

A Shallow System Prototype for Violent Action Detection in Italian Public Schools

Abstract
:1. Introduction
- The design and the development of a School Violence Detection (SVD) system, a low-cost integrated system, allowing for easy binary violence detection. It is consolidated by transfer learning techniques in order to extend its potentialities.
- The creation of Daily School Break (DSB), a new dataset of images and videos of Italian students recorded in school environments. Original for typology and subjects, this kind of dataset does not exist in the literature, and it can be used to compare different techniques.
2. Related Works
2.1. Violence Detection Systems

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Year | Parameters | Layers |
|---|---|---|---|
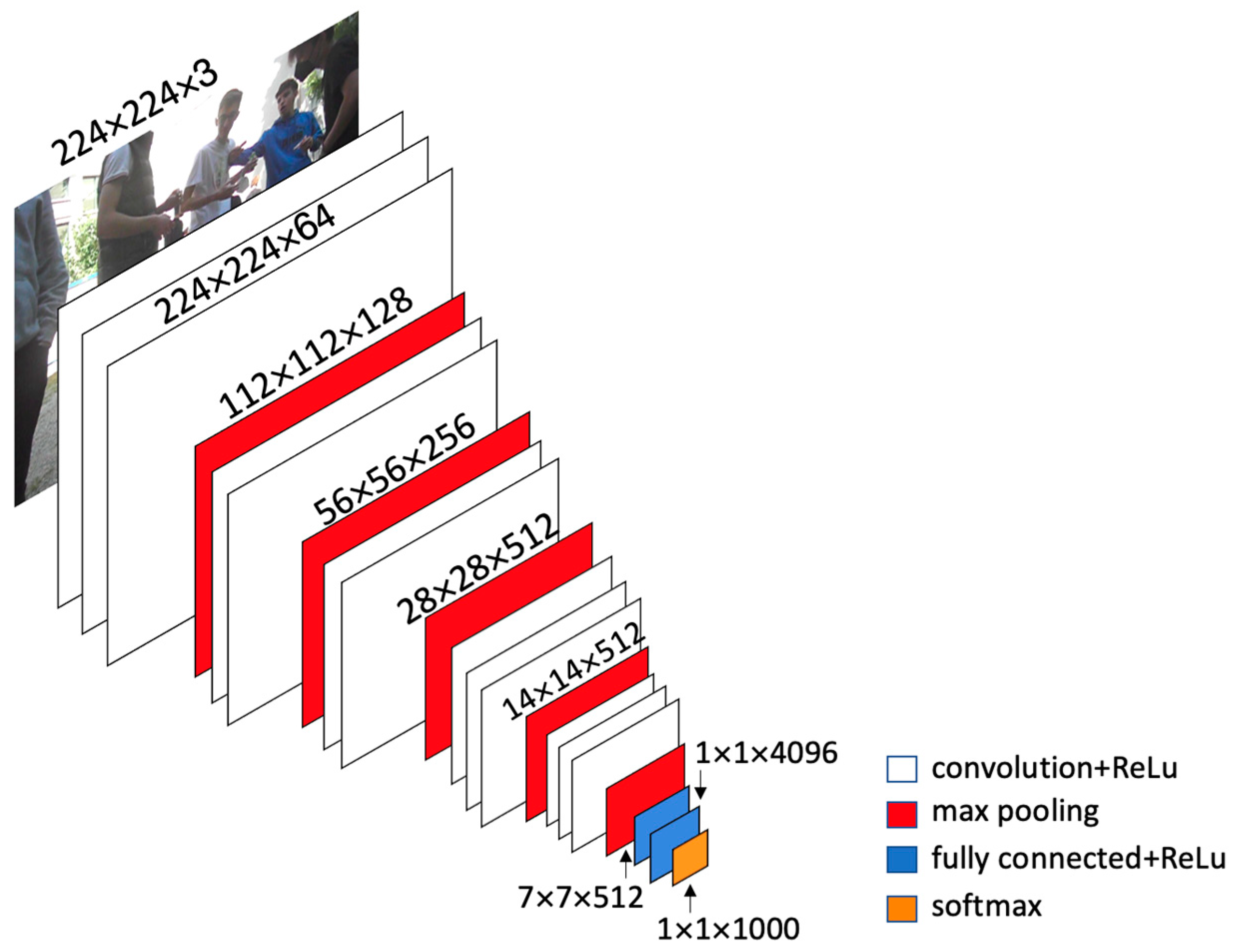
| VGG-16 | 2014 | 138 million | 16 weighted layers (Figure 1) |
| VGG-19 | 2014 | 143 million | 2 more convolutional layers than VVG16 |
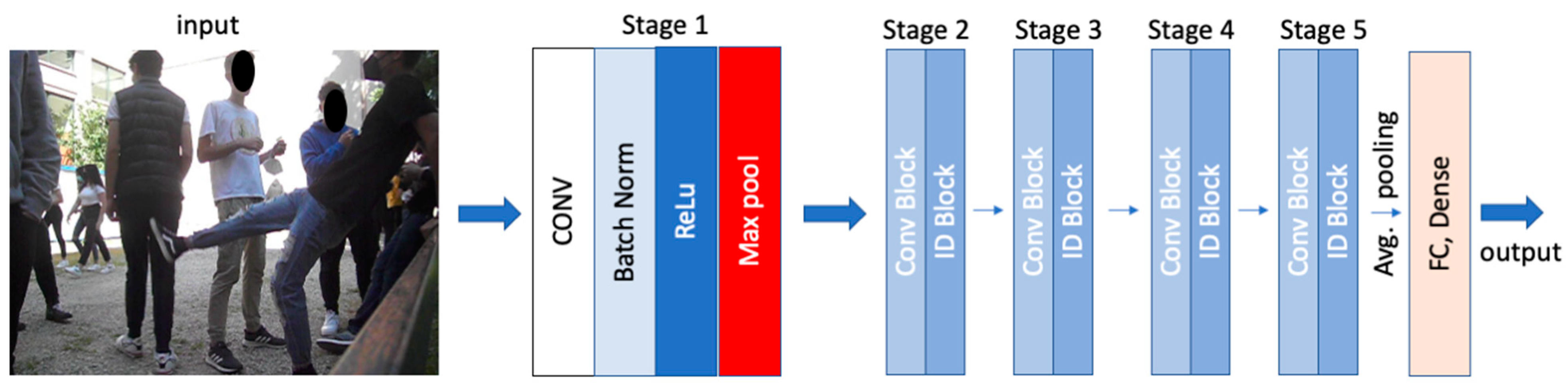
| ResNet-50 | 2015 | 25 million | 48 convolutional layers, 1 max-pooling and an average pooling. Its architecture is based on residual learning (Figure 2) |
- VGG16 is one of the most famous CNN architectures as it has been awarded the ILSVR ImageNet competition in 2014 [9]. VGG16, instead of having a large number of hyper-parameters, is focalized on the convolution layer. Its architecture combines layers of 3 × 3 filter of stride one and a maxpool layer of 2 × 2 filter of stride two.
- VGG19 is similar to the previous one, but deeper than VGG16. It can better recognize the image in terms of color and structure. The architecture of the fully connected layers is the same in all VGG networks, making this model quite easy to implement.
- ResNet-50 is a deep residual network and is a more accurate CNN subclass. It is organized in residual blocks. It adopts a technique called skip connection that allows the knowledge of processed data to be transfered to the next level by adding the output of the previous levels. In shallow neural networks, consecutive hidden layers are linked to each other, but in ResNet architecture, information is passed from the down sampling layers to the up sampling layers. The connection speeds up the training time and increases the capacity of the network [30]. Ref. [31] analyzed how ResNet-50 learns better color and texture features during the training phase due to the residual connection that avoids information loss [32].
2.2. Violence Detection Datasets
- Hockey Fight [11]: this contains 1000 clips divided into two groups of 500 labelled sequences (fight and non-fight for binary classification) extracted from the National Hockey League (NHL). Each clip consists of 50 low resolution frames. The main disadvantage is the lack of the diversity because the videos are captured in a single scene. Moreover, [24] presented the complexity of detecting these types of indoor scene.
- Movie Fight [33]: this consists of 200 video clips in which the scenes of violence are extracted from action movies. As with the previous one, both of these two datasets have video-level annotations, but nowadays the last one is less used due to the insufficient number of videos. In addition, all activities in [11,33] are captured in the center of the view.
- Dataset for Automatic Violence Detection [5] was co-sponsored by the Italian “Gabinetto Interregionale di Polizia Scientifica per le Marche e l’Abruzzo”. The aim of the project was to create a dataset with high resolution images describing violent situations. The clips were recorded in indoor environments with non-professional actors and the dataset is composed of 350 clips; 120 clips present non-violent behaviors and 230 clips violent behaviors. In particular, non-violent clips include hand claps, hugs, scenes of exultation, etc., which can cause false positives within a violence action recognition task due to the rapidity of the movements and the similarity to violent behaviors. The purpose of the dataset is to improve performance within the techniques of violence recognition and to verify their robustness. The violent clips include kicking, slapping, choking, gun shooting, etc. All the videos, tagged manually, were recorded inside the same room in natural light conditions. The primary limitation of this dataset is that the settings and lighting do not accurately reflect real-world environments.
- UCF-Crime [12]: this contains 1900 uncut or unedited videos recorded by surveillance cameras from all over the world. It is a large-scale dataset with over 128 hours of videos downloaded from YouTube via keyword research in multiple languages. It is used for violence classification and violence detection tasks as it provides a wide range of challenging real-world data within in-the-wild conditions. Darkness scenes, long length of videos with few level annotations and anomalous videos generate false alarms in the tested model [12]. Moreover, anomalies such as arrest, abuse, burglary, explosion, etc. have a significant impact on public safety, but they cannot be compared to the public actions usually expected in school environments.
- RWF-2000 [3]: this is the largest dataset currently available. It includes 2000 videos extracted from surveillance cameras with real scenes captured all around the world. They were collected from YouTube via keywords (e.g., “real fights” or “violent events”). The authors developed a program that automatically downloads YouTube videos based on keyword research. They proposed a new method based on 3DCNNs [34]. They achieved a level of 87% accuracy. Unfortunately, sometimes rapid movements could be wrongly targeted, especially during the prevention of false positives [5]. Since all the videos are captured by surveillance cameras, many images may not have a good quality. As a consequence, only some of the involved people appeared in the pictures and some scenes are crowded and chaotic.
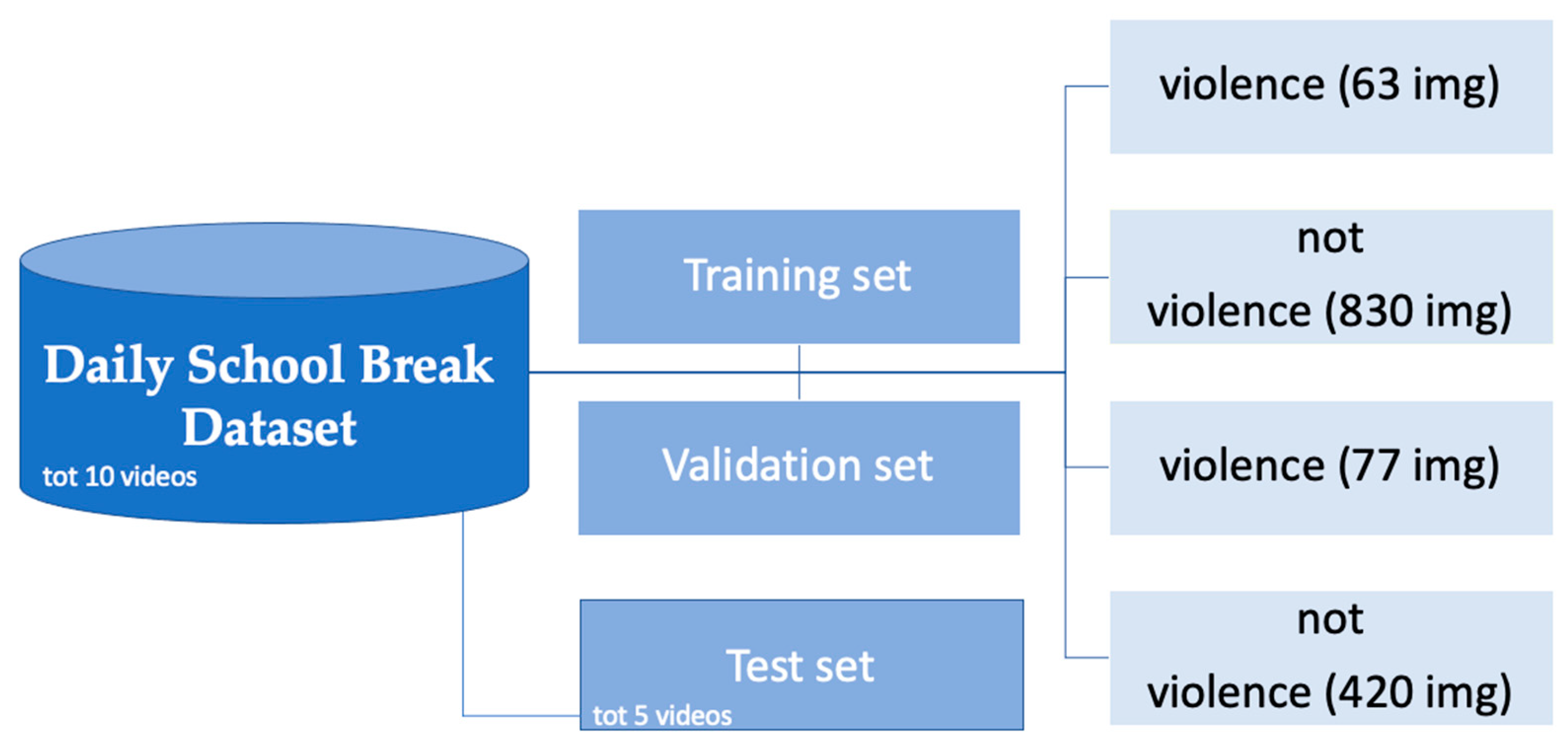
3. Daily School Break Dataset
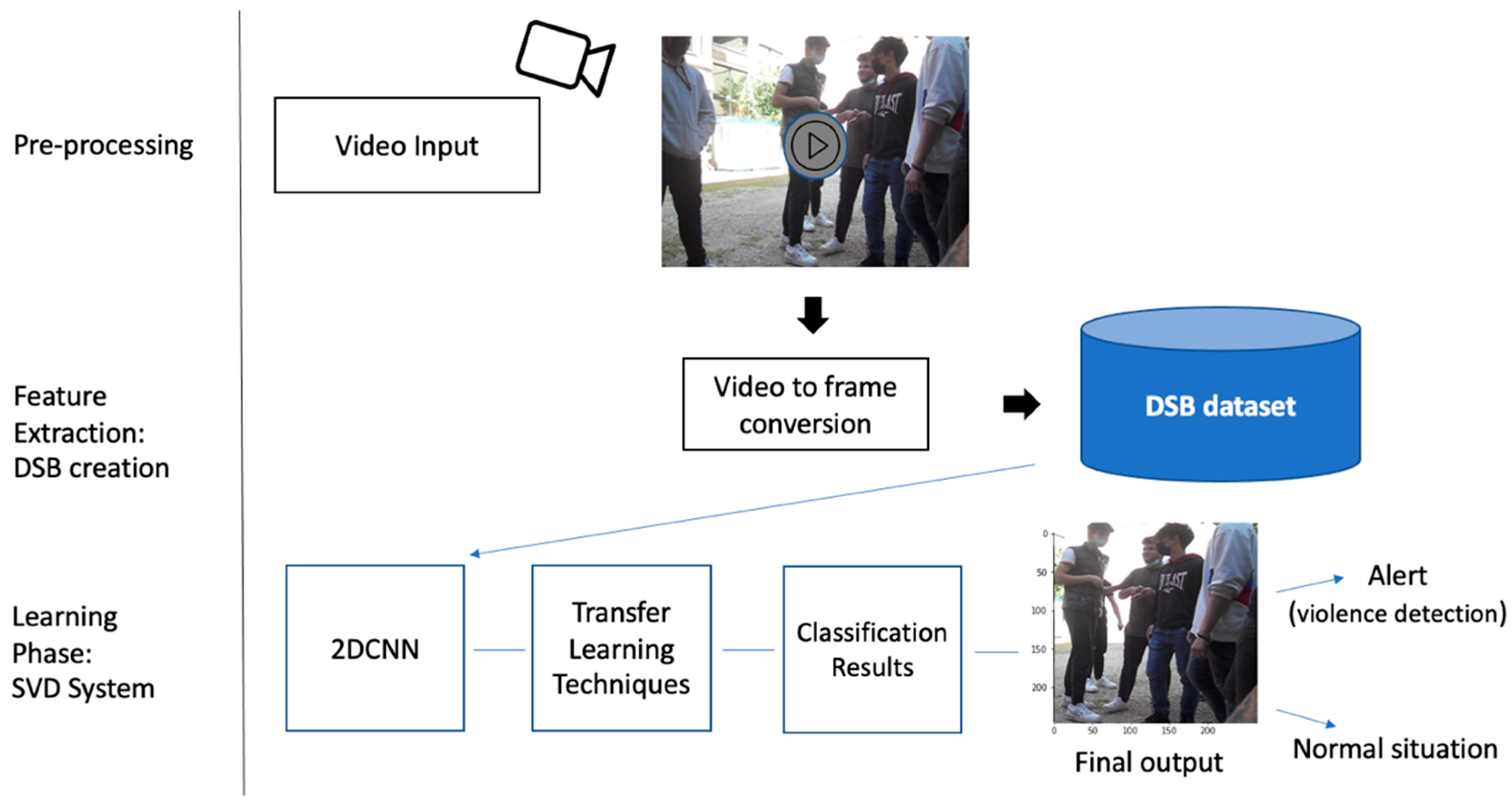
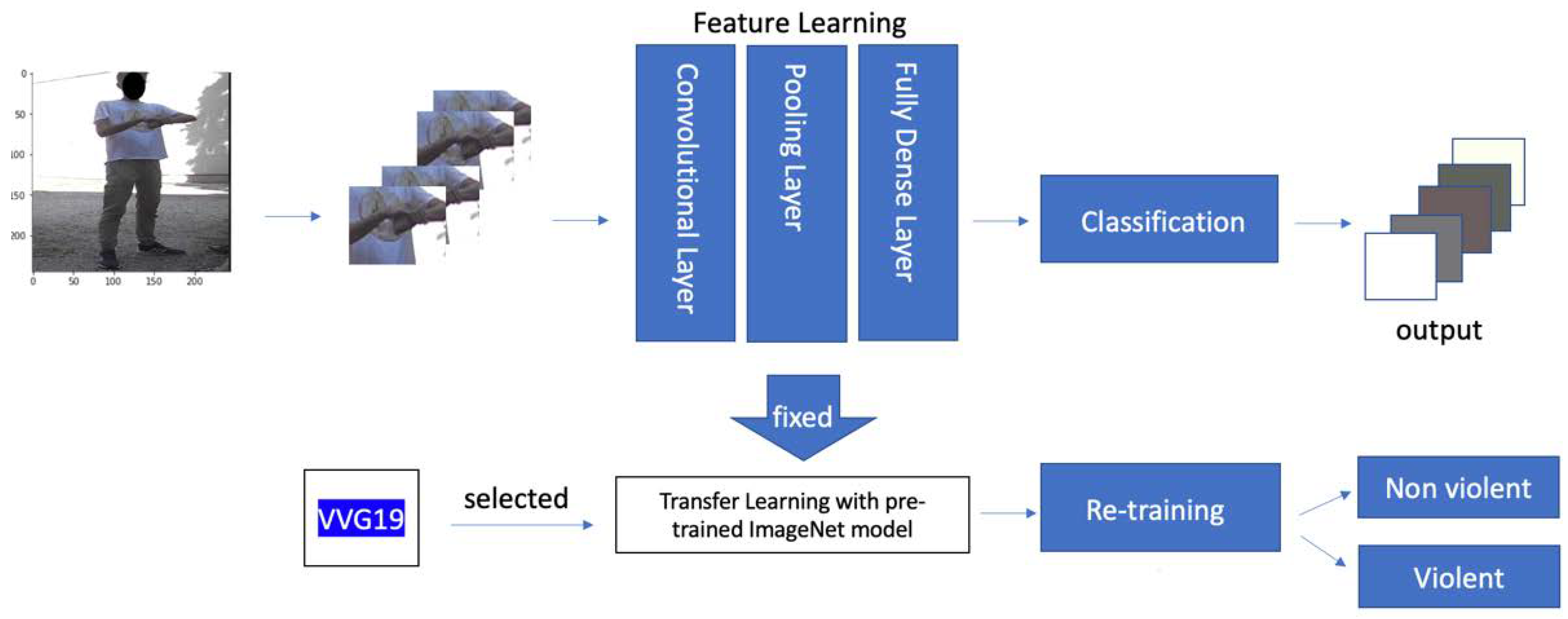
4. School Violence Detection system
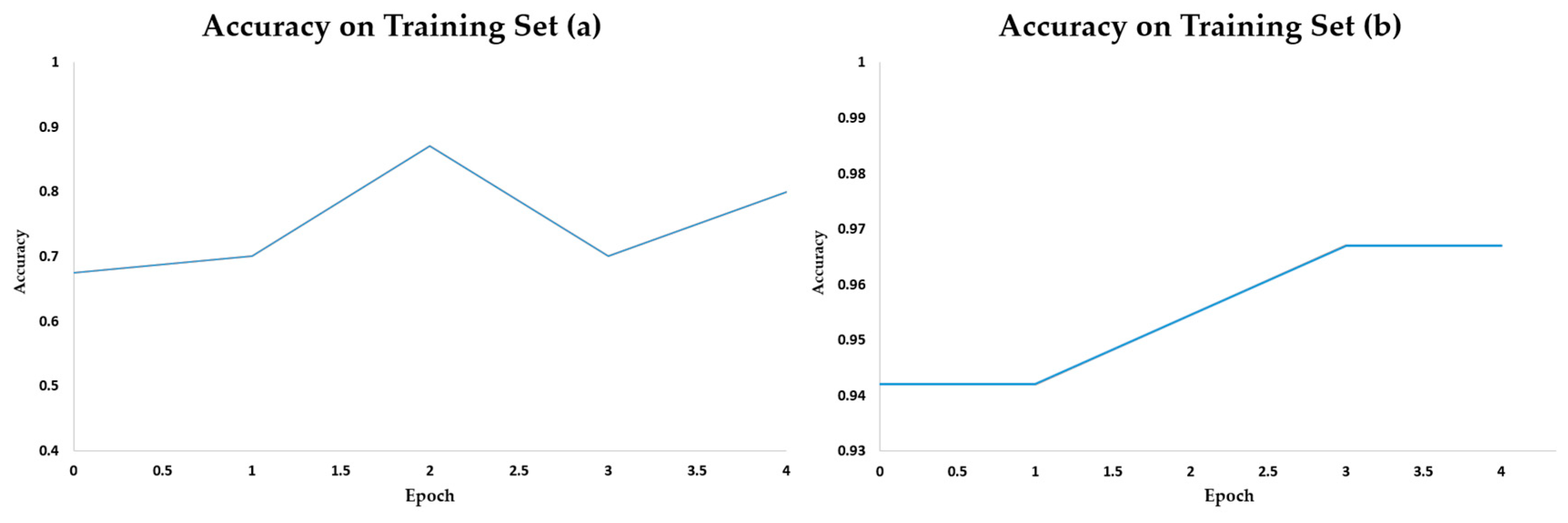
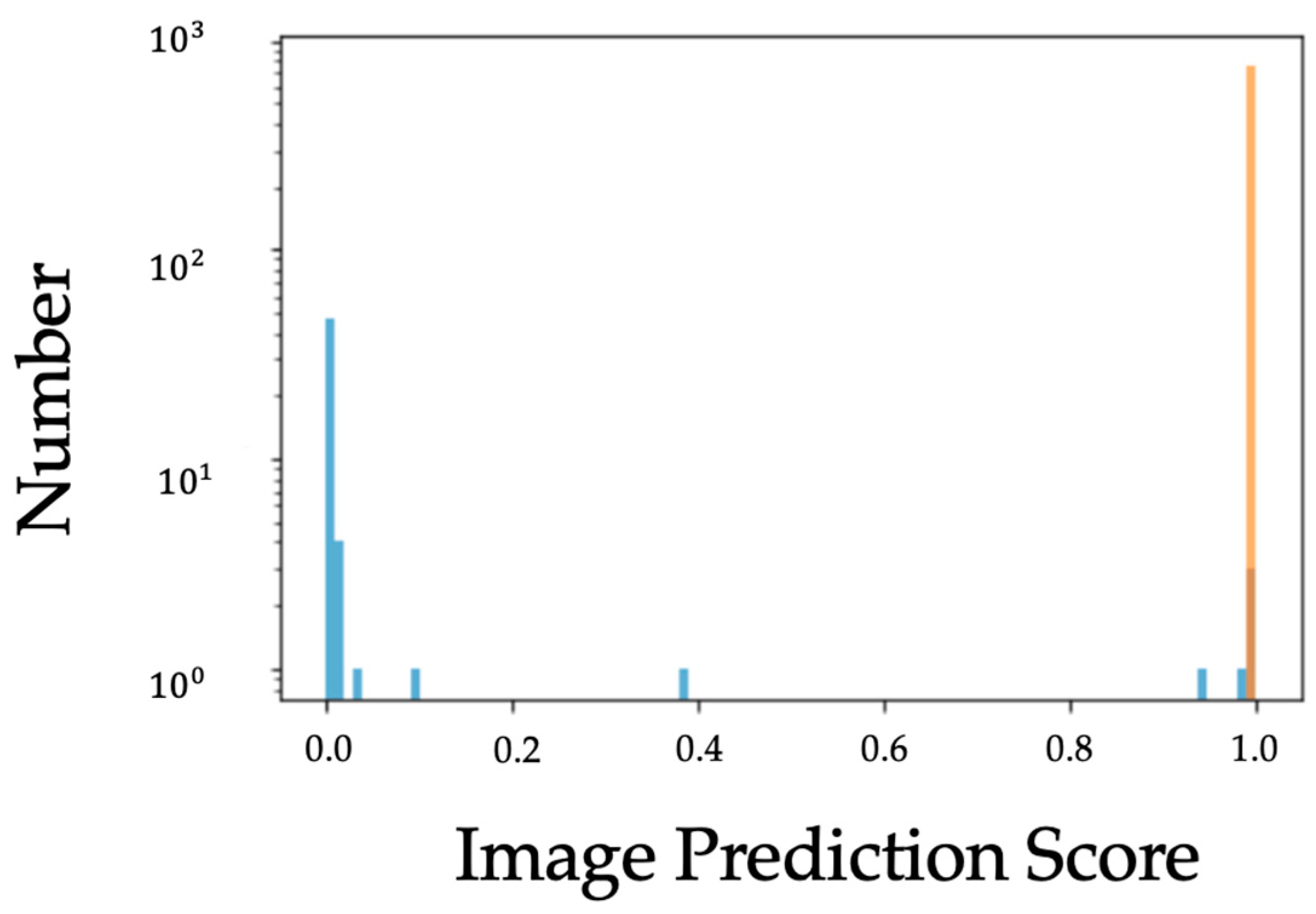
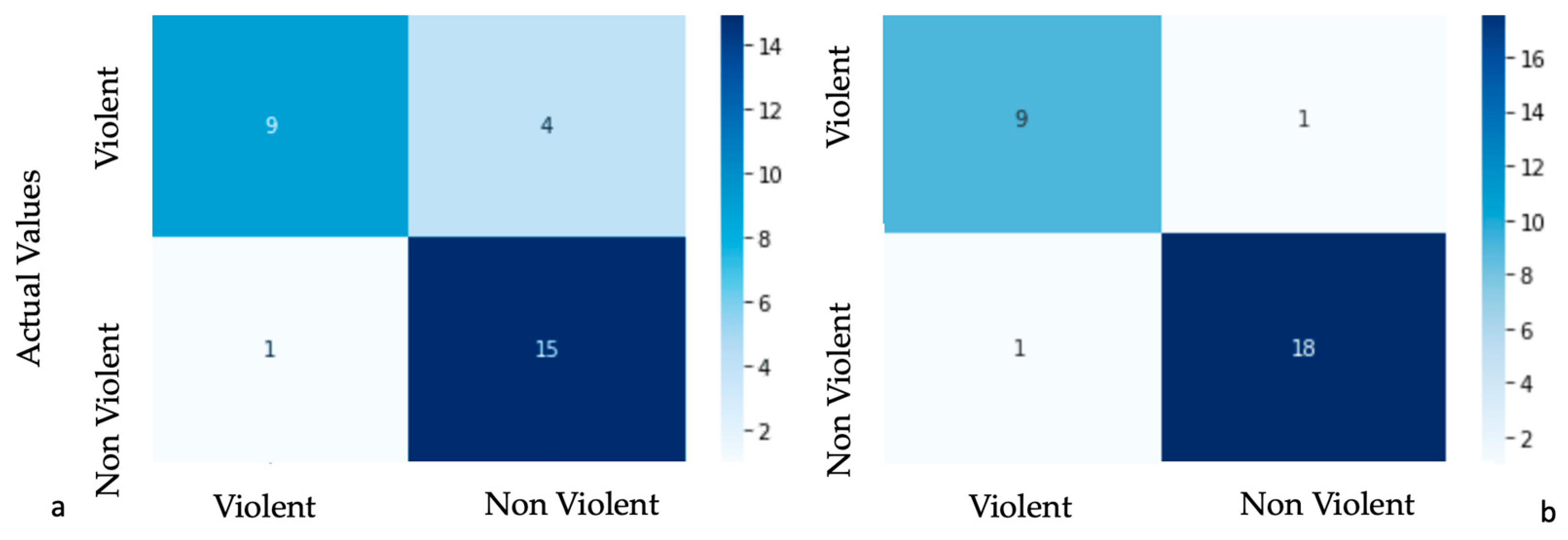
5. Experimental Results
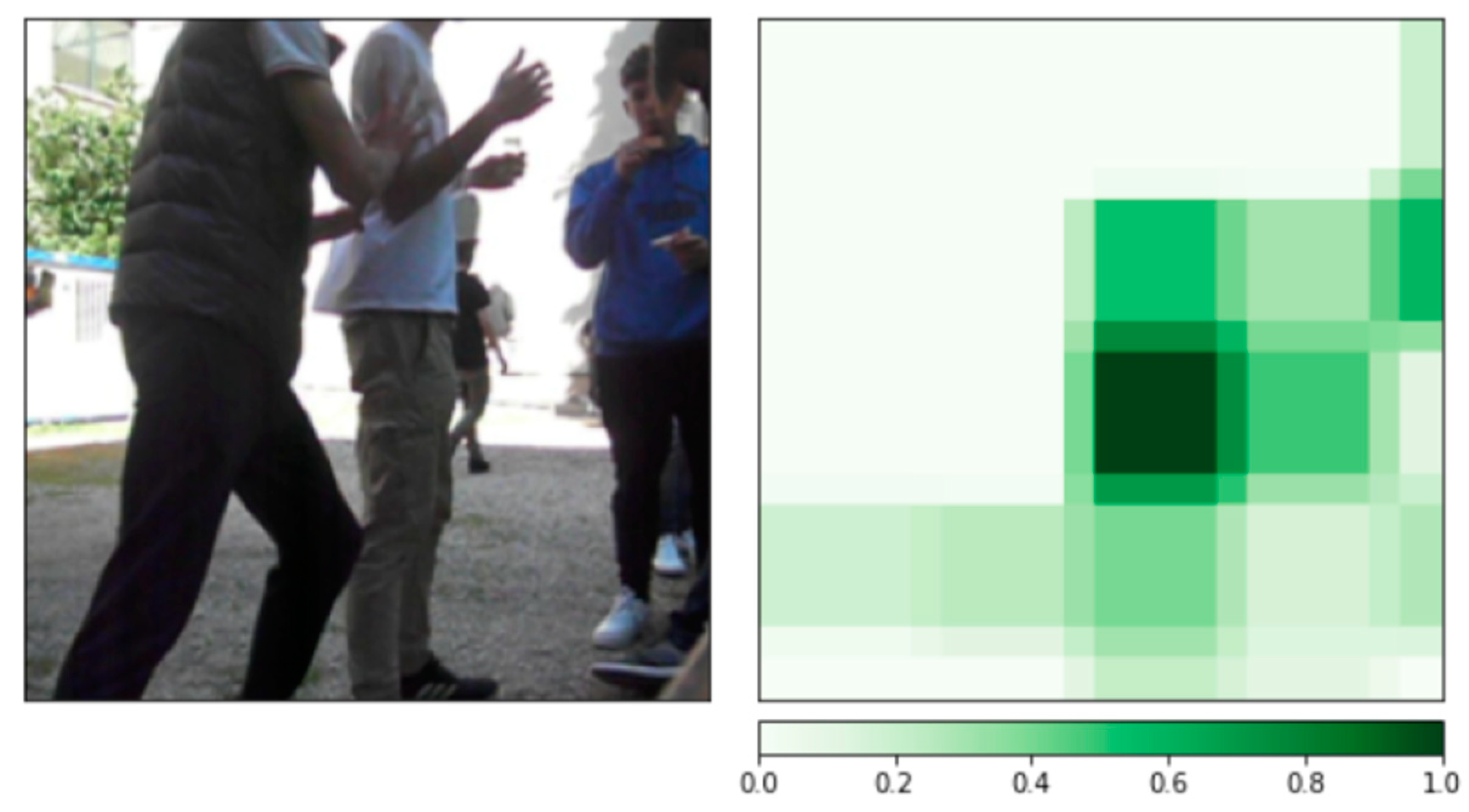
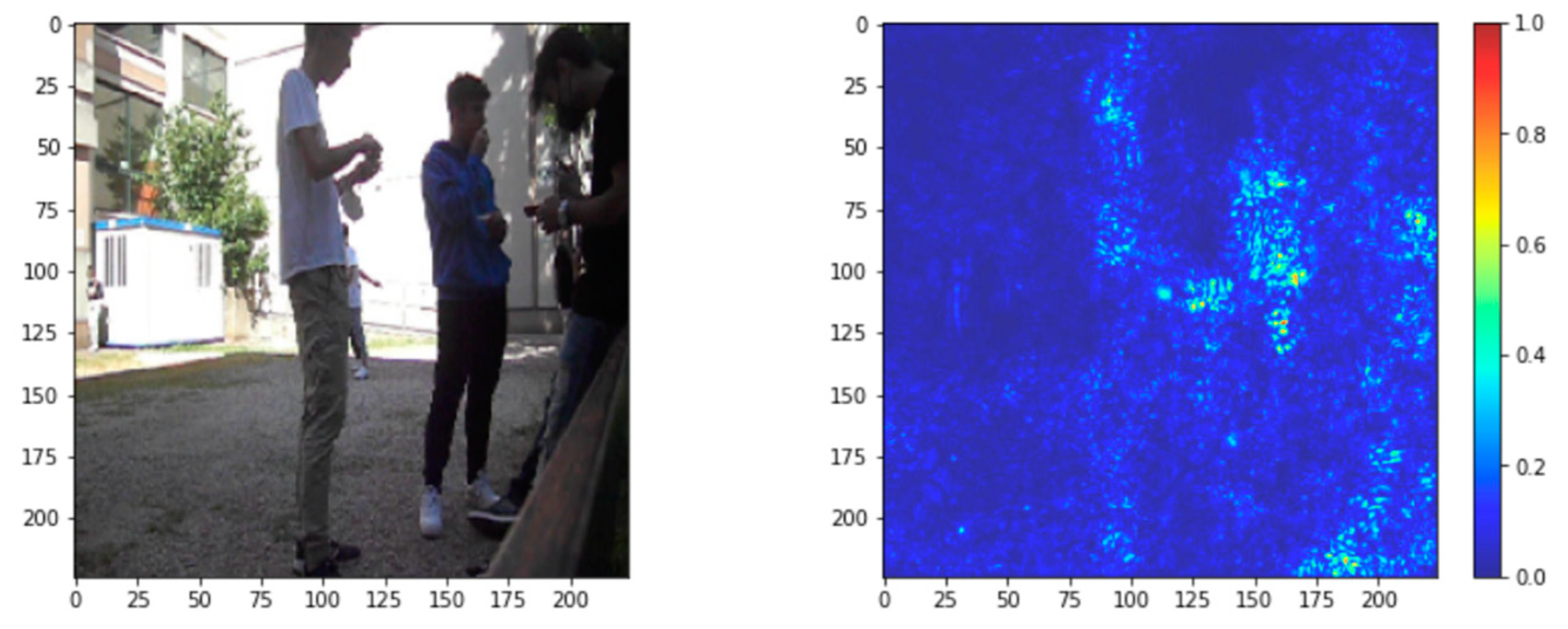
Robustness Evaluation of DSB Images
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sudhakaran, S.; Lanz, O. Learning to detect violent videos using convolutional long short-term memory. In Proceedings of the 14th IEEE International Conference on Advance Video and Signal Based Suirveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Accattoli, S.; Sernani, P.; Falcionelli, N.; Mekuria, D.N.; Dragoni, A.F. Violence Detection in Videos by Combining 3D Convolutional Neural Networks and Support Vector Machines. Appl. Artif. Intell. 2020, 34, 329–344. [Google Scholar] [CrossRef]
- Cheng, M.; Cai, K.; Li, M. RWT-2000: An open large scale video database for violence detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milano, Italy, 10–15 January 2021. [Google Scholar]
- Nievas, E.B.; Suarez, O.D.; Garcia, G.B.; Sukthankar, R. Hockey fight detection dataset. In Computer Analysis of Images and Patterns; Springer: Berlin/Heidelberg, Germany, 2011; pp. 332–339. [Google Scholar]
- Bianculli, M.; Falcionelli, N.; Sernani, P.; Tomassini, S.; Contardo, P.; Lombardi, M.; Dragoni, A.F. A dataset for automatic violence detection in videos. Data Brief 2020, 33, 106587. [Google Scholar] [CrossRef]
- Xing, Y.; Dai, Y.; Hirota, K.; Jia, A. Skeleton-based method for recognizing the campus violence. In Proceedings of the 9th International Symposium on Computational Intelligence and Industrial Applications, Beijing, China, 19–20 December 2020. [Google Scholar]
- Ye, L.; Liu, T.; Han, T.; Ferdinando, H.; Seppänen, T.; Alasaarela, E. Campus Violence Detection Based on Artificial Intelligent Interpretation of Surveillance Video Sequences. Remote. Sens. 2021, 13, 628. [Google Scholar] [CrossRef]
- Calzavara, I. Human Pose Augmentation for Facilitating Violence Detection in Videos: A Combination of the Deep Learning Methods DensePose and VioNet; Department of Information Technology and Media (ITM), Mid Sweden University: Sundsvall, Sweden, 2020. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Xiao, J.; Wang, J.; Cao, S.; Li, B. Application of a Novel and Improved VGG-19 Network in the Detection of Workers Wearing Masks. J. Phys. Conf. Ser. 2020, 1518, 012041. Available online: https://iopscience.iop.org/article/10.1088/1742-6596/1518/1/012041 (accessed on 9 November 2022). [CrossRef]
- Sumon, S.A.; Goni, R.; Bin Hashem, N.; Shahria, T.; Rahman, R.M. Violence Detection by Pretrained Modules with Different Deep Learning Approaches. Vietnam. J. Comput. Sci. 2019, 7, 19–40. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shad, M. Real-word anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. [Google Scholar]
- Bermejo, E.; Deniz, O.; Buono, G.; Sukthankar, R. Violence Detection in Video Using computer Vision Techniques. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, CAIP 2011, Seville, Spain, 29–31 August 2011; pp. 332–339. [Google Scholar]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, E. Two person interaction detection using body pose features and multiple distance learning. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–22 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 28–35. [Google Scholar]
- Perez, M.; Kot, A.C.; Rocha, A. Detection of a Real Word Fights in Surveillance Videos; IEEE: New York, NY, USA, 2019; pp. 2662–2666. [Google Scholar]
- Vijeikis, R.; Raudonis, V.; Dervinis, G. Efficient Violence Detection in Surveillance. Sensors 2022, 22, 2216. [Google Scholar] [CrossRef]
- Choqueluque-Roman, D.; Camara-Chavez, G. Weakly Supervised Violence Detection in Surveillance Video. Sensors 2022, 22, 4502. [Google Scholar] [CrossRef]
- Dong, Z.; Qin, J.; Wang, Y. Multi-Stream Deep Networks for Person to Person Violence Detection in Videos; Tan, T., Li, X., Chen, X., Zhou, J., Yang, J., Cheng, H., Eds.; Pattern Recognition. CCPR 2016. Communications in Computer and Information Science; Springer: Singapore, 2016; Volume 662. [Google Scholar] [CrossRef]
- Demarty, C.-H.; Penet, C.; Soleymani, M.; Gravier, G. VSD, a public dataset for the detection of violent scenes in movies: Design, annotation, analysis and evaluation. Multimed. Tools Appl. 2014, 74, 7379–7404. [Google Scholar] [CrossRef]
- Dandage, V.; Gautam, H.; Ghavale, A.; Mahore, R.; Sonewar, P.A. Review of Violence Detection System using Deep Learning. Int. Res. J. Eng. Technol. 2019, 6, 1899–1902. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Fraga, S. Methodological and ethical challenges in violence research. Porto Biomed. J. 2016, 1, 77–80. [Google Scholar] [CrossRef] [Green Version]
- Ramirez, H.; Velastin, S.A.; Meza, I.; Fabregas, E.; Makris, D.; Farias, G. Fall Detection and Activity Recognition Using Human Skeleton Features. IEEE Access 2021, 9, 33532–33542. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Obaidat, M.S.; Ullah, A.; Muhammad, K.; Hijji, M.; Baik, S.W. A Comprehensive Review on Vision-Based Violence Detection in Surveillance Videos. ACM Comput. Surv. 2023, 55, 1–44. [Google Scholar] [CrossRef]
- Wang, W.; Dong, S.; Zou, K.; Li, W. A Lightweight Network for Violence Detection. In Proceedings of the 2022 the 5th International Conference on Image and Graphics Processing (ICIGP 2022), Beijing, China, 7–9 January 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 15–21. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Obaidat, M.S.; Muhammad, K.; Ullah, A.; Baik, S.W.; Cuzzolin, F.; Rodrigues, J.J.P.C.; de Albuquerque, V.H.C. An intelligent system for complex violence pattern analysis and detection. Int. J. Intell. Syst. 2022, 37, 10400–10422. [Google Scholar] [CrossRef]
- Su, Y.; Lin, G.; Zhu, J.; Wu, Q. Human interaction learning on 3d skeleton point clouds for video violence recognition. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 74–90. [Google Scholar]
- De Boissiere, A.M.; Noumeir, R. Infrared and 3d skeleton feature fusion for rgb-d action recognition. IEEE Access 2020, 8, 168297–168308. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Fei-Fei, L. ImageNet: A large scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 255–258. [Google Scholar]
- Talo, M. Convolutional Neural Networks for Multi-class Histopathology Image Classification. arXiv 2019, arXiv:1903.10035. [Google Scholar]
- Veit, A.; Wilber, M.; Belongie, S. Residual networks behave like ensembles of relatively shallow networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 550–558. [Google Scholar]
- Olah, C.; Mordvintsev, A.; Schubert, L. Feature Visualization. How neural networks build up their understating of images. Distill 2017, 2, 0007. Available online: https://distill.pub/2017/feature-visualization (accessed on 28 March 2023).
- Hassner, T.; Pitcher, Y.; Kliper-Gross, O. Violent flows: Real time detection of violent crowd behavior. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–6. [Google Scholar]
- Ullah, F.U.M.; Ullah, A.; Muhammad, K.; Haq, I.U.; Baik, S.W. Violence Detection Using Spatiotemporal Features with 3D Convolutional Neural Network. Sensors 2019, 19, 2472. [Google Scholar] [CrossRef] [Green Version]
- Varga, D. No-Reference Image Quality Assessment with Convolutional Neural Networks and Decision Fusion. Appl. Sci. 2021, 12, 101. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Foresti, G.L.; Martinel, N.; Pannone, D.; Piciarelli, C. A UAV Video Dataset for Mosaicking and Change Detection from Low-Altitude Flights. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 2139–2149. [Google Scholar] [CrossRef] [Green Version]
- Mumtaz, N.; Ejaz, N.; Aladhadh, S.; Habib, S.; Lee, M.Y. Deep Multi-Scale Features Fusion for Effective Violence Detection and Control Charts Visualization. Sensors 2022, 22, 9383. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualizing Image Classification Models and Saliency Maps. arXiv 2013. [Google Scholar] [CrossRef]















| Filename | Time (min:s) | Illumination Conditions | Type of Action |
|---|---|---|---|
| P7020001.avi | 02:04 | high | Violent (kick) |
| P7020002.avi | 02:06 | high | Violent (push) |
| P7020003-1.mp4 | 01:34 | high | Non-violent |
| P7020003-2.mp4 | 01:45 | high | Non-violent |
| P7020004-1.mp4 | 01.31 | high | Non-violent |
| P7020004-2.mp4 | 01.37 | high | Non-violent |
| P7020005-1.mp4 | 01:15 | low | Non-violent |
| P7020005-1.mp4 | 01:18 | low | Non-violent |
| P7020005-3.mp4 | 01:17 | low | Non-violent |
| P7020006.avi | 00:45 | low | Non-violent |
| A (%) | Loss (%) | |
|---|---|---|
| Original SVD | 85 | 48 |
| Extended SVD | 95 | 26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perseghin, E.; Foresti, G.L. A Shallow System Prototype for Violent Action Detection in Italian Public Schools. Information 2023, 14, 240. https://doi.org/10.3390/info14040240
Perseghin E, Foresti GL. A Shallow System Prototype for Violent Action Detection in Italian Public Schools. Information. 2023; 14(4):240. https://doi.org/10.3390/info14040240
Chicago/Turabian StylePerseghin, Erica, and Gian Luca Foresti. 2023. "A Shallow System Prototype for Violent Action Detection in Italian Public Schools" Information 14, no. 4: 240. https://doi.org/10.3390/info14040240