
A Lightweight Sea Surface Object Detection Network for Unmanned Surface Vehicles


Abstract
:1. Introduction
- (1)
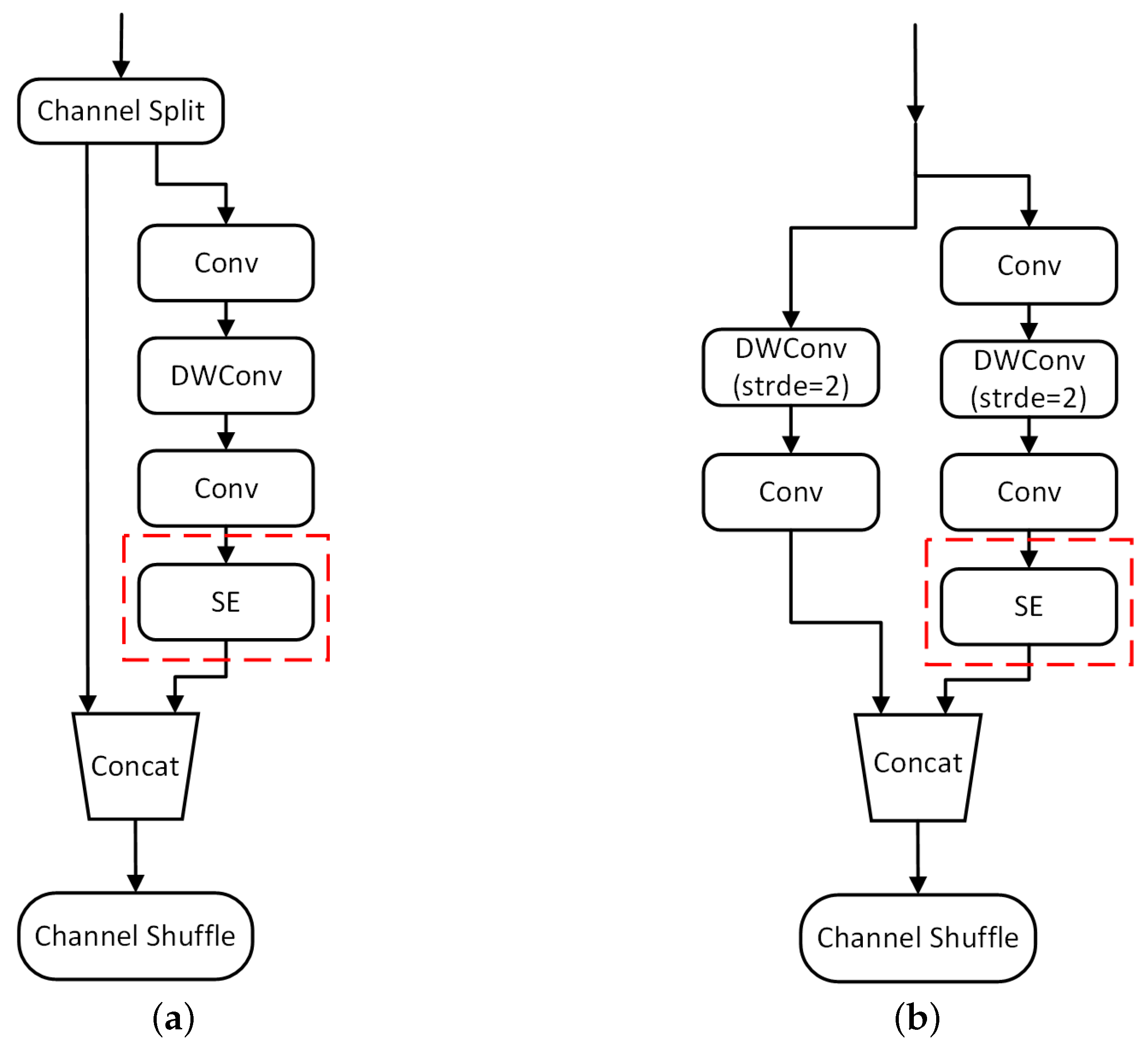
- An improved ShuffleNet v2 based on the SE attention mechanism was proposed as the backbone feature extraction network, which significantly reduces the number of model parameters.
- (2)
- A combination of the depth-wise separable convolution and the ADD feature fusion method was adopted to rebuilt the neck network, which is conducive to reducing the complexity of computation.
- (3)
- We provided a solution for deploying sea surface object detection algorithms on embedded devices carried by USVs. All experiments were tested on NVIDIA Jetson AGX XAVIER, and real-time performance was demonstrated.
2. Related Work
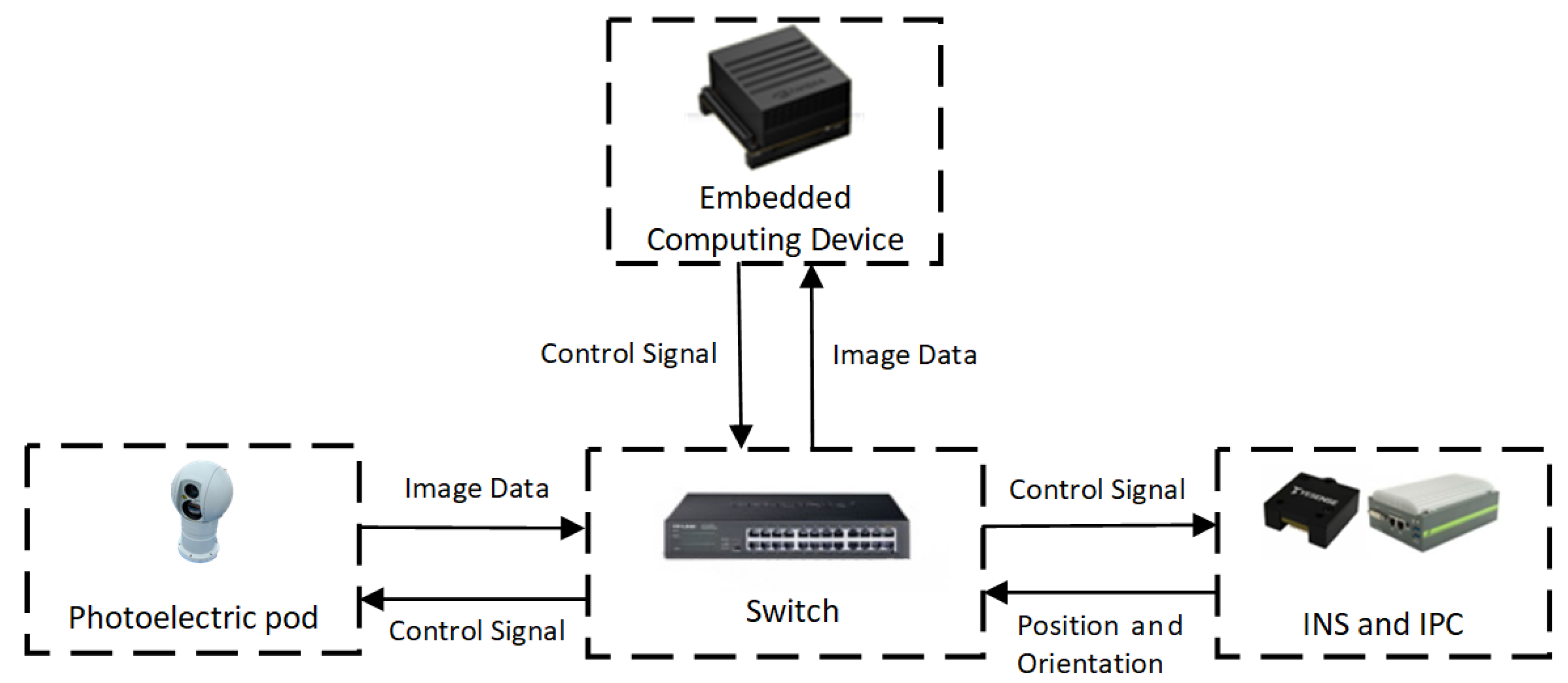
3. Perception System of USVs
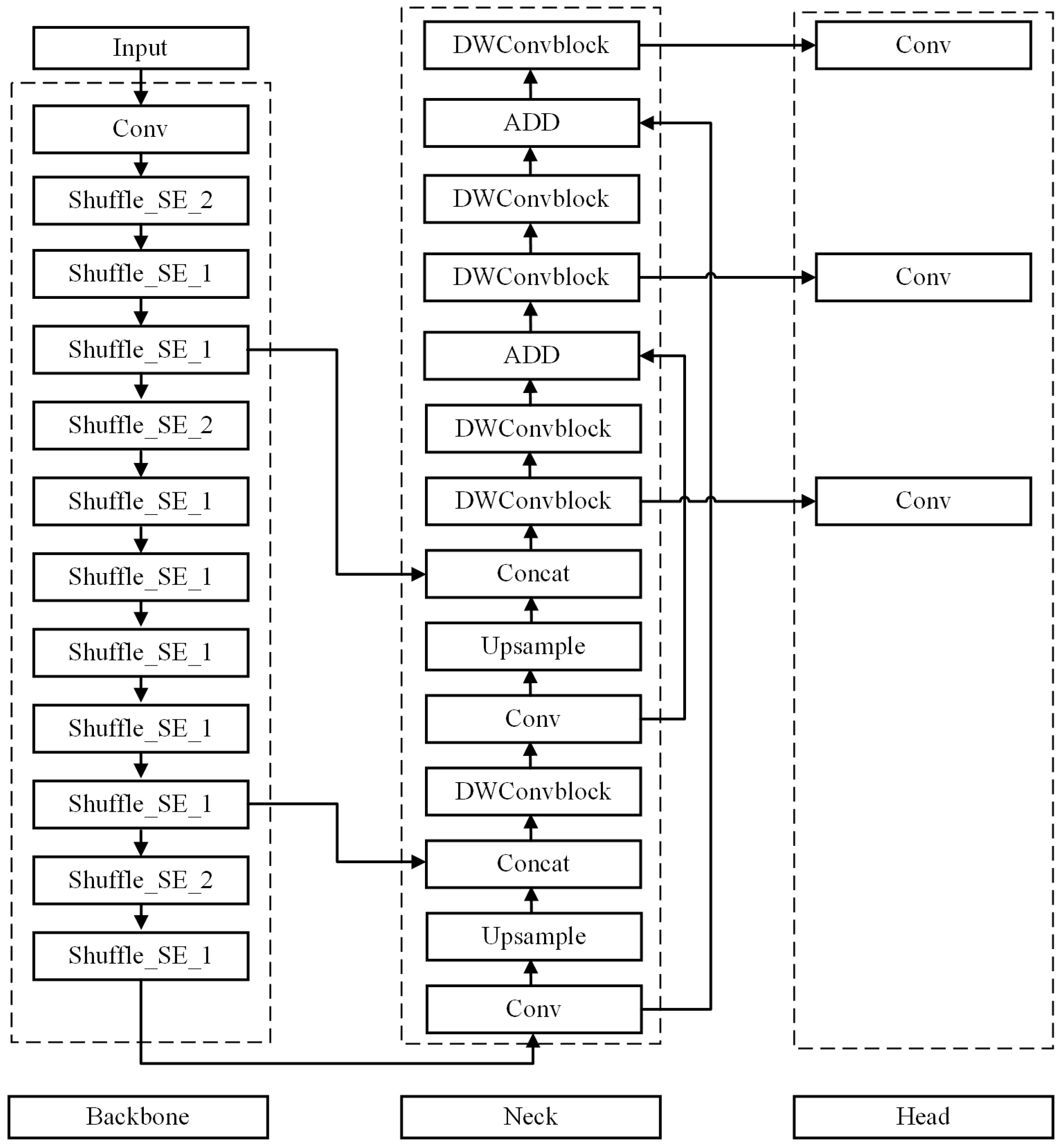
4. Method
4.1. Improvement of Backbone Network
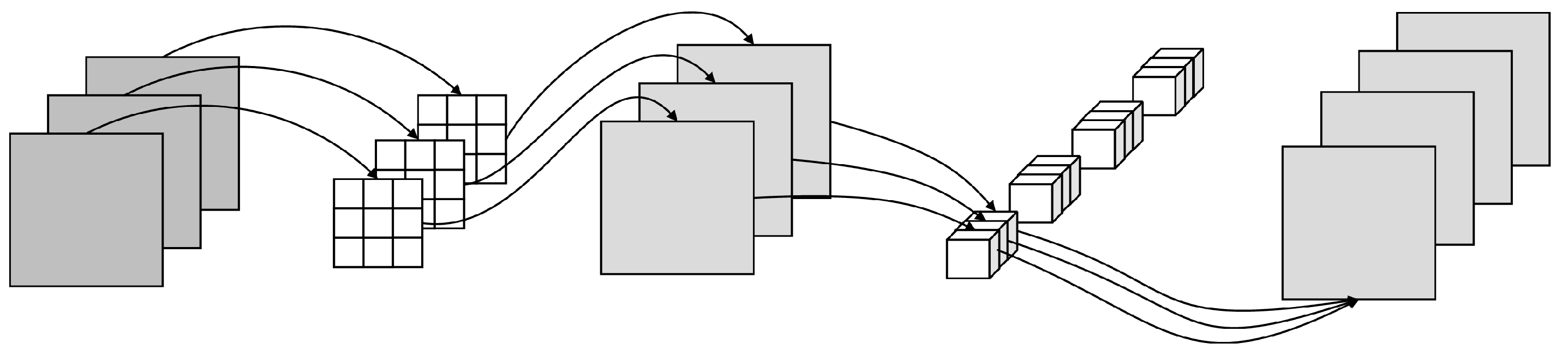
4.2. Depth-Wise Separable Convolution
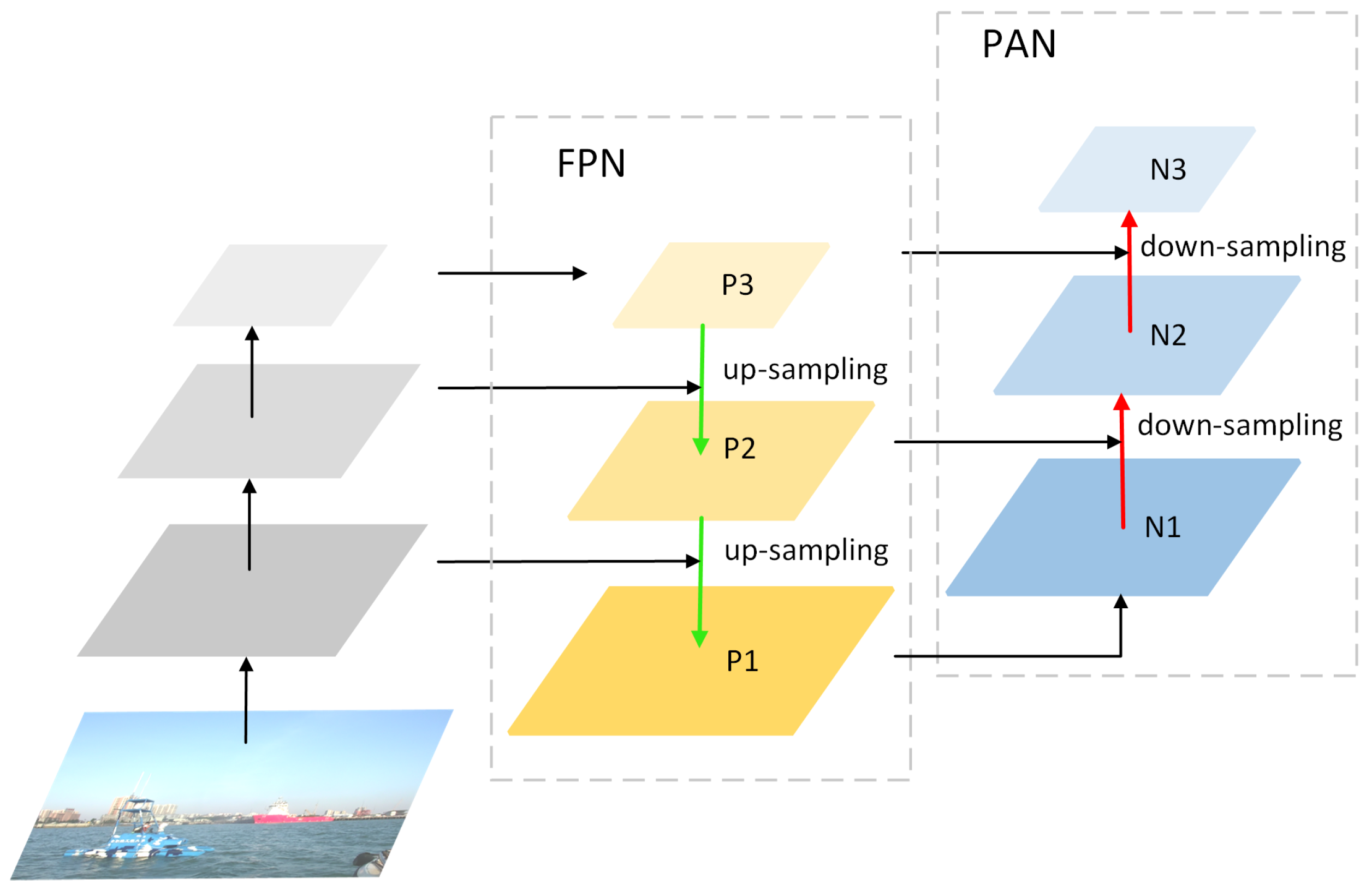
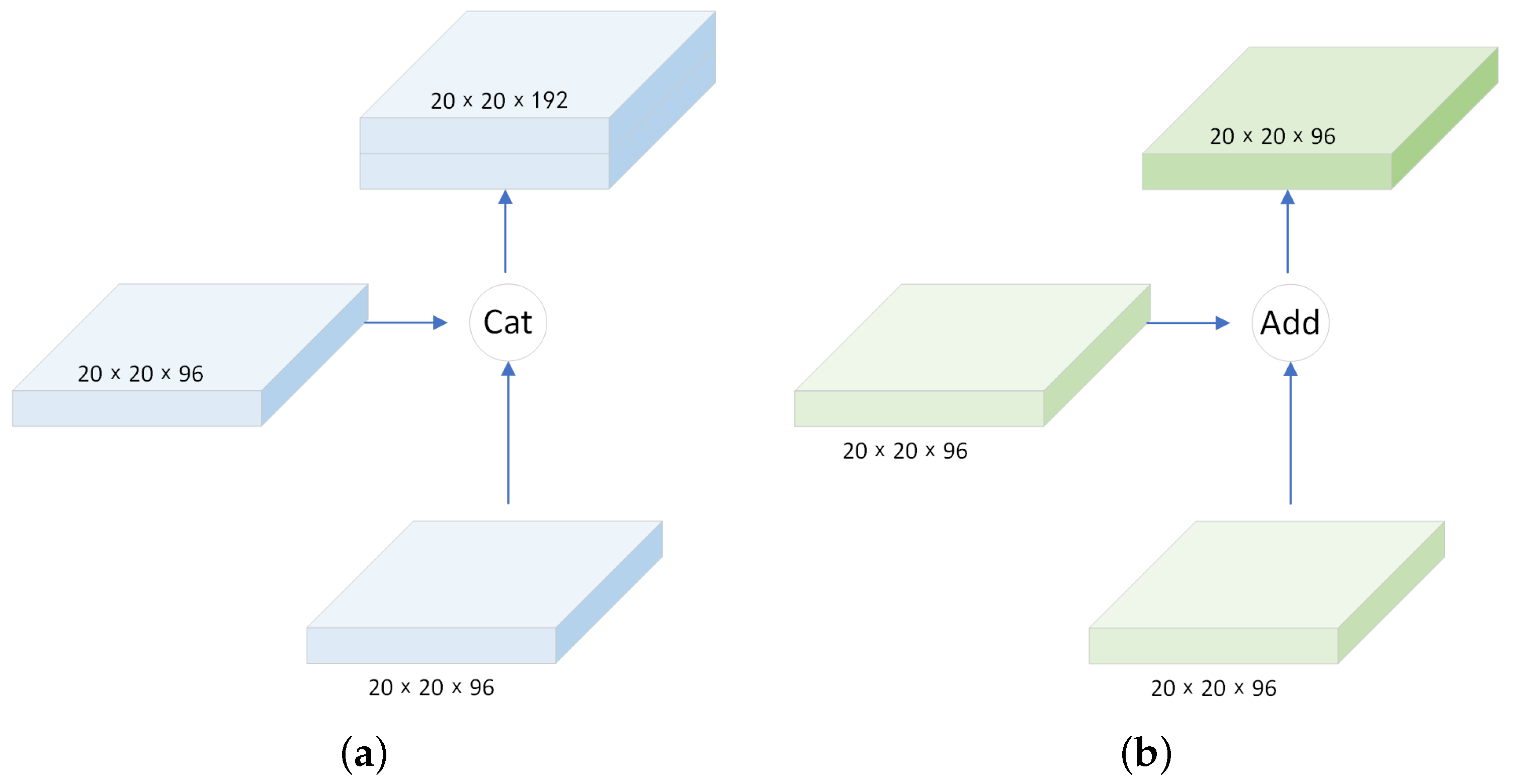
4.3. Improvement of Feature Fusion Module
5. Experiment
5.1. Introduction of Dataset
5.2. Mosaic Augmentation
5.3. Training Details
5.4. Evaluation Metrics
5.5. Ablation Experiments
5.6. Comparison with Other Object-Detection Algorithms
5.7. Detection Results on Singapore Maritime Dataset
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stateczny, A.; Kazimierski, W.; Gronska-Sledz, D.; Motyl, W. The empirical application of automotive 3D radar sensor for target detection for an autonomous surface vehicle’s navigation. Remote Sens. 2019, 11, 1156. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.Q.; Zheng, P.; Xu, S.t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Gupta, A.; Anpalagan, A.; Guan, L.; Khwaja, A.S. Deep learning for object detection and scene perception in self-driving cars: Survey, challenges, and open issues. Array 2021, 10, 100057. [Google Scholar] [CrossRef]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- YOLO v5. Available online: https://doi.org/10.5281/zenodo.5563715 (accessed on 12 October 2021). [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8440–8449. [Google Scholar]
- Liu, T.; Pang, B.; Zhang, L.; Yang, W.; Sun, X. Sea Surface Object Detection Algorithm Based on YOLO v4 Fused with Reverse Depthwise Separable Convolution (RDSC) for USV. J. Mar. Sci. Eng. 2021, 9, 753. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Li, Y.; Guo, J.; Guo, X.; Liu, K.; Zhao, W.; Luo, Y.; Wang, Z. A novel target detection method of the unmanned surface vehicle under all-weather conditions with an improved YOLOV3. Sensors 2020, 20, 4885. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sun, X.; Liu, T.; Yu, X.; Pang, B. Unmanned Surface Vessel Visual Object Detection Under All-Weather Conditions with Optimized Feature Fusion Network in YOLOv4. J. Intell. Robot. Syst. 2021, 103, 1–16. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.Z.; Zang, F.N. Ship detection for visual maritime surveillance from non-stationary platforms. Ocean Eng. 2017, 141, 53–63. [Google Scholar] [CrossRef]
- Liu, T.; Pang, B.; Ai, S.; Sun, X. Study on visual detection algorithm of sea surface targets based on improved YOLOv3. Sensors 2020, 20, 7263. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Wang, T.; Yuan, L.; Zhang, X.; Feng, J. Distilling object detectors with fine-grained feature imitation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4933–4942. [Google Scholar]
- Yu, G.; Chang, Q.; Lv, W.; Xu, C.; Cui, C.; Ji, W.; Dang, Q.; Deng, K.; Wang, G.; Du, Y.; et al. PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices. arXiv 2021, arXiv:2111.00902. [Google Scholar]
- NanoDet-Plus. Available online: https://github.com/dog-qiuqiu/Yolo-FastestV2 (accessed on 12 August 2021).
- YOLO-Fastest. Available online: https://github.com/RangiLyu/nanodet (accessed on 26 December 2021).
- Yang, L.; Zhang, P.; Huang, L.; Wu, L. Sea-sky-line Detection Based on Improved YOLOv5 Algorithm. In Proceedings of the 2021 IEEE 2nd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 17–19 December 2021; pp. 688–694. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Huang, G.; Liu, S.; Van der Maaten, L.; Weinberger, K.Q. Condensenet: An efficient densenet using learned group convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2752–2761. [Google Scholar]
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video processing from electro-optical sensors for object detection and tracking in a maritime environment: A survey. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1993–2016. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/cvf Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Instances | Percentage |
|---|---|---|
| Raft | 482 | 22.22% |
| Ship | 845 | 32.26% |
| Buoy | 979 | 37.38% |
| USV | 203 | 7.75% |
| Boat | 110 | 4.2% |
| Class | Instances | Percentage |
|---|---|---|
| Ferry | 8588 | 5.63% |
| Buoy | 2973 | 2.17% |
| Vessel/ship | 114,411 | 74.19% |
| Speed boat | 7780 | 4.95% |
| Boat | 1298 | 0.8% |
| Kayak | 4308 | 2.7% |
| Sail boat | 1926 | 1.18% |
| Other | 12,551 | 9.54% |
| Model | ShuffleNet | SE | DWConv | Add | mAP | Parameters | FLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| Model1 | 95.7% | 1.77 M | 4.2 G | 22.39 | ||||
| Model2 | √ | 91.2% | 0.53 M | 1.8 G | 29.82 | |||
| Model3 | √ | √ | 93.4% | 0.59 M | 1.9 G | 28.61 | ||
| Model4 | √ | √ | √ | 92.4% | 0.45 M | 1.4 G | 31.35 | |
| Model5 | √ | √ | √ | √ | 93.1% | 0.44 M | 1.3 G | 32.64 |
| Method | Parameters | mAP | FPS |
|---|---|---|---|
| YOLO v5n | 1.77 M | 95.7% | 22.39 |
| YOLO V4-tiny | 6.05 M | 91.0% | 11.26 |
| PP-PicoDet | 0.78 M | 89.8% | 27.18 |
| Nanodet | 0.39 M | 84.6% | 34.27 |
| YOLO-Fastest | 0.25 M | 82.3% | 46.32 |
| Ours | 0.44 M | 93.1% | 32.64 |
| Method | Ferry | Buoy | Vessel/Ship | Speed Boat | Boat | Kayak | Sail Boat | Other | mAP | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLO v5n | 97.5% | 99.5% | 98.9% | 93.0% | 87.7% | 97.4% | 99.4% | 98.9% | 96.5% | 22.06 |
| YOLO-Fastest | 82.8% | 92.5% | 95.7% | 68.9% | 87.8% | 38.4% | 99.5% | 82.3% | 81.0% | 45.98 |
| Our | 94.6% | 98.7% | 98.9% | 87.5% | 91.3% | 86.0% | 99.5% | 94.8% | 93.9% | 32.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Li, Y.; Wang, B.; Ding, S.; Jiang, P. A Lightweight Sea Surface Object Detection Network for Unmanned Surface Vehicles. J. Mar. Sci. Eng. 2022, 10, 965. https://doi.org/10.3390/jmse10070965
Yang Z, Li Y, Wang B, Ding S, Jiang P. A Lightweight Sea Surface Object Detection Network for Unmanned Surface Vehicles. Journal of Marine Science and Engineering. 2022; 10(7):965. https://doi.org/10.3390/jmse10070965
Chicago/Turabian StyleYang, Zhangqi, Ye Li, Bo Wang, Shuoshuo Ding, and Peng Jiang. 2022. "A Lightweight Sea Surface Object Detection Network for Unmanned Surface Vehicles" Journal of Marine Science and Engineering 10, no. 7: 965. https://doi.org/10.3390/jmse10070965