1. Introduction
Macular degeneration is one of the three major blindness diseases of the human eye [
1], which is mainly caused by the lesions of the macular retina and its underlying nutritional structures, the retinal pigment epithelium and choroid. Patients will encounter clinical symptoms of visual dysfunction and central visual acuity decline. If they are not screened and treated in time, they will face the danger of blindness. In addition, diseases such as diabetes and hypertension may also accumulate lesions in the macular region. Therefore, obtaining parameters related to the number and shape characteristics of key tissue targets, such as fundus macular edema, is of great significance for the diagnosis of macular degeneration and related diseases [
2].
With the maturity of optical imaging technology, optical coherence tomography (OCT) technology has been gradually applied to the construction of retinal images. It is an emerging technology firstly proposed by Huang D from the Massachusetts Institute of Technology in 1991 [
3]. It adopts optical coherent interferometer and confocal scanning microscopy technology, with a longitudinal resolution of 3–15 microns and about 400 to 27,000 A-scans per second [
4,
5]. It takes into account the advantages of high security, fast imaging, non-contact and non-invasive, high longitudinal resolution, and lateral resolution, and has become a biomedical optical imaging technology for detecting the internal microstructure of biological tissues in vivo, and can quickly obtain retinal microstructure images [
6].
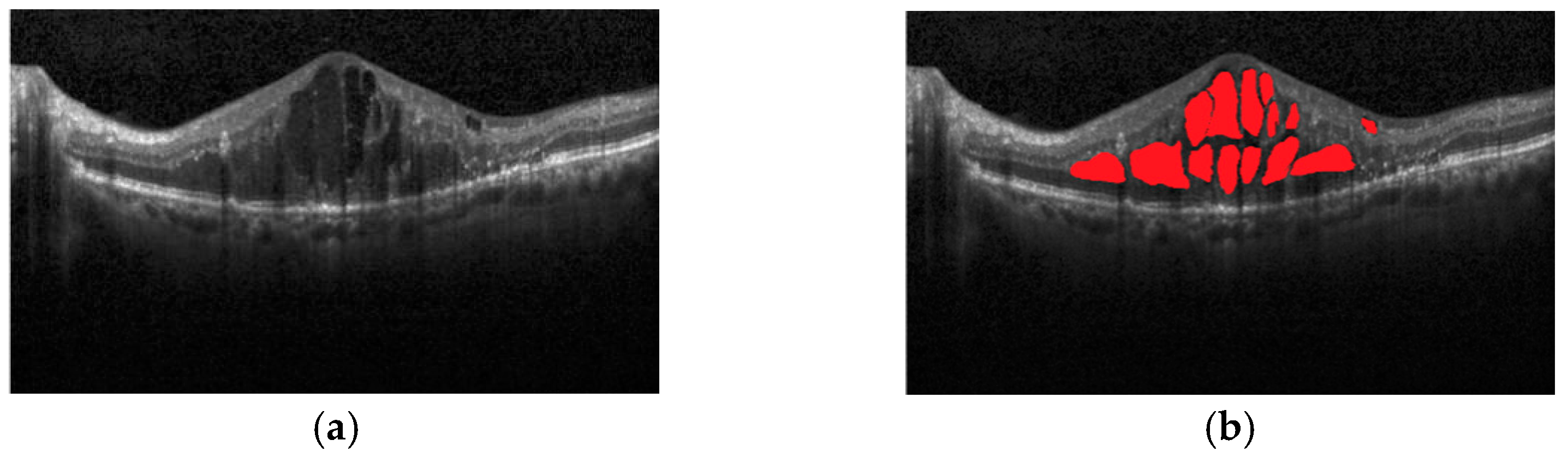
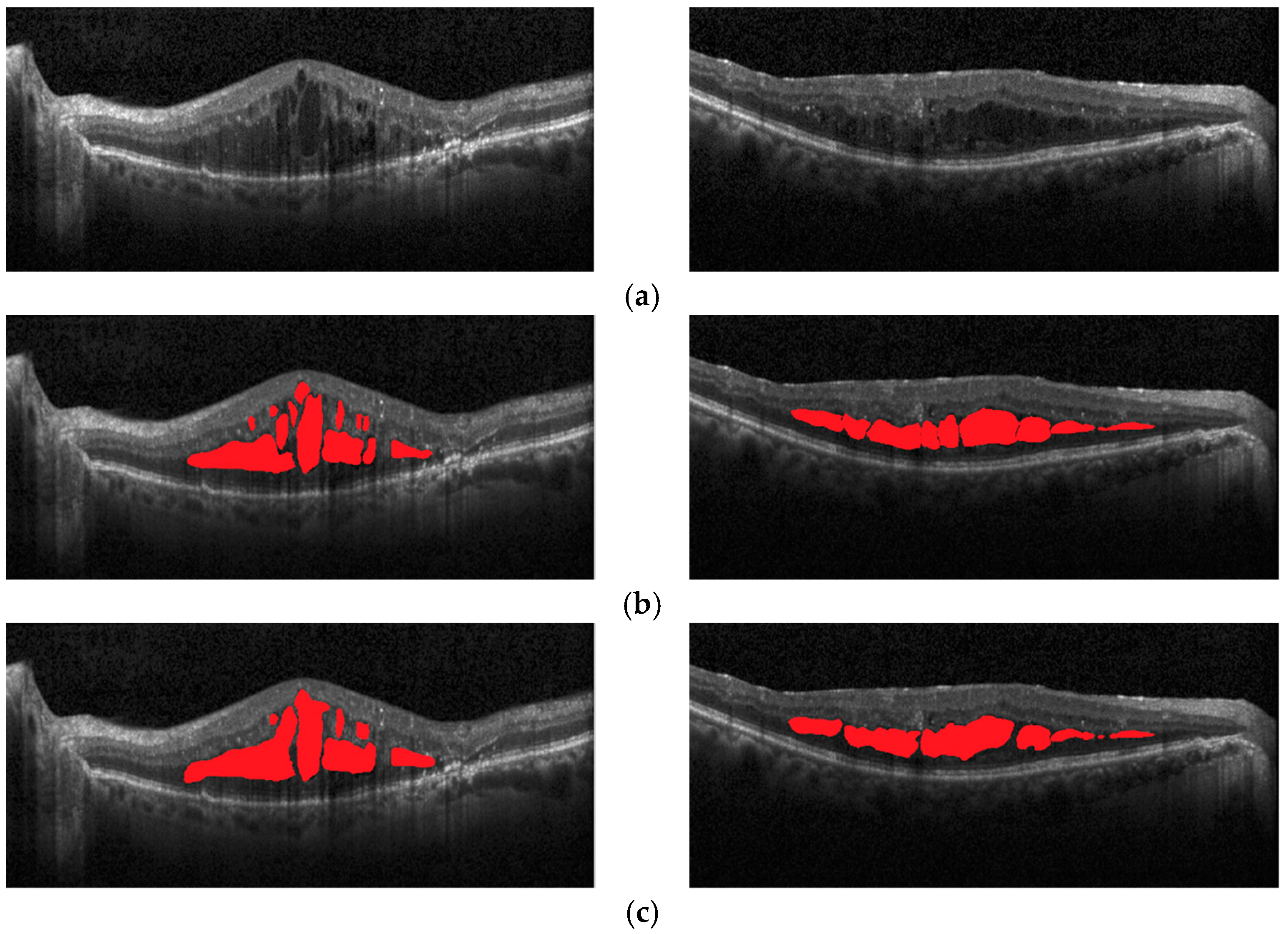
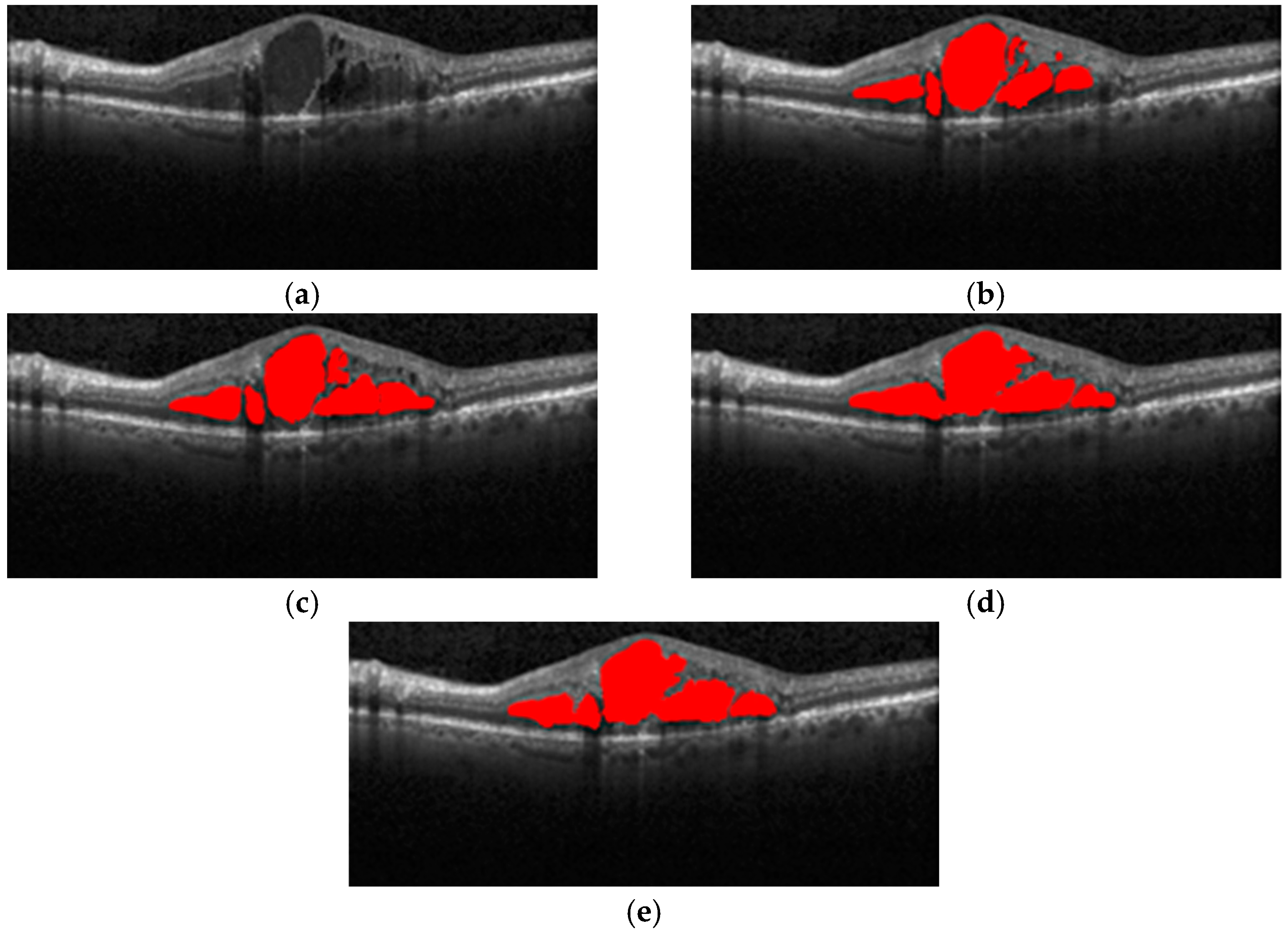
Figure 1a shows OCT images with macular edema, and
Figure 1b shows red regions in the image that are annotations of edema lesions. In this way, the image diagnosis information about on the lesions can be quickly obtained, and the ophthalmologist can make an accurate diagnosis or follow-up treatment for the patients with macular degeneration.
The early segmentation of macular edema in retinal OCT images was mainly performed manually by ophthalmologists, which was not only time-consuming and labor-intensive, but also prone to misclassification or omission due to the influence of doctors’ subjective factors. Therefore, in recent years, semi-automatic and fully automatic segmentation of macular edema in retinal OCT images has become a hot spot and focus of research by scholars. These methods can be mainly divided into two categories: traditional methods and semantic segmentation methods based on deep convolutional neural network learning.
Traditional retinal OCT image macular edema segmentation methods mainly include classical image segmentation methods based on graph theory, threshold segmentation, dynamic programming, coarse granularity, and fine granularity, and active contouring. For example, in 2010, Stephanie et al. proposed an automatic segmentation method of retinal layer of spectral domain optical coherence chromatography images based on graph theory and dynamic programming, using a strong gradient method to estimate the edge weights of OCT images, and then through dynamic programming, the shortest path between nodes was obtained to achieve segmentation of the edema region [
7]. In 2011, Quan et al. proposed a connected component extraction and localization method based on threshold segmentation that combines global and local. The global threshold segmentation is used to remove the irrelevant information in the image, and the set of connected components in the image is obtained from the global perspective, and then the lesion information in the image is accurately located using the local threshold extraction and locally connected component recognition method. Experimental results show that this method can accurately locate microaneurysms and hard exudates in fundus images of diabetic retinopathy [
8]. In 2013, Zheng et al. proposed an automatic segmentation method based on intraretinal fluid and subretinal fluid in OCT images. Firstly, all low-reflection regions in the image were automatically segmented into candidate regions, and then the candidate regions were preprocessed and coarsened. A four-step process approach for segmentation, sub-segmentation, and quantitative analysis [
9]. In 2014, Srinivasan et al. proposed an automatic segmentation method of the retinal layer of spectral domain OCT images based on sparse denoising, support vector machine, graph theory and dynamic programming, and obtained better results in segmenting the retinal boundary layer [
10]. In 2015, Chiu et al. developed a fully automatic OCT segmentation method based on Kernel Regression classification and analyzed the seven-layer segmentation of retinal macular edema on SD-OCT images, combined this method with graph theory, and dynamic programming methods, and obtained a good segmentation effect [
11]. In the same year, Zheng Shan proposed a new multiphase active contour segmentation model under ellipse constraints. According to the different area brightness of the view disc cup in the grayscale image, the model establishes a multiphase active contour model to achieve simultaneous segmentation of the viewer disk cup. The results show that the method can segment the optic disc and optic cup in medical fundus images and provide quantitative shape description information [
12].
In traditional methods, there are also 3D-based methods to solve the segmentation problem of medical images. In 2017, by combining the watershed transformation of grayscale labels with robust optimization algorithms, an automatic 3D medical image registration method was proposed by Ruppert et al., and can effectively reduce the number of key points required for registration, resulting in the fast estimation of the mapping function [
13].
Due to the expansion of dataset size and the improvement in computer computing performance, deep learning methods have been rapidly developed. In this context, a large number of deep learning-based semantic segmentation methods have also been introduced to the field of medical image segmentation, and these methods have achieved many outstanding achievements in retinal macular degeneration segmentation.
In May 2017, Abhay Shah et al. utilized Convolutional Neural Networks (CNN) to segment surfaces in 3D medical images by learning basic features and transformations from training data, without any human expert intervention, using a regional approach to learn local surface contours, and finally combined surfaces to obtain boundary maps, through this method, effective boundary segmentation is achieved on OCT images with normal and age-related macular degeneration [
14]. In the same year, Roy et al. proposed a ReLayNet network of OCT macular edema segmentation using U-Net [
15] as a framework, using the encoder’s contraction path to learn the hierarchy of contextual features, and then using the decoder’s expansion path of semantic segmentation, the network achieved end-to-end segmentation of retinal layers and liquid patches for the first time, and achieved good segmentation results [
16]. In 2018, Venhuizen et al. proposed a two-stage fully convolutional neural network based on U-Net, including a two-stage architecture. The first stage is used to extract features, and the second stage is used for edema segmentation to reduce the impact of background classes on the segmentation effect [
17]. In 2019, in order to solve the class imbalance problem of retinal OCT images, Li et al. used a 2D fully convolutional network for retinal segmentation and modified the network parameters and loss functions. In order to enhance the correlation between corresponding positions between adjacent images in space, a 3D fully convolutional network was proposed for retinal OCT image segmentation with improved segmentation accuracy [
18]. In 2020, Liu et al. proposed an enhanced nested U-Net structure using multi-scale input, multi-scale side output, and dual attention mechanism, which achieved excellent segmentation performance on multi-layer segmentation and multi-fluid segmentation [
19]. In the same year, Gao et al. used ResNet as the backbone network in U-Net++ [
20], redesigned the skip connection structure, used ResNeSt [
21] to improve the synthesized structure, studied the edema region in OCT images, and obtained good segmentation results [
22]. In the same year, Xie et al. used image enhancement and improved 3D U-Net to implement a fast and automatic hyper-reflection focus segmentation method, and also obtained good segmentation results [
23]. In 2021, Acevedo-Jake et al. used anti-angiogenic peptide hydrogel and pro-angiogenic peptide hydrogel to treat neovascular age macular degeneration [
24].
After the rise of the U-Net network, the combination of various convolutional neural network model algorithms appeared in the research field of image semantic segmentation. In 2017, Google proposed a Transformer model based on the self-attention mechanism structure to deal with sequence-related problems and achieved good results [
25]. In 2020, Dosovitskiy et al. proposed Visio Transformer [
26], and many subsequent applications of transformer-based medical image segmentation model algorithms have laid a solid foundation for application, such as Swin Transformer [
27] and TransUNet [
28].
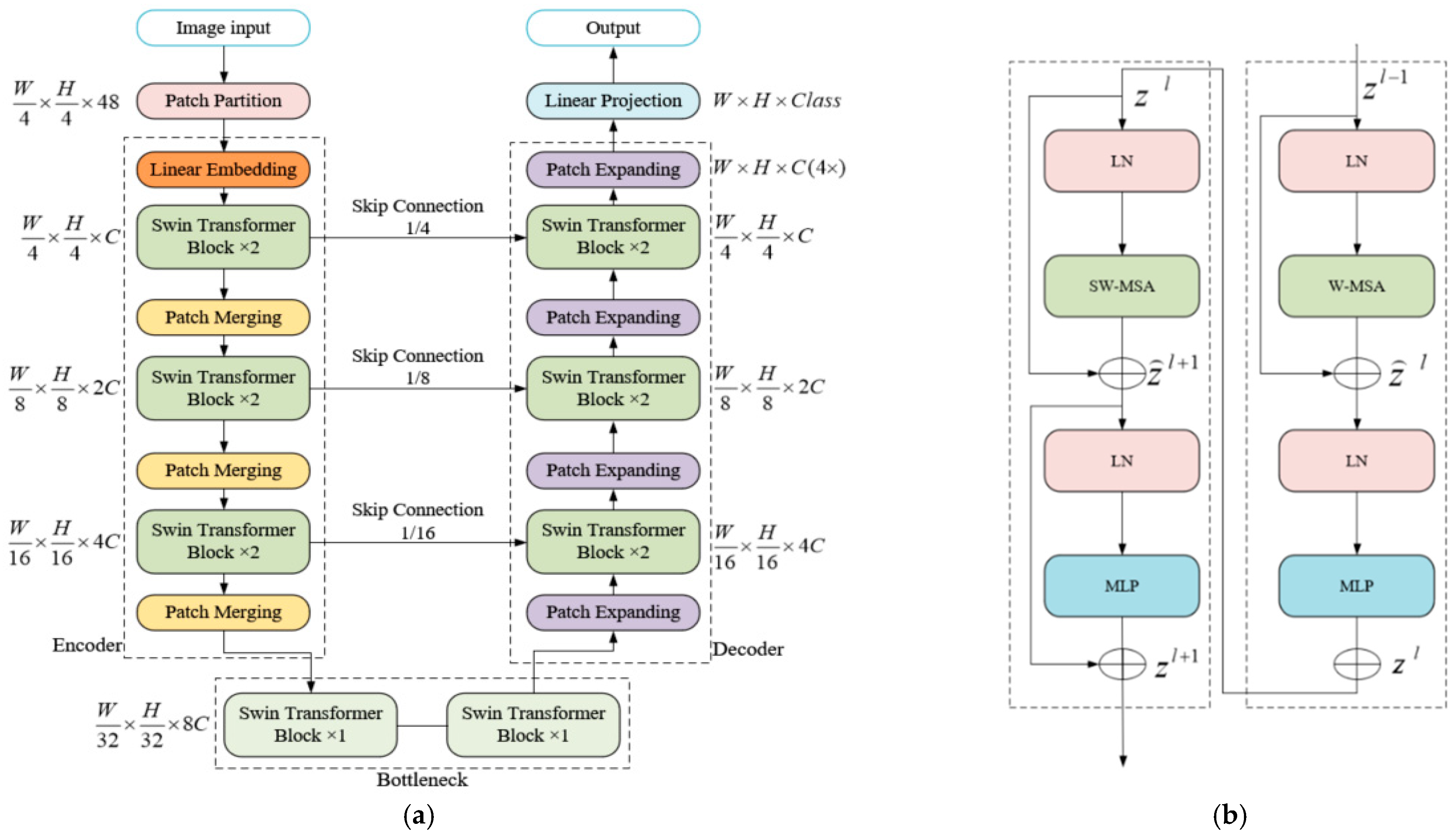
At present, although the Transformer model has a good global capture ability, when performing image segmentation and lesion detection in deep learning, only the global feature representation of the image is considered, and the local representation of learning details needs to be strengthened. In order to overcome the difficult problem of difficult segmentation of macular edema in OCT images with macular degeneration, such as multi-region, multi-scale, irregular shape, non-uniform gray level, and non-fixed position, Swin-Unet [
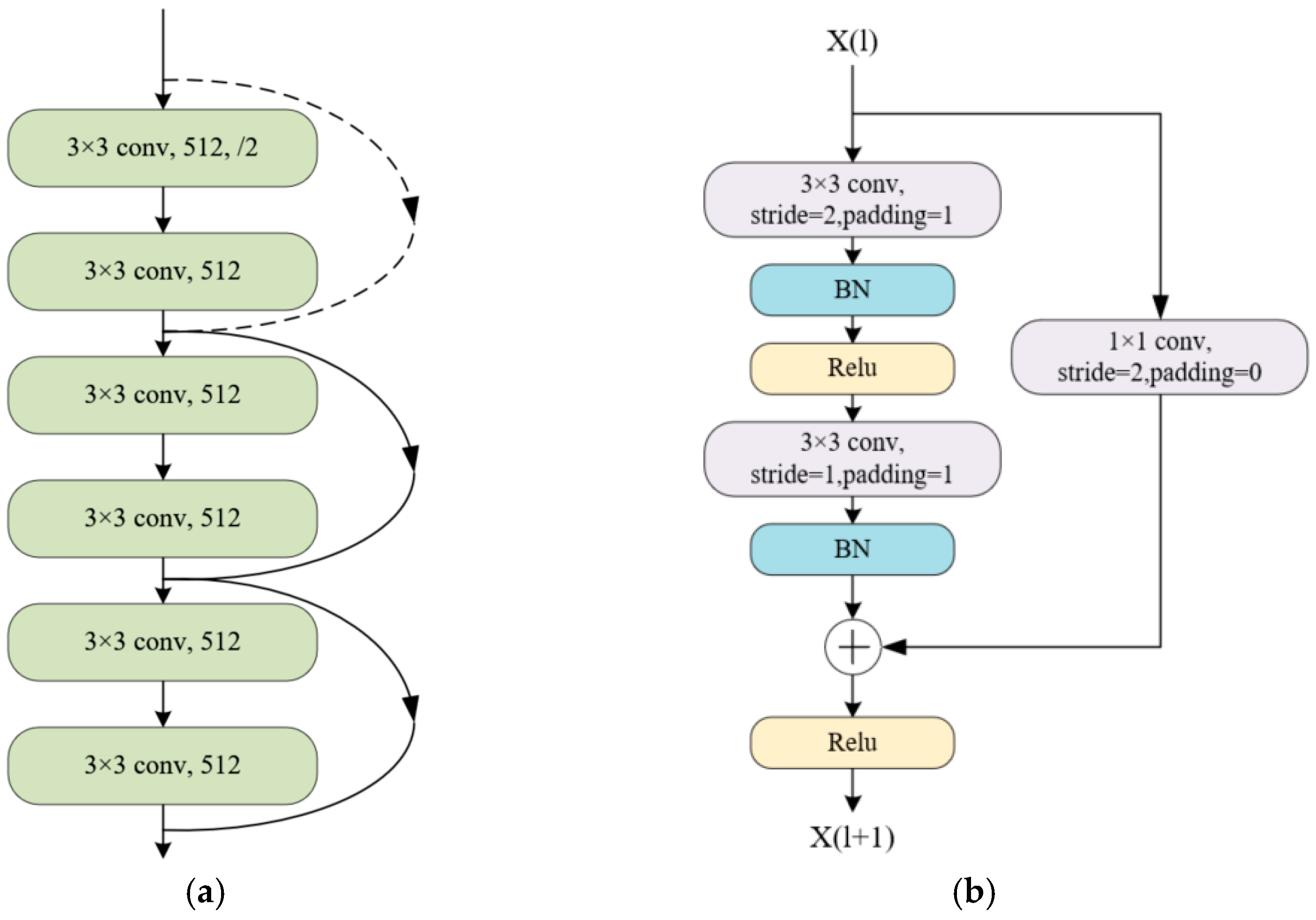
29] has local and global feature semantics. Inspired by learning and pixel-level segmentation features, this paper constructs an improved Swin-Unet model for semantic segmentation of macular edema in retinal OCT images. First of all, this paper uses the network layer of ResNet [
30] to improve the bottleneck of Swin-Unet, consequently enhancing the extraction and learning of sub-feature maps and preventing the calculation of image features in a deep transformer network from poot convergence [
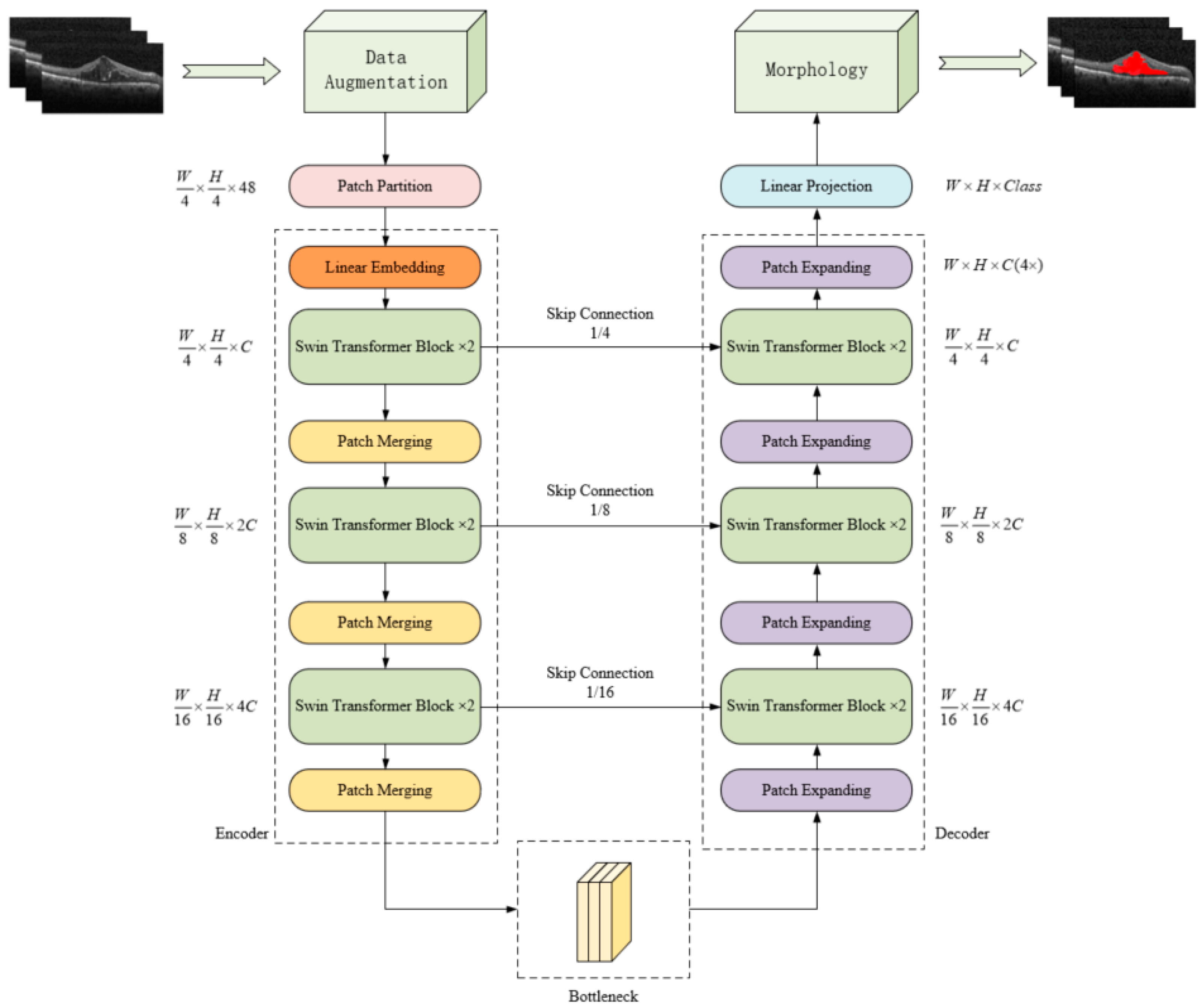
31]. Second, global and local learning is performed using Swin Transformer blocks and skip-connected structures. Then, morphological processing is performed on the lesion area after the semantic segmentation is completed, and finally, training, testing, and comparative analysis are performed on the OCT image dataset of macular edema patients published by Duke University.
The model utilizes the Swin Transformer block to implement a local-to-global self-attention mechanism in the encoder, and combines the captured global features with the patch extension layer and Swin Transformer block for pixel-level segmentation and prediction in the decoder, and Swin Transformer is based on Transformer, therefore, while reducing the loss of feature extraction in the deep network, it can also improve the segmentation accuracy of macular edema in retinal OCT images.
Specifically, the contributions of this paper can be summarized as:
- (1)
By introducing the Swin-Unet model, it can effectively extract context information and restore spatial resolution of the macular edema in retinal OCT images, so that the generalization performance of semantic segmentation for macular edema is improved in retinal OCT images.
- (2)
By using the fifth-layer network of ResNet34 as the bottleneck of the Swin-Unet model to increase the extraction of the sub-feature map, which improves the accuracy of lesion area segmentation.
- (3)
The edge of the predicted edema area is smoothed and denoised by the morphological opening operation to eliminate speckle noise in the image, improve the segmentation accuracy and increase the visual effect.
The rest of the paper is structured as follows:
Section 2 details the Swin-Unet method, and introduces the improved network model,
Section 3 describes the dataset and experimental related configurations, and presents the experimental results and comparative analysis,
Section 4 gives the discussion and ablation experiments are carried out, and
Section 5 summarizes the full text and draws the research conclusions.
4. Discussion
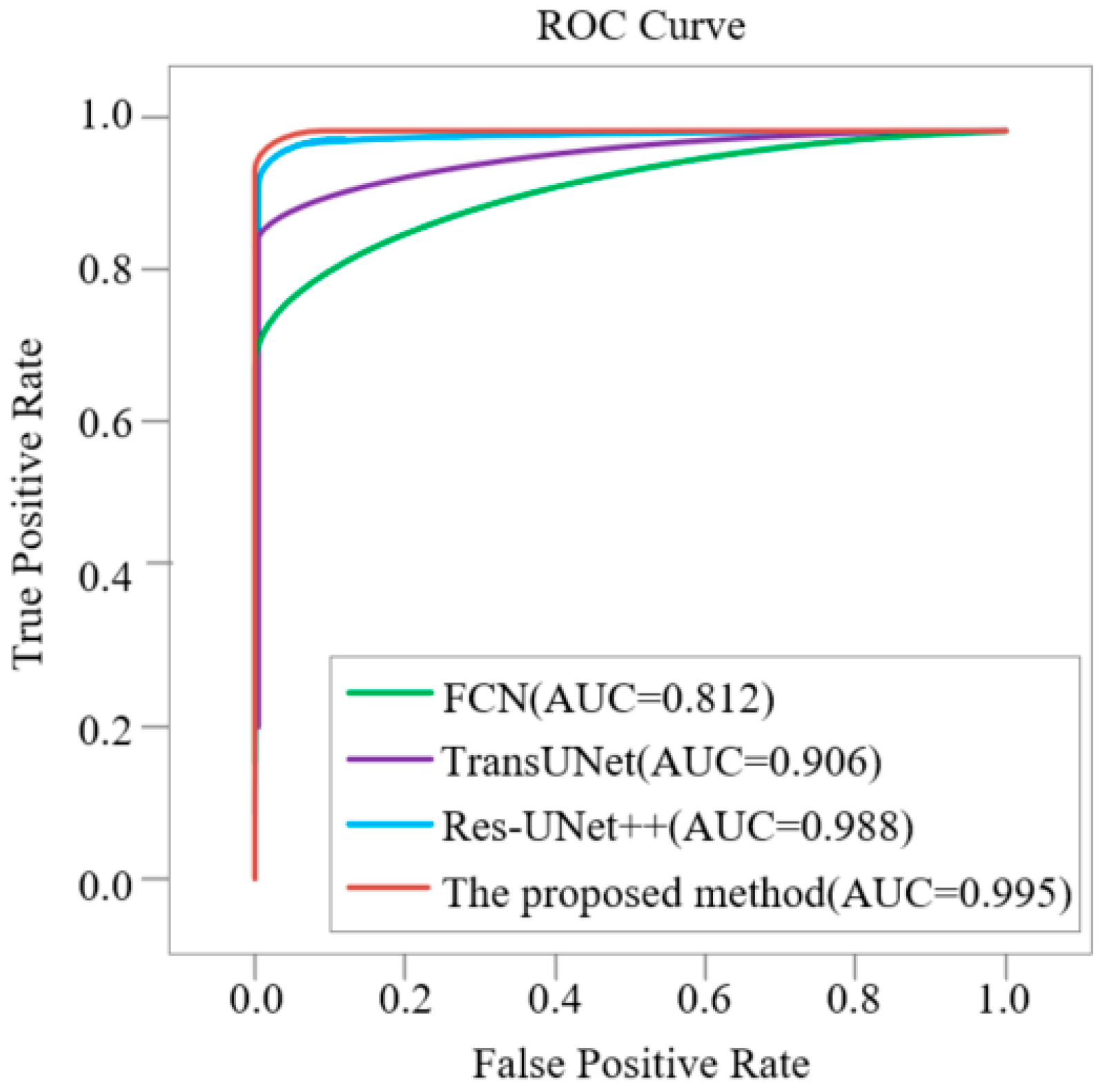
The two improvements of this paper are shown on the whole test set and the macular edema test dataset with multi-scale and multi-region, replacing the bottleneck and morphological processing and the significant effect of the introduced Swin-Unet model on improving the segmentation effect of macular edema in retinal OCT images. Through the ablation experiment, the results of the Swin-Unet method, Swin-Unet+morphological processing, Swin-Unet+replacement bottleneck method and the proposed method are compared on OCT images.
As listed in
Table 4, on the whole test dataset, compared with Swin-Unet+ replacement bottleneck method, Swin-Unet+morphological processing method and Swin-Unet method, the proposed method is improved to 0.01, 0.04 and 0.05 on Dice, 0.02, 0.04 and 0.05 on Iou, 0.03, 0.06 and 0.08 on Recall, 0.03, 0.04 and 0.04 on Precision.
As listed in
Table 5, on the macular edema test dataset with multi-scale and multi-region, compared with Swin-Unet+replacement bottleneck method, Swin-Unet+ morphological processing method and Swin-Unet method, the proposed method is improved to 0.02, 0.04 and 0.05 on Dice, 0.02, 0.04 and 0.05 on Iou, 0.03, 0.06 and 0.06 on Recall, 0.02, 0.06 and 0.06 on Precision.
In the Swin-Unet model, the number of skip connections also has an effective influence on the segmentation effect of macular edema in retinal OCT images. As shown in
Figure 2, in this model, skip connections are added at positions 1/4, 1/8, and 1/16. As listed in
Table 6, in the overall test set, except that the value of Iou with two skip connections is 0.01 higher than that with three hop connections, the other three quantitative indicators are the highest when the jump connection is 3, and the segmentation ability of the model increases as the number of skip connections increases, so the number of skip connections is set as 3 in this work.
Aiming at the bottleneck structure of the Swin-Unet network, the proposed method improves the fifth-layer network introduced by ResNet34. In the existing network, the fifth-layer network structure in ResNet101 is modified as a bottleneck to realize the pairing of sub-features. The deep feature extraction of the graph, and other structures are the same as the model structure of this work. As listed in
Table 7, for the two bottleneck replacement models, compared with the network model introduced with ResNet101, except that the model introduced with ResNet34 in this paper reduced by 0.01 in Iou, the ResNet101 network model improved to 0.01, 0.01, and 0.02 in Dice, Recall, and Precision, respectively.
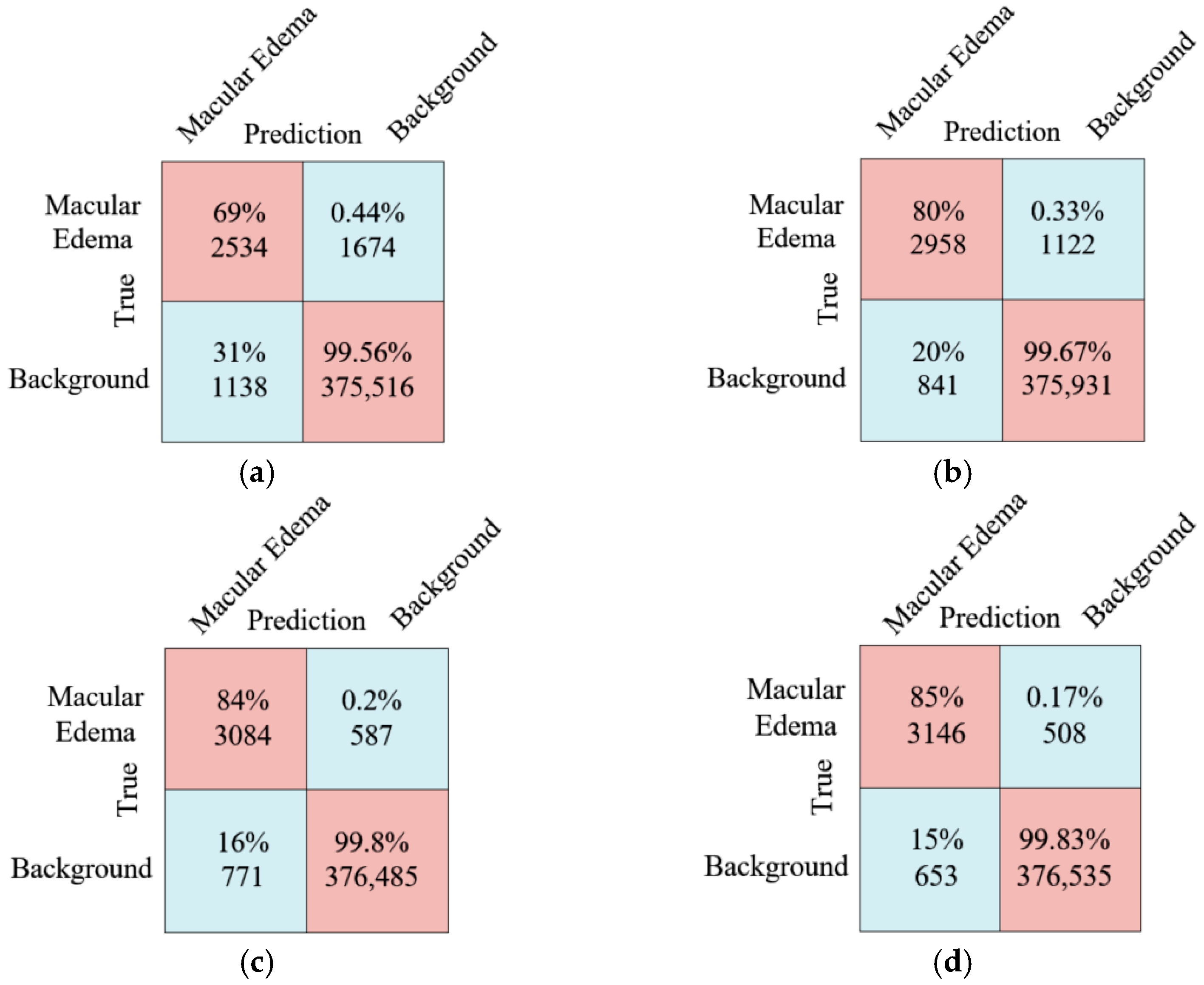
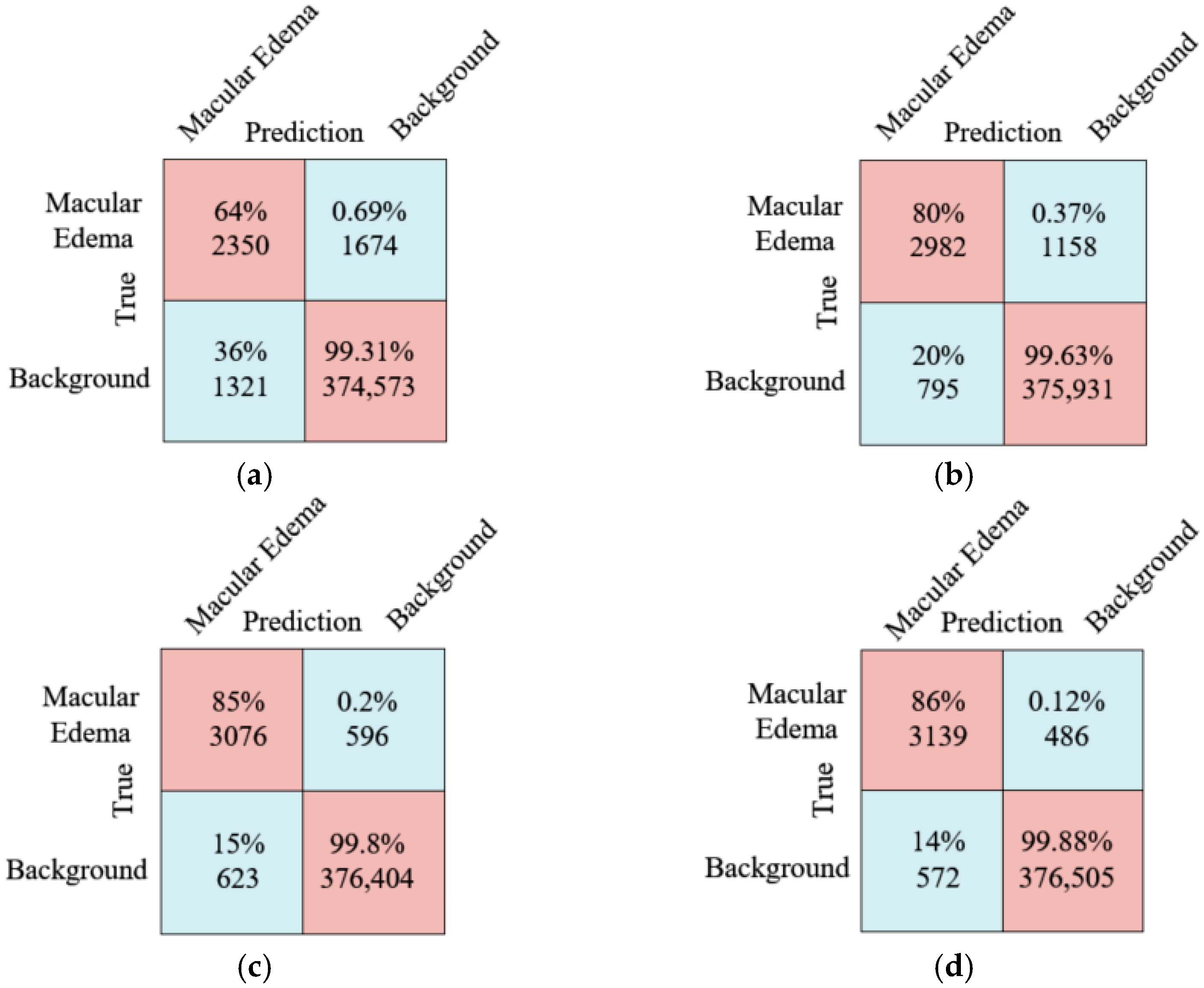
As shown in
Figure 11, the confusion matrix comparison diagram shows the comparison results of the model introduced by ResNet101 and the proposed method. For the mean number of pixels in the edema region is predicted, it can be clearly seen from the diagram that the proposed method is 84 more than the ResNet101 network layer, and the Recall improved by 1%. The prediction effect of the proposed method is much better than that of the ResNet101 network layer method.
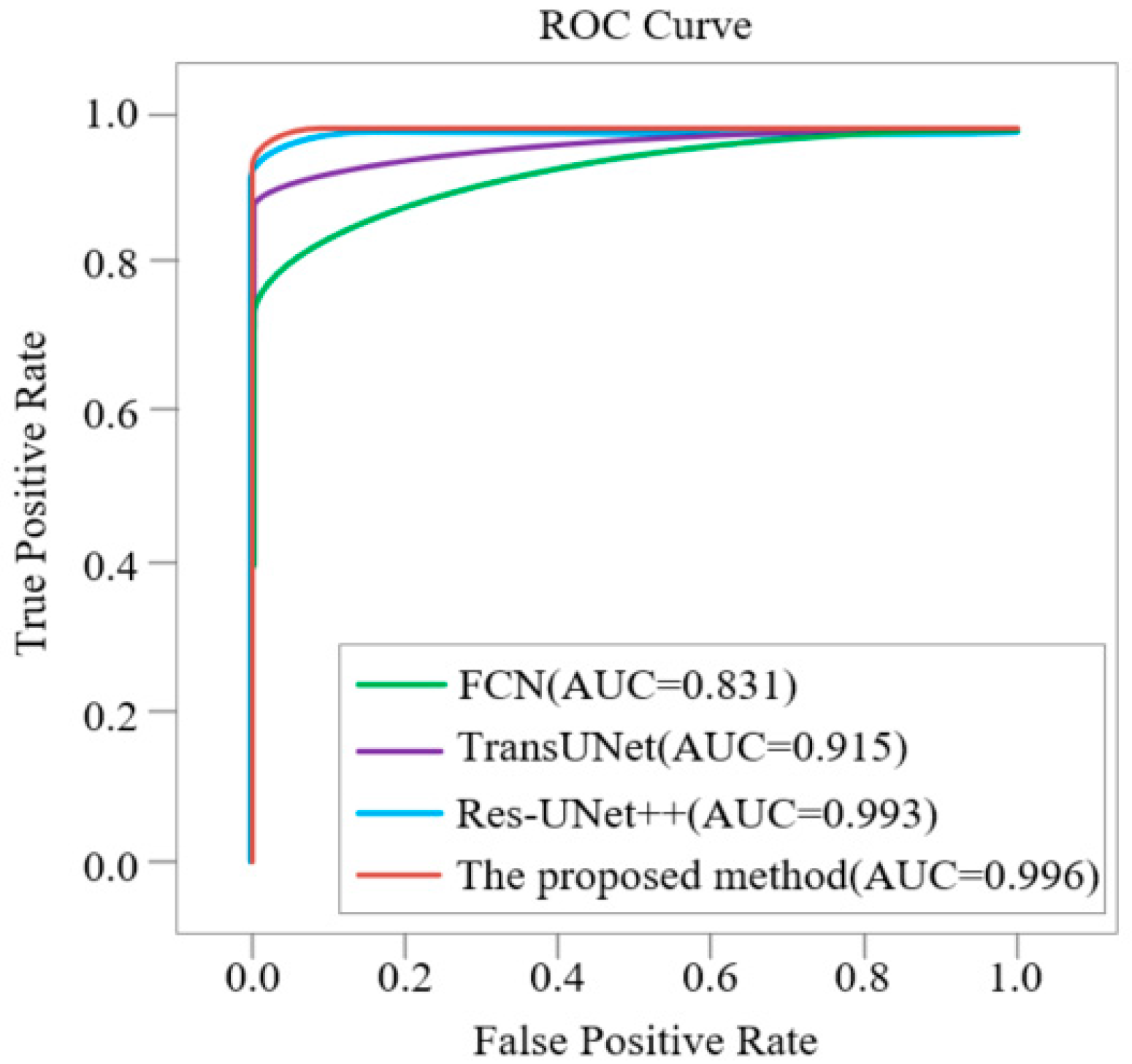
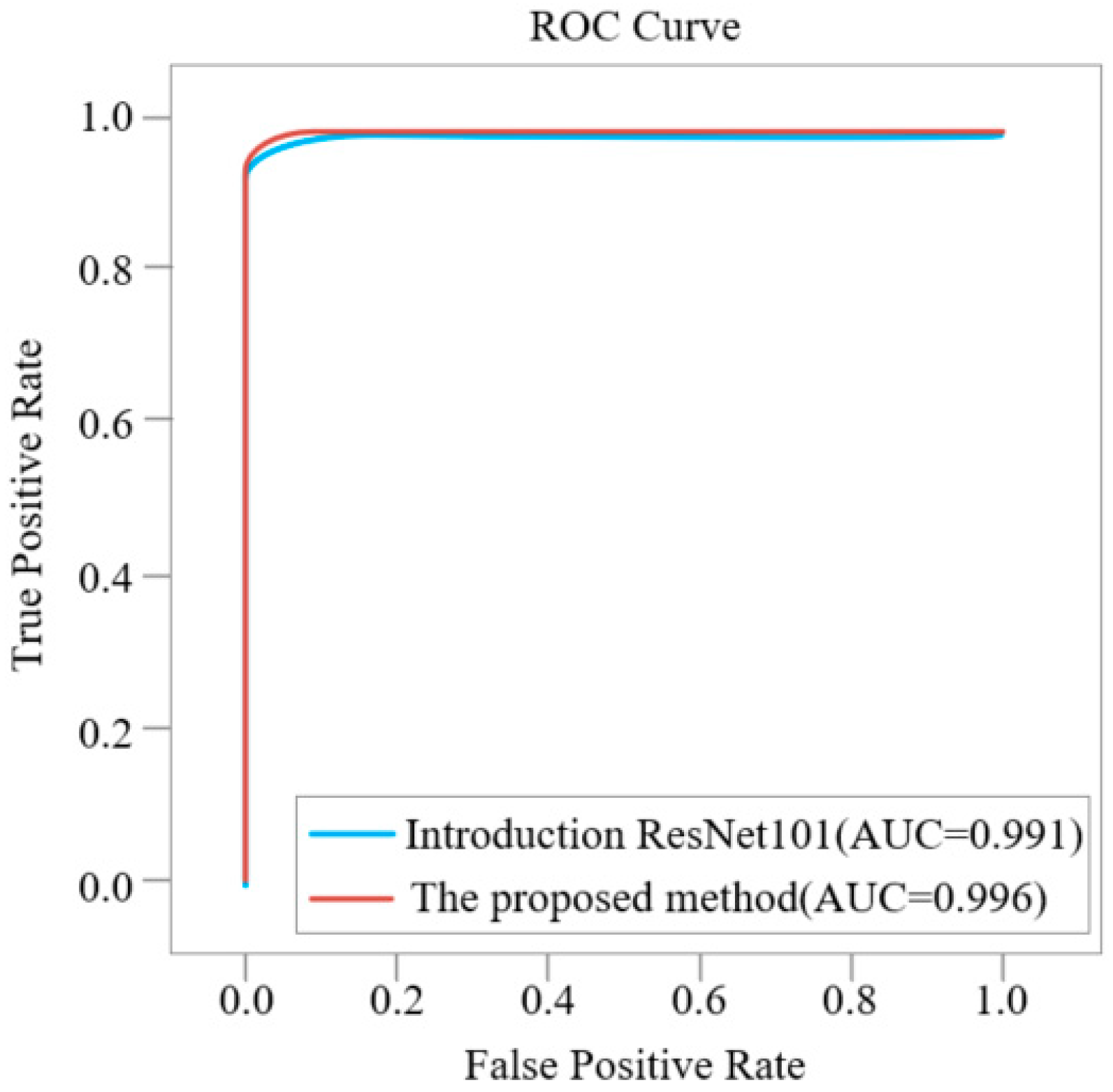
Figure 12 shows the method of introducing the ResNet101 network layer and the ROC curve of this method. It can be clearly seen from the figure that the AUC value of the method in this paper is 0.996, which is 0.005 higher than the AUC value of 0.991 introduced by the ResNet101 network layer model.
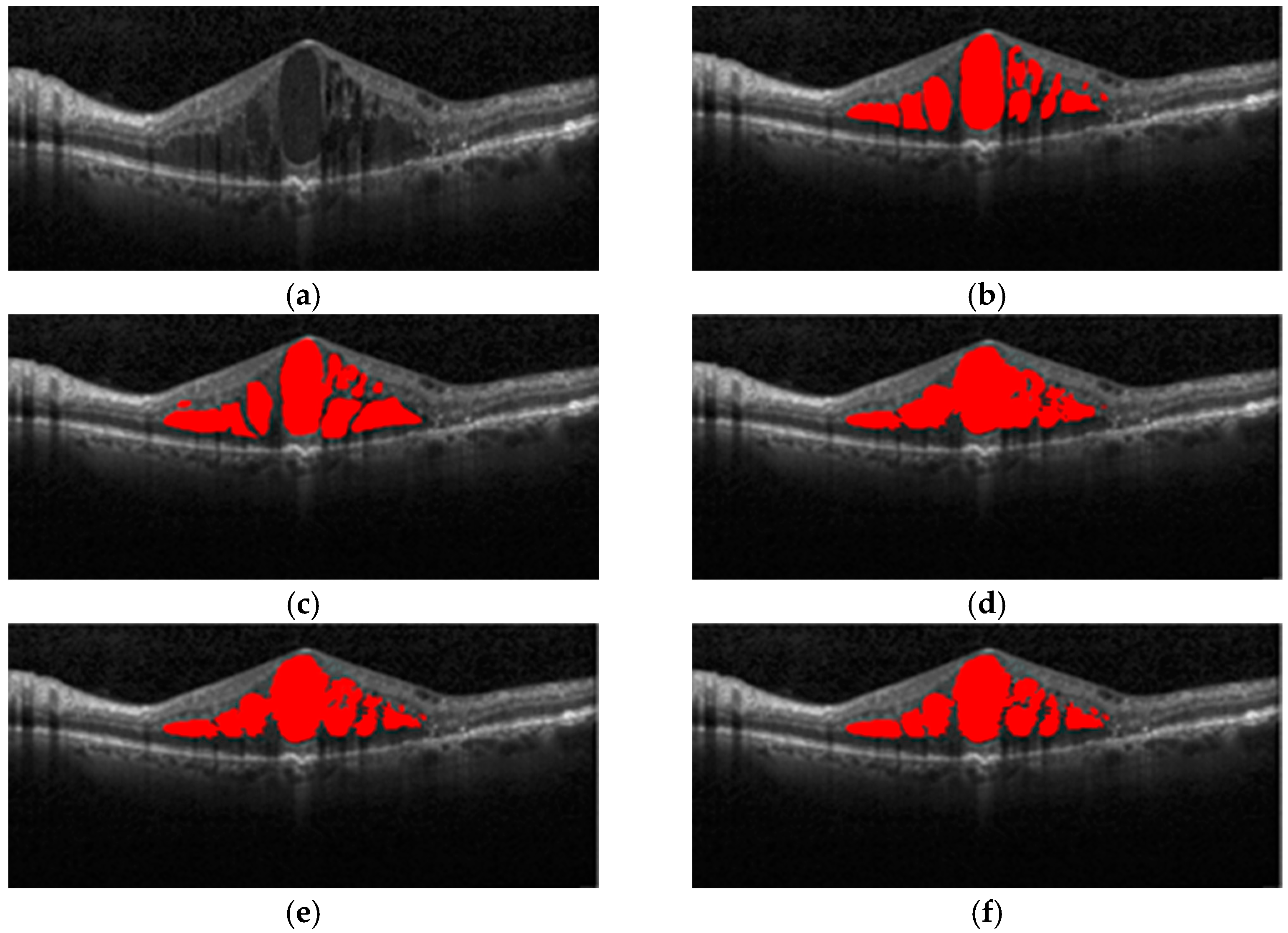
As shown in
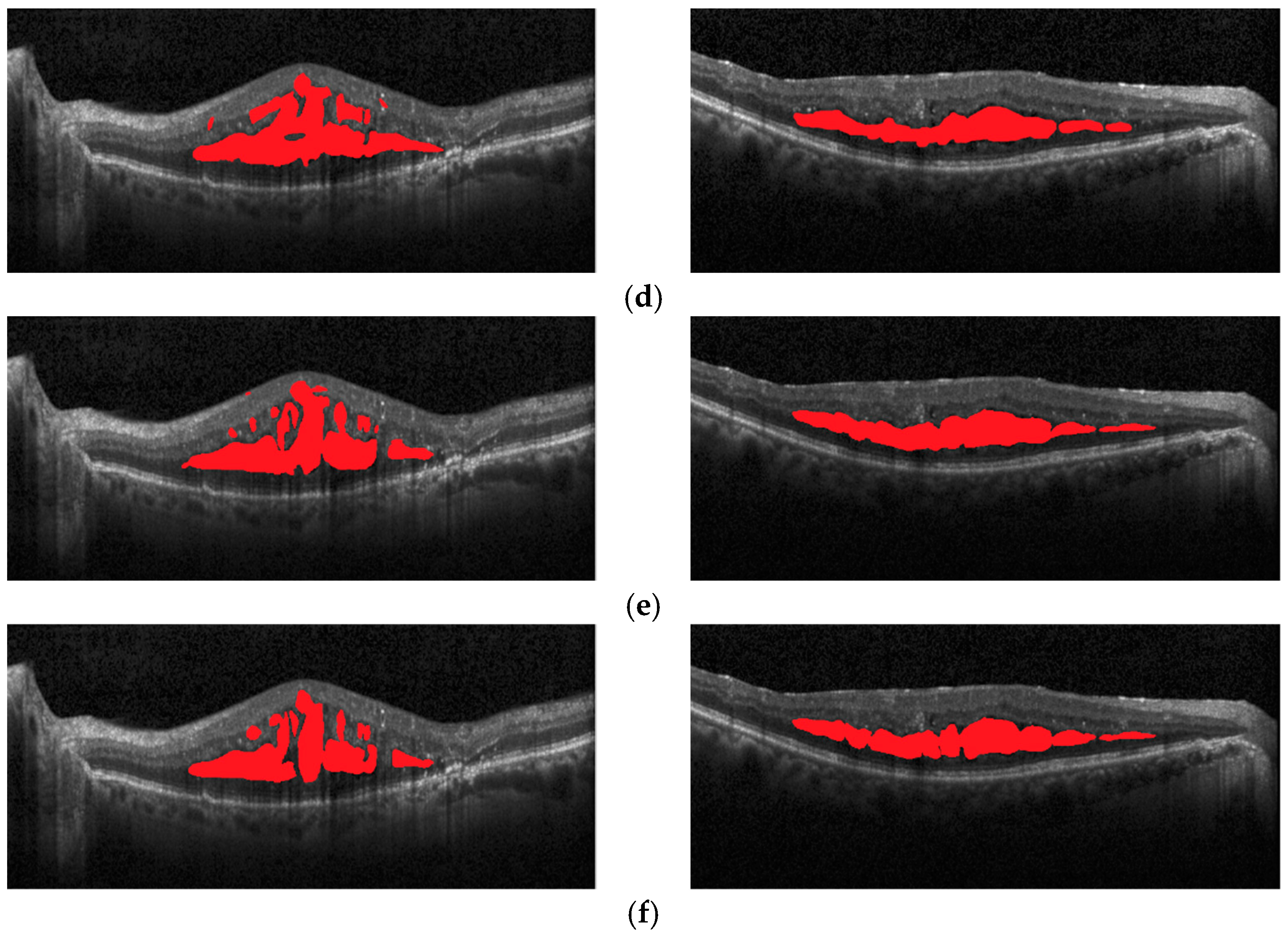
Figure 13, the original image, the image marked by expert 1, the image marked by expert 2, the ResNet101 network model, and the segmentation effect of the proposed method on a macular edema OCT image are shown respectively. In comparison, the semantic segmentation results of the proposed method are better close to the golden annotation standard of expert 1 in terms of the shape, number, and area of macular edema, which further improves the overall semantic segmentation performance of macular edema.
In summary, the two improvements in the proposed method replace the bottleneck and morphological processing, which have a significant effect on improving the segmentation accuracy of macular edema in retinal OCT images.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}