1. Introduction
Autonomous underwater vehicles have gained growing attention due to their irreplaceable role in marine data collection, subsea pipeline repair, subsea oil exploration, working in collaboration with divers, and thermocline analysis [
1,
2,
3,
4,
5,
6,
7]. Path planning and dynamic obstacle avoidance enable AUVs to reach the mission target safely without colliding with obstacles, which is an important guarantee for AUVs to perform the mission, and is the core technology of AUV autonomy. Path planning is divided into global path planning of known electronic charts and local path planning with unknown obstacles. The ability of AUV local path planning in a dynamic or uncertain underwater environment is crucial [
8]. In recent years, a variety of local path planning methods have been proposed. These methods improve the autonomy of AUVs, which mainly includes traditional methods and methods with learning capability.
The traditional local path planning methods mainly include Rapidly-exploring Random Tree (RRT), Artificial Potential Field (APF), and Fuzzy Logic Algorithm. It enables the AUV to avoid static and dynamic obstacles, and its path planning methods designed for specific working conditions is effective. However, these methods need to design the parameters of the algorithm according to underwater conditions, and the design of the algorithm depends more on the designer’s understanding of the underwater environment. Moreover, these methods do not have a learning capability and cannot improve the AUV path planning capability with task execution, so their performance is limited by the designer’s parameter design level. Traditional local path planning methods are listed below. Li et al. [
9] proposed an automatic ground map building and path planning algorithm in unmanned aerial/ground vehicles’ (UAV/UGV) cooperative systems, which outperforms the genetic algorithm and A star algorithm in path cost. Hermand et al. [
10] proposed a constrained control scheme based on the Explicit Reference Governor framework. The experiment verified that this method can control UAV while avoiding obstacles in the laboratory environment. Nie et al. [
11] proposed an improved RRT algorithm, which simplifies the environment model by simplifying the representation of space, thus avoiding the dimensional catastrophe during computation and improving the computational speed. Li et al. [
12] combined rolling planning with node screening and applied the improved RRT algorithm to underwater search and interception. Zacchini et al. [
13] used RRT for path planning and realized the submarine terrain inspection using forward-looking sonar. Franco et al. [
14] employed the APF algorithm to achieve the obstacle avoidance of AUV using scanning sonar. Noguchi et al. [
15] employed the APF algorithm to implement an intervention of the autonomous underwater vehicle (I-AUV) in the process of catching sea urchins. Considered the dynamic constraints of the UAV, Tang et al. [
16] proposed a trajectory planning algorithm based on the minimum snap trajectory method. The simulation experiment verified that this method can optimize the time and length of the generated trajectory in a simulation environment with simplified quay crane model. Meng et al. [
17] proposed the prediction planning interception (PPI) algorithm based on the APF algorithm. This method determines the interception position by the motion tracking of the target and employs the APF algorithm to plan the interception route, so as to achieve the moving target interception in the ocean current environment of the harbor. Fan et al. [
18] proposed an improved APF algorithm, and added a distance correction factor to the exclusion function to solve the local minimum problem. Lin et al. [
19] realized the path planning of multi AUVs through the APF method by considering potential underwater obstacles and AUV dynamics. Li et al. [
20] employed an improved APF algorithm to achieve obstacle avoidance in the process of target tracking. Li et al. [
21] designed a 3-input controller based on the fuzzy logic algorithm with obstacle distance change as input, which can achieve obstacle avoidance in the same direction as AUV. Traditional local path planning algorithms achieve obstacle avoidance of AUVs for both static and dynamic obstacles. However, these methods need to design the algorithm for different working conditions, and the performance of the algorithm is constrained by the experience of the designer. The algorithm does not have a learning capability and is easily trapped in local minima. Therefore, an algorithm with learning capabilities is subsequently proposed.
The Reinforcement Learning (RL)-based path planning method is a typical algorithm with learning capability. Distinguishing from traditional methods, the RL-based local path planning method does not need guidance signal in the unknown environment, and adapts to the environment by online learning and continuous trial and error. Reinforcement learning enables the AUV to gradually adapt to the environment and make decisions through training. It has a good generalization ability, and is suitable for complex and variable application scenarios. Li et al. [
22] combined the heuristic search strategy with Q-learning to reduce the energy consumption of mobile robot paths. Duguleana et al. [
23] implemented the path planning of mobile robots with Q-learning. This method realizes the obstacle avoidance of moving obstacles when global information is available. Taghavifar et al. [
24] combined the chaotic metaheuristic optimization with Q-learning to solve the obstacle avoidance path planning for robots under mobile obstacles. Singla et al. [
25] combined the DQN method. Ref. [
26] with UAV to achieve an obstacle avoidance of UAV in an unknown indoor environment. Sun et al. [
27] combined the hierarchical deep Q network (HDQN) with a prioritized experience replay to propose an AUV path planning method for 3D ocean conditions. The path planning was divided into three layers to reduce the dimensionality of the path planning task and avoid dimensional disaster. Simulation experiments and realistic tests verified that the algorithm can reduce the reinforcement learning training time and is safe and effective. Zhang et al. [
28] proposed the deep interactive RL method by adding human rewards on the basis of DQN. This method possesses faster convergence and better performance than DQN. Yuan et al. [
29] proposed an improved method based on the double deep Q-network (double-DQN) method [
30], which outperforms the double-DQN algorithm in terms of the success rate and obstacle avoidance performance. The RL-based local path planning method can perform obstacle avoidance in unknown or dynamic environments without modeling the environment. Pei et al. [
31] proposed the Dyna-Q algorithm by combined Q-learning based on Dyna architecture with simulated annealing mechanism, heuristic search strategies, and the reactive navigation principle. The practical experiment conducted by MATLAB and the robot operating system verified that this method can fulfill autonomous navigation tasks in the real world. Cui et al. [
32] proposed a multi-layer Q-learning path planning method. The method used a two-layer structure to handle local global information. Simulation experiments demonstrate the effectiveness of this path planning method. Considering the policy selection in the early search process of Q-learning, Ma et al. [
33] proposed the continuous local search Q-Learning (CLSQL) method. In this method, global environment was divided into independent local environments. The search between each intermediate point in the local environment was realized to reach the destination. This method outperforms Q-Learning, SARSA(
), and DQN in convergence speed and computation time. Focused on the slow convergence speed of UAV path planning, Boming et al. [
34] proposed the guided Sarsa algorithm. This method enhanced the convergence speed due to the return function based on the position information and improved status update strategy. Khamidehi and Sousa [
35] combined the double-DQN with a graph-based global path planning algorithm. This method improved the safety of the UAV path planning in a dynamic environment. Cao et al. [
36] proposed a new asynchronous advantages actor–critic (A3C) method [
37] based on the asynchronous variant of the actor–critic, which completes the target search in the simulation environment. Biferale et al. [
38] focused on the path planning in a ship sailing in a 2D turbulent sea and implemented the actor–critic (AC) method [
39] for ship path planning. Sun et al. [
40] proposed the Sum Tree-DDPG method based on the deep deterministic policy gradient (DDPG) [
41] method. This method improves the replay memory in the DDPG method and sets the reward function with reference to the APF method, which increases the stability of the AUV path planning method in an underwater canyons environment. Hong et al. [
42] combined the twin-delayed deep deterministic policy gradient (TD3) method [
43] with the frame stacking technique. This method can reduce the energy consumption of drones with the global energy-efficient path. Lan et al. [
44] improved the DDPG algorithm to solve the path planning of the underwater glider (UG) in an ocean current environment. This method integrated the UG kinematic motion into MDP in DDPG. The simulation experiment verified that this method can fulfill the UG autonomous navigation tasks in the ocean current environment based on the Tokyo Bay geography and the unacquainted ocean. The RL algorithm requires a lot of exploration to adapt to the environment, and therefore has high demands on the environment.
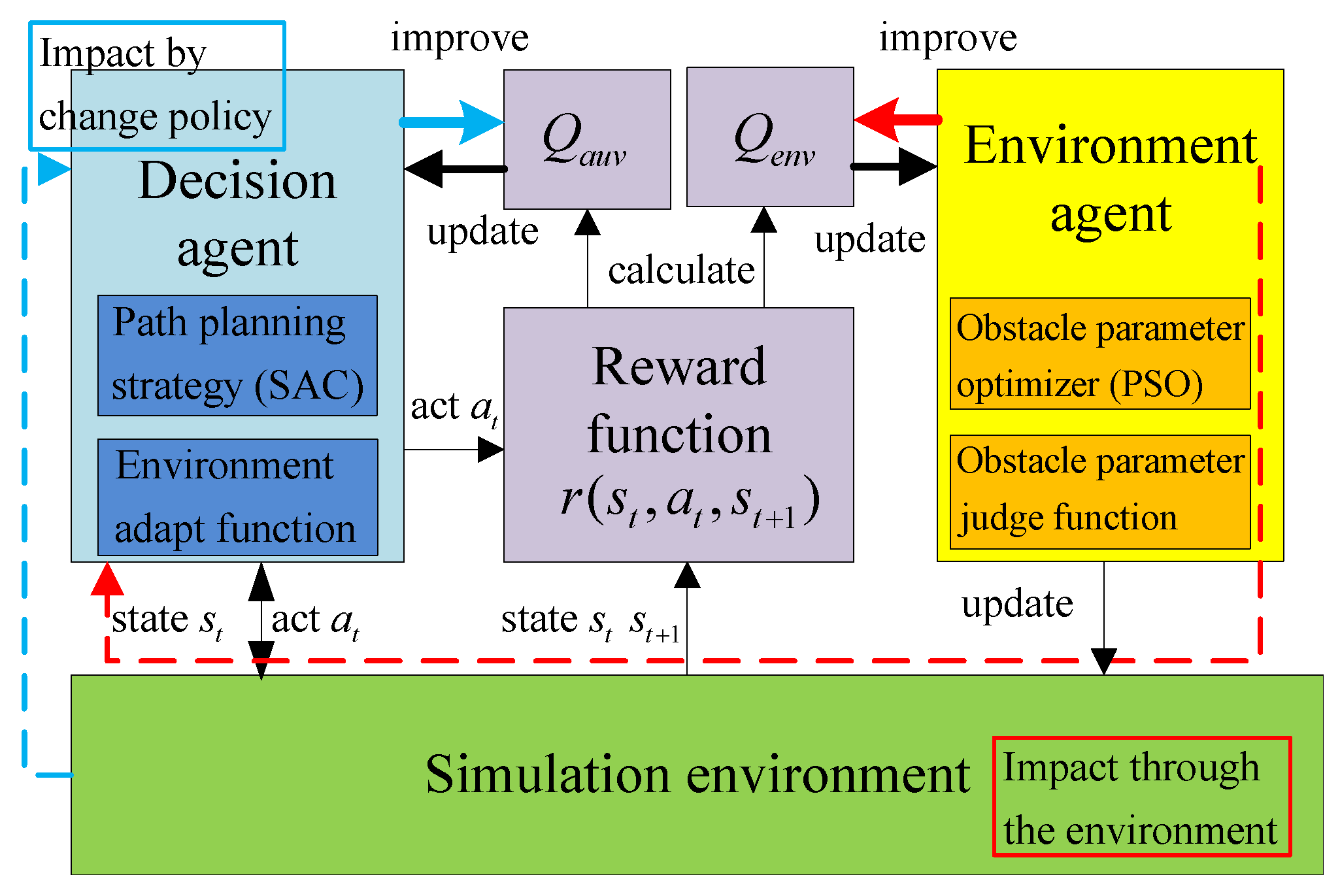
Due to the unknown and complex underwater environment, AUV needs to be explored in various environments. The high risk and cost of AUV field experiments determine that the simulation environment needs to be constructed to train AUV. The obstacle parameters (size, shape, number and location) in the simulation environment are generally designed based on human experience, so it is difficult to guarantee the exploration of RL. The game theory is introduced to SAC to meet the requirement of exploration in the simulation environment.
The study is organized, as follows: in
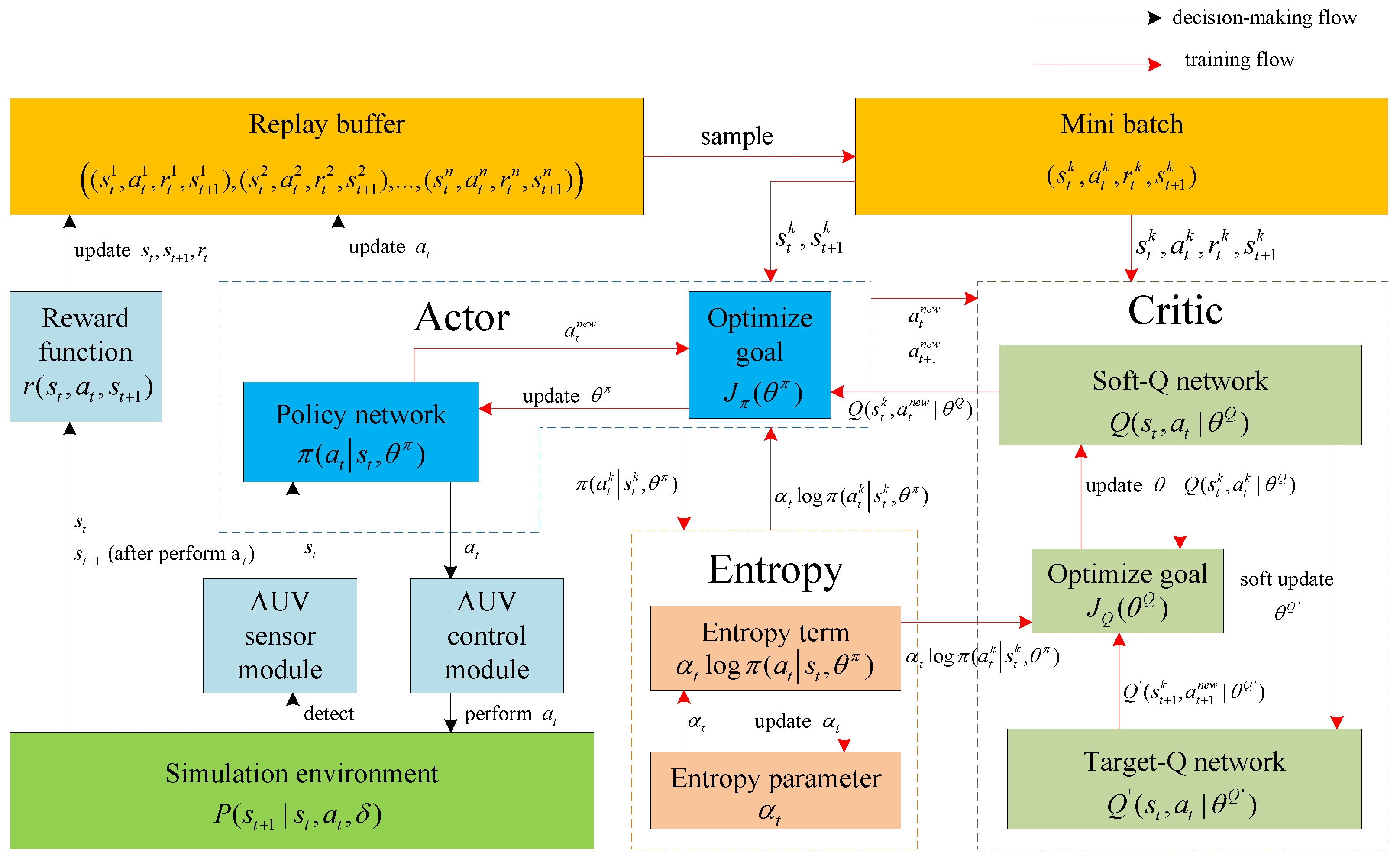
Section 2, the framework of the AUV path planning method is introduced and the mathematical model of the underwater environment is defined. The components of the AUV path planning method are presented in
Section 3. In
Section 4, the AUV path planning and obstacle avoidance method are discussed for path planning experiments in an unknown simulation environment.
Section 5 draws the conclusions.




 is the downward rounding function.
is the downward rounding function.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}