
A Multistep Interval Prediction Method Combining Environmental Variables and Attention Mechanism for Egg Production Rate
 ,
,
Abstract
:1. Introduction
- (1)
- Currently, the methods used to reduce the factors that reduce egg production rates primarily involve statistical analysis or feature extraction, but these approaches suffer from issues such as inadequate feature selection or low interpretability of extracted features.
- (2)
- Research on egg production rate prediction mainly focuses on single-step prediction, lacking studies on multistep prediction. Multistep prediction can provide more helpful information, which is significant for production estimation and regulation.
- (3)
- Research on egg production rate prediction has focused solely on point prediction, while lacking studies on interval prediction. Interval prediction can quantify the unavoidable bias brought about by multistep point prediction and better describe the uncertain information about egg production rate.
- A feature selection method is proposed in this study that combines XGBoost, LightGBM, CatBoost, and the RFE feature elimination approach. This method can filter out redundant environmental variables more thoroughly, ultimately reducing model training time and improving prediction accuracy.
- A multistep prediction strategy for egg production rates is also proposed. Due to limited egg production rate data, direct multistep prediction yields unsatisfactory results. Based on the idea of recursive multistep forecasting, we first performed autoregressive multistep forecasting of environmental variables on small time scales, and then averaged the forecasting results daily and combined them with historical egg production rate data to achieve multistep forecasting of future egg production rates.
- Furthermore, an egg production rate interval prediction model is introduced in this study. Compared to the current egg production rate prediction models, this model incorporates seq2seq architecture and attention mechanisms to enhance the utilization of environmental and egg production rate data and improve point prediction accuracy. Moreover, this model can output suitable prediction intervals to measure the uncertainty of the egg production rate. Lastly, the MOGWO multi-objective algorithm is used for optimization to ensure the accuracy and stability of both point and interval predictions.
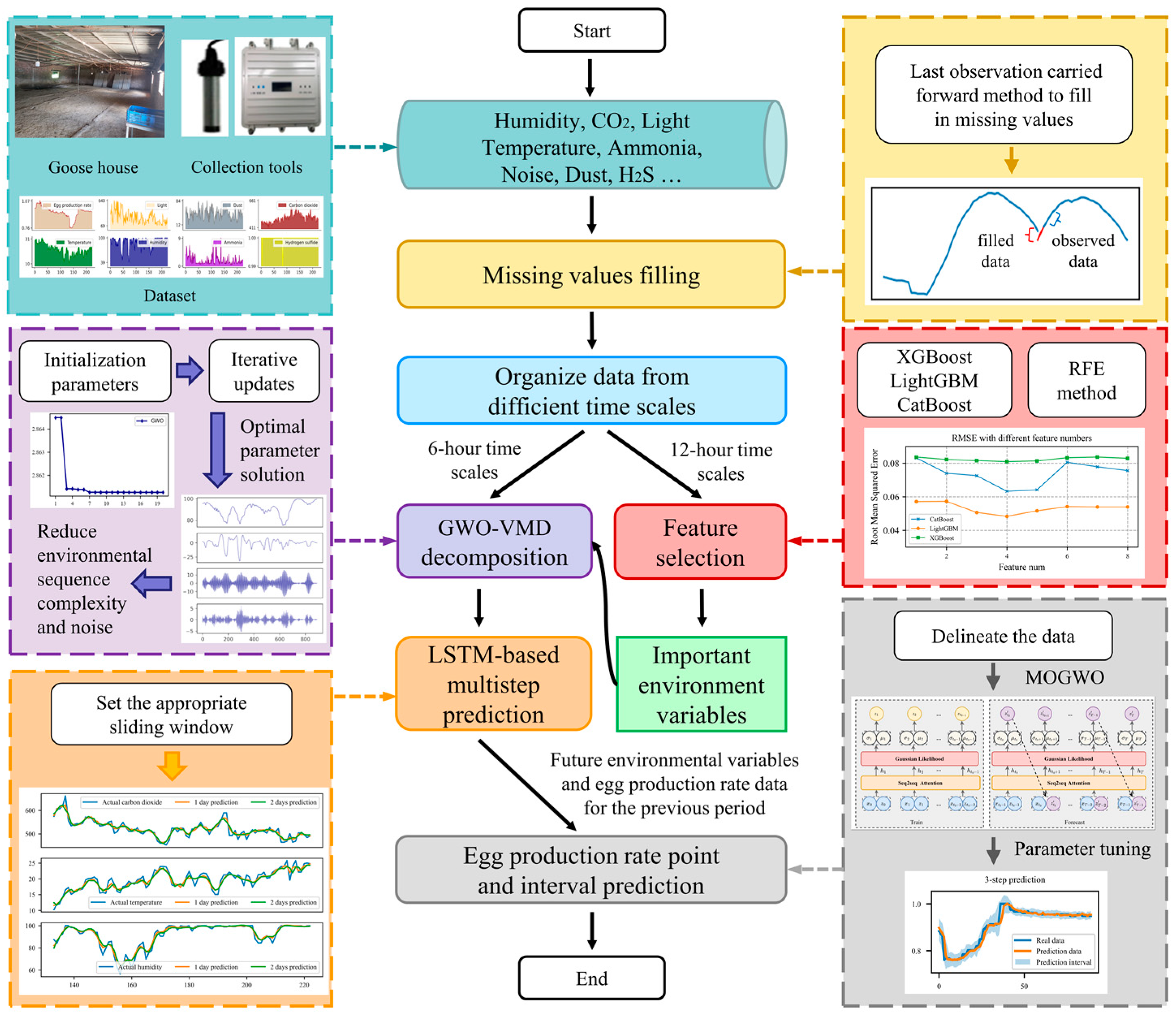
2. Materials and Methods
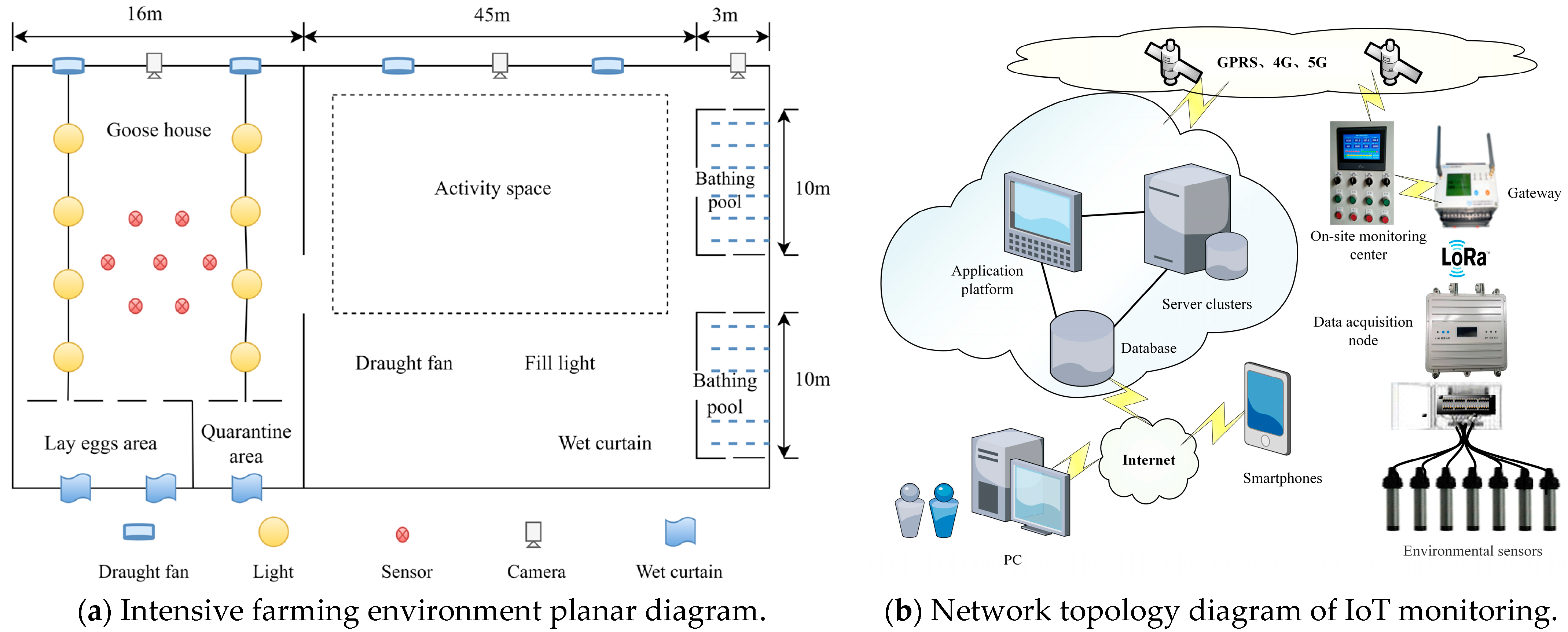
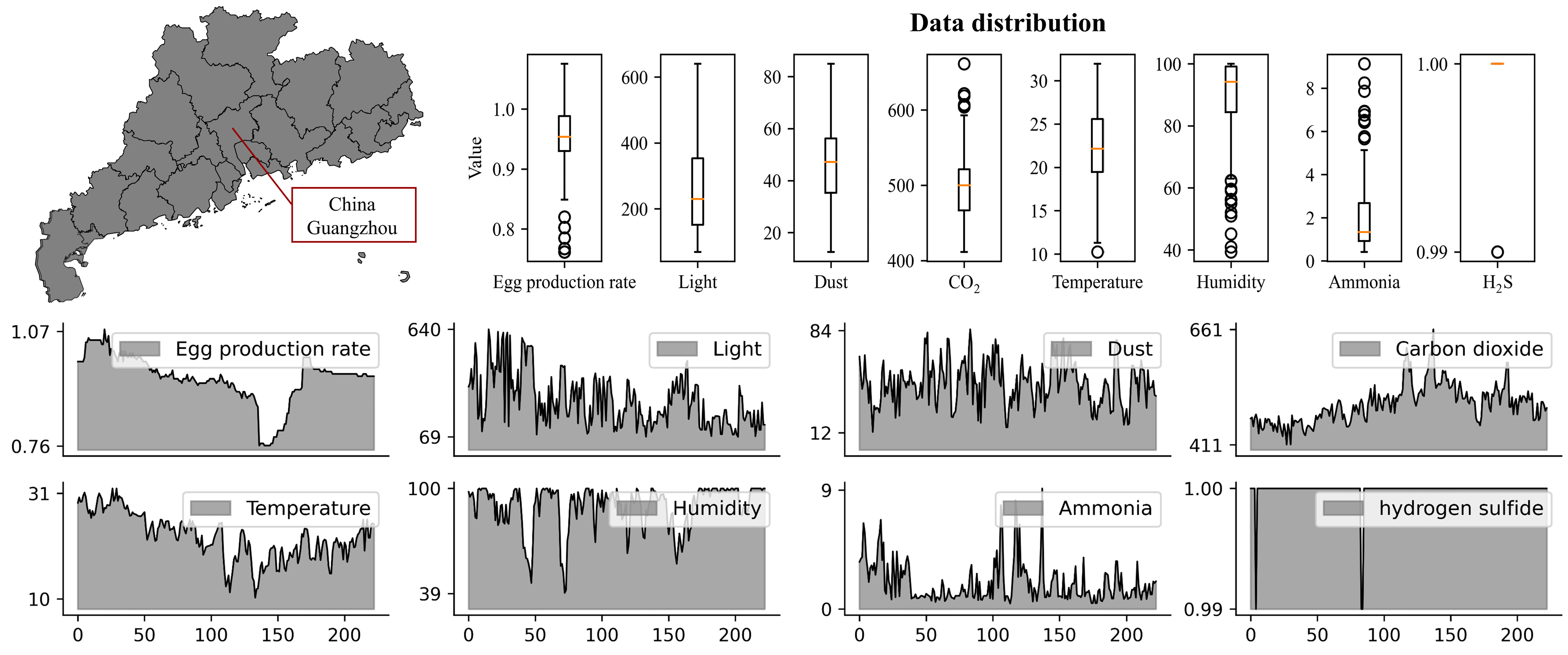
2.1. Study Area and Data Source
2.2. Feature Selection Method
2.2.1. Gradient Boosting Tree Model
2.2.2. Filtering Methods for Important Environment Variables
2.3. Optimization Algorithm Based on Grey Wolf Pack
2.3.1. Grey Wolf Optimizer Algorithm
2.3.2. Multi-Objective Grey Wolf Optimization Algorithm
2.4. GWO-VMD Method
2.4.1. Variational Mode Decomposition
2.4.2. Envelope Entropy
2.4.3. Environmental Time-Series Decomposition Method Based on GWO-VMD
- Step 1.
- Initialize the grey wolf population size N and set the maximum iteration of the algorithm to M.
- Step 2.
- Define the optimization ranges for the VMD parameters K and α, and initialize the other VMD parameters.
- Step 3.
- Iteratively update the grey wolf population information to find the optimal parameter combination.
- Step 4.
- Apply the optimized parameter combination (K, α) to VMD for decomposition and calculate the value of the fitness function pair.
- Step 5.
- Check if the iteration conditions are met and proceed to step 6 if satisfied, or return to step 3 otherwise.
- Step 6.
- Stop updating the iterations and obtain the optimized combination of parameters (K, α).
2.5. New Interval Prediction Model for Egg Production Rate
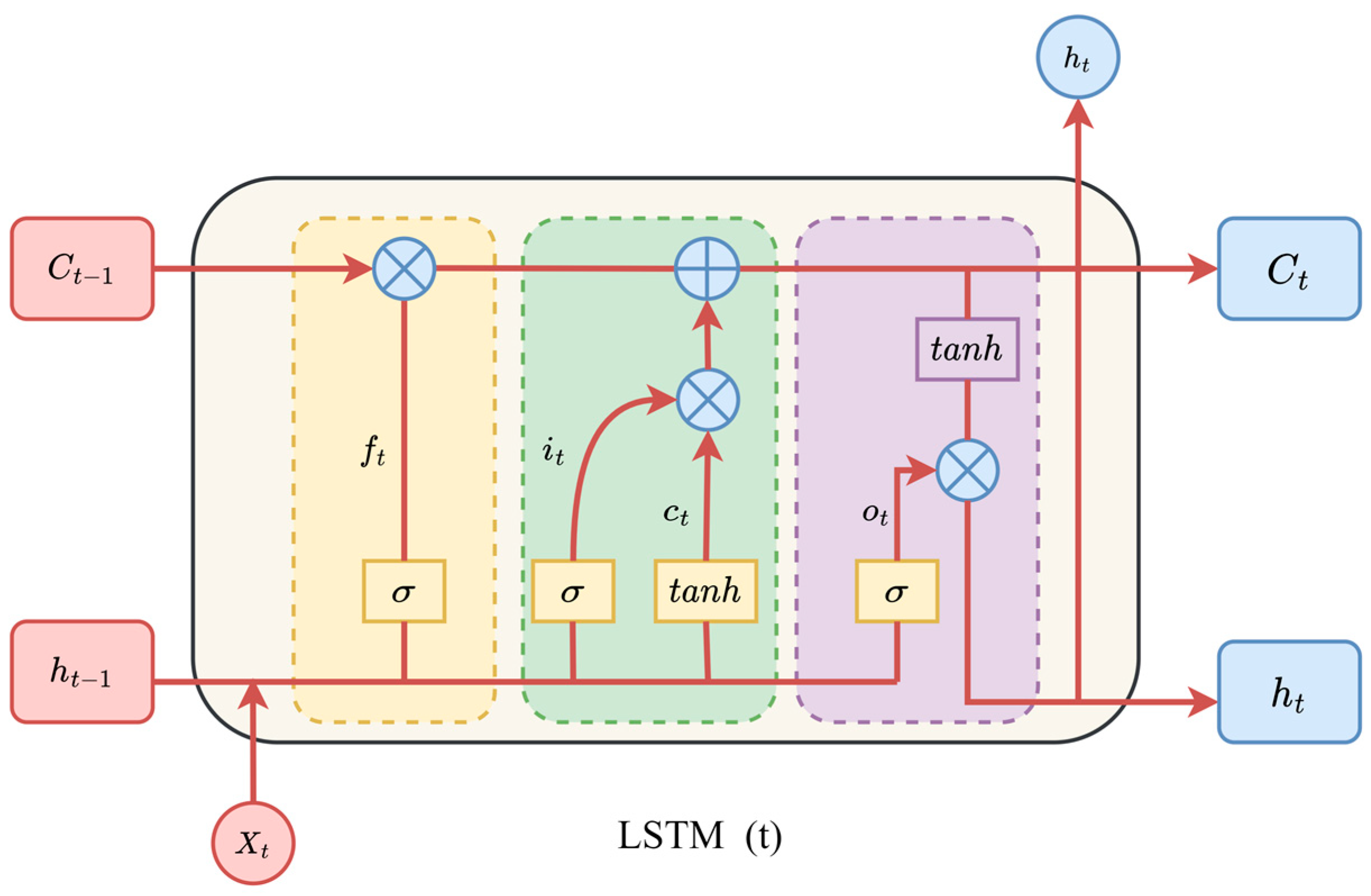
2.5.1. Long Short-Term Memory
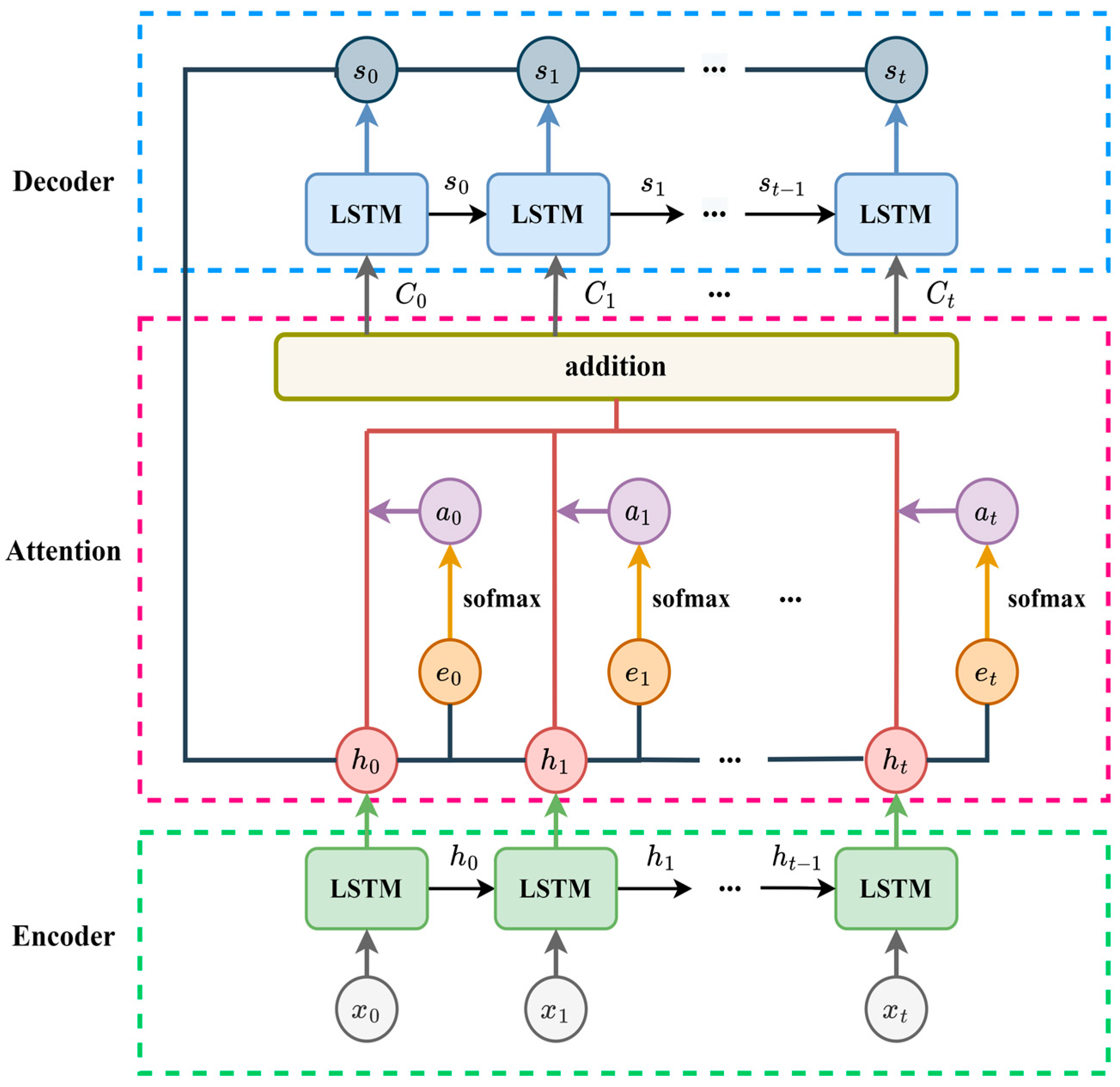
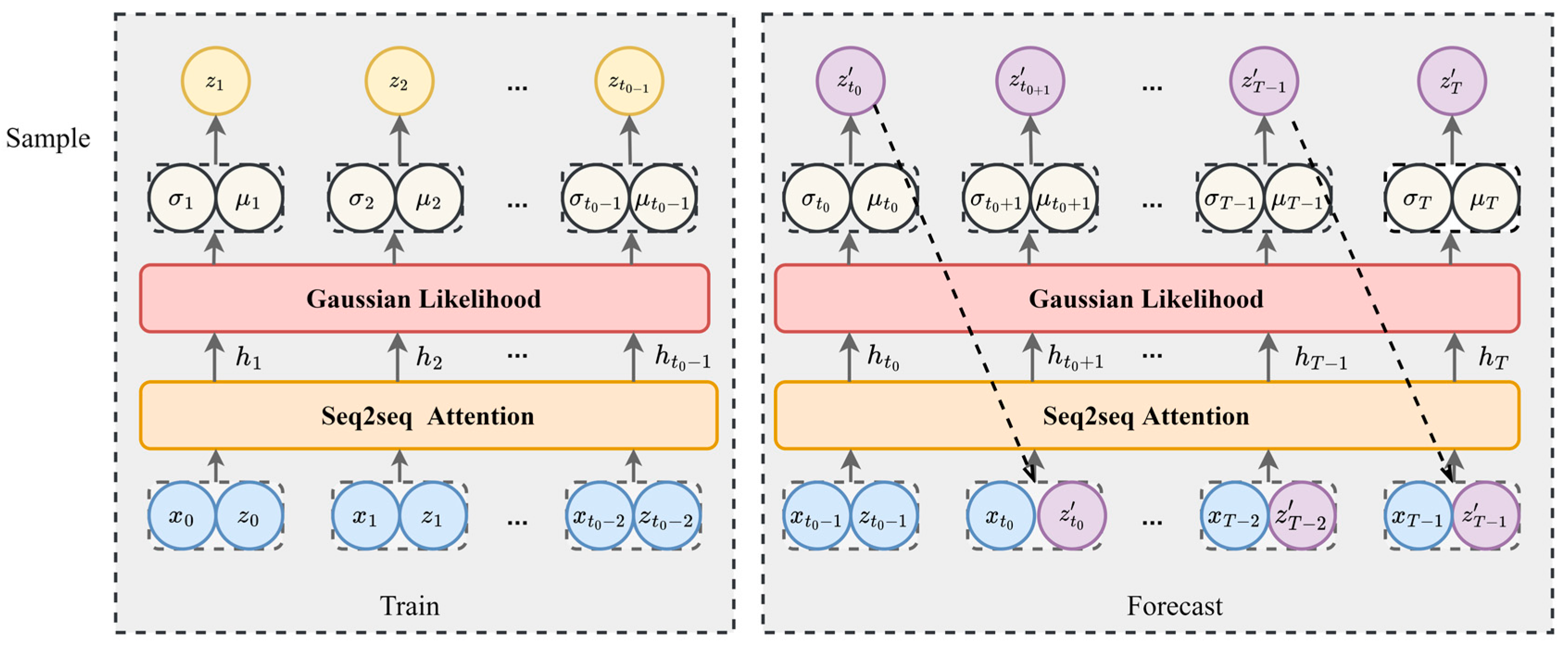
2.5.2. Seq2seq-Attention Architecture
2.5.3. Neural Networks Based on Gaussian and Seq2seq-Attention
2.6. Experimental Setup
2.7. Data Acquisition and Preprocessing
2.7.1. Datasets
2.7.2. Address the Issue of Missing Values
2.7.3. Data Conversion and Division
2.7.4. Normalization
2.8. Evaluation Metrics
2.8.1. Point Prediction Evaluation Metrics
2.8.2. Interval Prediction Evaluation Metrics
3. Results
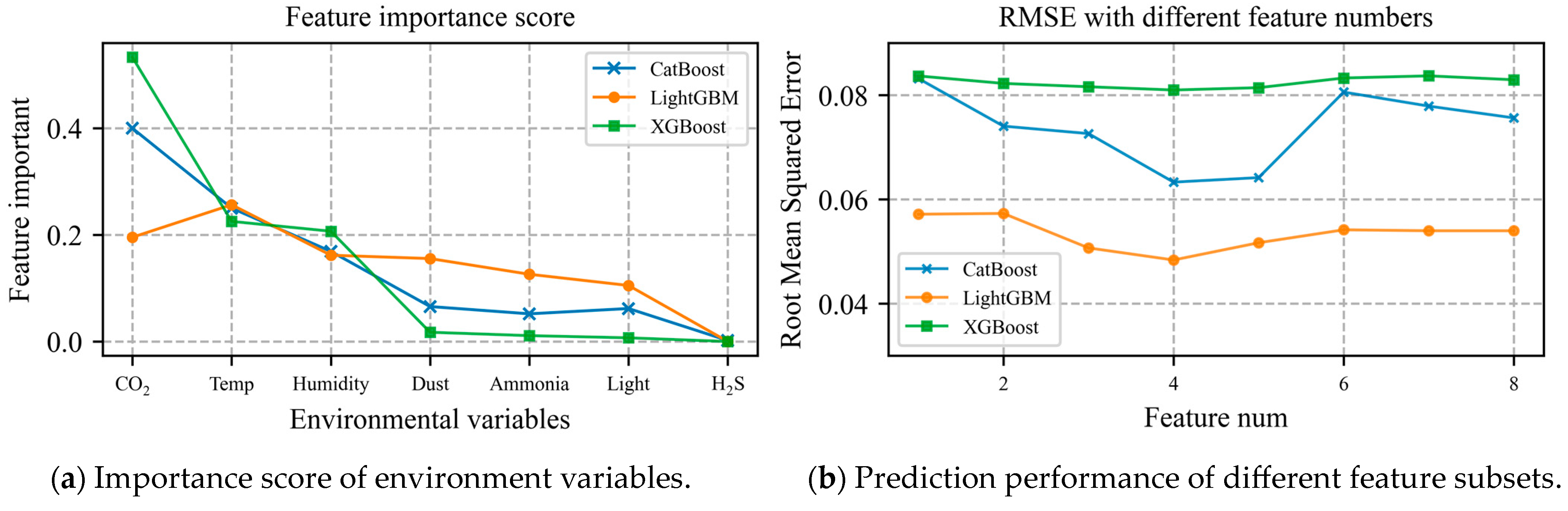
3.1. Feature Selection of Environmental Variables
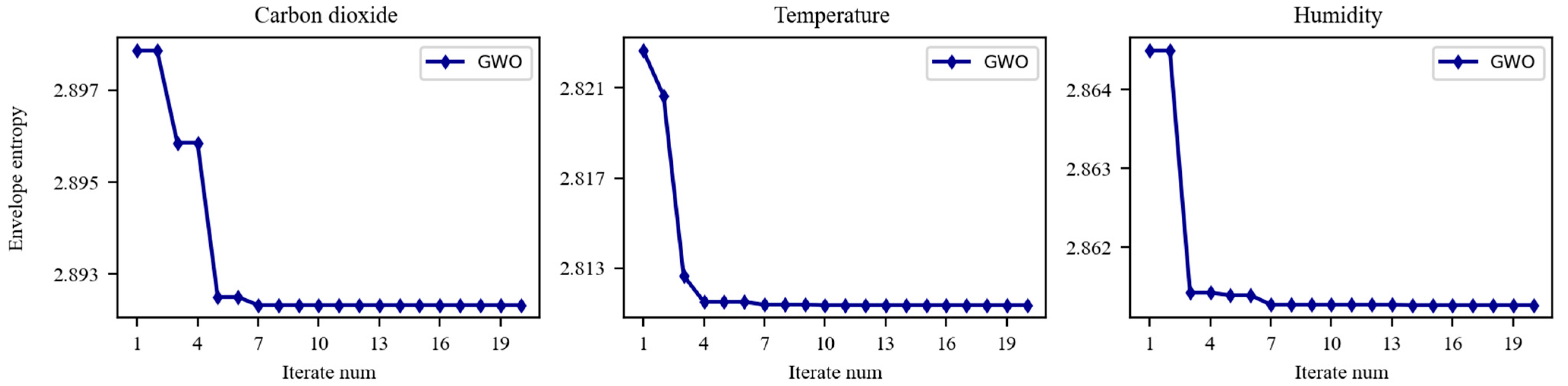
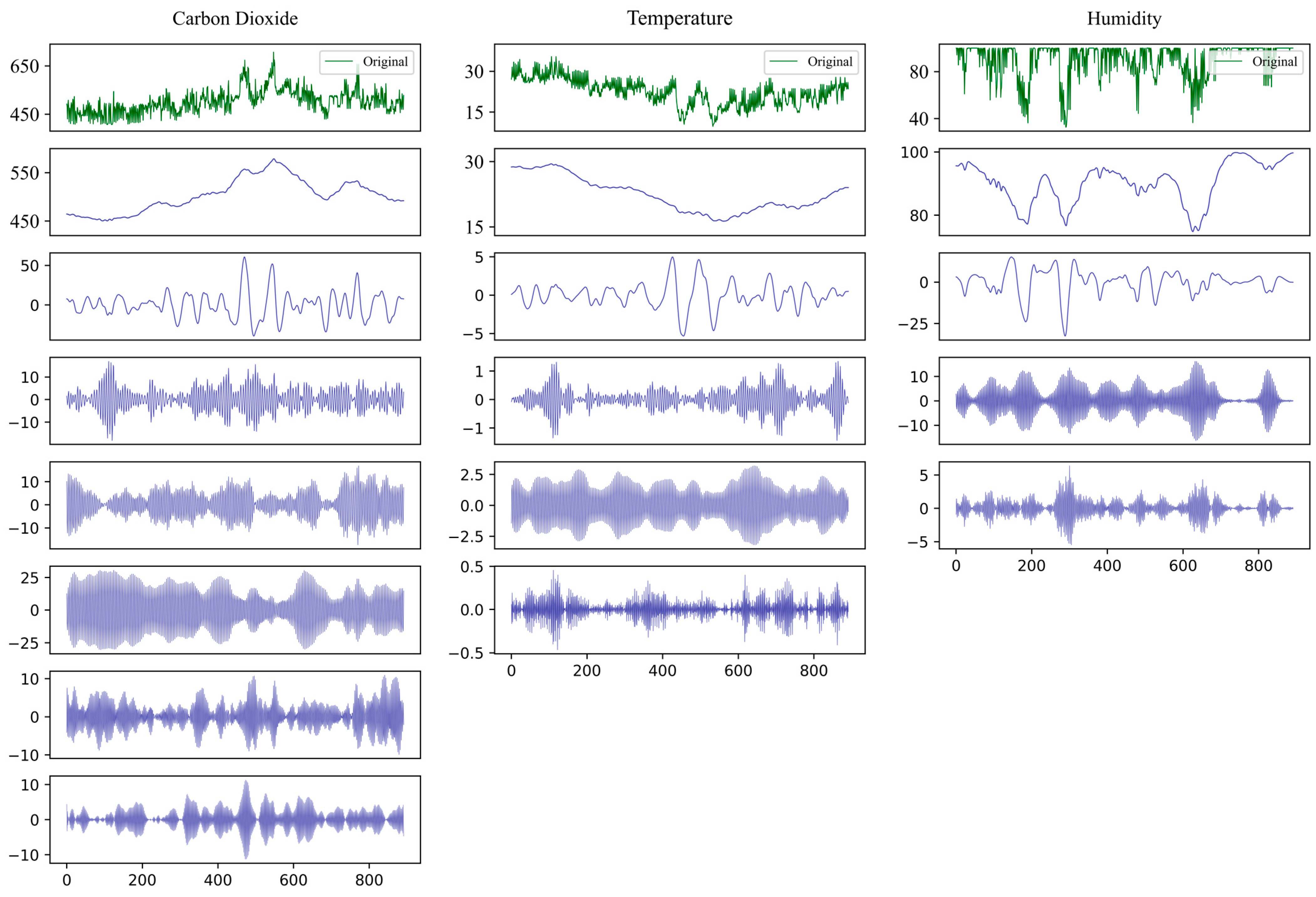
3.2. GWO-VMD Decomposition of Critical Environmental Variables
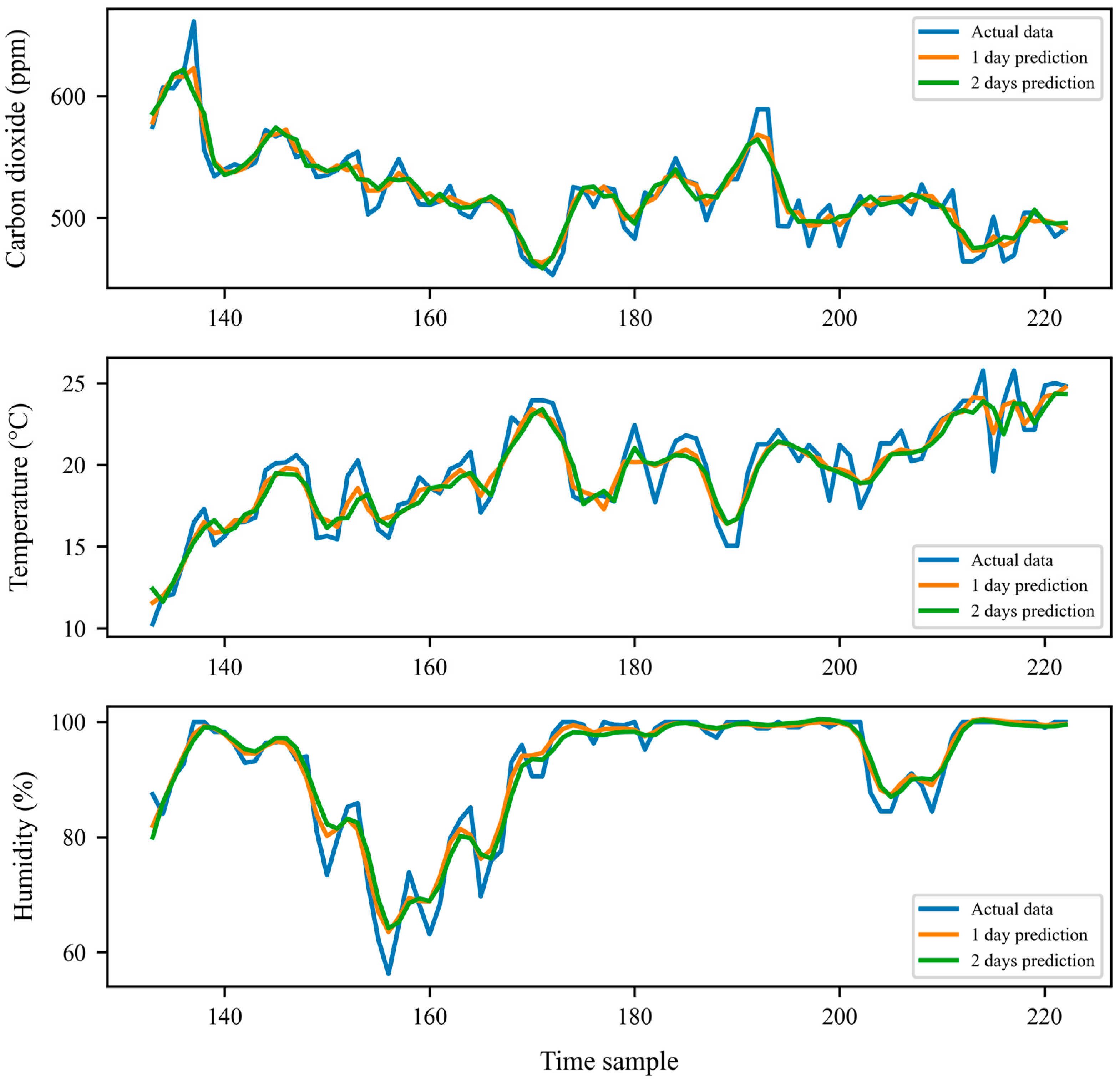
3.3. LSTM-Based Multistep Prediction of Environmental Variables
3.4. Prediction of Egg Production Rate
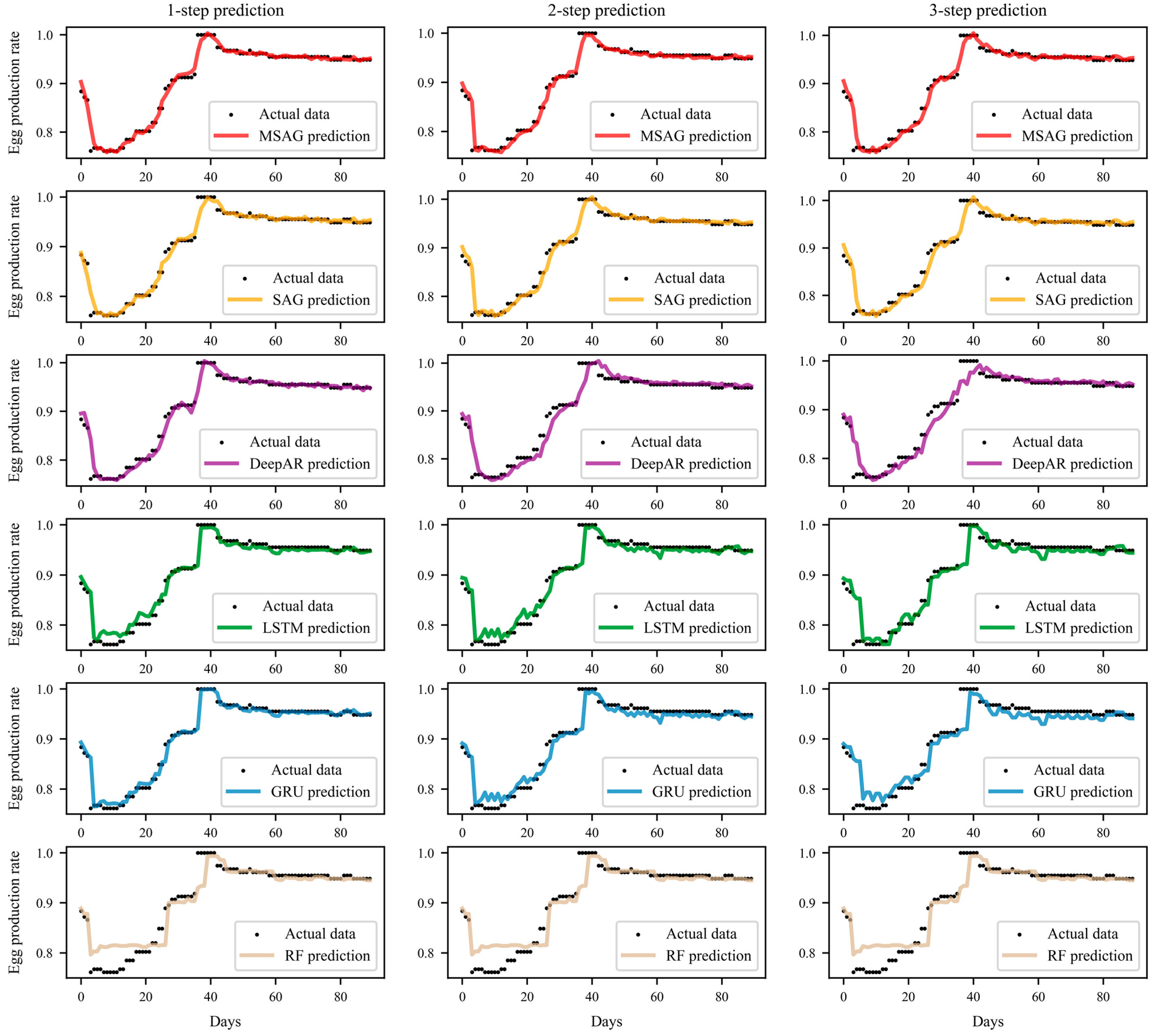
3.4.1. Point Prediction
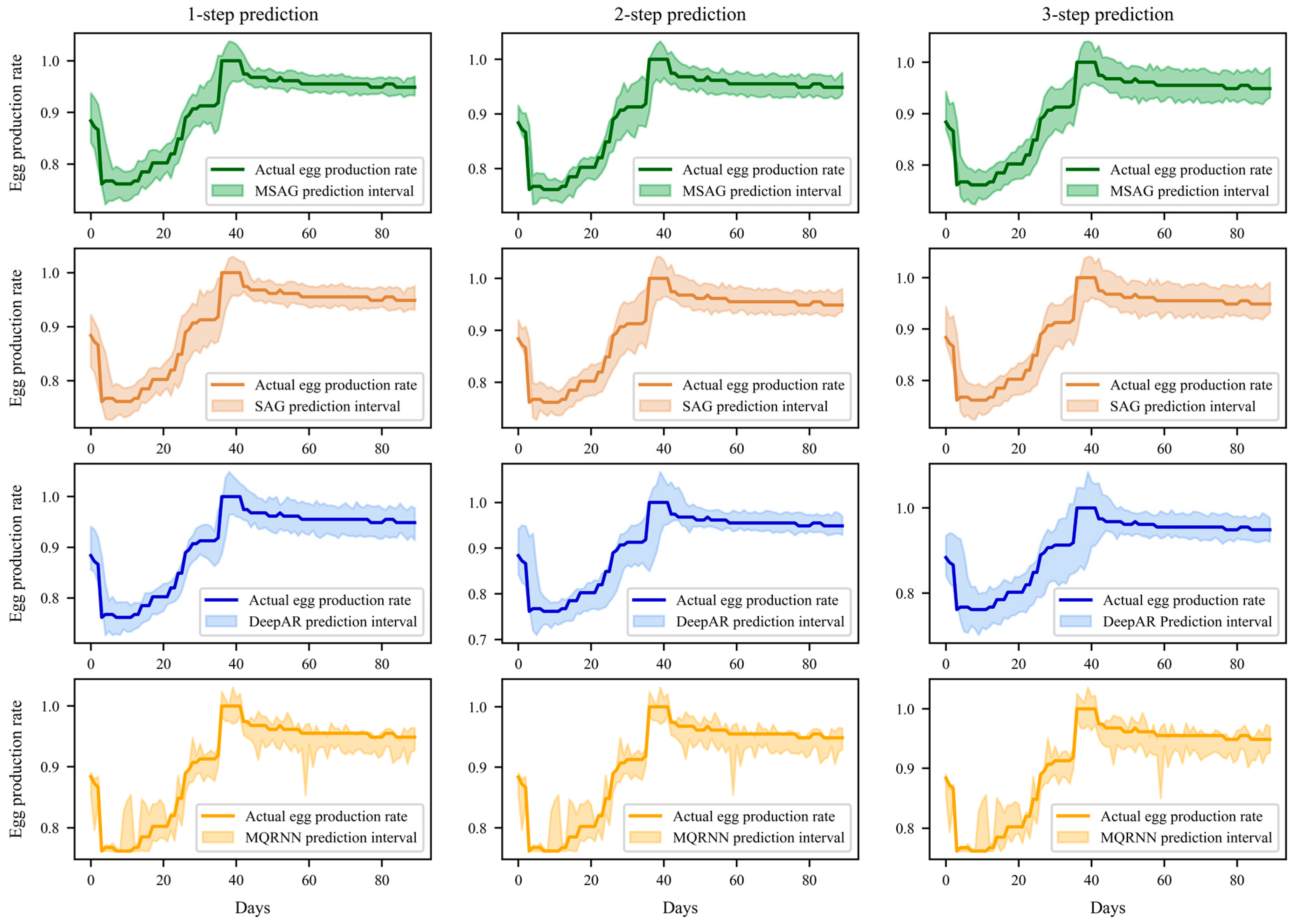
3.4.2. Interval Prediction
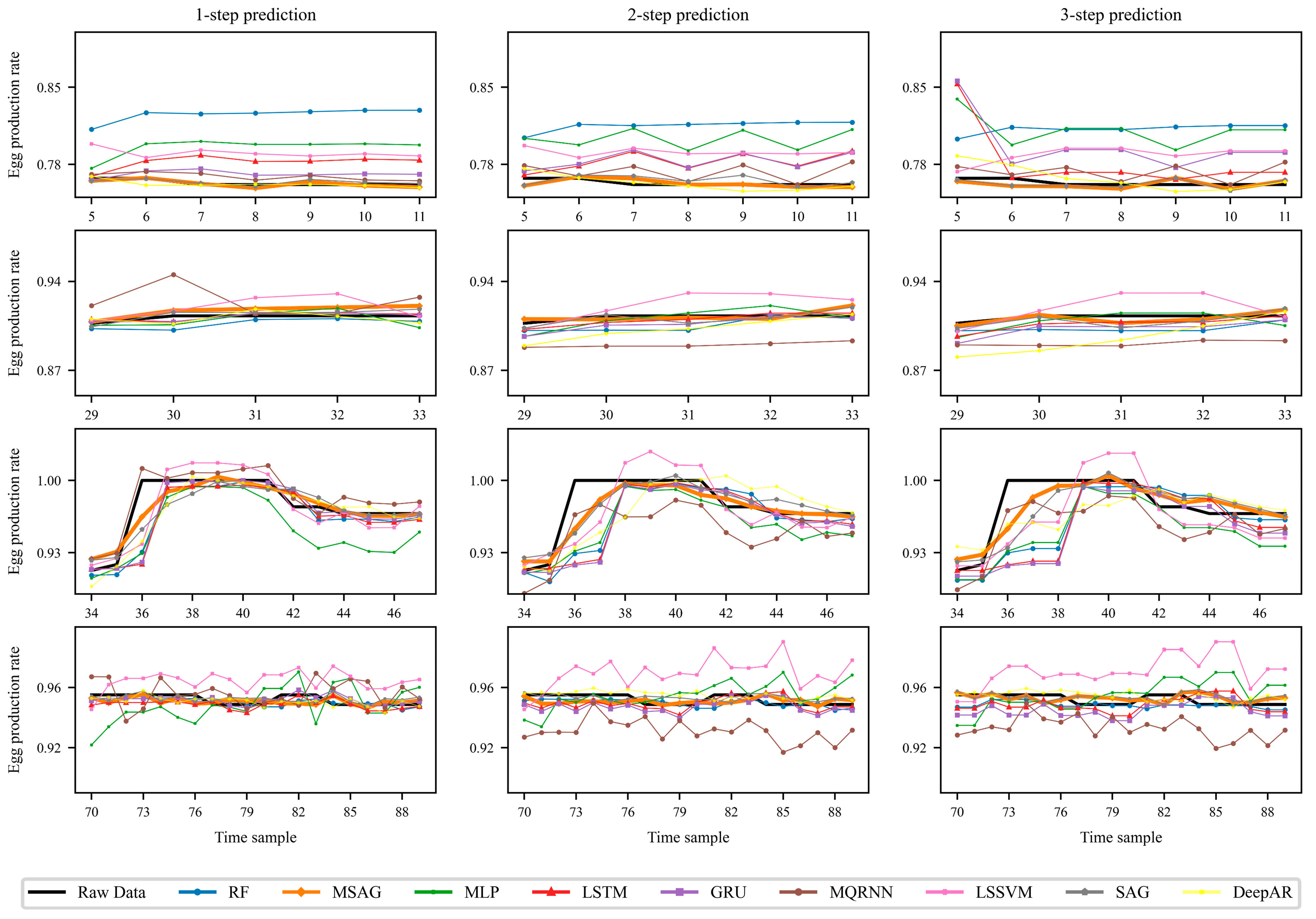
3.4.3. Prediction Using Different Feature Sets
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Flanders, F.; Gillespie, J.R. Modern Livestock & Poultry Production, 9th ed.; Cengage Learning: Boston, MA, USA, 2015. [Google Scholar]
- Wu, D.; Cui, D.; Zhou, M.; Ying, Y. Information perception in modern poultry farming: A review. Comput. Electron. Agric. 2022, 199, 107131. [Google Scholar] [CrossRef]
- Ramírez-Morales, I.; Fernández-Blanco, E.; Rivero, D.; Pazos, A. Automated early detection of drops in commercial egg production using neural networks. Br. Poult. Sci. 2017, 58, 739–747. [Google Scholar] [CrossRef] [Green Version]
- Long, A.; Wilcox, S. Optimizing Egg Revenue for Poultry Farmers. 2011, pp. 1–10. Available online: https://www.researchgate.net/publication/228452145_Optimizing_Egg_Revenue_for_Poultry_Farmers (accessed on 1 November 2022).
- Kim, D.H.; Lee, Y.K.; Kim, S.H.; Lee, K.W. The impact of temperature and humidity on the performance and physiology of laying hens. Animals 2020, 11, 56. [Google Scholar] [CrossRef] [PubMed]
- Geng, A.L.; Zhang, Y.; Zhang, J.; Wang, H.H.; Chu, Q.; Liu, H.G. Effects of lighting pattern and photoperiod on egg production and egg quality of a native chicken under free-range condition. Poult. Sci. 2018, 97, 2378–2384. [Google Scholar] [CrossRef] [PubMed]
- Shepherd, T.A.; Zhao, Y.; Li, H.; Hayes, M.; Xin, H.; Stinn, J. Environmental assessment of three egg production systems—Part II. Ammonia, greenhouse gas, and particulate matter emissions. Poult. Sci. 2015, 94, 534–543. [Google Scholar] [CrossRef]
- Saksrithai, K.; King, A.J. Controlling hydrogen sulfide emissions during poultry productions. J. Anim. Res. Nutr. 2018, 3, 2. [Google Scholar] [CrossRef]
- Abdallah, F.D.M. Role of time series analysis in forecasting egg production depending on ARIMA model. Appl. Math. 2019, 9, 1–5. [Google Scholar] [CrossRef]
- Omomule, T.G.; Ajayi, O.O.; Orogun, A.O. Fuzzy prediction and pattern analysis of poultry egg production. Comput. Electron. Agric. 2020, 171, 105301. [Google Scholar] [CrossRef]
- Minlan, J.; Peilun, W.; Haoran, C.; Xiaoxiao, L.; Yuanbiao, D. PSO-LSSVM Model for Hy-Line Brown Laying-Type Hens’ Egg-Laying Rate Prediction Based on PCA. IEEE Access 2020, 8, 167319–167327. [Google Scholar] [CrossRef]
- Gonzalez-Mora, A.F.; Rousseau, A.N.; Larios, A.D.; Godbout, S.; Fournel, S. Assessing environmental control strategies in cage-free aviary housing systems: Egg production analysis and Random Forest modeling. Comput. Electron. Agric. 2022, 196, 106854. [Google Scholar] [CrossRef]
- Ghazanfari, S.; Nobari, K.; Tahmoorespur, M. Prediction of egg production using artificial neural network. Iran. J. Appl. Anim. Sci. 2011, 1, 11–16. [Google Scholar]
- Felipe, V.P.S.; Silva, M.A.; Valente, B.D.; Rosa, G.J. Using multiple regression, Bayesian networks and artificial neural networks for prediction of total egg production in European quails based on earlier expressed phenotypes. Poult. Sci. 2015, 94, 772–780. [Google Scholar] [CrossRef]
- Liu, X.; Ye, X.; Li, M.; Li, H.; Zhan, K.; Li, J.; Liu, M. Egg-Laying Rate Prediction Based on PSO-DBN Model Under Multiple Variables. In Proceedings of the 2021 3rd International Academic Exchange Conference on Science and Technology Innovation (IAECST), Guangzhou, China, 10–12 December 2021; IEEE: New York, NY, USA, 2021; pp. 763–767. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Al Daoud, E. Comparison between XGBoost, LightGBM and CatBoost using a home credit dataset. Int. J. Comput. Inf. Eng. 2019, 13, 6–10. [Google Scholar]
- Chen, C.; Zhang, Q.; Yu, B.; Yu, Z.; Lawrence, P.J.; Ma, Q.; Zhang, Y. Improving protein-protein interactions prediction accuracy using XGBoost feature selection and stacked ensemble classifier. Comput. Biol. Med. 2020, 123, 103899. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, Y.; Jiang, X. Feature selection for global tropospheric ozone prediction based on the BO-XGBoost-RFE algorithm. Sci. Rep. 2022, 12, 1–10. [Google Scholar] [CrossRef]
- Banga, A.; Ahuja, R.; Sharma, S.C. Performance analysis of regression algorithms and feature selection techniques to predict PM 2.5 in smart cities. Int. J. Syst. Assur. Eng. Manag. 2021, 1–14. [Google Scholar] [CrossRef]
- Karbasi, M.; Jamei, M.; Ali, M.; Malik, A.; Yaseen, Z.M. Forecasting weekly reference evapotranspiration using Auto Encoder Decoder Bidirectional LSTM model hybridized with a Boruta-CatBoost input optimizer. Comput. Electron. Agric. 2022, 198, 107121. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of Gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Kim, K.; Kim, D.K.; Noh, J.; Kim, M. Stable forecasting of environmental time series via long short term memory recurrent neural network. IEEE Access 2018, 6, 75216–75228. [Google Scholar] [CrossRef]
- Salles, R.; Belloze, K.; Porto, F.; Gonzalez, P.H.; Ogasawara, E. Nonstationary time series transformation methods: An experimental review. Knowl.-Based Syst. 2019, 164, 274–291. [Google Scholar] [CrossRef]
- Gu, R.; Chen, J.; Hong, R.; Wu, W. Incipient fault diagnosis of rolling bearings based on adaptive variational mode decomposition and Teager energy operator. Measurement 2020, 149, 106941. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Comprehensive review of neural network-based prediction intervals and new advances. IEEE Trans. Neural Netw. 2011, 22, 1341–1356. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Huang, Y.; Hassan, S.G.; Xu, L.; Liu, S. Dissolved oxygen content interval prediction based on auto regression recurrent neural network. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 7255–7264. [Google Scholar] [CrossRef]
- Abbaszadeh, P.; Gavahi, K.; Alipour, A.; Deb, P.; Moradkhani, H. Bayesian multi-modeling of deep neural nets for probabilistic crop yield prediction. Agric. For. Meteorol. 2022, 314, 108773. [Google Scholar] [CrossRef]
- Li, G.; Li, F.; Ahmad, T.; Liu, J.; Li, T.; Fang, X.; Wu, Y. Performance evaluation of sequence-to-sequence-Attention model for short-term multi-step ahead building energy predictions. Energy 2022, 259, 124915. [Google Scholar] [CrossRef]
- Gao, S.; Zhang, S.; Huang, Y.; Han, J.; Luo, H.; Zhang, Y.; Wang, G. A new seq2seq architecture for hourly runoff prediction using historical rainfall and runoff as input. J. Hydrol. 2022, 612, 128099. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient Gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3149–3157. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S.; Saremi, S.; Mirjalili, S.M.; Coelho, L.D.S. Multi-objective grey wolf optimizer: A novel algorithm for multi-criterion optimization. Expert Syst. Appl. 2016, 47, 106–119. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environmental Variables | Measurement Range | Precision | Agreement |
|---|---|---|---|
| Carbon dioxide (ppm) | 0~50,000 | ±20 | PWM |
| Temperature (°C) | −40~105 | ±0.4 | IIC |
| Humidity (%) | 0~100 | ±5 | IIC |
| Dust (ppm) | 0~999.9 | ±7% | Modbus |
| Ammonia (ppm) | 0~100 | ±5% | Modbus |
| Light (lx) | 0~65,535 | ±5 | IIC |
| Hydrogen sulfide (ppm) | 0~100 | ±3% | PWM |
| Date | Egg Production Rate | Light (lx) | Dust (ppm) | Carbon Dioxide (ppm) | Temperature (°C) | Humidity (%) | Ammonia (ppm) | Hydrogen Sulfide (ppm) |
|---|---|---|---|---|---|---|---|---|
| 11 October 2018 | 0.9884 | 335.77 | 65.69 | 467.86 | 29.07 | 98.02 | 3.56 | 1 |
| 12 October 2018 | 0.9884 | 354.46 | 53.20 | 470.21 | 30.16 | 95.09 | 3.79 | 1 |
| 13 October 2018 | 0.9884 | 430.51 | 42.87 | 450.72 | 29.28 | 96.58 | 3.93 | 1 |
| 26 March 2019 | 0.9487 | 251.93 | 48.64 | 497.11 | 24.84 | 99.01 | 2.08 | 1 |
| 27 March 2019 | 0.9487 | 133.46 | 38.65 | 484.52 | 25.01 | 100.00 | 1.96 | 1 |
| 28 March 2019 | 0.9487 | 133.46 | 37.99 | 490.72 | 24.81 | 100.00 | 2.09 | 1 |
| Variable | XGBoost | LightGBM | CatBoost |
|---|---|---|---|
| Carbon dioxide | 0.533 | 0.195 | 0.400 |
| Temp | 0.225 | 0.256 | 0.250 |
| Humidity | 0.207 | 0.162 | 0.169 |
| Dust | 0.017 | 0.155 | 0.066 |
| Ammonia | 0.011 | 0.126 | 0.052 |
| Light | 0.007 | 0.105 | 0.062 |
| Hydrogen sulfide | 4.16 × 10−5 | 0.0 | 0.002 |
| Variable | Envelope Entropy | ||
|---|---|---|---|
| Carbon dioxide | 2.8923 | 2897.673 | 7 |
| Temperature | 2.8113 | 3012.798 | 5 |
| Humidity | 2.8612 | 1795.127 | 4 |
| Environment Variable | 6 h Average and GWO-VMD | 6 h Average | 24 h Average | |||
|---|---|---|---|---|---|---|
| 1 Day | 2 Days | 1 Day | 2 Days | 1 Day | 2 Days | |
| Carbon dioxide | 7.987 | 11.100 | 15.710 | 17.930 | 18.048 | 23.758 |
| Temperature | 0.800 | 0.964 | 1.434 | 1.540 | 1.421 | 1.989 |
| Humidity | 1.670 | 2.087 | 2.200 | 4.306 | 3.858 | 4.705 |
| Model | 1-Step | 2-Step | 3-Step | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | MAPE | RMSE | MAE | MAPE | RMSE | MAE | MAPE | RMSE | |
| MSAG | 0.0053 | 0.5985 | 0.0089 | 0.0062 | 0.7057 | 0.0132 | 0.0068 | 0.7677 | 0.0127 |
| SAG | 0.0059 | 0.6640 | 0.0100 | 0.0069 | 0.7804 | 0.0139 | 0.0081 | 0.9210 | 0.0151 |
| DeepAR | 0.0066 | 0.7542 | 0.0130 | 0.0106 | 1.2019 | 0.0177 | 0.0111 | 1.2516 | 0.0175 |
| MQRNN | 0.0078 | 0.8494 | 0.0094 | 0.0111 | 1.2249 | 0.0133 | 0.0187 | 2.0598 | 0.0210 |
| GRU | 0.0075 | 0.8657 | 0.0156 | 0.0121 | 1.3822 | 0.0200 | 0.0172 | 1.9669 | 0.0265 |
| LSTM | 0.0079 | 0.9025 | 0.0157 | 0.0114 | 1.2994 | 0.0198 | 0.0137 | 1.5569 | 0.0245 |
| LSSVM | 0.0155 | 1.7488 | 0.0188 | 0.0190 | 2.1188 | 0.0222 | 0.0199 | 2.2082 | 0.0239 |
| RF | 0.0137 | 1.6159 | 0.0234 | 0.0168 | 1.9668 | 0.0271 | 0.0315 | 3.4891 | 0.0412 |
| MLP | 0.0262 | 2.9749 | 0.0327 | 0.0315 | 3.5526 | 0.0397 | 0.0359 | 4.0450 | 0.0438 |
| Model | 1-Step | 2-Step | 3-Step | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PICP | PINRW | CWC | PICP | PINRW | CWC | PICP | PINRW | CWC | |
| MSAG | 1.0000 | 0.1886 | 0.1688 | 0.9778 | 0.1793 | 0.1735 | 0.9778 | 0.2108 | 0.2076 |
| SAG | 0.9888 | 0.2068 | 0.1890 | 0.9667 | 0.1893 | 0.1812 | 0.9667 | 0.2132 | 0.2099 |
| DeepAR | 0.9667 | 0.1985 | 0.1940 | 0.9778 | 0.2085 | 0.1831 | 0.9888 | 0.2588 | 0.2348 |
| MQRNN | 0.8666 | 0.1417 | 0.2572 | 0.8333 | 0.1995 | 0.3649 | 0.8000 | 0.2139 | 0.3980 |
| Metrics | MSAG-1 | MSAG-2 | MSAG-3 | MSAG-4 | MSAG-5 | MSAG-6 | MSAG-7 | MSAG-8 |
|---|---|---|---|---|---|---|---|---|
| MAE | 0.0143 | 0.0076 | 0.0067 | 0.0053 | 0.0062 | 0.0062 | 0.0069 | 0.0066 |
| RMSE | 0.0204 | 0.0115 | 0.0118 | 0.0089 | 0.0112 | 0.0101 | 0.0134 | 0.0113 |
| MAPE | 1.6029 | 0.8552 | 0.7654 | 0.5985 | 0.7066 | 0.6948 | 0.7923 | 0.7540 |
| PICP | 0.9333 | 1.0000 | 0.9778 | 1.0000 | 0.9889 | 0.9889 | 0.9889 | 1.0000 |
| PINRW | 0.3278 | 0.2546 | 0.2023 | 0.1886 | 0.1991 | 0.1995 | 0.2005 | 0.2304 |
| CWC | 1.1868 | 0.2335 | 0.1928 | 0.1688 | 0.1711 | 0.1706 | 0.1715 | 0.1941 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, H.; Wu, Z.; Wu, J.-C.; Chen, Y.; Chen, M.; Luo, S.; Gao, L.; Hassan, S.G. A Multistep Interval Prediction Method Combining Environmental Variables and Attention Mechanism for Egg Production Rate. Agriculture 2023, 13, 1255. https://doi.org/10.3390/agriculture13061255
Yin H, Wu Z, Wu J-C, Chen Y, Chen M, Luo S, Gao L, Hassan SG. A Multistep Interval Prediction Method Combining Environmental Variables and Attention Mechanism for Egg Production Rate. Agriculture. 2023; 13(6):1255. https://doi.org/10.3390/agriculture13061255
Chicago/Turabian StyleYin, Hang, Zeyu Wu, Jun-Chao Wu, Yalin Chen, Mingxuan Chen, Shixuan Luo, Lijun Gao, and Shahbaz Gul Hassan. 2023. "A Multistep Interval Prediction Method Combining Environmental Variables and Attention Mechanism for Egg Production Rate" Agriculture 13, no. 6: 1255. https://doi.org/10.3390/agriculture13061255