
High-Capacity Reversible Data Hiding in Encrypted Images Based on Hierarchical Quad-Tree Coding and Multi-MSB Prediction



Abstract
:1. Introduction
2. Proposed Method
2.1. Prediction Error Image Generation
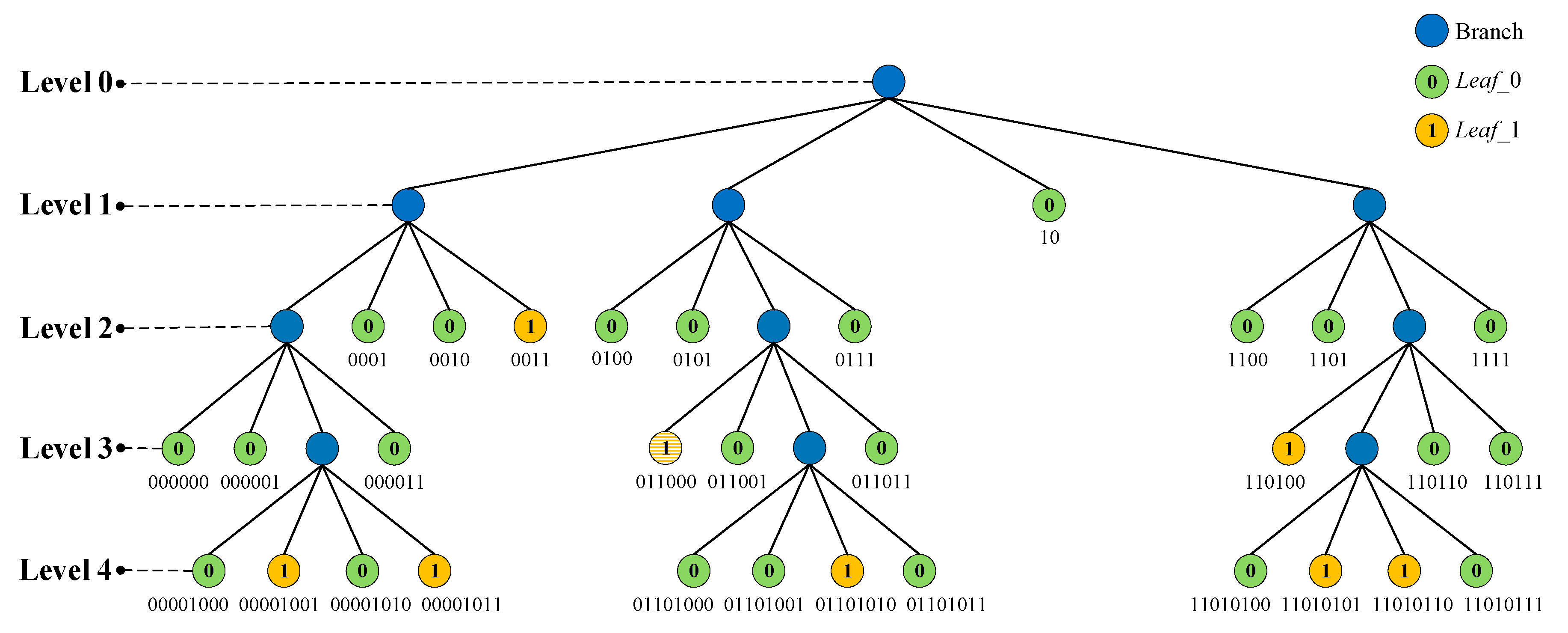
2.2. Hierarchical Quad-Tree Coding
- (a)
- Depth coding: Here, the depth of leaf nodes is their level denoted by L in quad-tree, which is calculated by Equation (5), where Ib is one bit-plane of Ig, and Ic is the bit-block in Ib corresponding to the specified leaf nodes. L needs to be converted to binary by Equation (3) as the depth code. For the bit-plane of size , the depth coding is a fixed-length coding. Let the depth of the root node be 0. Then the maximum depth of the corresponding quad-tree equals n. So at least bits are required to record the maximum depth. In other words, the length of depth coding is .
- (b)
- Value coding: The value of leaf nodes should be recorded so that the receiver could correctly recover the corresponding leaf nodes. Because there are only two values (0 and 1), it is sufficient for one bit to record the values of leaf nodes.
- (c)
- Number coding: Since there are at most 4L nodes in level L, the number of the two categories of leaf nodes in level L, i.e., and , is recorded by bits.
- (d)
- Path coding: According to the above quad-tree segmentation process, seen in Figure 4, four quadrant blocks I, II, III, and IV in each round of segmentation correspond to the quadrant codes 00, 01, 10, and 11, respectively. The main idea of path coding is that the corresponding quadrant code is added to the path code each time the segmentation is performed. Obviously, each leaf node requires 2L bits to record its path if the path is encoded separately. In Figure 6, we give an example to show the separate path code of each leaf node, which is composed of their parent nodes’ path codes and their own quadrant codes. However, some leaf nodes usually come from the same parent node and the front bits (i.e., the parent node’s path code) of the path code for these leaf nodes are the same. If these leaf nodes’ path is coded separately, there is a lot of redundancy information. Therefore, we propose a skill to compress the path code in the following. For the leaf nodes in level L, we first encode the path of their parent node, which requires bits. As we know, there are at most three leaf nodes with the same value from a parent node. Thereby, we use 2 bits to record the number of the leaf nodes from the same parent node and these 2 bits are spliced into the end of the parent node’s path code. Finally, we record the quadrant code (00 or 01 or 10 or 11) of each leaf node in order.
| Algorithm 1 Hierarchical quad-tree coding (HQC) Algorithm |
| Input: one bit-plane Ib of Ig 1: /* t = */ 2: /* binary(a, b) is the function that converts a into a b-bit binary sequence */ 3: /* B is the path code of nodes */ 4: node ← Ib 5: function HQC(node) 6: if the bits in node are not all the same then 7: [Top_left, Top_right, Bottom_left, Bottom_right] ← SEGMENT(node) 8: if the bits in Top_left are all the same then result ← CODING(Top_left) 9: else HQC(Top_left) 10: end if 11: if the bits in Top_right are all the same then result ← CODING(Top_right) 12: else HQC(Top_right) 13: end if 14: if the bits in Bottom_left are all the same then result ← CODING(Bottom_left) 15: else HQC(Bottom_left) 16: end if 17: if the bits in Bottom_right are all the same then result ←CODING(Bottom_right) 18: else HQC(Bottom_right) 19: end if 20: else 21: return result ← CODING(node) 22: end if 23: end function 24: 25: function SEGMENT(node) 26: node is segmented into four non-overlapping square quadrant blocks Top_left, Top_right, Bottom_left and Bottom_right 27: result ← [Top_left, Top_right, Bottom_left, Bottom_left] 28: return result 29: end function 30: 31: function CODING(node) 32: result ← binary(L, t) 33: if L = 0 then 34: if value of the node is 0 then result ← result + ‘0’ 35: else result ← result + ‘1’ 36: end if 37: else 38: if value of the node is 0 then result ← result + ‘0’ + + B 39: else result ← result + ‘1’ + + B 40: end if 41: end if 42: return result 43: end function Output: the code of the leaf nodes in level L |
2.3. Vacating Room for Data Embedding
- (1)
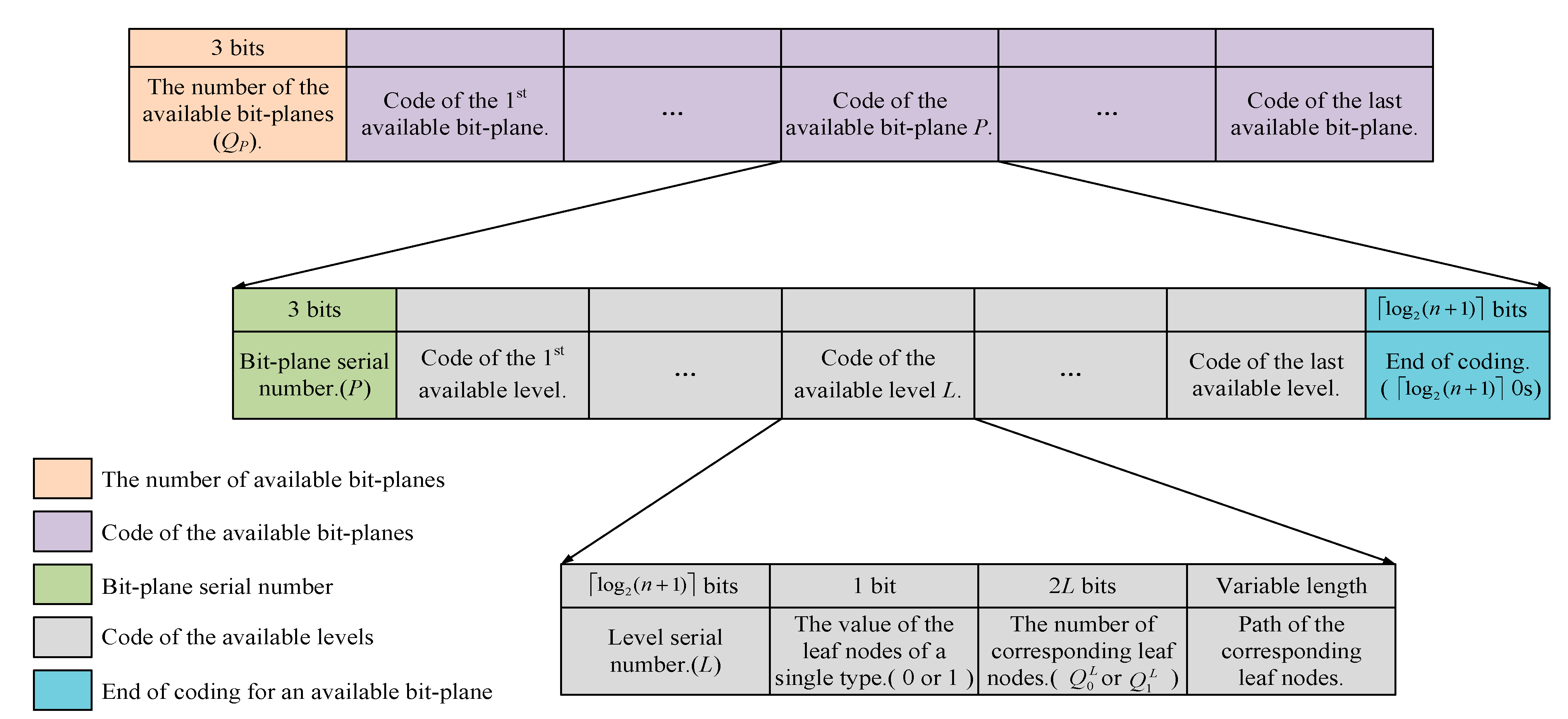
- Coding information: For the available bit-planes, we first concatenate all codes of the available leaf nodes in the increasing order of the bit-plane. The code structure is shown in Figure 8. The head of the code structure is the number of available bit-planes, denoted as Qp, and 3 bits are required to record it. For each available bit-plane, we use 3 bits to record the bit-plane serial number before performing the hierarchical quad-tree coding. Note that the serial number of MSB plane and LSB plane are recorded as 000 and 111, respectively. In addition, bits of 0s are required to mark the end of the coding for the current bit-plane.
- (2)
- Overflow pixels information: We use 2n bits to record the number of overflow pixels which is denoted by Qx. If Qx is not equal to 0, the location (i, j) of the overflow pixels also requires to be recorded. Specifically, there are three n-bit parts which need to be recorded, i.e., the row number i, the number of the overflow pixels on i-th row, and the corresponding column number j of each overflow pixel on i-th row. For example, let n be 4 and there are four overflow pixels on the same row. Suppose that their locations are (6,5), (6,7), (6,9), (6,10), respectively. Then the location sequence of these four overflow pixels is (0110 0100 0101 0111 1001 1010).
- (3)
- Uncompressed bits: The uncompressed bits in each bit-plane are concatenated in the increasing order of the bit-plane serial number and embedded after the information of overflow pixels.
Algorithm 2 Room vacating Algorithm Input: prediction error image Ip size by M × N, , overflow pixels information
1: if M = N ≠ 2n or M ≠ N then
2: Expanding the size to and the expanded part filled with 0s is added to the right or/and the bottom of the current bit-plane;
3: end if
4: Qp ← 0;
5: code ← [ ];
6: uncompressed bits ← [ ];
7: for each plane from MSB plane to LSB plane do
8: Quad-tree segmentation;
9: Construct a quad-tree corresponds to the current bit-plane;
10: for each level L from the root to the last level do
11: Calculate , ;
12: if or then
13: Available leaf nodes ← the corresponding leaf nodes;
14: end if
15: end for
16: if the current bit-plane contains available leaf nodes then
17: Qp ← Qp + 1;
18: code ← code + (bit-plane serial number + code of the available leaf nodes + end of coding);
19: end if
20: uncompressed bits ← uncompressed bits + all bits except the bits in the bit-blocks corresponding to the available leaf nodes;
21: end for
22: Record (Qp + code + overflow pixels information + the uncompressed bits) in the multi-MSB planes.
23: Place the available embedding capacity on the LSB plane.
Output: room-vacated image Iv size by M × N
2.4. Image Encryption
2.5. Data Embedding
2.6. Data Extraction and Image Recovery
- (a)
- Hierarchical Quad-tree Code Recovery
- (b)
- Overflow Pixels Recovery
- (c)
- Uncompressed Bits Recovery
3. Experimental Results and Analysis
3.1. Security Analysis
3.2. Performance Analysis
3.3. Comparison with Some State-of-the-Art Methods
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shi, Y.; Li, X.; Zhang, X.; Wu, H.; Ma, B. Reversible data hiding: Advances in the past two decades. IEEE Access 2016, 4, 3210–3237. [Google Scholar] [CrossRef]
- Chang, C.-C. Adversarial learning for invertible steganography. IEEE Access 2020, 8, 198425–198435. [Google Scholar] [CrossRef]
- Chang, Y.; Liu, C.-C.; Nguyen, T.S. A Novel Turtle Shell Based Scheme for Data Hiding. In Proceedings of the 2014 International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Kitakyushu, Japan, 27–29 August 2014; pp. 89–93. [Google Scholar]
- Celik, G.; Sharma, M.U.; Tekalp, A.M.; Saber, E. Lossless generalized-LSB data embedding. IEEE Trans. Image Process. 2005, 14, 253–266. [Google Scholar] [CrossRef]
- Tian, J. Reversible data embedding using a difference expansion. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 890–896. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Li, B.; Yang, B.; Zeng, T. General framework to histogram-shifting-based reversible data hiding. IEEE Trans. Image Process. 2013, 22, 2181–2191. [Google Scholar] [CrossRef]
- Wang, J.; Ni, J.; Zhang, X.; Shi, Y. Rate and distortion optimization for reversible data hiding using multiple histogram shifting. IEEE Trans. Cybern. 2017, 47, 315–326. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.-C.; Li, C.-T.; Shi, Y. Privacy-aware reversible watermarking in cloud computing environments. IEEE Access 2018, 6, 70720–70733. [Google Scholar] [CrossRef]
- Chang, C.-C.; Li, C.-T.; Chen, K. Privacy-Preserving Reversible Information Hiding Based on Arithmetic of Quadratic Residues. IEEE Access 2019, 7, 54117–54132. [Google Scholar] [CrossRef]
- Chang, C.-C.; Li, C.-T. Algebraic secret sharing using privacy homomorphisms for IoT-based healthcare systems. Math. Biosci. Eng. 2019, 16, 3367–3381. [Google Scholar] [CrossRef]
- Puech, W.; Chaumont, M.; Strauss, O. A reversible data hiding method for encrypted images. In Proceedings of the Security, Forensics, Steganography, and Watermarking of Multimedia Contents X, International Society for Optics and Photonics, San Jose, CA, USA, 18 March 2008; Volume 6819, pp. 534–542. [Google Scholar]
- Yi, S.; Zhou, Y.; Hua, Z. Reversible data hiding in encrypted images using adaptive block-level prediction-error expansion. Signal Process. Image Commun. 2018, 64, 78–88. [Google Scholar] [CrossRef]
- Huang, D.; Wang, J. High-capacity reversible data hiding in encrypted image based on specific encryption process. Signal Process. Image Commun. 2020, 80, 115632. [Google Scholar] [CrossRef]
- Zhang, X. Reversible data hiding in encrypted image. IEEE Signal Process. Lett. 2011, 18, 255–258. [Google Scholar] [CrossRef]
- Yu, J.; Zhu, G.; Li, X.; Yang, J. An improved algorithm for reversible data hiding in encrypted image. In Proceedings of the International Workshop on Digital Forensics and Watermarking, Shanghai, China, 31 October–3 November 2012; Volume 7809, pp. 384–394. [Google Scholar]
- Hong, W.; Chen, T.; Wu, H. An improved reversible data hiding in encrypted images using side match. IEEE Signal Process. Lett. 2012, 19, 199–202. [Google Scholar] [CrossRef]
- Zhang, X. Separable reversible data hiding in encrypted image. IEEE Trans. Inf. Forensics Secur. 2012, 7, 826–832. [Google Scholar] [CrossRef]
- Ma, K.; Zhang, W.; Zhao, X.; Yu, N.; Li, F. Reversible data hiding in encrypted images by reserving room before encryption. IEEE Trans. Inf. Forensics Secur. 2013, 8, 553–562. [Google Scholar] [CrossRef]
- Zhang, W.; Ma, K.; Yu, N. Reversibility improved data hiding in encrypted images. Signal Process. 2014, 94, 118–127. [Google Scholar] [CrossRef]
- Yi, S.; Zhou, Y. Binary-block embedding for reversible data hiding in encrypted images. Signal Process. 2017, 133, 40–51. [Google Scholar] [CrossRef]
- Shiu, P.; Tai, W.; Jan, J.; Chang, C.-C.; Lin, C. An Interpolative AMBTC-based high-payload RDH scheme for encrypted images. Signal Process. Image Commun. 2019, 74, 64–77. [Google Scholar] [CrossRef]
- Yi, S.; Zhou, Y. Separable and reversible data hiding in encrypted images using parametric binary tree labeling. IEEE Trans. Multimed. 2019, 21, 51–64. [Google Scholar] [CrossRef]
- Puteaux, P.; Puech, W. An efficient MSB prediction-based method for high-capacity reversible data hiding in encrypted images. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1670–1681. [Google Scholar] [CrossRef] [Green Version]
- Puyang, Y.; Yin, Z.; Qian, Z. Reversible data hiding in encrypted images with two-MSB prediction. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018. [Google Scholar]
- Puteaux, P.; Puech, W. EPE-based huge-capacity reversible data hiding in encrypted images. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018. [Google Scholar]
- Chen, K.; Chang, C.-C. High-capacity reversible data hiding in encrypted images based on extended run-length coding and block-based MSB plane rearrangement. J. Vis. Commun. Image Represent. 2019, 58, 334–344. [Google Scholar] [CrossRef]
- Yin, Z.; Xiang, Y.; Zhang, X. Reversible data hiding in encrypted images based on multi-MSB prediction and Huffman coding. IEEE Trans. Multimed. 2020, 22, 874–884. [Google Scholar] [CrossRef]
- Weinberger, G.; Seroussi, M.J.; Sapiro, G. The LOCO-I lossless image compression algorithm: Principles and standardization into JPEG-LS. IEEE Trans. Image Process. 2000, 9, 1309–1324. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bas, P.; Filler, T.; Pevny, T. Break our steganographic system: The ins and outs of organizing BOSS. In Proceedings of the 13th International Conference on Information Hiding, Prague, Czech Republic, 18–20 May 2011; pp. 59–70. [Google Scholar]
- Bas, P.; Furon, T. Image Database of BOWS-2. Available online: http://bows2.ec-lille.fr/ (accessed on 17 July 2007).
- Schaefer, G.; Stich, M. UCID—An uncompressed color image database. In Proceedings of the SPIE in Storage and Retrieval Methods and Applications for Multimedia, San Jose, CA, USA, 18–22 January 2004; Volume 5307, pp. 472–480. [Google Scholar]
- Weber, A.G. The USC-SIPI image database version 5. USC-SIPI Rep. 1997, 315, 1. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Available Plane | (Bits) | (Bits) | Extra Bits (Bits) | Payload (Bits) | ||||
|---|---|---|---|---|---|---|---|---|
| 0 | 188 (L = 7) | 114 (L = 7) | 45 (L = 7) | 32 (L = 7) | 3728 | 2548 | 7 | 1173 |
| 1 | 1 (L = 1), 3 (L = 2), 22 (L = 3), 34 (L = 4), 58 (L = 5), 77 (L = 6), 105 (L = 7) | 1 (L = 1), 1 (L = 2), 8 (L = 3), 13 (L = 4), 22 (L = 5), 30 (L = 6), 42 (L = 7) | 0 | 0 | 261,072 | 2015 | 7 | 259,050 |
| 2 | 18 (L = 3), 78 (L = 4), 196 (L = 5), 446 (L = 6), 1028 (L = 7) | 9 (L = 3), 37 (L = 4), 86 (L = 5), 201 (L = 6), 440 (L = 7) | 0 | 0 | 248,768 | 13,389 | 7 | 235,372 |
| 3 | 5 (L = 3), 48 (L = 4), 221 (L = 5), 720 (L = 6), 2335 (L = 7) | 5 (L = 3), 30 (L = 4), 104 (L = 5), 351 (L = 6), 1086 (L = 7) | 0 | 0 | 209,648 | 27,459 | 7 | 182,182 |
| 4 | 2 (L = 4), 39 (L = 5), 571 (L = 6), 3793 (L = 7) | 2 (L = 4), 25 (L = 5), 345 (L = 6), 1921 (L = 7) | 0 | 0 | 109,264 | 40,174 | 7 | 69,083 |
| 5 | 11 (L = 6), 619 (L = 7) | 8 (L = 6), 402 (L = 7) | 0 | 0 | 10,608 | 7020 | 7 | 3581 |
| 6 | 133 (L = 7) | 68 (L = 7) | 0 | 0 | 2128 | 1237 | 7 | 884 |
| 7 | 129 (L = 7) | 65 (L = 7) | 0 | 0 | 2064 | 1187 | 7 | 870 |
| Total | - | - | - | - | 847,280 | 95,029 | 56 | 752,195 |
| Qp Length (Bits) | Qx | Do (Bits) | EC Length (Bits) | Total EC (Bits) | Net Payload (Bpp) |
|---|---|---|---|---|---|
| 3 | 0 | 18 | 18 | 752,156 | 2.869 |
| Testing Images | Capacity (Bits) | Code Length (Bits) | Total Extra Bits (Bits) | Total EC (Bits) | Net Payload (Bpp) |
|---|---|---|---|---|---|
| Lena | 847,280 | 95,029 | 95 | 752,156 | 2.869 |
| Jetplane | 950,592 | 99,319 | 108 | 851,165 | 3.247 |
| Man | 764,080 | 117,486 | 115 | 646,479 | 2.466 |
| Baboon | 410,736 | 77,433 | 130 | 333,173 | 1.271 |
| Databases | BOSSbase [29] | BOWS-2 [30] | UCID [31] | |
|---|---|---|---|---|
| Best case | ER (bpp) | 7.824 | 7.145 | 5.335 |
| PSNR | +∞ | +∞ | +∞ | |
| SSIM | 1 | 1 | 1 | |
| Worst case | ER (bpp) | 0.476 | 0.418 | 0.192 |
| PSNR | +∞ | +∞ | +∞ | |
| SSIM | 1 | 1 | 1 | |
| Average | ER (bpp) | 3.504 | 3.394 | 2.746 |
| PSNR | +∞ | +∞ | +∞ | |
| SSIM | 1 | 1 | 1 | |
| Image Size | 256 × 256 | 1024 × 1024 | |
|---|---|---|---|
| Best case | ER (bpp) | 5.321 | 3.657 |
| PSNR | +∞ | +∞ | |
| SSIM | 1 | 1 | |
| Worst case | ER (bpp) | 1.436 | 1.099 |
| PSNR | +∞ | +∞ | |
| SSIM | 1 | 1 | |
| Average | ER (bpp) | 2.711 | 2.251 |
| PSNR | +∞ | +∞ | |
| SSIM | 1 | 1 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Feng, G.; Qin, C.; Lu, H.; Chang, C.-C. High-Capacity Reversible Data Hiding in Encrypted Images Based on Hierarchical Quad-Tree Coding and Multi-MSB Prediction. Electronics 2021, 10, 664. https://doi.org/10.3390/electronics10060664
Liu Y, Feng G, Qin C, Lu H, Chang C-C. High-Capacity Reversible Data Hiding in Encrypted Images Based on Hierarchical Quad-Tree Coding and Multi-MSB Prediction. Electronics. 2021; 10(6):664. https://doi.org/10.3390/electronics10060664
Chicago/Turabian StyleLiu, Ya, Guangdong Feng, Chuan Qin, Haining Lu, and Chin-Chen Chang. 2021. "High-Capacity Reversible Data Hiding in Encrypted Images Based on Hierarchical Quad-Tree Coding and Multi-MSB Prediction" Electronics 10, no. 6: 664. https://doi.org/10.3390/electronics10060664