
A Novel Method for the Classification of Butterfly Species Using Pre-Trained CNN Models

 , , , ,
, , , ,  , and
, and
Abstract
:1. Introduction
- Apply the data augmentation technique in order to obtain various combinations of original butterfly species.
- Apply the transfer learning technique to detect the type of the butterfly species without harming them physically. These augmented, i.e., transformed, data that are applied to various pre-trained CNN models help to improve the accuracy.
2. Related Works
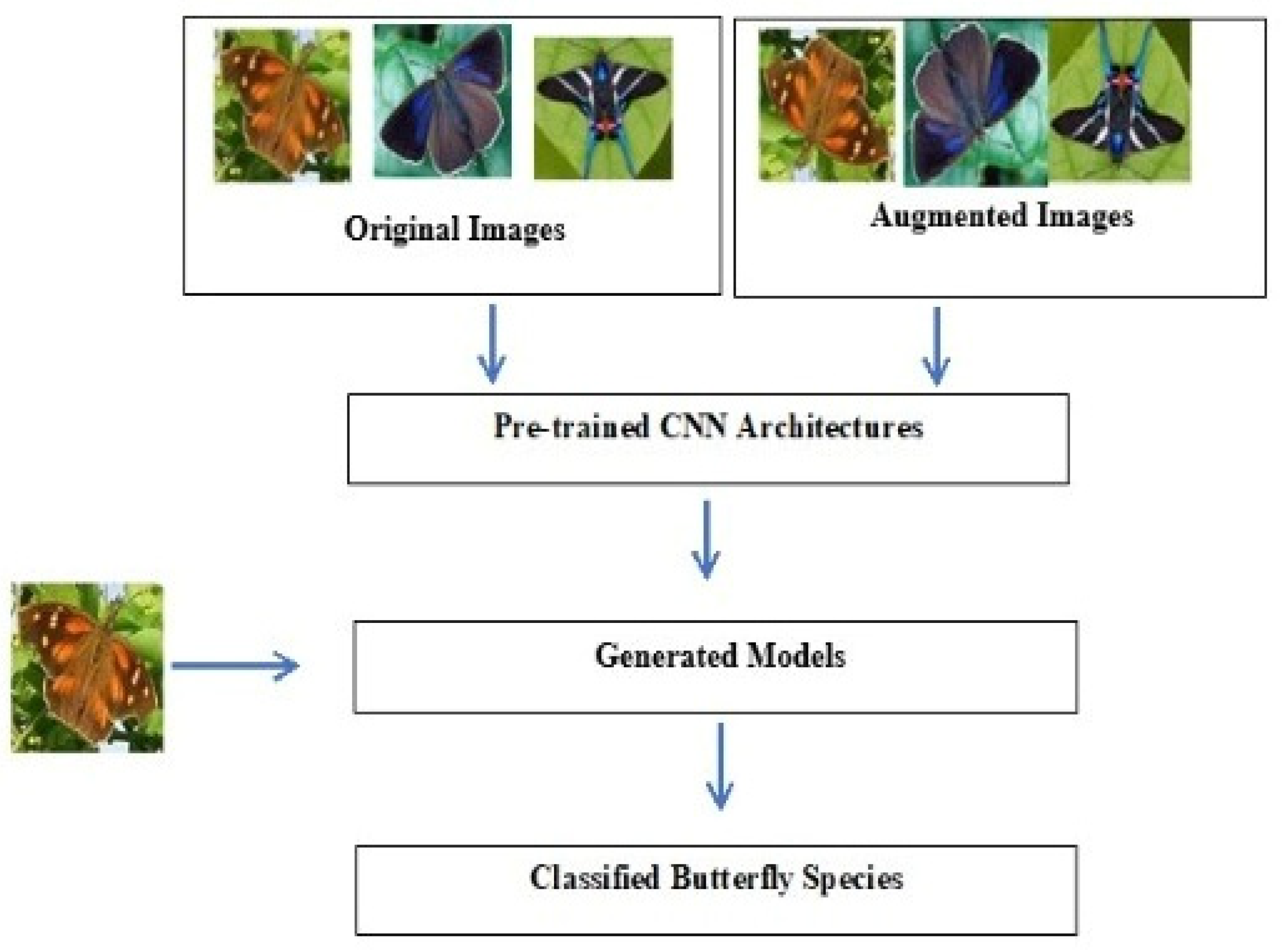
3. Proposed System Methodology
3.1. Dataset Description
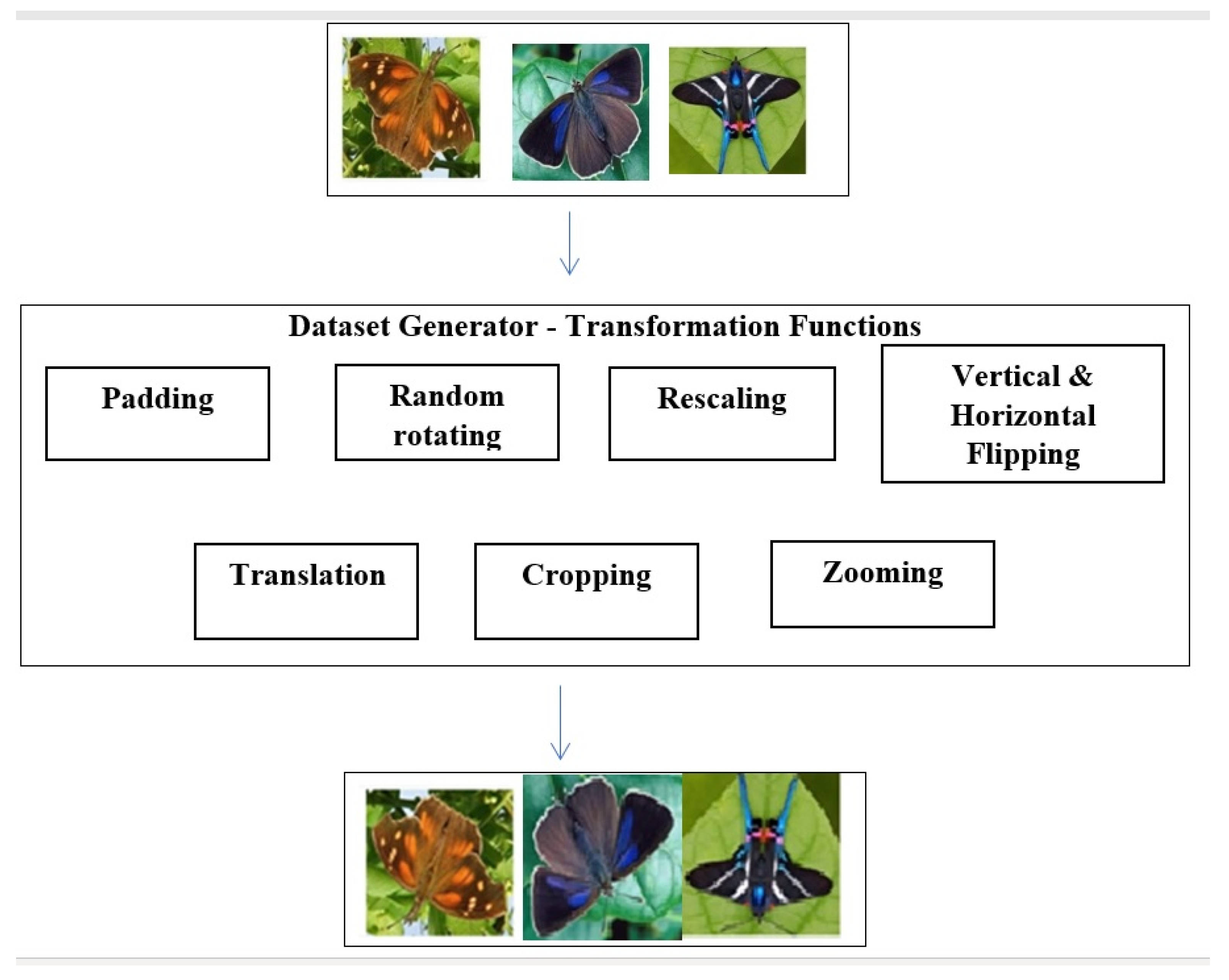
3.2. Data Augmentation
3.2.1. Cropping
3.2.2. Rescaling
3.2.3. Horizontal Flips
3.2.4. Fill Mode
3.2.5. Shear Range
3.2.6. Width Shift
3.2.7. Height Shift
3.2.8. Rotation Range
3.3. Transfer-Learning Models
3.3.1. VGG16
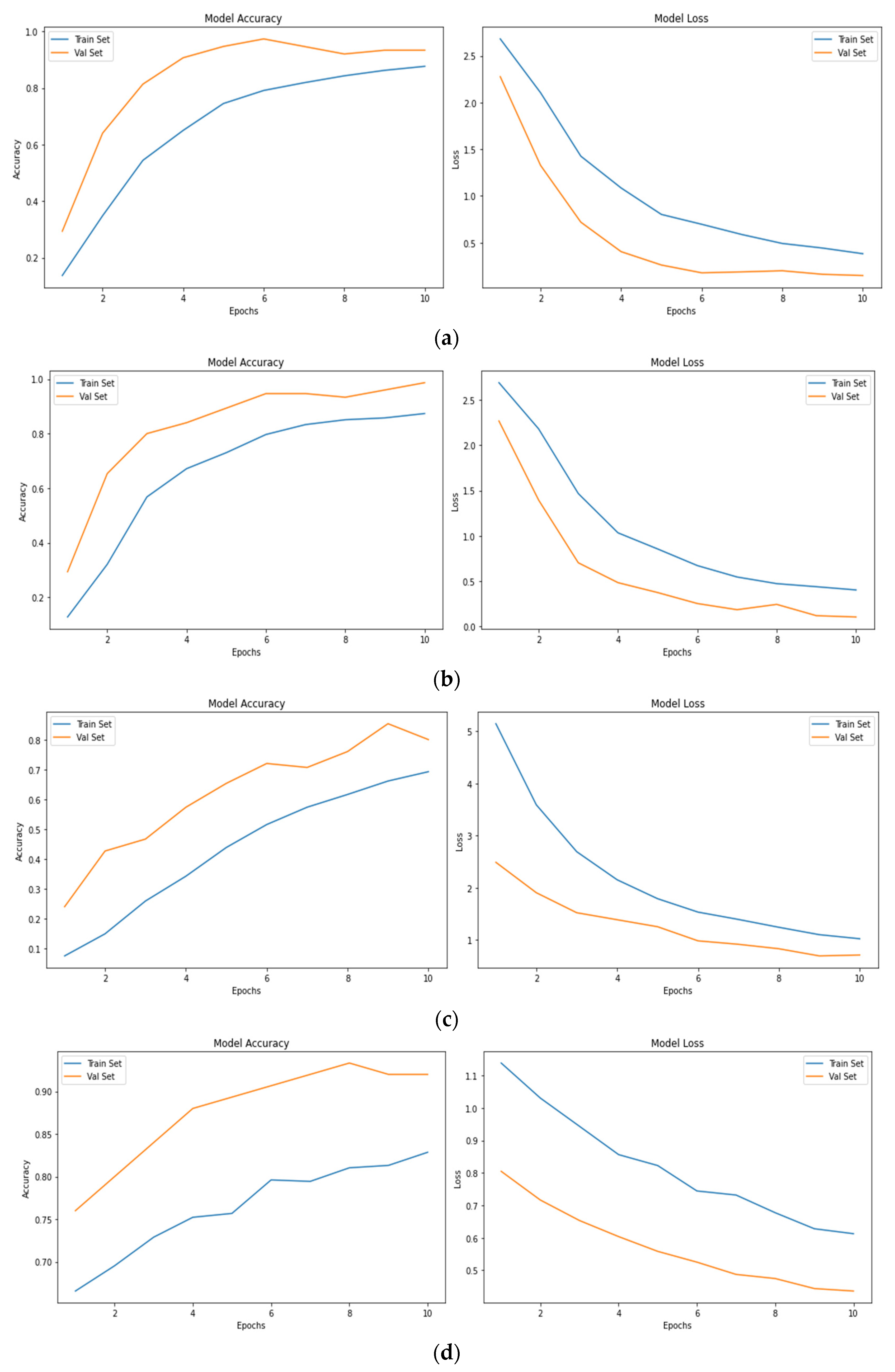
VGG16 without Data Augmentation
VGG16 with Data Augmentation
3.3.2. VGG19
VGG19 without Data Augmentation
VGG19 with Data Augmentation
3.3.3. MOBILENET
MobileNet without Data Augmentation
MobileNet with Data Augmentation
3.3.4. XCEPTION
Xception without Data Augmentation
Xception with Data Augmentation
3.3.5. RESNET50
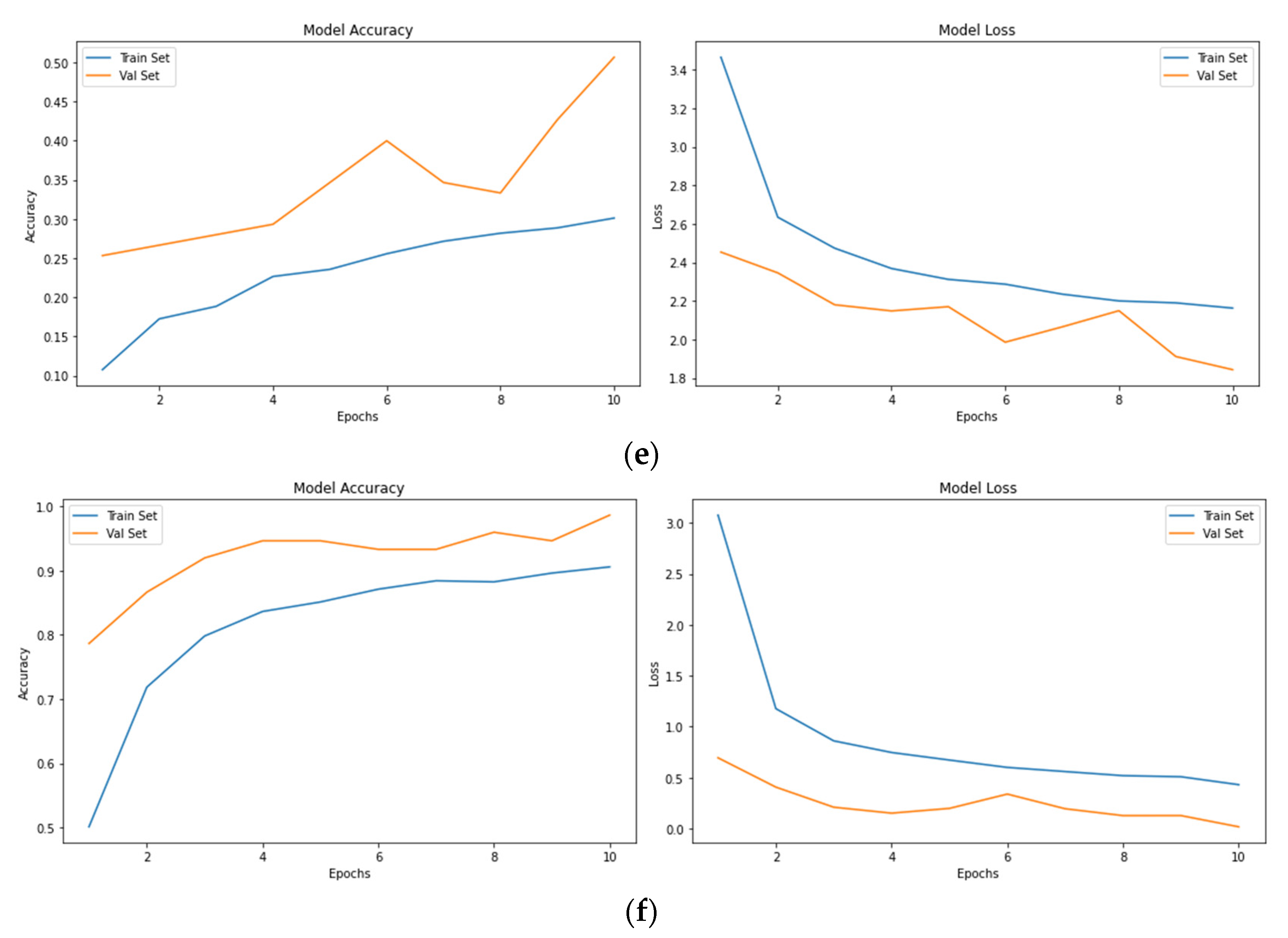
Resnet50 without Data Augmentation
Resnet50 with Data Augmentation
3.3.6. INCEPTIONV3
InceptionV3 without Data Augmentation
InceptionV3 with Data Augmentation
4. Performance Evaluation
4.1. Accuracy and Loss Values of Pre-Trained Transfer Learning Models
4.2. Accuracy of Pre-Trained Transfer Learning Models
4.3. Precision, Recall, F1-Score of Inception V3 Model
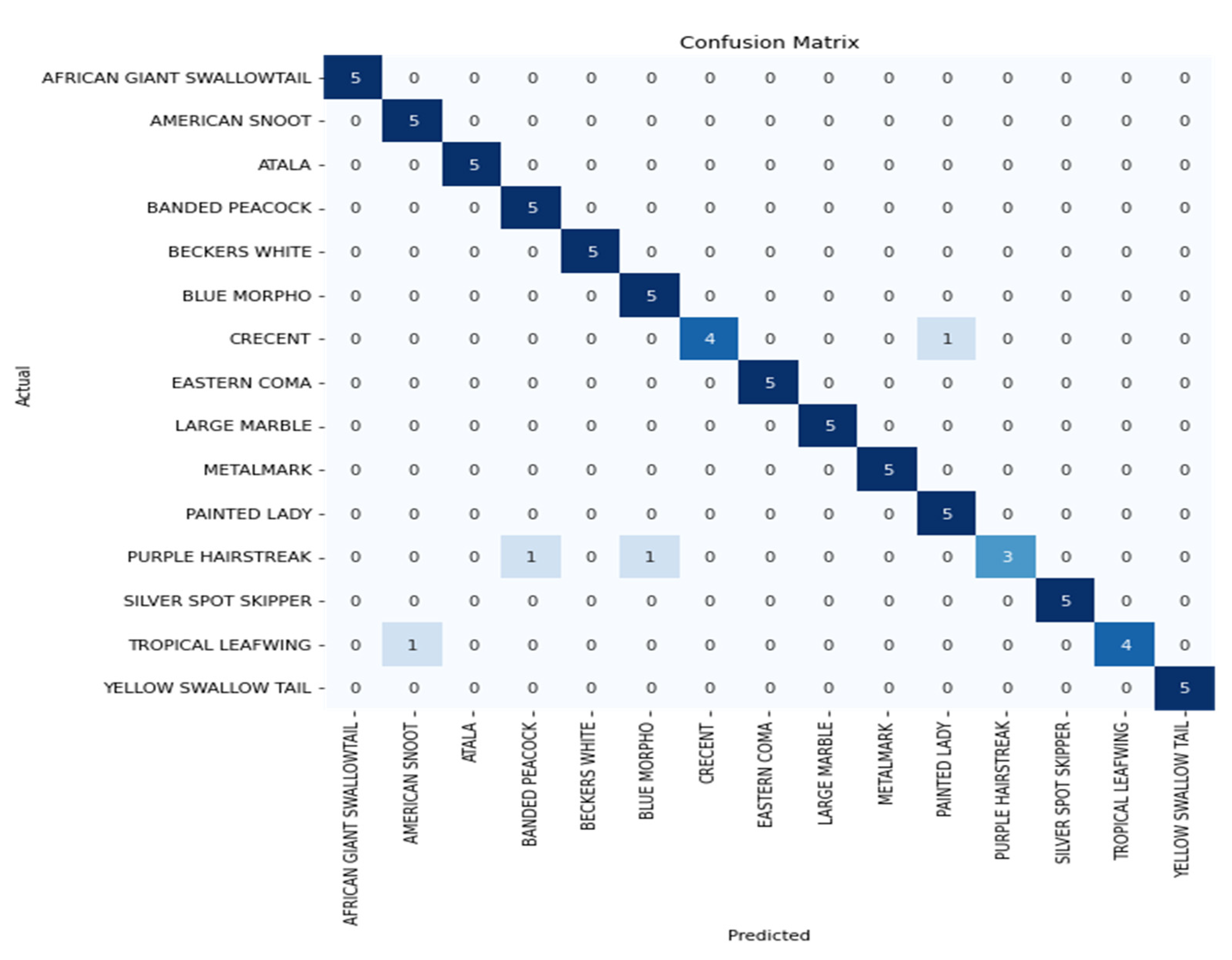
4.4. Confusion Matrix
5. Conclusions and Future Scope
Author Contributions
Funding
Conflicts of Interest
References
- Fauzi, F.; Permanasari, A.E.; Setiawan, N.A. Butterfly Image Classification Using Convolutional Neural Net-work (CNN). In Proceedings of the 2021 3rd International Conference on Electronics Representation and Algorithm (ICERA), Yogyakarta, Indonesia, 29–30 July 2021; pp. 66–70. [Google Scholar]
- Fan, L.; Zhou, W. An Improved Contour Feature Extraction Method for the Image Butterfly Specimen. In 3D Imaging Technologies—Multidimensional Signal Processing and Deep Learning; Springer: Singapore, 2021; pp. 17–26. [Google Scholar]
- Ali, M.A.S.; Balasubramanian, K.; Krishnamoorthy, G.D.; Muthusamy, S.; Pandiyan, S.; Panchal, H.; Mann, S.; Thangaraj, K.; El-Attar, N.E.; Abualigah, L.; et al. Classification of Glaucoma Based on Elephant-Herding Optimization Algorithm and Deep Belief Network. Electronics 2022, 11, 1763. [Google Scholar] [CrossRef]
- Chen, X.; Wang, B.; Gao, Y. Gaussian Convolution Angles: Invariant Vein and Texture Descriptors for Butterfly Species Identification. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5798–5803. [Google Scholar]
- Min, F.; Xiong, W. Butterfly Image Generation and Recognition Based on Improved Generative Adversarial Networks. In Proceedings of the 2021 4th International Conference on Robotics, Control and Automation Engineering (RCAE), Wuhan, China, 4–6 November 2021; pp. 40–44. [Google Scholar] [CrossRef]
- Xi, T.; Wang, J.; Han, Y.; Lin, C.; Ji, L. Multiple butterfly recognition based on deep residual learning and image analysis. Èntomol. Res. 2022, 52, 44–53. [Google Scholar] [CrossRef]
- Houssein, E.H.; Abdelminaam, D.S.; Hassan, H.N.; Al-Sayed, M.M.; Nabil, E. A hybrid barnacles mating optimizer algorithm with support vector machines for gene selection of microarray cancer classification. IEEE Access 2021, 9, 64895–64905. [Google Scholar] [CrossRef]
- Marta, S.; Luccioni, A.; Rolnick, D. Spatiotemporal Features Improve Fine-Grained Butterfly Image Classification. In Proceedings of the Conference on Neural Information Processing Systems; 2020. Available online: https://s3.us-east-1.amazonaws.com/climate-change-ai/papers/neurips2020/63/paper.pdf (accessed on 14 May 2022).
- Houssein, E.H.; Hassaballah, M.; Ibrahim, I.E.; AbdElminaam, D.S.; Wazery, Y.M. An automatic arrhythmia classification model based on improved marine predators algorithm and convolutions neural networks. Expert Syst. Appl. 2022, 187, 115936. [Google Scholar] [CrossRef]
- Almryad, A.; Kutucu, H. Automatic Detection of Butterflies by convolutional neural networks. Eng. Sci. Technol. Int. J. 2020, 23, 189–195. [Google Scholar]
- Houssein, E.H.; Abdelminaam, D.S.; Ibrahim, I.E.; Hassaballah, M.; Wazery, Y.M. A hybrid heartbeats classification approach based on marine predators algorithm and convolution neural networks. IEEE Access 2021, 9, 86194–86206. [Google Scholar] [CrossRef]
- Zhao, R.; Li, C.; Ye, S.; Fang, X. Deep-red fluorescence from isolated dimers: A highly bright excimer and imaging in vivo. Chem. Sci. 2001, 291, 213–225. [Google Scholar]
- Nijhout, H.F. Elements of butterfly wing patterns. J. Exp. Zool. 2001, 291, 213–225. [Google Scholar] [CrossRef]
- Pinzari, M.; Santonico, M.; Pennazza, G.; Martinelli, E.; Capuano, R.; Paolesse, R.; Di Rao, M.; D’Amico, A.; Cesaroni, D.; Sbordoni, V.; et al. Chemically mediated species recognition in two sympatric Grayling butterflies. PLoS ONE 2018, 13, e0199997. [Google Scholar] [CrossRef]
- Austin, G.T.; Riley, T.J. Portable bait traps for the study of butterflies. Trop. Lepid. Res. 1995, 6, 5–9. [Google Scholar]
- Ries, L.; Debinski, D.M.; Wieland, M.L. Conservation value of roadside prairie restoration to butterfly community. Conserv. Biol. 2001, 15, 401–411. [Google Scholar] [CrossRef]
- Fina, F.; Birch, P.; Young, R.; Obu, J.; Faithpraise, B.; Chatwin, C. Automatic plant pest detection and recognition using k-means clustering algorithm and correspondence filters. Int. J. Adv. Biotechnol. Res. 2013, 4, 189–199. [Google Scholar]
- Leow, L.K.; Chew Li Chong, V.C.; Dhillon, S.K. Automated identification of copepods using digital image processing and artificial neural network. BMC Bioinf. 2015, 16, S4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mayo, M.; Watson, A.T. Automatic species identification of live moths. Knowl. Based Syst. 2007, 20, 195–202. [Google Scholar] [CrossRef] [Green Version]
- Tan, A.; Zhou, G.; He, M. Rapid Fine-Grained Classification of Butterflies Based on FCM-KM and Mask R-CNN Fusion. IEEE Access 2020, 8, 124722–124733. [Google Scholar] [CrossRef]
- Salama AbdELminaam, D.; Almansori, A.M.; Taha, M.; Badr, E. A deep facial recognition system using computational intelligent algorithms. PLoS ONE 2020, 15, e0242269. [Google Scholar] [CrossRef]
- Kartika, D.S.Y.; Herumurti, D.; Rahmat, B.; Yuniarti, A.; Maulana, H.; Anggraeny, F.T. Combining of Extraction Butterfly Image using Color, Texture and Form Features. In Proceedings of the 6th Information Technology International Seminar (ITIS), Surabaya, Indonesia, 14–16 October 2020; pp. 98–102. [Google Scholar]
- Rodrigues, R.; Manjesh, R.; Sindhura, P.; Hegde, S.N.; Sheethal, A. Butterfly species identification using convolutional neural network. Int. J. Res. Eng. Sci. Manag. 2020, 3, 245–246. [Google Scholar]
- Theivaprakasham, H. Identification of Indian butterflies using Deep Convolutional Neural Network. J. Asia-Pacific Èntomol. 2021, 24, 329–340. [Google Scholar] [CrossRef]
- Lin, Z.; Jia, J.; Gao, W.; Huang, F. Fine-grained visual categorization of butterfly specimens at sub-species level via a convolutional neural network with skip-connections. Neurocomputing 2020, 384, 295–313. [Google Scholar] [CrossRef]
- Zhu, L.-Q.; Zhang, Z. Insect recognition based on integrated region matching and dual tree complex wavelet transform. J. Zhejiang Univ. Sci. C 2011, 12, 44–53. [Google Scholar] [CrossRef]
- da Silva, F.L.; Sella, M.L.G.; Francoy, T.M.; Costa, A.H.R. Evaluating classification and feature selection techniques for honeybee subspecies identification using wing images. Comput. Electron. Agric. 2015, 114, 68–77. [Google Scholar] [CrossRef]
- Wen, C.; Guyer, D. Image-based orchard insect automated identification and classification method. Comput. Electron. Agric. 2012, 89, 110–115. [Google Scholar] [CrossRef]
- Kaya, Y.; Kaycı, L. Application of artificial neural network for automatic detection of butterfly species using color and texture features. Visual Comput. 2014, 30, 71–79. [Google Scholar] [CrossRef]
- Xie, C.; Zhang, J.; Li, R.; Li, J.; Hong, P.; Xia, J.; Chen, P. Automatic classification for field crop insects via multiple-task sparse representation and multiple-kernel learning. Comput. Electron. Agric. 2015, 119, 123–132. [Google Scholar] [CrossRef]
- Feng, L.; Bhanu, B.; Heraty, J. A software system for automated identification and retrieval of moth images based on wing attributes. Pattern Recognit. 2016, 51, 225–241. [Google Scholar] [CrossRef]
- Abeysinghe, C.; Welivita, A.; Perera, I. Snake image classification using Siamese networks. In Proceedings of the 2019 3rd In-ternational Conference on Graphics and Signal Processing, Hong Kong, China, 1–3 June 2019; pp. 8–12. [Google Scholar] [CrossRef]
- Alsing, O. Mobile Object Detection Using Tensorflow Lite and Transfer Learning. Master’s Thesis, KTH School of Electrical Engineering and Computer Science (EECS), Stockholm, Sweden, 2018. [Google Scholar]
- Hernandez-Serna, A.; Jim’enez-Segura, L.F. Automatic identification of species with neural networks. PeerJ 2014, 2, e563. [Google Scholar] [CrossRef] [Green Version]
- Iamsaata, S.; Horataa, P.; Sunata, K.; Thipayanga, N. Improving butterfly family classification using past separating features extraction in extreme learning machine. In Proceedings of the 2nd International Conference on Intelligent Systems and Image Processing; The Institute of Industrial Applications Engineers: Kitakyushu, Fukuoka, Japan, 2014. [Google Scholar]
- Kang, S.-H.; Cho, J.-H.; Lee, S.-H. Identification of butterfly based on their shapes when viewed from different angles using an artificial neural network. J. Asia-Pacific Entomol. 2014, 17, 143–149. [Google Scholar] [CrossRef]
- Bouzalmat, A.; Kharroubi, J.; Zarghili, A. Comparative Study of PCA, ICA, LDA using SVM Classifier. J. Emerg. Technol. Web Intell. 2014, 6, 64–68. [Google Scholar] [CrossRef] [Green Version]
- Xin, D.; Chen, Y.-W.; Li, J. Fine-Grained Butterfly Classification in Ecological Images Using Squeeze-And-Excitation and Spatial Attention Modules. Appl. Sci. 2020, 10, 1681. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Spachos, P. Towards Image Classification with Machine Learning Methodologies for Smartphones. Mach. Learn. Knowl. Extr. 2019, 1, 1039–1057. [Google Scholar] [CrossRef] [Green Version]
- Rashid, M.; Khan, M.A.; Alhaisoni, M.; Wang, S.-H.; Naqvi, S.R.; Rehman, A.; Saba, T. A Sustainable Deep Learning Framework for Object Recognition Using Multi-Layers Deep Features Fusion and Selection. Sustainability 2020, 12, 5037. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Fadhel, M.; Al-Shamma, O.; Zhang, J.; Santamaría, J.; Duan, Y.; Oleiwi, S. Towards a Better Understanding of Transfer Learning for Medical Imaging: A Case Study. Appl. Sci. 2020, 10, 4523. [Google Scholar] [CrossRef]
- Barbedo, J.G.A. Detecting and Classifying Pests in Crops Using Proximal Images and Machine Learning: A Review. AI 2020, 1, 312–328. [Google Scholar] [CrossRef]
- Fang, X.; Jie, W.; Feng, T. An Industrial Micro-Defect Diagnosis System via Intelligent Segmentation Region. Sensors 2019, 19, 2636. [Google Scholar] [CrossRef] [Green Version]
- Elminaam, D.S.A.; Neggaz, N.; Ahmed, I.A.; Abouelyazed, A.E.S. Swarming Behavior of Harris Hawks Optimizer for Arabic Opinion Mining. Comput. Mater. Contin. 2021, 69, 4129–4149. [Google Scholar] [CrossRef]
- AbdElminaam, D.S.; Neggaz, N.; Gomaa, I.A.E.; Ismail, F.H.; Elsawy, A. AOM-MPA: Arabic Opinion Mining using Marine Predators Algorithm-based Feature Selection. In Proceedings of the 2021 International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 26–27 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 395–402. [Google Scholar]
- Shaban, H.; Houssein, E.H.; Pérez-Cisneros, M.; Oliva, D.; Hassan, A.Y.; Ismaeel, A.A.; Said, M. Identification of Parameters in Photovoltaic Models through a Runge Kutta Optimizer. Mathematics 2021, 9, 2313. [Google Scholar] [CrossRef]
- Deb, S.; Houssein, E.H.; Said, M.; Abdelminaam, D.S. Performance of Turbulent Flow of Water Optimization on Economic Load Dispatch Problem. IEEE Access 2021, 9, 77882–77893. [Google Scholar] [CrossRef]
- Abdul-Minaam, D.S.; Al-Mutairi, W.M.E.S.; Awad, M.A.; El-Ashmawi, W.H. An adaptive fit-ness-dependent optimizer for the one-dimensional bin packing problem. IEEE Access 2020, 8, 97959–97974. [Google Scholar] [CrossRef]
- El-Ashmawi, W.H.; Elminaam, D.S.A.; Nabil, A.M.; Eldesouky, E. A chaotic owl search algorithm based bilateral negotiation model. Ain Shams Eng. J. 2020, 11, 1163–1178. [Google Scholar] [CrossRef]
- Espejo-Garcia, B.; Malounas, I.; Vali, E.; Fountas, S. Testing the Suitability of Automated Machine Learning for Weeds Identification. AI 2021, 2, 34–47. [Google Scholar] [CrossRef]
- Valade, S.; Ley, A.; Massimetti, F.; D’Hondt, O.; Laiolo, M.; Coppola, D.; Walter, T.R. Towards global volcano monitoring using multisensor sentinel missions and artificial intelligence: The MOUNTS monitoring system. Remote Sens. 2019, 11, 1528. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Genus | Training Dataset | Testing Dataset | Validation Dataset |
|---|---|---|---|
| Africangaint Swallowtail | 107 | 75 | 75 |
| American Snoot | 119 | 75 | 75 |
| Atala | 143 | 75 | 75 |
| Banded Peacock | 116 | 75 | 75 |
| Becker’s White | 105 | 75 | 75 |
| Bkue Morphs | 138 | 75 | 75 |
| Crescent | 108 | 75 | 75 |
| Eastern Coma | 133 | 75 | 75 |
| Large Marble | 112 | 75 | 75 |
| Metamark | 116 | 75 | 75 |
| Painted Lady | 116 | 75 | 75 |
| Purple Hairstreak | 107 | 75 | 75 |
| Silver Spot Skipper | 113 | 75 | 75 |
| Tropical Leawing | 119 | 75 | 75 |
| Yellow Swallow Tail | 118 | 75 | 75 |
| Total | 1761 | 1125 | 1125 |
| Performance Measures | VGG16 | VGG19 | MobileNet | Xception | ResNet50 | Inception V3 |
|---|---|---|---|---|---|---|
| Batch Size | 5 | 5 | 5 | 5 | 5 | 5 |
| Image Dimension | 350 × 350 | 350 × 350 | 350 × 350 | 350 × 350 | 350 × 350 | 350 × 350 |
| Optimizer | SGD | Adam | SGD | SGD | SGD | RMSprop |
| Activation Function | Sigmoid | Sigmoid | Sigmoid | Sigmoid | Sigmoid | Sigmoid |
| Loss Function | Categorical Cross entropy | Categorical Cross entropy | Categorical Cross entropy | Categorical Cross entropy | Categorical Cross entropy | Categorical Cross entropy |
| Models | Without Data Augmentation | With Data Augmentation |
|---|---|---|
| InceptionV3 | 42.66 | 94.66 |
| VGG19 | 90.66 | 92.00 |
| Xception | 81.33 | 87.99 |
| VGG16 | 85.33 | 86.66 |
| MobileNet | 75.99 | 81.33 |
| ResNet50 | 38.66 | 43.99 |
| Species Classes | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| African Giant Swallowtail | 1.00 | 1.00 | 1.00 | 5 |
| American Snoot | 0.83 | 1.00 | 0.91 | 5 |
| Atala | 1.00 | 1.00 | 1.00 | 5 |
| Banded Peacock | 0.83 | 1.00 | 0.91 | 5 |
| Becker’s White | 1.00 | 1.00 | 1.00 | 5 |
| Blue Morpho | 0.83 | 1.00 | 0.91 | 5 |
| Crescent | 1.00 | 0.80 | 0.89 | 5 |
| Eastern Coma | 1.00 | 1.00 | 1.00 | 5 |
| Large Marble | 1.00 | 1.00 | 1.00 | 5 |
| Metalmark | 1.00 | 1.00 | 1.00 | 5 |
| Painted Lady | 0.83 | 1.00 | 0.91 | 5 |
| Purple Hairstreak | 1.00 | 0.60 | 0.75 | 5 |
| Silver Spot Skipper | 1.00 | 1.00 | 1.00 | 5 |
| Tropical Leafwing | 1.00 | 0.80 | 0.89 | 5 |
| Yellow Swallow Tail | 1.00 | 1.00 | 1.00 | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rajeena P. P., F.; Orban, R.; Vadivel, K.S.; Subramanian, M.; Muthusamy, S.; Elminaam, D.S.A.; Nabil, A.; Abulaigh, L.; Ahmadi, M.; Ali, M.A.S. A Novel Method for the Classification of Butterfly Species Using Pre-Trained CNN Models. Electronics 2022, 11, 2016. https://doi.org/10.3390/electronics11132016
Rajeena P. P. F, Orban R, Vadivel KS, Subramanian M, Muthusamy S, Elminaam DSA, Nabil A, Abulaigh L, Ahmadi M, Ali MAS. A Novel Method for the Classification of Butterfly Species Using Pre-Trained CNN Models. Electronics. 2022; 11(13):2016. https://doi.org/10.3390/electronics11132016
Chicago/Turabian StyleRajeena P. P., Fathimathul, Rasha Orban, Kogilavani Shanmuga Vadivel, Malliga Subramanian, Suresh Muthusamy, Diaa Salam Abd Elminaam, Ayman Nabil, Laith Abulaigh, Mohsen Ahmadi, and Mona A. S. Ali. 2022. "A Novel Method for the Classification of Butterfly Species Using Pre-Trained CNN Models" Electronics 11, no. 13: 2016. https://doi.org/10.3390/electronics11132016