1. Introduction
Accurate load forecasting is vital for the power grid’s operation stability, such as generating units’ scheduling, safety assessment, and reliability analysis [
1,
2]. With the development of the power system and the integration of renewable energy, it is essential to obtain accurate load forecasting results [
3,
4].
Load forecasting is categorized into three classes: long-term load forecasting (LTLF), medium-term load forecasting (MTLF), and short-term load forecasting (STLF) [
5]. LTLF and MTLF are applied for forecasting the electricity load from several weeks to a few years [
6], which are crucial for long-term power generation scheduling and seasonable electricity load analysis [
7]. In comparison, STLF ranges from several minutes to a few days. It is crucial for the daily operation of the power grid. It is worth noting that most electricity load series have apparent periodicity.
Nevertheless, the holiday effect and major emergencies also bring random fluctuations to the electricity load, limiting the forecasting efficiency. Therefore, many researchers have designed various STLF models to address this restriction. The existing load forecasting approaches are categorized into statistical and machine-learning-based models. For those data with fixed patterns, the statistical-learning-based methods can execute quickly and provide accurate forecasts. Mbamalu et al. [
8] proposed the auto-regressive (AR) model to forecast the electricity load. Moreover, the suboptimal least square method was used to estimate the model parameters and improve model generalization. Kuang et al. [
9] dealt with the STLF using the adaptive auto-regressive moving average (ARMA) model. However, AR and ARMA need the stationary input series, which is counterfactual to the actual input data. As a solution, Wang et al. [
10] adopted the auto-regressive integrated moving average (ARIMA) in which the integral part transforms the time series, making it stationary. Hence, it can relieve the problem that the STLF method is slightly strict with the input series.
Another popular model for STLF is based on machine learning. It usually begins with an input feature module that can yield hand-crafted features to construct a mapping between the input data and the output values of the network. In the training process, all the network’s neurons can learn the complex relationship between inputs and outputs with constantly updated parameters. The trained network is tested on the dataset of the other samples to evaluate the generalization capacity. Ceperic et al. [
11] first designed a feature extraction module to generate the model input. Then, the input data were fed into the support vector machine (SVM) to produce the final forecasting results. Wu et al. [
12] adopted the modified generalized regression neural network for STLF. Moreover, the multi-objective searching method was also used to achieve satisfactory performance. Chen et al. [
13] first used the similar-day load as their input data. Then, a wavelet neural network was applied to decompose the input series into different frequency components, which were the input of separate neural networks to obtain the final output.
Although the above methods can produce competitive forecasting performance, researchers need more accurate results. The electricity load data present complicated random patterns, and they are challenging to fit precisely [
14]. As a solution, deep learning is a powerful method for the forecasted task, as it has the advantage of nonlinear approximation capability [
15,
16,
17].
Recently, numerous works based on deep learning have studied STLF. Deng et al. [
18] concluded that it is hard to forecast the electricity load precisely. Moreover, a convolutional neural network (CNN) was used to produce competitive results. Dong et al. [
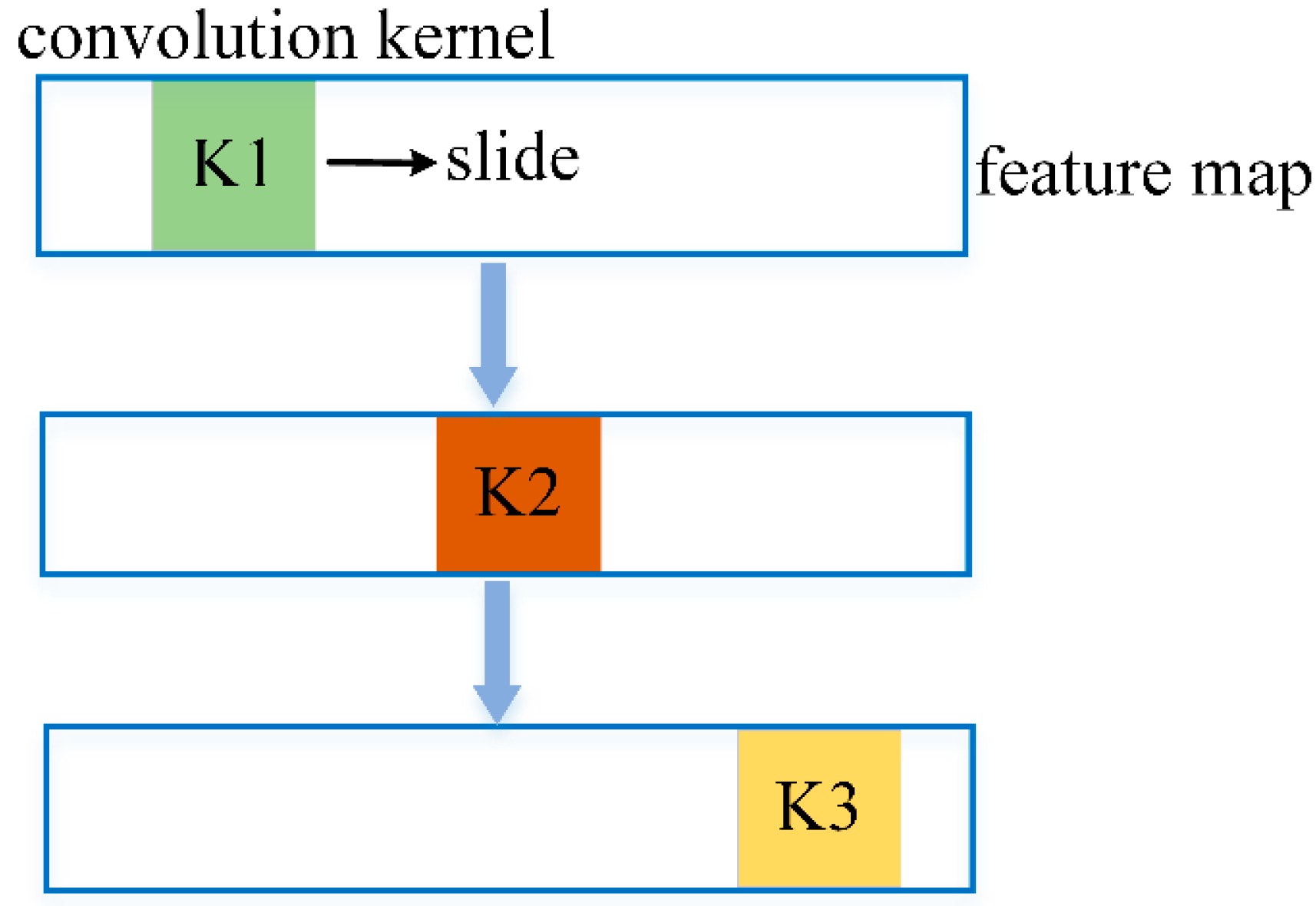
19] adopted the K-means algorithm to cluster a large dataset into a few subsets. Then, they were fed into a CNN to obtain the final forecasting result. However, the STLF models based on CNNs still have some limitations. Specifically, the basic requirement of adopting CNNs is space invariance [
20], which cannot be satisfied by the actual load data (we detail this problem in
Section 3 of this work). Another commonly used method is the long short-term memory network (LSTM). Tan et al. [
21] developed an ensemble network that can integrate multiple LSTMs to forecast the electricity load. Liu et al. [
22] indicated that the forecasting model based on those LSTM networks could obtain more accurate forecasting performance than artificial neural networks (ANNs) and ARIMA. However, these studies usually pay attention to extracting the features from different LSTM networks, and the generalization capacity of deep learning has not been fully exploited.
Table 1 shows a comparison between the proposed model and previous works in various aspects, including input features and forecasting horizon.
Overall, the generalization capacity of deep neural networks (DNNs) boosts as the network depth increases. Nevertheless, overfitting and gradient disappearance usually exist and significantly affect DNN performance as the scale of the DNN increases. Two methods have been applied to relieve this limitation: improving the layer itself and modifying the structure of the DNN. A common approach for the first method is the bidirectional long short-term memory network (Bi-LSTM) [
23]. Compared with LSTM, Bi-LSTM can train the network parameters in different directions, boosting the performance of time series learning. Toubeau et al. [
24] demonstrated that Bi-LSTM networks could yield significantly improved results compared with LSTM networks. The second method is based on residual learning, which transforms the structure of the DNN by adding shortcut connections [
25]. In addition, different residual learning variants have been proposed and achieved high performance [
26,
27]. Thus, the proposed model adopts hourly electricity load and temperature to forecast the electricity load on the following day. Specifically, the contributions of this study are summarized as follows:
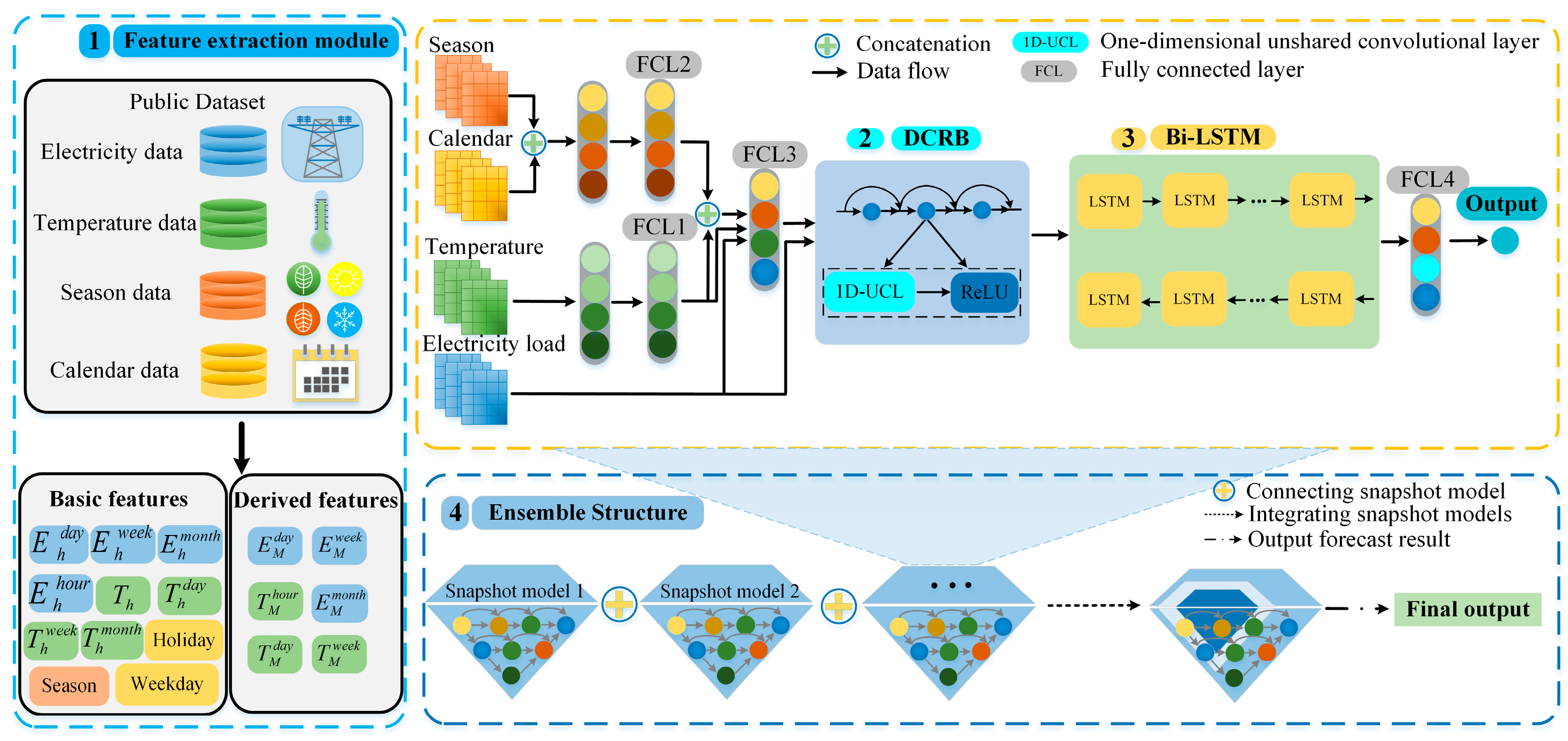
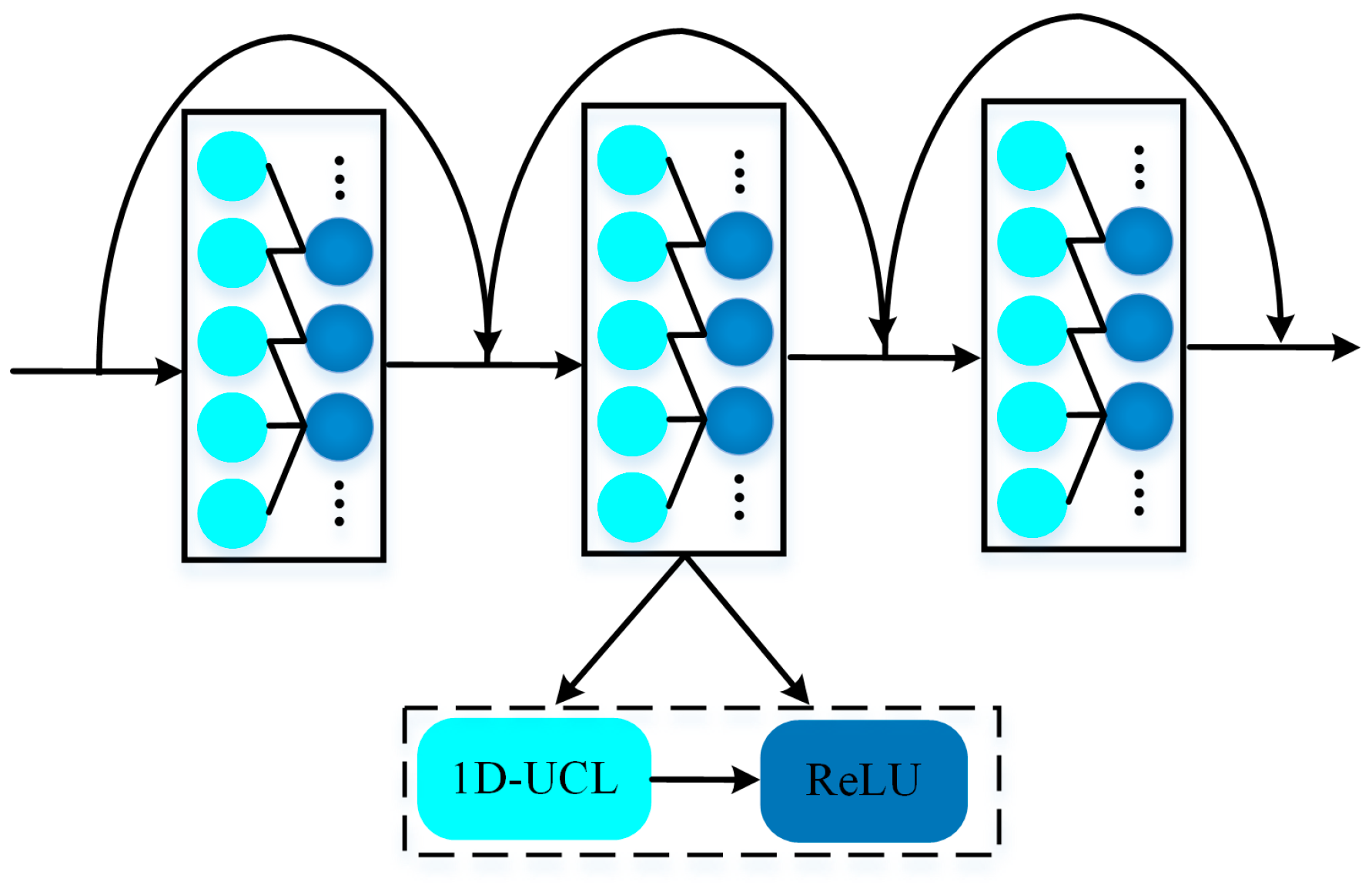
We designed a densely connected residual block (DCRB) based on an unshared convolutional layer (UCL), which can effectively relieve over-fitting and gradient disappearance;
We proposed a novel ensemble method for deterministic electricity load forecasting. The model includes a one-dimensional unshared convolutional neural network (1D-UCNN) and a bidirectional long short-term memory layer (Bi-LSTM). In addition, the generalization ability of the proposed model was verified by testing it on two benchmark datasets.
The rest of the paper is organized as follows:
Section 2 introduces the overall framework of the proposed ensemble model, which consists of a feature extraction module, a densely connected residual block (DCRB), Bi-LSTM, and the ensemble structure.
Section 3 shows the experiment results and demonstrates the performance comparison of the proposed method on two public datasets from North America and New England. Finally, the conclusions and future research direction are drawn in
Section 4.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}