
Research on TD3-Based Distributed Micro-Tillage Traction Bottom Control Strategy
Abstract
:1. Introduction
- A torque distribution strategy based on TD3 is proposed for a distributed micro-traction chassis for greenhouses to solve the control problem of electric equipment under complex agricultural operating conditions;
- Under the proposed control method, the energy utilization and straight-line driving stability of the chassis are improved.
2. Undercarriage Model Building
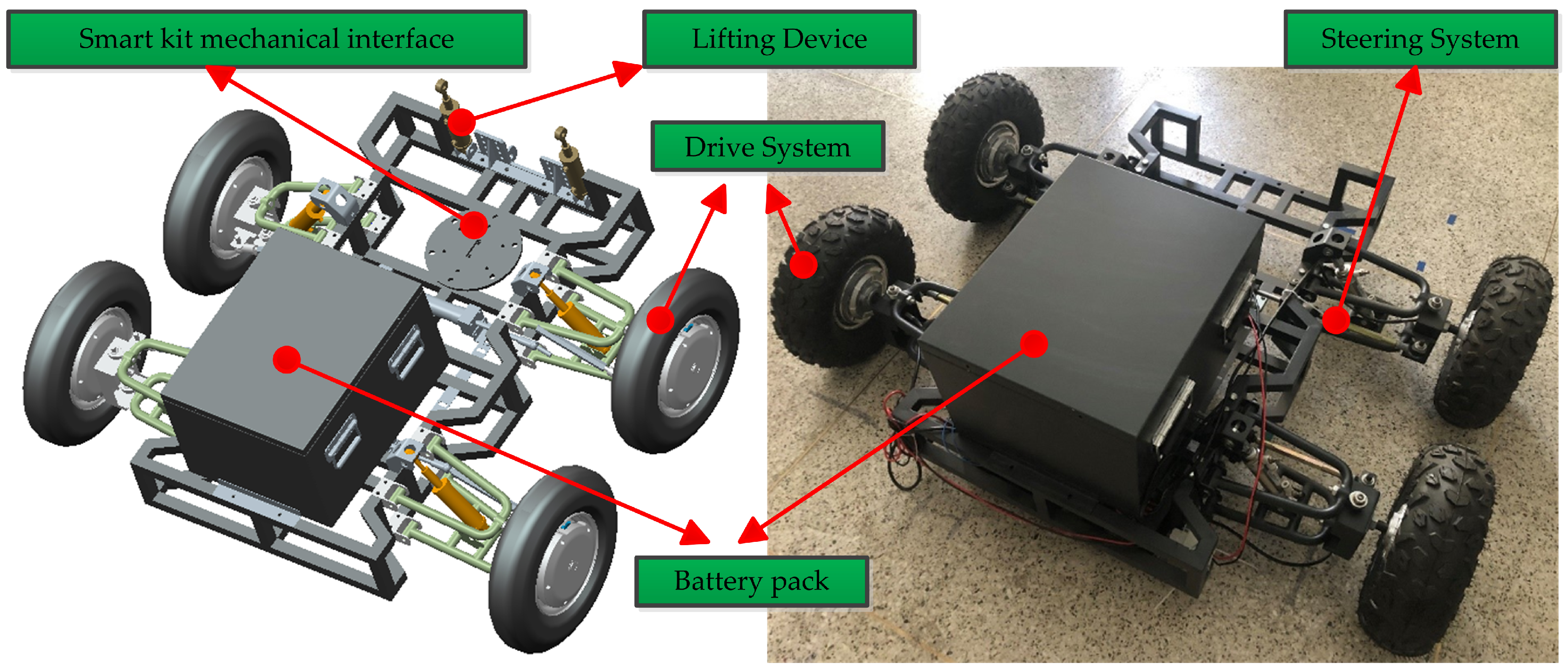
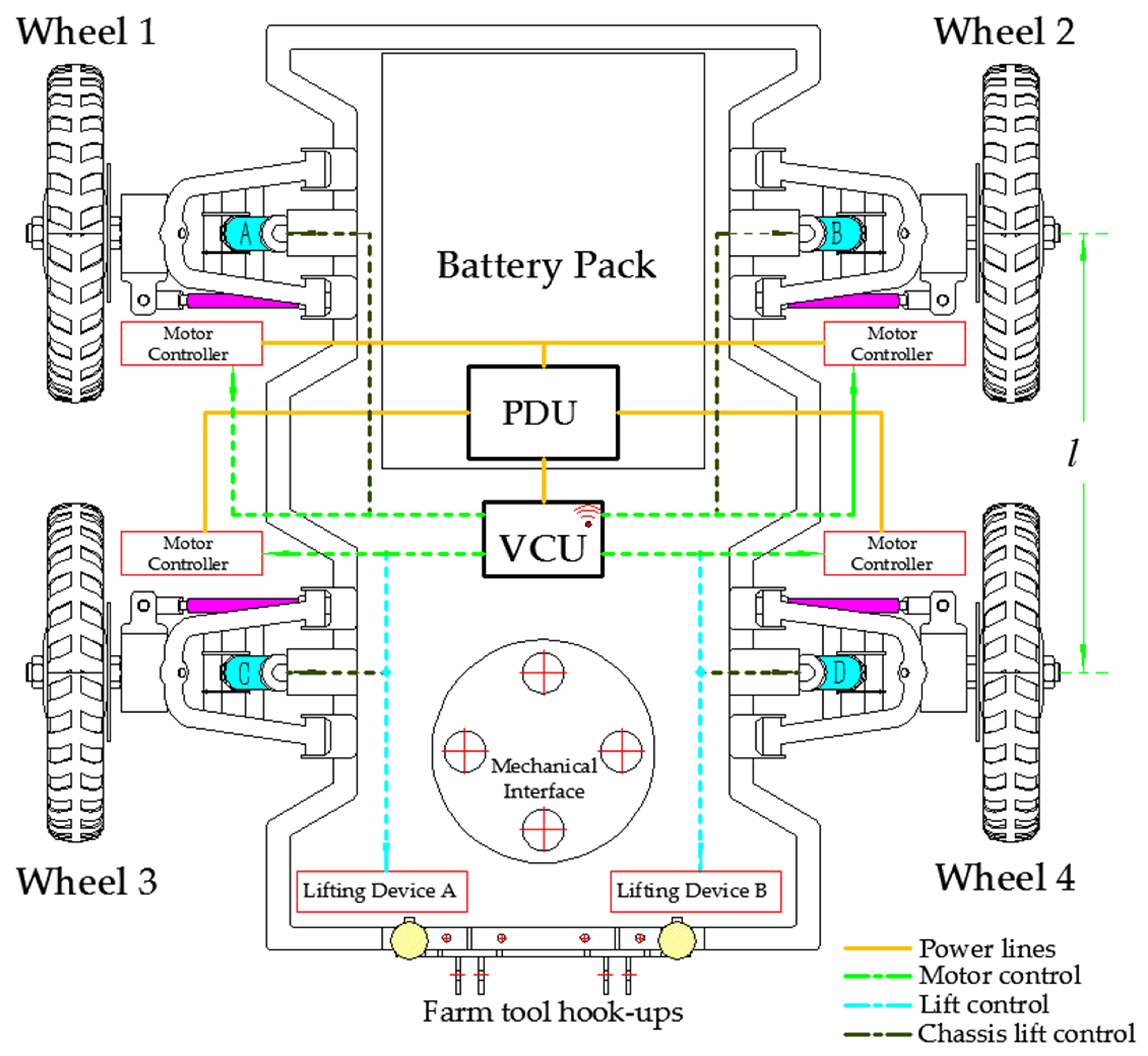
2.1. Overall Structure
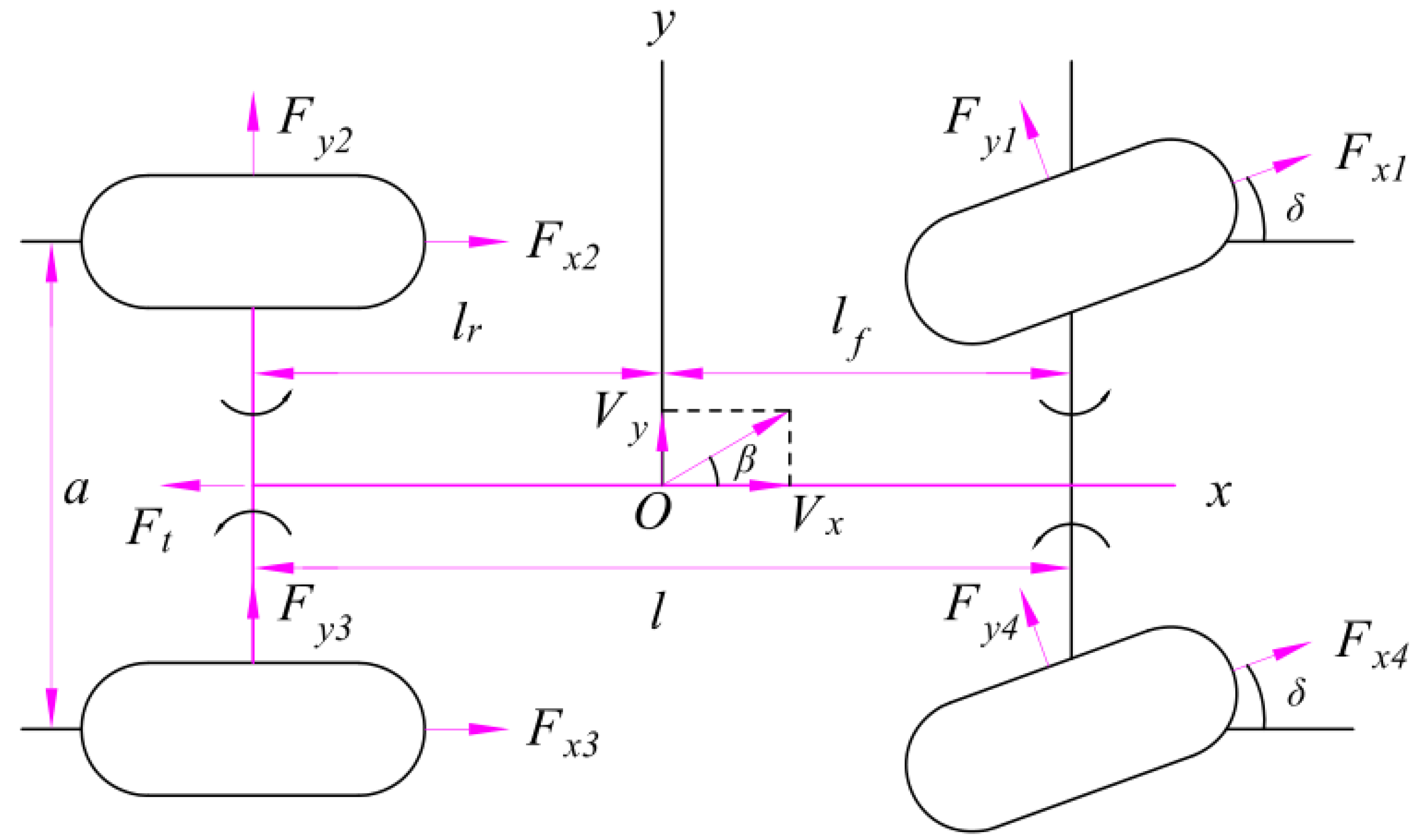
2.2. Longitudinal Dynamics Model of the Chassis
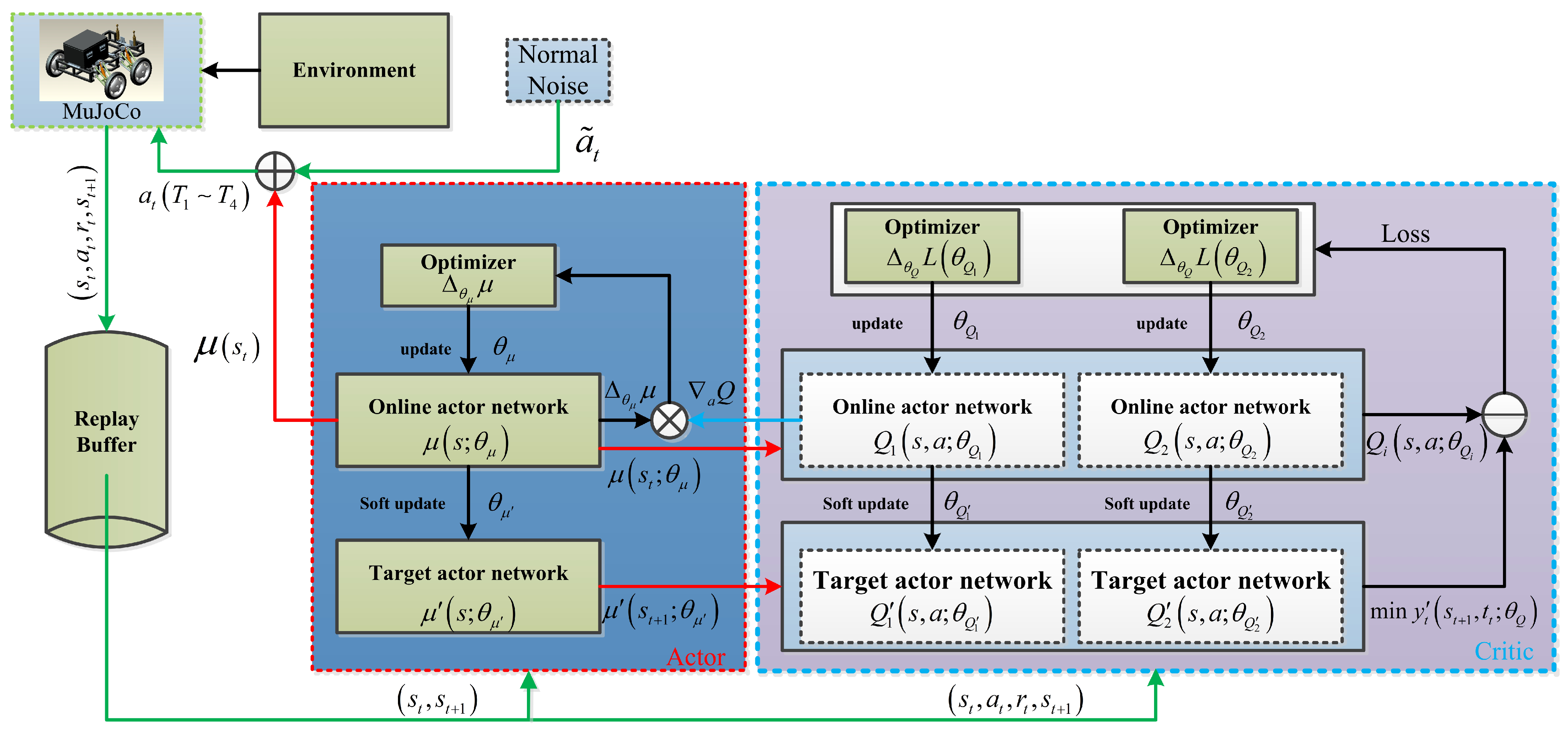
3. TD3-Based Control Strategy
3.1. Description of the Reinforcement Learning Algorithm
3.2. Q-Learning Algorithm and DQN Algorithm
3.3. DDPG Algorithm and TD3 Algorithm
3.3.1. DDPG Algorithm
3.3.2. TD3 Algorithm
- Clipped double-Q learning
- Delayed policy updates
- Target strategy smoothing
3.4. Micro-Tillage Chassis Drive Strategy Design
3.4.1. Overall Control Strategy Design
3.4.2. Intelligent Body Learning Environment Design
4. Results and Analysis
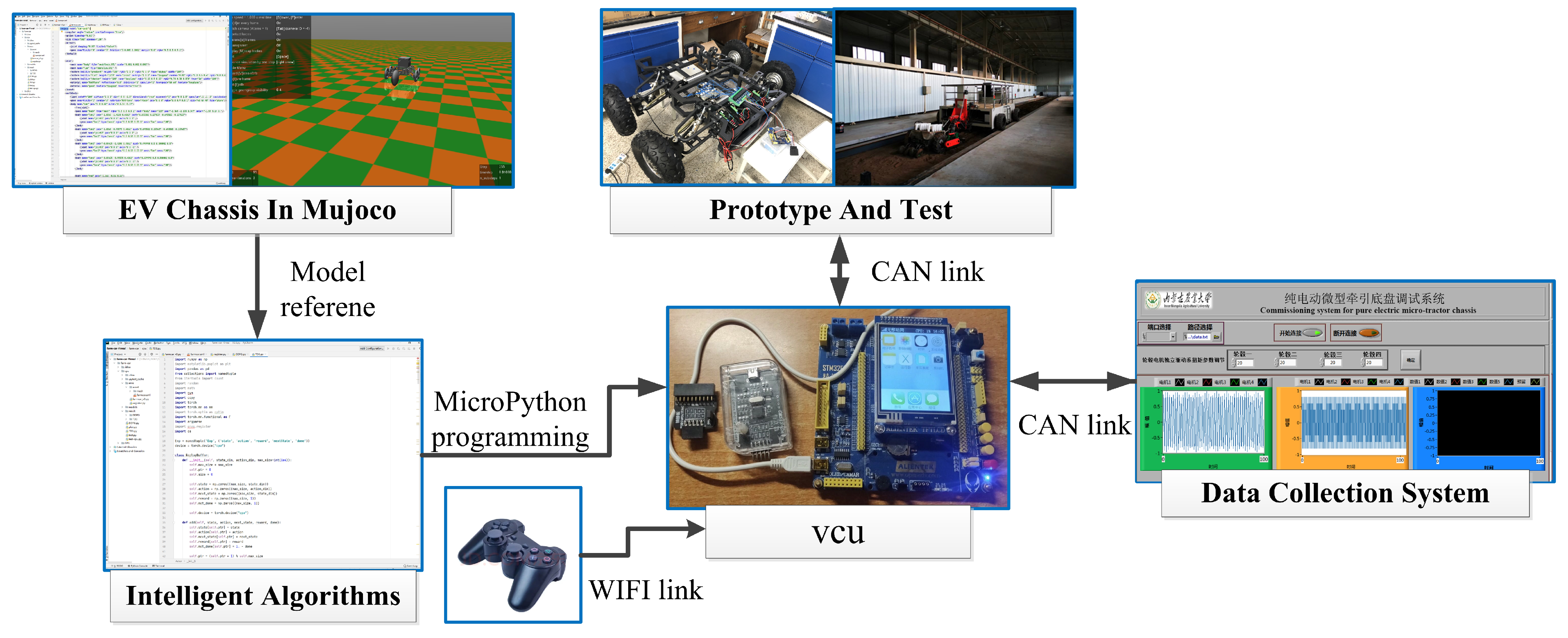
5. Test Verification
5.1. Experimental Equipment and Methods
5.2. Analysis of Experimental Results
6. Conclusions
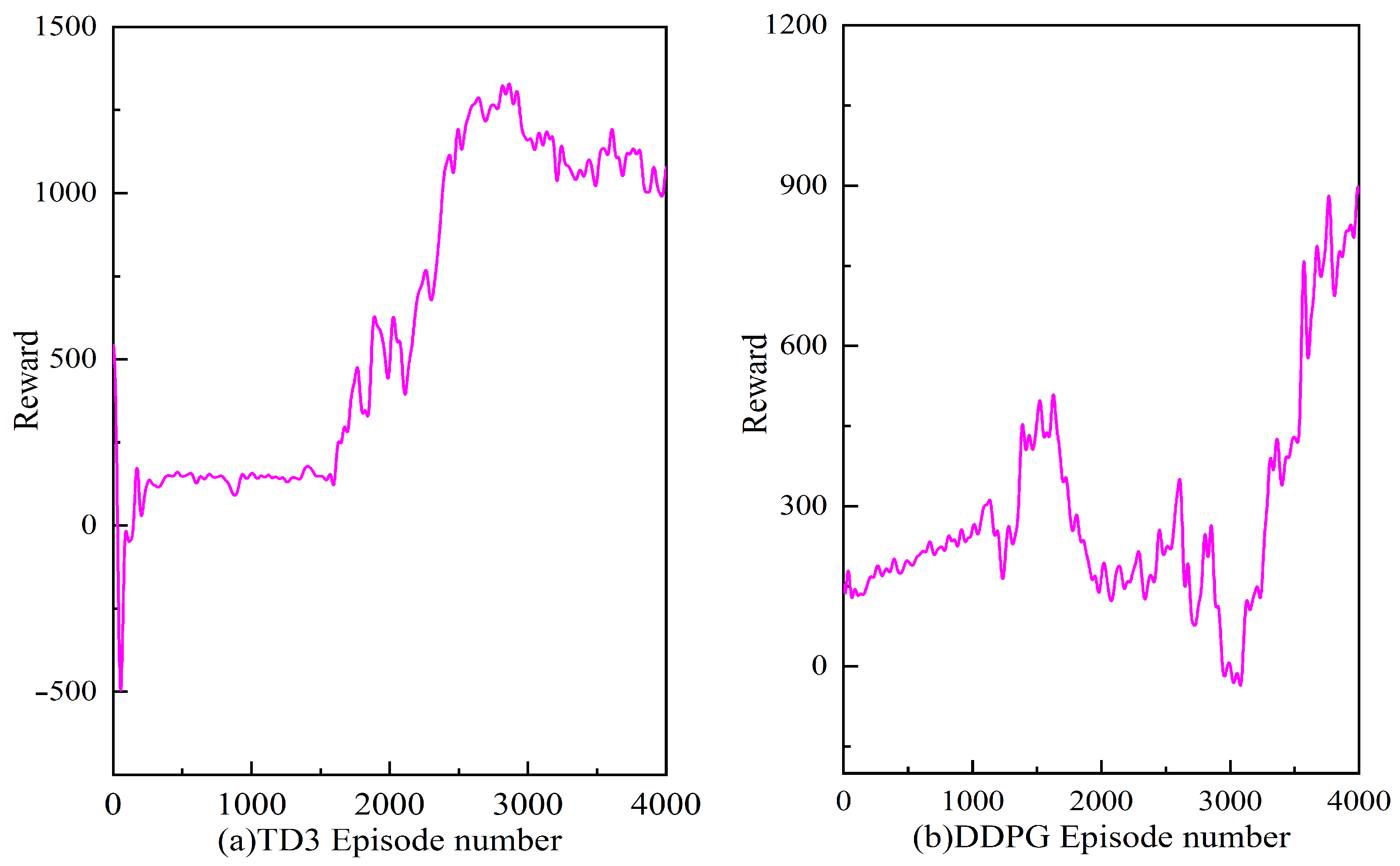
- The Actor–Critic network in the TD3 algorithm can effectively cope with the torque distribution problem of the micro-tillage traction chassis under complex operating conditions. The reward curves show that the adopted double-delay algorithm has higher learning efficiency and stability than the traditional deep deterministic policy gradient algorithm.
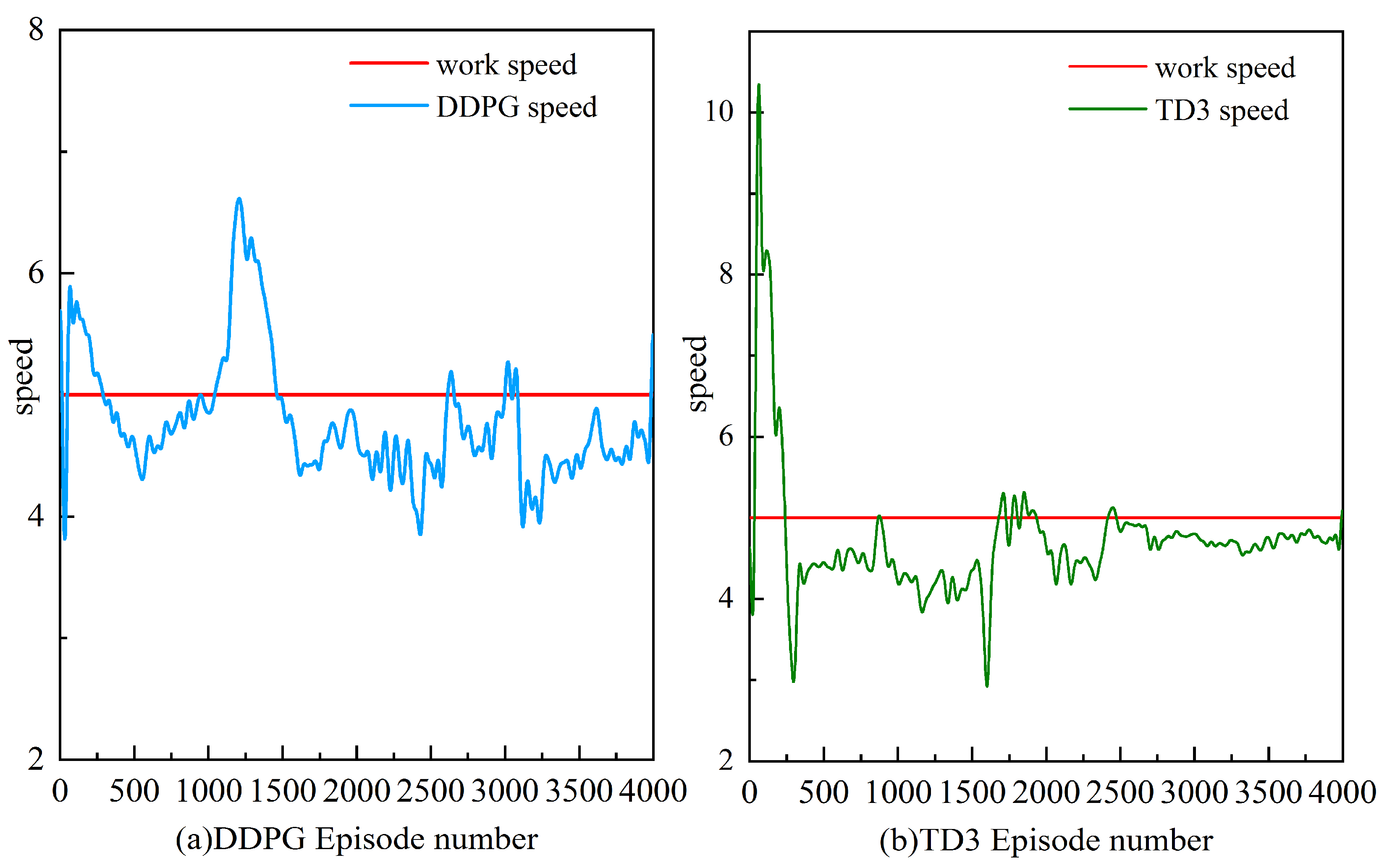
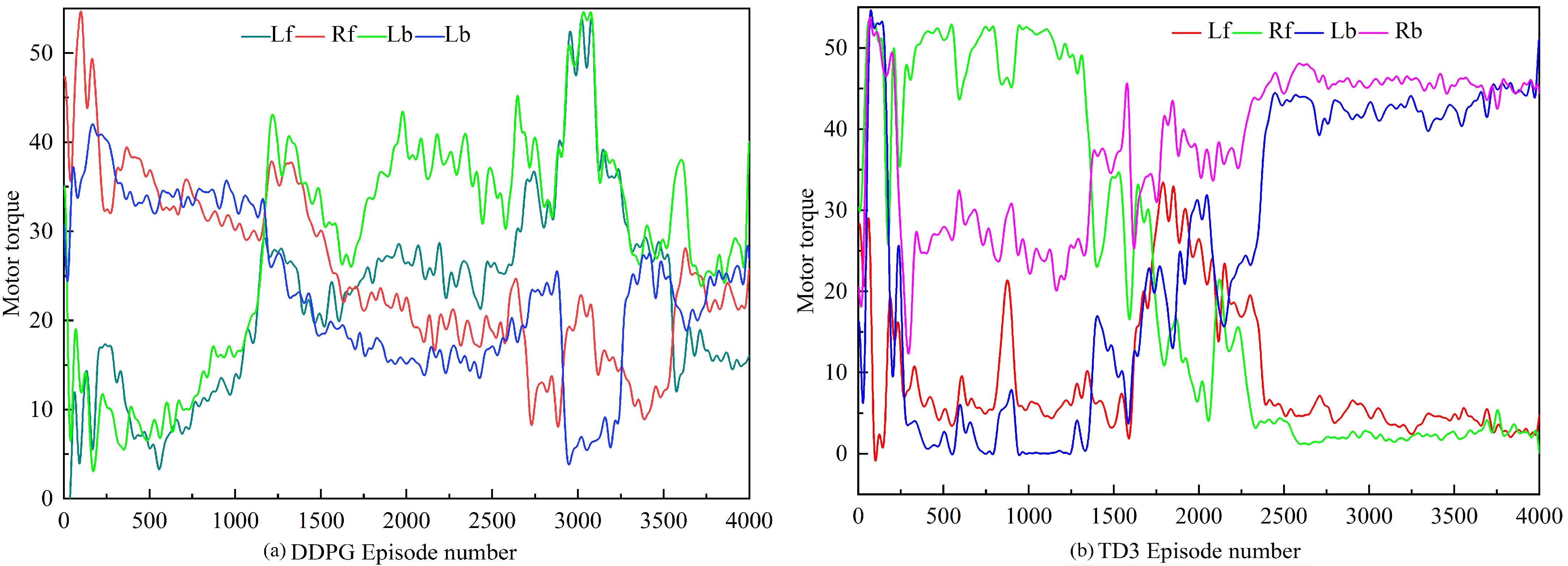
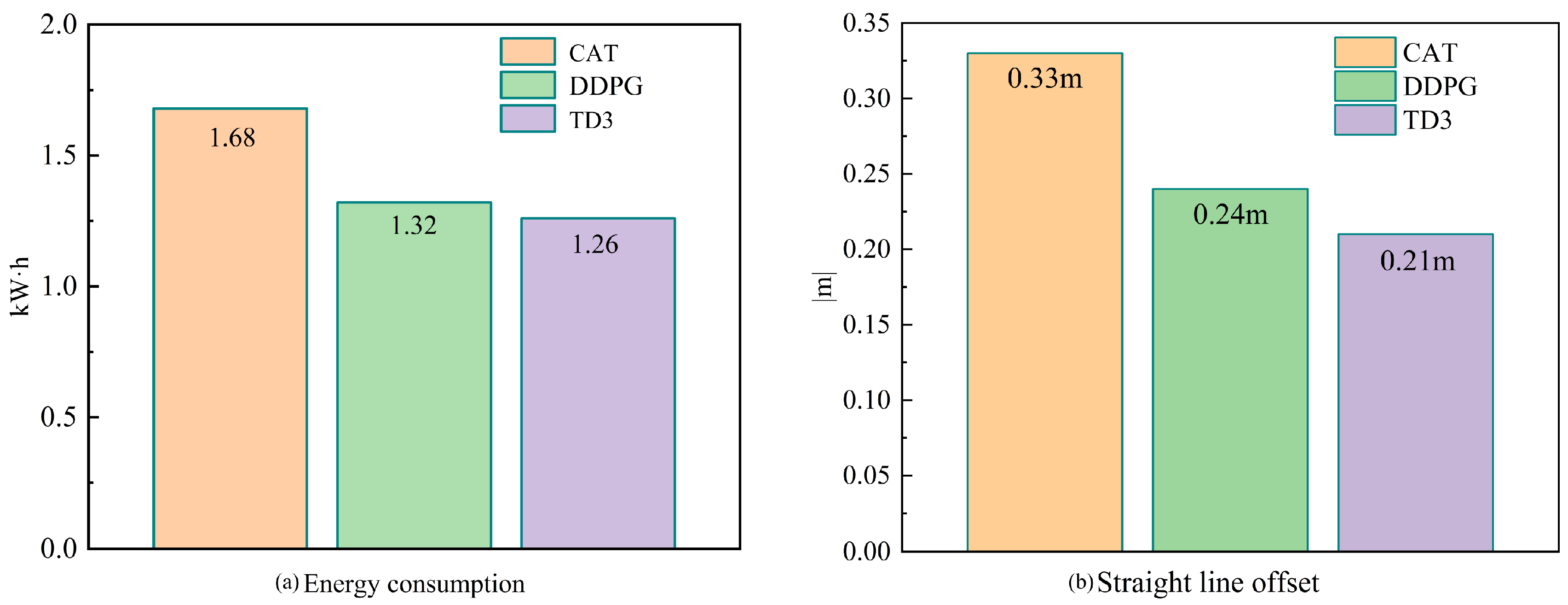
- Under the TD3-based torque distribution strategy, the micro-tillage traction chassis can effectively cope with the operational requirements in complex environments and maximize the reduction of energy consumption, while maintaining the chassis in a straight line. The TD3 algorithm improves energy utilization by 3.7% and 10.5%, respectively, compared with the DDPG algorithm and the traditional average torque distribution strategy.
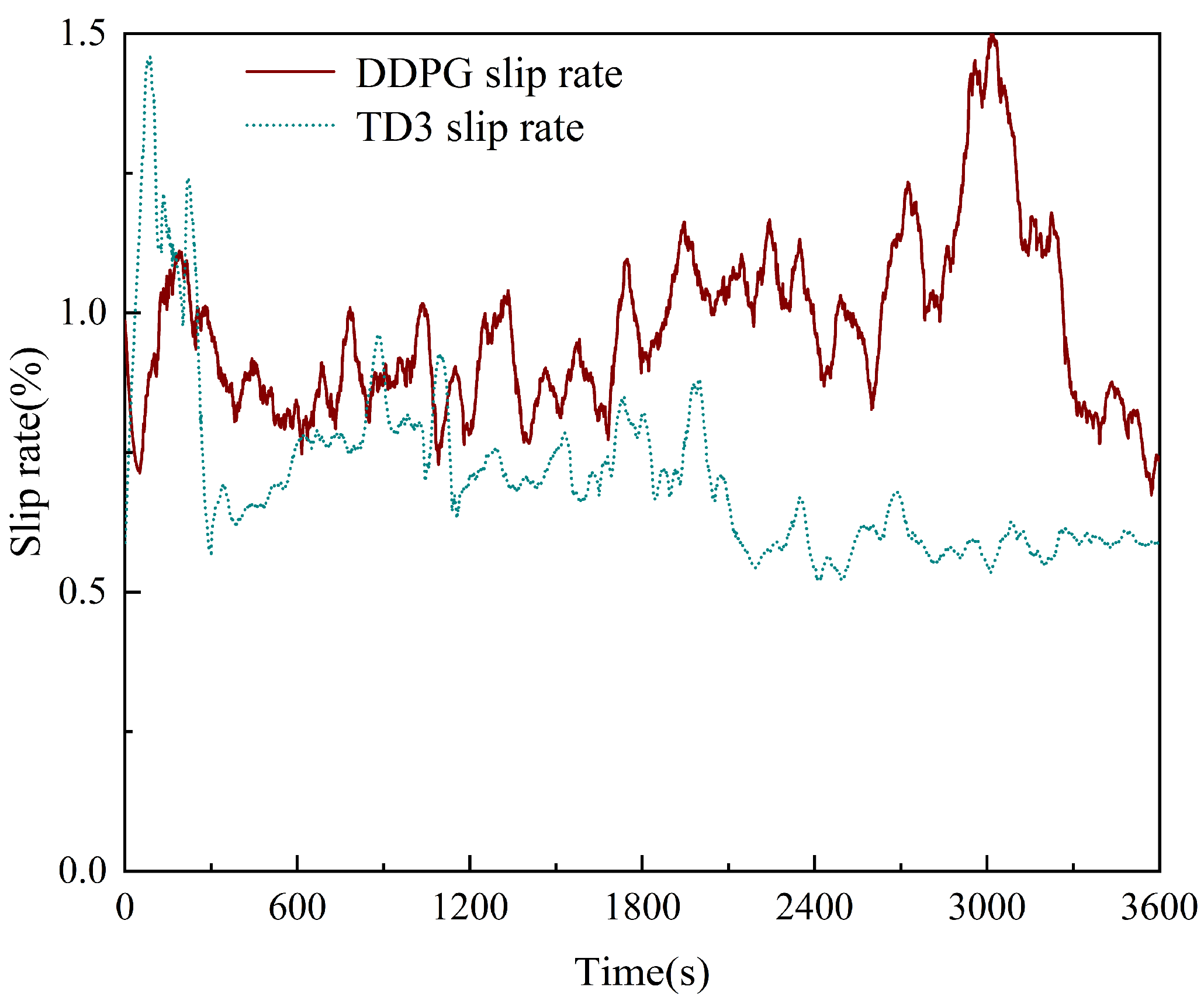
- The Soil-tank experimental verification shows that the TD3 algorithm can not only reasonably distribute the driving torque of the four wheels of the micro-tillage traction chassis under plowing conditions, but also effectively suppress the wheel slip rate, maximizing energy consumption, while ensuring the straight-line driving retention rate.
- The outdoor experiments verified the real-time executability of the control algorithm. In the future, we will continue our in-depth research to take more factors affecting torque distribution into account and conduct further experiments within the greenhouse environment.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Cheng, C.; Fu, J.; Su, H.; Ren, L. Recent Advancements in Agriculture Robots: Benefits and Challenges. Machines 2023, 11, 48. [Google Scholar] [CrossRef]
- Kondoyanni, M.; Loukatos, D.; Maraveas, C.; Drosos, C.; Arvanitis, K.G. Bio-Inspired Robots and Structures toward Fostering the Modernization of Agriculture. Biomimetics 2022, 7, 69. [Google Scholar] [CrossRef] [PubMed]
- Ghobadpour, A.; Monsalve, G.; Cardenas, A.; Mousazadeh, H. Off-Road Electric Vehicles and Autonomous Robots in Agricultural Sector: Trends, Challenges, and Opportunities. Vehicles 2022, 4, 843–864. [Google Scholar] [CrossRef]
- Bagagiolo, G.; Matranga, G.; Cavallo, E.; Pampuro, N. Greenhouse Robots: Ultimate Solutions to Improve Automation in Protected Cropping Systems—A Review. Sustainability 2022, 14, 6436. [Google Scholar] [CrossRef]
- Idoko, H.C.; Akuru, U.B.; Wang, R.-J.; Popoola, O. Potentials of Brushless Stator-Mounted Machines in Electric Vehicle Drives—A Literature Review. World Electr. 2022, 13, 93. [Google Scholar] [CrossRef]
- Hongxing, G.; Liqing, M. Analysis of the development status of electric micro-tiller. South. Agric. Mach. 2022, 53, 155–157. [Google Scholar]
- Zhao, Y.; Zhang, C.; Ni, Y.; He, S.; Wen, X. Development of Multifunctional Greenhouse Agricultural Robot. In Proceedings of the 2019 2nd International Conference on Informatics, Control and Automation (ICA 2019), Hangzhou, China, 26–27 May 2019; pp. 181–186. [Google Scholar]
- Li, Z.; Khajepour, A.; Song, J. A comprehensive review of the key technologies for pure electric vehicles. Energy 2019, 182, 824–839. [Google Scholar] [CrossRef]
- Shuyou, Y.; Wenbo, L.; Yi, L. Steering stability control of four-wheel independent drive electric vehicles. Control Theory Appl. 2021, 38, 719–730. [Google Scholar]
- Ani, O.A.; Uzoejinwa, B.B.; Ezeama, A.O.; Onwualu, A.P.; Ugwu, S.N.; Ohagwu, C.J. Overview of soil-machine interaction studies in soil bins. Soil Tillage Res. 2018, 175, 13–27. [Google Scholar] [CrossRef]
- Tangarife, H.I.; Díaz, A.E. Robotic Applications in the Automation of Agricultural Production under Greenhouse: A Review. In Proceedings of the 2017 IEEE 3rd Colombian Conference on Automatic Control (CCAC), Cartagena, Colombia, 18–20 October 2017; pp. 1–6. [Google Scholar]
- Yang, X.; Ma, Y. Current situation and development trend of vegetable mechanized seedling transplanting in facilities. J. Agric. Mech. Res. 2022, 44, 8–13+32. [Google Scholar]
- Wu, C.; Tang, X.; Xu, X. System Design, Analysis, and Control of an Intelligent Vehicle for Transportation in Greenhouse. Agriculture 2023, 13, 1020. [Google Scholar] [CrossRef]
- Azmi, H.N.; Hajjaj, S.S.H.; Gsangaya, K.R.; Sultan, M.T.H.; Mail, M.F.; Hua, L.S. Design and fabrication of an agricultural robot for crop seeding. Mater. Today Proc. 2021, 81, 283–289. [Google Scholar] [CrossRef]
- Rong, J.; Wang, P.; Yang, Q.; Huang, F. A Field-Tested Harvesting Robot for Oyster Mushroom in Greenhouse. Agronomy 2021, 11, 1210. [Google Scholar] [CrossRef]
- Shen, Y.; Zhang, B.; Liu, H.; Cui, Y.; Hussain, F.; He, S.; Hu, F. Design and Development of a Novel Independent Wheel Torque Control of 4WD Electric Vehicle. Mechanics 2019, 25, 210–218. [Google Scholar] [CrossRef] [Green Version]
- Yorozu, A.; Ishigami, G.; Takahashi, M. Human-Following Control in Furrow for Agricultural Support Robot. In IAS: 2021: Lecture Notes in Networks and Systems; Ang, M.H., Jr., Asama, H., Lin, W., Foong, S., Eds.; Springer: Cham, Switzerland, 2021; Volume 412. [Google Scholar] [CrossRef]
- Zhou, X.; Zhou, J. Optimization of autonomous driving state control of low energy consumption pure electric agricultural vehicles based on environmental friendliness. Environ. Sci. Pollut. Res. 2021, 28, 48767–48784. [Google Scholar] [CrossRef]
- Ren, Q. Intelligent Control Technology of Agricultural Greenhouse Operation Robot Based on Fuzzy Pid Path Tracking Algorithm. INMATEH-Agric. Eng. 2020, 62, 181–190. [Google Scholar]
- Cao, K.; Hu, M.; Wang, D.; Qiao, S.; Guo, C.; Fu, C.; Zhou, A. All-Wheel-Drive Torque Distribution Strategy for Electric Vehicle Optimal Efficiency Considering Tire Slip. IEEE Access 2021, 9, 25245–25257. [Google Scholar] [CrossRef]
- Kong, H.; Fang, Y.; Fan, L.; Wang, H.; Zhang, X.; Hu, J. A novel torque distribution strategy based on deep recurrent neural network for parallel hybrid electric vehicle. IEEE Access 2019, 7, 65174–65185. [Google Scholar] [CrossRef]
- Taherian, S.; Kuutti, S.; Visca, M.; Fallah, S. Self-adaptive Torque Vectoring Controller Using Reinforcement Learning. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar]
- Qi, X.; Luo, Y.; Wu, G.; Boriboonsomsin, K.; Barth, M. Deep reinforcement learning enabled self-learning control for energy efficient driving. Transp. Res. Part C Emerg. Technol. 2019, 99, 67–81. [Google Scholar] [CrossRef]
- Peng, H.; Wang, W.; Xiang, C.; Li, L.; Wang, X. Torque coordinated control of four in-wheel motor independent-drive vehicles with consideration of the safety and economy. IEEE Trans. Veh. Technol. 2019, 68, 9604–9618. [Google Scholar] [CrossRef]
- Zou, Y.; Liu, T.; Liu, D.; Sun, F. Reinforcement learning-based real-time energy management for a hybrid tracked vehicle. Appl. Energy 2016, 171, 372–382. [Google Scholar] [CrossRef]
- Srouji, M.; Zhang, J.; Salakhutdinov, R. Structured control nets for deep reinforcement learning. arXiv 2018, arXiv:1802.08311. [Google Scholar]
- Tan, H.; Zhang, H.; Peng, J.; Jiang, Z.; Wu, Y. Energy management of hybrid electric bus based on deep reinforcement learning in continuous state and action space. Energy Convers. Manag. 2019, 195, 548–560. [Google Scholar] [CrossRef]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. arXiv 2018, arXiv:1802.09477. [Google Scholar]
- Wang, X.; Han, Y.; Leung, V.C.M.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Values |
|---|---|---|
| M | Total Traction chassis mass | 225 kg |
| L × W × H | Overall dimensions about chassis (Length × Wide × High) | 1.2 × 1 × 0.6 |
| r | Radius of tire | 270 mm |
| h | Height of lift | 80 mm |
| l | Tracking between front wheel-axle and rear wheel-axle | 1.2 m |
| lf | Tracking between front wheel-axle and O | 0.36 m |
| V | Voltage of battery system | 48 V |
| Vx | Speed of operation | 5 km/h |
| Vmax | Maximum driving speed | 55 km/h |
| P | Power of motors | 1.5 kW |
| T | In-Wheel motor torque | 54 N·m |
| Python Toolkit | Version |
|---|---|
| gym | 0.21.0 |
| matplotlib | 3.4.2 |
| Mujoco_py | 2.1.2.14 |
| numpy | 1.19.5 |
| pandas | 1.2.5 |
| torch | 1.9.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ning, G.; Su, L.; Zhang, Y.; Wang, J.; Gong, C.; Zhou, Y. Research on TD3-Based Distributed Micro-Tillage Traction Bottom Control Strategy. Agriculture 2023, 13, 1263. https://doi.org/10.3390/agriculture13061263
Ning G, Su L, Zhang Y, Wang J, Gong C, Zhou Y. Research on TD3-Based Distributed Micro-Tillage Traction Bottom Control Strategy. Agriculture. 2023; 13(6):1263. https://doi.org/10.3390/agriculture13061263
Chicago/Turabian StyleNing, Guangxiu, Lide Su, Yong Zhang, Jian Wang, Caili Gong, and Yu Zhou. 2023. "Research on TD3-Based Distributed Micro-Tillage Traction Bottom Control Strategy" Agriculture 13, no. 6: 1263. https://doi.org/10.3390/agriculture13061263