1. Introduction
With the rapid development of science and technology, intelligent industrial production lines are gaining popularity, and the control of production quality by enterprises is becoming increasingly stringent. The ability to identify studs accurately and at a high speed directly determines the intelligence and efficiency of the production line. This is a key issue in the quality control of automotive companies. The traditional method of manually identifying studs is unsuitable for the intelligent development of automotive production lines for many reasons, such as its slow detection speed, low efficiency, high false detection rate, tendency to cause fatigue, and the partly luminous and heat-generating workpieces, which are harmful to the human eye [
1].
In response to the problems with manual inspection methods, experts and researchers have conducted extensive research on contactless inspection methods.
Traditional processing methods are primarily based on lasers, ultrasonic sensors, and manual feature extraction. Auerswald et al. [
2] used laser lines to detect fractures and defects in large gear workpieces. Li et al. [
3] proposed an industrial inspection method based on multilaser scanner point clouds with high detection accuracy; however, these sensors are expensive. Guo et al. [
4] used ultrasonic technology to detect defects on the workpiece surface, which achieved good results in terms of cost reduction but failed to achieve better optimization in terms of reliability and visualization. With the continuous development of computer vision techniques, the extraction of manually designed features from workpiece images to achieve the rapid recognition of defects has become a popular topic in industrial inspection. Lee et al. [
5] developed a histogram-based workpiece recognition method and used the difference, mean, and standard deviation to analyze workpiece images for recognition. Kumar et al. [
6] proposed a method for workpiece welding recognition based on the gray-level co-occurrence matrix, which is suitable for the texture recognition of workpieces. However, both methods require certain assumptions, e.g., a separable workpiece detection region. Therefore, they cannot detect the scene in the entire field of view, and the methods are very sensitive to hyperparameter settings. Zhang et al. [
7] proposed a detection method for aluminum alloy wheel artifacts that incorporated adaptive threshold segmentation and morphology. However, the improper selection of smoothing operators and thresholds can cause the method to fail to extract image features. Shi et al. [
8] proposed an improved Sobel detection algorithm for railway track surface artifact identification that uses filters to reduce image noise and remove artifact surface defect features. This method uses a filter to reduce image noise and extract features from the surface of the workpiece. However, it is not suitable for all random texture images and suffers from feature correlation. These methods are limited by the need to design explicit features based on the actual working conditions of the workpiece. Expert knowledge and manual design are essential, and the omission of key features, for example, can lead to poor detection results. As a result, these methods are more difficult to automate efficiently.
With the increase in hardware computing power, deep learning-based recognition methods are now used in various fields to automatically acquire target features and their valid information without requiring the manual design of the explicit features of the object to be detected. This advantage effectively avoids the problem of traditional recognition methods that require expert knowledge and manual configurations. In recent years, convolutional neural networks (CNNs) [
9] have been extensively used in the field of workpiece stud image recognition and target detection [
10,
11]. Liu et al. [
12] proposed an online stud measurement method based on photometric stereo measurements and deep learning theory. It uses a CNN to determine the key points of screws on automotive workpieces and can measure multiple studs with high accuracy. Current target detection algorithms in deep learning can be broadly classified into two main categories: those based on candidate regions and those based on regression [
13]. Candidate region-based target detection algorithms are also known as two-stage approaches, i.e., the target detection problem is divided into two stages. Candidate regions are generated in the first stage. For example, Ren et al. [
14] proposed the Faster R-CNN algorithm, which effectively speeds up the detection rate. Wang et al. [
15] proposed an automatic tag welding robot based on a cascaded R-CNN target detection system that automatically identifies and picks up screws for welding.
Although the two-stage algorithm can achieve high accuracy in target detection [
16], it still requires a selective search algorithm to generate candidate regions. Hence, the detection speed is inevitably limited by the need for repeated candidate region selection.
Regression-based detection techniques have emerged as solutions to above issue, requiring only one stage and performing regression directly on the projected target. Redmon et al. [
17] proposed the YOLO (You Only Look Once) algorithm, which concentrates on classification, localization, and detection in a single network. The input image can directly obtain the bounding box and predicted value of the target in the image after only one network calculation. However, because of the crude design of the network, it cannot satisfy the accuracy requirements of real-time target detection. Small and multiple targets cannot be accurately localized and are easily missed. Redmon et al. proposed the YOLOv2 [
18] and YOLOv3 [
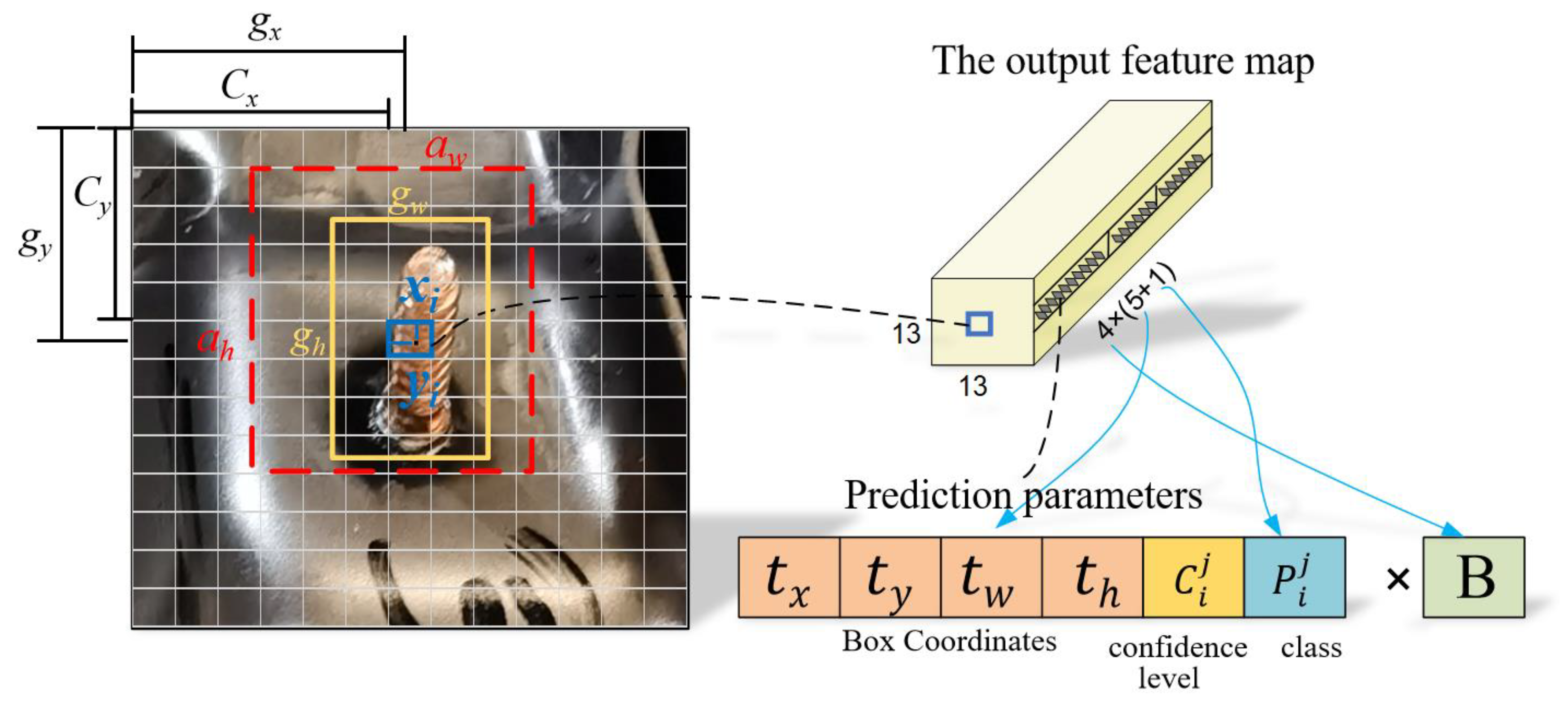
19] models. YOLOv3 is an updated version of YOLOv1 and YOLOv2 that introduces the feature pyramid concept and adds a batch normalization (
BN) layer to the boundary prediction. It predicts large, medium, and small targets at three scales by adding multiscale prediction and a basic backbone network [
20,
21,
22]. However, when targeting small targets, the traditional YOLOv3 model fails to detect large or medium targets [
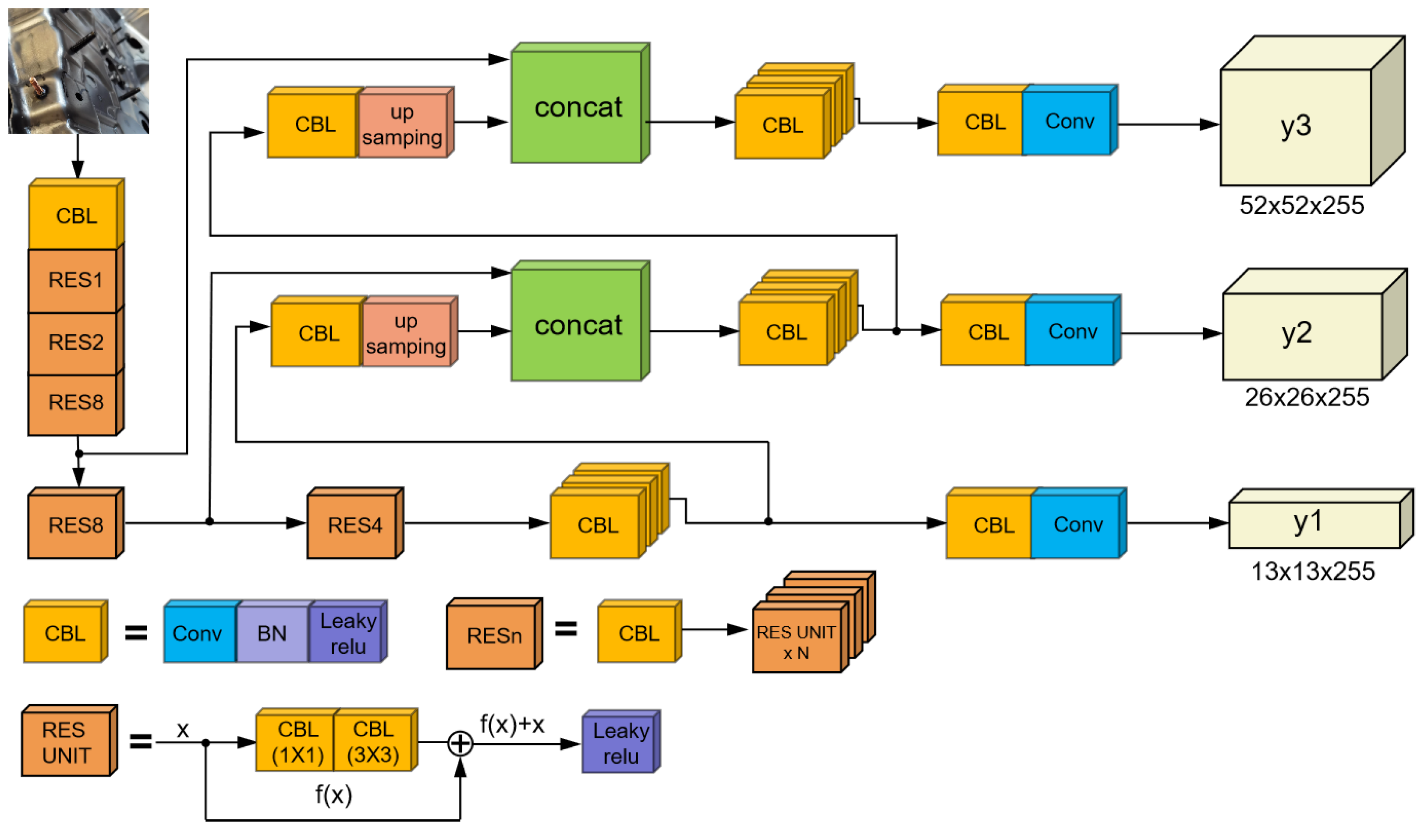
23]. Missed weld stud detection on automobile workpieces is a classic example of the challenge of tiny target detection in a complex environment. Hence, this paper proposes a new deep learning algorithm to achieve automatic feature extraction and general detection model to solve the problem of the real-time detection and localization of studs on automobile workpieces. The improved YOLOv3 deep learning algorithm is based on the traditional YOLOv3 network model, and this study improves and optimizes it using an image pyramid structure and focal loss function. The following is a description of this study’s main contributions. Experiments show that these methods are effective.
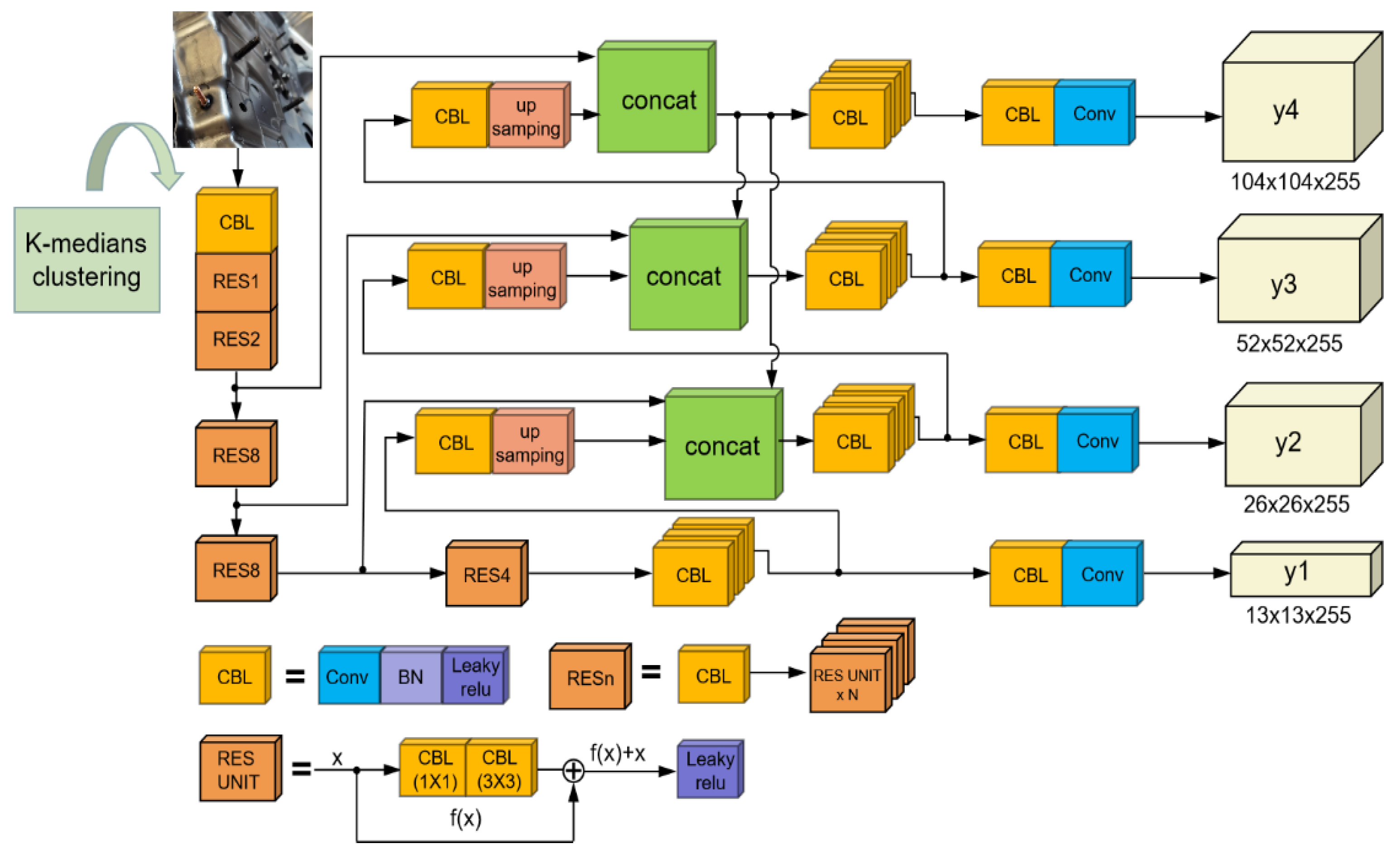
In this study, the layer in the prediction model are increased from three to four to more precisely anticipate the workpiece location of the stud. The image pyramid structure is employed to gather stud feature information at various scales, and shallow feature fusion is trained at different sizes to obtain additional stud contour details.
The positive and negative sample imbalance problem will reduce the model’s training efficiency and detection accuracy, and it is resolved in this study using the focal loss function. The focal loss function can decrease the weight of the straightforward background classes, allowing the algorithm to concentrate more on detecting the foreground classes and increasing the detection accuracy of studs.
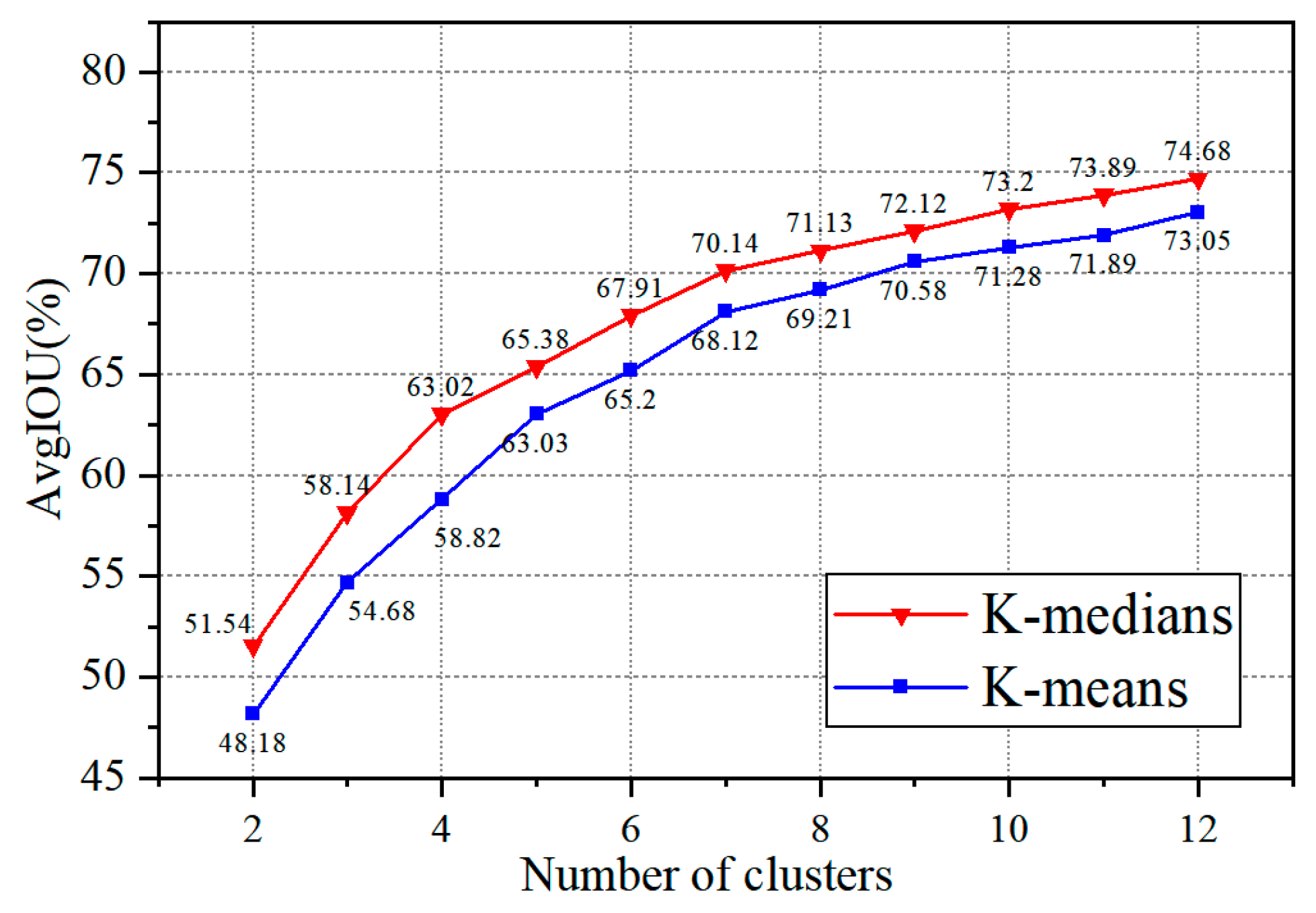
A median-based approach is used to solve the problem that the model’s K-means clustering algorithm [
18] is sensitive to the initial cluster centers and outliers. The K-medians approach is robust to noisy points or outliers, avoiding the model falling into a local optimum and thus improving the accuracy of the model for stud detection.
4. Discussion and Conclusions
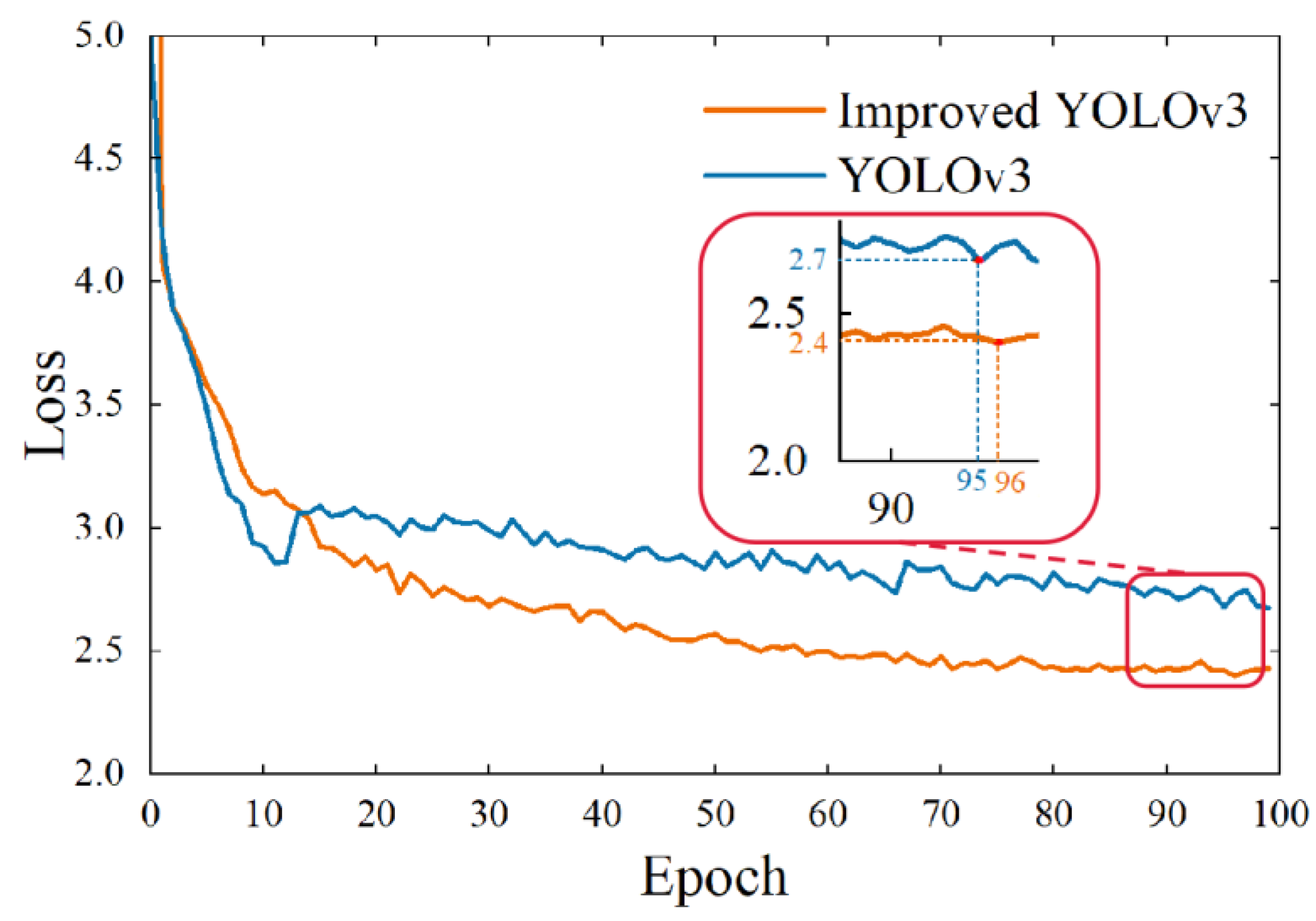
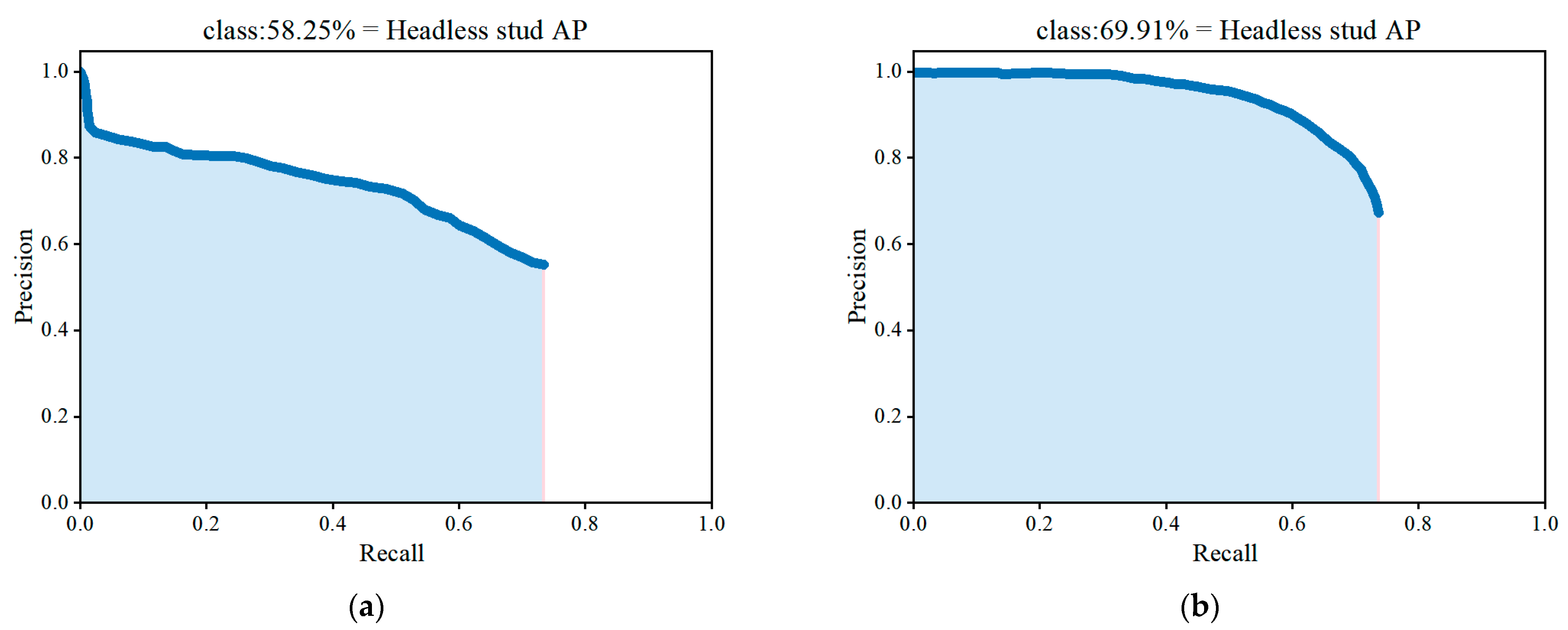
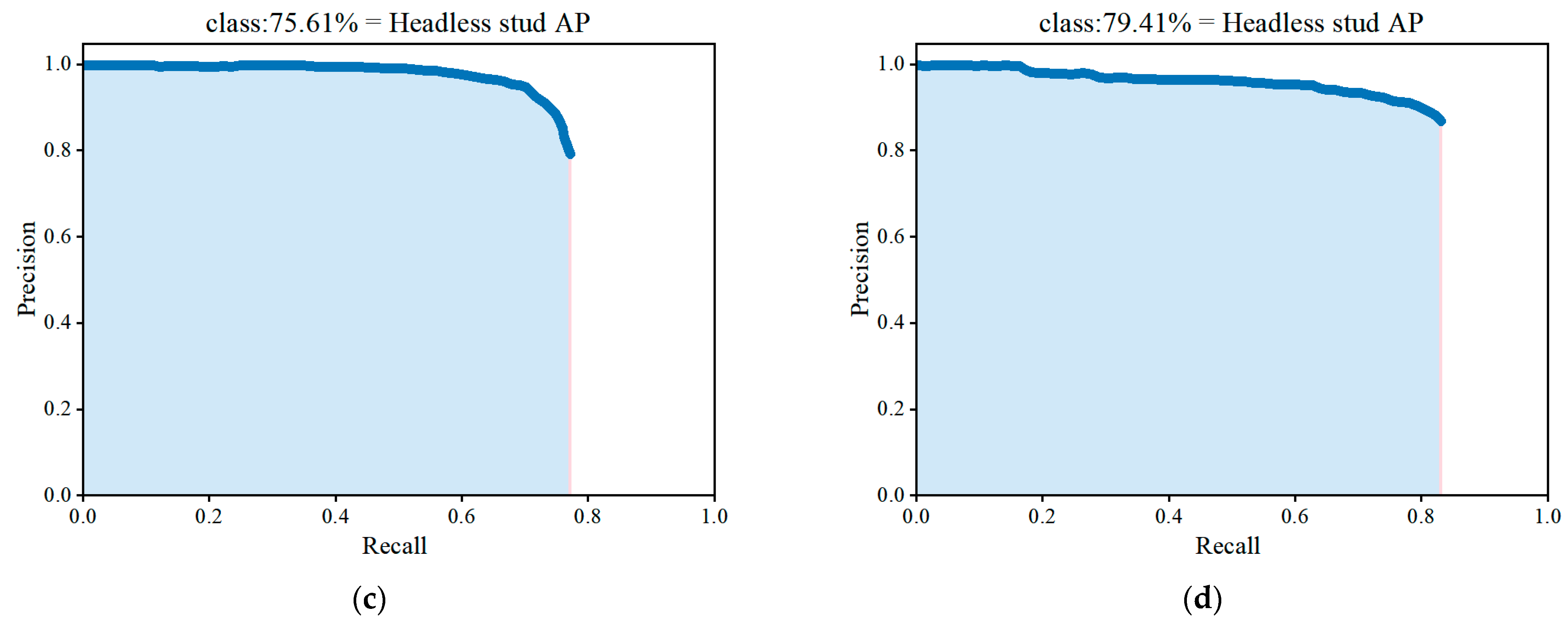
This study proposed a stud leakage detection algorithm based on an improved YOLOv3 model, which was designed to detect studs in automotive workpieces. Firstly, increased the prediction layers of the model structure was increased from three layers to four layers, extracting more details of the stud contours. Secondly, the focal loss function was introduced into the algorithm to solve the positive and negative sample imbalance problem. Finally, an improved K-median clustering method instead of K-means in the original algorithm was used to reduce the adverse effects of noisy points or outliers and prevent the algorithm from falling into local optima and overall oscillations to some extent. The experimental results showed that the modified clustering algorithm achieved an AvgIOU value of 74.68% on the stud dataset, which is 1.63% higher than that of the previous work. The overall algorithm mAP value is 80.3%, compared to 77%, 71.95%, and 62.73% for the conventional YOLOv3, Faster R-CNN, and SSD, respectively. The improved method can achieve a detection speed of 0.32 s to process an image, meeting the requirements of real-time stud detection. The series of experiments conducted in this study demonstrated the effectiveness of the proposed method for stud-detection tasks.
However, in this study, there is still the problem of false detection due to inadequate feature extraction in the case of insufficient light or backlight.In addition, the method still has room for improvement regarding detection speed.Therefore, the next step should improve the algorithm robustness in low-light scenes by adding an attention mechanism, and increase detection speed by reducing the algorithm complexity using model distillation techniques.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}