
An Adjacency Encoding Information-Based Fast Affine Motion Estimation Method for Versatile Video Coding
Abstract
:1. Introduction
- Distinguishing from most of the previous fast algorithms that focus on the CU partition, we fully explore the affine motion estimation in interprediction and propose a fast affine motion estimation algorithm based on the adjacency encoding information to achieve the savings of encoding time.
- We count the proportion of CUs that use affine mode as the best interprediction in test sequences with different resolutions. Then we analyze the trade-off between computational complexity and performance improvement based on statistical information.
- The affine motion estimation skipping method is proposed by exploring the relationship between affine and skip modes in interprediction.
2. Related Work
3. Materials and Methods
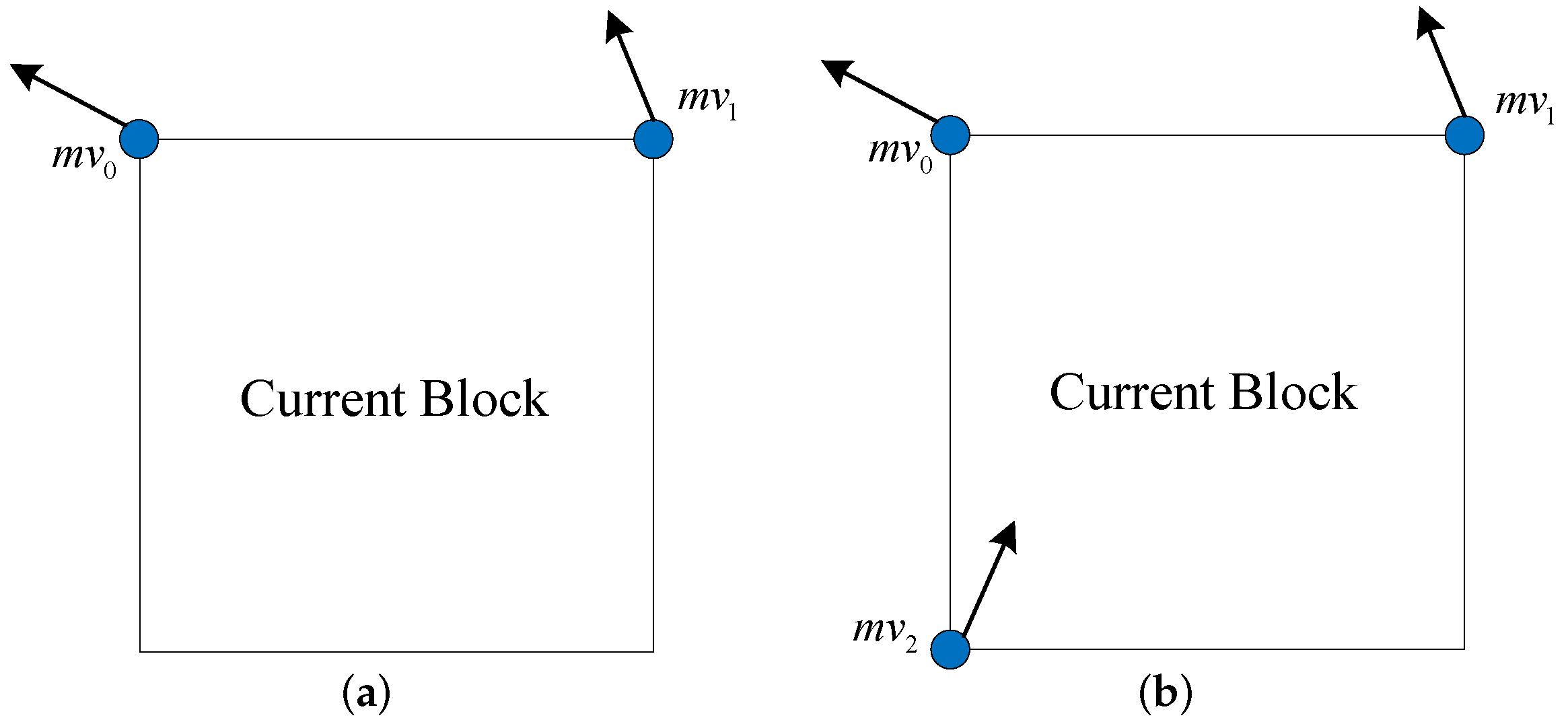
3.1. Statistics and Analysis of the Adjacency Encoding Information
3.2. Affine Motion Estimation Early Skipping Method
4. Experiments and Results Analysis
4.1. Experimental Settings
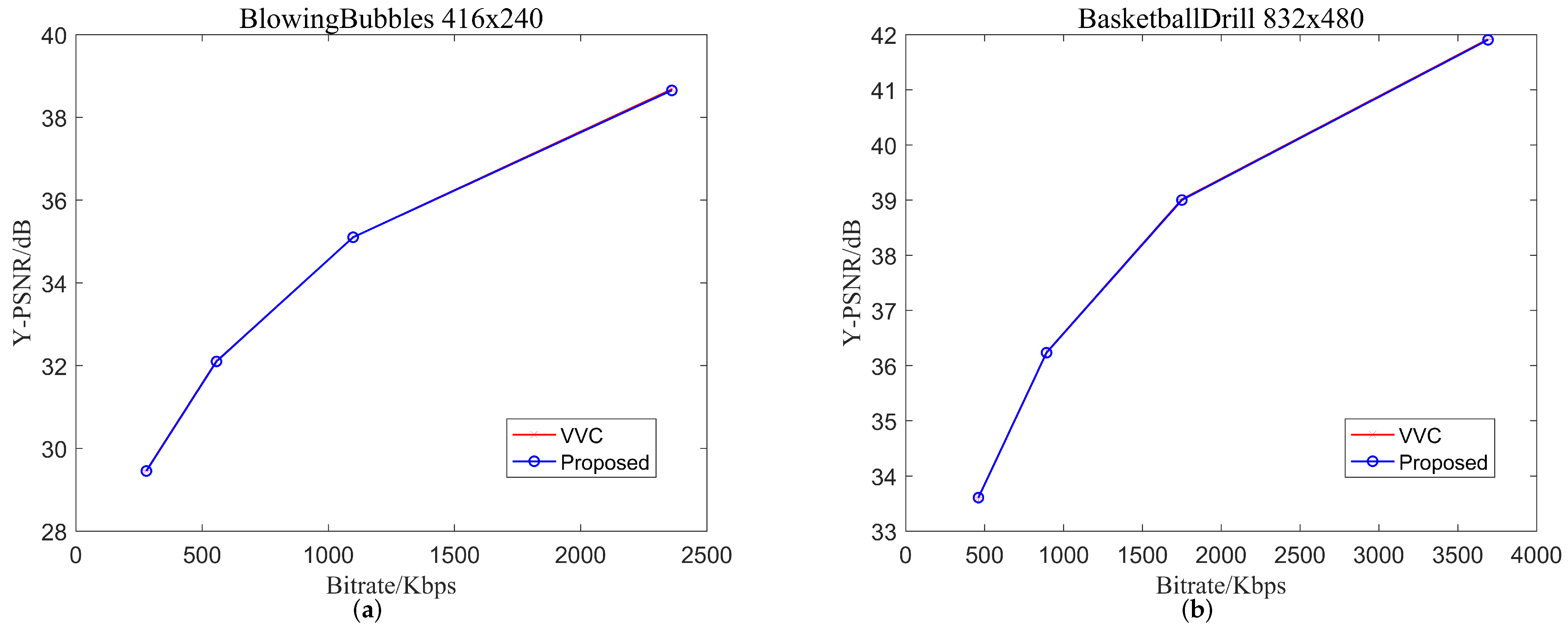
4.2. Experimental Results and Analyses
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bross, B.; Chen, J.; Liu, S. Versatile video coding (Draft 1), document JVET-J1001. In Proceedings of the 10th JVET Meeting, San Diego, CA, USA, 10–20 April 2018. [Google Scholar]
- Bross, B.; Chen, J.; Ohm, J.R.; Sullivan, G.J.; Wang, Y.K. Developments in international video coding standardization after avc, with an overview of versatile video coding (vvc). Proc. IEEE 2021, 109, 1463–1493. [Google Scholar] [CrossRef]
- Hamidouche, W.; Biatek, T.; Abdoli, M.; Francois, E.; Pescador, F.; Radosavljevic, M.; Menard, D.; Raulet, M. Versatile video coding standard: A review from coding tools to consumers deployment. IEEE Consum. Electron. Mag. 2022, 11, 10–24. [Google Scholar] [CrossRef]
- Sidaty, N.; Hamidouche, W.; Déforges, O.; Philippe, P.; Fournier, J. Compression performance of the versatile video coding: HD and UHD visual quality monitoring. In Proceedings of the 2019 Picture Coding Symposium (PCS), Ningbo, China, 12–15 November 2019; pp. 1–5. [Google Scholar]
- Li, X.; Chuang, H.C.; Chen, J.; Karczewicz, M.; Zhang, L.; Zhao, X.; Said, A. Multi-type-tree. JVET-D0117. In Proceedings of the 4th JVET Meeting, Chengdu, China, 15–21 October 2016. [Google Scholar]
- Schwarz, H.; Nguyen, T.; Marpe, D.; Wiegand, T. Hybrid video coding with trellis-coded quantization. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; pp. 182–191. [Google Scholar]
- Zhao, X.; Chen, J.; Karczewicz, M.; Said, A.; Seregin, V. Joint separable and non-separable transforms for next-generation video coding. IEEE Trans. Image Process. 2018, 27, 2514–2525. [Google Scholar] [CrossRef] [PubMed]
- Sethuraman, S. CE9: Results of DMVR Related Tests CE9. In 2.1 and CE9.2.2. In Proceedings of the 13th JVET Meeting, JVET-M0147, Marrakech, MA, USA, 9–18 January 2019. [Google Scholar]
- Xiu, X.; He, Y.; Ye, Y. CE9-Related: Complexity reduction and bit-width control for bi-directional optical flow (BIO). In Proceedings of the 12th JVET Meeting, JVET-L0256, Macao, China, 3–12 October 2018. [Google Scholar]
- Kato, Y.; Toma, T.A.K. Simplification of BDOF. In Proceedings of the 15th JVET Meeting, JVET-O0304, Gothenburg, Sweden, 3–12 July 2019. [Google Scholar]
- Lin, S.; Chen, H.; Zhang, H.; Maxim, S.; Yang, H.; Zhou, J. Affine transform prediction for next generation video coding, document COM16-C1016. In Proceedings of the Huawei Technologies, International Organisation for Standardisation Organisation Internationale De Normalisation ISO/IEC JTC1/SC29/WG11 Coding of Moving Pictures and Audio, ISO/IEC JTC1/SC29/WG11 MPEG2015/m37525, Geneva, Switzerland, 1 January 2017. [Google Scholar]
- Chen, J.; Karczewicz, M.; Huang, Y.W.; Choi, K.; Ohm, J.R.; Sullivan, G.J. The joint exploration model (JEM) for video compression with capability beyond HEVC. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1208–1225. [Google Scholar] [CrossRef]
- Meuel, H.; Ostermann, J. Analysis of affine motion-compensated prediction in video coding. IEEE Trans. Image Process. 2020, 29, 7359–7374. [Google Scholar] [CrossRef]
- Huo, J.; Ma, Y.; Wan, S.; Yu, Y.; Wang, M.; Zhang, K.; Gao, W. CE3-1.5: CCLM derived with four neighbouring samples. In Proceedings of the Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Document JVET N0271, Geneva, Switzerland, 19–27 March 2019. [Google Scholar]
- Laroche, G.; Taquet, J.; Gisquet, C.; Onno, P. CE3-5.1: On cross-component linear model simplification. In Proceedings of the Joint Video Exploration Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, JVET-L0191, Macao, China, 8–12 October 2018. [Google Scholar]
- Zhao, X.; Seregin, V.; Said, A.; Zhang, K.; Egilmez, H.E.; Karczewicz, M. Low-complexity intra prediction refinements for video coding. In Proceedings of the 2018 Picture Coding Symposium (PCS), San Francisco, CA, USA, 24–27 June 2018; pp. 139–143. [Google Scholar]
- Said, A.; Zhao, X.; Karczewicz, M.; Chen, J.; Zou, F. Position dependent prediction combination for intra-frame video coding. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 534–538. [Google Scholar]
- Koo, M.; Salehifar, M.; Lim, J.; Kim, S.H. Low frequency non-separable transform (LFNST). In Proceedings of the 2019 Picture Coding Symposium (PCS), Ningbo, China, 12–15 November 2019; pp. 1–5. [Google Scholar]
- Salehifar, M.; Koo, M. CE6: Reduced Secondary Transform (RST) (CE6-3.1). In Proceedings of the Document Joint Video Experts Team of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, JVET-N0193, Geneva, Switzerland, 19–27 March 2019. [Google Scholar]
- Yoon, Y.U.; Kim, J.G. Activity-Based Block Partitioning Decision Method for Versatile Video Coding. Electronics 2022, 11, 1061. [Google Scholar] [CrossRef]
- Min, B.; Cheung, R.C. A fast CU size decision algorithm for the HEVC intra encoder. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 892–896. [Google Scholar]
- Zhao, J.; Wu, A.; Zhang, Q. SVM-Based Fast CU Partition Decision Algorithm for VVC Intra Coding. Electronics 2022, 11, 2147. [Google Scholar] [CrossRef]
- Khan, S.N.; Muhammad, N.; Farwa, S.; Saba, T.; Khattak, S.; Mahmood, Z. Early Cu depth decision and reference picture selection for low complexity Mv-Hevc. Symmetry 2019, 11, 454. [Google Scholar] [CrossRef] [Green Version]
- Tang, N.; Cao, J.; Liang, F.; Wang, J.; Liu, H.; Wang, X.; Du, X. Fast CTU partition decision algorithm for VVC intra and inter coding. In Proceedings of the 2019 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Bangkok, Thailand, 11–14 November 2019; pp. 361–364. [Google Scholar]
- Lin, T.L.; Jiang, H.Y.; Huang, J.Y.; Chang, P.C. Fast binary tree partition decision in H. 266/FVC intra Coding. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Taipei, Taiwan, 6–8 July 2018; pp. 1–2. [Google Scholar]
- Lei, J.; Li, D.; Pan, Z.; Sun, Z.; Kwong, S.; Hou, C. Fast Intra Prediction Based on Content Property Analysis for Low Complexity HEVC-Based Screen Content Coding. IEEE Trans. Broadcast. 2017, 63, 48–58. [Google Scholar] [CrossRef]
- Jin, Z.; An, P.; Shen, L.; Yang, C. CNN oriented fast QTBT partition algorithm for JVET intra coding. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Tang, G.; Jing, M.; Zeng, X.; Fan, Y. Adaptive CU split decision with pooling-variable CNN for VVC intra encoding. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Pan, Z.; Zhang, P.; Peng, B.; Ling, N.; Lei, J. A CNN-based fast inter coding method for VVC. IEEE Signal Process. Lett. 2021, 28, 1260–1264. [Google Scholar] [CrossRef]
- Li, Y.; Li, L.; Fang, Y.; Peng, H.; Ling, N. Bagged Tree and ResNet-Based Joint End-to-End Fast CTU Partition Decision Algorithm for Video Intra Coding. Electronics 2022, 11, 1264. [Google Scholar] [CrossRef]
- Wu, S.; Shi, J.; Chen, Z. HG-FCN: Hierarchical Grid Fully Convolutional Network for Fast VVC Intra Coding. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5638–5649. [Google Scholar] [CrossRef]
- Sharabayko, M.P.; Ponomarev, O.G. Fast rate estimation for RDO mode decision in HEVC. Entropy 2014, 16, 6667–6685. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Tang, L.; Tang, T. Fast Sample Adaptive Offset Jointly Based on HOG Features and Depth Information for VVC in Visual Sensor Networks. Sensors 2020, 20, 6754. [Google Scholar] [CrossRef]
- He, L.; Xiong, S.; Yang, R.; He, X.; Chen, H. Low-Complexity Multiple Transform Selection Combining Multi-Type Tree Partition Algorithm for Versatile Video Coding. Sensors 2022, 22, 5523. [Google Scholar] [CrossRef] [PubMed]
- Ren, W.; He, W.; Cui, Y. An improved fast affine motion estimation based on edge detection algorithm for VVC. Symmetry 2020, 12, 1143. [Google Scholar] [CrossRef]
- Jung, S.; Jun, D. Context-Based Inter Mode Decision Method for Fast Affine Prediction in Versatile Video Coding. Electronics 2021, 10, 1243. [Google Scholar] [CrossRef]
- Bossen, F.; Boyce, J.; Li, X.; Seregin, V.; Sühring, K. JVET common test conditions and software reference configurations for SDR video. Jt. Video Expert. Team (JVET) ITU-T SG 2019, 16, 19–27. [Google Scholar]
- Bjontegaard, G. Improvements of the BD-PSNR model. In Proceedings of the ITU-T SG16/Q6, 35th VCEG Meeting, Berlin, Germany, 16–18 July 2008. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | |
|---|---|
| BlowingBubbles 416 × 240 | 10.7% |
| BQMall 832 × 480 | 10.3% |
| RaceHorsesC 832 × 480 | 9.8% |
| FourPeople 1280 × 720 | 9.0% |
| Cactus 1920 × 1080 | 12.2% |
| Campfire 3840 × 2160 | 15.9% |
| ParkRunning3 3840 × 2160 | 18.5% |
| Average | 12.3% |
| Mode | Transmission |
|---|---|
| Skip | index |
| Merge | Index and prediction residuals |
| AMVP | Index, prediction residuals, and MVD |
| Sequences | ||
|---|---|---|
| BlowingBubbles 416 × 240 | 0.14 | 0.20 |
| RaceHorsesC 832 × 480 | 0.10 | 0.17 |
| BasketballDrill 832 × 480 | 0.09 | 0.19 |
| FourPeople 1280 × 720 | 0.13 | 0.24 |
| Cactus 1960 × 1280 | 0.16 | 0.27 |
| Campfire 3840 × 2160 | 0.17 | 0.30 |
| ParkRunning3 3840 × 2160 | 0.23 | 0.36 |
| Average | 0.12 | 0.24 |
| Items | Descriptions |
|---|---|
| Software | VTM-7.0 |
| Configuration File | encoder lowdelay P vtm.cfg encoder lowdelay vtm.cfg encoder randomaccess vtm.cfg |
| Video Sequence Size | 416 × 240, 832 × 480, 1280 × 720, 1920 × 1080, 3840 |
| Quantization Parameter (QP) | 22, 27, 32 and 37 |
| Sampling of Luminance to Chrominance | 4:2:0 |
| Class | Sequences | Size | Bit-Depth | Frame Rate |
|---|---|---|---|---|
| A1 | Campfire | 3840 × 2160 | 10 | 30 |
| FoodMarket4 | 3840 × 2160 | 10 | 60 | |
| A2 | ParkRunning3 | 3840 × 2160 | 10 | 50 |
| CatRobot | 3840 × 2160 | 10 | 60 | |
| B | BasketballDrive | 1920 × 1280 | 8 | 50 |
| BQTerrace | 1920 × 1280 | 8 | 60 | |
| Cactus | 1920 × 1280 | 8 | 50 | |
| RitualDance | 1920 × 1280 | 10 | 60 | |
| BasketballDrill | 832 × 480 | 8 | 50 | |
| C | BQMall | 832 × 480 | 8 | 60 |
| PartyScene | 832 × 480 | 8 | 50 | |
| BasketballPass | 416 × 240 | 8 | 50 | |
| D | BlowingBubbles | 416 × 240 | 8 | 50 |
| RaceHorses | 416 × 240 | 8 | 30 | |
| FourPeople | 1280 × 720 | 8 | 60 | |
| E | Johhny | 1280 × 720 | 8 | 60 |
| KristenAndSara | 1280 × 720 | 8 | 60 | |
| Slideshow | 1280 × 720 | 8 | 20 | |
| F | SlideEditing | 1280 × 720 | 8 | 30 |
| BasketballDrillText | 832 × 480 | 8 | 50 |
| Class | Sequences | BDBR/% | BD-PSNR/db | /% | /% |
|---|---|---|---|---|---|
| A1 | Campfire | 0.20 | −0.010 | 10.32 | 47.62 |
| FoodMarket4 | 0.16 | −0.007 | 9.17 | 37.36 | |
| A2 | ParkRunning3 | 0.22 | −0.011 | 9.48 | 39.28 |
| CatRobot | 0.17 | −0.006 | 9.83 | 43.72 | |
| B | BasketballDrive | 0.18 | −0.007 | 9.04 | 35.27 |
| BQTerrace | 0.12 | −0.001 | 9.80 | 59.43 | |
| Cactus | 0.17 | −0.004 | 8.37 | 27.45 | |
| RitualDance | 0.15 | −0.003 | 9.13 | 35.82 | |
| BasketballDrill | 0.07 | −0.005 | 10.75 | 37.22 | |
| C | BQMall | 0.01 | 0.000 | 10.68 | 50.45 |
| PartyScene | 0.19 | −0.009 | 9.21 | 40.28 | |
| BasketballPass | 0.21 | −0.010 | 11.07 | 33.58 | |
| D | BlowingBubbles | 0.23 | −0.008 | 8.70 | 44.34 |
| RaceHorses | 0.25 | −0.010 | 9.13 | 50.16 | |
| FourPeople | 0.21 | −0.008 | 9.23 | 21.76 | |
| E | Johhny | 0.03 | 0.000 | 15.47 | 54.19 |
| KristenAndSara | 0.22 | −0.005 | 9.42 | 27.49 | |
| Slideshow | 0.09 | −0.004 | 11.85 | 49.71 | |
| F | SlideEditing | 0.06 | −0.003 | 12.27 | 51.86 |
| BasketballDrillText | 0.24 | −0.011 | 9.32 | 29.74 | |
| Average | - | 0.16 | −0.006 | 10.11 | 40.85 |
| Sequences | Ren et al. [36] | Proposed | ||
|---|---|---|---|---|
| BDBR/% | /% | BDBR/% | /% | |
| Cactus | 0.11 | 6.00 | 0.17 | 8.37 |
| BQTerrace | 0.04 | 8.00 | 0.12 | 9.80 |
| BasketballDrive | 0.08 | 5.00 | 0.18 | 9.04 |
| BQMall | 0.05 | 5.00 | 0.01 | 10.68 |
| PartyScene | 0.26 | 4.00 | 0.19 | 9.21 |
| BasketballDrill | 0.06 | 3.00 | 0.07 | 10.75 |
| BasketballPass | 0.08 | 2.00 | 0.21 | 11.07 |
| BlowingBubbles | 0.12 | 6.00 | 0.23 | 8.70 |
| RaceHorses | 0.08 | 5.00 | 0.25 | 9.13 |
| Average | 0.10 | 4.89 | 0.16 | 9.64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; He, J.; Li, Q.; Chen, X. An Adjacency Encoding Information-Based Fast Affine Motion Estimation Method for Versatile Video Coding. Electronics 2022, 11, 3429. https://doi.org/10.3390/electronics11213429
Li X, He J, Li Q, Chen X. An Adjacency Encoding Information-Based Fast Affine Motion Estimation Method for Versatile Video Coding. Electronics. 2022; 11(21):3429. https://doi.org/10.3390/electronics11213429
Chicago/Turabian StyleLi, Ximei, Jun He, Qi Li, and Xingru Chen. 2022. "An Adjacency Encoding Information-Based Fast Affine Motion Estimation Method for Versatile Video Coding" Electronics 11, no. 21: 3429. https://doi.org/10.3390/electronics11213429