In recent years, time series models have been explored to solve various engineering application problems. With the rise of the big data industry, the combination of big data and the financial field has formed big data finance [
1,
2,
3]. Time series forecasting of financial indicators has become a widely studied topic in recent years. However, the highly complex, highly time-varying, and highly nonlinear nature of data in the financial sector makes the forecasting of relevant indicators more challenging [
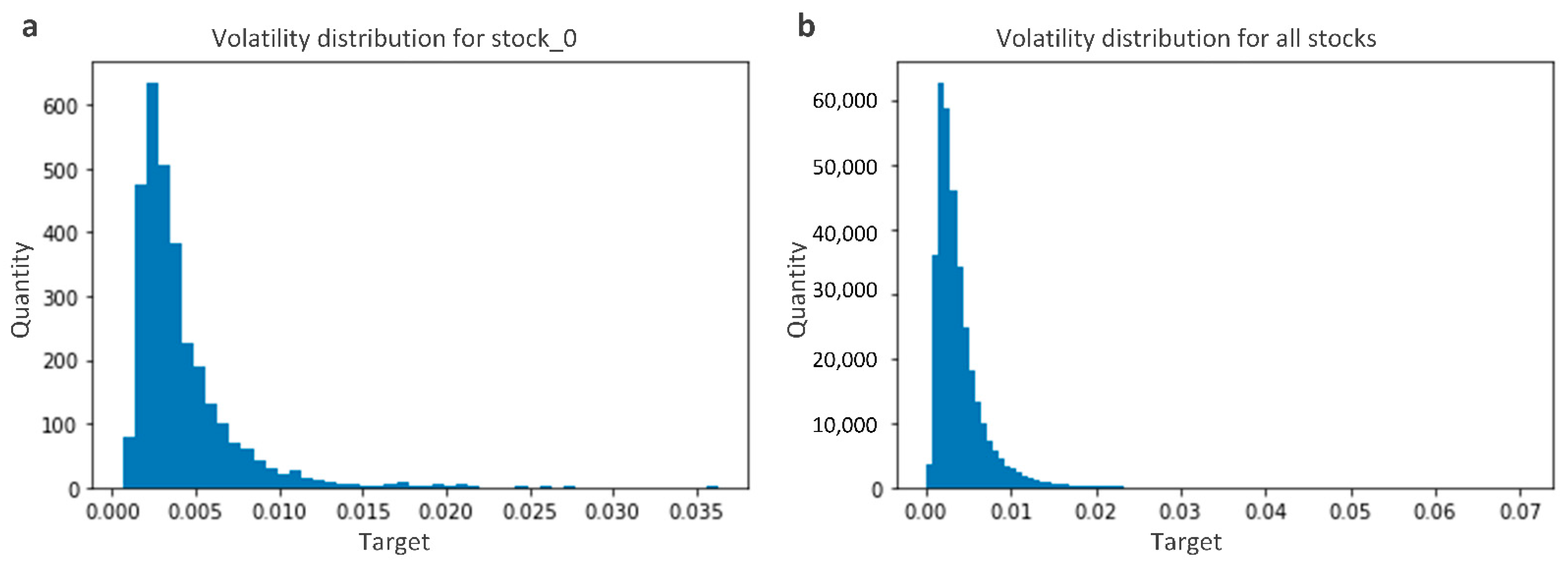
4]. In financial markets, investors are more concerned with forecasting future market trends than accurate price forecasts. Volatility reflects the magnitude of price fluctuations, and volatility is a measure of asset price variability using high-frequency data information [
5]. Volatility has extremely important decision-making value in risk management, option pricing, asset allocation, etc. Accurate forecasting of volatility can reduce uncertainty in investment decisions and improve investment efficiency for financial firms and investors [
6]. Volatility has become one of the most important quantitative indicators in the current financial industry [
7]. Therefore, the prediction model of volatility is of great academic and practical research importance.
1.1. Literature Review
In 1959, Osborme proposed the random walk theory which infers that stock prices are unpredictable [
8]. In 1970, Fama’s efficient market hypothesis also inferred that stock prices could not be efficiently predicted [
9]. However, in 1999, the nonrandom walk theory proposed by Lo and Mackinlay argued that stock prices could be predicted by economic modeling [
10]. In 1971, Barclays Investment Management in the United States issued the world’s first fund using quantitative investment strategies [
11]. The explosive growth and huge development prospects of the current global quantitative trading market have made stock-related time series forecasting a hot research topic [
12].
In past studies by numerous scholars and experts on time series models and the prediction of stock volatility, different researchers have proposed different modeling schemes. Depending on the research area, the models can be broadly classified into two types: statistical models and machine learning models.
In the field of economics, volatility is often predicted using statistical models, which are knowledge paradigms that focus on theoretical perfectionism (data–knowledge–problem). The autoregressive conditional heteroskedasticity (ARCH) model was first proposed by Engle in 1982 and used for volatility forecasting [
13]. The model was widely used in the field of time series forecasting because it was able to obtain good forecasting results for future information by using the variance function. By analyzing the actual situation, we can find that most time series forecasting research objects (such as stock volatility) will be affected by macroeconomics, national policies, company management, and other factors, and there will be strong randomness and sudden changes in future information. Based on this, in 1986, Bollerslev extended the variance function and further improved the ARCH model into a generalized autoregressive conditional heteroskedasticity (GARCH) model [
14]. In 2005, Awartani and Corradi proposed that symmetric and asymmetric GARCH is applicable to symmetric and asymmetric stock volatility forecasting [
15]. In 2021, Feng He and Libo Yin experimentally argued that linear regression models can also be effective in predicting stock volatility [
16].
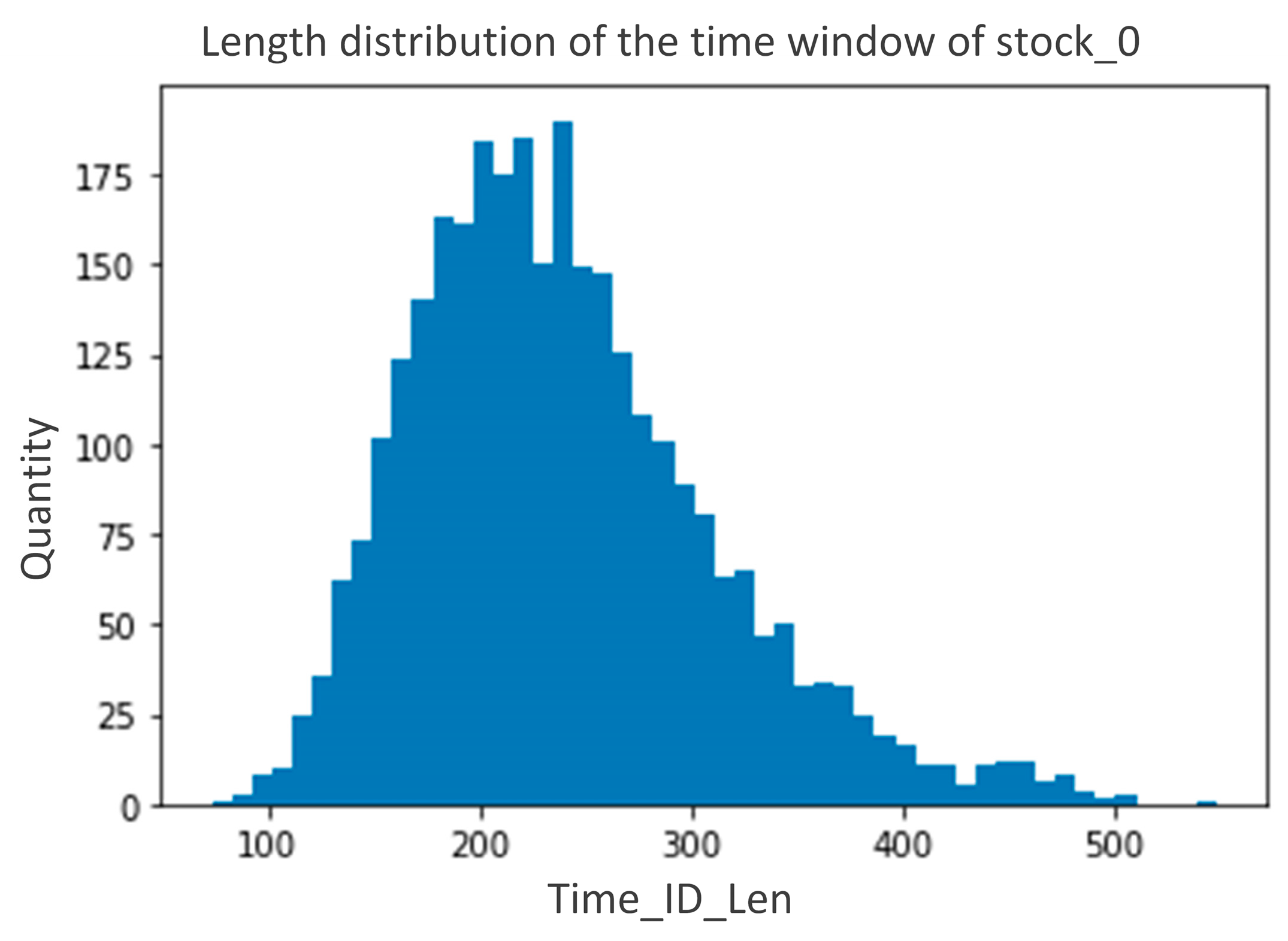
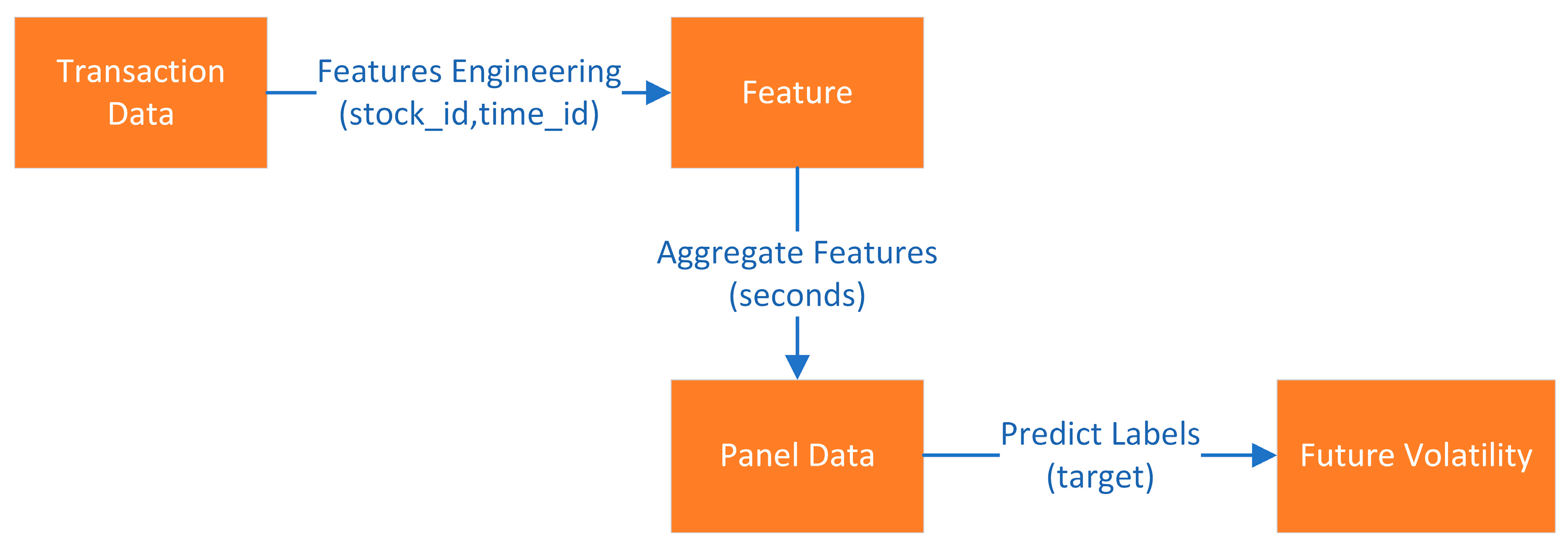
With the development of the computing performance of data centers and the improvement of financial markets, the data generated from real-time transactions and quantitative statistics have become more and more accurate, and financial big data with a precision of seconds is now commonly formed. High-frequency volatility has different characteristics than low-frequency volatility, with a negative correlation of time series, periodic U-shape, calendar effect, and long memory while the classical models based on low-frequency data (ARCH, SV, and GARCH) are difficult to use for the analysis of high-frequency data.
With the rise of artificial intelligence, machine learning has begun to be applied to solve various engineering challenges. While econometric models focus on being logic-driven, AI models focus more on being data-driven (data-problem), which is a kind of historical empiricism. In 2017, Li et al. accurately predicted the long- and short-term prices of copper using a regression tree model [
17]. With the development of machine learning, many scholars have shifted their attention from single models to ensemble learning models, which have proven to be powerful performance metalearning algorithms, such as boosting and bagging. In 2016, Khaidem successfully forecasted stock returns by building a random forest model using the bagging algorithm on a decision tree model. In 2019, Basak, S. et al. implemented gradient-boosting decision trees (GBDT) using the distributed computing framework XGBoost and demonstrated that the GBDT (decision tree and boosting) algorithm outperformed random forests in the forecasting of stock volatility [
18]. In 2022, Raubitzek and Neubauer et al. validated the powerful performance and advantages of GBDT in time series modeling (e.g., stock forecasting) [
19].
Artificial neural networks (ANN) and deep learning frameworks have been hot research topics in artificial intelligence in recent years. Deep learning is a feature learning approach that converts raw data into a higher-level, more abstract representation process through a set of simple transformation methods, that is, using enough simple transformation functions and their various combinations to learn a complex objective function. It was found that any finite continuous function can be approximated by artificial neural networks, so artificial neural nets have fewer restrictions on model training and work well for regression fitting of both linear and nonlinear relationships. In 1988, White et al. used artificial neural networks to successfully predict the daily volatility of IBM stock [
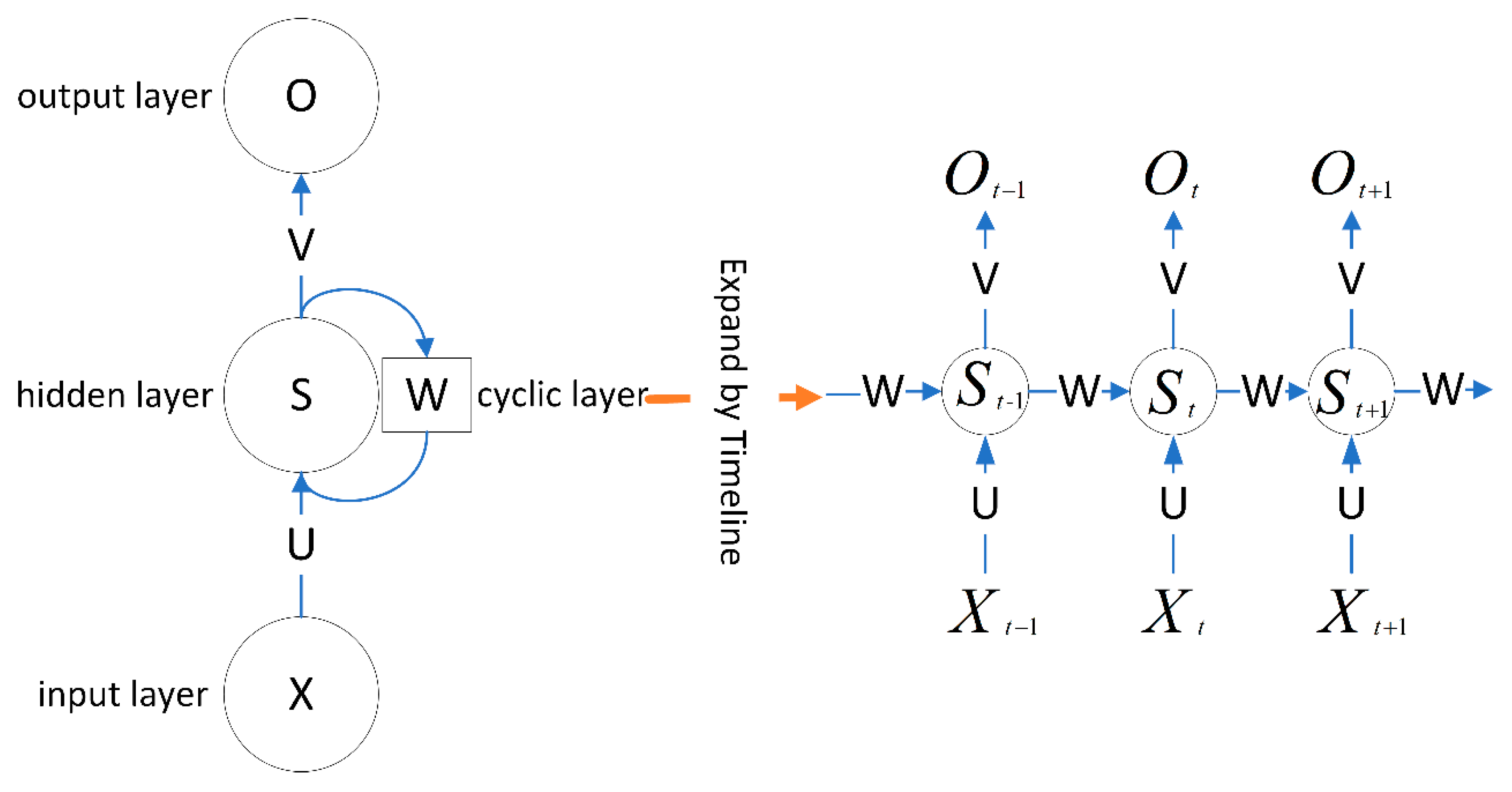
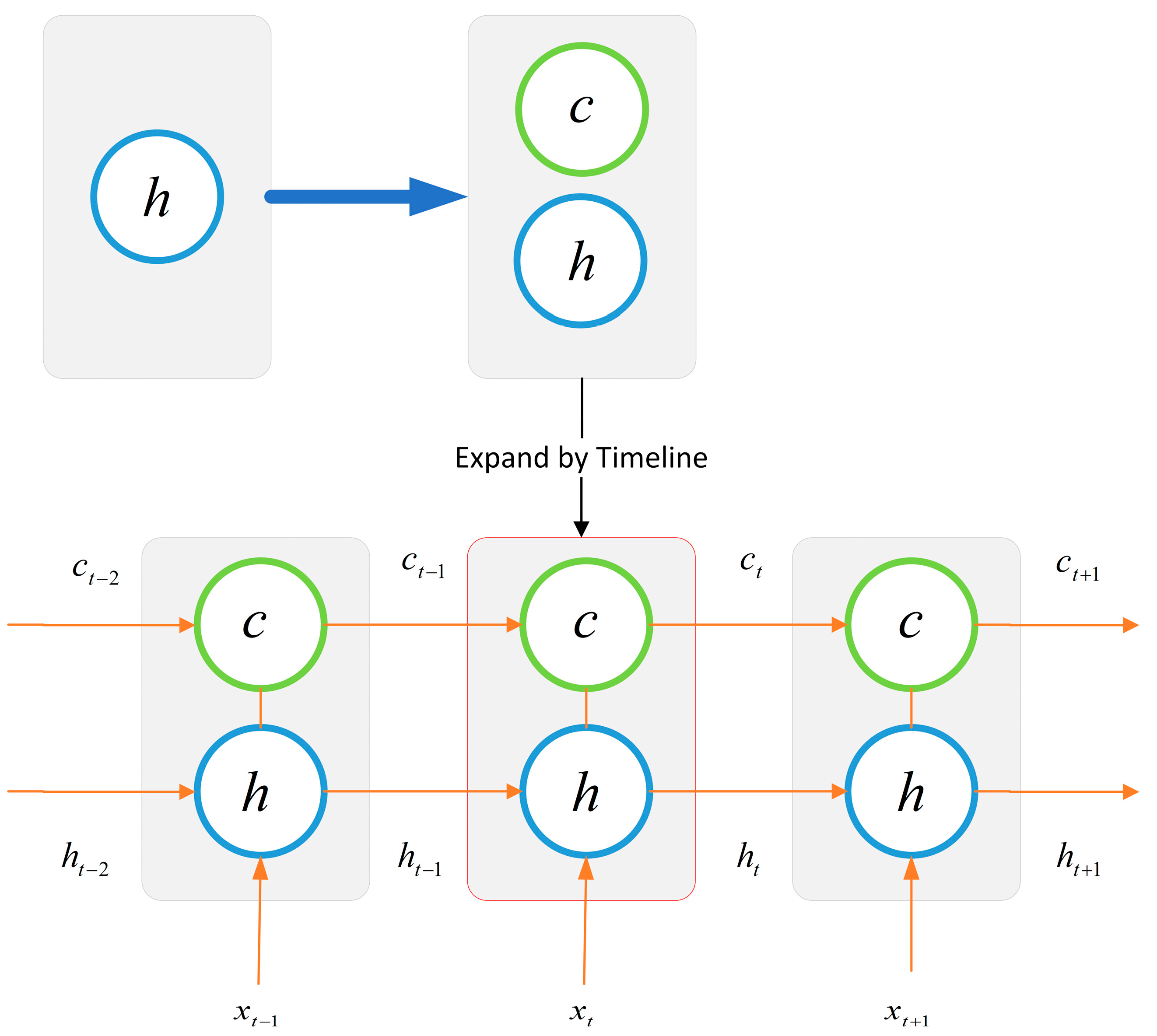
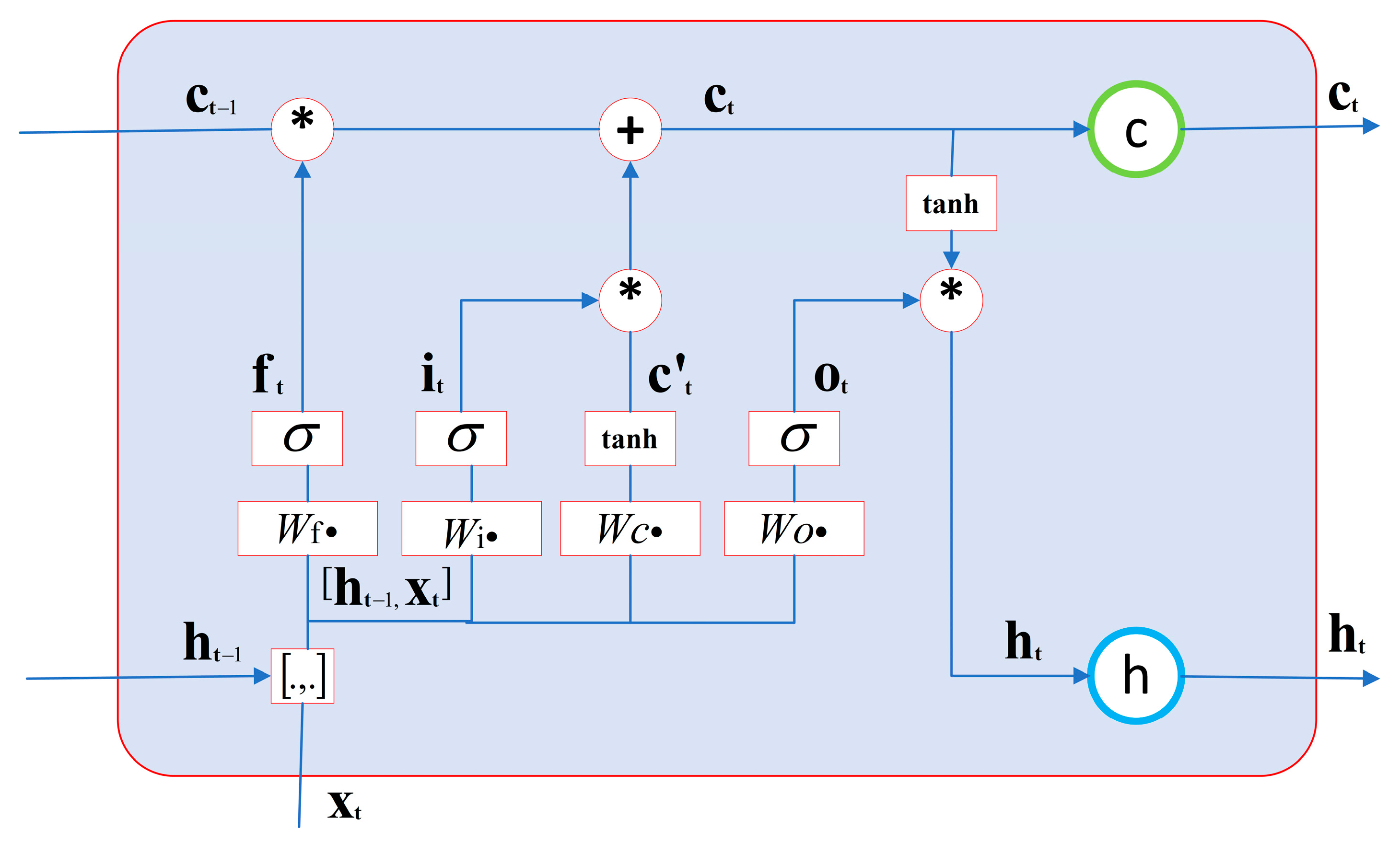
20]. However, the strong randomness and dynamic nonlinearity of financial big data make the fit of ordinary neural networks poor, and in 1997, Hochreiter et al. proposed the long short-term memory neural network (LSTM) [
21]. The LSTM can store temporal information and has proven to be a very successful deep learning framework in various engineering applications of time series modeling. The LSTM is a kind of recurrent neural network (RNN). Unlike feedforward neural networks, recurrent neural networks have the mode of learning time through feedback connections, so RNNs have unique advantages in modeling and analyzing data of time series. Based on the advantages of LSTM, many scholars have successfully applied it to the forecasting research of financial indicators. In 2012, Maknickiene and Maknickas improved the prediction performance of feedforward neural networks using LSTM models and demonstrated that RNN models outperformed CNN models for the prediction of financial data information [
22]. In 2015, Chen predicted the returns of the Chinese stock market by LSTM modeling [
23]. In 2017, Nelson et al. used an LSTM model to predict the volatility of the stock market [
24].
1.2. The Study of this Paper
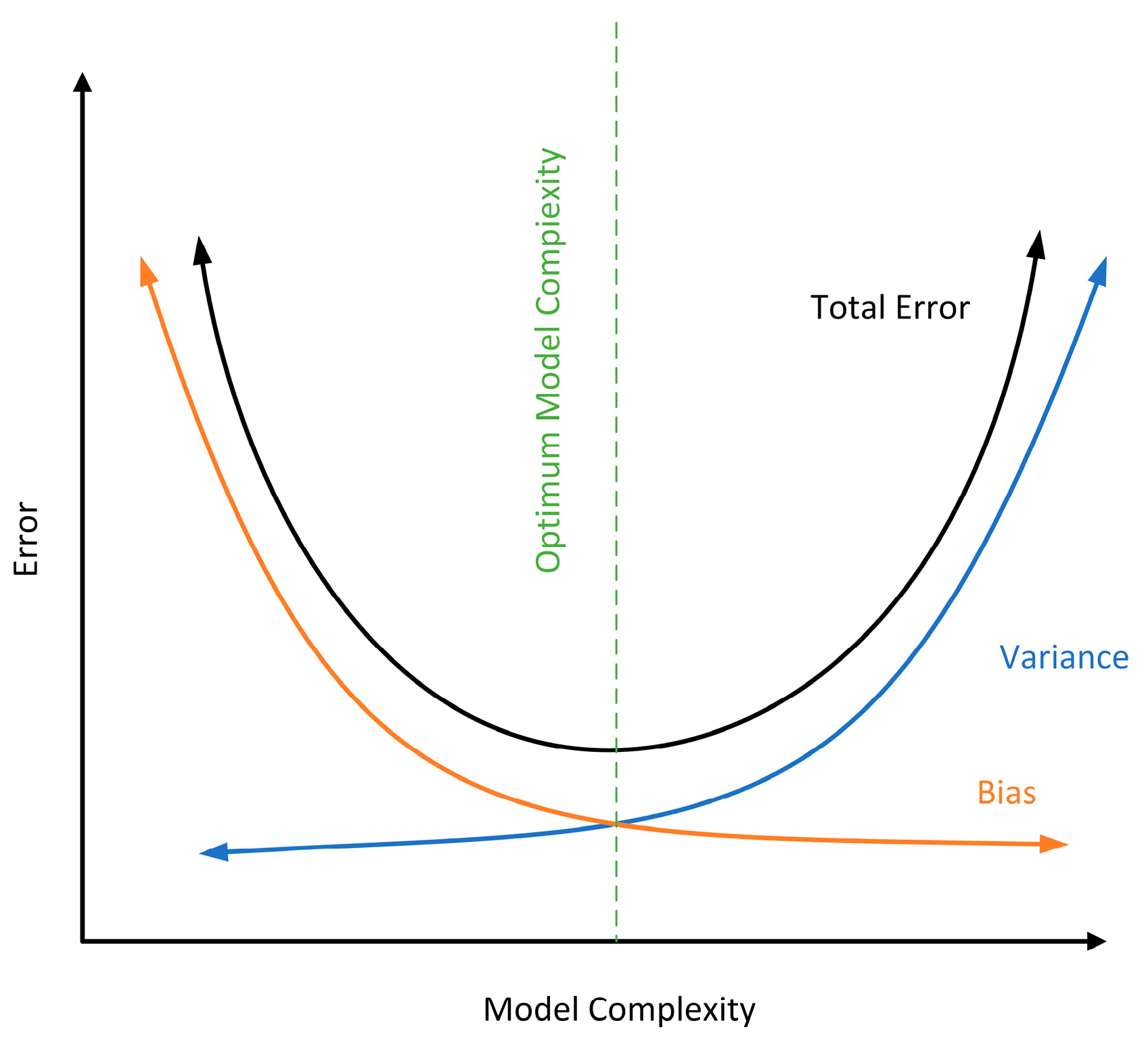
In the current research on time series models, although the relevant algorithms proposed by the above scholars have achieved good results, there are still some problems to be solved: (1) Initially, scholars used single machine learning for training, and the prediction error was relatively high. In recent years, ensemble learning models have been used to iteratively optimize the models, such as bagging to reduce variance and boosting to reduce bias, but there is no way to reduce both bias and variance. (2) If a neural network is directly used for training, the model has poor interpretability and high uncertainty, the increase of input parameters will cause the model complexity to be too high, and the time and computational resources consumed for model training are not optimistic. (3) Before the era of artificial intelligence, the contradiction of intelligent algorithms was between the lack of algorithms and the growing demand for algorithms from users. With the development of artificial intelligence and big data, the contradiction of intelligent algorithms becomes a contradiction between the limited versatility of algorithms and the diversity of engineering problems. Although this is an era of algorithm enrichment, there is no perfect algorithm and no universal model. In 1997, Wolpert and Macready proposed the “no free lunch” theorem that no single model can provide the most accurate predictions for all time series data and that specific modeling approaches must be found for specific problems because universal solutions are unlikely to emerge [
25,
26].
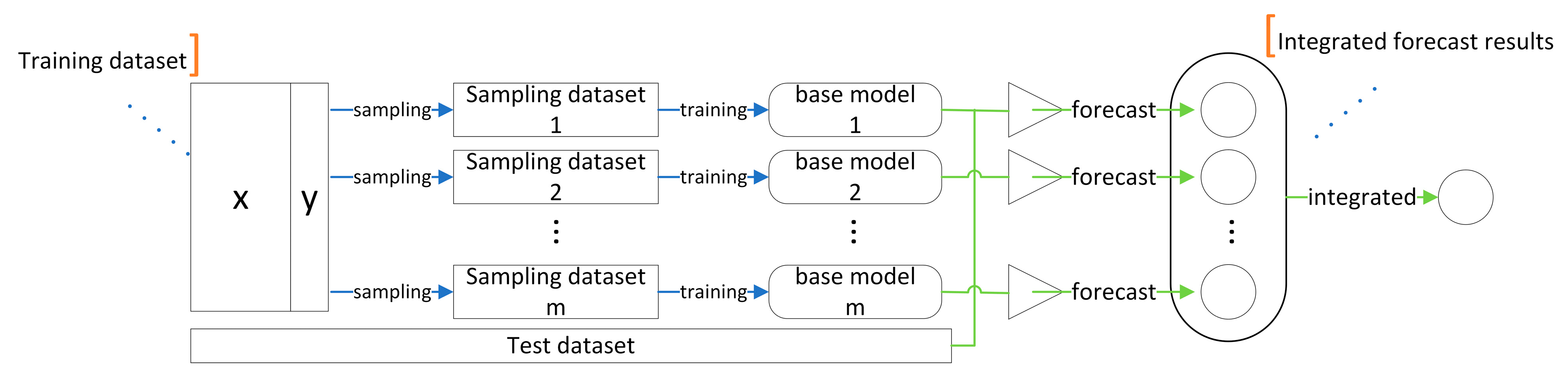
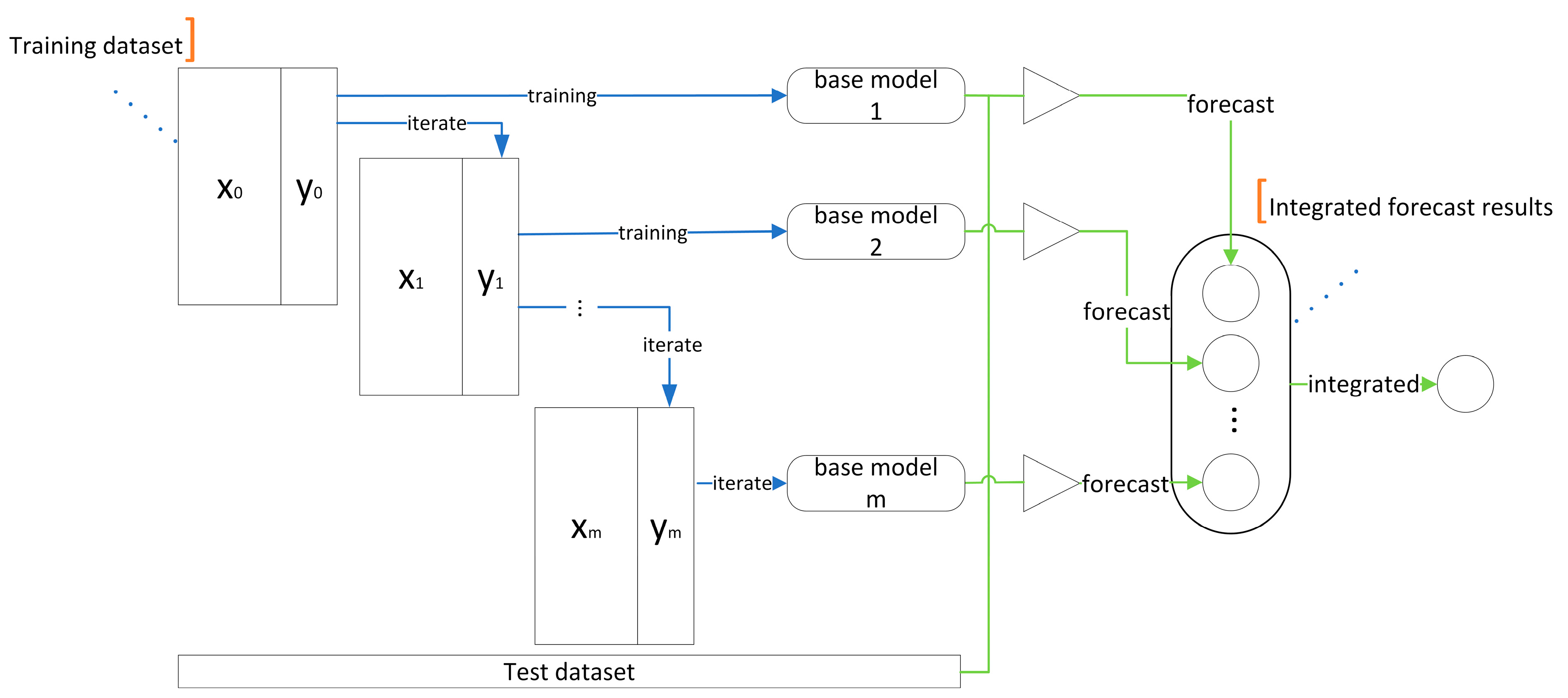
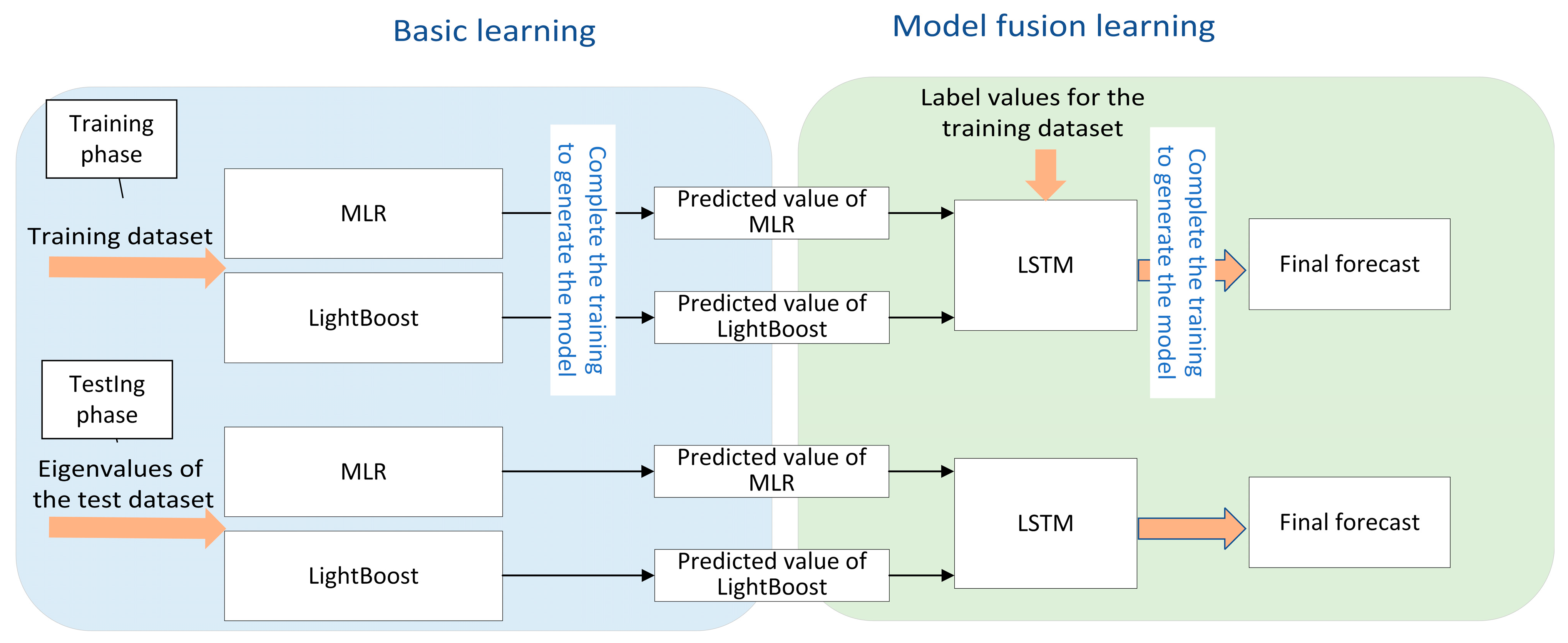
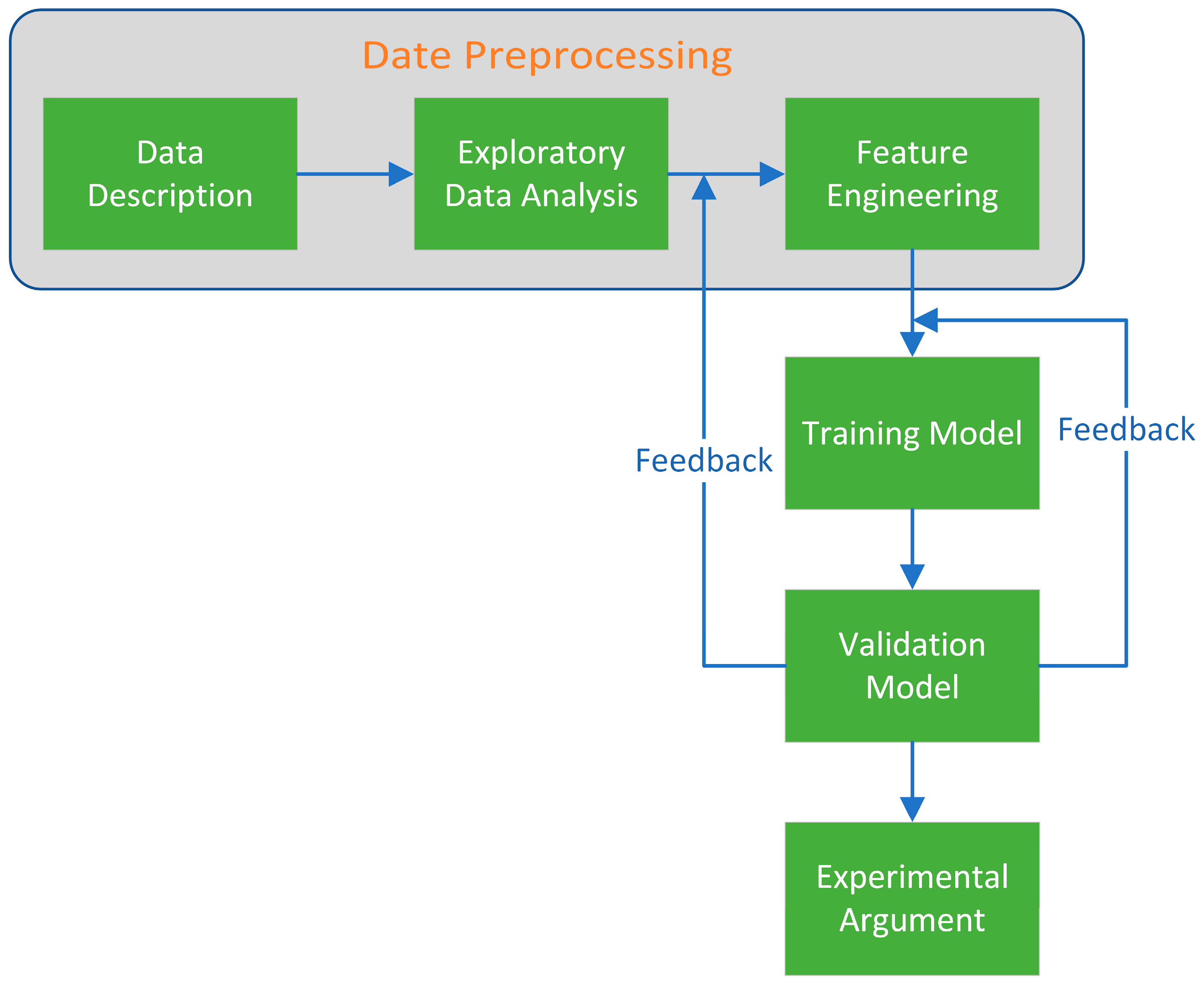
To address these issues, the following research is presented in this paper: Statistics and artificial intelligence are often distinguished, and it is generally believed that they belong to different research fields, with the former focusing on interpretable processes and the latter on optimal output results. From the perspective of data science, this paper organically combines the modeling techniques in these two fields to form a better modeling solution. In this paper, we innovatively propose a model fusion algorithm to jointly complete modeling with different and differentiated base models and model fusers according to different data sets in practical engineering applications, which not only can well-combine the unique advantages of each base model but also can adapt to different time series problems and improve the prediction accuracy and generalization ability.
The main contributions of this paper are as follows:
- (1)
The contradiction of current intelligent algorithms is pointed out: the contradiction between the limited generality of intelligent algorithms and the diversity of engineering problems. A model fusion algorithm is proposed to solve this contradiction, and a theoretical analysis was performed. The algorithm can improve the generality of existing models and can be applied to different practical engineering problems in the future, providing new ideas for the research direction of intelligent algorithms;
- (2)
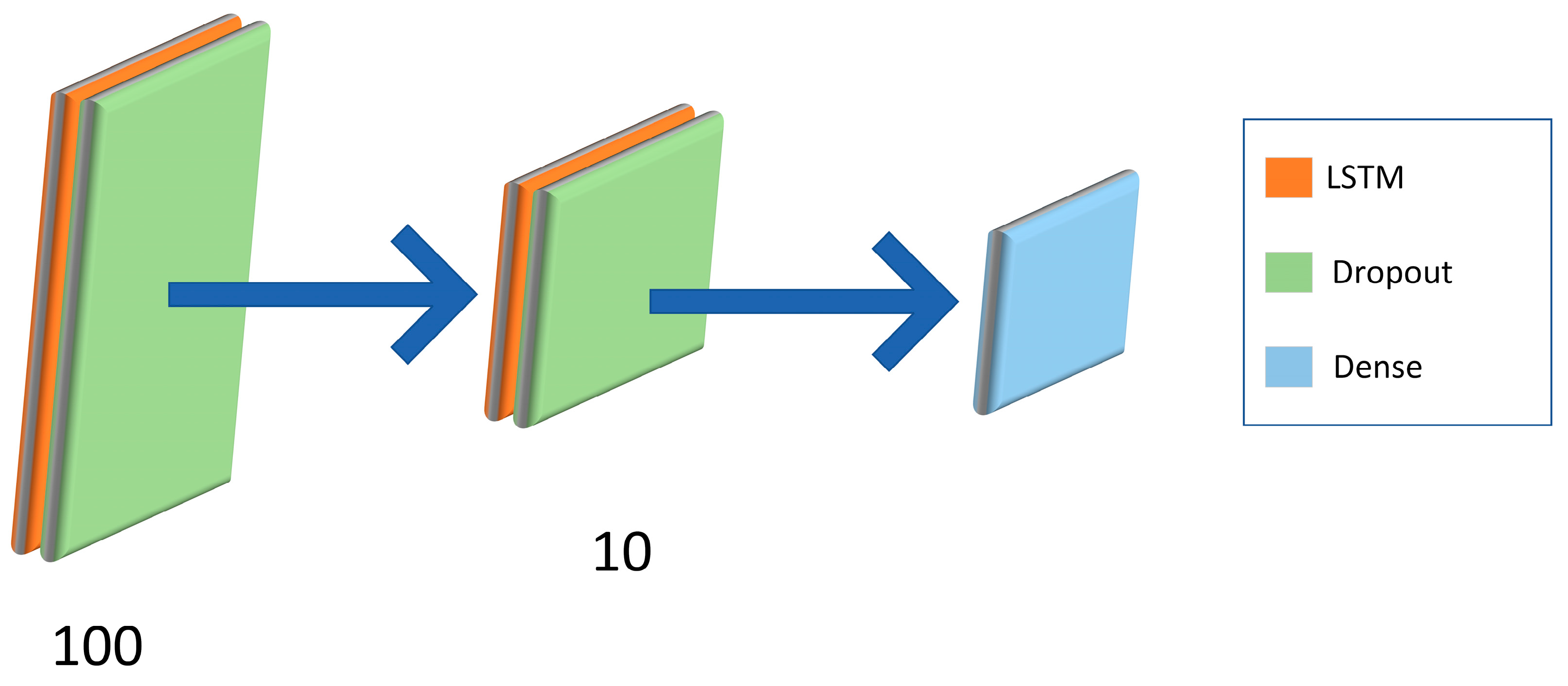
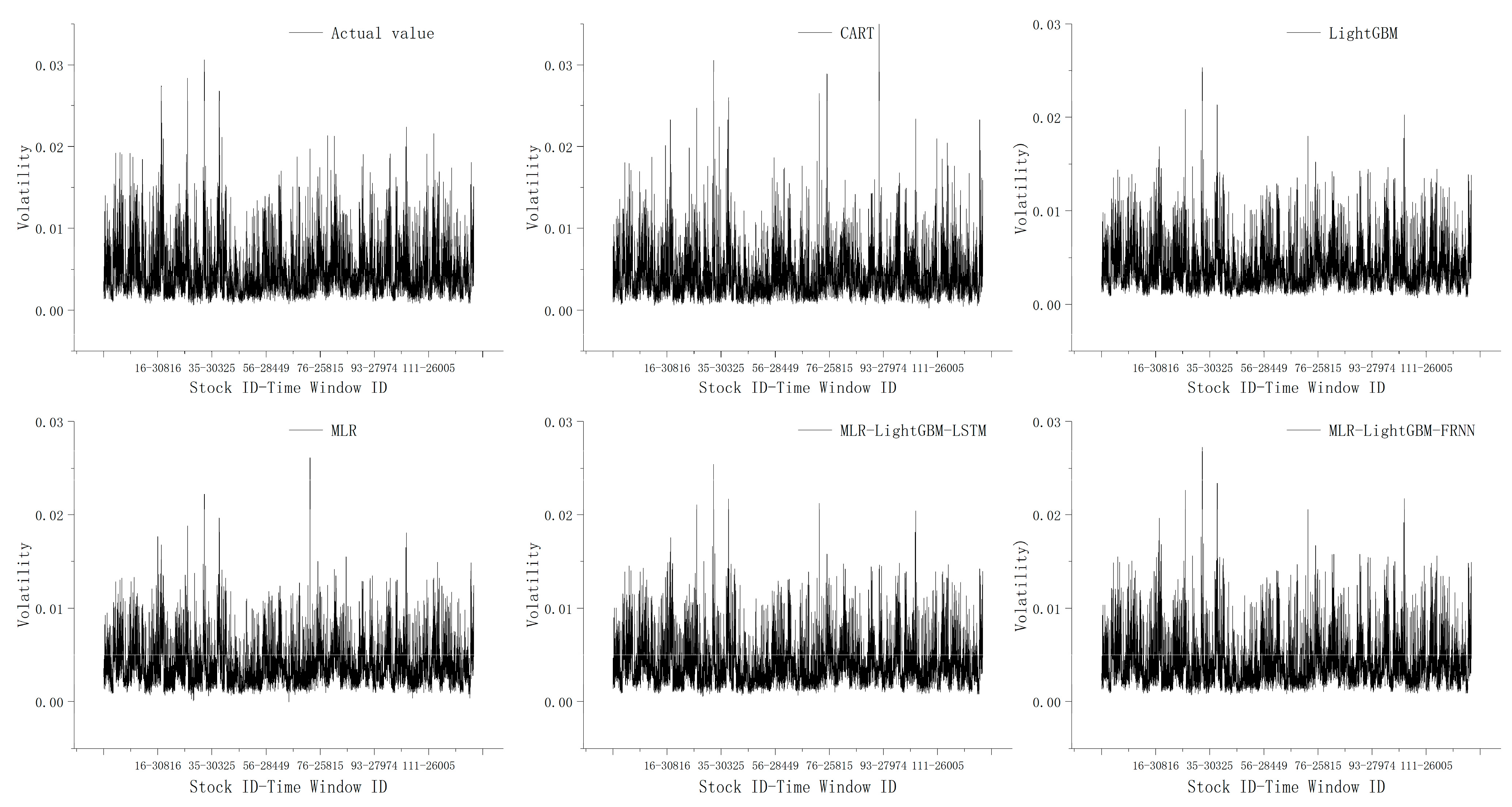
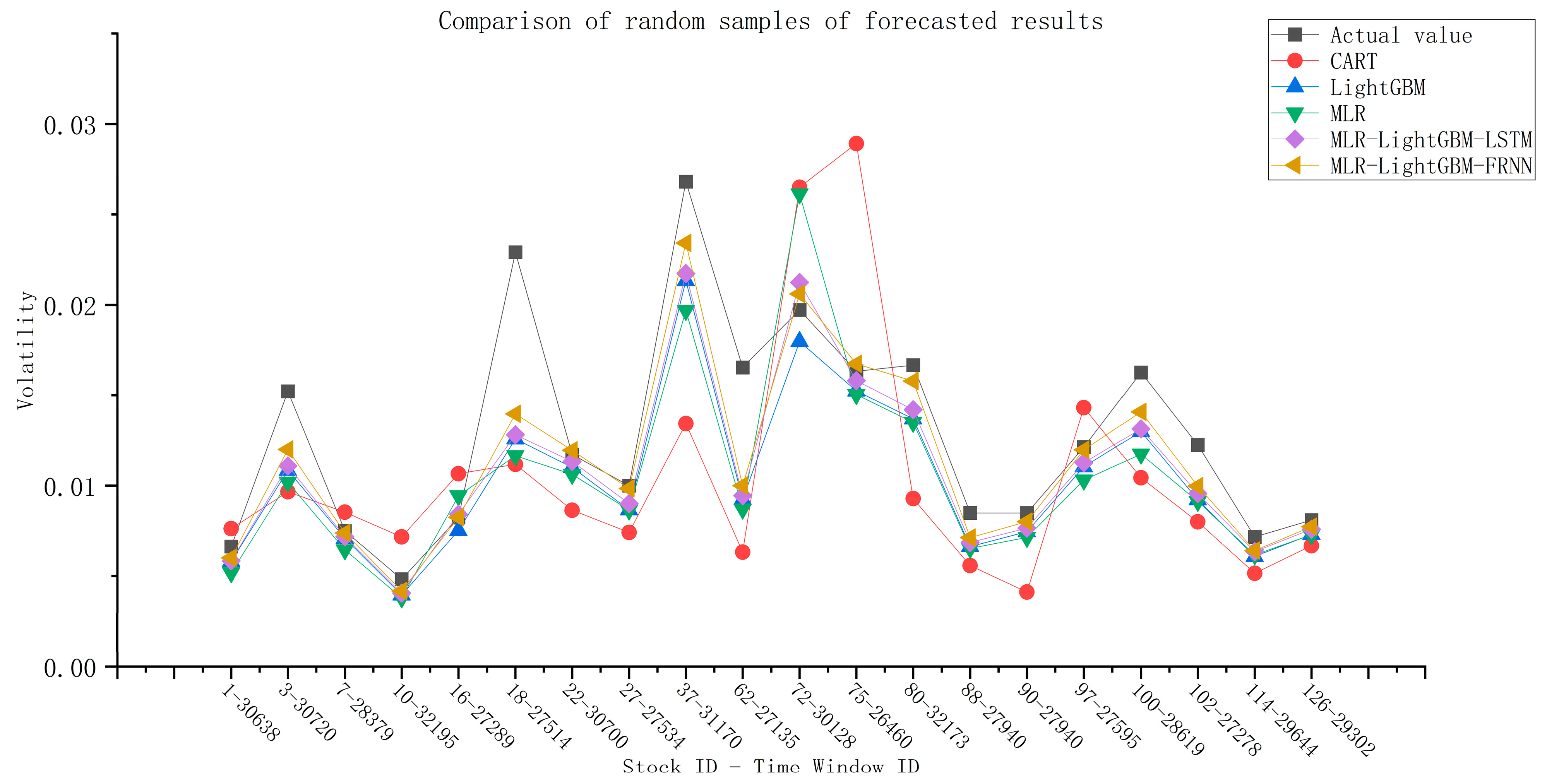
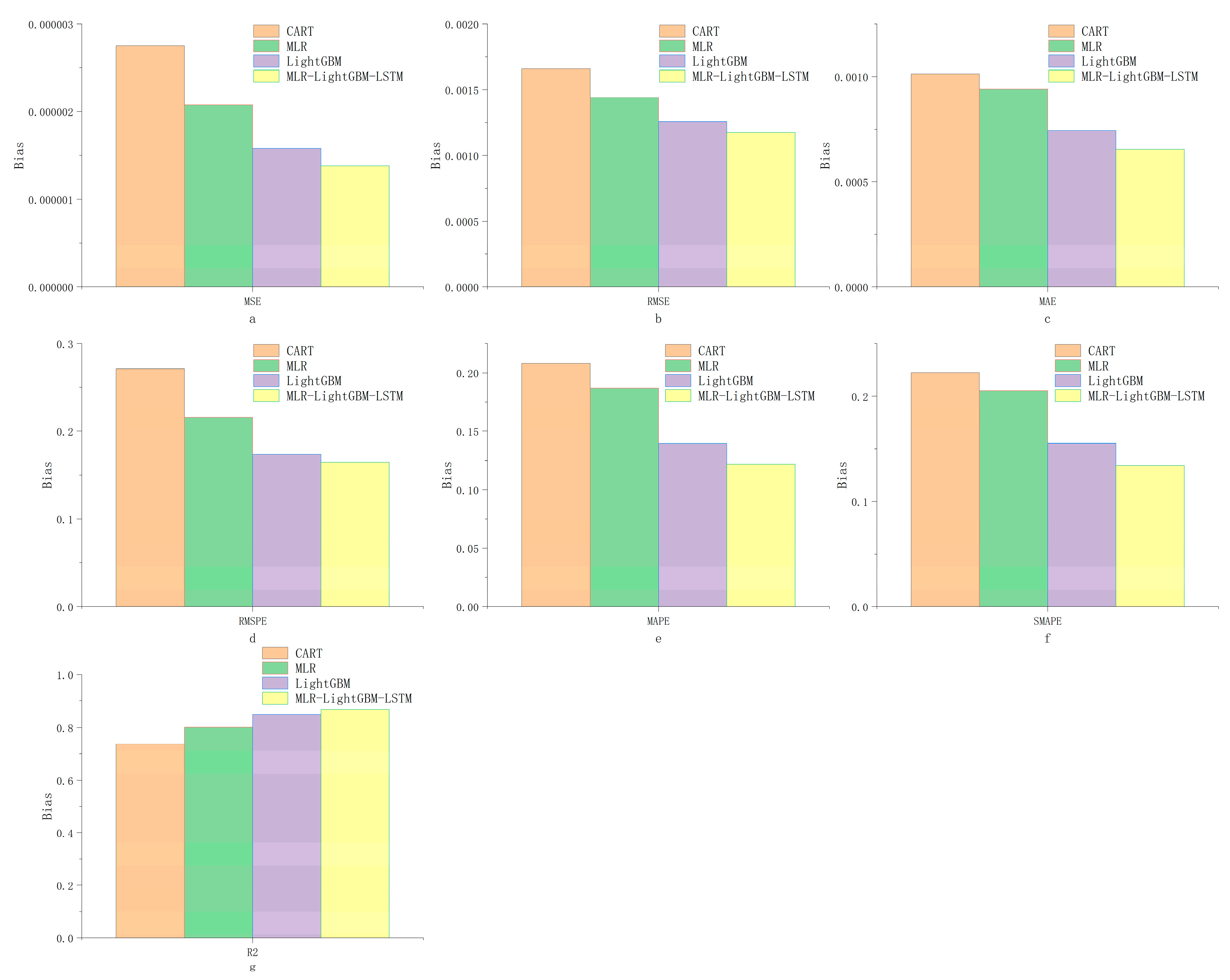
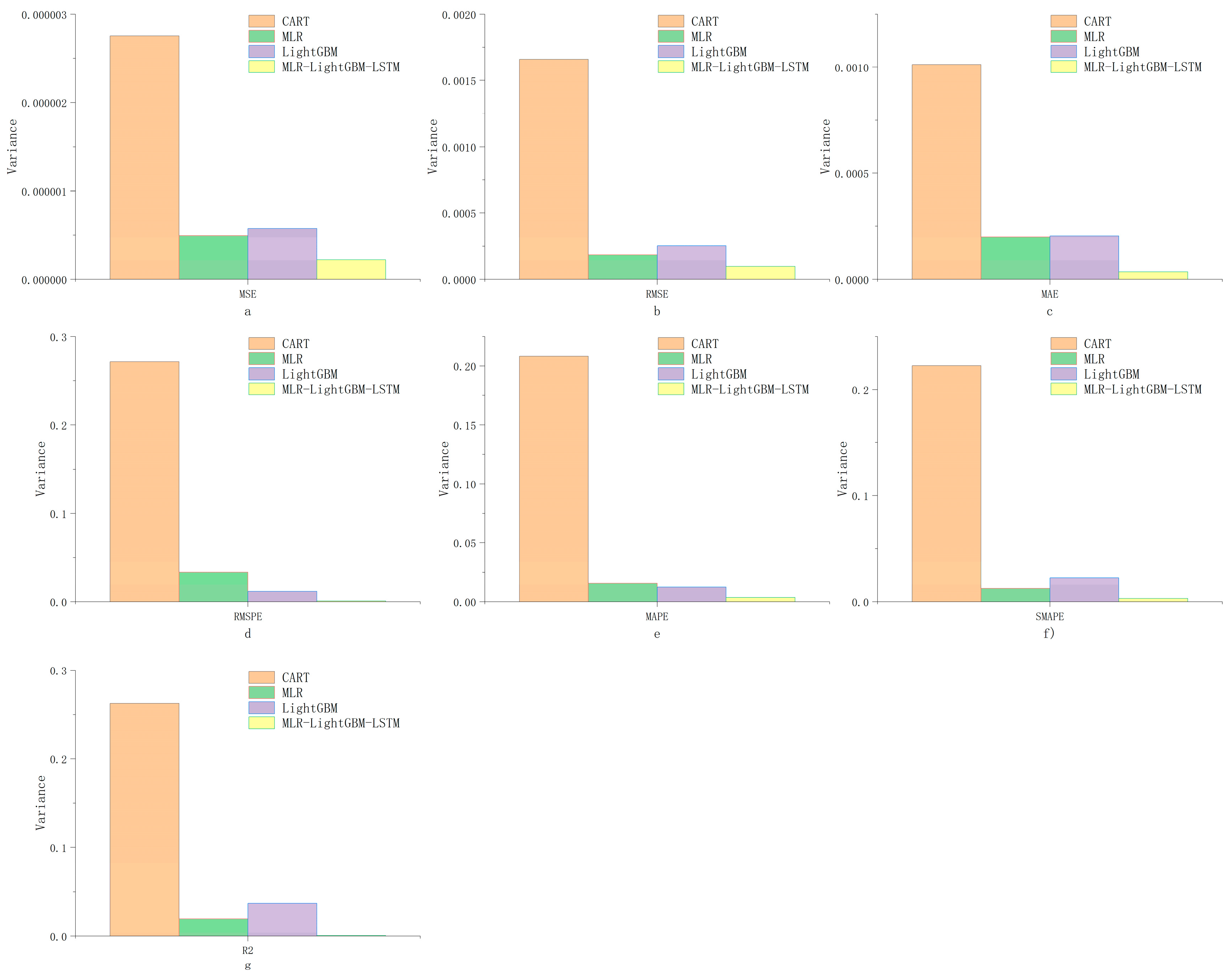
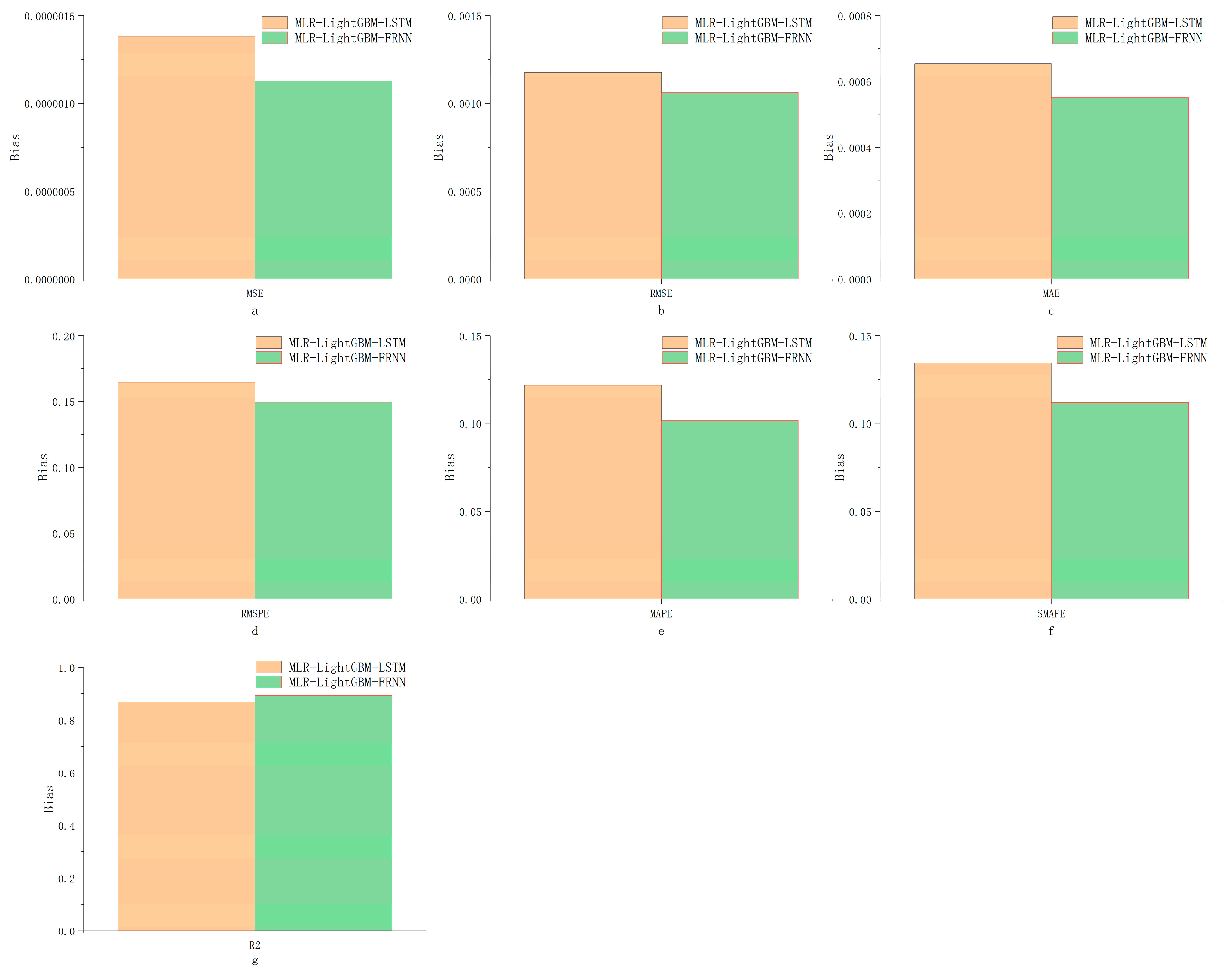
The MLR–LightGBM–LSTM and MLR–LightGBM–FRNN models are designed to predict the high-frequency volatility of 112 stocks from different industries, and the obtained prediction results have lower bias and variance than the existing mainstream models, and the model accuracy and credibility are further improved. In this paper, the same model was used to train and predict 112 stocks instead of modeling each stock separately, which is more in line with real engineering application scenarios;
- (3)
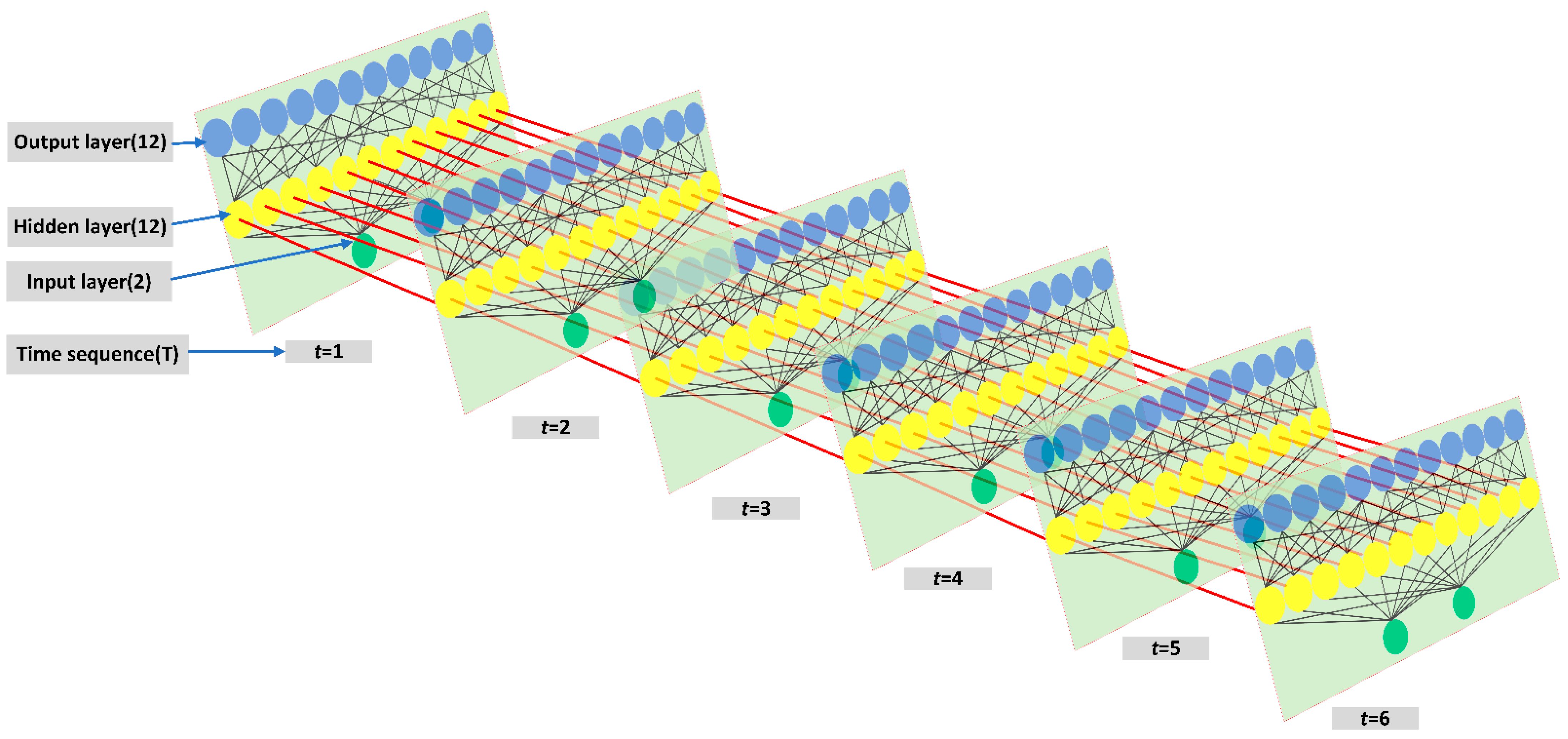
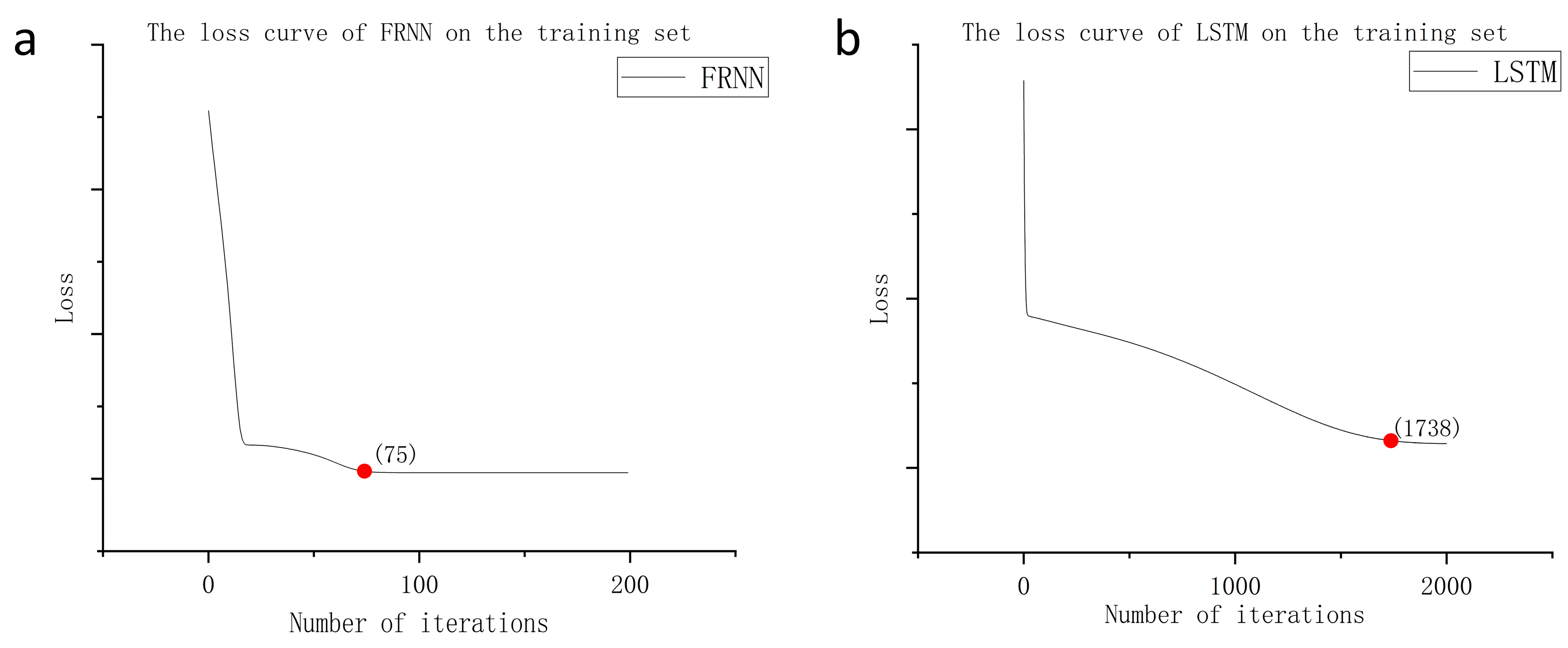
Using LSTM as a model fuser retains the advantage of predicting time series while avoiding the high expendability and instability caused by direct training with deep learning frameworks, providing a dimensionality reduction idea for deep learning modeling. In terms of error, using neural networks can quickly help the hybrid model find the balance of bias and variance, making the hybrid model simultaneously high-fitting and strongly generalizable;
- (4)
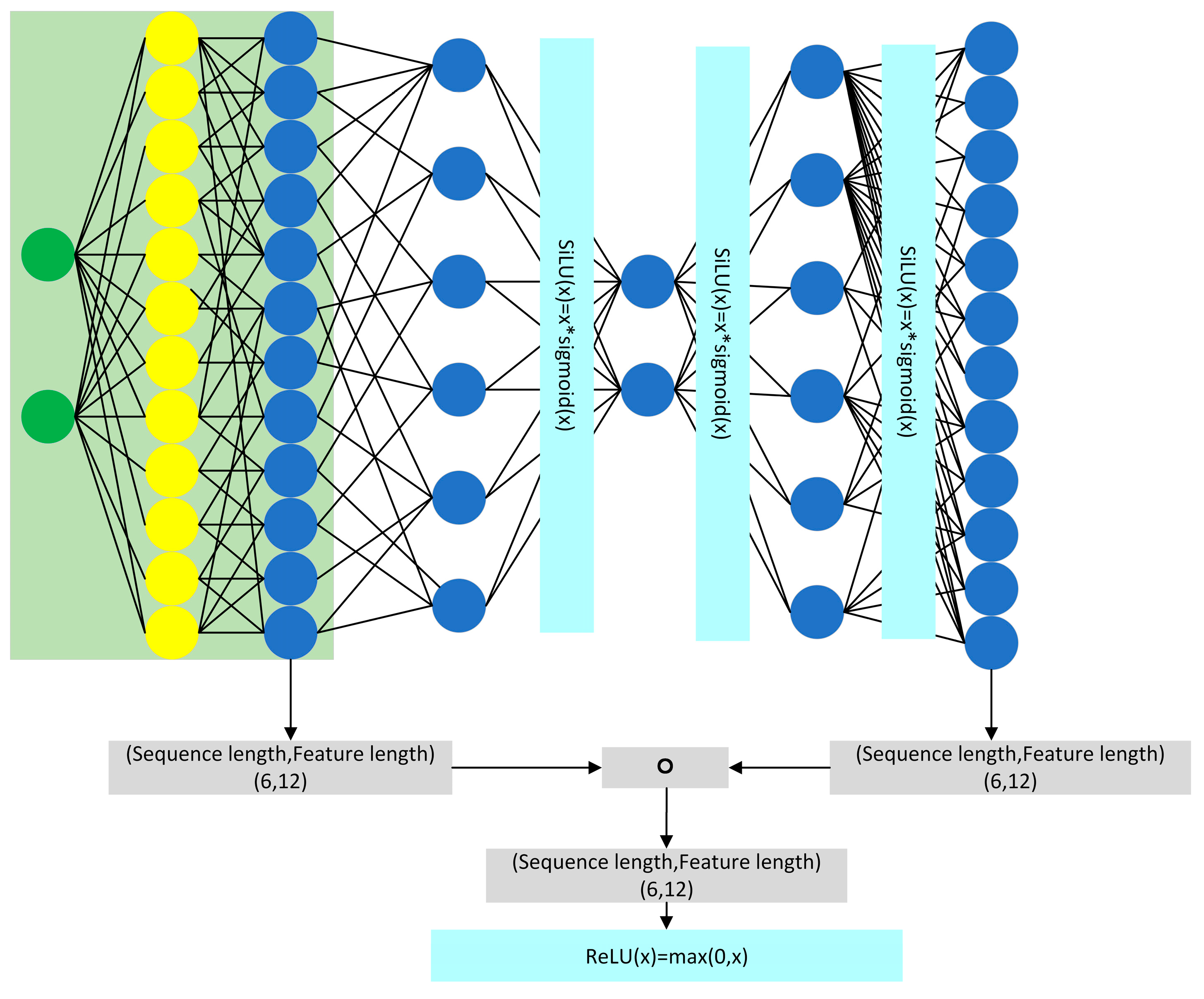
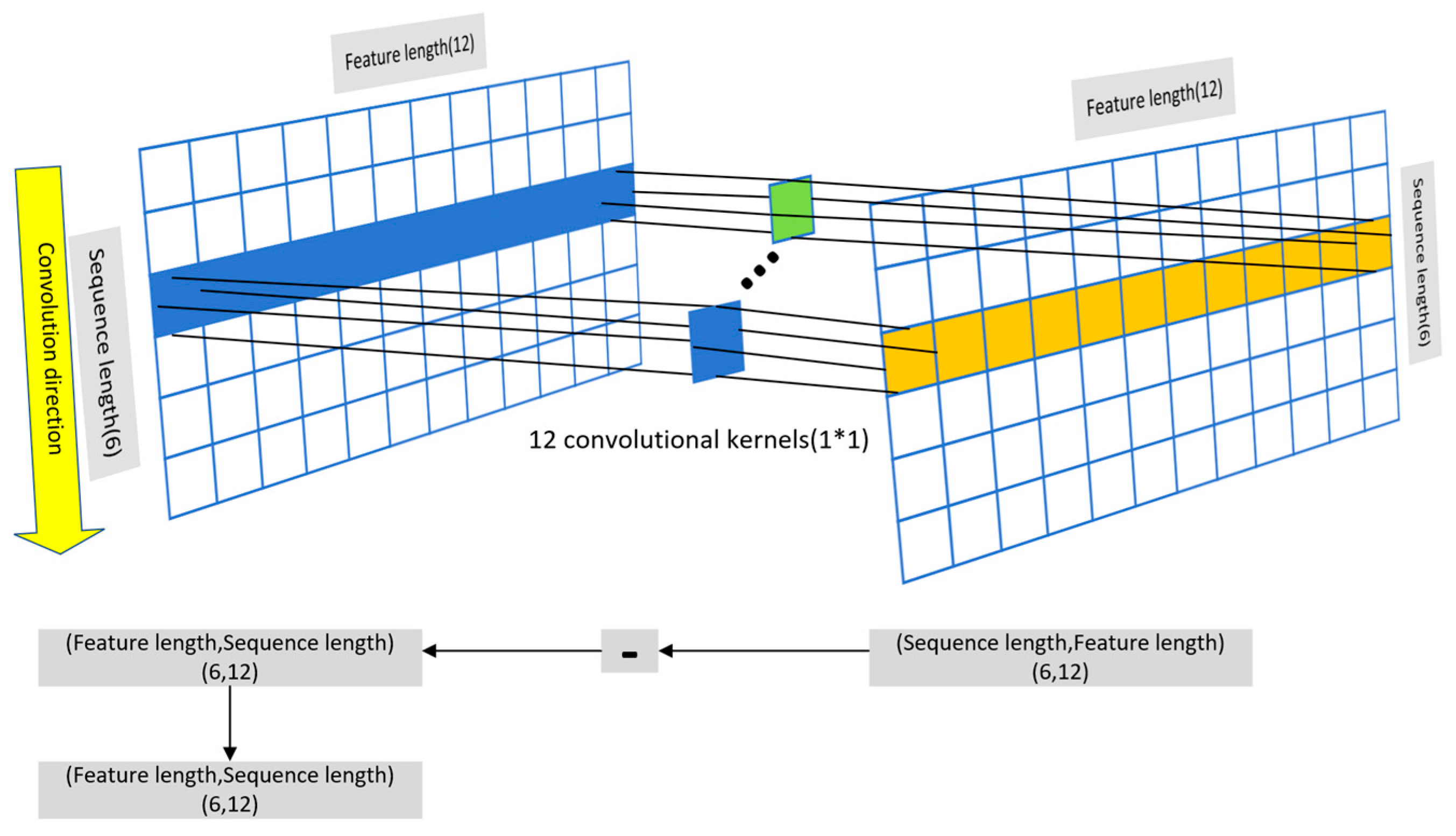
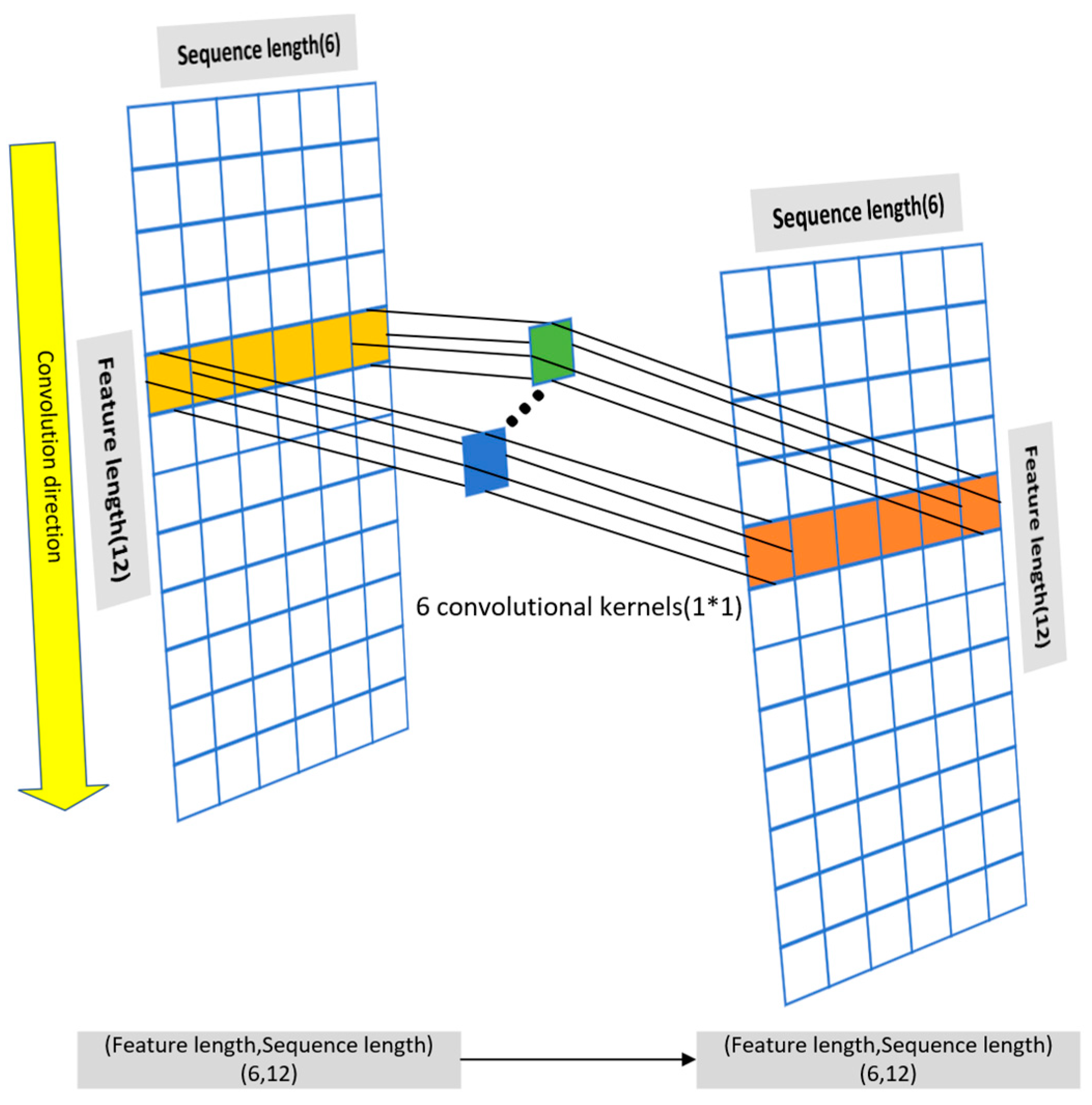
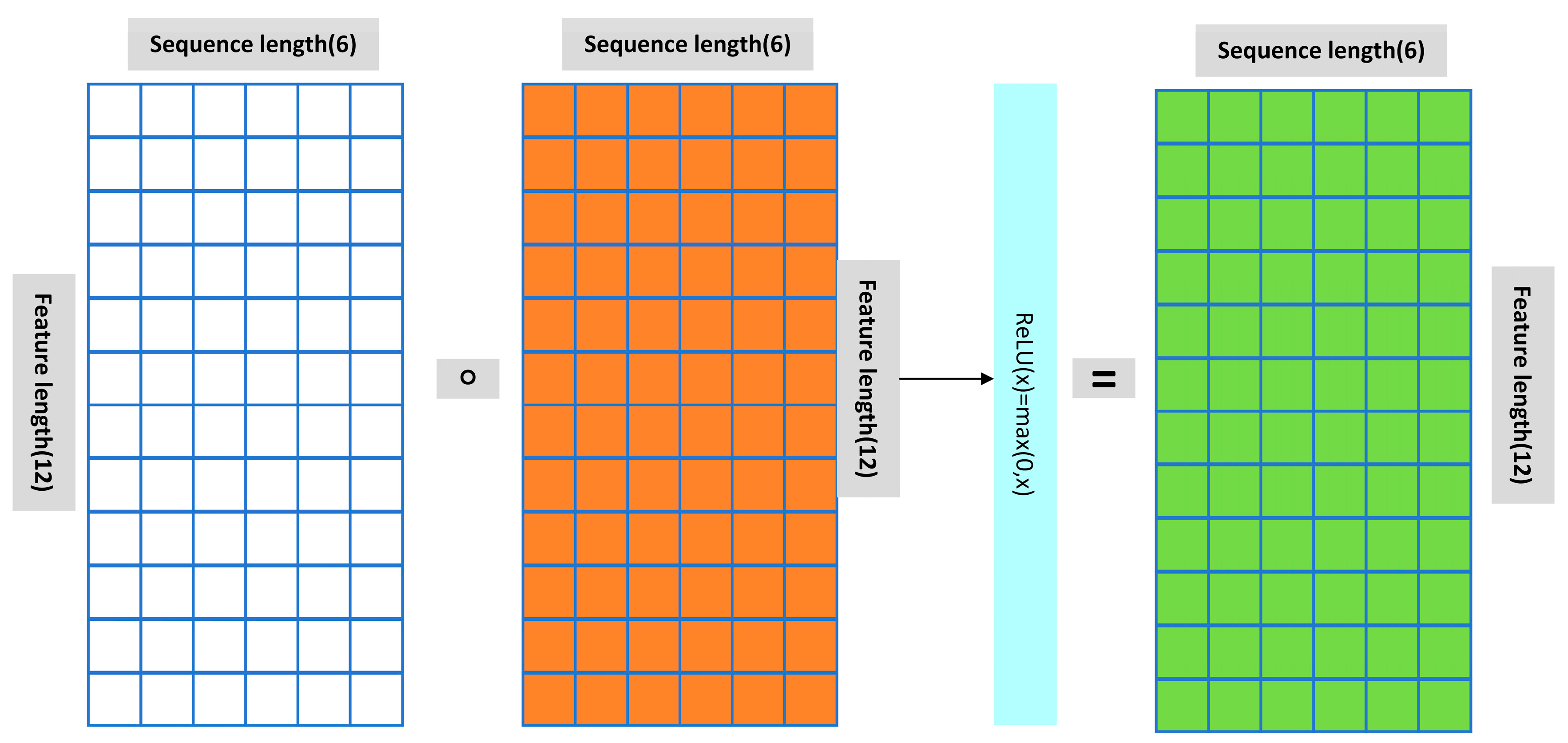
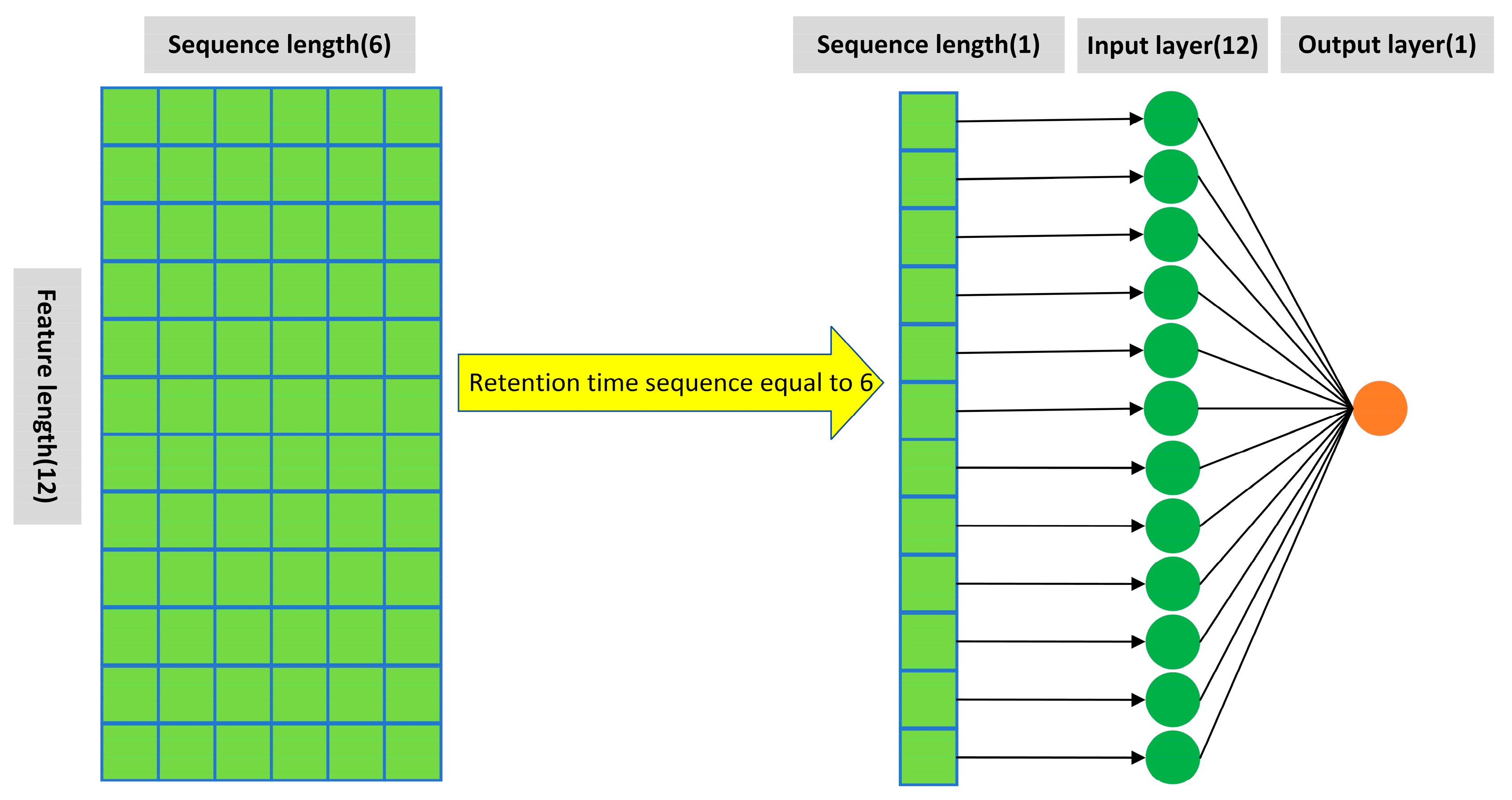
In this paper, a feature reconstruction neural network (FRNN) is innovatively proposed for datasets with few features. It can solve the problems of high error and slow fitting when existing neural networks are modeled for datasets with few features.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}