
Liver CT Image Recognition Method Based on Capsule Network

Abstract
:1. Introduction
2. Image Preprocessing
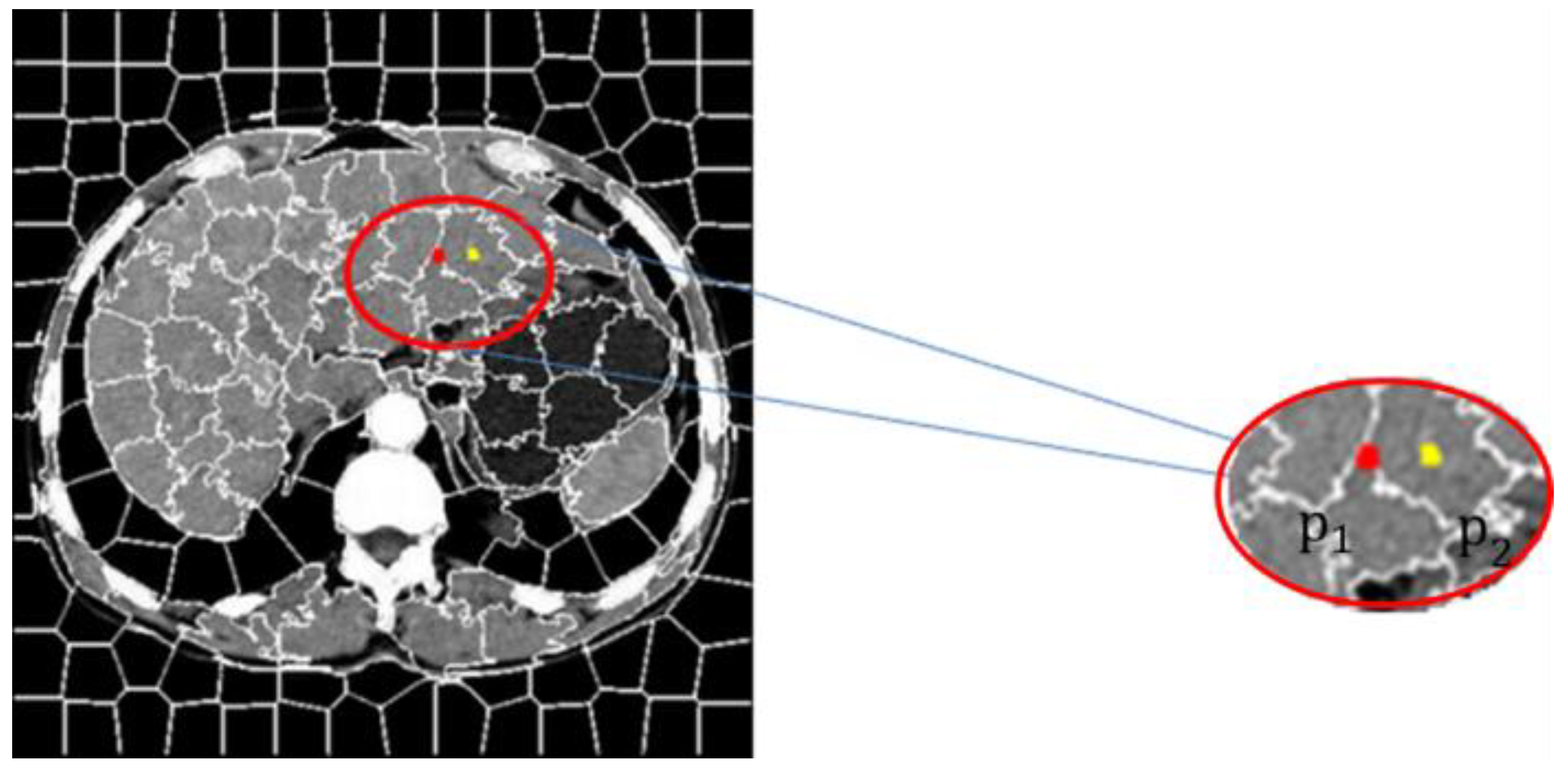
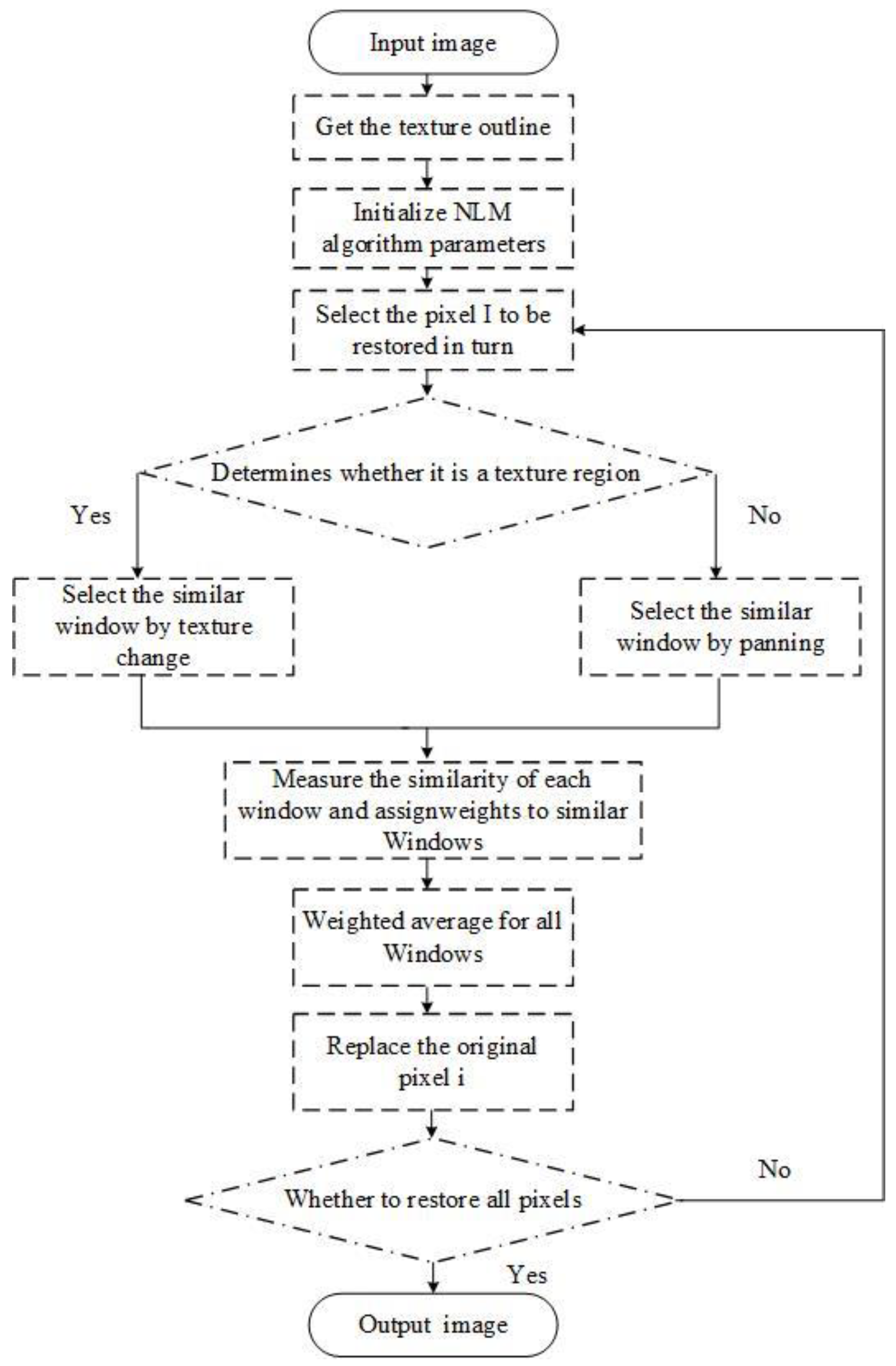
3. NLM Liver CT Image Denoising Method Based on SLIC Algorithm
4. Liver Cancer Image Recognition
4.1. CapsNet
4.2. Network Structure
5. Experiment
5.1. Experiment Preparation
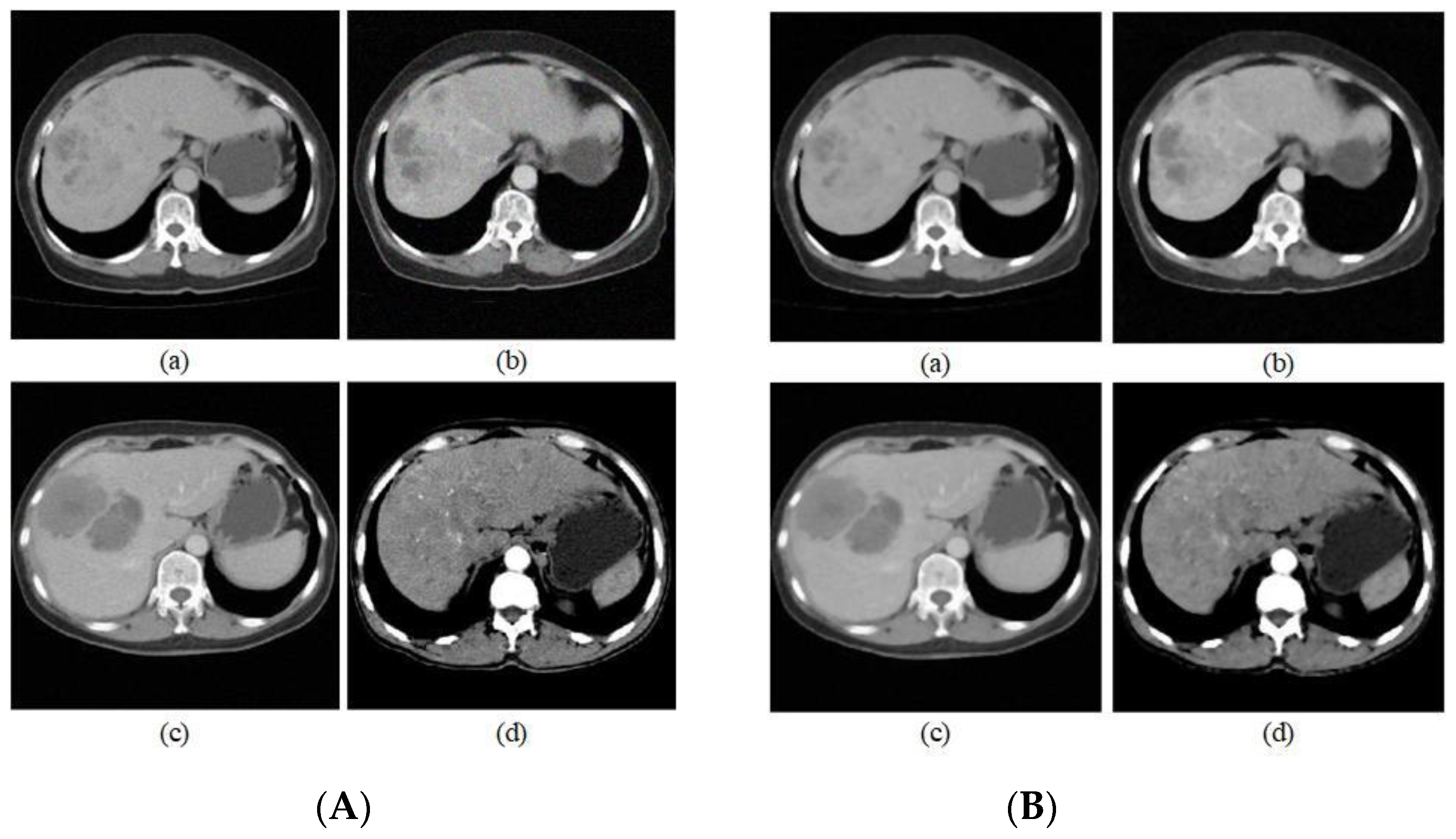
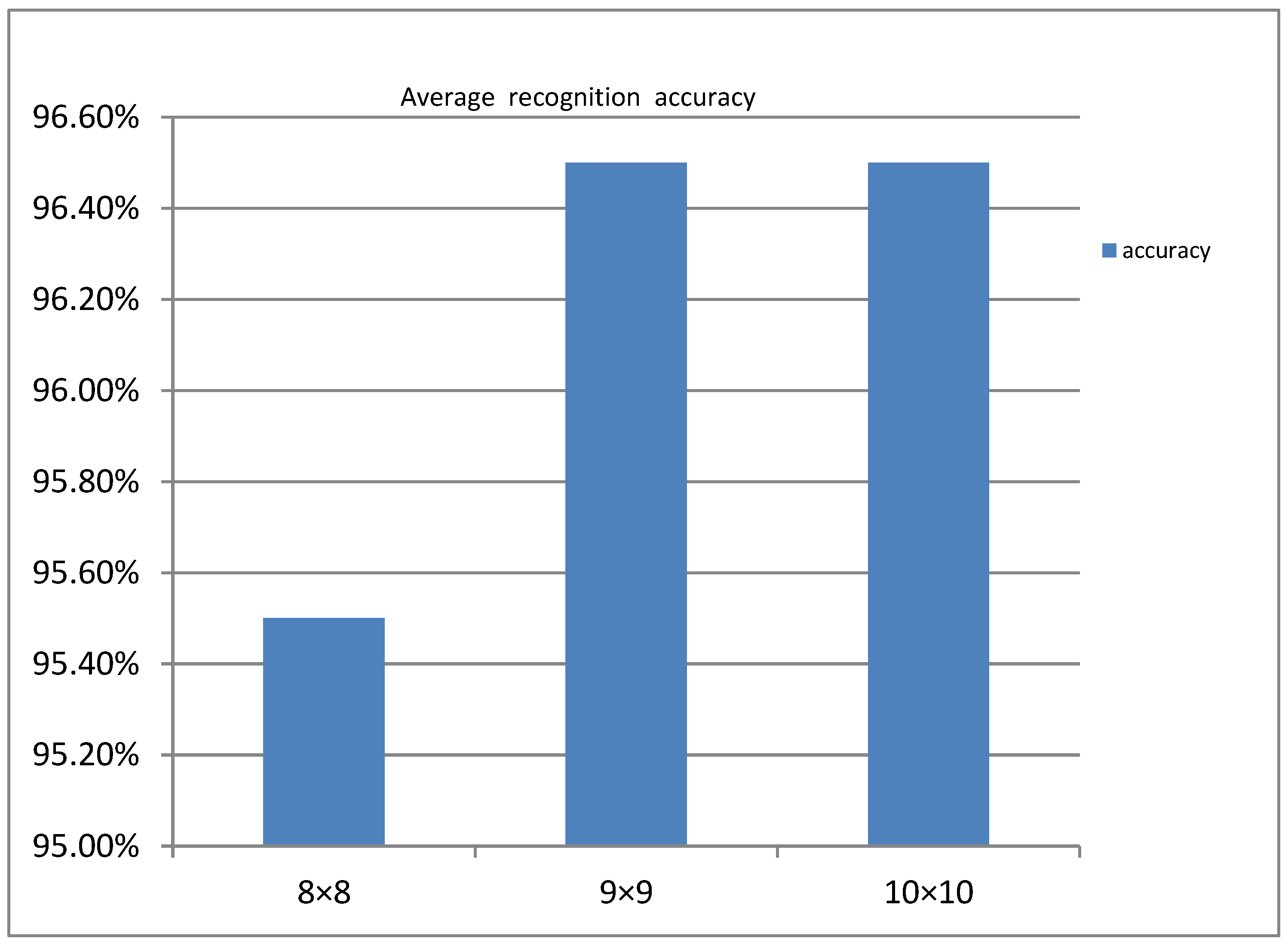
5.2. Analysis of Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA A Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [Green Version]
- Verma, A.; Khanna, G. A survey on digital image processing techniques for tumor detection. Indian J. Sci. Technol. 2016, 9, 15. [Google Scholar] [CrossRef]
- Anisha, P.R.; Reddy, C.K.K.; Prasad, L.V.N. A pragmatic approach for detecting liver cancer using image processing and data mining techniques; Signal processing and communication engineering systems (SPACES). In Proceedings of the 2015 International Conference on Signal Processing and Communication Engineering Systems, Guntur, India, 2–3 January 2015; pp. 352–357. [Google Scholar]
- Hu, Z.; Tang, J.; Wang, Z.; Zhang, K.; Zhang, L.; Sun, Q. Deep Learning for Image-based Cancer Detection and Diagnosis—A Survey. Pattern Recognit. 2018, 83, 134–149. [Google Scholar] [CrossRef]
- Lee, C.; Chen, S.H.; Tsai, H.M.; Chung, P.C.; Chiang, Y.C. Discrimination of liver diseases from CT images based on Gabor filters. In Proceedings of the 19th IEEE Symposium on Computer-Based Medical Systems (CBMS′06), Salt Lake City, UT, USA, 22–23 June 2006; pp. 203–206. [Google Scholar]
- Hao, T.; Zhang, Z. Texture analysis of CT images of primary liver cancer based on BP neural network. China Digit. Med. 2013, 8, 73–76. [Google Scholar]
- Liu, J.; Wang, J. Research on CT image diagnosis technology of liver cancer based on image processing. J. Tsinghua Univ. (Nat. Sci. Ed.) 2014, 54, 917–923. [Google Scholar]
- Li, W.; Jia, F.; Hu, Q. Automatic segmentation of liver tumor in CT images with deep convolutional neural networks. J. Comput. Commun. 2015, 3, 146. [Google Scholar] [CrossRef] [Green Version]
- Krishan, A.; Mittal, D. Detection and classification of liver cancer using CT images. Int. J. Recent Technol. Mech. Electr. Eng. 2015, 2, 93–98. [Google Scholar] [CrossRef]
- Li, Y.; Hao, Z.; Lei, H. Research review of convolutional neural network. Comput. Appl. 2016, 36, 2508–2515+2565. [Google Scholar]
- Luo, Y.; Zou, J.; Yao, C.; Li, T.; Bai, G. HSI-CNN: A Novel Convolution Neural Network for Hyperspectral Image. arXiv 2018, arXiv:1802.10478. [Google Scholar]
- Xi, E.; Bing, S.; Jin, Y. Capsule Network Performance on Complex Data. arXiv 2017, arXiv:1712.03480. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. Adv. Neural Inf. Process. Syst. 2017, 30, 3856–3866. [Google Scholar]
- Yu, C.; Xiong, D. Research on finger vein recognition based on capsule network. Appl. Electron. Tech. 2018, 44, 15–18. [Google Scholar]
- Zhang, W.; Tang, P.; Zhao, L. Remote Sensing Image Scene Classification Using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef] [Green Version]
- Yin, J.; Li, S.; Zhu, H.; Luo, X. Hyperspectral Image Classification Using CapsNet With Well-Initialized Shallow Layers. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1095–1099. [Google Scholar] [CrossRef]
- Xiang, C.; Zhang, L.; Tang, Y.; Zou, W.; Xu, C. MS-CapsNet: A Novel Multi-Scale Capsule Network. IEEE Signal Process. Lett. 2018, 25, 1850–1854. [Google Scholar] [CrossRef]
- Wang, X.; Tan, K.; Du, Q.; Chen, Y.; Du, P. Caps-TripleGAN: GAN-Assisted CapsNet for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7232–7245. [Google Scholar] [CrossRef]
- Wang, D.; Liang, Y.; Xu, D. Capsule network for protein post-translational modification site prediction. Bioinformatics 2019, 35, 2386–2394. [Google Scholar] [CrossRef] [PubMed]
- Toraman, S.; Alakus, T.; Turkoglu, I. Convolutional capsnet: A novel artificial neural network approach to detect COVID-19 disease from X-ray images using capsule networks. Chaos Solitons Fractals 2020, 140, 110122. [Google Scholar] [CrossRef] [PubMed]
- Goceri, E. CapsNet topology to classify tumours from brain images and comparative evaluation. IET Image Process. 2020, 14, 882–889. [Google Scholar] [CrossRef]
- Chao, H.; Dong, L.; Liu, Y.; Lu, B. Emotion Recognition from Multiband EEG Signals Using CapsNet. Sensors 2019, 19, 2212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Diwakar, M.; Kumar, M. CT image denoising using NLM and correlation-based wavelet packet thresholding. IET Image Process. 2018, 12, 708–715. [Google Scholar] [CrossRef]
- Zhu, H.; Wu, Y.; Li, P.; Wang, D.; Shi, W.; Zhang, P.; Jiao, L. A parallel Non-Local means denoising algorithm implementation with OpenMP and OpenCL on Intel Xeon Phi Coprocessor. J. Comput. Sci. 2016, 17, 591–598. [Google Scholar] [CrossRef]
- Xu, S.; Zhou, Y.; Xiang, H.; Li, S. Remote Sensing Image Denoising Using Patch Grouping-Based Nonlocal Means Algorithm. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2275–2279. [Google Scholar] [CrossRef]
- Vignesh, R.; Oh, B.; Kuo, C. Fast Non-Local Means (NLM) Computation With Probabilistic Early Termination. IEEE Signal Process. Lett. 2010, 17, 277–280. [Google Scholar] [CrossRef]
- Verma, R.; Pandey, R. Grey relational analysis based adaptive smoothing parameter for non-local means image denoising. Multimed. Tools Appl. 2018, 77, 25919–25940. [Google Scholar] [CrossRef]
- Lv, J.; Luo, X. Image Denoising via Fast and Fuzzy Non-local Means Algorithm. J. Inf. Process. Syst. 2019, 15, 1108–1118. [Google Scholar]
- Luo, Y.; Huang, W.; Zeng, K.; Zhang, C.; Yu, C.; Wu, W. Intelligent Noise Reduction Algorithm to Evaluate the Correlation between Human Fat Deposits and Uterine Fibroids under Ultrasound Imaging. J. Healthc. Eng. 2021, 2021, 5390219. [Google Scholar] [CrossRef]
- Lai, R.; Yang, Y. Accelerating non-local means algorithm with random projection. Electron. Lett. 2011, 47, 182-U669. [Google Scholar] [CrossRef]
- Cheng, C.-C.; Cheng, F.-C.; Huang, S.-C.; Chen, B.-H. Integral non-local means algorithm for image noise suppression. Electron. Lett. 2015, 51, 1494-U1124. [Google Scholar] [CrossRef]
- Qian, D. Non-local mean filtering of images based on pixel selection. Foreign Electron. Meas. Technol. 2008, 37, 6–9. [Google Scholar]
- Rahim, T.; Usman, M.A.; Shin, S.Y. A survey on contemporary computer-aided tumor, polyp, and ulcer detection methods in wireless capsule endoscopy imaging. Comput. Med. Imaging Graph. 2020, 85, 101767. [Google Scholar] [CrossRef] [PubMed]
- Ning, X.; Tian, W.; He, F.; Bai, X.; Sun, L.; Li, W. Hyper-sausage coverage function neuron model and learning algorithm for image classification. Pattern Recognit. 2023, 136, 109216. [Google Scholar] [CrossRef]
- Ning, X.; Xu, S.; Nan, F.; Zeng, Q.; Wang, C.; Cai, W.; Jiang, Y. Face editing based on facial recognition features. IEEE Trans. Cogn. Dev. Syst. 2022, 1, 2379–8939. [Google Scholar] [CrossRef]
- Ning, X.; Tian, W.; Yu, Z.; Li, W.; Bai, X.; Wang, Y. HCFNN: High-order coverage function neural network for image classification. Pattern Recognit. 2022, 131, 108873. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| a | b | c | d | |
|---|---|---|---|---|
| PSNR | 27.39 | 29.86 | 27.46 | 27.19 |
| SSIM | 93.70% | 89.51% | 94.46% | 94.96% |
| Class | Samples | Identify | Precision | Recall |
|---|---|---|---|---|
| Normal | 164 | 149 | 90.8% | 95.3% |
| Cancer | 136 | 125 | 91.9% | 96.7% |
| Class | Samples | Identify | Precision | Recall |
|---|---|---|---|---|
| Normal | 164 | 122 | 74.3% | 84.7% |
| Cancer | 136 | 102 | 75.0% | 85.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Chen, A.; Xue, Y. Liver CT Image Recognition Method Based on Capsule Network. Information 2023, 14, 183. https://doi.org/10.3390/info14030183
Wang Q, Chen A, Xue Y. Liver CT Image Recognition Method Based on Capsule Network. Information. 2023; 14(3):183. https://doi.org/10.3390/info14030183
Chicago/Turabian StyleWang, Qifan, Aibin Chen, and Yongfei Xue. 2023. "Liver CT Image Recognition Method Based on Capsule Network" Information 14, no. 3: 183. https://doi.org/10.3390/info14030183