
An Efficient Hidden Markov Model with Periodic Recurrent Neural Network Observer for Music Beat Tracking


Abstract
:1. Introduction
- We propose an efficient deep neural network and HMM based method to take advantage of the characteristic of period music beat;
- We propose a new module based on attention mechanism called PRNN, which can capture partial period states in RNN;
- We combine the PRNN module with HMM algorithm for beat tracking task and experimental results show the inference time is much reduced.
2. Related Works
2.1. Traditional Feature Extraction
2.2. Deep Learning-Based Feature Extraction
2.3. Periodic Pattern Recognition
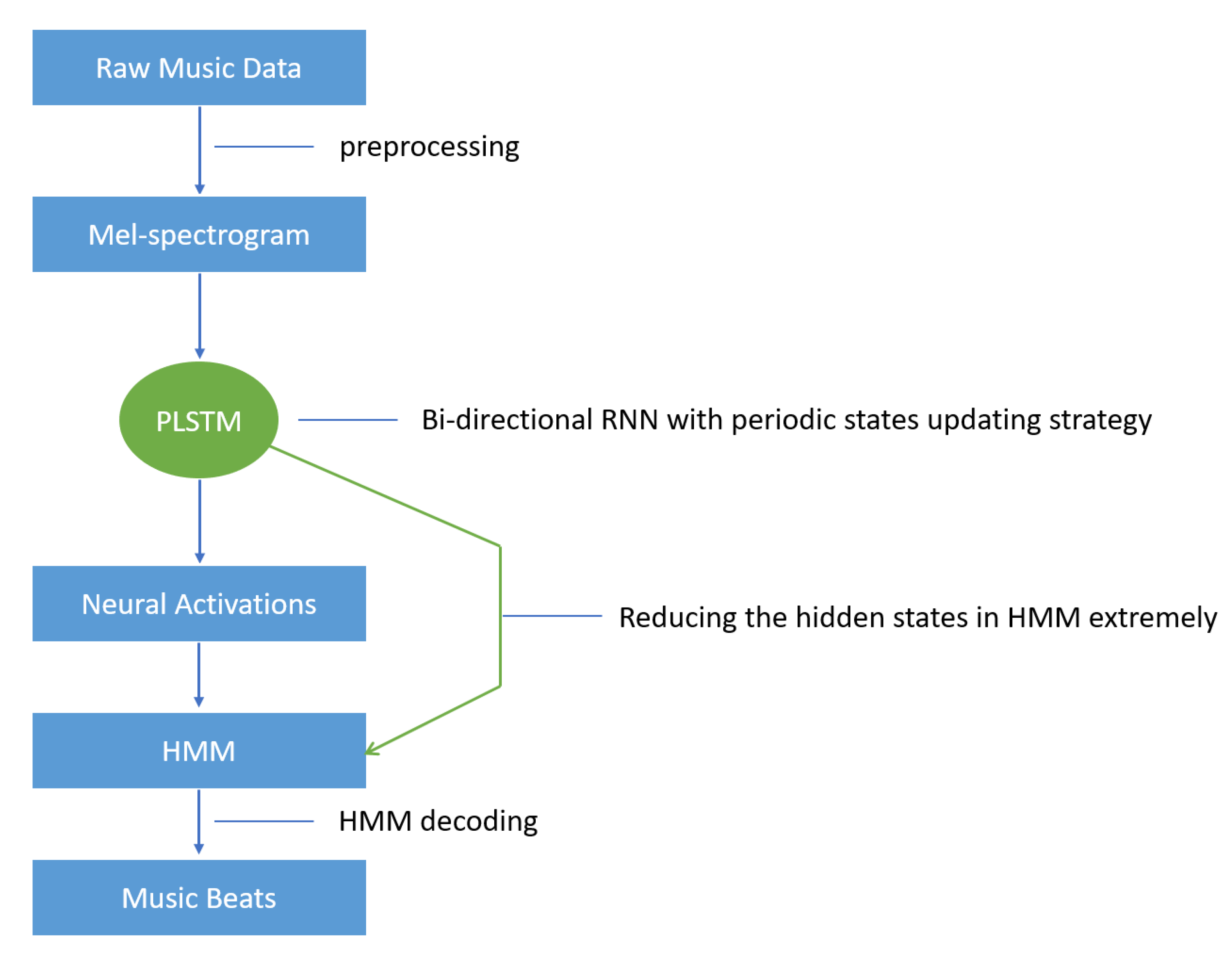
3. Proposed Model
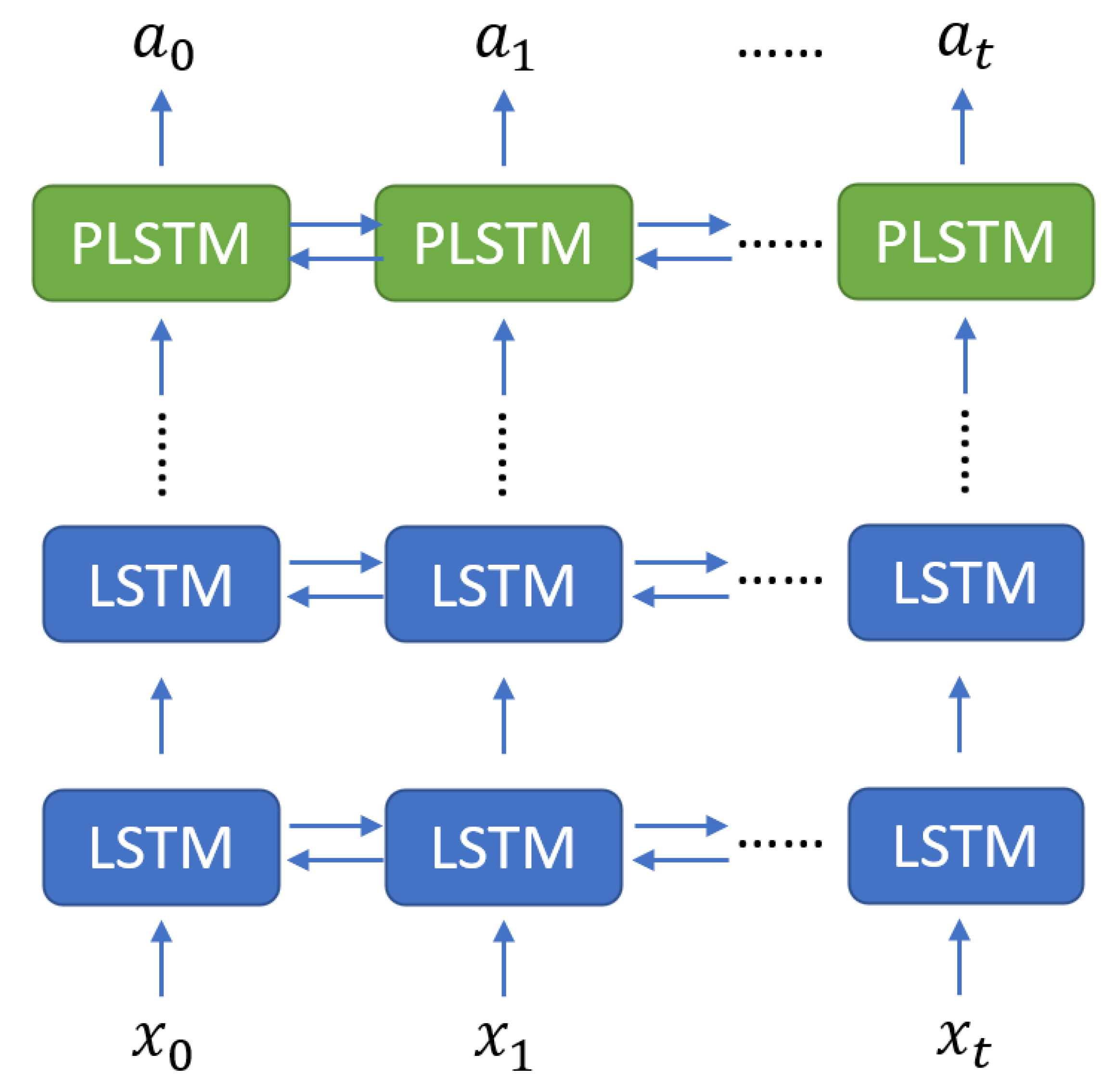
3.1. Periodic Recurrent Neural Network
| Algorithm 1 Update of period states in PRNN | |
| Require: | |
| ▹t the time step, T the total time step, S the matrix saves the past hidden states of window size w and is the hidden state of time step t | |
| Ensure: | ▹ updated with period states |
| for do | ▹ Initialization |
| end for | |
| fordo | ▹ Update period states vector |
| if then | ▹ Window size w |
| ▹ Scaled dot-product attention | |
| ▹ Attention scores | |
| ▹ is a learnable parameter | |
| end if | |
| ▹ Dequeue the first state vector | |
| ▹ Enqueue the current hidden state | |
| end for | |
3.2. Periodic LSTM in HMM
4. Experimental Settings
4.1. Datasets
- GTZANThe GTZAN (http://marsyas.info/downloads/datasets.html, accessed on 11 January 2022) dataset contains 1000 excerpts of 10 genres evenly. Each clip lasts 30 s and the total length is 8 h 20 min. This dataset was originally used for music genre classification and its annotations were extended for beat tracking in [53].
- BallroomThe Ballroom (http://mtg.upf.edu/ismir2004/contest/tempoContest/node5.html, accessed on 11 January 2022) dataset has 698 instances of ballroom dancing music with different genres, such as Samba, Tango, Waltz, etc. The duration of each excerpt is 30 s and total length is 5 h 50 min.
- HainsworthIn total, 222 excerpts taken direct from CD recordings are in Hainsworth (http://www.marsyas.info/tempo, accessed on 11 January 2022) [54] dataset. The examples have been categorized into different genres, such as dance, pop, and choral. This dataset consists of 3 h 20 min of audio, therefore giving a length of about 60 s for each clip.
- SMC_MIRUMThe SMC_MIRUM (http://smc.inescporto.pt/data/SMC_MIREX.zip, accessed on 11 January 2022) [55,56] dataset was formed with a purpose of challenging beat tracking systems. Several properties including changes in tempo, wide dynamic range, pauses, poor audio quality, etc., make this set more difficult. In total, 217 valid beat annotations are in this dataset. Each sample lasts 40 s and the total length of audio recordings in this dataset is 2 h and 25 min.
4.2. Preprocessing and Training Settings
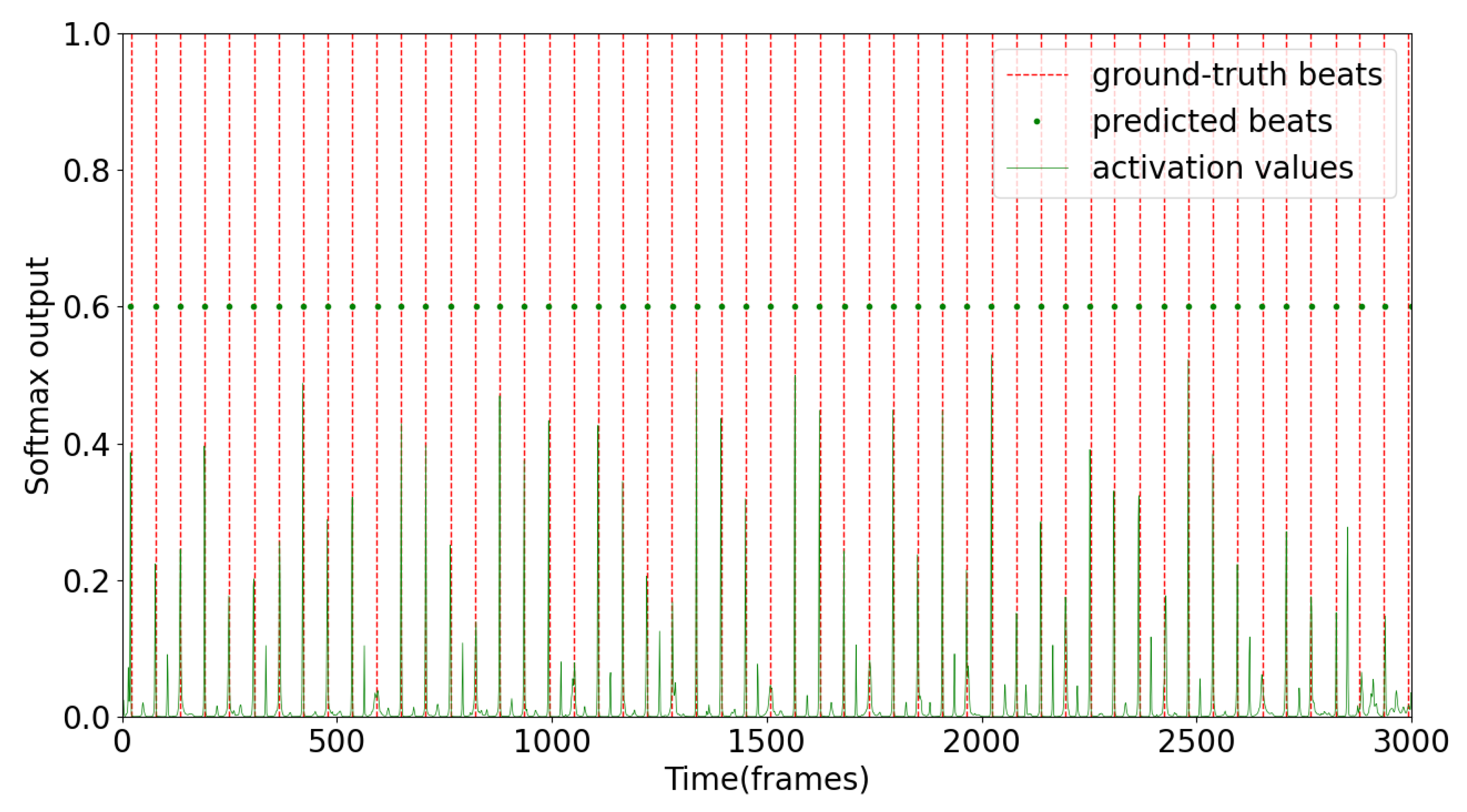
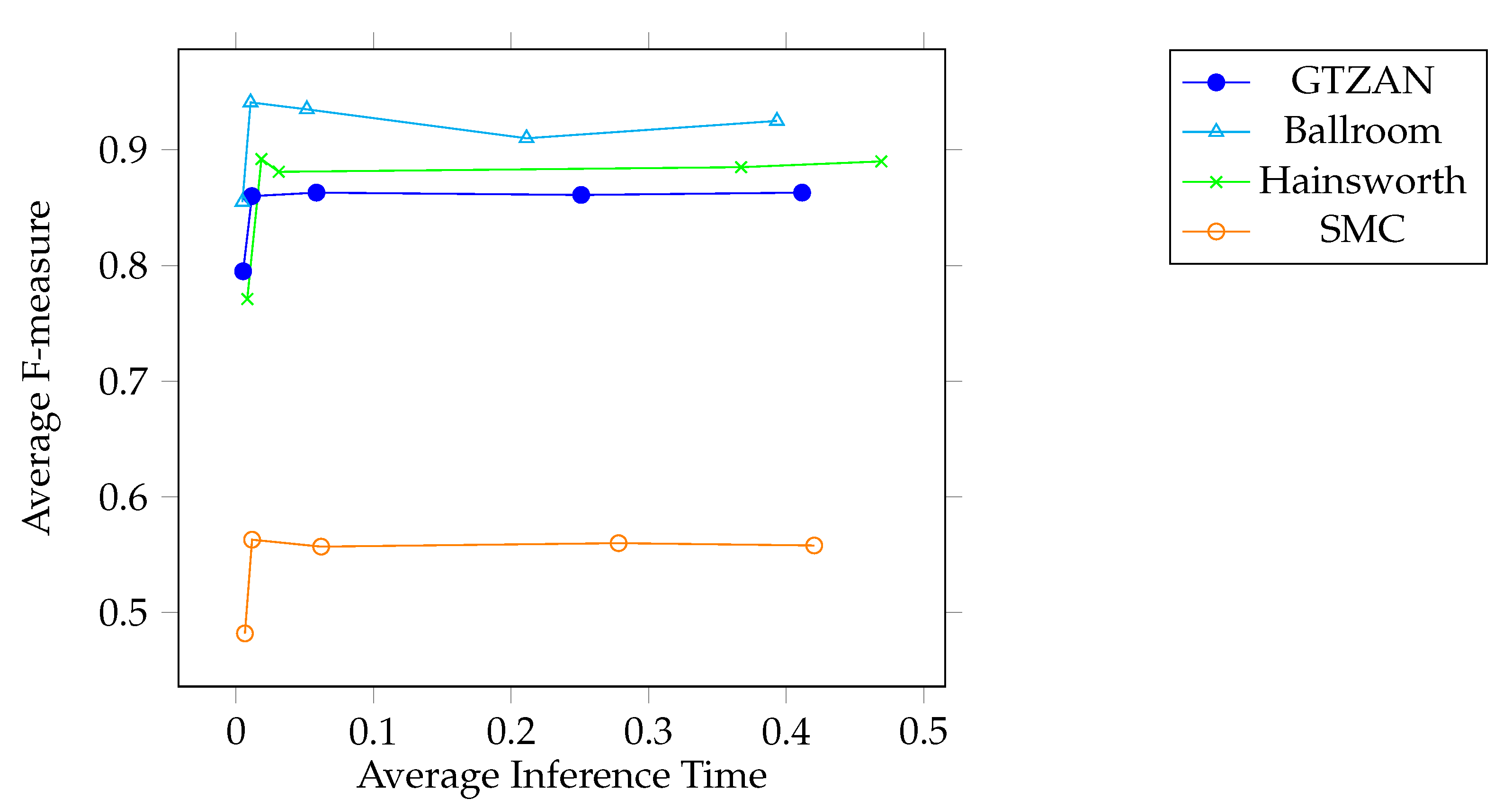
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MIR | Music Information Retrieval |
| HMM | Hidden Markov Model |
| RNN | Recurrent Neural Network |
| PRNN | Periodic Recurrent Neural Network |
| STFT | Short-term Fourier Transform |
| MFCC | Mel-frequency Cepstral Coefficients |
| CRNN | Convolutional Recurrent Neural Network |
| TCN | Temporal Convolutional Network |
| LSTM | Long-short Term Memory |
| GRU | Gated Recurrent Unit |
| JND | Just Noticeable Difference |
| BPM | Beats Per Minute |
Appendix A. Hidden Markov Model in Music Beat Tracking
References
- Lenc, T.; Keller, P.E.; Varlet, M.; Nozaradan, S. Neural tracking of the musical beat is enhanced by low-frequency sounds. Proc. Natl. Acad. Sci. USA 2018, 115, 8221–8226. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, G.; Wang, Z.; Han, F.; Ding, S.; Iqbal, M.A. Music auto-tagging using deep Recurrent Neural Networks. Neurocomputing 2018, 292, 104–110. [Google Scholar] [CrossRef]
- Kim, K.L.; Lee, J.; Kum, S.; Park, C.L.; Nam, J. Semantic Tagging of Singing Voices in Popular Music Recordings. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1656–1668. [Google Scholar] [CrossRef]
- Song, G.; Wang, Z.; Han, F.; Ding, S.; Gu, X. Music auto-tagging using scattering transform and convolutional neural network with self-attention. Appl. Soft Comput. 2020, 96, 106702. [Google Scholar] [CrossRef]
- Wu, W.; Han, F.; Song, G.; Wang, Z. Music genre classification using independent recurrent neural network. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 192–195. [Google Scholar]
- Yu, Y.; Luo, S.; Liu, S.; Qiao, H.; Liu, Y.; Feng, L. Deep attention based music genre classification. Neurocomputing 2020, 372, 84–91. [Google Scholar] [CrossRef]
- Yadav, A.; Vishwakarma, D.K. A unified framework of deep networks for genre classification using movie trailer. Appl. Soft Comput. 2020, 96, 106624. [Google Scholar] [CrossRef]
- Dong, Y.; Yang, X.; Zhao, X.; Li, J. Bidirectional convolutional recurrent sparse network (BCRSN): An efficient model for music emotion recognition. IEEE Trans. Multimed. 2019, 21, 3150–3163. [Google Scholar] [CrossRef]
- Panda, R.; Malheiro, R.M.; Paiva, R.P. Audio features for music emotion recognition: A survey. IEEE Trans. Affect. Comput. early access. 2020. [Google Scholar] [CrossRef]
- Sigtia, S.; Benetos, E.; Dixon, S. An end-to-end neural network for polyphonic piano music transcription. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 927–939. [Google Scholar] [CrossRef] [Green Version]
- Benetos, E.; Dixon, S.; Duan, Z.; Ewert, S. Automatic music transcription: An overview. IEEE Signal Process. Mag. 2018, 36, 20–30. [Google Scholar] [CrossRef]
- Wu, Y.T.; Chen, B.; Su, L. Multi-Instrument Automatic Music Transcription With Self-Attention-Based Instance Segmentation. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2796–2809. [Google Scholar] [CrossRef]
- Böck, S.; Krebs, F.; Widmer, G. Joint Beat and Downbeat Tracking with Recurrent Neural Networks. In Proceedings of the ISMIR, New York, NY, USA, 7–11 August 2016; pp. 255–261. [Google Scholar]
- Müller, M.; McFee, B.; Kinnaird, K.M. Interactive learning of signal processing through music. IEEE Signal Process. Mag. 2021. accepted for publication. [Google Scholar] [CrossRef]
- Gkiokas, A.; Katsouros, V. Convolutional Neural Networks for Real-Time Beat Tracking: A Dancing Robot Application. In Proceedings of the ISMIR, Suzhou, China, 23–28 October 2017; pp. 286–293. [Google Scholar]
- Cheng, T.; Fukayama, S.; Goto, M. Convolving Gaussian kernels for RNN-based beat tracking. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Eternal, Rome, 3–7 September 2018; pp. 1905–1909. [Google Scholar]
- Istvanek, M.; Smekal, Z.; Spurny, L.; Mekyska, J. Enhancement of Conventional Beat Tracking System Using Teager–Kaiser Energy Operator. Appl. Sci. 2020, 10, 379. [Google Scholar] [CrossRef] [Green Version]
- Böck, S.; Schedl, M. Enhanced beat tracking with context-aware neural networks. In Proceedings of the International Conference Digital Audio Effects, Paris, France, 19–23 September 2011; pp. 135–139. [Google Scholar]
- Fuentes, M.; McFee, B.; Crayencour, H.; Essid, S.; Bello, J. Analysis of common design choices in deep learning systems for downbeat tracking. In Proceedings of the 19th International Society for Music Information Retrieval Conference, Paris, France, 23–27 September 2018. [Google Scholar]
- Cano, E.; Mora-Ángel, F.; Gil, G.A.L.; Zapata, J.R.; Escamilla, A.; Alzate, J.F.; Betancur, M. Sesquialtera in the colombian bambuco: Perception and estimation of beat and meter. In Proceedings of the International Society for Music Information Retrieval Conference, Montreal, QC, Canada, 11–16 October 2020; pp. 409–415. [Google Scholar]
- Pedersoli, F.; Goto, M. Dance beat tracking from visual information alone. In Proceedings of the International Society for Music Information Retrieval Conference, Montreal, QC, Canada, 11–16 October 2020; pp. 400–408. [Google Scholar]
- Holzapfel, A.; Stylianou, Y. Beat tracking using group delay based onset detection. In Proceedings of the ISMIR-International Conference on Music Information Retrieval (ISMIR), Philadelphia, PA, USA, 14–18 September 2008; pp. 653–658. [Google Scholar]
- Laroche, J. Efficient tempo and beat tracking in audio recordings. J. Audio Eng. Soc. 2003, 51, 226–233. [Google Scholar]
- MatthewDavies, E.; Böck, S. Temporal convolutional networks for musical audio beat tracking. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Böck, S.; Davies, M.E.; Knees, P. Multi-Task Learning of Tempo and Beat: Learning One to Improve the Other. In Proceedings of the ISMIR, Delft, The Netherlands, 4–8 November 2019; pp. 486–493. [Google Scholar]
- Ellis, D.P. Beat tracking by dynamic programming. J. New Music. Res. 2007, 36, 51–60. [Google Scholar] [CrossRef] [Green Version]
- Lartillot, O.; Grandjean, D. Tempo and metrical analysis by tracking multiple metrical levels using autocorrelation. Appl. Sci. 2019, 9, 5121. [Google Scholar] [CrossRef] [Green Version]
- Böck, S.; Krebs, F.; Widmer, G. Accurate Tempo Estimation Based on Recurrent Neural Networks and Resonating Comb Filters. In Proceedings of the ISMIR, Malaga, Spain, 26–30 October 2015; pp. 625–631. [Google Scholar]
- Cemgil, A.T.; Kappen, B.; Desain, P.; Honing, H. On tempo tracking: Tempogram representation and Kalman filtering. J. New Music. Res. 2000, 29, 259–273. [Google Scholar] [CrossRef]
- Krebs, F.; Böck, S.; Widmer, G. An Efficient State-Space Model for Joint Tempo and Meter Tracking. In Proceedings of the ISMIR, Malaga, Spain, 26–30 October 2015; pp. 72–78. [Google Scholar]
- Chuang, Y.C.; Su, L. Beat and Downbeat Tracking of Symbolic Music Data Using Deep Recurrent Neural Networks. In Proceedings of the 2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Auckland, New Zealand, 7–10 December 2020; pp. 346–352. [Google Scholar]
- Peeters, G.; Flocon-Cholet, J. Perceptual tempo estimation using GMM-regression. In Proceedings of the Second International ACM workshop on Music Information Retrieval with User-Centered and Multimodal Strategies, Nara, Japan, 2 November 2012; pp. 45–50. [Google Scholar]
- Percival, G.; Tzanetakis, G. Streamlined tempo estimation based on autocorrelation and cross-correlation with pulses. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1765–1776. [Google Scholar] [CrossRef]
- Whiteley, N.; Cemgil, A.T.; Godsill, S.J. Bayesian Modelling of Temporal Structure in Musical Audio. In Proceedings of the ISMIR, Victoria, BC, Canada, 8–12 October 2006; pp. 29–34. [Google Scholar]
- Krebs, F.; Böck, S.; Widmer, G. Rhythmic Pattern Modeling for Beat and Downbeat Tracking in Musical Audio. In Proceedings of the ISMIR, Curitiba, Brazil, 4–8 November 2013; pp. 227–232. [Google Scholar]
- Srinivasamurthy, A.; Holzapfel, A.; Cemgil, A.T.; Serra, X. Particle filters for efficient meter tracking with dynamic bayesian networks. In Proceedings of the ISMIR 2015, Malaga, Spain, 26–30 October 2015. [Google Scholar]
- Krebs, F.; Holzapfel, A.; Cemgil, A.T.; Widmer, G. Inferring metrical structure in music using particle filters. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 817–827. [Google Scholar] [CrossRef] [Green Version]
- Müller, M.; Ewert, S. Chroma Toolbox: MATLAB implementations for extracting variants of chroma-based audio features. In Proceedings of the 12th International Conference on Music Information Retrieval (ISMIR), Miami, FL, USA, 24–28 October 2011. [Google Scholar]
- Fuentes, B.; Liutkus, A.; Badeau, R.; Richard, G. Probabilistic model for main melody extraction using constant-Q transform. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5357–5360. [Google Scholar]
- Durand, S.; Bello, J.P.; David, B.; Richard, G. Robust downbeat tracking using an ensemble of convolutional networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 25, 76–89. [Google Scholar] [CrossRef]
- Di Giorgi, B.; Mauch, M.; Levy, M. Downbeat tracking with tempo-invariant convolutional neural networks. arXiv 2021, arXiv:2102.02282. [Google Scholar]
- Hung, Y.N.; Wang, J.C.; Song, X.; Lu, W.T.; Won, M. Modeling beats and downbeats with a time-frequency Transformer. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 401–405. [Google Scholar]
- Desblancs, D.; Hennequin, R.; Lostanlen, V. Zero-Note Samba: Self-Supervised Beat Tracking; hal-03669865. 2022. Available online: https://hal.archives-ouvertes.fr/hal-03669865/file/desblancs2022jstsp_supplementary.pdf (accessed on 11 January 2022).
- Zonoozi, A.; Kim, J.j.; Li, X.L.; Cong, G. Periodic-CRN: A convolutional recurrent model for crowd density prediction with recurring periodic patterns. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 3732–3738. [Google Scholar]
- Chen, C.; Li, K.; Teo, S.G.; Zou, X.; Wang, K.; Wang, J.; Zeng, Z. Gated residual recurrent graph neural networks for traffic prediction. In Proceedings of the AAAI conference on artificial intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 485–492. [Google Scholar]
- He, Z.; Chow, C.Y.; Zhang, J.D. STCNN: A spatio-temporal convolutional neural network for long-term traffic prediction. In Proceedings of the 2019 20th IEEE International Conference on Mobile Data Management (MDM), Hong Kong, 10–13 June 2019; pp. 226–233. [Google Scholar]
- Karim, M.E.; Maswood, M.M.S.; Das, S.; Alharbi, A.G. BHyPreC: A novel Bi-LSTM based hybrid recurrent neural network model to predict the CPU workload of cloud virtual machine. IEEE Access 2021, 9, 131476–131495. [Google Scholar] [CrossRef]
- Wu, H.; Ma, Y.; Xiang, Z.; Yang, C.; He, K. A spatial–temporal graph neural network framework for automated software bug triaging. Knowl.-Based Syst. 2022, 241, 108308. [Google Scholar] [CrossRef]
- Abdelraouf, A.; Abdel-Aty, M.; Yuan, J. Utilizing attention-based multi-encoder-decoder neural networks for freeway traffic speed prediction. IEEE Trans. Intell. Transp. Syst. 2021, 23, 11960–11969. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Elowsson, A. Beat tracking with a cepstroid invariant neural network. In Proceedings of the 17th International Society for Music Information Retrieval Conference (ISMIR 2016), New York, NY, USA, 7–11 August 2016; pp. 351–357. [Google Scholar]
- Marchand, U.; Fresnel, Q.; Peeters, G. Gtzan-Rhythm: Extending the Gtzan Test-Set with Beat, Downbeat and Swing Annotations. In Proceedings of the Extended abstracts for the Late-Breaking Demo Session of the 16th International Society for Music Information Retrieval Conference, Malaga, Spain, 26–30 October 2015. [Google Scholar]
- Hainsworth, S.W. Techniques for the Automated Analysis of Musical Audio. Ph.D. Dissertation, Cambridge University, Cambridge, UK, 2004. [Google Scholar]
- Holzapfel, A.; Davies, M.E.; Zapata, J.R.; Oliveira, J.L.; Gouyon, F. Selective sampling for beat tracking evaluation. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 2539–2548. [Google Scholar] [CrossRef]
- Holzapfel, A.; Davies, M.E.; Zapata, J.R.; Oliveira, J.L.; Gouyon, F. On the automatic identification of difficult examples for beat tracking: Towards building new evaluation datasets. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 89–92. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Preprocessing | Neural Network Type | Post Processing |
|---|---|---|---|
| Bock [25] | STFT | Bi-directional LSTM | DBN |
| Davies [24] | STFT | Temporal Convolutional Network | DBN |
| Elowsson [52] | HP separation MF estimation | Cepstroid Neural Network | CQT |
| Ours | STFT | Period LSTM | DBN |
| F-Measure | CMLt | AMLt | |
|---|---|---|---|
| GTZAN | |||
| Bock [25] | 0.864 | 0.768 | 0.927 |
| Davies [24] | 0.843 | 0.715 | 0.914 |
| Ours | 0.860 | 0.754 | 0.925 |
| Ballroom | |||
| Bock [25] | 0.938 | 0.892 | 0.953 |
| Elowsson [52] | 0.925 | 0.903 | 0.932 |
| Davies [24] | 0.933 | 0.881 | 0.929 |
| Ours | 0.941 | 0.902 | 0.959 |
| Hainsworth | |||
| Bock [25] | 0.884 | 0.808 | 0.916 |
| Elowsson [52] | 0.742 | 0.676 | 0.792 |
| Davies [24] | 0.874 | 0.795 | 0.930 |
| Ours | 0.892 | 0.796 | 0.928 |
| SMC | |||
| Bock [25] | 0.529 | 0.428 | 0.567 |
| Elowsson [52] | 0.375 | 0.225 | 0.332 |
| Davies [24] | 0.543 | 0.432 | 0.632 |
| Ours | 0.563 | 0.450 | 0.685 |
| k | GTZAN | Ballroom | Hainsworth | SMC |
|---|---|---|---|---|
| 3 | 0.0052 0.795 | 0.0047 | 0.855 | 0.0082 | 0.771 | 0.0065 | 0.482 |
| 5 | 0.0116 | 0.860 | 0.0106 | 0.941 | 0.0185 | 0.892 | 0.0117 | 0.563 |
| 10 | 0.0585 | 0.863 | 0.0515 | 0.935 | 0.0311 | 0.881 | 0.0619 | 0.557 |
| 15 | 0.2509 | 0.861 | 0.2112 | 0.910 | 0.3672 | 0.885 | 0.2781 | 0.560 |
| 20 | 0.4115 | 0.863 | 0.3932 | 0.925 | 0.4691 | 0.890 | 0.4203 | 0.558 |
| GTZAN | Ballroom | Hainsworth | SMC | |
|---|---|---|---|---|
| Avg. State Number | 400 | 344 | 342 | 414 |
| Avg. Inference Time | 0.0116 | 0.0106 | 0.0185 | 0.0117 |
| State Number | 5617 | |||
| Avg. Inference Time | 0.775 | 0.778 | 1.282 | 0.776 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, G.; Wang, Z. An Efficient Hidden Markov Model with Periodic Recurrent Neural Network Observer for Music Beat Tracking. Electronics 2022, 11, 4186. https://doi.org/10.3390/electronics11244186
Song G, Wang Z. An Efficient Hidden Markov Model with Periodic Recurrent Neural Network Observer for Music Beat Tracking. Electronics. 2022; 11(24):4186. https://doi.org/10.3390/electronics11244186
Chicago/Turabian StyleSong, Guangxiao, and Zhijie Wang. 2022. "An Efficient Hidden Markov Model with Periodic Recurrent Neural Network Observer for Music Beat Tracking" Electronics 11, no. 24: 4186. https://doi.org/10.3390/electronics11244186