
Deep Learning-Based Semantic Segmentation Methods for Pavement Cracks

Abstract
:1. Introduction
1.1. Image Processing-Based Methods
1.2. Deep Learning-Based Methods
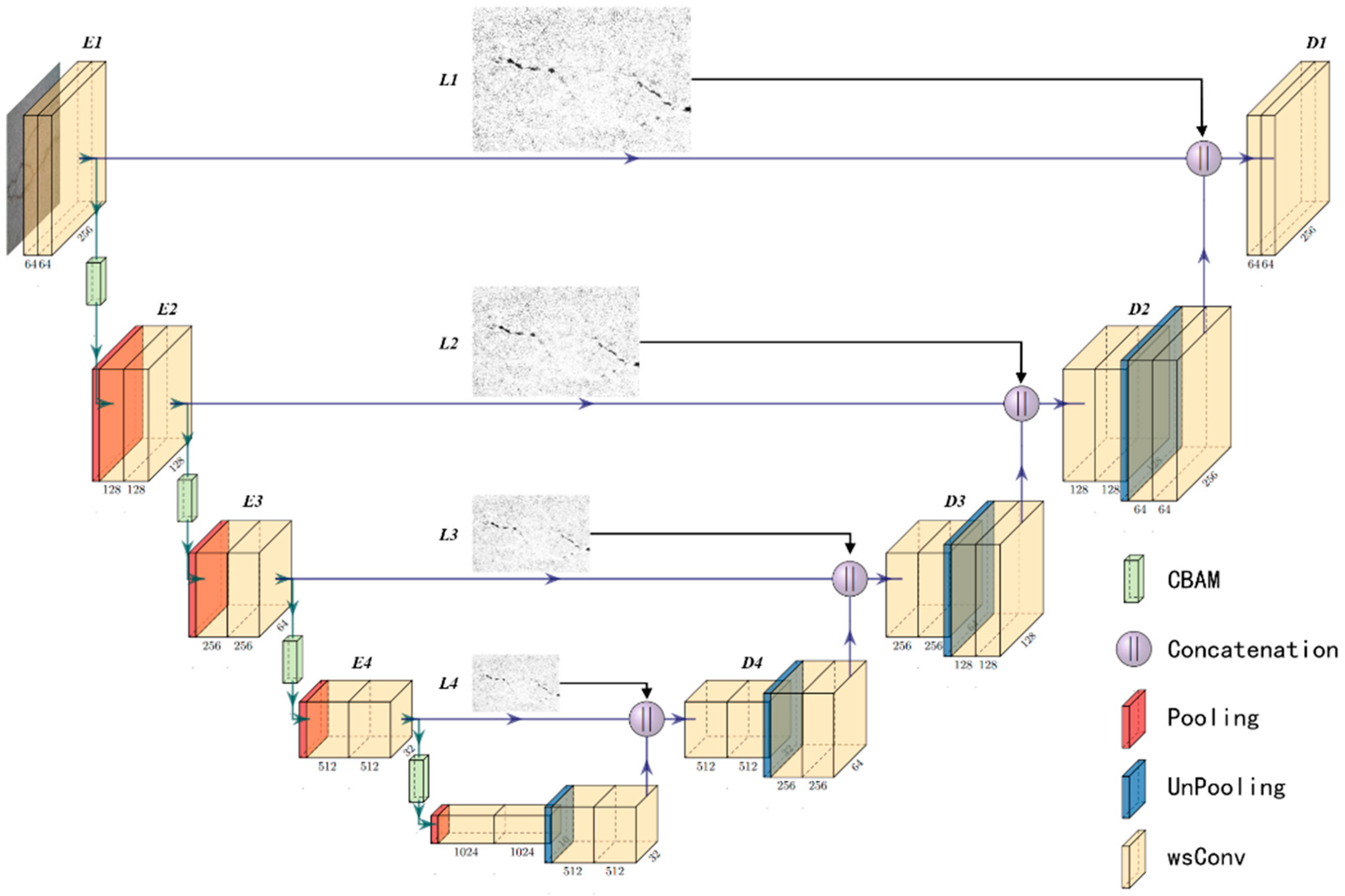
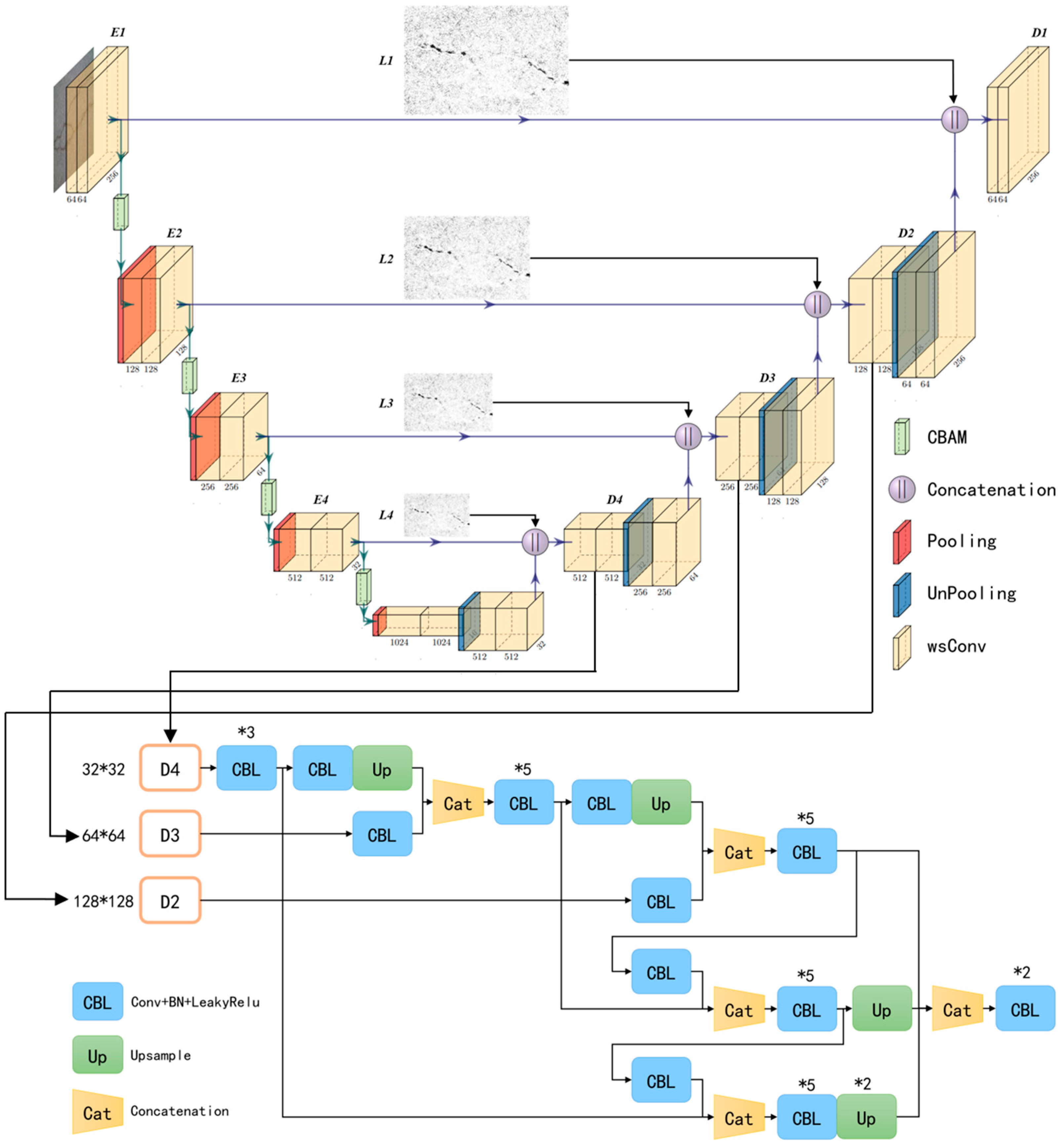
2. Proposed Method
2.1. CBAM-Unet Model
2.2. Laplacian Pyramid
2.3. PAN Path-Aggregation Auxiliary Head
2.4. Loss Function
3. Results
3.1. Training
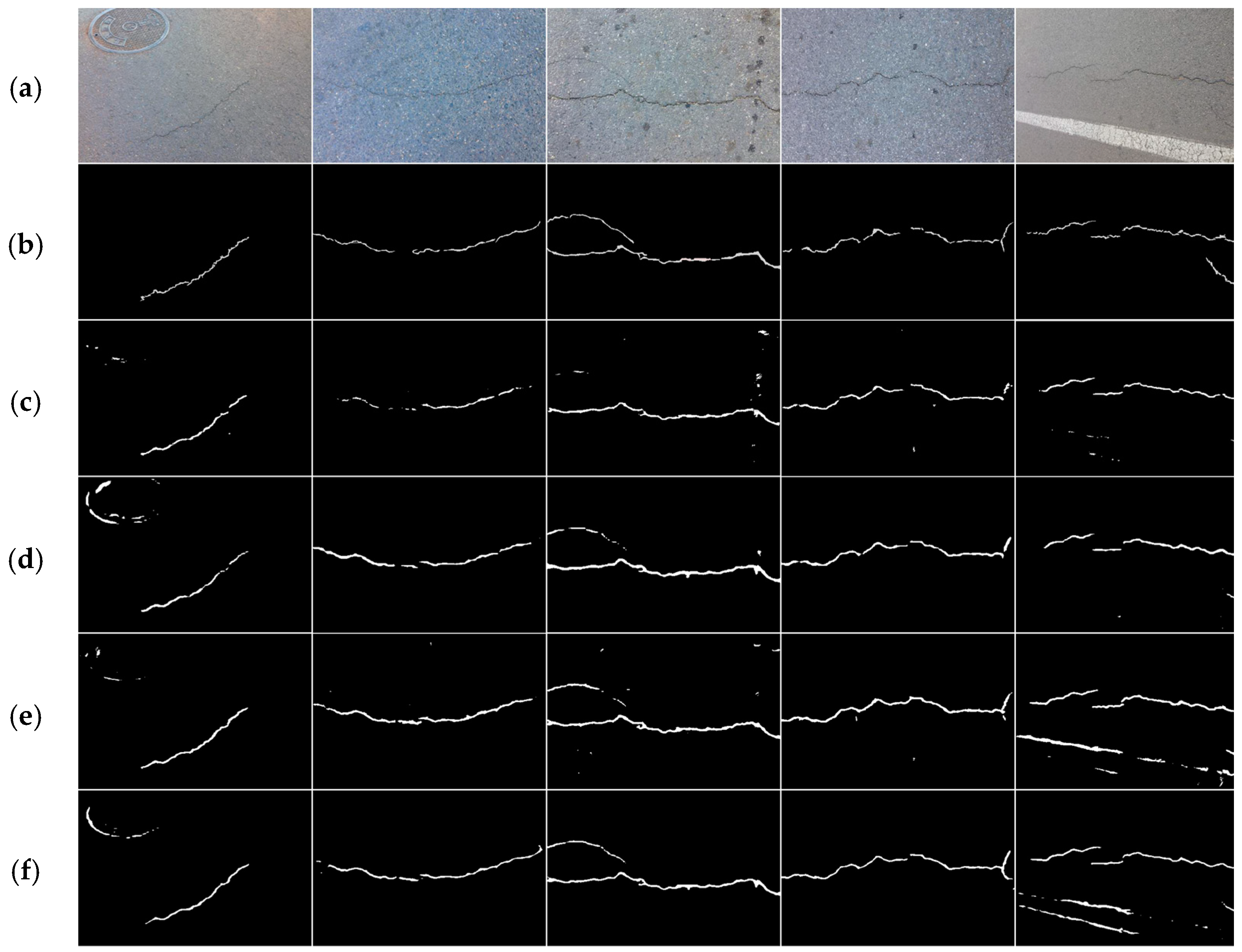
3.2. Performance Evaluation
3.3. Ablation Study
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huyan, J.; Li, W.; Tighe, S.; Xu, Z.; Zhai, J. CrackU-net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control Health Monit. 2020, 27, e2551. [Google Scholar] [CrossRef]
- Wang, K.C.P.; Elliott, R.P. Investigation of Image Archiving for Pavement Surface Distress Survey; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9999, pp. 1–13. [Google Scholar]
- Oliveira, H.; Correia, P.L. Automatic road crack detection and characterization. IEEE Trans. Intell. Transp. Syst. 2012, 14, 155–168. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Hoang, N.D.; Nguyen, Q.L.; Tien Bui, D. Image processing–based classification of asphalt pavement cracks using support vector machine optimized by artificial bee colony. J. Comput. Civ. Eng. 2018, 32, 04018037. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. Road surface crack detection: Improved segmentation with pixel-based refinement. In Proceedings of the IEEE 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017. [Google Scholar]
- Lu, G.; Zhao, Q.; Liao, J.; He, Y. Pavement crack identification based on automatic threshold iterative method. In Proceedings of the Seventh International Conference on Electronics and Information Engineering, Nanjing, China, 17–18 September 2016; Volume 10322, pp. 320–325. [Google Scholar]
- Dinh, T.H.; Ha, Q.P.; La, H.M. Computer vision-based method for concrete crack detection. In Proceedings of the 2016 14th international conference on control, automation, robotics and vision (ICARCV), Phuket, Thailand, 13–15 November 2016; pp. 1–6. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Zhang, A.; Wang, K.C.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep-learning network. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Mandal, V.; Uong, L.; Adu-Gyamfi, Y. Automated road crack detection using deep convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5212–5215. [Google Scholar]
- König, J.; Jenkins, M.D.; Barrie, P.; Mannion, M.; Morison, G. A convolutional neural network for pavement surface crack segmentation using residual connections and attention gating. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1460–1464. [Google Scholar]
- Garbowski, T.; Gajewski, T. Semi-automatic inspection tool of pavement condition from three-dimensional profile scans. Procedia Eng. 2017, 172, 310–318. [Google Scholar] [CrossRef]
- Seo, H.; Huang, C.; Bassenne, M.; Xiao, R.; Xing, L. Modified U-Net (mU-Net) with incorporation of object-dependent high level features for improved liver and liver-tumor segmentation in CT images. IEEE Trans. Med. Imaging 2019, 39, 1316–1325. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer International Publishing: New York, NY, USA, 2015; pp. 234–241. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514 2018. [Google Scholar]
- Song, M.; Lim, S.; Kim, W. Monocular depth estimation using laplacian pyramid-based depth residuals. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4381–4393. [Google Scholar] [CrossRef]
- Wang, Z.; Cui, Z.; Zhu, Y. Multi-modal medical image fusion by Laplacian pyramid and adaptive sparse representation. Comput. Biol. Med. 2020, 123, 103823. [Google Scholar] [CrossRef] [PubMed]
- Ghiasi, G.; Fowlkes, C.C. Laplacian pyramid reconstruction and refinement for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Germany, 2016; pp. 519–534. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhao, R.; Qian, B.; Zhang, X.; Li, Y.; Wei, R.; Liu, Y.; Pan, Y. Rethinking dice loss for medical image segmentation. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 851–860. [Google Scholar]
- Crum, W.R.; Camara, O.; Hill, D.L.G. Generalized overlap measures for evaluation and validation in medical image analysis. IEEE Trans. Med. Imaging 2006, 25, 1451–1461. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architectures | ||||||
|---|---|---|---|---|---|---|
| UNet | 0.7595 | 0.5273 | 0.8089 | 0.7624 | 0.7213 | 0.6225 |
| UperNet | 0.7369 | 0.5543 | 0.8144 | 0.7731 | 0.7261 | 0.6301 |
| ResUNet | 0.8261 | 0.5265 | 0.8192 | 0.7625 | 0.7324 | 0.6431 |
| Pointrend | 0.7559 | 0.5717 | 0.8234 | 0.7846 | 0.7372 | 0.6510 |
| Architectures | ||||||
|---|---|---|---|---|---|---|
| Pointrend | 0.7559 | 0.5717 | 0.8234 | 0.7846 | 0.7372 | 0.6510 |
| Att-UNet | 0.7987 | 0.5491 | 0.8232 | 0.7735 | 0.7368 | 0.6508 |
| AttWS-UNet | 0.7965 | 0.5514 | 0.8237 | 0.7747 | 0.7373 | 0.6482 |
| AL-UNet | 0.8125 | 0.5653 | 0.8313 | 0.7817 | 0.7459 | 0.6667 |
| ALP-UNet | 0.8208 | 0.5802 | 0.8379 | 0.7889 | 0.7464 | 0.6798 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Gao, X.; Zhang, H. Deep Learning-Based Semantic Segmentation Methods for Pavement Cracks. Information 2023, 14, 182. https://doi.org/10.3390/info14030182
Zhang Y, Gao X, Zhang H. Deep Learning-Based Semantic Segmentation Methods for Pavement Cracks. Information. 2023; 14(3):182. https://doi.org/10.3390/info14030182
Chicago/Turabian StyleZhang, Yu, Xin Gao, and Hanzhong Zhang. 2023. "Deep Learning-Based Semantic Segmentation Methods for Pavement Cracks" Information 14, no. 3: 182. https://doi.org/10.3390/info14030182