
A Novel Intelligent Detection Algorithm of Aids to Navigation Based on Improved YOLOv4

Abstract
:1. Introduction
2. YOLOv4 Algorithm
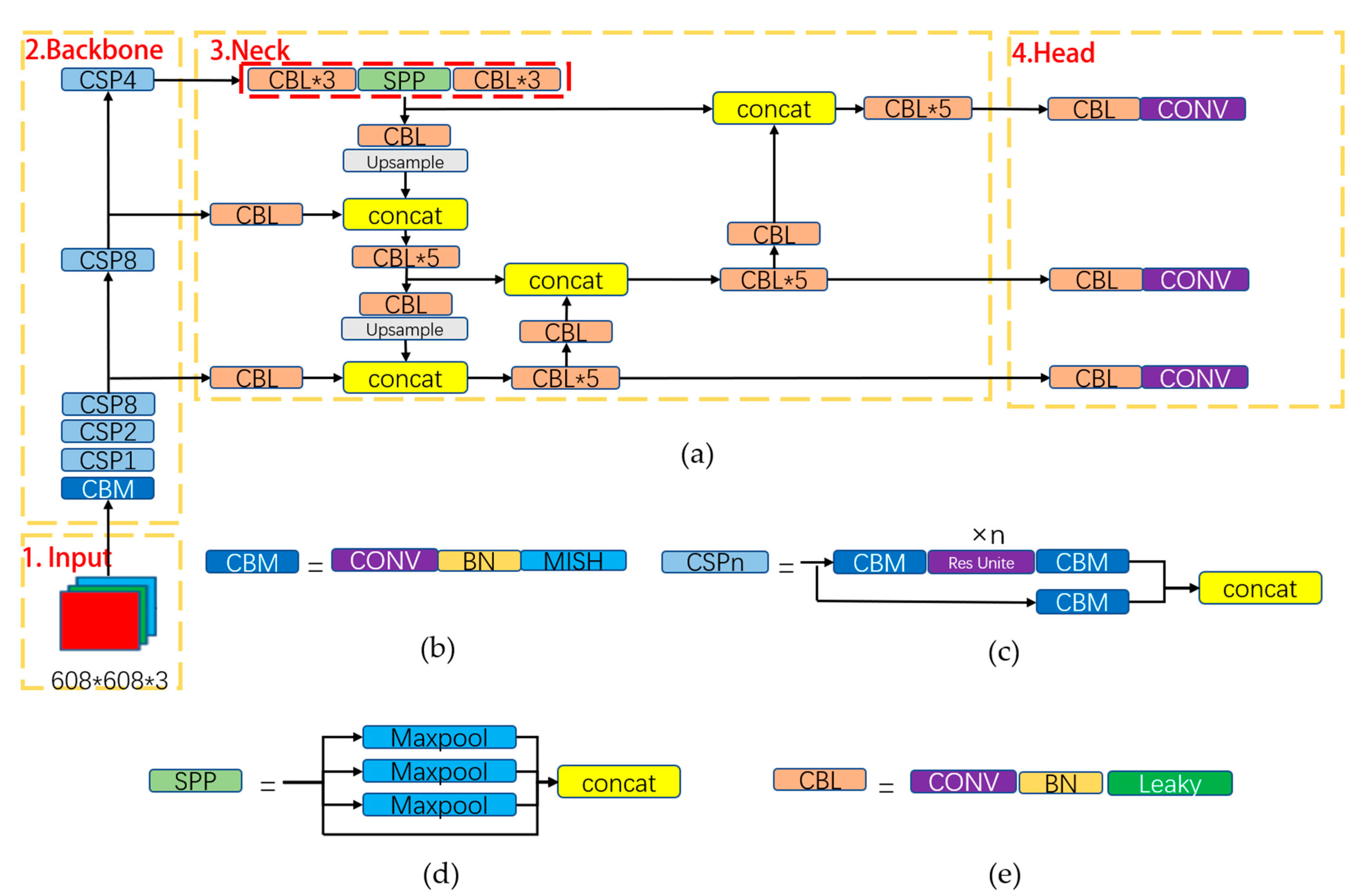
2.1. Algorithm Model Structure
2.2. Spatial Pyramid Pooling Structure
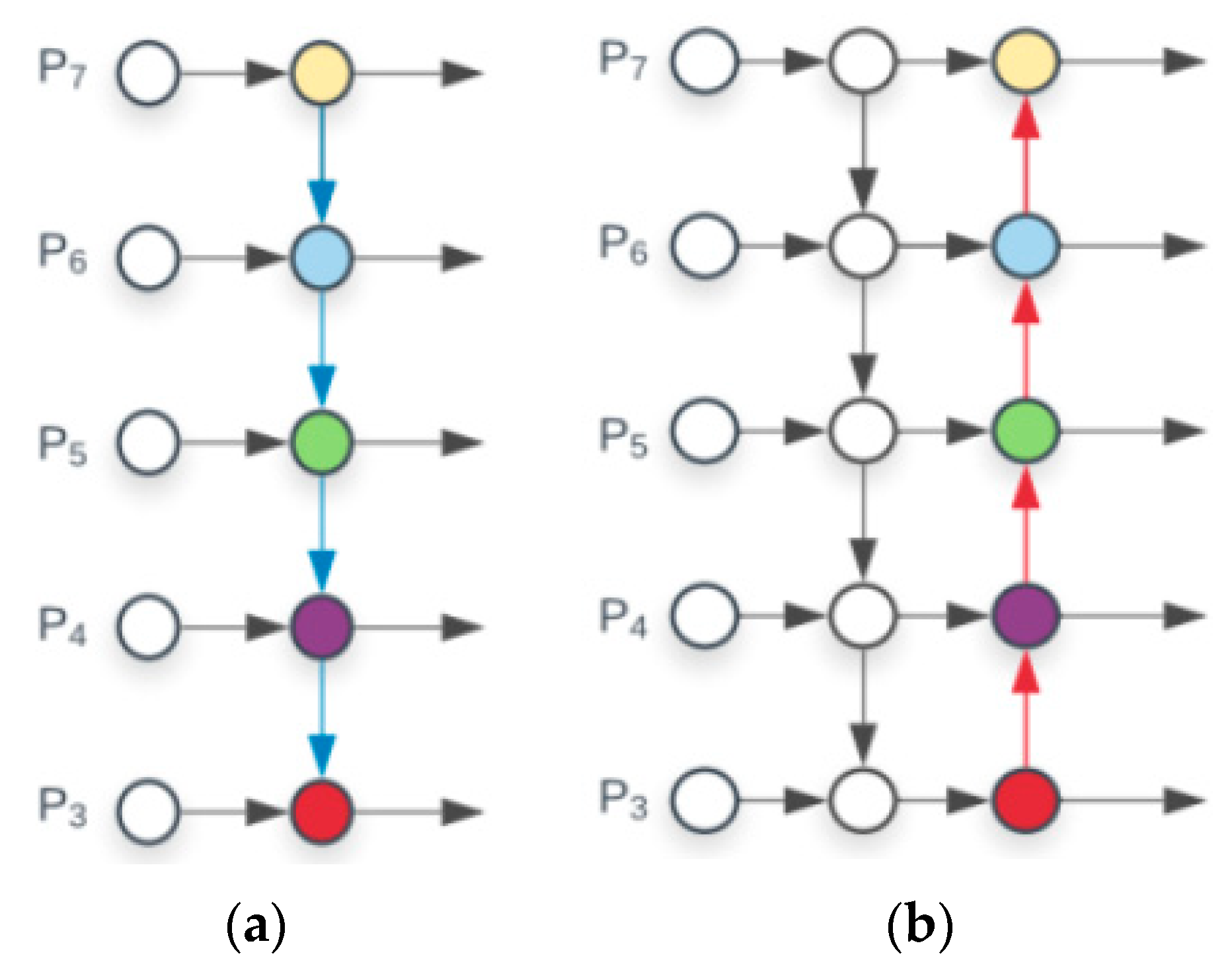
2.3. Path Aggregation Network Structure
2.4. CIoU of YOLOv4
3. AN-YOLOv4 Algorithm
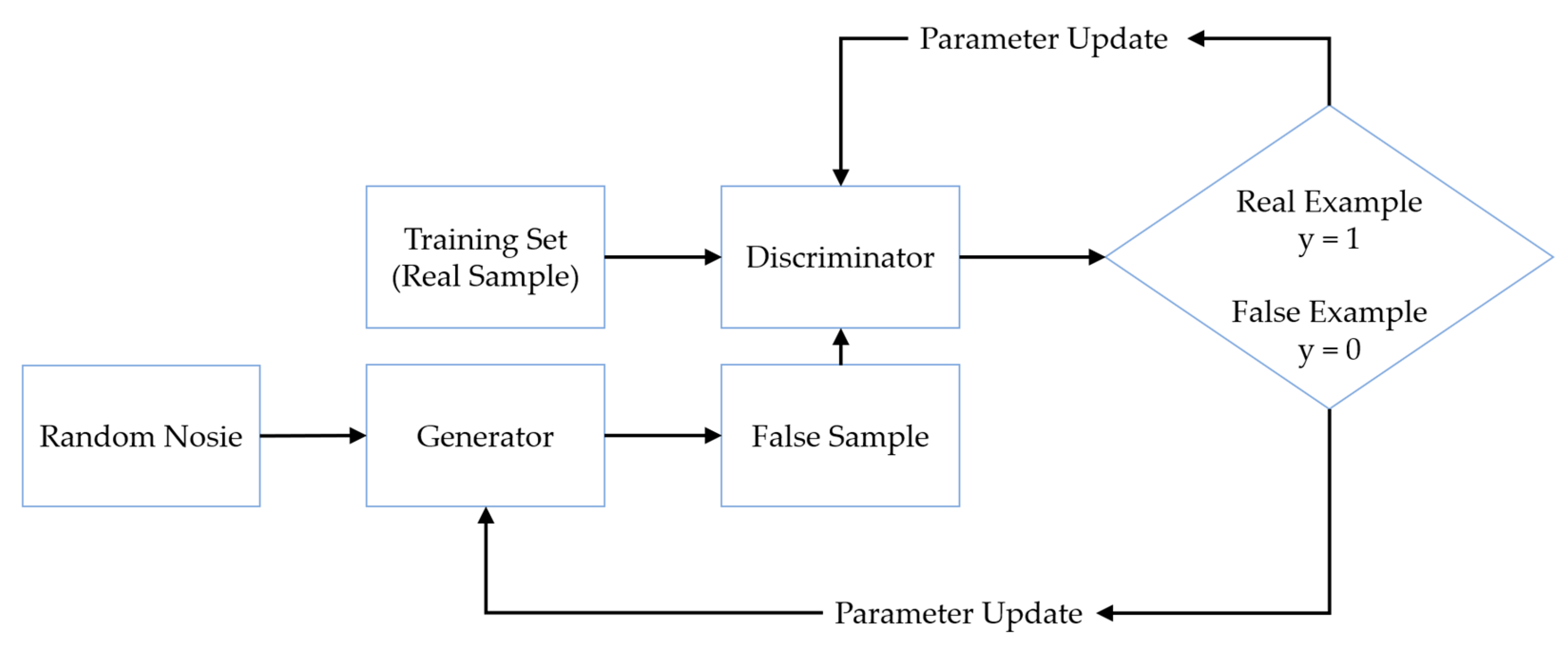
3.1. Data Enhancement Based on DCGAN
3.2. Data Expansion Based on Image Feature Pyramid
3.3. Algorithm Improvement Based on k-means Clustering
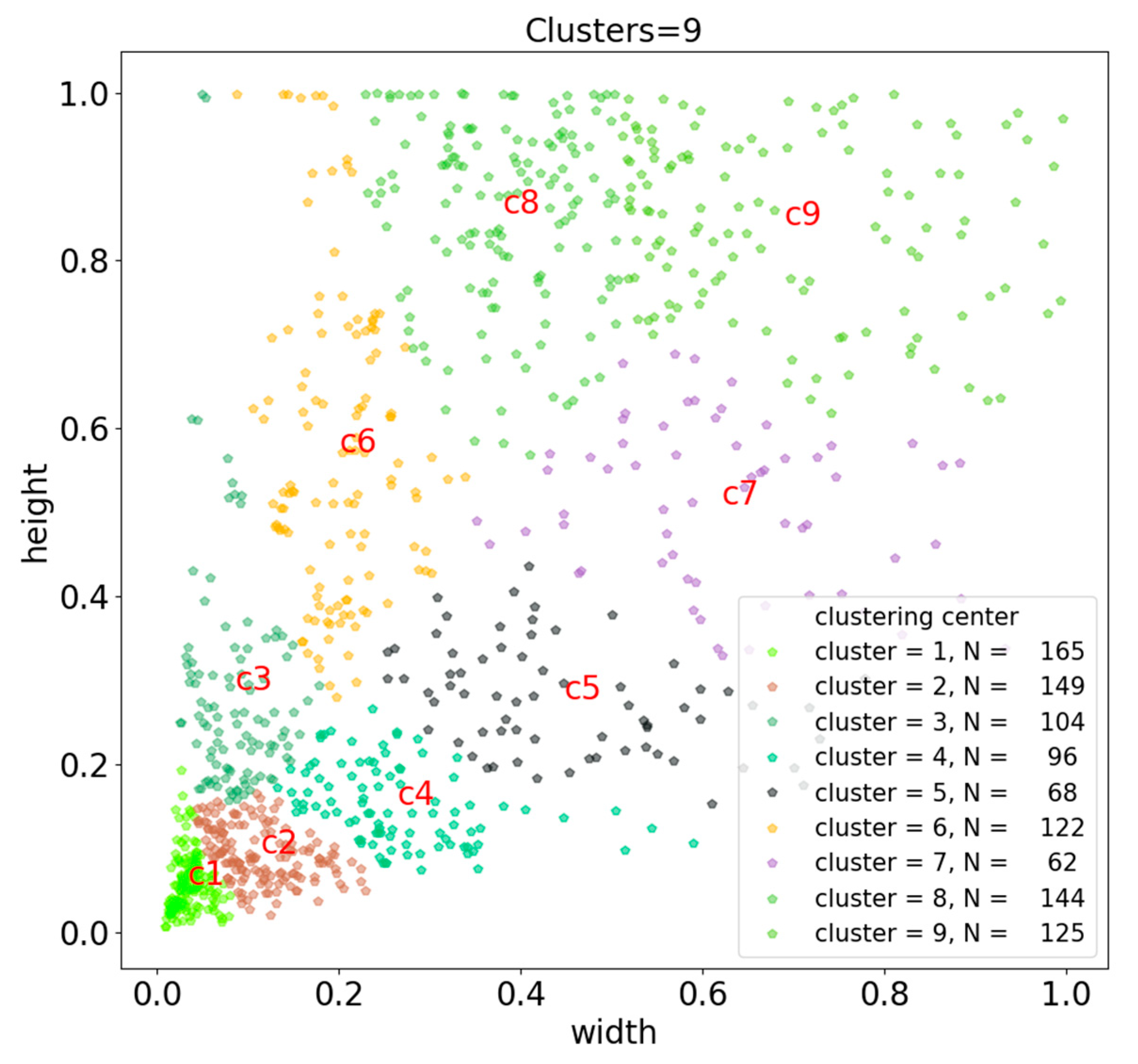
3.3.1. Introduction to the k-means Algorithm
3.3.2. Determination of AN-YOLOv4 Candidate Box Based on k-means
4. Evaluation
4.1. Data Preparation
4.2. Experimental Environment and Parameter Configuration
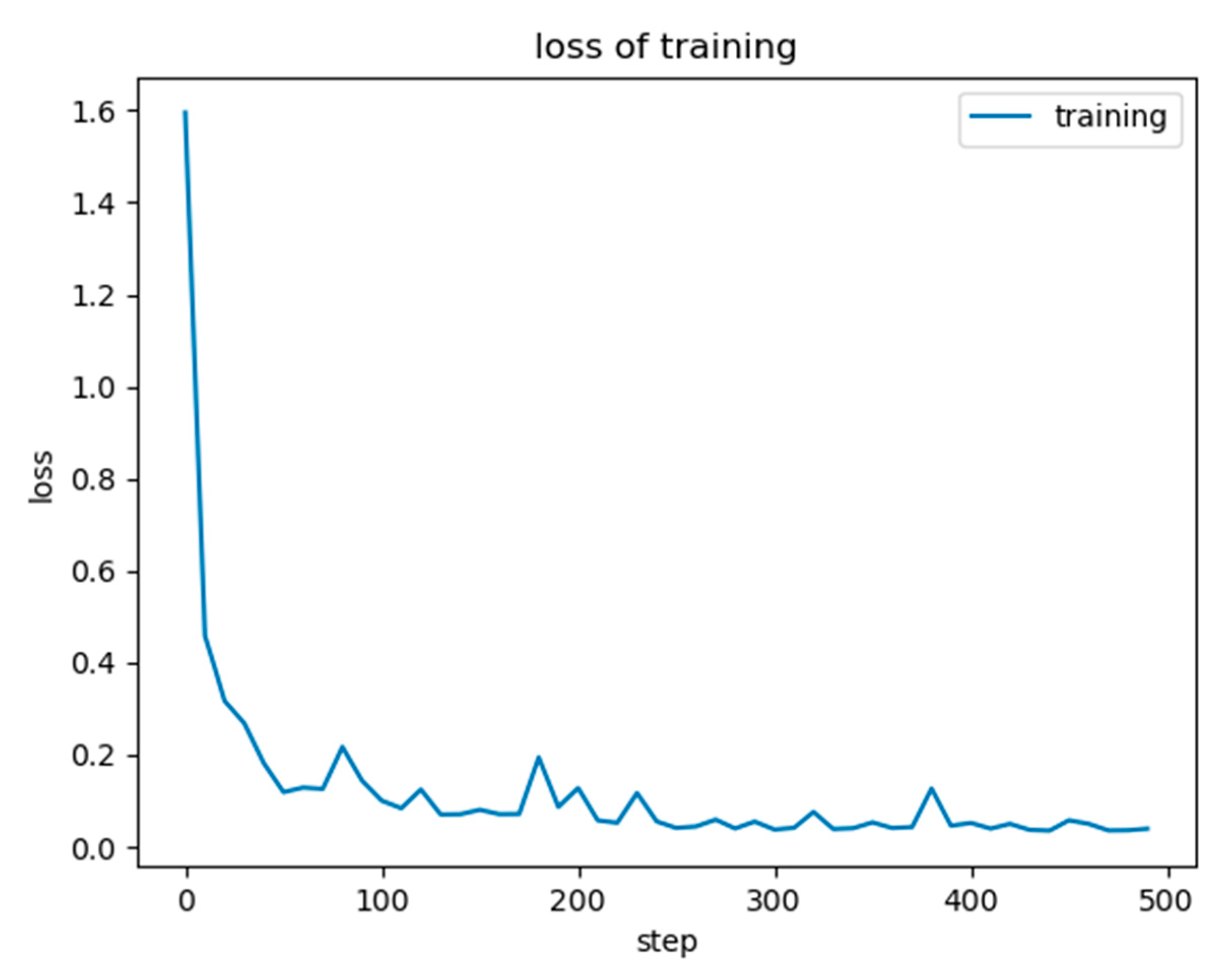
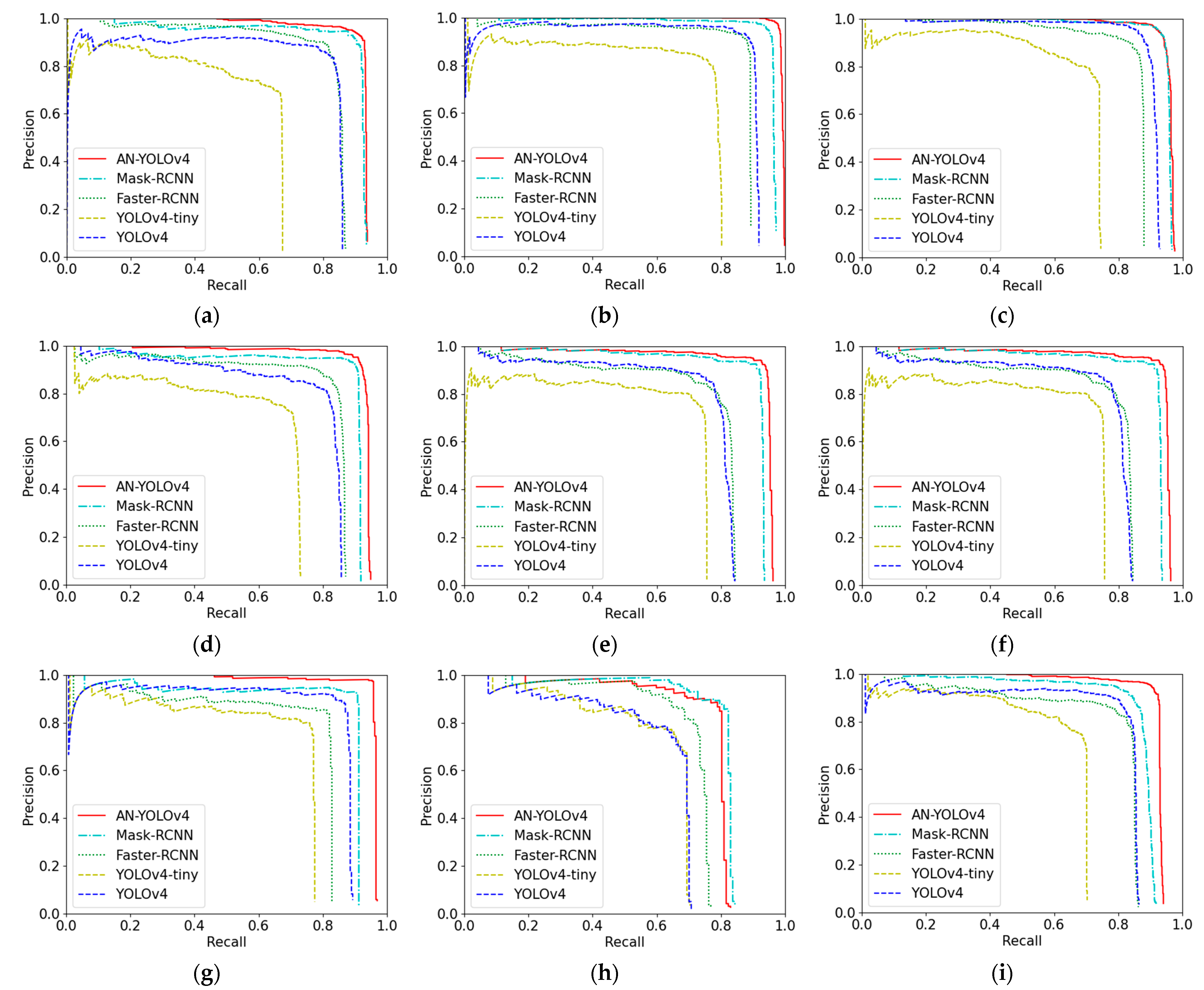
4.3. Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, S.B.; Huang, Y.J.; Duan, J.; Huang, D.W. Research on key technologies of visualization of navigation safety information. Hydrographic Surveyi. 2020, 40, 73–77. [Google Scholar]
- Zhu, B.; Wen, S.; Sun, H.F.; Wu, X.K. Application of nautical safety class notation on VLOC. Ship Eng. 2020, 42, 110–112+315. [Google Scholar]
- Chen, X.Q.; Li, Z.B.; Yang, Y.S.; Qi, L.; Ke, R. High-Resolution vehicle trajectory extraction and denoising from aerial videos. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3190–3202. [Google Scholar] [CrossRef]
- Ai, W.Z.; Ding, T.M. Research on fairway layout in bridge waters. J. Transp. Syst. Eng. Inf. Technol. 2014, 14, 131–137. [Google Scholar]
- Chen, X.Q.; Wang, S.Z.; Shi, C.J.; Wu, H.F.; Zhao, J.S.; Fu, J.J. Robust ship tracking via Multiview learning and sparse representation. J. Navig. 2019, 72, 176–192. [Google Scholar] [CrossRef]
- Chen, X.Q.; Ling, J.; Wang, S.Z.; Yang, Y.S.; Luo, L.J.; Yan, Y. Ship detection from coastal surveillance videos via an ensemble Canny-Gaussian-morphology framework. J. Navig. 2021, 74, 1252–1266. [Google Scholar] [CrossRef]
- Qiao, D.L.; Liu, G.Z.; Lv, T.Z.; Li, W.; Zhang, J. Marine vision-based situational awareness using discriminative deep learning: A survey. J. Mar. Sci. Eng. 2021, 9, 397. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.W. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.; Tang, W.L.; Jiang, L.; Fu, C.W. SE-SSD: Self-Ensembling single-stage object detector from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 14489–14498. [Google Scholar]
- Zheng, L.Y.; Tang, M.; Chen, Y.Y.; Zhu, G.B.; Wang, J.Q.; Lu, H.Q. Improving multiple object tracking with single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–24 June 2021; pp. 2453–2462. [Google Scholar]
- Feng, C.J.; Zhong, Y.J.; Gao, Y.; Scott, M.R.; Huang, W.L. TOOD: Task-aligned one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 3490–3499. [Google Scholar]
- Xuan, S.Y.; Zhang, S.L. Intra-Inter camera similarity for unsupervised person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 11921–11930. [Google Scholar]
- Cengil, E.; Cinar, A. Poisonous Mushroom Detection using YOLOV5. Turk. J. Sci. 2021, 16, 119–127. [Google Scholar]
- Redmon, J.; Diwala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science: Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Chang, Y.-L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.-Y.; Lee, W.-H. Ship detection based on YOLOv2 for SAR imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Deng, L.B.; Yang, C.; Liu, J.B.; Gu, Z.Q. Enhanced YOLO v3 tiny network for real-time ship detection from visual image. IEEE Access 2021, 9, 16692–16706. [Google Scholar] [CrossRef]
- Tang, G.; Liu, S.B.; Fujino, I.; Claramunt, C.; Wang, Y.D.; Men, S.Y. H-YOLO: A single-shot ship detection approach based on region of interest preselected network. Remote Sens. 2020, 12, 4192. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- You, Y.N.; Li, Z.Z.; Ran, B.H.; Cao, J.Y.; Lv, S.D.; Liu, F. Broad area target search system for ship detection via deep convolutional neural network. Remote Sens. 2019, 11, 1965. [Google Scholar] [CrossRef] [Green Version]
- Gao, L.R.; He, Y.Q.; Sun, X.; Jia, X.P.; Zhang, B. Incorporating negative sample training for ship detection based on deep learning. Sensors 2019, 19, 684. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.M.; Wu, R.Z.; Xu, K.Y.; Wang, J.M.; Sun, W.W. R-CNN-Based ship detection from high resolution remote rensing imagery. Remote Sens. 2019, 11, 631. [Google Scholar] [CrossRef] [Green Version]
- Li, L.Y.; Wu, D.F.; Wu, Z.M.; Yang, R.F. Fast maritime target detection method based on deep learning. Ship Eng. 2020, 42, 94–99. [Google Scholar]
- Liu, R.W.; Yuan, W.Q.; Chen, X.Q.; Lu, Y.X. An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system. Ocean Eng. 2021, 235, 109435. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Misra, D. Mish: A self regularized nonmonotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Lecture Notes in Computer Science: Computer Vision—Eccv 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; Volume 8691, pp. 346–361. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.F.; Shi, J.P.; Jia, J.Y. Path aggregation network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Cision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yu, J.H.; Jiang, Y.N.; Wang, Z.Y.; Cao, Z.M.; Huang, T. UnitBox: An advanced object detection network. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CFV Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.H.; Wang, P.; Liu, W.; Li, J.Z.; Ye, R.G.; Ren, D.W. Distance-IoU Loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. Acm. 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Yu, X.M.; Hong, S.; Yu, J.X.; Lu, Y.B.; Peng, Y. Research on a ship target data augmentation method of visible remote sensing image. Chin. J. Sci. Instrum. 2020, 41, 261–269. [Google Scholar]
- Liu, W.; Yang, M.F.; Nie, J.T.; Zhang, Y.; Yang, H.L.; Xiong, Z.H. Low-Light maritime image enhancement based on local generative adversarial network. Comput. Eng. 2021, 47, 16–23. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Guo, W. Automatic Ship Detection in Optical Remote Sensing Images Based on Deep Learning. Master’ Thesis, Wuhan University, Wuhan, China, 2019. [Google Scholar]
- Zheng, J. The Object Detection Method for Pedestrian Video Based on YOLOv3. Master’s Thesis, Xidian University, Xi’an, China, 2019. [Google Scholar]
- Nie, X.; Liu, W.; Wu, W. Ship detection based on enhanced YOLOv3 under complex environments. J. Omput. Appl. 2020, 40, 2561–2570. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 5–12 September 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Khasawneh, N.; Fraiwan, M.; Fraiwan, L. Detection of K-complexes in EEG signals using deep transfer learning and YOLOv3. Clust. Comput. 2022, 1–11. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers Name | Filter Size/Stride | Operations | Input Layer | Output Size (W × H × C) | |
|---|---|---|---|---|---|
| Generator | G-random input | N/A | 1 × 1 × 100 | ||
| Reshape | BN | G-random input | 4 × 4 × 1024 | ||
| T-Conv1 | 4 × 4/2 | BN, ReLU | Reshape | 8 × 8 × 512 | |
| T-Conv2 | 4 × 4/2 | BN, ReLU | T-Conv1 | 16 × 16 × 512 | |
| T-Conv3 | 4 × 4/2 | BN, ReLU | T-Conv2 | 32 × 32 × 256 | |
| T-Conv4 | 4 × 4/2 | BN, ReLU | T-Conv3 | 64 × 64 × 256 | |
| T-Conv5 | 4 × 4/2 | BN, ReLU | T-Conv4 | 128 × 128 × 128 | |
| T-Conv6 | 4 × 4/2 | BN, ReLU | T-Conv5 | 256 × 256 × 128 | |
| T-Conv7 | 4 × 4/2 | BN, tanh | T-Conv6 | 512 × 512 × 3 | |
| Discriminator | D-input | 3 × 3/2 | N/A | 512 × 512 × 3 | |
| Conv1 | 3 × 3/2 | LeakyReLU | D-input | 256 × 256 × 128 | |
| Conv2 | 3 × 3/2 | BN, LeakyReLU | Conv1 | 128 × 128 × 128 | |
| Conv3 | 3 × 3/2 | BN, LeakyReLU | Conv2 | 64 × 64 × 256 | |
| Conv4 | 3 × 3/2 | BN, LeakyReLU | Conv3 | 32 × 32 × 256 | |
| Conv5 | 3 × 3/2 | BN, LeakyReLU | Conv4 | 16 × 16 × 512 | |
| Conv6 | 3 × 3/2 | BN, LeakyReLU | Conv5 | 8 × 8 × 512 | |
| Conv7 | 3 × 3/2 | BN, LeakyReLU | Conv6 | 4 × 4 × 1024 | |
| flatten | N/A | Conv7 | 1 × 1 × 16384 | ||
| Sigmoid | N/A | flatten | 1 × 2 × 1 |
| Number | Candidate Box Coordinates | Ration |
|---|---|---|
| 1 | 17, 28 | 0.61:1 |
| 2 | 58, 47 | 1.23:1 |
| 3 | 44, 147 | 0.30:1 |
| 4 | 135, 77 | 1.75:1 |
| 5 | 229, 141 | 1.62:1 |
| 6 | 102, 292 | 0.35:1 |
| 7 | 318, 260 | 1.22:1 |
| 8 | 194, 438 | 0.44:1 |
| 9 | 352, 431 | 0.82:1 |
| Types of AtoN | Original Training Set | Improving Training Set | Testing Set |
|---|---|---|---|
| left lateral marks | 40 | 148 | 20 |
| right lateral marks | 39 | 148 | 20 |
| north side marks | 42 | 150 | 20 |
| south side marks | 41 | 149 | 20 |
| west side marks | 37 | 147 | 20 |
| east side marks | 35 | 138 | 20 |
| isolated danger marks | 51 | 155 | 20 |
| total | 285 | 1035 | 140 |
| Algorithm | DG | IPN | K-m | STA | APleft | APright | APeast | APwest | APsouth | APnorth | APdanger | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv4_0 | 0.78 | 0.88 | 0.90 | 0.77 | 0.78 | 0.75 | 0.83 | 0.60 | 0.79 | |||
| YOLOv4_1 | √ | 0.82 | 0.95 | 0.93 | 0.80 | 0.82 | 0.76 | 0.88 | 0.71 | 0.84 | ||
| YOLOv4_2 | √ | √ | 0.89 | 0.95 | 0.95 | 0.88 | 0.83 | 0.90 | 0.87 | 0.80 | 0.88 | |
| YOLOv4_3 | √ | 0.82 | 0.95 | 0.92 | 0.82 | 0.81 | 0.82 | 0.82 | 0.72 | 0.84 | ||
| YOLOv4_4 | √ | √ | 0.85 | 0.95 | 0.95 | 0.90 | 0.91 | 0.88 | 0.92 | 0.77 | 0.90 | |
| AN-YOLOv4 | √ | √ | √ | 0.92 | 1 | 0.95 | 0.92 | 0.93 | 0.93 | 0.95 | 0.78 | 0.92 |
| Algorithm | STA | APleft | APright | APeast | APwest | APsouth | APnorth | APdanger | mAP | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv4 | 0.78 | 0.88 | 0.9 | 0.77 | 0.78 | 0.75 | 0.83 | 0.6 | 0.79 | 30.8 |
| YOLOv4-tiny | 0.54 | 0.7 | 0.67 | 0.6 | 0.61 | 0.6 | 0.59 | 0.6 | 0.62 | 62 |
| Faster-RCNN | 0.82 | 0.86 | 0.85 | 0.8 | 0.72 | 0.76 | 0.75 | 0.71 | 0.78 | 12.0 |
| Mask-RCNN | 0.89 | 0.93 | 0.95 | 0.87 | 0.82 | 0.88 | 0.87 | 0.8 | 0.87 | 9.5 |
| AN-YOLOv4 | 0.92 | 1 | 0.95 | 0.92 | 0.93 | 0.93 | 0.95 | 0.78 | 0.92 | 30.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhen, R.; Ye, Y.; Chen, X.; Xu, L. A Novel Intelligent Detection Algorithm of Aids to Navigation Based on Improved YOLOv4. J. Mar. Sci. Eng. 2023, 11, 452. https://doi.org/10.3390/jmse11020452
Zhen R, Ye Y, Chen X, Xu L. A Novel Intelligent Detection Algorithm of Aids to Navigation Based on Improved YOLOv4. Journal of Marine Science and Engineering. 2023; 11(2):452. https://doi.org/10.3390/jmse11020452
Chicago/Turabian StyleZhen, Rong, Yingdong Ye, Xinqiang Chen, and Liangkun Xu. 2023. "A Novel Intelligent Detection Algorithm of Aids to Navigation Based on Improved YOLOv4" Journal of Marine Science and Engineering 11, no. 2: 452. https://doi.org/10.3390/jmse11020452