
Scientometric Analysis and Classification of Research Using Convolutional Neural Networks: A Case Study in Data Science and Analytics



Abstract
:1. Introduction
2. Literature Review
3. Model Development
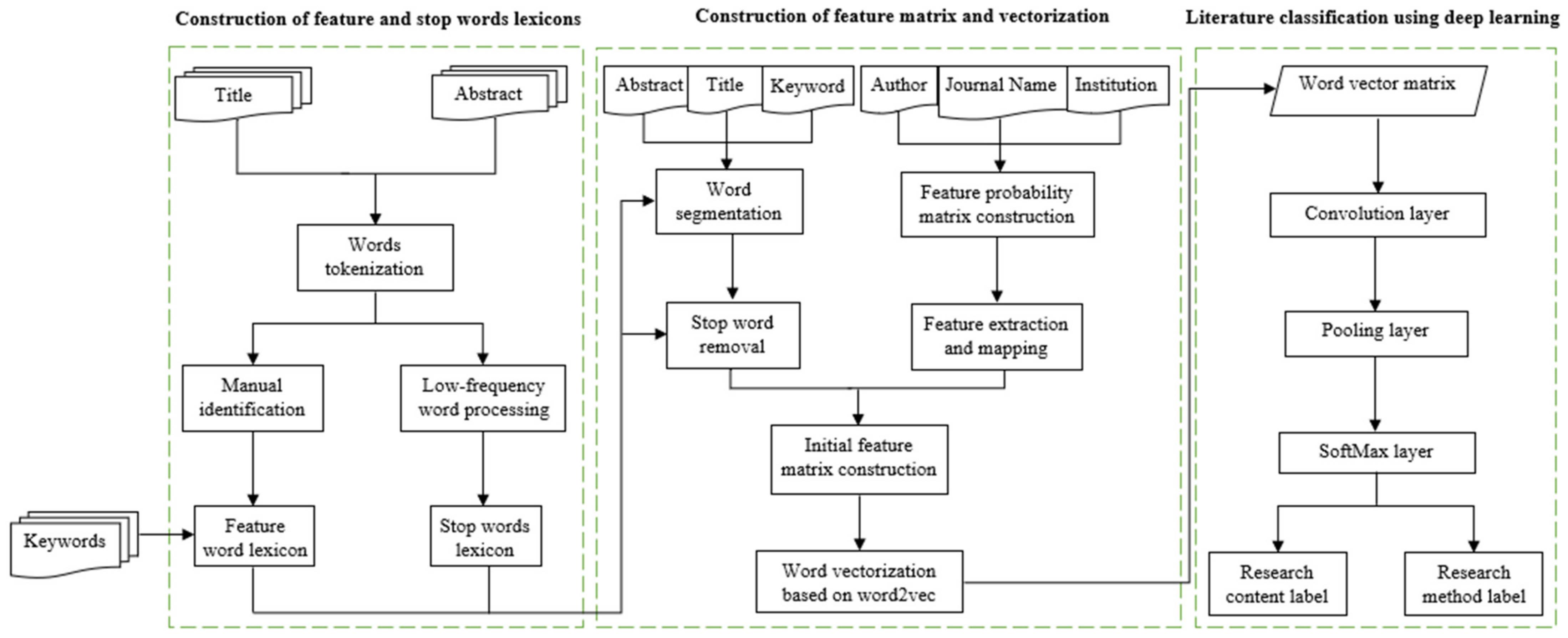
3.1. Building Stop and Feature Terms Lexicons
3.2. Feature Matrix Construction and Vectorization
3.2.1. Extraction of Explicit Features
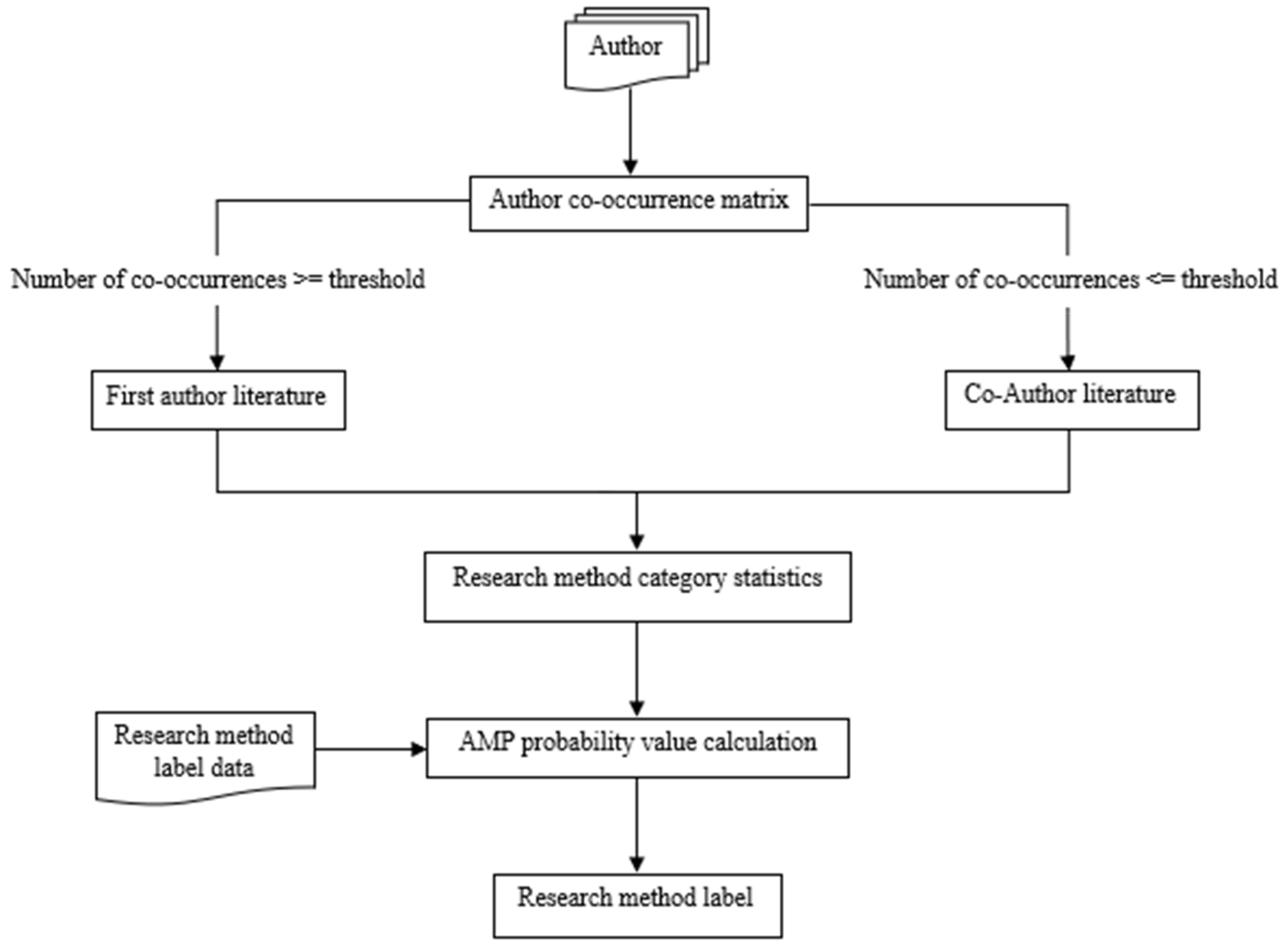
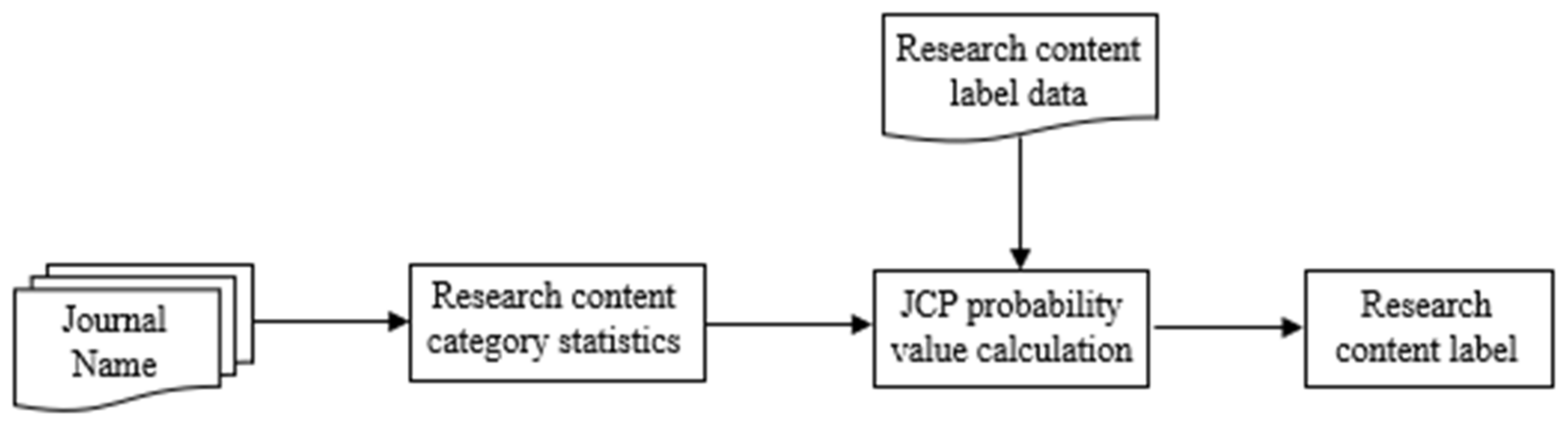
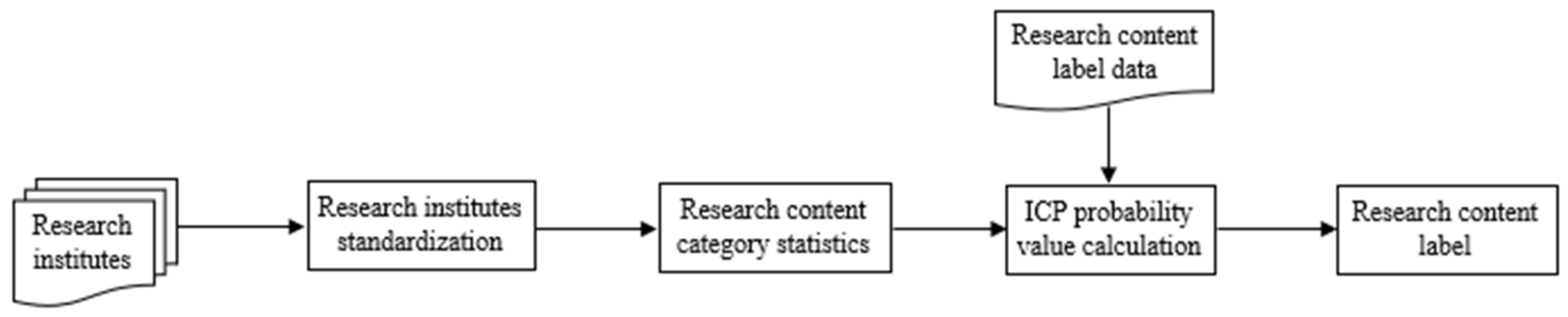
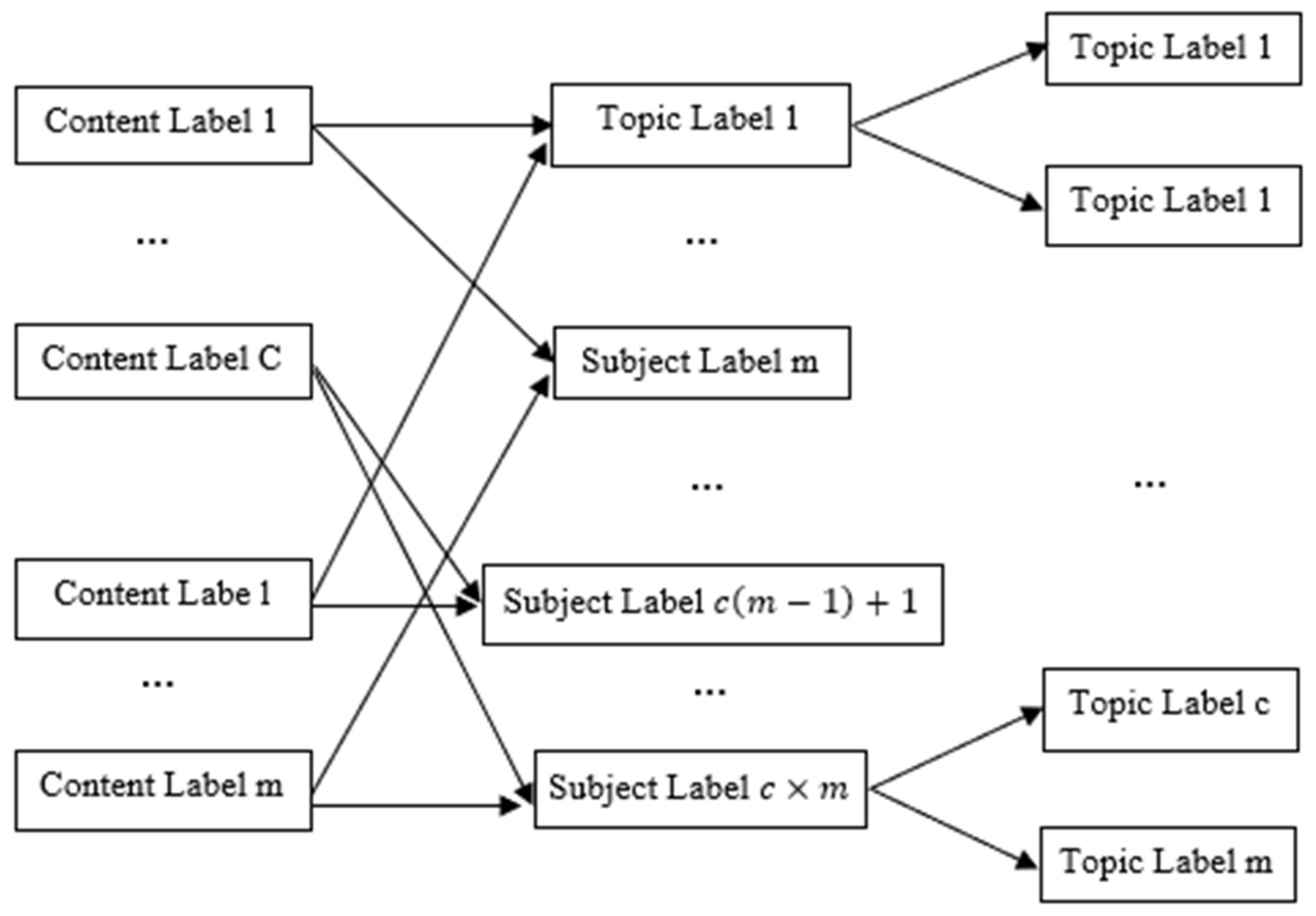
3.2.2. Implicit Feature Mapping
3.2.3. Term Vectorization/Embeddings
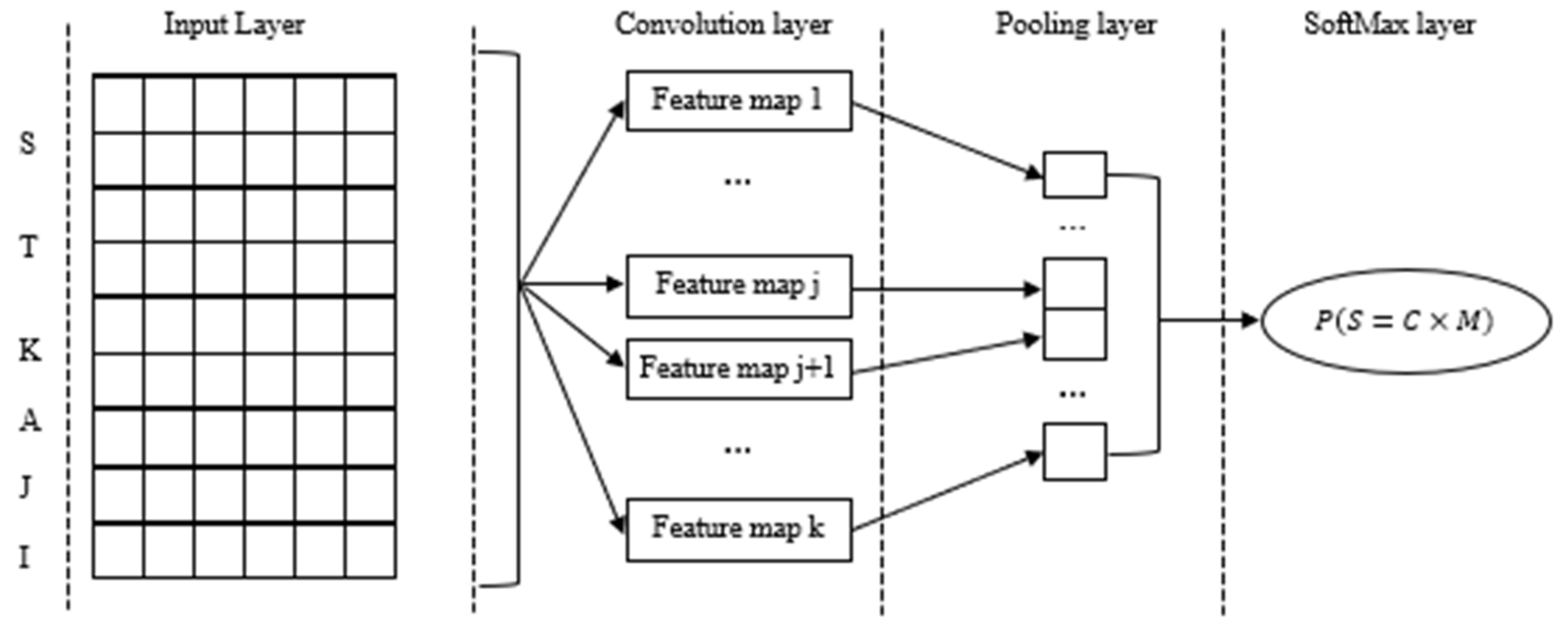
3.3. Deep Learning for Literature Classification
4. Experimental Validation
4.1. Data Source and Collection
4.2. Manual Annotation
4.3. Experimental Analysis
4.3.1. Evaluation Criteria
4.3.2. Comparative Analysis
4.3.3. Limitations and Future Research
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Serenko, A. A structured literature review of scientometric research of the knowledge management discipline: A 2021 update. J. Knowl. Manag. 2021, 25, 1889–1925. [Google Scholar] [CrossRef]
- Huang, H.; Zhu, D.; Wang, X. Evaluating scientific impact of publications: Combining citation polarity and purpose. Scientometrics 2021, 126, 1–25. [Google Scholar] [CrossRef]
- Makabate, C.T.; Musonda, I.; Okoro, C.S.; Chileshe, N. Scientometric analysis of BIM adoption by SMEs in the architecture, construction and engineering sector. Eng. Constr. Arch. Manag. 2021; ahead of print. [Google Scholar] [CrossRef]
- Sood, S.K.; Kumar, N.; Saini, M. Scientometric analysis of literature on distributed vehicular networks: VOSViewer visualization techniques. Artif. Intell. Rev. 2021, 54, 6309–6341. [Google Scholar] [CrossRef]
- Zhang, Z.; Tam, W.; Cox, A. Towards automated analysis of research methods in library and information science. Quant. Sci. Stud. 2021, 2, 698–732. [Google Scholar] [CrossRef]
- Adnani, H.; Cherraj, M.; Bouabid, H. Similarity indexes for scientometric research: A comparative analysis. Malays. J. Libr. Inf. Sci. 2020, 25, 31–48. [Google Scholar]
- Liakata, M.; Saha, S.; Dobnik, S.; Batchelor, C.; Rebholz-Schuhmann, D. Automatic recognition of conceptualization zones in scientific articles and two life science applications. Bioinformatics 2012, 28, 991–1000. [Google Scholar] [CrossRef]
- Wickett, K.; Sacchi, S.; Dubin, D.; Renear, A.H. Identifying content and levels of representation in scientific data. Proc. Am. Soc. Inf. Sci. Technol. 2012, 49, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Eykens, J.; Guns, R.; Engels, T.C.E. Fine-grained classification of social science journal articles using textual data: A comparison of supervised machine learning approaches. Quant. Sci. Stud. 2021, 2, 89–110. [Google Scholar] [CrossRef]
- Ozcan, S.; Boye, D.; Arsenyan, J.; Trott, P. A Scientometric Exploration of Crowdsourcing: Research Clusters and Applications. IEEE Trans. Eng. Manag. 2020, 64, 1–15. [Google Scholar] [CrossRef]
- Wahid, N.N.; Warraich, M.T. Group level scientometric analysis of Pakistani authors. COLLNET. J. Scientometr. Inf. Manag. 2021, 15, 287–304. [Google Scholar]
- Mosallaie, S.; Rad, M.; Schiffauerova, A.; Ebadi, A. Discovering the evolution of artificial intelligence in cancer research using dynamic topic modeling. Collnet J. Sci. Inf. Manag. 2021, 15, 225–240. [Google Scholar] [CrossRef]
- Andriamamonjy, A.; Saelens, D.; Klein, R. A combined scientometric and conventional literature review to grasp the entire BIM knowledge and its integration with energy simulation. J. Build. Eng. 2019, 22, 513–527. [Google Scholar] [CrossRef]
- Hernández-Alvarez, M.; Gomez, J. Survey about citation context analysis: Tasks, techniques, and resources. Nat. Lang. Eng. 2016, 22, 327–349. [Google Scholar] [CrossRef]
- Ravenscroft, J.E.; Liakata, M.; Clare, A.; Duma, D. Measuring scientific impact beyond academia: An assessment of existing impact metrics and proposed improvements. PLoS ONE 2017, 12, e0173152. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, S.; Hassan, S.-U.; Aljohani, N.R.; Alelyani, S.; Nawaz, R.; Bornmann, L. A decade of in-text citation analysis based on natural language processing and machine learning techniques: An overview of empirical studies. Scientometrics 2021, 126, 6551–6599. [Google Scholar] [CrossRef]
- Wang, G.; Cheng, L.; Lin, J.; Dai, Y.; Zhang, T. Fine-grained classification based on multi-scale pyramid convolution networks. PLoS ONE 2021, 16, e0254054. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, J.; Jiao, S.; Zhang, X.; Zhu, N.; Chen, G. Important citation identification by exploiting the syntactic and contextual information of citations. Scientometrics 2020, 125, 2109–2129. [Google Scholar] [CrossRef]
- Accuosto, P.; Saggion, H. Mining arguments in scientific abstracts with discourse-level embeddings. Data Knowl. Eng. 2020, 129, 101840. [Google Scholar] [CrossRef]
- Mercer, R.E.; Di Marco, C. The Importance of Fine-Grained Cue Phrases in Scientific Citations. In Advances in Artificial Intelligence. Canadian AI 2003. Lecture Notes in Computer Science (Lecture Notes in Artificial Intelligence); Xiang, Y., Chaib-draa, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2671. [Google Scholar] [CrossRef]
- An, X.; Sun, X.; Xu, S.; Hao, L.; Li, J. Important citations identification by exploiting generative model into discriminative model. J. Inf. Sci. 2021, 48, 0165551521991034. [Google Scholar] [CrossRef]
- Caselli, T.; Sprugnoli, R.; Moretti, G. Identifying communicative functions in discourse with content types. Lang. Resour. Eval. 2021, 56, 417–450. [Google Scholar] [CrossRef] [PubMed]
- Hernández-Alvarez, M.; Gomez Soriano, J.M.; Martínez-Barco, P. Citation function, polarity and influence classification. Nat. Lang. Eng. 2017, 23, 561–588. [Google Scholar] [CrossRef]
- González-Alcaide, G.; Salinas, A.; Ramos, J. Scientometrics analysis of research activity and collaboration patterns in Chagas cardiomyopathy. PLoS Neglected Trop. Dis. 2018, 12, e0006602. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.C.; Nam, S.; Wang, F.; Zhu, Y. Mapping scientific landscapes in UMLS research: A scientometric review. J. Am. Med. Inform. Assoc. 2020, 27, 1612–1624. [Google Scholar] [CrossRef]
- Nosratabadi, S.; Mosavi, A.; Duan, P.; Ghamisi, P.; Filip, F.; Band, S.; Reuter, U.; Gama, J.; Gandomi, A. Data Science in Economics: Comprehensive Review of Advanced Machine Learning and Deep Learning Methods. Mathematics 2020, 8, 1799. [Google Scholar] [CrossRef]
- Purnomo, A.; Rosyidah, E.; Firdaus, M.; Asitah, N.; Septiano, A. Data Science Publication: Thirty-Six Years Lesson of Scientometric Review. In Proceedings of the 2020 International Conference on Information Management and Technology (ICIMTech), Bandung, Indonesia, 13–14 August 2020. [Google Scholar]
- Bhatt, C.; Kumar, I.; Vijayakumar, V.; Singh, K.U.; Kumar, A. The state of the art of deep learning models in medical science and their challenges. Multimedia Syst. 2021, 27, 599–613. [Google Scholar] [CrossRef]
- Ho, Y.-S.; Shekofteh, M. Performance of highly cited multiple sclerosis publications in the Science Citation Index expanded: A scientometric analysis. Mult. Scler. Relat. Disord. 2021, 54, 103112. [Google Scholar] [CrossRef]
- Salazar-Reyna, R.; Gonzalez-Aleu, F.; Granda-Gutierrez, E.M.; Diaz-Ramirez, J.; Garza-Reyes, J.A.; Kumar, A. A systematic literature review of data science, data analytics and machine learning applied to healthcare engineering systems. Manag. Decis. 2020, 60, 300–319. [Google Scholar] [CrossRef]
- Kandimalla, B.; Rohatgi, S.; Wu, J.; Giles, C.L. Large Scale Subject Category Classification of Scholarly Papers With Deep Attentive Neural Networks. Front. Res. Metrics Anal. 2021, 5. [Google Scholar] [CrossRef]
- Dunham, J.; Melot, J.; Murdick, D. Identifying the Development and Application of Artificial Intelligence in Scientific Text. arXiv 2020, arXiv:abs/2002.07143. [Google Scholar]
- Vortmann, L.-M.; Putze, F. Combining Implicit and Explicit Feature Extraction for Eye Tracking: Attention Classification Using a Heterogeneous Input. Sensors 2021, 21, 8205. [Google Scholar] [CrossRef] [PubMed]
- Aljohani, N.; Fayoumi, A.; Hassan, S. An in-text citation classification predictive model for a scholarly search system. Scientometrics 2021, 126, 5509–5529. [Google Scholar] [CrossRef]
- Aljuaid, H.; Iftikhar, R.; Ahmad, S.; Asif, M.; Afzal, M.T. Important citation identification using sentiment analysis of in-text citations. Telematics Informatics 2021, 56, 101492. [Google Scholar] [CrossRef]
- Rajput, N.; Grover, B. A multi-label movie genre classification scheme based on the movie’s subtitles. Multimed. Tools Appl. 2022, 81, 1–22. [Google Scholar] [CrossRef]
- Setyanto, A.; Laksito, A.; Alarfaj, F.; Alreshoodi, M.; Kusrini; Oyong, I.; Hayaty, M.; Alomair, A.; Almusallam, N.; Kurniasari, L. Arabic Language Opinion Mining Based on Long Short-Term Memory (LSTM). Appl. Sci. 2022, 12, 4140. [Google Scholar] [CrossRef]
- Sagnika, S.; Mishra, B.S.P.; Meher, S.K. An attention-based CNN-LSTM model for subjectivity detection in opinion-mining. Neural Comput. Appl. 2021, 33, 17425–17438. [Google Scholar] [CrossRef]
- Wang, L.; Liu, Y.; Di, H.; Qin, C.; Sun, G.; Fu, Y. Semi-Supervised Dual Relation Learning for Multi-Label Classification. IEEE Trans. Image Process. 2021, 30, 9125–9135. [Google Scholar] [CrossRef]
- Zhao, D.; Gao, Q.; Lu, Y.; Sun, D. Learning view-specific labels and label-feature dependence maximization for multi-view multi-label classification. Appl. Soft Comput. 2022, 124, 109071. [Google Scholar] [CrossRef]
- Gryncewicz, W.; Sitarska-Buba, M. Data Science in Decision-Making Processes: A Scientometric Analysis. Eur. Res. Stud. J. 2021, 24, 1061–1067. [Google Scholar] [CrossRef]
- Sarker, I. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 16. [Google Scholar] [CrossRef]
- Porter, M. Snowball: A Language for Stemming Algorithms. 2001. Available online: http://snowball.tartarus.org/texts/introduction.html (accessed on 23 April 2020).
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment Analysis of Comment Texts Based on BiLSTM. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Daradkeh, M. Analyzing Sentiments and Diffusion Characteristics of COVID-19 Vaccine Misinformation Topics in Social Media: A Data Analytics Framework. Int. J. Bus. Anal. 2021, 9, 55–88. [Google Scholar] [CrossRef]
- Daradkeh, M. Organizational Adoption of Sentiment Analytics in Social Media Networks: Insights from a Systematic Literature Review. Int. J. Inf. Technol. Syst. Approach 2022, 15, 15–45. [Google Scholar]
- Guo, D.; Chen, H.; Long, R.; Lu, H.; Long, Q. A Co-Word Analysis of Organizational Constraints for Maintaining Sustainability. Sustainability 2017, 9, 1928. [Google Scholar] [CrossRef] [Green Version]
- Kozlowski, A.; Taddy, M.; Evans, J. The Geometry of Culture: Analyzing the Meanings of Class through Word Embeddings. Am. Sociol. Rev. 2019, 84, 905–949. [Google Scholar] [CrossRef] [Green Version]
- Ravikiran, M.; Nonaka, Y.; Mariyasagayam, N. A Sensitivity Analysis (and Practitioners’ Guide to) of DeepSORT for Low Frame Rate Video. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020. [Google Scholar]
- Timoshenko, A.; Hauser, J. Identifying Customer Needs from User-Generated Content. Mark. Sci. 2019, 38, 1–20. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, J.; Marques, M.R.G.; Botti, S.; Marques, M.A.L. Recent advances and applications of machine learning in solid-state materials science. npj Comput. Mater. 2019, 5, 83. [Google Scholar] [CrossRef]
- Medeiros, M.N.; Hoppen, N.; Maçada, A. Data science for business: Benefits, challenges and opportunities. Bottom Line 2020, 33, 149–163. [Google Scholar] [CrossRef]
- Provost, F.; Fawcett, T. Data Science and its Relationship to Big Data and Data-Driven Decision Making. Big Data 2013, 1, 51–59. [Google Scholar] [CrossRef]
- Vicario, G.; Coleman, S. A review of data science in business and industry and a future view. Appl. Stoch. Model. Bus. Ind. 2020, 36, 6–18. [Google Scholar] [CrossRef] [Green Version]
- Waller, M.A.; Fawcett, S. Data Science, Predictive Analytics, and Big Data: A Revolution That Will Transform Supply Chain Design and Management. J. Bus. Logist. 2013, 34, 77–84. [Google Scholar] [CrossRef]
- Wimmer, H.; Aasheim, C. Examining Factors that Influence Intent to Adopt Data Science. J. Comput. Inf. Syst. 2019, 59, 43–51. [Google Scholar] [CrossRef]
- Luo, J.; Huang, S.; Wang, R. A fine-grained sentiment analysis of online guest reviews of economy hotels in China. J. Hosp. Mark. Manag. 2021, 30, 71–95. [Google Scholar] [CrossRef]
- Daradkeh, M. Determinants of Self-Service Analytics Adoption Intention: The Effect of Task-Technology Fit, Compatibility, and User Empowerment. J. Organ. End User Comput. (JOEUC) 2019, 31, 19–45. [Google Scholar] [CrossRef]
- Daradkeh, M.; Al-Dwairi, R. Self-Service Business Intelligence Adoption in Business Enterprises: The Effects of Information Quality, System Quality, and Analysis Quality. In Operations and Service Management: Concepts, Methodologies, Tools, and Applications; A. Information Resources Management, IGI Global: Hershey, PA, USA, 2018; pp. 1096–1118. [Google Scholar]
- Brack, A.; D’Souza, J.; Hoppe, A.; Auer, S.; Ewerth, R. Domain-Independent Extraction of Scientific Concepts from Research Articles. Advances in Information Retrieval. In Proceedings of the 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–17 April 2020; Part I, 12035. pp. 251–266. [Google Scholar]
- Krippendorff, K. Content analysis: An Introduction to Its Methodology; Sage: Thousand Oaks, CA, USA, 2012. [Google Scholar]
- Daradkeh, M. Determinants of visual analytics adoption in organizations: Knowledge discovery through content analysis of online evaluation reviews. Inf. Technol. People 2019, 32, 668–695. [Google Scholar] [CrossRef]
- Mukhamediev, R.; Symagulov, A.; Kuchin, Y.; Yakunin, K.; Yelis, M. From Classical Machine Learning to Deep Neural Networks: A Simplified Scientometric Review. Appl. Sci. 2021, 11, 5541. [Google Scholar] [CrossRef]
- Wang, J.; Lu, Y. A novel CNN model for fine-grained classification with large spatial variants. J. Phys. Conf. Ser. 2020, 1544, 012138. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Method-1 | Research Method-2 | Research Method-3 | Research Method-4 | |
|---|---|---|---|---|
| Author-1 | 0 | 1 | 0 | 0 |
| Co-Author-2 | 0.8 | 0.2 | 0 | 0 |
| Author-3 | 0 | 0 | 0.5 | 0.5 |
| Co-Author-4 | 0.6 | 0 | 0.4 | 0 |
| Author-5 | 0 | 0 | 1 | 0 |
| Research Content-1 | Research Content-2 | Research Content-3 | Research Content-4 | Research Content-5 | |
|---|---|---|---|---|---|
| Journal-1 | 0.60 | 0 | 0 | 0.40 | 0 |
| Journal-2 | 0.15 | 0.10 | 0.75 | 0 | 0 |
| Journal-3 | 0 | 0 | 0.34 | 0.33 | 0.33 |
| Journal-4 | 0 | 1 | 0 | 0 | 0 |
| Journal-5 | 0.25 | 0 | 0.20 | 0.25 | 0.30 |
| Research Content-1 | Research Content-2 | Research Content-3 | Research Content-4 | Research Content-5 | |
|---|---|---|---|---|---|
| Institution-1 | 0.60 | 0 | 0 | 0.40 | 0 |
| Institution-2 | 0.15 | 0.10 | 0.75 | 0 | 0 |
| Institution-3 | 0 | 0 | 0.34 | 0.33 | 0.33 |
| Institution-4 | 0 | 1 | 0 | 0 | 0 |
| Institution-5 | 0.25 | 0 | 0.20 | 0.25 | 0.30 |
| Subject Terms | Frequency | Journal | Frequency | Research Institution | Frequency |
|---|---|---|---|---|---|
| Data analytics | 136 | International Journal of Data Science and Analytics | 291 | Boston University | 82 |
| Big data analytics | 131 | Data Science Journal | 290 | California Institute of Technology | 77 |
| Machine learning | 109 | International Journal of Data Science and Analytics | 233 | Case Western Reserve University | 75 |
| Deep learning | 77 | Intelligent Data Analysis | 179 | Cornell University | 68 |
| Business analytics | 73 | International Journal of Behavioral Analytics | 166 | Davidson College | 66 |
| Business intelligence | 72 | MIS Quarterly | 133 | University of Chicago | 65 |
| Deep learning and neural networks | 68 | Data Science and Management | 115 | University of Georgia | 57 |
| Data mining | 68 | Intelligent Data Analysis | 115 | University of Michigan | 52 |
| Artificial intelligence | 67 | The Journal of Finance and Data Science | 106 | University of Notre Dame | 46 |
| Internet of Things | 63 | Statistical Analysis and Data Mining | 85 | University of Pennsylvania | 44 |
| Categories | Topic Labels | No. |
|---|---|---|
| Research Content | Machine learning; business analytics; business intelligence; decision support systems; Internet of Things; big data analytics; deep learning and neural networks; data visualization, financial analytics; marketing analytics; data mining, text analytics, sentiment analytics, artificial intelligence, predictive analytics, operation research; prescriptive analytics; self-service analytics. | 18 |
| Research Method | Theoretical studies; empirical studies; case studies; systematic literature review (SLR) | 4 |
| Total | 22 |
| Research Content Label | Main Feature Terms |
|---|---|
| Machine learning | Database, computer vision, supervised learning, unsupervised learning, Reinforcement learning, neural network, classification, clustering, association rule mining. |
| Business analytics | Business, decision support systems, statistical model, descriptive analytics, diagnostic analytics, predictive analytics, prescriptive analytics, quantitative methods. |
| Business intelligence | Database, data warehouse, visualization, descriptive analytics, business performance management, key performance indicators, dashboard, scorecards, decision support. |
| Decision support systems | Online reviews, pricing research, consumer preferences. |
| Big data analytics | Recommendation algorithms, cloud computing. |
| Deep learning and neural networks | Deep learning, neural networks, long short-term memory. |
| Data visualization | Visualization techniques, graphics, descriptive analytics, data representation, communication, decision support. |
| Internet of Things | IoT data analytics, cloud computing, real-time streaming, network, smart manufacturing, interconnected devices, cloud manufacturing, fog computing, smart city. |
| Text analytics | Natural language processing text classification, topic modeling, social media, document frequency, corpus, lexicon, online reviews. |
| Sentiment analytics | Machine learning, user-generated content, opinion mining, voice, users, customers, subjective information, computational linguistics, biometrics, social network analysis. |
| Predictive analytics | Machine learning, predictive model, statistical analysis, supervised learning, unsupervised learning, reinforcement learning, classification, feature selection. |
| Artificial intelligence | Machine learning, augmented analytics, robotics, self-service analytics, deep learning, neural networks, decision making. |
| Operations research | Problem solving, optimization, decision making, prescriptive analytics, management science, simulation, supply chain management, planning, enterprise resource planning, risk management. |
| Prescriptive analytics | Management science, business performance management, optimization, decision making, sensitivity analysis. |
| Data mining | Statistics and modeling techniques, clickstream data. |
| Self-service analytics | Business user, report, dashboard, data-driven organizations, citizen data scientist, ad hoc analysis, queries, reports. |
| Financial analytics | Ad hoc analysis, forecast, business questions, financial data, financial risk. |
| Marketing analytics | Marketing campaigns, customer analytics, marketing channels, customer behavior, online reviews, brand management. |
| Research Topics | Performance Indicators | |||
|---|---|---|---|---|
| Category | Label | P | R | F1-Score |
| Research Content | Machine learning | 0.95 | 0.95 | 0.95 |
| Business analytics | 0.93 | 0.92 | 0.92 | |
| Business intelligence | 0.91 | 0.94 | 0.92 | |
| Decision support systems | 0.84 | 0.84 | 0.84 | |
| Big data analytics | 0.85 | 0.81 | 0.83 | |
| Deep learning and neural networks | 0.88 | 0.82 | 0.85 | |
| Data visualization | 0.87 | 0.91 | 0.89 | |
| Internet of Things | 0.59 | 0.56 | 0.57 | |
| Text analytics | 0.94 | 0.93 | 0.93 | |
| Sentiment analytics | 0.93 | 0.89 | 0.91 | |
| Predictive analytics | 0.88 | 0.84 | 0.86 | |
| Artificial intelligence | 0.88 | 0.88 | 0.88 | |
| Operations research | 0.88 | 0.86 | 0.87 | |
| Prescriptive analytics | 0.88 | 0.88 | 0.88 | |
| Data mining | 0.91 | 0.92 | 0.91 | |
| Self-service analytics | 0.89 | 0.85 | 0.87 | |
| Financial analytics | 0.74 | 0.74 | 0.74 | |
| Marketing analytics | 0.74 | 0.77 | 0.75 | |
| Research Method | Theoretical research | 0.72 | 0.76 | 0.74 |
| Empirical research | 0.93 | 0.91 | 0.92 | |
| Qualitative research | 0.91 | 0.89 | 0.90 | |
| Case study | 0.61 | 0.66 | 0.63 | |
| Systematic literature review | 0.72 | 0.79 | 0.75 | |
| Input Data and Preprocessing | Performance Indicators | |||||
|---|---|---|---|---|---|---|
| Research Content | Research Method | |||||
| P | R | F1 | P | R | F1 | |
| Classification model of this study | 0.73 | 0.74 | 0.73 | 0.88 | 0.84 | 0.86 |
| By directly adding the journal name, author, and institution | 0.62 | 0.61 | 0.61 | 0.74 | 0.71 | 0.72 |
| Title and abstract only | 0.72 | 0.73 | 0.72 | 0.76 | 0.75 | 0.75 |
| Using only English Snowball stop term list [43] | 0.70 | 0.71 | 0.70 | 0.76 | 0.77 | 0.76 |
| Model | Performance Indicators | |||||
|---|---|---|---|---|---|---|
| Research Content | Research Method | |||||
| P | R | F1 | P | R | F1 | |
| Fine-grained classification model based on CNN | 0.72 | 0.73 | 0.74 | 0.88 | 0.80 | 0.81 |
| SVM | 0.57 | 0.60 | 0.58 | 0.69 | 0.41 | 0.51 |
| NBM | 0.64 | 0.67 | 0.65 | 0.70 | 0.67 | 0.68 |
| KNN | 0.50 | 0.50 | 0.50 | 0.69 | 0.45 | 0.54 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daradkeh, M.; Abualigah, L.; Atalla, S.; Mansoor, W. Scientometric Analysis and Classification of Research Using Convolutional Neural Networks: A Case Study in Data Science and Analytics. Electronics 2022, 11, 2066. https://doi.org/10.3390/electronics11132066
Daradkeh M, Abualigah L, Atalla S, Mansoor W. Scientometric Analysis and Classification of Research Using Convolutional Neural Networks: A Case Study in Data Science and Analytics. Electronics. 2022; 11(13):2066. https://doi.org/10.3390/electronics11132066
Chicago/Turabian StyleDaradkeh, Mohammad, Laith Abualigah, Shadi Atalla, and Wathiq Mansoor. 2022. "Scientometric Analysis and Classification of Research Using Convolutional Neural Networks: A Case Study in Data Science and Analytics" Electronics 11, no. 13: 2066. https://doi.org/10.3390/electronics11132066