1. Introduction
Marine surface vessels autonomously sailing at sea has been the dream of ship designers for several decades. With the development of artificial intelligent decision-making technology, advanced sensors, and control methodology, this dream might come true soon [
1]. Therefore, the concept of the marine autonomous surface vessel (MASS) was introduced by the International Maritime Organization (IMO) for fueling present ship intelligent collision avoidance decision-making research [
2]. The issue of autonomous collision avoidance on ships is one of the decision-making optimization problems that scholars have paid long attention to.
Numerous model-based collision avoidance methods have been proposed in the field of MASS, such as the artificial potential field (APF) method, the velocity obstacle (VO) method, the A* method, particle swarm optimization (PSO) path planning, and the inference of the time of collision avoidance algorithm [
3,
4,
5,
6,
7,
8]. However, the model-based method does not have self-learning ability, and the model complexity is too high [
9]. Although the model-based ship collision avoidance method has a good effect on the known model problems, it is difficult to establish a complete anti-collision model for numerous problems due to the complexity of real sea conditions. Most model-based algorithms have difficulty predicting the uncertainty in practical applications.
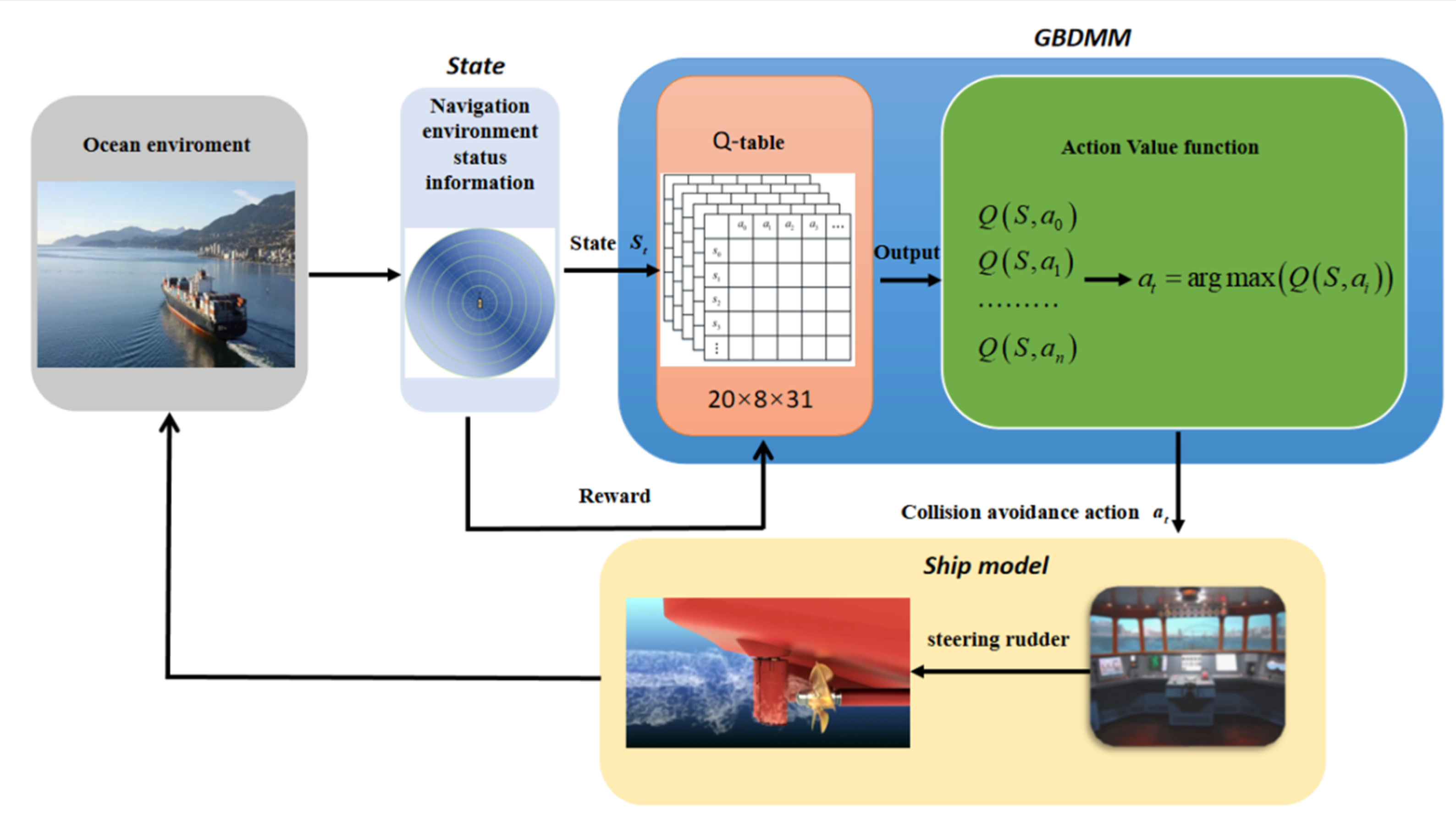
In recent years, with the rapid development of machine learning, especially reinforcement learning, artificial intelligence technology has been applied to ship collision avoidance decision-making. Model-free RL methods have strong self-learning ability, which is the most suitable method to solve those problems. The RL has the advantage that it does not depend on model construction. Relying on the state transition information collected through interaction with the environment, bypassing the complex problems such as system modeling, the RL agent can implement sequential decision-making through the Q-tables updates. Although fruitful research results based on the RL have been presented, there are still some problems to be solved in RL-based research. In previous studies, the model via RL algorithm, which is applied to the collision avoidance process, might increase the state transition chain length and lead to an explosion in computation complexity. Furthermore, the RL algorithm relies heavily on the input of the observation state, which directly affects the learning speed of the agent. In previous studies, the ship kinematic, dynamic, and environmental information, such as own ship’s and target ships’ course, speed, distance to the target, bearing, and so on, have usually been used as the input of the behavior decision-making Q-table model. That leads to a multi-dimensional Q-table structure to solve this problem. All the more so, the quantity of target ships might result in “dimensionality curse“ of observed states. In addition, in previous studies, most RL-based collision avoidance models make decisions that conform to COLREGs by designing complex reward functions. Due to the overly complex model, this method will lead to model learning difficulties. Motivated by the above analysis of the previous research problems, the contributions of this paper can be concluded as follows:
- (1)
The GBDM model trained via RL algorithm is only used in the collision avoidance behavior decision-making stage, which reduces the model computation burden and improves the efficiency of the model executive performance.
- (2)
Based on the virtual sensor called the grid sensor, the grid sensor is quantified as the input to the RL agent, which determines the dimensionality of the observation state of the GBDM model and clusters similar ship collision avoidance scenarios.
- (3)
When designing the reward function of RL, COLREGs are taken into account so that the ship’s collision avoidance operation is mainly starboard side alteration.
- (4)
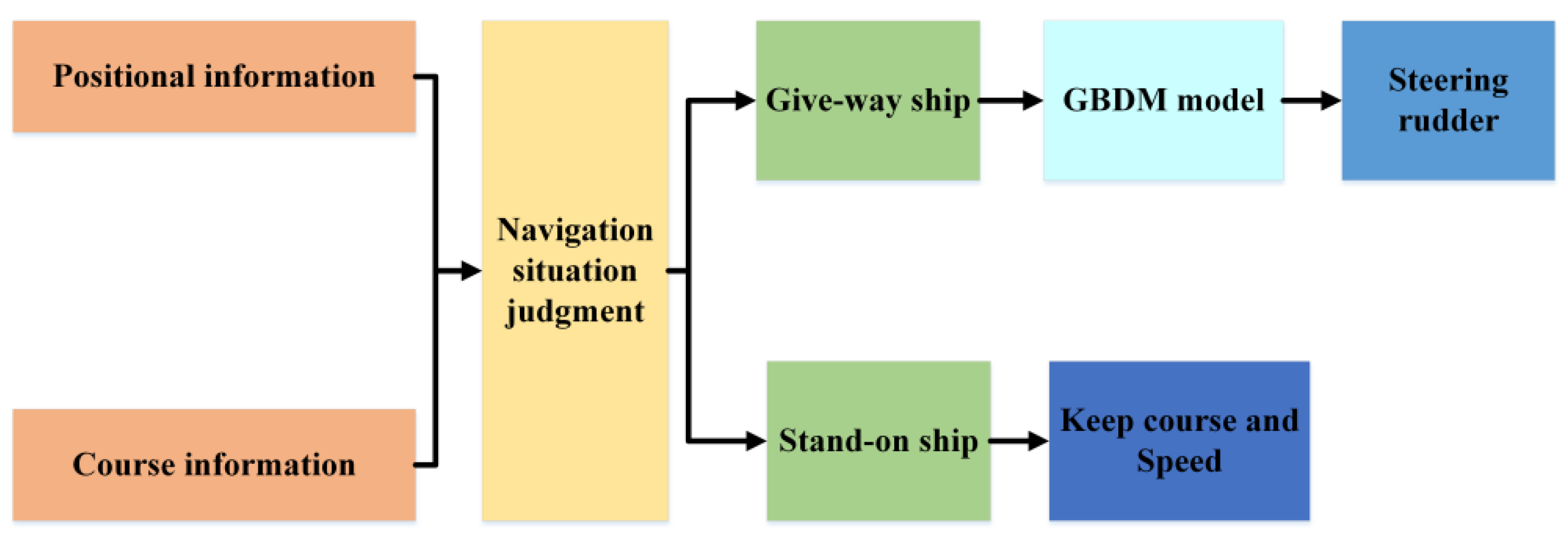
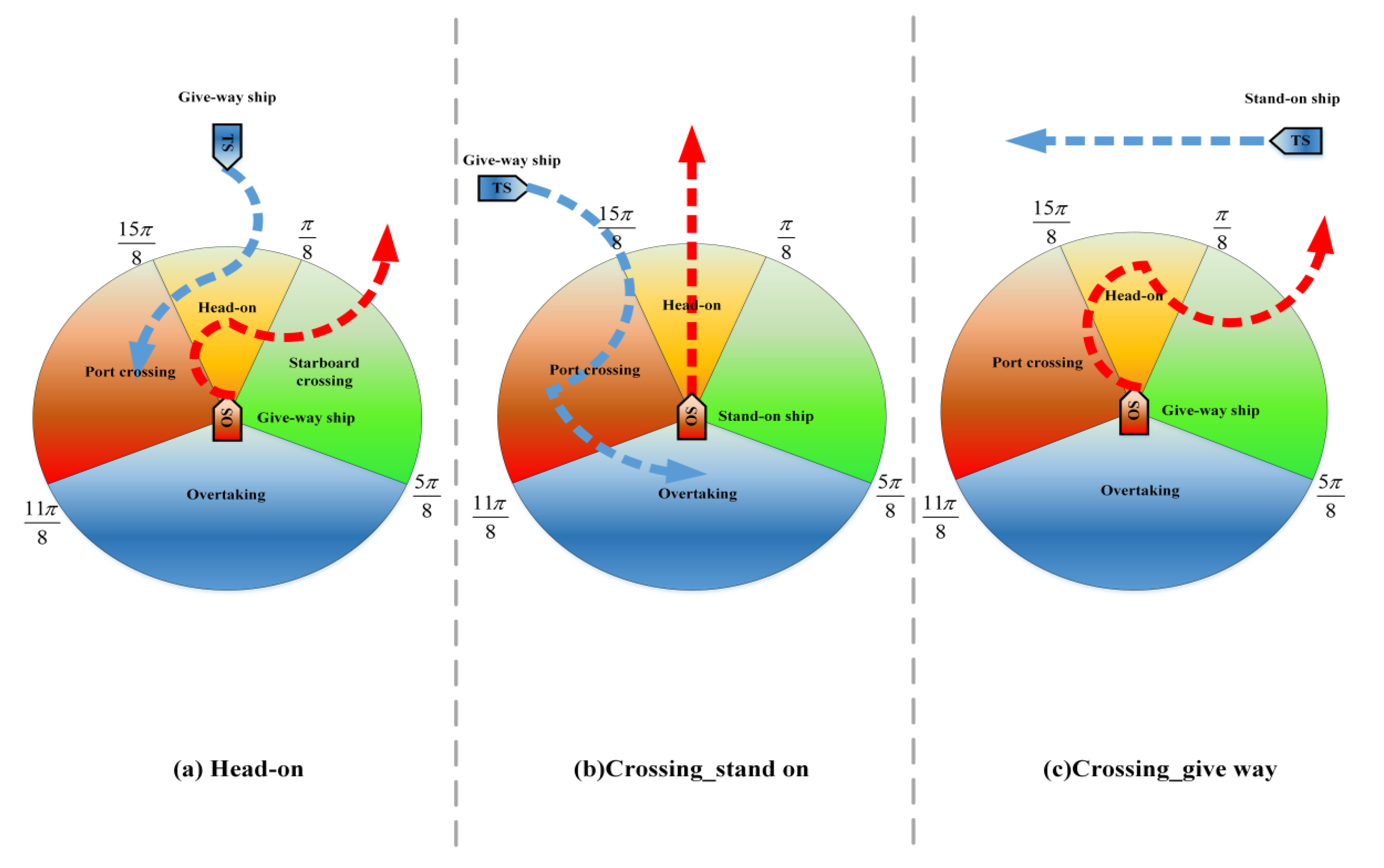
With the introduction of the navigational situation judgement, the ship can be recognized to be the give-way vessel or the stand-on vessel before the GBDM model makes an avoidance decision, which makes the decision-making more compliant with COLREGs without the increase in model complexity.
2. Literature Review and Motivation
So far, the issue of automatic collision avoidance in ships has attracted the attention of numerous researchers, and related theories and techniques have been continuously updated and developed. Generally, two major methods are divided: the model-based method and the model-free method. Before the rapid development of machine learning, model-based collision avoidance algorithms such as the APF method, the VO method, the A* method, PSO path planning, and inference of the time of collision avoidance algorithm were proposed. Based on the general requirements of COLREGs and APF method, Lee et al. proposed a multi-ship collision avoidance and route generation algorithm [
3]. The simulation results showed that the proposed anti-collision formulation can safely avoid collisions within a pre-determined distance. Lyu et al. proposed an improved APF, which contained a new improved repulsive potential field function and the corresponding virtual force to solve the collision avoidance problem between dynamic obstacles and static obstacles. Simulation results highlighted that the proposed method could quickly determine path planning in complex situations and take into account the unpredictable strategies of different ships [
4]. Wang et al. proposed a ship collision avoidance decision-making system based on the improved VO method. The improved VO method had good robustness and effectiveness in various ocean scenarios [
5]. Liu et al. proposed an improved A* algorithm that considers COLREGs and ship maneuverability, and the automatically generated path was economical and safe [
6]. E Krell et al. proposed an improved PSO to solve the problem of the PSO algorithm falling into local optimum [
7]. In order to evaluate the risk of collision avoidance, Wang et al. proposed a risk assessment system based on TCPA and DCPA to estimate the risk of ship collision [
8].
Although some studies have demonstrated the ability of the model-based method to ship collision-free paths, several challenges must be addressed. As the marine traffic become more complex, model-based methods cannot be effectively extended to deal with a large number of target ships in dense traffic. In addition, the model-based methods make the model overly complex for considering all possible situations. Hence, minor changes in the environment may cause failure. Since model-based methods do not have self-learning ability, most algorithms cannot predict uncertainty in practical applications. The model-free RL algorithm can excellently adapt to complex systems and has good self-learning ability, which provides an effective way to solve extremely complex systems and find the optimal policies from unknown environments through trial and error interaction [
10,
11,
12].
In recent years, many scholars have focused on multi-ship obstacle avoidance decision problems based on RL algorithm. Shen et al. proposed an automatic collision avoidance algorithm based on deep Q-learning (DQN). Through experiments, it is proved that the DQN-trained model has the possibility of achieving ships automatic collision avoidance [
13]. Based on the Deep Neural Network (DNN), Zhao et al. proposed a multi-ship collision avoidance method that could directly map the states of encountered ships to the steering rudder angle via the decision model. Moreover, the ship encounter situations are classified into four regions based on COLREGs, and only the nearest ships in each region are considered as the target ships. The simulation results indicated that the trained DNN model can avoid collision in the most encounter situations [
14]. Guo et al. designed a DQN algorithm using environmental state information as the training space, which could be quantified according to the actual navigation environment and COLREGs. Shipping navigation safety could be guaranteed by setting a series of collision avoidance reward functions [
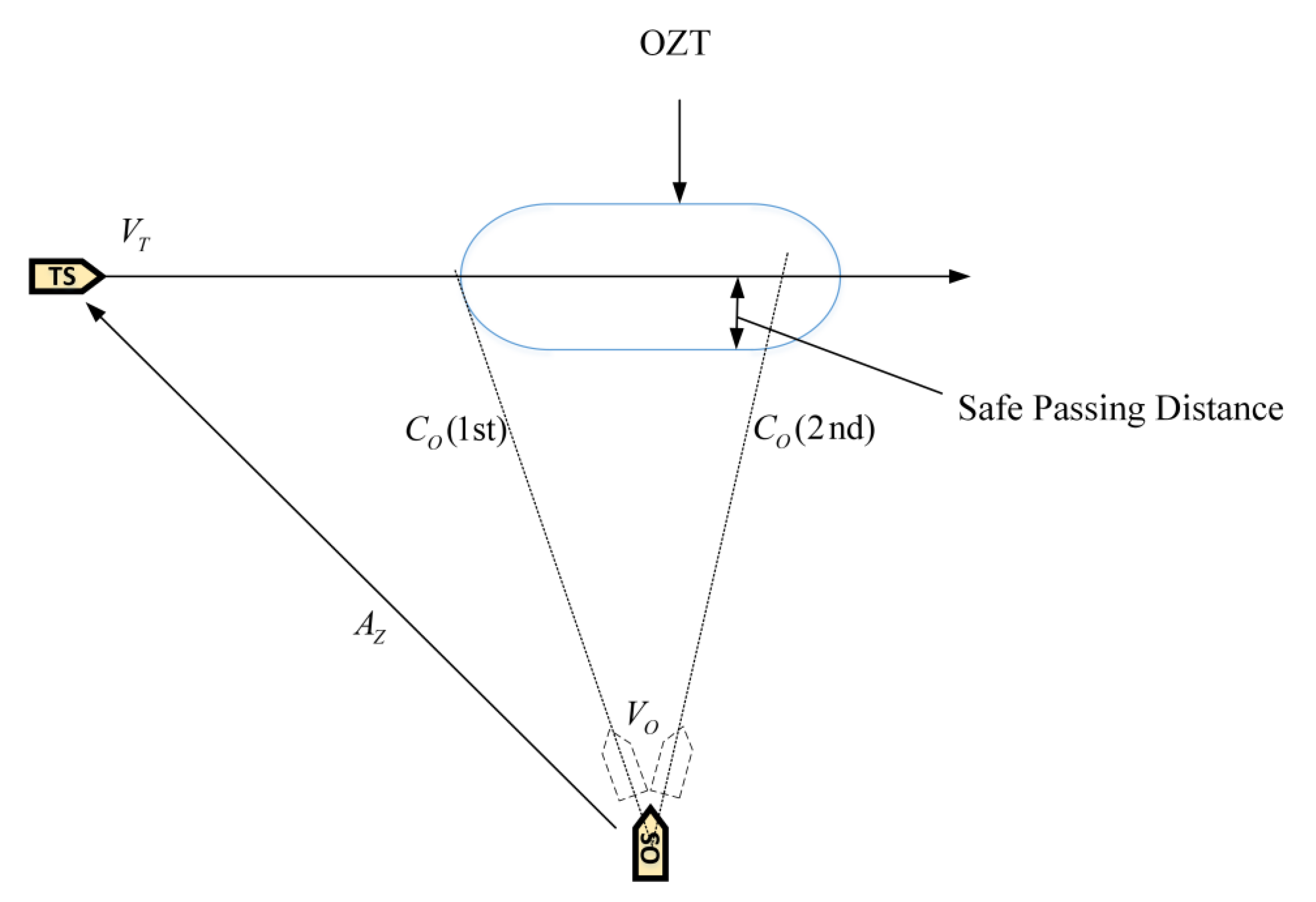
15]. Sawada et al. presented an automatic collision avoidance algorithm based on proximal policy optimization (PPO). Then, they proposed a novel virtual sensor based on the obstacle zone by target (OZT). Simulation results indicated that the model could handle up to three target ships [
16]. Woo et al. presented a new grid map representation based on the visual recognition ability of convolutional neural network (CNN). The DRL was applied to the model training for the USV collision avoidance problem. The experiments and simulations indicated the collision avoidance ability of the trained model [
17]. Chun et al. proposed a collision risk assessment method based on the ship domain and the closest point of approach (CPA). The results indicated that the improved algorithm could effectively avoid collision and enhance navigation safety [
18]. Li et al. utilized the APF algorithm to improve the action space and reward function of the DRL algorithm and set the collision avoidance zone based on the COLREGs. The simulation results showed that the improved DRL could achieve automatic collision avoidance and conform to COLREGs [
19].
In summary, although fruitful research results based on the RL have been presented, the problems of complicated models and excessive input of observation states are also prominent. Related issues are shown in
Table 1.
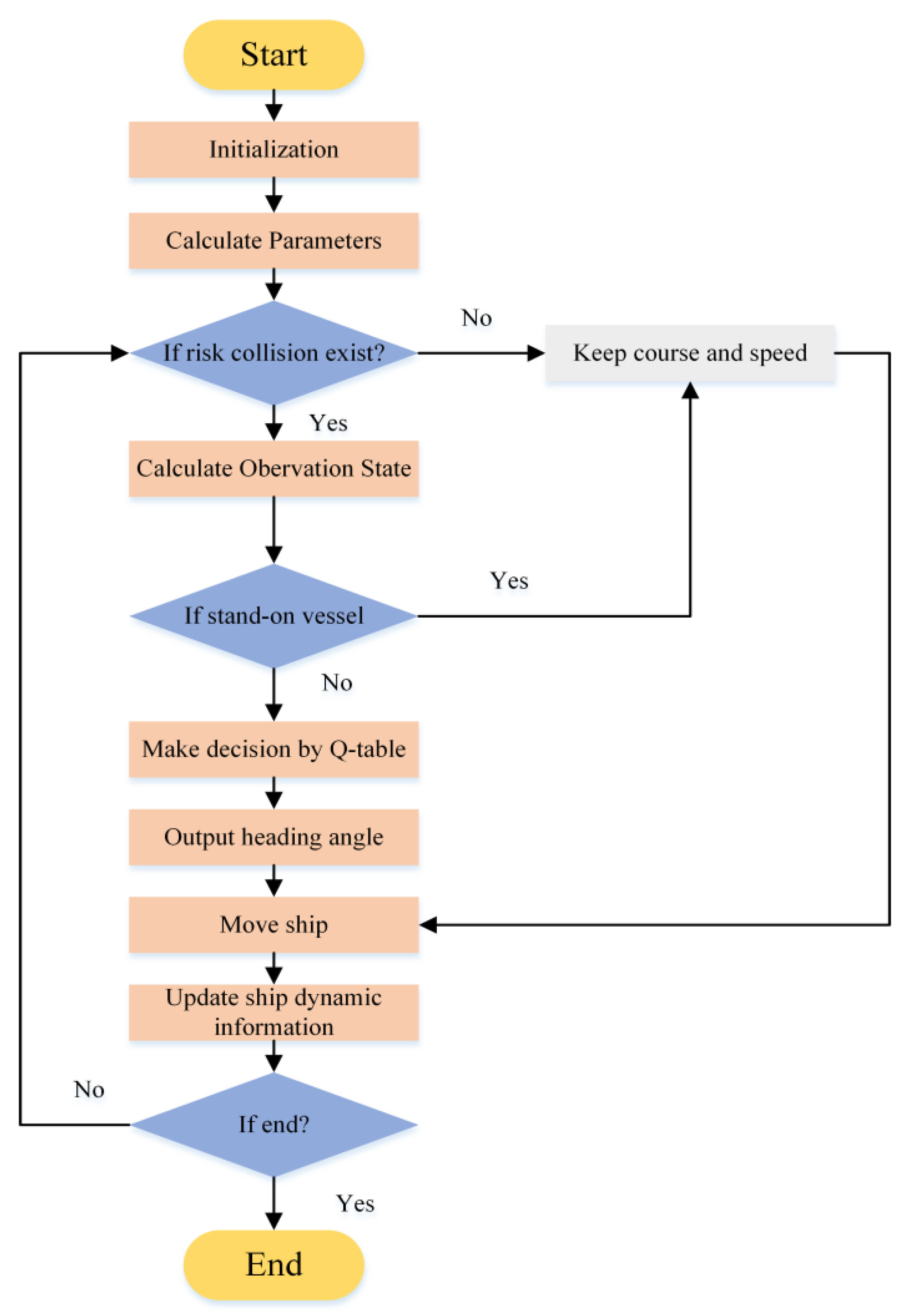
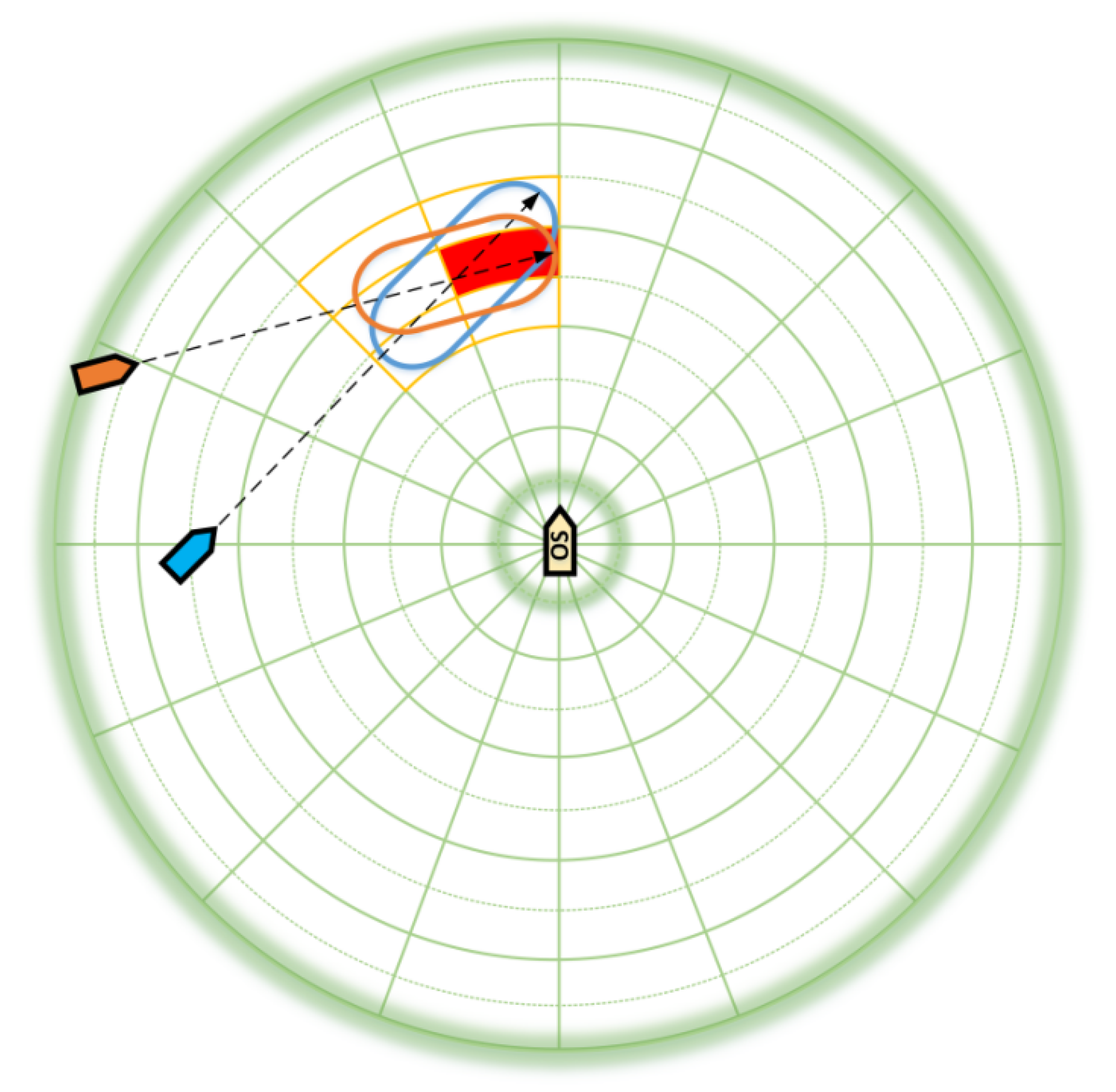
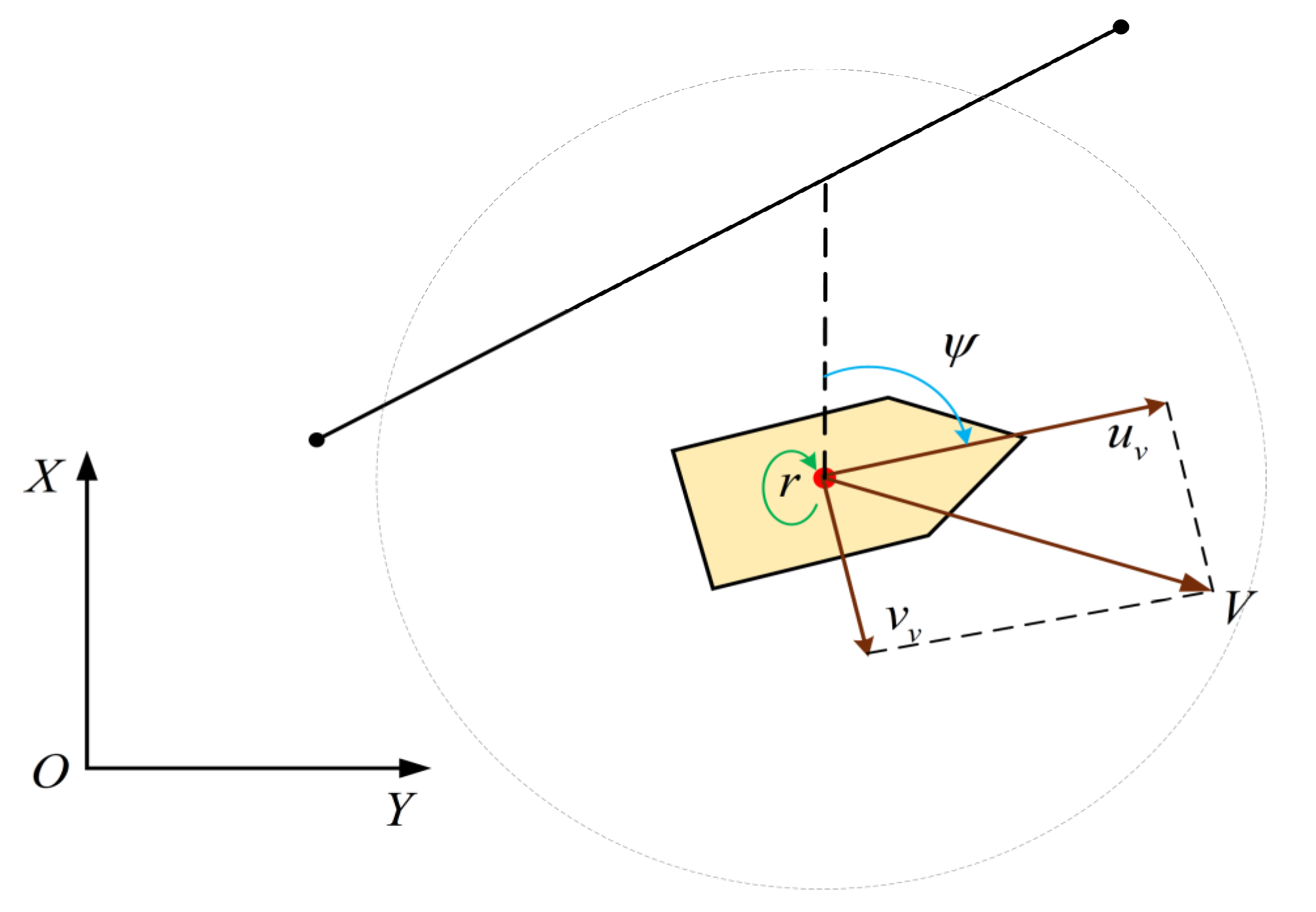
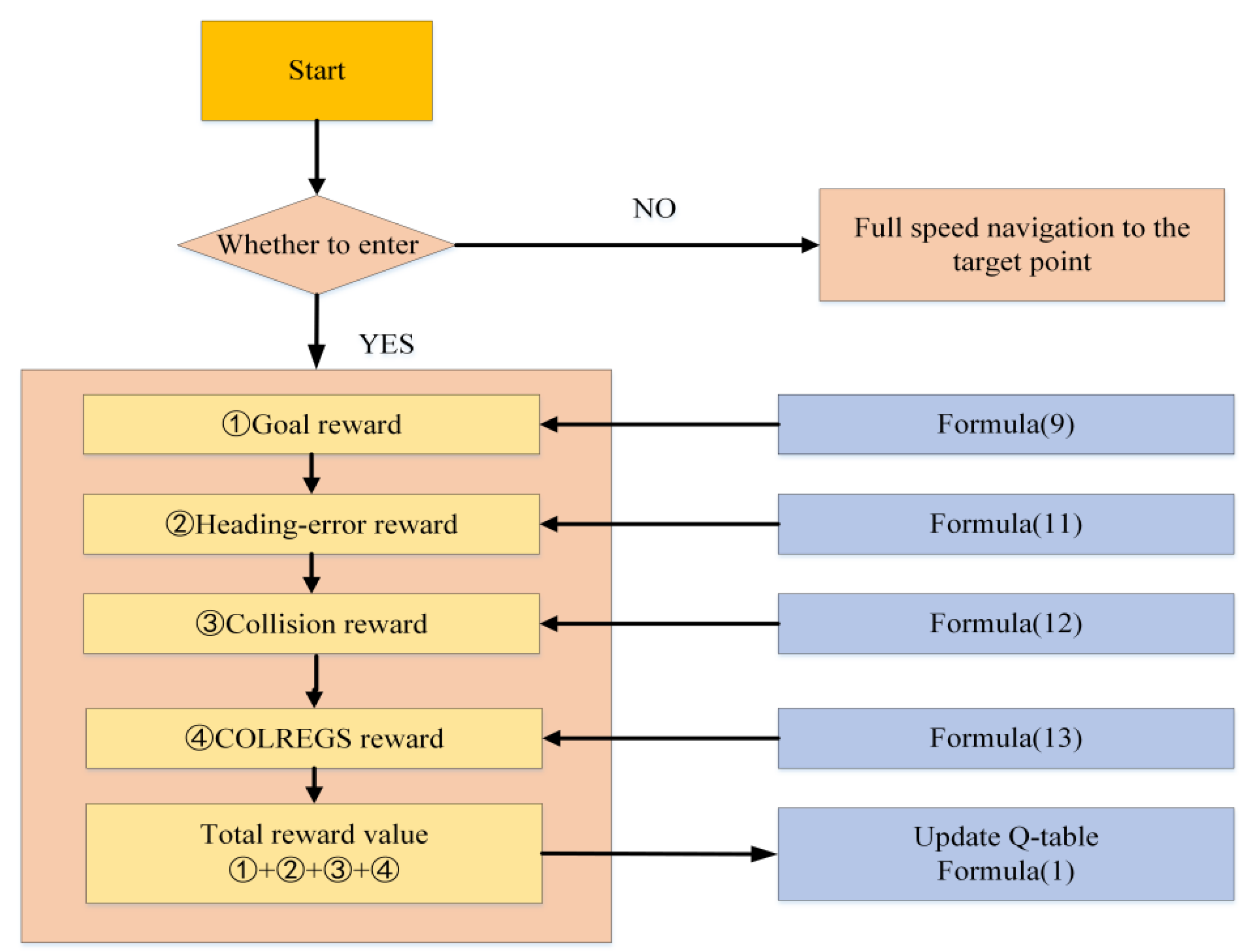
In this study, a GBDM model based on reinforcement learning, namely the Q-learning algorithm, is proposed. The grid sensor is quantified as the input of the RL algorithm, which reduces the input of observation states. The OZT algorithm is used for detection and clustering. In order to realize automatic collision avoidance of multiple ships, ship maneuverability is considered. The study also uses a three-degree-of-freedom (3-DOF) Nomoto ship motion mathematical model to simulate ship maneuvering, and the model’s action space is discrete rudder angles. This study also simplifies the reward function and introduces the navigation situation judgement to comply with the COLREGs. Finally, the trained GBDM model is only used in the collision avoidance behavior decision-making stage to improve the efficiency of the ship autonomous navigation system.
The organizational structure of this paper is as follows:
Section 3describes the principle and application of reinforcement learning algorithm. In
Section 4, the method of detecting collision risk is given firstly. Then, the ship motion model as the basis of ship collision avoidance is described. Furthermore, the design of the reward function is explained.
Section 5 and
Section 6 contain the simulation results of the multi-ship collision avoidance. In
Section 7, we discuss the experimental results and potential applications.
Section 8 is the conclusion of this paper.
5. Simulation and Analysis
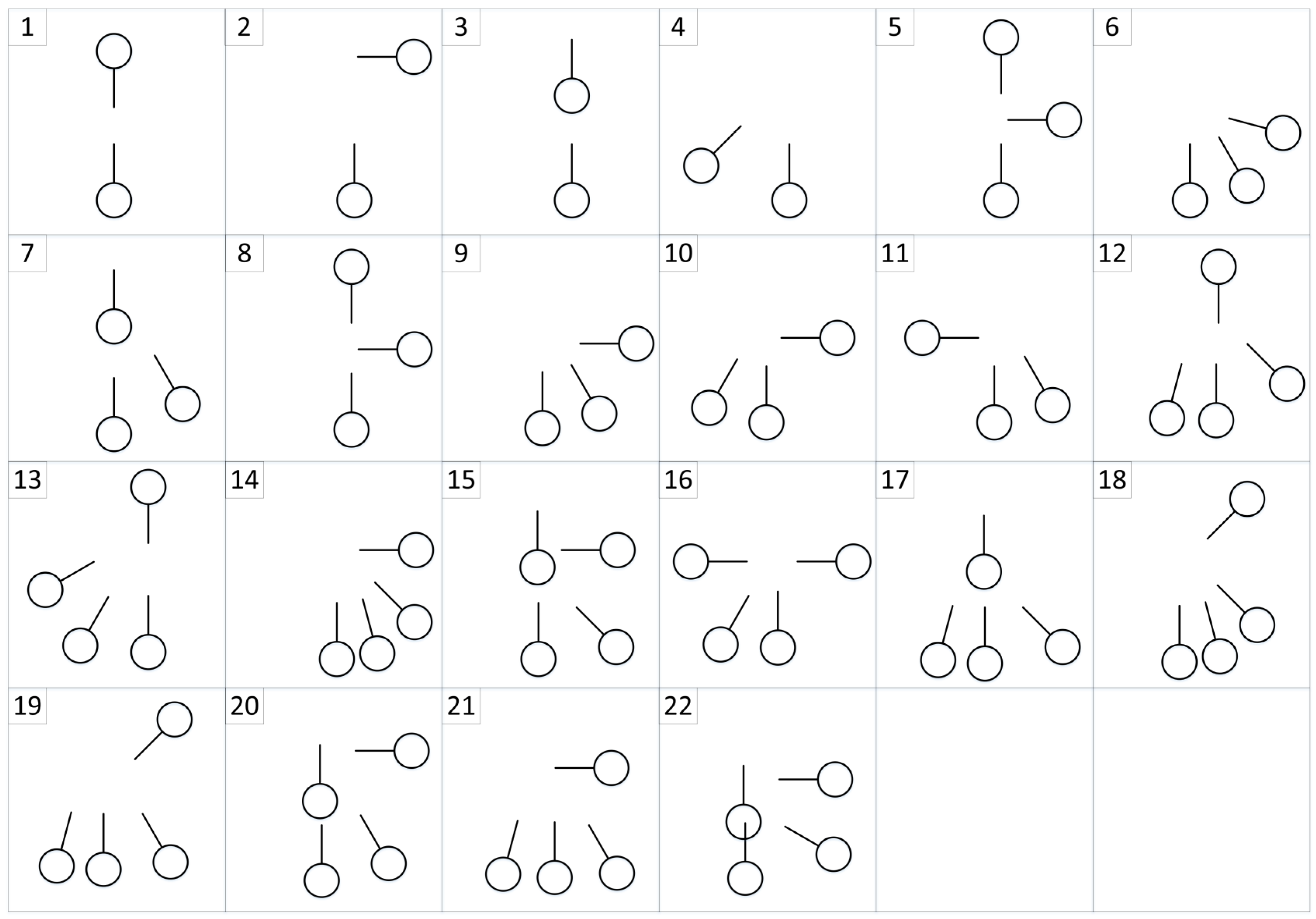
In this paper, it is assumed that the multi-ship encounter situations are at open sea without obstacles such as coastlines and buoys. The Imazu problem is treated as a learning scenario [
28]. The Imazu problem includes basic one-to-one ship encounter situations and different multi-ship encounter situations. As shown in
Figure 9, the number of cases for the Imazu problem is represented. Each circle represents the initial coordinates of the ship, and each bar represents the velocity vector of the ship. In addition, in order to improve the generalization performance of the GBDM model, this paper sets 60 different ship encounter situations based on the Imazu problem. The environment consists of OS and TSs. All intelligent ships in the encounter situations are intelligent ships and use the same GBDM model. The OS shall sail to the target points while avoiding target ships. Each intelligent ship updates the action value of the corresponding action on the Q-table during the training process. After finishing the multi-ship encounter situations training, the trained GBDM model (Q-table) is imported into the test environment to verify the training effectiveness. The test scenarios are shown in
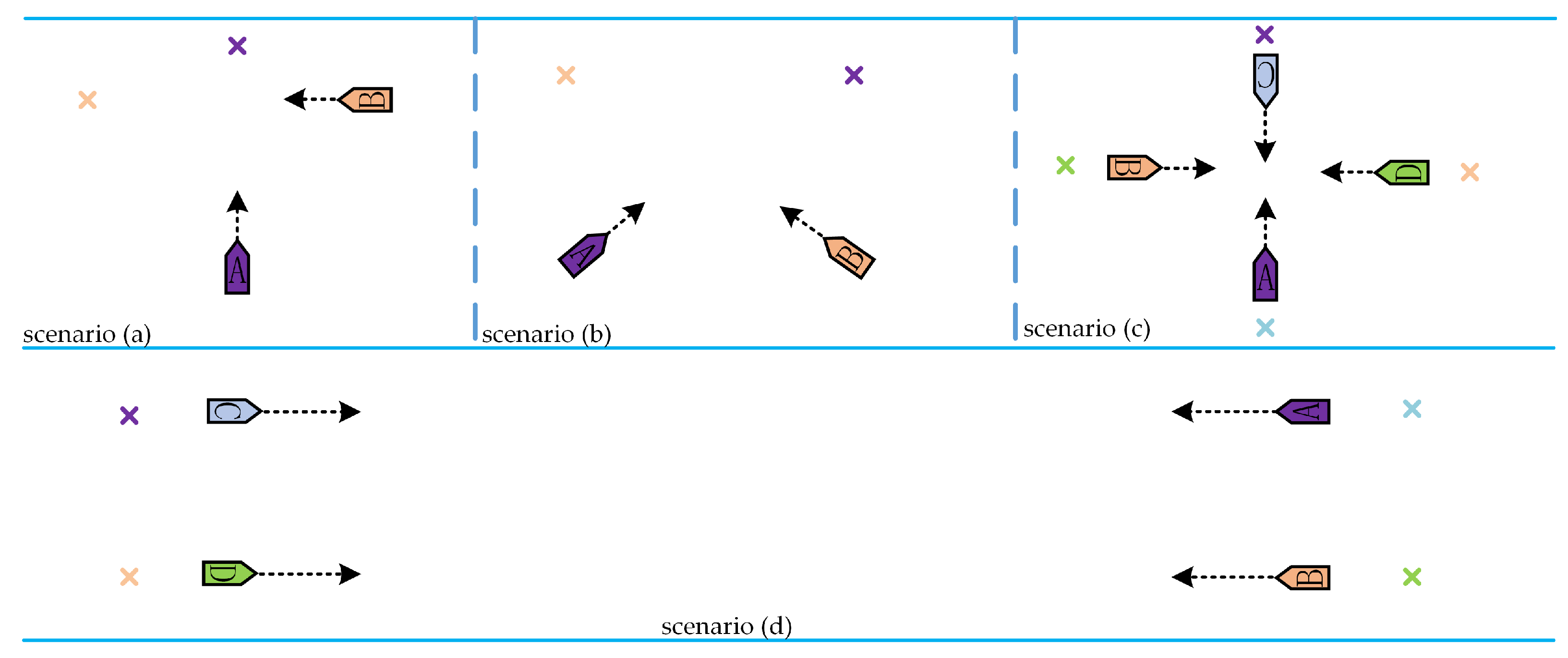
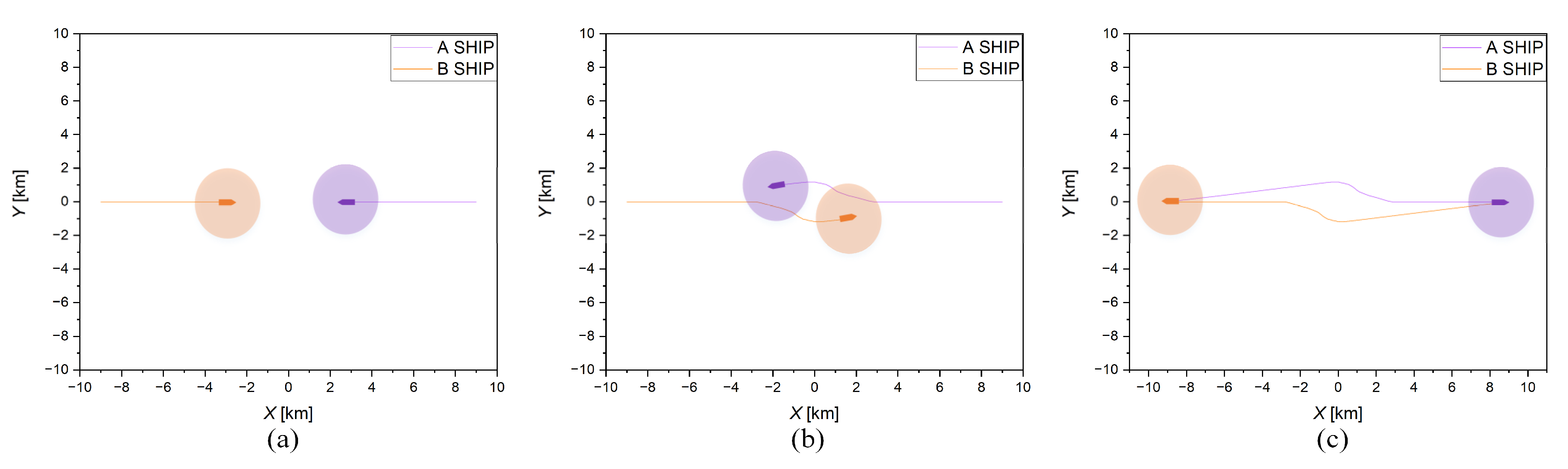
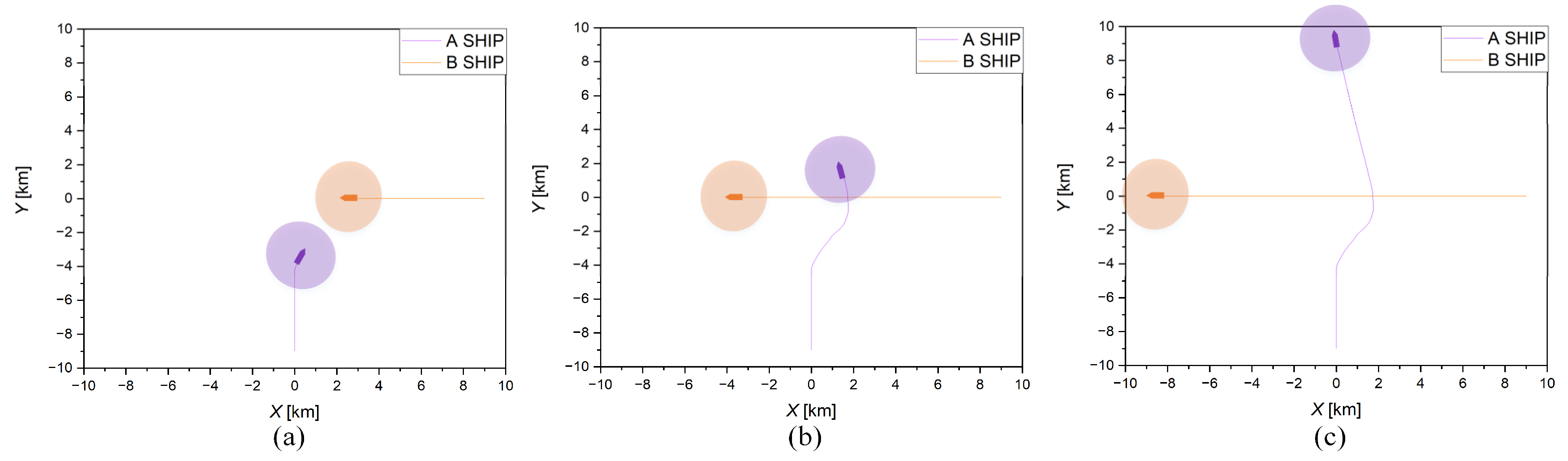
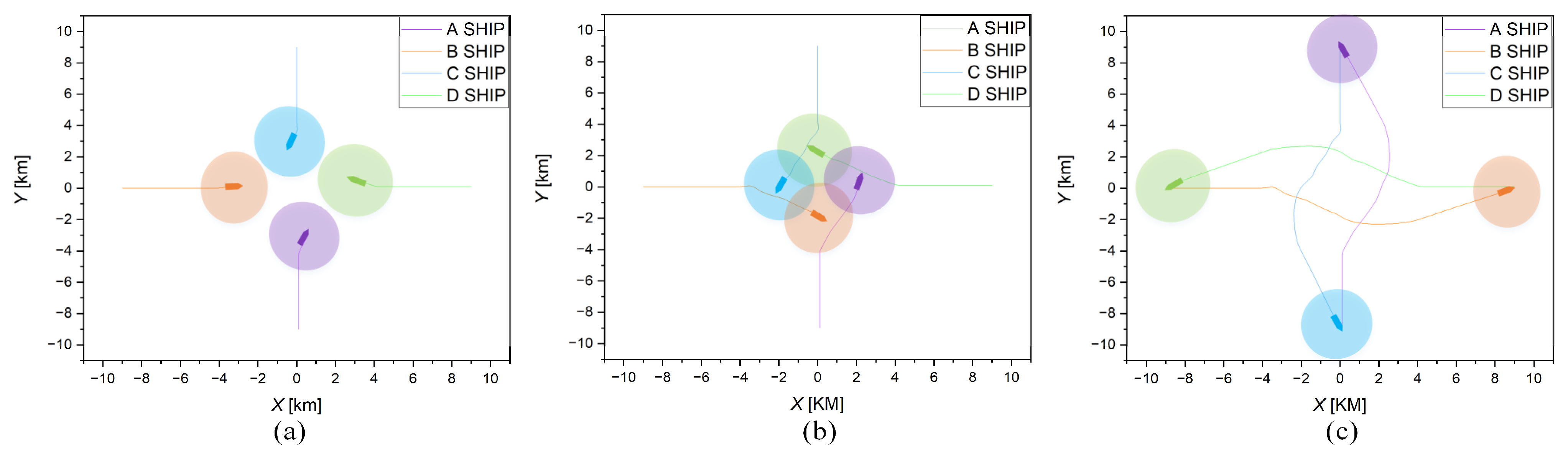
Figure 10. The four scenes contain two ship-to-ship crossing situations and two multi-ship encounter situations.
In this section, the training process based on the risk assessment of the COLREGs is presented. The intelligent ship is trained in 60 scenarios, and a total of 60 training environments are trained in one episode. Furthermore, each scenario is trained two rounds, and one round is trained 100 times. In order to test the trained GBDM model, scenario (a), scenario (b), scenario (c), and scenario (d) are simulated. The simulation scenario of the ship distribution is shown in
Figure 10, and the coordinates of the ship starting and target points are shown in
Table 4.
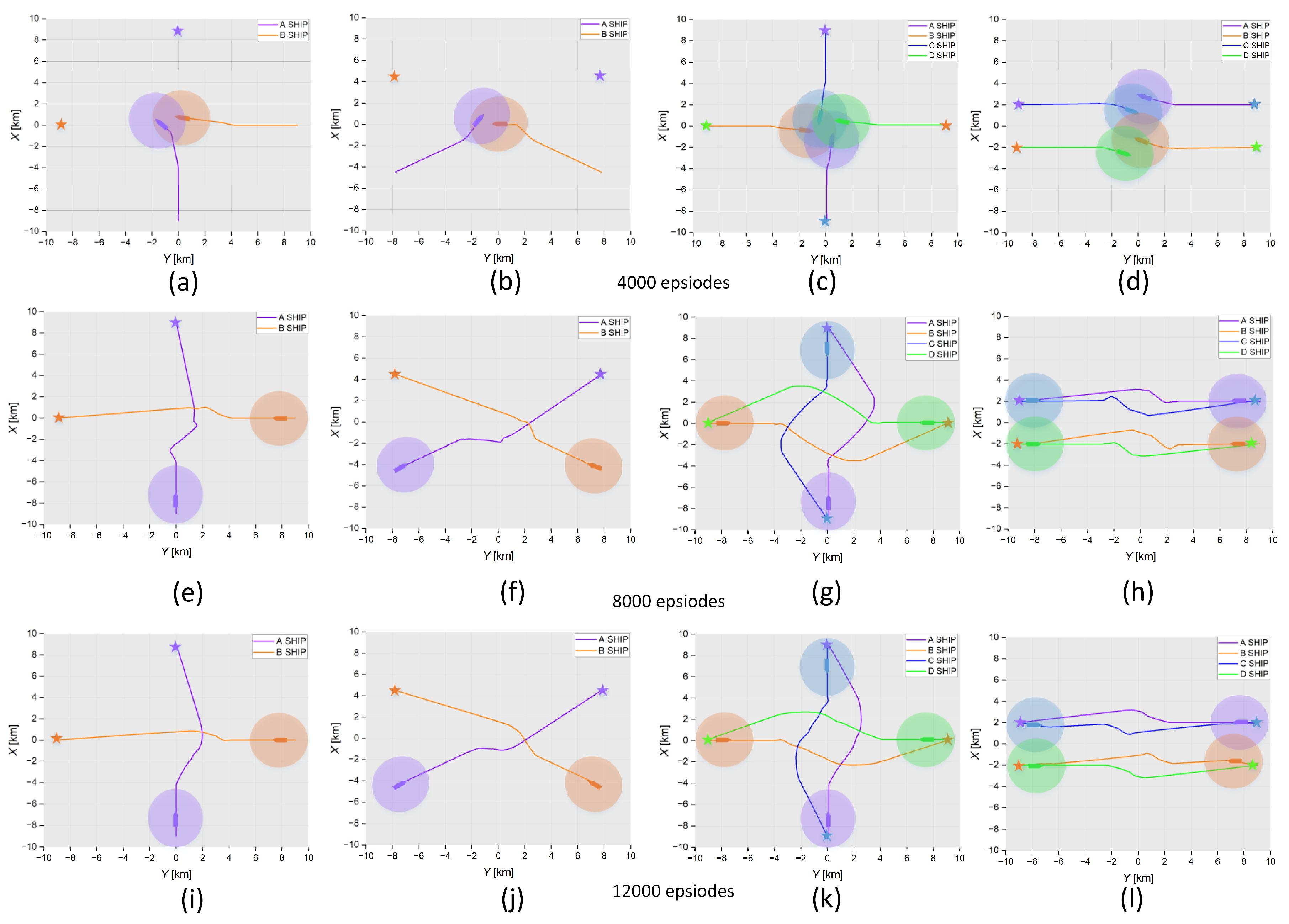
To inspect the effect of the GBDM model on the decision-making of ship collision avoidance after training different episodes, this paper conducted experimental simulation verification after training 4000, 8000, and 12,000 episodes in four scenarios, respectively. The results are shown in
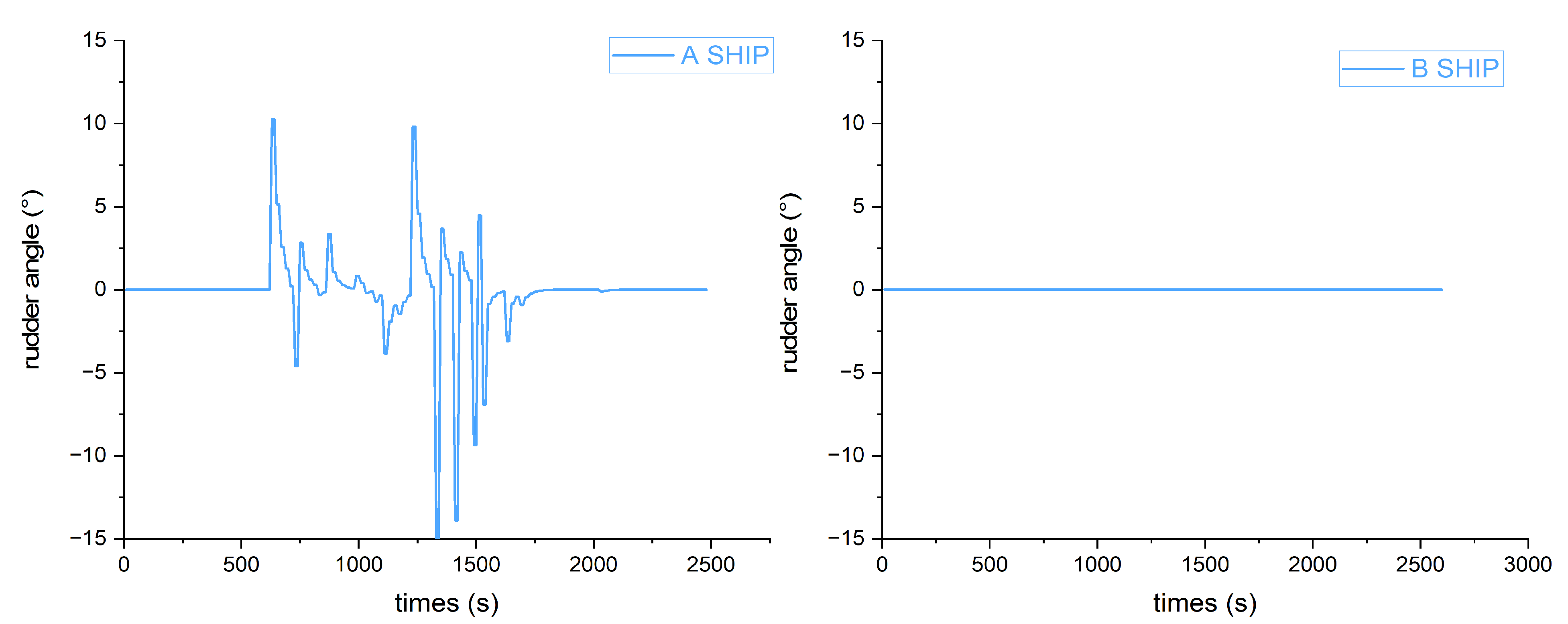
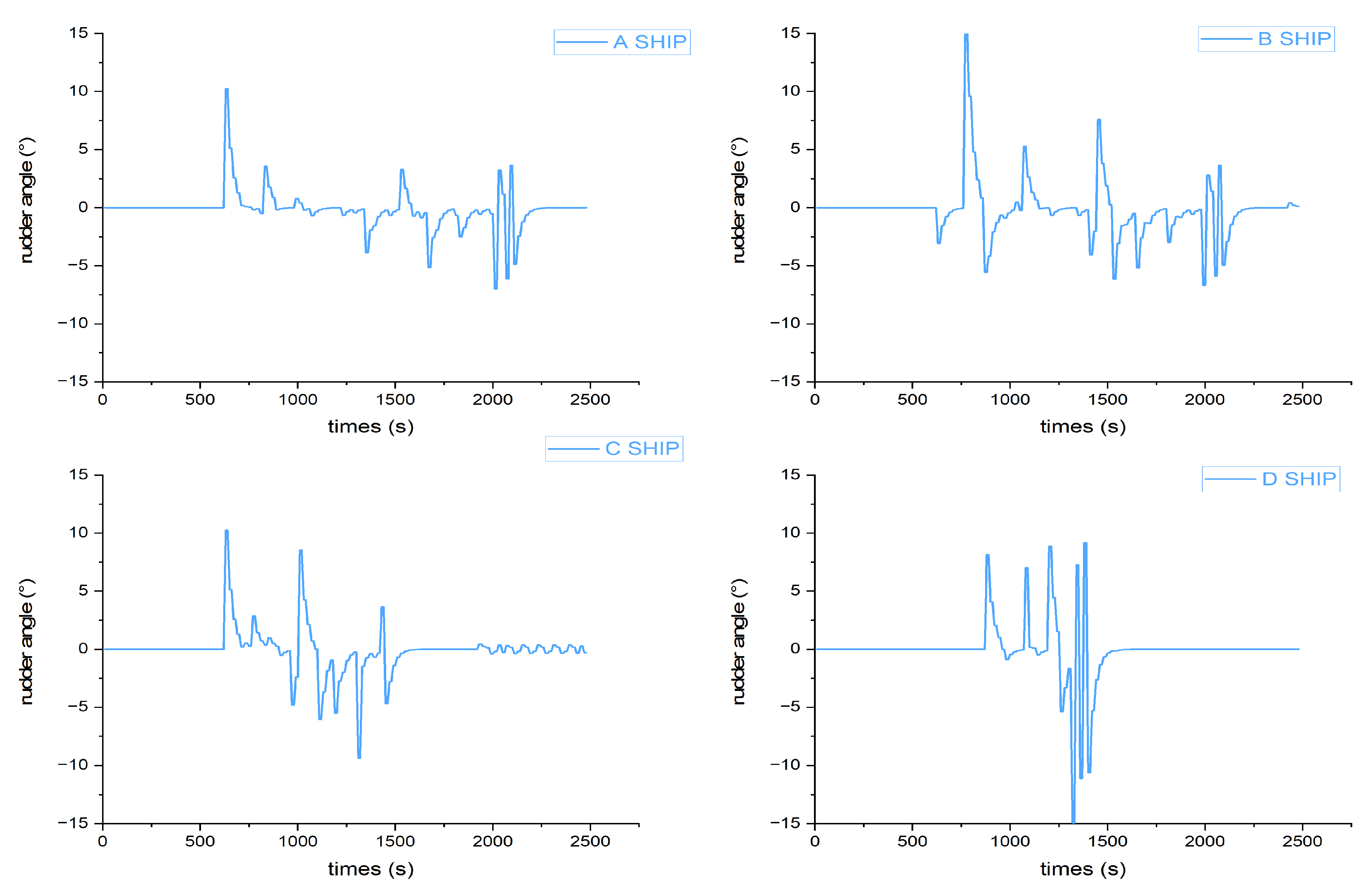
Figure 11. The four graphs in each row represent the results after different training episodes in scenarios (a–d). Scenario (a) is a two-ships head-on situation, scenario (b) is a two-ships crossing situation, and scenario (c) and scenario (d) are four-ships encounter situations. The initial settings of the ships in four different scenarios are shown in
Table 4. The first four graphs (a–d) are the results of 4000 training episodes. It can be seen that the trained GBDM model could not pass the scenarios test. Graphs (e–h) are the results of 8000 training episodes. The trained GBDM model barely passes the scenarios test, the ships are oversteered, and the path is not smooth. It is indicated that the collision avoidance behaviors are not optimal. After 12,000 training episodes, the results are shown in graphs (i–l). It is obvious that the trained ship GBDM model can provide a better collision avoidance decision. The trained model scenarios tests demonstrate the GBDM model’s ability of safety navigation and collision avoidance, but it is necessary to further test and verify whether the trained model conforms to COLREGs.
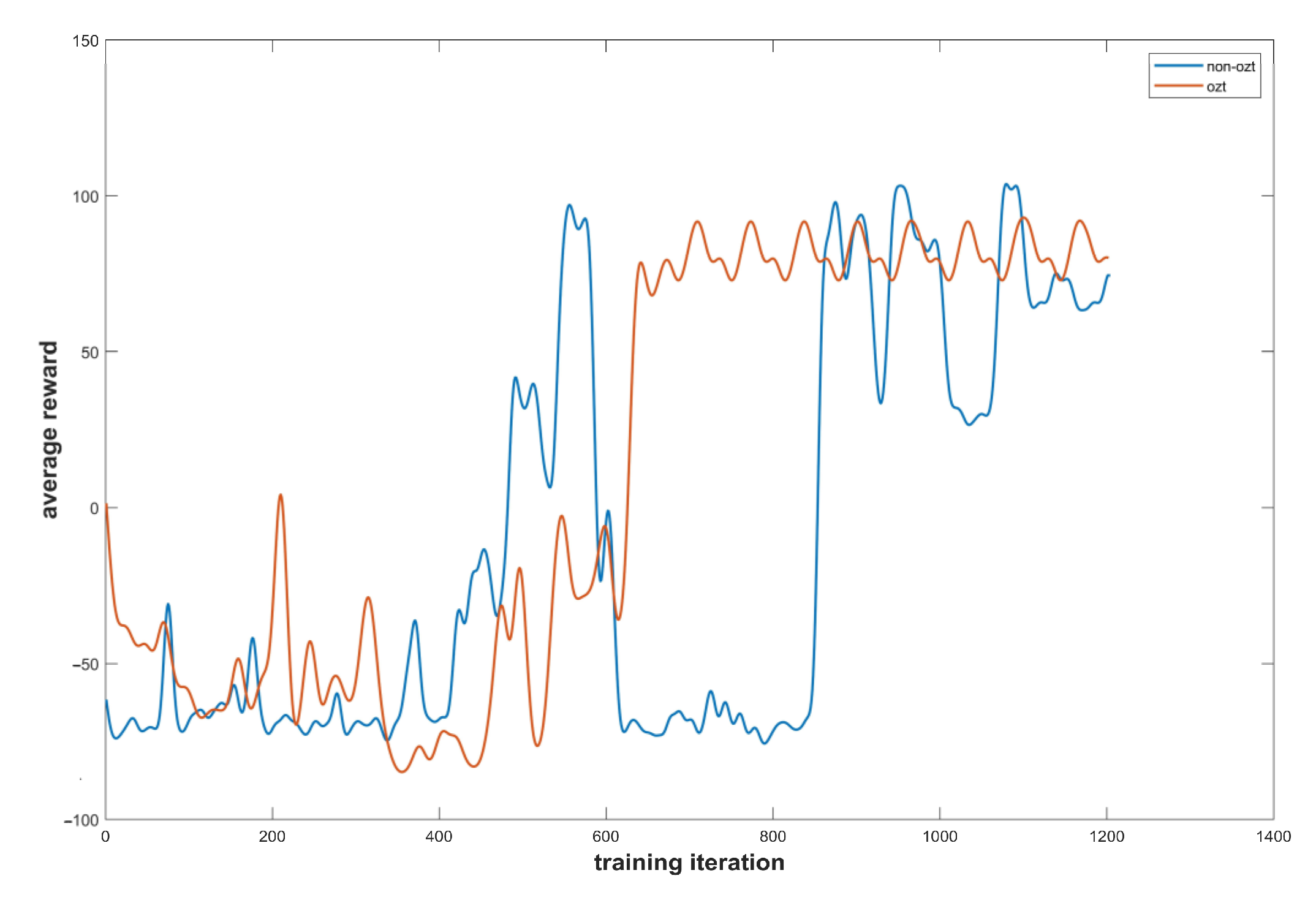
Figure 12 is the Q-learning algorithm comparison experiment results with and without the OZT. The orange line represents the average reward value per ten iterations with the OZT, and the blue line represents the average reward value per ten iterations without the OZT. It can be concluded that compared with non-OZT, the Q-learning algorithm can converge faster with the introduction of the OZT.
7. Discussion
This study simplifies the input of observation states and improves the convergence rate by introducing grid sensors and OZT, as shown in
Figure 11. The experimental results show that, with introducing the navigation situation into dividing the avoidance responsibility, the GBDM model can distinguish the give-way vessel and the stand-on vessel under the premise of complying with COLREGs as shown in
Figure 16 and
Figure 17. Furthermore, the input of observation states, the reward functions, and the action stages of the model are simplified by relevant methods in this paper. Finally, the experimental results demonstrate that the trained model can achieve multi-ship collision avoidance on the Imazu problem and converge faster. In some previous studies, Shen et al. [
13], Zhao et al. [
14], and Woo et al. [
17] used complex input of observation states to perceive the surrounding navigation environment. By contrast, the method in this paper shows that using the grid sensor as the input of observation states can simplify the input and also well perceive the surrounding environment. In this paper, based on the improved grid sensor proposed by Sawada et al. [
24], the observation state generated by the grid sensor can be applied to reinforcement learning without a complex neural network structure. In addition, in previous studies, Guo et al. [
15] and Li et al. [
19] designed complex reward functions to distinguish between the give-way vessel and the stand-on vessel. By contrast, this paper introduces the concept of navigation situation to judge the avoidance responsibility. The research results show that the GBDM model can distinguish between the give-way vessel and the stand-on vessel without increasing the complexity of the model. Compared with the previous experimental results, this paper improves the convergence speed of the model and obtains good experimental results in different collision situations.
The potential of this study is as follows: This paper provides a good research idea for designing a generalized ship collision avoidance decision-making model that complies with COLREGs without a complex reward function design. Since the proposed model is only used in the collision avoidance behavior decision-making stage, the proposed model has small computation burden. Due to the simple structure and low input dimension, the proposed GBDM model has strong real-time executive capability in the face of a complex navigation environment. In addition, the good convergence of the proposed GBDM model is highlighted. Future research is planned to use more complex scenarios and real marine traffic data to check the validity of the proposed model.
8. Conclusions
In this paper, an GBDM model via RL algorithm is proposed. Firstly, grid sensor detection OZT is used to reduce the complexity of GBDM model input information. Moreover, combining with the OZT detection technique and reinforcement learning algorithm, the proposed grid sensors can cluster the different ship-to-ship and multi-ship encounter situations. The convergence speed of the RL algorithm was also improved obviously. Furthermore, since the interaction between the designed GBDM model and the environment only occurs in the collision avoidance decision-making stage, the generalization and self-learning ability of the trained GBDM model is significantly improved. Moreover, the actions generated by the GBDM model can distinguish between a give-way ship and a stand-on ship without increasing the complexity of the model. Finally, a variety of collision avoidance scenario tests were carried out to evaluate the validity of the trained GBDM model. The simulation results indicate that the multiple ships could determine their collision avoidance actions simultaneously and in a timely manner to avoid each other and drive to the target point safely and effectively. In addition, it is prominent that the proposed method has a good generalization ability and can be applied to many different tasks, from ship-to-ship collision avoidance to multi-ship collision avoidance.
Although the method proposed in this paper can make collision avoidance decisions well in multi-ship encounters, there are still some problems to be explored in future research.
- (1)
The ship detection area does not explore the stern area of the ship; thus, the ship’s overtaking situation has not been considered.
- (2)
The interference of the ship navigation environment has not been considered in the collision avoidance decision-making model training, which might be necessary for practical implementation of the proposed method.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}