


FedUA: An Uncertainty-Aware Distillation-Based Federated Learning Scheme for Image Classification


Abstract
:1. Introduction
- The server quantifies the network’s uncertainty of the uploading client, which serves as the basis for building a more adaptable aggregation scheme to deal with the inhomogeneity of client side models;
- The server introduces the sample’s quality evaluation to effectively sieve through samples to suppress the influences of data uncertainty and improve learning efficiency;
- As a knowledge distillation aggregation architecture, our work can effectively separate the information of uncertainty and inter-class relationships. This separation helps solve the non-IID data issue and provides a good learning performance while limiting the transmission costs.
2. Preliminary Backgrounds
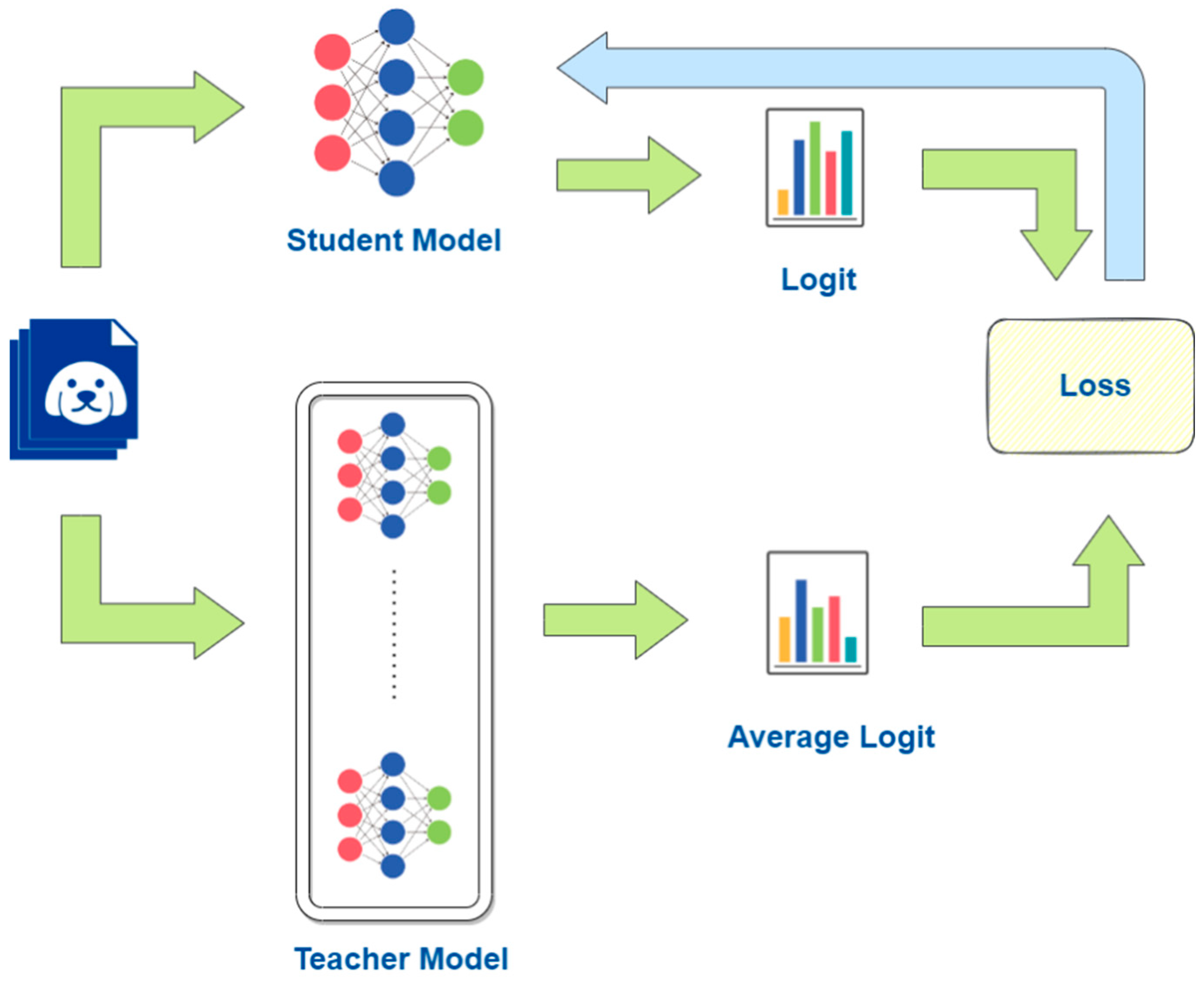
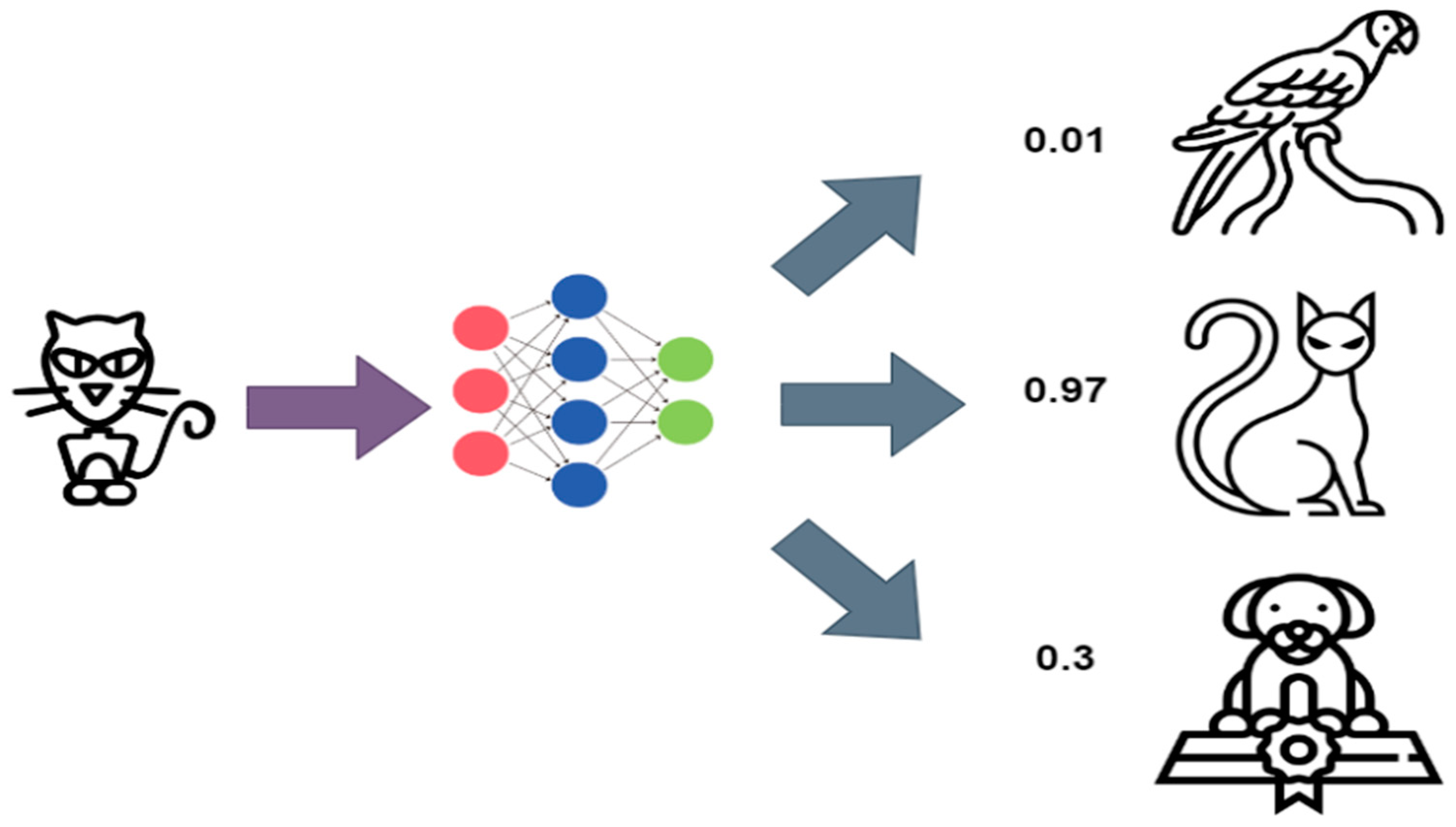
2.1. Knowledge Distillation
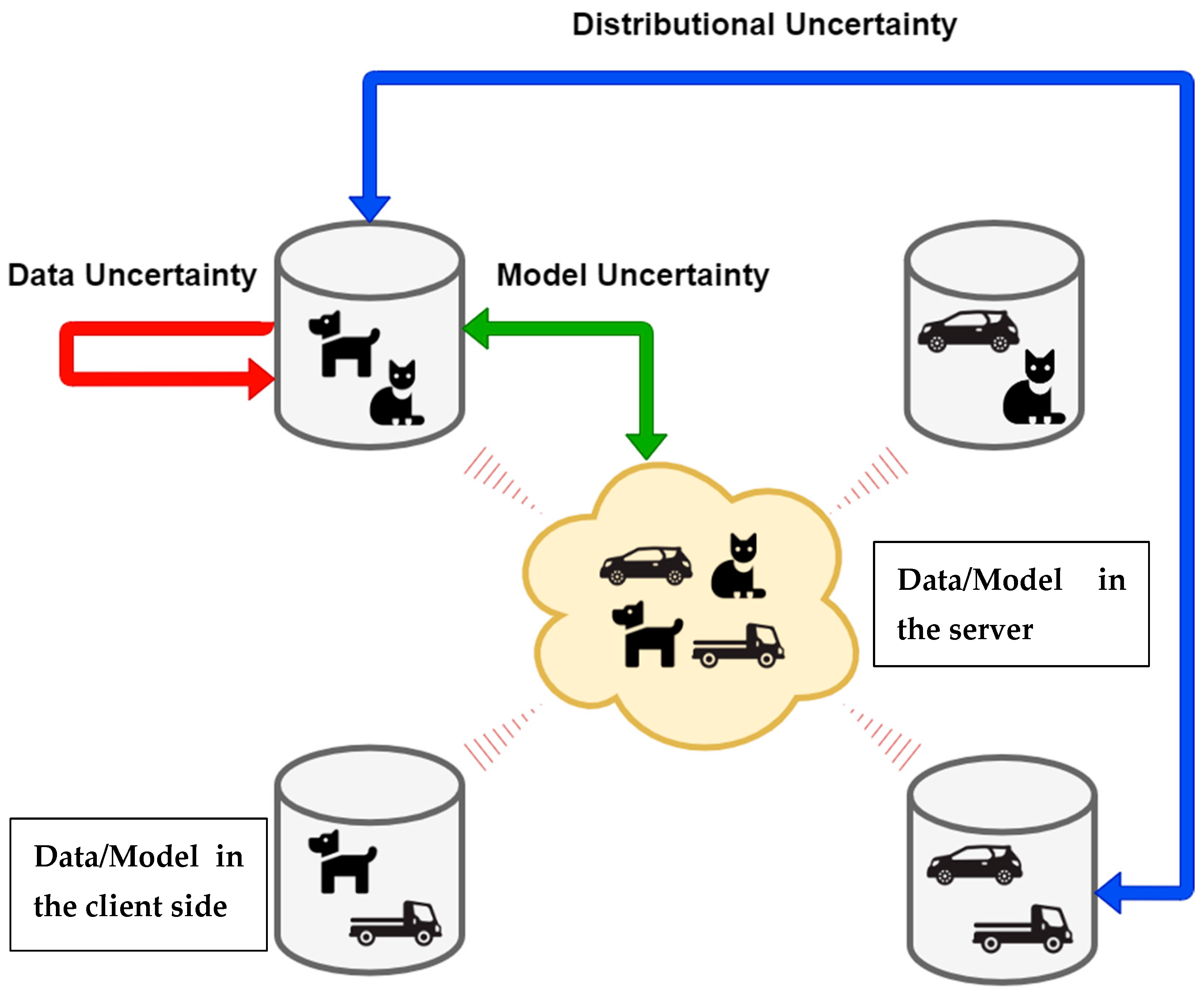
2.2. Uncertainties in DNNs
- Data uncertainty—the uncertainty inherent in the data; even with a well-calibrated model, such an uncertainty still exists;
- Model uncertainty—the model needs to be built with more knowledge. Generally speaking, this kind of uncertainty can be suppressed by improving the training process or calibrating the model;
- Distributional uncertainty—the uncertainty of the distribution prediction itself. From another viewpoint, such an uncertainty can be an essential basis for out-of-distribution detection [22,23,24,25]. Figure 3 shows the classification of the uncertainties of NNs. We refer interested readers to find the detailed definition of each uncertainty class in [22].
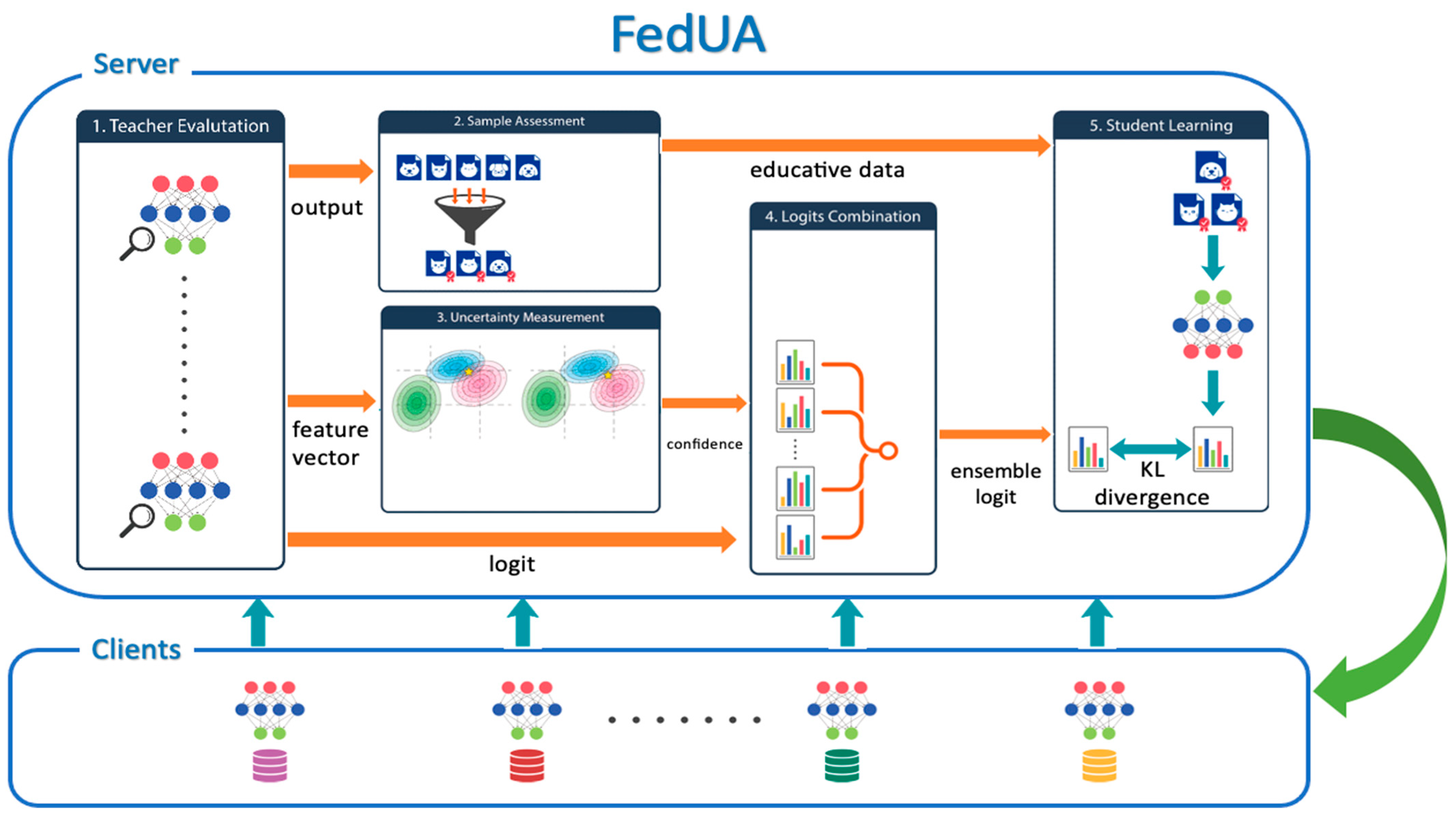
3. The Proposed Method: FedUA
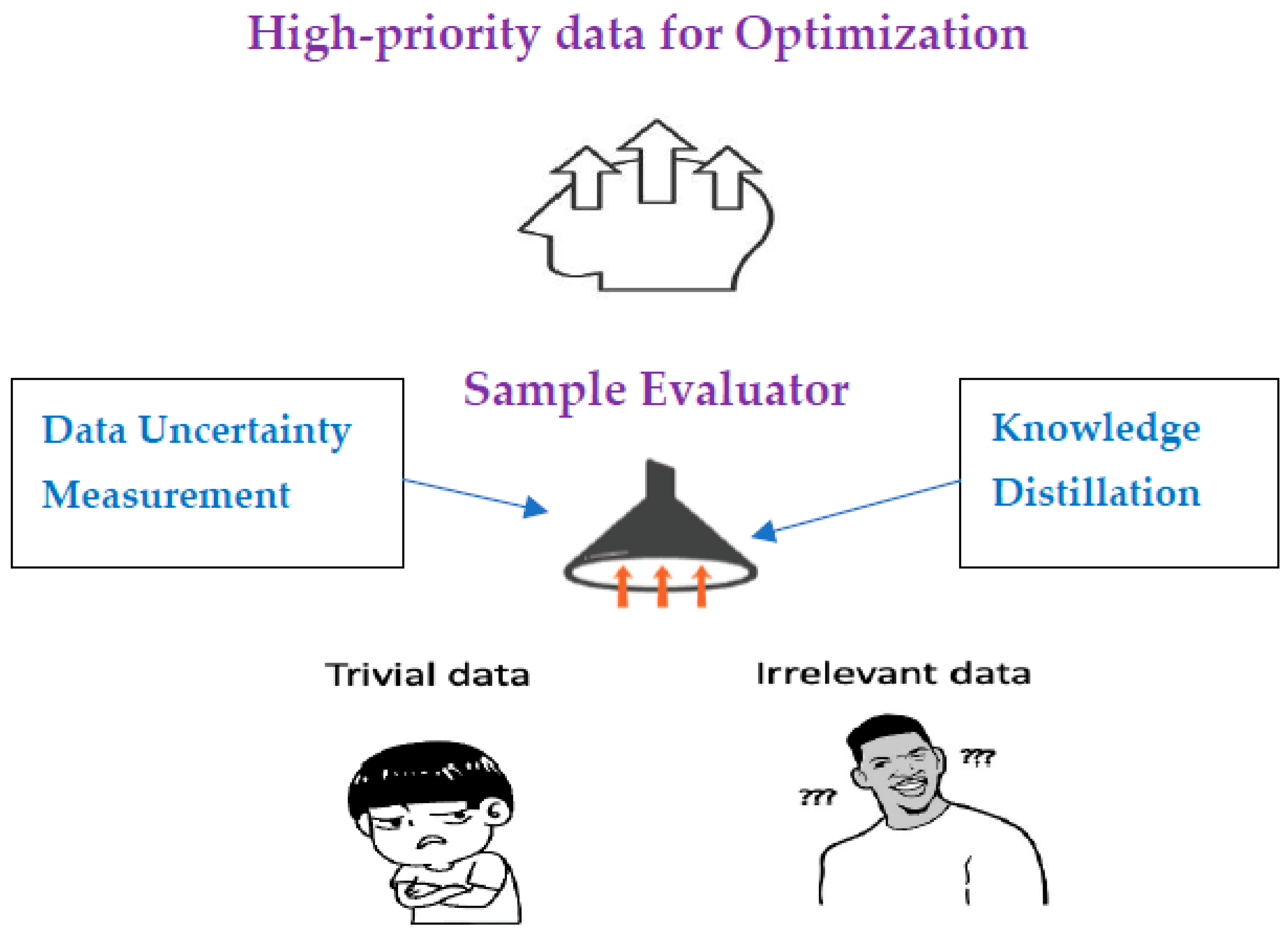
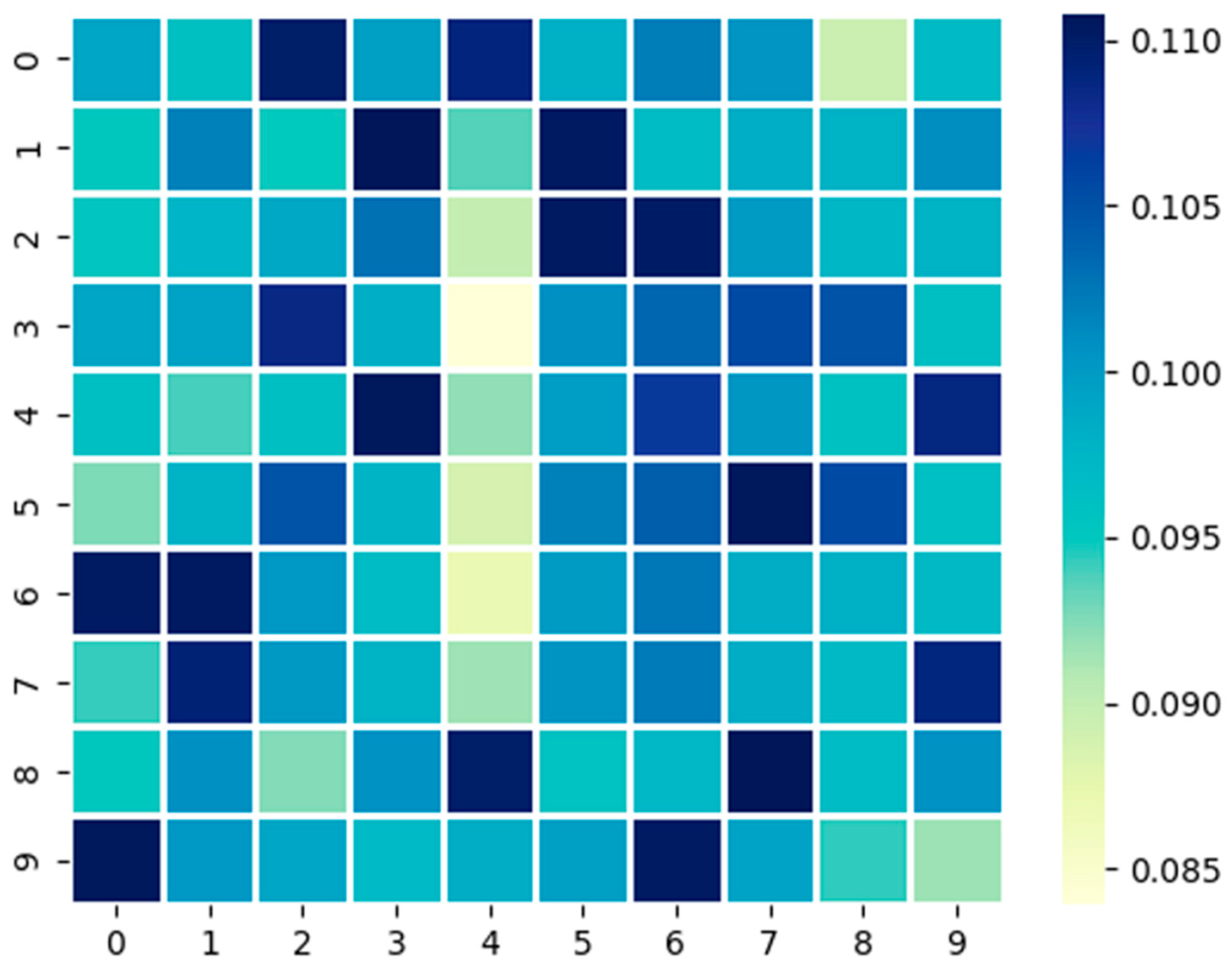
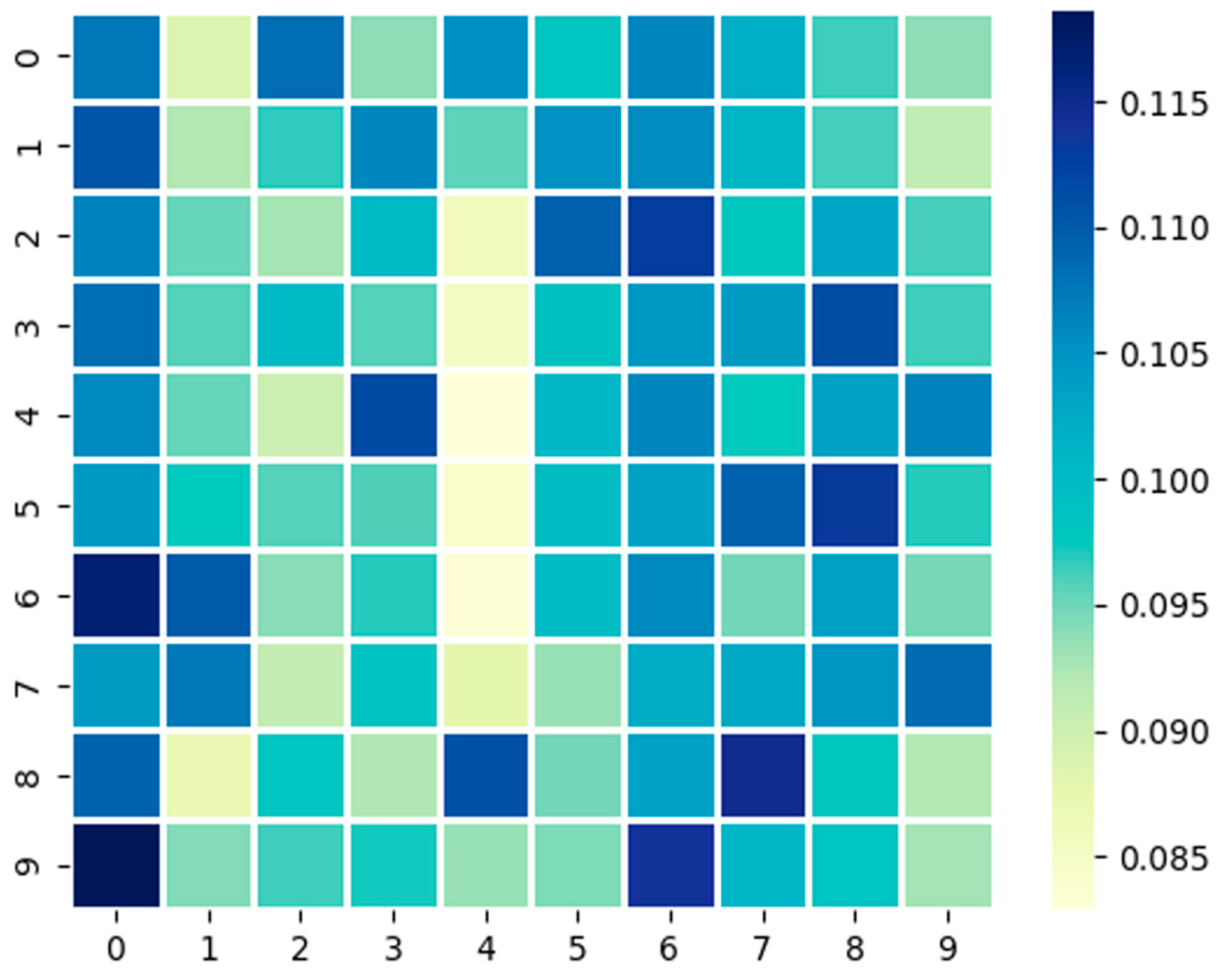
3.1. Uncertainty Measurement
3.2. Sample Assessment
3.3. Overall Architecture
4. Experiments
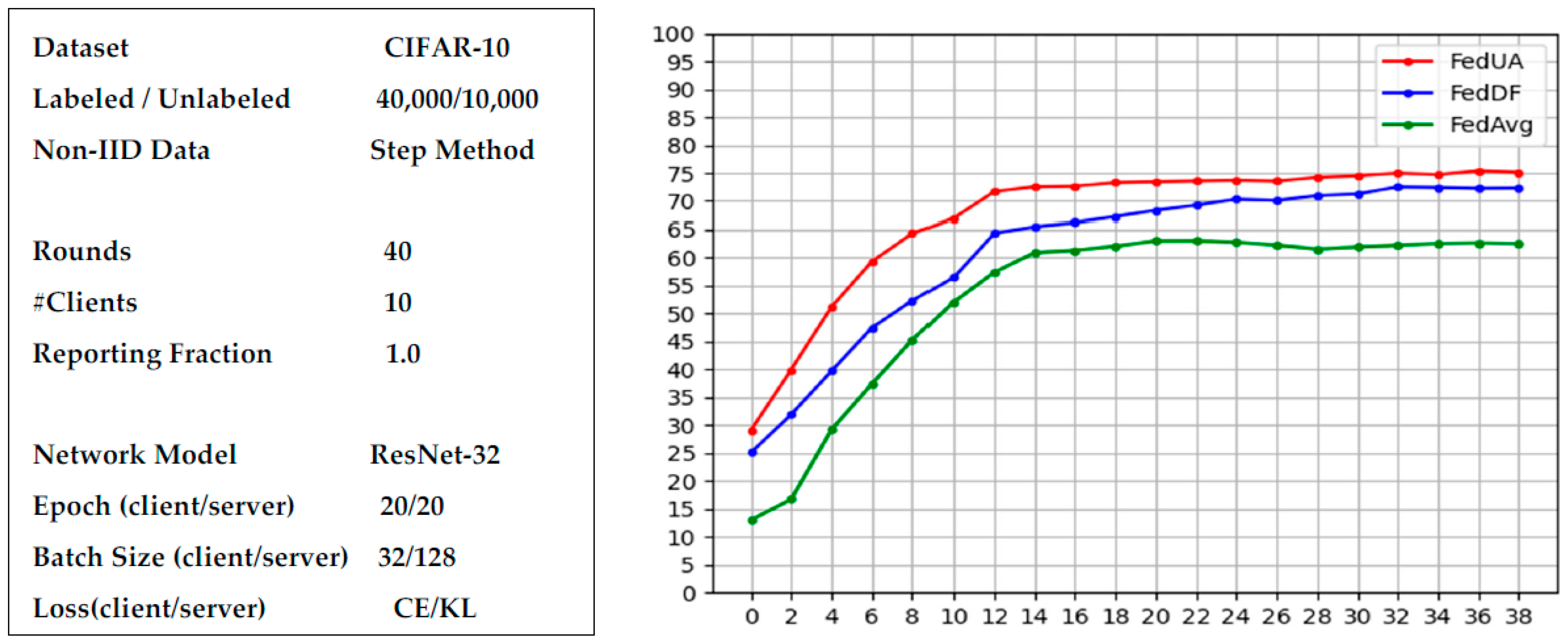
4.1. Experimental Settings
- (a)
- Datasets and Network Models
- (b)
- Detailed Processes
4.2. Results and Analyses
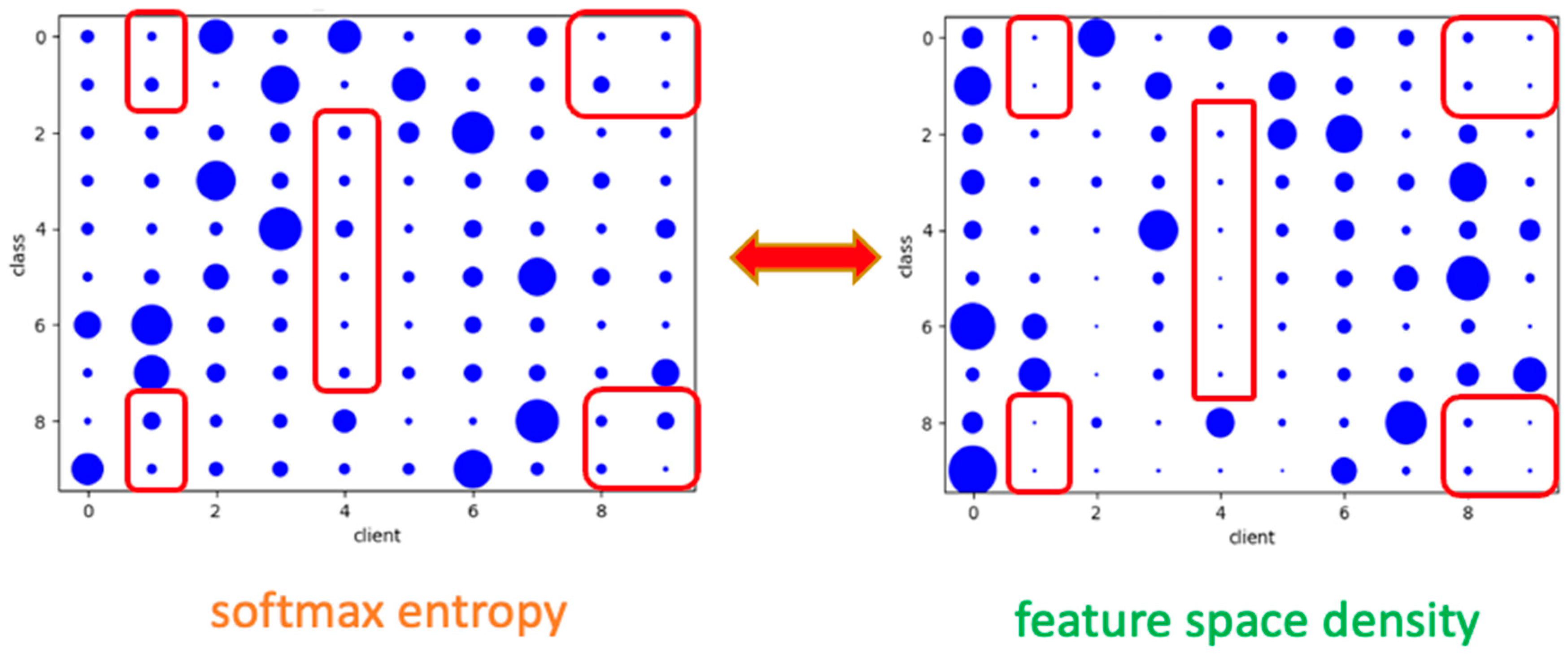
4.2.1. Ablation Analysis
- (a)
- The Impact of the Sample Assessment
- (b)
- The Impact of the Uncertainty Measurement
4.2.2. Performance Comparisons among the Benchmarked Works
- (a)
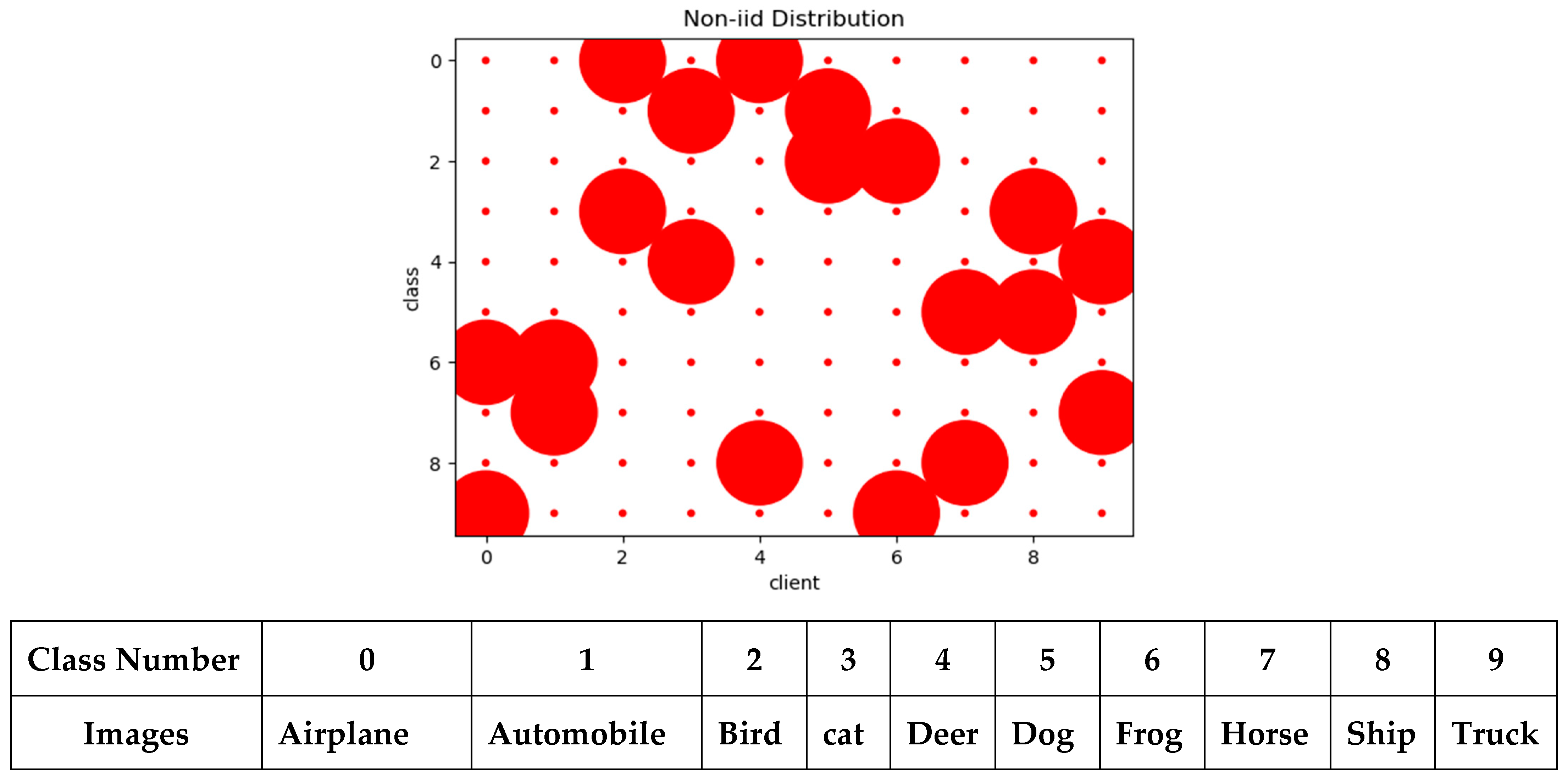
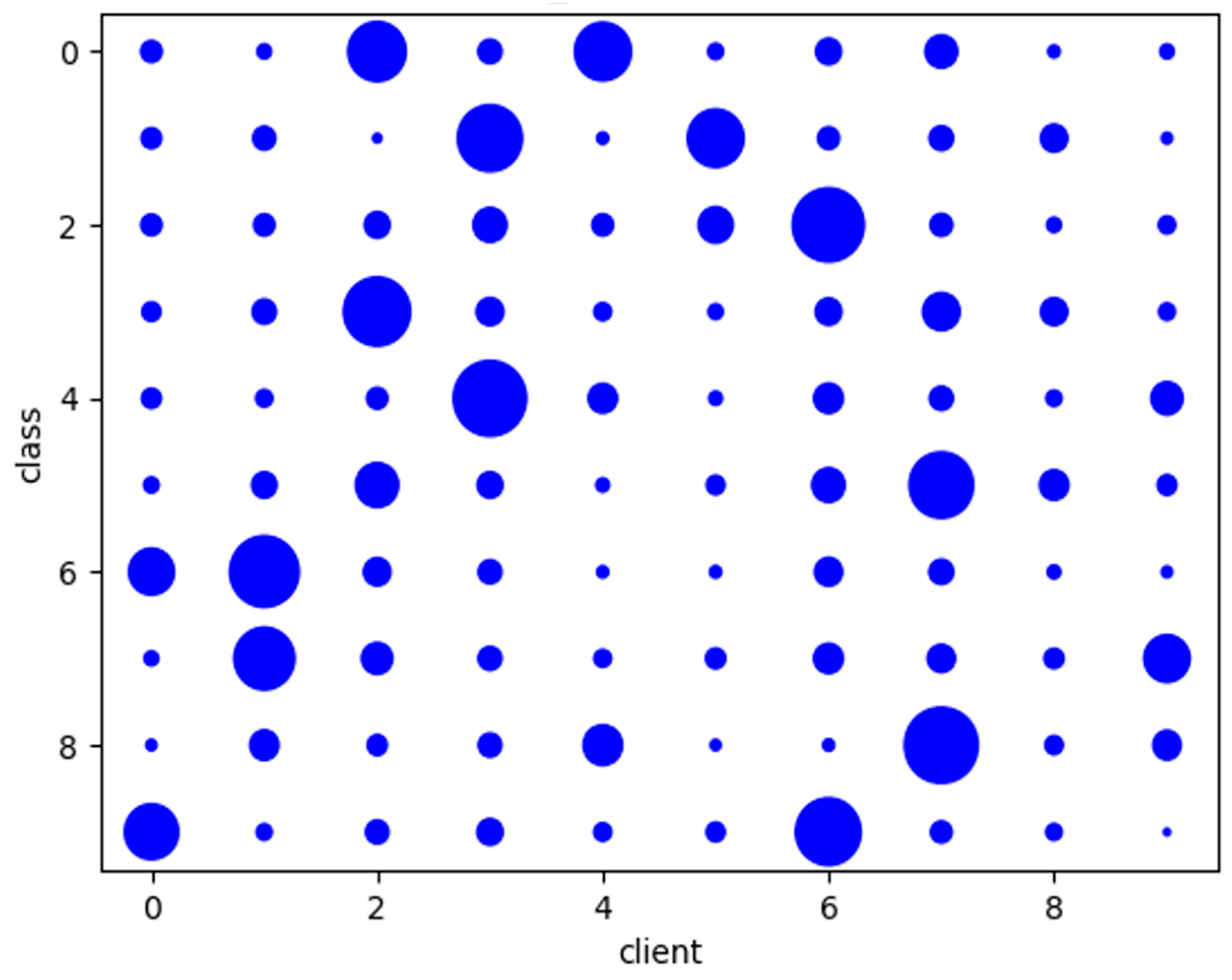
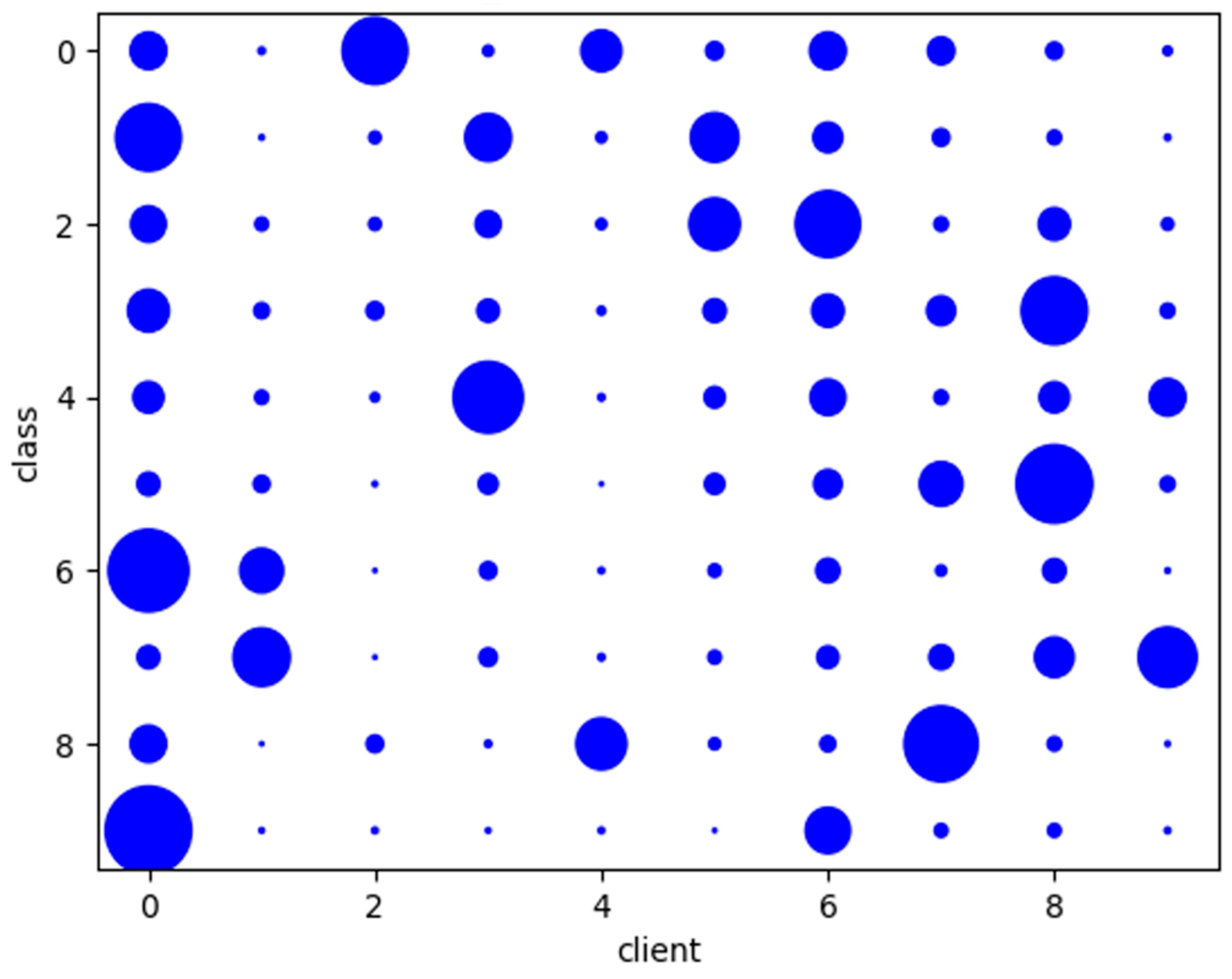
- Learning Behaviors of the Different FL-schemes on Non-IID Data
- (b)
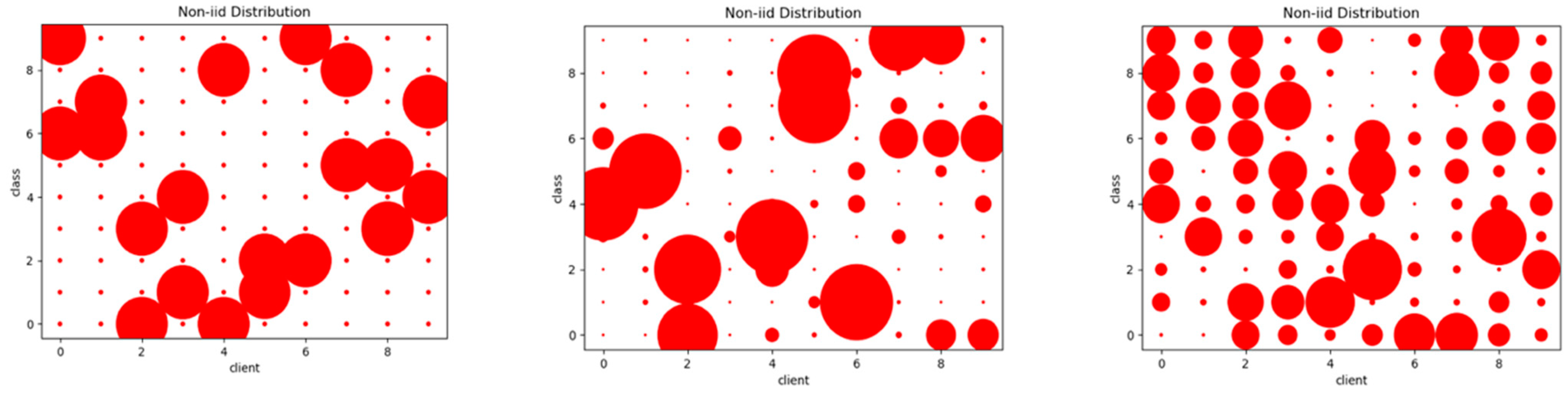
- The Impact of Different Non-IID Data Partitions
- (c)
- The Effects of Limited Allowable Communication Capacity
5. Discussions and Conclusions
5.1. Current Progress in FL Dealing with Non-IID Data
5.2. Conclusions and Possible Contributions of This Work
- We built an effective, adaptable aggregation scheme to deal with the inhomogeneity of client side models based on the proposed quantifiable network uncertainty of the uploading client;
- Based on the evaluated sample quality, we introduced an effective sample sieve scheme to the server to suppress the influences of data uncertainty and improve the learning efficiency;
- As a knowledge distillation aggregation architecture, our work can effectively separate the information of uncertainty and the inter-class relationships. This separation helps solve the non-IID data issue and provides a good learning performance while limiting the transmission cost;
- Through a series of experiments on the image classification task, we confirmed that the proposed model aggregation scheme could effectively solve the problem of non-IID data, especially when the affordable transmission cost is limited.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Artificial Intelligence and Statistics; PMLR. 2017. Available online: https://proceedings.mlr.press/v54/mcmahan17a/mcmahan17a.pdf (accessed on 1 April 2023).
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-IID data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Xiao, P.; Cheng, S.; Stankovic, V.; Vukobratovic, D. Averaging Is Probably Not the Optimum Way of Aggregating Parameters in Federated Learning. Entropy 2020, 22, 314. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated learning on non-IID data: A survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]
- Yoshida, N.; Nishio, T.; Morikura, M.; Yamamoto, K.; Yonetani, R. Hybrid-FL for wireless networks: Cooperative learning mechanism using non-IID data. In Proceedings of the ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 7–11. [Google Scholar] [CrossRef]
- Duan, M.; Liu, D.; Chen, X.; Tan, Y.; Ren, J.; Qiao, L.; Liang, L. Astraea: Self-Balancing Federated Learning for Improving Classification Accuracy of Mobile Deep Learning Applications. In Proceedings of the 2019 IEEE 37th International Conference on Computer Design (ICCD), Abu Dahbi, United Arab Emirates, 17–20 November 2019; pp. 246–254. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, A.; Hong, J.; Yin, D.; Ramchandran, K. Robust federated learning in a heterogeneous environment. arXiv 2019, arXiv:1906.06629. [Google Scholar]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An Efficient Framework for Clustered Federated Learning. IEEE Trans. Inf. Theory 2022, 68, 8076–8091. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020; 2, 429–450. [Google Scholar]
- Hsu, T.-M.H.; Qi, H.; Brown, M. Measuring the effects of non-identical data distribution for federated visual classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]
- Wang, K.; Mathews, R.; Kiddon, C.; Eichner, H.; Beaufays, F.; Ramage, D. Federated evaluation of on-device personalization. arXiv 2019, arXiv:1910.10252. [Google Scholar]
- Arivazhagan, M.G.; Aggarwal, V.; Singh, A.; Choudhary, S. Federated learning with personalization layers. arXiv 2019, arXiv:1912.00818. [Google Scholar]
- Smith, V.; Chiang, C.-K.; Sanjabi, M.; Talwalkar, A. Federated multi-task learning. Adv. Neural Inf. Process. Syst. NeurIPS 2017, 30. Available online: https://papers.nips.cc/paper_files/paper/2017 (accessed on 1 April 2023).
- Liu, B.; Wang, L.; Liu, M. Lifelong Federated Reinforcement Learning: A Learning Architecture for Navigation in Cloud Robotic Systems. IEEE Robot. Autom. Lett. 2019, 4, 4555–4562. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Pu, G.; Ma, X.; Li, X.; Wu, D. Distilled one-shot federated learning. arXiv 2020, arXiv:2009.07999. [Google Scholar]
- Jeong, E.; Oh, S.; Kim, H.; Park, J.; Bennis, M.; Kim, S.-L. Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data. arXiv 2018, arXiv:1811.11479. [Google Scholar]
- Li, D.; Wang, J. Fedmd: Heterogenous federated learning via model distillation. arXiv 2019, arXiv:1910.03581. [Google Scholar]
- Lin, T.; Kong, L.; Stich, S.; Jaggi, M. Ensemble Distillation for Robust Model Fusion in Federated Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2351–2363. [Google Scholar] [CrossRef]
- Chen, H.-Y.; Chao, W.-L. Fedbe: Making bayesian model ensemble applicable to federated learning. arXiv 2020, arXiv:2009.01974. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Gawlikowski, J.; Vinyals, O.; Dean, J. A survey of uncertainty in deep neural networks. arXiv 2021, arXiv:2107.03342. [Google Scholar]
- Hendrycks, D.; Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv 2016, arXiv:1610.02136. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1050–1059. [Google Scholar]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/file/9ef2ed4b7fd2c810847ffa5fa85bce38-Paper.pdf (accessed on 1 April 2023).
- Ovadia, Y.; Fertig, E.; Ren, J.; Nado, Z.; Sculley, D.; Nowozin, S.; Dillon, J.V.; Lakshminarayanan, B.; Snoek, J. Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty under Dataset Shift. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://proceedings.neurips.cc/paper/2019/file/8558cb408c1d76621371888657d2eb1d-Paper.pdf (accessed on 1 April 2023).
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K. On calibration of modern neural networks. In International Conference on Machine Learning; PMLR. 2017. Available online: https://proceedings.mlr.press/v70/guo17a/guo17a.pdf (accessed on 1 April 2023).
- Mukhoti, J.; Kirsch, A.; van Amersfoort, J.; Torr, P.H.S.; Gal, Y. Deep Deterministic Uncertainty: A Simple Baseline. arXiv 2021, arXiv:2102.11582. [Google Scholar]
- Gal, Y.; Islam, R.; Ghahramani, Z. Deep bayesian active learning with image data. In International Conference on Machine Learning; PMLR. 2017. Available online: https://proceedings.mlr.press/v70/gal17a/gal17a.pdf (accessed on 1 April 2023).
- Śmietanka, M.; Pithadia, H.; Treleaven, P. Federated Learning for Privacy-Preserving Data Access. 2020. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3696609 (accessed on 1 April 2023).
- Lumin, L.; Zhang, J.; Song, S.; Letaief, K. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the IEEE International Conference on Communications (ICC, IEEE), Dublin, Ireland, 7–11 June 2020. [Google Scholar] [CrossRef]
- Tian, L.; Sanjabi, M.; Beirami, A.; Smith, V. Fair Resource Allocation in Federated Learning. ICLR 2020. arXiv 2019, arXiv:1905.10497. [Google Scholar]
- Paragliola, G.; Coronato, A. Definition of a novel federated learning approach to reduce communication costs. Expert Syst. Appl. 2022, 189, 116109. [Google Scholar] [CrossRef]
- Paragliola, G. Evaluation of the trade-off between performance and communication costs in federated learning scenario. Futur. Gener. Comput. Syst. 2022, 136, 282–293. [Google Scholar] [CrossRef]
- Paragliola, G. A federated learning-based approach to recognize subjects at a high risk of hypertension in a non-stationary scenario. Inf. Sci. 2023, 622, 16–33. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SR = 0.2 | SR = 0.4 | SR = 0.6 | SR = 0.8 | SR = 1.0 | |
|---|---|---|---|---|---|
| Random | 71.5 ± 0.61 | 71.3 ± 0.78 | 71.8 ± 0.66 | 72.3 ± 0.66 | 72.1 ± 0.55 |
| BALD | 72.0 ± 0.24 | 72.5 ± 0.36 | 73.9 ± 0.46 | 73.7 ± 0.33 | 73.2 ± 0.48 |
| Classification Accuracy vs. Parameter α | |||
|---|---|---|---|
| Step Method [20] | Dirichlet (α = 0.1) | Dirichlet (α = 0.5) | |
| FedAvg | 62.6 ± 0.23 1 1 | 59.6 ± 1.03 −4.7% 1 | 80.1 ± 0.45 +28% 1 |
| FedDF FedDF-α-Step FedDF-FedAvg | 72.3 ± 0.49 1 15.5 % | 64.4 ± 0.93 −11% 8.0% | 82.8 ± 0.47 +14.5% 3.4% |
| FedUA FedUA-α-Step FedUA-FedAvg | 74.8 ± 0.45 1 19.5% | 65.3 ± 0.78 −12.7% 9.6% | 83.4 ± 0.24 +11.5% 4.1% |
| Classification Accuracy vs. Participation Ratio | |||
|---|---|---|---|
| C = 1.0 | C = 0.7 | C = 0.4 | |
| FedAvg Accur-drop | 62.6 ± 0.23 1 | 61.3 ± 0.35 2.1% | 58.1 ± 0.26 7.2% |
| FedDF Accur-drop | 72.3 ± 0.49 1 | 68.1 ± 0.61 5.9% | 63.8 ± 1.03 11.8 |
| FedUA Accur-drop | 74.8 ± 0.45 1 | 71.8 ± 0.56 4.0% | 68.3 ± 0.85 8.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.-M.; Wu, J.-L. FedUA: An Uncertainty-Aware Distillation-Based Federated Learning Scheme for Image Classification. Information 2023, 14, 234. https://doi.org/10.3390/info14040234
Lee S-M, Wu J-L. FedUA: An Uncertainty-Aware Distillation-Based Federated Learning Scheme for Image Classification. Information. 2023; 14(4):234. https://doi.org/10.3390/info14040234
Chicago/Turabian StyleLee, Shao-Ming, and Ja-Ling Wu. 2023. "FedUA: An Uncertainty-Aware Distillation-Based Federated Learning Scheme for Image Classification" Information 14, no. 4: 234. https://doi.org/10.3390/info14040234