
Real-Time Facemask Detection for Preventing COVID-19 Spread Using Transfer Learning Based Deep Neural Network

 , , , , and
, , , , and
Abstract
:1. Introduction
- A real-time system was built for determining whether a person on a webcam is wearing a mask or not.
- A balanced dataset for a facemask with a nearly one-to-one imbalance ratio was generated using random oversampling (ROS).
- An object detection approach (ensemble) combined a one-stage and two-stage detector to recognize objects from real-time video streams with a short inference time (high speed) and high accuracy.
- Transfer learning was utilized in ResNet50V2 for fusing high-level semantic information in diverse feature maps by extracting new features from learned characteristics.
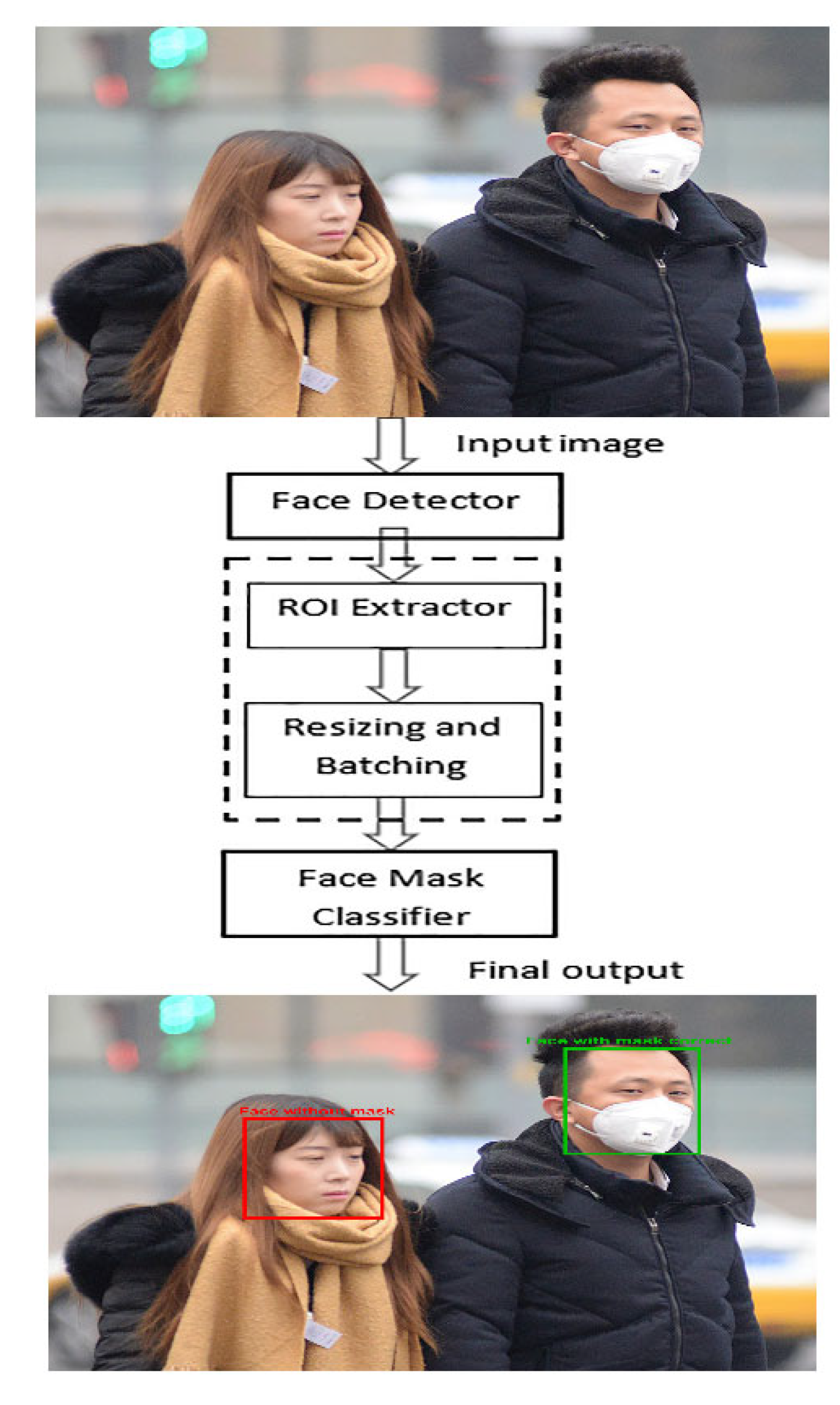
- An improved affine (bounding box) transformation was applied in the cropped region of interest (ROI) as there are many changes in the size of the face and location.
2. Literature Review
- Various models have been pretrained on standard datasets, but only a limited number of datasets handle facemask detection to overcome the COVID-19 spread.
- Due to the limitedness of facemask datasets, varying degrees of occlusion and semantics are essential for numerous mask types.
- However, none of them are ideal for real-time video surveillance systems.
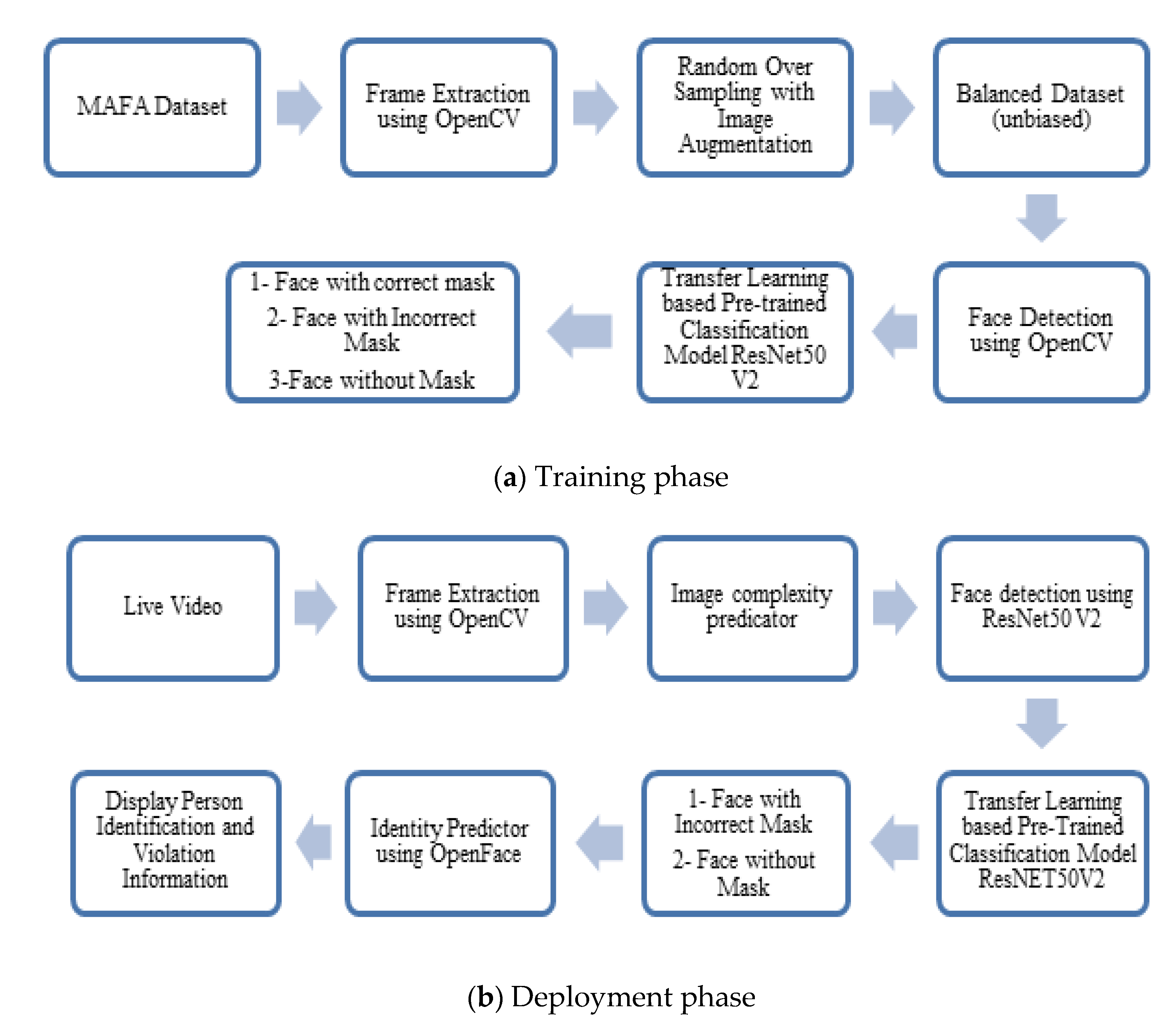
3. Proposed Methodology
| Algorithm 1. Training phase | |
| Input: | MAFA dataset containing videos |
| Processes: | Frame extraction, random oversampling, image augmentation, face detection and transfer learning with pretrained classification |
| Frame extraction using OpenCV: | |
| Step 1: | Split the video captured using cv2.VideoCapture(<path_of_video>) through inbuilt camera into frames and save using cv2.imwrite() |
| Random over sampling: | |
| Step 2: | Unequal number of classes is balanced by performing imbalance computation and ROS using ρ where Dmi and Dma are majority and minority classes of D, |
| Image augmentation and Face detection: | |
| Step 3: | At various locations, the image is passed through a large number of convolutional layers, which extract feature maps. |
| Step 4: | In each of those feature maps, a 4 × 4 filter is used to determine a tiny low default box and predict each box’s bounding box offset. |
| Step 5: | Five predictions are included in each bounding box output: x, y, w, h, and confidence. The centroid of the box is represented by x and y in relation to the grid cell limits |
| Step 6: | Conditional class probabilities are also predicted in each grid cell, |
| Step 7: | The truth boxes are matched with the expected boxes using intersection over union (IOU), |
| Transfer Learning: | |
| Step 8: | Replace last predicting layer of the pretrained model with its own predicting layers to implement fine-tuned transfer learning. |
| Step 9: | Generic features are learnt by the network’s initial lower layers from the pretrained Model, and its weights are frozen and not modified during the training. |
| Step 10: | Task-specific traits are learned at higher layers which can be pretrained and fine-tuned. |
| Pre-trained classification: | |
| Step 11: | Apply pretrained classification model, ResNET50V2 to classify images. |
| Output: | Images in the dataset are classified into three classes: face with correct mask, face with incorrect mask, and face without mask. |
| Algorithm 2. Deployment phase | |
| Input: | Live video |
| Processes: | Frame extraction, image complexity predictor, transfer learning with pretrained classification and identity prediction |
| Frame extraction: | |
| Step 1: | Split the video captured using cv2.VideoCapture(<path_of_video>) through inbuilt camera into frames and save using cv2.imwrite() |
| Step 2: | Face detection using MobileNetV2 and ResNET50V2 is performed by comparing with trained images |
| Step 3: | During testing, class-specific confidence scores are obtained using |
| Step 4: | The truth boxes are matched with the expected boxes using IOU, |
| Image Complexity Prediction: | |
| Step 5: | To identify whether the image is soft or hard, object classification using semi-supervised approach is applied. |
| Step 6: | For predicting the class of soft pictures, the MobileNet-SSD model is used, where N is the total number of matched boxes with the final set of matched boxes, Lbox is the L1 smooth loss indicating the error of matched boxes, and Lclass is the softmax loss for classification. |
| Step 7: | For predicting challenging pictures, a faster RCNN based on ResNet50V2 is used. |
| Transfer Learning: | |
| Step 8: | Replace last predicting layer of the pretrained model with its own predicting layers to implement fine-tuned transfer learning. |
| Step 9: | Generic features are learnt by the network’s initial lower layers from the pretrained Model, and its weights are frozen and not modified during the training. |
| Step 10: | Task-specific traits are learned at higher layers which can be pre-trained and fine-tuned. |
| Pre-trained classification: | |
| Step 11: | By applying pretrained classification model, ResNet50V2, images are classified into face with mask, face with no mask, and face with incorrect mask. |
| Identity prediction: | |
| Step 12: | OpenFace is applied to detect the face is with or without mask. Affine transformation is applied to detect the non-mask faces. |
| Output: | Display the personal information such as identity and name and violation information (such as location, timestamp, camera type, ID, and violation category, e.g., face without mask and face with incorrect mask). |
3.1. Dataset Characteristics
3.2. Image Prepocessing and Face Detection
3.3. Image Complexity Prediction
| Algorithm 3. Image complexity predictor | |
| Input: | Images from the MAFA dataset containing videos |
| Processes: | Single- and two-stage detectors |
| Step 1: | Split soft images (very few people in an image) and hard images (group of people in different poses and locations with background). |
| Step 2: | Apply a single-stage detector to process soft images. |
| Step 3: | Apply a two-stage detector to process hard images. |
| Output: | Set of region proposals (R denotes image left position with height and width, and G denotes bounding box around the image) |
3.4. Transfer Learning-Based Pretrained Classification Model
3.5. Identity Prediction
3.6. Loss Function and Optimization
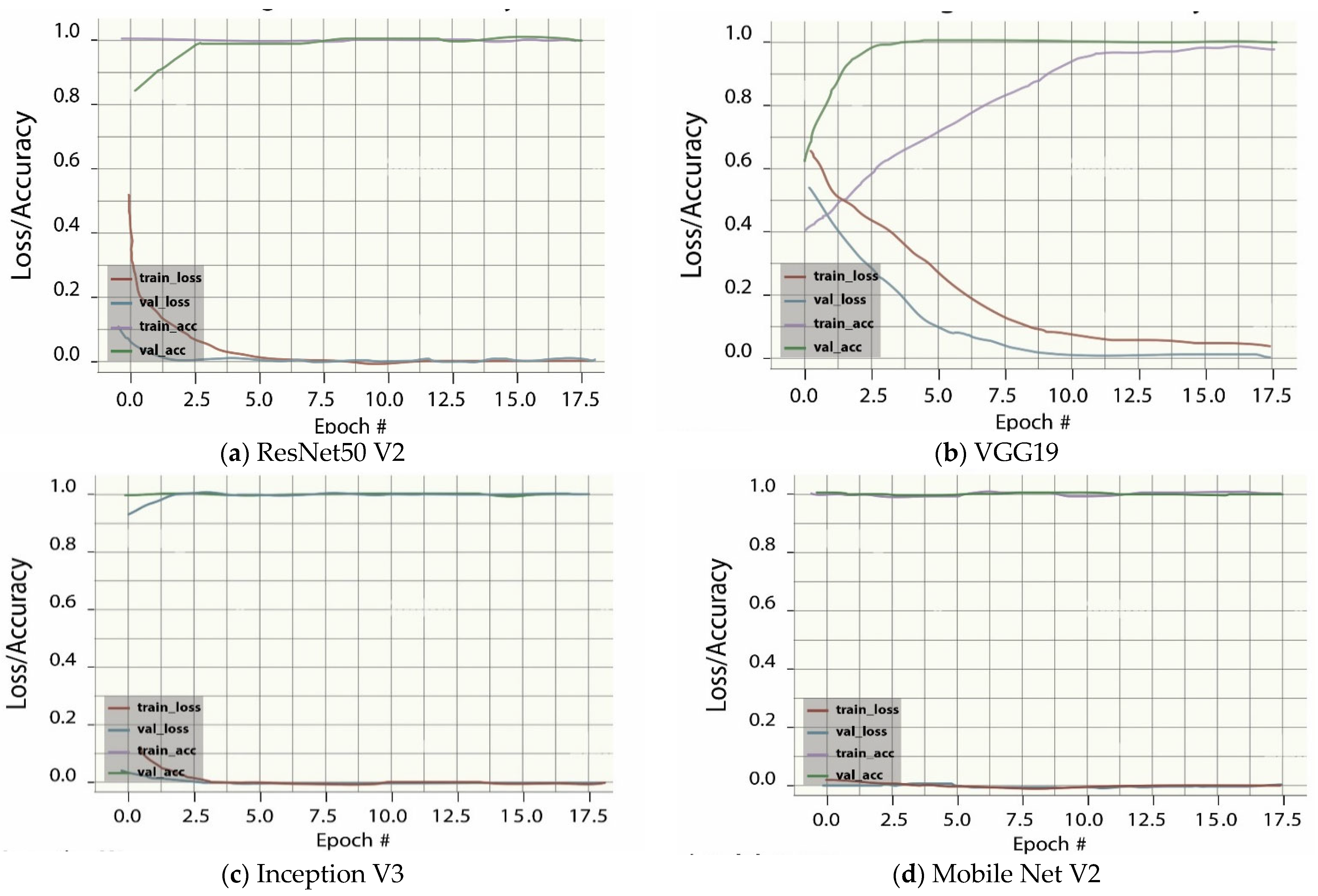
3.7. Control of Overfitting
3.8. Evaluation Parameters
- Face wearing mask correctly:
- Face wearing mask incorrectly:
- Face wearing no mask:
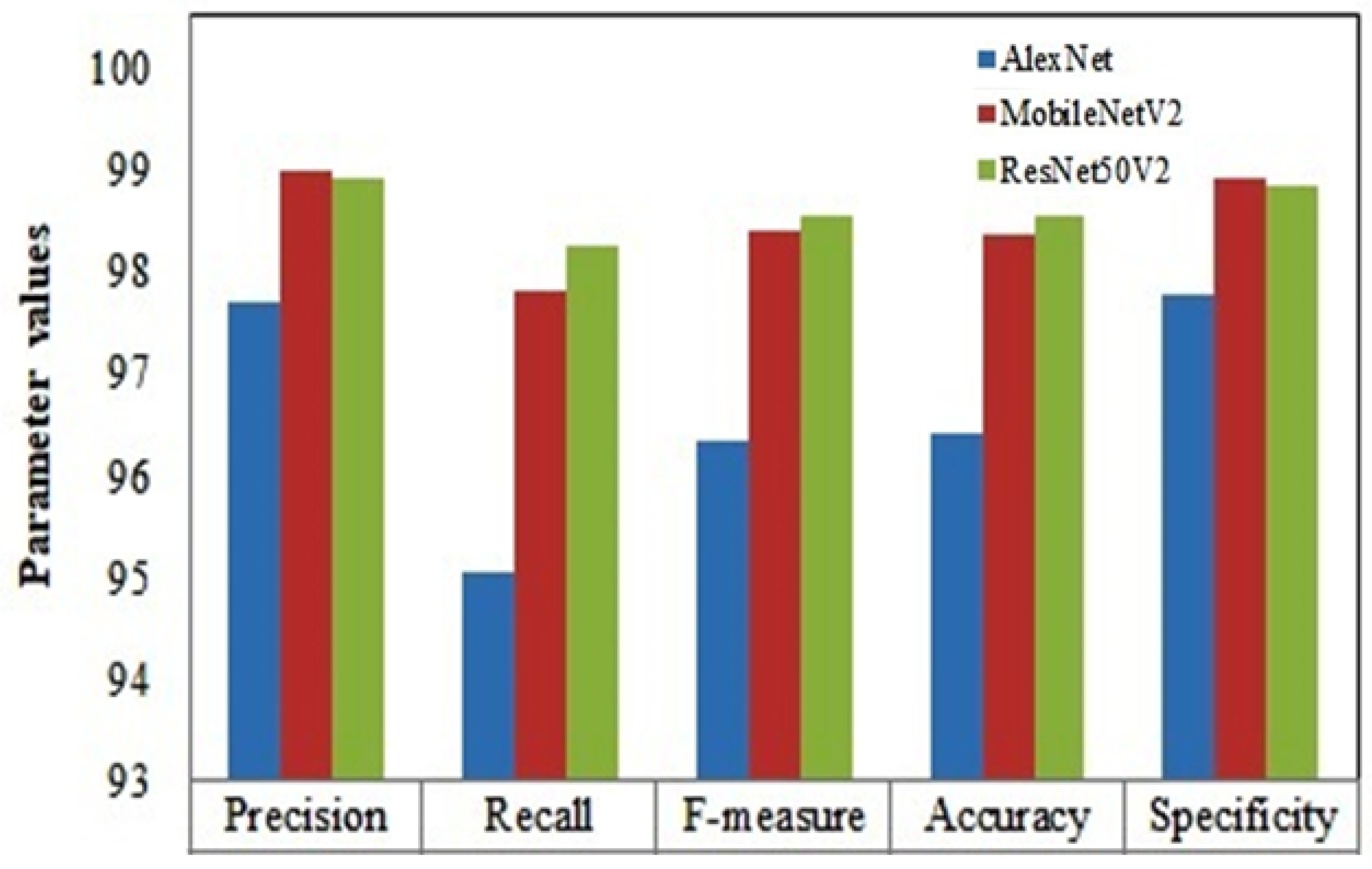
4. Results and Discussion
5. Comparison with Related Works and Discussion
6. Improvement in Accuracy Using MAFA Dataset in the Proposed Method
- In the original imbalanced MAFA dataset, random oversampling was applied to obtain the balanced dataset, and image augmentation was also performed to improve the accuracy.
- In a large dataset ranging from simple to complex images, transfer learning was applied to pretrain the parameters, especially for small objects, which also improved the accuracy of the model.
- In the fine-tuning phase of transfer learning, all the layers in the system were pretrained. Accordingly, the optimum value for each parameter was obtained, which was used to improve the accuracy of the model.
- Using MobileNetV2 for face detection and ResNet50V2 for mask detection improved the accuracy of the system.
- Two-stage detection for classifying images according to groups, distant views, and occlusions also improved the accuracy but at the cost of computational time.
- The batch normalization layer in ResNet50V2 for pretraining the parameters and L2 normalization to accurately predict the image complexity were used to improve the accuracy of the system.
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviation
| CNN | Convolutional neural network |
| ResNet | Residual network |
| ROI | Region of interest |
| YOLO | You only look once |
| R-CNN | Region-based convolutional neural network |
| ROS | Random oversampling |
| IOU | Intersection over union |
| MFN | MaskedFace-Net |
| FFHQ | Flickr-Faces-HQ Dataset |
| ROBL | Random opposition-based learning |
| OBL | Opposition-based learning |
References
- Howard, J.; Huang, A.; Li, Z.; Tufekci, Z.; Zdimal, V.; van der Westhuizen, H.-M.; von Delft, A.; Price, A.; Fridman, L.; Tang, L.-H.; et al. An evidence review of face masks against COVID-19. Proc. Natl. Acad. Sci. USA 2021, 118, e2014564118. [Google Scholar] [CrossRef] [PubMed]
- Godoy, L.R.G.; Jones, A.E.; Anderson, T.N.; Fisher, C.L.; Seeley, K.M.; Beeson, E.A.; Zane, H.K.; Peterson, J.W.; Sullivan, P.D. Facial protection for healthcare workers during pandemics: A scoping review. BMJ Glob. Health 2020, 5, e002553. [Google Scholar] [CrossRef] [PubMed]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Handcrafted vs. non-handcrafted features for computer vision classification. Pattern Recognit. 2017, 71, 158–172. [Google Scholar] [CrossRef]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable Object Detection using Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2147–2154. [Google Scholar]
- Sethi, S.; Kathuria, M.; Kaushik, T. Face mask detection using deep learning: An approach to reduce risk of Coronavirus spread. J. Biomed. Inform. 2021, 120, 103848. [Google Scholar] [CrossRef]
- Sen, S.; Sawant, K. Face mask detection for COVID-19 pandemic using pytorch in deep learning. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1070, 012061. [Google Scholar] [CrossRef]
- Balaji, S.; Balamurugan, B.; Kumar, T.A.; Rajmohan, R.; Kumar, P.P. A Brief Survey on AI Based Face Mask Detection System for Public Places. Ir. Interdiscip. J. Sci. Res. 2021, 5, 108–117. [Google Scholar]
- Cheng, G.; Li, S.; Zhang, Y.; Zhou, R. A Mask Detection System Based on Yolov3-Tiny. Front. Soc. Sci. Technol. 2020, 2, 33–41. [Google Scholar]
- Sakshi, S.; Gupta, A.K.; Yadav, S.S.; Kumar, U. Face Mask Detection System using CNN. In Proceedings of the 2021 IEEE International Conference on Advanced Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021; pp. 212–216. [Google Scholar]
- Jiang, M.; Fan, X.; Yan, H. RetinaMask: A Face Mask Detector. 2020. Available online: http://arxiv.org/abs/2005.03950 (accessed on 5 April 2021).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 779–788. [Google Scholar]
- Kumar, Z.; Zhang, J.; Lyu, H. Object detection in real time based on improved single shot multi-box detector algorithm. EURASIP J. Wirel. Commun. Netw. 2020, 1, 1–18. [Google Scholar] [CrossRef]
- Morera, Á.; Sánchez, Á.; Moreno, A.B.; Sappa, Á.D.; Vélez, J.F. SSD vs. YOLO for Detection of Outdoor Urban Advertising Panels under Multiple Variabilities. Sensors 2020, 20, 4587. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Nguyen, N.-D.; Do, T.; Ngo, T.D.; Le, D.-D. An Evaluation of Deep Learning Methods for Small Object Detection. J. Electr. Comput. Eng. 2020, 2020, 3189691. [Google Scholar] [CrossRef]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Dvornik, N.; Shmelkov, K.; Mairal, J.; Schmid, C. BlitzNet: A Real-Time Deep Network for Scene Understanding. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liang, Z.; Shao, J.; Zhang, D.; Gao, L. Small Object Detection Using Deep Feature Pyramid Networks. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2018; Volume 11166, pp. 554–564. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Roy, B.; Nandy, S.; Ghosh, D.; Dutta, D.; Biswas, P.; Das, T. MOXA: A Deep Learning Based Unmanned Approach For Real-Time Monitoring of People Wearing Medical Masks. Trans. Indian Natl. Acad. Eng. 2020, 5, 509–518. [Google Scholar] [CrossRef]
- Ionescu, R.T.; Alexe, B.; Leordeanu, M.; Popescu, M.; Papadopoulos, D.P.; Ferrari, V. How hard can it be? Estimating the difficulty of visual search in an image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2157–2166. [Google Scholar]
- Soviany, P.; Ionescu, R.T. Optimizing the Trade-Off between Single-Stage and Two-Stage Deep Object Detectors using Image Difficulty Prediction. In Proceedings of the 2018 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 20–23 September 2018. [Google Scholar] [CrossRef]
- Devi Priya, R.; Sivaraj, R.; Anitha, N.; Devisurya, V. Forward feature extraction from imbalanced microarray datasets using wrapper based incremental genetic algorithm. Int. J. Bio-Inspired Comput. 2020, 16, 171–180. [Google Scholar] [CrossRef]
- Devi Priya, R.; Sivaraj, R.; Anitha, N.; Rajadevi, R.; Devisurya, V. Variable population sized PSO for highly imbalanced dataset classification. Comput. Intell. 2021, 37, 873–890. [Google Scholar]
- Chen, K. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Goyal, H.; Sidana, K.; Singh, C. A real time face mask detection system using convolutional neural network. Multimed. Tools Appl. 2022, 81, 14999–15015. [Google Scholar] [CrossRef]
- Farman, H.; Khan, T.; Khan, Z.; Habib, S.; Islam, M.; Ammar, A. Real-Time Face Mask Detection to Ensure COVID-19 Precautionary Measures in the Developing Countries. Appl. Sci. 2022, 12, 3879. [Google Scholar] [CrossRef]
- Mbunge, E.; Simelane, S.; Fashoto, S.G.; Akinnuwesi, B.; Metfula, A.S. Application of deep learning and machine learning models to detect COVID-19 face masks—A review. Sustain. Oper. Comput. 2021, 2, 235–245. [Google Scholar] [CrossRef]
- Tomás, J.; Rego, A.; Viciano-Tudela, S.; Lloret, J. Incorrect Facemask-Wearing Detection Using Convolutional Neural Networks with Transfer Learning. Healthcare 2021, 9, 1050. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Gao, T.; Zhu, Z.; Zhao, Y. Real-Time Face Mask Detection Method Based on YOLOv3. Electronics 2021, 10, 837. [Google Scholar] [CrossRef]
- Hussain, S.; Yu, Y.; Ayoub, M.; Khan, A.; Rehman, R.; Wahid, J.; Hou, W. IoT and Deep Learning Based Approach for Rapid Screening and Face Mask Detection for Infection Spread Control of COVID-19. Appl. Sci. 2021, 11, 3495. [Google Scholar] [CrossRef]
- Awan, M.J.; Bilal, M.H.; Yasin, A.; Nobanee, H.; Khan, N.S.; Zain, A.M. Detection of COVID-19 in Chest X-ray Images: A Big Data Enabled Deep Learning Approach. Int. J. Environ. Res. Public Health 2021, 18, 10147. [Google Scholar] [CrossRef]
- Ardabili, S.; Mosavi, A.; Várkonyi-Kóczy, A.R. Systematic review of deep learning and machine learning models in biofuels research. In Engineering for Sustainable Future; Springer: Cham, Switzerland, 2020; pp. 19–32. [Google Scholar] [CrossRef]
- Abdelminaam, D.S.; Ismail, F.H.; Taha, M.; Taha, A.; Houssein, E.H.; Nabil, A. Coaid-deep: An optimized intelligent framework for automated detecting COVID-19 misleading information on Twitter. IEEE Access 2021, 9, 27840–27867. [Google Scholar] [CrossRef] [PubMed]
- Emadi, M.; Taghizadeh-Mehrjardi, R.; Cherati, A.; Danesh, M.; Mosavi, A.; Scholten, T. Predicting and Mapping of Soil Organic Carbon Using Machine Learning Algorithms in Northern Iran. Remote Sens. 2020, 12, 2234. [Google Scholar] [CrossRef]
- Salama AbdELminaam, D.; Almansori, A.M.; Taha, M.; Badr, E. A deep facial recognition system using intelligent computational algorithms. PLoS ONE 2020, 15, e0242269. [Google Scholar] [CrossRef]
- Mahmoudi, M.R.; Heydari, M.H.; Qasem, S.N.; Mosavi, A.; Band, S.S. Principal component analysis to study the relations between the spread rates of COVID-19 in high risks countries. Alex. Eng. J. 2020, 60, 457–464. [Google Scholar] [CrossRef]
- Ardabili, S.; Mosavi, A.; Várkonyi-Kóczy, A.R. Advances in Machine Learning Modeling Reviewing Hybrid and Ensemble Methods. In Engineering for Sustainable Future; Springer: Cham, Switzerland, 2020; pp. 215–217. [Google Scholar] [CrossRef]
- AbdElminaam, D.S.; ElMasry, N.; Talaat, Y.; Adel, M.; Hisham, A.; Atef, K.; Mohamed, A.; Akram, M. HR-Chat bot: Designing and Building Effective Interview Chat-bots for Fake CV Detection. In Proceedings of the 2021 International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 26–27 May 2021; pp. 403–408. [Google Scholar] [CrossRef]
- Rezakazemi, M.; Mosavi, A.; Shirazian, S. ANFIS pattern for molecular membranes separation optimization. J. Mol. Liq. 2018, 274, 470–476. [Google Scholar] [CrossRef]
- Torabi, M.; Hashemi, S.; Saybani, M.R.; Shamshirband, S.; Mosavi, A. A Hybrid clustering and classification technique for forecasting short-term energy consumption. Environ. Prog. Sustain. Energy 2018, 38, 66–76. [Google Scholar] [CrossRef] [Green Version]
- Ardabili, S.; Abdolalizadeh, L.; Mako, C.; Torok, B.; Mosavi, A. Systematic Review of Deep Learning and Machine Learning for Building Energy. Front. Energy Res. 2022, 10, 786027. [Google Scholar] [CrossRef]
- Houssein, E.H.; Hassaballah, M.; Ibrahim, I.E.; AbdElminaam, D.S.; Wazery, Y.M. An automatic arrhythmia classification model based on improved Marine Predators Algorithm and Convolutions Neural Networks. Expert Syst. Appl. 2021, 187, 115936. [Google Scholar] [CrossRef]
- Deb, S.; Abdelminaam, D.S.; Said, M.; Houssein, E.H. Recent Methodology-Based Gradient-Based Optimizer for Economic Load Dispatch Problem. IEEE Access 2021, 9, 44322–44338. [Google Scholar] [CrossRef]
- Elminaam, D.S.A.; Neggaz, N.; Ahmed, I.A.; Abouelyazed, A.E.S. Swarming Behavior of Harris Hawks Optimizer for Arabic Opinion Mining. Comput. Mater. Contin. 2021, 69, 4129–4149. [Google Scholar] [CrossRef]
- Band, S.S.; Ardabili, S.; Sookhak, M.; Chronopoulos, A.T.; Elnaffar, S.; Moslehpour, M.; Csaba, M.; Torok, B.; Pai, H.-T.; Mosavi, A. When Smart Cities Get Smarter via Machine Learning: An In-Depth Literature Review. IEEE Access 2022, 10, 60985–61015. [Google Scholar] [CrossRef]
- Mohammadzadeh, S.D.; Kazemi, S.-F.; Mosavi, A.; Nasseralshariati, E.; Tah, J.H. Prediction of compression index of fine-grained soils using a gene expression programming model. Infrastructures 2019, 4, 26. [Google Scholar] [CrossRef] [Green Version]
- Deb, S.; Houssein, E.H.; Said, M.; Abdelminaam, D.S. Performance of Turbulent Flow of Water Optimization on Economic Load Dispatch Problem. IEEE Access 2021, 9, 77882–77893. [Google Scholar] [CrossRef]
- Abdul-Minaam, D.S.; Al-Mutairi, W.M.E.S.; Awad, M.A.; El-Ashmawi, W.H. An Adaptive Fitness-Dependent Optimizer for the One-Dimensional Bin Packing Problem. IEEE Access 2020, 8, 97959–97974. [Google Scholar] [CrossRef]
- Mosavi, A.; Golshan, M.; Janizadeh, S.; Choubin, B.; Melesse, A.M.; Dineva, A.A. Ensemble models of GLM, FDA, MARS, and RF for flood and erosion susceptibility mapping: A priority assessment of sub-basins. Geocarto Int. 2020, 2541–2560. [Google Scholar] [CrossRef]
- Mercaldo, F.; Santone, A. Transfer learning for mobile real-time face mask detection and localization. J. Am. Med. Inform. Assoc. 2021, 28, 1548–1554. [Google Scholar] [CrossRef]
- Teboulbi, S.; Messaoud, S.; Hajjaji, M.A.; Mtibaa, A. Real-Time Implementation of AI-Based Face Mask Detection and Social Distancing Measuring System for COVID-19 Prevention. Sci. Program. 2021, 2021, 8340779. [Google Scholar] [CrossRef]
- Hussain, D.; Ismail, M.; Hussain, I.; Alroobaea, R.; Hussain, S.; Ullah, S.S. Face Mask Detection Using Deep Convolutional Neural Network and MobileNetV2-Based Transfer Learning. Wirel. Commun. Mob. Comput. 2022, 2022, 1536318. [Google Scholar] [CrossRef]
- Shaban, H.; Houssein, E.H.; Pérez-Cisneros, M.; Oliva, D.; Hassan, A.Y.; Ismaeel, A.A.; AbdElminaam, D.S.; Deb, S.; Said, M. Identification of parameters in photovoltaic models through a runge kutta optimizer. Mathematics 2021, 9, 2313. [Google Scholar] [CrossRef]
- Houssein, E.H.; Abdelminaam, D.S.; Hassan, H.N.; Al-Sayed, M.M.; Nabil, E. A hybrid barnacles mating optimizer algorithm with support vector machines for gene selection of microarray cancer classification. IEEE Access 2021, 9, 64895–64905. [Google Scholar] [CrossRef]
- Vibhuti; Jindal, N.; Singh, H.; Rana, P.S. Face mask detection in COVID-19: A strategic review. Multimedia Tools Appl. 2022, 1–30. [Google Scholar] [CrossRef] [PubMed]
- Ejaz, M.S.; Islam, M.R.; Sifatullah, M.; Sarker, A. Implementation of principal component analysis on masked and non-masked face recognition. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, 3–5 May 2019; pp. 1–5. [Google Scholar]
- Din, N.U.; Javed, K.; Bae, S.; Yi, J. A Novel GAN-Based Network for Unmasking of Masked Face. IEEE Access 2020, 8, 44276–44287. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Values | ||||
|---|---|---|---|---|
| Face Wearing Mask Correctly | Face Wearing Mask Incorrectly | Face Wearing No Mask | ||
| Actual values | Face wearing mask correctly | a | b | c |
| Face wearing mask incorrectly | d | e | f | |
| Face wearing no mask | g | h | i | |
| Predicted Value | ||||
| face wearing mask correctly | face wearing mask incorrectly | face wearing no mask | ||
| Actual Values | face wearing mask correctly | 0.94 | 0.058 | 0.002 |
| face wearing mask incorrectly | 0.079 | 0.9 | 0.021 | |
| face wearing no mask | 0.005 | 0.00497 | 0.99 | |
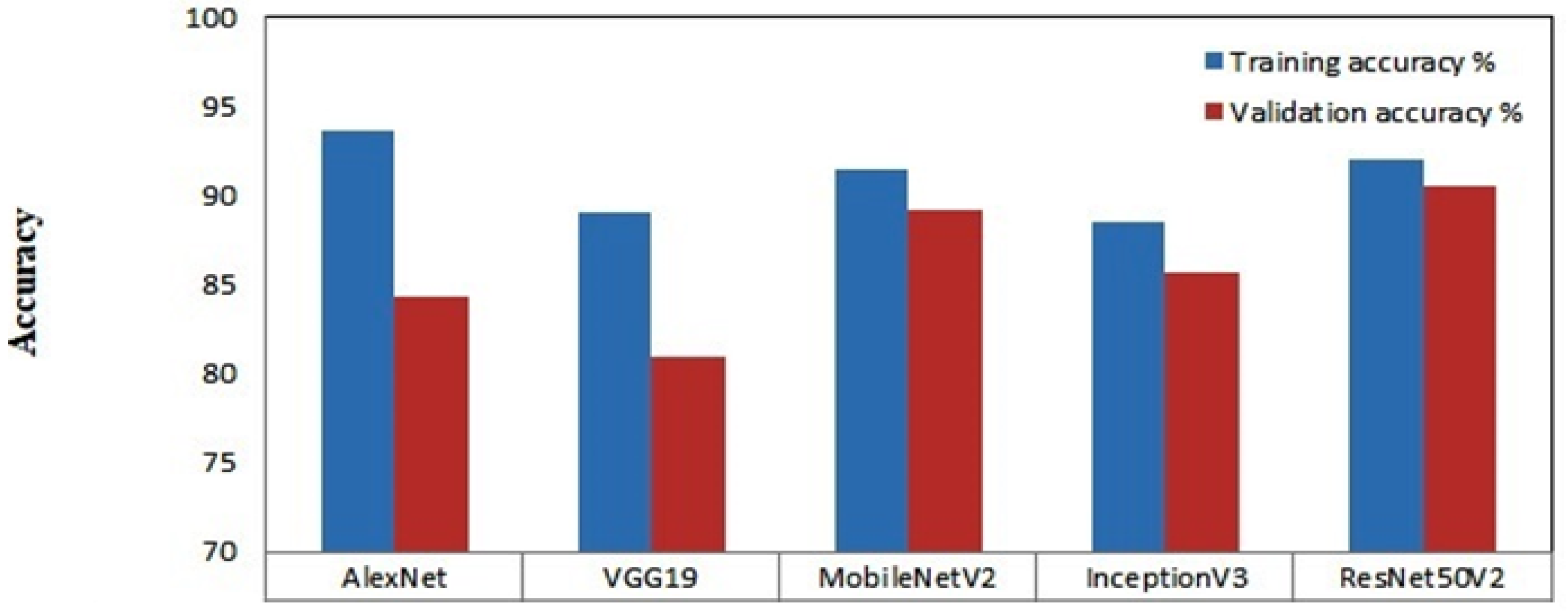
| Models | Total Number of Trainable and Nontrainable Parameters | Precision | Recall | F1-score | Inference Time (ms) | Training Accuracy | Validation Accuracy |
|---|---|---|---|---|---|---|---|
| MobileNetV2 | 2,422,339 | 0.97 | 0.96 | 0.97 | 15 | 91.49 | 89.18 |
| VGG19 | 20,090,435 | 0.94 | 0.94 | 0.94 | 11 | 89.01 | 81 |
| InceptionV3 | 22,065,443 | 0.91 | 0.9 | 0.91 | 9 | 88.55 | 85.59 |
| ResNet50V2 | 23,827,459 | 0.97 | 0.97 | 0.97 | 7 | 91.93 | 90.49 |
| Reference | Methodology | Classification | Detection | Result |
|---|---|---|---|---|
| (Ejaz et al., 2019) [59] | PCA | Yes | No | AC = 70% |
| (Ud Din et al., 2020) [60] | GAN | Yes | Yes | - |
| Proposed | Improved ResNetV2 | Yes | Yes | AC = 91.93% AP = 97% Recall = 97% F-Score = 97% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ai, M.A.S.; Shanmugam, A.; Muthusamy, S.; Viswanathan, C.; Panchal, H.; Krishnamoorthy, M.; Elminaam, D.S.A.; Orban, R. Real-Time Facemask Detection for Preventing COVID-19 Spread Using Transfer Learning Based Deep Neural Network. Electronics 2022, 11, 2250. https://doi.org/10.3390/electronics11142250
Ai MAS, Shanmugam A, Muthusamy S, Viswanathan C, Panchal H, Krishnamoorthy M, Elminaam DSA, Orban R. Real-Time Facemask Detection for Preventing COVID-19 Spread Using Transfer Learning Based Deep Neural Network. Electronics. 2022; 11(14):2250. https://doi.org/10.3390/electronics11142250
Chicago/Turabian StyleAi, Mona A. S., Anitha Shanmugam, Suresh Muthusamy, Chandrasekaran Viswanathan, Hitesh Panchal, Mahendran Krishnamoorthy, Diaa Salama Abd Elminaam, and Rasha Orban. 2022. "Real-Time Facemask Detection for Preventing COVID-19 Spread Using Transfer Learning Based Deep Neural Network" Electronics 11, no. 14: 2250. https://doi.org/10.3390/electronics11142250