3.1. Initial Threat Model
The applicative scenario we chose is detailed here. The victim application we targeted ran computations implying a secret value. We considered that it is isolated from other processes for security purposes preventing any eavesdropping by software means. We considered this victim application to be compromised either by a library containing a Trojan or a buggy implementation causing leakages at the micro architectural level. This strong hypothesis is legitimate as the recent Ripple20 series of vulnerabilities [
17] has shown it: a series of critical vulnerability was discovered in a widely used TCP/IP library deployed in a vast range of applications. We consider an attacker that is aware of this leakage and willing to recover the secret used by the victim process. The secret information is recovered using the micro architectural leakage, crossing the security boundaries introduced by the logical isolation.
The technical target consists in a mono-core and mono thread scenario. The mono-core scenario first adds some difficulty for a potential attacker as they cannot take advantage of high-end optimization mechanisms (out-of-order execution, Simultaneous Multi-Threading…) to gather information. These mechanisms are widely used in micro architectural attacks to recover data from a neighboring process located on another logical core. More generally, a simpler core design implies a restricted number of attack paths available. It also reduces the available covert channel techniques that are applicable, as several of them require the use of the mechanisms named above. However, even if a multi-core scenario causes a greater attack surface, the exploited hardware resources are shared among several cores. This implies a significantly higher amount of perturbation for the attacker trying to leak data from these resources. In the specific case of caches, the previous logic still applies with a variation induced by the cache’s size. Even if there is more contention in a multi-core system, if the cache’s size is sufficient, there might be no additional contention compared to a mono-core system.
In a mono threaded use-case, the execution time is shared only by a single processing thread. It results in more time for the attacker to leverage a covert channel and less chances of being interrupted during the attack.
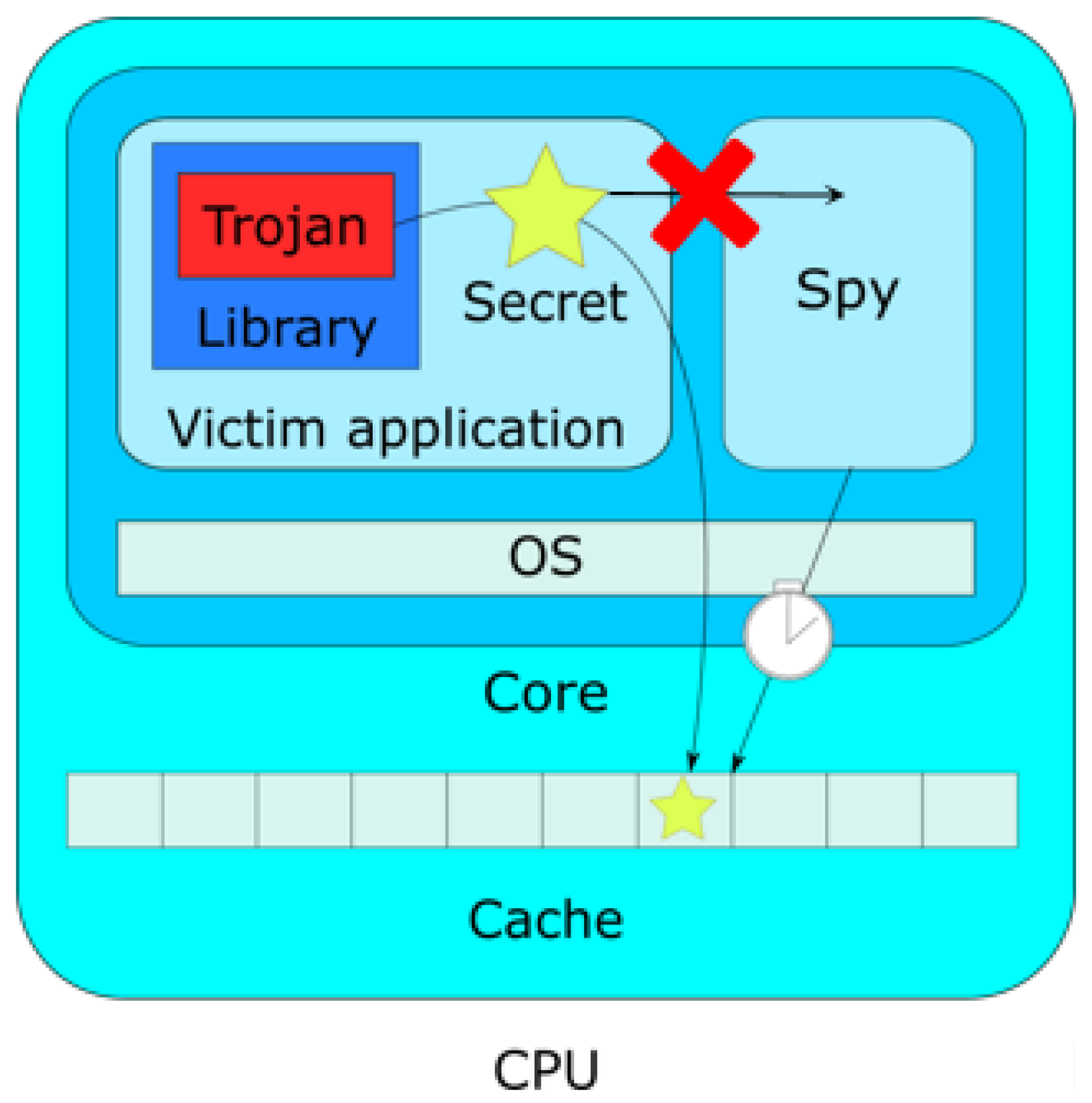
The victim runs on a CVA6 that runs an operating system (OS) on top of which runs the victim within a first domain, considered to be trusted. This victim program is assumed to be compromised by a Trojan trying actively to leak the secret information from the victim application.
The attacker itself is contained in a second untrusted security domain. They time-share the core with the victim application and run a spy program that tries to recover the information leaked by the Trojan. The threat model is summarized in
Figure 2. Both the victim and the attacker applications run in the user land. Indeed, CVA6 does enable the use of timestamp instructions in user mode. It might not be the case for other CPUs where developing kernel modules would therefore be required to access those necessary instructions in order to carry out a time or access-driven cache covert channel.
3.2. Experimental Setup
We now detail the setup we used during our experimentations. For the hardware configuration, we chose to work with the default version of CVA6, as directly available from the Open Hardware Group’s Github repository [
15]. More specifically, this meant that the core we worked on used 64-bit addresses, and had the default cache configuration corresponding to the one introduced in
Section 2.2.
We instantiated this CVA6 on a Genesys 2 FPGA platform from Digilent [
18], as there were a lot of tools and configurations available to work with. The Digilent Genesys 2 board was based on the latest Kintex-7™ Field Programmable Gate Array (FPGA) from Xilinx and is a high-speed FPGA. We communicated with the FPGA platform using a Linux computer through SSH and using the Ethernet port available on the Genesys 2 board.
For the software configuration, we relied on the toolchain contained in the Open Hardware Group’s Github repository to compile and synthetize the RTL into an exploitable bitstream and memory configuration file. We then used the Xilinx’s Vivado Design Suite [
19] to instantiate the results of the synthesis on the FPGA board. We then selected a Linux OS, generating our own Linux image using the toolchain available on CVA6-SDK Github repository [
20]. It was based on a pre-built image directly available on the same repository, but we slightly modified it to fit our specific needs, adding support for SSH communication. The Linux image is lightweight, and we chose not to add any tool or process that could hinder our experimentations. The Linux image is then embedded in a standard 64 Gb SD Card and inserted inside the Genesys 2. The OS will then be loaded at each reset of the FPGA board.
3.3. First Experimentations on Information Transmission and Statistical Analysis
To carry out a micro-architectural covert channel, it is beneficial to have a good picture of the targeted cache architecture and its mechanisms. A first advantage for an attacker targeting an open-source core is the availability of the sources of the targeted data cache. The reverse engineering efforts are considerably sped up in an open-source scenario, even if this effort remains not negligible. In our case, we leveraged the work done in [
16] where the authors detailed both the cache structure and its implementation.
We further carried out several preliminary experiments in order to identify a potential encoding technique e.g., a specific method to place the secret information inside the data cache in order to transmit it. Our initial idea was to propose an implementation of the Prime + Probe covert channel, therefore we began by observing the cache misses. A simple application causing cache eviction by filling an array structure was used as a preliminary victim. A second application measured the time it takes to access its own data before (when it was in the cache) and after the victim has been run (when the data has supposedly been evicted) similarly to the prime and probe steps of the related covert channel. These tests aimed at two different objectives: confirm our comprehension of the cache’s implementation and achieve a first level of information transmission via controlled cache evictions.
Based on the same idea as the experiment described above, several tests and variations of this experimentation have been made in order to establish a correlation between the activity we caused with a given code (the victim filling an array with data), and the resulting evictions. These experiments included filling different sizes and types of array structures (smaller than the cache, same size as the cache, bigger than the cache for example) for causing different cache eviction patterns. We then measured where the evictions happened inside the cache using the second application. The understanding of the hardware implementation of the data cache was a valuable input for these first experiments. We started out by running a skeleton of Prime + Probe covert channel consisting of an attacker process (or spy process) filling the cache with its own data (Prime step) and a second process (or victim process, containing the Trojan) trying to cause evictions equal to a given secret value that was hardcoded inside it. We then proceeded to timing measurements inside the spy process (that carried out the Prime step) using the RDCYCLE RISC-V instruction [
21] in order to observe the different cache evictions caused by the victim process and its Trojan.
The spy process also generated a log file containing all of its measurements that we statistically analyzed thoroughly after using Python scripts. This statistical analysis over a large number of experimentations is a mandatory step compared to a BareMetal context as the OS causes multiple unwanted cache evictions because of the concurrent processes that are running. Considering multiple experimentations and subtracting the results of the experimentation without the victim process running (normal activity only with the OS running) enabled us to reduce the impact of this unwanted “noise” in our measurements, and observe only the useful evictions caused by the Trojan contained in the victim process.
After these experiments, we were able to observe a difference between the cases in which the victim process creates evictions and the other cases. Recognizable patterns caused by the victim process’ activity (generating cache evictions) showed that it was possible to transmit information, even if the OS adds some “noise” that could hinder the transmission. In this specific case, the information transmitted consists in the binary decomposition of the secret value, encoded in the amount of cache evictions caused by the victim application containing the Trojan. The secret value’s binary decomposition is transformed into a specific cache contention pattern (further details about the contention pattern are given in
Section 3.4). The Trojan then causes the corresponding cache evictions to match this pattern that is then recovered by the attacker during the prime phase of the covert channel. More cache evictions than a fixed threshold (determined during preliminary experimentations to differentiate the cache hits from cache misses) imply a value of 1, less evictions than the threshold means the recovery of a 0.
It also enabled us to create a set of analysis tools to minimize the impact of the OS on the observed traces and visualize the results of our minimal Prime + Probe covert channel. The next step consisted in establishing a covert channel, enabling us to transmit a given value through the data cache.
3.4. Implementation of a Basic Tailored Covert Channel on the CVA6
To build a micro architectural cache covert channel, it is mandatory to be able to recover a precise value hidden by the Trojan inside the data cache. According to the previously presented observations, and the understanding of the data cache’s structure, we built a covert channel on the CVA6 capable of transmitting up to 256 bits of information with the default data cache configuration.
Applying the same code structure as in
Section 3.3 inspired by the Prime + Probe technique,
Figure 3 gives the pseudocode of the improved version of our initial covert channel.
Considering the characteristics of the data cache, the spy process builds an extraction array fitting the cache’s structure. This array contained 2048 cells of 16 bytes, analogously to the CVA6′s data cache. This array was used to fill the cache during the Prime step, made by the spy process. As the cache used a no-write-allocate policy, it is necessary to cause a read-miss on every element of the extraction array in order to bring them inside the data cache. To this end, we sequentially allocated and then read back each cell of the array.
Once the cache was filled, the spy process created a thread running the victim and the Trojan it contains. We discuss the realism and the applicability in a real-life context of this scenario in a later section. For this iteration of the experimentations, the victim simply consisted in an addition and the secret was the result of the operation, or even just a hard coded value acting as a secret to be extracted. The rest of the victim code is composed of the Trojan that will cause targeted evictions inside the data cache. In order for the evictions to be effective and transmit the desired value, it is required to take into consideration the structure and behaviour of the data cache.
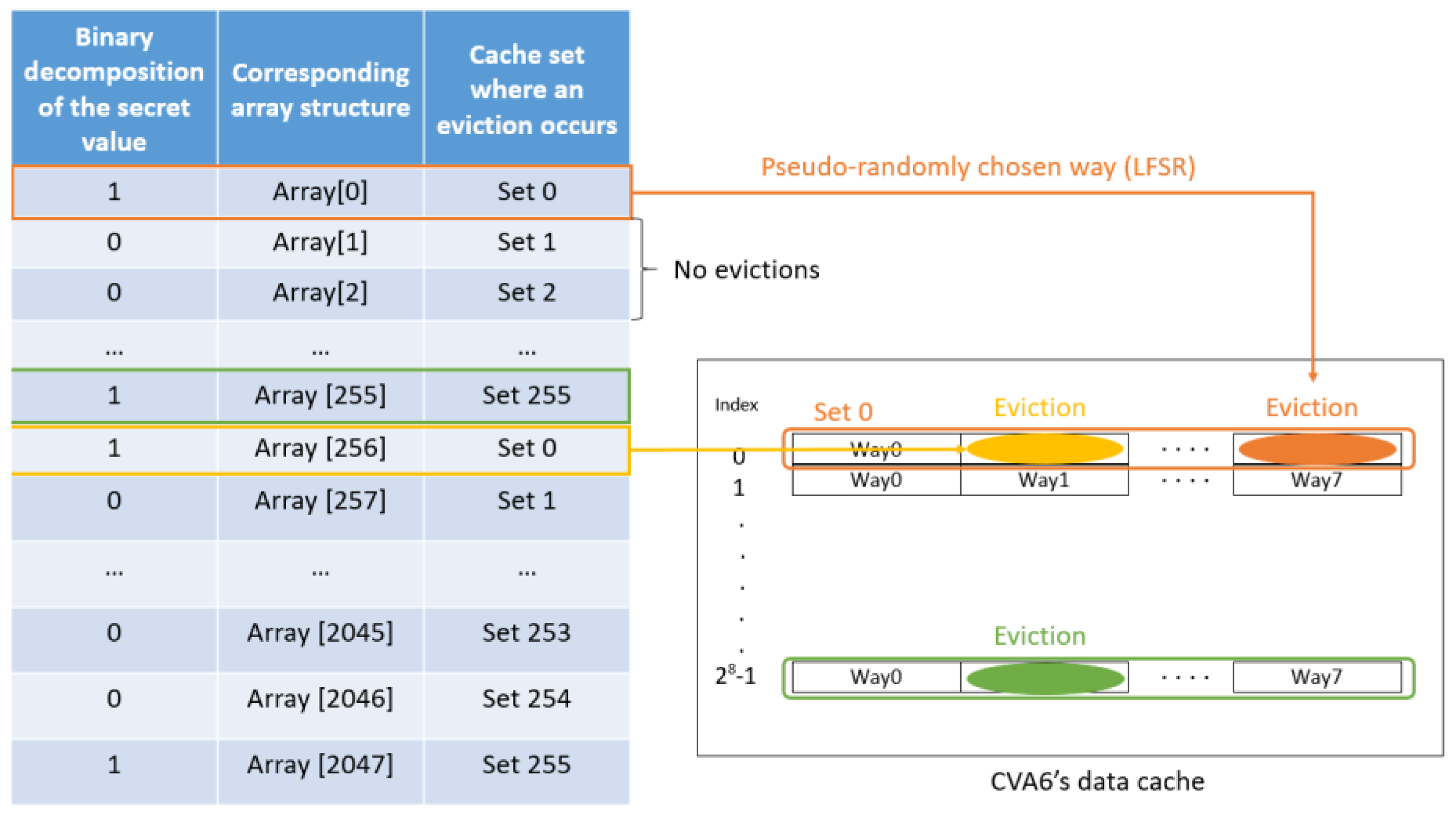
We noticed that working with the cache sets produced the expected results, and was easier to implement than working at the cache way granularity, mainly because of the pseudo-random eviction policy. The secret value was transmitted bit by bit, meaning that a cache miss was interpreted as a value of 1, whereas a cache hit was interpreted as a value of 0 (because the spy’s value was not evicted).
The Trojan proceeded similarly to the spy process during the Prime step and was allocated then read again cells in another array (called “Trojan’s extraction array”) with the exact same dimensions as the cache. However, the Trojan did not fill every cell of the array, but only the cells with indexes that corresponded to a value to be extracted equal to 1. It ignored cells with indexes corresponding to a value to be extracted equal to 0. The main idea was that filling specific regions (bit of the secret equal to 1) of the Trojan’s extraction array directly translated in a cache miss for the spy inside the corresponding cache sets inside the data cache while for the untouched regions (bit of the secret equal to 0) it translated in a cache hit.
Figure 4 represents the situation and shows the corresponding evictions caused by the Trojan’s action.
In practice, the Trojan therefore fills its extraction array at specific locations to cause evictions in the corresponding cache set. Given that we wanted to extract a value equal to 1 as the first bit in the secret’s value decomposition, the Trojan therefore filled its array cells having indexes that verify:
Hence, in the default cache configuration we studied throughout this article, and for the first bit of the binary decomposition (thus we target the set number 0) this translates to:
The value written inside the cells does not matter at all, as only the cache eviction is useful for the covert channel. Each time the Trojan fills one of the cells, it causes a corresponding eviction inside the set having an index equal to the second term of the previous equation. For our example, the eviction was caused in the set 0. There were 8 possible ways to be replaced inside each set, and we could not easily predict, or choose which one was evicted. This is the reason for choosing a “cache set encoding” technique instead of working at cache line granularity that proved to be harder since the choice is made pseudo-randomly by the LFSR. We had no guarantee however that the evictions caused inside a given set will occur on different cache ways. It might happen that the way 0 inside the set 0 is evicted twice for example (as an example, when filling Array [0* Total_number_of_sets] and Array [2* Total_number_of_sets]). Overall, and on several repetitions of the covert channel, we are capable of distinguishing data sets where “a lot” (will be quantified in the next section) of evictions occurred, caused by the Trojan, compared to data sets where no evictions were caused and the spy’s data are still intact, leading to the reconstruction of the secret value.
This reconstruction was made possible by the spy process’ measurements during the Probe step. Once the Trojan filled its extraction array according to the secret’s binary decomposition, we ran the spy process again. It measured the time it takes to access again to all of its data. We were then capable to distinguish data that have been evicted from data that have not been evicted, using the RDCYCLE instruction. Indeed, some cells inside the spy’s array experienced a higher access time compared to the others; thus, they were evicted from the cache. Using these measurements and our Python script that processed the logs generated by the spy process, we reconstructed the secret value to be extracted. Experimental results proving that our attack implementation was practical on a simple applicative example are given in the next section.
To summarize, the main aspect of this covert channel consisted in translating the binary decomposition of the secret value to a corresponding contention inside the matching data sets. Having a value of 1 to extract at a given index, called p, in the binary decomposition, meant that we wanted to create contention inside the cache set number p. For that purpose, the Trojan fills all of the cells in Trojan_table that will cause evictions inside the set number p. By experimenting, we found out that these cells are the ones verifying: . Filling these cells with Trojan’s data caused an eviction of the Spy’s data inside the set number p. These data were previously allocated inside the cache during the Prime phase. Therefore, when the Spy Probes its data again to verify the time it takes to access it, it can conclude about the sets that contain contention or not by looking at the amount of cache misses for every cache set. According to the evictions caused by the Trojan’s activity, a high number of cache misses for the set number p is identified. This means that the Spy process will experience a higher access time for all the cells of Spy_table verifying: .
3.5. Example and Experimental Results on a Simple Victim
For this section, let us take a schoolbook victim to apply the previously presented covert channel. Our considered victim therefore only performed an addition on 40 bits to simplify the understanding of this toy example. The secret to be extracted was the result of this addition. We now applied the code presented in
Figure 3 to this new victim. For demonstration purposes, we gathered 2000 samples for an easier visualization (in practice we need much less samples to extract a secret value). Let us consider that the result of the addition is 672726424737. This corresponded to the binary decomposition: 1001110010100001100111101001110010100001 (40 bits in total). As detailed in the previous section, our covert channel proceeded as follows:
The spy code Primed the data cache with any data, as the value itself did not matter. This is agnostic from the victim’s behavior and was therefore held for whatever process involving a secret value. Changing the cache’s characteristics (number of sets, cache’s size, associativity) and the cache’s filling policy would require to only change this part of the covert channel;
The victim made its addition. The Trojan was run as it was contained in the victim. It decomposed the result of the addition in binary. For each bit, it would, or would not, replace some values inside its array (named
Trojan_table in
Figure 3). The leftmost bit (i.e., at position p = 0) being a 1, the Trojan filled its array at all the following indexes: 0, 256, 512, 768, 1024, 1280, 1536, 1792. All these 8 indexes verified
, where 256 was the total number of sets and 0 the position of the value to leak in the binary decomposition. This operation then caused 8 cache misses in the set number 0. The next 1 in the binary decomposition was the bit at position p = 3. The Trojan therefore replaced its array at all indexes verifying
. Therefore, it filled the following indexes: 3, 259, 515, 771, 1027, 1283, 1539, and 1795. This caused 8 evictions inside the set number 3 (starting from set number 0). The Trojan repeated these steps for the whole binary decomposition of the secret value to extract;
The spy Probed its array and measured the time it took to access every cell. It also generated the logs.
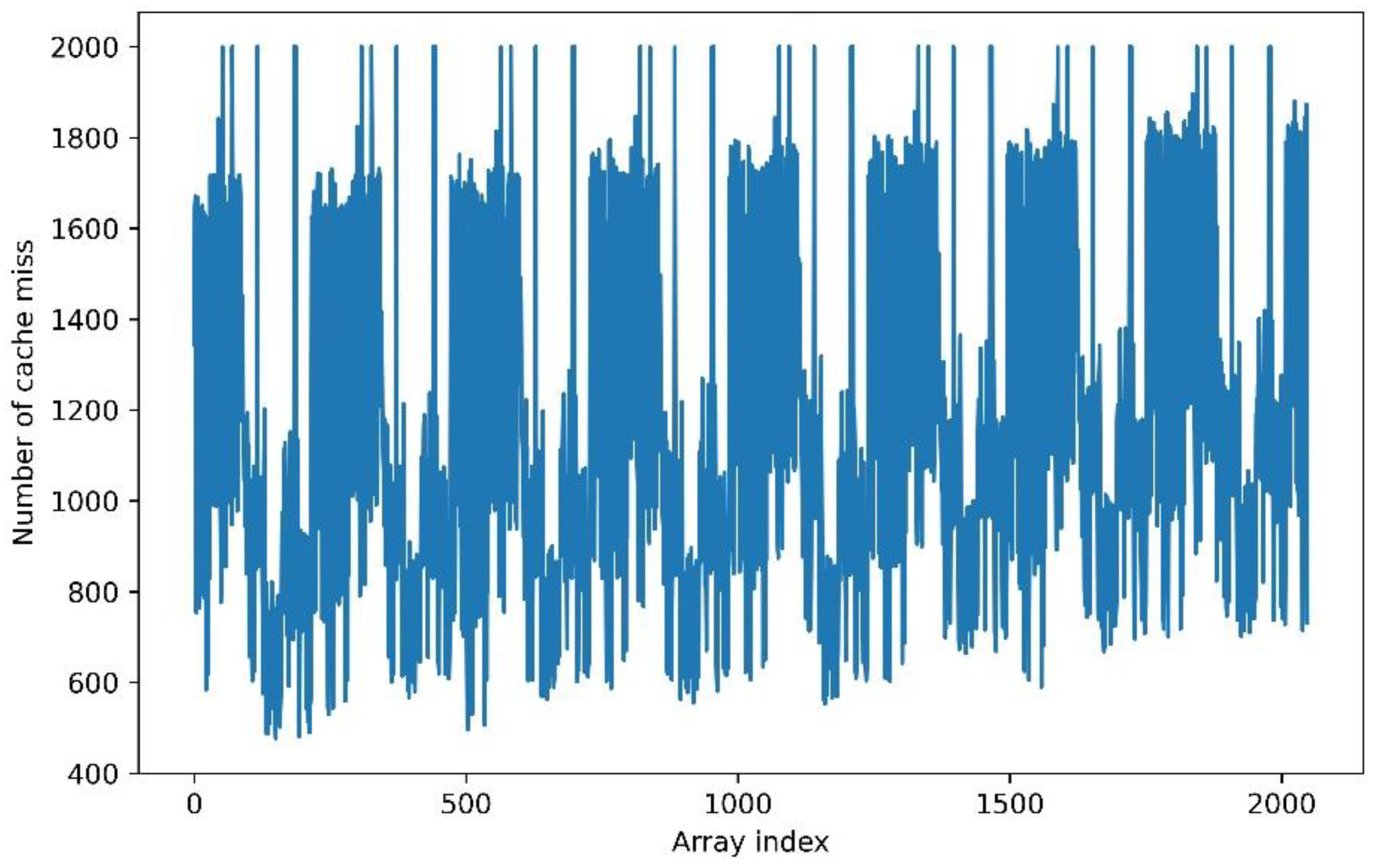
This experiment produced the results given in
Figure 5. In the figure, we represented the number of cache misses at every index in
Spy_table cumulated over the 2000 iterations of the covert channel. We can clearly see 8 patterns corresponding to the 8 ways of the targeted set that represent the Trojan’s activity. Those patterns highlight the associativity of the data in the default cache configuration we are studying. The patterns were very similar and carried the same information about the secret to be extracted. In fact, these patterns directly correspond to the evictions done by the Trojan at the cells verifying
. Each pattern contained one “peak” corresponding to one of the eight possible values verifying the equation for a given value of
p. If we considered the previous example, the Trojan replaced the indexes 3, 259, 515, 771, 1027, 1283, 1539, and 1795 (for
p = 3). This means that one of the 8 patterns had a peak corresponding to the eviction caused on the index number 3, and another pattern had the peak for the index 259. What is important to note here is that these peaks, however, had the same position inside all of the 8 patterns: the third position. This is because they were all related to an eviction caused in the cache set number 3 corresponding to the fourth bit (i.e., at index number 3) in the binary decomposition of the secret value.
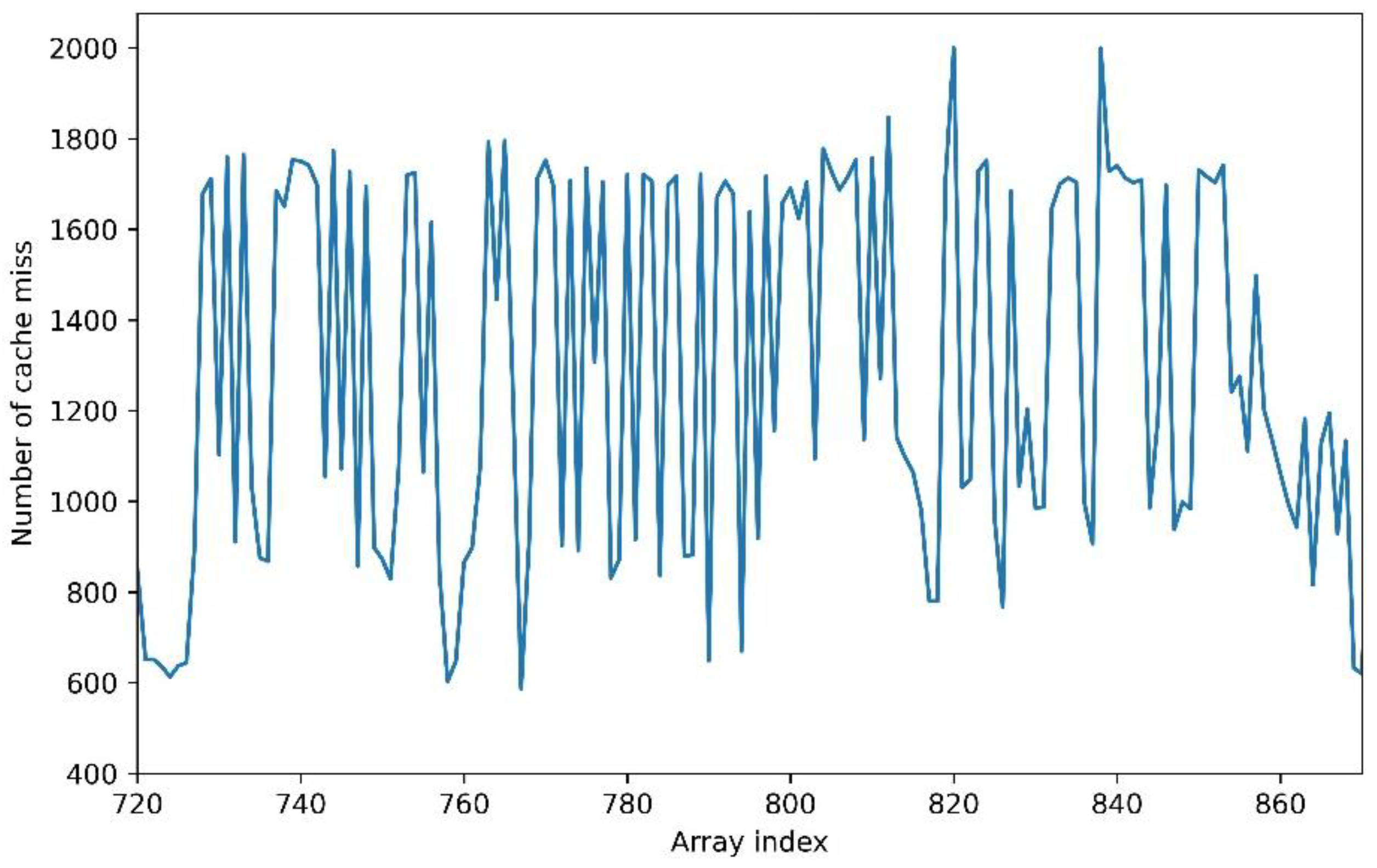
Here we wanted to extract 40 bits of secret data; therefore, we targeted the sets number 0 to 39. We noticed the presence of an “offset” at the beginning of the trace, but it did not hinder the analysis in any way. In this figure, every pattern corresponded to the activity of one way inside the cache sets from 0 to 39. For example, the pattern number p represents the amount of cache misses on the way number p inside every cache set from 0 to 39. As we had 8 patterns, we covered all the possible way placements in the figure, as there were 8 ways in total (corresponding to the value of the associativity) in the configuration we study. The data between each pattern corresponded to the amount of cache misses inside the rest of the sets, from 40 to 255. In the sets numbers 40 to 255, the Trojan did not cause any eviction because we only wanted to extract 40 bits therefore we needed only the first 40 cache sets to encode our secret. One can note that we were capable of distinguishing the activity at the cache way granularity here. However, we were forced to cause the Trojan to act at the cache set granularity because of the LFSR. We cannot choose easily and precisely which way the eviction will occur inside a given cache set, as the choice was pseudo-random. Predicting the outcome of the LFSR was possible. However, it implied a longer computation time, thus reducing the overall stealth of the attack.
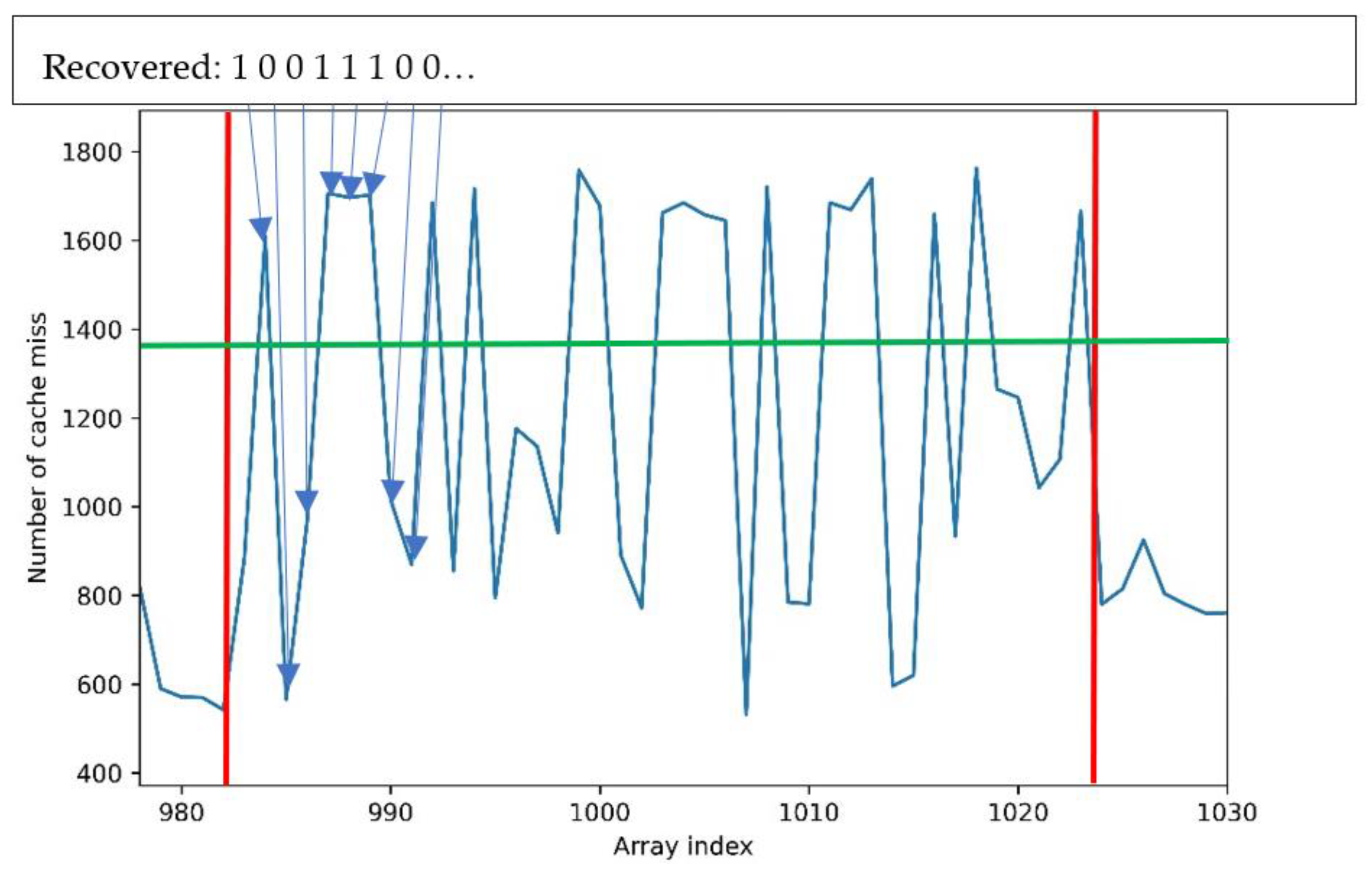
When we zoomed in on one of the patterns (the circled one in
Figure 5), we obtained what is represented in
Figure 6. Each pattern was made of 40 values, corresponding to the 40 bits we wanted to extract. A threshold was required to differentiate what we considered as 0 on the trace from what we consider as a 1. We observed that the arithmetic mean of the extreme values of the whole trace (number of cache misses), or
, worked perfectly for that purpose. Considering the peaks going beyond this value as ones, and the others as zeros, we recovered a value of 1001110010100001100111101001110010100001. This corresponds to the result of the victim’s addition; therefore, we recovered the secret value through the CVA6′s data cache with a running Linux OS.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








