1. Introduction
Large search engines use significant hardware and energy resources to process billions of document requests per day. This has motivated a large body of research that aims to reduce the cost of processing queries. Keyword-based Boolean query is the typical one in search engines, which utilizes the logical
and/
or expression to represent the set of keywords contained by the target documents. Generally, search engines use inverted index structures to quickly obtain the ordered sets (document IDs) for the keywords, then retrieve the target documents by evaluating the corresponding set expression [
1]. For example, the keyword-based Boolean query “(
data or knowledge)
and (
mining or science)” retrieves the documents containing at least one of the keywords in {
data mining,
data science,
knowledge mining,
knowledge science}, the set expression
is evaluated to identify the target documents, where
is the ordered set of IDs for the documents containing the keyword
w.
With the rapid growth of the number of internet users, traditional centralized document retrieval mechanisms may not be an appropriate strategy, when documents are distributed on the local caching servers and each local caching server corresponds to a certain sub-region of the network. Instead, document retrieval requests should be processed in a localized and distributed fashion, while only the intermediate results computed by the local caching servers should be aggregated to the cloud server. We argue that this decentralized strategy is appropriate in the context of distributed documents, especially when documents are large in volume. In recent years, edge computing has been widely adopted in many applications, which aims to decentralize the procedure of query processing and reduce the system energy consumption [
2,
3]. To this end, we explore the Boolean query processing for document retrieval in edge computing in this paper, which aims to improve the query efficiency by processing the user queries in a distributed and localized fashion as much as possible.
Traditional techniques process the Boolean queries for document retrieval in a centralized fashion. These methods can be divided into comparison-based and non-comparison-based algorithms. The comparison based algorithms generally compile the Boolean query to a parse tree, then utilize the parse tree to guide the comparisons for the elements in the ordered sets of
Q [
4,
5,
6]. The algorithms introduced in [
4,
5] obtain a worst-case optimal complexity on the sizes of ordered document sets in the query, they utilize a bottom-up fashion to compute the intermediate results for each internal node of the parse tree, and the final evaluation results are obtained as the intermediate results for the root of parse tree are computed. An adaptive algorithm is proposed in [
6], which preferentially computes the individual evaluation result. Additionally, the comparison-based algorithms for multi-list intersection can be used for the Boolean query problem by only considering the intersection [
1,
7,
8,
9,
10,
11,
12]. Bille P. et al. proposed the non-comparison-based techniques on the Boolean query problem [
13]. They adopted the approximate set representation for the ordered sets by computing the hash function values for the original ordered sets. Although the non-comparison based algorithm achieves efficient performance on the evaluation time, it only obtains the approximate results.
To the best of our knowledge, a distributed and localized method has not been investigated to support the Boolean queries for document retrieval. To address this challenge, this paper proposes an aggregated Boolean query processing technique in edge computing. In this context, the network is divided into sub-regions, where each sub-region corresponds to an edge network regulated by an edge server (i.e., the local caching server). Additionally, all edge servers are connected to a center node (cloud server) of the network. Boolean queries are initially processed at the cloud server of the network, then the following processing tasks are assigned to the edge servers, where documents are retrieved locally, and finally the results of the document retrieval are aggregated at the cloud server. To summarize, we make the following contributions in this paper.
- -
Aggregated Boolean query processing in contiguous edge networks. We design a marginal edge network query mechanism for the document retrieval request, which distributes the converted user query to the edge servers. This query mechanism computes the intermediate query results in each edge server with limited data transmission between edge servers, and the accurate query results are finally aggregated in the cloud server.
- -
Processing Boolean queries in single edge networks. For the query processing in the single edge network, we propose the evaluation tree-based plan to compute results for the document request query in the edge server, which avoids unnecessary checks for the document sets. We also design optimization techniques for skipping invalid element comparisons to further accelerate the query evaluation.
The rest of the paper is organized as follows:
Section 3 gives the problem definition and introduces the necessary background. We introduce the marginal edge network query mechanism in
Section 4, and present the query processing method for single-edge networks in
Section 5. Experimental results are presented and analyzed in
Section 6.
Section 2 surveys the related work. At last, we conclude this paper in
Section 7.
2. Literature Review
The existing work related with our problem can be broadly classified into two streams. One stream is concerned with the research in edge computing, while the other stream addresses the problem of Boolean query processing.
2.1. Edge Computing
Along with the popularity of IoT applications, edge computing has been proposed in recent years as the complement of cloud computing [
14,
15,
16], which shifts the computational and storage resources toward the edge of the network. We review the following three directions in the field of edge computing that relate to our studied problem.
2.1.1. Decentralized Query Processing in Edge Computing
Query processing as an important ingredient of the IoT applications in edge computing has been studied recently, where the applications are processed in a decentralized fashion as much as possible [
17,
18,
19,
20]. A typical work is presented in [
18], which processes the multi-attribute aggregation query in a decentralized fashion by constructing the energy-aware IR-tree in single-edge networks. A blockchain-based decentralized platform CoopEdge is proposed to support cor-operative edge computing [
21], where an edge server can safely publish a computation task for others, and reliable edge servers are selected. In addition, the research field of serverless-enabled edge computing, which aims to bring computational resources closer to the data source, can also realize the decentralized query processing in edge computing [
22,
23,
24,
25]. A decentralized framework for serverless edge computing is proposed to minimize the query processing time by dispatching the stateless tasks to executors of the network [
26]. In [
27], a simulation tool is designed for the testing and evaluation for the serverless edge computing applications.
Although these techniques propose some solutions for decentralized query processing in edge computing, the query processing mechanisms cannot be reused for different types of queries, and these techniques cannot be directly utilized for the Boolean query processing problem.
2.1.2. Computation Offloading in Edge Computing
Computation offloading is a critical direction in edge computing, in which the computation tasks are offloaded from the resource-limited edge devices to the powerful network edges so that the applications obtain low latency [
28,
29,
30,
31]. Existing computation offloading techniques can be divided into two categories: traditional heuristic rule-based offloading schemes and learning-based intelligent offloading schemes. Traditional offloading schemes utilize heuristic algorithms to solve different optimization objectives, including network delay and energy consumption [
32,
33]. Intelligent offloading schemes solve the network delay and energy consumption problem, using the technique of online learning [
34,
35,
36].
Computation offloading is a different problem than decentralized Boolean query processing. Therefore, the techniques for computation offloading cannot be used for our studied problem.
2.1.3. Privacy Preserving in Edge Computing
Some works have studied the privacy-preserving problem in edge computing [
37,
38,
39,
40]. The application in edge computing achieves efficient data/query processing by sinking parts of the cloud server business to the edge of the device and enabling the data/query to be processed in the edge devices. The security protocols/frameworks are then proposed to protect the privacy of user data in the edge devices under the edge computing environment. A security framework for big data analytics in VANETs equipped with edge computing nodes was proposed in [
41]. A method integrating edge computing, cloud computing and differential privacy was devised to provide efficient privacy preservation for the location-based data stream processing [
42]. Additionally, some techniques solve the data privacy issue in the edge devices using homomorphic encryption [
43,
44,
45], which enables the protection of the data privacy for the edge devices with good computing ability.
In our problem setting, user documents are distributively stored in the edge devices. Although the data privacy issue also exists in this setting, we only focus on the method of Boolean query processing in this paper. These techniques protecting data privacy in edge computing are orthogonal to our proposed method.
2.2. Boolean Query Processing
Traditional techniques have been developed to support Boolean query processing, which can be divided into comparison-based and non-comparison-based algorithms. The basic idea of comparison-based algorithms is to compare the elements in the ordered sets of the query and find the results satisfying the Boolean logic [
4,
5,
6]. They generally compile the query to a parse tree, which can be used to guide the comparison order for the elements. An algorithm obtaining a worst-case optimal complexity on the sizes of ordered sets is introduced in [
4], it computes the evaluation results using the parse tree in a bottom-up fashion. For each internal node
V of the parse tree, the intermediate evaluation results for
V are computed by applying multiple ordered sets intersection (respectively, union) if
V is an intersection (respectively, union) node. Finally, the evaluation results for the root node of the parse tree are the evaluation results of the query. An adaptive algorithm was proposed in [
6], which also utilizes the parse tree to compute the evaluation results. Its basic idea is iteratively checking the picked candidate elements to obtain the evaluation results. In each iteration, the algorithm first computes a candidate element from the ordered sets of the query that could be the evaluation result, then checks it by the parse tree. A non-comparison based algorithm for processing Boolean queries was proposed in [
13]. The approximate set representations for the ordered sets are computed through the hash values of the original ordered sets. In order to store the hash values into a word so that the word-level parallelism can be used, they also utilized a compressed representation for the hash values. Afterwards, the evaluation results are computed by performing the set operations on the mapping compressed hash values, rather than the original ordered sets.
Additionally, the multi-list intersection algorithms can also be used to process the query that only contains intersection operations [
1,
7,
8,
9,
10,
11,
12]. A straightforward algorithm is widely used, called
, which iteratively applies the two-set intersection in increasing order by size, i.e., starting with the two smallest ordered sets.
can be viewed as a variant of
, which selects the candidate element from the set with the least remaining elements, rather than the initial smallest set [
11,
12]. If a mismatch occurs before all sets have been checked, the sets are reordered based on the number of remaining elements in each set, and the new candidate element is picked from the smallest remaining subset.
is proposed in [
1], which does not need to reorder the sets when picking a candidate element. As a mismatch occurs, the element that leads to the previous candidate element to be mismatched is used to skip the invalid elements on the smallest set, choosing the successor on the smallest set as the new candidate element.
Discussion: In the context of edge computing, these traditional methods can be adopted for processing Boolean queries in a centralized fashion, that is, collecting all data in the cloud server and then evaluating the queries by these methods. Compared to the traditional centralized methods, our proposed approach improves the query efficiency from two aspects. At first, we design a decentralized query mechanism for Boolean queries which assigns the decomposed Boolean queries to the edge servers (
Section 4). Another aspect is that an efficient evaluation algorithm for the decomposed Boolean queries in single networks is proposed (
Section 5).
3. Preliminaries
The inverted index is widely used for document retrieval [
1]. For each word
w in the document collections, an ordered set with respect to
w is built that records the ID of documents containing
w. An inverted index for document collections consists of the ordered sets for all words. Given a keyword
, we can quickly obtain the ordered set
for
through the pre-built inverted index.
In general, users specify a keyword-based expression to retrieval the target documents. The processing system obtains the document sets of the keywords from the pre-built inverted index, then performs the corresponding Boolean set expression using these document sets.
In this paper, a Boolean set expression Q is defined recursively as follows. (i) is a Boolean set expression which represents a document set ; (ii) is a Boolean set expression which denotes a set intersected by the document sets of and , where and are the Boolean set expressions; and (iii) is a Boolean set expression which denotes the union for the document sets of and . Since the query processing system evaluates the Boolean set expression to retrieve the documents describing by an user-specified keyword expression, we consider the Boolean query as a Boolean set expression directly in the remainder of this paper.
Example 1. For the user-specified keyword expression bigdata ∧ ((review ∧ (ACM ∨ IEEE)) ∨ (MDPI ∧ paper)) ∧ research, it is used to retrieve the documents, where each result document must contain a set of keywords (e.g., {bigdata, MDPI, paper, research}) described by the expression. Let be the keywords bigdata, review, …, research, and be the corresponding ordered sets storing the IDs of documents that contain the keywords , respectively. The user query is answered by evaluating the following ordered set-based Boolean query. Figure 1 shows the fragments of five document samples, which contain the keywords in above example. Additionally, this figure shows the ordered sets for the keywords, e.g.,
since the keyword
:
bigdata exists in the first three samples. By evaluating the Boolean query
Q, we know that the document with id = 2 is a result for the user query since this document contains words
.
In this paper, the region of a network consists of several disjoint edge networks in edge computing, and each edge network is managed by an edge server which stores the documents and the corresponding inverted index in this sub-region, i.e., the documents are distributed and stored on different edge servers. A marginal edge network is formally defined as follows.
Definition 1. (Marginal edge network) A marginal edge network is defined as a tuple , where is the collection of edge servers contained in marginal edge networks and all edge servers in are connected to each other, and is the cloud server connecting to all edge servers in .
Aggregated Boolean Query Processing. The user sends a document request by a Boolean query Q to the cloud server . Then, the request is distributed to all edge servers by , and each edge server in processes the document request locally and obtains the intermediate results. The results of Q are finally aggregated at the cloud server by the intermediate results from edge servers.
4. Marginal Edge Network Query Processing
In this section, we discuss how to process the query in the marginal edge network. A straightforward method is to process the query in each edge server, then aggregate the results of the edge servers in the cloud server. Although this method avoids the data transmission between edge networks, the final results computed in the cloud server may not be accurate, since each edge server only considers the documents in the related edge network when processing a query.
In order to compute the accurate results (documents) for the query Q, we can transfer the ordered sets of all related documents of Q from the edge servers to the cloud server and process the query on it. However, this way will lead to massive data transmission from the edge server to the cloud server. In this section, we introduce a method that enables the intermediate results to be computed in the edge server with limited data transmission between edge servers, and the accurate result is aggregated in the cloud server by the intermediate results from edge servers.
4.1. Marginal Edge Network Query Mechanism
Given a query Q, let R be the accurate result set for Q over all documents in the cloud. Assuming that there are M edge networks, is the result set computed from the i-th edge server , where . Our target is to aggregate the results in the cloud server to compose R, that is, R can be computed by , so that only the results are transferred from the edge servers to the cloud server, and the results are computed in a distributed way.
Let be the document set containing the keyword over the whole edge servers (named as global set) and be the document set in the edge server (named as local set), i.e., . Although , i.e., the union of sets can be computed separately in each edge server, the intersection operation does not satisfy this property since , so cannot be simply computed in an edge server by replacing with for the query Q. To this end, we develop another way for the intersection operations so that the set intersections can be performed separately in each edge server.
Since , we can obtain . According to the distributive law of set operations, this equation can be expanded to . Therefore, when is computed in the edge server , the results of can be obtained in the cloud server by union of the intermediate results sent from the edge servers. is the set of documents stored in and can be accessed directly, while is the global document set over all edge networks. In order to access in an edge server, we need to broadcast to other edge servers for each . Although this operation leads to the data transmission between edge servers, the transferred data size is limited, and the query can be processed in a distributed fashion.
The above property gives the opportunity of processing the query Q in edge servers. Next, we introduce how to decompose Q to for an edge server . Since Q is recursively defined and consists of two cases, we separately discuss them. (i) , where represent the set expression (sub-query) or the set of document. In this case, is easily obtained by . (ii) . According to the above introduced method, either or is converted to the local set, and another one is still the global set, then is computed by or . In this way, for any edge server , the corresponding query can be computed by recursively applying the above two conversions on Q.
Theorem 1. Give a Boolean query Q for document sets, R is the result of Q over all edge networks. is the decomposed query from Q for the edge server , is the result of computed in . R can be computed by , where M is the number of edge networks.
4.2. Query Processing
The procedure of query processing is presented at Algorithm 1. In each edge server
,
is computed from
Q by the aforementioned method. Then, all global sets in
are broadcast between the edge servers so that each edge server
has the corresponding document sets for processing
locally. Next,
is processed in
(line 6), and the query processing in single edge networks is detailed in
Section 5. At last, the intermediate results
computed by edge servers are aggregated in the cloud server, and the final result
R is obtained by taking union for these intermediate results
.
| Algorithm 1: |
![Electronics 11 01908 i001]() |
When computing from Q, one of the operands for the set intersection operation should be selected as the global set, e.g., or should be the global set for the set intersection . Since the global sets are needed to be broadcast between the edge servers, the selected global sets affect the size of the transferred data. In order to minimize the broadcast data, we need to select the document sets with a smaller size as the global sets. To this end, we store the size of all document sets in the cloud server and utilize this size information to determine the global sets of Q in the cloud server, so each edge server can directly apply the same strategy to select global sets when computing in the edge server.
Considering the set intersection and letting and be the size of result sets and for and , the size of is estimated by since the result set size is bounded by the minimum of and . On the contrary, the size of is estimated by the size upper bound . For the recursively defined query Q, we can use these two rules to estimate the result size for the operands of set intersection, then select the one with a smaller size as the global set to minimize the transferred data.
For example, consider the running example, suppose that the size of document sets is recorded in the cloud server and . At first, consider the set intersection between and ; is selected as the global set since it has the smaller size. Then, the query conversion is applied to the later sub-query. The size of is estimated by , which is greater than ; is selected as the next global set of the sub-query, and the query conversion is applied to . Because both of the operands for the set union should be applied to the query conversion, we can obtain the converted sub-query by using the above rules. Eventually, is computed for the edge server in which , and represent the local document sets in . In the cloud server, the result R of Q is computed by performing .
5. Single Edge Network Query Processing
In this section, we introduce the method of processing the decomposed Boolean query in the single edge network. In this scenario, the edge server contains all necessary ordered sets of documents for the decomposed query. At first, we parse the Boolean query into a graph structure in
Section 5.1. The method of Boolean query processing in the single-edge network is presented in
Section 5.2, which computes an execution plan from the parsed graph.
5.1. Parsing Boolean Set Expression
To evaluate the Boolean set expression, a naive way is to perform pair-wise set intersection (or union) starting from the inner set operations. However, this way leads to inefficient query processing since the irrelative elements in ordered sets are compared and the intermediate results are recomputed [
1]. For the multi-set intersection problem (which is a simple case for the set expression), it is shown that a holistic element comparison outperforms the pair-wise set comparison; this motivates us to design a holistic element comparison method to compute the results for the set expression.
Example 2. The query is used as the example (decomposed query) to illustrate query processing in single-edge networks. For simplification, we use to represent in this section, where and represent and ; and represent and , respectively. The example of sets in the edge server are shown in Table 1, and the result of Q on these sets is . In order to evaluate the query Q, we design a graph structure to parse Q, named the union-intersection graph, as follows.
Definition 2. (Union-intersection Graph) A union-intersection graph (UIGraph) is an undirected graph which represents a set expression Q, where is a set of nodes, among which one is the initial node I and one is the final node F. is a set of edges which are the sets from Q.
For the UIGraph, the conjunctive and disjunctive structures are used to represent the intersection and union of ordered sets, respectively.
Figure 2 shows the two basic structure for
and
. Hence, a query
Q can be represented by an UIGraph
G with nested conjunctive and disjunctive structures.
We can compute the UIGraph
G for the query
Q by constructing conjunctive and disjunctive structures for intersection and union operations, respectively.
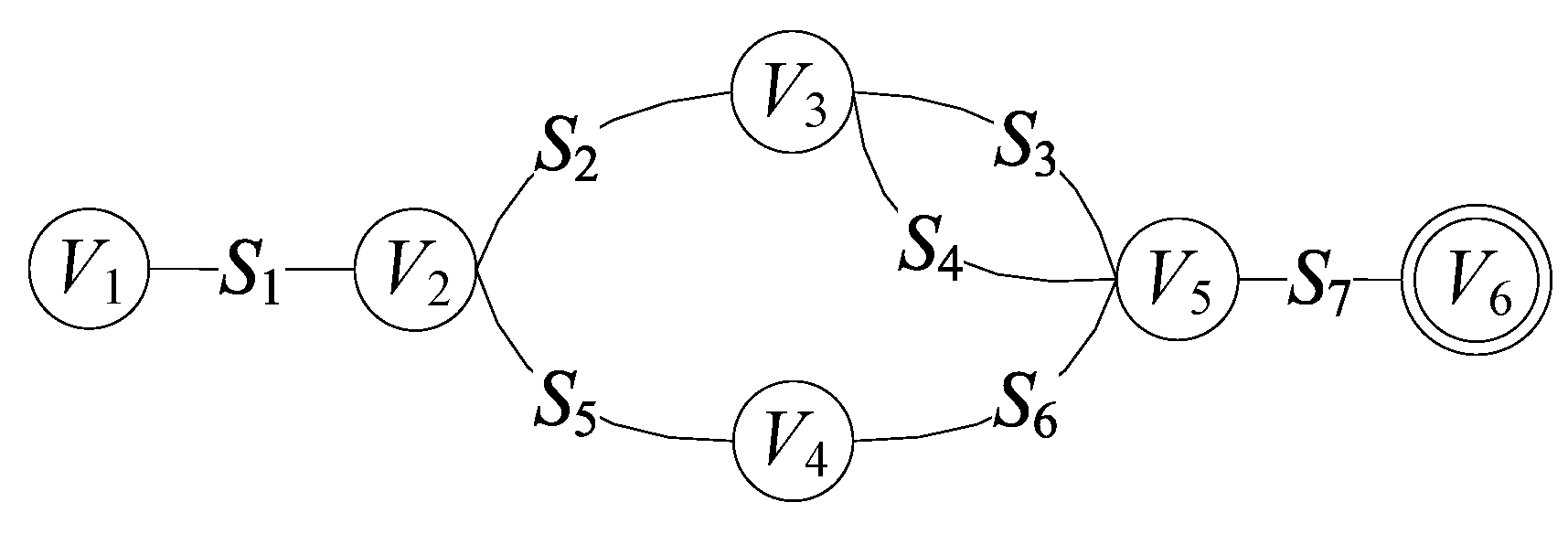
Figure 3 shows the built UIGraph
G for the running example.
For a graph, a path
P starting from the initial node and ending at the final node is called a
simple path if all of its nodes are distinct [
46]. The UIGraph also contains the simple paths, e.g., there are three simple paths for the UIGraph in
Figure 3 that are
-
-
-
,
-
-
-
and
-
-
-
.
Theorem 2. For each simple path P in a UIGraph G, if and only if there is an element e such that e exists in all the order sets of P, then e is an evaluation result of the query Q.
For example, 39 is contained by sets , , and which are the ordered sets of a simple path, so 39 is an evaluation result of Q. We omit the detailed proof for Theorem 2; it can be easily proved based on the fact that the element exists in the sets of a simple path of G must satisfy the logical requirements of Q.
5.2. Boolean Query Processing in Single Edge Networks
5.2.1. Evaluation Tree
According to Theorem 2, we know that for any result
e of
Q,
e must be contained by the ordered sets in a simple path of
G. In order to obtain all results, we use the elements in a
s-t cut [
46] of
G as
candidate elements, which may be the final results.
Definition 3. (s-t cut) A s-t cut is a collection of edges (ordered sets) of UIGraph G which partitions the nodes of G into two disjoint subsets, and the initial and final nodes belong to different subsets [46]. We use to denote a s-t cut of G. For any simple path P on G, P contains at least a set in a s-t cut of G. Accordingly, any evaluation result of Q must be contained by the sets in a s-t cut. Given a s-t cut of G, we call candidate sets and use the elements in the sets of as candidate elements. For example, and are two different s-t cuts of G, which can be used as the candidate sets separately.
For a candidate element from a candidate set , the verification for is to check if there exists a simple path P such that all order sets of P contain , which can be represented by a Boolean expression, . However, not all simple paths of G can produce an evaluation result . Since , in order to verify , we only need to consider the ordered sets in the simple paths which contain . The Boolean expression consists of a set of variables on such ordered sets, which indicate whether an element exists in an ordered set .
Example 3. Consider the running example, assume that is the set of candidate document sets. The corresponding Boolean expressions of and are shown as below. Consider the candidate element from , since is true, we can obtain that 10 is a result of Q. So far, to verify a candidate element
, we only need to evaluate the corresponding Boolean expression
. Borrowing the idea of evaluating a Boolean expression by using the binary decision tree [
47], we define an
evaluation tree to guide the checks for the ordered sets in a Boolean expression
.
Definition 4. (Evaluation Tree) An evaluation tree is a rooted binary tree used to verify a candidate element , in which each internal node indicates the result of checking if an ordered set contains , and leaf nodes are the verification results.
There are two types of leaf nodes, called 1-leaf and 0-leaf, which represent the true and false results of verifying . Each internal node is a variable in , i.e., , abbreviated as . If is true, then there is an element existing in the set .
The expected matching cost of the evaluation tree indicates the expected number of checked ordered sets to verify a candidate element
. In order to minimize the matching cost, we compute the evaluation tree with minimal expected cost for each Boolean expression
where
. The dynamic programming algorithm introduced in [
48] is employed in this paper to compute the evaluation tree with minimal expected cost, which has the time complexity
, where
r is the number of sets, and
N is the number of set operations in
Q.
5.2.2. Performing Evaluation Tree-Based Plan
An execution plan consists of the candidate sets and the collection of the corresponding evaluation trees which are used to verify the candidate elements in . We next show how to compute the evaluation results using . The procedure is described in Algorithm 2. There are two issues that need to be solved when performing an execution plan: (1) the scheme of verifying candidate elements in candidate sets; and (2) how to verify a candidate element using evaluation tree.
For the first issue, a basic scheme is to individually verify each candidate set in
. However, this way loses the chance to skip some invalid candidate elements. We observe that if the candidate elements are verified in the ascending order, then some candidate elements that cannot be the evaluation results can be quickly skipped using the intermediate obtained results (we give the details in
Section 5.2.3). To achieve this goal, we build a heap
H for the top elements of ordered sets in
which costs time
to obtain an element [
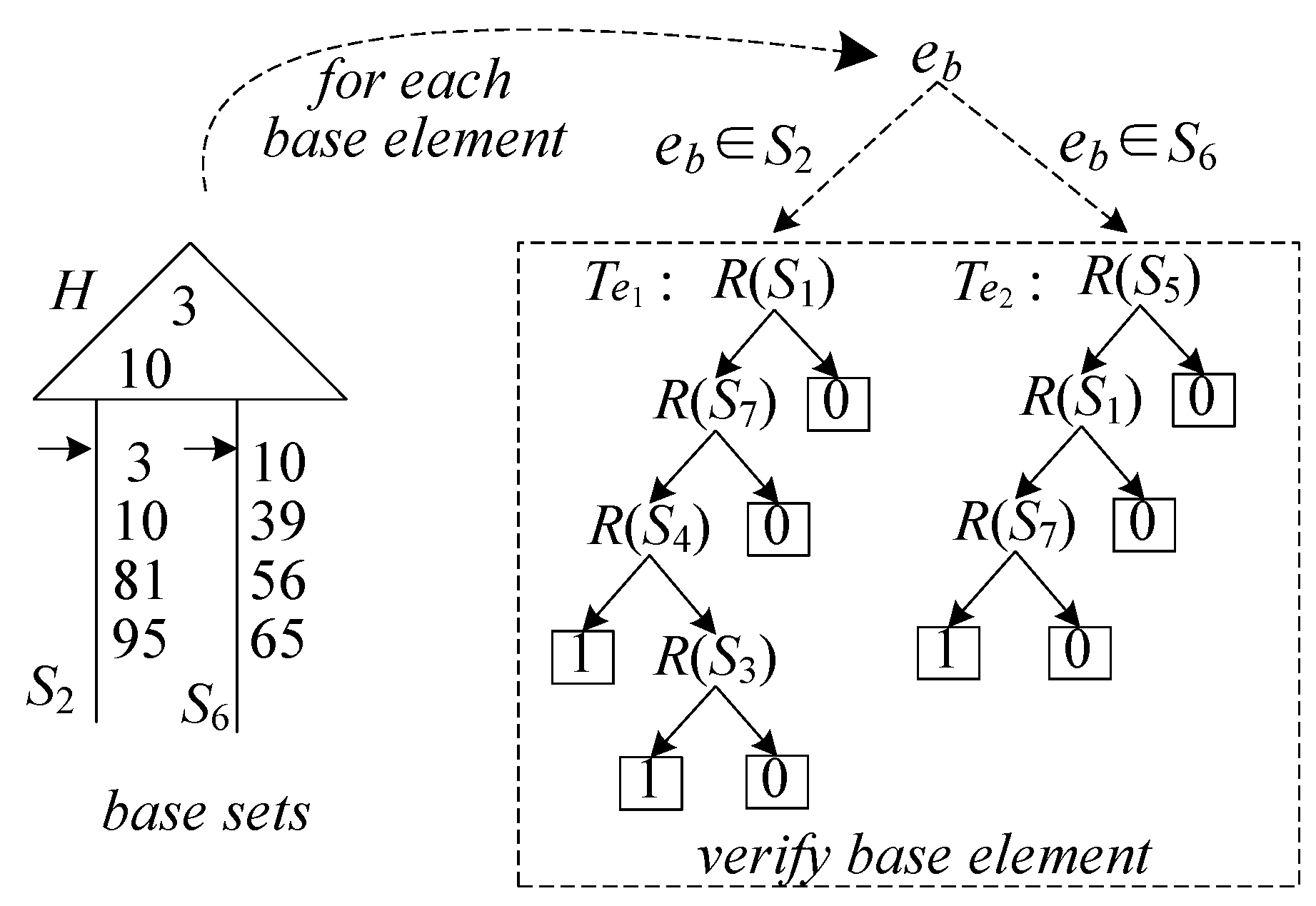
49]. For example, as shown in
Figure 4, a heap is built for
and
, and the candidate elements are verified in the order
.
| Algorithm 2: |
![Electronics 11 01908 i002]() |
For the second issue, for each candidate element
obtained from
H, it is verified by the corresponding evaluation tree
. The algorithm checks the internal nodes of
starting from the root until a leaf node is reached (lines 8–14). In each internal node
, the result is checking if
contains the candidate element
. In this work, we employ the gallop search [
50] to search an element from
, which has time complexity
(log
K), where
K is the largest size of the ordered sets in
Q. If a 1-leaf node is reached, then
is an evaluation result of
Q (lines 15–16). Note that the candidate elements obtained from
H could be repeated, e.g., 10 is repeated in the running example, for the repeated element
, if
is already turned out to be an evaluation result, then it is unnecessary to verify it again (lines 4–5).
Let L be the number of ordered sets in Q, and let be the number of candidate elements in . The algorithm spends time to verify a candidate element. To obtain candidate elements in the ascending order, time is used to adjust the heap H after a candidate element is popped. Hence, the time complexity of is .
Example 4. For the execution plan shown in Figure 4, the procedure of computing evaluation results by the execution plan is shown in Figure 5. verifies 7 candidate elements and only checks the ordered sets 18 times in total, in which elements 10 and 39 are turned out to be the results since 1-leaf nodes are reached when verifying them. 5.2.3. Optimizing Execution Plan by Skipping Invalid Candidate Elements
In the previous example, all candidate elements are verified. We observe that some candidate elements that cannot be the evaluation results (called invalid candidate elements) can be safely skipped without verification using the obtained verification results. In this section, we present the technique to skip the invalid candidate elements.
Recall the procedure of verifying a candidate element ; in order to obtain the result of each internal node in a root-to-leaf path of , we search on and return the first element such that . If the returned element , then is false. Actually, in this case, because the candidate elements are processed in ascending order, the returned failed element indicates that the next candidate element should be no less than if contains the next evaluation result. Based on this property, if the result of verifying is false (i.e., a 0-leaf node is reached), then a lower bound for the next candidate element can be computed through the obtained failed elements in the internal nodes of the root-to-leaf path.
For a candidate element
, let
be the root-to-leaf path (i.e., with 0-leaf node) when verifying
, and
be the set of failed elements returned by the ordered sets in
, then
is computed as follows.
Apparently, the next evaluation result should be no less than . Hence, the candidate elements which are less than can be safely skipped. When verifying a candidate element , the failed elements can be recorded by the matching algorithm (line 11 in Algorithm 2), that is, the minimum of the failed elements can be computed in the time complexity . Therefore, skipping invalid candidate elements has the time complexity .
Example 5. Consider the example shown in Figure 5; when checking , the failed element is returned by . Since only is false in the root-to-leaf path, we can compute . Then, the next candidate element can be skipped since . In the next, a 0-leaf node is reached when verifying and two failed elements and are obtained, so we obtain . The following candidate element is skipped by the lower bound . After skipping the invalid candidate elements, only 5 candidate elements are verified and the ordered sets are checked 14 times. 6. Experiments
In this section, we present the experimental results of our proposed algorithms with traditional algorithms on two real-world datasets.
6.1. Experimental Setup
In order to simulate the context of edge computing, we built a network with 10 nodes in which 9 nodes represent the edge servers and 1 node represents the cloud server of the network. In edge computing, each edge server is used to manage the sub-region (edge network) of the network, that is, each edge server caches the documents for the corresponding sub-region for our studied problem. Therefore, documents are distributed to the edge server nodes in this setting. We used two datasets (documents) with different data sizes in the following experiments, and each dataset is divided into 9 subsets with a random percentage and stored in edge server nodes.
The details of the datasets are shown as follows.
Source Files is a set of source code files that extracted from Github, including Python, Ruby, JavaScript, Java, C and C++ files; it contains 697,485 text files in 3.69 GB of text.
Medline is a bibliographic database of life sciences and biomedical information. We used a late-2008 snapshot of Medline, which consists of 17,104,854 citation entries with abstracts.
In each edge server node, the inverted lists for each word in the subset of dataset are built. The inverted lists are ordered sets that contain the IDs of files. For the source file dataset, we collected the real Boolean queries from the online library and forums (
http://www.regexlib.com, accessed on 27 December 2021), which aim to find files that contain certain keywords. Among the collected real queries, we used 80 queries whose evaluation results are not empty in this dataset. For the Medline dataset, we used a full-day’s query log of PubMed that was obtained from the NLM FTP site (refer to [
51] to access the query log). These queries were issued by 626,554 distinct users, in which we also chose 80 queries that contain
and/
or operators as Boolean queries.
In order to study the impact of the complexity of queries on query efficiency, we further classified the Boolean queries into six categories using the number of keywords contained by each query, as shows in
Table 2.
As far as we know, existing algorithms for document retrieval can only process the Boolean queries in a centralized fashion. We compared our proposed method with these centralized algorithms on the query efficiency. We selected the following algorithms as the representatives of existing algorithms for the Boolean query evaluation.
For the first three comparative algorithms, they process the Boolean queries in a centralized fashion, that is, all inverted lists for the relative documents of the query are collected to the cloud server node, then the query is evaluated in the cloud server node.
The experiments were carried out on a PC with an Intel i7-6700 3.4 GHz processor and 8 GB RAM, running Ubuntu 14.04.3. The algorithms were implemented in C++.
6.2. Comparison with Traditional Centralized Algorithms
The first experiment compares the running time of our proposed algorithm
and the comparative algorithms.
,
and
are the above introduced comparative algorithms. We also tested our proposed algorithm in the centralized mode (labeled by
-
), i.e., collecting all inverted lists of related documents to the cloud server node and using the algorithm in
Section 5.2 to process the Boolean query. For the centralized algorithms, we separately recorded the time of data transmission and the elapsed time of algorithms, where the time of data transmission is labeled by
-
. Since
processes the queries in the edge server nodes, the running time of
includes the data transmission time and the intermediate results aggregation time.
For each query category
, we averaged the running time of queries in
. We plot the average running time of different algorithms for the two real datasets in
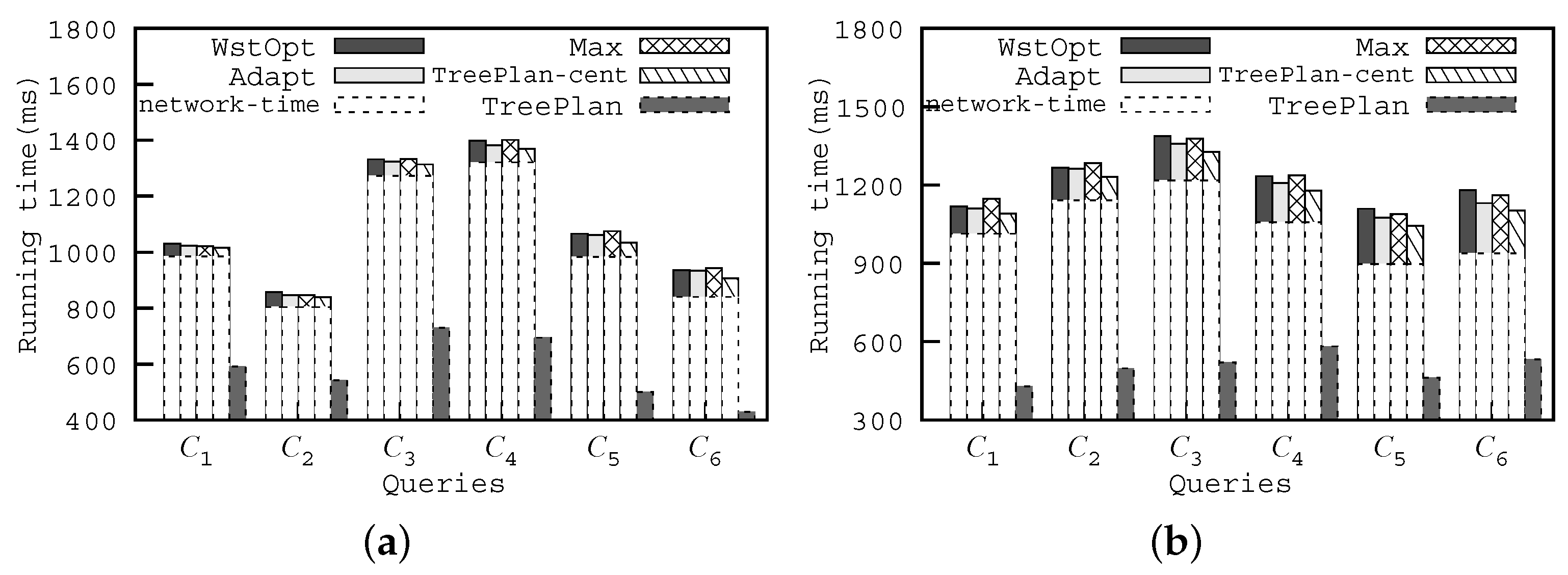
Figure 6. We can see that
obtains a great advantage on the query time over the centralized algorithms on both datasets. For example, for the queries
in the source codes dataset, the running time spent by
is only 429 ms, while the running spent by other algorithms is more than 2× to the running time of
. The main reason is that the data transmission time for
is far less than the time for the centralized algorithms. Additionally, from the view of centralized algorithms, our proposed algorithm is also more efficient than the comparative algorithms.
-
has the same data transmission time as
,
and
, while it spends less time on the phase of query evaluation.
6.3. Evaluating Tree-Based Query Plan
In this experiment, we tested the tree-based query plan proposed in
Section 5.2. To evaluate the algorithm performance accurately, we collected all documents in the cloud server node and queries are processed locally on it, i.e., the running time indicates the elapsed time of the algorithm.
6.3.1. Cost Analysis for Tree-Based Query Plan
In
Section 5.2, we computed the optimal execution plan with the minimal matching cost for our proposed algorithm. An alternative way is computing the execution plan using the heuristic rule that utilizes the min-cut [
46] of an UIGraph as the candidate sets. We used
and
to represent the algorithms that utilize heuristic and optimal evaluation plan, respectively. Both of
and
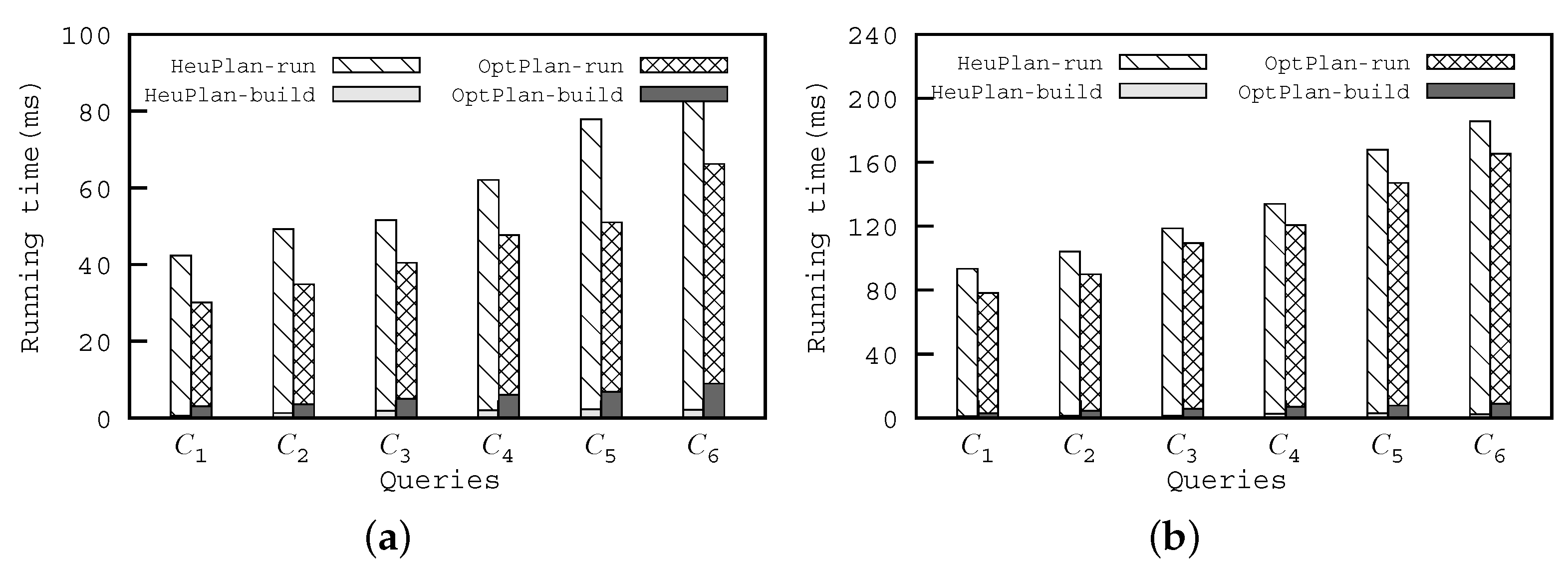
are our proposed algorithms which employ different execution plan computing strategies. We separately tested the time of the computing evaluation plan and using plan to find the evaluation results, which are annotated with the suffixes
and
in
Figure 7.
As we can see from
Figure 7,
achieves better performance than
for the different datasets and queries.
needs more time to build the evaluation plan than
, but
spends less time than
in the phase of plan execution. For example, for the queries
in source code dataset,
spends only 2.23 ms to build the evaluation plan, versus 6.8 ms used by
. However,
only spends 44.22 ms to performing evaluation plan, which is less than the time used by
. Meanwhile, we can find that, regardless of the datasets, the evaluation plan can be efficiently built, and the time of building an evaluation plan for any category of queries is less than 10 ms.
6.3.2. Effect of Skipping Invalid Candidate Elements
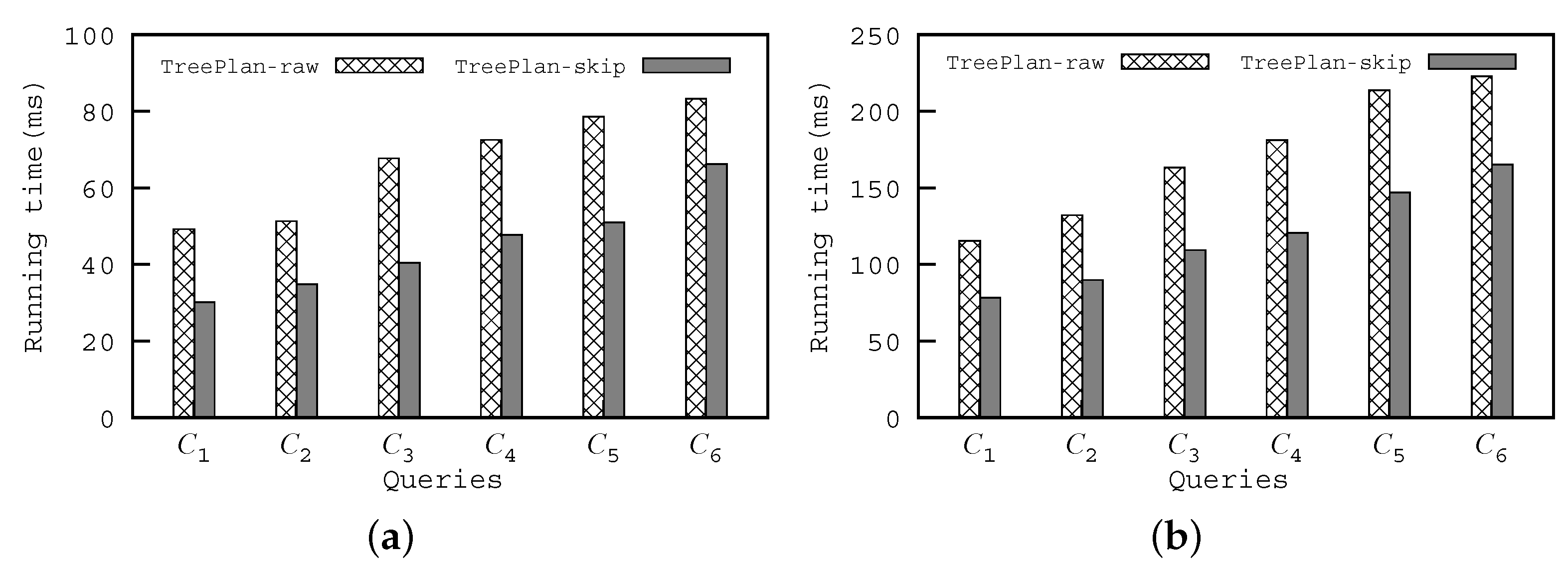
In this experiment, we tested the effect of an optimization technique that skips the invalid candidate elements which cannot be the final evaluation results (see
Section 5.2.3). We used
-
and
-
to respectively represent our proposed algorithms that employ the optimization technique and without optimization. The results are shown in
Figure 8. In different dataset and queries,
-
always spends less running time than
-
since
-
checks fewer candidate elements. The gap of the running time between the two algorithms is most obvious for the queries in
in source file dataset, i.e., the running times of
-
against
-
are 40.47 ms and 67.05 ms.
As for the time cost for skipping invalid candidate elements, we showed that the time complexity for this optimization is
in
Section 5.2.3. Additionally, to analyze the practical time cost, we tested the algorithm that still computes the minimum
of the failed elements for each candidate element, but without skipping the invalid candidates. The time for this algorithm is almost the same as the time spent by
-
, which means that the cost for skipping invalid candidate elements is minuscule.
7. Conclusions
Considering the large scale of the network and the swift growth of users for search engines, the traditional centralized methods for document retrieval may not be efficient and applicable when documents are distributed on the local caching servers, thus edge computing is employed to facilitate the distributed Boolean query processing for document retrieval. In this paper, we propose an aggregated Boolean query mechanism in edge computing to support efficient document retrieval. Specifically, we design a marginal edge network boolean query mechanism, which enables the query to be processed in the edge servers by a decentralized fashion. To achieve this goal, the original Boolean query is decomposed in the cloud server and assigned to edge servers. The global sets caused by the intersection operations in decomposed Boolean queries are broadcast among edge servers so that each boolean query can be processed locally (
Section 4), and the number of intersections positively correlates with the number of global sets. Therefore, our proposed algorithm has a greater advantage in processing the Boolean queries with fewer intersections and more unions.
We also propose an evaluation tree-based method to process the queries in single-edge networks, and design optimization techniques of skipping invalid element comparisons to accelerate the query evaluation. Extensive experiments on real-world datasets were conducted, and the results show that our proposed technique outperforms the traditional centralized methods in query efficiency.














{kind=link}
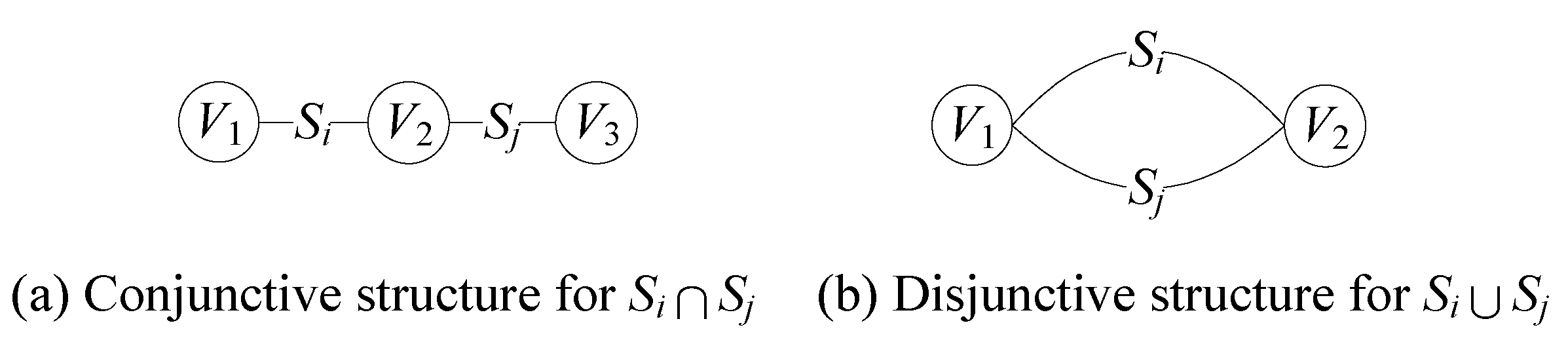{kind=link}
{kind=link}
{kind=link}
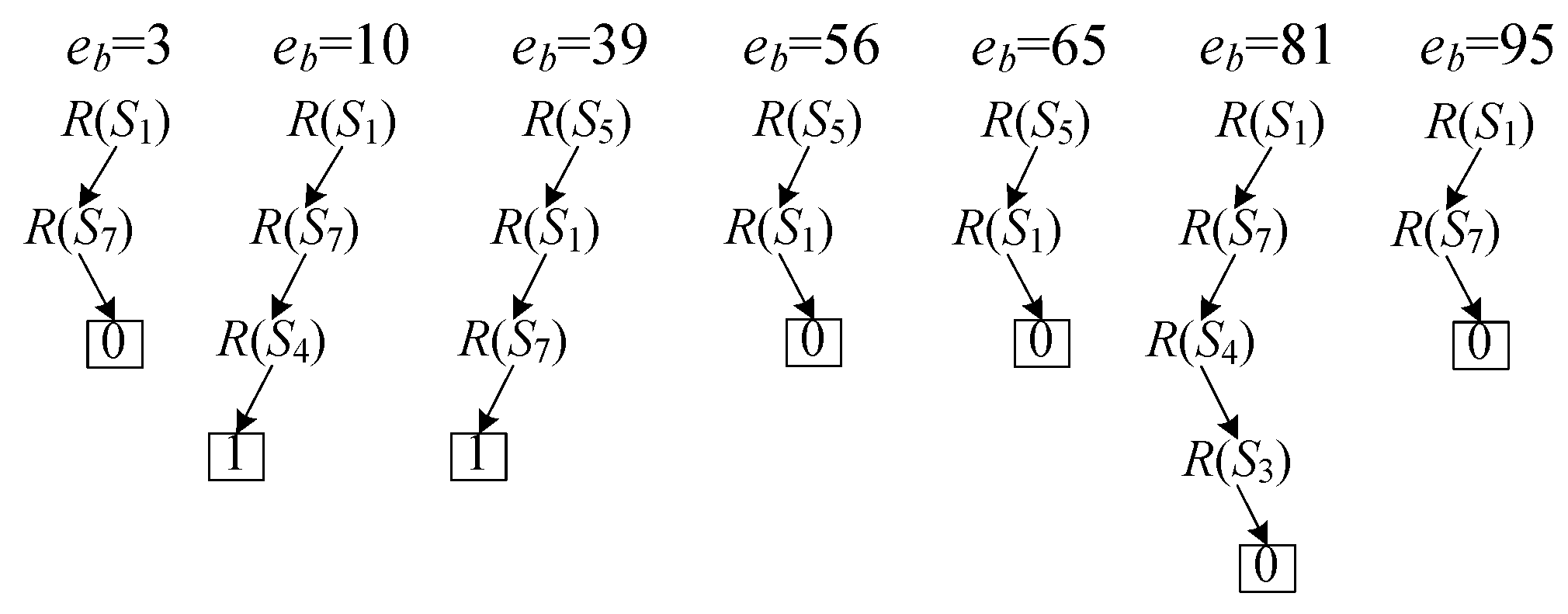{kind=link}
{kind=link}
{kind=link}
{kind=link}