
TSSTNet: A Two-Stream Swin Transformer Network for Salient Object Detection of No-Service Rail Surface Defects


Abstract
:1. Introduction
- (1)
- When the rail is heated, due to unreasonable technology and techniques, thermal stresses are created in the rail material, forming cracks on the surface;
- (2)
- If the billet is not cleaned or is cleaned improperly, the impurities attached to the billet remain on the surface of the finished rail after heating and rolling deformation. This is known as scarring;
- (3)
- The presence of linear or curved grooves of varying depths on the surface of the rails, either continuously or intermittently distributed on the local surface, is known as a scratch. This is usually caused by improper installation of equipment during the rolling process.
- (1)
- For the SOD of no-service rail surface detection, we propose a supervised deep learning network named TSSTNet and innovatively introduce the transformer as the backbone of the network;
- (2)
- A two-stream encoder and a three-stream decoder are proposed to eliminate the adverse effects between tasks;
- (3)
- A contour alignment module is presented to connect multitasking and reduce the noise at the edges of the saliency maps;
- (4)
- A multi-feature fusion module is proposed to converge the feature maps in the three different streams of the decoder;
- (5)
2. Related Works
2.1. Detection of Rail Defects
2.2. Saliency Detection in RGB Images
2.3. Contour Information Learning
2.4. Transformer
3. Methodology
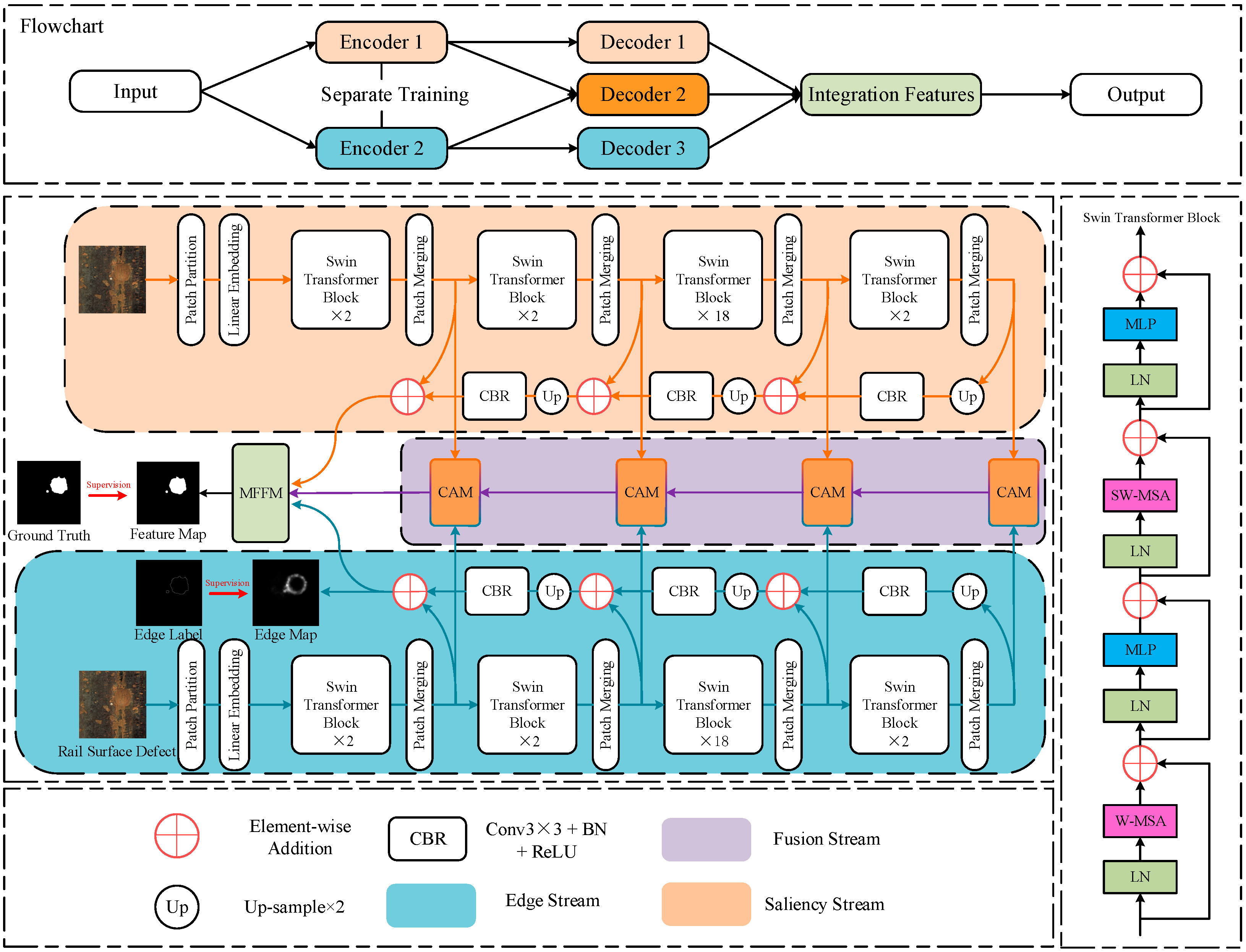
3.1. Overview of the TSSTNet Framework
3.2. Two-Stream Encoder and Three-Stream Decoder
3.3. Swin Transformer Backbone
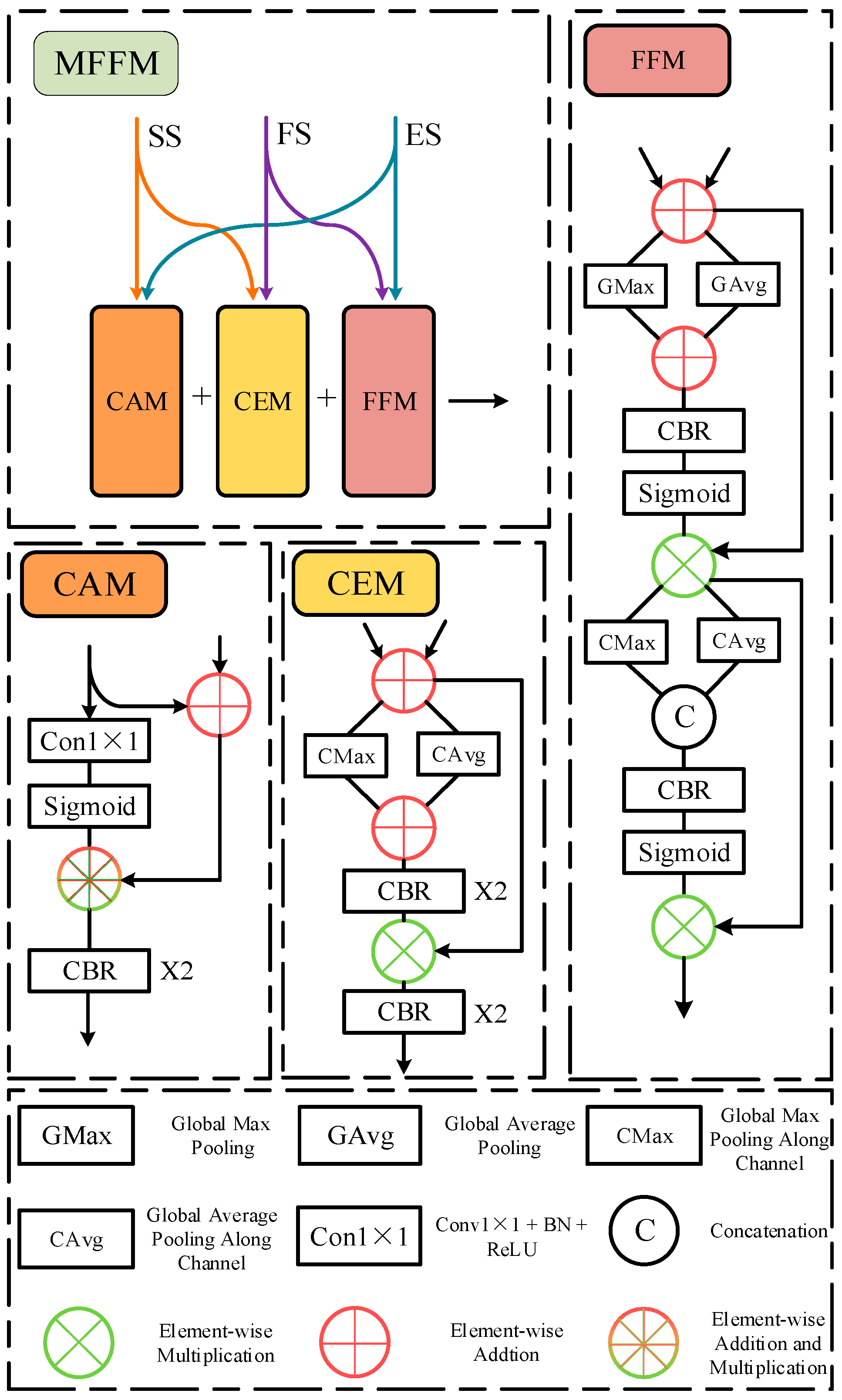
3.4. Multi-Feature Fusion Module
3.4.1. Contour Alignment Module
3.4.2. Contour Enhancement Module and Feature Fusion Module
3.5. Training
4. Experimental Section
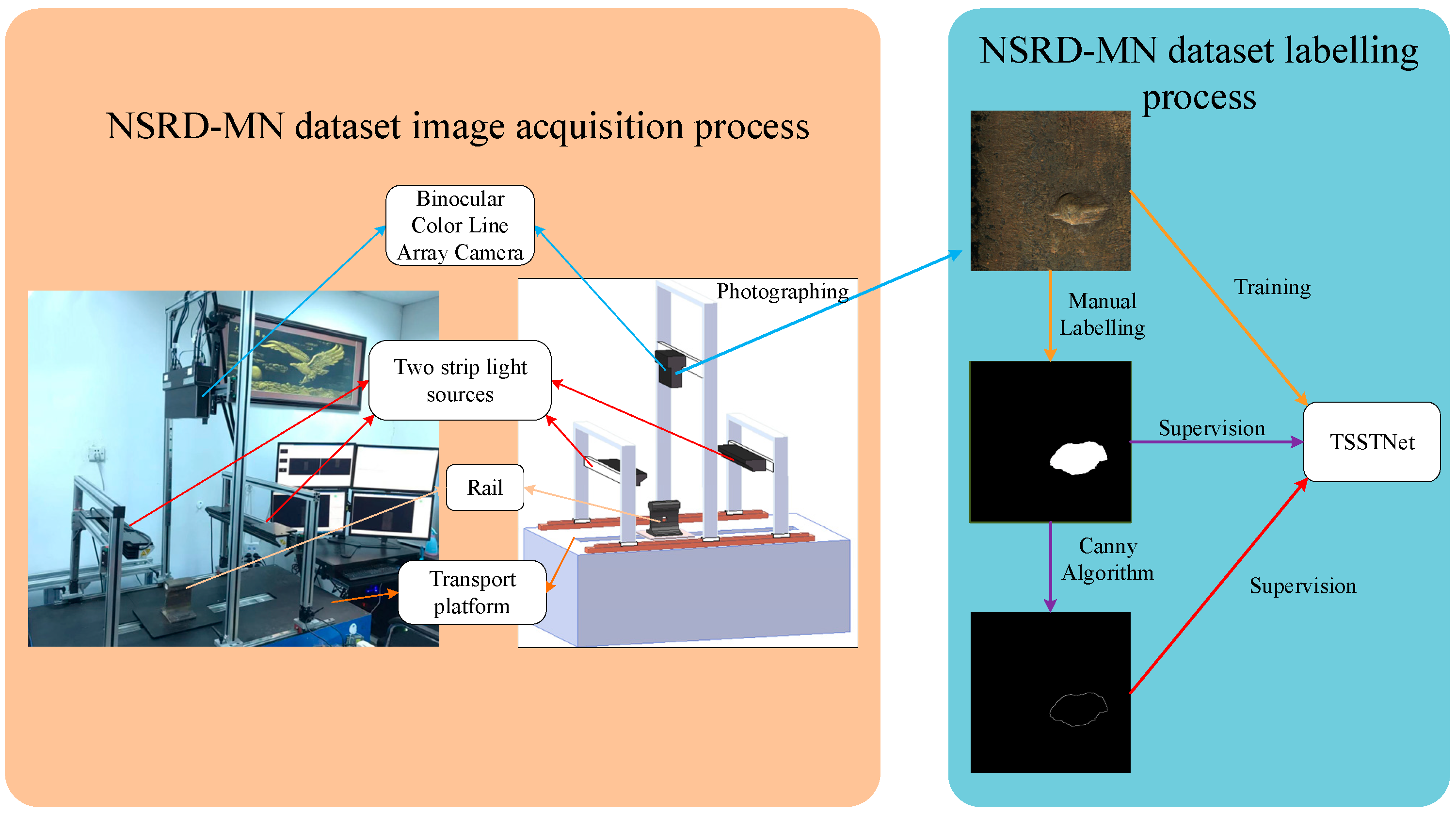
4.1. Datasets
4.2. Evaluation Metrics and Loss Function
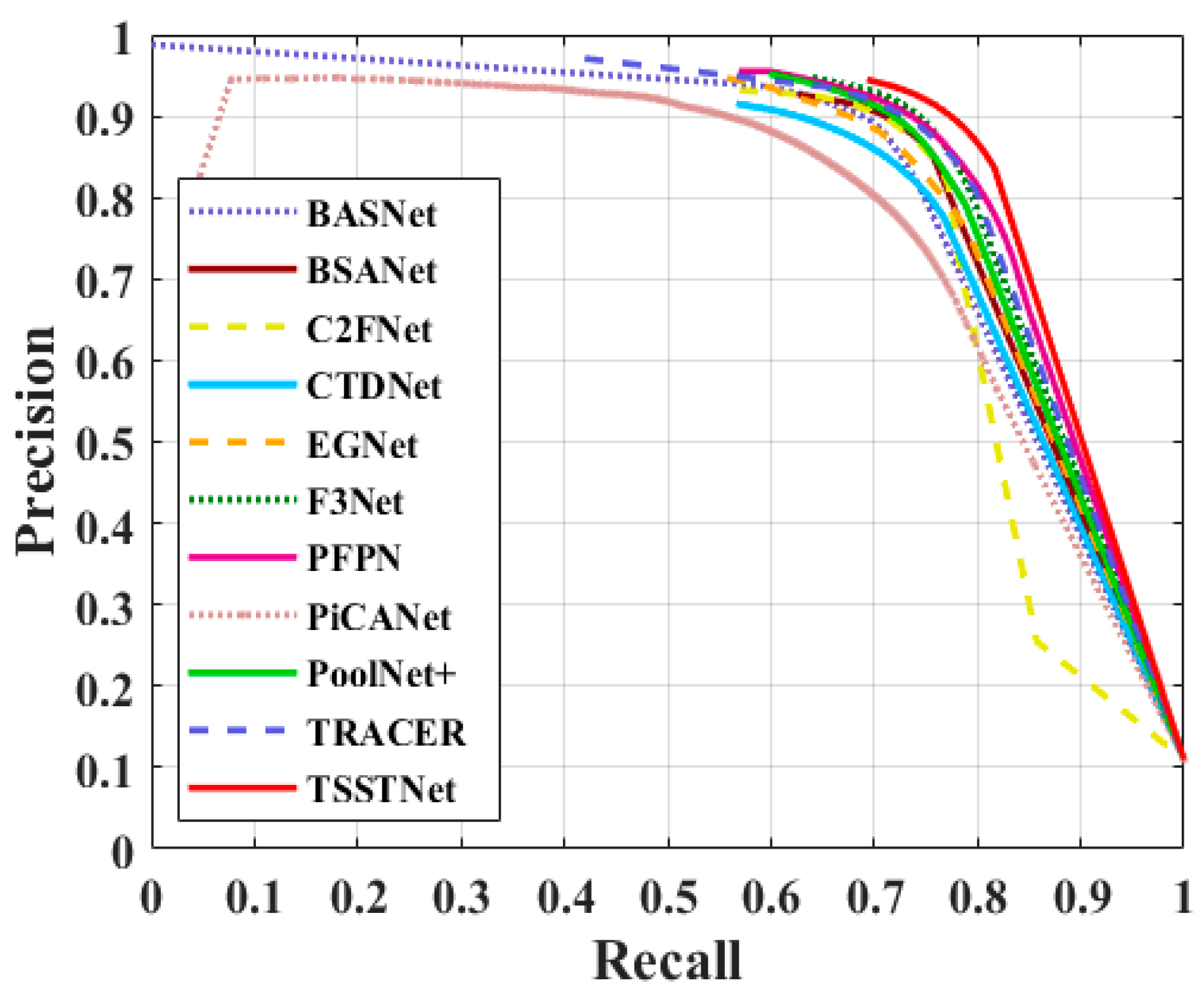
4.3. Comparison of Method Performance
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gan, J.; Li, Q.; Wang, J.; Yu, H. A hierarchical extractor-based visual rail surface inspection system. IEEE Sens. J. 2017, 17, 7935–7944. [Google Scholar] [CrossRef]
- Zhang, D.; Song, K.; Xu, J.; He, Y.; Niu, M.; Yan, Y. MCnet: Multiple Context Information Segmentation Network of No-Service Rail Surface Defects. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- Xu, P.; Zeng, H.; Qian, T.; Liu, L. Research on defect detection of high-speed rail based on multi-frequency excitation composite electromagnetic method. Measurement 2022, 187, 110351. [Google Scholar] [CrossRef]
- Hao, F.; Shi, J.; Zhang, Z.; Chen, R.; Zhu, S. Canny edge detection enhancement by general auto-regression model and bi-dimensional maximum conditional entropy. Optik 2014, 125, 3946–3953. [Google Scholar] [CrossRef]
- Cao, B.; Li, J.; Liu, C.; Qin, L. Defect detection of nickel plated punched steel strip based on improved least square method. Optik 2020, 206, 164331. [Google Scholar] [CrossRef]
- Hao, Q.; Zhang, X.; Wang, Y.; Shen, Y.; Makis, V. A novel rail defect detection method based on undecimated lifting wavelet packet transform and Shannon entropy-improved adaptive line enhancer. J. Sound Vib. 2018, 425, 208–220. [Google Scholar] [CrossRef]
- Shakeel, M.S.; Zhang, Y.; Wang, X.; Kang, W.; Mahmood, A. Multi-scale Attention Guided Network for End-to-End Face Alignment and Recognition. J. Vis. Commun. Image Represent. 2022, 88, 103628. [Google Scholar] [CrossRef]
- Baffour, A.A.; Qin, Z.; Wang, Y.; Qin, Z.; Choo, K.K.R. Spatial self-attention network with self-attention distillation for fine-grained image recognition. J. Vis. Commun. Image Represent. 2021, 81, 103368. [Google Scholar] [CrossRef]
- Borji, A.; Cheng, M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. Comput. Vis. Media 2019, 5, 117–150. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhao, Z.; Xia, C.; Xie, C.; Li, J. Complementary trilateral decoder for fast and accurate salient object detection. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4967–4975. [Google Scholar]
- Li, X.; Yang, F.; Cheng, H.; Liu, W. Contour knowledge transfer for salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 355–370. [Google Scholar]
- Murugesan, B.; Sarveswaran, K.; Shankaranarayana, S.M.; Ram, K.; Joseph, J.; Sivaprakasam, M. Psi-Net: Shape and boundary aware joint multi-task deep network for medical image segmentation. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 7223–7226. [Google Scholar] [CrossRef]
- Tu, Z.; Ma, Y.; Li, C.; Tang, J.; Luo, B. Edge-guided non-local fully convolutional network for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 582–593. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Li, S.; Yan, Y.; Ni, Z.; Ni, H. Surface Defect Classification of Steel Strip with Few Samples Based on Dual-Stream Neural Network. Steel Res. Int. 2022, 93, 2100554. [Google Scholar] [CrossRef]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention, module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ding, L.; Goshtasby, A. On the Canny edge detector. Pattern Recognit. 2001, 34, 721–725. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar] [CrossRef] [Green Version]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. arXiv 2018, arXiv:1805.10421. [Google Scholar]
- Antipov, A.G.; Markov, A.A. Detectability of Rail Defects by Magnetic Flux Leakage Method. Russ. J. Nondestruct. Test. 2019, 55, 277–285. [Google Scholar] [CrossRef]
- Jian, H.; Lee, H.R.; Ahn, J.H. Detection of bearing/rail defects for linear motion stage using acoustic emission. Int. J. Precis. Eng. Manuf. 2013, 14, 2043–2046. [Google Scholar] [CrossRef]
- Mehel-Saidi, Z.; Bloch, G.; Aknin, P. A subspace method for detection and classification of rail defects. In Proceedings of the 2008 16th European Signal Processing Conference, Lausanne, Switzerland, 25–29 August 2008; pp. 1–5. [Google Scholar]
- Shi, H.; Zhuang, L.; Xu, X.; Yu, Z.; Zhu, L. An Ultrasonic Guided Wave Mode Selection and Excitation Method in Rail Defect Detection. Appl. Sci. 2019, 9, 1170. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Song, Y.; Chen, Y.; Zhong, H. MRSDI-CNN: Multi-model rail surface defect inspection system based on convolutional neural networks. IEEE Trans. Intell. Transp. Syst. 2021, 23, 11162–11177. [Google Scholar] [CrossRef]
- Meng, S.; Kuang, S.; Ma, Z.; Wu, Y. MtlrNet: An Effective Deep Multitask Learning Architecture for Rail Crack Detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y. EGNet: Edge guidance network for salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–November 2019; pp. 8779–8788. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–27 June 2019; pp. 3085–3094. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Zhu, L.; Feng, S.; Zhu, W.; Chen, X. ASNet: An adaptive scale network for skin lesion segmentation in dermoscopy images. In Medical Imaging 2020: Biomedical Applications in Molecular, Structural, and Functional Imaging; SPIE: Bellingham, WA, USA, 2020; Volume 11317, pp. 226–231. [Google Scholar]
- Mohammadi, S.; Noori, M.; Bahri, A.; Majelan, S.G. CAGNet: Content-aware guidance for salient object detection. Pattern Recognit. 2020, 103, 107303. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.J.; Hou, Q.; Cheng, M.M. A simple pooling-based design for real-time salient object detection. arXiv 2019, arXiv:1904.09569. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 7 October 2022).
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.; Tay, F.E.H.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 558–567. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning, PMLR 2021, Virtual, 18–24 July 2021; Volume 139, pp. 10347–10357. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 2016; pp. 770–778. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 7479–7489. [Google Scholar]
- Zhu, H.; Li, P.; Xie, H.; Yan, X.; Liang, D.; Chen, D.; Wei, M.; Qin, J. I can find you! Boundary-guided Separated Attention Network for Camouflaged Object Detection. AAAI 2022. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/20273 (accessed on 7 October 2022).
- Sun, Y.; Chen, G.; Zhou, T.; Zhang, Y.; Liu, N. Context-aware cross-level fusion network for camouflaged object detection. arXiv 2021, arXiv:2105.12555. [Google Scholar]
- Wei, J.; Wang, S.; Huang, Q. F3Net: Fusion, feedback and focus for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence 2020, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12321–12328. [Google Scholar]
- Wang, B.; Chen, Q.; Zhou, M.; Zhang, Z.; Jin, X.; Gai, K. Progressive feature polishing network for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence 2020, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12128–12135. [Google Scholar]
- Liu, J.; Hou, Q.; Liu, Z.; Cheng, M. PoolNet+: Exploring the Potential of Pooling for Salient Object Detection. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Lee, M.S.; Shin, W.S.; Han, S.W. TRACER: Extreme Attention Guided Salient Object Tracing Network (Student Abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, Pomona, CA, USA, 24–28 October 2022; Volume 36, pp. 12993–12994. [Google Scholar]
- Song, K.; Wang, J.; Bao, Y.; Huang, L.; Yan, Y. A Novel Visible-Depth-Thermal Image Dataset of Salient Object Detection for Robotic Visual Perception. In IEEE/ASME Transactions on Mechatronics; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
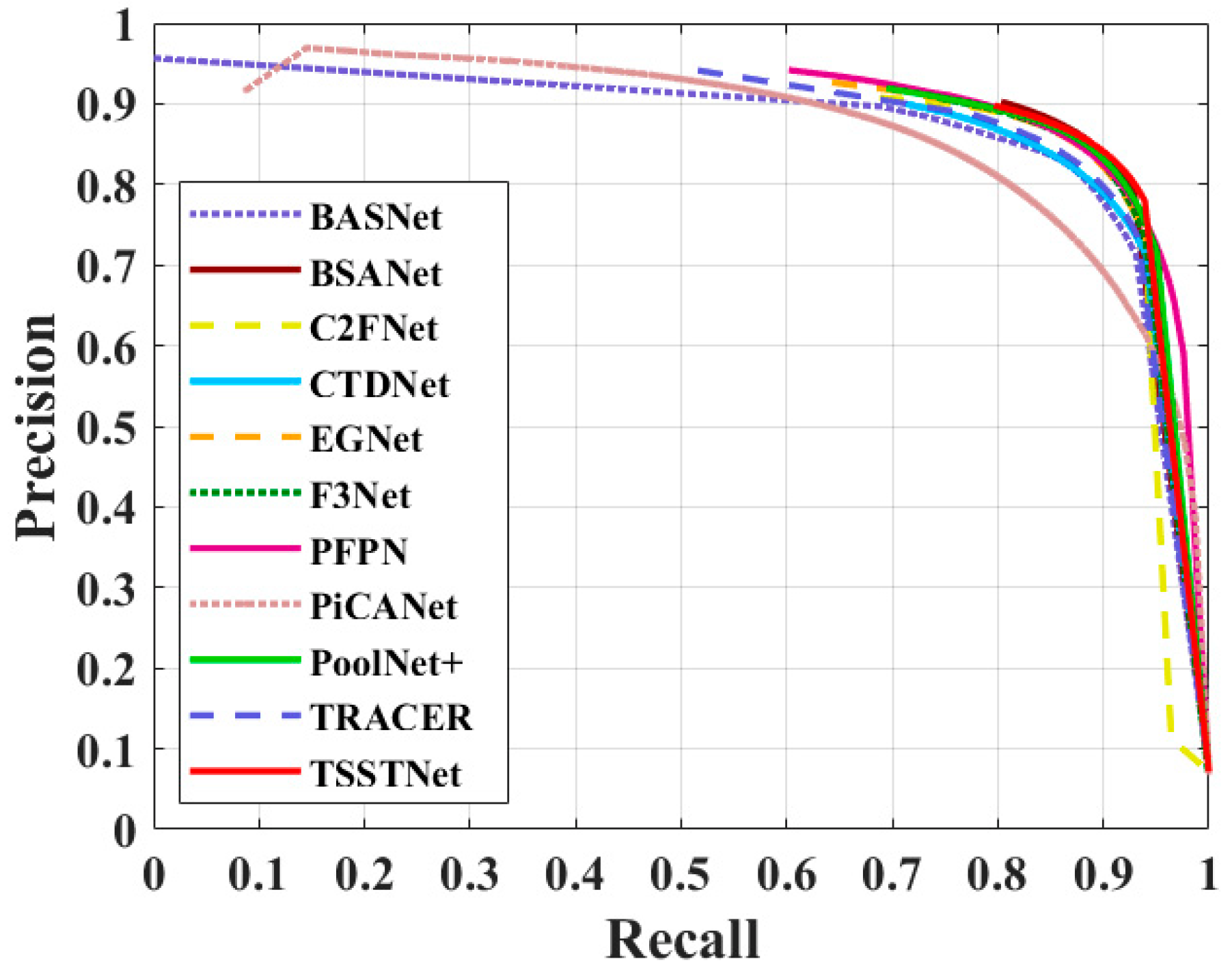{kind=link}
| Methods | NRSD-MN Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Real | Craft | |||||||||
| MAE ↓ | mFβ ↑ | wFβ ↑ | Sα ↑ | Eξ ↑ | MAE ↓ | mFβ ↑ | wFβ ↑ | Sα ↑ | Eξ ↑ | |
| BASNet | 0.065 | 0.748 | 0.730 | 0.797 | 0.830 | 0.021 | 0.802 | 0.775 | 0.866 | 0.944 |
| BSANet | 0.064 | 0.761 | 0.740 | 0.808 | 0.837 | 0.017 | 0.844 | 0.820 | 0.884 | 0.958 |
| C2FNet | 0.063 | 0.761 | 0.705 | 0.805 | 0.850 | 0.021 | 0.817 | 0.738 | 0.859 | 0.949 |
| CTDNet | 0.068 | 0.734 | 0.708 | 0.779 | 0.828 | 0.020 | 0.808 | 0.779 | 0.865 | 0.948 |
| EGNet | 0.063 | 0.746 | 0.723 | 0.798 | 0.840 | 0.019 | 0.814 | 0.797 | 0.872 | 0.948 |
| F3Net | 0.060 | 0.771 | 0.754 | 0.822 | 0.847 | 0.018 | 0.824 | 0.799 | 0.879 | 0.950 |
| PFPN | 0.059 | 0.759 | 0.742 | 0.819 | 0.857 | 0.019 | 0.798 | 0.793 | 0.871 | 0.940 |
| PiCANet | 0.076 | 0.679 | 0.633 | 0.749 | 0.826 | 0.031 | 0.718 | 0.695 | 0.819 | 0.901 |
| PoolNet+ | 0.061 | 0.760 | 0.740 | 0.811 | 0.839 | 0.017 | 0.825 | 0.805 | 0.875 | 0.953 |
| TRACER | 0.058 | 0.772 | 0.753 | 0.819 | 0.859 | 0.019 | 0.825 | 0.805 | 0.875 | 0.953 |
| Ours | 0.052 | 0.798 | 0.781 | 0.839 | 0.867 | 0.016 | 0.841 | 0.816 | 0.883 | 0.958 |
| Swin Transformer Backbone | Two-Stream Encoder | Three-Stream Decoder | MFFM | NRSD-MN Dataset | MAE ↓ | mFβ ↑ | wFβ ↑ | Sα ↑ | Eξ ↑ | |
|---|---|---|---|---|---|---|---|---|---|---|
| Test1 | √ | Real | 0.056 | 0.787 | 0.767 | 0.825 | 0.856 | |||
| Test2 | √ | √ | 0.053 | 0.805 | 0.776 | 0.820 | 0.874 | |||
| Test3 | √ | √ | √ | 0.099 | 0.705 | 0.359 | 0.732 | 0.835 | ||
| TSSTNet | √ | √ | √ | √ | 0.052 | 0.798 | 0.781 | 0.839 | 0.867 | |
| Test4 | √ | Craft | 0.017 | 0.831 | 0.807 | 0.880 | 0.955 | |||
| Test5 | √ | √ | 0.020 | 0.833 | 0.810 | 0.860 | 0.954 | |||
| Test6 | √ | √ | √ | 0.062 | 0.761 | 0.389 | 0.771 | 0.921 | ||
| TSSTNet | √ | √ | √ | √ | 0.016 | 0.841 | 0.816 | 0.883 | 0.958 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, C.; Ma, S.; Song, K. TSSTNet: A Two-Stream Swin Transformer Network for Salient Object Detection of No-Service Rail Surface Defects. Coatings 2022, 12, 1730. https://doi.org/10.3390/coatings12111730
Wan C, Ma S, Song K. TSSTNet: A Two-Stream Swin Transformer Network for Salient Object Detection of No-Service Rail Surface Defects. Coatings. 2022; 12(11):1730. https://doi.org/10.3390/coatings12111730
Chicago/Turabian StyleWan, Chi, Shuai Ma, and Kechen Song. 2022. "TSSTNet: A Two-Stream Swin Transformer Network for Salient Object Detection of No-Service Rail Surface Defects" Coatings 12, no. 11: 1730. https://doi.org/10.3390/coatings12111730