4.3. Evaluation Metrics
SSIM [
47] uses the brightness, contrast, and structure of the image to measure the image similarity, and its value belongs to [0, 1]. The larger the value of SSIM, the better the registration effect. The calculation formula can be described as:
where
and
denote warped and ground-truth images, respectively.
and
represent the mean of all pixels in
and
, respectively.
and
represent the standard deviations of
and
, respectively.
represents the covariance of the two images.
and
represent constants to maintain stability.
MI [
50] reflects the degree of correlation by calculating the entropy and joint entropy of both the warped and ground-truth images. The larger the value, the higher the similarity. The calculation formula of MI can be described as:
where
and
denote warped and ground-truth images, respectively.
and
denote the calculation functions of entropy and joint entropy, respectively.
PSNR [
51] can directly reflect the difference in the grayscale of the two images as a whole. The larger the PSNR value, the smaller the gray difference between the two images, that is, the more similar the image pair is. The calculation formula of PSNR is as follows:
where
and
denote warped and ground-truth images, respectively.
and
represent the pixel locations in the image row and column, respectively.
is the number of bits per sample value.
Average corner error (ACE) [
41,
43] evaluates the homography performance by transforming the corners with estimated and ground-truth homography, respectively. The smaller the ACE value, the better the homography estimation performance, that is, the better the registration performance. The calculation formula of ACE can be expressed as:
where
and
are the corner
transformed by the estimated homography and the ground-truth homography, respectively.
Point matching error (PME) [
40,
42] utilizes manually annotated feature points for homography estimation performance evaluation, and it regards the average l2 distance between warped source and target points for each pair of test images as an error metric. The smaller the PME value, the better the homography estimation performance, that is, the better the registration performance. The calculation formula of PME is as follows:
where
denotes the feature points produced by the estimated homography transformation.
represents the target feature point marked manually.
represents the number of manually labeled feature point pairs.
4.4. Comparison on Synthetic Benchmark Dataset
We conduct quantitative comparisons with 11 algorithms on synthetic benchmark dataset, including traditional feature-based methods and deep learning-based methods. The evaluation results on warped infrared images and infrared ground-truth images are shown in
Table 4. In
Table 4, I
3×3 indicates that the 3 × 3 identity matrix is used as the “no-warping” homography matrix, and “-” indicates that the algorithm fails. We used evaluation metrics such as SSIM, MI, PSNR, ACE [
41], and AFRR in the quantitative comparison. Since MSE is calculated similarly to ACE [
41] and PME [
40], we do not use it as our evaluation metric in the future. In particular, partial deep learning-based methods are difficult to fit on infrared and visible datasets, such as UDHN [
39], MBL-UDHEN [
42], etc.
As shown in
Table 4, our algorithm significantly outperforms feature-based methods on most of the evaluation metrics, only worse than SIFT [
25] + RANSAC [
36] on the evaluation metric AFRR. Although this class of methods achieves the best on AFRR, it is the algorithm with the highest failure rate except for KAZE [
30] + MAGSAC++ [
48], as shown in
Figure 8. This shortcoming will greatly limit the practical application, and the rest of the traditional methods usually suffer from algorithm failures on infrared and visible datasets. In addition, we can observe that the ACE [
41] of the traditional method is generally large, which is caused by the characteristic of calculating the evaluation value through the corner position, so the size of the evaluation value reflects the degree of distortion of the image.
Furthermore, our algorithm slightly outperforms CADHN [
40] on every evaluation metric. In particular, the algorithm performance is significantly improved by 3.24% on ACE [
41].
4.5. Comparison on Real Dataset
Qualitative comparison. We performed qualitative comparisons with 11 contrasting algorithms on real dataset and fused the blue and green channels of the visible warped image with the red channel of the infrared target image to evaluate the registration performance. The fusion results are shown in
Figure 9, where “-” indicates that the algorithm fails. We can see that the feature-based solutions are severely distorted, and the algorithm is prone to failure. Therefore, it is difficult for the feature-based method to obtain a more accurate homography matrix in infrared and visible scenarios. In particular, the KAZE [
30] + MAGSAC++ [
48] algorithm fails on the test set.
In addition, the deep learning-based solution significantly outperforms the feature-based solution, resulting in more accurate warped images. Although it is difficult to see a significant difference between our method and CADHN [
40] in qualitative comparison, according to the PME [
40] in the lower right corner of
Figure 9, our results in both examples are significantly better than CADHN [
40]. The PME [
40] drops significantly from 4.04 and 5.86 to 3.43 and 5.19, respectively, where the red ghost in the fusion result of our method and CADHN [
40] represents the texture in the infrared target image.
Quantitative comparison. We use evaluation metrics such as SSIM, MI, PSNR, PME [
40], and AFRR to quantitatively compare visible warped images with infrared target images to demonstrate the effectiveness of our method, as shown in
Table 5. Infrared and visible image pairs have large grayscale differences, so evaluation metrics based on the pixel values are no longer applicable to this task. As shown in
Table 5, despite the severe distortion of the feature-based solutions, their SSIM and PSNR are consistent with the neural network-based methods, and even the PSNR of most of the feature-based methods is slightly higher than that of the neural network-based methods, which is obviously unrealistic.
In addition, MI measures the correlation between sets, so it can better reflect the registration performance than SSIM and PSNR. However, MI is also affected by image pixel values, so it cannot accurately express the image registration performance, nor can it reflect the registration performance of severely distorted wrapped images. Only a rough evaluation can be made. As can be seen from
Table 5, the deep learning-based solution significantly outperforms the feature-based solution.
Since the PME [
40] is calculated based on the position of the feature points, it is not affected by the gray level, which can well reflect the accuracy of the predicted homography matrix. As in column 5 in
Table 5, the feature-based solution cannot estimate a more accurate homography matrix, and the neural network-based solution performs well. In particular, since our method pays more attention to the details in the image pair, the performance of PME [
40] is improved by 3.94%.
As shown in column 6 in
Table 5, the AFRR evaluation value of the feature-based methods is 0, which is consistent with the severe distortion they appear in the qualitative comparison. In particular, our method significantly outperforms CADHN [
40] with a significant improvement in AFRR performance from 0.11 to 0.16. Although our evaluation metric AFRR can distinguish the registration performance of different algorithms to a certain extent, its accuracy is not high enough. This is because it has the defect of SIFT [
25], that is, it is difficult to extract feature point pairs of better quality in heterologous image pairs, which affects the calculation of AFRR itself.
4.6. Ablation Studies
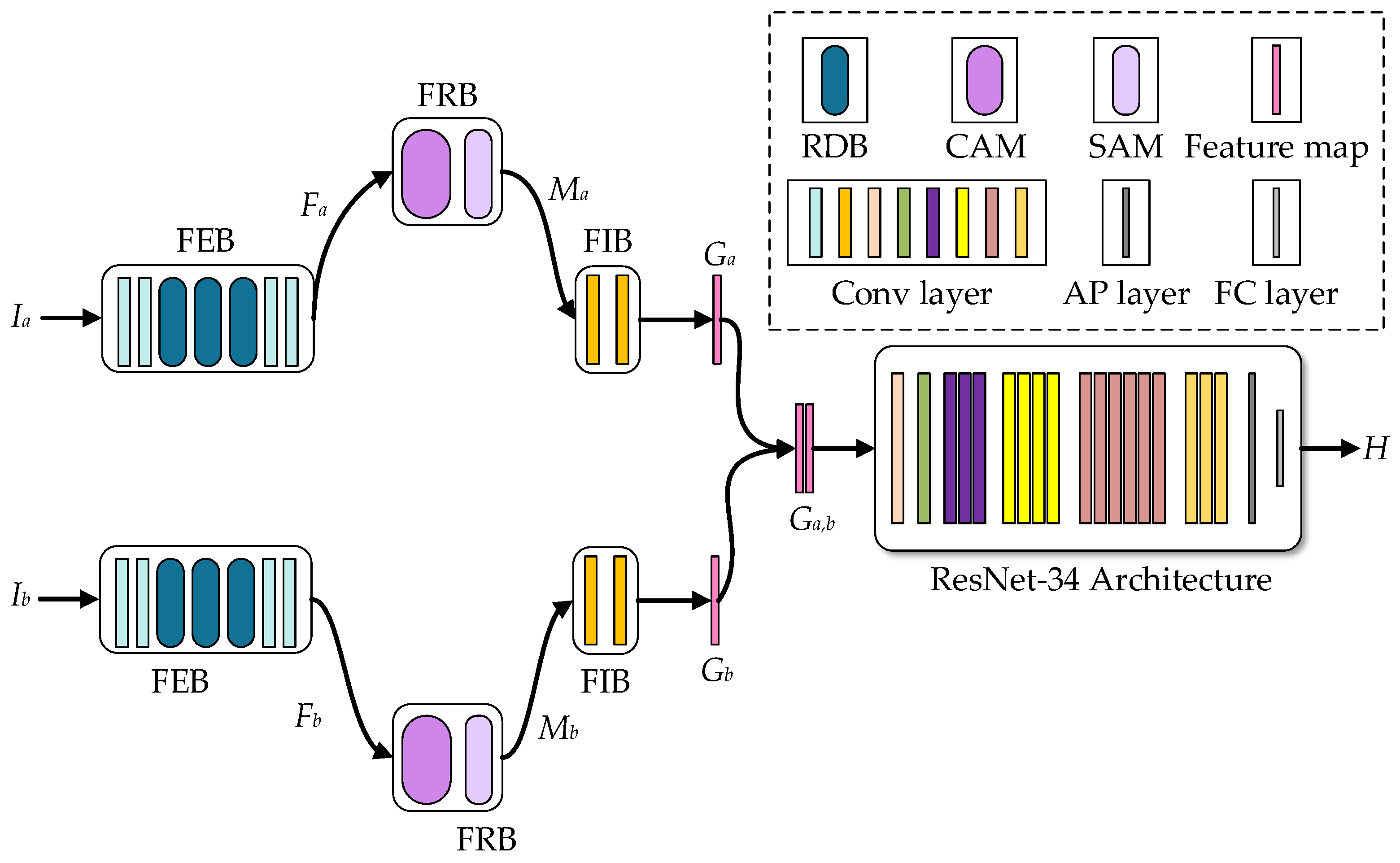
Feature extraction block. We conduct ablation experiments on a synthetic benchmark dataset and verify its effectiveness by replacing the feature extractor in [
40] with the feature extraction block and feature integration block in our model. The main reason for adding a feature integration block is to keep the number of output channels of the feature extractor in [
40] consistent. In
Figure 10, we visualize the feature extraction results of these two methods. According to the observation, compared with the feature extractor of [
40], the feature extraction block can extract the deep-level features in the image, and the outline is more precise. As shown in rows 2 and 3 in
Table 6, the evaluation metric ACE [
41] drops significantly from 5.25 to 5.19, but the remaining four evaluation metrics are basically unchanged. The main reason is that the evaluation metric ACE [
41] is calculated on the wrapped source and target points, so it has a high sensitivity to small changes in the image. However, due to the calculation characteristics of the rest of the evaluation indicators, the subtle changes in the image cannot be clearly reflected. In the subsequent ablation experiments of the evaluation metric AFRR, we explain it in more detail.
Feature refinement block. We demonstrate its effectiveness from both the location of the feature refinement block and itself. First, we show that the performance of generating attention maps directly from features is slightly better than that of generating attention maps from the images themselves. Specifically, we modified the position of the mask predictor to the “Feature extraction block & Feature integration block” and then compared it with the “Feature extraction block & Feature integration block” to prove the importance of the position. The result is shown in row 4 in
Table 6. We can see that ACE [
41] drops significantly from 5.25 to 5.19, and the rest of the evaluation metrics remain unchanged.
Second, we replace the mask predictor in the network framework of the “Backshift mask predictor” with our feature refinement block and modify its position to be in the middle of the feature extraction block and feature integration block to demonstrate the effectiveness of the feature refinement block. The main reason for modifying the position is that we need to perform attention mapping on the channel and space dimensions, and the original number of output channels is 1, which obviously cannot meet our needs. The comparison results are shown in rows 4 and 5 in
Table 6. We can see that the ACE [
41] drops significantly from 5.15 to 5.13, and the rest of the evaluation indicators remain unchanged. This shows that the feature refinement block can improve the network performance to a certain extent.
In addition, for a more intuitive understanding of the performance of the feature refinement block, we use Grad-CAM [
45] to visualize the attention maps produced in the feature refinement block. The results are shown in
Figure 11. Since the attention map in “Feature extraction block & Feature integration block” is generated from the original grayscale image, the other two comparison algorithms are generated from the feature map of the image patch, the visual image content of these two algorithms is less than “Feature extraction block & Feature integration block”. As shown in columns 2 and 3 in
Figure 11, compared to “Feature extraction block & Feature integration block”, “Backshift mask predictor” focuses more on the image features themselves but cannot identify deep-level features in the image. But as shown in column 4 in
Figure 11, after introducing the feature refinement block, not only the features can be refined, but also more deep-level features can be extracted.
DFL. To demonstrate the effectiveness of our proposed DFL, we compare by modifying the DFL in our network to “Triplet Loss” in [
40]. The results are shown in
Table 6 and
Figure 12. According to the visualization results in
Figure 12, we can see that the proposed loss can retain more detailed information by using the integrated refined features to calculate. According to rows 5 and 6 in
Table 6, the proposed loss can effectively improve the performance of the network, especially for SSIM and AFRR, the performance is improved by 1.82% and 1.35%, respectively. In summary, the detailed information can help improve the homography estimation performance between infrared and visible images.
Evaluation indicator AFRR. To demonstrate the effectiveness of the proposed evaluation metrics, we explain them from two perspectives. First, we use ORB [
27] and SIFT [
25] as the feature point extraction algorithm in AFRR, respectively, to demonstrate the effectiveness of the used feature point extraction algorithm.
Figure 13 shows the number of feature corresponding points extracted by ORB [
27] and SIFT [
25] on 42 pairs of warped images and ground-truth images, where the proposed algorithm predicts the warped images. As shown in
Figure 13, the overall trend of the number of feature-corresponding points of ORB [
27] and SIFT [
25] is consistent, but the number of feature-corresponding points of SIFT [
25] is significantly more than that of ORB [
27]. In addition, we can see that ORB [
27] cannot match the feature corresponding points on the three image pairs clearly, but the warped images in these three image pairs are not severely distorted. Therefore, ORB [
27] is often not applicable in practical evaluation scenarios.
In addition, for infrared and visible images, the homography estimation often produces severely distorted wrapped images in traditional algorithms, so we randomly selected the four group results from ORB [
27] + RANSAC [
36] and the algorithm in this paper. Four groups of wrapped images and ground-truth images are used to compare different evaluation metrics, thus proving the effectiveness of AFRR, including severely distorted and well-performing wrapped images. The results are shown in
Figure 14.
Table 7 shows the results of the four groups of images on various evaluation indicators, in which SSIM and PSNR are easily affected by the black background that does not belong to the original image content. MI reflects the registration effect to a certain extent, but cannot more accurately reflect the registration results of severely distorted wrapped images, as shown in (b) in
Figure 14 and in row 3 and column 3 of
Table 7. In addition, since ACE [
41] is obtained from the corners transformed by the estimated homography and ground truth homography, respectively, the estimated value is higher for images with severe distortion and a large number of black backgrounds. This method directly calculates the corner coordinates, so it is more sensitive to image changes, and its accuracy is significantly better than other evaluation indicators, but it is only suitable for synthetic benchmark dataset with ground truth. In short, compared with other evaluation indicators, AFRR can more accurately identify distorted wrapped images and more accurately estimate the registration rate of images, which is more in line with the feeling of the human eye. In particular, due to the computational characteristics of AFRR itself, its accuracy is slightly worse than that of ACE [
41].




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}