1. Introduction
With the growing development of Android applications and the plethora of services offered by mobile devices, security threats are on the rise. This trend is further exacerbated in the context of ongoing crises, including the coronavirus one, which brought along a sudden need for businesses and their employees to start or increase working from home. Indeed, as an example, a recent report from McAfee [
1] states that cyber criminals have been exploiting the global interest in the COVID-19 pandemic and vaccines by creating fake applications masquerading as official health department mobile applications.
In the mobile arena, malware is becoming the most prominent and dangerous threat that causes various security incidents, and result in a range of financial damage. Especially for devices based on the Android platform, each year, new and more sophisticated malware is being detected [
1]. In this respect, contemporary malware detection techniques, including heuristic detection and signature-based detection, are not considered sufficient anymore to detect new malicious applications [
2].
In an effort to detect and confront Android malware, various approaches have been proposed so far. In general, Android malware detection can be categorized into signature-based and anomaly-based. The latter usually employs Machine Learning (ML) to distinguish anomalies, i.e., deviations from the trained model, which are regarded as malicious behavior.
Furthermore, malware detection schemes can be classified into two main categories: static analysis and dynamic analysis. Static analysis uses syntactic features that can be extracted from each Android Package Kit (APK) file, without executing the application. This is considered a much safer and quicker process that also reduces the overall computational overhead. On the other hand, dynamic analysis requires the application to be executed on either a real device or a simulated environment, e.g., a Virtual Machine (VM). This is an important factor which makes research on this field lean towards static analysis [
3].
In this context, in order to handle the detection of sophisticated, modern mobile malware, as well as the demand for more accurate predictions, diverse techniques such as ML algorithms are brought to the foreground [
3,
4]. Specifically, ML is a sub-set of Artificial Intelligence (AI) that gains applicability in various domains, while different mobile applications were developed. Especially in security targeting mobile devices, legacy ML algorithms such as Support Vector Machine (SVM), Logistic Regression (LR), and Decision Tree (DT) have been extensively assessed, showing promising results in classifying Android malware. Overall, ML models can be used to overcome the limitations of traditional detection methods and provide superior prediction scores [
5].
More recently, several researchers have started to employ different Neural Networks (NN) for anomaly-based malware detection. Specifically, Deep Neural Networks (DNN), Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), and Feed-Forward networks (FFN) have been applied to various detection schemes with promising results.
However, applying ML techniques for predicting malware applications is generally a cumbersome process, due to various factors that influence their training and prediction accuracy, and therefore such methods call for careful and thorough exploration. The first major consideration is the quality and the quantity of the input data used for training the ML algorithms. Furthermore, it is also crucial to inspect the various ML algorithms for comparing their detection performance, which in turn will assist in finding the more suitable one for a given problem. Finally, ML hyperparameter tuning is also key to the prediction performance and may include the enabling of techniques, including early stopping classifiers, the use of different topologies and activation functions, as well as the selection of different batches and epochs [
6].
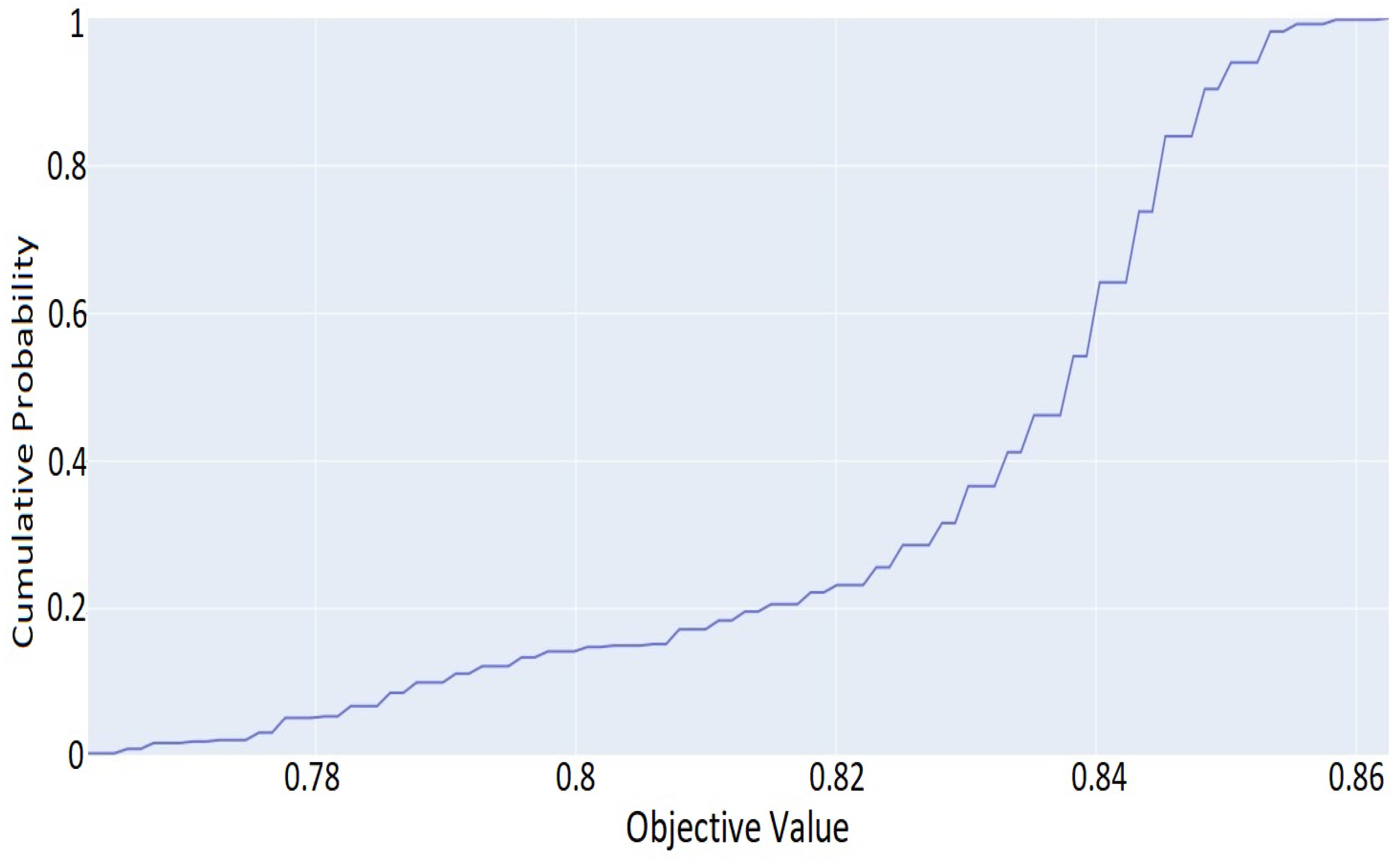
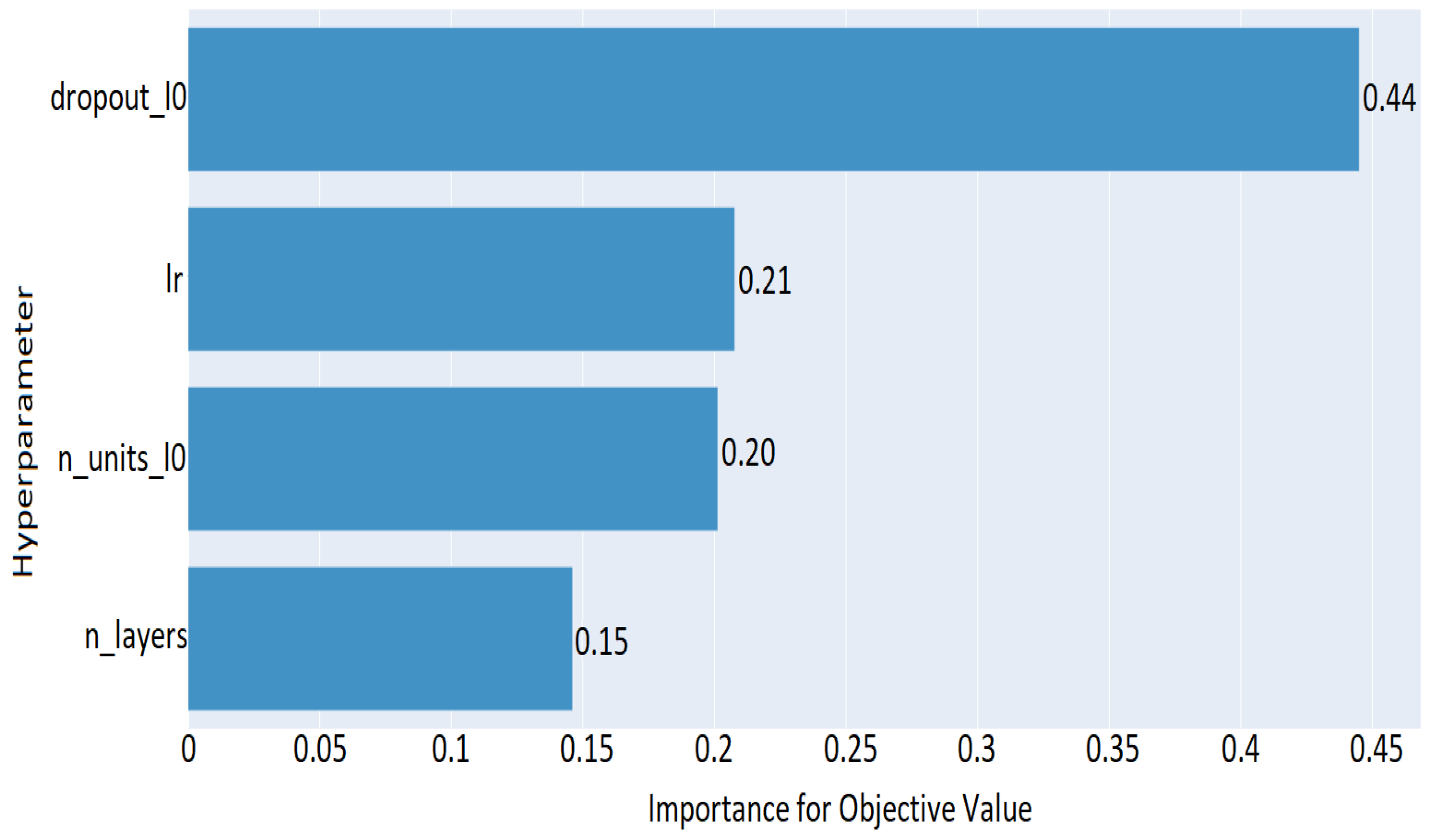
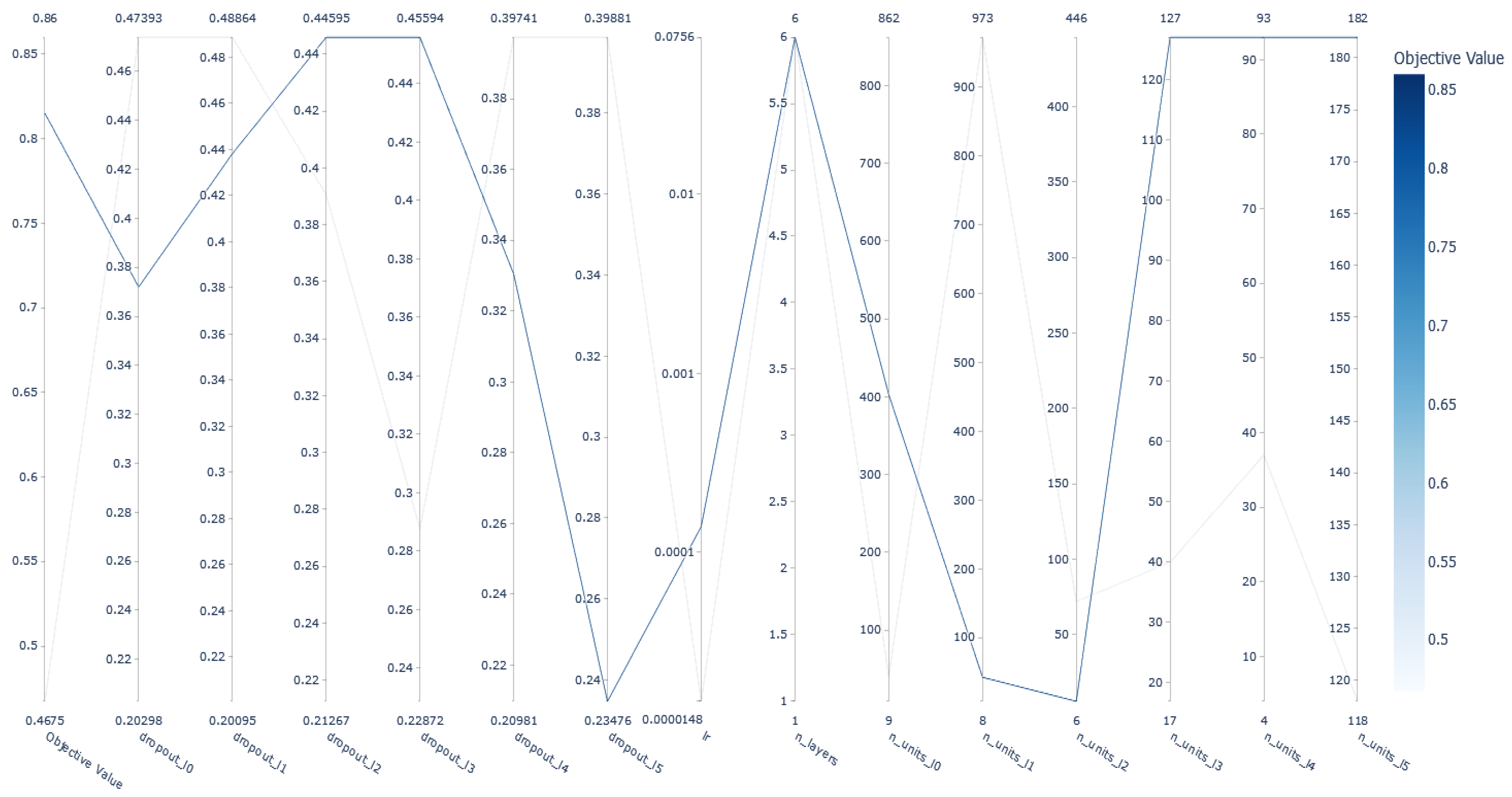
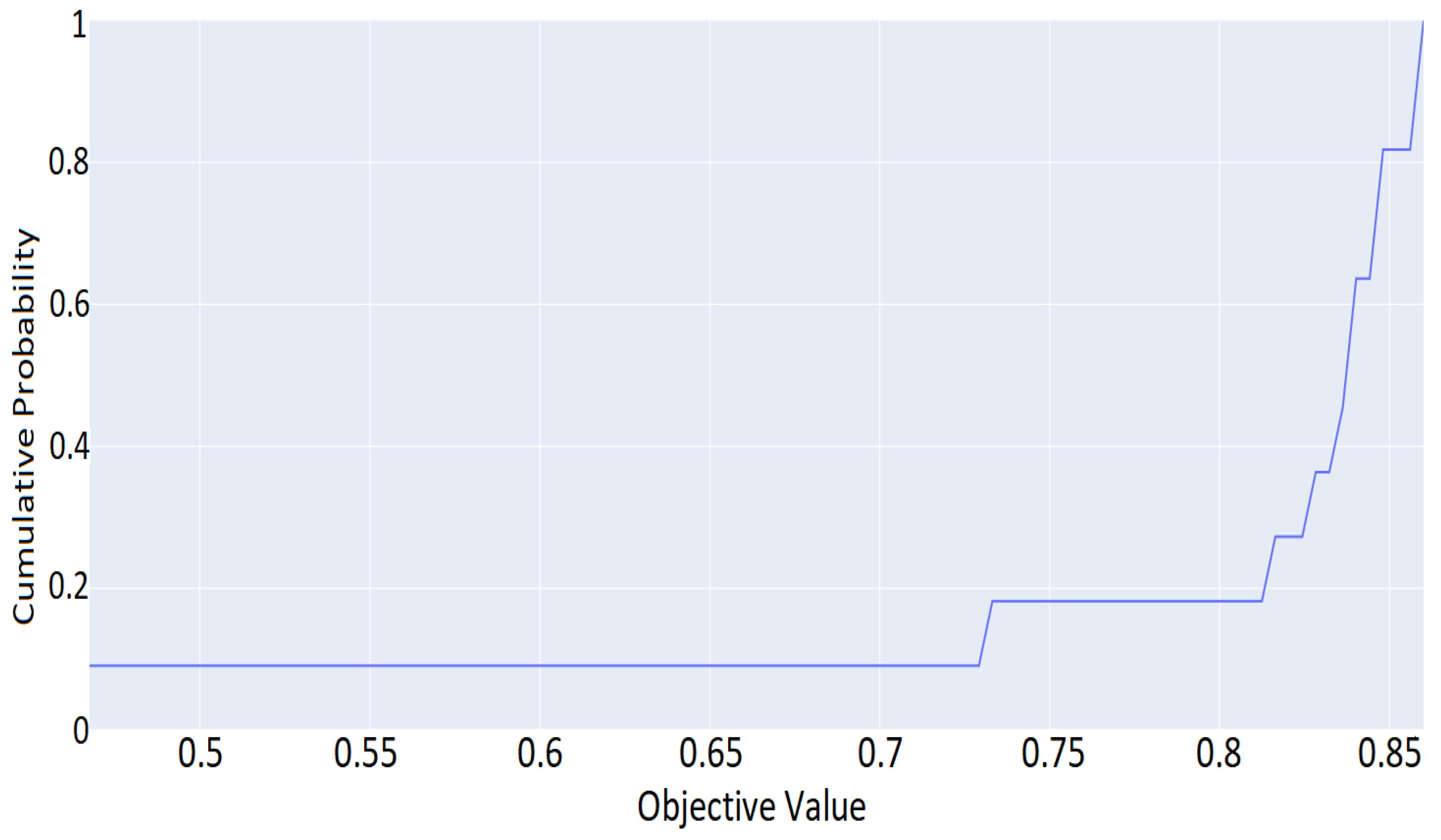
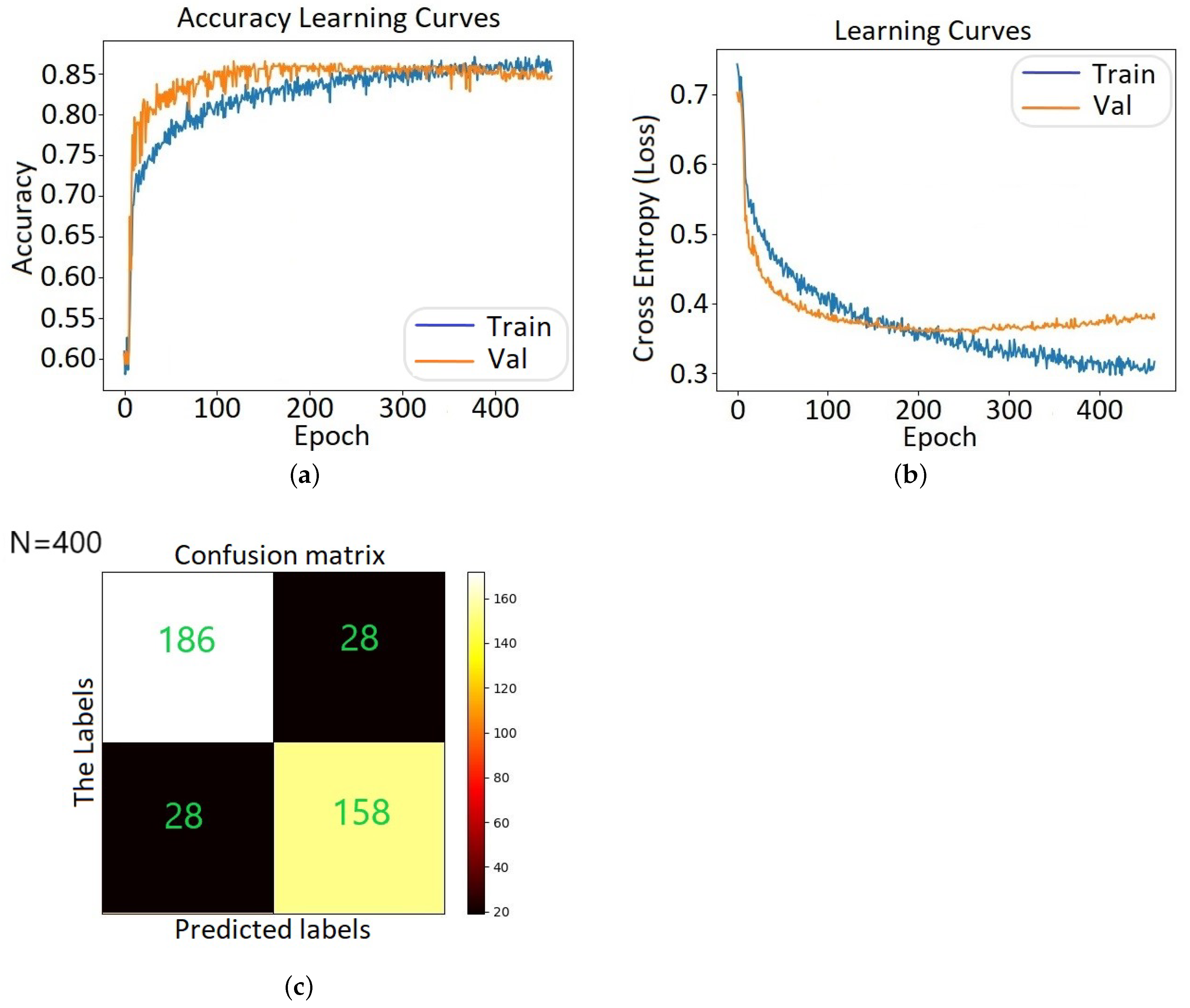
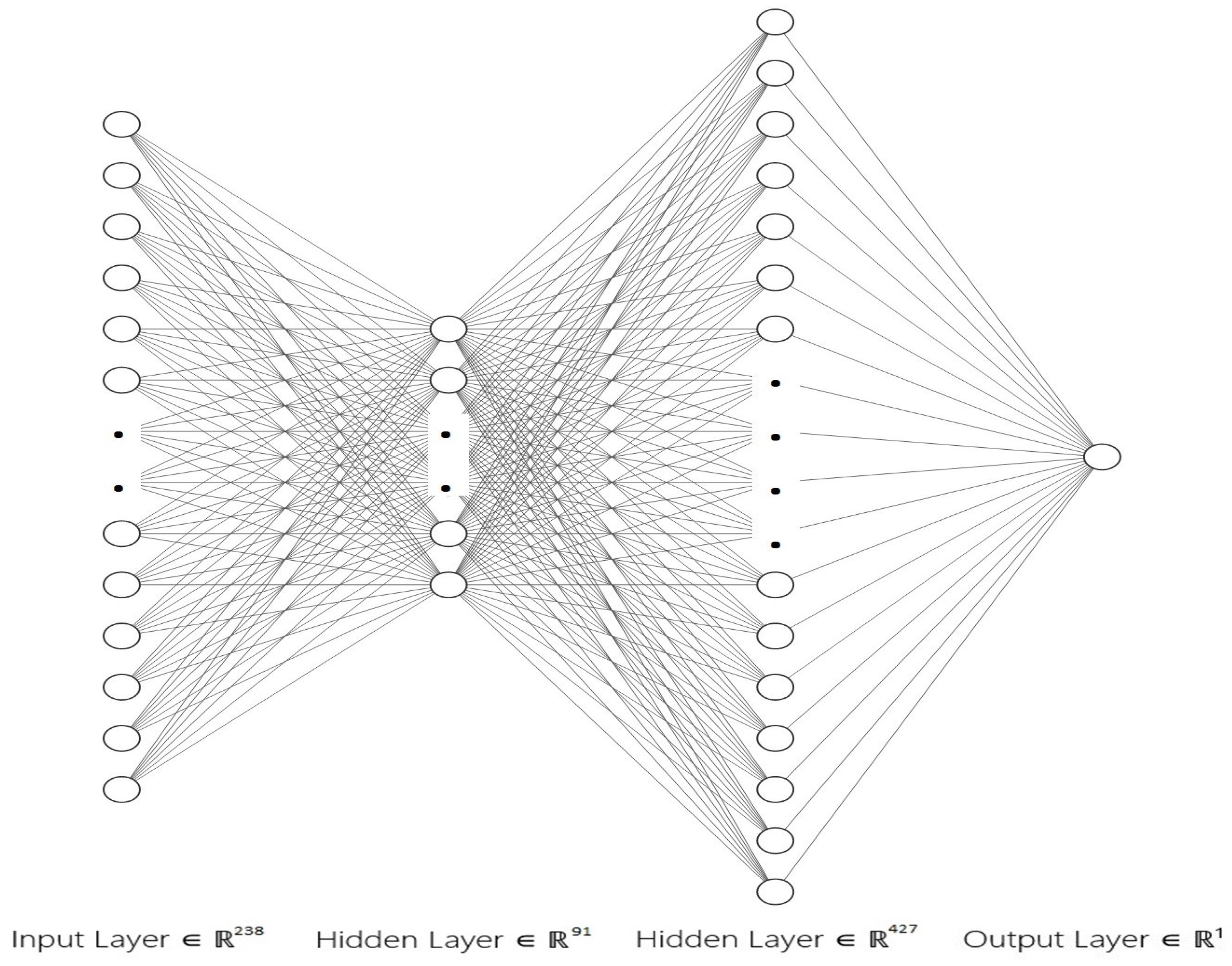
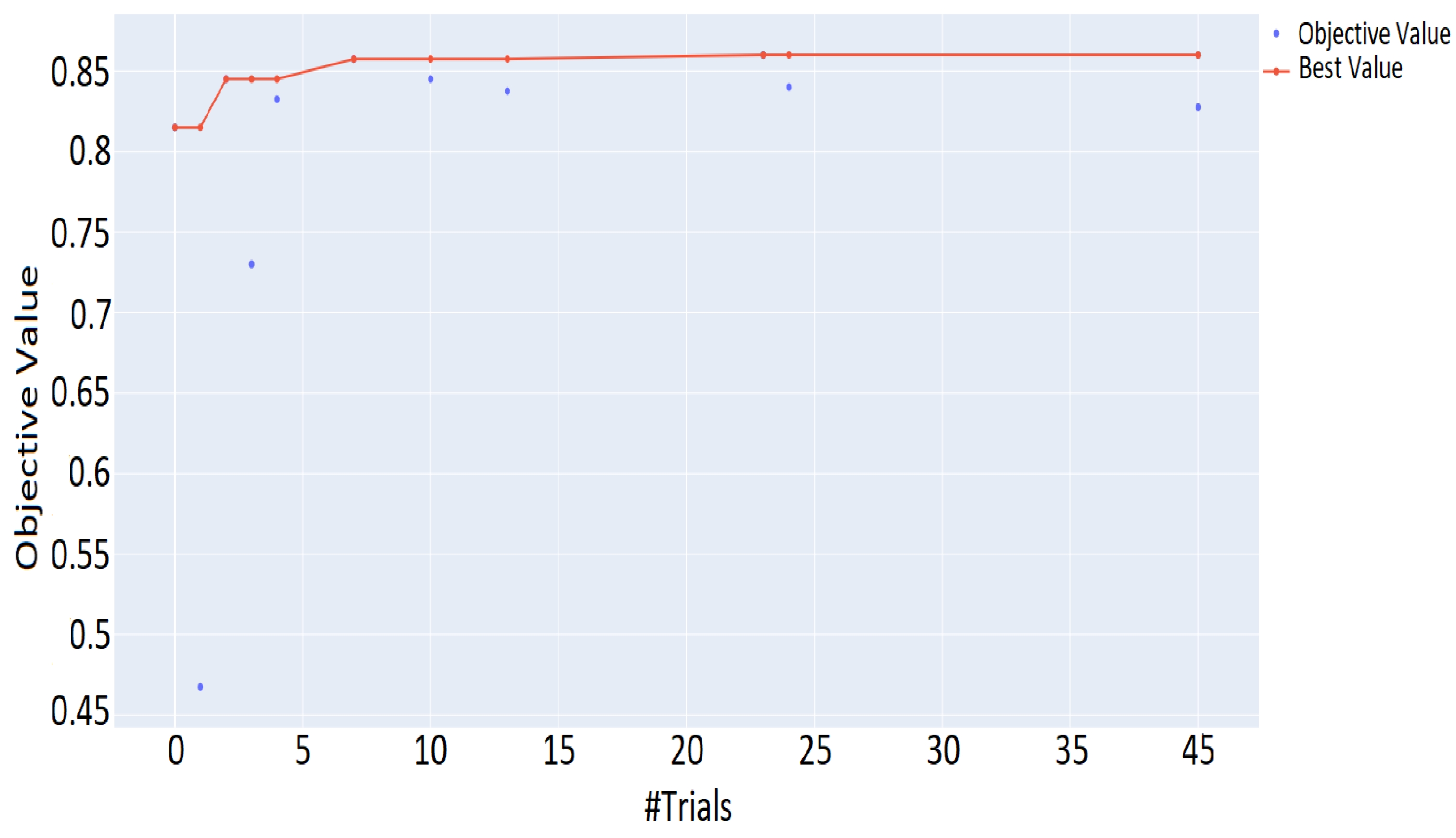
Altogether, the current work intends to investigate in a more comprehensive manner the use of ML algorithms for mobile malware detection, by applying different optimization techniques. Specifically, we explored and validated the performance of 28 different supervised and semi-supervised ML algorithms, including a DNN model, regarding their capacity in identifying Android malware. We conducted a comparative analysis in terms of prediction accuracy, and other relevant key metrics. We proceeded with a hyperparameter tuning of the selected DNN model, by using the Optuna framework, for exploring further its prediction accuracy. Last but not least, due to the existence of different input data, a side goal of the current study is to shed light on these input features that significantly affect the performance of malware prediction. Precisely, we enabled the SHAP framework for scrutinizing the ML algorithms and revealed key classification features that affect prediction performance.
To summarize, the work at hand contributes to the following goals:
A large dataset of contemporary malware is collected to extract features using static analysis;
Twenty seven different ML models were trained, using the aforementioned dataset in an effort to find the best performer;
A DNN model is tuned and optimized after conducting hyperparameters importance analysis, by using the Optuna framework on our benchmark dataset.
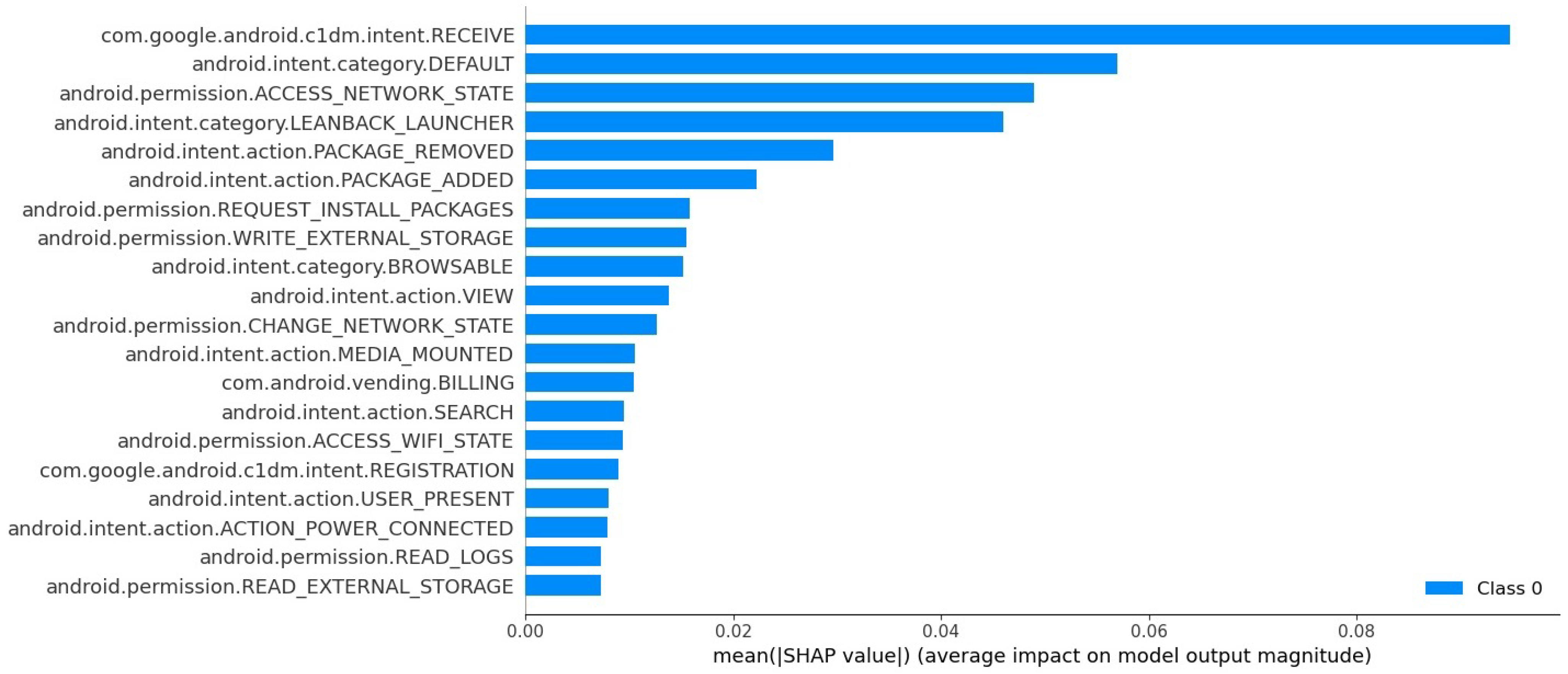
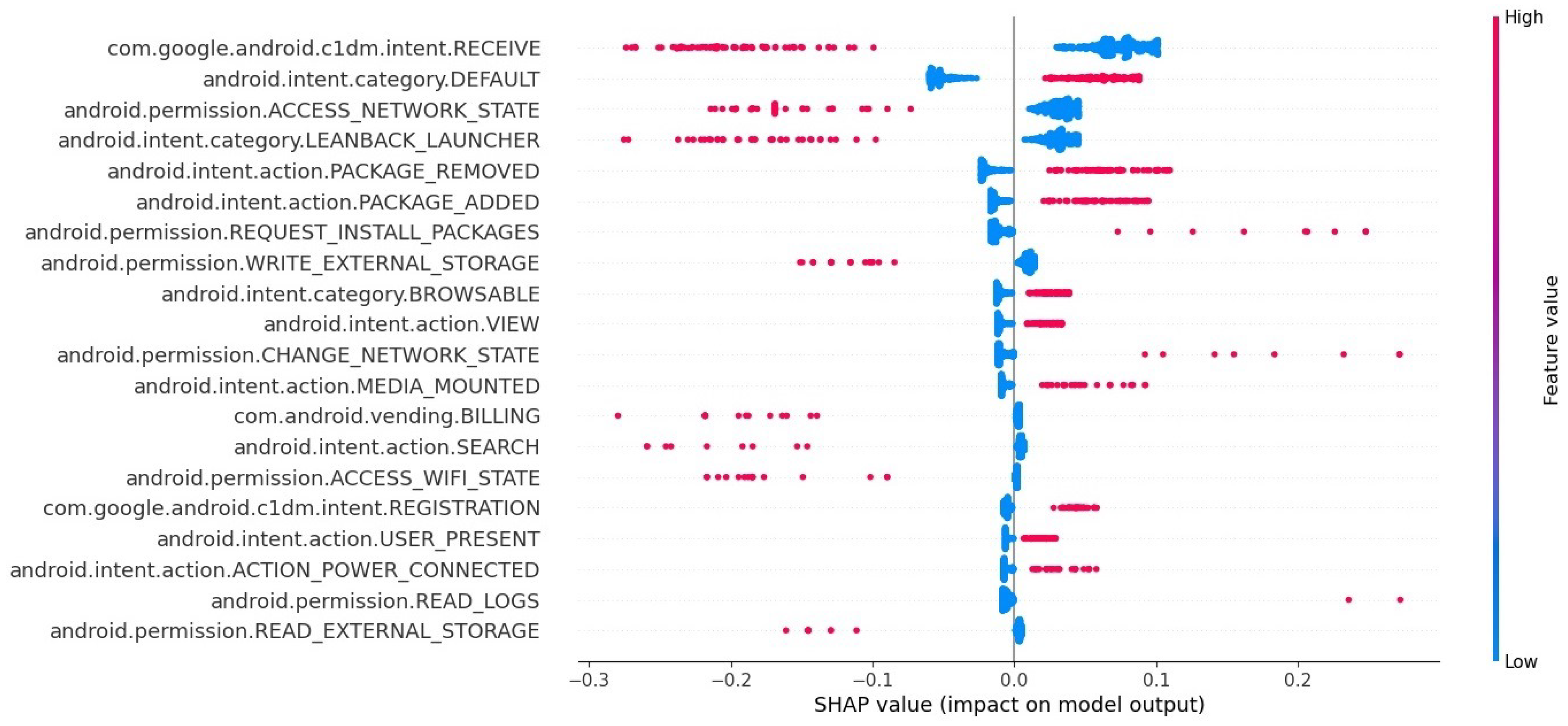
Feature importance analysis is performed using the SHAP framework on the best performing ML model to reveal the most significant classification features.
The outline of the rest of the paper is as follows: The next section focuses on the existing work on the field.
Section 3 details the methodology used to conduct this study, including the utilized dataset, the testbed, and the relevant performance metrics.
Section 4 focuses on the evaluation of 27 shallow ML models, while
Section 5 concentrates on DNN model evaluation.
Section 6 elaborates on feature importance. The final section concludes and provides future directions.
2. Related Work
As of today, several works in the literature relied on Deep Learning (DL) for malware detection in the Android platform. This section offers a chronologically ordered review of recent works on this topic. Specifically, we concentrate on studies published over the last five years, that is, from 2018 to 2022, considering only contributions that employed static analysis for feature extraction and DL for classification.
Table 1 compares our approach with the works included in this section based on five criteria, namely number of models examined and compared, optimization techniques, hyperparameter tuning, feature importance, and dataset(s) used to train the models. For the latter criterion, we consider a dataset as contemporary if it comprises malware samples not older than five years. A plus symbol designates that this subject is addressed by the respective work, while a hyphen denotes the opposite.
Dongfang et al. [
7] proposed a DL-based method for Android malware detection. The authors employed static analysis to extract features, i.e., permissions and API calls from the Drebin dataset [
8] and used them to train their models. The authors reported an accuracy of 97.16%.
Karbab et al. [
9] contributed an automatic Android malware detection framework called “MalDozer”. The latter can extract API call sequences from Android applications and detect malicious patterns using sequences of classification by employing DL techniques. The authors evaluated their scheme against a large dataset comprising Android applications from three well-known datasets, namely, MalGenome [
10], Drebin [
8], as well as their own dataset called MalDozer. Their results yielded an F1 score between 96% and 99%.
Wenjia et al. [
11] proposed a DL-based scheme for Android malware characterization and identification. The authors extracted various features from the Drebin dataset [
8], i.e., permissions, intents, IP addresses and URLs, and API calls. Different weights were given to classification feature combinations. Based on previous work, these weight-adjusted features were then used to train their model. The experimental results reported an accuracy of over 90% using 237 features.
Xu et al. [
12] presented a DL-based Android malware detection technique, which leverages both XML files and bytecode of Android applications. Firstly, DeepRefiner retrieves XML values by performing lightweight preprocessing on all XML files included in the application, to extract information about the required resources. If an application is considered suspicious, it is further analyzed by looking at the bytecode semantics, which provides comprehensive information about programming behaviors. The authors evaluated the detection performance of DeepRefiner over 62,915 malicious and 47,525 benign applications collected from the VirusShare [
13] and MassVet datasets and reported an accuracy of 97.74%.
Zegzhda et al. [
14] proposed a DL-based approach for Android malware detection, which uses a CNN to identify malicious Android applications. The authors extracted API calls from a dataset comprising 7214 benign and 24,439 malicious samples. The benign applications were collected from third-party libraries and verified using VirusTotal [
15], while malicious samples were collected from the Android Malware Dataset (AMD) [
16]. The authors evaluated their results and reported an Accuracy of 93.64%.
Zhiwu et al. [
17] proposed CDGDroid, an approach for Android malware detection based on DL. Their approach relies on the semantics graph representations, i.e., control flow graph, data flow graph, and their possible combinations, as the features to characterize an Android application as malware or benign. These graphs are then encoded into matrices, which are used to train the classification model through CNN. The authors conducted experiments using various datasets, namely Marvin [
18], Drebin [
8], VirusShare [
13], and ContagioDump, and reported an F1 score of up to 98.72%.
Kim et al. [
19] presented a framework that uses a multimodal DL method to detect Android malware applications. The proposed framework uses seven types of features stemming from static analysis, namely strings, method opcodes, API calls, shared library function opcodes, permissions, components, and environment settings. To evaluate the performance of their framework, the authors collected 41,260 applications, out of which 20K were benign. Their results showed a precision, recall, F1, and Accuracy rate of 0.98, 0.99, 0.99, and 0.98, respectively.
Masum and Shahriar [
20] proposed a DL-based framework for Android malware classification, called “Droid-NNet”. Droid-NNet’s Neural Network consists of three layers, namely input, hidden, and output. A threshold is applied to the output layer to classify the examined application as malware or benign. The input layer comprises 215 neurons, which is the number of features used during the training phase. The hidden layer contains 25 neurons, while the output layer includes only one neuron since the classification is binary. Additionally, the authors applied binary cross-entropy as a loss function and an Adaptive Moment Estimation (Adam) optimizer for calculating error and updating the relevant parameters. To train the model, the authors used the 215 static features provided by the Drebin [
8] and Malgenome [
10] datasets. Their results yielded an F-beta rate of 0.992 and 0.988, on Malgenome and Drebin datasets, respectively.
Niu et al. [
21] presented a DL-based approach for Android malware detection based on OpCode-level Function Call Graph (FCG). The FCG was obtained through static analysis of Operation Code (OpCode). The authors used the Long Short-Term Memory (LSTM) model and trained it using 1796 Android malware samples collected from the Virusshare [
13] and AndroZoo [
22] datasets, as well as 1K benign Android applications. Their experimental results showed that their approach was able to achieve an accuracy of 97%.
Pektas and Acarman [
23] contributed a malware detection method that relies on a pseudo-dynamic analysis of Android applications and constructs an API call graph for each execution path. In other words, the proposed approach focuses on information extraction related to an application’s execution paths and embedding of graphs into a low-dimensional feature vector, which is used to train a DNN. According to the authors, the trained DNN is able to detect API call graph and binary code similarities to determine whether an application is malicious or not. Finally, the DL parameters are tuned, and the Tree-structured Parzen Estimator is applied to seek the optimum parameters in the parameter hyper-plane. Their method achieved an F1 and accuracy score of 98.65% and 98.86%, respectively, on the AMD dataset [
16].
Zou et al. [
24] proposed ByteDroid, an Android malware detection scheme that analyzes Dalvik bytecode using DL. ByteDroid resizes the raw bytecode and constructs a learnable vector representation as the input to the neural network. Next, ByteDroid adopts a CNN to automatically extract the malware features and perform the classification. The authors tested their method against four datasets, namely FalDroid [
25], PRAGuard [
26], Virushare [
13], and a dataset from Kang et al. [
27], and reported a detection rate of 92.17%.
Karbab et al. [
28] proposed a DL-based Android malware detection framework called “PetaDroid”. This framework analyzes bytecode and an ensemble of CNN to detect Android malware. First, for each sample, the PetaDroid disassembles the DEX bytecode into Dalvik assembly to create sequences of canonical instructions. Additionally, the framework utilizes code-fragment randomization during the training phase to render the model more resilient to common obfuscation techniques. The authors evaluated PetaDroid against various datasets, namely MalGenome, Drebin, MalDozer, AMD, and VirusShare. PetaDroid achieved an F1 score of 98% to 99%, under different evaluation settings with high homogeneity in the produced clusters (96%).
Millar et al. [
29] contributed a DL-based Android malware detector with a CNN-based approach for analyzing API call sequences. Their approach employs static analysis to extract opcodes, permissions, and API calls from each Android application. The authors carried out various experiments, including hyper-parameter tuning for the opcodes CNN and the APIs CNN and zero-day malware detection. The proposed model achieved an F1 score of 99.2% and 99.6% using the Drebin and AMD datasets, respectively. Additionally, the authors reported an 81% and 91% detection rate during the zero-day experiments on the AMD and Drebin datasets, respectively.
Vu et al. [
30] contributed an approach that trains a CNN to classify mobile malware. In addition, their approach converts an application’s source code, i.e., API calls extracted from APK files, into a two-dimensional adjacency matrix, to improve classification performance. According to the authors, their approach allows better feature embedding than when using feature vectors, and can achieve comparable performance to call-graph analysis. The authors trained their model using samples from the Drebin and AMD datasets, and achieved a detection and classification rate of 98.26% and over 97%, respectively.
Zhang et al. [
31] proposed “TC-Droid”, an automatic Android malware detection framework that employs text classification. Precisely, TC-Droid feeds on the text sequence of APIs analysis reports, generated by AndroPyTool and uses CNN to gather significant information. Specifically, TC-Droid analyzes four types of static features, i.e., permissions, services, intents, and receivers. The authors evaluated their framework using malware samples from ContagioDump and MalGenome datasets and reported an accuracy of 96.6%.
Yumlembam et al. [
32] proposed the use of a Graph Neural Networks (GNN) based classifier to generate an API graph embedding fed by permissions and intents to train multiple ML and DL algorithms for Android malware detection. Their approach achieved an accuracy of 98.33% and 98.68% with the CICMaldroid2020 [
33] and Drebin datasets, respectively.
Musikawan et al. [
34] introduced a DL-based Android malware classifier, in which the predictive output of each of the hidden layers given by a base classifier is combined via a meta-classifier to produce the final prediction. The authors tested their approach on two dynamic and one static datasets. On the static dataset, i.e., CICMalDroid2020 [
33], their approach achieved an F1 score of 98.1%.
Table 1.
Overview of the related work. A plus sign denotes that the respective work addresses the criterion of the corresponding column. The figures in the third column denote the number of ML models examined by each study. A dash in the same column means that the respective work did not make a comparison between two or more different models.
| Work | Year | Models Compared | Model Optimization | Hyperparameters Tuning | Feature Importance | Contemporary Dataset |
|---|
| [7] | 2018 | - | - | - | - | - |
| [9] | 2018 | - | - | - | - | - |
| [11] | 2018 | - | - | - | - | - |
| [12] | 2018 | - | - | - | - | - |
| [14] | 2018 | - | - | - | - | - |
| [17] | 2018 | - | - | - | - | - |
| [19] | 2019 | - | - | - | - | - |
| [20] | 2020 | - | - | - | - | - |
| [21] | 2020 | 8 | - | - | - | + |
| [23] | 2020 | - | - | + | - | - |
| [24] | 2020 | - | - | + | - | - |
| [28] | 2021 | - | - | + | - | - |
| [29] | 2021 | - | - | + | - | - |
| [30] | 2021 | - | - | - | + | - |
| [31] | 2021 | - | - | - | - | - |
| [32] | 2022 | 12 | + | + | + | + |
| [34] | 2022 | - | + | + | + | + |
| This work | 2022 | 27 | + | + | + | + |
As observed from
Table 1, the relevant recent work on this topic falls short of providing an adequate, full-fledged view of Android malware detection through ML techniques. That is, from the third column of the Table, it is obvious that the great majority of works rely only on a single ML model. In this respect, the current study sees the problem from multiple viewpoints, namely by examining and comparing the detection performance of diverse ML models, both shallow and DL. On top of that, the provided analysis includes hyperparameter tuning and feature importance evaluation. In this regard, the methodology and outcomes of this work can serve as a guide and reference point for future research in this rapidly evolving field.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













