
Application of a Deep Neural Network for Acoustic Source Localization Inside a Cavitation Tunnel

Abstract
:1. Introduction
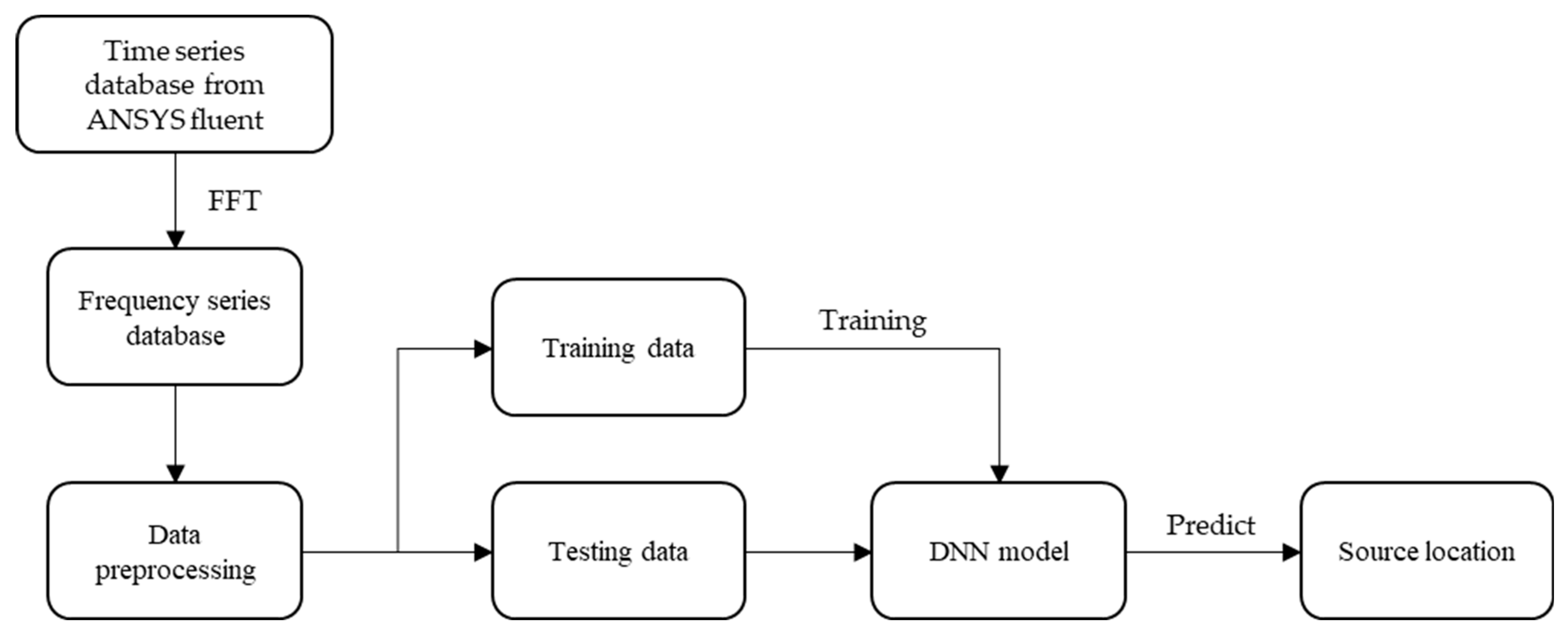
2. Neural Network Algorithms and the Training of AI Models
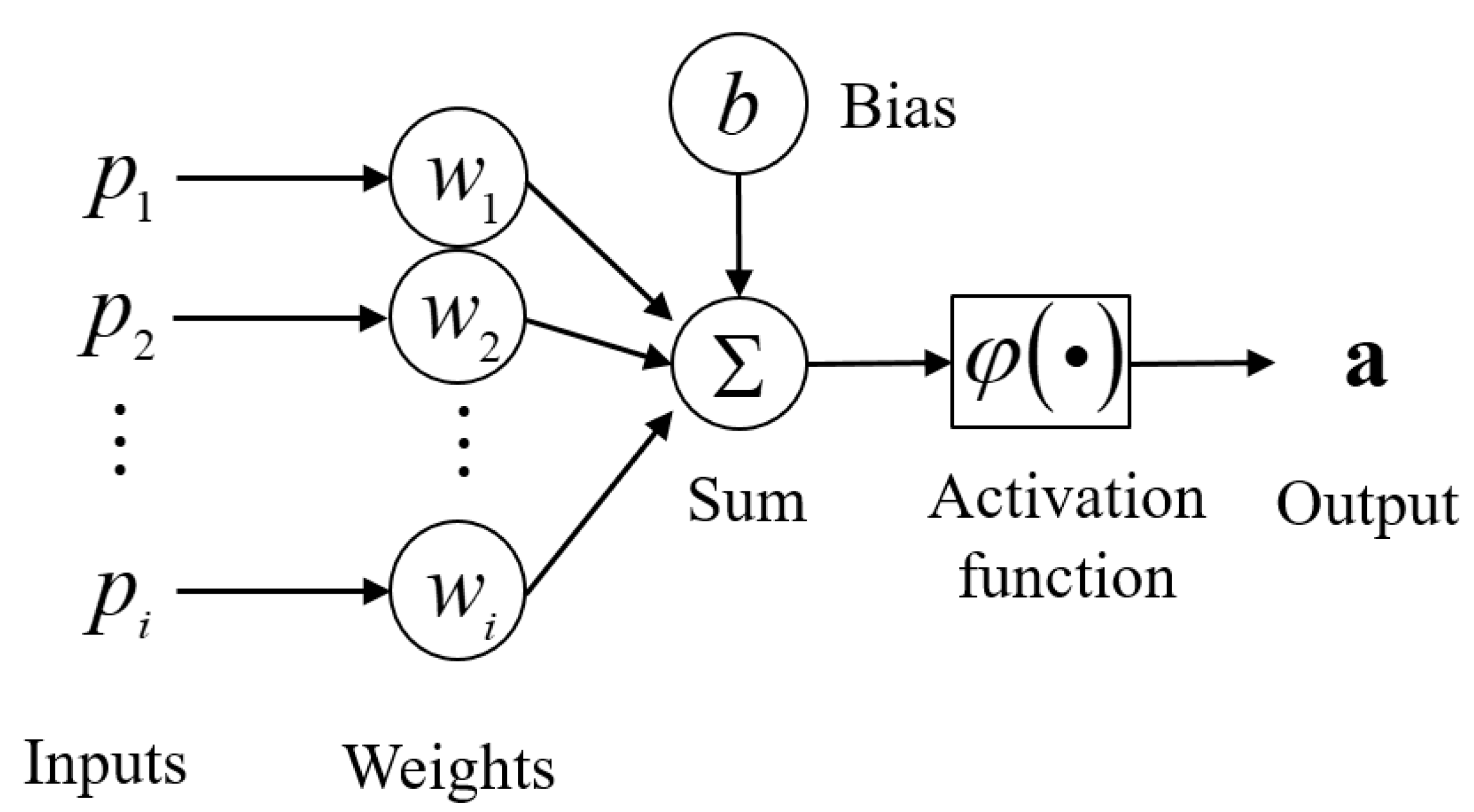
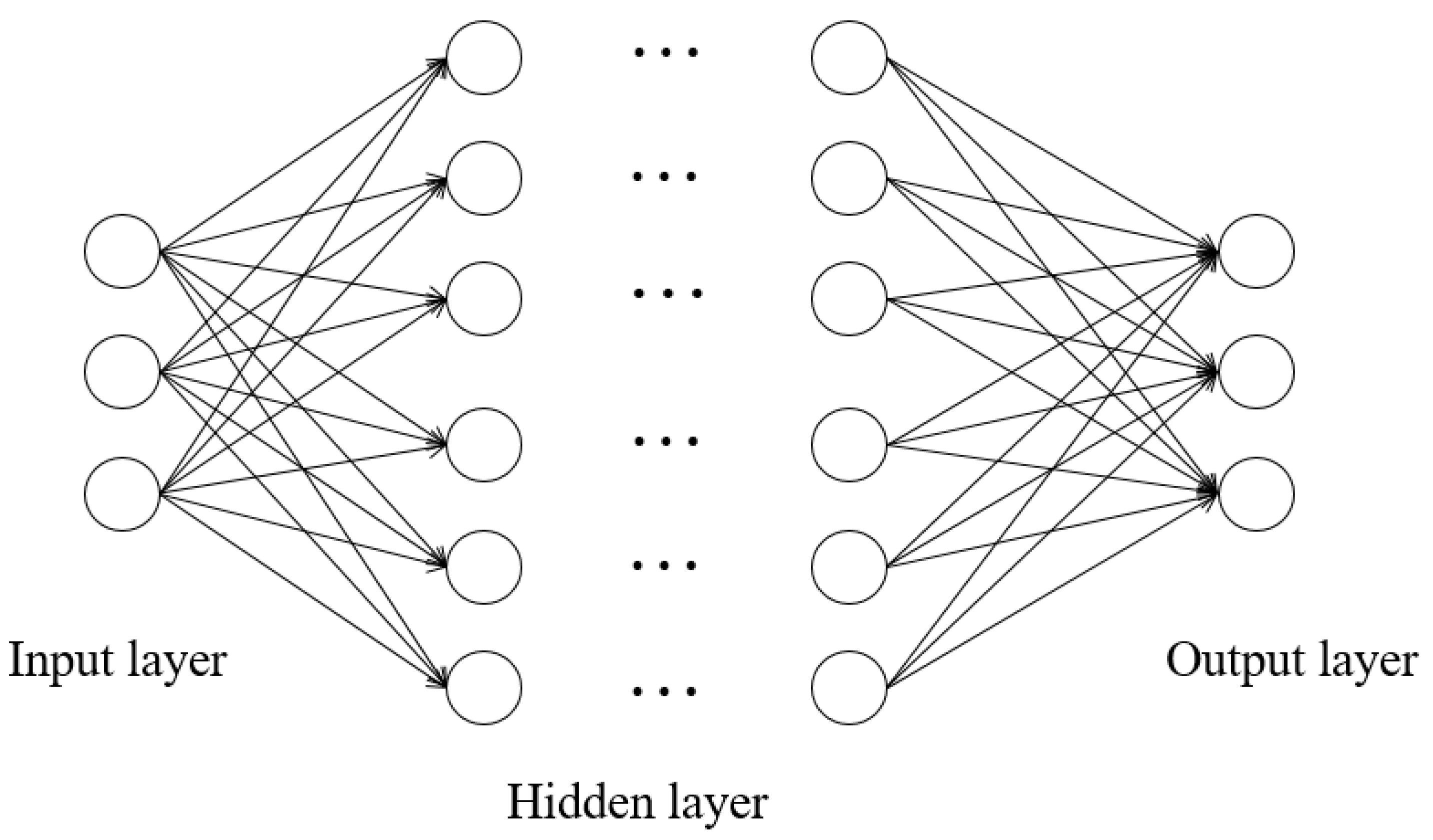
2.1. Neural Networks
2.2. Backpropagation Algorithm
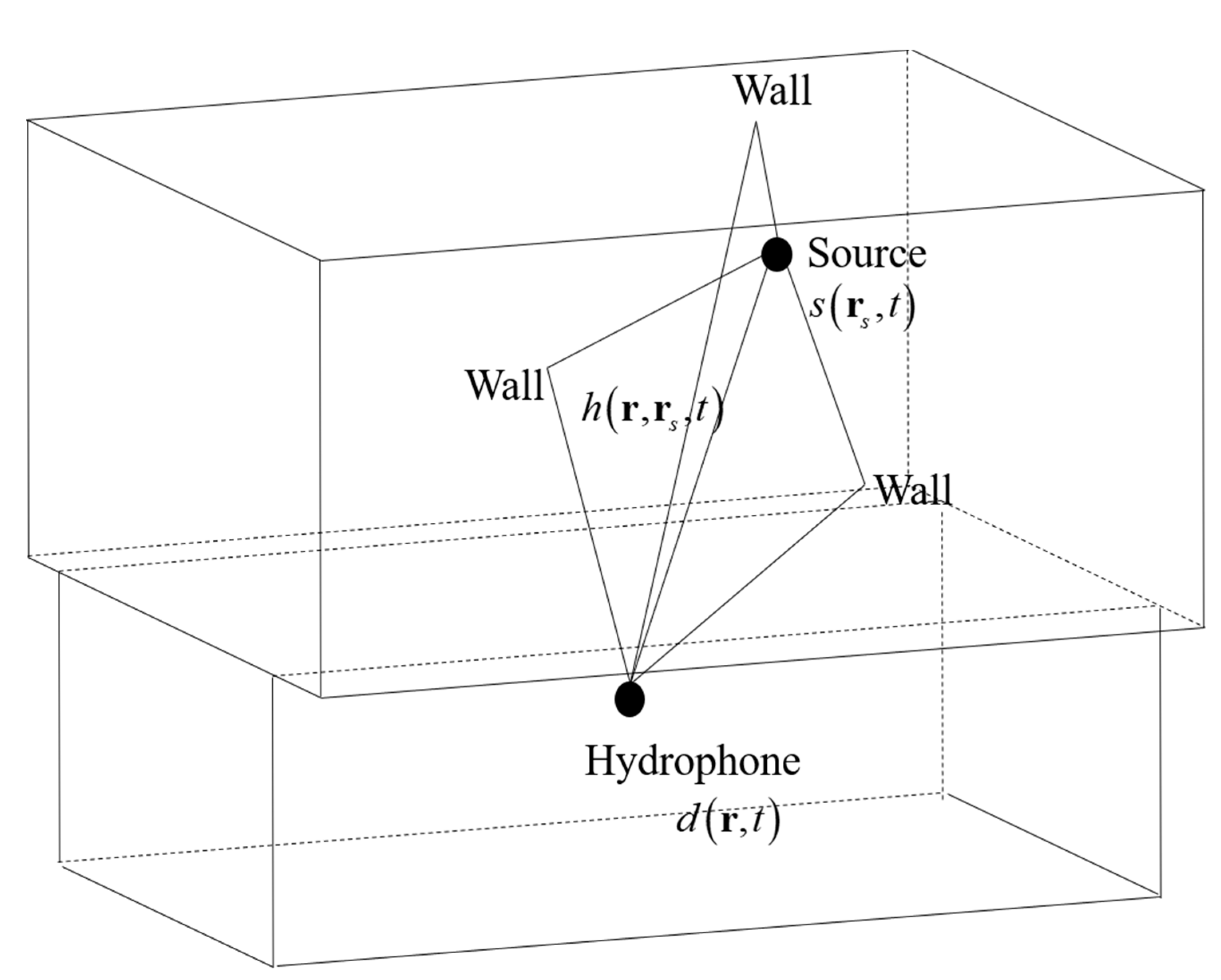
3. Water Tank Acoustic Field and Data Features
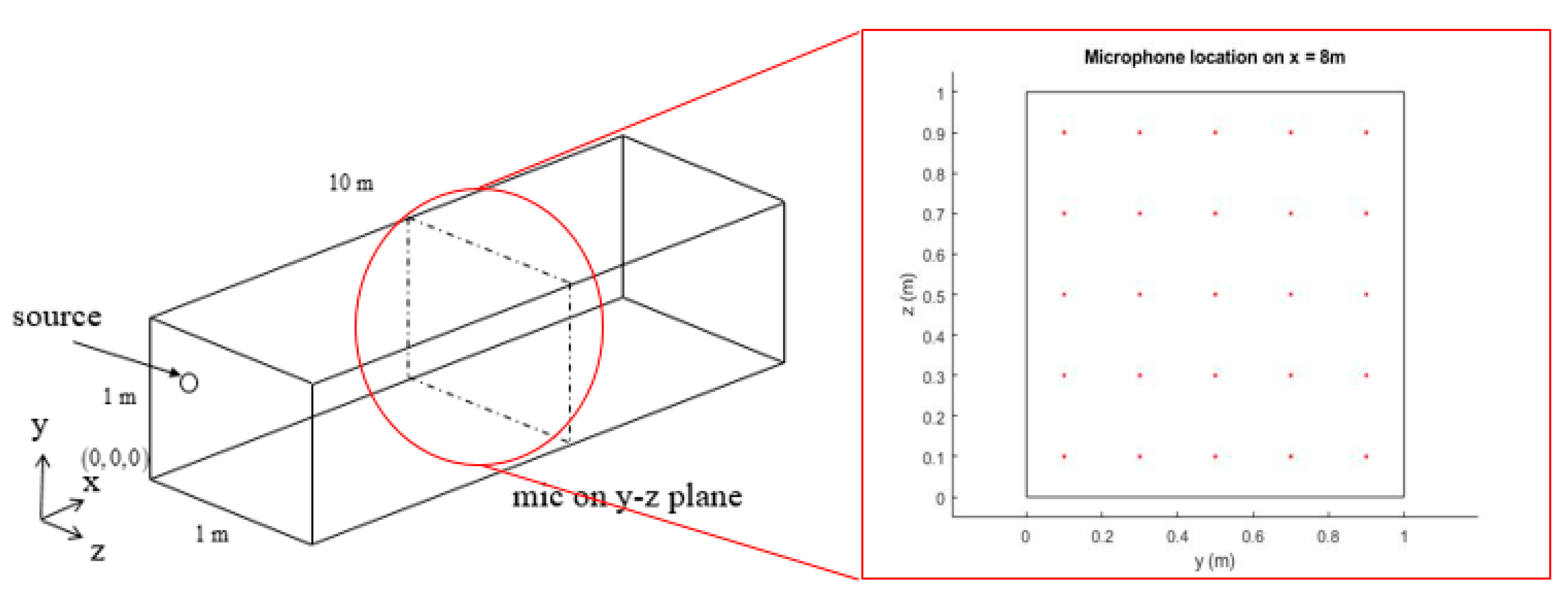
3.1. Setting of the Water Tank Acoustic Field
3.2. Data Feature Extraction
4. Numerical Simulation on the Simple Rectangular Cuboid Acoustic Field Model
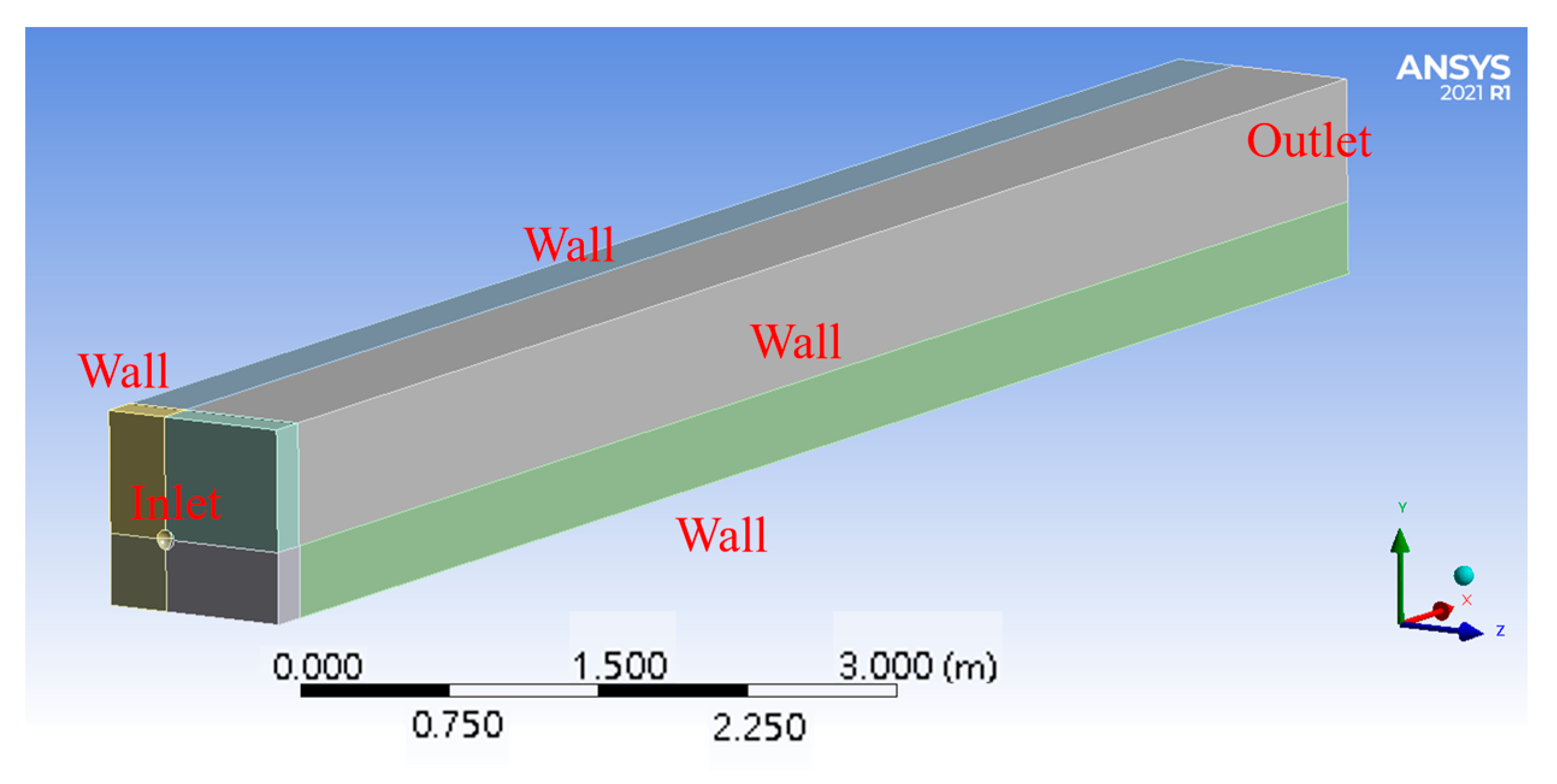
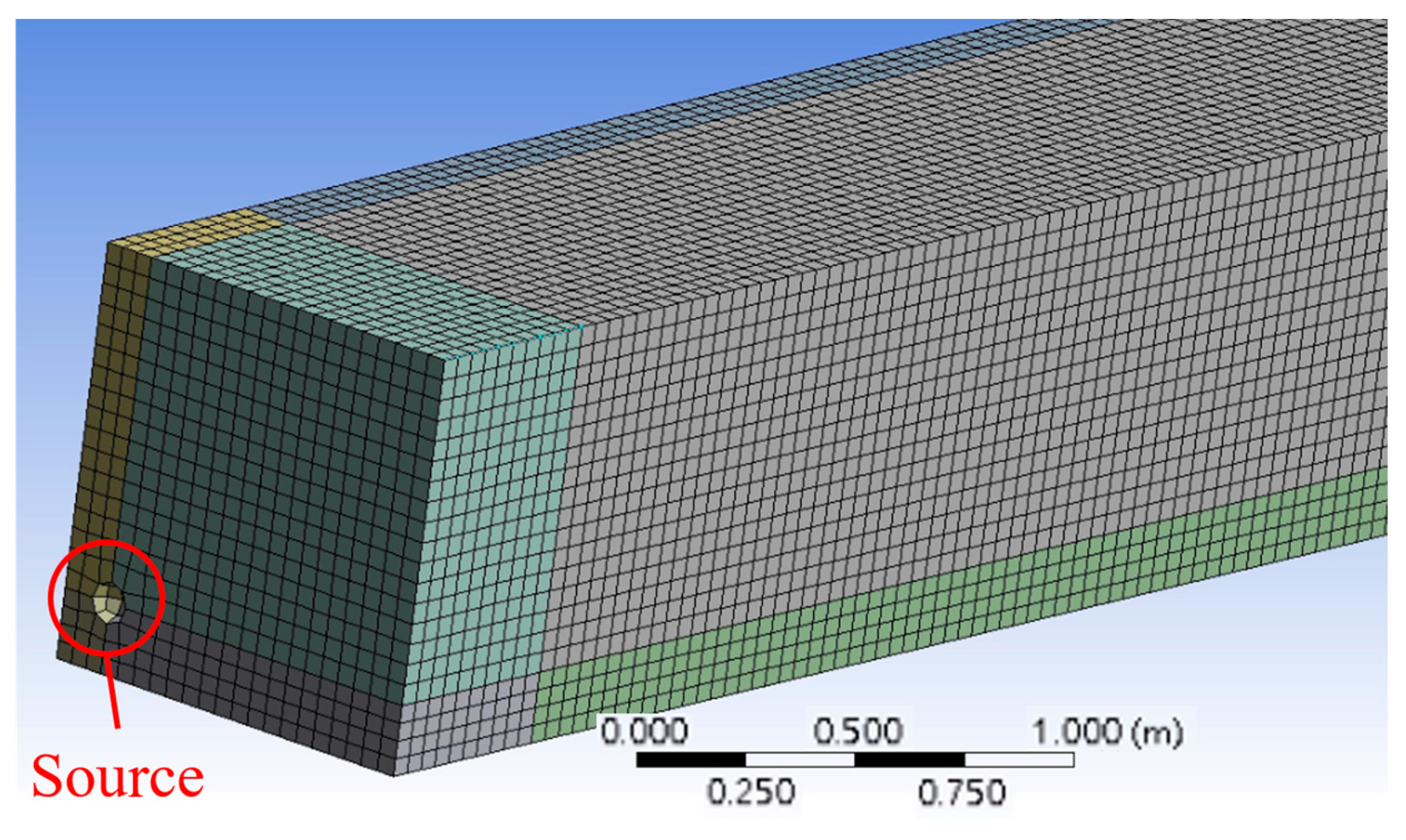
4.1. Numerical Setup
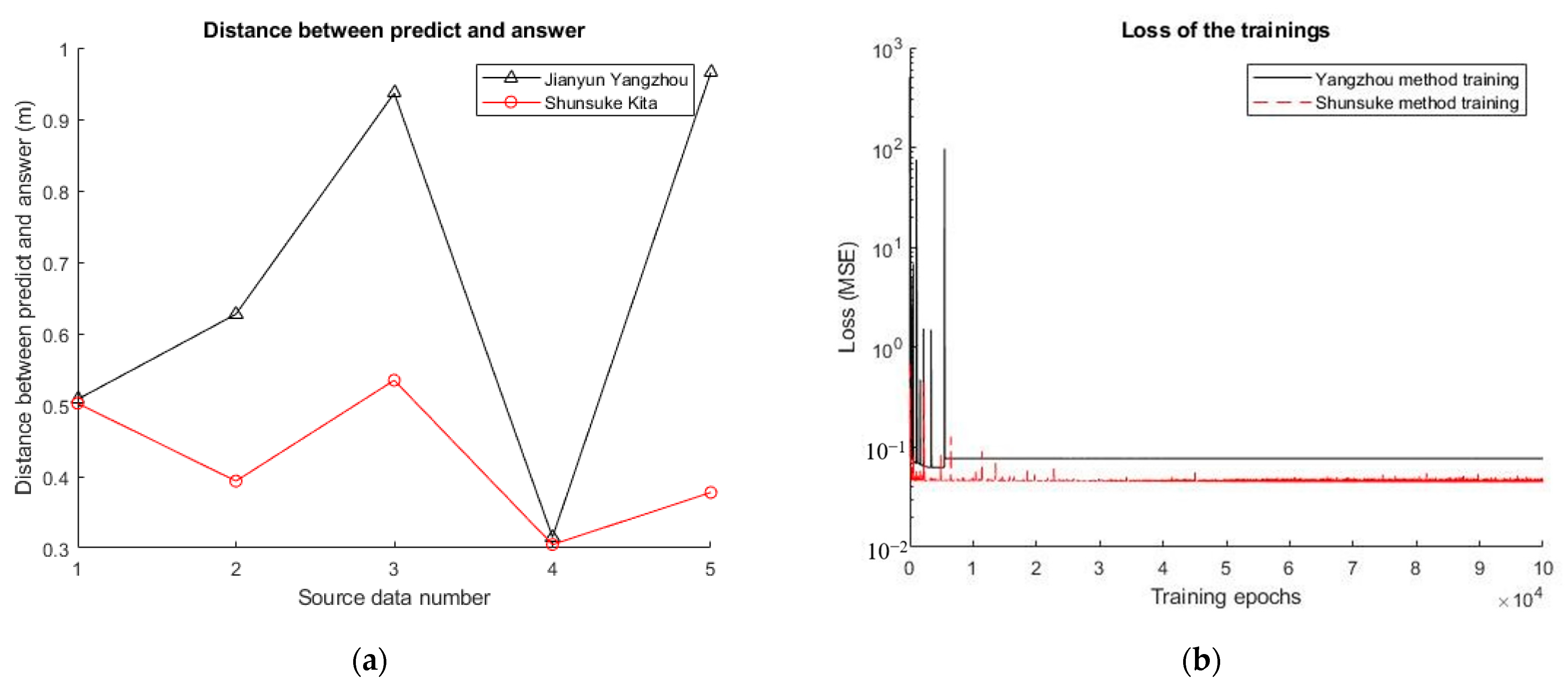
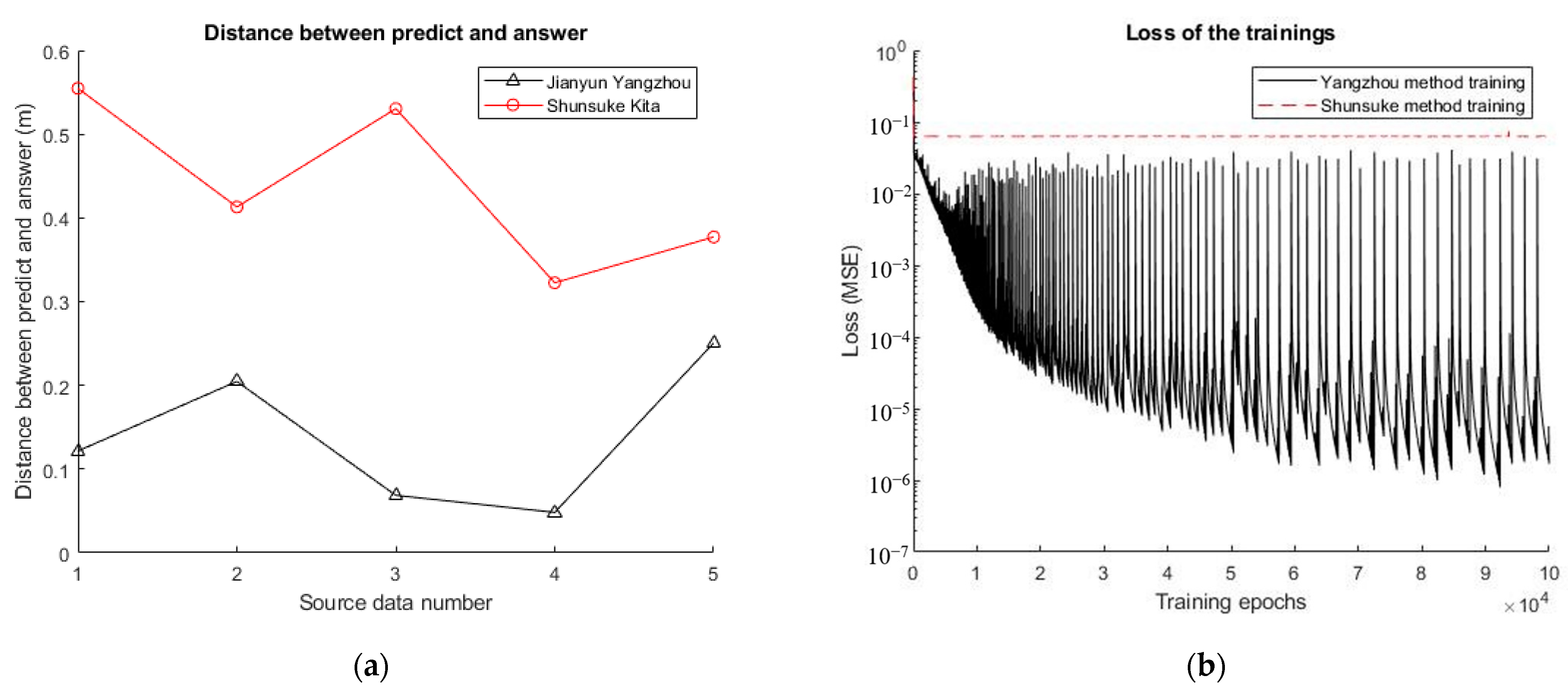
4.2. Comparison between the Yangzhou’s Method and Shunsuke’s Method Prior to Min–Max Normalization
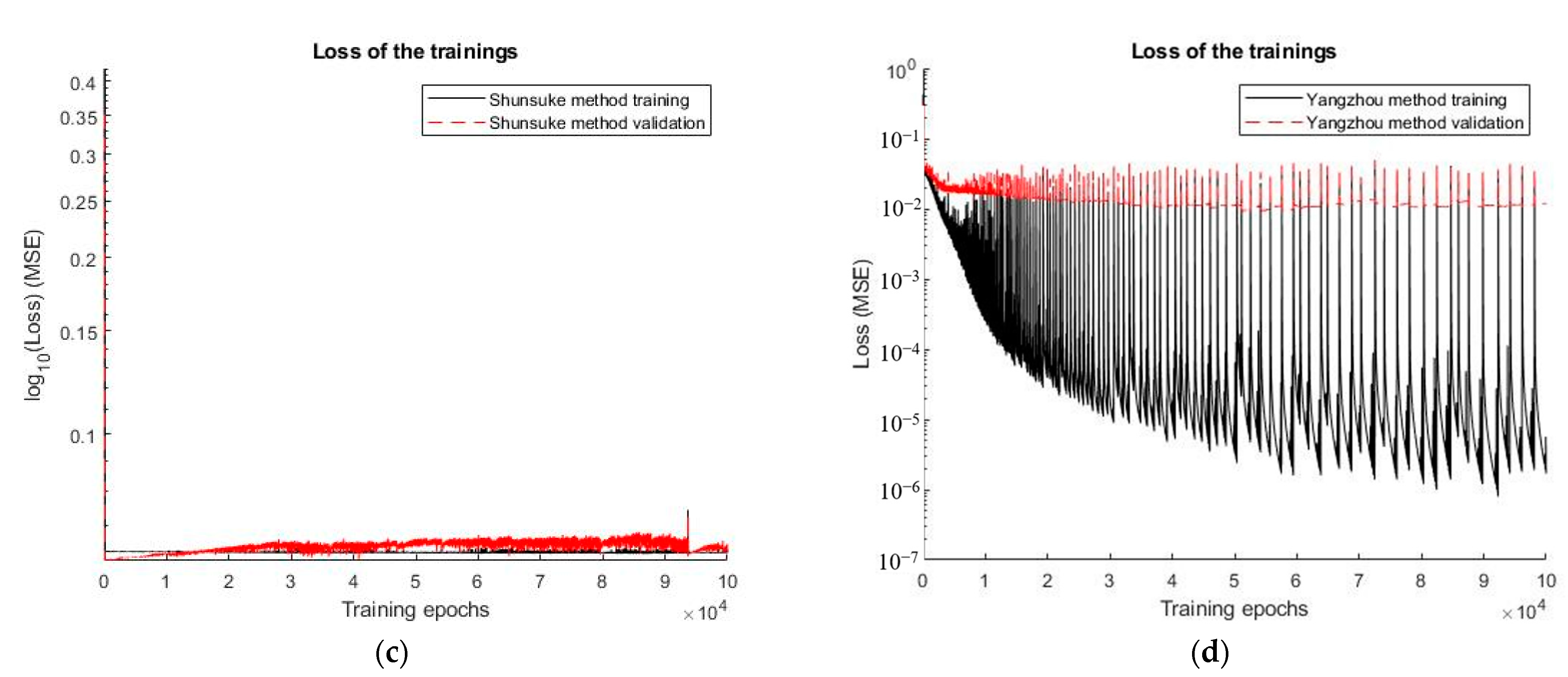
4.3. Comparison between Yangzhou’s Method and Shunsuke ‘s Method after Min–Max Normalization
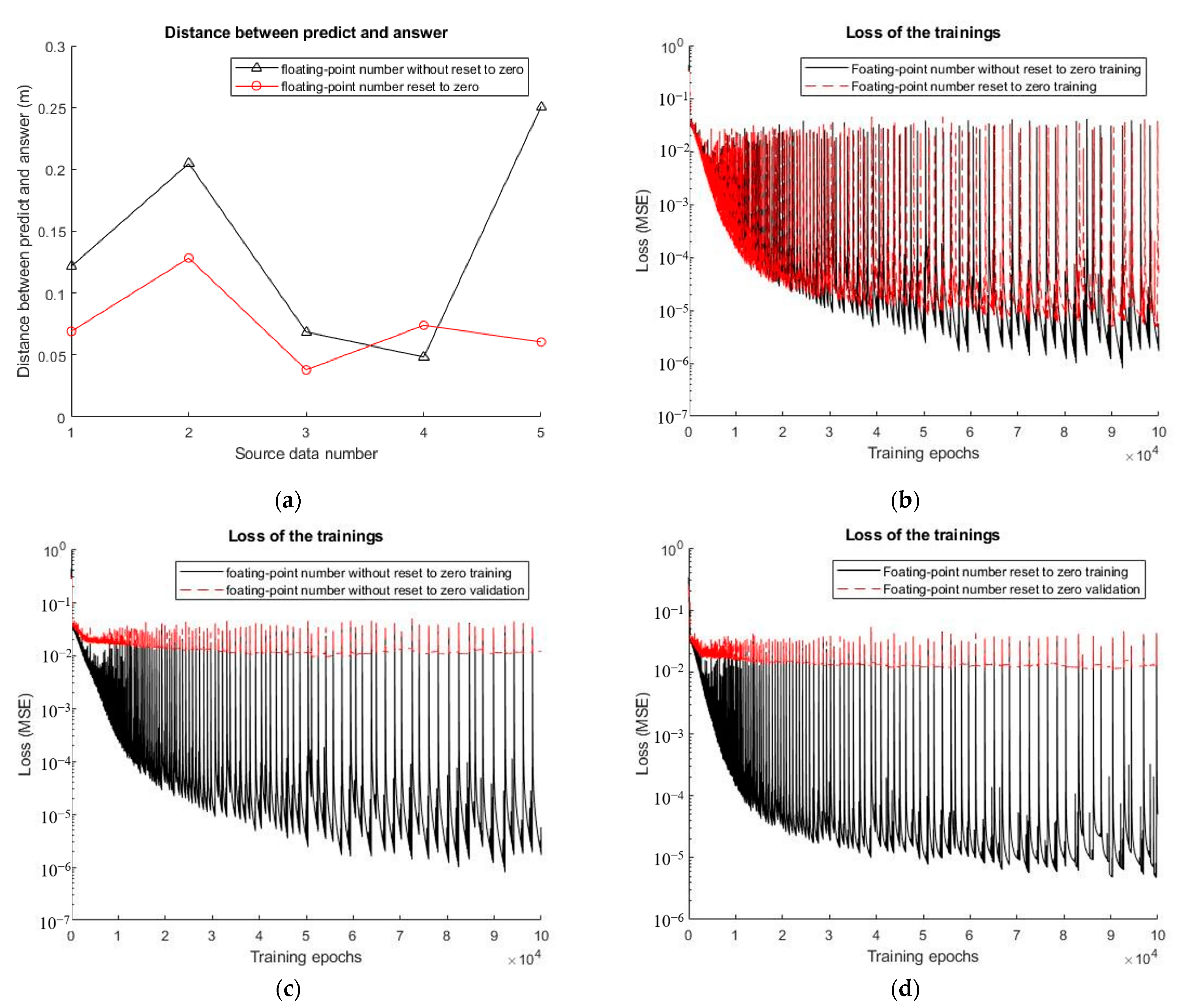
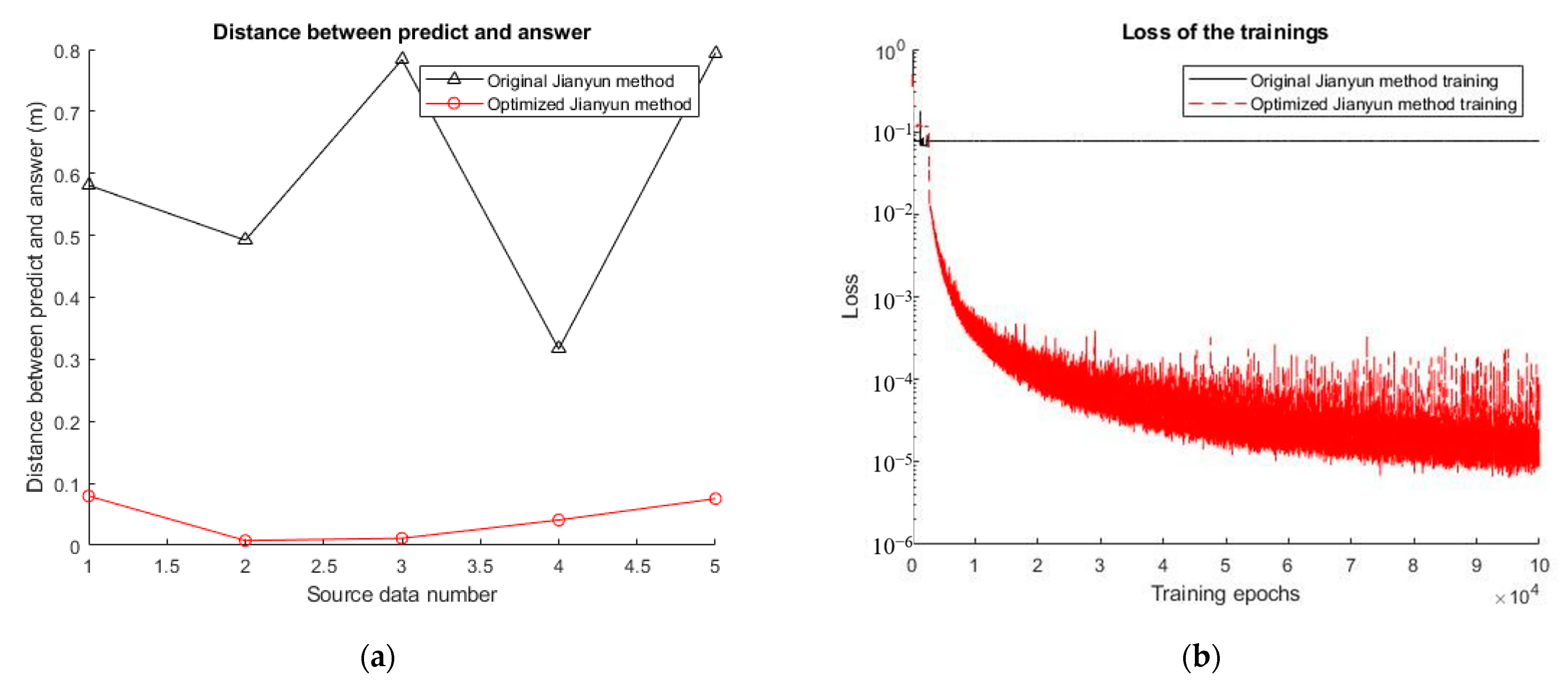
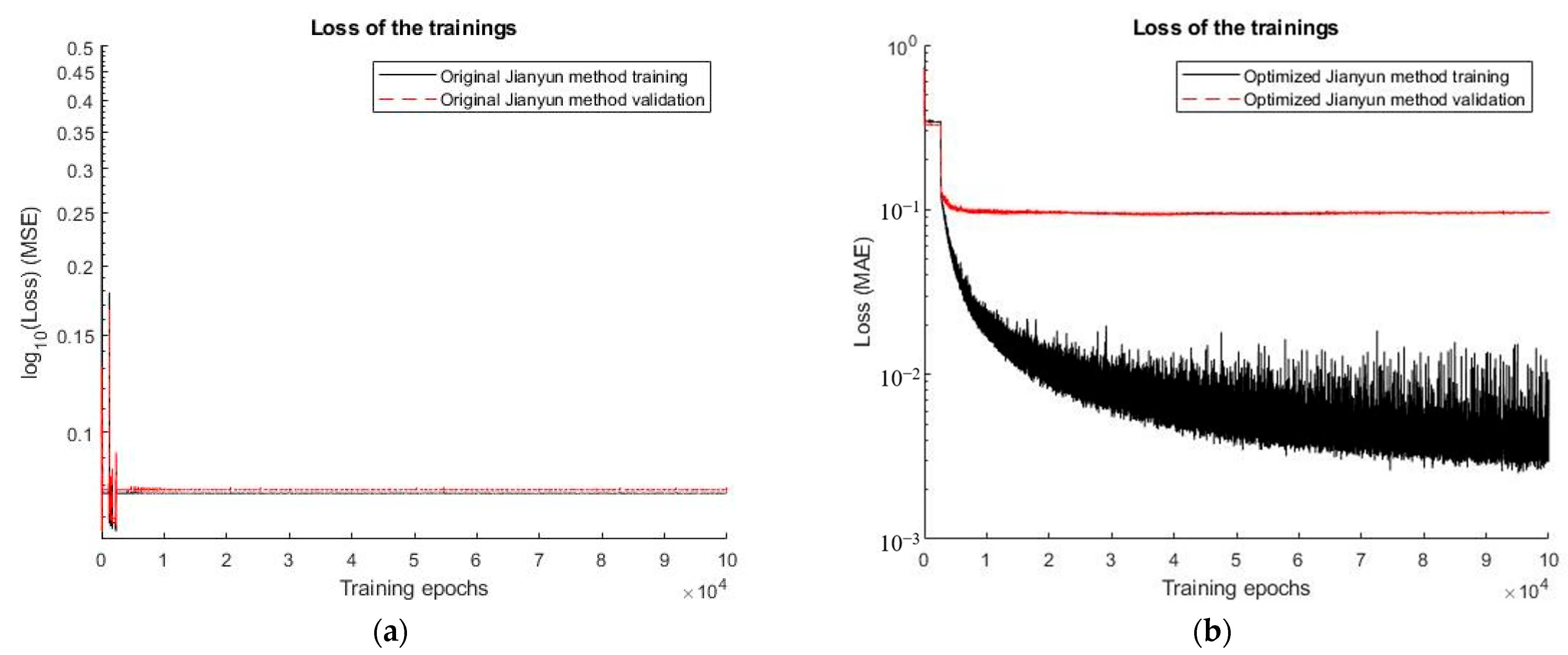
4.4. Optimizing the Yangzhou’s Method through Floating-Point Number Preprocessing
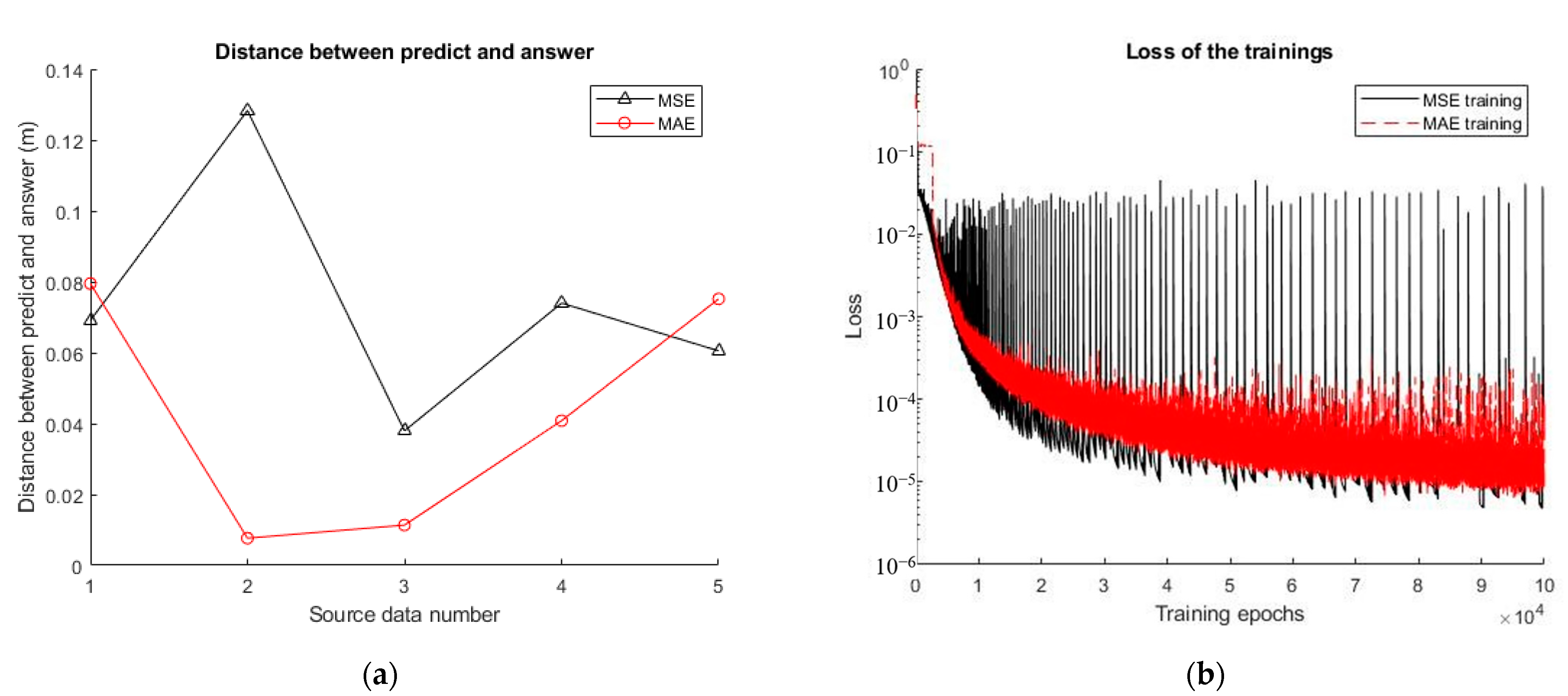
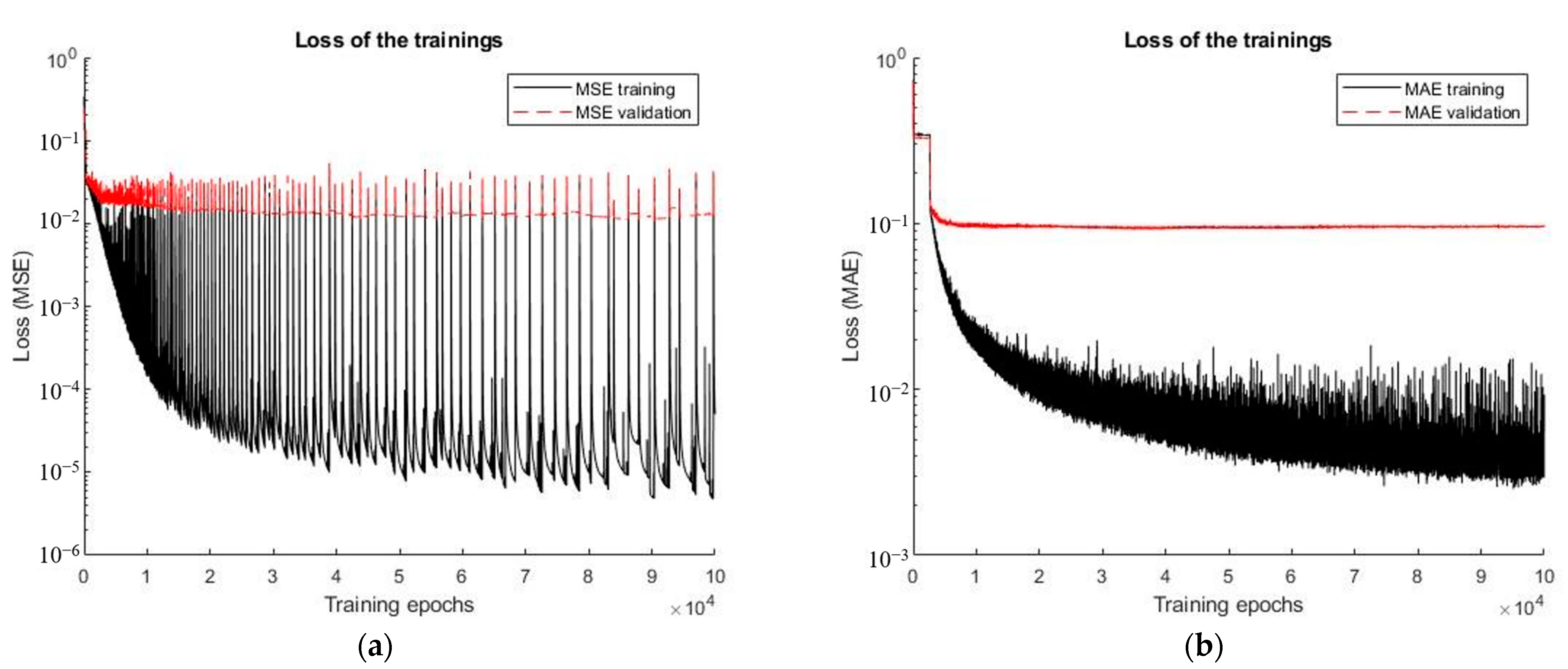
4.5. Effects of the MSE and MAE as Loss Functions on Training
4.6. Comparison of the Yangzhou’s Method before and after Optimization
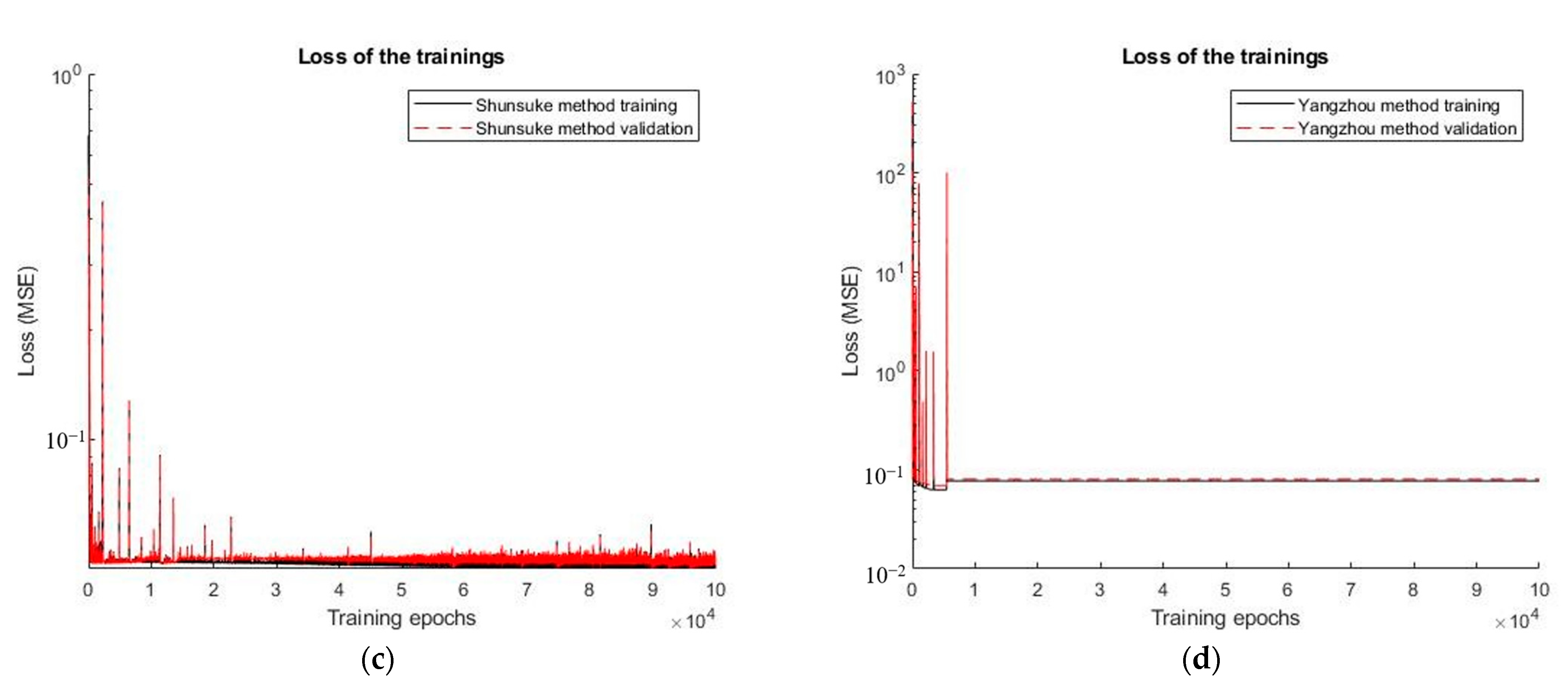
5. Numerical Simulation on a Large Cavitation Tank Acoustic Field Model
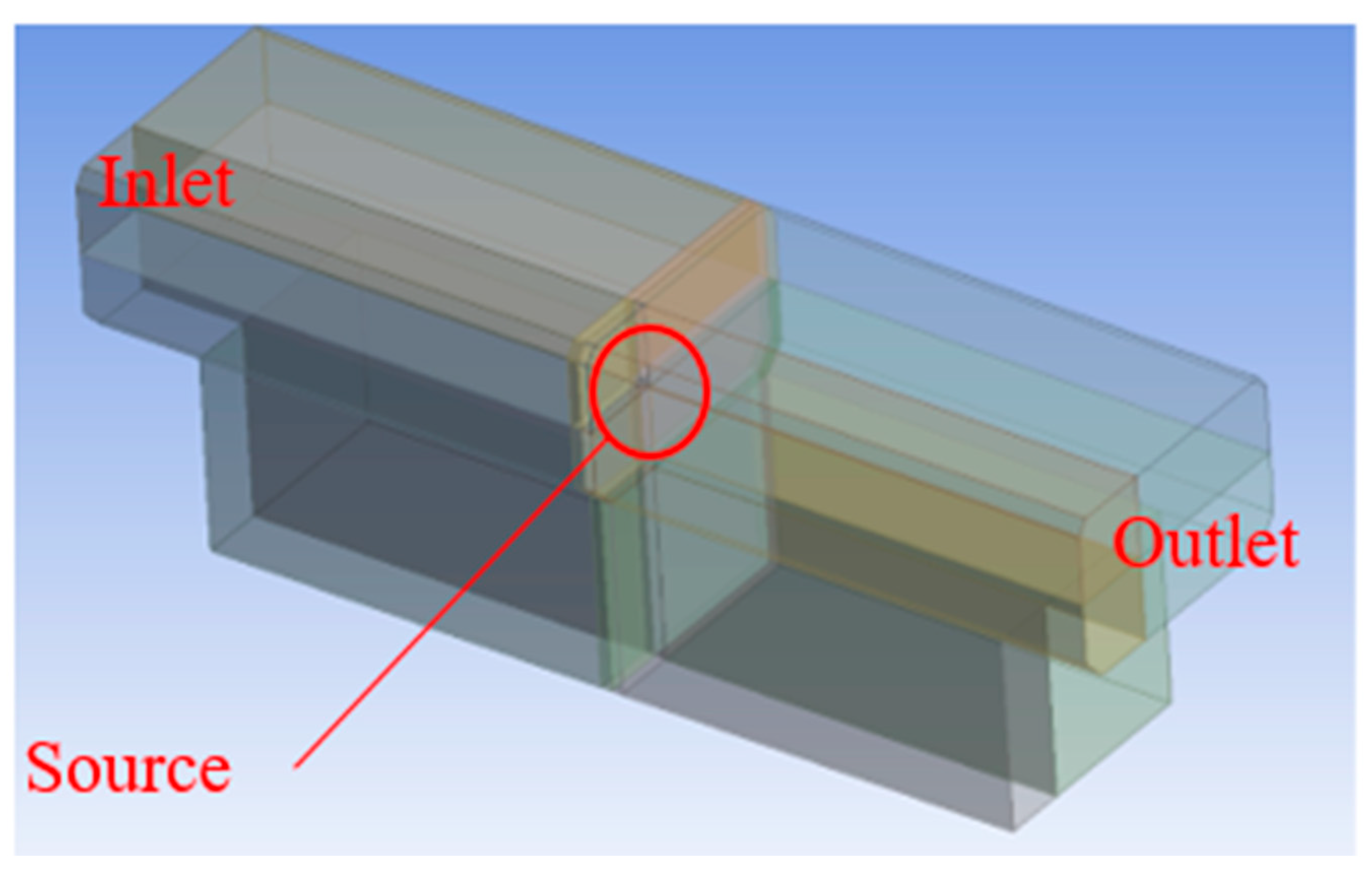
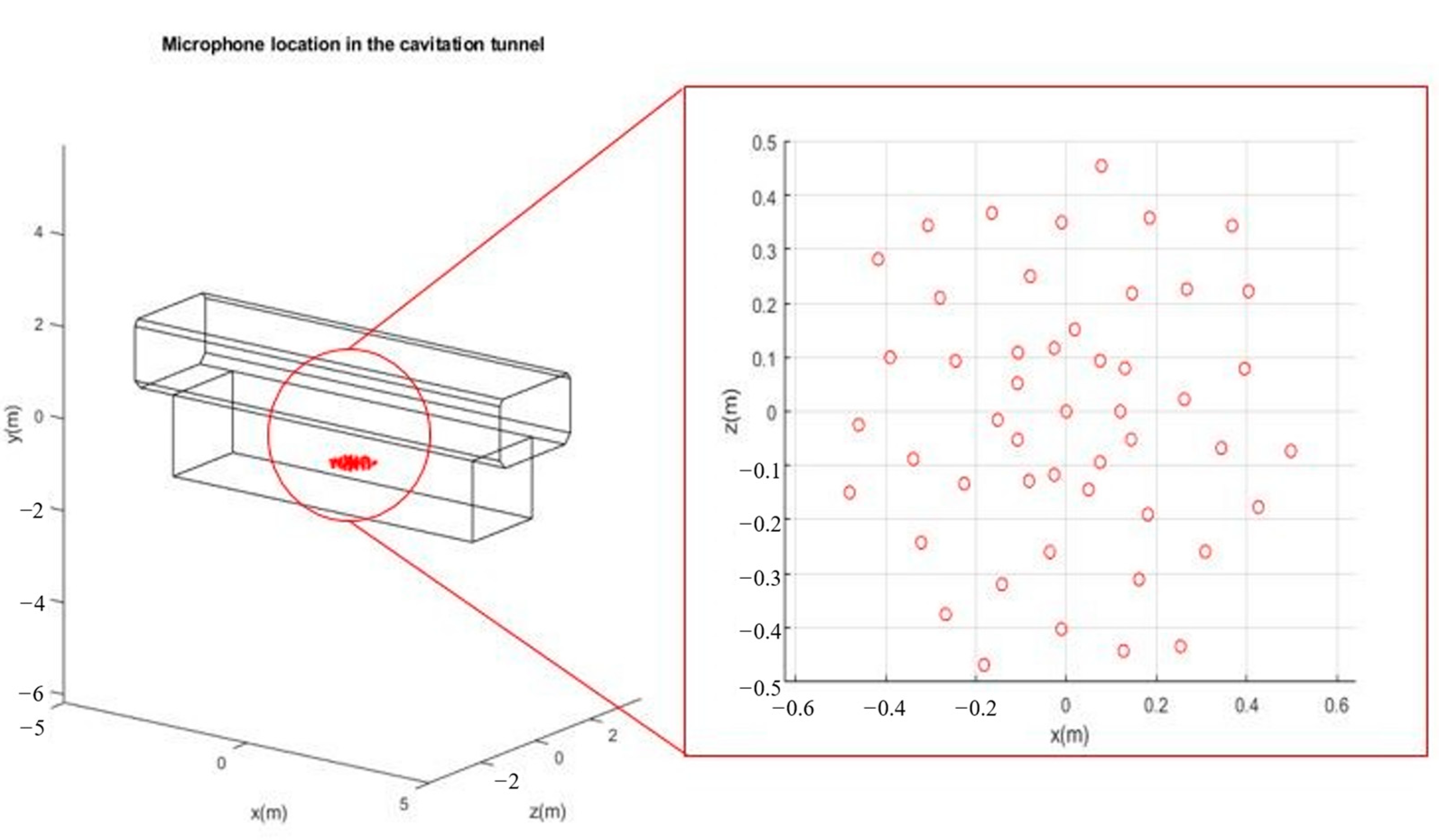
5.1. Numerical Setup
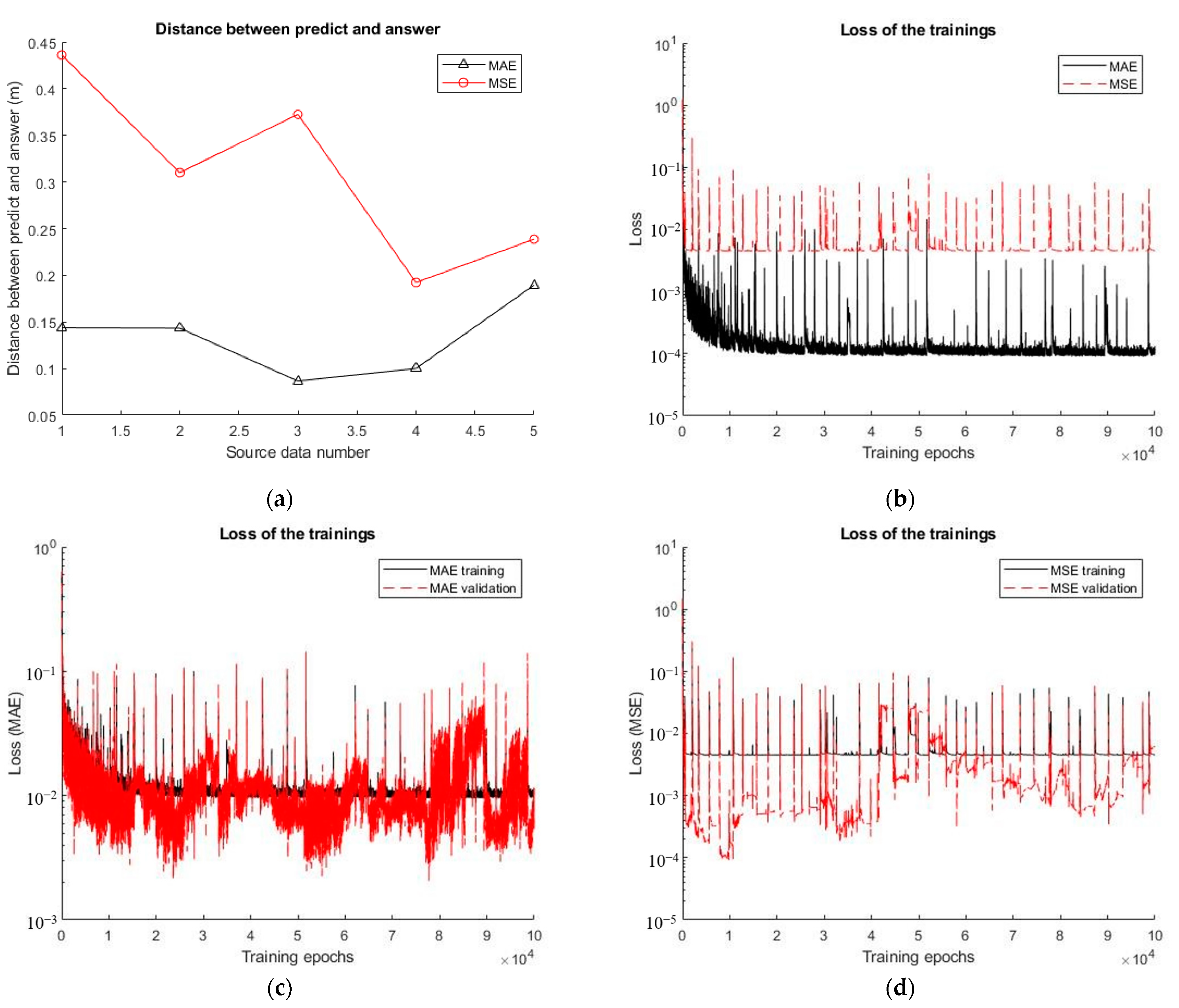
5.2. Effects of the MSE and MAE as Loss Functions on Training
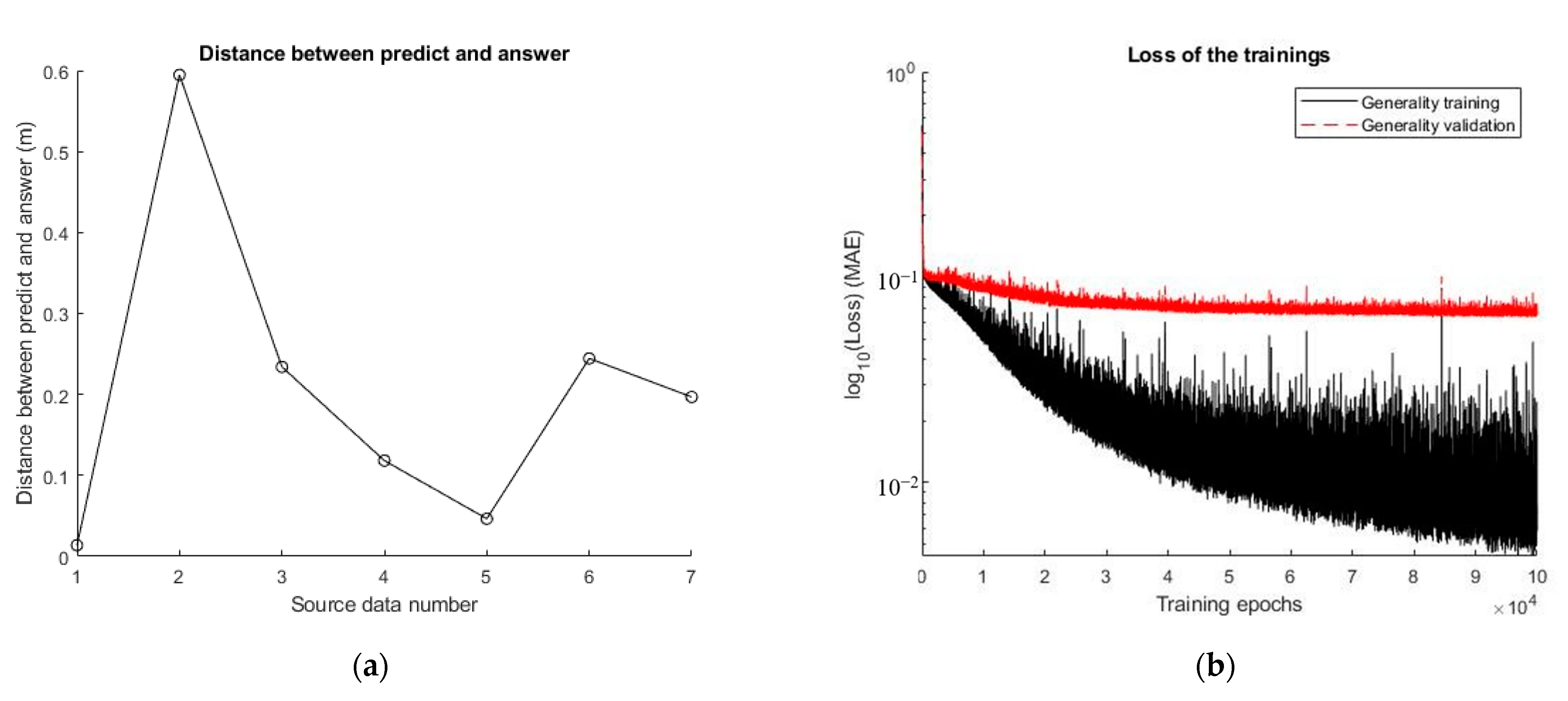
5.3. Universal Applicability Test
6. Discussion and Conclusions
- Introducing the min-max normalization to strengthen the characteristics from all frequencies.
- Using floating-point number preprocessing to remove amplification of random floating error raised by any normalization processes.
- Replacing the original MSE based loss function with MAE to stabilize the convergence of iteration.
- Using ReLU to replace the other smooth activation functions such as tanh or sigmoid functions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Skarsoulis, E.K.; Piperakis, G.; Kalogerakis, M.; Orfanakis, E.; Papadakis, P.; Dosso, S.E.; Frantzis, A. Underwater Acoustic Pulsed Source Localization with a Pair of Hydrophones. Remote Sens. 2018, 10, 883. [Google Scholar] [CrossRef] [Green Version]
- Niu, H.; Reeves, E.; Gerstoft, P. 2017 Source localization in an ocean waveguide using supervised machine learning. J. Acoust. Soc. Am. 2017, 142, 1176. [Google Scholar] [CrossRef] [Green Version]
- Jin, P.; Li, L.; Chao, P.; Xie, F. Semi-supervised underwater acoustic source localization based on residual convolutional autoencoder. EURASIP J. Adv. Signal Process. 2022, 1, 107. [Google Scholar] [CrossRef]
- Hu, Z.; Huang, J.; Xu, P.; Nan, M.; Lou, K.; Li, G. Underwater Acoustic Source Localization via Kernel Extreme Learning Machine. Front. Phys. 2021, 9, 653875. [Google Scholar] [CrossRef]
- Kim, S.M.; Oh, S.; Byun, S.H. Underwater Source Localization in a Tank with Two Parallel Moving Hydrophone Arrays; OCEANS 2015–MTS/IEEE: Washington, DC, USA, 2015. [Google Scholar]
- Liu, K.W.; Huang, C.J.; Too, G.P.; Shen, Z.Y.; Sun, Y.D. 2022 Underwater Sound Source Localization Based on Passive Time-Reversal Mirror and Ray Theory. Sensors 2022, 22, 2420. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Zhang, L.; Wei, H.; Xiao, Z.; Qiu, Z.; Sun, R.; Pang, F.; Wang, T. Underwater acoustic source localization based on phase-sensitive optical time domain reflectometry. Opt. Express 2021, 29, 12880–12892. [Google Scholar] [CrossRef]
- Park, C.; Kim, G.D.; Park, Y.H.; Lee, K.; Seong, W. Noise localization method for model tests in a large cavitation tunnel using a hydrophone array. Remote Sens. 2016, 8, 195. [Google Scholar] [CrossRef] [Green Version]
- Lee, L.C.; Ou, J.S.; Huang, M.C. Underwater acoustic localization by principal components analyses based probabilistic approach. Appl. Acoust. 2009, 70, 1168–1174. [Google Scholar] [CrossRef]
- Moon, T.K.; Stirling, W.C. Mathematical Methods and Algorithms for Signal Processing; Prentice Hall: Hoboken, NJ, USA, 2000. [Google Scholar]
- Lefort, R.; Real, G.; Drémeau, A. Direct regression for underwater acoustic source localization in fluctuating oceans. Appl. Acoust. 2017, 116, 303–310. [Google Scholar] [CrossRef]
- Nadarava, E.A. On Estimating Regression. Theory Probab. Its Appl. 1964, 9, 141–142. [Google Scholar] [CrossRef]
- Kramer, O. Unsupervised nearest neighbor regression for dimensionality reduction. Soft Comput. 2015, 19, 1647–1661. [Google Scholar] [CrossRef]
- Vera-Diaz, J.M.; Pizarro, D.; Macias-Guarasa, J. Towards end-to-end acoustic localization using deep learing: From audio signals to source position coordinates. Sensor 2018, 18, 3418. [Google Scholar] [CrossRef] [Green Version]
- Yangzhou, J.; Ma, Z.; Huang, X. A deep neural network approach to acoustic source localization in a shallow water tank experiment. J. Acoust. Soc. Am. 2019, 146, 4802–4811. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cooley, J.W.; Tukey, J.W. An algorithm for the machine calculation of complex Fourier series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Zhu, X.; Dong, H.; Salvo Rossi, P.; Landrø, M. Feature selection based on principal component regression for underwater source localization by deep learning. Remote Sens. 2021, 13, 1486. [Google Scholar] [CrossRef]
- Chen, M.; Shi, X.; Wu, D.; Guizani, M. Deep features learning for medical image analysis with convolutional autoencoder neural network. Big Data 2021, 7, 750–758. [Google Scholar] [CrossRef]
- Shunsuke, K.; Yoshinobu, K. Fundamental study on sound source localization inside a structure using a deep neural network and computer-aided engineering. J. Sound Vib. 2021, 513, 116400. [Google Scholar]
- Reich, Y.; Barai, S. Evaluating machine learning models for engineering problems. Artif. Intell. Eng. 1999, 13, 257–272. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hagan, M.T.; Demuth, H.B.; Beale, M. Neural Network Design; PWS Publishing Co.: Boston, MA, USA, 1997. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Frank, J.F. Foundations of Engineering Acoustics; Elsevier Science Publishing Co., Inc.: San Diego, CA, USA, 2000. [Google Scholar]
- Steffen, M. Six boundary elements per wavelength: Is that enough. J. Comput. Acoust. 2002, 10, 25–51. [Google Scholar]
- James, R.U. Aeroacoustic phase array testing in low speed wind tunnels. In Aeroacoustic Measurements; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Model | Acoustic Source Location | |
|---|---|---|---|
| Actual | Predicted | ||
| 1 | Cavitation tank | (0.2, 0.75, 0.5) | (0.214, 0.753, 0.501) |
| 2 | Cavitation tank | (0.3, 0.75, −0.5) | (−0.013, 0.750, 0.005) |
| 3 | Rectangular cuboid | (2.6, 0.87, 0.83) | (2.459, 0.852, 0.644) |
| 4 | Rectangular cuboid | (3.2, 0.83, 0.29) | (3.314, 0.830, 0.259) |
| 5 | Rectangular cuboid | (3.5, 0.21, 0.91) | (3.454, 0.210, 0.903) |
| 6 | Rectangular cuboid | (2.8, 0.33, 0.25) | (2.920, 0.517, 0.352) |
| 7 | Rectangular cuboid | (3.6, 0.55, 0.87) | (3.498, 0.570, 0.703) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, B.-J.; Guan, P.-C.; Chang, H.-T.; Hsiao, H.-W.; Lin, J.-H. Application of a Deep Neural Network for Acoustic Source Localization Inside a Cavitation Tunnel. J. Mar. Sci. Eng. 2023, 11, 773. https://doi.org/10.3390/jmse11040773
Lin B-J, Guan P-C, Chang H-T, Hsiao H-W, Lin J-H. Application of a Deep Neural Network for Acoustic Source Localization Inside a Cavitation Tunnel. Journal of Marine Science and Engineering. 2023; 11(4):773. https://doi.org/10.3390/jmse11040773
Chicago/Turabian StyleLin, Bo-Jie, Pai-Chen Guan, Hung-Tang Chang, Hong-Wun Hsiao, and Jung-Hsiang Lin. 2023. "Application of a Deep Neural Network for Acoustic Source Localization Inside a Cavitation Tunnel" Journal of Marine Science and Engineering 11, no. 4: 773. https://doi.org/10.3390/jmse11040773