
A Semi-Supervised Inspection Approach of Textured Surface Defects under Limited Labeled Samples

Abstract
:1. Introduction
- (1)
- An SSL framework that integrates a customized GAN to generate new samples is proposed to classify defects under limited labeled samples.
- (2)
- A label assignment algorithm that includes the unlabeled samples generated by GAN into training together with labeled ones is proposed.
- (3)
- A detailed analysis on the CNNs used in defect inspection and the network ALLnet is designed for representation learning that is used in our SSL pipeline.
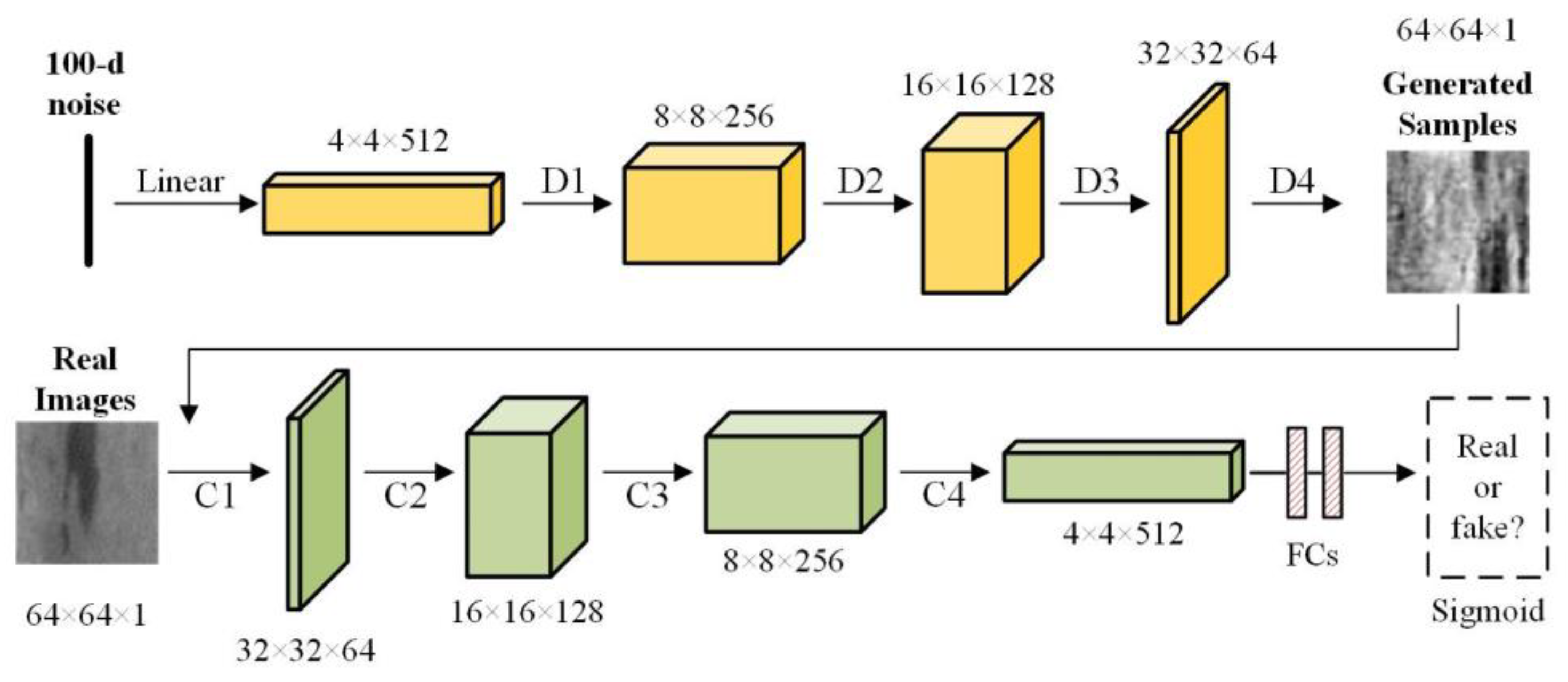
2. Unlabeled Samples Generation
2.1. Standard GAN
2.2. The Customized GAN
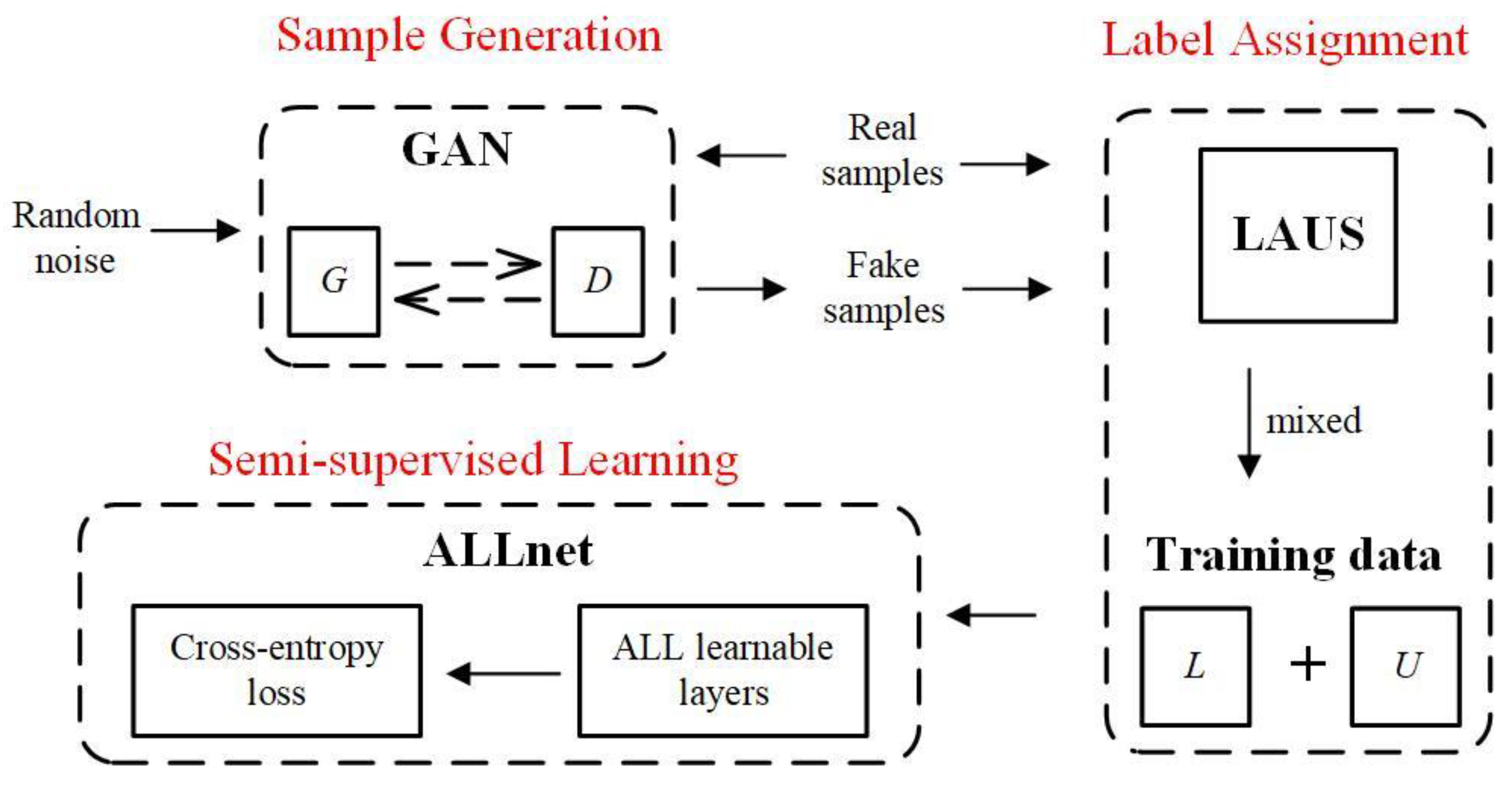
3. Methodology
3.1. Overview of the SSL Framework
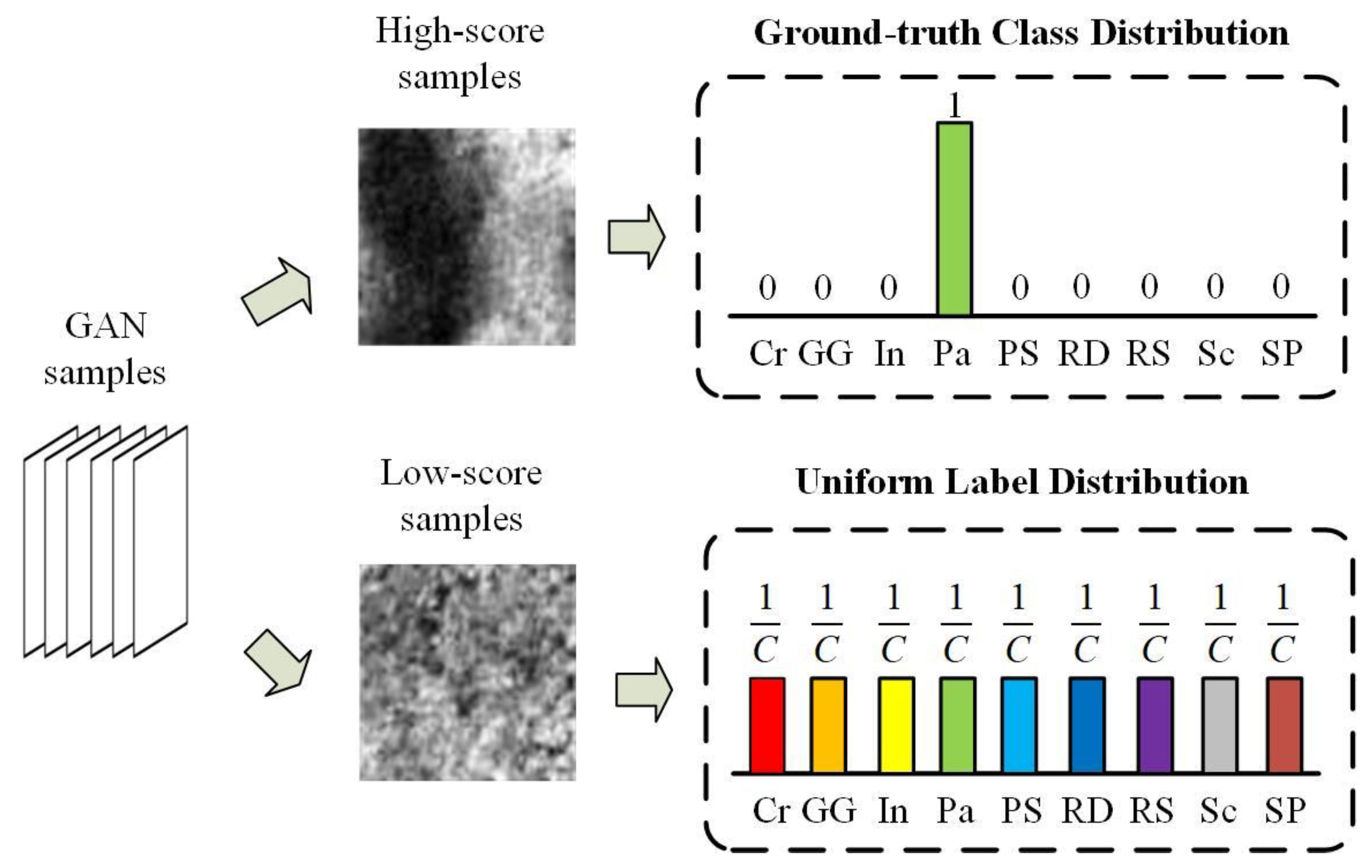
3.2. LAUS Algorithm
| Algorithm 1: LAUS Algorithm | |
| Input: GAN samples , real samples , and ground-truth class labels . | |
| 1: | Train ALLnet on {,} => startup model . |
| 2: | for i in : |
| 3: | if no : |
| 4: | Label as a uniform label distribution . |
| 5: | ←, ←. |
| 6: | break |
| 7: | end if |
| 8: | use on => class scores . |
| 9: | if : |
| 10: | label as according to . |
| 11: | ←. |
| 12: | else: |
| 13: | label as . |
| 14: | ←.. |
| 15: | end if |
| 16: | ←. |
| 17: | Training data ←. |
| 18: | end for |
| 19: | Return |
3.3. ALLnet
3.4. Training
3.4.1. Loss Function
3.4.2. Implementation
4. Experiments
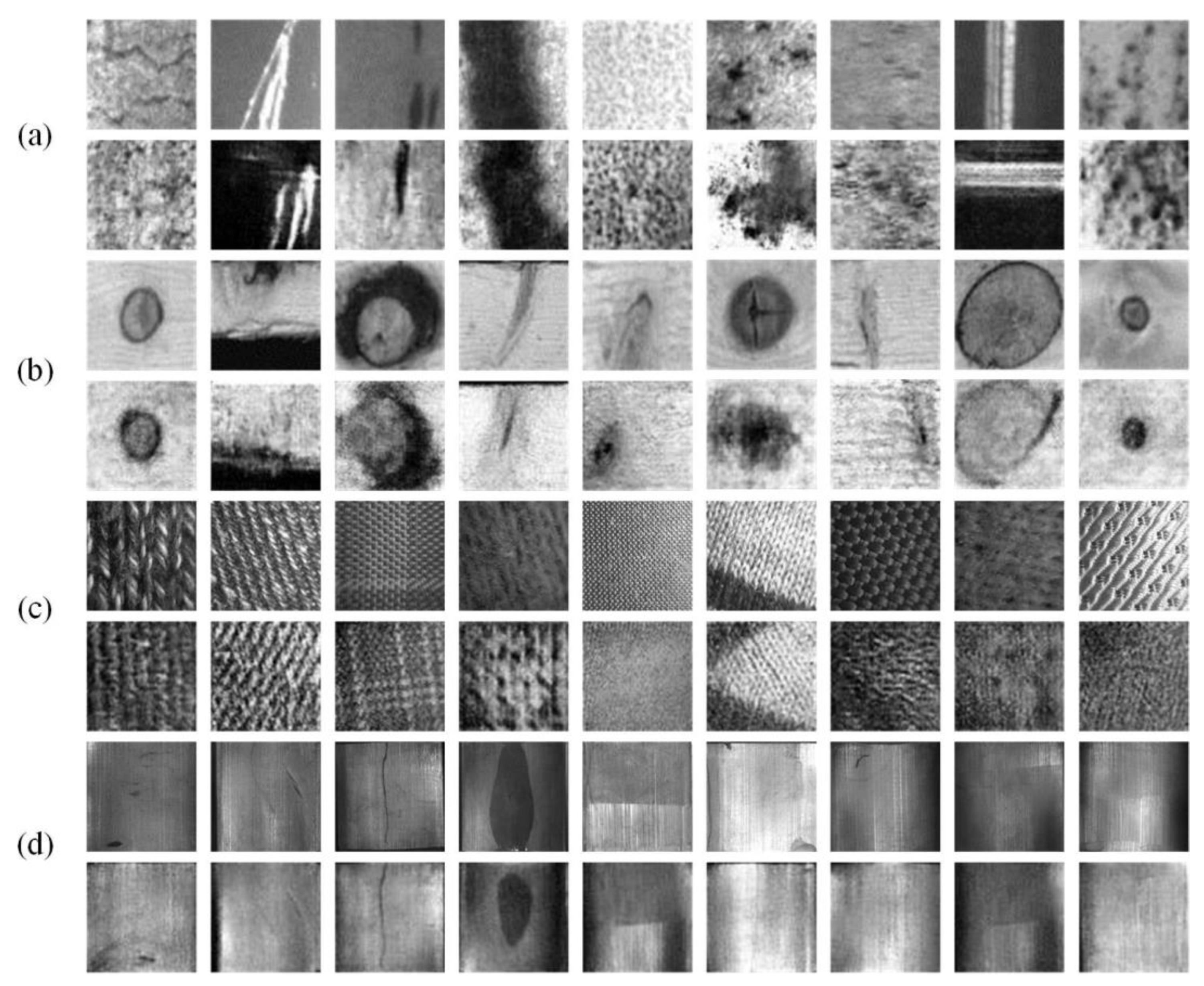
4.1. Defect Datasets
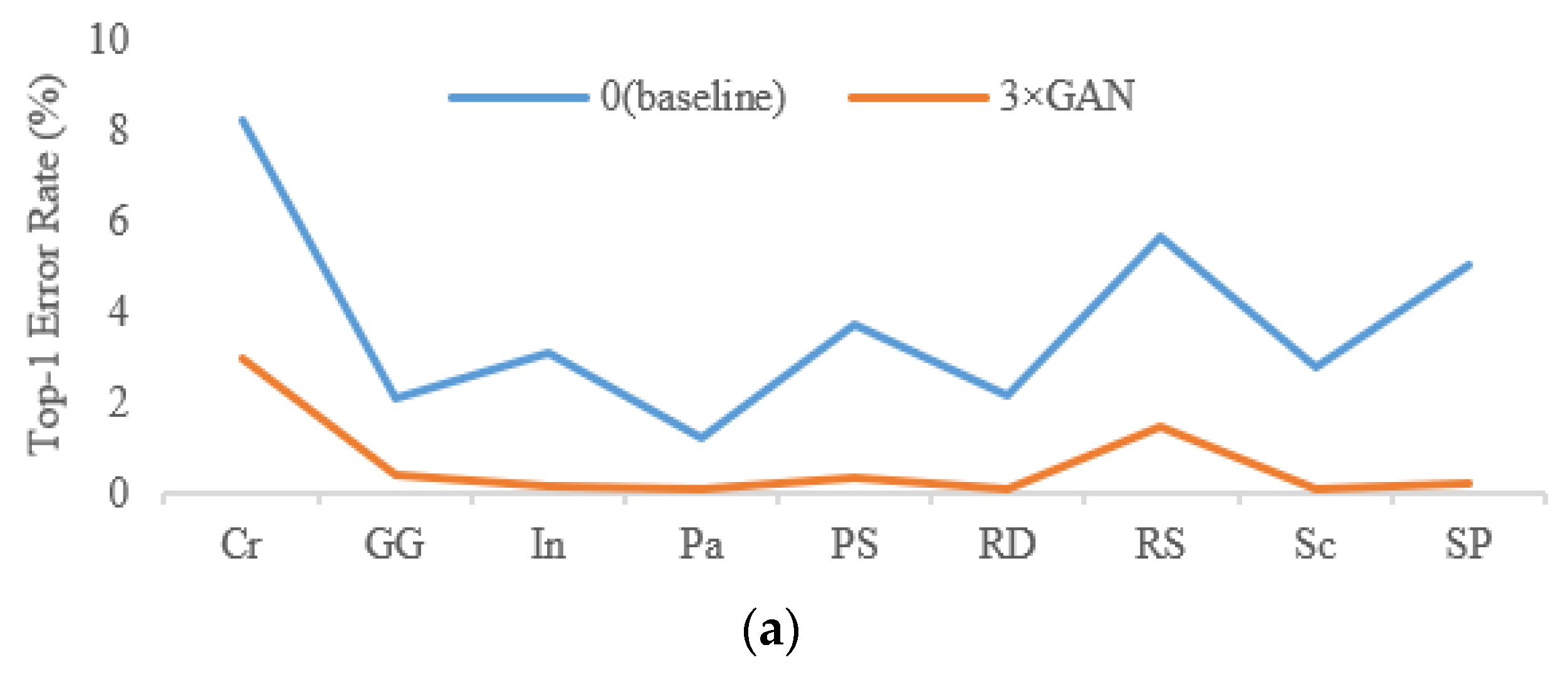
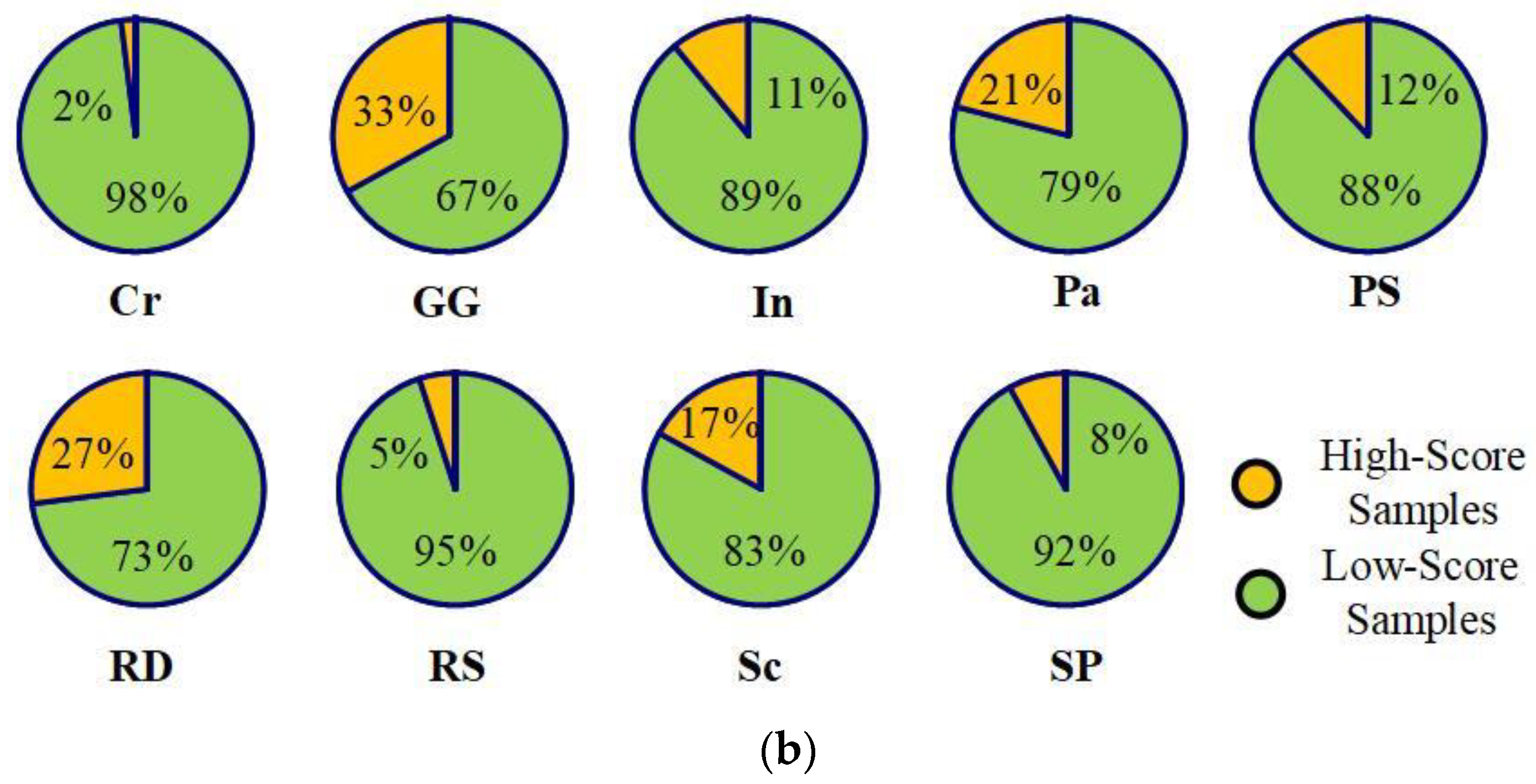
4.2. GAN Results
4.3. Comparison with Other Label Assignment Algorithms
4.4. Comparison with Baseline CNNs
4.5. Comparison with Other Defect Classifiers
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, H.; Li, Q.; Tan, Y.; Gan, J.; Wang, J.; Geng, Y.-A.; Jia, L. A Coarse-to-Fine Model for Rail Surface Defect Detection. IEEE Trans. Instrum. Meas. 2018, 68, 656–666. [Google Scholar] [CrossRef]
- Niskanen, M.; Kauppinen, H. Wood inspection with non-supervised clustering. Mach. Vis. Appl. 2003, 13, 275–285. [Google Scholar] [CrossRef] [Green Version]
- Kampouris, C.; Zafeiriou, S.; Ghosh, A.; Malassiotis, S. Fine-grained material classification using micro-geometry and reflectance. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–12 October 2016; pp. 778–792. [Google Scholar]
- Kahraman, Y.; Durmuşoğlu, A. Deep learning-based fabric defect detection: A review. Text. Res. J. 2022. [Google Scholar] [CrossRef]
- Kahraman, Y.; Durmuşoğlu, A. Classification of Defective Fabrics Using Capsule Networks. Appl. Sci. 2022, 12, 5285. [Google Scholar] [CrossRef]
- Zhang, Z.; Wen, G.; Chen, S. Audible Sound-Based Intelligent Evaluation for Aluminum Alloy in Robotic Pulsed GTAW Mechanism, Feature Selection, and Defect Detection. IEEE Trans Ind. Inf. 2018, 14, 2973–2983. [Google Scholar] [CrossRef]
- Park, Y.; Kweon, I.S. Ambiguous Surface Defect Image Classification of AMOLED Displays in Smartphones. IEEE Trans. Ind. Inform. 2016, 12, 597–607. [Google Scholar] [CrossRef]
- Wang, H.Y.; Zhang, J.; Tian, Y.; Chen, H.Y.; Sun, H.X.; Liu, K. A Simple Guidance Template-Based Defect Detection Method for Strip Steel Surfaces. IEEE Trans. Ind. Inform. 2018, 15, 2798–2809. [Google Scholar] [CrossRef]
- Luo, Q.; Sun, Y.; Li, P.; Sun, Y.; Li, P.; Simpson, O.; Tian, L.; He, Y. Generalized Completed Local Binary Patterns for Time-Efficient Steel Surface Defect Classi-fication. IEEE Instrum. Meas 2018, 68, 667–679. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.; Chen, Y.; Zhang, D.; Xie, J.; Zhou, Y. Classification of surface defects on steel sheet using convolutional neural networks. Mater. Teh. 2017, 51, 123–131. [Google Scholar] [CrossRef]
- Hossain, M.S.; Al-Hammadi, M.; Muhammad, G. Automatic Fruit Classification Using Deep Learning for Industrial Ap-plications. IEEE Trans. Ind. Inf. 2019, 15, 1027–1034. [Google Scholar] [CrossRef]
- Huang, H.-W.; Li, Q.-T.; Zhang, D.-M. Deep learning based image recognition for crack and leakage defects of metro shield tunnel. Tunn. Undergr. Space Technol. 2018, 77, 166–176. [Google Scholar] [CrossRef]
- Wen, W.; Xia, A. Verifying edges for visual inspection purposes. Pattern Recognit. Lett. 1999, 20, 315–328. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the ProceNeural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Ren, R.; Hung, T.; Tan, K.C. A Generic Deep-Learning-Based Approach for Automated Surface Inspection. IEEE Trans. Cybern. 2017, 48, 929–940. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Mei, S.; Song, K.; Tao, B.; Yin, Z. Transfer-Learning-Based Online Mura Defect Classification. IEEE Trans. Semicond. Manuf. 2017, 31, 116–123. [Google Scholar] [CrossRef]
- Natarajan, V.; Hung, T.-Y.; Vaikundam, S.; Chia, L.-T. Convolutional networks for voting-based anomaly classification in metal surface inspection. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Toronto, ON, Canada, 22–25 March 2017; pp. 986–991. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Liu, C.; Su, K.; Yang, L.; Li, J.; Guo, J. Detection of Complex Features of Car Body-in-White under Limited Number of Samples Using Self-Supervised Learning. Coatings 2022, 12, 614. [Google Scholar] [CrossRef]
- Papandreou, G.; Chen, L.-C.; Murphy, K.P.; Yuille, A.L. Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation. In Proceedings of the International Conference on Computer Vision. (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1742–1750. [Google Scholar]
- Song, K.; Wang, J.; Bao, Y.; Huang, L.; Yan, Y. A Novel Visible-Depth-Thermal Image Dataset of Salient Object Detection for Robotic Visual Perception. IEEE/ASME Trans. Mechatron. 2022, 1–12. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Semi-Supervised Deep Learning Using Pseudo Labels for Hyperspectral Image Classification. IEEE Trans. Image Process 2017, 27, 1259–1270. [Google Scholar] [CrossRef]
- Odena, A. Semi-Supervised Learning with Generative Adversarial Networks. In Proceedings of the International Conference on Machine Learning. (ICML), New York, NY, USA, 6–11 June 2015. [Google Scholar]
- He, D.; Xu, K.; Zhou, P.; Dongdong, Z. Surface defect classification of steels with a new semi-supervised learning method. Opt. Lasers Eng. 2019, 117, 40–48. [Google Scholar]
- Larsen, A.B.L.; Kaae, S.S.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning. (ICML), New York, NY, USA, 19–24 June 2016; pp. 1558–1566. [Google Scholar]
- Alec, R.; Luke, M.; Soumith, C. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Li, P.; Chen, Z.; Yang, L.T.; Zhang, Q.; Deen, M.J. Deep Convolutional Computation Model for Feature Learning on Big Data in Internet of Things. IEEE Trans. Ind. Inform. 2017, 14, 790–798. [Google Scholar] [CrossRef]
- Kingma, P.D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Song, K.; Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar] [CrossRef]
- Huang, Y.; Qiu, C.; Guo, Y. Saliency of magnetic tile surface defects. In Proceedings of the 14th IEEE International Conference on Auto-Mation and Engineering, Munich, Germany, 18–22 June 2018. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets (Num.) | Defect Type and Num. |
|---|---|
| NEU-CLS-64 (7226) | Cr (1210), GG (296), In (775), Pa (1148), PS (797), RD (200), RS (1589), Sc (773), SP (438). |
| KNOTS (425) | Dry (69), Edge (65), Encased (30), Horn (35), Leaf (47), Sound (179). |
| Fabrics (1173) | Cotton (588), Denim (162), Nylon (57), Polyester (226), Silk (50), Wool (90). |
| MT (392) | Blowhole (115), Break (85), Crack (57), Fray (32), Uneven (103). |
| LAUS | Another Label | Pseudo Label | |
|---|---|---|---|
| acc. (%) | acc. (%) | acc. (%) | |
| 0 (baseline) | 96.24 | 96.24 | 96.24 |
| 1× | 98.04 | 98.19 | 98.39 |
| 2× | 98.40 | 98.60 | 98.55 |
| 3× | 99.37 | 98.92 | 98.41 |
| 4× | 99.13 | 99.04 | 97.90 |
| 5× | 98.97 | 99.02 | 97.61 |
| Models | Input Size | Parameters | Accuracy (%) | Runtime (ms/Float) |
|---|---|---|---|---|
| AlexNet | 224 × 224 | 5.8×107 | 99.10 | 42.1 |
| VGG16 | 224 × 224 | 13×107 | 99.62 | 66.2 |
| InceptionV3 | 299 × 299 | 2.4×107 | 99.29 | 21.0 |
| ResNet101 | 224 × 224 | 4.0×107 | 99.47 | 29.7 |
| ALLnet(2B) | 64 × 64 | 0.2×106 | 97.50 | 6.9 |
| ALLnet(3B) | 64 × 64 | 0.7×106 | 98.44 | 8.4 |
| ALLnet(4B) * | 64 × 64 | 2.9×106 | 99.37 | 8.6 |
| ALLnet(4B) | 128 × 128 | 2.9×106 | 99.37 | 21.0 |
| ALLnet(5B) | 64 × 64 | 12×106 | 99.38 | 10.2 |
| Dataset | NEU-CLS-64 | KNOTS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | S1 | S2 | T1 | T2 | Ours | S1 | S2 | T1 | T2 | Ours | |
| 0 (baseline) | 87.50 | 88.14 | 92.87 | 97.00 | 96.24 | 79.69 | 73.44 | 80.21 | 73.81 | 80.38 | |
| 1 × GANs | B | 93.25 | 92.04 | 96.84 | 97.87 | 98.04 | 84.38 | 89.06 | 85.28 | 89.31 | 89.06 |
| U | 93.64 | 91.16 | 95.66 | 96.87 | 97.86 | 78.91 | 84.38 | 82.09 | 85.29 | 86.72 | |
| 2 × GANs | B | 95.62 | 95.40 | 97.76 | 98.58 | 98.40 | 90.63 | 89.84 | 88.69 | 92.30 | 91.14 |
| U | 94.72 | 93.25 | 95.89 | 98.00 | 98.79 | 87.50 | 85.90 | 83.56 | 88.69 | 90.63 | |
| 3 × GANs | B | 97.94 | 97.11 | 99.10 | 99.34 | 99.37 | 94.53 | 94.01 | 96.62 | 97.49 | 97.49 |
| U | 96.63 | 95.16 | 97.60 | 98.89 | 98.87 | 93.49 | 91.41 | 92.20 | 94.62 | 95.31 | |
| 4 × GANs | B | 97.26 | 95.81 | 98.55 | 99.12 | 99.13 | 92.97 | 92.96 | 93.02 | 97.00 | 95.00 |
| U | 96.13 | 94.28 | 96.16 | 92.87 | 98.36 | 88.80 | 90.89 | 90.55 | 92.37 | 94.53 | |
| 5 × GANs | B | 96.65 | 95.66 | 97.75 | 98.13 | 98.87 | 91.41 | 93.49 | 92.37 | 96.53 | 94.68 |
| U | 84.90 | - | 91.34 | 90.43 | 84.91 | 88.67 | 91.46 | 86.32 | 93.02 | 83.33 | |
| Datasets | Fabrics | MT | |||||||||
| 0 (baseline) | - | - | 73.47 | 82.33 | 65.42 | 96.88 | 90.31 | 92.60 | 59.32 | 92.19 | |
| 1 × GANs | B | 67.71 | 73.70 | 83.33 | 90.55 | 80.02 | 91.41 | 92.19 | 94.88 | 66.87 | 96.09 |
| U | 69.27 | - | 79.93 | 88.22 | 77.60 | 89.84 | 91.41 | 92.90 | 64.62 | 95.31 | |
| 2 × GANs | B | 86.91 | 85.32 | 90.10 | 91.70 | 88.93 | 92.58 | - | 97.51 | 79.62 | 97.40 |
| U | 79.84 | 82.34 | 86.40 | 91.09 | 84.21 | 94.53 | 96.88 | 92.33 | 64.99 | 92.19 | |
| 3 × GANs | B | 90.94 | 91.99 | 91.90 | 93.07 | 93.80 | 95.31 | - | 99.09 | 82.84 | 99.22 |
| U | 90.00 | 90.04 | 89.01 | 92.80 | 90.31 | 99.22 | 98.18 | 96.68 | 81.63 | 97.65 | |
| 4 × GANs | B | 87.30 | 89.55 | 91.04 | 91.61 | 91.40 | 97.92 | - | 98.82 | 82.77 | 98.17 |
| U | 88.09 | 86.33 | 88.64 | 91.54 | 90.09 | 97.66 | 97.66 | 95.31 | 82.59 | 97.39 | |
| 5 × GANs | B | 85.68 | 89.50 | 87.99 | 92.98 | 90.04 | 96.61 | - | 97.79 | 83.82 | 98.88 |
| U | 83.33 | 82.50 | 87.50 | 91.15 | 86.98 | 97.40 | 97.27 | 95.01 | 85.77 | 94.27 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Wen, X.; Xu, J. A Semi-Supervised Inspection Approach of Textured Surface Defects under Limited Labeled Samples. Coatings 2022, 12, 1707. https://doi.org/10.3390/coatings12111707
He Y, Wen X, Xu J. A Semi-Supervised Inspection Approach of Textured Surface Defects under Limited Labeled Samples. Coatings. 2022; 12(11):1707. https://doi.org/10.3390/coatings12111707
Chicago/Turabian StyleHe, Yu, Xin Wen, and Jing Xu. 2022. "A Semi-Supervised Inspection Approach of Textured Surface Defects under Limited Labeled Samples" Coatings 12, no. 11: 1707. https://doi.org/10.3390/coatings12111707