
A Distribution-Preserving Under-Sampling Method for Imbalance Defect Recognition in Castings
Abstract
:1. Introduction
2. Methods
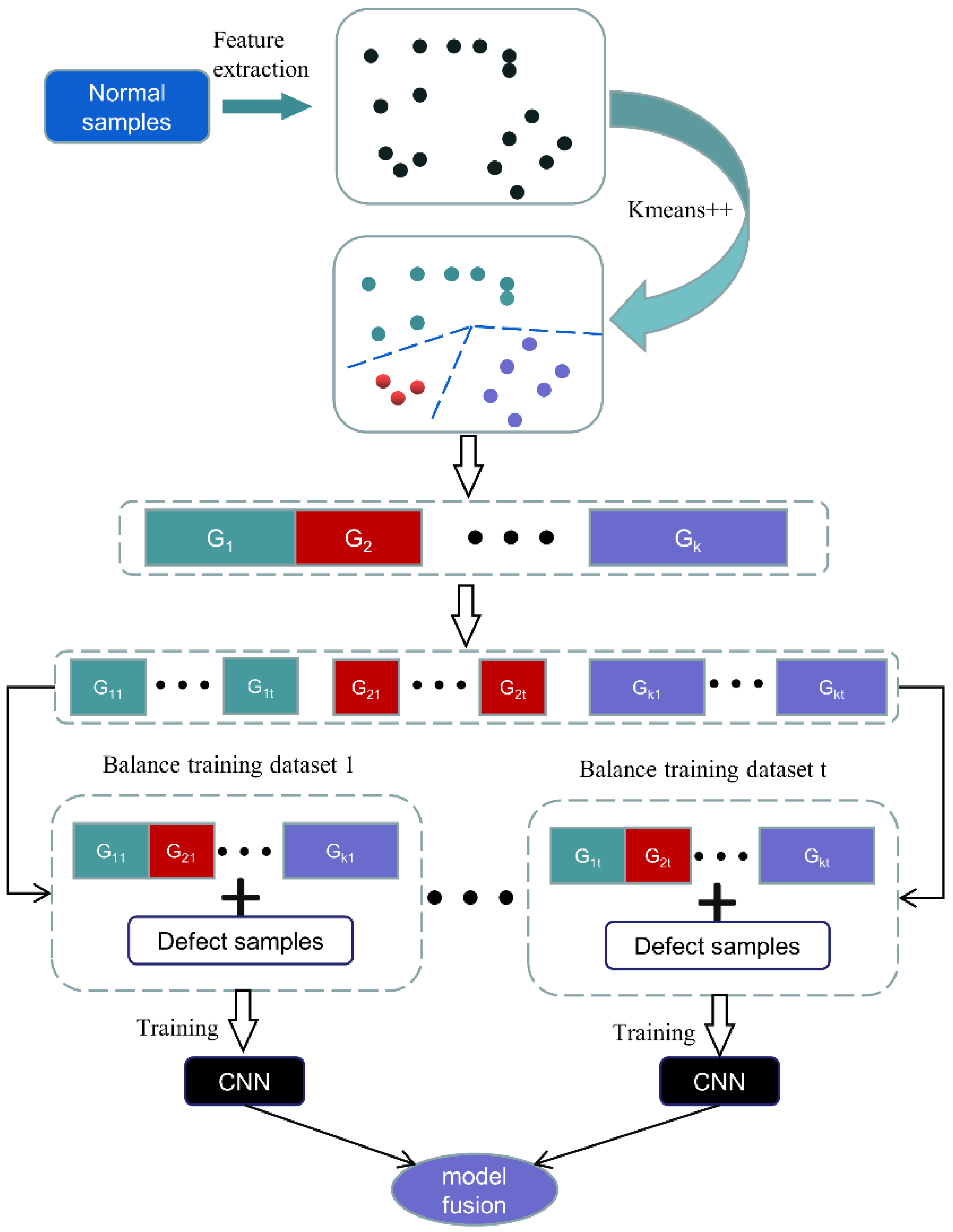
2.1. Overview
2.2. Distribution-Preserving Under-Sample
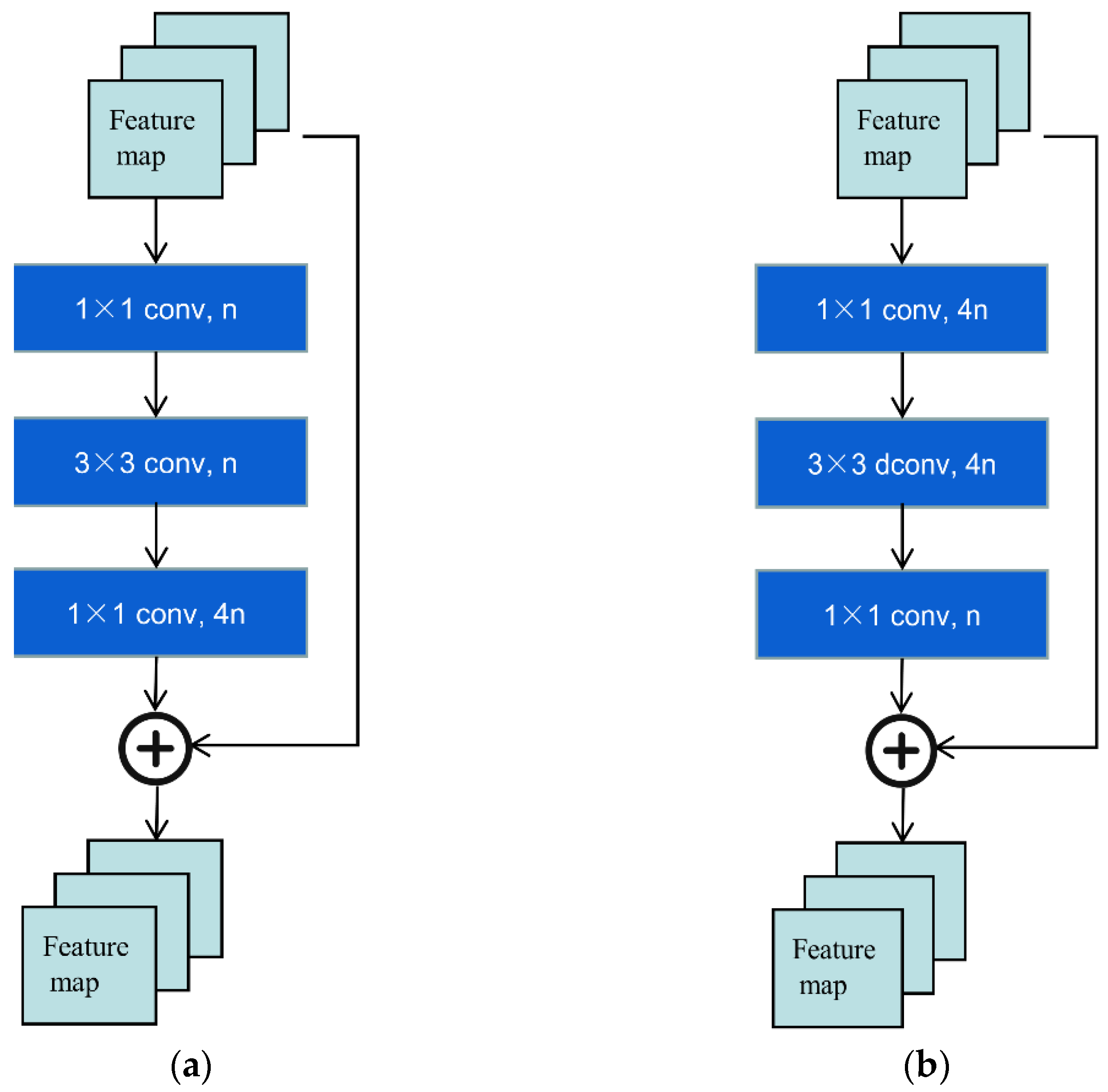
2.3. Network
2.4. Model Fusion
3. Experimental Setup
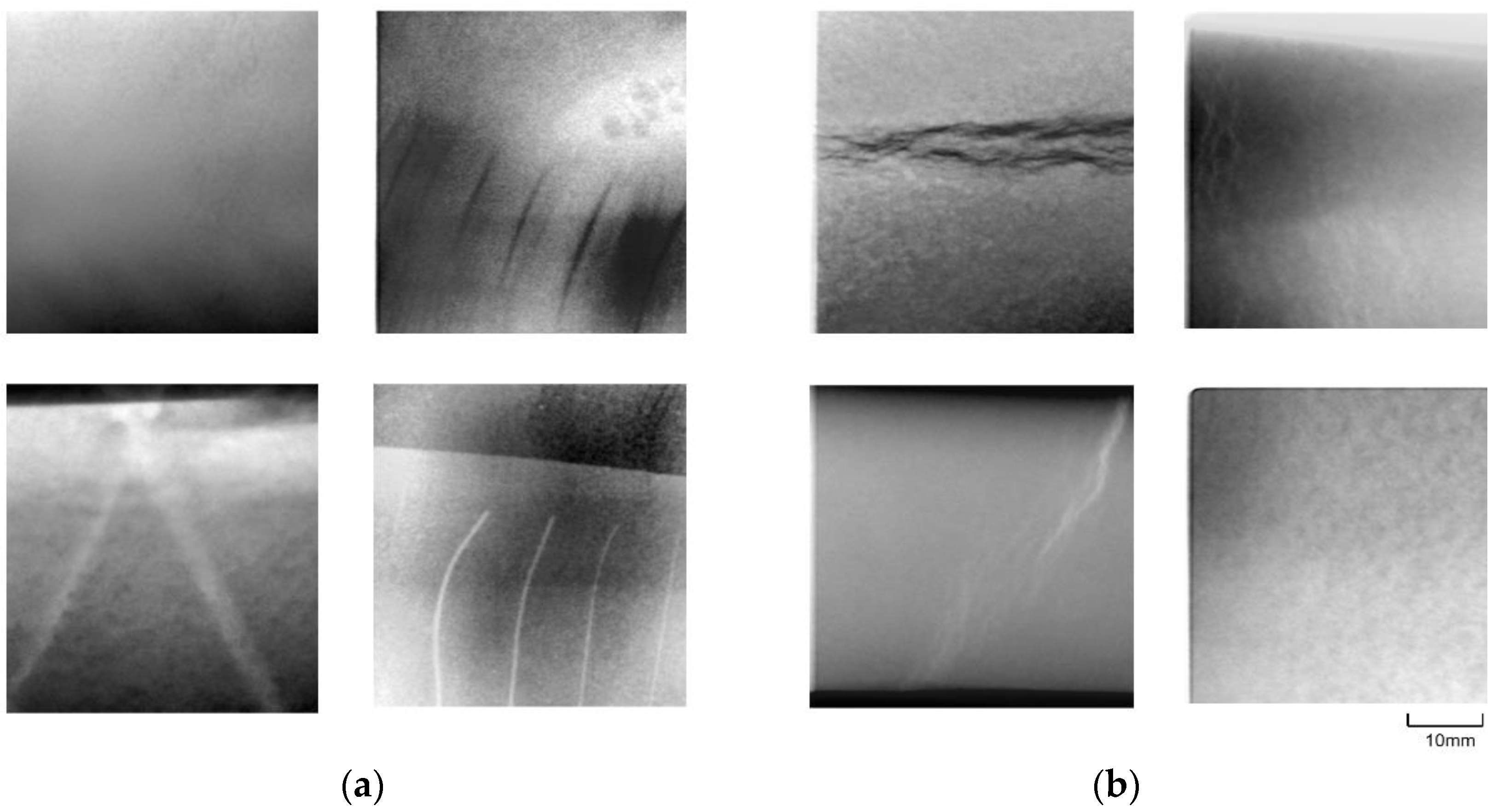
3.1. Datasets
3.2. Implementation Details
3.3. Evaluation Metric
4. Results and Discussion
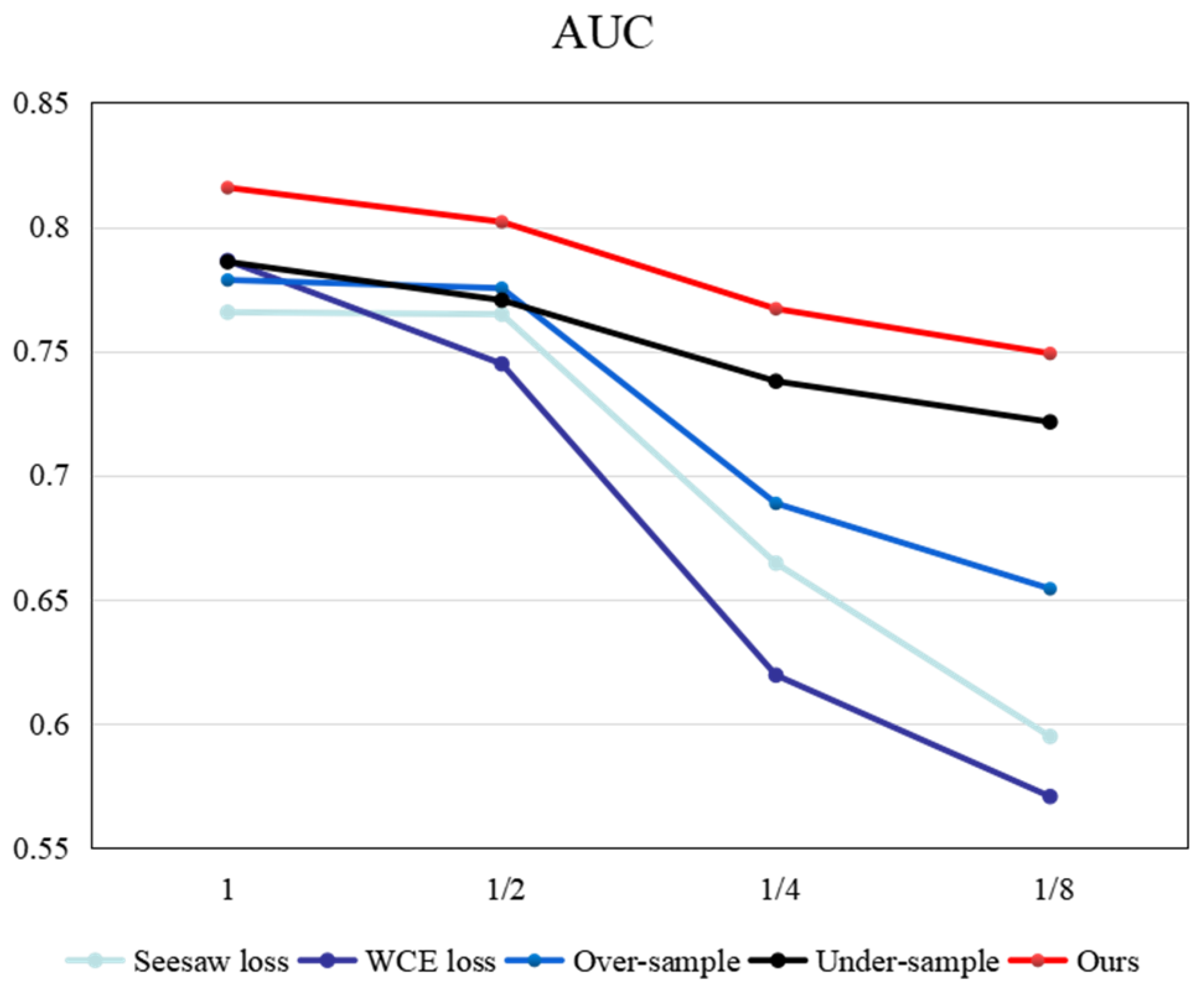
4.1. Compare with Other Methods
4.2. The Influence on Different Imbalance Ratios
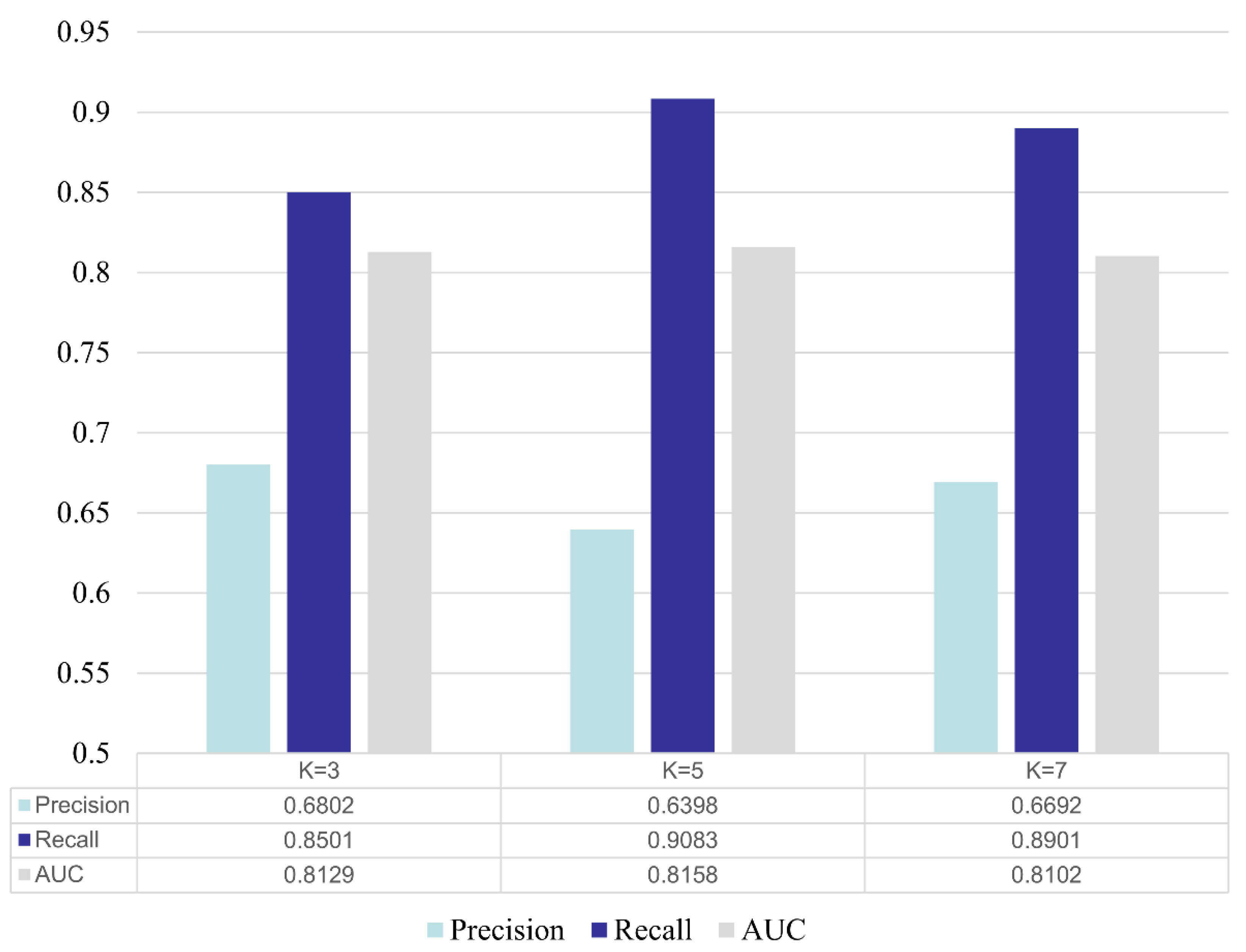
4.3. The Influence on Cluster Number K
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mery, D.; Filbert, D. Automated flaw detection in aluminum castings based on the tracking of potential defects in a radioscopic image sequence. IEEE Trans. Robot. Autom. 2002, 18, 890–901. [Google Scholar] [CrossRef] [Green Version]
- Hernández, S.; Sáez, D.; Mery, D.; Silva, R.D.; Sequeira, M. Automated defect detection in aluminum castings and welds using neuro-fuzzy classifiers. In Proceedings of the 16th World Conference on NDT, Montreal, QC, Canada, 30 August 2004. [Google Scholar]
- Zhao, X.; He, Z.; Zhang, S.; Liang, D. A sparse-representation-based robust inspection system for hidden defects classification in casting components. Neurocomputing 2015, 153, 1–10. [Google Scholar] [CrossRef]
- Du, W.; Shen, H.; Fu, J.; Zhang, G.; He, Q. Approaches for improvement of the X-ray image defect detection of automobile casting aluminum parts based on deep learning. NDT E Int. 2019, 107, 102144. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017. [Google Scholar]
- Yu, H.; Li, X.; Song, K.; Shang, E.; Liu, H.; Yan, Y. Adaptive depth and receptive field selection network for defect semantic segmentation on castings X-rays. NDT E Int. 2020, 116, 102345. [Google Scholar] [CrossRef]
- Liu, J.; Kim, J.H. A Variable Attention Nested UNet++ Network-Based NDT X-ray Image Defect Segmentation Method. Coatings 2022, 12, 634. [Google Scholar] [CrossRef]
- Mery, D.; Arteta, C. Automatic Defect Recognition in X-Ray Testing Using Computer Vision. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 27 March 2017. [Google Scholar]
- Mery, D.; Riffo, V.; Zscherpel, U. GDXray: The Database of X-ray Images for Nondestructive Testing. J. Nondestruct. Eval. 2015, 34, 1–12. [Google Scholar] [CrossRef]
- Mery, D. Aluminum Casting Inspection Using Deep Learning: A Method Based on Convolutional Neural Networks. J. Nondestruct. Eval. 2020, 39, 1–12. [Google Scholar] [CrossRef]
- Tang, Z.; Tian, E.; Wang, Y.; Wang, L.; Yang, T. Non-destructive defect detection in castings by using spatial attention bilinear convolutional neural network. IEEE Trans. Ind. Inform. 2020, 17, 82–89. [Google Scholar] [CrossRef]
- Hu, C.; Wang, Y. An efficient cnn model based on object-level attention mechanism for casting defects detection on radiography images. IEEE Trans. Ind. Electron. 2020, 67, 10922–10930. [Google Scholar] [CrossRef]
- Jiang, L.; Wang, Y.; Tang, Z.; Miao, Y.; Chen, S. Casting defect detection in X-ray images using convolutional neural networks and attention-guided data augmentation. Measurement 2021, 170, 108736. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, W.; Zang, Y.; Cao, Y.; Pang, J.; Gong, T.; Chen, K.; Liu, Z.; Loy, C.C.; Lin, D. Seesaw loss for long-tailed instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19 June 2021. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22 October 2017. [Google Scholar]
- Estabrooks, A.; Jo, T.; Japkowicz, N. A multiple resampling method for learning from imbalanced data sets. Comput. Intell. 2004, 20, 8–36. [Google Scholar] [CrossRef]
- Liu, X.-Y.; Wu, J.; Zhou, Z.-H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. 2008, 39, 539–550. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Miami, FL, USA, 22 January 2006. [Google Scholar]
- He, K.; Zhang, K.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 16 June 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 18 June 2009. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 17 June 2018. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Normal | Defect | Total |
|---|---|---|---|
| Train | 2430 | 430 | 2860 |
| Validation | 100 | 100 | 200 |
| Test | 100 | 100 | 200 |
| Backbone | Method | Precision | Recall | AUC |
|---|---|---|---|---|
| ResNet18 | CE loss | 0.5005 ± 0.001 | 0.996 ± 0.008 | 0.5509 ± 0.0735 |
| WCE loss | 0.668 ± 0.0333 | 0.846 ± 0.0301 | 0.7437 ± 0.0291 | |
| Focal loss | 0.538 ± 0.0571 | 0.494 ± 0.2463 | 0.5613 ± 0.0435 | |
| Seesaw loss | 0.668 ± 0.0098 | 0.89 ± 0.0482 | 0.74 ± 0.0232 | |
| Over-sample | 0.6534 ± 0.0163 | 0.824 ± 0.0508 | 0.7797 ± 0.0202 | |
| Under-sample | 0.6537 ± 0.0757 | 0.75 ± 0.1838 | 0.7408 ± 0.035 | |
| Ours | 0.6326 ± 0.0227 | 0.84 ± 0.0562 | 0.7891 ± 0.0168 | |
| MobileNetV2 | CE loss | 0.5 ± 0.0 | 1 ± 0 | 0.5101 ± 0.075 |
| WCE loss | 0.709 ± 0.0256 | 0.846 ± 0.0287 | 0.7864 ± 0.0355 | |
| Focal loss | 0.529 ± 0.0208 | 0.598 ± 0.0838 | 0.5408 ± 0.0194 | |
| Seesaw loss | 0.675 ± 0.037 | 0.868 ± 0.0343 | 0.7656 ± 0.0236 | |
| Over-sample | 0.6712 ± 0.0316 | 0.84 ± 0.0701 | 0.7786 ± 0.0153 | |
| Under-sample | 0.6674 ± 0.0203 | 0.8224 ± 0.0528 | 0.7859 ± 0.0069 | |
| Ours | 0.6398 ± 0.0155 | 0.9080 ± 0.0192 | 0.8158 ± 0.0160 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, H.; Li, X.; Li, X.; Hou, C.; Liu, S.; Xie, H. A Distribution-Preserving Under-Sampling Method for Imbalance Defect Recognition in Castings. Coatings 2022, 12, 1808. https://doi.org/10.3390/coatings12121808
Yu H, Li X, Li X, Hou C, Liu S, Xie H. A Distribution-Preserving Under-Sampling Method for Imbalance Defect Recognition in Castings. Coatings. 2022; 12(12):1808. https://doi.org/10.3390/coatings12121808
Chicago/Turabian StyleYu, Han, Xinyue Li, Xingjie Li, Chunyu Hou, Shangyu Liu, and Huasheng Xie. 2022. "A Distribution-Preserving Under-Sampling Method for Imbalance Defect Recognition in Castings" Coatings 12, no. 12: 1808. https://doi.org/10.3390/coatings12121808