
RefinePose: Towards More Refined Human Pose Estimation


Abstract
:1. Introduction
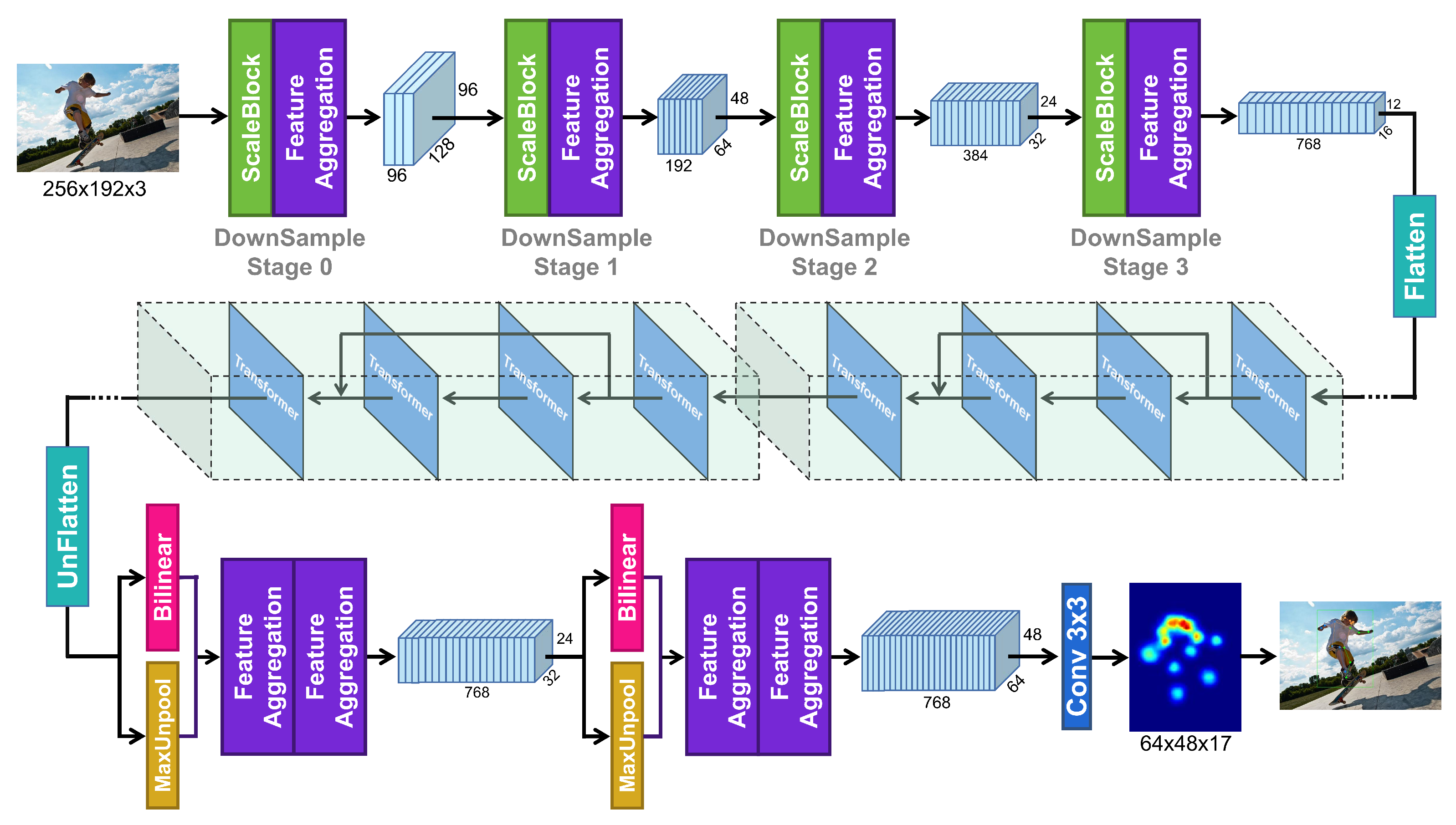
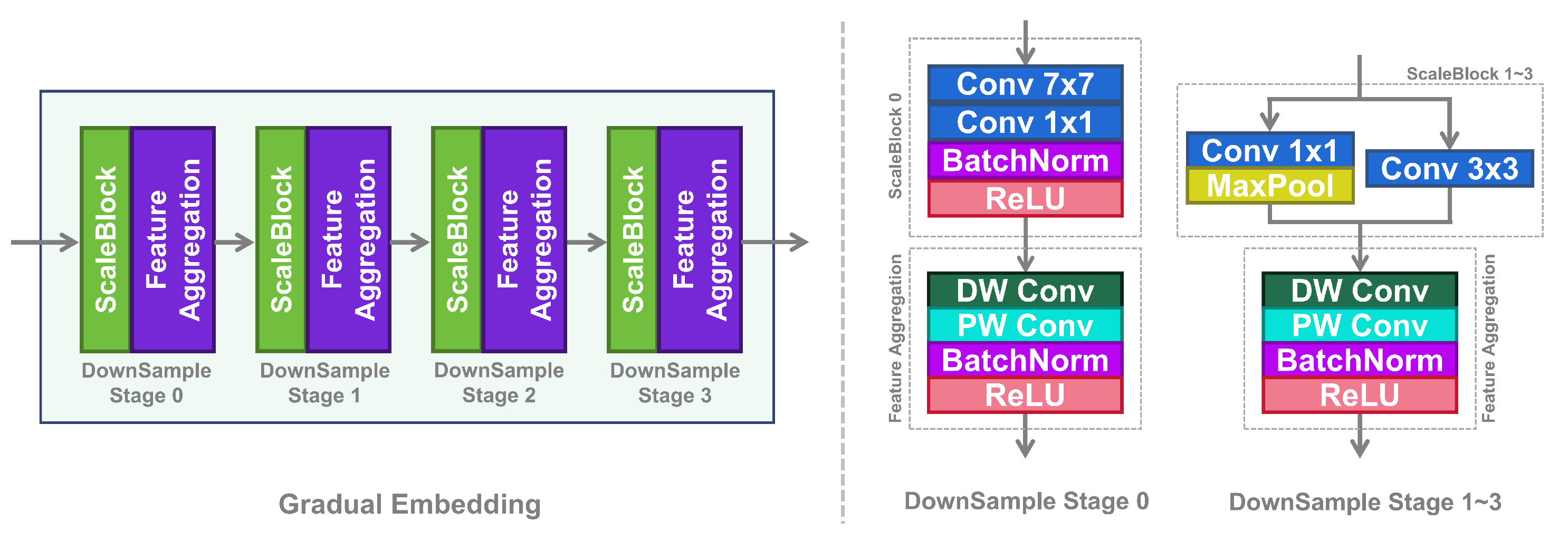
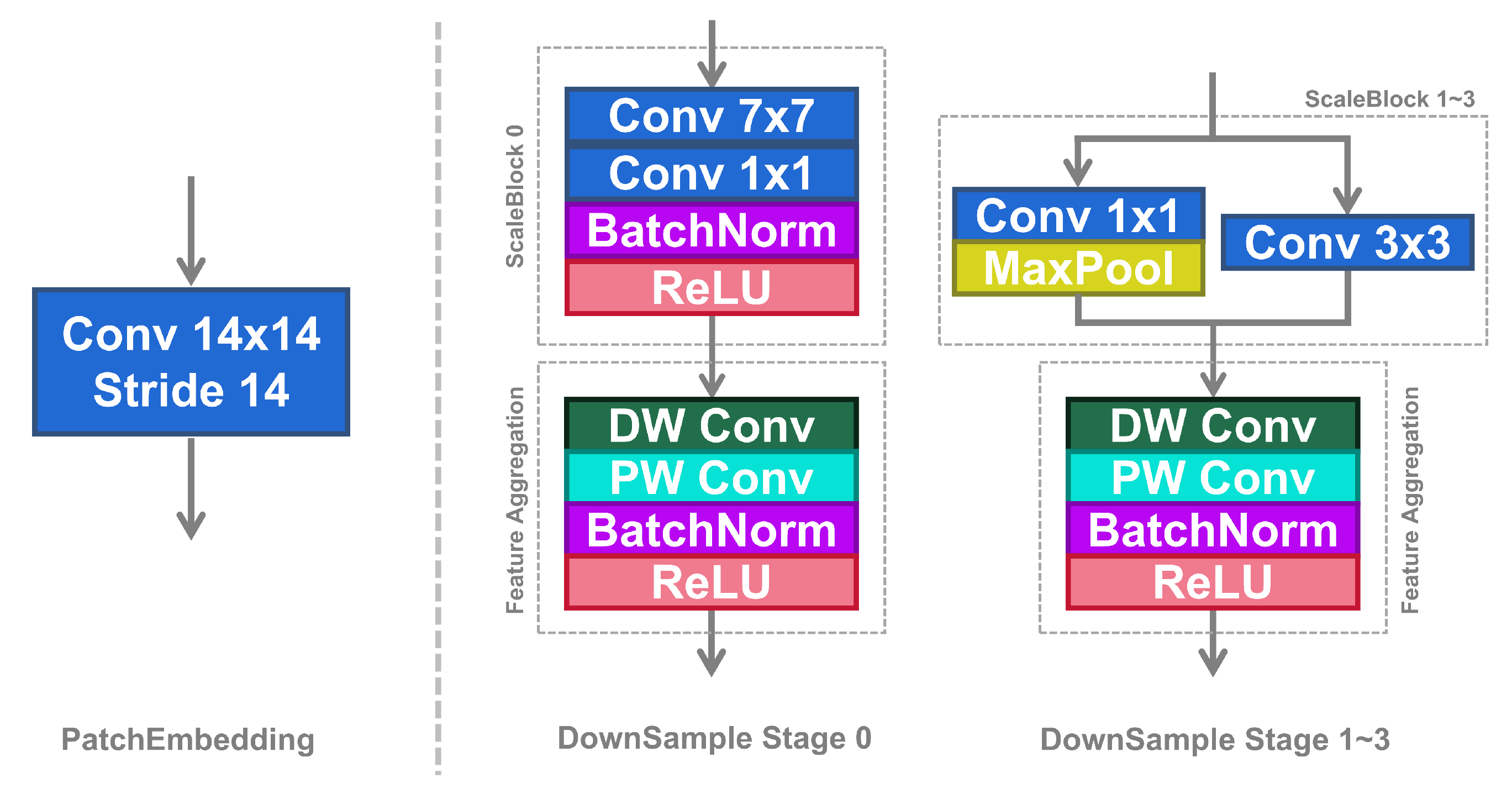
- We design a novel GradualEmbedding module, which uses a progressive downsampling strategy to scale down input images. Additionally, it combines convolutional layers and MaxPool layers to retain more meaningful feature information during the downsampling process.
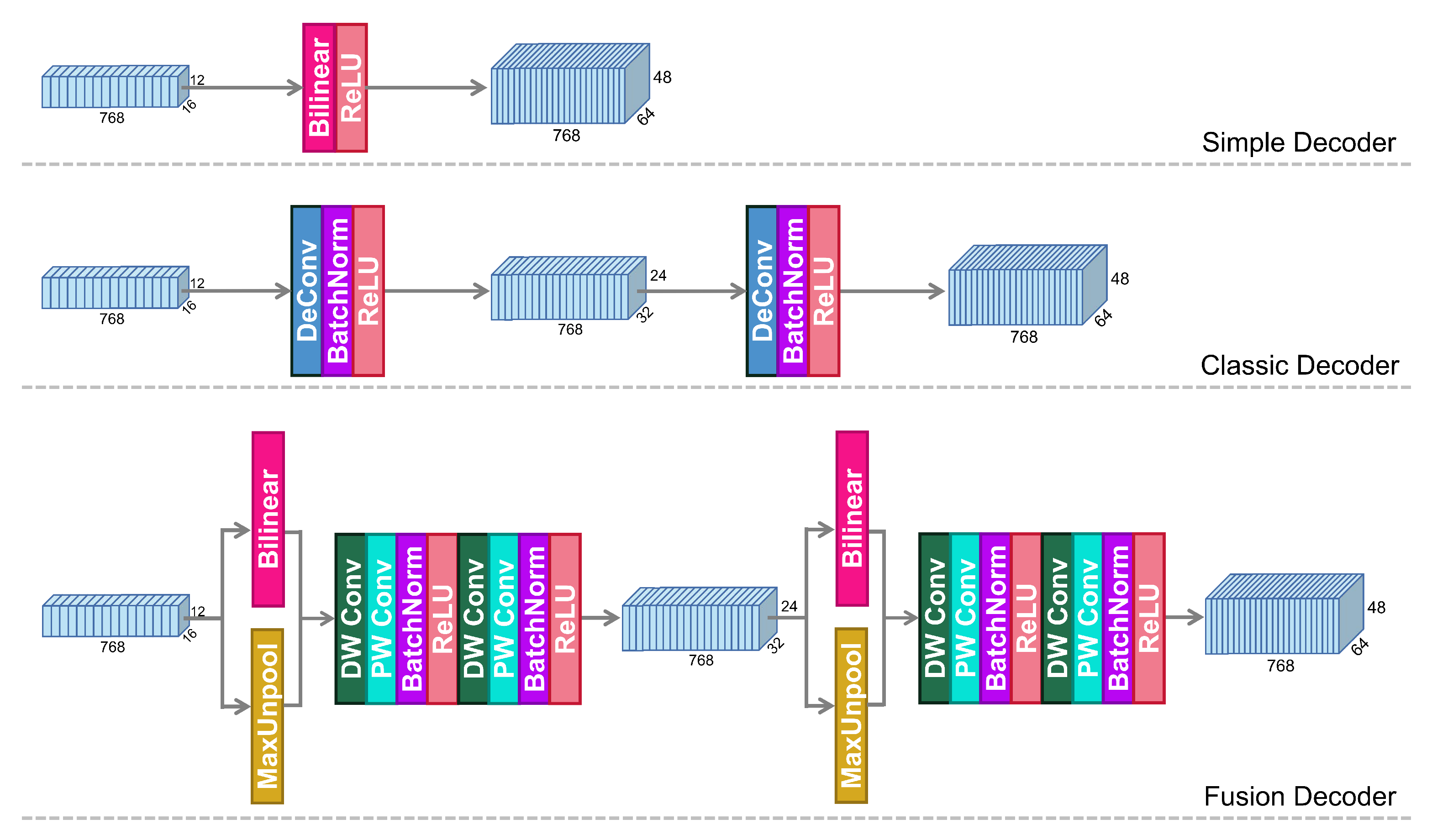
- We propose a more refined decoding method, termed Fusion Decoder. It combines bilinear interpolation and MaxUnpool together to decode more refined heatmaps.
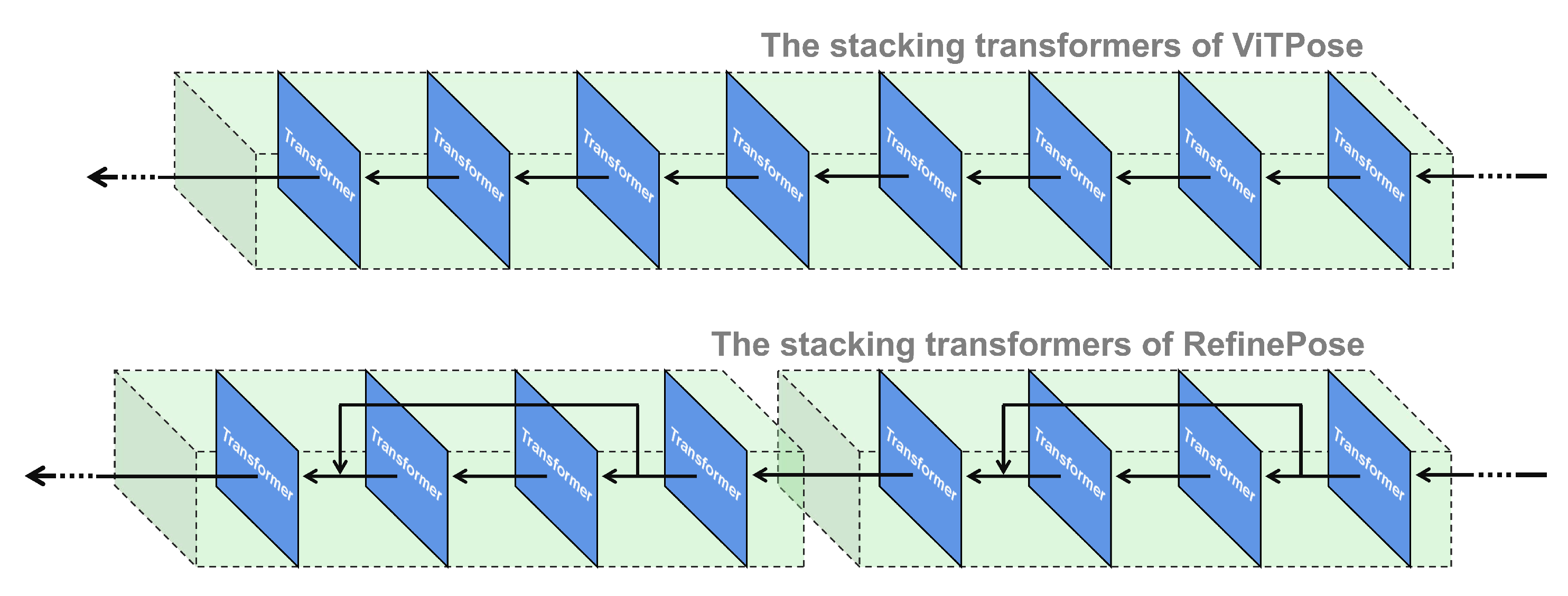
- We add shortcuts to the stacking module of transformers to alleviate insufficient feature extraction on small datasets.
2. Vision Transformer for Human Pose Estimation
3. Method
3.1. The Proposed GradualEmbedding
3.2. The Proposed Fusion Decoder
3.3. Auxiliary Optimization
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Experimental Results
4.3.1. Experimental Results on the COCO Dataset
4.3.2. Experimental Results on the MPII Dataset
4.4. Ablation Experiments
4.4.1. Effectiveness of the GradualEmbedding Module
4.4.2. Effectiveness of the Fusion Decoder
4.4.3. Effectiveness of The Shortcut
4.5. Comparison with the ViTPose
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation. arXiv 2022, arXiv:2204.12484. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Huang, B.; Ge, L.; Chen, G.; Radenkovic, M.; Wang, X.; Duan, J.; Pan, Z. Nonlocal graph theory based transductive learning for hyperspectral image classification. Pattern Recognit. 2021, 116, 107967. [Google Scholar] [CrossRef]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022. Early Access. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, Y.; Zhou, J.; Duan, S.; Zhao, H.; Wang, R. SG-Net: Syntax Guided Transformer for Language Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3285–3299. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, Z.; Zhao, H.; Wang, R.; Chen, K.; Utiyama, M.; Sumita, E. Text Compression-Aided Transformer Encoding. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3840–3857. [Google Scholar] [CrossRef]
- Fan, H.; Yang, Y.; Kankanhalli, M. Point Spatio-Temporal Transformer Networks for Point Cloud Video Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2022. Early Access. [Google Scholar] [CrossRef]
- Xue, Z.; Tan, X.; Yu, X.; Liu, B.; Yu, A.; Zhang, P. Deep Hierarchical Vision Transformer for Hyperspectral and LiDAR Data Classification. IEEE Trans. Image Process. 2022, 31, 3095–3110. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2021, arXiv:2010.04159. [Google Scholar]
- Huang, B.; Ge, L.; Chen, X.; Chen, G. Vertical Structure-Based Classification of Oceanic Eddy Using 3-D Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4203614. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, Y.; Zhan, X.; Cheng, M. P2T: Pyramid Pooling Transformer for Scene Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2022. Early Access. [Google Scholar] [CrossRef]
- Dalmaz, O.; Yurt, M.; Çukur, T. ResViT: Residual Vision Transformers for Multimodal Medical Image Synthesis. IEEE Trans. Med. Imaging 2022, 41, 2598–2614. [Google Scholar] [CrossRef]
- Yu, H.; Xu, Z.; Zheng, K.; Hong, D.; Yang, H.; Song, M. MSTNet: A Multilevel Spectral–Spatial Transformer Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 5532513. [Google Scholar] [CrossRef]
- Li, K.; Wang, S.; Zhang, X.; Xu, Y.; Xu, W.; Tu, Z. Pose Recognition with Cascade Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1944–1953. [Google Scholar]
- Yang, S.; Quan, Z.; Nie, M.; Yang, W. TransPose: Keypoint Localization via Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 11782–11792. [Google Scholar]
- Ma, H.; Wang, Z.; Chen, Y.; Kong, D.; Chen, L.; Liu, X.; Yan, X.; Tang, H.; Xie, X. PPT: Token-Pruned Pose Transformer for monocular and multi-view human pose estimation. arXiv 2022, arXiv:2209.08194. [Google Scholar]
- McNally, W.J.; Vats, K.; Wong, A.; McPhee, J.J. Rethinking Keypoint Representations: Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation. arXiv 2021, arXiv:2111.08557. [Google Scholar]
- Li, Y.; Yang, S.; Liu, P.; Zhang, S.; Wang, Y.; Wang, Z.; Yang, W.; Xia, S. SimCC: A Simple Coordinate Classification Perspective for Human Pose Estimation. In Computer Vision—ECCV 2022; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. HRFormer: High-Resolution Transformer for Dense Prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar]
- Jiang, W.; Jin, S.; Liu, W.; Qian, C.; Luo, P.; Liu, S. PoseTrans: A Simple Yet Effective Pose Transformation Augmentation for Human Pose Estimation. arXiv 2022, arXiv:2208.07755. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.; Zhou, E. TokenPose: Learning Keypoint Tokens for Human Pose Estimation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 11293–11302. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Huang, J.; Zhu, Z.; Guo, F.; Huang, G. The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5699–5708. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5385–5394. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. In Computer Vision—ECCV 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Su, Z.; Ye, M.; Zhang, G.; Dai, L.; Sheng, J. Cascade Feature Aggregation for Human Pose Estimation. arXiv 2019, arXiv:1902.07837. [Google Scholar]
- Bin, Y.; Cao, X.; Chen, X.; Ge, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Gao, C.; Sang, N. Adversarial Semantic Data Augmentation for Human Pose Estimation. In Computer Vision—ECCV 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Input | COCO val | COCO test-dev | ||
|---|---|---|---|---|---|---|
| Resolution | AP | AR | AP | AR | ||
| HigherHRNet [34] | HRNet-W48 | 384 × 288 | 72.1 | - | 70.5 | 74.9 |
| SimpleBaseline [35] | ResNet-152 | 256 × 192 | 73.5 | 79.0 | - | - |
| HRNet [29] | HRNet-W32 | 256 × 192 | 74.4 | 78.9 | - | - |
| HRNet [29] | HRNet-W32 | 384 × 288 | 75.8 | 81.0 | 74.9 | 80.1 |
| HRNet [29] | HRNet-W48 | 256 × 192 | 75.1 | 80.4 | - | - |
| HRNet [29] | HRNet-W48 | 384 × 288 | 76.3 | 81.2 | 75.5 | 80.5 |
| UDP [33] | HRNet-W48 | 384 × 288 | 77.2 | 82.0 | - | - |
| TokenPose-L/D24 [28] | HRNet-W48 | 256 × 192 | 75.8 | 80.9 | 75.1 | 80.2 |
| TransPose-H/A6 [22] | HRNet-W48 | 256 × 192 | 75.8 | 80.8 | 75.0 | - |
| HRFormer [26] | HRFormer-B | 256 × 192 | 75.6 | 80.8 | - | - |
| HRFormer [26] | HRFormer-B | 384 × 288 | 77.2 | 82.0 | 76.2 | 81.2 |
| ViTPose [1] | ViT-B | 256 × 192 | 75.8 | 81.1 | 75.1 | 80.3 |
| ViTPose [1] | ViT-L | 256 × 192 | 78.3 | 83.5 | 77.3 | 82.4 |
| ViTPose [1] | ViT-H | 256 × 192 | 79.1 | 84.1 | 78.1 | 83.1 |
| RefinePose | ViT-B | 256 × 192 | 75.9 | 82.1 | 75.3 | 80.5 |
| RefinePose | ViT-L | 256 × 192 | 78.5 | 83.7 | 77.5 | 82.3 |
| RefinePose | ViT-H | 256 × 192 | 79.3 | 84.0 | 78.4 | 83.3 |
| Method | Backbone | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean |
|---|---|---|---|---|---|---|---|---|---|
| CPM [36] | CPM | 96.2 | 95.0 | 87.5 | 82.2 | 87.6 | 82.7 | 78.4 | 87.7 |
| SimpleBaseline [35] | ResNet-152 | 86.9 | 95.4 | 89.4 | 84.0 | 88.0 | 84.6 | 82.1 | 89.0 |
| HRNet [29] | HRNet-W32 | 96.9 | 85.9 | 90.5 | 85.9 | 89.1 | 86.1 | 82.5 | 90.0 |
| HRNet [29] | HRNet-W48 | 97.1 | 95.8 | 90.7 | 85.6 | 89.0 | 86.8 | 82.1 | 90.1 |
| CFA [37] | ResNet-101 | 95.9 | 95.4 | 91.0 | 86.9 | 89.8 | 87.6 | 83.9 | 90.1 |
| ASDA [38] | HRNet-W48 | 97.3 | 96.5 | 91.7 | 87.9 | 90.8 | 88.2 | 84.2 | 91.4 |
| TransPose-H/A6 [22] | RNet-W48 | - | - | - | - | - | - | - | 92.3 |
| ViTPose [1] | ViT-B | 97.6 | 97.4 | 93.7 | 90.1 | 92.4 | 91.9 | 88.3 | 93.4 |
| ViTPose [1] | ViT-L | 97.7 | 97.4 | 94.0 | 91.5 | 93.1 | 92.2 | 89.7 | 93.9 |
| ViTPose [1] | ViT-H | 97.7 | 97.6 | 94.3 | 91.2 | 93.3 | 92.5 | 90.1 | 94.1 |
| RefinePose | ViT-B | 97.8 | 97.5 | 93.9 | 90.3 | 92.4 | 92.0 | 89.4 | 93.6 |
| RefinePose | ViT-L | 97.8 | 97.7 | 94.4 | 91.6 | 93.2 | 92.4 | 90.0 | 94.1 |
| RefinePose | ViT-H | 97.9 | 97.8 | 94.6 | 91.3 | 93.4 | 92.7 | 90.3 | 94.2 |
| DownSample with Conv2d | DownSample with MaxPool | Feature Aggregation | AP | AR |
|---|---|---|---|---|
| ✓ | - | - | 73.1 | 79.2 |
| - | ✓ | - | 72.6 | 78.3 |
| ✓ | ✓ | - | 74.5 | 80.2 |
| ✓ | ✓ | ✓ | 75.3 | 80.5 |
| UpSample | AP | AR |
|---|---|---|
| Bilinear | 74.2 | 79.6 |
| Bilinear + MaxUnpool | 74.9 | 80.1 |
| Bilinear + MaxUnpool + FA | 75.3 | 80.5 |
| Shortcut | Mean (PCKh@0.5) |
|---|---|
| - | 93.2 |
| ✓ | 93.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, H.; Wang, G.; Chen, C.; Zhang, X. RefinePose: Towards More Refined Human Pose Estimation. Electronics 2022, 11, 4060. https://doi.org/10.3390/electronics11234060
Dong H, Wang G, Chen C, Zhang X. RefinePose: Towards More Refined Human Pose Estimation. Electronics. 2022; 11(23):4060. https://doi.org/10.3390/electronics11234060
Chicago/Turabian StyleDong, Hao, Guodong Wang, Chenglizhao Chen, and Xinyue Zhang. 2022. "RefinePose: Towards More Refined Human Pose Estimation" Electronics 11, no. 23: 4060. https://doi.org/10.3390/electronics11234060