laboratory test results, as well as demographics values, outperformed all the conventional algorithms. They also showed a large margin of improvement over traditional scoring systems at the time of sepsis onset. The best results were obtained using the XGBoost model implementing the information gain feature selection technique, achieving 0.911 AUC-ROC for 24 h of look back data in a t = 1 h prediction time.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













