
Risky Maritime Encounter Patterns via Clustering

Abstract
:1. Introduction
2. Problem Statement and Application Area
2.1. Problem Statement
- With respect to varying degrees of risk, how can the patterns for risky encounters be discovered and validated through model variables?
- Is it possible to detect vessel size and vessel speed as risky encounter parameters in predicting potential near–miss situations?
- Can the grey zones between risk/non-risky encounters be identified?
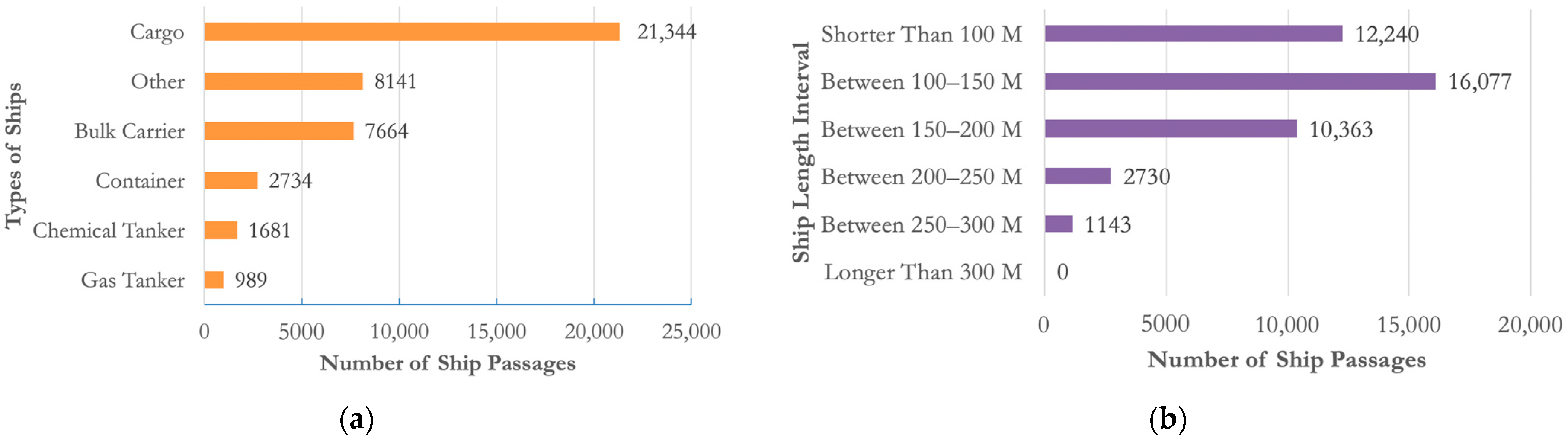
2.2. Application Area
3. Conceptual Basis
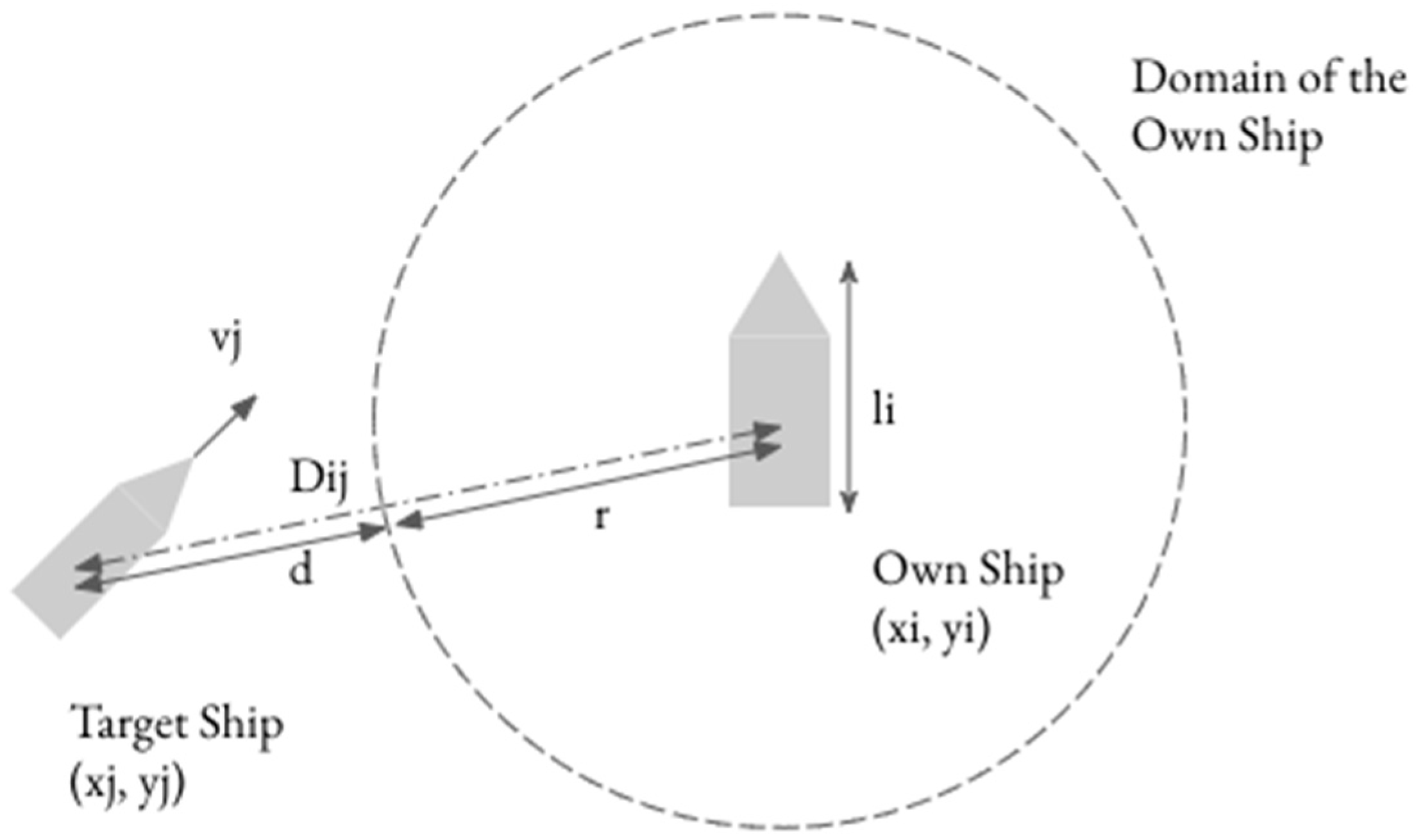
3.1. Ship Domain Violation
3.2. Model Variables
4. Materials and Methods
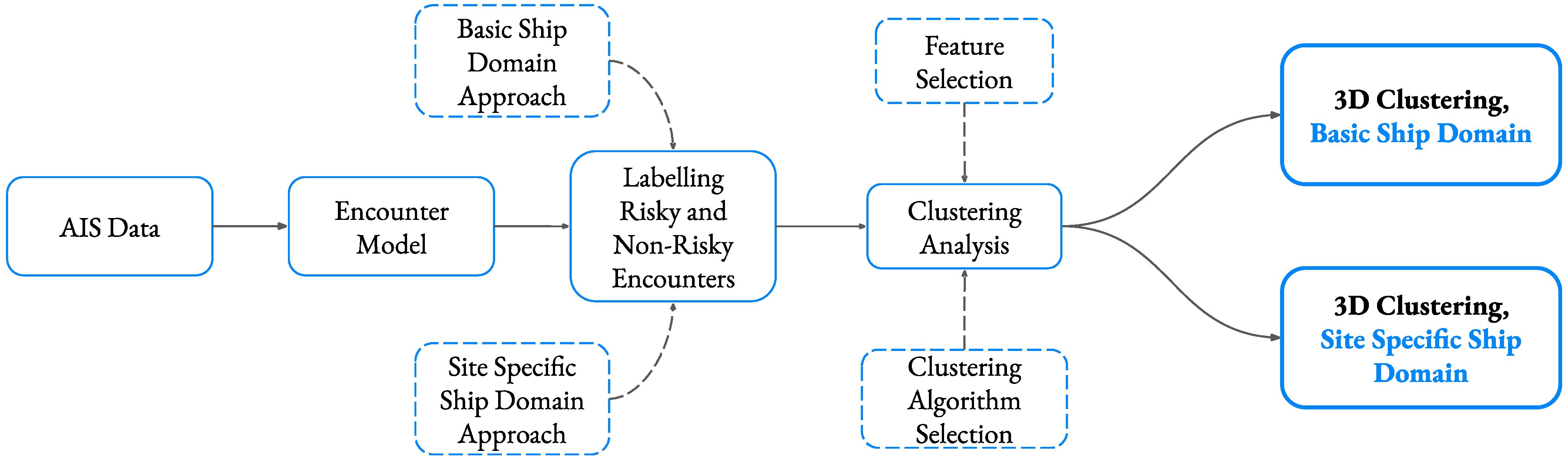
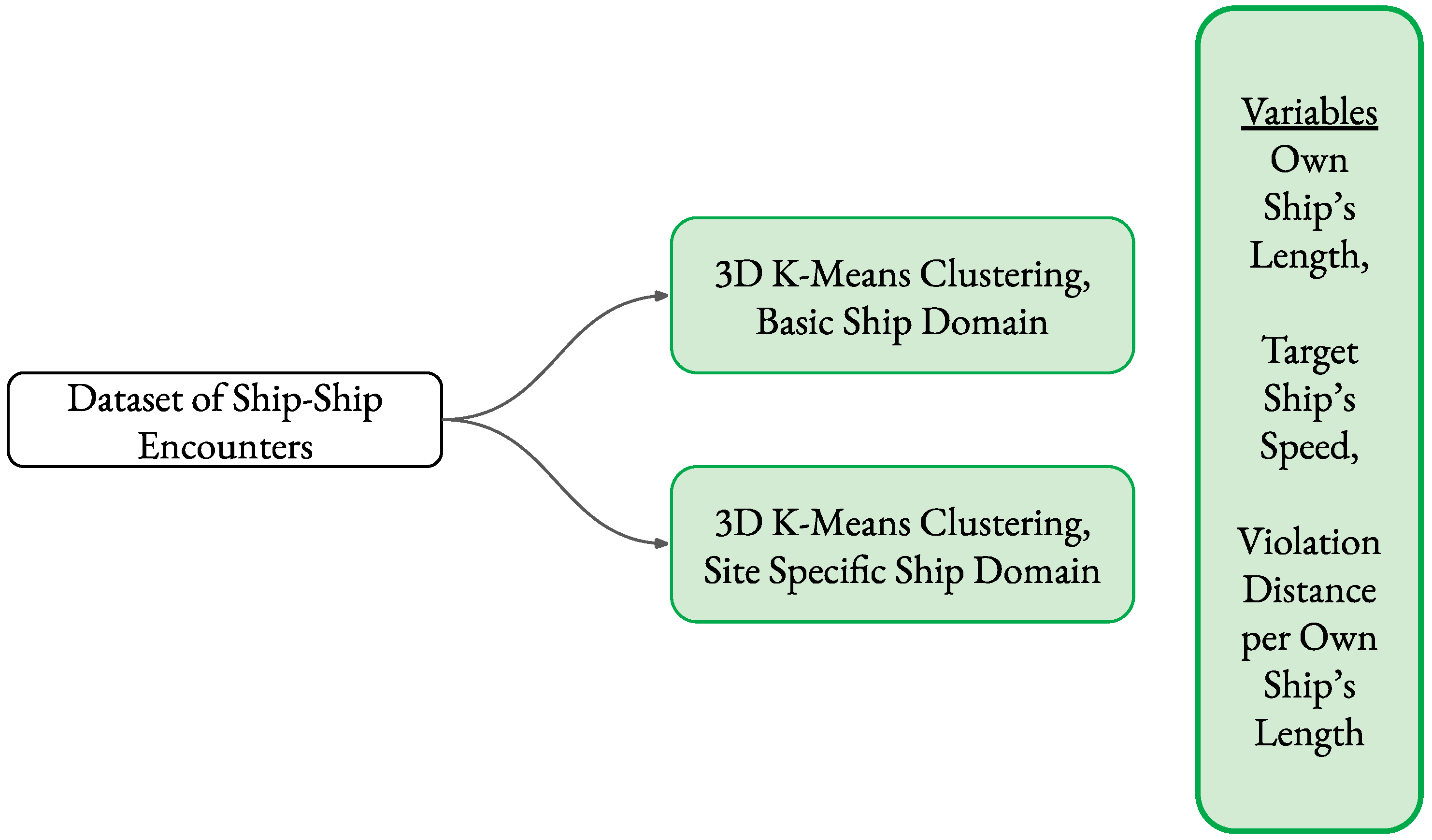
4.1. Framework of the Procedure
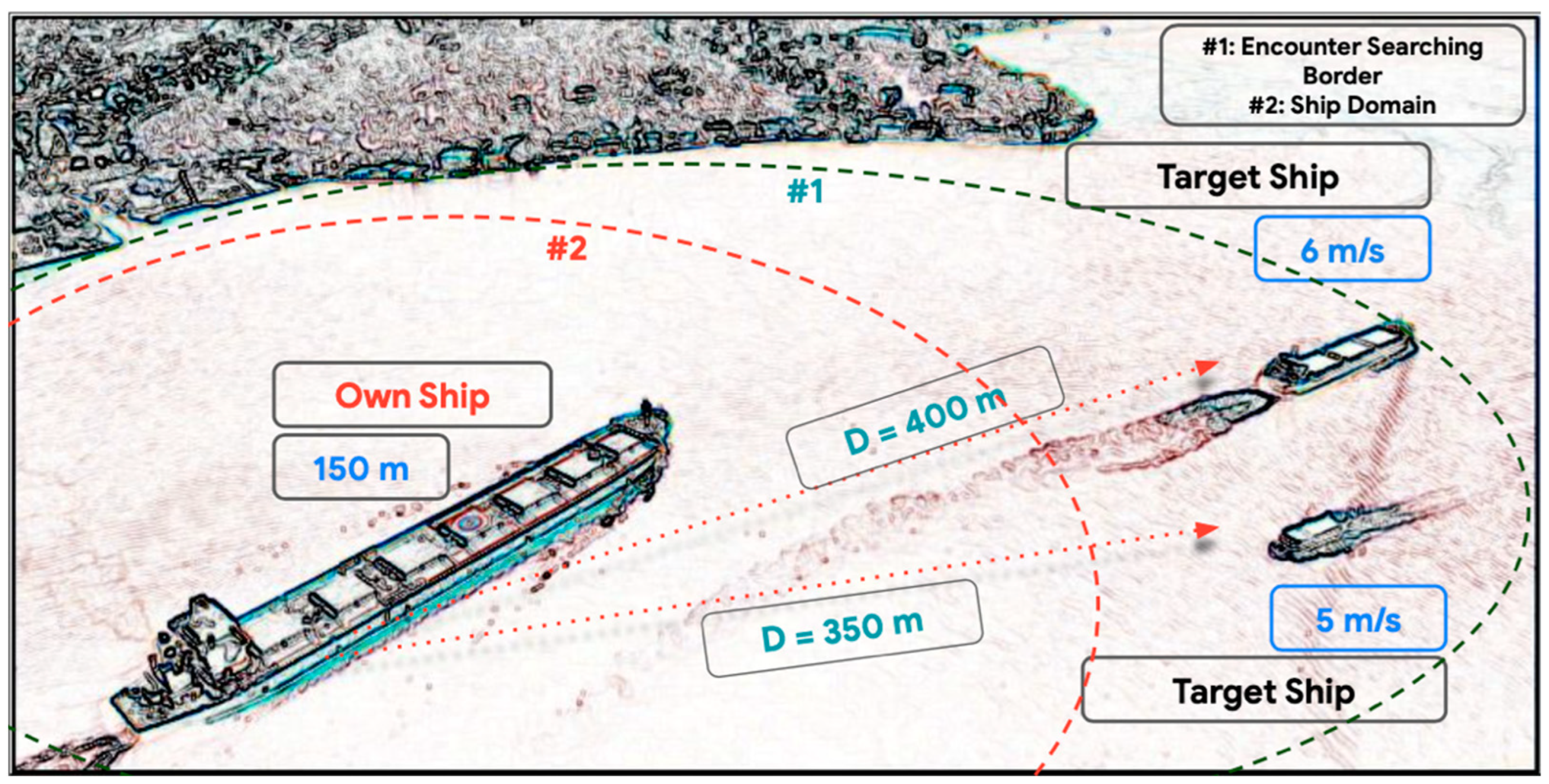
4.2. Encounter Model
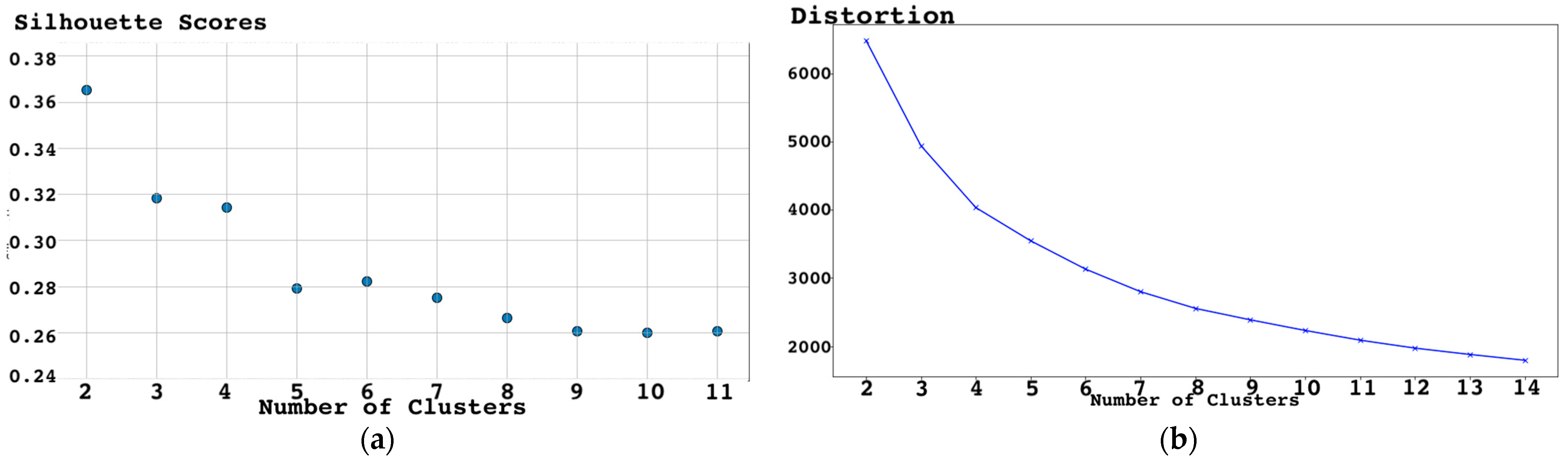
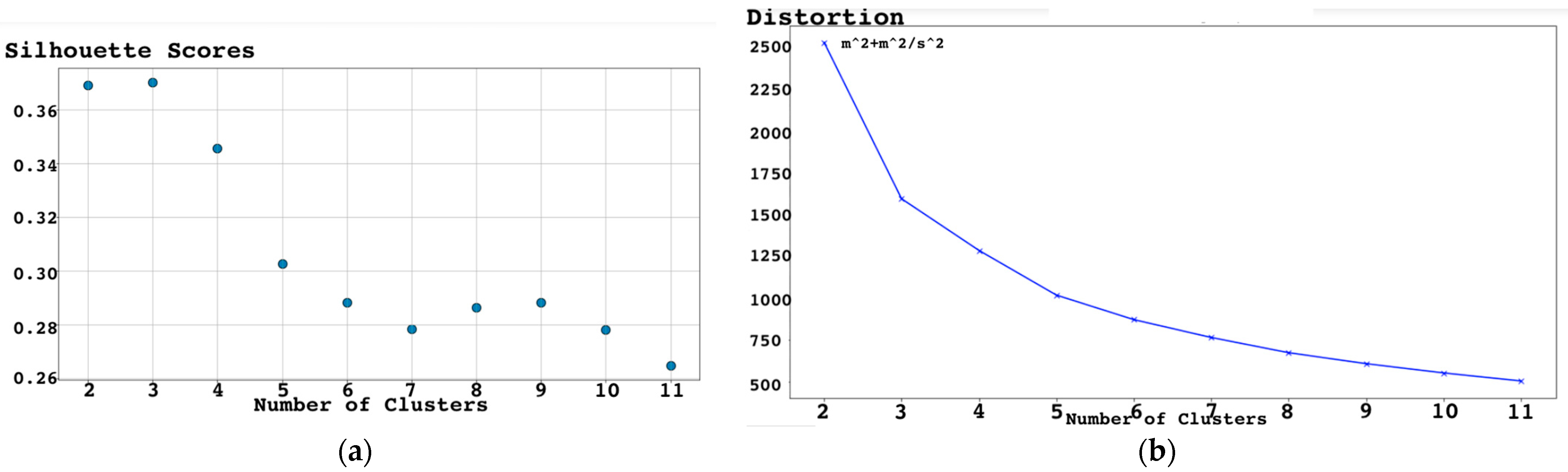
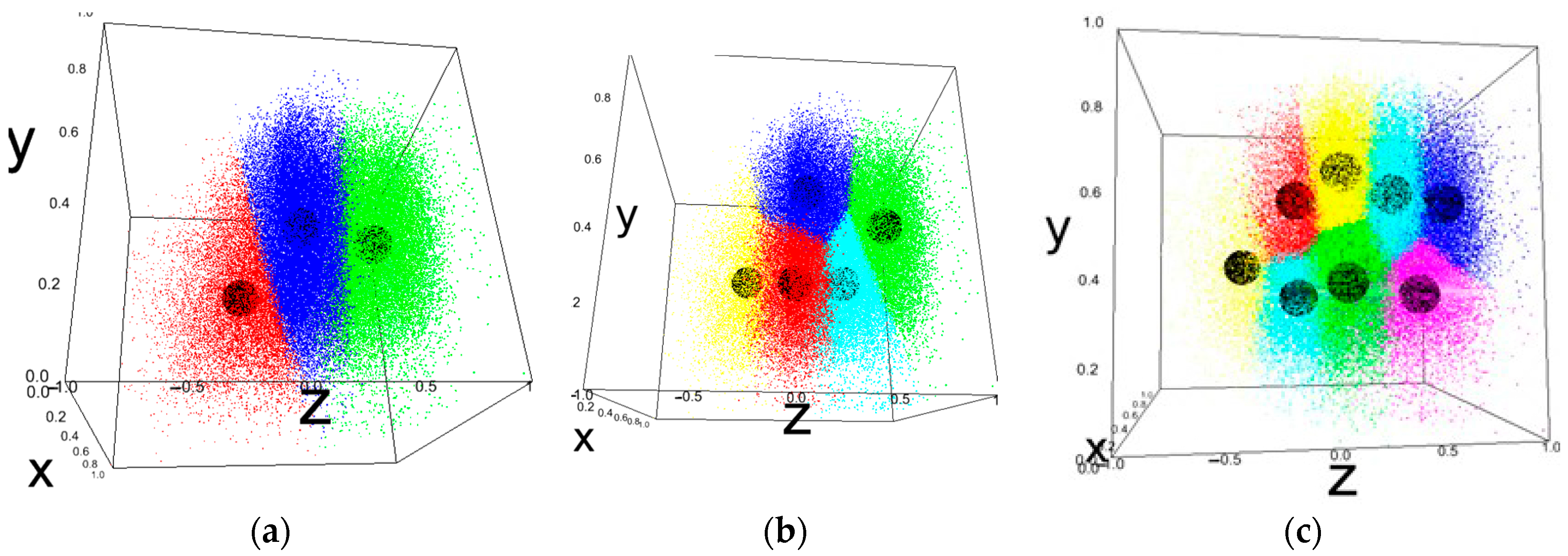
4.3. Clustering Model
5. Results and Discussion
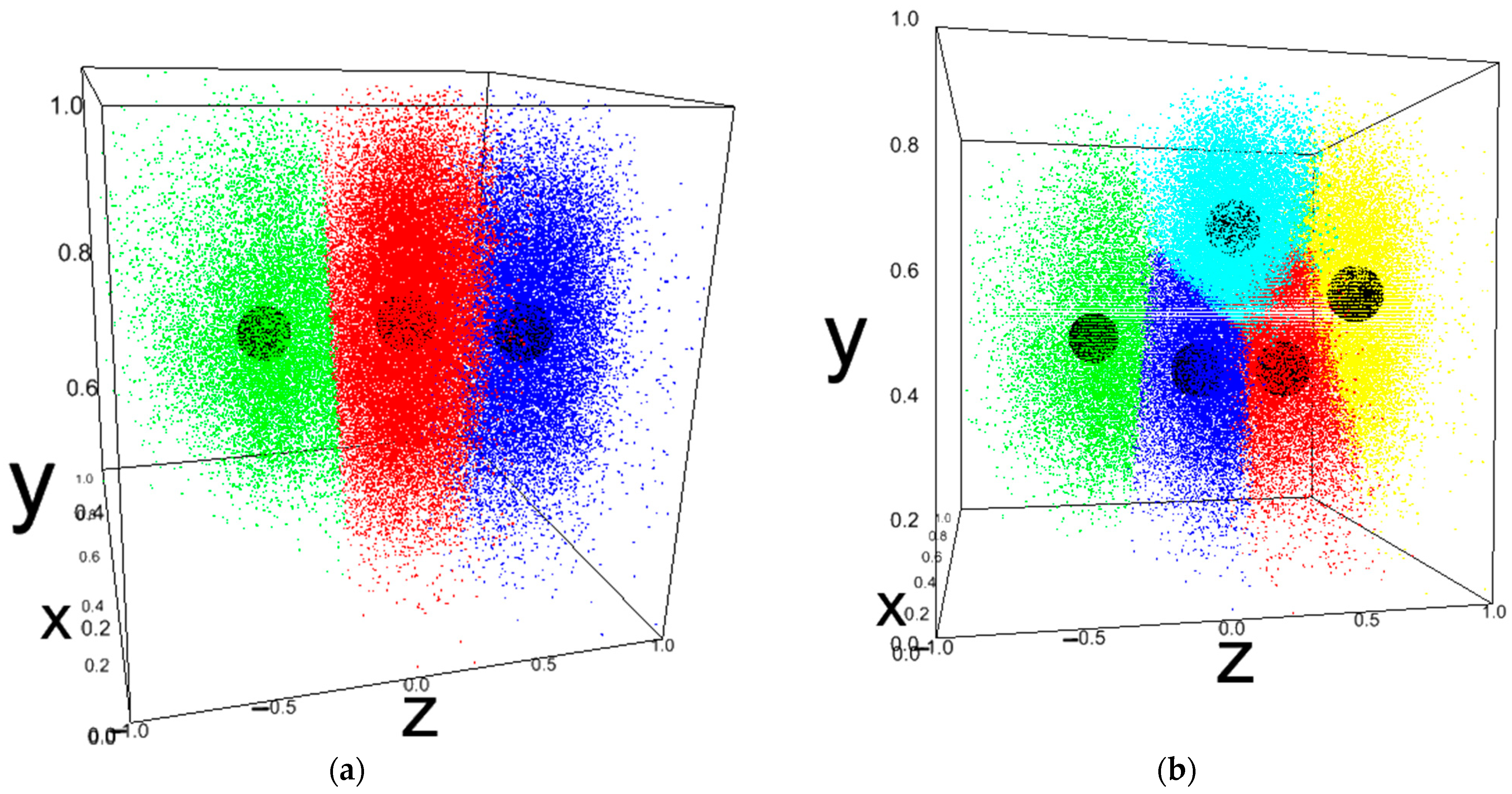
- x = Own Ship’s Length, Scaled (0 to 1)
- y = Target Ship’s Speed, Scaled (0 to 1)
- z = Violation Distance per Own Ship’s Length (V.D.P.O.S.L.), Scaled (−1 to 1)
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wan, Z.; Chen, J.; El Makhloufi, A.; Sperling, D.; Chen, Y. Four routes to better maritime governance. Nature 2016, 540, 27–29. [Google Scholar] [CrossRef]
- Goerlandt, F.; Goite, H.; Banda, O.A.V.; Höglund, A.; Ahonen-Rainio, P.; Lensu, M. An analysis of wintertime navigational accidents in the Northern Baltic Sea. Saf. Sci. 2017, 92, 66–84. [Google Scholar] [CrossRef]
- Qu, X.; Meng, Q.; Suyi, L. Ship collision risk assessment for the Singapore Strait. Accid. Anal. Prev. 2011, 43, 2030–2036. [Google Scholar] [CrossRef]
- Montewka, J.; Hinz, T.; Kujala, P.; Matusiak, J. Probability modelling of vessel collisions. Reliab. Eng. Syst. Saf. 2010, 95, 573–589. [Google Scholar] [CrossRef]
- Kujala, P.; Hänninen, M.; Arola, T.; Ylitalo, J. Analysis of the marine traffic safety in the Gulf of Finland. Reliab. Eng. Syst. Saf. 2009, 94, 1349–1357. [Google Scholar] [CrossRef]
- Mostafa, M.M. Forecasting the Suez Canal traffic: A neural network analysis. Marit. Policy Manag. 2004, 31, 139–156. [Google Scholar] [CrossRef]
- Wu, X.; Mehta, A.L.; Zaloom, V.A.; Craig, B.N. Analysis of waterway transportation in Southeast Texas waterway based on AIS data. Ocean Eng. 2016, 121, 196–209. [Google Scholar] [CrossRef]
- Mazaheri, A.; Montewka, J.; Kujala, P. Modeling the risk of ship grounding—A literature review from a risk management perspective. WMU J. Marit. Aff. 2013, 13, 269–297. [Google Scholar] [CrossRef]
- Kum, S.; Sahin, B. A root cause analysis for Arctic Marine accidents from 1993 to 2011. Saf. Sci. 2015, 74, 206–220. [Google Scholar] [CrossRef]
- Pallotta, G.; Vespe, M.; Bryan, K. Vessel Pattern Knowledge Discovery from AIS Data: A Framework for Anomaly Detection and Route Prediction. Entropy 2013, 15, 2218–2245. [Google Scholar] [CrossRef]
- Otay, E.N.; Özkan, Ş. Stochastic Prediction of Maritime Accidents in the strait of Istanbul. In Proceedings of the 3rd International Conference on Oil Spills in the Mediterranean and Black SEA Regions, Istanbul, Turkey, 31 October–3 November 2003; pp. 92–104. [Google Scholar]
- Merrick, J.R.W.; van Dorp, J.R.; Mazzuchi, T.; Harrald, J.R.; Spahn, J.E.; Grabowski, M. The Prince William Sound Risk Assessment. INFORMS J. Appl. Anal. 2002, 32, 25–40. [Google Scholar] [CrossRef]
- Chen, P.; Huang, Y.; Mou, J.; van Gelder, P. Ship collision candidate detection method: A velocity obstacle approach. Ocean Eng. 2018, 170, 186–198. [Google Scholar] [CrossRef]
- Tu, E.; Zhang, G.; Rachmawati, L.; Rajabally, E.; Huang, G.-B. Exploiting AIS Data for Intelligent Maritime Navigation: A Comprehensive Survey From Data to Methodology. IEEE Trans. Intell. Transp. Syst. 2017, 19, 1559–1582. [Google Scholar] [CrossRef]
- Du, L.; Goerlandt, F.; Kujala, P. Review and analysis of methods for assessing maritime waterway risk based on non-accident critical events detected from AIS data. Reliab. Eng. Syst. Saf. 2020, 200, 106933. [Google Scholar] [CrossRef]
- Debnath, A.K.; Chin, H.C. Navigational Traffic Conflict Technique: A Proactive Approach to Quantitative Measurement of Collision Risks in Port Waters. J. Navig. 2009, 63, 137–152. [Google Scholar] [CrossRef]
- Zhang, W.; Goerlandt, F.; Kujala, P.; Wang, Y. An advanced method for detecting possible near miss ship collisions from AIS data. Ocean Eng. 2016, 124, 141–156. [Google Scholar] [CrossRef]
- Debnath, A.; Chin, H.C. Analysis of marine conflicts. In Proceedings of the 19th KKCNN Symposium on Civil Engineering, Kyoto, Japan, 10–12 December 2006. [Google Scholar]
- Zhang, W.; Goerlandt, F.; Montewka, J.; Kujala, P. A method for detecting possible near miss ship collisions from AIS data. Ocean Eng. 2015, 107, 60–69. [Google Scholar] [CrossRef]
- Zhang, W.; Feng, X.; Goerlandt, F.; Liu, Q. Towards a Convolutional Neural Network model for classifying regional ship collision risk levels for waterway risk analysis. Reliab. Eng. Syst. Saf. 2020, 204, 107127. [Google Scholar] [CrossRef]
- Rong, H.; Teixeira, A.; Soares, C.G. Spatial correlation analysis of near ship collision hotspots with local maritime traffic characteristics. Reliab. Eng. Syst. Saf. 2021, 209, 107463. [Google Scholar] [CrossRef]
- Watawana, T.; Caldera, A. Analyse Near Collision Situations of Ships Using Automatic Identification System Dataset. In Proceedings of the 2018 5th International Conference on Soft Computing & Machine Intelligence (ISCMI), Nairobi, Kenya, 21–22 November 2018; pp. 155–162. [Google Scholar] [CrossRef]
- Li, Y.-P.; Liu, Z.-J.; Kai, J.S. Study on complexity model and clustering method of ship to ship encoun-tering risk. J. Mar. Sci. Technol. 2019, 27, 153–160. [Google Scholar] [CrossRef]
- Szlapczynski, R.; Szlapczynska, J. A ship domain-based model of collision risk for near-miss detection and Collision Alert Systems. Reliab. Eng. Syst. Saf. 2021, 214, 107766. [Google Scholar] [CrossRef]
- Rawson, A.; Brito, M. A critique of the use of domain analysis for spatial collision risk assessment. Ocean Eng. 2020, 219, 108259. [Google Scholar] [CrossRef]
- Öztürk, Ü.; Boz, H.A.; Balcisoy, S. Visual analytic based ship collision probability modeling for ship navigation safety. Expert Syst. Appl. 2021, 175, 114755. [CrossRef]
- Du, L.; Banda, O.A.V.; Goerlandt, F.; Huang, Y.; Kujala, P. A COLREG-compliant ship collision alert system for stand-on vessels. Ocean Eng. 2020, 218, 107866. [Google Scholar] [CrossRef]
- Goerlandt, F.; Kujala, P. On the reliability and validity of ship–ship collision risk analysis in light of different perspectives on risk. Saf. Sci. 2014, 62, 348–365. [Google Scholar] [CrossRef]
- Weng, J.; Liao, S.; Wu, B.; Yang, D. Exploring effects of ship traffic characteristics and environmental conditions on ship collision frequency. Marit. Policy Manag. 2020, 47, 523–543. [Google Scholar] [CrossRef]
- Fang, Z.; Yu, H.; Ke, R.; Shaw, S.-L.; Peng, G. Automatic Identification System-Based Approach for Assessing the Near-Miss Collision Risk Dynamics of Ships in Ports. IEEE Trans. Intell. Transp. Syst. 2019, 20, 534–543. [Google Scholar] [CrossRef]
- Debnath, A.K.; Chin, H.C. Modelling Collision Potentials in Port Anchorages: Application of the Navigational Traffic Conflict Technique (NTCT). J. Navig. 2015, 69, 183–196. [Google Scholar] [CrossRef]
- Liu, K.; Yuan, Z.; Xin, X.; Zhang, J.; Wang, W. Conflict detection method based on dynamic ship domain model for visualization of collision risk Hot-Spots. Ocean Eng. 2021, 242, 110143. [Google Scholar] [CrossRef]
- Feng, H.; Grifoll, M.; Yang, Z.; Zheng, P. Collision risk assessment for ships’ routeing waters: An information entropy approach with Automatic Identification System (AIS) data. Ocean Coast. Manag. 2022, 224, 106184. [Google Scholar] [CrossRef]
- Zhou, Y.; Daamen, W.; Vellinga, T.; Hoogendoorn, S.P. Ship classification based on ship behavior clustering from AIS data. Ocean Eng. 2019, 175, 176–187. [Google Scholar] [CrossRef]
- Wang, J.; Zhu, C.; Zhou, Y.; Zhang, W. Vessel Spatio-temporal Knowledge Discovery with AIS Trajectories Using Co-clustering. J. Navig. 2017, 70, 1383–1400. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, Y.; Zhang, C. Data mining approach for automatic ship-route design for coastal seas using AIS trajectory clustering analysis. Ocean Eng. 2021, 236, 109535. [Google Scholar] [CrossRef]
- Mieczyńska, M.; Czarnowski, I. K-means clustering for SAT-AIS data analysis. WMU J. Marit. Aff. 2021, 20, 377–400. [Google Scholar] [CrossRef]
- Park, J.; Jeong, J.-S. An Estimation of Ship Collision Risk Based on Relevance Vector Machine. J. Mar. Sci. Eng. 2021, 9, 538. [Google Scholar] [CrossRef]
- Rawson, A.; Brito, M. A survey of the opportunities and challenges of supervised machine learning in maritime risk analysis. Transp. Rev. 2022, 43, 108–130. [Google Scholar] [CrossRef]
- Altan, Y.C.; Otay, E.N. Maritime Traffic Analysis of the Strait of Istanbul based on AIS data. J. Navig. 2017, 70, 1367–1382. [Google Scholar] [CrossRef]
- Ożoga, B.; Montewka, J. Towards a decision support system for maritime navigation on heavily trafficked basins. Ocean Eng. 2018, 159, 88–97. [Google Scholar] [CrossRef]
- Fujii, Y.; Tanaka, K. Traffic Capacity. J. Navig. 1971, 24, 543–552. [Google Scholar] [CrossRef]
- Weng, J.; Meng, Q.; Qu, X. Vessel Collision Frequency Estimation in the Singapore Strait. J. Navig. 2012, 65, 207–221. [Google Scholar] [CrossRef]
- Hansen, M.G.; Jensen, T.K.; Lehn-Schiøler, T.; Melchild, K.; Rasmussen, F.M.; Ennemark, F. Empirical Ship Domain based on AIS Data. J. Navig. 2013, 66, 931–940. [Google Scholar] [CrossRef]
- Altan, Y.C.; Meijers, B.M. Ship Domain Variations in the Strait of Istanbul. In Proceedings of the WCTRS SIGA2 2021 Conference, Antwerp, Belgium, 5–7 May 2021. [Google Scholar]
- Degré, T.; Lefèvre, X. A Collision Avoidance System. J. Navig. 1981, 34, 294–302. [Google Scholar] [CrossRef]
- Lenart, A.S. Collision Threat Parameters for a new Radar Display and Plot Technique. J. Navig. 1983, 36, 404–410. [Google Scholar] [CrossRef]
- Kuwata, Y.; Wolf, M.T.; Zarzhitsky, D.; Huntsberger, T.L. Safe Maritime Navigation with COLREGS Using Velocity Obstacles; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2011; pp. 4728–4734. [Google Scholar] [CrossRef]
- Mou, J.M.; van der Tak, C.; Ligteringen, H. Study on collision avoidance in busy waterways by using AIS data. Ocean Eng. 2010, 37, 483–490. [Google Scholar] [CrossRef]
- Szlapczynski, R.; Szlapczynska, J. Review of ship safety domains: Models and applications. Ocean Eng. 2017, 145, 277–289. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R.; Springer: New York, NY, USA, 2013; p. 426. ISBN 978-1-4614-7137-0. [Google Scholar] [CrossRef]
- Barlow, H.; Laboratory, P.L.H.B.C.; Xiong, H.; Rodríguez-Sánchez, A.J.; Szedmak, S.; Piater, J.; Lagorce, X.; Ieng, S.-H.; Clady, X.; Pfeiffer, M.; et al. Unsupervised Learning. Neural Comput. 1989, 1, 295–311. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; The MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. Ser. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Thorndike, R.L. Who belongs in the family? Psychometrika 1953, 18, 267–276. [Google Scholar] [CrossRef]
- Bittmann, R.M.; Gelbard, R.M. Decision-making method using a visual approach for cluster analysis problems; indicative classification algorithms and grouping scope. Expert Syst. 2007, 24, 171–187. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ship Length (m) | Basic Ship Domain (m) | Site Specific Ship Domain (m) |
|---|---|---|
| Length (li) ≤ 157 m | 2 × li | 1.75 × li |
| Length (li) > 157 m | 2 × li | 3 × li |
| Variable | Value |
|---|---|
| Own Ship’s Length (m) | 157 |
| Target Ship’s Speed (m/s) | 4.5 |
| Basic Ship Domain (m) | 157 × 2 |
| Site-specific Ship Domain (m) | 157 × 1.75 |
| Distance (m) | 350 |
| Violation Distance per Own Ship’s Length (B.S.D.) | ((157 × 2) − 350)/157 |
| Violation Distance per Own Ship’s Length (S.S.S.D.) | ((157 × 1.75) − 350)/157 |
| Violation Indicator (0 or 1) (Basic Ship Domain) | 0 |
| Violation Indicator (0 or 1) (Site-specific Ship Domain) | 1 |
| Non-Scaled, Basic Ship Domain | |||
|---|---|---|---|
| 3 Clusters Fitted Centers | |||
| Cluster No. | Own Ship’s Length (m) | Target Ship’s Speed (m/s) | V.D.P.O.S.L. |
| 1 | 96.872 | 4.821 | −0.203 |
| 2 | 266.912 | 3.722 | 0.573 |
| 3 | 139.928 | 3.562 | 0.161 |
| 5 Clusters Fitted Centers | |||
| Cluster No. | Own Ship’s Length (m) | Target Ship’s Speed (m/s) | V.D.P.O.S.L. |
| 1 | 229.16 | 5.421 | 0.278 |
| 2 | 109.352 | 3.502 | 0.055 |
| 3 | 97.808 | 5.275 | −0.278 |
| 4 | 186.728 | 3.262 | 0.348 |
| 5 | 284.384 | 3.489 | 0.655 |
| 9 Clusters Fitted Centers | |||
| Cluster No. | Own Ship’s Length (m) | Target Ship’s Speed (m/s) | V.D.P.O.S.L. |
| 1 | 129.008 | 5.035 | −0.054 |
| 2 | 298.424 | 3.262 | 0.724 |
| 3 | 76.592 | 3.442 | 0.08 |
| 4 | 236.024 | 3.289 | 0.511 |
| 5 | 91.256 | 5.654 | −0.39 |
| 6 | 117.152 | 3.249 | 0.115 |
| 7 | 285.944 | 5.181 | 0.493 |
| 8 | 173.624 | 3.282 | 0.302 |
| 9 | 205.136 | 5.315 | 0.208 |
| Non-Scaled, Site-Specific Ship Domain | |||
|---|---|---|---|
| 3 Clusters Fitted Centers | |||
| Cluster No. | Own Ship’s Length (m) | Target Ship’s Speed (m/s) | V.D.P.O.S.L. |
| 1 | 124.64 | 5.055 | 0.15 |
| 2 | 207.008 | 4.435 | −0.312 |
| 3 | 109.352 | 4.921 | 0.604 |
| 5 Clusters Fitted Centers | |||
| Cluster No. | Own Ship’s Length (m) | Target Ship’s Speed (m/s) | V.D.P.O.S.L. |
| 1 | 120.584 | 4.135 | 0.384 |
| 2 | 116.216 | 6.101 | 0.163 |
| 3 | 105.608 | 5.181 | 0.677 |
| 4 | 145.232 | 4.082 | 0.052 |
| 5 | 210.44 | 4.515 | −0.359 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oruc, M.F.; Altan, Y.C. Risky Maritime Encounter Patterns via Clustering. J. Mar. Sci. Eng. 2023, 11, 950. https://doi.org/10.3390/jmse11050950
Oruc MF, Altan YC. Risky Maritime Encounter Patterns via Clustering. Journal of Marine Science and Engineering. 2023; 11(5):950. https://doi.org/10.3390/jmse11050950
Chicago/Turabian StyleOruc, M. Furkan, and Yigit C. Altan. 2023. "Risky Maritime Encounter Patterns via Clustering" Journal of Marine Science and Engineering 11, no. 5: 950. https://doi.org/10.3390/jmse11050950