
Utilizing Virtualized Hardware Logic Computations to Benefit Multi-User Performance †



Abstract
:1. Introduction
2. Background and Related Work
2.1. Hardware Virtualization
2.1.1. Temporal Partitioning of Net Lists
2.1.2. Temporal Partitioning of State
2.1.3. Virtual Execution
2.1.4. Virtual Machine
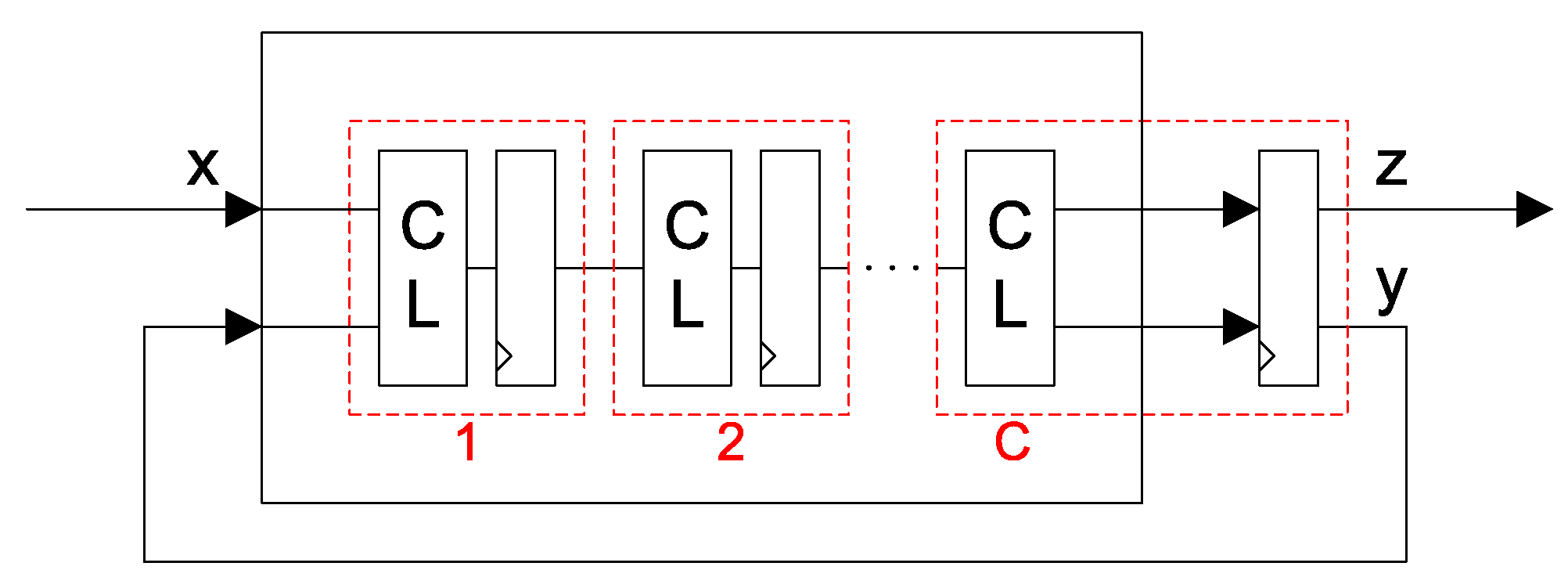
2.2. C-Slow Transformation
2.3. Vacations in Queueing Models
3. Methods
3.1. Virtual Hardware Configuration
3.2. M/G/1 Model Development
3.2.1. Vacation Waiting Time Model
3.2.2. Service Time Model
3.2.3. Queueing Model
3.3. Simulation Models
3.3.1. Discrete-Event Simulation
3.3.2. Logic Simulation
- The specifics of the secondary memory are left unspecified in Figure 4.
- In the analytic and discrete-event simulation models, we assume that neither the input queueing and multiplexer data path nor the scheduler and other control logic limit the operating clock frequency of the system.
- The only scheduling algorithm investigated so far is a hierarchical round-robin algorithm.
3.4. Clock Model
3.5. Model Validation
3.5.1. Verifying Assumptions
3.5.2. Cross-Validation of Performance Models
3.6. Example Applications
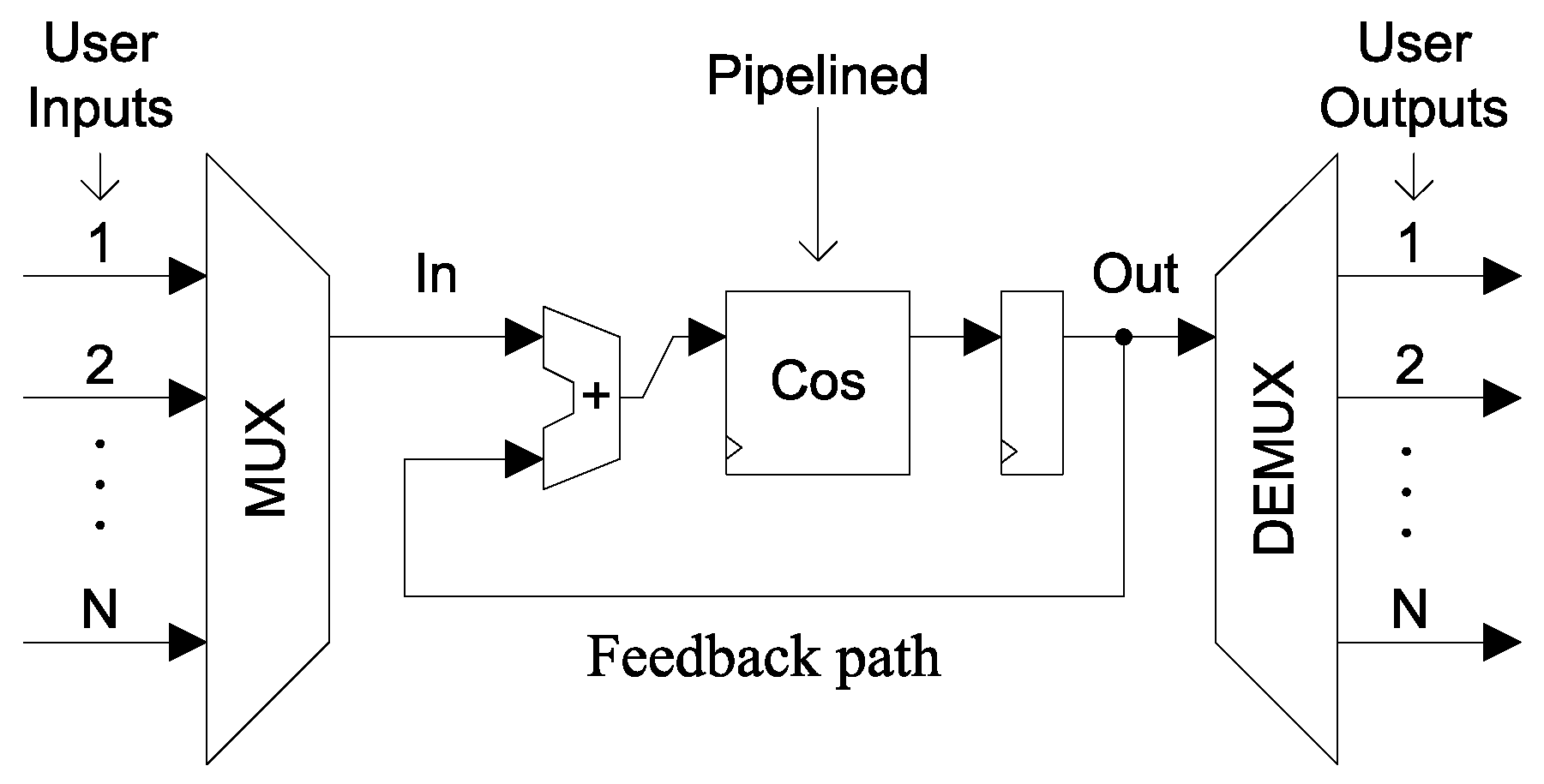
3.6.1. Synthetic Cosine Application with Added Feedback (COS)
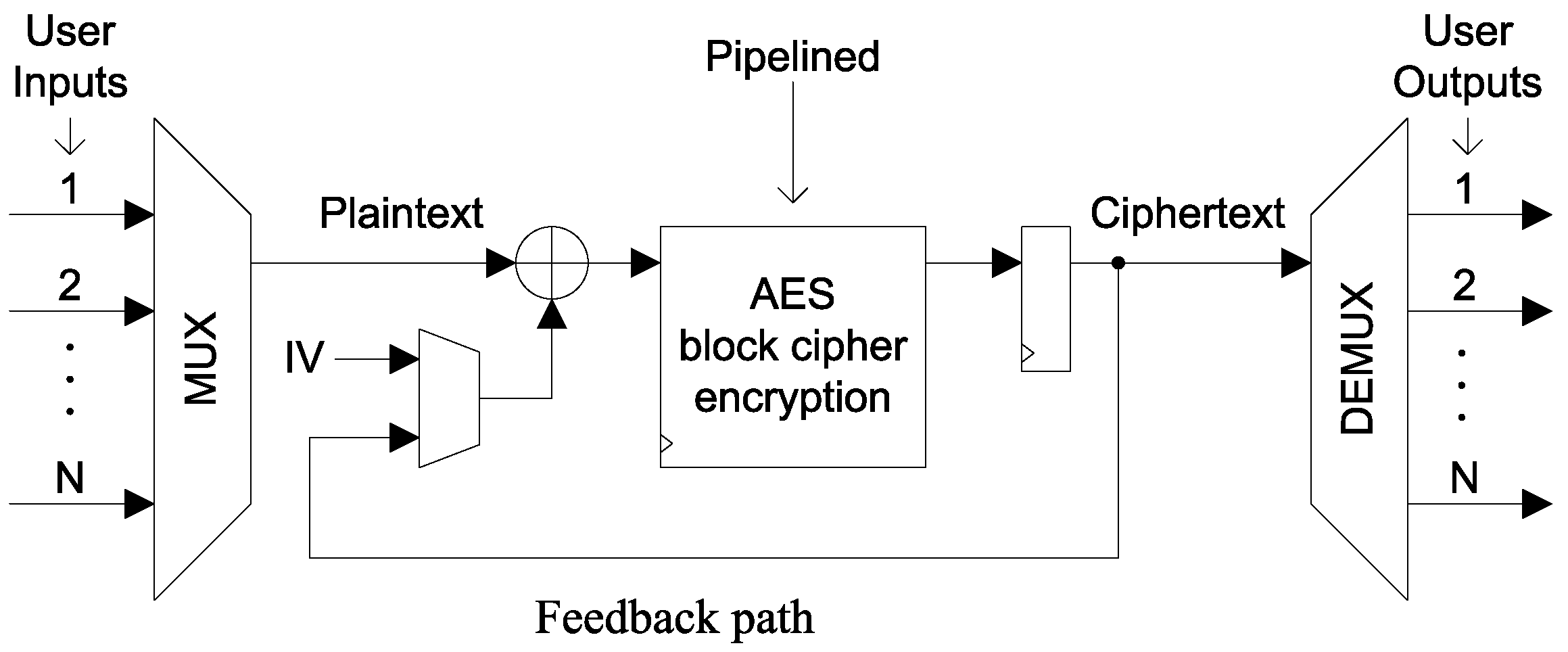
3.6.2. Advanced Encryption Standard (AES) Cipher in Cipher-Block Chaining Mode
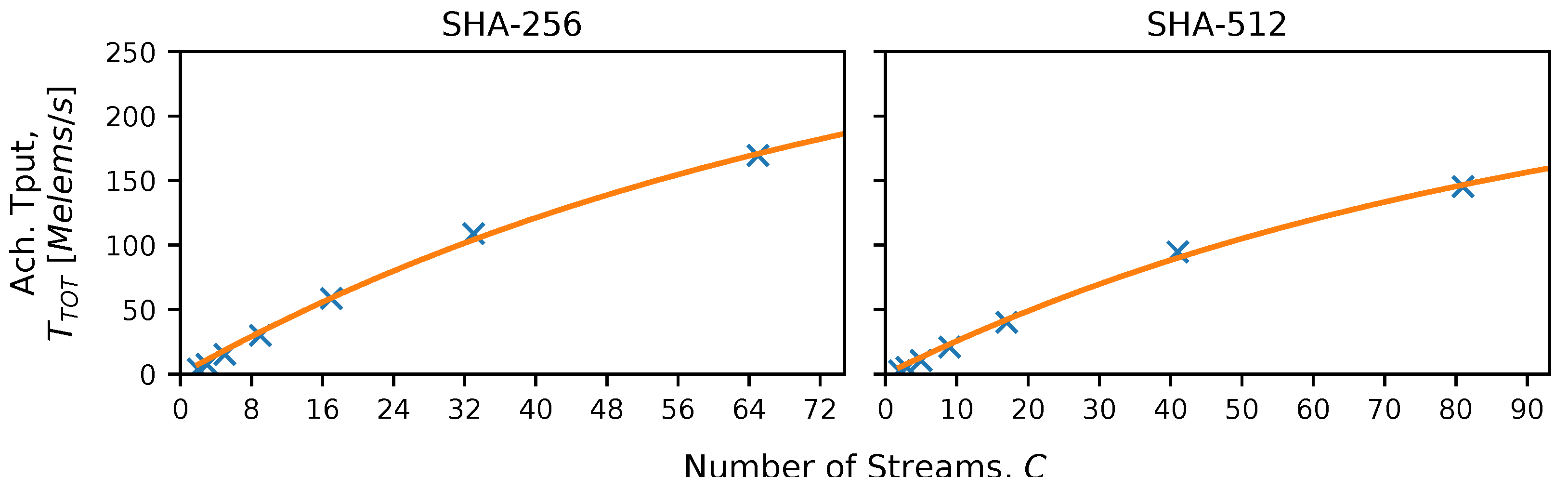
3.6.3. Secure Hash Algorithm (SHA-2) with 256 and 512 bit Digests
4. Results and Discussion
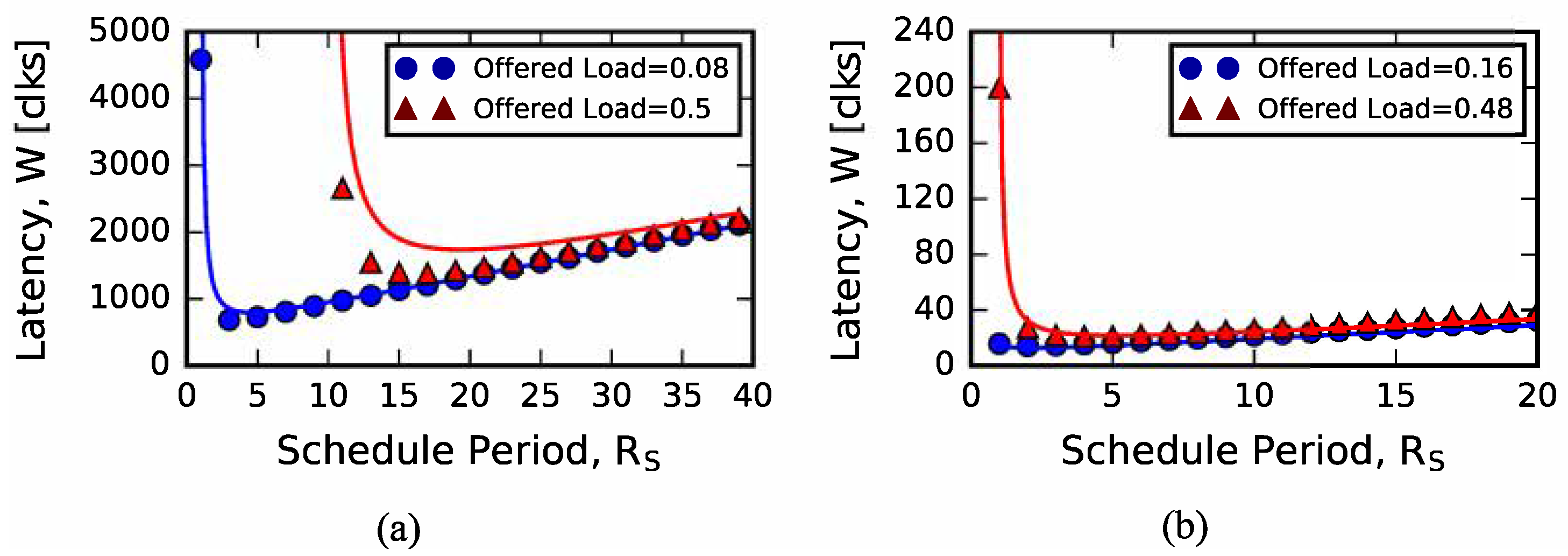
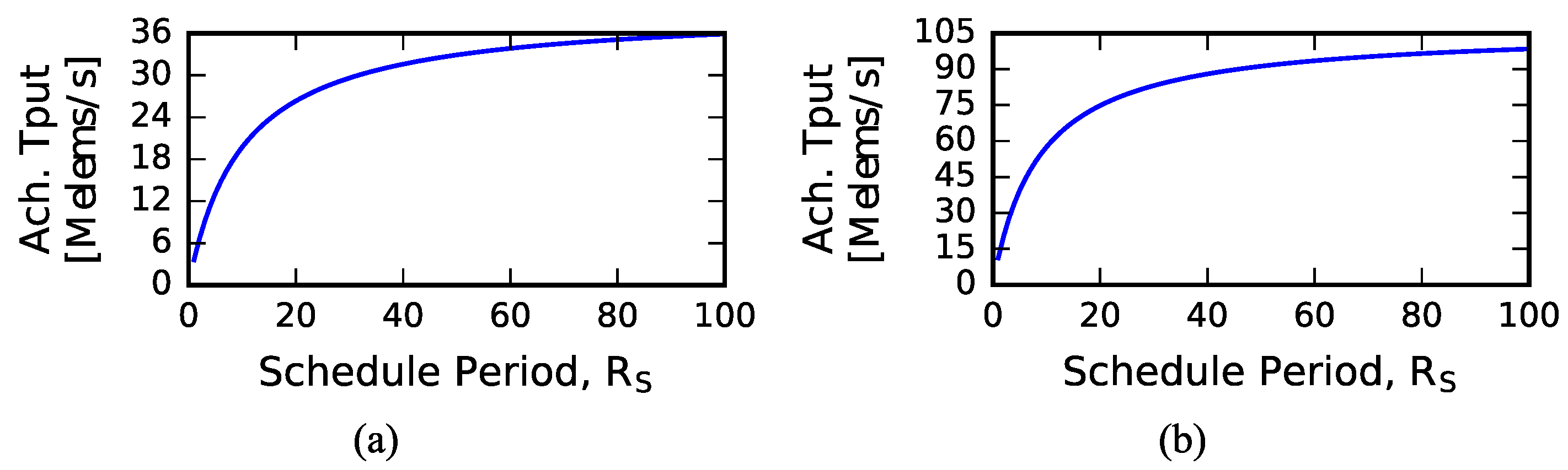
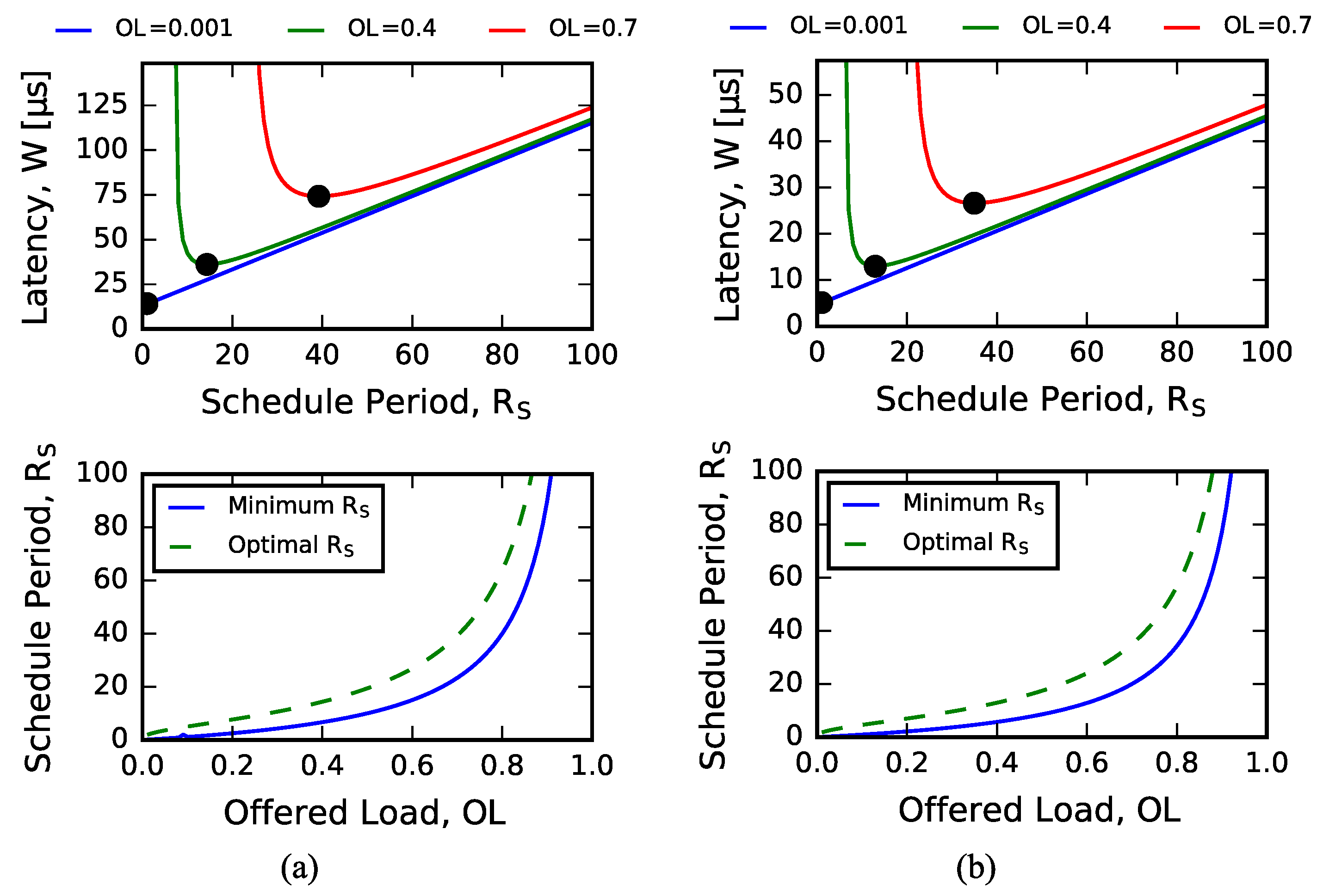
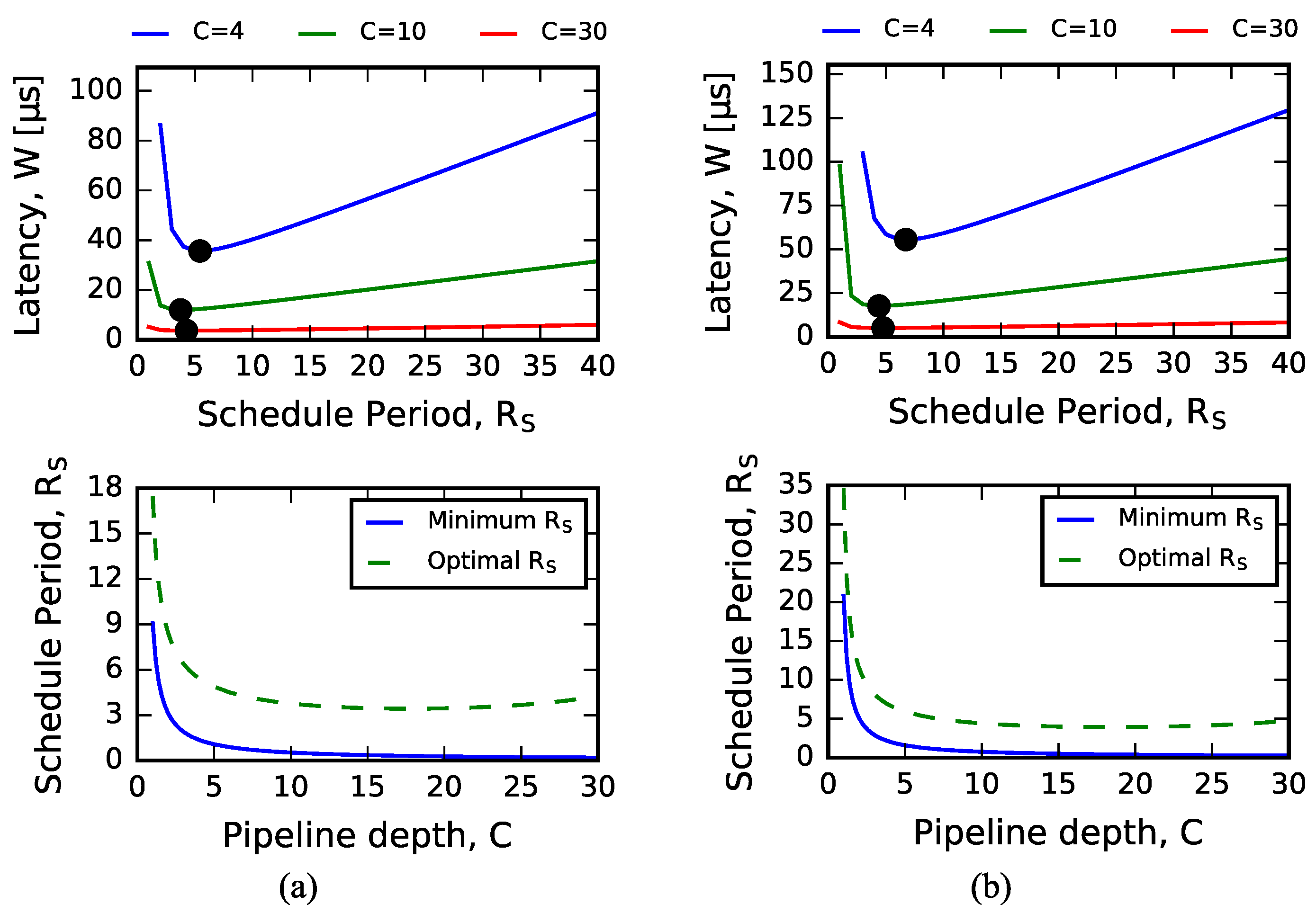
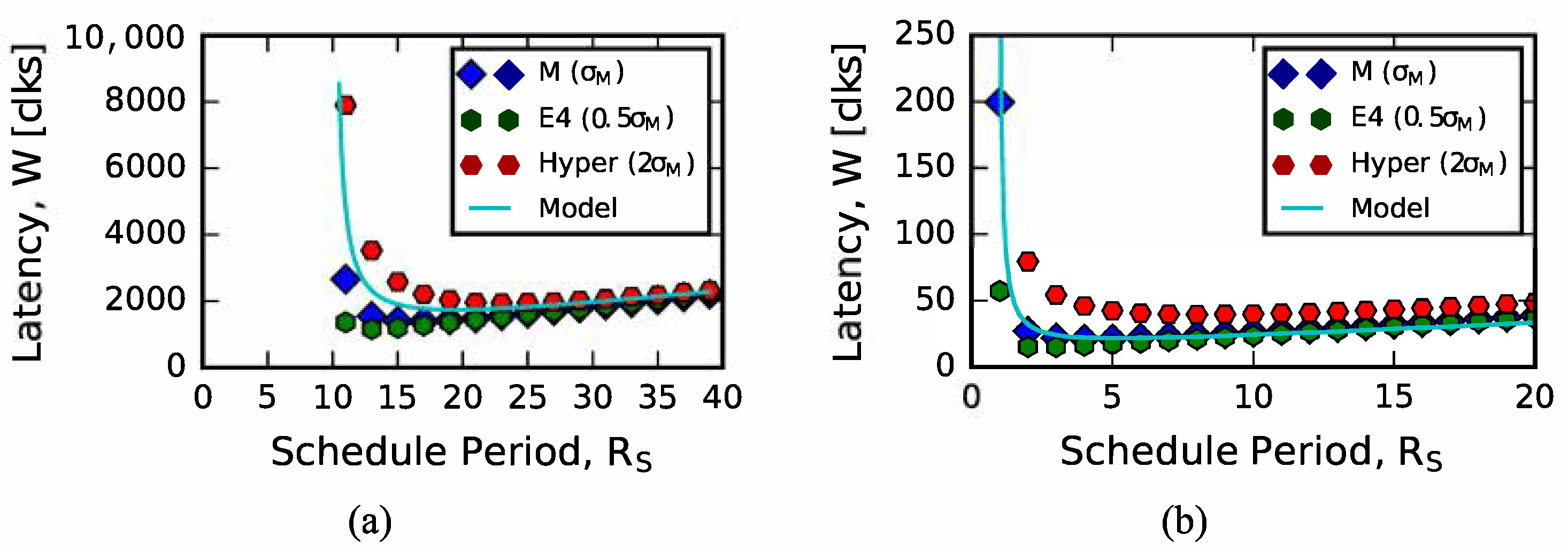
4.1. Analytical Model Predictions
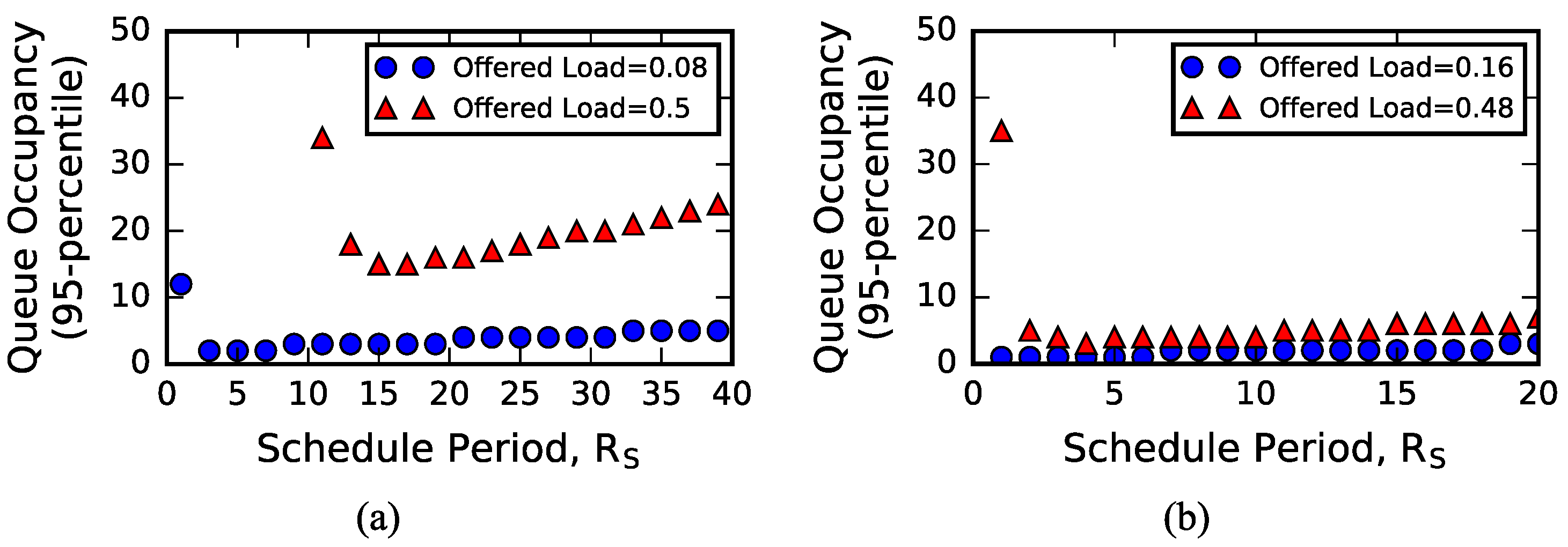
4.2. Sizing Input Queues
4.3. Exploring Arrival Process Distribution
4.4. Alternate Scheduling Algorithms
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Calibration of Clock Model
Appendix A.1. Synthetic Cosine Application with Added Feedback (COS)
Appendix A.2. Advanced Encryption Standard (AES) Cipher in Cipher-Block Chaining Mode
Appendix A.3. Secure Hash Algorithm (SHA-2) with 256 and 512 bit Digests
References
- Moore, G.E. Cramming more components onto integrated circuits. Electronics 1965, 38, 114–117. [Google Scholar] [CrossRef]
- Dennard, R.H.; Gaensslen, F.H.; Rideout, V.L.; Bassous, E.; LeBlanc, A.R. Design of ion-implanted MOSFET’s with very small physical dimensions. IEEE J. Solid-State Circuits 1974, 9, 256–268. [Google Scholar] [CrossRef] [Green Version]
- Esmaeilzadeh, H.; Blem, E.; St. Amant, R.; Sankaralingam, K.; Burger, D. Dark Silicon and the End of Multicore Scaling. IEEE Micro. 2012, 32, 122–134. [Google Scholar] [CrossRef] [Green Version]
- TOP500 List. Available online: https://www.top500.org/lists/top500/2020/11/ (accessed on 6 February 2021).
- Amazon EC2 Instance Types. Available online: https://aws.amazon.com/ec2/instance-types/ (accessed on 6 February 2021).
- Barham, P.; Dragovic, B.; Fraser, K.; Hand, S.; Harris, T.; Ho, A.; Neugebauer, R.; Pratt, I.; Warfield, A. Xen and the Art of Virtualization. Sigops Oper. Syst. Rev. 2003, 37, 164–177. [Google Scholar] [CrossRef]
- Chisnall, D. The Definitive Guide to the Xen Hypervisor; Prentice Hall: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Caulfield, A.M.; Chung, E.S.; Putnam, A.; Angepat, H.; Fowers, J.; Haselman, M.; Heil, S.; Humphrey, M.; Kaur, P.; Kim, J.Y.; et al. A Cloud-scale Acceleration Architecture. In Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture, Taipei, Taiwan, 15–19 October 2016; IEEE Press: Piscataway, NJ, USA, 2016. [Google Scholar]
- Cusumano, M. Cloud Computing and SaaS as New Computing Platforms. Commun. ACM 2010, 53, 27–29. [Google Scholar] [CrossRef]
- Tizzei, L.P.; Nery, M.; Segura, V.C.V.B.; Cerqueira, R.F.G. Using Microservices and Software Product Line Engineering to Support Reuse of Evolving Multi-Tenant SaaS. In Proceedings of the of 21st International Systems and Software Product Line Conference, Sevilla, Spain, 25–29 September 2017; Volume A, pp. 205–214. [Google Scholar] [CrossRef]
- Plessl, C.; Platzner, M. Virtualization of Hardware—Introduction and Survey. In Proceedings of the 4th International Conference on Engineering of Reconfigurable Systems and Algortihms, Las Vegas, NV, USA, 31 August–4 September 2004; pp. 63–69. [Google Scholar]
- Tullsen, D.M.; Eggers, S.; Emer, J.; Levy, H. Exploiting choice: Instruction fetch and issue on an implementable simultaneous multithreading processor. In Proceedings of the 23rd International Symposium on Computer Architecture, Philadelphia, PA, USA, May 1996; pp. 191–202. [Google Scholar]
- Chuang, K.K. A Virtualized Quality of Service Packet Scheduler Accelerator. Master’s Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2008. [Google Scholar]
- Goldstein, S.; Schmit, H.; Budiu, M.; Cadambi, S.; Moe, M.; Taylor, R. PipeRench: A reconfigurable architecture and compiler. Computer 2000, 33, 70–77. [Google Scholar] [CrossRef]
- Leiserson, C.; Saxe, J. Retiming synchronous circuitry. Algorithmica 1991, 6, 5–35. [Google Scholar] [CrossRef]
- Weaver, N.; Markovskiy, Y.; Patel, Y.; Wawrzynek, J. Post-placement C-slow retiming for the Xilinx Virtex FPGA. In Proceedings of the 11th International Symposium on Field Programmable Gate Arrays, Monterey, CA, USA, 23–25 February 2003; pp. 185–194. [Google Scholar] [CrossRef]
- Su, M.; Zhou, L.; Shi, C.J. Maximizing the throughput-area efficiency of fully-parallel low-density parity-check decoding with C-slow retiming and asynchronous deep pipelining. In Proceedings of the 25th International Conference on Computer Design, Lake Tahoe, CA, USA, 7–10 October 2007; pp. 636–643. [Google Scholar] [CrossRef]
- Akram, M.A.; Khan, A.; Sarfaraz, M.M. C-slow Technique vs. Multiprocessor in designing Low Area Customized Instruction set Processor for Embedded Applications. Int. J. Comput. Appl. 2011, 36, 30–36. [Google Scholar]
- Hall, M.J.; Chamberlain, R.D. Performance Modeling of Virtualized Custom Logic Computations. In Proceedings of the 24th ACM International Great Lakes Symposium on VLSI, Houston, TX, USA, 21–23 May 2014. [Google Scholar] [CrossRef] [Green Version]
- Hall, M.J.; Chamberlain, R.D. Performance modeling of virtualized custom logic computations. In Proceedings of the 25th IEEE International Conference on Application-Specific Systems, Architectures and Processors, Zurich, Switzerland, 28–20 June 2014; pp. 72–73. [Google Scholar] [CrossRef] [Green Version]
- Hall, M.J.; Chamberlain, R.D. Using M/G/1 queueing models with vacations to analyze virtualized logic computations. In Proceedings of the 2015 33rd IEEE International Conference on Computer Design (ICCD), New York, NY, USA, 18–21 October 2015; pp. 78–85. [Google Scholar] [CrossRef]
- Bertsekas, D.; Gallager, R. Data Networks, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 1992. [Google Scholar]
- Takagi, H. Queueing Analysis: Vacation and Priority Systems; North Holland: Amsterdam, The Netherland, 1991; Volume 1. [Google Scholar]
- Tian, N.; Zhang, Z.G. Vacation Queueing Models: Theory and Applications; Springer: New York, NY, USA, 2006; Volume 93. [Google Scholar]
- Little, J.D.C. A Proof for the Queuing Formula: L = λW. Oper. Res. 1961, 9, 383–387. [Google Scholar] [CrossRef]
- SimPy. Available online: https://pypi.org/project/simpy/ (accessed on 6 February 2021).
- Hall, M.J. Utilizing Magnetic Tunnel Junction Devices in Digital Systems. Ph.D. Thesis, Department of Computer Science and Engineering, Washington University in St. Louis, St. Louis, MO, USA, 2015. [Google Scholar]
- NIST. FIPS-197: Advanced Encryption Standard; Federal Information Processing Standards (FIPS) Publication; NIST: Gaithersburg, MD, USA, 2001. [Google Scholar]
- Chodowiec, P.R. Comparison of the Hardware Performance of the AES Candidates Using Reconfigurable Hardware. Master’s Thesis, George Mason University, Fairfax, VA, USA, 2002. [Google Scholar]
- NIST. FIPS 180-4: Secure Hash Standard (SHS); Federal Information Processing Standards (FIPS) Publication; NIST: Gaithersburg, MD, USA, 2012. [Google Scholar]
- Zhang, P.; Lin, C.; Ma, X.; Ren, F.; Li, W. Monitoring-Based Task Scheduling in Large-Scale SaaS Cloud. In Service-Oriented Computing; Sheng, Q.Z., Stroulia, E., Tata, S., Bhiri, S., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 140–156. [Google Scholar]
- Demirkan, H.; Cheng, H.K.; Bandyopadhyay, S. Coordination Strategies in an SaaS Supply Chain. J. Manag. Inf. Syst. 2010, 26, 119–143. [Google Scholar] [CrossRef]
- Daigle, J.N. Queue length distributions from probability generating functions via discrete fourier transforms. Oper. Res. Lett. 1989, 8, 229–236. [Google Scholar] [CrossRef]
- Riska, A.; Smirni, E. MAMSolver: A Matrix Analytic Methods Tool. In Computer Performance Evaluation: Modelling Techniques and Tools, Proceedings of the 12th International Conference TOOLS 2002, London, UK, 14–17 April 2002; Field, T., Harrison, P.G., Bradley, J., Harder, U., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 205–211. [Google Scholar] [CrossRef]
- Neuts, M.F. Matrix-Geometric Solutions in Stochastic Models: An Algorithmic Approach; The Johns Hopkins University Press: Baltimore, MD, USA, 1981. [Google Scholar]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Label | Term | Label |
|---|---|---|---|
| N | Number of data streams | Vacation time | |
| C | Pipeline depth | Service time fraction | |
| S | Context switch cost | Mean vacation waiting time | |
| Schedule period | Mean service time | ||
| Clock period | Service time second moment | ||
| Total schedule time | Total achievable throughput |
| Abbr. | Name | Description |
|---|---|---|
| COS | Cosine application | Synthetic cosine application implemented via a Taylor series expansion with added feedback |
| AES | AES application | Advanced Encryption Standard (AES) cipher in cipher-block chaining (CBC) mode for encryption |
| SHA | SHA-2 application | Secure Hash Algorithm (SHA-2) with 256 and 512 bit digests (SHA-256 and SHA-512) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hall, M.J.; Olson, N.E.; Chamberlain, R.D. Utilizing Virtualized Hardware Logic Computations to Benefit Multi-User Performance. Electronics 2021, 10, 665. https://doi.org/10.3390/electronics10060665
Hall MJ, Olson NE, Chamberlain RD. Utilizing Virtualized Hardware Logic Computations to Benefit Multi-User Performance. Electronics. 2021; 10(6):665. https://doi.org/10.3390/electronics10060665
Chicago/Turabian StyleHall, Michael J., Neil E. Olson, and Roger D. Chamberlain. 2021. "Utilizing Virtualized Hardware Logic Computations to Benefit Multi-User Performance" Electronics 10, no. 6: 665. https://doi.org/10.3390/electronics10060665