Figure 1.
Overview of the power modeling.
Figure 1.
Overview of the power modeling.
Figure 2.
Connection of external power supply to the phone.
Figure 2.
Connection of external power supply to the phone.
Figure 3.
(a) Frequency domain spectrum of the data before and after filtering. The black rectangle shows the major component of the power. (b) Time domain representation of the raw power, filtered power, and de-spiked power.
Figure 3.
(a) Frequency domain spectrum of the data before and after filtering. The black rectangle shows the major component of the power. (b) Time domain representation of the raw power, filtered power, and de-spiked power.
Figure 4.
Display power variation with brightness and color.
Figure 4.
Display power variation with brightness and color.
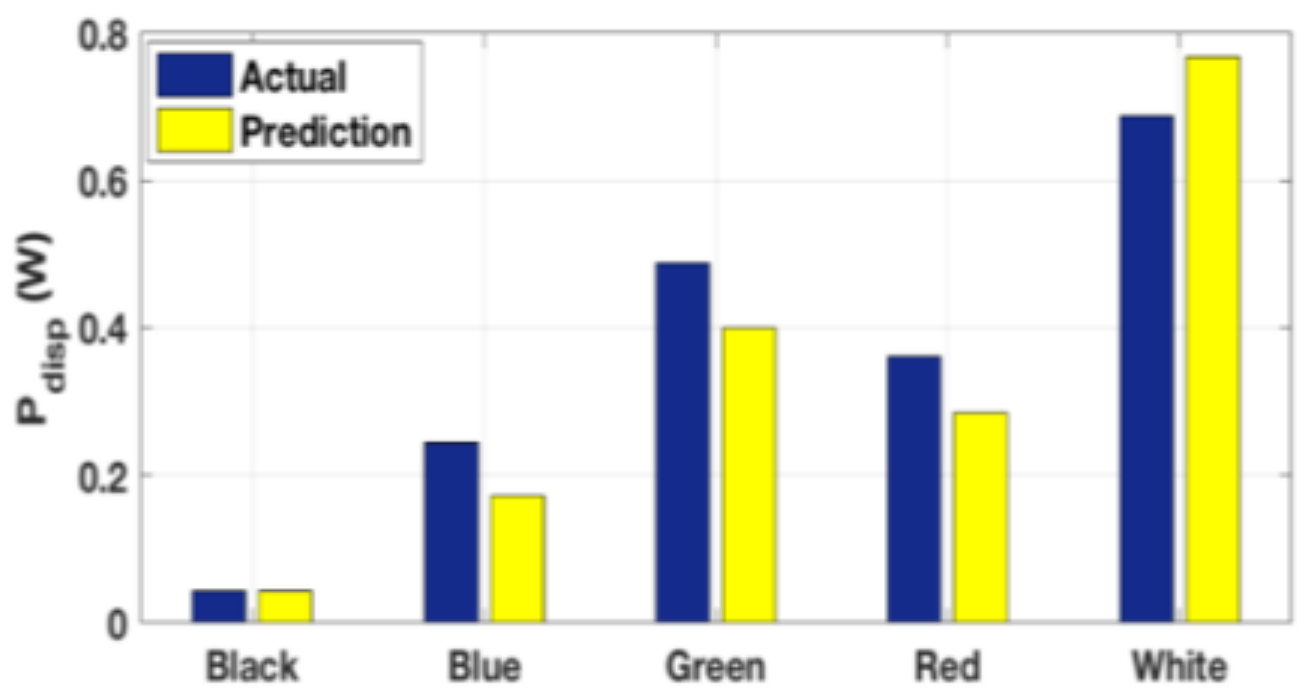
Figure 5.
Comparison of actual and predicted display power for different colors.
Figure 5.
Comparison of actual and predicted display power for different colors.
Figure 6.
The test image.
Figure 6.
The test image.
Figure 7.
Comparison of actual and predicted display power for the test image.
Figure 7.
Comparison of actual and predicted display power for the test image.
Figure 8.
Power estimation when total power is dominated by leakage of A57 cores.
Figure 8.
Power estimation when total power is dominated by leakage of A57 cores.
Figure 9.
Reference and estimated dynamic power consumption for the A57 cluster running at 1.24 GHz.
Figure 9.
Reference and estimated dynamic power consumption for the A57 cluster running at 1.24 GHz.
Figure 10.
(a) Behavior of the total power of the A53 cluster running at 860 MHz as a function of the temperature. The figure shows both measured and estimated power at two configurations. (b) Behavior of the dynamic power with temperature. The dynamic power is constant since the processor is idle. (c) Behavior of the leakage power with respect to the temperature. The leakage power shows an increase with temperature due to the temperature term in Equation (5).
Figure 10.
(a) Behavior of the total power of the A53 cluster running at 860 MHz as a function of the temperature. The figure shows both measured and estimated power at two configurations. (b) Behavior of the dynamic power with temperature. The dynamic power is constant since the processor is idle. (c) Behavior of the leakage power with respect to the temperature. The leakage power shows an increase with temperature due to the temperature term in Equation (5).
Figure 11.
Comparison of measured and estimated dynamic power for the A53 cluster running at 1.24 GHz. Each sample is 50 ms.
Figure 11.
Comparison of measured and estimated dynamic power for the A53 cluster running at 1.24 GHz. Each sample is 50 ms.
Figure 12.
Variation of power with temperature and frequency.
Figure 12.
Variation of power with temperature and frequency.
Figure 13.
The reference and estimated C_(dyn,gpu) at 600 MHz.
Figure 13.
The reference and estimated C_(dyn,gpu) at 600 MHz.
Figure 14.
Actual power consumption and average execution time of PCA benchmark for all the bandwidths.
Figure 14.
Actual power consumption and average execution time of PCA benchmark for all the bandwidths.
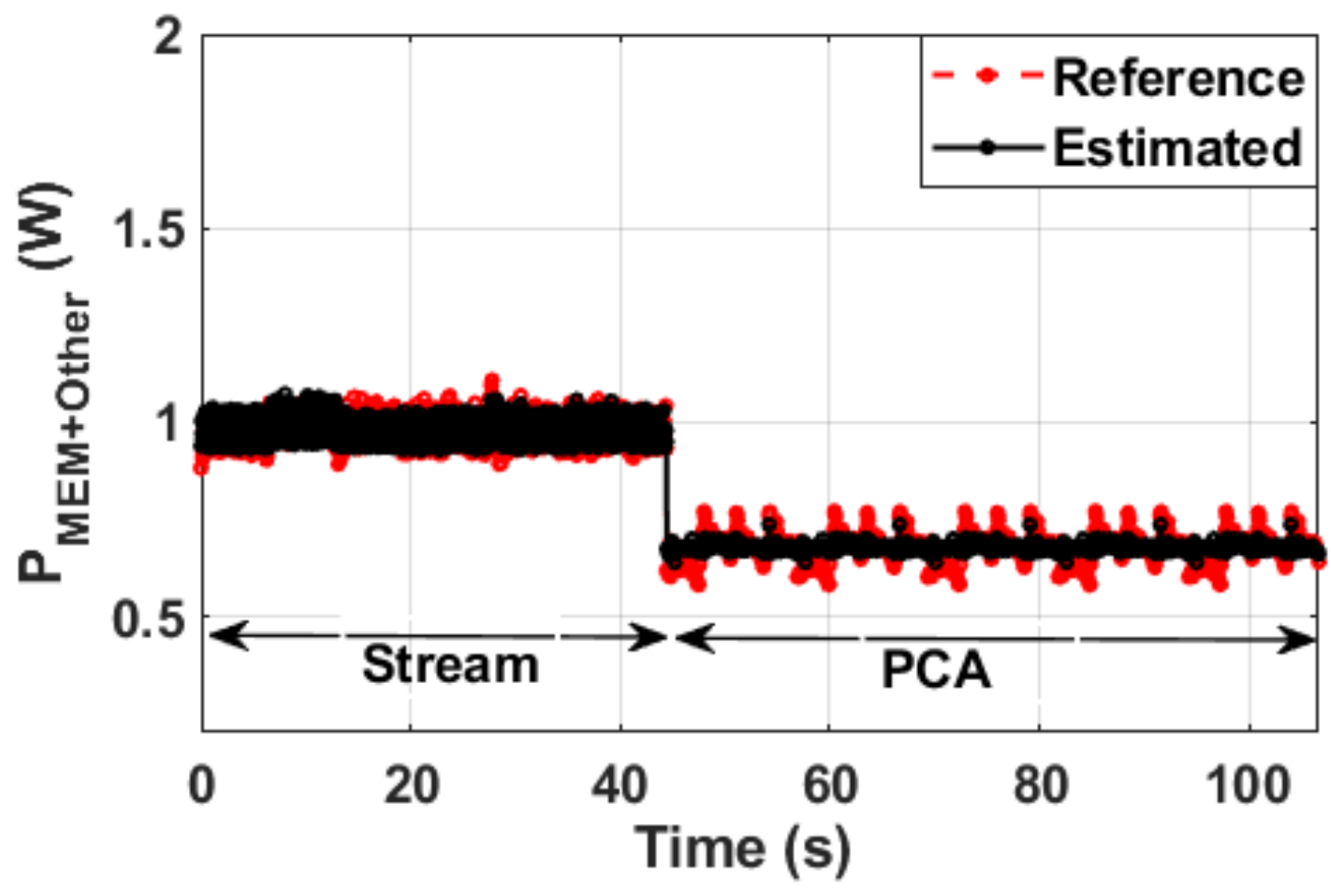
Figure 15.
Comparison of actual and predicted memory power for PCA and Stream benchmarks.
Figure 15.
Comparison of actual and predicted memory power for PCA and Stream benchmarks.
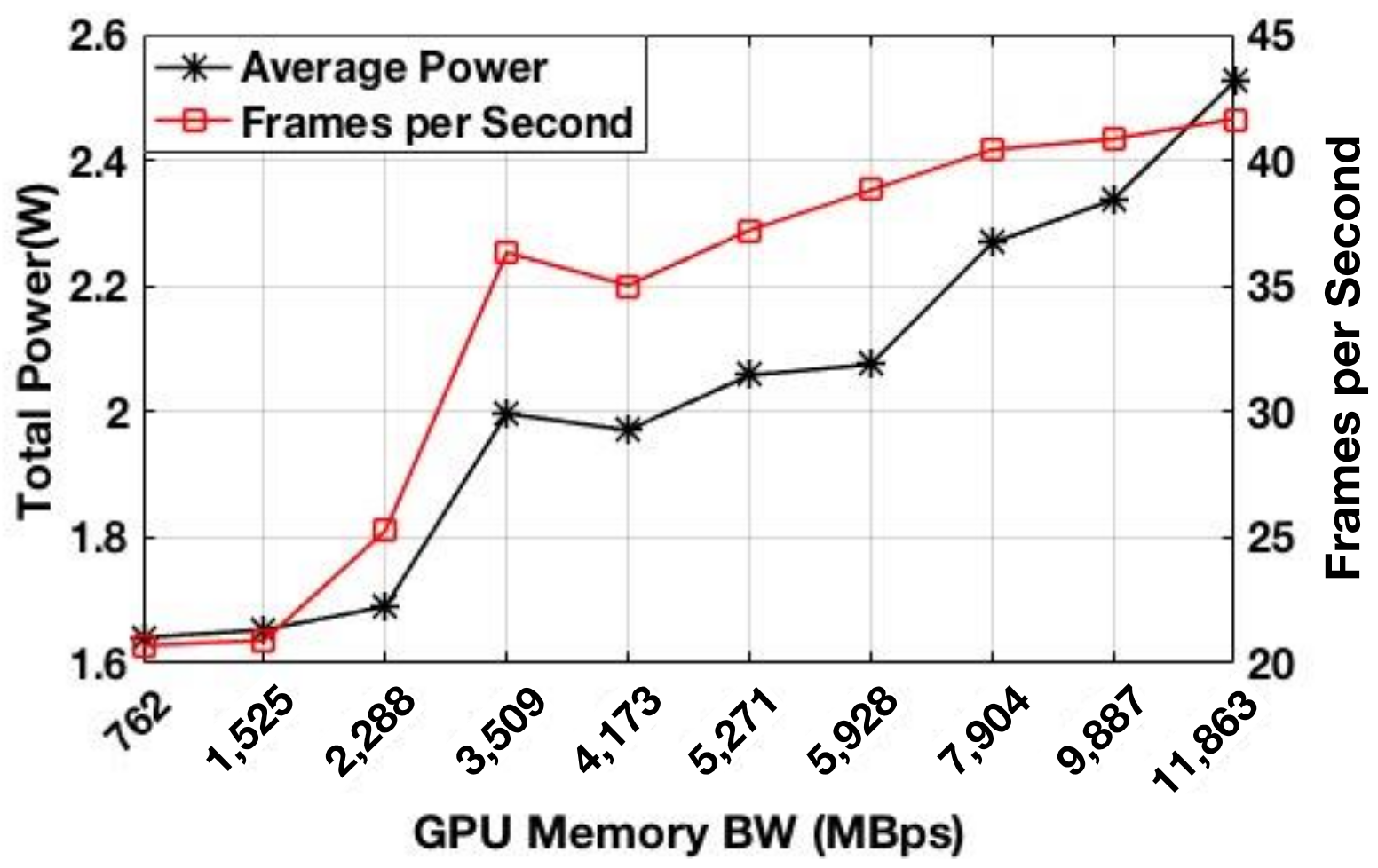
Figure 16.
Actual power consumption and execution time of the Candy Crush game for all the GPU memory bandwidths.
Figure 16.
Actual power consumption and execution time of the Candy Crush game for all the GPU memory bandwidths.
Figure 18.
(a). Instructions for the Angry Bird game app without alignment (b). Instructions for the Angry Bird game app with alignment of instructions.
Figure 18.
(a). Instructions for the Angry Bird game app without alignment (b). Instructions for the Angry Bird game app with alignment of instructions.
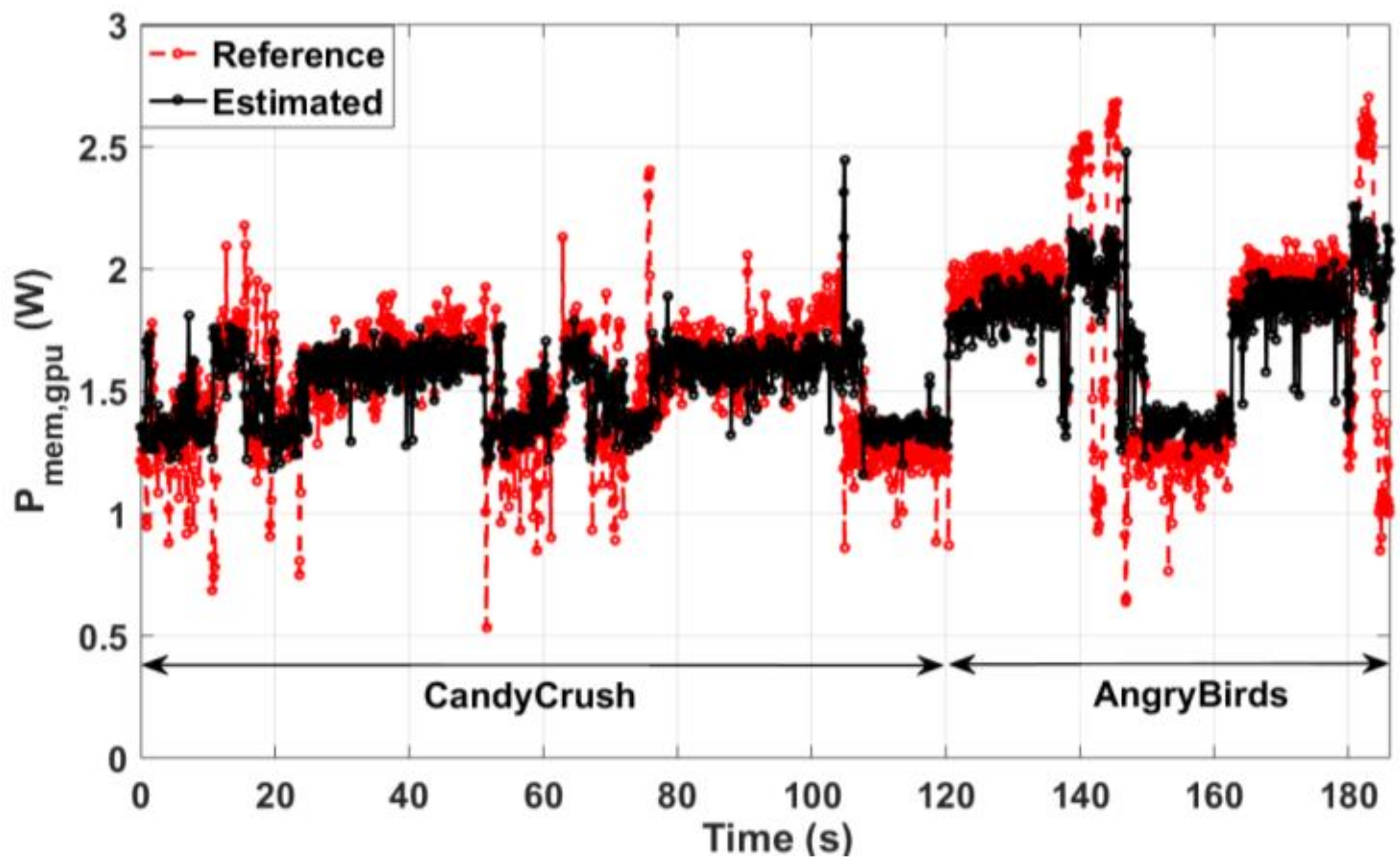
Figure 19.
Comparison of actual and predicted memory power for the Angry Birds game benchmark.
Figure 19.
Comparison of actual and predicted memory power for the Angry Birds game benchmark.
Figure 20.
Comparison of the reference power consumption and the estimated power consumption for (a) BasicMath, (b) PCA, (c) MEL, (d) FFT, and (e) Spectral benchmarks using leave-one-out analysis.
Figure 20.
Comparison of the reference power consumption and the estimated power consumption for (a) BasicMath, (b) PCA, (c) MEL, (d) FFT, and (e) Spectral benchmarks using leave-one-out analysis.
Figure 21.
(a). Wi-Fi packet transfer for an application download (b). Wi-Fi packet transfer for Google Hangouts Call.
Figure 21.
(a). Wi-Fi packet transfer for an application download (b). Wi-Fi packet transfer for Google Hangouts Call.
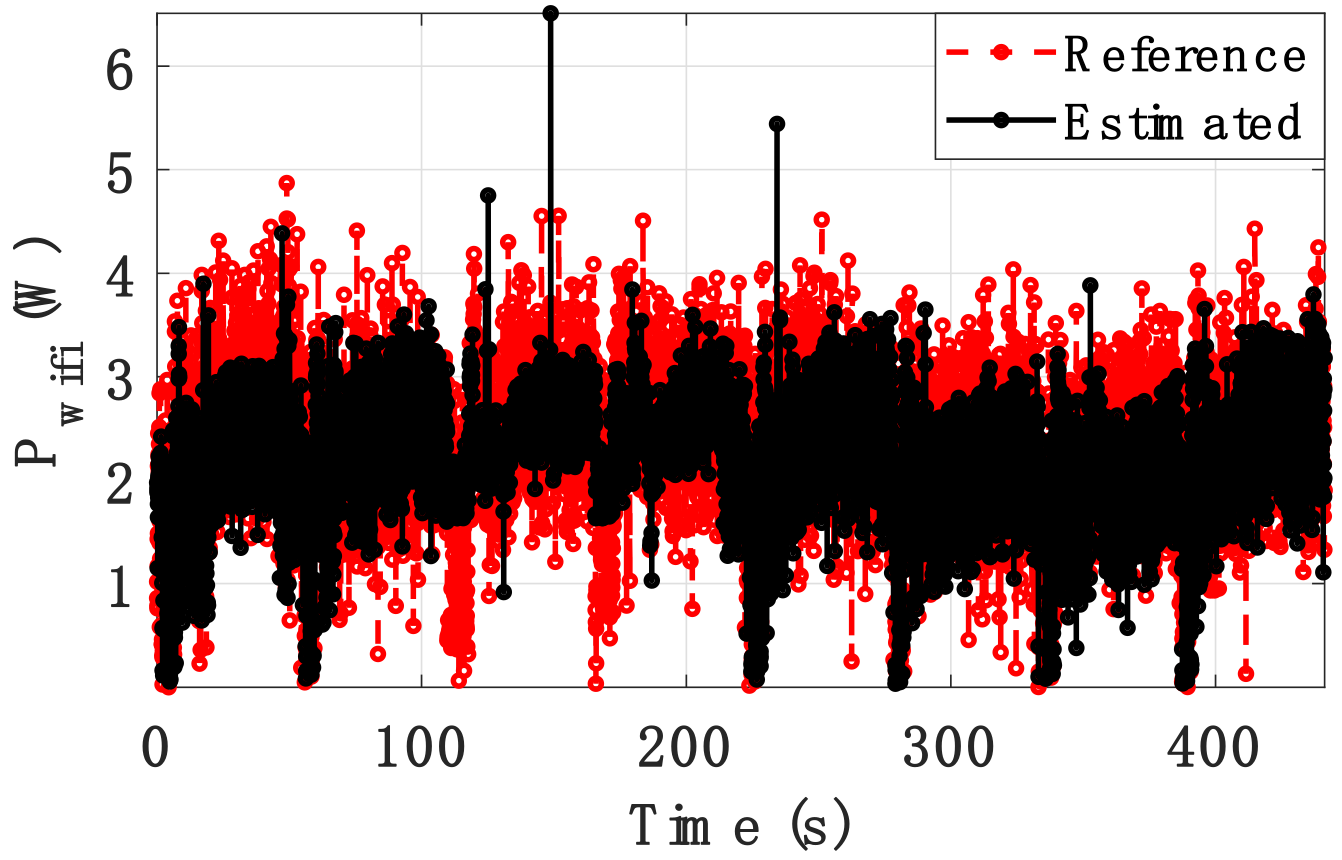
Figure 22.
Comparison of reference and estimated power for the WiFi power.
Figure 22.
Comparison of reference and estimated power for the WiFi power.
Figure 23.
Comparison of reference and estimation of the Wi-Fi power.
Figure 23.
Comparison of reference and estimation of the Wi-Fi power.
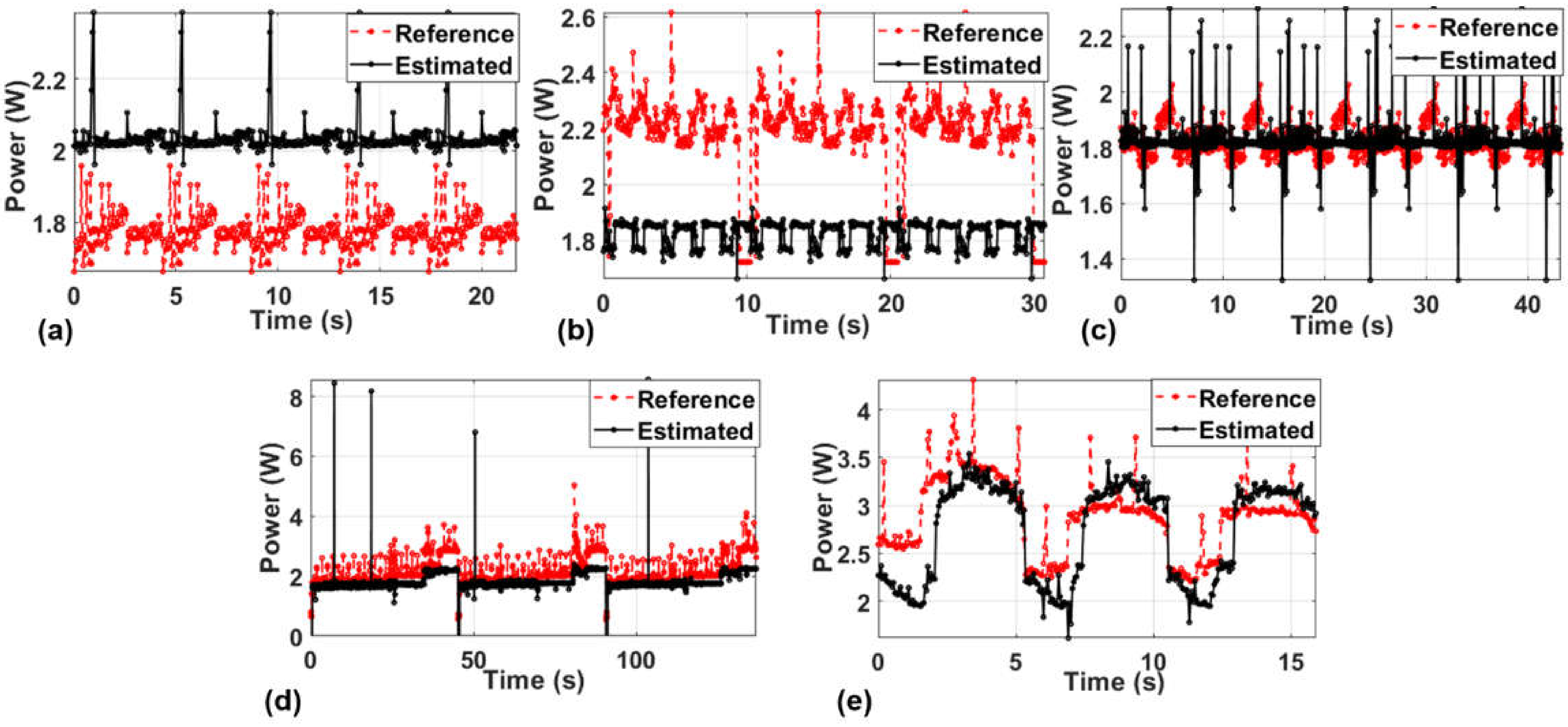
Figure 24.
Comparison of each power component when the WiFi is turned off randomly.
Figure 24.
Comparison of each power component when the WiFi is turned off randomly.
Table 1.
CPU feature selection table.
Table 1.
CPU feature selection table.
| Feature Id | Performance Counters | Feature Id | Performance Counters |
|---|
| 1 | Aggregated Normalized Instructions | 6 | Max Utilization—U1 |
| 2 | CPU Cycles per Instruction | 7 | 2nd highest Utilization—U2 |
| 3 | L2 References per Instruction | 8 | 3rd highest Utilization—U3 |
| 4 | L2 Misses per Instruction | 9 | 4th highest Utilization—U4 |
| 5 | Branch misses per Instruction | | |
Table 2.
Benchmarks used in dynamic power estimation and their runtime.
Table 2.
Benchmarks used in dynamic power estimation and their runtime.
| Benchmark | Runtime (Approximated) |
|---|
| BasicMath | 4 s |
| PCA | 10 s |
| MEL | 10 s |
Table 3.
Summary of results for the A57 cluster dynamic power estimation.
Table 3.
Summary of results for the A57 cluster dynamic power estimation.
| Benchmark | Core | Frequency (GHz) | MAPE | RMSE | Feature Selection |
|---|
| PCA + MEL | Big | 1.96 | 2.7 | 0.086 | 1 2 3 4 5 9 10 |
| Combined 1 | Big | 1.25 | 6.4 | 0.129 | 1 3 4 5 8 9 |
| Combined 1 | Big | 0.38 | 8.8 | 0.2718 | 1 3 4 5 8 9 10 |
Table 4.
Summary of results for the A57 cluster with the union of features.
Table 4.
Summary of results for the A57 cluster with the union of features.
| Benchmark | Core | Frequency (GHz) | MAPE (Selected) | MAPE (Union) |
|---|
| PCA + MEL | Big | 1.96 | 2.7 | 2.67 |
| Combined 1 | Big | 1.25 | 6.4 | 6.4 |
| Combined 1 | Big | 0.38 | 8.8 | 8.8 |
Table 5.
Summary of results for A53 dynamic power modeling.
Table 5.
Summary of results for A53 dynamic power modeling.
| Benchmark | Core | Frequency (GHz) | MAPE | RMSE | Feature Selection |
|---|
| Combined 1 | Little | 1.55 | 4.80 | 0.0372 | 1 2 3 4 5 8 |
| Combined 1 | Little | 1.25 | 5.50 | 0.0439 | 1 3 4 6 7 |
| Combined 1 | Little | 0.60 | 11.40 | 0.1213 | 1 2 3 7 8 9 |
Table 6.
Summary of results with union of features.
Table 6.
Summary of results with union of features.
| Benchmark | Core | Frequency (GHz) | MAPE (Selected) | MAPE (Union) |
|---|
| Combined 1 | Little | 1.55 | 4.80 | 4.80 |
| Combined 1 | Little | 1.25 | 5.50 | 5.43 |
| Combined 1 | Little | 0.60 | 11.40 | 11.39 |
Table 7.
Leakage power parameters for the GPU.
Table 7.
Leakage power parameters for the GPU.
| Parameter | Value | Parameter | Value |
|---|
| 0.2561 | | 0.1496 |
| −3740 | | 0.6003 |
| 8.6 × 10−8 | | 1.2985 |
| 0.3789 | | |
Table 8.
GPU feature selection table.
Table 8.
GPU feature selection table.
| Feature Id | Performance Counters | Feature Id | Performance Counters |
|---|
| 1 | GPU Capacity | 7 | L2 Misses per Instruction |
| 2 | GPU Utilization | 8 | Branch misses per Instruction |
| 3 | GPU Frame Count | 9 | Max Utilization—U1 |
| 4 | Aggregated Normalized Instructions | 10 | 2nd highest Utilization—U2 |
| 5 | CPU Cycles per Instruction | 11 | 3rd highest Utilization—U3 |
| 6 | L2 References per Instruction | 12 | 4th highest Utilization—U4 |
Table 9.
Summary of results for the GPU dynamic power model.
Table 9.
Summary of results for the GPU dynamic power model.
| Frequency (MHz) | MAPE | MAPE (One Second Average) | MAPE (Per Trace Average) | Feature Selection |
|---|
| 600 | 8.82 | 7.04 | 4.25 | 3 4 5 6 8 9 11 12 |
| 510 | 10.90 | 8.77 | 4.21 | 1 2 4 5 6 8 9 11 12 |
| 450 | 13.10 | 10.95 | 3.19 | 2 3 4 5 6 8 9 11 12 |
| 390 | 14.62 | 11.99 | 3.71 | 1 4 5 8 9 11 12 |
| 305 | 18.86 | 15.31 | 3.76 | 3 4 5 6 7 8 9 11 12 |
| 180 | 17.49 | 11.10 | 4.00 | 2 4 5 7 8 9 10 11 |
Table 10.
Summary of results with the union of features for the GPU dynamic power.
Table 10.
Summary of results with the union of features for the GPU dynamic power.
| Frequency (MHz) | MAPE | MAPE (One Second Average) | MAPE (Per Trace Average) |
|---|
| Selected | Union | Selected | Union | Selected | Union |
|---|
| 600 | 8.82 | 8.50 | 7.04 | 7.00 | 4.25 | 4.21 |
| 510 | 10.90 | 11.00 | 8.77 | 8.78 | 4.21 | 4.12 |
| 450 | 13.10 | 12.55 | 10.95 | 10.83 | 3.19 | 3.32 |
| 390 | 14.62 | 15.14 | 11.99 | 11.77 | 3.71 | 3.74 |
| 305 | 18.86 | 16.99 | 15.31 | 15.41 | 3.76 | 2.30 |
| 180 | 17.49 | 19.34 | 11.10 | 14.53 | 4.00 | 4.44 |
Table 11.
CPU memory controller features.
Table 11.
CPU memory controller features.
| Feature Id | Performance Counters | Feature Id | Performance Counters |
|---|
| 1 | Aggregated Normalized Instructions | 6 | Max Utilization—U1 |
| 2 | L2 References per Instruction | 7 | 2nd highest Utilization—U2 |
| 3 | Raw Memory Accesses per Instruction | 8 | 3rd highest Utilization—U3 |
| 4 | Normalized CPU Memory Bytes | 9 | 4th highest Utilization—U4 |
| 5 | CPU Memory Time | | |
Table 12.
Summary of results for the CPU memory controller power model.
Table 12.
Summary of results for the CPU memory controller power model.
| Memory BandWidth (MBps) | MAPE | MAPE (One Second Average) | MAPE (Per Trace Average) | Feature Selection |
|---|
| 1525 | 3.95 | 2.93 | 2.06 | 1 2 4 5 9 |
| 2288 | 5.08 | 3.42 | 4.08 | 1 2 4 5 7 9 |
| 3509 | 3.63 | 2.65 | 2.89 | 1 4 5 6 7 9 |
| 4066 | 2.95 | 1.83 | 0.36 | 1 4 5 6 8 9 |
| 5126 | 3.28 | 2.43 | 3.08 | 1 4 5 6 7 8 9 |
| 5928 | 2.94 | 1.95 | 2.23 | 1 4 5 6 7 |
| 7904 | 2.82 | 2.03 | 1.25 | 1 2 3 4 5 6 7 8 9 |
| 9887 | 2.90 | 1.85 | 1.65 | 1 2 4 6 7 8 9 |
| 11,863 | 2.98 | 1.77 | 2.16 | 1 2 4 6 |
Table 13.
Summary of results with the union of features for the CPU memory controller.
Table 13.
Summary of results with the union of features for the CPU memory controller.
| Memory Bandwidth (MBps) | MAPE | MAPE (One Second Average) | MAPE (Per Trace Average) |
|---|
| Selected | Union | Selected | Union | Selected | Union |
|---|
| 1525 | 3.95 | 3.92 | 2.93 | 2.91 | 2.06 | 1.97 |
| 2288 | 5.08 | 5.09 | 3.42 | 3.42 | 4.08 | 4.1 |
| 3509 | 3.63 | 3.63 | 2.65 | 2.65 | 2.89 | 2.89 |
| 4066 | 2.95 | 2.95 | 1.83 | 1.83 | 0.36 | 0.36 |
| 5126 | 3.28 | 3.28 | 2.43 | 2.43 | 3.08 | 3.08 |
| 5928 | 2.94 | 2.95 | 1.95 | 1.95 | 2.23 | 2.25 |
| 7904 | 2.82 | 2.82 | 2.03 | 2.03 | 1.25 | 1.25 |
| 9887 | 2.90 | 2.90 | 1.85 | 1.85 | 1.65 | 1.65 |
| 11,863 | 2.98 | 2.96 | 1.77 | 1.75 | 2.16 | 2.14 |
Table 14.
GPU memory controller features.
Table 14.
GPU memory controller features.
| Feature Id | Performance Counters | Feature Id | Performance Counters |
|---|
| 1 | Aggregated Normalized Instructions | 8 | Max Utilization—U1 |
| 2 | CPU Cycles per Instruction | 9 | 2nd highest Utilization—U2 |
| 3 | Raw Memory Accesses per Instruction | 10 | 3rd highest Utilization—U3 |
| 4 | Normalized CPU Memory Bytes | 11 | 4th highest Utilization—U4 |
| 5 | CPU Memory Time | 12 | GPU Capacity |
| 6 | Normalized GPU Memory Bytes | 13 | GPU Utilization |
| 7 | GPU Memory Time | 14 | Frames Count |
Table 16.
Summary of results with averaging the iterations for the GPU memory controller.
Table 16.
Summary of results with averaging the iterations for the GPU memory controller.
| Frequency (MHz) | MAPE | MAPE (One Second Average) | MAPE (Per Trace Average) |
|---|
| Selected | Union | Selected | Union | Selected | Union |
|---|
| 762 | 14.00 | 14.02 | 10.58 | 10.63 | 0 | 0 |
| 1525 | 14.57 | 14.88 | 12.83 | 13.03 | 0 | 0 |
| 2288 | 18.77 | 17.44 | 14.65 | 13.36 | 0.15 | 0 |
| 3509 | 14.16 | 14.32 | 12.47 | 12.71 | 0 | 0 |
| 4173 | 11.86 | 11.10 | 9.95 | 8.94 | 0.08 | 0 |
| 5271 | 6.48 | 6.19 | 5.19 | 4.99 | 0.01 | 0 |
| 5928 | 9.42 | 9.67 | 7.55 | 7.68 | 0.06 | 0 |
| 7904 | 5.98 | 6.22 | 5.01 | 5.22 | 0 | 0 |
| 9887 | 7.08 | 6.53 | 5.04 | 4.77 | 0 | 0 |
| 11,863 | 3.67 | 3.64 | 2.52 | 2.56 | 0.01 | 0 |
Table 17.
CPU feature selection table.
Table 17.
CPU feature selection table.
| Feature Id | Performance Counters | Feature Id | Performance Counters |
|---|
| 1 | Normalized Instructions | 8 | 3rd highest Utilization—U3 |
| 2 | CPU Cycles per Instruction | 9 | 4th highest Utilization—U4 |
| 3 | L2 References per Instruction | 10 | Normalized CPU MEM Bytes |
| 4 | L2 Misses per Instruction | 11 | CPU Memory Time |
| 5 | Branch misses per Instruction | 12 | CPU Cycles per MEM bytes |
| 6 | Max Utilization—U1 | 13 | L2 References per MEM bytes |
| 7 | 2nd highest Utilization—U2 | 14 | Raw Memory Accesses per MEM Bytes |
Table 18.
Benchmarks used for CPU and GPU power validation.
Table 18.
Benchmarks used for CPU and GPU power validation.
| No | Training Set | Test Benchmark |
|---|
| 1 | PCA + MEL + FFT + Spectral | BasicMath |
| 2 | BasicMath + MEL + FFT + Spectral | PCA |
| 3 | BasicMath + PCA + FFT + Spectral | MEL |
| 4 | BasicMath + PCA + MEL + Spectral | FFT |
| 5 | BasicMath + PCA +MEL + FFT | Spectral |
Table 19.
Summary of results with leave-one-out experiments.
Table 19.
Summary of results with leave-one-out experiments.
| Benchmark | Core | Frequency (GHz) | MAPE (Leave One out) |
|---|
| BasicMath | Big | 1.25 | 17.13 |
| PCA | Big | 1.25 | 10.2 |
| MEL | Big | 1.25 | 3.3 |
| FFT | Big | 1.25 | 7.60 |
| Spectral | Big | 1.25 | 9.73 |
Table 20.
Platform settings for Wi-Fi power modeling.
Table 20.
Platform settings for Wi-Fi power modeling.
| Feature | Performance Counters |
|---|
| Little Core frequency | 1.24 GHz |
| GPU Frequency | 510 MHz |
| CPU Mem BW | 11,863 MBps |
| GPU Mem BW | 11,863 MBps |
Table 21.
Features used for Wi-Fi power modeling.
Table 21.
Features used for Wi-Fi power modeling.
| Feature Id | Performance Counters | Feature Id | Performance Counters |
|---|
| 1 | Max Utilization—U1 | 4 | 4th highest Utilization—U4 |
| 2 | 2nd highest Utilization—U2 | 5 | Transmitted packets |
| 3 | 3rd highest Utilization—U3 | 6 | Received packets |
Table 22.
Training error for WiFi power model.
Table 22.
Training error for WiFi power model.
| Error Metric | Percentage Error |
|---|
| MAPE | 24.90% |
| MAPE (1 s Avg) | 11.45% |
| MAPE (trace Avg) | 6.22% |
| RMSE | 2.32% |
Table 23.
Summary of the estimated parameters and performance of the estimation model.
Table 23.
Summary of the estimated parameters and performance of the estimation model.
| Parameter | Features | Equation in the Paper | Estimation Error | Validated | Section |
|---|
| PDisplay | Brightness, Proportion of color | 2 | 10–17% | Yes | Section 3.1 |
| Pleak,A57 | Voltage, Temperature | 5 | <1% | Yes | Section 3.2 |
| Pdyn,A57 | Union of Features in Table 3 | 7, 8 | 6% | Yes | Section 3.2 |
| Pleak,A53 | Voltage, Temperature | 5 | <1% | Yes | Section 3.3 |
| Pdyn,A53 | Union of Features in Table 6 | 7, 8 | 7% | Yes | Section 3.3 |
| Pleak,gpu | GPU Voltage, GPU Temperature | 14 | <1% | Yes | Section 3.4 |
| Pdyn,gpu | Union of Features in Table 9 | 17,19 | 4% | Yes | Section 3.4 |
| PMEM,gpu | Union of Features in Table 12 | 22 | 2% | Yes | Section 3.5 |
| PMEM,gpu | Union of Features in Table 15 | 24 | 10% | Yes | Section 3.5 |
| Pwifi+other | Table 21 | 27 | 11% | Yes | Section 3.6 |


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}























