
A Cuckoo Filter-Based Name Resolution and Routing Method in Information-Centric Networking

Abstract
:1. Introduction
- We compare the differences in the false positive rates between commonly used probabilistic data structures, including the bloom filter, the cuckoo filter and some variants. We propose a simplified adaptive cuckoo filter (SACF) which maintains efficient query performance with some error correction capability and performs well in multiple queries on popular content. We also apply it for the first time to name resolution and routing in ICN.
- We design a new name resolution and routing scheme based on the SACF. This hierarchical resolution scheme accommodates both flat names and hierarchical names, and it integrates name resolution into the routing and forwarding process. Requests will be forwarded to the resolution node closest to the content copy as much as possible to reduce resolution latency.
- We design a content movement support mechanism for our scheme to make content removal reliable, as well as an error correction feedback mechanism to address false positives caused by the filter, thus achieving a better balance between the efficiency and overhead of name routing.
2. Related Work
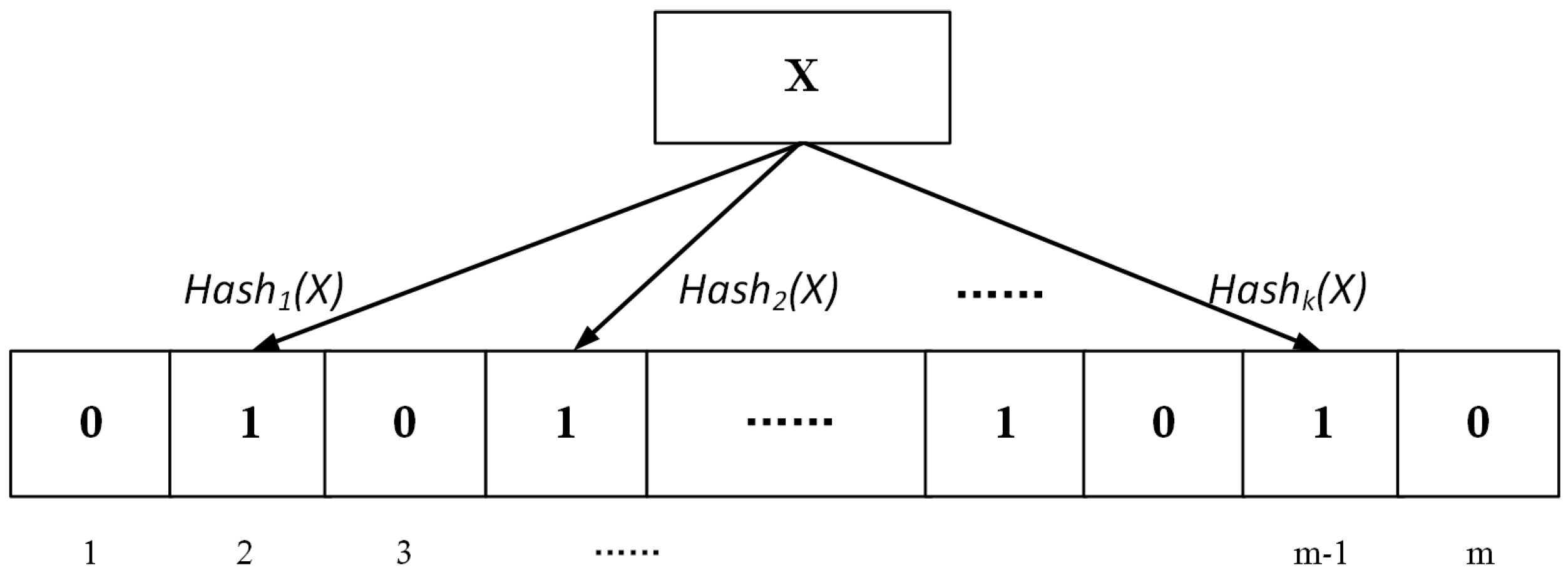
2.1. Bloom Filter-Based Routing Approach
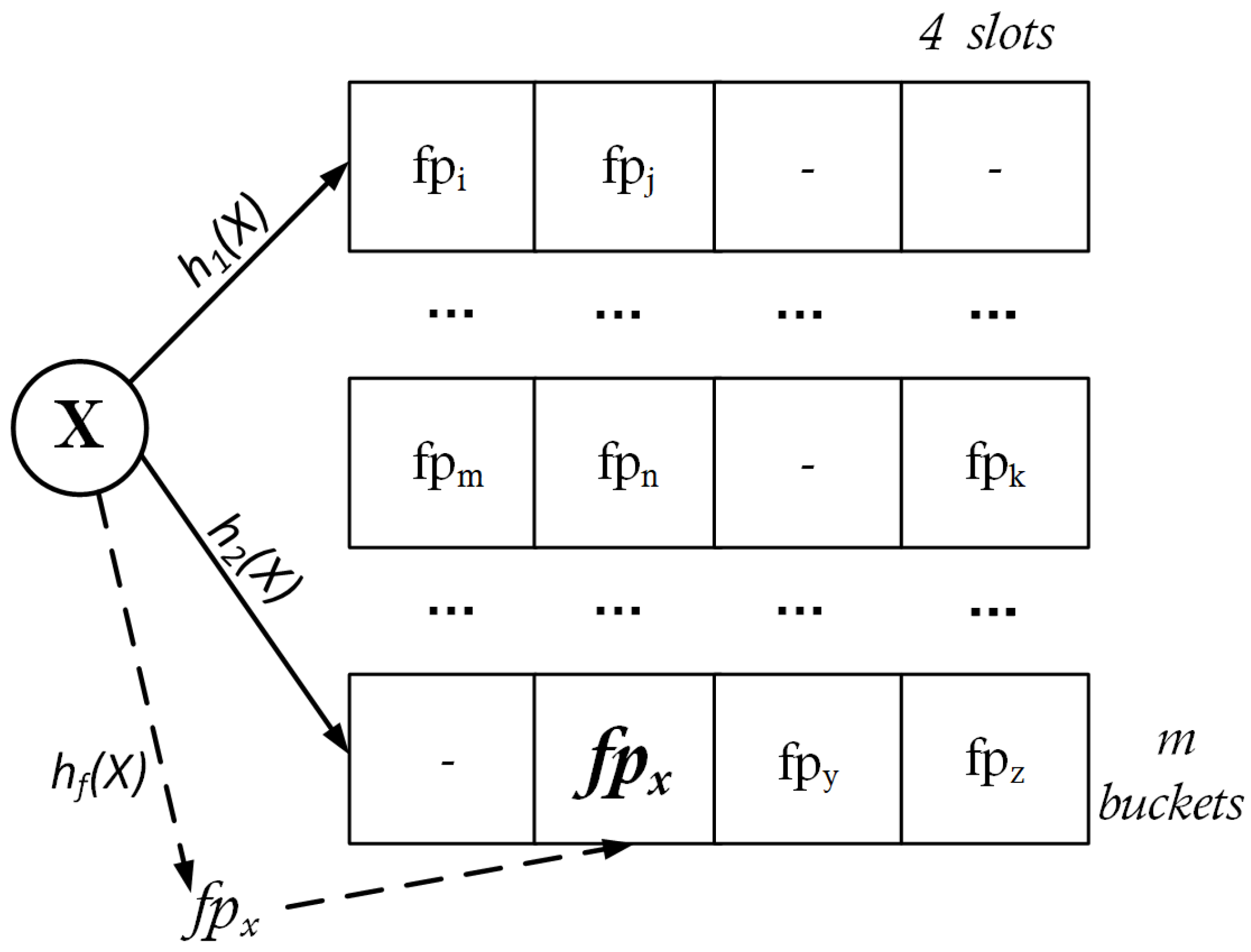
2.2. Cuckoo Filter
3. Proposed Method
3.1. Problem Statement
- Keep the false positive rate low at the filter level;
- Avoid relying only on filters for continuous multi-hop forwarding decisions;
- Design a reasonable multiple match resolution (MMR) strategy.
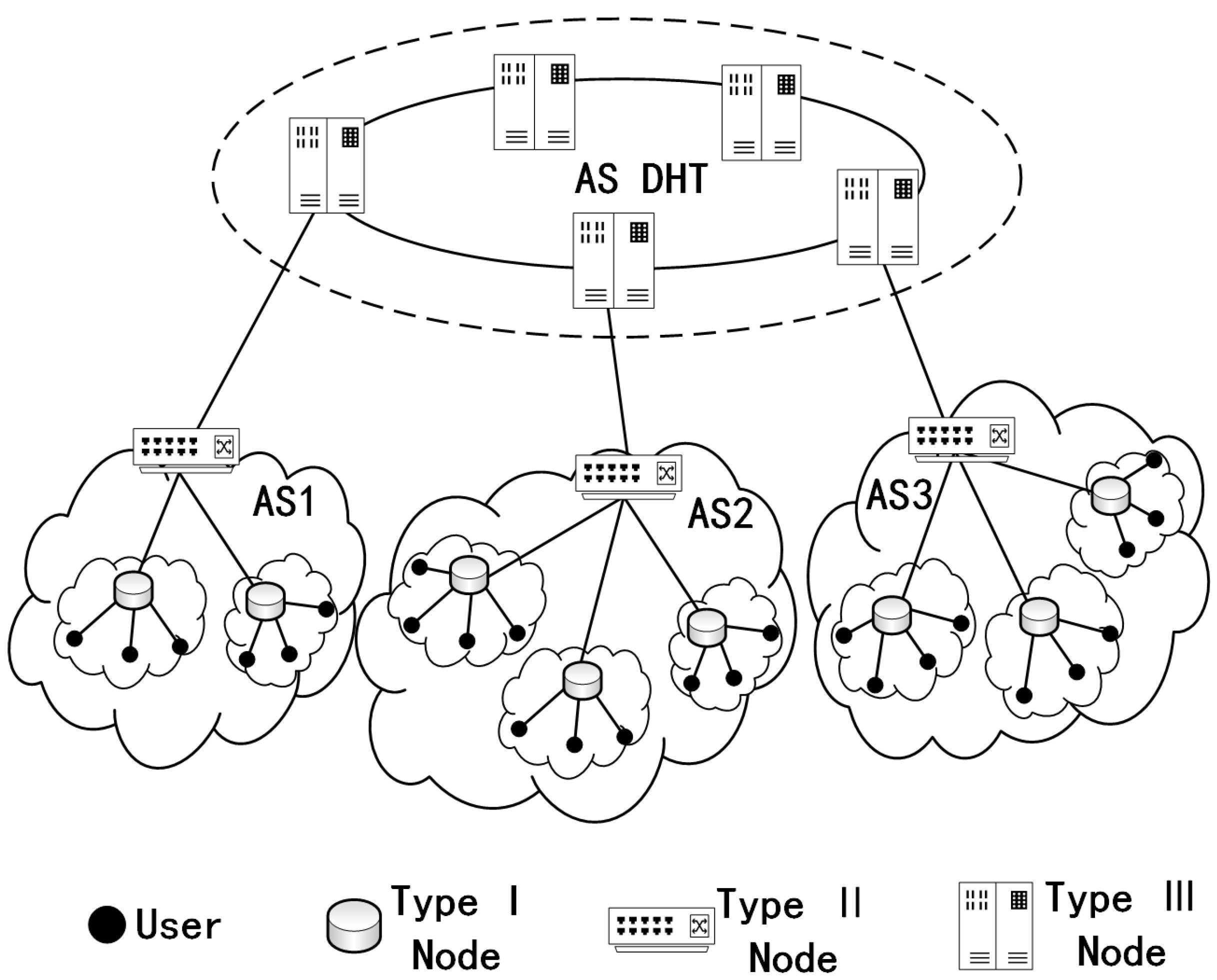
3.2. System Model
| Algorithm 1 Name resolution and routing. |
|
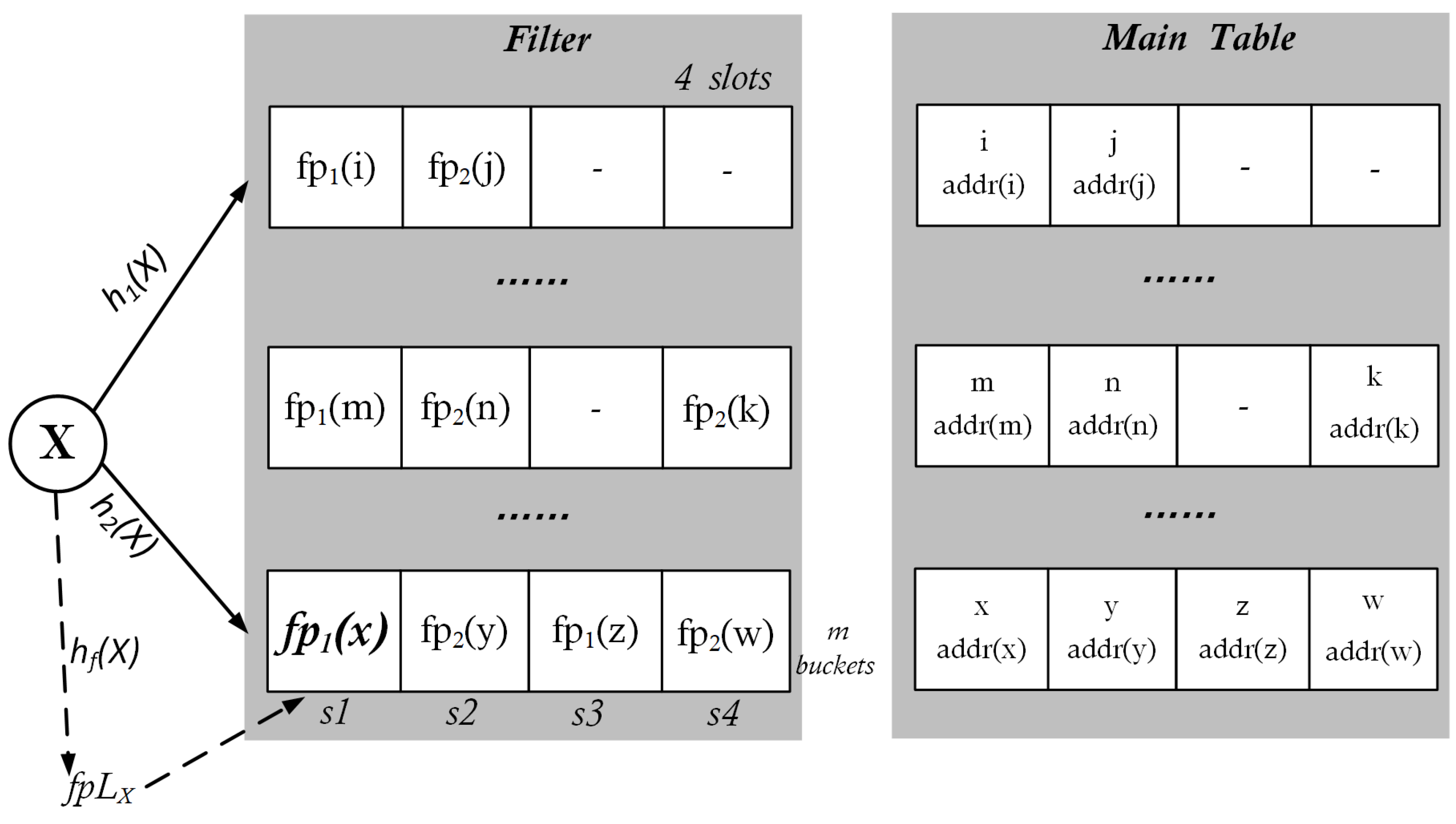
3.3. Simplified Adaptive Cuckoo Filter for a Resolution System
| Algorithm 2 Lookup for an item x. |
|
3.4. SACF-Based Name Resolution and Routing
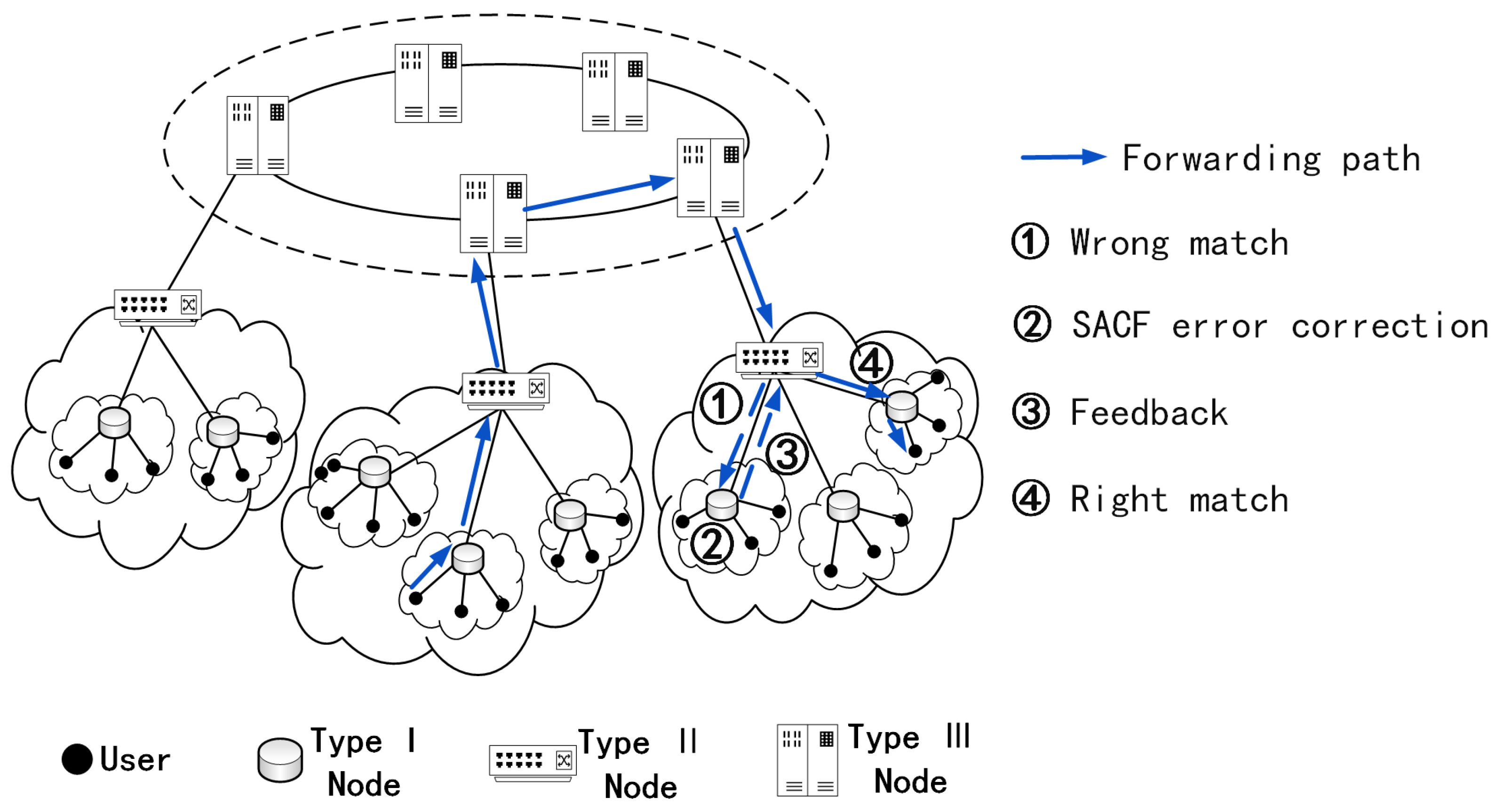
3.4.1. Error Correction Feedback Mechanism
- Sensing error forwarding: Although we already know that the error forwarding is due to multiple matches in the Type II Node, it does not know that an SACF has a false positive when it selects the next resolution node for forwarding. When the request is forwarded to a Type I Node, the SACF will also have a false positive because it stores the same fingerprint as the SACF with the false positive in the Type II Node. However, the main table will return a lookup failure. At this point, the Type I Node perceives that this is a request forwarded incorrectly.
- Error correction and feedback: The Type I Node first corrects its SACF. It replaces the fingerprint that was incorrectly matched with another type of fingerprint, and the modified bucket of the SACF is repackaged with the request and sent back to the Type II Node.
- Synchronize and re-query: The Type II Node receives the repacking request, replaces the corresponding bucket in the SACF where the false positive occurred with the bucket carried in the repacking request and then continues with this name resolution and forwarding in the remaining SACFs.
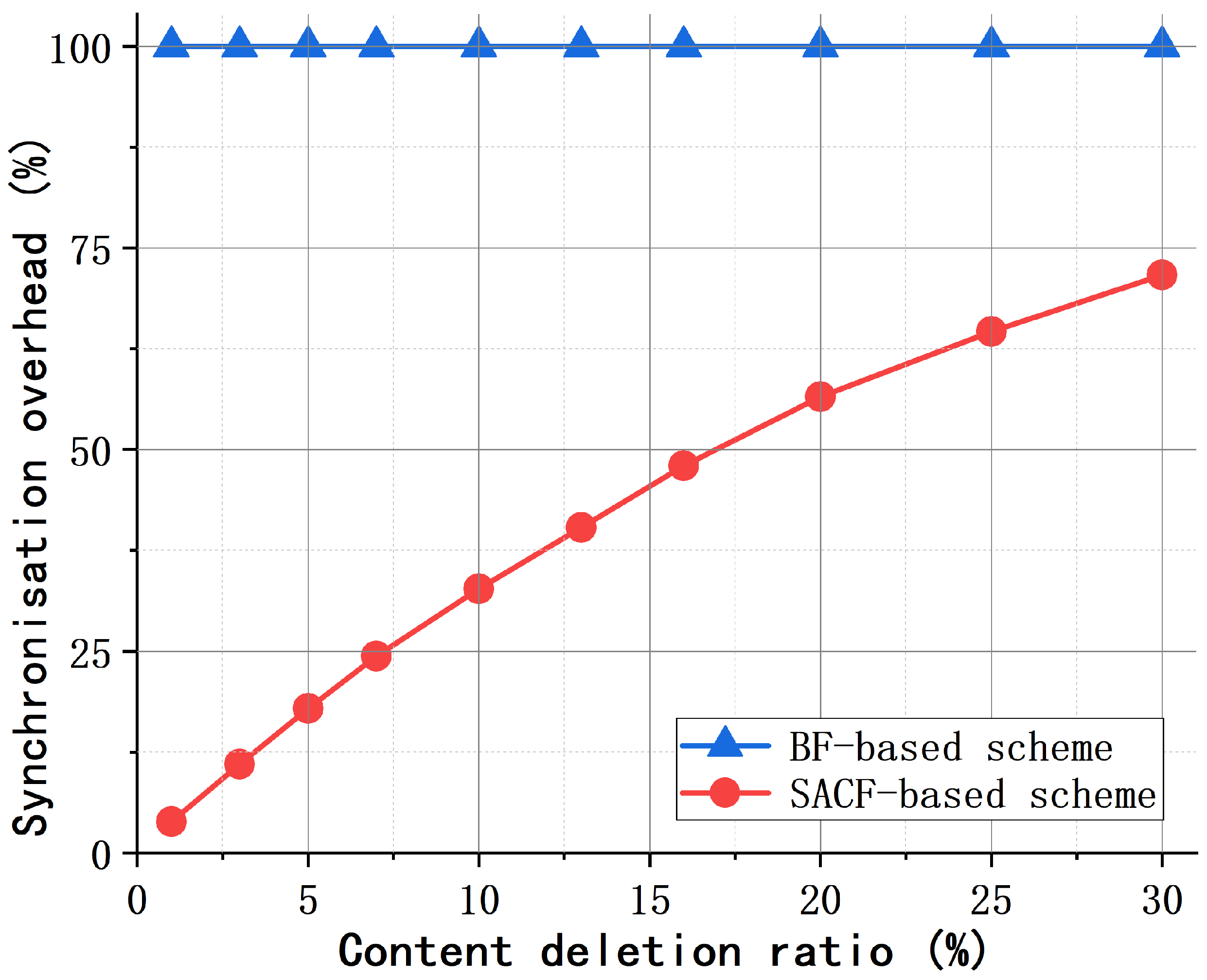
3.4.2. Content Movement Support Mechanism
4. Performance Evaluation
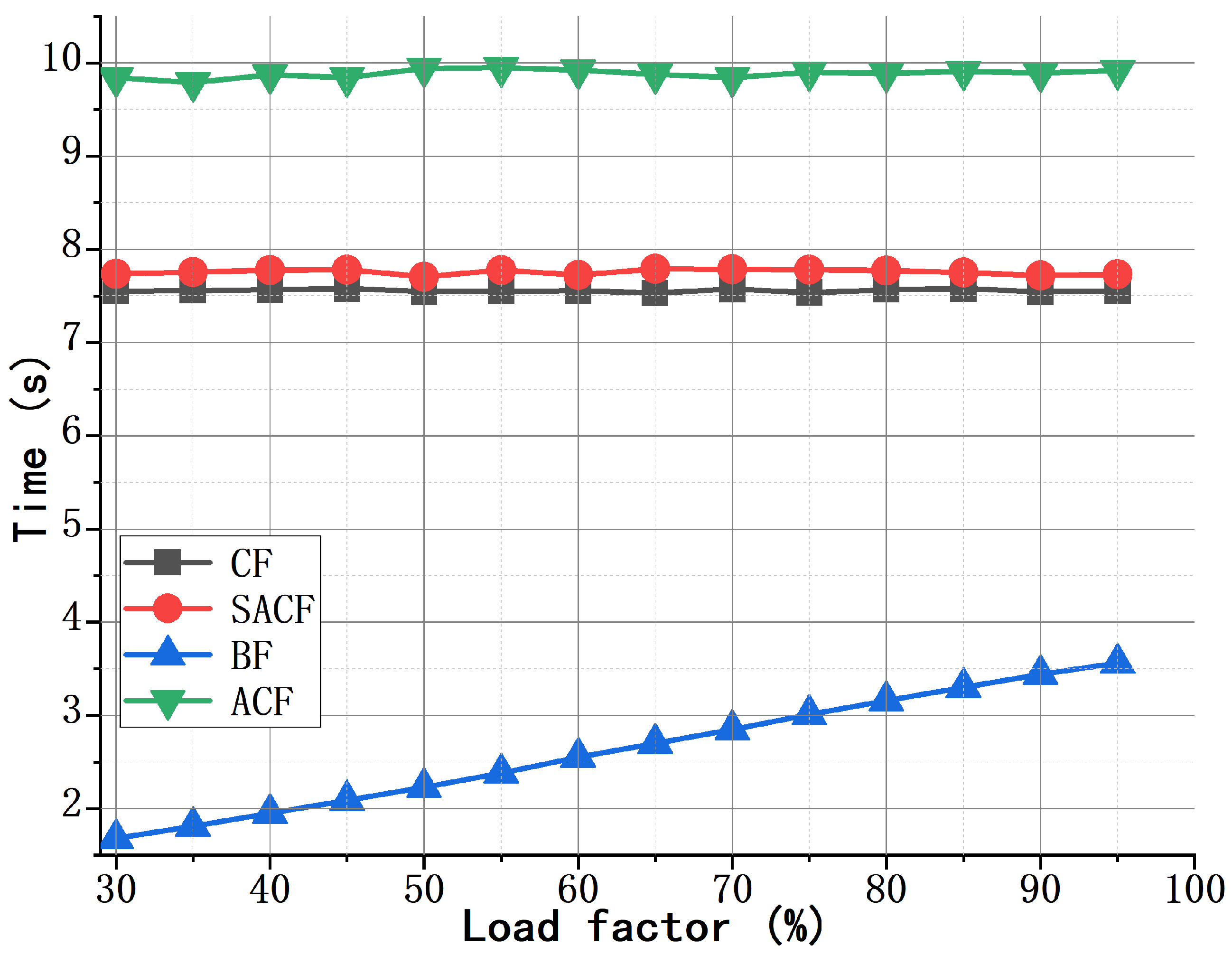
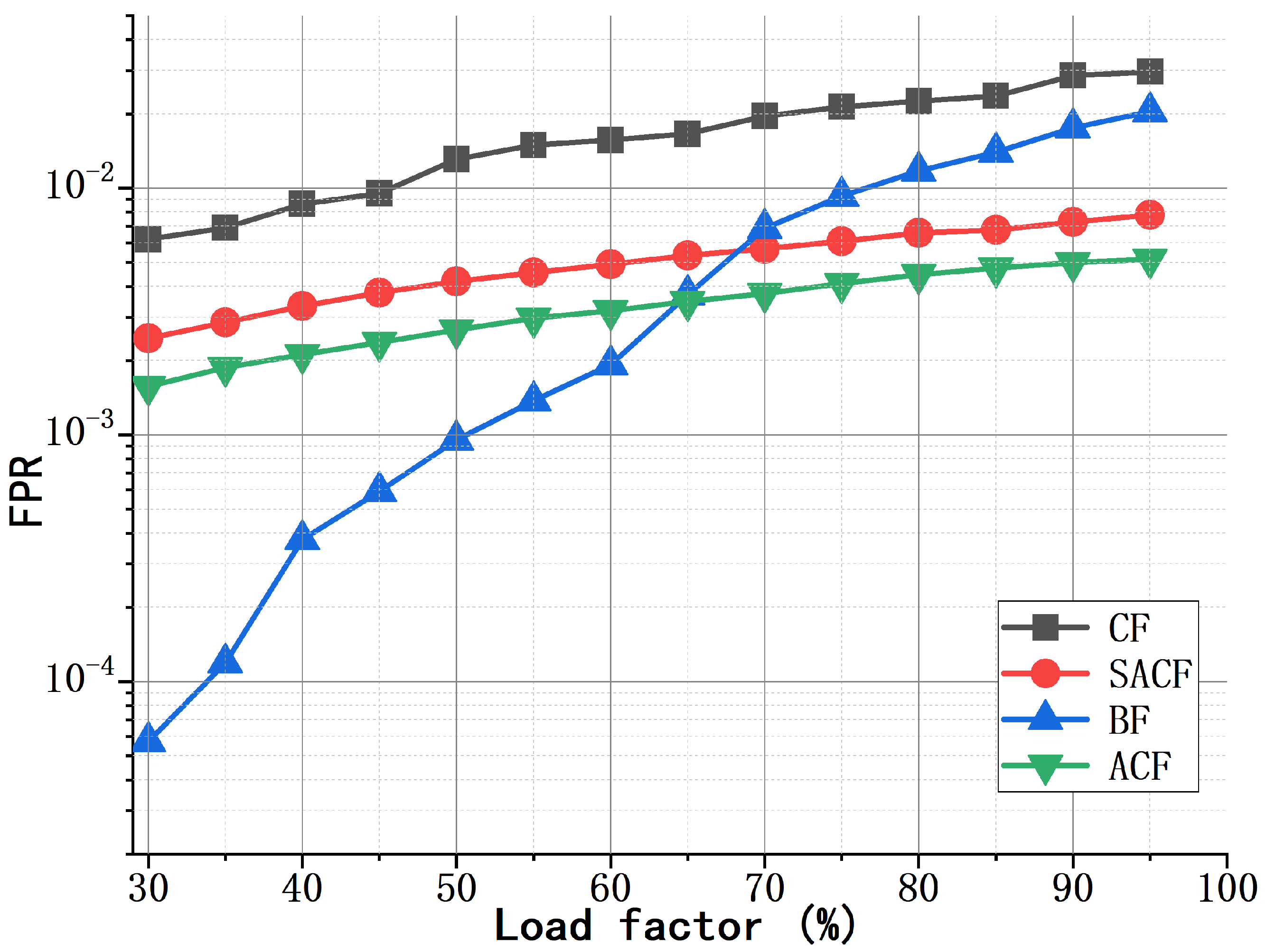
4.1. Performance of the SACF
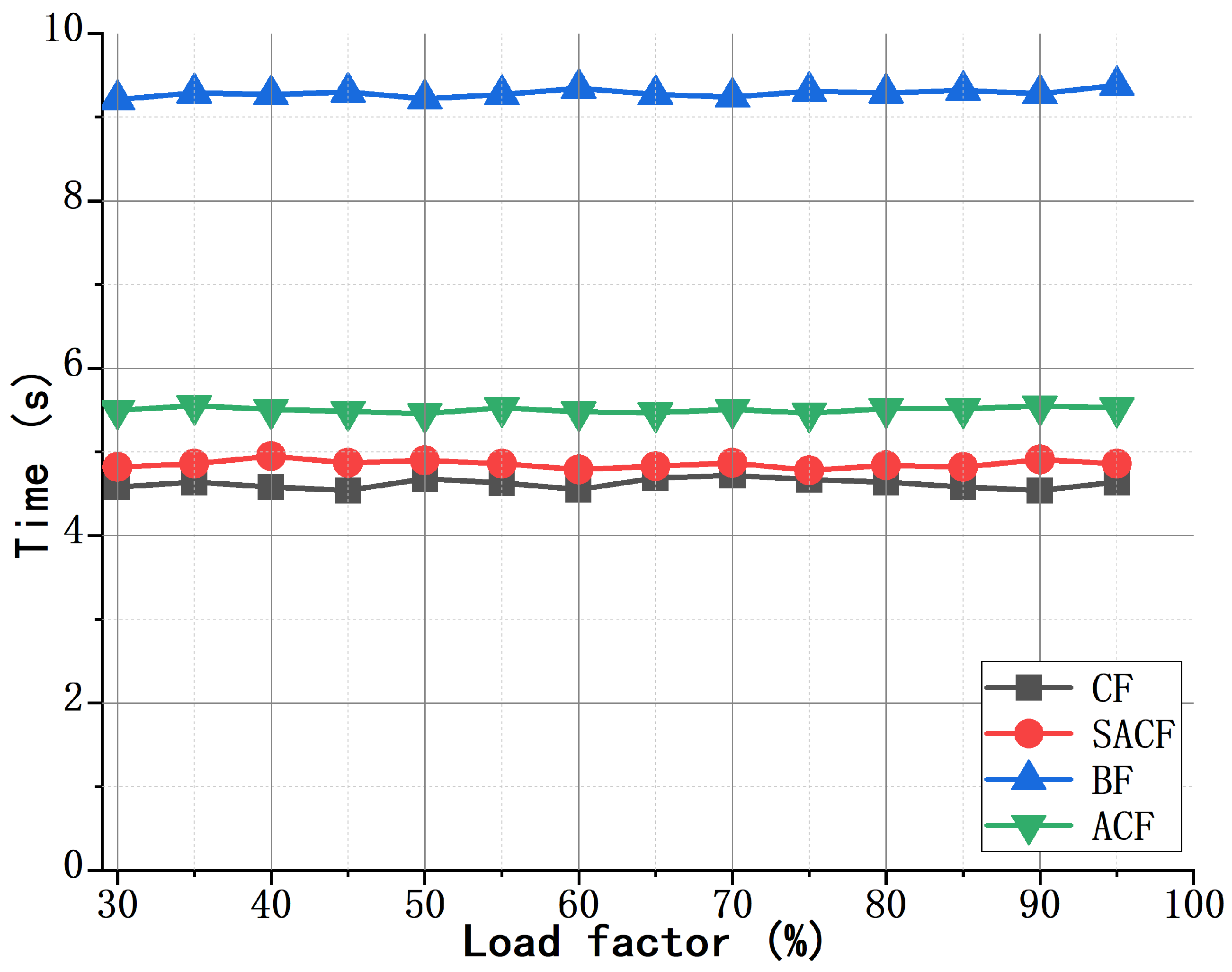
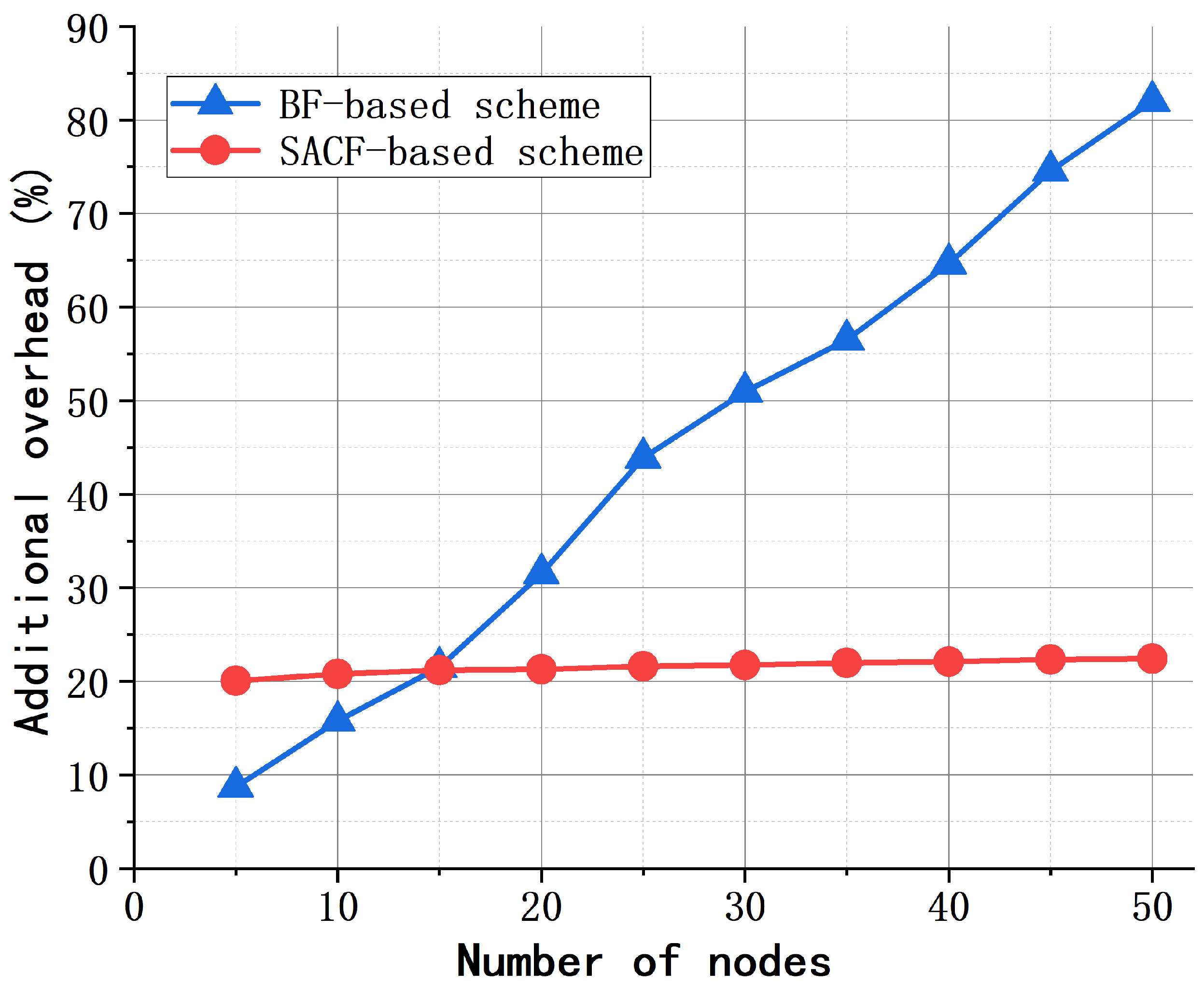
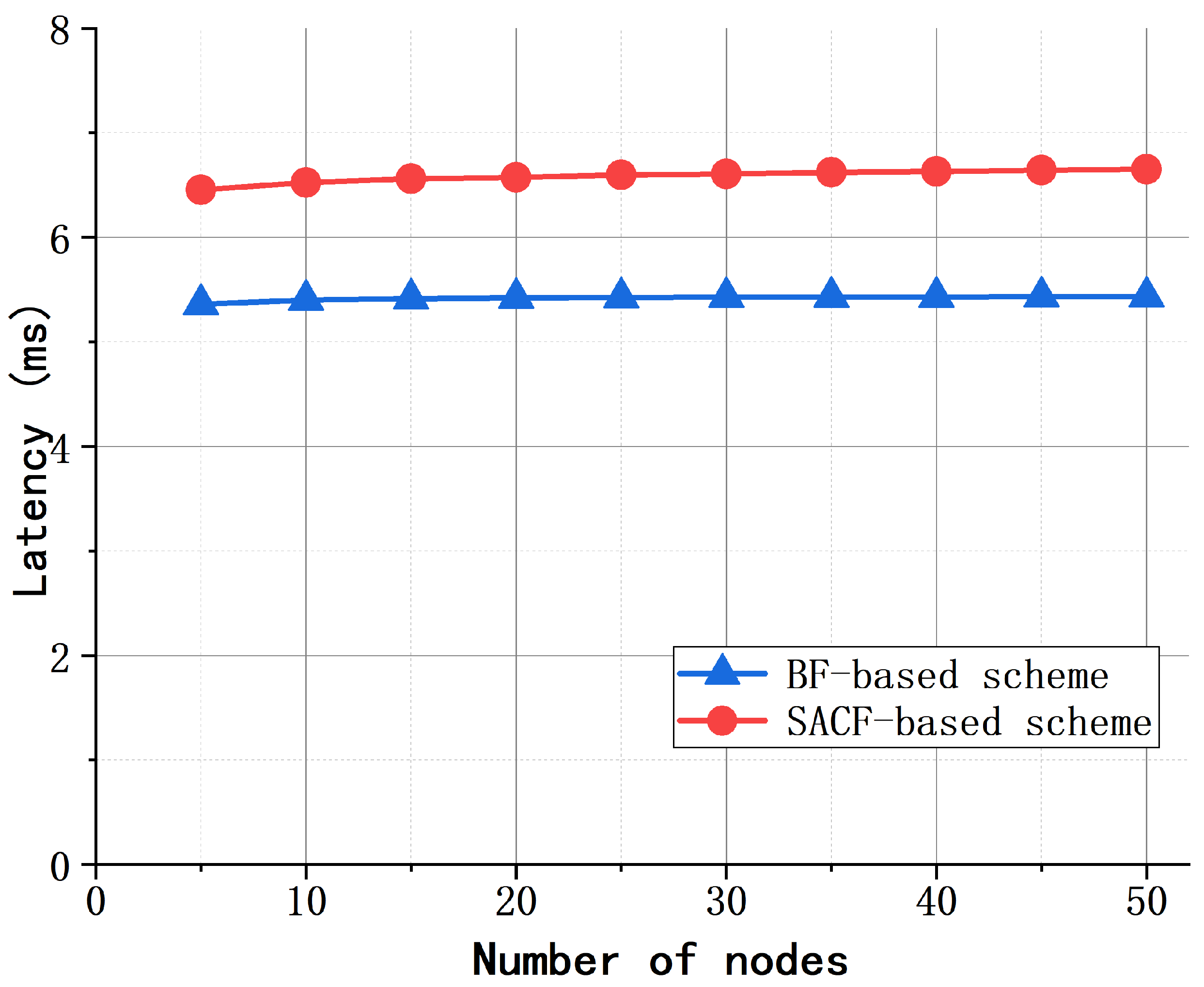
4.2. Performance of the SACF-Based Scheme
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, L.; Afanasyev, A.; Burke, J.; Jacobson, V.; Claffy, K.; Crowley, P.; Papadopoulos, C.; Wang, L.; Zhang, B. Named data networking. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Venkataramani, A.; Kurose, J.F.; Raychaudhuri, D.; Nagaraja, K.; Mao, M.; Banerjee, S. Mobilityfirst: A mobility-centric and trustworthy internet architecture. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 74–80. [Google Scholar] [CrossRef]
- Wang, J.; Chen, G.; You, J.; Sun, P. Seanet: Architecture and technologies of an on-site, elastic, autonomous network. J. Netw. New Media 2020, 6, 1–8. [Google Scholar]
- Jacobson, V.; Smetters, D.K.; Thornton, J.D.; Plass, M.F.; Briggs, N.H.; Braynard, R.L. Networking named content. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies, Rome, Italy, 1–4 December 2009; pp. 1–12. [Google Scholar]
- Fotiou, N.; Nikander, P.; Trossen, D.; Polyzos, G.C. Developing information networking further: From PSIRP to PURSUIT. In Proceedings of the International Conference on Broadband Communications, Networks and Systems, Malaga, Spain, 4–6 November 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–13. [Google Scholar]
- Koponen, T.; Chawla, M.; Chun, B.G.; Ermolinskiy, A.; Kim, K.H.; Shenker, S.; Stoica, I. A data-oriented (and beyond) network architecture. In Proceedings of the 2007 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Kyoto, Japan, 27–31 August 2007; pp. 181–192. [Google Scholar]
- Liu, H.; Azhandeh, K.; De Foy, X.; Gazda, R. A comparative study of name resolution and routing mechanisms in information-centric networks. Digit. Commun. Netw. 2019, 5, 69–75. [Google Scholar] [CrossRef]
- Hoque, A.M.; Amin, S.O.; Alyyan, A.; Zhang, B.; Zhang, L.; Wang, L. NLSR: Named-data link state routing protocol. In Proceedings of the 3rd ACM SIGCOMM Workshop on Information-Centric Networking, Hong Kong, China, 12 August 2013; pp. 15–20. [Google Scholar]
- Tortelli, M.; Grieco, L.A.; Boggia, G.; Pentikousisy, K. Cobra: Lean intra-domain routing in ndn. In Proceedings of the 2014 IEEE 11th Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 10–13 January 2014; pp. 839–844. [Google Scholar]
- D’Ambrosio, M.; Dannewitz, C.; Karl, H.; Vercellone, V. MDHT: A hierarchical name resolution service for information-centric networks. In Proceedings of the ACM SIGCOMM Workshop on Information-Centric Networking, Toronto, ON, Canada, 15–19 August 2011; pp. 7–12. [Google Scholar]
- Liu, H.; De Foy, X.; Zhang, D. A multi-level DHT routing framework with aggregation. In Proceedings of the Second Edition of the ICN Workshop on Information-Centric Networking, Helsinki, Finland, 17 August 2012; pp. 43–48. [Google Scholar]
- Bloom, B.H. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Yu, M.; Fabrikant, A.; Rexford, J. BUFFALO: Bloom filter forwarding architecture for large organizations. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies, Rome, Italy, 1–4 December 2009; pp. 313–324. [Google Scholar]
- Rodrigues, A.; Steenkiste, P.; Aguiar, A. Analysis and improvement of name-based packet forwarding over flat id network architectures. In Proceedings of the 5th ACM Conference on Information-Centric Networking, Boston, MA, USA, 21–23 September 2018; pp. 148–158. [Google Scholar]
- Papalini, M.; Carzaniga, A.; Khazaei, K.; Wolf, A.L. Scalable routing for tag-based information-centric networking. In Proceedings of the 1st ACM Conference on Information-Centric Networking, Paris France, 24–26 September 2014; pp. 17–26. [Google Scholar]
- Papalini, M.; Khazaei, K.; Carzaniga, A.; Rogora, D. High throughput forwarding for ICN with descriptors and locators. In Proceedings of the 2016 Symposium on Architectures for Networking and Communications Systems, Santa Clara, CA, USA, 17–18 March 2016; pp. 43–54. [Google Scholar]
- Marandi, A.; Braun, T.; Salamatian, K.; Thomos, N. A comparative analysis of bloom filter-based routing protocols for information-centric networks. In Proceedings of the 2018 IEEE Symposium on Computers and Communications (ISCC), Natal, Brazil, 25–28 June 2018; pp. 00255–00261. [Google Scholar]
- Marandi, A.; Braun, T.; Salamatian, K.; Thomos, N. BFR: A bloom filter-based routing approach for information-centric networks. In Proceedings of the 2017 IFIP Networking Conference (IFIP Networking) and Workshops, Stockholm, Sweden, 12–16 June 2017; pp. 1–9. [Google Scholar]
- Marandi, A.; Hofer, V.; Gasparyan, M.; Braun, T.; Thomos, N. Bloom filter-based routing for dominating set-based service-centric networks. In Proceedings of the NOMS 2020-2020 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 20–24 April 2020; pp. 1–9. [Google Scholar]
- Marandi, A.; Braun, T.; Salamatian, K.; Thomos, N. Pull-based bloom filter-based routing for information-centric networks. In Proceedings of the 2019 16th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019; pp. 1–6. [Google Scholar]
- Marandi, A.; Braun, T.; Salamatian, K.; Thomos, N. Network coding-based content retrieval based on bloom filter-based content discovery for ICN. In Proceedings of the ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–7. [Google Scholar]
- Lee, J.; Byun, H.; Lim, H. Dual-load Bloom filter: Application for name lookup. Comput. Commun. 2020, 151, 1–9. [Google Scholar] [CrossRef]
- Broder, A.; Mitzenmacher, M. Network applications of bloom filters: A survey. Internet Math. 2004, 1, 485–509. [Google Scholar] [CrossRef] [Green Version]
- Lim, H.; Lee, J.; Byun, H.; Yim, C. Ternary bloom filter replacing counting bloom filter. IEEE Commun. Lett. 2016, 21, 278–281. [Google Scholar] [CrossRef]
- Komatsu, K.; Asaka, T. Routing information management for content oriented networks using Bloom Filters. In Proceedings of the 2013 15th Asia-Pacific Network Operations and Management Symposium (APNOMS), Hiroshima, Japan, 25–27 September 2013; pp. 1–5. [Google Scholar]
- Patgiri, R.; Nayak, S.; Borgohain, S.K. Hunting the pertinency of bloom filter in computer networking and beyond: A survey. J. Comput. Netw. Commun. 2019, 2019, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, H.; Jin, H.; Chen, L.; Liu, Y.; Ni, L.M. Optimizing bloom filter settings in peer-to-peer multikeyword searching. IEEE Trans. Knowl. Data Eng. 2011, 24, 692–706. [Google Scholar] [CrossRef]
- Ariyoshi, T.; Fujita, S. Efficient processing of conjunctive queries in p2p dhts using bloom filter. In Proceedings of the International Symposium on Parallel and Distributed Processing with Applications, Taipei, China, 6–9 September 2010; pp. 458–464. [Google Scholar]
- Gao, W.; Nguyen, J.; Wu, Y.; Hatcher, W.G.; Yu, W. Routing in Large-scale Dynamic Networks: A Bloom Filter-based Dual-layer Scheme. ACM Trans. Internet Technol. (TOIT) 2020, 20, 1–24. [Google Scholar] [CrossRef]
- Katsaros, K.V.; Chai, W.K.; Pavlou, G. Bloom filter based inter-domain name resolution: A feasibility study. In Proceedings of the 2nd ACM Conference on Information-Centric Networking, San Francisco, CA, USA, 30 September–2 October 2015; pp. 39–48. [Google Scholar]
- Fan, B.; Andersen, D.G.; Kaminsky, M.; Mitzenmacher, M.D. Cuckoo filter: Practically better than bloom. In Proceedings of the 10th ACM International on Conference on emerging Networking Experiments and Technologies, Sydney, Australia, 2–5 December 2014; pp. 75–88. [Google Scholar]
- Reviriego, P.; Martínez, J.; Larrabeiti, D.; Pontarelli, S. Cuckoo filters and Bloom filters: Comparison and application to packet classification. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2690–2701. [Google Scholar] [CrossRef]
- Mitzenmacher, M.; Pontarelli, S.; Reviriego, P. Adaptive Cuckoo Filters. ACM J. Exp. Algorithm. 2020, 25, 1–20. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filter | Deletion Support | FPR for Optimal Settings | Extra Cost |
|---|---|---|---|
| BF | No | Good (0.021) | No |
| CBF | Yes | Same as BF | Counters |
| TBF | Partial | Same as BF | Counters |
| CF | Yes | Close to BF (0.029) | No |
| ACF | Yes | Better for repeat queries (0.005) | Flags and a main table for elements |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lian, W.; Li, Y.; Wang, J.; You, J. A Cuckoo Filter-Based Name Resolution and Routing Method in Information-Centric Networking. Electronics 2022, 11, 3243. https://doi.org/10.3390/electronics11193243
Lian W, Li Y, Wang J, You J. A Cuckoo Filter-Based Name Resolution and Routing Method in Information-Centric Networking. Electronics. 2022; 11(19):3243. https://doi.org/10.3390/electronics11193243
Chicago/Turabian StyleLian, Wenhan, Yang Li, Jinlin Wang, and Jiali You. 2022. "A Cuckoo Filter-Based Name Resolution and Routing Method in Information-Centric Networking" Electronics 11, no. 19: 3243. https://doi.org/10.3390/electronics11193243