
Power-Efficient Trainable Neural Networks towards Accurate Measurement of Irregular Cavity Volume

Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions
- (1)
- We design a micro-compressed air method to collect parameters related to the irregular cavity volume. To ensure that the read-to-measure parts are not damaged, the closed atmospheric air in the irregular cavity parts is slightly compressed, and the measurement parameters are collected.
- (2)
- We propose a method to analyze the main controlling factors affecting the volume detection of irregular cavity parts. We screen seven main characteristic parameters: pressure, temperature, humidity, gas equilibration time, etc. We carried out linear and nonlinear correlation analysis, feature selection, and normalization processing for the characteristic parameters. On this basis, we establish an irregular cavity volume measurement model based on FCNNs and the HSIC.
- (3)
- During the training process, we propose a new training scheme based on the HSIC. This method solves the challenges existing in the traditional BP-based methods. This method can reduce the error as much as possible and make the predicted value closer to the ground truth.
- (4)
- We conduct extensive experiments to evaluate the proposed neural network. We build a dataset for irregular volume measurement. The samples are collected in real-world applications. The results show the effectiveness and outperformance of the proposed method.
2. Preliminary
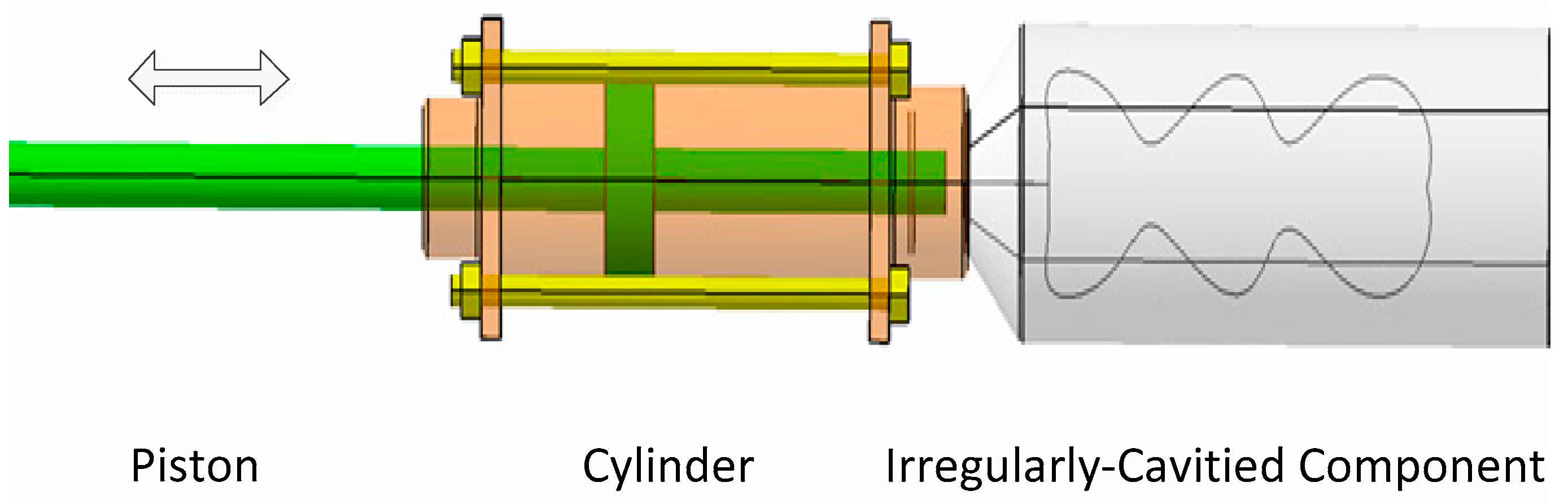
- (1)
- Under the environment of normal temperature and pressure, the parts of the irregular cavity to be tested are filled with air of normal pressure;
- (2)
- Seal the air in the irregular cavity components to be tested. Record the ambient atmospheric pressure , the stable differential pressure of the gas in the cavity of the component to be tested, and the temperature ;
- (3)
- The precision piston is controlled to extend completely into the cavity of the part to be tested, and the gas is slightly compressed. The volume of the piston completely entering the irregular cavity part to be tested is recorded as ;
- (4)
- After thermodynamic equilibrium is achieved, experimental data are recorded including the ambient atmospheric pressure , the stable differential pressure of the gas in the parts, and the temperature ;
3. Method
3.1. Preprocessing of Feature Data for Volume Prediction of Irregular Cavity Parts
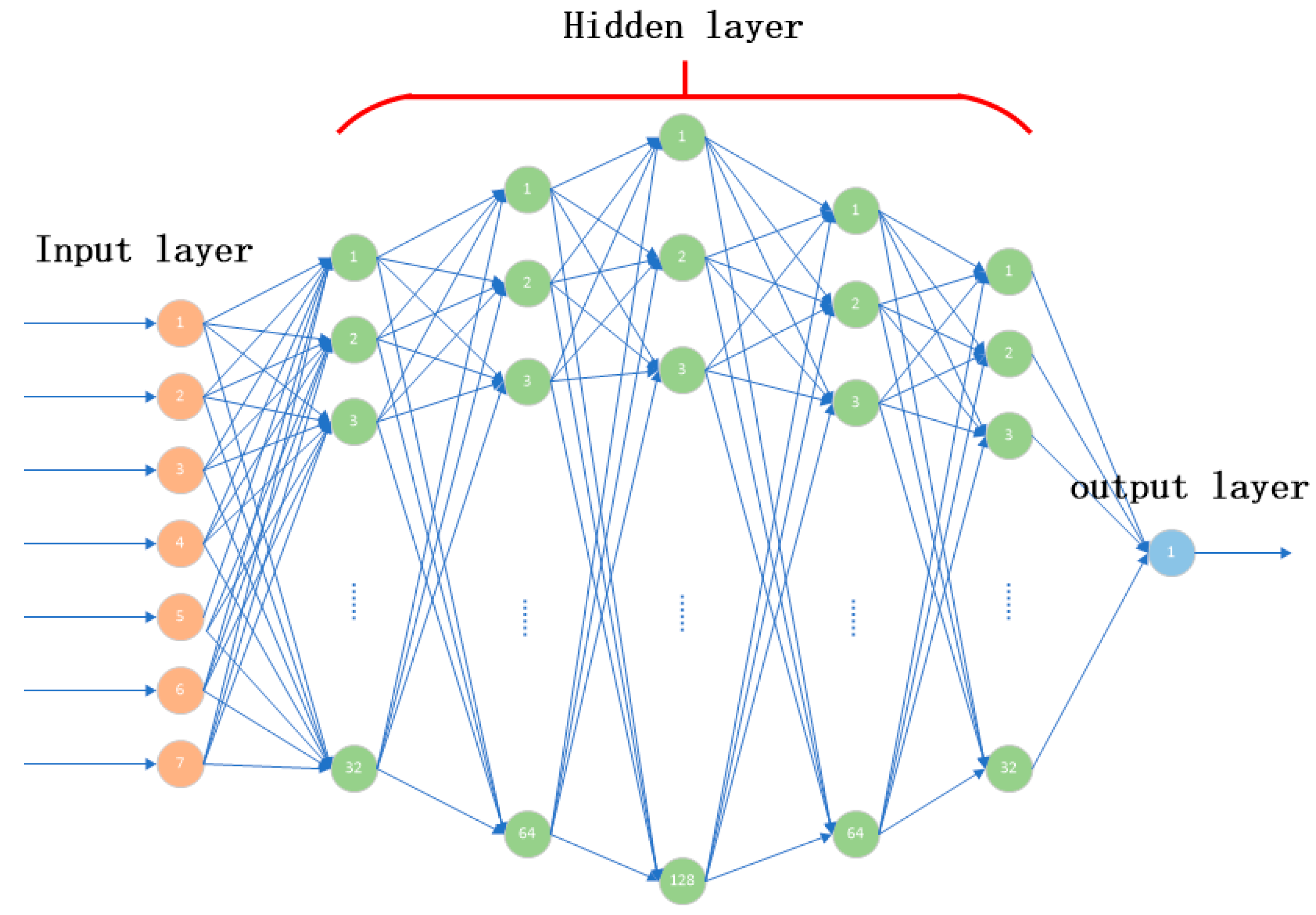
3.2. Establishment of the Volume Prediction Model of Irregular Cavity Components with Fully Connected Neural Network
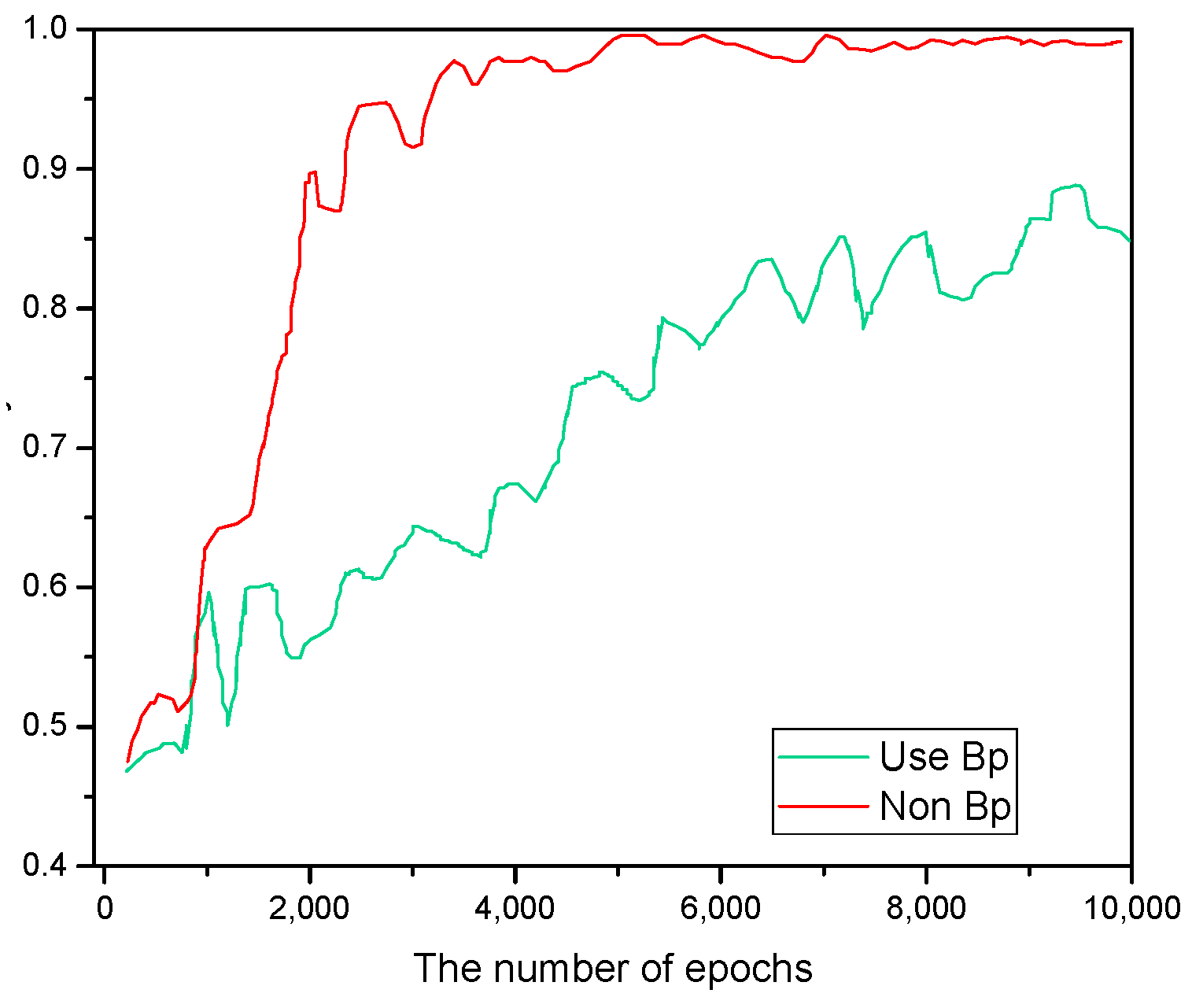
3.3. HSIC Bottleneck Method
4. Experiments
4.1. Experimental Settings
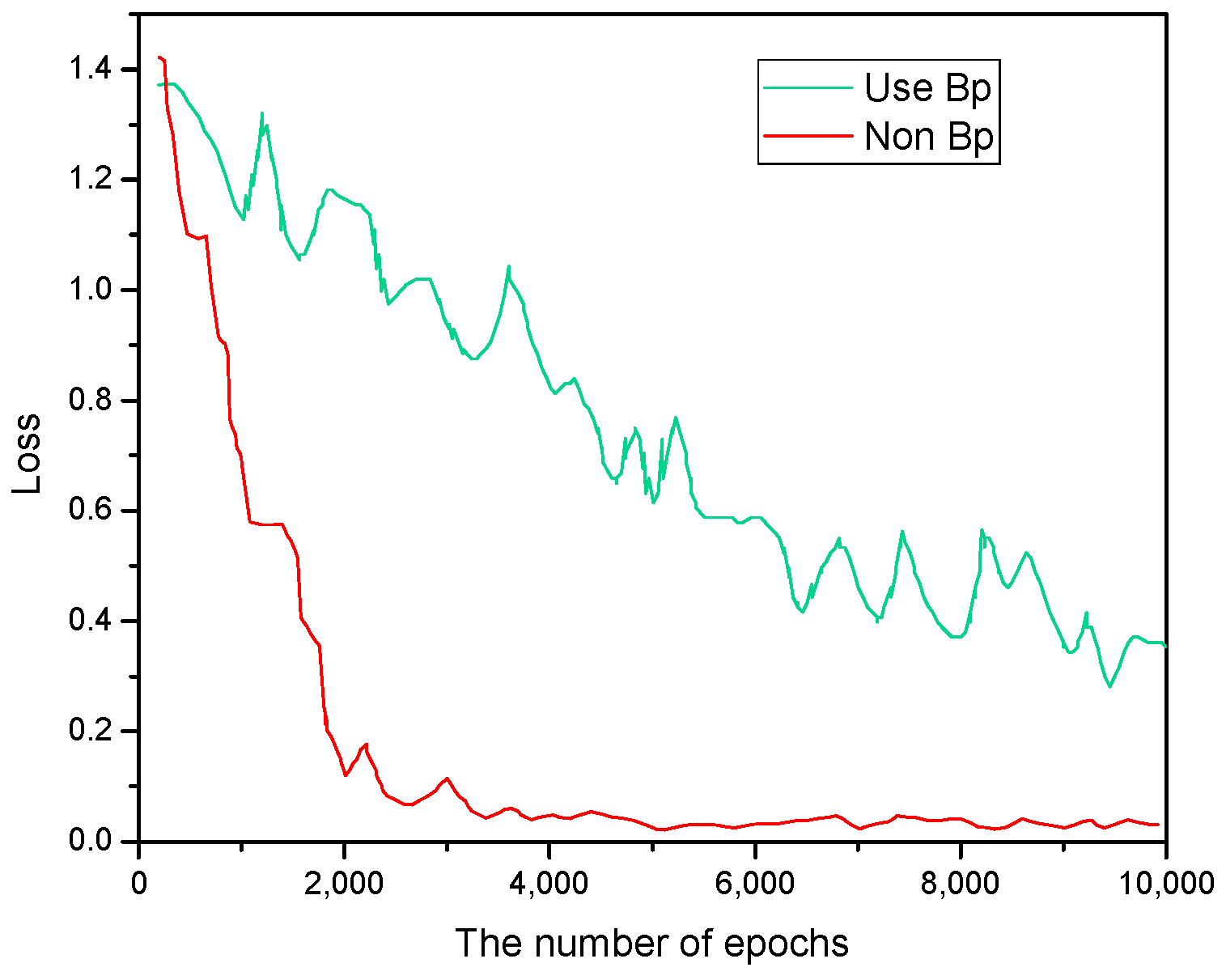
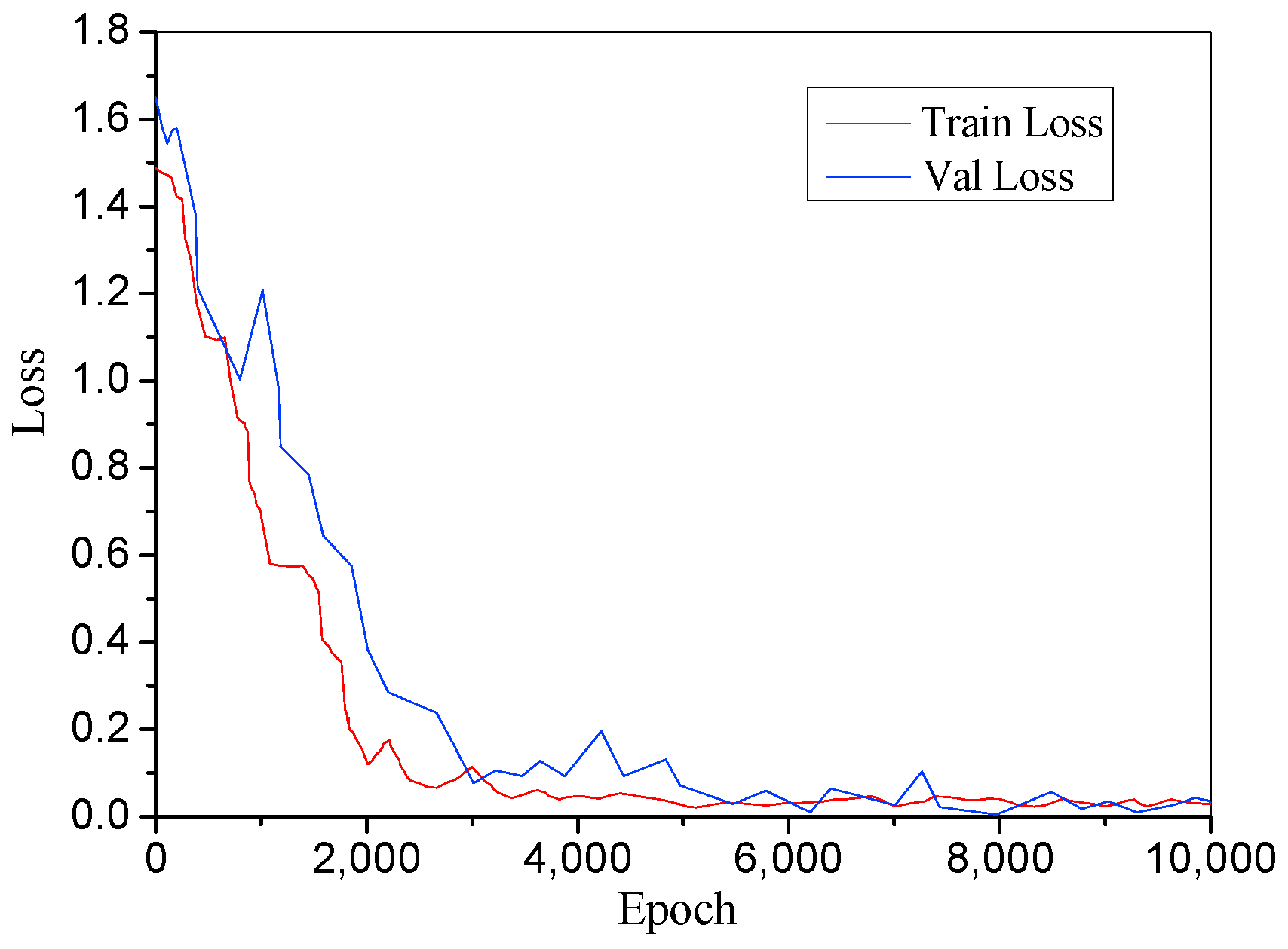
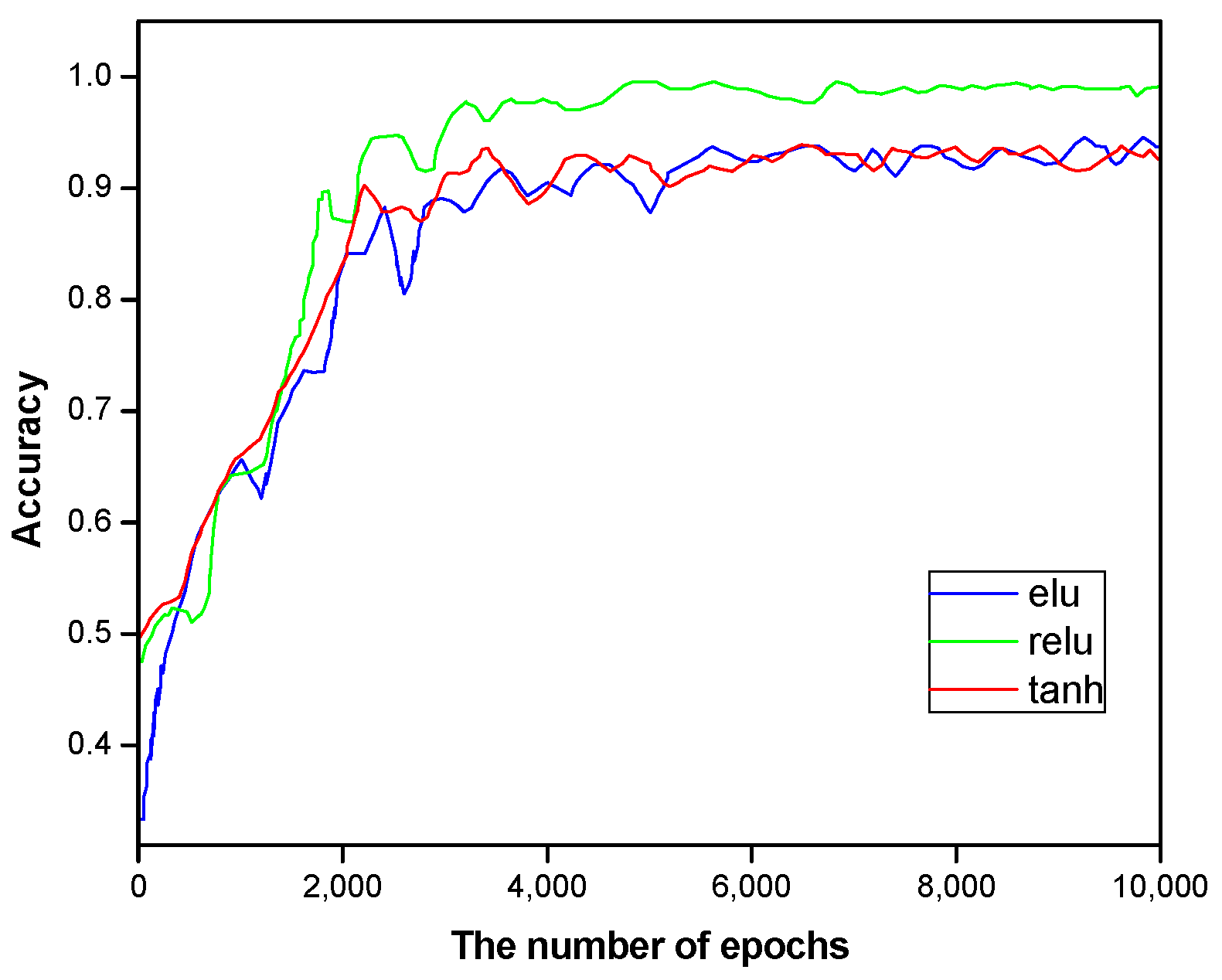
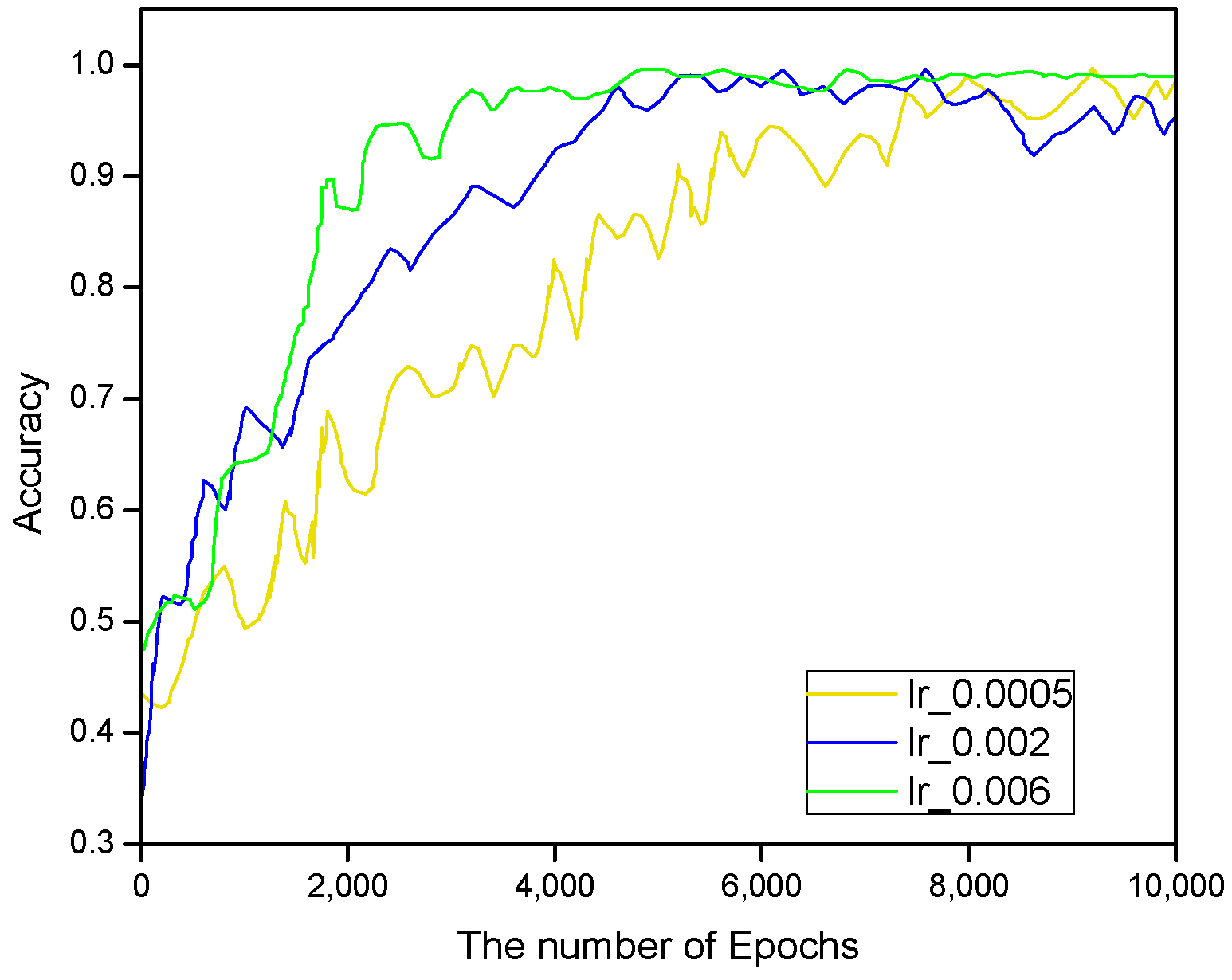
4.2. Ablation Studies
4.3. Comparison and Application
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hao, G.U.; Jin-liang, F.E.; Yao-yu, Z.H.; Cun-liang, C.A.; Si-qi, L.I. High Precision Measurement of Cartridge Volume. Acta Armamentarii 2015, 36, 758. [Google Scholar]
- Strelnikova, E.; Gnitko, V.; Krutchenko, D.; Naumemko, Y. Free and forced vibrations of liquid storage tanks with baffles. Mod. Technol. Eng. 2018, 3, 15–52. [Google Scholar]
- Rogovyi, A. Energy performances of the vortex chamber supercharger. Energy 2018, 163, 52–60. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, Z.; Hashimoto, T.; Zhang, Y. Optically quantifying spatiotemporal responses of water injection-induced strain via downhole distributed fiber optics sensing. Fuel 2021, 283, 118948. [Google Scholar] [CrossRef]
- Song, H.; Wang, Q.; Liu, M.; Cai, Q. A novel fiber Bragg grating vibration sensor based on orthogonal flexure hinge structure. IEEE Sens. J. 2020, 20, 5277–5285. [Google Scholar] [CrossRef]
- Bai, Y.; Zeng, J.; Huang, J.; Yan, Z.; Wu, Y.; Li, K.; Wu, Q.; Liang, D. Air pressure measurement of circular thin plate using optical fiber multimode interferometer. Measurement 2021, 182, 109784. [Google Scholar] [CrossRef]
- Cripe, J.; Aggarwal, N.; Lanza, R.; Libson, A.; Singh, R.; Heu, P.; Follman, D.; Cole, G.D.; Mavalvala, N.; Corbitt, T. Measurement of quantum back action in the audio band at room temperature. Nature 2019, 568, 364–367. [Google Scholar] [CrossRef]
- Cao, R.; Zhang, S.; Banthia, N.; Zhang, Y.; Zhang, Z. Interpreting the early-age reaction process of alkali-activated slag by using combined embedded ultrasonic measurement, thermal analysis, XRD, FTIR and SEM. Compos. Part B Eng. 2020, 186, 107840. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, T.; Cheng, X.; Qin, Y. Volume measurement of moving irregular objects using linear laser and camera. In Proceedings of the 2018 IEEE 8th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Tianjin, China, 19–23 July 2018; pp. 1288–1293. [Google Scholar]
- Kalantari, D.; Jafari, H.; Kaveh, M.; Szymanek, M.; Asghari, A.; Marczuk, A.; Khalife, E. Development of a machine vision system for the determination of some of the physical properties of very irregular small biomaterials. Int. Agrophys. 2022, 36, 27–35. [Google Scholar] [CrossRef]
- Arulmurugan, R.; Anandakumar, H. Early detection of lung cancer using wavelet feature descriptor and feed forward back propagation neural networks classifier. In Computational Vision and Bio Inspired Computing; Springer: Cham, Switzerland, 2018; pp. 103–110. [Google Scholar]
- Lyu, Z.; Yu, Y.; Samali, B.; Rashidi, M.; Mohammadi, M.; Nguyen, T.N.; Nguyen, A. Back-propagation neural network optimized by K-fold cross-validation for prediction of torsional strength of reinforced Concrete beam. Materials 2022, 15, 1477. [Google Scholar] [CrossRef]
- Wang, X.; An, S.; Xu, Y.; Hou, H.; Chen, F.; Yang, Y.; Zhang, S.; Liu, R. A back propagation neural network model optimized by mind evolutionary algorithm for estimating Cd, Cr, and Pb concentrations in soils using Vis-NIR diffuse reflectance spectroscopy. Appl. Sci. 2019, 10, 51. [Google Scholar] [CrossRef] [Green Version]
- Shaik, N.B.; Pedapati, S.R.; Taqvi, S.A.; Othman, A.R.; Dzubir, F.A. A feed-forward back propagation neural network approach to predict the life condition of crude oil pipeline. Processes 2020, 8, 661. [Google Scholar] [CrossRef]
- Jiang, H.; Tian, H.; Hua, Y.; Tang, B. Research on control of intelligent vehicle human-simulated steering system based on HSIC. Appl. Sci. 2019, 9, 905. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, M.; Mazzara, M.; Distefano, S. Regularized cnn feature hierarchy for hyperspectral image classification. Remote Sens. 2021, 13, 2275. [Google Scholar] [CrossRef]
- Ma, W.D.; Lewis, J.P.; Kleijn, W.B. The HSIC bottleneck: Deep learning without back-propagation. In Proceedings of the AAAI Conference on Artificial Intelligence 2020, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5085–5092. [Google Scholar]
- Kuzevičová, Ž.; Gergeľová, M.; Kuzevič, Š.; Palková, J. Spatial interpolation and calculation of the volume an irregular solid. Int. J. Eng. 2014, 4, 8269. [Google Scholar]
- Ghimire, D.; Kil, D.; Kim, S.H. A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration. Electronics 2022, 11, 945. [Google Scholar] [CrossRef]
- Wang, H.; Shi, H.; Lin, K.; Qin, C.; Zhao, L.; Huang, Y.; Liu, C. A high-precision arrhythmia classification method based on dual fully connected neural network. Biomed. Signal Process. Control 2020, 58, 101874. [Google Scholar] [CrossRef]
- Ganju, K.; Wang, Q.; Yang, W.; Gunter, C.A.; Borisov, N. Property inference attacks on fully connected neural networks using permutation invariant representations. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 619–633. [Google Scholar]
- Aspri, M.; Tsagkatakis, G.; Tsakalides, P. Distributed Training and Inference of Deep Learning Models for Multi-Modal Land Cover Classification. Remote Sens. 2020, 12, 2670. [Google Scholar] [CrossRef]
- Aspri, M.; Tsagkatakis, G.; Panousopoulou, A.; Tsakalides, P. On Realizing Distributed Deep Neural Networks: An Astrophysics Case Study. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of deep-learning approaches for remote sensing observation enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef] [Green Version]
- Kobayashi, K.; Bolatkan, A.; Shiina, S.; Hamamoto, R. Fully-connected neural networks with reduced parameterization for predicting histological types of lung cancer from somatic mutations. Biomolecules 2020, 10, 1249. [Google Scholar] [CrossRef]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Tomczyk, K.; Piekarczyk, M.; Sokal, G. Radial Basis Functions Intended to Determine the Upper Bound of Absolute Dynamic Error at the Output of Voltage-Mode Accelerometers. Sensors 2019, 19, 4154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tomczyk, K. Polynomial approximation of the maximum dynamic error generated by measurement systems. Prz. Elektrotech 2019, 95, 124–127. [Google Scholar] [CrossRef]
- Yuan, C.; Chen, J.; Chen, M.; Gu, W. A Lightweight CNN Using HSIC Fine-Tuning for Fingerprint Liveness Detection. In Proceedings of the Chinese Conference on Biometric Recognition 2021, Shanghai, China, 10–12 September 2021; Springer: Cham, Switzerland, 2021; pp. 240–247. [Google Scholar]
- Yue, J.; Xu, K.J.; Liu, W.; Zhang, J.G.; Fang, Z.Y.; Zhang, L.; Xu, H.R. SVM based measurement method and implementation of gas-liquid two-phase flow for CMF. Measurement 2019, 145, 160–171. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
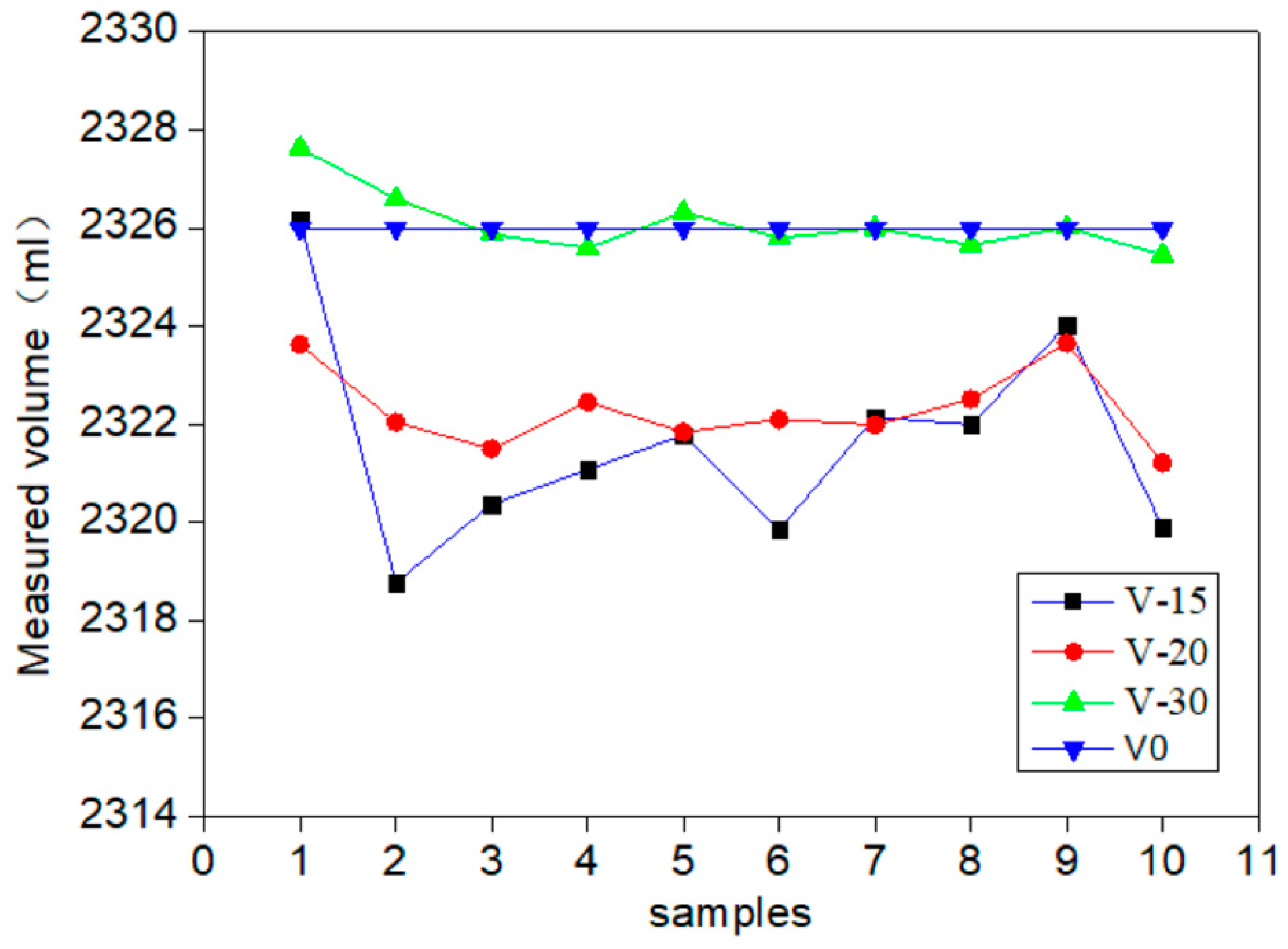
| Group | V0 mL | V-15 mL | V-20 mL | V-30 mL |
|---|---|---|---|---|
| 1 | 2326 | 2326.16 | 2323.62 | 2327.63 |
| 2 | 2326 | 2318.77 | 2322.04 | 2326.60 |
| 3 | 2326 | 2320.37 | 2321.49 | 2325.88 |
| 4 | 2326 | 2321.07 | 2322.45 | 2325.59 |
| 5 | 2326 | 2321.78 | 2321.84 | 2326.32 |
| 6 | 2326 | 2319.85 | 2322.10 | 2325.80 |
| 7 | 2326 | 2322.14 | 2321.98 | 2325.99 |
| 8 | 2326 | 2321.99 | 2322.51 | 2325.66 |
| 9 | 2326 | 2324.02 | 2323.65 | 2326.01 |
| 10 | 2326 | 2319.89 | 2321.21 | 2325.45 |
| Number | Feature Parameters |
|---|---|
| 1 | Atmospheric pressure |
| 2 | Atmospheric humidity |
| 3 | Temperature before micro-compression |
| 4 | Stable differential pressure before micro-compression |
| 5 | Temperature after micro-compression |
| 6 | Stable differential pressure after micro-compression |
| 7 | Gas equilibration time |
| lr | 0.0005 | 0.001 | 0.002 | 0.003 | 0.004 | 0.005 | 0.006 | 0.007 | 0.008 |
| MAE | 0.011 | 0.010 | 0.009 | 0.007 | 0.006 | 0.006 | 0.005 | 0.006 | 0.006 |
| Layers | Parameters | MAE |
|---|---|---|
| 4 | 4096 | 1.112 |
| 6 | 20,480 | 0.005 |
| 8 | 86,016 | 0.005 |
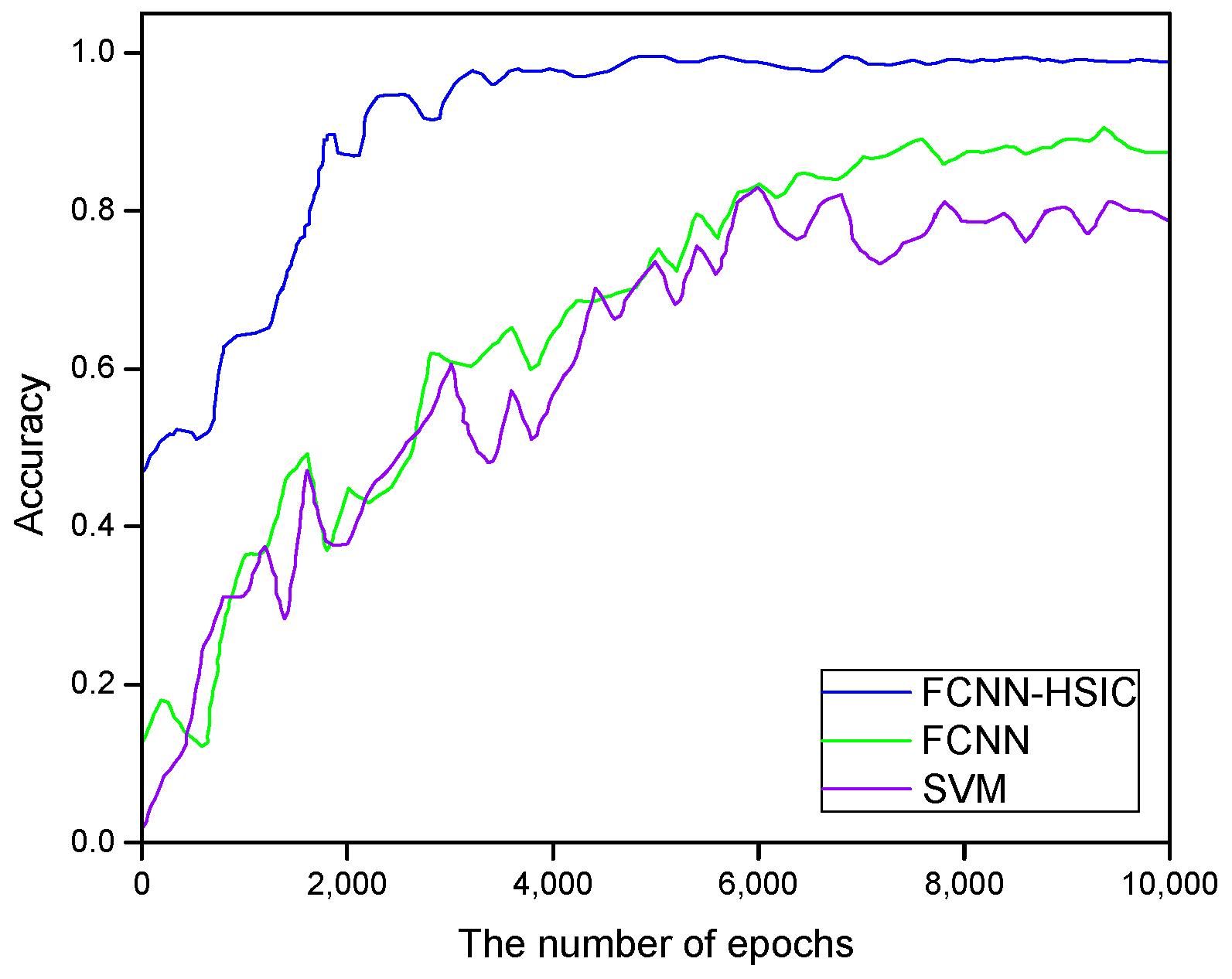
| Method | Per Step CPU Time | Accuracy in Test Set |
|---|---|---|
| SVM | 0.326125 s | 0.76 |
| FCNN | 0.576233 s | 0.85 |
| Proposed | 0.176329 s | 0.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Jiang, Y.; Gao, H.; Yang, W.; Liang, Z.; Liu, B. Power-Efficient Trainable Neural Networks towards Accurate Measurement of Irregular Cavity Volume. Electronics 2022, 11, 2073. https://doi.org/10.3390/electronics11132073
Zhang X, Jiang Y, Gao H, Yang W, Liang Z, Liu B. Power-Efficient Trainable Neural Networks towards Accurate Measurement of Irregular Cavity Volume. Electronics. 2022; 11(13):2073. https://doi.org/10.3390/electronics11132073
Chicago/Turabian StyleZhang, Xin, Yueqiu Jiang, Hongwei Gao, Wei Yang, Zhihong Liang, and Bo Liu. 2022. "Power-Efficient Trainable Neural Networks towards Accurate Measurement of Irregular Cavity Volume" Electronics 11, no. 13: 2073. https://doi.org/10.3390/electronics11132073