1. Introduction
The idea that brains are essentially prediction machines is one of the unified theories in cognitive science. It holds that brain functions, such as perception, motor control and memory, are all formed and modulated by prediction. Particularly, it also forms a sensorimotor framework (predictive coding) for understanding how a human takes an action based on predictions. It proposes that most functions in the brain follow a predictive framework, which is expressed by our brain’s internal model. Therefore, the brain can continuously predict and form our perceptions, on the basis of which we can also execute motor actions. Such an internal predictive model, shaped by the neurons’ representations, is also always learning and updating itself in order to predict the changing environment better. This idea, if it is properly implemented by learning architectures, could also be useful in practical applications such as video-frame prediction.
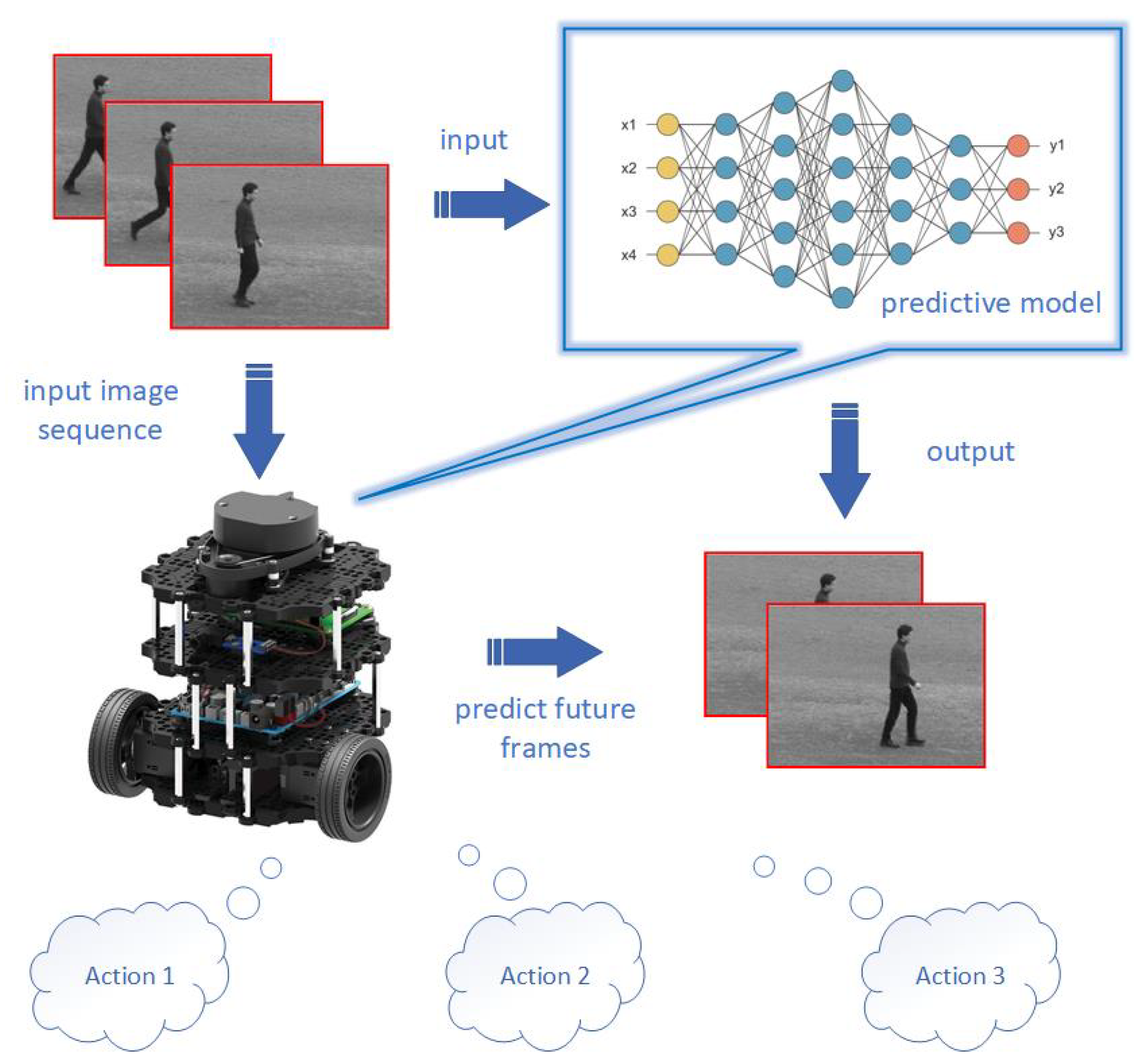
The so-called video-frame prediction task involves predicting the future of a visual frame based on the given contextual frames. From the perspective of applications, being able to predict the future is of great significance. Adaptive systems that can predict how future scenes may unfold based on an internal model that can learn from context will offer numerous possibilities.For example, a predictive ability would enable robots to foresee the future and even to understand humans’ intentions by analyzing their movements, actions, etc., to perform correct actions ahead of time (
Figure 1). Self-driving cars can anticipate forthcoming situations and make judgments beforehand [
1]. Moreover, there are a number of applications for this ability, such as anticipating activities and events [
2], long-term planning, the prediction of pedestrian trajectories in traffic [
3], precipitation forecasting [
4] and so on. With the predictive ability, applications can become more efficient, they can foresee a changing future and react accordingly in advance, making their behavior smoother and more energy-efficient. In different domains, the methods used may have some subtle differences (for instance, in the field of autonomous driving, the scene may be more complex, and a larger and deeper neural network, or other effective preprocessing or post-processing methods may be required), but the overall framework of the model should be unchanged.
Although several models and methods of visual-frame prediction have been proposed based on the success of deep learning, the accuracy of the predicted frames is still far from the requirements of the above applications.This problem is more severe when performing long-term predictions or predicting visual sequences with large changes between frames. Moreover, in view of the large computational overheads of existing models, developing a model that can perform calculations in a more efficient way to promote the implementation of the algorithm is another promising direction of research.
Therefore, in this work, we proposed to combine the theoretical framework of predictive coding and deep learning methods in order to design a more efficient network model for the task of visual-frame prediction. This cognitive-inspired framework is a hierarchical processing model, which mimics the hierarchical processing structure of the cerebral cortex. One of the main advantages of such a predictive coding model is that the internal model is updated through the combination of bottom-up and top-down information streams, instead of merely relying on outside information. This provides a possible framework for simulating and predicting its environment, which is also the approach that early works tried to implement in their computational models [
5,
6].
The main contributions of this work are as follows: (1) We propose and construct a novel artificial neural network model. This model is a hierarchical network, which we call the pyramidal predictive network (PPNet). It was modified on the basis of a generic framework proposed via “predictive coding”. As the name suggests, the updating rateof neurons decreases with an increase in the network level, which mimics the phenomenon of lower oscillations in the higher area of the visual cortex, and means that the model encodes information at various temporal and spatial scales. (2) The loss function is improved to match the video prediction task. Inspired by the attention mechanism (for example, when the prediction differs greatly from the reality, the brain will react more strongly), we introduced the method of an adaptive weight in the loss function, that is, the greater the prediction error, the greater the weight provided.According to the results, the proposed method was used to obtain a better prediction with a lower computational cost and with a more compact and more time-dependent architecture. Below, we introduce our methods and their theoretical basis in detail.
The rest of this article is organized as follows. First,
Section 2 reviews the related work about “Predictive Brains” and existing visual-frame prediction models briefly. Next,
Section 3 introduces the network structure and methods in detail.
Section 4 shows the experimental results obtained in quantitative and qualitative evaluations of our methods compared with the baseline.
Section 5 presents a brief discussion on the proposed method. Finally, in
Section 6 we present our conclusion and our thoughts about future directions of study.
2. Related Work
In order to better integrate predictive coding theory into neural networks, it was necessary to undertake a detailed review of both aspects. In this section, the conceptual models of predictive coding and its related learning frameworks, as well as the state-of-the-art methods for visual-frame prediction from the perspective of machine learning, are reviewed.
Predictive coding, which is a computational model of cognition, asserts that our perception mostly comes from the brain’s own internal inference model, combining sensory information with expectations. Those expectations can come from the current context, from an internal model in the memory or as an ongoing prediction over time. As a theoretical ancestor, Helmholtz first proposed the concept of unconscious inference occurring in the predictive brain [
7]. For example, an identical image can be perceived in different ways. Since the image formed on the retina does not change, perception must be the result of an unconscious process that deduces the cause of sensory information from the top down.Later, in the 1940s, through empirical psychological studies, Bruner demonstrated that perception is a result of the interaction between sensory stimuli (from the bottom up as a recognition model) and conceptual knowledge (from the top down as a generative model) [
8]. Bar proposed a cognitive framework in which the learned representation could be used in generating predictions, rather than passively “waiting" to be activated by sensory input [
9]. From the neuroscience perspective, Blom et al. also argued that predictions drive neural representations of visual events ahead of the arrival of incoming sensory information [
10], which suggests that neural representations are driven by predictions generated by the brain, rather than the actual inputs.
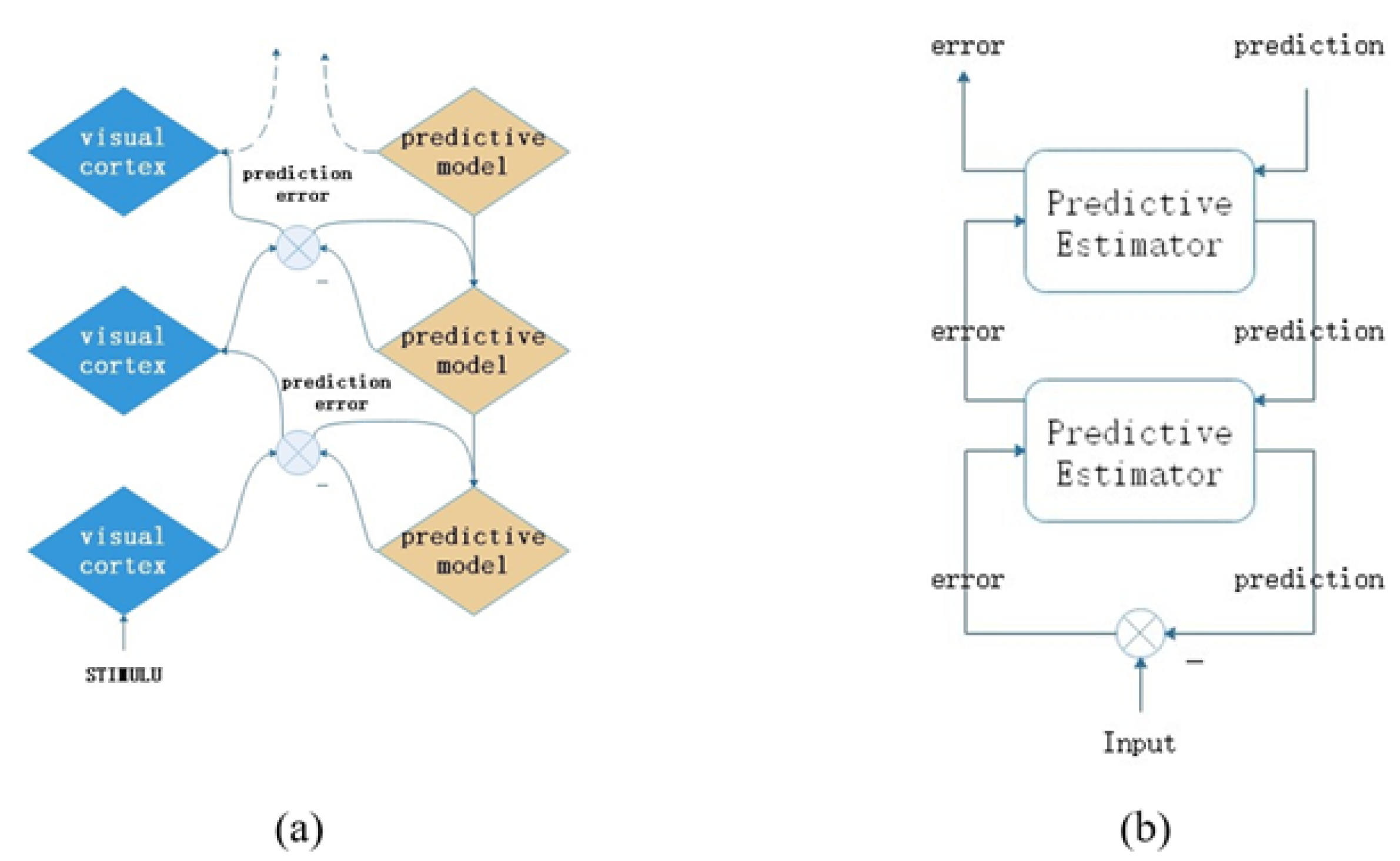
Depicting the predictive framework using a more rigorous expression, the term “predictive coding” has been imported from the field of signal processing. This is an algorithmic-based cognitive model, aiming at providing an explanation of human cognition using the predictive framework. It has been applied in building computational models to explain different perceptual and neurobiological phenomena of the visual cortex [
11]. Specifically, it describes a simple hierarchical computational framework: neurons at a higher level propagate predictions downwards, whereas neurons at a lower level propagate prediction errors upwards [
12], as shown in
Figure 2. The entire model is updated through a combination of bottom-up and top-down information flows, so it does not rely solely on external information. Furthermore, the propagation of prediction errors constitutes effective feedback, allowing the model to perform self-supervised learning. The above characteristics make the predictive coding framework available and valuable to apply to the field of signal processing. For example, Whittington et al. proposed that a network developed in the predictive coding framework can efficiently perform supervised learning with simple local Hebbian plasticity. The activity of the prediction error node is similar to the error term in the backpropagation algorithm, so the weight change required by the backpropagation algorithm can be approximated by means of a simple Hebbian plasticity of connections in the prediction encoding network [
13].
In the field of visual-frame prediction, substantial work has been conducted on the basis of predictive coding. One of most successful applications is the PredNet model, proposed by Lotter et al. [
15]. It is a ConvLSTM-based model which stacks several ConvLSTMs vertically to generate the top-down propagation of predictions. On the other hand, a bottom-up propagation process delivers the error values.This model achieved state-of-the-art performance in a few tasks, such as video-frame prediction. Elsayed et al. [
16] implemented a novel ConvLSTM-based network called the Reduced-Gate ConvLSTM, which showed better performance. However, although these works strictly followed the predictive coding style, the details were not adequately taken into account. The predictive coding computational framework only roughly explains how the brain works, but some details, such as transmission delays, are ignored. The transmission delay has been discussed in the work of Hogendoorn et al. [
17] in detail. They pointed out that only when the concept of transmission delay is added can a predictive coding model be regarded as a temporal prediction model. In addition, other neuroscientific phenomena, such as the different frequencies of oscillations in different levels of the cortex, are equally important. Therefore, we designed a video prediction method with a comprehensive consideration of the different biological evidence mentioned above.
In addition to the above methods, more predictive models have been proposed, building on the recent success of deep learning. The early state-of-the-art machine learning techniques are usually based on encoder-decoder training. Using an end-to-end training method, consecutive frames are used as inputs and outputs to train visual offsets or their coherent semantic meanings. On the basis of the encoder-decoder network and LSTM, Villegas et al. proposed a novel method which decomposes the motion and content [
18], and which encodes the local dynamics and the spatial layout separately, so as to simplify the task of prediction. However, the motion referred to is simply obtained by subtracting
from
. It describes changes at the pixel level only. Jin et al. [
19] also explored inter-frame variations, in an approach which is similar to that of MCNet. Their innovation was the use of GDL (gradient difference loss) regularization as a loss function to sharpen their predictions. In addition, Shi et al. also implemented the use of an CNN-LSTM-based model for precipitation nowcasting [
20]. Unlike the previous two works, they embedded convolutional neural networks directly into the LSTM, which led to better performance in capturing spatial-temporal correlations, and this approach has also been adopted into our network architecture.
Moreover, training in an adversarial fashion is another popular method, since the use of GAN (generative adversarial network) shows excellent performance in image generation for predictions. For example, Aigner et al. [
21] proposed the FutureGAN method based on the concept of PGGAN (progressive growing of GANs) in 2018. They extended this concept to the task of visual-frame prediction using a 3D convolutional encoder-decoder model to capture the spatial-temporal information. However, 3D convolution undoubtedly consumes more computational resources than other methods. Before PredNet, Lotter et al. also proposed a GAN-based model named a predictive generative network (PGN), which was trained in [
22] with a weighted MSE and adversarial loss approach for visual-frame prediction.
In summary, there are two main problems with the previous studies in this area of research. (1) There is still room for improvement in terms of network structure and training strategies. For instance, the encoder-RNN-decoder network only performs predictions in the high-level semantic space, meaning that most of the low-level details are ignored. (2) The computational cost is too high, with these methods consuming a lot of resources (especially during training). The question of how to reduce the computational overhead through reasonable pruning is also important. We have previously introduced the characteristics of predictive coding and the related theories, which provide an efficient and reliable theoretical computing framework. Therefore, in order to reduce the consumption of resources and achieve sustainable artificial intelligence, we suggest combining this efficient cognitive framework and advanced data-driven machine learning methods to design an efficient predictive network model, which can not only improve predictive accuracy, but also reduce computational costs. Next, we will introduce our model in detail.
3. Network Model and Methods
In this section, we introduce the cognition-inspired model, which is specialized for visual-frame frame predictions. As its name (PPNet) suggests, its pyramid-like architecture is beneficial to predicting visual frames, as the neurons on the lower levels encode and predict the actual frames and the neurons on top encode the scenarios, which usually only change within a few visual frames (
Figure 3). We explain this idea in the next subsection. Then, the detailed architecture, as well as the algorithm, are introduced in the subsequent subsections.
3.1. Efficiency in the Pyramid Architecture
In this work, we mainly referred to the design concept of PredNet [
15] when building the network structure. As early as 2016, Lotter et al. proposed such a typical predictive coding model, which strictly follows the dual-way flow at every time-step and which has achieved outstanding performance. Nevertheless, the processing of information can be improved in at least two aspects.
First, according to predictive processing framework, at least two kinds of neurons are required: an internal representation neuron for generating predictions and an error calculation neuron for computing prediction errors. In the PredNet model, bottom-up inputs at each level only served as targets of error calculation neurons for the performance of comparisons with top-down predictions to generate prediction errors, and the information that was propagated upward was related only to the prediction error itself. However, we argue that it is necessary to use the past and present sensory information (represented here as video frames) as the inputs of the representation neurons to generate predictions with higher accuracy. The formed memory can be formulated in a Bayesian framework, which is necessary to use in order to generate predictions. Through the use of such a Bayesian model in the learning process, we can maximize the marginal likelihood or the entropy [
23].
Second, as a cognitively inspired model, we suggest that such predictions and sensory inputs can be respectively implemented in at least two information streams in a hierarchical manner. This not only is inspired by the human nervous system, but it is also a way to integrate inputs from different network layers to obtain more spatiotemporal information—an approach which has also been widely used in deep learning architectures such as ResNet, DenseNet and so on.
Based on the above assumptions, we have proposed and designed a predictive model in which the updating ratesof neurons on different levels can differ. Alternatively, this can be also interpreted as a delay in information transmission. In general, it takes time for information to be transmitted from a lower level to a higher level, so there is a delay in transmissions between different layers. However, neurons at the bottom layer do not passively wait for information transmitted from the top layer before making a prediction. The changes in biological synapses are determined only by the activity of presynaptic and postsynaptic neurons [
13]. Therefore, in PPNet, once the prediction unit (ConvLSTM) receives a sensory input (green), it will immediately combine this with the prediction from a higher level (if any) to make predictions. As we mentioned in
Section 2, the delay in information transmission has been discussed in detail in the work of Hogendoorn et al. [
17]. They argue that traditional predictive coding models such as the one first proposed by Rao and Ballard [
14] do not predict the future, but hierarchically predict what is happening. When the concept of a transmission delay is added, the task of the predictive coding model changes from hierarchical prediction to temporal prediction.
As a result, PPNet could be regarded as an equivalent to the large-scale brain network (LSBN) in which the higher cognitive function is conducted in a higher level of the deep learning network. According to the neuroscientific evidence, such a cognitive function which is processed in the PFC (prefrontal cortex) can be also used to predict the situated scenarios in our visual-frame prediction application for an agent.Therefore, our model is built considering the balance between biological evidence and efficiency in computing.
3.2. Network Architecture
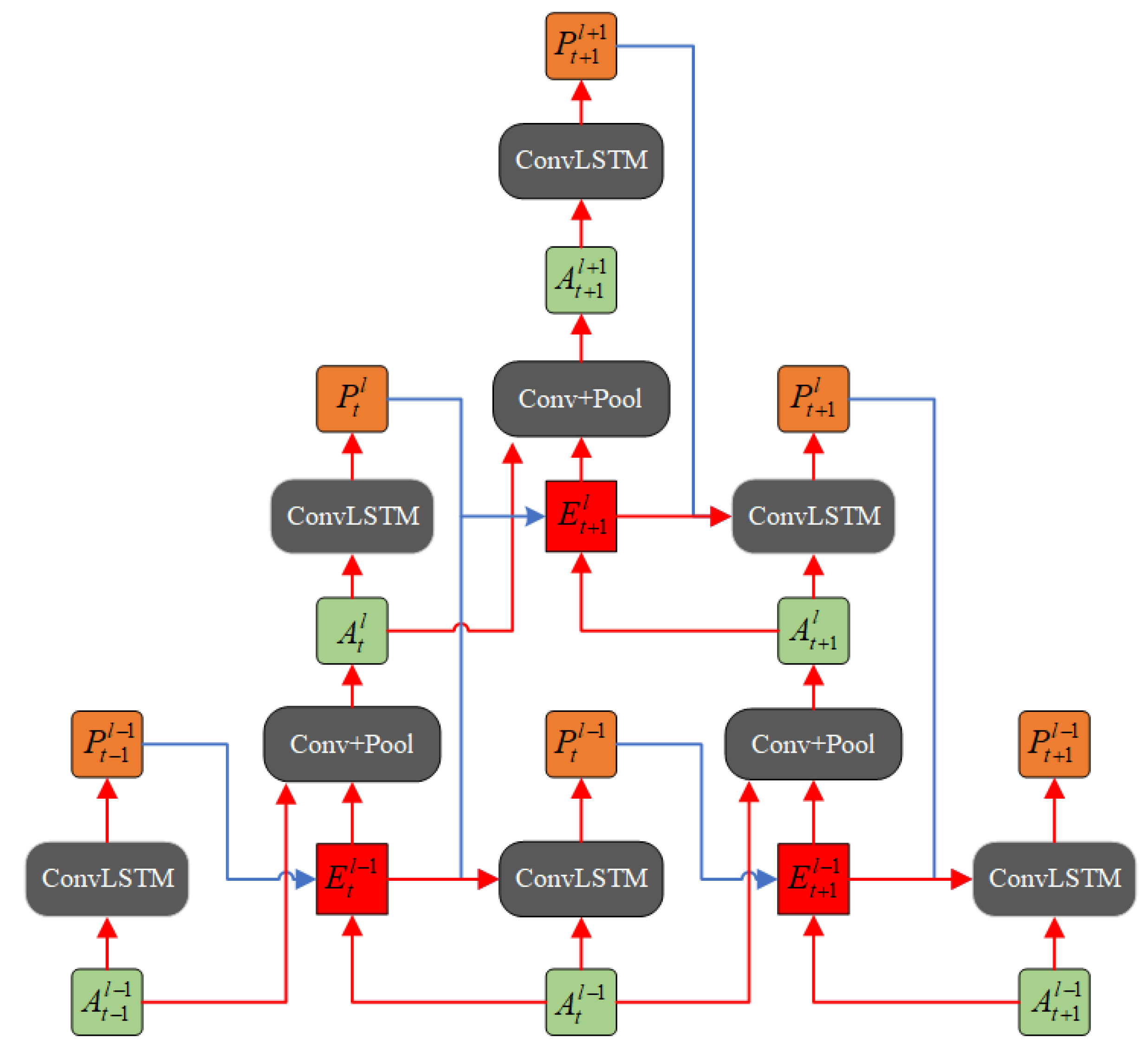
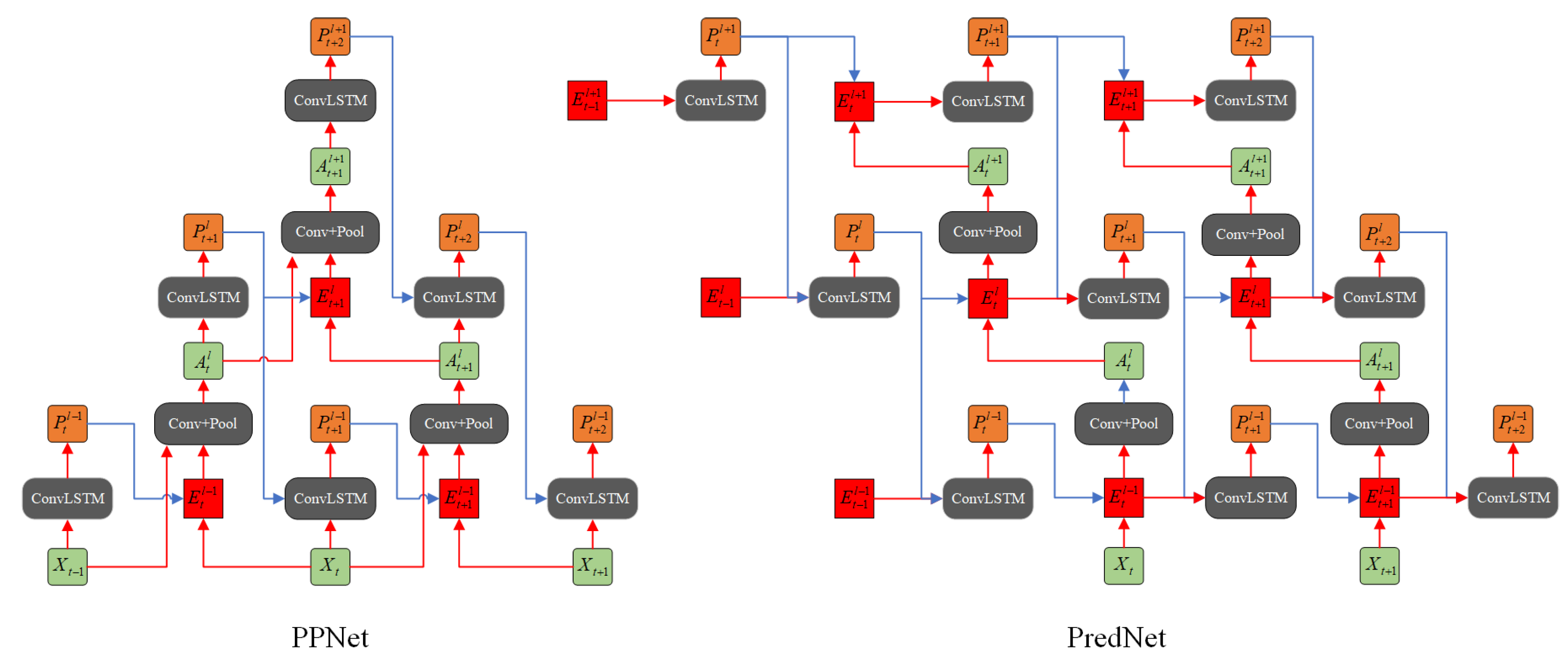
In this section, we introduce our network model in detail. The architecture of our model is shown in
Figure 3. For the sake of understandability, it is necessary to state the meanings of the symbols in the figure before conducting a detailed comparison and analysis.
: depicted in green, represents the sensory input at level and time step ;
: depicted in orange, represents the prediction at level and time step . Its prediction object is the sensory input at level and time step (); and
: depicted in red, represents the prediction error at level and time step . It is calculated based on the previous prediction and the current sensory input .
Inspired by PredNet, PPNet also uses ConvLSTM componentsas its basic components, as they provide prediction flows with long-term dependency. Similarly, each layer of the network can be roughly divided into three parts:
A predictive unit, which is made up of the recurrent convolutional network (ConvLSTM). It receives a sensory input and a prediction from higher level (if any), to generate a local prediction of next time step.
A generative unit, which consists of a convolutional layer and a pooling layer. This unit is responsible for turning the local input , as well as the prediction error , into the input of the next level.
An error representation layer, which is split into separate rectified positive () and negative () error populations.
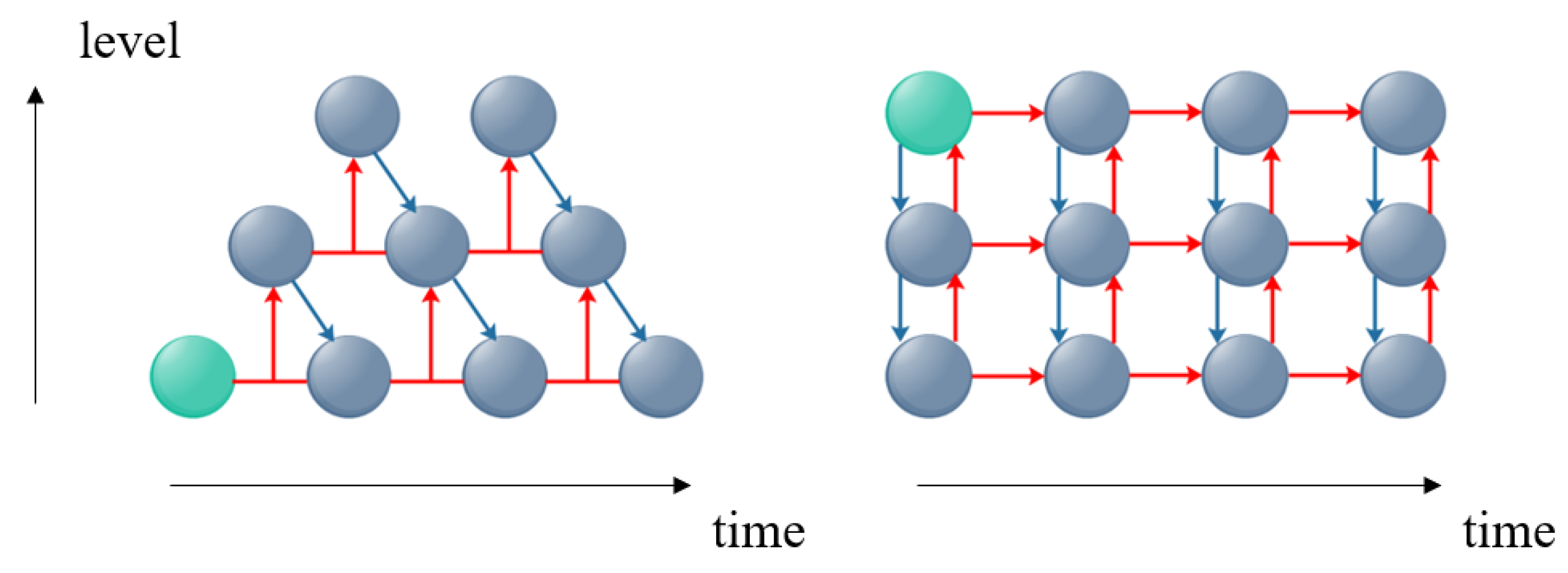
In order to process the prediction only when it is necessary, we show that the dual-direction propagationcan be carried out in a more efficient way. For a better understanding and comparison, a diagram (
Figure 4) is provided below regarding the ways in which information propagates, comparing our model and the PredNet model.
First, the computation process of our model begins at the lowest layer after receiving the first sensory input. This is consistent with the design concept mentioned in
Section 3.1, which is different from that of PredNet, which first starts at the top level by generating a prediction without any prior information. Second, in our model, the bottom-up input of a higher-level unit comes from the combination of information from the lower-level units of two time-steps. Specifically, the current input
is fed into internal representation neuron (ConvLSTM) to generate a local prediction
at the time step
, which is then compared with the next time step input
to generate the prediction error
. In other words,
is not only a bottom-up sensory input for an internal representation neuron at time step
, it is also the target of the previous step
, which is different from PredNet (in which
serves merely as a target at time-step
).
Note that with both the prediction (
) and the target (
) PPNet can generate a prediction error for upward propagation. That is, at least two continuous sensory inputs
and
are required to generate a prediction error for upward propagation, with the former serving as an input to produce the prediction, whereas the latter serves as a target. As a result, the computations of neurons at different levels are not updated in a synchronized way at different levels, and the update frequency of neurons decreases as the network level increases, which is consistent with the biological evidence: deep neurons oscillate at a lower frequency [
24]. For this reason, the bottom-up input of the top level contains information for multiple time-steps at the bottom-level, which means that PPNet has a stronger temporal correlation in its structure, rather than relying solely on the temporal correlation of LSTM. In addition, it allows PPNet to reduce the computational load by not having to update higher-level neurons.
3.3. Training Loss and Adaptive Weight
The training loss in our model is defined as the concatenation of positive and negative errors (Equation (
1)), where
denotes a prediction and
Y is a target.
denotes the “rectified linear activation function”, which is defined in Equation (
2).
refers to concatenating two multidimensional matrices together (for example, concatenating two matrices of dimension (b, c, h, w) into a matrix of (b, 2c, h, w)). Equation (
1) indicates the error population in the neurons, incorporating both positive errors and negative errors [
14]. Furthermore, to sharpen the predictions, we introduce an adaptive weight into the loss function, inspired by the attention mechanism.
At the beginning of the visual sequences, the error is usually quite large since it drives the top-down prediction to minimize the error. That is, the greater the prediction error, the stronger the brain response. We argue that the brain’s response can be seen as a weighting of the prediction error. Based on this idea, we propose to add more weights to increase the contributions of prediction errors with higher values (for example, at the beginnings of sequences). When one has a lower value, itscontribution is reduced. A set of experiments performed by Kutas & Hillyard [
25] showed that, when a prediction was seriously inconsistent with the environment, the brain reacted more strongly. Higher accuracy means less uncertainty, which is reflected in a higher gain in the relevant error units to complete the update.In other words, the error units become more adaptive, driving learning and plasticity, if they are given an increasing weight. Therefore, we have introduced a method of adaptive weights into our model, with a higher value of the prediction error resulting in a higher weight.
The adaptive weight for every time-step is calculated by directly multiplying the error itself by a coefficient (shown in Equation (
3)).
denotes the prediction error at time step
t, whereas
p is a changeable hyper-parameter. Thus, the training loss is defined as in Equation (
4), where
T denotes the length of input sequences and
denotes the weighting factors by time. However, the error with a value less than
will become smaller after being weighted.
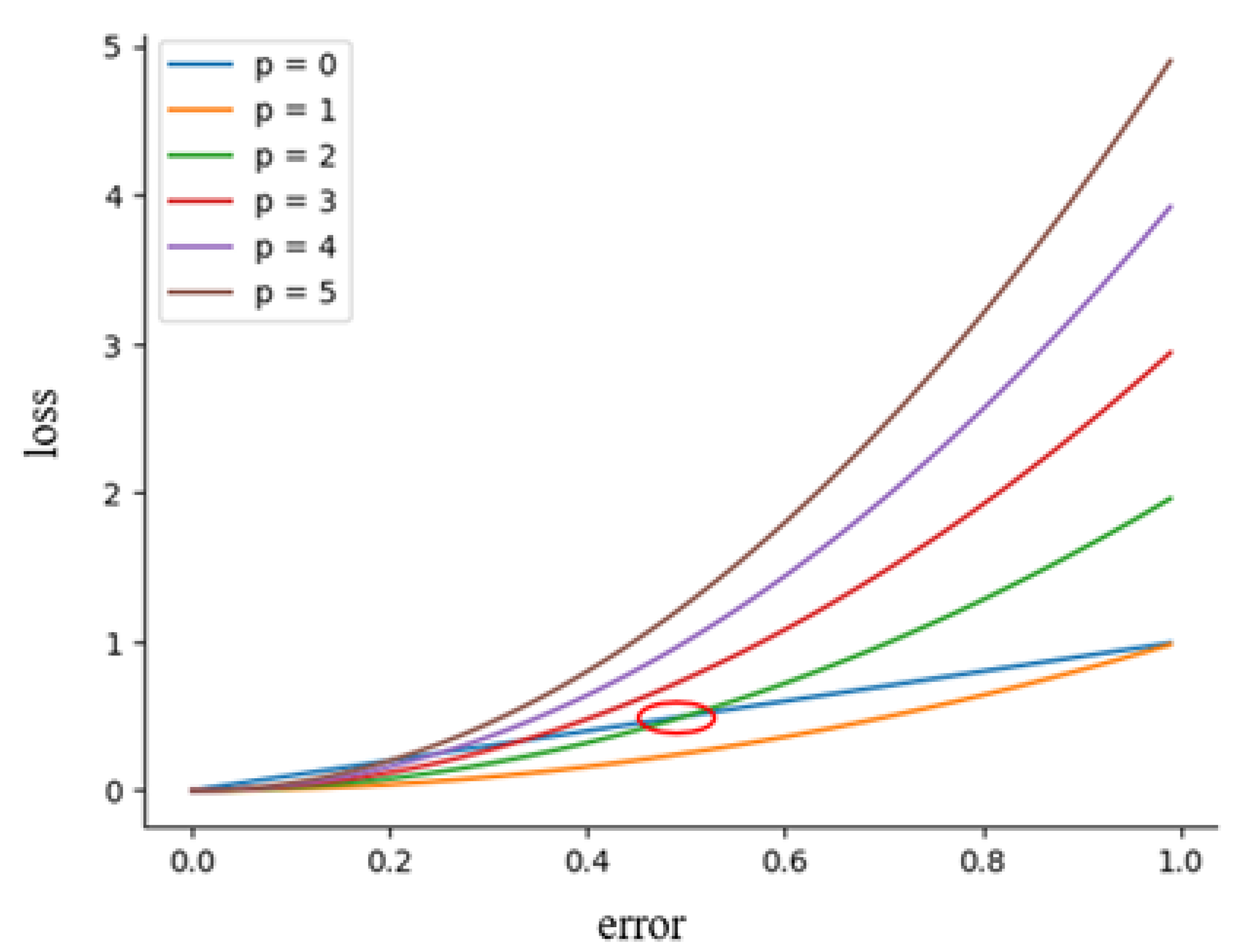
Figure 5 shows the relationship between
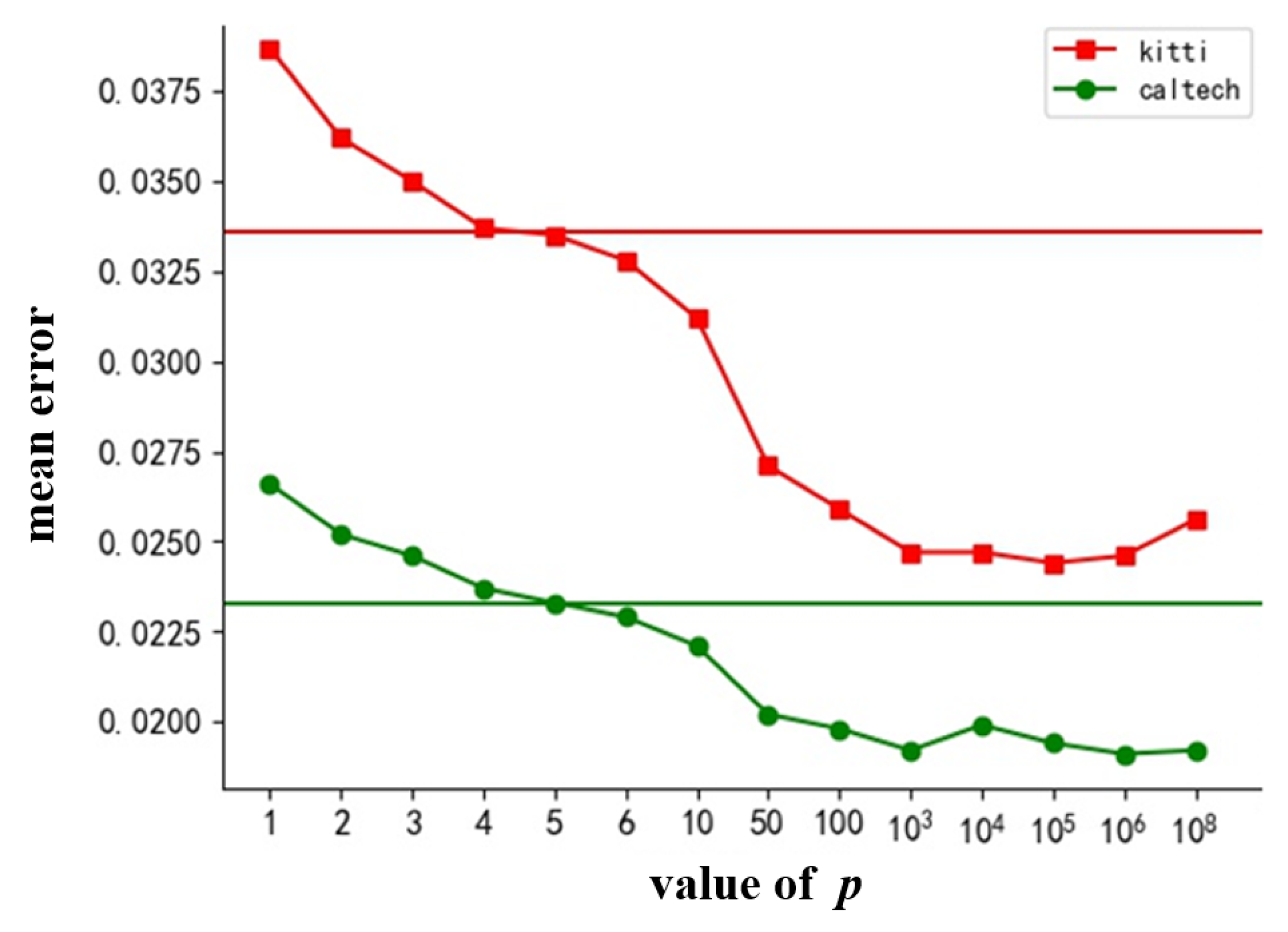
p and the loss. When the error is greater than the threshold (e.g., the intersection of the red circle), it will be enlarged. However, it will be reduced if it is less than the threshold. From an attention mechanism perspective, we pay more attention to errors that are larger than the threshold and pay less attention to errors that are smaller than the threshold. Therefore, the choice of threshold is extremely important. We further explore the influence of the hyper-parameter
p in the following experiments.
3.4. Algorithm
In this section, we introduce the algorithm to implement the above model based on the architecture and computation process mentioned in
Section 3.2. To better serve the following description, we reiterate the definition of each parameter as follows.
: The prediction error;
: The combination of hidden state and cell state ;
: The input, as well as the target, of each layer;
: The image at frame in the input sequence;
: The prediction; and
: The length of the input sequence.
The complete algorithms are listed in Equations (
5) to (
9). The model is trained to minimized the training loss, defined as in Equation (
5), and our implementation is described in Algorithm 1. The information flows through two streams: (1) a top-down propagation, in which the hidden states
of ConvLSTM are updated and the local prediction
is generated, and (2) a bottom-up stream in which the prediction error
is calculated and propagated up to a higher level, along with the local input
. Due to the pyramid design, the computation in our network updates the lowest layer (i.e., layer 0) at the first time-step. However, for the convenience of programming, we refer to the programming method of PredNet and thus perform the calculation of the top-down information flow first (lines 2–11 in Algorithm 1), and then calculate the prediction error and update the sensory input of the higher level (lines 12–19 in Algorithm 1). In contrast, if there is no sensory input
at time-step
t and level
l, the calculation of this predictive unit is skipped without generating any predictions and the hidden state of ConvLSTM
stays the same.
| Algorithm 1: Calculation of the Pyramidal Predictive Network |
![Electronics 11 02969 i001]() |
6. Conclusions
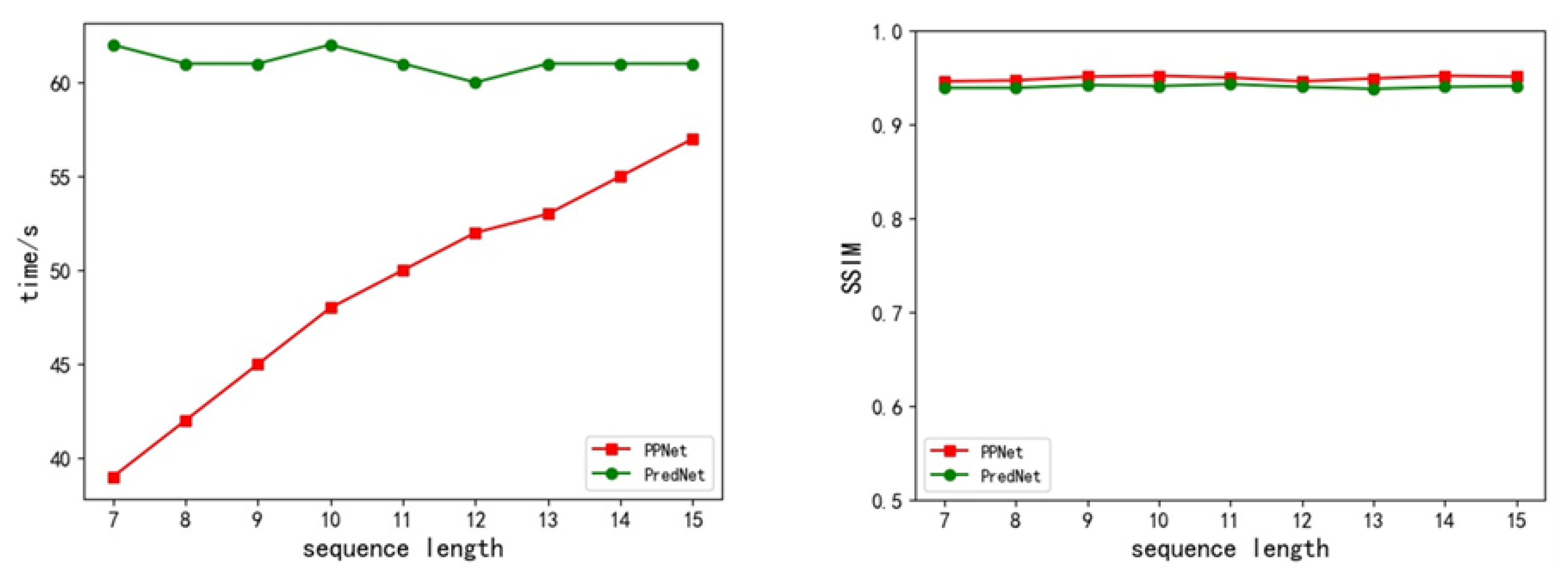
In this paper, we have demonstrated the use of a pyramidal predictive network for visual-frame prediction based on the predictive coding concept, along with the consideration of efficient computational performance. This model encodes information at various temporal and spatial scales, with an up-down propagation of predictions and a bottom-up propagation of the combination of sensory inputs and prediction errors. It has a stronger temporal correlation in its structure and requires lower computation costs. We analyzed the rationality of the model in detail from the perspectives of predictive processing and machine learning. Importantly, this proposed model achieved a remarkable performance compared to state-of-the-art models, according to the experimental results.
Nevertheless, there is still room for improvement of the proposed model. In the long-term forecasting process, false “prediction errors” may cause the model to average the possible future predictions into a single, fuzzy forecast, which is an urgent problem existing in most predictive models. In addition, performing predictions on the basis of directly predicting natural visual frames is still a challenging task due to the curse of dimensionality. Therefore, in the future, we intend to reduce the prediction space to high-level representations, such as semantic and instance segmentation, and depth space, in order to simplify the prediction task, which will make it easier for intelligent robots to predict and perform advanced actions.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}